A Lightweight Model for Hot-Rolled Steel Strip Surface Defect Recognition
Naixuan Guo, Haonan Fan, Qin Dong, Rongchen Gu, Sen Xu

TL;DR
This paper introduces a lightweight model for detecting defects on hot-rolled steel strips, suitable for mobile devices and achieving high accuracy.
Contribution
A novel lightweight model optimized for mobile deployment with high accuracy and reduced computational requirements.
Findings
The model achieves 96.333% accuracy on the NEU-CLS dataset.
Classification time is reduced by 155.010% compared to the original model.
The model is successfully deployed on a Raspberry Pi for real-time defect recognition.
Abstract
With the rapid development of intelligent manufacturing and industrial automation, defect recognition and detection of hot-rolled strip steel have become crucial to ensuring both production efficiency and product quality. However, existing hot-rolled strip steel detection systems often rely on expensive, energy-intensive, stationary equipment, making them unsuitable for mobile applications, such as outdoor use. To address this challenge, this paper proposes and designs a lightweight dual-surface defect recognition model for hot-rolled steel strips that can be implemented on mobile low-power devices (e.g., Raspberry Pi). First, to train the lightweight model, the NEU-CLS dataset is augmented through image generation via StyleGAN3, denoising with a water-wave-like noise removal algorithm, and super-resolution with Real-ESRGAN. Then, MMAM-EfficientNet-B0 is pruned during training, and the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
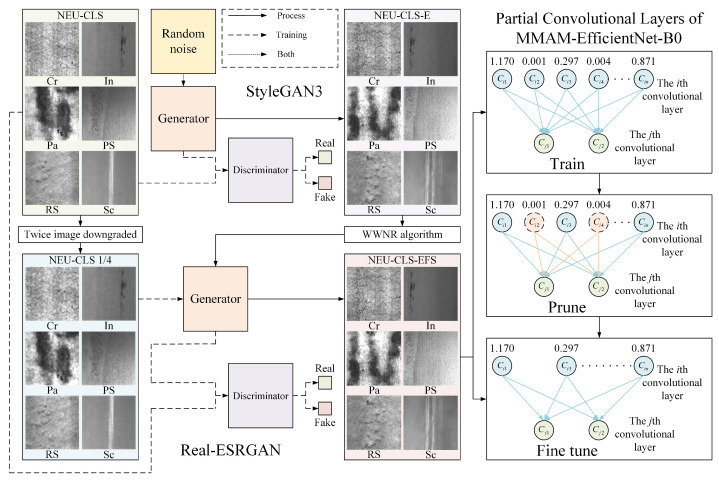 Figure 1
Figure 1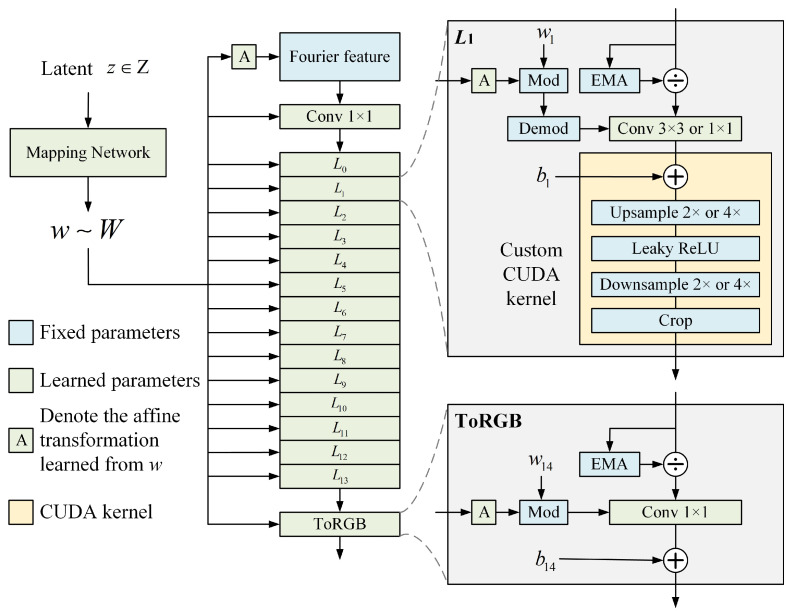 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4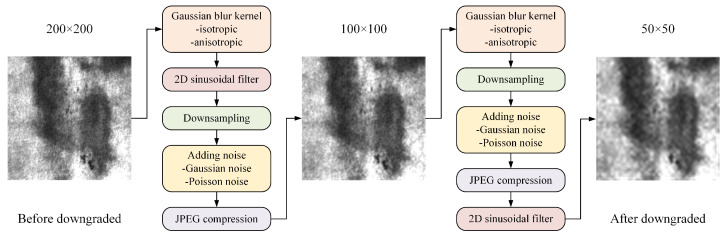 Figure 5
Figure 5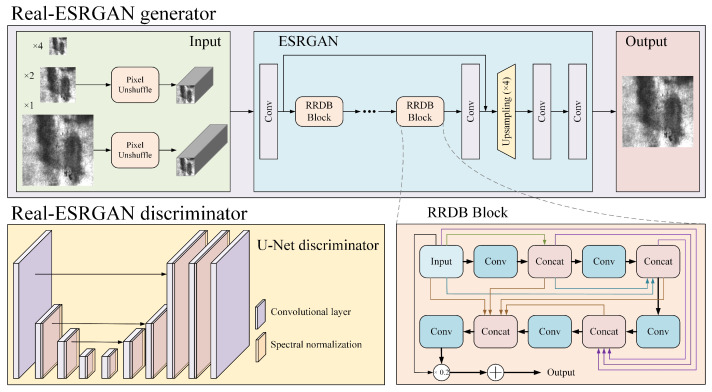 Figure 6
Figure 6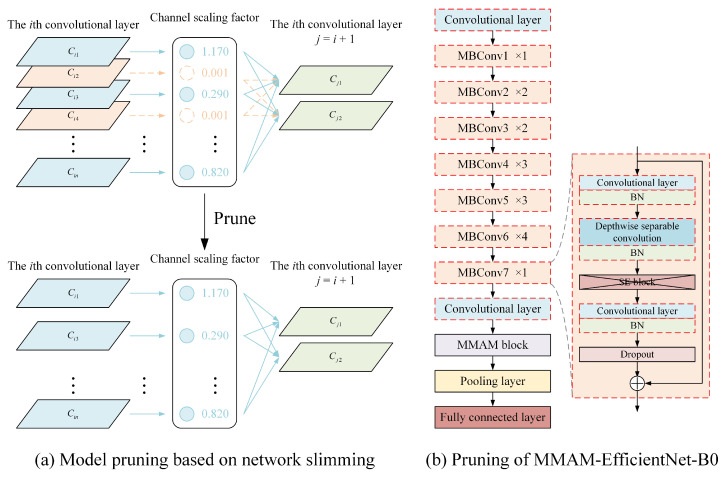 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9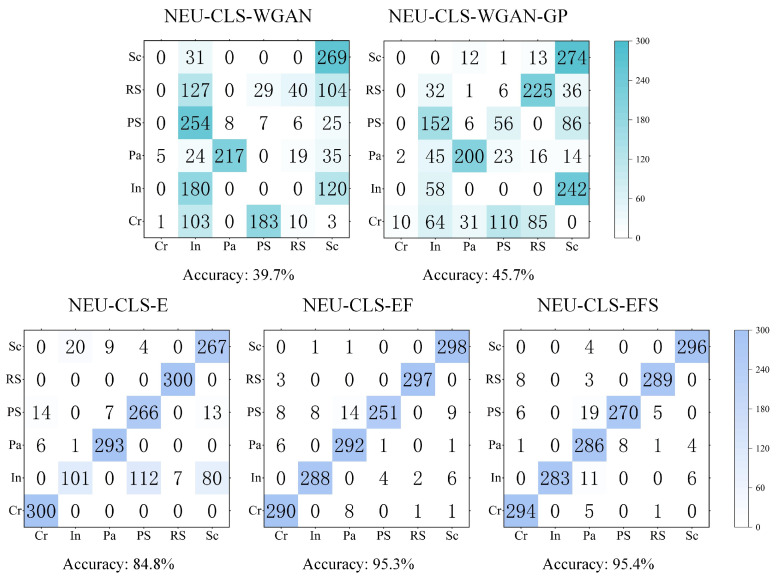 Figure 10
Figure 10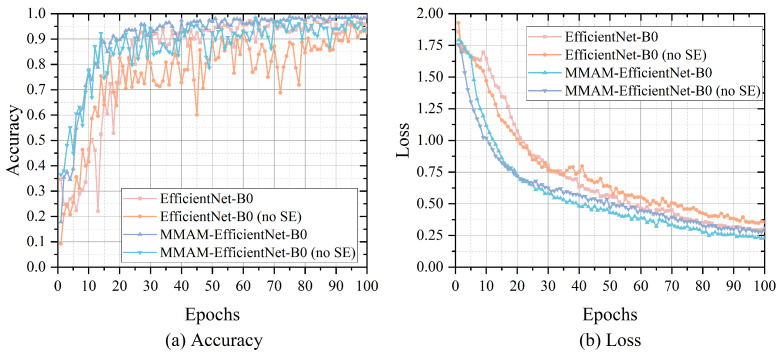 Figure 11
Figure 11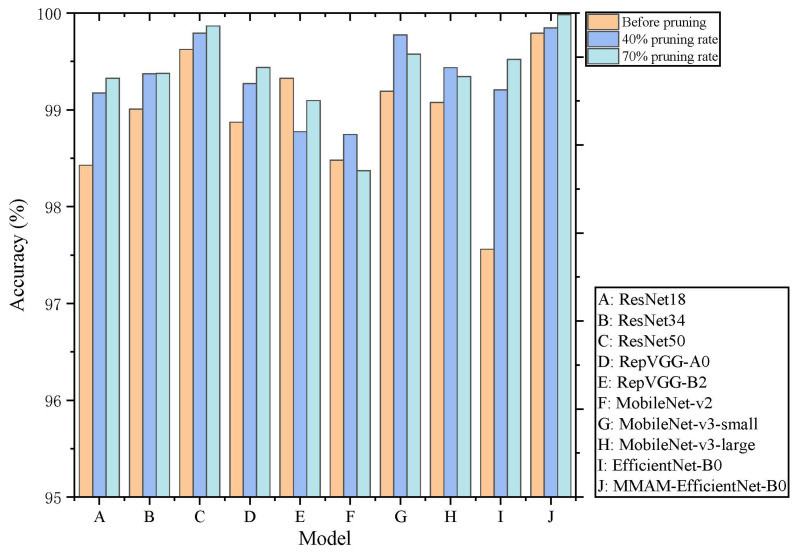 Figure 12
Figure 12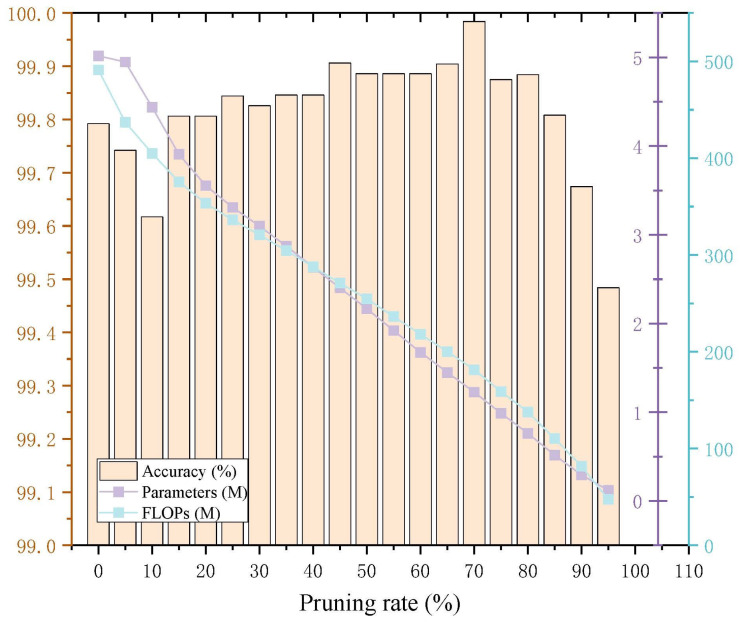 Figure 13
Figure 13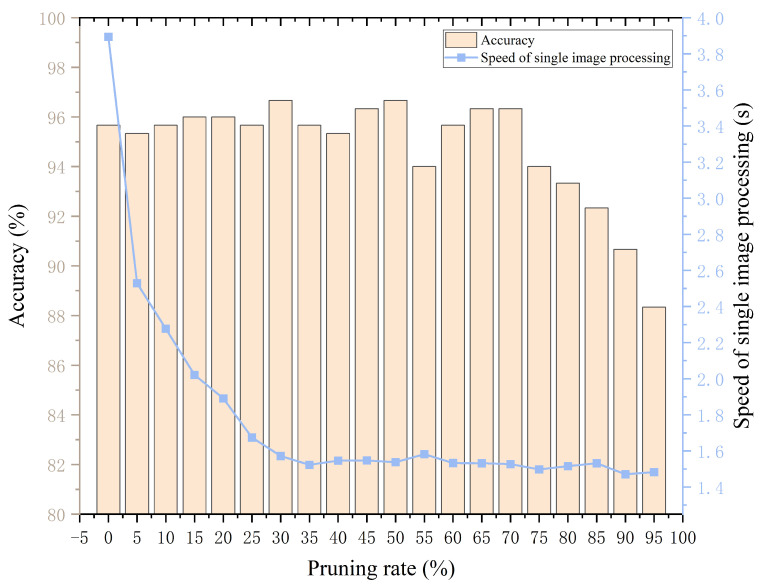 Figure 14
Figure 14 Figure 15
Figure 15- —Jiangsu Provincial Key Laboratory of Network and Information Security, China
- —Natural Science Foundation of the Jiangsu Higher Education Institutions, China
- —Yancheng Basic Research Fund Project, China
- —Funding for School-Level Research Projects of Yancheng Institute of Technology, China
- —2023 Graduate Student Outstanding Dissertation Cultivation Program, China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIndustrial Vision Systems and Defect Detection · Advanced Neural Network Applications · Surface Roughness and Optical Measurements
1. Introduction
With the development of the global economy, steel enterprises are shifting from increasing production capacity to intelligent and refined production, in which defect detection and recognition on the surface of hot-rolled steel strips (HRSSs) is a key technology to improve the quality of steel products and realize intelligent production [1]. At present, the production line speed is gradually increasing, the user’s product quality requirements are increasingly strict, and there is an urgent need to improve the detection efficiency and recognition accuracy of surface defects in strip steel. However, existing defect detection and recognition methods often rely on expensive GPUs with high computational power. These devices are usually stationary, consume a lot of energy, and are not suitable for detection in mobile or no-power-supply scenarios. Therefore, it is necessary to study a more lightweight model that can run in embedded devices, meeting the mobility requirements of industrial production while ensuring accuracy.
Among the many HRSS classification models proposed, most of them focus on improving classification accuracy [2,3,4]. Among these approaches, few scholars have ported HRSS classification algorithms to the embedded end, making them ineffective for mills. The obsession with accuracy will inevitably make the network deeper and the model bloated, which further leads to excessive energy consumption during operation. To solve this problem, many scholars have proposed different methods. Li et al. [5] proposed a lightweight network, CASI-Net, which can effectively reduce the parameters through the design of lightweight modules in the network; unfortunately, the authors did not port the algorithm to the embedded side for further research. Lu et al. [6] used knowledge distillation to improve the performance of the model by using a larger training network to teach a smaller network, and obtained high accuracy using only 0.03 MB of parameters. Although the article states that it can be applied to small mobile devices, it is not put into practice. Currently, research in this area faces the following shortcomings:
- There is a lack of a light and convenient HRSS dual-surface defect detection and recognition model with high efficiency and accuracy;
- There are insufficient samples in the commonly used NEU-CLS dataset for HRSS surface defects, resulting in subpar performance when used for training pruned models [7];
- Model pruning algorithms have rarely been applied to HRSS surface defect classification methods.
To compensate for the above shortcomings, this paper proposes a lightweight model for detecting and recognizing dual-surface defects in HRSS. The MMAM-EfficientNet-B0 model [8] is chosen for the basic model of the recognition algorithm, and the model is pruned and improved. Before pruning training, we perform data augmentation on the NEU-CLS dataset to expand 1800 images to 6000 images using StyleGAN3 [9] to generate the images, the water-wave-like noise removal (WWNR) algorithm to denoise them, and Real-ESGAN [10] to repair them with super-resolution. In the pruning process, we remove the squeeze-and-excitation (SE) module from MMAM-EfficientNet-B0, prune the original model to 70% of its original size using the Network Slimming [11] method, and obtain an accuracy of 99.875% in the expanded dataset. The pruned recognition algorithm ported to Raspberry Pi obtains a 96.333% accuracy in the original NEU-CLS dataset, and the recognition classification time for a single image is much less compared to the original model.
In summary, the main contributions of this work are:
- A lightweight HRSS dual-surface defect detection model with high efficiency and accuracy is proposed and designed;
- Combination of StyleGAN3-generated images, WWNR algorithm denoising, and Real-ESGAN super-resolution restoration of images, and used for data augmentation of the NEU-CLS dataset;
- A pruned and modified for the MMAM-EfficientNet-B0 model is proposed, and we apply it to the Raspberry Pi.
The remainder of this paper is organized as follows. Section 2 introduces related work. Section 3 presents the design of our algorithm model. Section 4 describes the experimental process and analyzes the experimental results. Section 5 discusses and summarizes the methods employed in this paper.
2. Related Works
Given that this paper focuses on HRSS data augmentation and lightweight classification models, this section provides an overview of representative and relevant studies in these two research directions.
2.1. Data Augmentation Based on Generative Adversarial Networks
In 2014, Ian Goodfellow et al. [12] combined a restricted Boltzmann machine with a variational autoencoder, introduced the idea of maximal and minimal bilateral games, and proposed a generative adversarial network model consisting of a discriminator and generator to form a generative adversarial network (GAN). GAN was proposed for generating realistic images, and later, many scholars improved and optimized this architecture and used it for the augmentation of different types of data.
Cui et al. [13] applied GAN to Synthetic aperture radar (SAR) image data augmentation by utilizing Wasserstein GAN (WGAN-GP) to increase the number of samples in the training dataset based on the existing SAR data. Based on this, filters are added to extract high-quality and specific azimuthal angles from the generated samples to avoid randomness in data augmentation and to improve the quality of the newly generated training samples. Gao et al. [14] proposed a leaf-bootstrapping method to improve the performance of DCGAN (Deep Convolutional Generative Adversarial Network) under the opportunity of a lack of labeled data in Civil Engineering problems. Mok et al. [15] applied data augmentation with GAN to the medical imaging field, using the data augmentation method of GAN to address the challenge of deep neural network training difficulties due to limited training samples for brain tumor segmentation containing annotations. The application of GANs for data augmentation effectively addresses the problem of insufficient training samples in medical imaging [16]. Sandfort et al. [17] applied CycleGAN to the task of visceral CT segmentation, which reduces the manual segmentation effort and cost in CT imaging. Liu et al. [18] proposed a Leaf GAN model, which provides a feasible solution for data augmentation of grape leaf disease images, improves the recognition accuracy, and overcomes the overfitting problem faced by the recognition models.
The generative ability of GANs is not limited to images; many scholars have also used the method to generate other types of data, such as speech, signals, and so on. Qian et al. [19] used a GAN to generate speech samples by generating spectral features based on spectral features applied to a noisy task and got significant improvement. Shao et al. [20] obtained convincing sensor data by applying the framework of ACGAN for data augmentation in machine fault diagnosis of mechanical sensor signals machines. Gao et al. [21] applied WGAN-GP to the challenge of low data or unbalanced datasets in industrial fault diagnosis to generate data samples that complement the low data input set in the field of fault diagnosis and contribute to the improvement of fault diagnosis accuracy. Fahimi et al. [22] introduced a DCGAN-based framework for generating artificial electroencephalography (EEG) data to enhance the performance of brain-computer interface (BCI) classifiers. The proposed method achieved promising results in generating subject-specific artificial EEG data to reduce the calibration time in EEG-based BCI applications.
2.2. Research on Lightweight Surface Defect Classification Algorithms for HRSS
With advances in graphical computing and deep learning, the classification of surface defects in strip steel has gradually shifted from manual methods to computer vision. Lightweighting of the model is essential if the proposed visual model is to be applied in practice.
Zhou et al. [23] lightened YOLOv5s by using the Ghost module, which was used to replace parts of the network’s structure to reduce the model parameters and complexity, thus reducing the model’s parameters and computation and improving efficiency. The experimental results prove that the proposed model meets the demand for real-time recognition of HRSS defects in industrial production. Bouguettaya et al. [24] selected two state-of-the-art MobileNet-V2 and Xception lightweight models as the infrastructure and combined them with transfer learning for training. The selection of these lightweight models improves the speed of model recognition and helps in the real-time development of a surface defect recognition system for HRSS. The following year, they [3] compared the then state-of-the-art convolutional neural network (CNN) models in terms of classification performance by screening them on the NEU-CLS dataset, and concluded that the methods based on MobileNet-V2 and InceptionResNetV2 outperformed the other models in terms of accuracy, loss, training and inference time, and model size. Shao et al. [25] proposed a multi-scale lightweight neural network model for the classification of surface defects of steel bars, which takes the fusion coding module as the core and utilizes the Gaussian difference pyramid to construct a multi-scale neural network, which not only reduces the number of model parameters but also compresses the model size and achieves better classification accuracy.
In addition to lightweighting the model itself, there are other ideas to improve the efficiency of strip inspection. Luo et al. [26] proposed selectively dominant local binary patterns (SDLBPs) for the classification of defects, which requires less computing power. For surface defect detection, the SDLBP framework achieves a balanced performance between classification accuracy and time efficiency, with the flexibility to obtain various variants depending on the application. Zhang et al. [27] are to remove spatial redundancy, coding redundancy, and extraneous information redundancy from an image by image compression, thus reducing the storage space of the image and improving the transmission efficiency. The method uses a Convolutional Autoencoder for image compression preprocessing to remove noise unrelated to defects in the detection of defects on the surface of HRSS, which improves the accuracy and efficiency of defect detection.
In summary, although some researchers focus on the lightweight model itself and claim the method can be used on mobile devices, few scholars have conducted tests on mobile devices.
3. Recognition Algorithm Model Optimization
In this section, we will introduce the model optimization of the HRSS surface defect recognition algorithm. We describe the overall structure of the model optimization, then introduce data augmentation and model pruning. In data augmentation, this is achieved through StyleGAN3 image generation, WWNR denoising, and Real-ESGAN super-resolution. In model pruning, the MMAM-EfficientNet-B0 model is pruned using the newly generated dataset and the Network Slimming algorithm [11] to achieve model compression.
3.1. Overall Structure of the Model Optimization Method for Recognition Algorithm
The recognition algorithm we used is based on MMAM-EfficientNet-B0, data expansion by GAN, and network compression by Network Slimming. The overall flowchart is shown in Figure 1.
To realize MMAM-EfficientNet-B0 for better and faster recognition of surface defects on HRSS at the embedded end, network pruning is performed by the Network Slimming method, and the data required for network pruning is expanded by a combination of StyleGAN3 [9] and Real-ESRGAN [10]. We import the original dataset NEU-CLS into the StyleGAN3 model for training. After the training is completed, the data named NEU-CLS-E is obtained by random vectors brought into the generator of the GAN. The NEU-CLS dataset will be described in detail in Section 4.1.1. There is a lot of water-wave-like noise in NEU-CLS-E. To remove the effect of these noises on the model compression training, the WWNR algorithm is utilized for denoising, and then super-resolution computation is carried out through the Real-ESRGAN model, and the size is adjusted to obtain the final expanded dataset NEU-CLS-EFS. The NEU-CLS-EFS contains much more data than the original dataset, enabling better results in the Network Slimming model training [7]. In model pruning, the compression of the network is achieved through pre-training, pruning, and fine-tuning to obtain the final network structure and weights, where both pre-training and fine-tuning are performed on the NEU-CLS-EFS dataset.
3.2. Data Augmentation
We first perform data augmentation with StyleGAN3 and discover the problem of waterline noise that can arise. Fan et al. [8] Clarifies the limitations of traditional data augmentation methods, and emphasizes the core advantages of the proposed augmentation method combining Generative Adversarial Networks (GAN) in terms of defect feature expansion and sample authenticity. To address this problem, we propose the WWNR algorithm to remove the waterline noise, and then use the Real-ESRGAN super-resolution method to repair the removed image details, which ultimately realizes the data enhancement.
3.2.1. StyleGAN3 Data Augmentation
We apply StyleGAN3, a face-expansion model, to the HRSS surface defects dataset, and the images trained on the NEU-CLS dataset are more detailed and lifelike than those from other datasets. The unique feature of this model is the generator network, as shown in Figure 2.
We follow the method’s guidelines and divide the generator into two sub-networks: the mapping network and the synthesis network, whose roles are to generate diversification parameters and images, respectively. In the mapping network, the input is a latent z that conforms to a uniform or Gaussian distribution, so the coupling between the variables is relatively large, and the mapping network is needed to decouple z into w, which is then fed into the synthesized network through affine transformations, respectively. In the synthesis network, a 13-layer style block adapts the input features according to w, thus affecting the direction of final image generation.
The key improvement of StyleGAN3 over its predecessor is the mapping of discrete features to continuous features, which allows Fourier features to be easily subjected to translation and rotation operations, resulting in more realistic and detailed images. But this also consequently appears as a water-wave-like noise in the generated image, as shown in Figure 3. The more representative water-wave-like noise is marked out in red.
3.2.2. Water-Wave-like Noise-Removal Algorithm
To minimize the effect of water-wave-like noise in the generated image, we propose a water-wave-like noise-removal (WWNR) algorithm. Based on the properties of water ripples, we found the center point of the ripples through morphological operations. Morphological operations can be used to thin and connect the water wave by an erosion operation and then to find the center of the water wave by an expansion operation. Once a candidate region for the centroid of the water wave has been identified, the least-squares method can be used to further optimize the centroid’s location and to use it as the center to form a mask in preparation for later filtering and noise reduction.
Bilateral filtering is chosen as a filtering and noise-reduction method that can preserve edges while smoothing noise, making it more suitable for removing water-wave-like noise. Like other filtering principles, such as mean filtering, bilateral filtering uses weighted averaging to represent the intensity of a particular pixel as a weighted average of the surrounding pixel brightness values, and the weighted average used is based on a Gaussian distribution. In bilateral filtering, the weights take into account not only the Euclidean distance of the pixels, but also the radial differences in the pixel range domain, such as the degree of similarity between the pixels in the convolution kernel and the center pixel, the color intensity, and the depth distance. These two weights are considered simultaneously in the calculation process as shown in Equation (1):
where the normalization factor is as follows:
In the above two equations, denotes the value of pixel p after bilateral filtering, is the value of pixel q, and S denotes the window centered at p. is a spatial domain kernel that depends on the distance of the pixel position. is a pixel domain kernel that depends on the difference in pixel values. In the flat region of the image, the pixel values vary less, and the corresponding pixel range domain weights are close to 1. At this time, the spatial domain weights play a dominant role, and the Gaussian blurring effect is realized. Whereas, in the edge region of the image, the pixel values vary more, and the pixel range domain weights are increased so that the edge information is preserved.
In Equations (1) and (2), the spatial domain kernel is calculated as follows:
The equation for the pixel domain kernel is as follows:
In Equations (3) and (4), and are set parameters, and n are coordinate position variables during the computation process, represents the center of the window represents a value q in the sliding window.
The water-wave-like noise removal method for HRSS defective images generated by SyleGAN3 is shown in Algorithm 1. The WWNR algorithm removes most of the water-wave-like noise, but it also mistakenly removes some details of the strip defects, which can have an impact on the subsequent model training, as shown in Figure 4.
Algorithm 1: Water-Wave-like Noise-Removal Algorithm
3.2.3. Real-ESRGAN Super-Resolution
To compensate for the loss of details brought about by the WWNR algorithm on the generated images, we employ the Real-ESRGAN network to repair and refine the details. We self-construct the NEU-CLS high-resolution, low-resolution paired dataset. The Real-ESRGAN network is then trained on this data to obtain the generator’s training weights. Then the filtered and denoised image is imported into the Real-ESRGAN generator, super-resolved to a high-resolution image. The final image is compressed to its original resolution.
The self-constructed NEU-CLS super-resolution dataset is obtained by taking the original NEU-CLS dataset as the high-resolution data and performing two first-order degradations [10] on this data to obtain pairs of low-resolution data, as shown in Figure 5. The first-order degradation model is the conventional degradation model, as shown in Equation (5):
where x denotes the degraded image, D denotes the degradation function, y denotes the original image, k denotes the blur kernel, r denotes the reduction ratio, n denotes the added noise and JPEG denotes the compression performed. For the Gaussian blur kernel, isotropic and anisotropic kernels are included. The purpose of adding a 2D sinusoidal filter is mainly to set different parameters to mimic the ringing and overshoot artifacts in practice. For downsampling, we use bilinear interpolation to realize the image reduction operation. The added noise obeys not only the Gaussian distribution but also the Poisson distribution. JPEG compression reduces the size of image files while maintaining high image quality.
The Real-ESRGAN network has the same basic structure as a GAN and consists of two parts, the generator and the discriminator, as shown in Figure 6. The generative network is ESRGAN, which adds image sharpness enhancement with scaling factors of ×2 and ×1 to the original. For the super-resolution of the input image with a scaling factor ×4, the network is fully consistent with the ESRGAN generator structure; For the super-resolution of the input image with scaling factors ×1 and ×2, the incoming feature maps are first pixel-unshuffled. Here, pixel-unshuffle is the inverse operation of pixel-shuffle, i.e., the tensor with shape is rearranged and converted to a tensor with shape . The number of image channels is expanded to reduce image resolution, and the processed image is then fed into an ESRGAN network comprising a convolutional layer, a Residual-in-Residual Dense Block (RRDB) module, an upsampling layer, etc., for super-resolution reconstruction. The discriminative network is selected from U-Net’s discriminative network [28], which is capable of judging the authenticity of individual generated pixels, ensuring that the details of the generated image are attended to while the generated image as a whole remains authentic. The network mainly consists of convolutional layers and spectral normalization. The introduction of spectral normalization helps to alleviate the training instability problem caused by complex datasets and network structures.
3.3. Model Pruning
We use channel-wise pruning methods to achieve model sparsity, unlike methods such as weighted pruning, which require specialized software or hardware gas pedals to accelerate inference. It mainly achieves model compression by pruning certain layers or channels of the original network, but this also leads to the problem of less flexibility. Its effectiveness is not significant until the network is deep enough. Relative to other techniques, channel-wise sparsity strikes a balance between flexibility and ease of implementation, as it can be applied to any typical CNN or fully connected network, generating results that are essentially simplified versions of the original network.
Our method is guided by Network Slimming [11], which crops the convolutional and BN layers of MMAM-EfficientNet-B0, and the realization is shown in Figure 7a. Figure 7b shows the layers that need to be pruned for this network and the improvements made to the network before pruning. Where the red dashed box is the layer to be pruned, containing the convolutional layer, the BN layer, and the depthwise separable convolutional layer. The deletion of the SE module, on the one hand, reduces the influence of the convolutional layer in the SE module caused by pruning, and on the other hand, it can further streamline the network, and the structure of the MMAM-EfficientNet-B0 model has been described in detail in a previous study [8].
In Network Slimming, each channel adds a scaling factor, multiplied by the output of that channel. The network weights and these scaling factors are then trained jointly, and sparse regularization is applied to the latter. Finally, the channels with small scaling factors are directly clipped, and the trimmed network is fine-tuned. Specifically, the overall goal equation for Network Slimming is as follows:
where denotes the input and target values for training, W denotes the trainable weights, denotes the value of the training loss of the CNN, is the penalty term imposed on the scaling factor, and is the balancing factor of the two terms. L1 paradigms are employed in our experiments to achieve sparsity, i.e., , specifically using subgradient descent as an optimization method for non-smooth L1 penalty terms. By applying an L1 paradigm to a channel, pruning all incoming and outgoing connections of that channel, a streamlined network is directly obtained without resorting to special sparse computation packages. The scaling factor indicates the importance of channel selection, and since the regular term of the scaling factor and the weight loss function work together to perform the optimization, the network can automatically identify unimportant channels and remove them, with little impact on the generalization performance of the network.
Currently, most CNNs include a Batch Normalization (BN) layer, which is a standard method for accelerating network convergence and improving performance. The BN layer performs the transformation operation by normalizing the internal activation values with a small number of statistical properties as follows:
where and are the inputs and outputs of the BN layer, respectively; B denotes the current small batch, and are the mean and standard deviation values of the input activation on B; and are trainable affine transformation parameters, representing scale and shift, respectively, which provide the possibility of a linear transformation for the normalized activation. We utilize the BN layer in MMAM-EfficientNet-B0 as the scaling factor required for Network Slimming. The biggest advantage of this method is that it does not introduce additional overhead to the network.
With the introduction of the scaling factor regularity term, many of the scaling factors in the generated model converge to zero. Channel pruning is performed by removing channels that have a near-zero scaling factor, eliminating all their incoming and outgoing connections and associated weights. Prune the channel on all layers using a global threshold that is some percentile of all scaling factor values. If a scaling factor of 70% is selected for pruning, then 70% of the channels with lower weights will be pruned. This results in a more compact network with fewer parameters, less runtime memory, and fewer computational operations. Although this may temporarily lead to some loss of accuracy at higher pruning rates, this can be compensated for by fine-tuning the pruned network.
4. Experiment and Results
In this section, each of the three parts of data expansion, model pruning, and embedded practical test testing will be described.
4.1. NEU-CLS Dataset Expansion
Our NEU-CLS dataset expansion is mainly obtained by StyleGAN3 for generating fake images, the WWNR algorithm for removing water-wave-like noise, and Real-ESRGAN for repairing the details, and the quality of GAN-generated images is judged by the image presentation and quantitative metrics in the experiments.
4.1.1. Experimental Environment Setup and Dataset Introduction
The experiments in this subsection are based on the following hardware and software environments: an Intel(R) Xeon(R) Gold 6258R CPU @2.7GHz processor, 512 G RAM, two NVIDIA Tesla V100s-PCIE GPUs with 32 GB of RAM for each GPU respectively, a Python-3.9 interpreter, a PyTorch-1.11 deep learning library, CUDA-12.0 parallel computing architecture, and Windows 10 operating system.
The dataset used in our experiments comes from NEU-CLS, created by Song et al. [29] at Northeastern University. The dataset contains six classes of HRSS surface defects, as shown in Figure 8, namely Rolled-in Scale (RS) formed by pressing in of secondary iron oxide formed between finishing mills due to roughness of finishing work roll surfaces, Patches (Pa) formed by pressing in of iron filings and other detritus from cracked edges attached to the steel plate during rolling, Crazing (Cr) caused by poor cleaning and overheating of slab edges, Pitted Surface (PS) due to poor management of cooling water in the rolling bath or improper cooling methods, Inclusion (In) due to debris pressed into the steel plate by various rolls attached to the rolling and finishing lines, and Scratches (Sc) due to fixed protrusions on the rolling and finishing lines. There are 300 images of 200 × 200 size for each defect class, and the dataset images are scaled to 224 × 224 × 3 for the convenience of modeling, corresponding to width, height, and channel, respectively.
4.1.2. Data Expansion and Ablation Experiments
In StyleGAN3’s NEU-CLS image generation experiments for surface defects on HRSS, the learning rates for the generator and discriminator networks are set to 0.002, and the batch size is 32. The gamma is set to 6.6, which is the R1 regularization weight; the larger the value, the more stable the model is, and the smaller the value, the more diverse the model is. The cfg selects StyleGAN3-R mode, i.e., it means that isotropic translations and rotations are included in the generated image. The total number of iterations for a training session is 1000 rounds, and the training duration is 20 h with the support of 2 GPUs. There are six classes of defects in the NEU-CLS dataset, which need to be trained six times to get the generator weights for the six defects. The obtained weights are then used to generate 10,000 images per class, for a total of 60,000 images, named NEU-CLS-E. Then the noise is removed using the WWNR algorithm according to the method in Section 3.2.2 to obtain the NEU-CLS-EF. Finally, NEU-CLS-EF is super-resolved by the trained Resl-ESRGAN network and resized to the original size to obtain NEU-CLS-EFS. To compare the quality of the generated images, WGAN and WGAN-GP were also added in this study, and the generated images were NEU-CLS-WGAN and NEU-CLS-WGAN-GP, respectively. The images generated by these two models and the images generated by StyleGAN3 under the same configuration are shown in Figure 9. It can be seen that the images generated by WGAN and WGAN-GP are mainly dark, with no obvious change in brightness, and there is no StyleGAN3-generated image that has the feeling of natural light and shadow, which appears to be not real enough. And there are obvious jagged lines in Cr, Pa, and PS of NEU-CLS-WGAN, which are seriously inconsistent with the target image. It is moderated in the NEU-CLS-WGAN-GP images, but most of the images in Sc are too dark and the jagged grain is more pronounced in the lighter images. A lot of water-wave-like noise can be seen in the NEU-CLS-E image generated by StyleGAN3, especially In1, In2, and Sc2 are very obvious. With the WWNR algorithm, the water-wave-like noise in the image is reduced significantly, and the details are repaired using Real-ESRGAN to obtain the final dataset NEU-CLS-EFS.
Compared to the original dataset, to the naked eye, there is very little difference in either light and shadow or generation detail. Of course, it is not possible to evaluate the dataset solely with the naked eye, and we use the MMAM-EfficientNet-B0 model from a previous study [8], and the weights trained to achieve 100% accuracy to evaluate images generated by WGAN, WGAN-GP, and StyleGAN3. Each generative model generates 10,000 images per class of defects, for a total of 5 × 6 × 10,000 images, plus the common generative image metric FID (Frechet Inception Distance), to obtain the experimental results shown in Table 1. PV > 0.9 (Predicted Value) denotes that 10,000 defective images generated are recognized as such by the MMAM-EfficientNet-B0 model with weights, and the predicted value is greater than 0.9. UPV (Usable Predicted Value) denotes the average of all PVs recognized as PV > 0.9, and APV (Average Predicted Value) denotes the average of all 10,000 image-recognized PVs. The FID metric measures the distance between the generated samples and the real samples, with smaller values indicating that the generation quality is closer to the original dataset. From the data, our method is not always the best in terms of quality metrics for generating each class of defective images, but these metrics do not fully account for the strengths and weaknesses of the dataset generation, especially the FID values. Currently, the metrics for generated images are evaluated using weights trained on the ImageNet dataset with the Inception V3 network as the recognition network. However, the dataset images used for the experiments are not contained within the ImageNet dataset, so the results of the evaluation are not very accurate.
Based on this, we test the quality of the generated data by using the generated images instead of the original dataset for training; i.e., the generated images serve as the training set, and the original images as the test set. 1000 images of each class of defects generated in this experiment are selected, and a total of 6000 images for each dataset to be tested are used as MMAM-EfficientNet-B0 training sets, respectively. The dataset to be tested is divided into 8:2 according to the training set and test set, and the stochastic gradient descent (SGD) optimizer is selected, with an initial learning rate of 0.01, decreasing learning rate by cosine annealing algorithm, with momentum set to 0.9, weight decay of 10-4, and a batch size of 4, and training is carried out for 50 epochs. Train according to the same experimental parameters to get the trained network weights and test the original dataset NEU-CLS by the network paired with the weights, and the obtained experimental results are shown in Figure 10:
The figure shows that the generated image of WGAN trained as a training set is very poor in recognizing the NEU-CLS image, except for the Sc and Pa class defects, which are relatively well recognized; the other class defects are very poorly recognized, and the total recognition accuracy is only 39.7%. The recognition performance of the network on Cr, In, and PS types of defects is relatively poor after training on the dataset generated by the WGAN-GP method, with an accuracy of 45.7%. After training on a dataset generated directly by StyleGAN3, recognition performance for defects is significantly improved, with an accuracy of 84.8%, except for the In defect, which still shows relatively poor recognition performance. After denoising by the WWNR algorithm, the recognition of defects in each class is dramatically improved, and the recognition accuracy is increased to 95.3%. Finally, after training the NEU-CLS-EFS dataset obtained from the Real-ESRGAN supplemental details, the defect recognition for each class is further improved, achieving 95.4% recognition accuracy. It can be seen that the training effect of the NEU-CLS-EFS dataset obtained after the method of Section 3.2 in MMAM-EfficientNet-B0 is very close to that of the original dataset NEU-CLS, and also, therefore, the method is very effective for the data expansion of NEU-CLS.
4.2. MMAM-EfficientNet-B0 Model Pruning
The pruning to implement the MMAM-EfficientNet-B0 model implements the pruning of the EfficientNet-B0 model. In the network model of EfficientNet-B0, the main part is composed of 16 MBConv modules with different parameters, and the Network Slimming method focuses on pruning the convolutional, depthwise separable convolutional, and BN layers in this module.
4.2.1. Experimental Environment Setup
The experiments in this subsection are based on the following hardware and software environments: an Intel 12-core Xeon E5 processor with 8 G RAM, an Nvidia RTX 3070 Ti GPU with 8 G of graphics memory, the Python-3.7 interpreter, the PyTorch-1.7 deep learning library, the CUDA-11.3 parallel computing architecture, the cuDNN-8.2 deep neural network library, the PyTorch-Lightning acceleration framework version 1.1.5, Windows 10 operating system.
4.2.2. Comparison of Multi-Model Pruning Experiments
A set of controlled experiments is designed to investigate the effect of removing the SE attention module from the EfficientNet-B0 and MMAM-EfficientNet-B0 models on recognition accuracy and model lightweight. These two original models and the model with the SE module removed are trained on the dataset separately, and the accuracy, Loss value, number of parameters, number of floating point computations per second (FLOPs), and training duration of the models are recorded.
In the experiments, the expanded dataset NEU-CLS-EFS obtained in Section 4.1 is divided into 8:2 according to the training set and the test set, and preprocessing operations such as random cropping, flipping, rotating, and erasing are performed. The SGD optimizer is selected, the initial learning rate is set to 0.01, the learning rate is decayed according to the cosine annealing algorithm, the momentum is set to 0.9, the weight decay is set to 10-4, and the batch size is set to 2 for 100 epochs of training. The accuracy and Loss value versus epoch curves of their experimental results are shown in Figure 11. From the figure, it can be seen that the MMAM-EfficientNet-B0 model converges significantly faster than EfficientNet-B0 on the extended NEU-CLS dataset, and the recognition accuracy is also higher. On the comparison of the results with and without the SE module, the EfficientNet model without the SE module converges relatively fast, but due to the poorer convergence values of accuracy and Loss values than the model with the SE module, it results in catching up at a later stage and produces intersections, which is particularly evident in Figure 11b. In terms of the stability of the training results, the network with the SE module gets smoother accuracy per epoch, while the stability of the network without the SE module is not as strong. As shown in Table 2, the effect of the EfficientNet-B0 model with and without the SE module on the number of network parameters, computational complexity, and training duration is demonstrated. Where the accuracy and loss values are averaged over the last 10 epochs of training taken, and the results of FLOPs are calculated with inputs of [1, 3, 224, 224] ([batch size, channel, width, height]).
From the data in the Table 2, it can be seen that the same model without an SE module network decreases the accuracy by about 3 percentage points compared to the original model, the Loss goes up by about 0.06, the parameters decrease by 15.92%, the FLOPs decrease by 0.15%, and the training duration is shortened by 50%. The experimental results show that in the EfficientNet-B0 and MMAM-EfficientNet-B0 models, the lack of an SE module does not have a significant effect on the accuracy, but it greatly reduces the training time and improves the training efficiency of the models. Therefore, the networks with SE modules in the following experiments have the SE modules removed.
The multiple networks selected in this subsection include ResNet18, ResNet34, ResNet50, RepVGG-A0, RepVGG-B2, MobileNet-v2, MobileNet-v3-small, MobileNet-v3-large, EfficientNet-B0, MMAME-fficientNet-B0, totaling 10 common network structures. In the experiments, the learning rate for normal training is set to 0.01, and 120 epochs are trained; the learning rate for fine-tuning training is set to 0.001, and 120 epochs are also trained. The L1 regularization factor is 0.0001, and the batch size is 4. Model training, pruning, and fine-tuning are performed on the NEU-CLS-EFS dataset using the original model, as well as models pruned by 40% and 70%, as shown in Table 3. It can be seen that the recognition accuracy of most models after pruning and fine-tuning has not been reduced, and in some cases has even improved. Channel-level pruning of the convolutional, depthwise separable convolutional, and BN layers results in varying degrees of reductions in the model’s parameter count and computational cost. Among them, MMAM-EfficientNet-B0 has the highest recognition accuracy on the NEU-CLS-EFS dataset among the compared models at different pruning rates, as shown in Figure 12, and the number of parameters and computational effort is relatively low.
4.2.3. Experiments on the Relationship Between Pruning Rate and Changes in Accuracy Before and After Pruning
To select the appropriate pruning rate for model compression of the MMAM-EfficientNet-B0 model, the model is set to be pruned every 5 percentage points. The experimental parameters are the same as in the previous subsection, and the results are shown in Table 4. It can be seen that the MMAM-EfficientNet-B0 model achieves high accuracy across different pruning rates, and its parameters and FLOPs decrease as the pruning rate increases. Figure 13 shows the pruning effects of MMAM-EfficientNet-B0. It can be seen that the accuracy of MMAM-EfficientNet-B0 increases slowly and then decreases sharply with the pruning rate. The parameters and FLOPs decrease slowly, and the accuracy reaches a maximum at a 70% pruning rate. It can be seen that the MMAM-EfficientNet-B0 model works best when the pruning rate reaches 70%.
4.3. Raspberry Pi Practical Test Experiment
All the above experiments are implemented on a computer with Windows OS using a GPU, to further demonstrate the recognition and operation effects on the embedded side. In this subsection, we experiment with the recognition and compression effect of the MMAM-EfficientNet-B0 model by Raspberry Pi with a camera.
4.3.1. Raspberry Pi-Based Environment Setup
The experiments in this subsection are based on the following hardware and software environments: a Raspberry Pi 4B with an 8G motherboard with a Logitech camera, a 64-bit Raspberry Pi operating system (Linux), the PyTorch 1.7 deep learning library, and the PyTorch Lightning 1.4.9 acceleration framework.
4.3.2. MMAM-EfficientNet-B0 Recognition and Compression Experiment on Embedded Side
In this subsection, 50 images of each defect of the NEU-CLS dataset are selected, for a total of 300 images for the practical test experiments on the Raspberry Pi. We take pictures with the camera during the detection process, and then perform identification and analysis on them. The MMAM-EfficientNet-B0 model with different pruning rates is imported sequentially to recognize these 300 images, and the average time and recognition accuracy for recognizing a defective image are calculated as shown in Figure 14. From the figure, we can see the results of MMAM-EfficientNet-B0 with different pruning rates on a Raspberry Pi, including recognition accuracy and the average execution speed per image. Where the recognition speed of a single image decreases relatively fast until the pruning rate reaches 30%, after which it is based on smoothness. The recognition accuracy is around 96% until the pruning rate reaches 70%, after which the accuracy declines more rapidly. To ensure that the model is lightweight enough while guaranteeing recognition accuracy, we choose MMAM-EfficientNet-B0 at a 70% pruning rate, at which time the accuracy is 96.333%, and the recognition and classification time for a single image is 1.527 s, which is reduced by 155.010% compared to the original model. This shows that the model compression method based on Network Slimming is quite effective for MMAM-EfficientNet-B0.
5. Conclusions
This paper proposes a lightweight model for detecting surface defects in hot-rolled steel strips. We perform channel-level pruning of the MMAM-EfficientNet-B0 model by removing the SE module inside the model; as a result, we retain 30% of the backbone network. For data expansion, we employ StyleGAN3 to generate fake images, the WWNR algorithm to remove waterline noise, and Real-ESRGAN to repair the details. Finally, in the practical test on Raspberry Pi, a recognition accuracy of 96.333% is obtained, and the recognition and classification time for a single image is 1.527 s, which is reduced by 155.010% compared to the original model. Our work aims to alleviate some of the limitations of existing hot-rolled strip steel detection systems, which rely on complex, costly equipment, are cumbersome to operate, and struggle to meet real-time requirements. They also seek to reduce the computational burden of deep neural networks in real-time detection and large-scale data processing. In the future, we plan to extend our approach to include the classification of a wider variety of steel surface defects, beyond just hot-rolled steel strips. By broadening the scope to encompass more defect types rather than limiting it to the six categories currently addressed, we aim to make our method more general and robust, thereby improving its applicability across diverse industrial scenarios.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Davis J. Edgar T. Porter J. Bernaden J. Sarli M. Smart manufacturing, manufacturing intelligence and demand-dynamic performance Comput. Chem. Eng.20124714515610.1016/j.compchemeng.2012.06.037 · doi ↗
- 2He D. Xu K. Zhou P. Defect detection of hot-rolled steels with a new object detection framework called classification priority network Comput. Ind. Eng.201912829029710.1016/j.cie.2018.12.043 · doi ↗
- 3Bouguettaya A. Zarzour H. CNN-based hot-rolled steel strip surface defects classification: A comparative study between different pre-trained CNN models Int. J. Adv. Manuf. Technol.202413239941910.1007/s 00170-024-13341-0 · doi ↗
- 4Zhao Y. Sun X. Yang J. Automatic recognition of surface defects of hot-rolled strip steel based on deep parallel attention convolution neural network Mater. Lett.202335313531310.1016/j.matlet.2023.135313 · doi ↗
- 5Li Z. Wu C. Han Q. Hou M. Chen G. Weng T. CASI-Net: A novel and effect steel surface defect classification method based on coordinate attention and self-interaction mechanism Mathematics 20221096310.3390/math 10060963 · doi ↗
- 6Lu K. Wang W. Feng X. Zhou Y. Chen Z. Zhao Y. Wang B. FCC Net: Surface Defects Identification of hot-rolled Strip Based on Lightweight Convolutional Neural Network ISIJ Int.2023632010201610.2355/isijinternational.ISIJINT-2023-182 · doi ↗
- 7Luo J.H. Wu J. Neural network pruning with residual-connections and limited-data Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Seattle, WA, USA 13–19 June 202014581467
- 8Fan H. Dong Q. Guo N. Surface defect classification of hot-rolled steel strip based on mixed attention mechanism Robot. Intell. Autom.20234345546710.1108/RIA-01-2023-0001 · doi ↗