Artificial Intelligence for Preoperative Prediction of Lymph Node Metastasis and Depth of Invasion in Oral Tongue Squamous Cell Carcinoma: A Systematic Review and Meta-Analysis
Yi-Yun Ho, Chun-Wei Hsu, Ta-Yi Chu, Chun-Ju Lin, Yi-Hsin Ho, Cheng-Hsien Wu, Ching-Po Lin

TL;DR
This paper reviews AI models for predicting lymph node metastasis and tumor depth in tongue cancer, finding moderate accuracy but highlighting the need for better validation and reporting.
Contribution
The study is the first to systematically evaluate AI-based predictive models for lymph node metastasis and depth of invasion in oral tongue cancer using meta-analysis.
Findings
AI models showed moderate pooled sensitivity (0.679) and specificity (0.762) for predicting lymph node metastasis and depth of invasion.
Deep learning and hybrid models outperformed traditional machine learning approaches in accuracy.
Only one of nine studies used true external validation, and most lacked clinician-comparator analyses or calibration reporting.
Abstract
Background: Occult lymph node metastasis (OLNM) and depth of invasion (DOI) are key determinants of elective neck dissection in clinically node-negative oral tongue squamous cell carcinoma (OTSCC), yet accurate preoperative risk stratification remains challenging. This study evaluated the diagnostic performance of artificial intelligence (AI)-based predictive models for OLNM and DOI in OTSCC. Methods: A systematic review and meta-analysis were conducted in accordance with PRISMA 2020 guidelines. A structured search of PubMed identified twelve eligible studies, nine of which provided extractable 2 × 2 contingency data for inclusion in the primary bivariate meta-analysis. One additional study modeling DOI-derived pT stage was synthesized narratively. Pooled sensitivity and specificity were estimated using a bivariate random-effects model. Heterogeneity, threshold effects, and publication…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
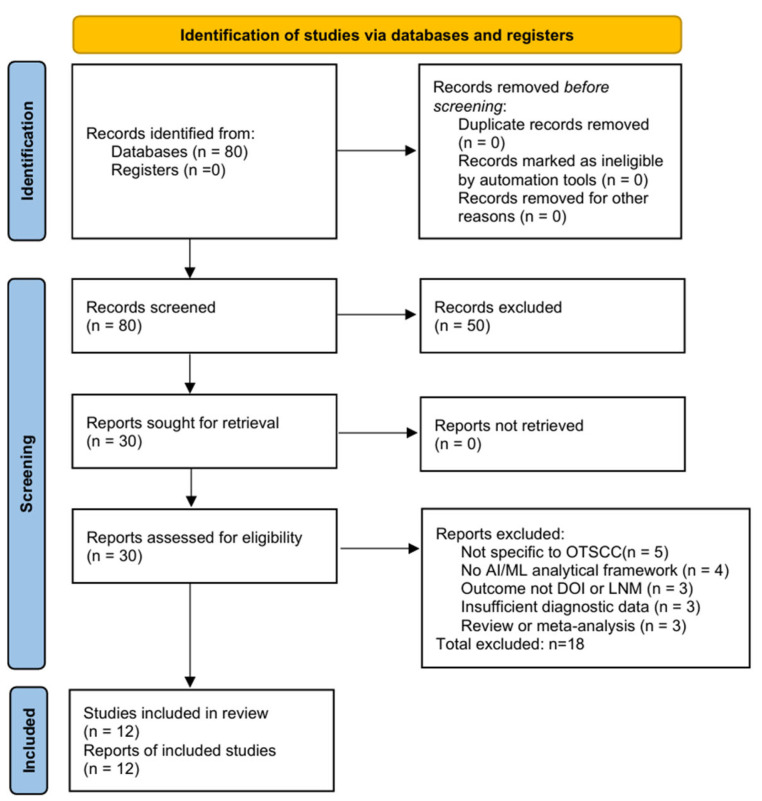 Figure 1
Figure 1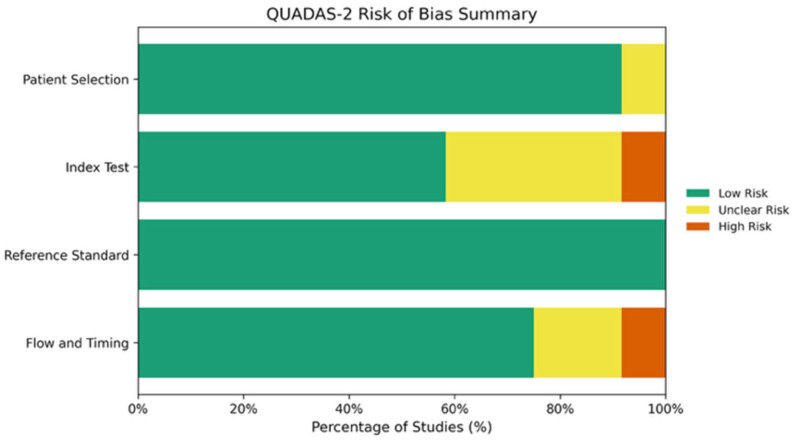 Figure 2
Figure 2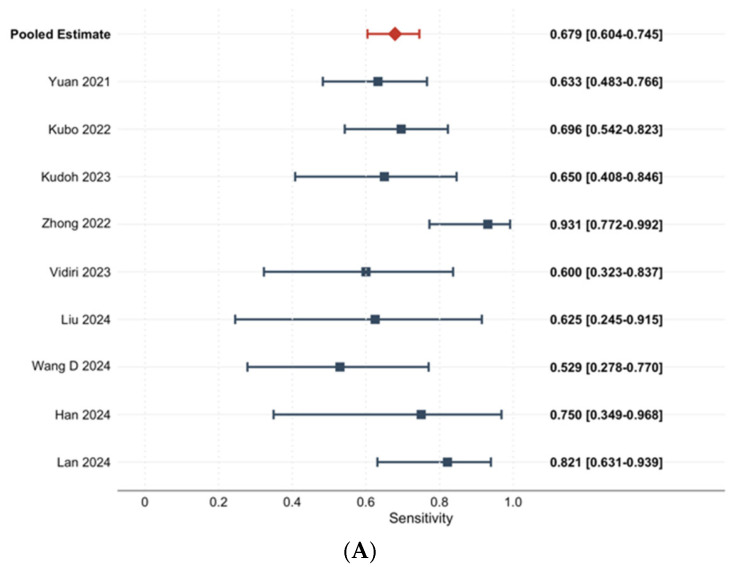 Figure 3
Figure 3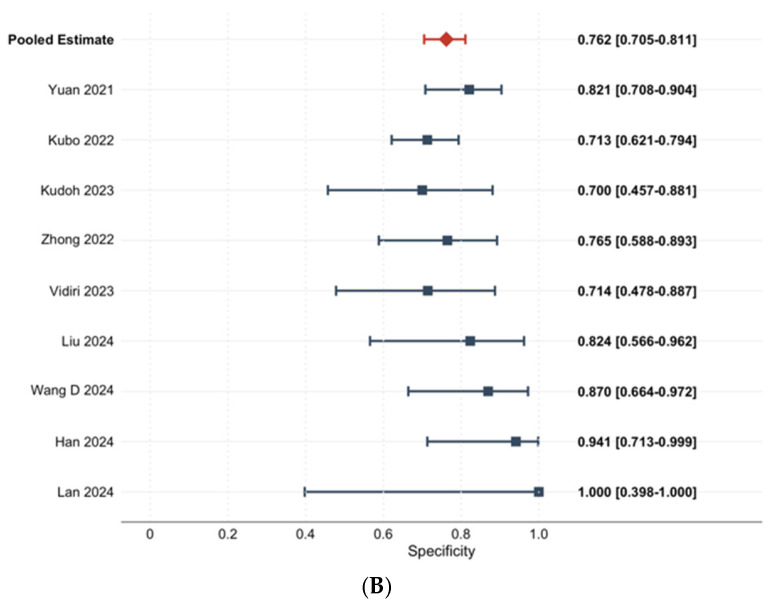 Figure 4
Figure 4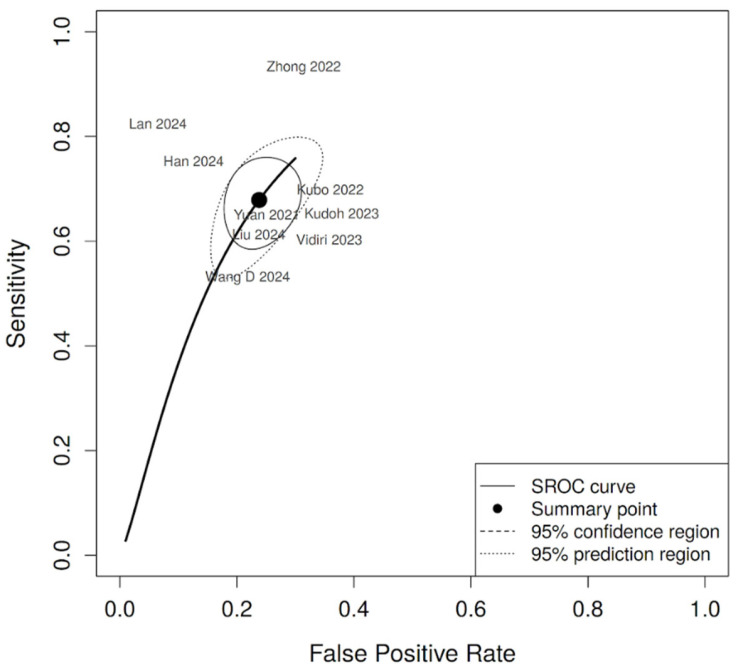 Figure 5
Figure 5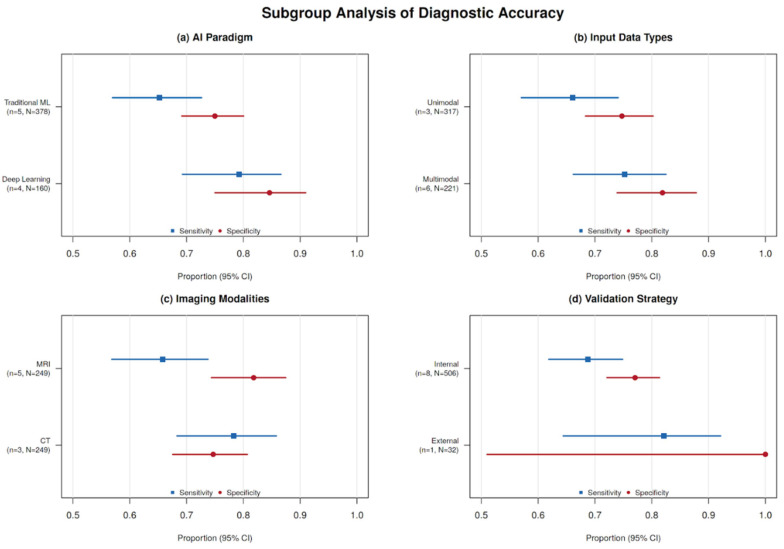 Figure 6
Figure 6 Figure 7
Figure 7| Study | AI-Specific Methodological Items | Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ICC Reported | Imbalance Handled | External Validation | Calibration | DCA | Clinician Comparison | Reporting Guideline | Code/Data Available | ||
| Committeri et al. [ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ (Zenodo) | 1/8 |
| Csüry et al. [ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 0/8 |
| Han et al. [ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 0/8 |
| Kubo et al. [ | ✗ | ✓ (SMOTE) | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 1/8 |
| Kudoh et al. [ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 0/8 |
| Lan et al. [ | ✗ | ✓ (SMOTE) | ✓ (True Ext) | ✓ | ✓ | ✗ | ✓ (STARD) | ✗ | 5/8 |
| Liu et al. [ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | 2/8 |
| Vidiri et al. [ | ✓ | ✓ (SMOTE-NC) | ✗ | ✗ | ✗ | ✗ | ✓ (TRIPOD) | ✗ | 3/8 |
| Wang et al. [ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | 2/8 |
| Wang et al. [ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 1/8 |
| Yuan et al. [ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 1/8 |
| Zhong et al. [ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ (NRI) | ✗ | ✓ (GitHub) | 3/8 |
|
|
|
|
|
|
|
|
| ||
- —Center for Healthy Longevity and Aging Sciences and the Brain Research Center
- —National Yang Ming Chiao Tung University
- —Higher Education Sprout Project by the Ministry of Education (MOE)
- —National Science and Technology Council
- —Department of Health, Taipei City Government, Taiwan
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHead and Neck Cancer Studies · Radiomics and Machine Learning in Medical Imaging · Salivary Gland Tumors Diagnosis and Treatment
1. Introduction
Oral tongue squamous cell carcinoma (OTSCC) represents a major clinical challenge and remains the most common and one of the most aggressive subtypes of oral cavity squamous cell carcinoma (OSCC). According to U.S. registry data, OTSCC accounts for approximately 41.7% of oral cavity SCC cases in the United States [1,2]. Its annual incidence has continued to increase, particularly among non-Hispanic White female individuals and younger patients, suggesting a shifting epidemiologic pattern [3]. In patients with clinically node-negative (cN0) necks, treatment planning remains complex. Although preoperative imaging and clinical examination may indicate node-negative status, a meaningful proportion of patients harbor occult lymph node metastasis (OLNM), which may lead to regional recurrence and reduced survival if unrecognized [4,5]. Conversely, performing elective neck dissection (END) in patients without pathologic nodal involvement may expose patients to unnecessary morbidity and long-term quality-of-life impairment, highlighting a persistent overtreatment-versus-undertreatment dilemma [4,5].
Depth of invasion (DOI) is another key prognostic factor and has been incorporated into the AJCC 8th edition T-classification for oral cavity SCC [6]. However, accurate preoperative estimation of DOI remains challenging in routine practice because of inherent imaging limitations and reliance on postoperative histopathologic assessment. To minimize conceptual ambiguity, this review distinguishes two related but clinically distinct endpoints. “OLNM” refers specifically to pathologically confirmed cervical nodal metastasis in patients who are clinically node-negative (cN0) on preoperative evaluation—the clinical scenario most directly relevant to elective neck dissection (END) decision-making. In contrast, “LNM” is used more broadly to describe cervical nodal metastasis in mixed cN0/cN+ cohorts, where the clinical objective concerns overall nodal staging rather than occult detection. This distinction is maintained consistently throughout the Methods, Results, and Discussion sections, and operational definitions for each included study.
Conventional imaging modalities, including computed tomography (CT) and magnetic resonance imaging (MRI), are widely used for nodal assessment and DOI evaluation in OTSCC; however, reported diagnostic performance has been inconsistent across studies [7,8,9]. With the increasing availability of high-dimensional imaging data and advances in computational capability, artificial intelligence (AI)—including machine learning (ML) and deep learning (DL)—has emerged as a potential adjunct in head and neck oncology [10,11,12,13]. By extracting quantitative image-derived features or learning hierarchical representations from imaging and clinical inputs, AI-based models have been developed for OLNM and DOI prediction.
Prior broader meta-analyses in oral and head-and-neck cancer settings reported pooled AUC values of approximately 0.89–0.92 for imaging-based LNM prediction; however, the direct applicability of these findings to OTSCC-specific cN0 and OLNM decision contexts remains uncertain [11,14]. Despite these encouraging findings, several barriers limit clinical translation. Many published models are derived from single-center cohorts with internal validation only, increasing the risk of overfitting and potentially inflating reported performance [10,15]. Furthermore, heterogeneity in imaging protocols, segmentation workflows, feature engineering strategies, model architecture, and evaluation metrics constrains cross-study comparability and robust synthesis. Although previous reviews have summarized AI applications in head and neck cancer, few have focused specifically on OTSCC, which has distinct biological behavior and treatment decision pathways [16].
Accordingly, an OTSCC-focused systematic review and meta-analysis of AI-based predictive models was conducted with prespecified endpoint separation. OLNM/LNM prediction was treated as the primary diagnostic endpoint for quantitative synthesis, whereas DOI-related prediction was summarized separately when direct pooling was methodologically inappropriate. Pooled diagnostic accuracy was estimated using a unified bivariate random-effects framework to derive summary sensitivity, specificity, and SROC AUC. Predefined subgroup analyses were performed to explore methodological factors associated with performance variability. In addition to QUADAS-2, an AI-specific methodological checklist was applied to provide complementary appraisal of clinical interpretability and translation readiness.
2. Materials and Methods
2.1. Search Strategy
A systematic literature search was conducted in PubMed (MEDLINE) in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA 2020) guidelines. The completed PRISMA 2020 checklist is provided in the Supplementary Materials. The search encompassed all records from database inception through 15 January 2026.
The search strategy combined controlled vocabulary (Medical Subject Headings, MeSH) and free-text terms related to oral tongue squamous cell carcinoma (OTSCC), artificial intelligence, and diagnostic prediction.
Search terms encompassed disease-related keywords (“oral tongue squamous cell carcinoma”, “oral squamous cell carcinoma”, “OTSCC”, “OSCC”), imaging modalities (“magnetic resonance imaging”, “MRI”, “computed tomography”, “CT”, “PET/CT”), and analytical approaches (“artificial intelligence”, “machine learning”, “deep learning”, “radiomics”, “texture analysis”). Predictive outcome terms, including “depth of invasion”, “lymph node metastasis”, and “cervical lymph node”, were incorporated to ensure the comprehensive retrieval of relevant studies. Boolean operators (AND/OR) were applied to combine predefined concept blocks.
PubMed was selected as the primary database because it comprehensively indexes peer-reviewed biomedical literature in oncology, radiology, and medical informatics, which represent the core disciplines relevant to AI-based diagnostic modeling in OTSCC. Given the focused clinical scope of this review, PubMed provides a high coverage of relevant studies while maintaining specificity.
To further minimize retrieval bias, the reference lists of all included articles were manually screened for additional eligible studies.
No date or language restrictions were applied. The search was limited to human studies. The complete electronic search strategy is provided in Table A1.
2.2. Study Selection
Original studies were eligible if they applied machine learning (ML) or deep learning (DL) models to magnetic resonance imaging (MRI), computed tomography (CT), PET/CT imaging, or histopathological whole-slide imaging for the prediction of depth of invasion (DOI) or lymph node metastasis (LNM) in patients with OTSCC. PET/CT-based radiomic studies were explicitly included in both the search strategy and eligibility criteria; by Kudoh et al. [17] was identified and included. Only articles published in English were considered.
Eligible studies were required to provide a clear description of the imaging and analytical workflow and to report quantitative diagnostic performance metrics sufficient for evaluation. Histopathologic assessment served as the reference standard for DOI and/or nodal status when applicable.
Exclusion criteria comprised case reports, editorials, letters, reviews, meta-analyses, conference abstracts, and studies lacking sufficient methodological detail or outcome data. Articles not specifically focused on OTSCC or not employing ML/DL-based analytical frameworks were also excluded.
After the removal of duplicate records, two independent reviewers (Y.Y. HO and T.Y. CHU) screened titles and abstracts for relevance. Full-text articles were subsequently assessed for eligibility. Discrepancies were resolved through consensus discussion.
2.3. Data Extraction and Quality Assessment
Data were independently extracted from all eligible studies using a predefined data extraction form. Extracted variables included first author, year of publication, study design, imaging modality, sample size, and reference standard. Detailed characteristics of the artificial intelligence (AI) methodology were also collected, including model type, input configuration (imaging-only or multimodal), region-of-interest definition, preprocessing or feature extraction procedures, and validation strategy (internal versus external).
To address clinical heterogeneity in endpoint definitions, studies were classified into prespecified outcome subgroups according to harmonization rules. Studies were categorized as OLNM-specific when the study population was restricted to clinically N0 patients and the primary endpoint was histopathologically confirmed lymph node metastasis, either identified at elective neck dissection or during a defined follow-up period. Studies including mixed cN0/cN+ populations were classified as general LNM. When both overall and cN0-subgroup results were reported, the most clinically homogeneous dataset was selected for quantitative synthesis. DOI- or pT stage-based prediction models were analyzed separately in narrative form. These classification decisions were independently performed by two reviewers, with discrepancies resolved through consensus.
Diagnostic performance metrics—including sensitivity, specificity, true-positive, false-positive, true-negative, and false-negative counts, as well as areas under the receiver operating characteristic curve (AUC)—were extracted when available.
Methodological quality and risk of bias were independently assessed using the Quality Assessment of Diagnostic Accuracy Studies 2 (QUADAS-2) tool. Disagreements were resolved by consensus. In addition, an AI-specific methodological checklist (Table 1) was applied to evaluate eight domains critical for AI-based diagnostic models: segmentation reproducibility (ICC), class imbalance handling, external validation, calibration reporting, decision-curve analysis, clinician comparison, reporting guideline adherence, and code/data availability. A QUADAS-2 × AI cross-reference matrix (Table A2) was constructed to identify studies with low conventional risk of bias but important AI-specific methodological limitations.
Pooled sensitivity and specificity were jointly estimated using a bivariate random-effects model (Reitsma et al., 2005) [18,19], generating a summary receiver operating characteristic (SROC) curve. The threshold effect was assessed using Spearman rank correlation between logit(sensitivity) and logit(1—specificity). Between-study heterogeneity was described using I^2^ statistics for forest plots, while variance–covariance parameters from the bivariate model were considered the primary measure of between-study variability. Publication bias was evaluated using Deeks’ funnel plot asymmetry test [20].
Prespecified sensitivity analyses included: (a) leave-one-out analysis; (b) extended analysis incorporating methodologically borderline studies (k = 11); and (c) exclusion of mixed-site populations. The full search strategy is provided in Table A1. This review was conducted and reported in accordance with PRISMA 2020 and STARD principles and was registered in the PROSPERO database (CRD420251164051).
3. Results
3.1. Literature Search and Study Selection
Figure 1 illustrates the PRISMA flow diagram of the literature search and study selection process. A total of 80 records were identified from PubMed. Following title and abstract screening, 50 records were excluded. Thirty full-text articles were assessed for eligibility, of which 18 were excluded for reasons detailed in Figure 1. Ultimately, twelve studies met the inclusion criteria and were included in the qualitative synthesis.
Of these, nine studies provided extractable 2 × 2 contingency data and were included in the primary bivariate meta-analysis. Three studies (Committeri et al. [21], Csüry et al. [22], Wang et al. [29]) were included in the systematic review but excluded from the primary quantitative synthesis due to high risk of bias, non-imaging input modality, or insufficient extractable data, respectively.
The imaging modalities represented were MRI (n = 5), CT (n = 3), 18F-FDG PET/CT (n = 1), and histopathological whole-slide imaging (n = 1). Sample sizes ranged from 25 to 319 patients. AI approaches comprised traditional machine learning models (n = 7), including support vector machines (SVM), random forests (RF), artificial neural networks (ANN), logistic regression, classification and regression decision trees (CIDT), and threshold-based methods, as well as deep learning or hybrid deep learning–radiomics models (n = 5), including LightGBM, multilayer perceptron (MLP), and ResNet50 combined with radiomics.
Operationalized endpoint definitions and subgroup classifications for all twelve studies are summarized in Table 2.
3.2. Quality Assessment
Figure 2 and Table 3 summarize the QUADAS-2 assessment of risk of bias and applicability across four domains: patient selection, index test, reference standard, and flow and timing.
Risk of bias for patient selection was rated as low in 11 out of 12 studies (91.7%), with one study judged unclear due to insufficient reporting of consecutive enrollment. All twelve studies (100%) were considered to have used an appropriate reference standard. The index test domain demonstrated the greatest methodological concern, with 7 out of 12 studies (58.3%) rated as low risk, 4 as unclear, and 1 as high risk (Committeri et al. [21]), primarily due to the absence of an independent validation set. Flow and timing was rated as low risk in 9 out of 12 studies (75.0%), unclear in 2, and high risk in 1 (Committeri et al. [21]).
Overall, applicability concerns were judged to be low across all studies, indicating that the included evidence was generally relevant to the review objectives.
Risk of bias and applicability concerns were evaluated across four domains: patient selection, index test, reference standard, and flow and timing. Overall, the majority of studies demonstrated a low risk of bias and low applicability concerns. Patient selection was rated low risk in 11/12 studies (91.7%), with one unclear. All twelve studies (100%) used an adequate reference standard. The index test domain showed the most variation: 7/12 low risk, 4/12 unclear, and 1/12 high risk (Committeri et al. [21]). Flow and timing was low risk in 9/12, with 2/12 unclear and 1/12 high risk. The summary bar chart indicates that 91.7% of studies were rated low risk for patient selection, 100% for reference standard, 58.3% for the index test, and 75.0% for flow and timing. All studies had low applicability concerns across all domains.
3.3. Methodological Quality Items
The methodological evaluation integrated QUADAS-2 with an AI-specific checklist to assess modeling transparency, validation strategy, and potential clinical utility. Overall, methodological rigor was moderate.
All twelve studies (100%) used postoperative histopathology as the reference standard, resulting in low risk of bias in that domain. Patient selection was rated as low risk in eleven studies (91.7%), with one study judged unclear due to insufficient reporting of consecutive enrollment. Potential bias was most frequently observed in the patient selection and index test domains, largely attributable to retrospective single-center designs and limited reporting of blinding between AI outputs and reference standard pathology.
Regarding model development, eleven studies (91.7%) constructed predictive models using radiomic or deep learning features derived from MRI, CT, or PET/CT. However, only five studies (41.7%; Yuan et al. [30], Zhong et al. [31], Zhong et al. [31], Vidiri et al. [27], Wang et al. [29]) assessed feature reproducibility or inter-reader reliability, and three explicitly addressed class imbalance. Eleven studies (91.7%) implemented data-driven feature selection strategies, including LASSO regression (n = 6), principal component analysis (n = 2), and statistical ranking methods (n = 3), whereas only one study (Csüry et al. [22]) applied end-to-end classification without explicit feature selection.
Internal validation was performed in eleven studies (91.7%), whereas only one study (8.3%) employed true external validation. Confidence intervals for sensitivity and specificity were reported in seven studies, and only one study used bootstrap or permutation resampling to estimate uncertainty.
Most studies did not report calibration analysis, decision-curve analysis, or head-to-head comparisons with radiologist interpretation, thereby limiting the assessment of clinical utility.
Cross-referencing QUADAS-2 with the AI-specific checklist (Table A2) revealed notable discordance. Six out of the nine primary meta-analysis studies (Yuan et al. [30], Zhong et al. [31], Han et al. [23], Liu et al. [26], Wang et al. [28], Lan et al. [25]) were rated as low risk across all four QUADAS-2 domains yet concurrently exhibited multiple AI-specific methodological gaps (ranging from 3 to 8 unfulfilled items out of 8). This pattern suggests that QUADAS-2 alone may be insufficient for a comprehensive evaluation of AI-based diagnostic models [32].
Among the twelve included studies, only Vidiri et al. [27] modeled DOI/pT stage as an AI-predicted outcome in addition to a separate LNM model. The DOI/pT model utilized MRI-derived radiomic features to classify tumors as pT1 versus pT2–pT3, achieving an AUC of 0.71 with a sensitivity of 0.667 and specificity of 0.714 in the test set (n = 36). Given that this represents a single study, quantitative synthesis was not performed. These findings are reported for completeness and should be interpreted cautiously in light of the limited sample size and absence of external validation.
3.4. Diagnostic Accuracy
The diagnostic reference standards, endpoint definitions, and key performance metrics are summarized in Table 4. Nine studies providing extractable 2 × 2 contingency data were included in the primary bivariate meta-analysis. Individual and pooled sensitivity and specificity estimates are presented in Figure 3.
The pooled sensitivity was 0.679 (95% CI: 0.604–0.745), and the pooled specificity was 0.762 (95% CI: 0.705–0.811). Between-study heterogeneity was moderate for sensitivity (I^2^ = 41.8%) and low for specificity (I^2^ = 23.4%). No significant threshold effect was observed (Spearman ρ = −0.117, p = 0.776). The summary ROC curve (Figure 4) yielded an AUC of 0.786, with a diagnostic odds ratio of 6.76, a positive likelihood ratio of 2.85, and a negative likelihood ratio of 0.42.
Subgroup analyses across AI paradigms, input types, imaging modalities, and validation strategies are summarized in Figure 5. The Deeks’ funnel plot (Figure 6) demonstrated no significant asymmetry (p = 0.596), although the statistical power of this test was limited with k = 9.
Exploratory subgroup analyses by outcome definition showed the following results: OLNM (k = 4), sensitivity = 0.690 (95% CI: 0.575–0.784) and specificity = 0.785 (95% CI: 0.668–0.868); general LNM (k = 5), sensitivity = 0.678 (95% CI: 0.571–0.769) and specificity = 0.769 (95% CI: 0.696–0.829). Deep learning or hybrid models (k = 4) achieved a sensitivity = 0.765 and specificity = 0.832, compared with traditional machine learning models (k = 5; sensitivity = 0.652, specificity = 0.750). MRI-based models (k = 5) showed a sensitivity = 0.643 and specificity = 0.802, whereas CT-based models (k = 3) showed a sensitivity = 0.806 and specificity = 0.749. Multimodal input studies (k = 6) yielded a sensitivity = 0.714 (95% CI: 0.569–0.826) and specificity = 0.815 (95% CI: 0.744–0.871) compared with unimodal approaches (k = 3; sensitivity = 0.666 [95% CI: 0.558–0.760], specificity = 0.712 [95% CI: 0.635–0.778]). Given the limited number of studies per subgroup (k = 3–6), formal statistical comparisons were not performed, and these findings should be interpreted as exploratory.
Only one of the nine primary studies (Lan et al. [25]) employed true external validation; therefore, a formal comparison between internal and external validation strategies was not undertaken. Leave-one-out sensitivity analysis demonstrated stable pooled estimates across all nine iterations (sensitivity range: 0.657–0.697; specificity range: 0.743–0.787), indicating no disproportionate influence of any single study.
An extended analysis incorporating methodologically borderline studies (Committeri et al. [21] and Csüry et al. [22]; k = 11) yielded a sensitivity = 0.688, specificity = 0.809, and AUC = 0.828. The modest increase in AUC was partly attributable to the high-performing Csüry et al. [22] model (histopathologic input, AUC = 0.83), indicating that inclusion of non-imaging models would inflate the apparent performance of imaging-based approaches. Exclusion of Kubo et al. [24] (delayed-detection OLNM definition) resulted in stable OLNM subgroup estimates (sensitivity = 0.685, specificity = 0.787). Similarly, exclusion of Lan et al. [25] (which included oropharyngeal SCC cases) yielded a sensitivity = 0.664, specificity = 0.770, and AUC = 0.766.
Overall, AI-based diagnostic models demonstrated moderate discriminative performance for the preoperative prediction of LNM in OTSCC. However, the limited use of external validation and substantial methodological heterogeneity indicate restricted readiness for clinical translation.
Forest plots showing the individual and pooled diagnostic performance of AI-based models for predicting lymph node metastasis (OLNM or general LNM) in oral tongue squamous cell carcinoma (OTSCC). Studies are labeled by first author and publication year (Yuan et al. [30], Kubo et al. [24], Kudoh et al. [17], Zhong et al. [31], Vidiri et al. [27], Liu et al. [26], Wang et al. [28], Han et al. [23], and Lan et al. [25]).
In the sensitivity analysis, each horizontal line represents the 95% confidence interval (CI) for an individual study, and the red diamond indicates the pooled estimate derived from the bivariate random-effects model. The pooled sensitivity was 0.679 (95% CI: 0.604–0.745; k = 9), with moderate between-study heterogeneity (I^2^ = 41.8%).
In the specificity analysis, squares represent point estimates for individual studies, with horizontal lines indicating the corresponding 95% CIs. The pooled specificity was 0.762 (95% CI: 0.705–0.811; k = 9), with low between-study heterogeneity (I^2^ = 23.4%).
Blue markers indicate sensitivity, and red markers indicate specificity, with horizontal lines representing the corresponding 95% confidence intervals (CI).
(a) AI paradigm: Deep learning or hybrid models (k = 4) demonstrated higher pooled sensitivity (0.765) and specificity (0.832) compared with traditional machine learning approaches (k = 5; sensitivity = 0.652, specificity = 0.750).
(b) Input data types: Multimodal input strategies (k = 6) yielded a pooled sensitivity of 0.714 and specificity of 0.815, whereas unimodal approaches (k = 3) showed a sensitivity of 0.666 and specificity of 0.712.
(c) Imaging modalities: MRI-based models (k = 5) achieved a pooled sensitivity of 0.643 and specificity of 0.802, while CT-based models (k = 3) demonstrated a higher pooled sensitivity (0.806) but slightly lower specificity (0.749).
(d) Validation strategy: Only one study (Lan et al. [25]) employed true external validation. Because of the limited number of studies within each subgroup (k = 3–6), formal statistical comparisons between subgroups were not performed. These subgroup analyses should therefore be interpreted as exploratory.
4. Discussion
This systematic review and bivariate meta-analysis demonstrate that artificial intelligence (AI)-based models show moderate potential for supporting preoperative risk stratification in oral tongue squamous cell carcinoma (OTSCC). The pooled sensitivity (0.679) and specificity (0.762) indicated a fair diagnostic performance, with a summary ROC AUC of 0.786. Compared with our initial analysis, the current estimates were slightly lower, reflecting the application of a more rigorous bivariate framework and the inclusion of studies reporting more conservative performance metrics [33]. These findings suggest that AI may serve as a complementary adjunct to conventional imaging and clinical assessment rather than a standalone decision-making tool.
Subgroup analyses demonstrated a consistent performance advantage of deep learning (DL) or hybrid architectures over traditional radiomics-based machine learning (ML) approaches [14]. From a methodological standpoint, DL models benefit from hierarchical feature learning and the ability to capture complex nonlinear spatial relationships directly from the imaging data, thereby reducing dependence on handcrafted radiomic descriptors. This architectural flexibility likely contributes to the superior pooled sensitivity and specificity observed in our analysis. However, this apparent advantage warrants cautious interpretation. Several included DL studies exhibited substantial train–test performance gaps—for example, Wang et al. [28] reported a ΔAUC of 0.232 between training and test cohorts—raising concerns regarding overfitting in small-sample medical imaging datasets. As emphasized by Varoquaux and Cheplygina [15], internal validation frameworks frequently produce optimistically biased performance estimates. Thus, the observed DL superiority may reflect both genuine modeling capacity and residual methodological inflation.
From a clinical perspective, multimodal models integrating imaging-derived features with clinical variables demonstrated improved diagnostic performance, particularly in specificity [10]. This finding aligns with real-world oral oncology practice, where decisions regarding elective neck dissection rely on integrated radiologic and clinical assessment. Studies such as Liu et al. [26] and Wang et al. [28] illustrate the incremental value of incorporating contrast-enhanced MRI sequences or clinical lymph node status into predictive pipelines. These observations are consistent with broader trends toward multi-input fusion architectures in medical imaging AI [34,35]. Similarly, MRI-based models tended to demonstrate higher specificity than CT-based models, consistent with MRI’s established advantage in soft-tissue delineation and depth of invasion (DOI) assessment in oral tongue lesions [36]. Nevertheless, given the limited number of studies per subgroup and absence of formal interaction testing, these findings should be interpreted as exploratory rather than definitive evidence of superiority.
Several methodological gaps identified in our structured quality assessment have direct clinical implications. Only 3 out of 12 studies reported calibration metrics, and none formally evaluated model interpretability using approaches such as SHAP or Grad-CAM [37,38]. Without calibration assessment, predicted probabilities cannot be reliably translated into clinically actionable decision thresholds—an essential requirement when considering elective neck dissection in cN0 patients. Likewise, the absence of interpretability analyses limits clinician trust and transparency. Only one study (Zhong et al. [31]) directly compared model performance against radiologist interpretation, reporting net reclassification improvement up to 40%. In the absence of head-to-head comparisons, the incremental clinical value of AI beyond expert judgment remains uncertain.
The near absence of true external validation represents a major limitation of the current evidence base [39]. After systematic re-verification, only one study (Lan et al. [25]) employed genuine external validation across independent hospital cohorts, whereas most studies relied on internal split-sample or cross-validation designs. Such validation strategies are known to inflate performance metrics in medical imaging AI. If similar optimism bias applies across studies, the true diagnostic performance of AI models for OLNM or DOI prediction may be lower than the pooled AUC of 0.786 observed in this analysis. Strengthening generalizability through multicenter prospective validation remains an urgent priority.
Adherence to reporting guidelines was limited. Only one study referenced TRIPOD, one referenced STARD, and none explicitly adhered to the CLAIM checklist for AI in medical imaging [40,41,42]. Inadequate reporting reduces reproducibility and hampers meaningful cross-study comparison. Greater compliance with TRIPOD-AI and CLAIM frameworks [16,43] is essential to mitigate optimism bias and promote transparent translation into clinical practice.
Importantly, the discordance observed between QUADAS-2 ratings and AI-specific methodological checklist results further underscores the limitations of applying conventional diagnostic accuracy tools alone to AI research. While QUADAS-2 appropriately evaluates bias in patient selection, index testing, and reference standards, it does not capture AI-specific methodological risks such as data leakage, absence of true external validation, lack of calibration analysis, or limited interpretability assessment. Our three-layer assessment framework therefore provides a more nuanced and AI-appropriate appraisal of methodological rigor in diagnostic modeling.
Despite substantial methodological heterogeneity—including variation in imaging protocols, segmentation approaches, feature extraction pipelines, algorithm types, and disease prevalence—statistical heterogeneity was only moderate for sensitivity (I^2^ = 41.8%) and low for specificity (I^2^ = 23.4%), with no evidence of a threshold effect (ρ = −0.117, p = 0.776). This suggests that performance variability may reflect dataset composition and validation strategy differences rather than the fundamental instability of AI modeling approaches in OTSCC.
Deeks’ funnel plot asymmetry testing did not demonstrate significant publication bias (p = 0.596). However, given the relatively small number of included studies (k = 9), the statistical power of this test to detect subtle small-study effects remains limited.
Despite increasing interest in AI applications for head and neck imaging, research specifically addressing preoperative prediction of occult lymph node metastasis (OLNM) and DOI in OTSCC remains at an early stage. Only twelve eligible studies were identified, and nine provided sufficient data for bivariate meta-analysis. Key limitations include limited external validation, inconsistent calibration reporting, heterogeneity in outcome definitions (OLNM vs. general LNM), small test-set sizes, and exclusive reliance on retrospective designs. Furthermore, 2 × 2 contingency tables were back-calculated in most studies, potentially introducing rounding-related imprecision. Individual patient data were unavailable, precluding patient-level threshold optimization or subgroup analysis by tumor thickness or grade.
To enhance clinical applicability, future research should prioritize: (i) prospective multicenter external validation across heterogeneous scanners and populations; (ii) standardized reporting of calibration metrics and decision-curve analysis; (iii) direct comparison with expert radiologist interpretation to demonstrate incremental value; (iv) robust multimodal modeling strategies; (v) integration of interpretable AI techniques; and (vi) strict adherence to the TRIPOD-AI and CLAIM standards [16,43]. Such measures are necessary to ensure the responsible and methodologically sound translation of AI-assisted diagnostic tools into routine dental and oral oncology practice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ramadan S. Mokhtari T.E. Al-Qurayshi Z. Rich J.T. Harbison R.A. Zolkind P. Jackson R.S. Pipkorn P. Kang S.Y. Mazul A.L. Trends in incidence of oral cavity squamous cell carcinoma in the United States, 2001–2019 Surg. Oncol. Insights 2024110005510.1016/j.soi.2024.100055 · doi ↗
- 2Stepan K.O. Mazul A.L. Larson J. Shah P. Jackson R.S. Pipkorn P. Kang S.Y. Puram S.V. Changing epidemiology of oral cavity cancer in the United States Otolaryngol. Head Neck Surg.202316876176810.1177/0194599822109801135503657 PMC 10154079 · doi ↗ · pubmed ↗
- 3Sakr Y. Hamdy O. Eldeghedi M. Abdelaziz R. El Moctar E.M.S. Alharazin M. Awny S. Shifting epidemiology trends in tongue cancer: A retrospective cohort study Cancers 202315568010.3390/cancers 1523568038067383 PMC 10705286 · doi ↗ · pubmed ↗
- 4Chaudhary N. Verma R.K. Agarwal U. Gupta S. Jaitly S. Incidence of occult metastasis in clinically N 0 oral tongue squamous cell carcinoma and its association with tumour staging, thickness, and differentiation J. Head Neck Physicians Surg.20175758010.4103/jhnps.jhnps_17_17 · doi ↗
- 5Merck Manual Professional Version. Oral Squamous Cell Carcinoma Available online: https://www.merckmanuals.com/professional/ear-nose-and-throat-disorders/tumors-of-the-head-and-neck/oral-squamous-cell-carcinoma(accessed on 15 September 2024)
- 6Ghantous Y. Nashef A. Sidransky D. Abdelraziq M. Alkeesh K. Araidy S. Koch W. Brait M. Abu El-Naaj I. Clinical and prognostic significance of the eighth edition oral cancer staging system Cancers 202214463210.3390/cancers 1419463236230555 PMC 9562893 · doi ↗ · pubmed ↗
- 7Van Dijk L.V. Fuller C.D. Artificial intelligence and radiomics in head and neck cancer care: Opportunities, mechanics, and challenges ASCO Educ. Book 202141 e 225e 23510.1200/EDBK_320951 PMC 821831233929877 · doi ↗ · pubmed ↗
- 8Broggi G. Maniaci A. Lentini M. Palicelli A. Zanelli M. Zizzo M. Koufopoulos N. Salzano S. Mazzucchelli M. Caltabiano R. Artificial intelligence in head and neck cancer diagnosis: A comprehensive review with emphasis on radiomics, histopathological, and molecular applications Cancers 202416362310.3390/cancers 1621362339518063 PMC 11545333 · doi ↗ · pubmed ↗