Preclinical HistoBench: A Pilot Benchmark Dataset for Evaluating Large Language Models on Preclinical Histopathological Classification
Avan Kader, Marie-Luise H. H. Ranner-Hafferl, Felix Reuter, Miriam L. Fichtner, Marcus R. Makowski, Keno K. Bressem, Lisa C. Adams

TL;DR
This paper introduces a benchmark dataset to test how well large language models can classify preclinical histology samples, finding that they vary in performance and are not yet reliable for standalone use.
Contribution
The paper introduces the first pilot benchmark dataset for evaluating large language models on multi-dimensional histopathological classification tasks.
Findings
GPT-4.1 had the best mouse identification (70.4% sensitivity) but failed with minority species.
Llama 3.2 uniquely identified all three species but performed poorly on mouse recognition.
Staining classification showed Llama 3.2 with >88% sensitivity for most types, while preparation type classification was particularly challenging.
Abstract
This study evaluates the capability of large language models to perform multi-dimensional classification of preclinical histological samples, addressing the absence of standardized benchmarks in this domain. We assessed three language models (GPT-4.1, GPT-4o-mini, and Llama 3.2) using 378 histological samples across four classification dimensions: species identification (mouse, rabbit, rat), organ recognition (kidney, liver, prostate, spleen), staining method classification (including H&E and specialized stains), and preparation technique determination (frozen versus paraffin-embedded). Our findings reveal substantial variability in model performance across tasks, with pronounced sensitivity to class imbalance. GPT-4.1 demonstrated superior performance for mouse identification (70.4% sensitivity) but failed to recognize minority species, while Llama 3.2 uniquely identified all three…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
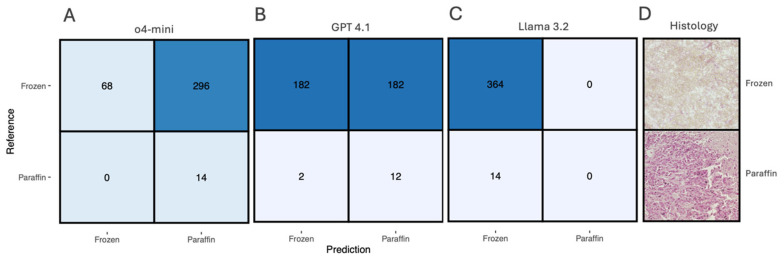 Figure 1
Figure 1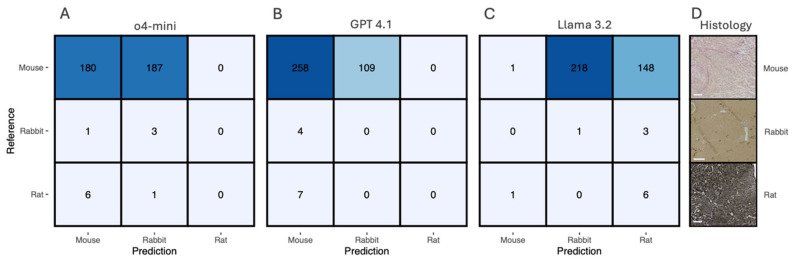 Figure 2
Figure 2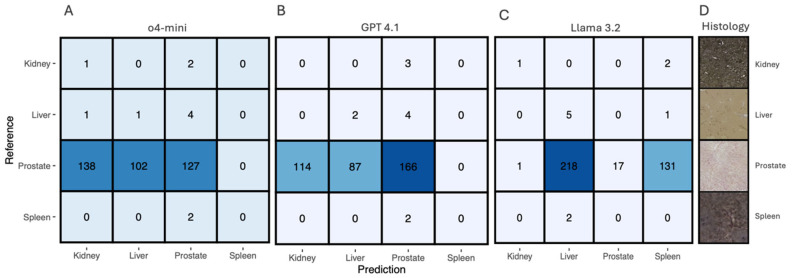 Figure 3
Figure 3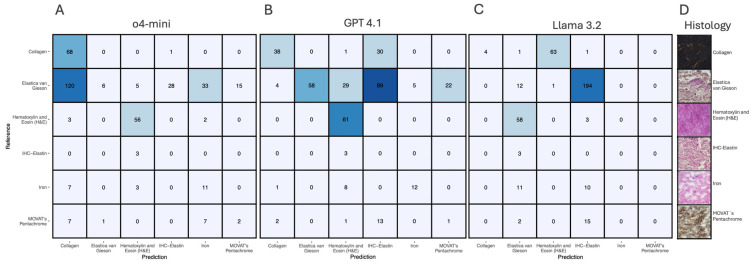 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Biomedical Text Mining and Ontologies · Cell Image Analysis Techniques