GENet: A Geometry-Enhanced Network for LiDAR Semantic Segmentation
Yuchen Wu, Hanbing Wei

TL;DR
GENet is a new network for LiDAR data that improves segmentation accuracy and efficiency by using geometry-aware features.
Contribution
GENet introduces a geometry-aware network with novel modules for efficient and accurate LiDAR semantic segmentation.
Findings
GENet uses a novel ASRA module to aggregate geometry-aware features efficiently.
The GCM mechanism improves semantic features by incorporating geometric priors.
GENet achieves real-time performance with fewer parameters and computation.
Abstract
LiDAR has been widely applied in autonomous driving and mobile robotics. Recently, many studies focus on real-time point cloud segmentation, aiming to achieve higher accuracy while maintaining real-time inference speed. Current real-time methods mostly rely on 2D projection, which inevitably leads to spatial information loss. To address the limitations of 2D projection methods, we propose a Geometry-Enhanced Network called GENet that exploits spatial priors. The network employs an Atrous Separable Range Attention (ASRA) module to explicitly utilize spatial priors from range images, enabling geometry-aware feature aggregation with large receptive field at linear complexity. A Geometry-Context Modulation (GCM) mechanism is then used to calibrate semantic features, incorporating geometric priors while preserving the discriminative ability of original features across different categories.…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1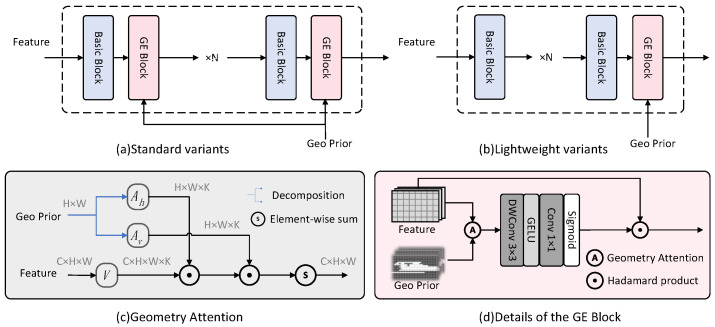 Figure 2
Figure 2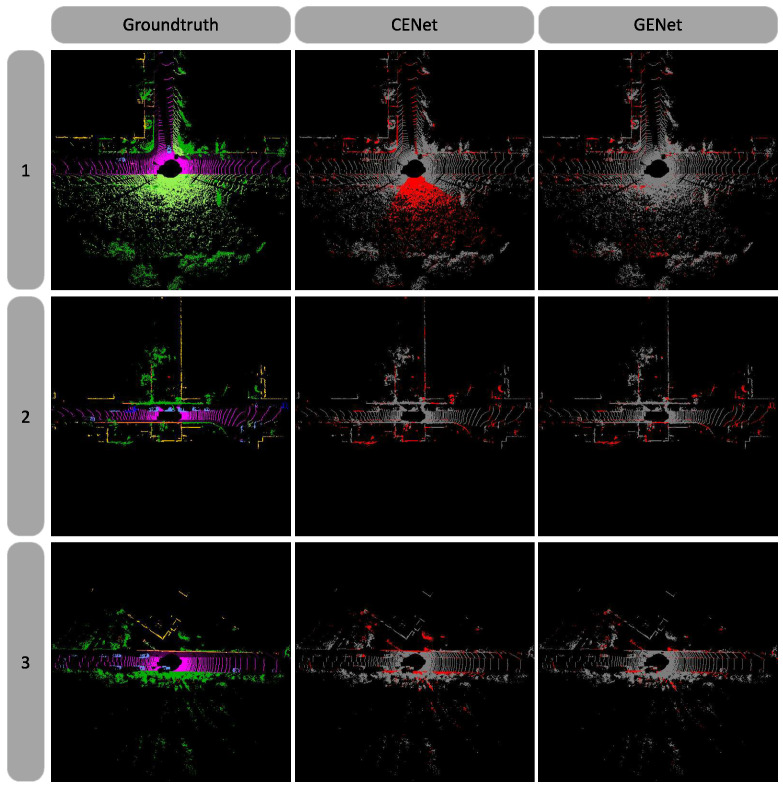 Figure 3
Figure 3- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Robotics and Sensor-Based Localization · 3D Shape Modeling and Analysis
1. Introduction
In recent years, with the rapid development of edge computing chips and the wide application of mobile robots in various scenarios, LiDAR has become a popular sensor choice due to its accuracy and robustness. Compared to other 3D sensors like RGB-D cameras and stereo cameras, LiDAR has natural advantages such as long sensing range and robustness to lighting conditions. Therefore, LiDAR-based environment perception, especially 3D point cloud semantic segmentation, has been a research focus in 3D computer vision.
LiDAR point clouds are direct samplings of real scenes, with characteristics like irregularity, sparsity, and non-uniformity, making them difficult for deep neural networks to learn. To handle this problem, there are several approaches. Point-based methods operate directly on raw point clouds, generally following the PointNet++ [1] paradigm to obtain local geometric shapes through hierarchical sampling and aggregation. Some of these methods achieve high segmentation accuracy, but the per-point processing and extensive 3D spatial searches cause high computational complexity, failing to meet real-time requirements. Voxel-based methods discretize point clouds into regular 3D grids and use existing 3D convolutions for feature learning. However, the computation and memory costs of 3D convolutions grow cubically with voxel resolution, making them unsuitable for resource-limited platforms. Projection-based methods project point clouds onto 2D planes (e.g., range view, bird’s-eye view) and use efficient 2D convolutional networks for processing, offering strong speed advantages. However, the spatial geometric information loss from projection leads to lower segmentation accuracy than the above two methods. In summary, how to balance accuracy and speed in point cloud semantic segmentation has become a hot research topic. Some studies propose multi-view fusion methods, incorporating the complementarity of different view representations into spatial prior information. For example, range views preserve neighborhood scanning structures while bird’s-eye views preserve spatial structures, which further improves the accuracy of multi-view methods.
Although multi-view fusion methods have excellent segmentation accuracy, multi-branch networks significantly increase parameter count and model complexity compared to single-branch networks, reducing inference speed. Therefore, this paper considers a new perspective for introducing geometric prior information, enhancing point cloud semantic segmentation performance while maintaining computational efficiency. Unlike using separate neural network branches to encode prior information, we propose a learning-free geometry attention module that can be embedded into any backbone network. As shown in Figure 1, this module explicitly uses range images to guide feature aggregation and modulates original features by combining semantic and geometric context. Experiments show that our method achieves efficient information fusion while maintaining real-time performance. Compared to other methods, it requires fewer parameters and less computation, achieving a favorable balance between accuracy and real-time performance.
The main contributions of this paper are as follows:
- We introduce a learning-free geometry attention mechanism for point cloud semantic segmentation, enhancing network capability without additional learnable parameters.
- We design a Geometry-Enhanced (GE) Block that efficiently fuses 2D semantic features with 3D geometric cues. We develop two network architectures, GENet and GENet-Light, tailored for different efficiency requirements.
- We propose a novel range view interpolation strategy that efficiently searches for potential interpolation points and performs interpolation based on spatial distance.
- Comprehensive experiments on SemanticKITTI and SemanticPOSS demonstrate that our method achieves an optimal trade-off between accuracy and efficiency.
2. Related Work
Point Cloud Semantic Segmentation: Point cloud semantic segmentation is a fundamental task in computer vision, aiming to assign point-wise semantic labels. Point-based methods [2,3,4,5] follow the PointNet++ paradigm, directly processing raw point clouds by partitioning them into multiscale point sets through hierarchical sampling, then employing shared MLPs or transformer blocks to capture local geometric features. Due to the irregularity and sparsity of point clouds, many methods organize them into structured 2D representations, such as range views or bird’s-eye views, to leverage efficient 2D visual backbones. To restore 2D segmentation results to 3D space, RangeNet++ [6] proposes a KNN-based post-processing method, while FIDNet [7] employs an interpolation-based decoder with dilated convolutions and a nearest assignment strategy, improving efficiency while maintaining accuracy. CENet [8] utilizes a carefully designed training architecture with multi-scale auxiliary losses, achieving state-of-the-art results among projection-based methods.
Despite their efficiency, projection-based methods inherently suffer from spatial information loss, preventing them from matching the performance of point-based approaches. Some works attempt to concatenate additional geometric information to the input, such as normal maps [9], but with limited effectiveness. Therefore, how to effectively recover the geometric information lost during projection without incurring excessive computational overhead has become a key challenge for improving projection-based methods.
Feature Fusion: To address these challenges, researchers have extensively explored feature-level fusion strategies to exploit the complementarity of multi-modal or multi-view information. Recent works have investigated efficient fusion of information from different modalities, such as RGB, point clouds, optical flow, and depth maps, which provide additional contextual cues to enhance model understanding. In the RGB-D segmentation domain, numerous studies have demonstrated that feature-level fusion is an effective paradigm. CMX [10] builds a general multi-modal feature interaction framework using cross-attention; building upon this, AsymFormer [11] further optimizes computational resource allocation with an asymmetric dual-branch architecture for efficient segmentation. In point cloud segmentation, researchers have noted the complementary nature of different views and proposed multi-view feature fusion methods to compensate for spatial information compression caused by single-view projection. RPVNet [12] employs range, voxel, and point branches to extract features from different views, performing multi-level gated fusion across multiple stages. 2DPASS [13] additionally utilizes 2D images during training to generate semantic priors at multiple scales, and introduces texture and color priors into the 3D backbone through multi-scale multi-modal fusion distillation. Additionally, SqueezeSegV3 [14] explores incorporating more information within a single view, proposing a spatially adaptive convolution module that implicitly leverages spatial priors in a single-branch network.
Despite these advancements, several challenges persist: multi-view fusion methods achieve higher accuracy but the multi-branch architecture significantly increases computational overhead; single-view methods often sacrifice real-time performance when incorporating geometric information. Therefore, how to effectively fuse geometric priors while maintaining single-branch network efficiency remains an open problem worth exploring.
3. Materials and Methods
3.1. Problem Definitions
Recent studies have proposed projecting point clouds into spherical coordinates to obtain a compact 2D representation, addressing the inherent sparsity of LiDAR sampling in outdoor scenes. This approach enables the use of mature 2D visual backbones, making real-time 3D semantic segmentation feasible. For any point in space, given the vertical and horizontal resolution of the range view, the corresponding projected coordinates can be computed as:
where,
denotes the distance from each point to the sensor, and
denotes the vertical field of view of the LiDAR, with and representing the pitch angles. The result is a multi-channel 2D image, where each pixel contains 5 channels , representing the point coordinates, range, and reflectance intensity, respectively. Although this transformation converts point cloud segmentation into a 2D multi-channel image segmentation problem, addressing the unordered and sparse nature of point clouds, it compresses spatial information, preventing 2D convolutions from capturing local geometric structures and leading to erroneous feature aggregation. The goal of this work is to learn a geometry-aware feature enhancement transformation for a 2D point cloud feature map and a range image :
This transformation should satisfy two design principles: (1) points that are spatially proximate in 3D space should exhibit stronger feature interactions; (2) the semantic discriminability of the original features should be preserved.
3.2. Method Overview
This paper proposes a geometry-aware feature enhancement module (GE Block) for range view point cloud semantic segmentation. The network architecture is illustrated in Figure 2. The module can be integrated with any 2D feature extraction backbone to enhance geometric awareness; we adopt ResNet [15] blocks for fair comparison with prior works. The module comprises two core components: (1) Geometry Attention Module (GAM), which combines atrous sampling with separable attention design, achieving geometry-aware feature aggregation with a large receptive field while maintaining linear computational complexity; (2) Geometry-Context Modulation (GCM), which transforms geometric context into channel-wise enhancement/suppression signals, incorporating geometric priors while preserving the discriminability of original features.
3.3. Geometry Attention Module
3.3.1. Geometry Prior Generated from Range Image
Let q denote the query with coordinates , and k denote other points within the window with coordinates . The Euclidean distance between them is defined as
A Gaussian kernel is applied to map this distance to attention weights
where is a learnable factor that controls the decay rate of attention with respect to distance, adapting to geometric characteristics at different scales. Through this geometry window attention mechanism, the model effectively captures spatial relationships of point clouds while maintaining computational efficiency.
3.3.2. Atrous Separable Range Attention Module
Although geometry window attention effectively captures local geometric relationships, directly applying it on high-resolution feature maps incurs computational and memory overhead. Inspired by sparse attention research, we propose Atrous Separable Range Attention (ASRA), which reduces complexity to through axial decomposition, significantly improving efficiency. Specifically, standard window attention requires each query to interact with keys; ASRA employs axial decomposition, first computing attention with K points along the horizontal axis, then with K points along the vertical axis. The cascaded operations cover the same neighborhood, but the total number of interactions is only . Meanwhile, atrous sampling is introduced to maintain a large receptive field without increasing the number of sampling points. Furthermore, different dilation rates can be set for horizontal and vertical directions to mitigate horizontal distortion in range views at different resolutions.
Specifically, given input features and range image , the fixed-window attention is decomposed into horizontal and vertical attention. Each query point computes attention with k neighboring points along horizontal and vertical directions with strides and following (6). Thus, for each query point , the attention weight for its k-neighborhood is computed as:
where K is the number of sampling points, d is the dilation rate, and is the decay rate. Through atrous sampling, the effective receptive field is expanded to . In our implementation, we set , , and is initialized to 1.0, achieving an effective receptive field of 33 pixels in both horizontal and vertical directions.
This yields the attention weight matrices for horizontal and vertical directions, denoted as and , respectively. The geometry-prior aggregated feature maps and can then be computed as:
Then, through cascaded operations, the final aggregated feature map is obtained. The entire module can be formulated as:
The complete procedure of ASRA is summarized in Algorithm 1. Algorithm 1 Atrous Separable Range Attention (ASRA)
- 1:Input: Feature map , Range image , Kernel size K, Dilation rates , , Learnable decay rate
- 2:Output: Geometry-aware aggregated feature
- 3:// Horizontal Attention
- 4:for each position do
- 5: for to do
- 6: // Range distance
- 7: // Gaussian weight
- 8: end for
- 9: // Normalize
- 10: // Weighted aggregation
- 11:end for
- 12:// Vertical Attention
- 13:for each position do
- 14: for to do
- 15: // Range distance
- 16: // Gaussian weight
- 17: end for
- 18: // Normalize
- 19: // Weighted aggregation
- 20:end for
- 21:
- 22:return
3.4. Geometry-Context Modulation
An intuitive idea is to directly aggregate features from geometrically similar neighborhoods using geometric cues. However, this hard aggregation strategy is suboptimal—geometric similarity does not necessarily imply semantic similarity. For example, two spatially adjacent points may lie on the same plane yet belong to entirely different object categories; directly fusing their features based on spatial similarity would undermine semantic discriminability and blur object boundaries. To address this, we propose a progressive geometric information incorporation mechanism: instead of letting geometric cues dominate feature aggregation, we employ adaptive gating to enhance or suppress original features—fusing geometric and semantic information to generate spatial modulation maps for adaptive feature recalibration. Specifically, the context feature obtained after geometry-guided aggregation encodes both geometric structural information (injected by the geometry attention module) and semantic content (from features extracted by the 2D backbone). Using this hybrid context, a lightweight convolutional head predicts a dense modulation map :
where denotes the depthwise separable convolution for capturing local spatial patterns, and is the sigmoid activation function that constrains the modulation coefficients to the interval . The modulation map is then applied to the original features via a residual gating mechanism:
where ⊙ denotes element-wise multiplication. This design ensures that the identity mapping is preserved when , while allowing the network to selectively enhance information-rich regions when . By conditioning the modulation map on geometry-aware context—rather than raw geometric distances—GCM achieves a more flexible and semantically consistent feature enhancement, jointly considering geometric structure and semantic coherence.
3.5. Model Architecture
As shown in Figure 2c, combining the geometry attention module and the geometry-context modulation module yields the GE Block, a geometry enhancement module that can be embedded into any 2D backbone network. Each module takes a range image with the same spatial dimensions as the input feature map to compute geometric priors. By inserting this enhancement module after the feature extraction blocks of a standard 2D backbone, we obtain the proposed Geometry-Enhanced Network, GENet. Specifically, we design two integration strategies: the lightweight version inserts a GE Block only at the output of each backbone stage for feature calibration; the standard version inserts a GE Block after each feature extraction block for fine-grained geometry-semantic fusion. Figure 2a illustrates the overall architecture of the proposed GENet.
3.6. Range Interpolation
When projecting 3D LiDAR point clouds onto 2D range images, the sparsity and non-uniformity of LiDAR sampling inevitably result in numerous holes in the generated range images. To mitigate this issue, we propose a range view interpolation strategy. For each pixel in candidate regions, we query its k nearest neighbors from the valid projected point set using KD-Tree, and compute the interpolation via inverse distance weighting (IDW):
where denotes the Euclidean distance between pixel i and its neighbor j on the image plane. This simple yet effective interpolation operation densifies the range image while preserving local geometric consistency, enabling subsequent convolutional layers to operate on more complete and coherent inputs.
4. Results
4.1. Experimental Setup
We conduct experiments on two popular benchmark datasets. SemanticKITTI [16] is the most widely used large-scale benchmark for point cloud semantic segmentation, built upon the KITTI Odometry dataset, containing 22 sequences with 43,552 frames and 19 semantic classes (including roads, buildings, vehicles, pedestrians, vegetation, and other common objects in urban driving scenes). Sequences 00–10 are used for training, sequence 08 for validation, and sequences 11–21 for testing. SemanticPOSS [17] is a more challenging small-scale dataset with 2988 frames and 14 semantic classes. Its scenes contain more dynamic objects and sparser point cloud distributions, making it suitable for evaluating model generalization.
For implementation details, all experiments are conducted on a single NVIDIA V100 GPU. We use AdamW as the optimizer with a cosine annealing scheduler and a learning rate of 0.001. Weight decay is set to 0.001. The model is trained for 80 epochs on SemanticKITTI and 100 epochs on SemanticPOSS, with a batch size of 8.
4.2. Results
Experimental results of GENet on the SemanticKITTI benchmark are shown in Table 1, reporting mean IoU, per-class IoU, and FPS. Compared with multi-view methods, although our method does not show significant performance advantages, it clearly outperforms in terms of parameter count (6.9 M) and real-time capability (41.6 FPS). Compared with voxel-based and projection-based methods, GENet improves segmentation accuracy (67.4%) while maintaining real-time performance, achieving an optimal trade-off between efficiency and accuracy. Notably, GENet-Light achieves the fastest inference speed (41.6 FPS) while still outperforming previous best results among range view projection methods. Table 2 presents quantitative comparison results on the SemanticPOSS dataset. Due to its smaller scale and sparser distribution, the performance gaps among methods are relatively small; nevertheless, our method still shows improvement over the baseline on this dataset. Figure 3 presents qualitative comparison with the baseline model CENet, showing that our method is more accurate in preserving geometric boundaries and achieves notable improvement in overall segmentation quality.
4.3. Ablation Study
To quantitatively analyze the effectiveness and necessity of each proposed component, we conduct comprehensive ablation studies. Following previous works, experiments are performed on the SemanticKITTI validation set for efficient training and comparison, with 2D resolution fixed at 64 × 512.
We first compare the performance impact of different information enhancement strategies on the 2D backbone of range view methods: concatenating range residual matrices to the input (representing input-level fusion), inserting CBAM blocks at each backbone stage (representing semantically-guided feature fusion), and our proposed method (geometry-guided feature fusion). All these enhancement strategies improve the performance of the baseline model CENet, indicating that existing 2D backbones still cannot fully extract point cloud information. Our method integrates both semantic and geometric cues, among which GENet-Light achieves the fastest inference speed (41.6 FPS), GENet-Standard achieves the highest segmentation accuracy (65.4%) and real-time performance still outperforms other methods with the same accuracy. The results are shown in Table 3.
We further analyze the impact of individual components, including the geometry attention aggregation module, geometry modulation module, and range interpolation algorithm. CENet [8] is adopted as the baseline, and we compare performance metrics under different configurations, including mIoU and FPS. The second row reports the effectiveness of the range interpolation algorithm, which searches for potential interpolation points via morphological operations and performs nearest neighbor label assignment, significantly alleviating the sparsity issue of point clouds. As shown, this method gets 0.5% mIoU improvement. The third row reports results of applying the geometry attention aggregation module alone. Unfortunately, using this module alone for feature aggregation only brings a 0.7% improvement. We attribute this to the fact that geometric similarity does not equate to semantic similarity; thus, forcing feature aggregation based solely on geometric relations cannot achieve optimal results. The fourth row reports results of applying the context modulation module to 2D backbone features alone, yielding approximately 0.3% improvement. This is because when only semantic information is input, the module essentially functions as a lightweight spatial attention module similar to CBAM; however, the texture information in range images contains substantial noise, making it difficult to achieve optimal results using semantic information alone. When the geometry attention aggregation module and context modulation module are applied together, a 2.2% mIoU improvement is achieved, demonstrating the effectiveness of our proposed progressive strategy for fusing semantic and geometric information. Component ablation results are shown in Table 4.
Finally, we discuss the generalization of the proposed module across different backbones. We select the modern convolutional network ConvNeXt V2 [29] as the experimental backbone. Compared with ResNet, ConvNeXt V2 incorporates successful design principles from Vision Transformer, comprehensively modernizing the pure convolutional architecture and achieving stronger representation capability, making it a strong baseline for various vision tasks. Experiments with ConvNeXt V2-atto achieve 62.9% mIoU, outperforming the CENet+HardNet baseline with comparable parameter counts. This demonstrates the generalization of our proposed module across different backbones, while also establishing a new lightweight baseline. Results are shown in Table 5.
5. Conclusions
This work proposes a Geometry-Enhanced Network called GENet for LiDAR point cloud segmentation, the core components of which can be integrated into any 2D backbone. The method contains two core components: the Geometry Attention Module uses range information to explicitly model geometric relationships among points and guides semantic feature aggregation accordingly; the Geometry-Context Modulation (GCM) module uses an adaptive modulation mechanism to fuse geometric information while preserving the semantic representation ability of the backbone. We also propose a new range view interpolation strategy to solve the hole problem when projecting point clouds to 2D images. Experiments show that our method achieves a good balance between efficiency and performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Qi C.R. Yi L. Su H. Guibas L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space Proceedings of the Advances in Neural Information Processing Systems Long Beach, CA, USA 4–9 December 2017 Volume 30
- 2Qi C.R. Su H. Mo K. Guibas L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Honolulu, HI, USA 21–26 July 2017652660
- 3Thomas H. Qi C.R. Deschaud J.E. Marcotegui B. Goulette F. Guibas L.J. Kpconv: Flexible and deformable convolution for point clouds Proceedings of the IEEE/CVF International Conference on Computer Vision Seoul, Republic of Korea 27 October–2 November 201964116420
- 4Hu Q. Yang B. Xie L. Rosa S. Guo Y. Wang Z. Trigoni N. Markham A. Randla-net: Efficient semantic segmentation of large-scale point clouds Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Seattle, WA, USA 13–19 June 20201110811117
- 5Wu X. Lao Y. Jiang L. Liu X. Zhao H. Point transformer v 2: Grouped vector attention and partition-based pooling Proceedings of the Advances in Neural Information Processing Systems New Orleans, LA, USA 28 November–9 December 2022 Volume 353333033342
- 6Milioto A. Vizzo I. Behley J. Stachniss C. Rangenet++: Fast and accurate lidar semantic segmentation 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems IEEE Piscataway, NJ, USA 201942134220
- 7Zhao Y. Bai L. Huang X. Fidnet: Lidar point cloud semantic segmentation with fully interpolation decoding 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems IEEE Piscataway, NJ, USA 202144534458
- 8Cheng H.X. Han X.F. Xiao G.Q. Cenet: Toward concise and efficient lidar semantic segmentation for autonomous driving 2022 IEEE International Conference on Multimedia and Expo IEEE Piscataway, NJ, USA 202216