A Novel Dual-Modality Dual-View Hybrid Deep Learning–Machine Learning Framework for the Prediction of Carotid Plaque Vulnerability via Late Fusion
Wenxuan Zhang, Chao Hou, Xinyi Wang, Hongyu Kang, Shuai Li, Yu Sun, Yongping Zheng, Wei Zhang, Sai-Kit Lam

TL;DR
This study develops an AI model using dual-modality ultrasound images to accurately predict carotid plaque vulnerability, which could help identify stroke risks.
Contribution
The novel hybrid deep learning–machine learning framework uses dual-modality and dual-view ultrasound imaging for plaque vulnerability classification.
Findings
The hybrid VGG-RF model achieved an AUC of 0.908 in identifying vulnerable carotid plaques.
Long-axis views of B-Mode and contrast-enhanced ultrasound images were key features for discrimination.
The model outperformed other settings in precision, recall, and specificity.
Abstract
Background: Ultrasound imaging is an ideal tool for regular carotid plaque screening to identify individuals at high risk of stroke for clinical intervention. However, no existing study leverages multi-modal multi-view ultrasound imaging for AI-enabled auto-classification of carotid plaque vulnerability. This study aims to develop and validate an effective AI model for carotid plaque vulnerability classification through the applications of dual-modal (B-Mode and contrast-enhanced mode) dual-view (longitudinal and cross-sectional) settings to maximize the utility and potential of ultrasound imaging. Methods: Hybrid deep-learning (DL) and machine-learning (ML) methods were employed to balance between model discriminability and interpretability. B-Mode ultrasound (BMUS) and contrast-enhanced ultrasound (CEUS) images from 241 patients were retrospectively analyzed using the proposed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
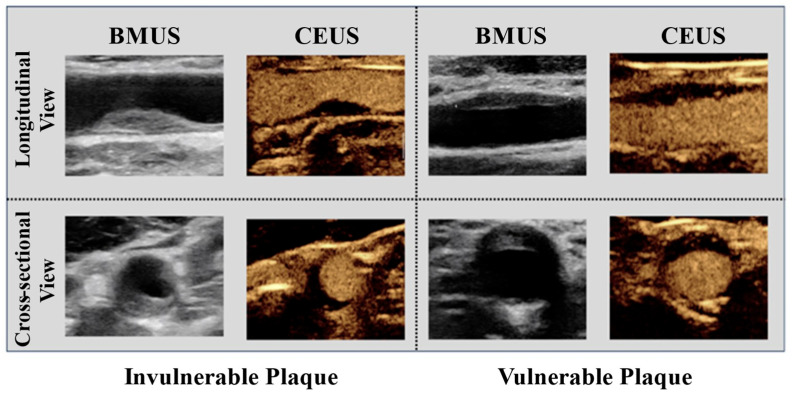 Figure 1
Figure 1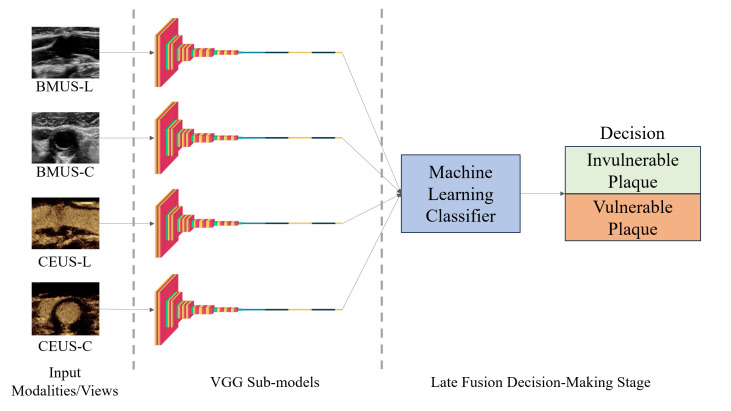 Figure 2
Figure 2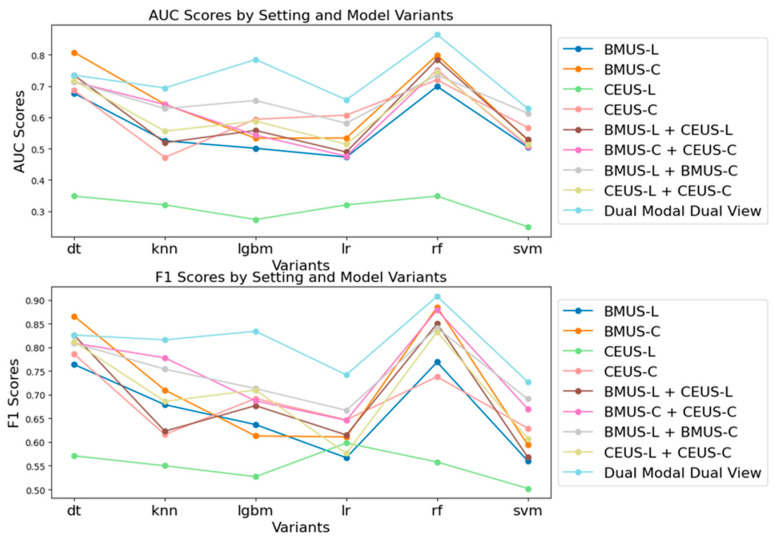 Figure 3
Figure 3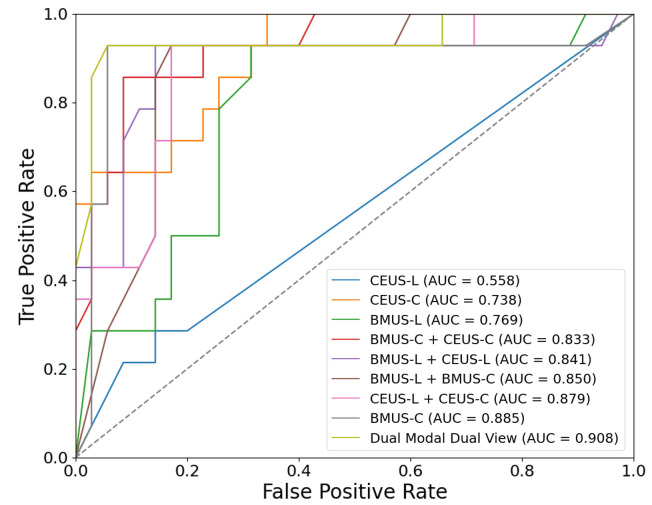 Figure 4
Figure 4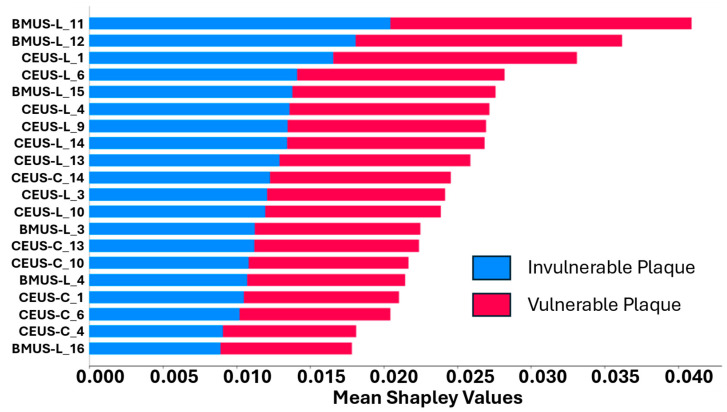 Figure 5
Figure 5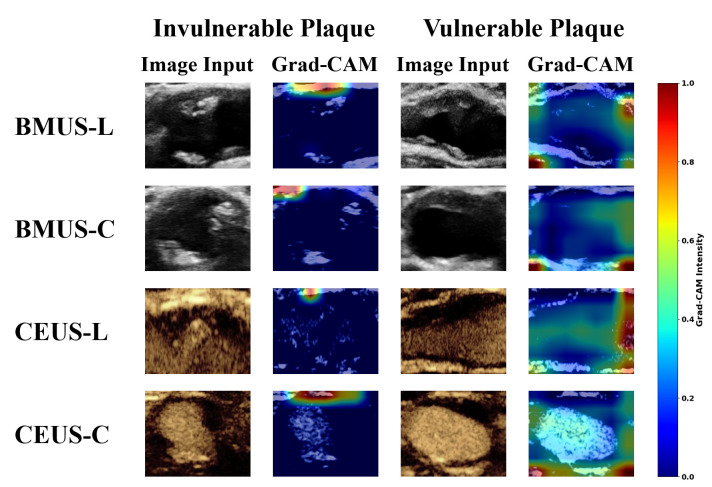 Figure 6
Figure 6- —University Grants Committee (Hong Kong SAR, China) through the Hong Kong Polytechnic University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCerebrovascular and Carotid Artery Diseases · Cardiovascular Health and Disease Prevention · Ultrasound Imaging and Elastography
1. Introduction
Stroke is one of the most prevalent aging-associated diseases worldwide [1]. Its incidence is rising rapidly with the ever-expanding aging population worldwide [2,3]. Carotid plaque, an accumulation of fat deposits and other materials in the carotid arteries, is highly associated with stroke occurrence and recurrence [4,5,6]. It triggers ischemic incidents in two ways: by constricting the artery and diminishing blood circulation or by detaching and obstructing a small artery within the brain [7]. The more vulnerable a plaque is, the more likely it is to detach and trigger a stroke. In light of this, there is a growing clinical interest in the community to deploy carotid plaque vulnerability as a biomarker for selecting and identifying high-risk patients ahead of their clinical presentation [8,9].
In clinical carotid plaque assessments, ultrasound imaging presents the most prevalent first-line and frequent surveillance tool among other imaging techniques, such as Magnetic Resonance Imaging (MRI), Computed Tomography (CT), and Positron Emission Tomography/Computed Tomography (PET/CT) [10,11]. Although MRI has become the gold standard for carotid plaque imaging owing to its superior image resolution and detection sensitivity, the applicability of MRI has been largely restricted by its nature of low accessibility, low affordability, and its contraindication to patients with metallic implants or claustrophobia [12]. CT provides high-resolution imaging and identification of ulceration and calcification; notwithstanding, its nature of radiation hazards has posed a significant barrier for routine, regular, frequent, and population-wide screening for carotid plaque. Similarly, although PET/CT could be effective to detect active inflammation within the plaque, it shared similar deficiencies as CT imaging on top of its shortcomings in assessing plaque characteristics, such as ulceration, intraplaque hemorrhage, or lipid-rich necrotic core. By contrast, ultrasound imaging is a cost-effective approach for evaluating plaque morphology and characteristics, and it offers sufficient resolution for carotid plaque detection and assessments. Furthermore, ultrasound scanners are more portable, financially affordable, and free of ionizing radiation hazards [13,14]. These unique features of ultrasound imaging have been increasingly consolidating its role as an ideal imaging tool for routine, regular, repeated, and large-scale population-wide screening and identification of high-risk individuals for stroke.
Despite the abovementioned superiorities, plaque assessment via ultrasound imaging is still challenging due to artifacts, noises [15,16], and observer variability [17]. For this reason, AI-assisted methods are in great demand for ultrasound imaging-based carotid plaque assessment. Moreover, the potential of ultrasound imaging in the domain of AI-assisted carotid plaque assessment could be further strengthened by leveraging its multi-modality (e.g., BMUS, CEUS) and multi-view (e.g., longitudinal view, cross-sectional view). Over the past decades, multi-modality/multi-view analysis has shown promising results in the clinical field compared to single-modal/single-view imaging [18,19]. Additional modalities beyond conventional ultrasound imaging, i.e., BMUS, could provide extra information on the research topic concerned, enhancing the understanding of its underlying mechanism. For example, a recent study by Cheng et al. (2023) [20] employed a set of features extracted from Shear Wave Elastography (SWE) and Superb Microvascular Imaging (SMI) on carotid plaque. In their study, SWE provided tissue stiffness information, and SMI provided insights into neovascularization, leading to its efficacy in plaque condition assessment and prediction of short-term outcome after stroke. Although their findings are encouraging, SWE and SMI have not been widely adopted in routine clinical practice compared to BMUS and CEUS. Another study by [21] leveraged CEUS to detect neovascularization inside plaques. In addition, multi-view analysis facilitates the acquisition and interpretation of data from diverse vantage points, thereby enriching the comprehensiveness of the research investigation. For example, Ref. [22] employed front and side views of neck region photographs in their radiation dermatitis severity grading network, resulting in a comparable performance to human assessors with higher efficiency. In the case of carotid plaques, a longitudinal view provides characteristics of the length and morphology of the plaque, while a cross-sectional view offers insights into the depth and composition. As such, it is pertinent that these views may work in tandem to provide complementary information for carotid plaque vulnerability in the context of AI.
Notably, there is no existing study in the current body of literature leveraging a multi-modal multi-view of ultrasound images to maximize its utility and potential for AI-enabled auto-classification of carotid plaque vulnerability. This may be ascribed to the practical challenges in obtaining both modalities for each individual and obtaining accurate manual delineations of carotid plaques by experienced clinicians for all the studied ultrasound imaging modalities, which itself could be an overwhelmingly resource- and expertise-demanding procedure. On top of that, most of the existing models are either based on DL algorithms that are highly predictive but of low interpretability due to the intrinsic properties of DL [23,24] or based on ML algorithms that are interpretable but with limited discriminability due to their relatively inferior classification power when compared to DL [25,26]. Of note, there is a severe lack of studies combining both DL and ML for achieving a balance between model discriminability and interpretability in the context of carotid plaque vulnerability classification.
Confronted with this, the present study aimed to bridge this gap by benchmarking the best-performing hybrid DL-ML model that leverages dual-modal (BMUS and CEUS) and dual-view (longitudinal view and cross-sectional view) ultrasound images for discriminating vulnerable carotid plaques against their counterparts. Key contributions of this study include the following:
- This study proposed a novel dual-modal dual-view DL-ML framework, which enables automatic classification of carotid plaque vulnerability on B-Mode and contrast-enhanced ultrasound images with longitudinal and cross-sectional views.
- To overcome the data variety introduced by the dual-modal dual-view data setting, a late fusion hybrid DL-ML method was proposed to effectively fuse features extracted from different ultrasound image modalities and views.
- This research benchmarked the hybrid VGG-RF model as the best-performing model among all model variants, with an AUC of 0.908, a precision of 0.785, a recall of 0.953, a specificity of 0.895, and an F1 score of 0.865. Its performance is comparable to peer models trained on a single-view, single-modality settings, i.e., BMUS longitudinal view on larger cohorts [24].
- To our best knowledge, the first of its kind to use bounding box ROI in US-based plaque vulnerability prediction. This strategy offers an alternative to the delineation ROI definition adapted by prior studies [23,24,27]. It broadens accessibility across imaging modalities, mitigates potential information loss from indistinct boundaries, and enhances ease of use for clinicians.
2. Materials and Methods
2.1. Patient Data
Patient data were retrospectively retrieved from Beijing Tiantan Hospital between 2014 and 2022. Ethical approval was obtained from the Human Subject Ethics Sub-committee of the Hong Kong Polytechnic University (HSEARS20240719004) and from the Ethics Board of Beijing Tiantan Hospital, Capital Medical University (No. KT2022-015-04). BMUS and CEUS images from 241 patients were included in this study after screening 1088 subjects in total. Both longitudinal and cross-sectional views of BMUS and CEUS were analyzed as shown in Figure 1. For each patient sample, a single representative image was selected per view to ensure consistency. The images were acquired from two different ultrasound scanners. The first scanner was a Canon Aplio 900 (Canon Medical Systems Corporation, Ōtawara, Tochigi, Japan) with a 10–15 MHz i18LX5 transducer. The second scanner was a Supersonic Imagine Aixplorer (SuperSonic Imagine, Aix-en-Provence, France) with a 6–9 MHz SL10-2 transducer. A bounding box region-of-interest (ROI) was generated to cover the carotid plaque on the images for downstream analysis. Ground truth for plaque vulnerability was provided by experienced physicians through consensus at Beijing Tiantan Hospital.
2.2. Design of the Hybrid DL-ML Model
In this study, a total of four types of input data were processed in the proposed dual-modal dual-view image fusion networks. They are BMUS longitudinal view (BMUS-L), BMUS cross-sectional view (BMUS-C), CEUS longitudinal view (CEUS-L), and CEUS cross-sectional view (CEUS-C), as shown in Figure 1.
Multimodal fusion methods can be broadly classified into early fusion and late fusion approaches, depending on when the fusion process is introduced. Early fusion refers to concatenating and jointly learning features within the network, which can capture cross-modal interactions but may be sensitive to modality imbalance and noise. Late fusion, in contrast, combines complementary outputs from separate networks at the decision level, generating a joint prediction. Beyond these two categories, recent reviews highlight intermediate and hybrid strategies, such as hierarchical fusion and attention-based fusion, which aim to balance feature-level integration with decision-level robustness [28]. In medical imaging and cancer research, early fusion has been applied to integrate omics and imaging features, while late fusion has been favored when modalities differ substantially in scale or quality. Guided fusion strategies have also been proposed, where secondary data (e.g., clinical records) indirectly influence feature selection of primary data (e.g., imaging or omics) without direct concatenation.
In this study, late fusion was adopted to integrate dual-modality (BMUS and CEUS) and dual-view (longitudinal and cross-sectional) information. This design leverages the complementary strengths of each modality and view while maintaining flexibility and interpretability at the classifier level. Several considerations further motivated the choice of late fusion in this study:
- Similar hybrid DL settings have been tested to be effective on carotid plaque classification tasks [24].
- Given the retrospective design of this study, data from different modalities and views were not aligned on a real-time level or in exactly the same field of view (FOV). This, along with our dual-modal dual-view data setting, which introduced greater data variety, makes late fusion more suitable than early fusion. Early fusion could potentially impact performance due to these misalignments [29].
- Based on the final classifier chosen, late fusion methods can enhance interpretability by highlighting which features from each modal/view contribute to the model.
Visual Geometry Group (VGG) [30] was chosen as a core neural network for deep feature extraction from each of the dual-modal dual-view ultrasound images. Ultrasound images primarily contain low-level anatomical and physiological information, such as tissue structures and blood flow. These features are relatively subtle and would benefit from applying deeper feature extraction mechanisms to divulge imaging biomarkers. Therefore, VGG was chosen owing to its capability of extracting deep features from images. Sanagala et al.’s [23] work also showed that VGG was the most effective model for the transfer learning method on carotid plaque images among various models. Pretrained weights obtained from ImageNet [31] were loaded to speed up the training process.
Subsequently, six ML algorithms were independently applied to the output features derived from the VGG models, serving as their inputs to fit each of these classifiers. These algorithms include Decision Tree (DT), K-Nearest Neighbors (KNN), Random Forest (RF), Support Vector Machines (SVMs), Logistic Regression (LR), and Light Gradient Boosting Machine (LGBM) [32]. A general schematic diagram for the proposed hybrid DL-ML models is illuminated in Figure 2.
2.3. Experimental Protocol
2.3.1. Data Split
The dataset contains 241 samples (55 positive, 186 negative). Patient-level splitting was strictly enforced so that no patient appeared in more than one set within a fold. To evaluate model performance, a stratified 5-fold cross-validation was conducted on the whole dataset. In each fold, the dataset was partitioned into training and testing sets with a ratio of 80/20, yielding training sets of 192 samples (41 positive, 151 negative) and test sets of 49 samples (14 positive, 35 negative). Stratification preserved the ratio of positive and negative cases in every fold. For the VGG network, validation sets were further split from the training sets in each fold with a ratio of 80/20, resulting in validation sets of 39 samples (5 positive, 34 negative) and the remaining 153 samples (36 positive, 117 negative) used for training. This procedure was designed to prevent data leakage and provide a more stable estimate of model generalizability in the context of a relatively small and imbalanced dataset.
Although the dataset is imbalanced, with approximately 23% vulnerable plaques, this distribution closely reflects real-world prevalence. Resampling strategies (e.g., SMOTE) were not applied to the training set because the limited number of minority cases may yield synthetic samples with low diversity, risking overfitting and inflated performance [33,34,35]. Down-sampling may further discard the majority-class patients, which could be problematic for CNN training stability. Instead, several classifiers (RF, SVMs, LR, LGBM) incorporate adaptive class weighting, which partially mitigates imbalance effects without altering the dataset distribution.
2.3.2. Model Development
Firstly, four distinct VGG models, each representing a specific modality and view, were trained independently. These models were trained on the BMUS-L, BMUS-C, CEUS-L, and CEUS-C data from the training set, respectively. The validation set was used to optimize the performance and guide the training process of each of these models. Subsequently, the logits of the last layer before prediction from the four VGG models were loaded. These logits were then sent into various ML models, including DT, KNN, RF, SVMs, LR, and LGBM, to fuse the complementary features between different modalities and views of input ultrasound images. For the VGG network, the Adam optimizer was employed with categorical cross-entropy loss. These settings are consistent with widely adopted defaults in deep learning frameworks and have been shown to provide stable convergence in medical imaging tasks, particularly when datasets are relatively small and imbalanced [36,37]. A fixed learning rate of 1 × 10^−4^ was used rather than a decay schedule, as this choice offered stable training dynamics and reproducibility in the context of a limited dataset. For the machine learning classifiers, hyperparameters were selected using grid search with cross-validation on the training set. This procedure ensured that parameter tuning was systematic and reproducible while reducing the risk of overfitting to a particular partition [38,39]. The best-performing parameter set identified through this process was then used for subsequent evaluation. This approach was adopted to fully leverage the potential of the ML classifiers and to enable a fair comparison with the deep learning models under consistent evaluation conditions.
To evaluate the effectiveness of the developed models, four experimental settings were adapted to train on different input combinations, namely single-modal single-view, single-modal dual-view, dual-modal single-view, and dual-modal dual-view. Their input combinations are shown in Table 1. The models developed in the single-modal single-view setting were regarded as baselines for model performance comparisons against models developed in other experimental settings. The models generated in the single-modal dual-view and dual-modal single-view settings were employed to provide an evaluation of model performance against the dual-modal dual-view models, which leverage complementary imaging features from all modalities and views of ultrasound images.
2.3.3. Model Evaluation
A thorough evaluation of models was conducted on the testing set, which was developed based on different combinations of modalities and views: single-modal single-view, single-modal dual-view, dual-modal single-view, and dual-modal dual-view. The primary metrics for this evaluation were the AUC and F1 score. To quantify the variability of model performance, 95% confidence intervals (CIs) were calculated for AUC and F1 scores based on fold-level results from cross-validation. The DeLong test [40] was utilized for comparisons between ROC-AUC curves of different models. A p-value less than 0.05 indicates statistical significance of the performance differences between the ROC-AUC curves compared.
The best-performing hybrid DL-ML variant was then benchmarked using the AUC and F1 score on the testing set. This model was further evaluated in terms of precision, sensitivity, and specificity. Additionally, model interpretability was assessed by SHAPLEY values [41,42], which revealed the average contributions of each feature to the model output. Complementary qualitative insights into CNN feature extraction were obtained for each modality and view through Grad-CAM visualizations [43]. This comprehensive evaluation process ensured that both the average performance and the variability/stability of the model performance were assessed, providing a comprehensive understanding of the proposed models’ effectiveness.
3. Results
3.1. Comparative Analysis of Experimental Settings
Table 2 and Table 3 depict the ROC-AUC values and F1 scores, respectively, of the models developed in different experimental settings. Figure 3 shows the comparison of AUC and F1 scores on different experimental settings and model variants. Three key findings were generated:
Enhancement through modality and view fusion: The experimental results indicated that the fusion of either two modalities (dual-modal single-view) or two views (single-modal dual-view) generally leads to an improvement in model performance compared to the respective baselines (e.g., BMUS-L + CEUS-L compared to BMUS-L and CEUS-L). This suggests that the integration of additional modalities or views of ultrasound images can effectively enhance the predictive power of the deep learning models.
Superiority of dual-modal dual-view setting: The dual-modal dual-view setting, which incorporates all available modalities and views, consistently outperformed other settings across most models except VGG-DT and VGG-KNN, as reflected by the AUC and F1 scores. This finding substantiates our hypothesis that a comprehensive fusion of multi-modal multi-view images could potentially optimize the performance of AI models using carotid plaque ultrasound imaging.
Optimal performance of the VGG-RF model: Among the various hybrid DL-ML variants, the VGG-RF (VGG with Random Forest) model demonstrated superior performance across all settings (AUC: 0.908; F1 score: 0.865). This underscores the effectiveness of the VGG-RF model in leveraging multi-modal multi-view data for enhanced predictive accuracy.
DeLong tests were performed to evaluate the statistical significance of the difference between each ROC-AUC curve. As shown in Table 4, the majority of the comparisons yielded p-values less than 0.05, indicating statistically significant differences in performance between dual-modal dual-view and other settings. The ROC-AUC curves are shown in Figure 4. However, several comparisons (e.g., vs. BMUS-C and vs. BMUS-C + CEUS-C) did not reach statistical significance. These exceptions suggest that while the dual-modality dual-view approach generally provides improved performance, its superiority is not universal across all settings. Nonetheless, the overall performance metrics and the majority of significant comparisons support the practical value of dual-modal dual-view fusion in plaque vulnerability classification. The overall DeLong test results for all models and settings are attached in appendices, as shown in Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6.
3.2. Benchmarking the Optimal Hybrid DL-ML Variant
The VGG-RF model consistently demonstrated superior performance in a dual-modal, dual-view setting. This is evident in the AUC values and F1 scores presented in Table 2 and Table 3, respectively. The VGG-RF model achieved an outstanding AUC value of 0.908 in a dual-modal dual-view setting (BMUS-L/C + CEUS-L/C), which yielded the highest AUC value across all models and settings. Meanwhile, it also achieved the highest F1 score of 0.865 in a dual-modal dual-view setting, underscoring the effectiveness of the VGG-RF model in leveraging multi-modal multi-view data for enhanced predictive accuracy.
3.3. In-Depth Evaluation and Interpretability of the Benchmarked Model
The performance metrics of the VGG-RF model across different experimental settings are presented in Table 5. The metrics include AUC, precision, recall, specificity, and F1 score. The dual-modal dual-view setting, specifically with the combination of BMUS-L/C + CEUS-L/C, demonstrates superior performance. This is evidenced by an AUC of 0.908, precision of 0.785, recall of 0.953, specificity of 0.895, and an F1 score of 0.865. These metrics indicate a high level of effectiveness in this particular setting.
As for model interpretability, Figure 5 displays the SHAPLEY values for each of the selected imaging features in the benchmarked VGG-RF model. It shows that BMUS-L exhibits the most significant influence on the model’s classification decision, followed by CEUS-L. Notably, while CEUS-L alone demonstrates poor predictive performance with an AUC of 0.558, it significantly enhances the overall model performance when combined with other features. This highlights the effectiveness of modality fusion in improving predictive accuracy. The major contribution comes from the longitudinal view of ultrasound images (i.e., BMUS-L and CEUS-L), indicating that features from longitudinal views are crucial in determining the predictive outcomes of the VGG-RF model when compared to cross-sectional views, offering valuable insights into how the model makes its decisions in classifying plaque vulnerability. However, it should be noted that this interpretability analysis is partial: SHAP explains the contribution of imaging features within the ML classifiers but does not directly account for the CNN feature extraction process.
As shown in Figure 6, complementary qualitative insights were obtained through Grad-CAM visualizations for each modality and view from the trained VGG models. For invulnerable plaques, the model’s attention was primarily concentrated along the upper boundary of the vessel, which may suggest reliance on surface morphology cues, consistent with guideline descriptions of stable plaque features [13]. In contrast, for vulnerable plaques, Grad-CAM highlighted more nuanced regions within the vessel lumen and surrounding structures, which may reflect the irregular boundaries and heterogeneous textures often reported in unstable plaques [44].
4. Discussion
This study pioneers the use of dual-modal dual-view ultrasound images for AI-enabled carotid plaque classification. It demonstrated the effectiveness of the proposed approach with the dual-modal, dual-view setting that outperformed other experimental settings compared in the present study. Notably, the VGG-RF model emerged as the best-performing network among all the hybrid DL-ML variants studied, achieving an optimal performance with an AUC of 0.908 in the testing set, along with precision of 0.785, recall of 0.953, specificity of 0.895, and an F1 score of 0.865, suggesting that the benchmarked model is a promising network for carotid plaque classification on the basis of dual-modal dual-view ultrasound images. The inherent interpretability of the RF was embedded in the VGG-RF model, divulging that a longitudinal view of BMUS and CEUS images was the major contributing feature for discriminating vulnerable carotid plaques against their counterparts.
4.1. Model Discrepancies
From the results in Table 2, the VGG-DT model achieved an AUC score of 0.866 in a single-modal, single-view setting with the input BMUS-C. This performance deviates from the general trend where models tend to perform better with the integration of additional modalities or views. DT, being relatively straightforward models, are well-suited for less intricate data. The incorporation of additional modalities or views may introduce a level of complexity that the decision tree model might struggle to handle effectively, potentially leading to diminished performance in these settings. Furthermore, DTs are prone to overfitting [45], which could explain their suboptimal performance in more complex settings.
Conversely, ensemble methods such as RF and LGBM have demonstrated superior performance across all models. These methods integrate multiple DTs, thereby capturing a wider range of interactions when fitting complex data. RF, in particular, introduces diversity into the model by using a subset of features for each tree and by bootstrapping the samples. This diversity could enhance the model’s robustness and generalization capability, making it more adept at handling the complexity introduced by additional modalities or views [46]. This observation suggests ensemble learning methods could be a promising direction for further exploration in multi-modal multi-view image analysis.
4.2. Benchmarking of the Hybrid DL-ML Variants
In this study, we elected to benchmark our proposed model, VGG-RF, against the work of [24] for two primary reasons. Firstly, Skandha et al.’s model represented the state-of-the-art (SOTA) in a single-modal single-view (SMSV) setting. Secondly, their model employed a hybrid DL structure that is analogous to the studied models in the current study, making it a relevant point of comparison. Performance benchmarking with state-of-the-art models is presented in Table 6.
The proposed VGG-RF model, trained on a dataset of 241 samples, achieved a mean AUC of 0.908 and a recall of 0.953. The CNN-DT model trained on the MixD dataset (2600 samples) reported a mean AUC of 0.983 and a recall of 0.983, while the LisD cohort (1500 samples) achieved an AUC of 0.825 and a recall of 0.880. These results demonstrate variability in performance across datasets of different sizes and levels of curation. Additionally, a trend was observed in the performance of the CNN-DT model: as the size of the training dataset increased, the model’s performance also improved. In contrast, the VGG-RF model was trained on a smaller, retrospective dataset, which may limit generalizability. Moreover, both LonD and LisD were dedicatedly designed for plaque tissue classification research [25,47] while this study employed a retrospective dataset. These distinctions of smaller sample size and differences in dataset curation underscore the need for cautious interpretation. Validation in larger, multi-center cohorts will be required to determine whether similar performance could be consistently reproduced and to assess the potential for further optimization.
4.3. Study Strengths
The primary novelty of this framework lies in its pioneering use of a dual-modal, dual-view approach, a strategy that has not been previously explored in the literature. This approach allows for a comprehensive interpretation of specific modalities and views of ultrasound images, thereby providing complementary clinical insights for physicians to identify at-risk patients ahead of their clinical presentation.
The second strength of this model is its hybrid deep learning-machine learning (DL-ML) structure, enabling satisfying model discriminability and model interpretability. The third notable advantage is the model’s stable performance despite being trained on retrospective data. This performance is comparable to models trained on larger, more specific datasets tailored for carotid plaque research.
Lastly, the use of a bounding box ROI in US-based plaque vulnerability prediction. Compared to the delineation ROI in existing studies [23,24,27], bounding box ROI has accessibility to more modalities. For example, in contrast-enhanced ultrasound, tissues would appear as a low-echo area. In such a case, a delineation of plaque tissues will contain very little info, while a bounding box ROI could provide context by including its surroundings. Also, a bounding box ROI may avoid potential information loss due to blurry boundaries of plaques caused by artifacts due to motion, air, or calcification tissues, and is easier to use for clinicians.
4.4. Limitations
The first limitation of this study is its retrospective nature in study design. This may lead to insufficient learning and uncontrollable factors such as types of modalities, patient clinical data, and acquisition settings. In addition, model evaluation was based on a single cross-validation scheme, which may limit the robustness of performance estimates. Future studies with larger, prospective datasets and more comprehensive validation strategies (e.g., repeated or nested cross-validation) are needed to strengthen the reliability of the findings and enhance the performance of the model.
Secondly, this study was conducted in a single center, which raises questions about the generalizability of the proposed model to other medical centers. Although scans in this study were acquired from multiple ultrasound vendors, no contrast normalization was applied, and the framework was evaluated directly on unprocessed CEUS images to reflect typical clinical practice. However, the absence of normalization may further limit generalizability, as inter-vendor variability was not addressed. A solution to this problem would be to conduct future studies across multiple centers, include more ultrasound machine vendors, and investigate whether normalization techniques could reduce variability and improve robustness [48,49].
Thirdly, this study was limited to certain imaging modalities, i.e., BMUS and CEUS, leaving the applicability to other imaging modalities untested. To address this, including modalities such as SWE and SMI in future studies is suggested [20,50,51]. Incorporating clinical information may also potentially enhance the model’s performance and interpretability, which is another potential area for improvement, as the current method utilizing SHAPLEY values only divulges feature contributions in ML classifiers and does not cover the DL part of the model.
In addition to these considerations regarding imaging modalities and the scope of SHAP-based feature attribution, another important limitation concerns the broader interpretability of the deep learning component. In this study, complementary qualitative insights were already explored through Grad-CAM visualizations, revealing distinct attention patterns between invulnerable and vulnerable plaques. While these visualizations highlight how CNNs focus on vessel boundaries or internal structures, such a visualization provides only partial interpretability. Building on this, future work should explore the application of Explainable AI (XAI) techniques [52,53,54,55,56]. These techniques aim to make the decision-making process of AI models more understandable to humans, which is crucial in the clinical field, as interpretability could be as important as accuracy.
Lastly, while bounding box ROI provides a practical alternative to delineation-based ROI, no direct experimental comparison with delineation-based ROI was performed in this study, and operator variability was not quantified. These aspects should be further investigated in future work.
5. Conclusions
In summary, this study underscores the effectiveness of modality and view fusion. Hybrid DL-ML models developed from dual-modal dual-view ultrasound images generally outperformed those developed from single-modal single-view, single-modal dual-view, and dual-modal single-view ultrasound images for identifying vulnerable carotid plaques. Among the studied variants, the hybrid VGG-RF framework achieved the strongest performance, with an AUC of 0.908, precision of 0.785, recall of 0.953, specificity of 0.895, and F1 score of 0.865. These results were obtained despite the relatively small retrospective dataset of 241 patients, underscoring the potential of the dual-modal dual-view integration strategy. Longitudinal views of BMUS and CEUS emerged as the most informative imaging features for discriminating vulnerable plaques in the proposed dual-modal dual-view framework.
Although the findings are encouraging, the retrospective design of the study and the small sample size may limit the strength of the results. Further prospective studies with larger cohorts are warranted to validate these findings. Multi-center studies to evaluate model generalizability to different medical centers and data acquisition settings, inclusion of additional modalities of ultrasound images and clinical patient information, and application of XAI techniques are also suggested in future studies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kuriakose D. Xiao Z. Pathophysiology and Treatment of Stroke: Present Status and Future Perspectives Int. J. Mol. Sci.202021760910.3390/ijms 2120760933076218 PMC 7589849 · doi ↗ · pubmed ↗
- 2Grefkes C. Fink G.R. Recovery from stroke: Current concepts and future perspectives Neurol. Res. Pract.202021710.1186/s 42466-020-00060-633324923 PMC 7650109 · doi ↗ · pubmed ↗
- 3Mukherjee D. Patil C.G. Epidemiology and the Global Burden of Stroke World Neurosurg.201176 S 85S 9010.1016/j.wneu.2011.07.02322182277 · doi ↗ · pubmed ↗
- 4Fleg J.L. Stone G.W. Fayad Z.A. Granada J.F. Hatsukami T.S. Kolodgie F.D. Ohayon J. Pettigrew R. Sabatine M.S. Tearney G.J. Detection of high-risk atherosclerotic plaque: Report of the NHLBI Working Group on current status and future directions JACC Cardiovasc. Imaging 2012594195510.1016/j.jcmg.2012.07.00722974808 PMC 3646061 · doi ↗ · pubmed ↗
- 5Gupta A. Baradaran H. Schweitzer A.D. Kamel H. Pandya A. Delgado D. Dunning A. Mushlin A.I. Sanelli P.C. Carotid plaque MRI and stroke risk: A systematic review and meta-analysis Stroke 2013443071307710.1161/STROKEAHA.113.00255123988640 · doi ↗ · pubmed ↗
- 6Halliday A. Harrison M. Hayter E. Kong X. Mansfield A. Marro J. Pan H. Peto R. Potter J. Rahimi K. 10-year stroke prevention after successful carotid endarterectomy for asymptomatic stenosis (ACST-1): A multicentre randomised trial Lancet 20103761074108410.1016/S 0140-6736(10)61197-X 20870099 PMC 2956884 · doi ↗ · pubmed ↗
- 7Dong L. Paul L. Xin L. Lin Z. Qingguo M. Mi Z. Wenjun Z. Rapid Screening of Carotid Plaque in Cloud Handheld Ultrasound System Based on 5G and AI Technology Adv. Ultrasound Diagn. Ther.2023715210.37015/audt.2023.230018 · doi ↗
- 8Saba L. Cau R. Murgia A. Nicolaides A.N. Wintermark M. Castillo M. Staub D. Kakkos S.K. Yang Q. Paraskevas K.I. Carotid Plaque-RADS: A Novel Stroke Risk Classification System JACC Cardiovasc. Imaging 202417627510.1016/j.jcmg.2023.09.00537823860 · doi ↗ · pubmed ↗