Prognostic Models for Predicting Coronary Heart Disease Risk in Patients with Type 2 Diabetes Mellitus: A Systematic Review and Meta-Analysis
Maicol Cortez-Sandoval, César J. Eras Lévano, Joaquín Fernández Álvarez, Jorge López-Leal, Lady Morán Valenzuela, Raul H. Sandoval-Ato, Hady Keita, Martin Gomez-Lujan, Fernando M. Quevedo Candela, Jesús I. Parra Prado, José Luis Muñoz-Carrillo, Oriana Rivera-Lozada

TL;DR
This study reviews and evaluates prediction models for coronary heart disease in patients with type 2 diabetes, finding moderate accuracy but significant variability.
Contribution
The paper systematically reviews and meta-analyzes prognostic models for CHD in T2DM, highlighting variability and suggesting directions for future model development.
Findings
Pooled AUC of 0.69 with high heterogeneity (I² = 97.4%) indicates moderate discrimination but significant variability across models.
Machine learning and imaging models showed higher AUC but faced limitations like small sample sizes and poor calibration reporting.
Applicability issues were common in models requiring advanced imaging or molecular platforms.
Abstract
Background: Individuals with type 2 diabetes mellitus (T2DM) are at markedly increased risk of developing coronary heart disease (CHD); however, the generalizability and transportability of existing prediction models remain uncertain. Objective: To identify and evaluate multivariable prognostic models developed to predict CHD in adults with T2DM. Methods: We conducted a PRISMA-guided systematic review and meta-analysis of multivariable prognostic models predicting CHD in T2DM populations. Model characteristics and performance metrics were extracted following the CHARMS and TRIPOD-SRMA frameworks, and pooled discrimination was estimated on the logit-transformed AUC scale using a random-effects model (REML, Hartung–Knapp adjustment). Between-study heterogeneity and 95% prediction intervals were quantified, while risk of bias and applicability were assessed using the PROBAST tool. Results:…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
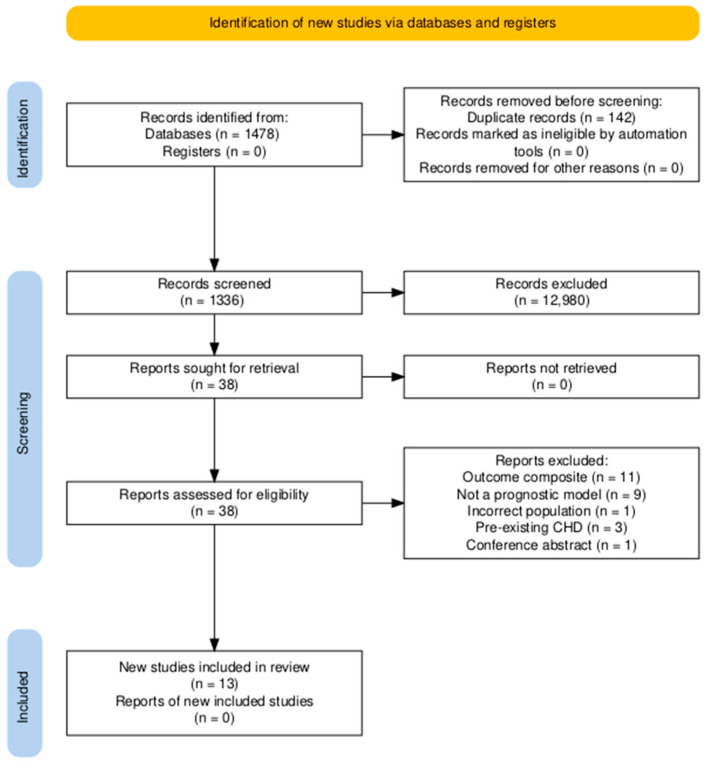 Figure 1
Figure 1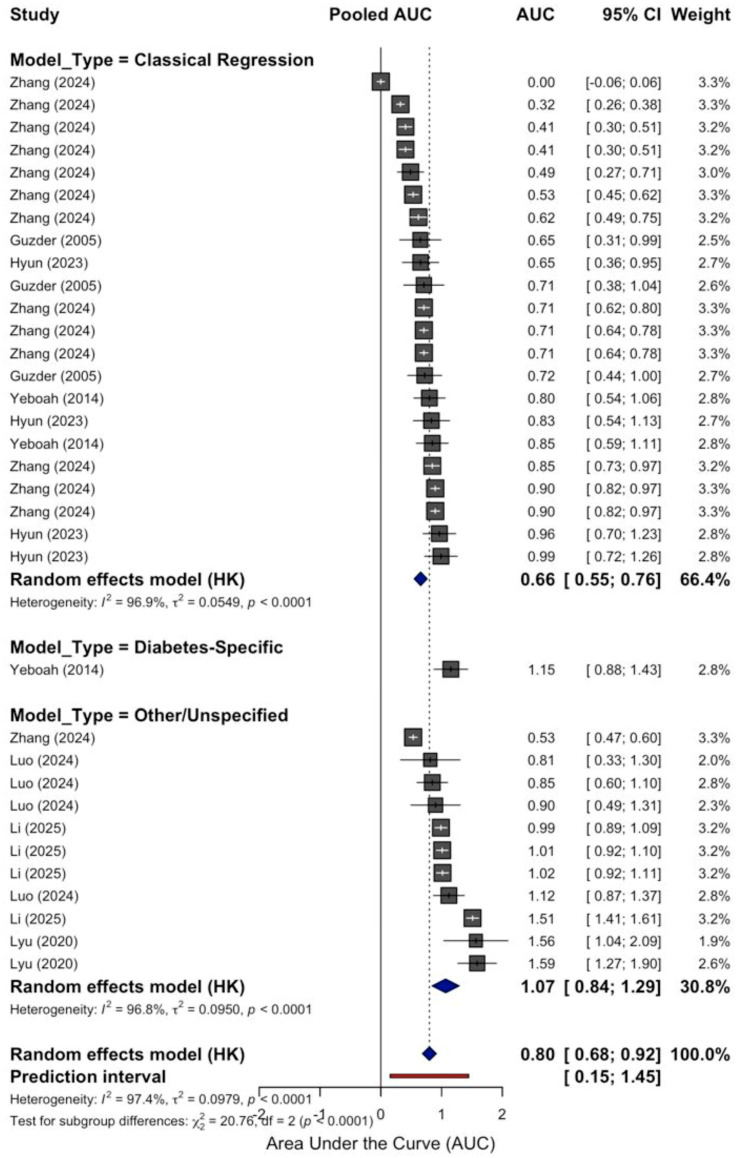 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCardiac Imaging and Diagnostics · Cardiovascular Function and Risk Factors · Diabetes, Cardiovascular Risks, and Lipoproteins
1. Introduction
Type 2 diabetes mellitus (T2DM) is closely linked with a markedly elevated risk of developing coronary heart disease (CHD), a condition that continues to be the principal cause of mortality among individuals with T2DM [1,2]. This association highlights the importance of accurately assessing cardiovascular risk in this population, both to guide clinical decision-making and to implement targeted preventive strategies [3]. In response, a variety of prognostic models have been designed to estimate the probability of CHD events specifically in people with T2DM. These models span from widely recognized tools such as the Framingham Risk Score and the UK Prospective Diabetes Study (UKPDS) Risk Engine [4,5] to more advanced approaches that integrate imaging technologies, proteomic data, demographic characteristics, and serum biomarkers. However, the predictive reliability and applicability of these models often vary when tested across different populations. External validations have revealed notable inconsistencies in both discrimination and calibration, particularly when models are applied to cohorts with distinct demographic or clinical profiles. Moreover, a significant proportion of these tools were developed using small sample sizes, lacked external validation, or combined heterogeneous outcomes, limiting their generalizability. Even models like UKPDS-OM2 (Outcomes Model version 2) and RECODe—which are relatively well-established—have produced inconsistent results depending on the outcome assessed and the characteristics of the validation population. Given these limitations, there is a compelling need to consolidate the existing evidence surrounding CHD risk prediction models in people with T2DM. A systematic review and meta-analysis following established guidelines such as CHecklist for critical Appraisal and data extraction for systematic Reviews of prediction Modelling Studies (CHARMS) and PROBAST [6,7] provides an appropriate methodological framework for critically evaluating the development processes, validation approaches, and performance metrics of these models. The present meta-analysis is designed to address this need by systematically identifying and appraising multivariable prognostic models developed for predicting CHD in adults with T2DM. The objective is to evaluate model discrimination and calibration, assess risk of bias, and explore validation strategies, ultimately offering insights to support better risk prediction and clinical application in diverse diabetic populations.
2. Materials and Methods
This systematic review and meta-analysis was conducted in accordance with the PRISMA 2020 [8] guidelines and followed the methodological standards outlined in the CHARMS and TRIPOD-SRMA frameworks [9]. The primary objective is to evaluate and synthesise evidence from prognostic model studies aiming to predict the risk of CHD in patients diagnosed with T2DM. The protocol has been registered in the PROSPERO database (CRD420251152663).
2.1. Study Design and Eligibility Criteria
Studies were included that developed or validated multivariable prognostic models designed to predict the risk of CHD in adults with T2DM without a history of CHD. The outcome was clearly defined and included myocardial infarction, coronary revascularization (such as angioplasty or bypass surgery), stable or unstable angina, or cardiovascular death. Only original research articles with an observational cohort design, either prospective or retrospective, were considered. Developmental studies were included, which incorporated internal validation techniques such as bootstrap, cross-validation, or data-splitting. External validation studies were included, which assessed model performance in an independent cohort—whether temporal, geographical, or population-based—to determine generalizability. All included studies reported at least one performance metric, such as discrimination (e.g., area under the ROC curve), calibration (slope or intercept), or clinical utility measures, such as net benefit or reclassification indices. Studies focusing on type 1 diabetes mellitus, gestational diabetes, or mixed populations that did not present stratified results for T2DM were excluded. Narrative reviews, editorials, conference abstracts, letters to the editor, and studies conducted in animals or in vitro settings were also excluded. In cases of overlapping study populations, only the most complete and methodologically sound version was retained.
Although inclusion was restricted to coronary heart disease–related outcomes, we anticipated variability in endpoint definitions across studies, ranging from hard coronary events to revascularization procedures and imaging-derived endpoints, which was considered in the interpretation of heterogeneity.
2.2. Eligible Population
The target population for this systematic review comprised adults (≥18 years) diagnosed with T2DM, regardless of duration or treatment status, who were at risk of developing CHD. Eligible studies included participants with a confirmed diagnosis of T2DM according to established clinical or biochemical criteria (e.g., ADA or WHO definitions) and did not restrict inclusion to specific subgroups, such as individuals with established CHD at baseline, gestational diabetes, or other forms of secondary diabetes. Studies that included mixed diabetic populations were only considered if they presented stratified outcomes specific to T2DM.
The outcomes of interest were related to the development of CHD, defined by clinical endpoints such as myocardial infarction, angina pectoris, coronary revascularization (percutaneous or surgical), or cardiovascular mortality. Studies in which CHD was operationalized solely through diagnostic imaging without clinical correlation were included only if their prognostic relevance was explicitly addressed. No restrictions were placed on geographic location, sex distribution, or ethnicity of the study population, although these factors were considered in the heterogeneity analysis.
2.3. Candidate Prognostic Factors
The prognostic models identified in this review were expected to incorporate a broad range of candidate predictors that have been empirically or mechanistically linked to the risk of CHD in individuals with T2DM. These predictors could be clinical, biochemical, genetic, or imaging-based. Among the most consistently evaluated factors were classical cardiovascular risk variables such as age, sex, smoking status, duration of diabetes, systolic and diastolic blood pressure, and body mass index (BMI).
Metabolic and inflammatory biomarkers, including glycated hemoglobin (HbA1c), total cholesterol, low-density lipoprotein cholesterol (LDL-C), high-density lipoprotein cholesterol (HDL-C), triglycerides, and markers of systemic inflammation such as C-reactive protein (CRP) and neutrophil-to-lymphocyte ratio (NLR), were carefully examined. Emerging proteomic biomarkers such as PCSK9, CD27, and NRP1, as well as large endothelin-1 (Big ET-1), were also evaluated for inclusion in validated models and their relative contribution to predictive accuracy. Studies incorporating composite indices such as non-HDL cholesterol, the wide red blood cell-to-albumin distribution width (RAR), or multi-omics data were also included when reported in a prognostic modeling context.
Each predictor was extracted based in terms of its definition, measurement method, unit of analysis, timing of assessment, and whether it was retained in the final model. The frequency and consistency of inclusion across models were documented, and where possible, the relative prognostic weight or effect size was reported. This review provides a comparative synthesis of prognostic factors across different studies to determine which predictors consistently demonstrate strong and independent associations with the risk of CHD in populations with T2DM.
2.4. Search Strategy
A comprehensive electronic search was conducted in MEDLINE (via PubMed), Embase, Scopus, and Web of Science to identify relevant studies from inception to April 2025. The search strategy employed a combination of controlled vocabulary and free-text terms related to (“type 2 diabetes mellitus”), (“coronary heart disease”), (“prediction model”), (“risk score”), (“prognostic”), and (“validation”). No language restrictions were applied. In addition, the reference lists of all included relevant articles and reviews were reviewed to identify further eligible studies. The complete search strategy for each database is included in the Supplementary Material.
2.5. Study Selection Process
All retrieved records were uploaded into EndNote 20 for de-duplication and then imported into the Rayyan platform for systematic screening. The selection process was conducted in two phases: an initial screening of titles and abstracts, followed by a full-text review. Two reviewers trained in systematic review methodology performed both stages independently. Discrepancies were resolved through discussion and, when necessary, by a third reviewer. A PRISMA flow diagram was used to document the screening process and justify exclusions at each stage.
2.6. Data Extraction and Management
Data extraction was performed independently by two reviewers using a standardized and pilot-tested form developed based on the CHARMS checklist. Extracted data included general study characteristics (authors, year, country, setting), participant characteristics (age, sex, diabetes duration, comorbidities), model specifications (type of model, predictors used, method of selection, modeling techniques), outcome definitions and follow-up duration, performance metrics (e.g., AUC, calibration slope, Brier score), and the nature of internal or external validation (e.g., split-sample, bootstrapping, temporal or geographical validation). Where necessary, authors of primary studies were contacted to obtain missing or incomplete information.
2.7. Risk of Bias and Applicability Assessment
To evaluate the methodological quality and applicability of each included study, the Prediction Model Bias Risk Assessment Tool (PROBAST) was used [10]. This tool assesses risk of bias across four domains: participants, predictors, outcome, and analysis. Each domain was rated as low, high, or unclear risk of bias, and an overall judgment was provided for each model. Applicability was also assessed based on the relevance of the study population, predictors, and outcomes to the review question. Two reviewers conducted the assessment independently, and discrepancies were resolved by consensus.
To improve clarity and facilitate interpretation of the PROBAST assessments across multiple domains, a standardized color-coding scheme was applied. Each background color corresponds directly to the categorical judgments defined by the PROBAST tool and was used consistently across all risk-of-bias and applicability domains.
Specifically, green indicates low risk of bias or low concern for applicability, yellow indicates some concerns, and redindicates high risk of bias or high concern for applicability. This visual representation was implemented solely to enhance readability and allow rapid identification of methodological patterns across studies.
2.8. Data Synthesis and Statistical Analysis
A random-effects meta-analysis was conducted to synthesize the discriminative performance of prognostic models for predicting CHD in individuals with T2DM. The primary outcome of interest was the area under the receiver operating characteristic curve (AUC), extracted or derived from studies reporting external validation of prognostic models in at least two independent cohorts. To account for the asymmetry and bounded nature of the AUC scale, reported AUC values were logit-transformed prior to pooling. The meta-analysis was performed using the Metagen function from the {meta} package in R (version 4.3.0), employing a random-effects model with restricted maximum likelihood (REML) estimation and Hartung–Knapp adjustments. Between-study heterogeneity was assessed using the I^2^ statistic and τ^2^ estimates. A 95% prediction interval was computed to evaluate the potential variability in performance across future settings.
Given the expected conceptual heterogeneity across prognostic model classes (clinical scores, imaging-augmented, omics/genetic, and machine-learning approaches), we pre-specified the quantitative synthesis of AUC as an exploratory summary of discriminative performance rather than a clinically transportable estimate. Accordingly, narrative synthesis was prioritized to contextualize performance according to model purpose, predictor requirements, and intended care pathway, and subgroup analyses were used to partially account for differences in model class.
The pooled logit (AUC) was then back transformed to the original AUC scale to facilitate clinical interpretation. Study-specific logit (AUC) values and standard errors were also back-transformed, and a forest plot was constructed using ggplot2 to display the AUC values and corresponding 95% confidence intervals visually. The reference line at AUC = 0.5 was added to denote chance-level discrimination. The pooled AUC across studies was 0.69 (95% CI: 0.66 to 0.71), indicating the included prognostic models’ good discriminative ability. The substantial between-study heterogeneity (I^2^ = 97.4%, τ^2^ = 0.0979, p < 0.0001) suggests that model performance varies across settings and populations. A prediction interval of [0.54 to 0.81] was also estimated on the logit scale, highlighting the potential spread of future AUC values.
Calibration performance was not pooled quantitatively due to inconsistent reporting and definitional variability; instead, it was summarized narratively. Future efforts should focus on standardizing calibration reporting and improving transparency in model validation.
3. Results
3.1. Selection of Studies
Our search identified 1478 records through database searches (PubMed, n = 64; Scopus, n = 1237; Web of Science, n = 123; Embase, n = 54). After removing 142 duplicates, 1336 records were screened by title/abstract, and 1298 were excluded. Thirty-eight full-text reports were assessed for eligibility; 25 were excluded for the following reasons: outcome composite (n = 11), not a prognostic model (n = 9), incorrect population (n = 1), pre-existing CHD (n = 3), and conference abstract (n = 1). Thirteen studies met the inclusion criteria and were included in the review (Figure 1) [11,12,13,14,15,16,17,18,19,20,21,22,23].
3.2. Characteristics of Included Studies
A total of 13 prognostic models externally validated in T2DM populations were identified and evaluated (Table 1). The studies spanned multiple countries, including the United Kingdom, the United States, France, Germany, China, Japan, South Korea, and Malaysia, with publication years ranging from 2005 to 2025. The target population studies comprised adults with T2DM, often without a prior history of cardiovascular disease (CVD), although some studies specifically included high-risk individuals. Sample sizes varied substantially, from fewer than 200 participants to over 20,000.
The predicted outcome in the studies was primarily CHD, encompassing both acute and chronic presentations such as myocardial infarction and stable or unstable angina. However, our focus was restricted to studies that reported CHD as an outcome. We excluded studies that evaluated only composite endpoints—such as major adverse cardiovascular events (MACE)—in which CHD was not reported as an individual outcome (e.g., those including only heart failure, stroke, or other non-coronary events). Some models also examined additional outcomes, including all-cause mortality, heart failure, nephropathy, or stroke, but these were not considered in the primary analyses.
Outcome definitions varied substantially across studies, including hard CHD events (myocardial infarction and coronary death), revascularization-based endpoints, composite cardiovascular outcomes, and, in imaging-focused studies, surrogate or intermediate measures, contributing to between-study heterogeneity.
The predictors used in the models included traditional clinical and laboratory variables (e.g., age, sex, blood pressure, HbA1c, lipids) [24], imaging-derived measures (e.g., coronary artery calcium score [CACS], myocardial perfusion entropy) [25] and, in more recent models, proteomic biomarkers [26]. Modeling approaches were diverse, ranging from traditional regression techniques (e.g., Cox regression, logistic regression) to more complex machine learning methods (e.g., random forests, gradient boosting, LASSO, neural networks). Several studies compared multiple modeling techniques within the same cohort. Validation methods varied, with some models undergoing internal and external validation using independent datasets, while others only performed split-sample or cross-validation. Performance was most frequently reported using the C-statistic or AUC, with values ranging from 0.50 to 0.83. In most studies, inclusion of advanced predictors or machine learning approaches led to modest improvements in discrimination. Calibration metrics were inconsistently reported but indicated variability across models. Notably, the RECODe model [27] and UKPDS Outcomes Model 2 (OM2) [28] were frequently evaluated and served as comparators in several studies. Overall, the heterogeneity in model predictors, populations, and validation methods underscores the variability in performance and the need for context-specific application. Several models demonstrated good discrimination, but overprediction and poor calibration were frequent, especially when applied to contemporary T2DM populations differing from the original derivation cohorts.
3.3. PROBAST Assessment in Included Studies
The PROBAST assessment represents co-primary evidence alongside quantitative performance metrics, providing critical insight into the credibility and transportability of reported model performance.
Across development studies, the analysis domain emerged as the predominant source of high risk of bias, particularly among machine-learning and omics-based models, driven by internal-only validation, limited events per predictor, and incomplete calibration reporting.
Using PROBAST, most studies were methodologically acceptable with respect to who was included and what was measured, but the analysis domain was a consistent weak point (Table 2). Populations were generally well described and appropriate for the review question, particularly in large, population-based cohorts and pragmatic trial datasets. Concerns arose mainly in highly selected settings—such as surgical candidates, hospital high-risk clinics, or asymptomatic individuals undergoing coronary CT angiography—where spectrum effects and referral pathways limit representativeness for routine T2DM care. Predictors were usually routine clinical and laboratory variables (age, sex, blood pressure, HbA1c, lipids), yielding low concern for measurement and availability. Issues surfaced when models depended on non-routine predictors—advanced imaging, large proteomic panels, or ancestry-dependent polygenic scores—where platform dependence, standardization, and resource needs complicate real-world implementation and raise applicability concerns. Outcomes were typically “hard” coronary events (MI, coronary death, revascularization) with clear definitions and ascertainment; uncertainty was more likely when composite endpoints mixed coronary with non-coronary events or when adjudication procedures were insufficiently detailed.
Across studies, the analysis domain drove most of the risk of bias. Development papers—especially those using machine learning, imaging, or proteomics—frequently relied on internal validation only (split-sample or k-fold cross-validation), with limited events per predictor, data-driven variable selection without adequate penalization, incomplete handling of missing data, and sparse reporting of calibration. These features are prone to optimism in apparent performance and undermine transportability. By contrast, large external validations of legacy scores were stronger analytically and more transparent but often revealed miscalibration (typically overprediction) when models were applied to contemporary T2DM cohorts, underscoring the need for recalibration or model updating.
Risk of bias assessment using PROBAST was considered co-primary evidence alongside quantitative performance metrics. In particular, a high risk of bias in the analysis domain was consistently identified, especially among machine-learning, imaging-based, and omics-driven models. This was primarily driven by reliance on internal-only validation strategies, limited events per predictor, data-driven variable selection, and incomplete calibration assessment. Consequently, apparent gains in discriminative performance were interpreted cautiously, as they are likely influenced by optimism bias, restricted external validation, and feasibility constraints that limit transportability to routine clinical settings.
3.4. Meta-Analysis of Prognostic Models
In the pooled analysis of prognostic models for CHD in patients with T2DM, the overall discriminative performance was moderate to good.
The random-effects model yielded a pooled AUC of 0.69 (95% CI 0.66–0.71), with substantial heterogeneity (I^2^ = 97.4%) and a wide prediction interval (0.54–0.81), indicating marked variability in performance across settings. Accordingly, the pooled estimate should be interpreted cautiously as an exploratory summary rather than a directly generalizable performance measure (Figure 2).
Given the substantial clinical, methodological, and conceptual heterogeneity across included studies, the pooled AUC should be interpreted strictly as an exploratory summary of discriminative performance rather than as a clinically transportable estimate. In this context, discrimination alone is insufficient to support clinical implementation. Consequently, pooled AUC values should not be interpreted as evidence for direct clinical adoption of any prognostic model without prior local external validation, appropriate recalibration to baseline risk and treatment patterns, and demonstration of clinical utility through decision-analytic or impact studies.
Subgroup analyses by model type revealed notable differences. Models classified as Classical Regression (e.g., Framingham and UKPDS-derived scores) contributed the largest proportion of studies and showed a pooled AUC of 0.66 (95% CI 0.63–0.68), suggesting only modest discrimination in this population. In contrast, Diabetes-Specific models were underrepresented, with only one eligible study [12], which reported an AUC of 0.76 (95% CI 0.71–0.81); however, the limited evidence precludes robust conclusions. Models grouped under Other/Unspecified, which encompassed mixed or machine learning approaches, showed higher pooled discrimination (AUC 0.74, 95% CI 0.70–0.78), although heterogeneity remained considerable (I^2^ = 96.8%). The test for subgroup differences was statistically significant (χ^2^ = 20.76, df = 2, p < 0.0001), indicating that part of the variability may be explained by the type of model employed. Variability in endpoint definitions likely contributed to the observed heterogeneity and limits the clinical interpretability of pooled discrimination estimates across studies.
Because included studies addressed different clinical questions and care pathways and used heterogeneous predictor sets, the pooled AUC should be interpreted as an exploratory quantitative snapshot rather than a summary applicable to any single implementation context.
Taken together, these findings underscore that while prognostic models for CHD in T2DM demonstrate potentially useful discriminative capacity, their performance varies substantially across methodological approaches and populations. Classical regression-based scores appear to underperform compared to newer approaches, but the latter are often limited by small sample sizes, potential overfitting, and insufficient external validation. The wide prediction interval emphasizes the importance of local validation before clinical implementation.
4. Discussion
4.1. Principal Findings
Across 13 external validations and model developments in people with T2DM, discrimination for CHD-related outcomes was generally modest-to-good. The pooled analysis yielded an overall AUC of 0.69, but with extreme between-study heterogeneity.Given the extreme between-study heterogeneity, the pooled AUC should be interpreted as an exploratory summary of discriminative performance rather than a clinically transportable estimate, with the wide prediction interval underscoring substantial context dependency [11,12,15,16,21,23]. Machine-learning models rarely outperformed strong regression baselines by large margins, and gains were more consistent when models incorporated richer phenotyping (coronary imaging, liver phenotype) or high-dimensional omics [14,17,18,19,20,22]. Transportability remained a critical fault line: model performance and calibration varied substantially across cohorts and care settings, even for widely used tools [13,23].
A key methodological consideration is that the included models are conceptually heterogeneous, spanning classical clinical scores, imaging-augmented tools, and omics/ML approaches that are designed for distinct clinical pathways. We therefore interpret the pooled AUC primarily as an exploratory descriptor of the overall discriminative landscape and as a vehicle to quantify variability (e.g., prediction intervals), rather than as evidence of generalizable performance. The primary contribution of this review lies in the context-specific narrative synthesis and the PROBAST-based appraisal of model credibility and implementation constraints across model classes.
Despite efforts to focus on coronary heart disease outcomes, substantial variability in endpoint definitions across studies remains an important limitation. Some models targeted hard coronary events, whereas others incorporated revascularization, composite cardiovascular endpoints, or surrogate imaging-based measures. These differences reflect distinct clinical questions and care pathways and likely contribute to the extreme heterogeneity observed. Consequently, pooled discrimination metrics should not be interpreted as reflecting performance for a single, uniform CHD outcome.
Importantly, increased algorithmic or molecular complexity should not be interpreted as evidence of clinical superiority per se. In the absence of robust external validation, adequate calibration, and demonstrated impact on clinical decision-making, apparent improvements in discriminative performance remain insufficient to justify clinical implementation. Furthermore, heterogeneity in outcome definitions and endpoint operationalization across studies reflects differences in clinical questions and care pathways and represents a major contributor to the substantial between-study heterogeneity observed in quantitative synthesis.
4.2. Classic Diabetes-Specific Versus General Cardiovascular Scores
Early work comparing UKPDS [29] and Framingham [30] in newly diagnosed T2DM already signaled imperfect transportability: both tools stratified risk but showed limitations when applied outside their derivation era and setting [11]. More recently, UKPDS-OM2 performed sub-optimally in a contemporary UK trial cohort, highlighting calibration drift and emphasizing the need to re-estimate or recalibrate legacy models for present-day care and therapeutics [13]. By contrast, large-scale external validation in UK Biobank suggested that population-based scores such as QRISK/Score can show respectable discrimination in T2DM, but miscalibration is common and clinically meaningful [23]. Together, these data argue that neither “diabetes-specific” nor “general CVD” equations are plug-and-play across T2DM populations without local updating.
4.3. What Do Machine-Learning Models Add?
Although several machine-learning and omics-based models report higher point estimates of discrimination, these incremental gains are generally modest, inconsistent across outcomes, and rarely supported by independent external validation. Importantly, algorithmic complexity should not be conflated with clinical superiority, as many of these models rely on internal-only validation and lack robust calibration assessment, increasing susceptibility to optimism bias.
Moreover, the reliance on resource-intensive predictors, specialized platforms, and limited availability of omics or advanced imaging data substantially constrains the feasibility of these models in routine clinical practice.
Aminian et al. developed individualized 10-year risk tools for surgical and non-surgical T2DM populations; their best AUCs were ~0.79–0.81 for mortality and ~0.66–0.67 for coronary events, with calibration curves close to ideal. In head-to-head testing, the IDC models outperformed RECODe among non-surgical patients, but ML only modestly surpassed regression in select endpoints [16]. A national study from Malaysia applied ML to predict diabetes complications, reporting respectable discrimination using routine clinical data, again underscoring that careful feature curation and validation often matter more than the specific algorithm [15]. Overall, ML helped operationalize multi-outcome calculators and improved usability but did not consistently deliver large accuracy jumps over well-specified regression.
Importantly, apparent gains in discrimination observed in machine-learning and molecular models should be interpreted in light of PROBAST findings, as high risk of bias in the analysis domain suggests that optimism bias likely contributes to their reported superiority.
Consistent with PROBAST findings, the apparent superiority of some machine-learning and molecular models is likely influenced by high risk of bias in the analysis domain rather than by true improvements in generalizable prognostic performance.
4.4. Imaging and Organ-Specific Phenotyping
Several studies demonstrate that imaging enriches risk stratification in T2DM beyond traditional factors. A cohort of asymptomatic T2DM followed for 11 years showed that coronary CT angiography (CCTA) provided strong long-term prognostic information for cardiac death and myocardial infarction [21]. SPECT myocardial perfusion “entropy”—a texture/heterogeneity metric—carried independent prognostic value in high-risk T2DM, highlighting microvascular/perfusion heterogeneity as a pathophysiologic signal [19]. Non-alcoholic fatty liver disease (NAFLD), assessed in patients with suspected CAD, was also independently associated with future cardiovascular events, suggesting hepatic phenotype as an accessible enrichment marker [18]. Earlier development work combining MESA and HNR cohorts showed that adding coronary artery calcium (CAC) to a diabetes-specific CHD tool materially improved discrimination and reclassification, especially in men (2AUC0.73–0.79) [12]. Collectively, these results suggest that an “organ-informed” approach (coronary and hepatic phenotypes) can meaningfully sharpen CHD risk estimates in T2DM.
4.5. Molecular Risk: Proteomics and Polygenic Scores
Two large proteomic studies found that circulating protein signatures in T2DM are strongly associated with incident CHD, with evidence that proteomic signals mediate part of the diabetes–CHD link and may support individualized risk assessment [14,22]. A complementary line of evidence shows that a CHD polygenic risk score (PRS) meaningfully improves discrimination and reclassification in T2DM even after adjustment for traditional risk factors and therapies (statins, antihypertensives, glucose-lowering drugs) [13]. Integration pathways remain a gap: we still lack pragmatic frameworks that blend PRS and proteomic signals with clinical and imaging features in transportable models, and few studies test clinical utility via decision-curve or impact analyses.
4.6. Context Matters: Who Is the Model for?
Risk equations performed differently across: (i) newly diagnosed vs. longstanding T2DM; (ii) asymptomatic screening vs. suspected CAD; (iii) surgical vs. usual care cohorts; and (iv) Asian vs. Western settings [11,15,16,19,20]. For instance, the IDC models were built explicitly to contrast surgical and non-surgical trajectories, while CCTA studies targeted asymptomatic individuals [16,19]. A model for “average clinic patients” without imaging will not be the right tool for a surgical decision or for asymptomatic screening; conversely, image-augmented models may be poorly transportable to primary care without access to CCTA or CAC. These observations reinforce the need for model-to-task alignment and for impact studies that demonstrate net benefit in the intended workflow.
4.7. Calibration, Updating, and Transportability
From a clinical perspective, usefulness depends on accurate absolute risk estimation, appropriate calibration, and demonstrated impact on decision-making, rather than discrimination alone. Across included studies, calibration metrics such as calibration slope, intercept, or calibration-in-the-large were inconsistently reported, precluding quantitative synthesis and limiting clinical interpretability. Consequently, even models with acceptable or high AUC values cannot be assumed to be clinically useful without adequate calibration within the intended care pathway.
Although several studies reported decision-analytic metrics such as NRI, IDI, or net benefit, these measures were not quantitatively synthesized due to heterogeneity in definitions, thresholds, and reference models, which precluded meaningful pooling.
Across validations, miscalibration was frequent and clinically relevant [13,23]. Even when discrimination was acceptable, risk estimates often required recalibration to local outcome rates and treatment patterns. The UKPDS-OM2 [20] example in a modern trial cohort is instructive: therapy evolution (e.g., statins, SGLT2i/GLP-1RA uptake), risk factor control, and case-mix drift can erode the transportability of legacy tools; periodic updating and local recalibration should be the rule, not the exception [13].
Importantly, PROBAST assessments should be considered co-primary evidence alongside quantitative synthesis, as high risk of bias in the analysis domain—particularly among ML-, imaging-, and omics-based models—likely contributes to optimism in apparent performance estimates.
Accordingly, quantitative discrimination metrics and PROBAST-based risk-of-bias assessment should be interpreted jointly, as apparent performance advantages are not clinically meaningful when methodological credibility is compromised.
4.8. Where Are the Biggest Gaps?
First, heterogeneity of outcomes and predictors still complicates synthesis: many models target composite MACE, while relatively fewer report CHD-specific discrimination with full uncertainty (CIs) and calibration plots [16,23]. Second, few studies evaluate net clinical benefit or decision impact; most stop at AUC and internal/external validation [16]. Third, high-dimension markers (imaging, omics, PRS) show promise, but we lack head-to-head comparisons that test incremental value on top of robust clinical baselines, and we have limited evidence in underrepresented regions and ethnic groups [12,14,15,17,18,20,22]. Finally, consistent handling of missing data, transparent feature selection, and prospective impact studies remain under-delivered relative to current reporting standards.
Beyond discrimination, calibration emerged as a critical and consistently underreported limitation across studies. Although several models demonstrated acceptable AUC values, incomplete reporting of calibration metrics—such as calibration slope, intercept, or calibration-in-the-large—precluded quantitative synthesis and limits clinical interpretability. As absolute risk estimation is fundamental for clinical decision-making, the absence of standardized calibration reporting represents a major barrier to real-world implementation, regardless of discriminative performance.
From a broader methodological perspective, these findings align with prior evidence-synthesis work conducted by our group, which consistently demonstrates that high between-study heterogeneity, incomplete reporting of calibration, and reliance on single performance metrics substantially limit the clinical interpretability and transportability of predictive models across diverse settings. Across different clinical domains, our previous systematic reviews and meta-analyses have highlighted the importance of integrating quantitative synthesis with structured risk-of-bias assessment, transparent reporting standards, and context-aware interpretation to avoid overgeneralization of pooled estimates. Collectively, this body of work reinforces that robust methodological appraisal and cautious interpretation are essential prerequisites for translating prognostic models into meaningful clinical decision support [31,32,33,34].
5. Conclusions
Increased algorithmic or molecular complexity should not be interpreted as evidence of clinical superiority in the absence of robust external validation, adequate calibration, and demonstrated impact on clinical decision-making.
In this systematic review of prognostic models for CHD in people with T2DM, average discrimination was moderate-to-good, but performance varied widely across studies and settings. Classical regression tools—often the most extensively validated—showed modest discrimination and frequent miscalibration in contemporary cohorts, underscoring the need for local updating. Newer approaches that incorporate machine learning, imaging, proteomics, or polygenic scores can raise point estimates of discrimination, yet these gains are tempered by high between-study heterogeneity, analysis-domain bias (internal-only validation, limited events per predictor, optimism), and practical constraints that limit transportability.
Therefore, pooled discrimination metrics should not be interpreted as supporting direct clinical adoption of any model class without prior local validation, recalibration, and demonstration of decision-analytic benefit.
From a methodological standpoint, PROBAST highlighted the analysis domain as the principal weak point. Many development studies did not provide independent external validation, robust handling of missing data, shrinkage/penalization, or thorough calibration assessment. By contrast, large external validations in population-based samples were more robust but consistently revealed calibration drift of legacy scores—emphasizing that periodic recalibration should be standard practice.
For clinical use, a stepwise strategy is warranted: begin with a strong, locally recalibrated clinical model; add higher-yield enhancers (e.g., CAC/CCTA, hepatic phenotype) in appropriate contexts; and consider molecular predictors (proteomics, PRS) only where platforms, ancestry considerations, and workflow integration permit. Implementation should be contingent on local validation and demonstrated decision-analytic benefit.
Future research should prioritize (i) standardized CHD endpoints with full reporting of discrimination and calibration (including slope and calibration-in-the-large), (ii) pre-registered, independent external validations with explicit updating strategies, (iii) decision-curve and impact analyses to prove clinical usefulness, and (iv) transparent, updateable multimodal models evaluated across diverse regions and ancestries. Until such evidence is routine, model adoption in T2DM should proceed with careful local validation, recalibration, and clear acknowledgment of setting-specific limitations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhang H. Shi H. Construction of a Prediction Model for Coronary Heart Disease in Type 2 Diabetes Mellitus: A Cross-Sectional Study Sci. Rep.202515700310.1038/s 41598-025-85692-x 40016247 PMC 11868600 · doi ↗ · pubmed ↗
- 2American Diabetes Association Professional Practice Committee 10 Cardiovascular Disease and Risk Management: Standards of Care in Diabetes-2025 Diabetes Care 202548 S 207S 23810.2337/dc 25-S 01039651970 PMC 11635050 · doi ↗ · pubmed ↗
- 3Einarson T.R. Acs A. Ludwig C. Panton U.H. Prevalence of Cardiovascular Disease in Type 2 Diabetes: A Systematic Literature Review of Scientific Evidence from Across the World in 2007–2017 Cardiovasc. Diabetol.2018178310.1186/s 12933-018-0728-629884191 PMC 5994068 · doi ↗ · pubmed ↗
- 4Rathod M.B. Moukthika S. Karikunnel A.J. Harika K. Talla P. Jalakam M. A Cross-Sectional Evaluation of Cardiovascular Risk Assessment in Type 2 Diabetes Mellitus Patients Using the Framingham Risk Score Cureus 20241611910.7759/cureus.5802638738131 PMC 11088481 · doi ↗ · pubmed ↗
- 5Kavaric N. Klisic A. Ninic A. Cardiovascular Risk Estimated by UKPDS Risk Engine Algorithm in Diabetes Open Med.20181361061710.1515/med-2018-008630847393 PMC 6400147 · doi ↗ · pubmed ↗
- 6Moons K.G.M. de Groot J.A.H. Bouwmeester W. Vergouwe Y. Mallett S. Altman D.G. Reitsma J.B. Collins G.S. Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modelling Studies: The CHARMS Checklist P Lo S Med.201411 e 100174410.1371/journal.pmed.100174425314315 PMC 4196729 · doi ↗ · pubmed ↗
- 7Fernandez-Felix B.M. López-Alcalde J. RoquéM. Muriel A. Zamora J. CHARMS and PROBAST at Your Fingertips: A Template for Data Extraction and Risk of Bias Assessment in Systematic Reviews of Predictive Models BMC Med. Res. Methodol.2023234410.1186/s 12874-023-01849-036800933 PMC 9936746 · doi ↗ · pubmed ↗
- 8Page M.J. Mc Kenzie J.E. Bossuyt P.M. Boutron I. Hoffmann T.C. Mulrow C.D. Shamseer L. Tetzlaff J.M. Akl E.A. Brennan S.E. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews BMJ 2021372 n 7110.1136/bmj.n 7133782057 PMC 8005924 · doi ↗ · pubmed ↗