Cardiology knowledge assessment of retrieval-augmented open versus proprietary large language models
Constantine Tarabanis, Shaan Khurshid, Areti Karamanou, Rodo Piperaki, Lucas A. Mavromatis, Aris Hatzimemos, Dimitrios Tachmatzidis, Constantinos Bakogiannis, Vassilios Vassilikos, Patrick T. Ellinor, Lior Jankelson, Evangelos Kalampokis

TL;DR
Open-weight AI models performed as well or better than commercial models in cardiology tests, especially when given access to medical references.
Contribution
Demonstrated that open-weight models with retrieval-augmented generation can outperform proprietary models in cardiovascular medicine assessments.
Findings
The open-weight model DeepSeek R1 outperformed all proprietary models and the human average in cardiology board-style questions.
Retrieval-Augmented Generation improved performance across all models, with the most significant gains for smaller models.
Open-weight models offer a viable, lower-cost alternative to proprietary models for clinical applications due to their transparency and configurability.
Abstract
To evaluate the performance of open-weight and proprietary LLMs, with and without Retrieval-Augmented Generation (RAG), on cardiology board-style questions and benchmark them against the human average. We tested 14 LLMs (6 open-weight, 8 proprietary) on 449 multiple-choice questions from the American College of Cardiology Self-Assessment Program (ACCSAP). Accuracy was measured as percent correct. RAG was implemented using a knowledge base of 123 guideline and textbook documents. The open-weight model DeepSeek R1 achieved the highest accuracy at 86.9% (95% CI: 83.4–89.7%), outperforming proprietary models and the human average of 78%. GPT 4o (80.9%, 95% CI: 77.0–84.2%) and the commercial platform OpenEvidence (81.3%, 95% CI: 77.4–84.7%) demonstrated similar performance. A positive correlation between model size and performance was observed within model families, but across families,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
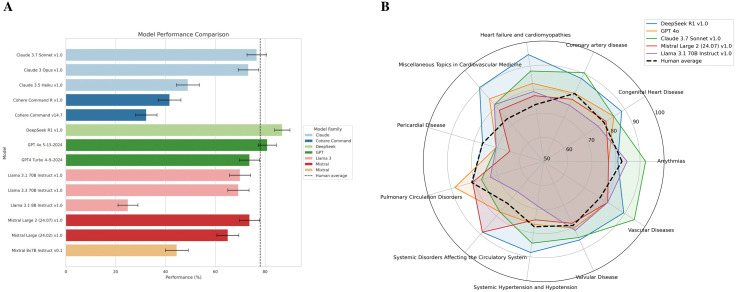 Figure 1
Figure 1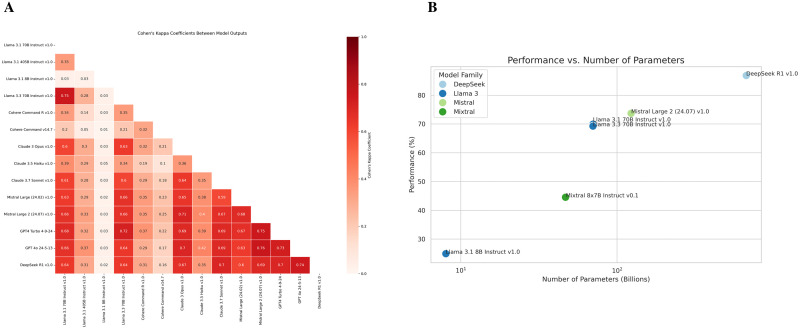 Figure 2
Figure 2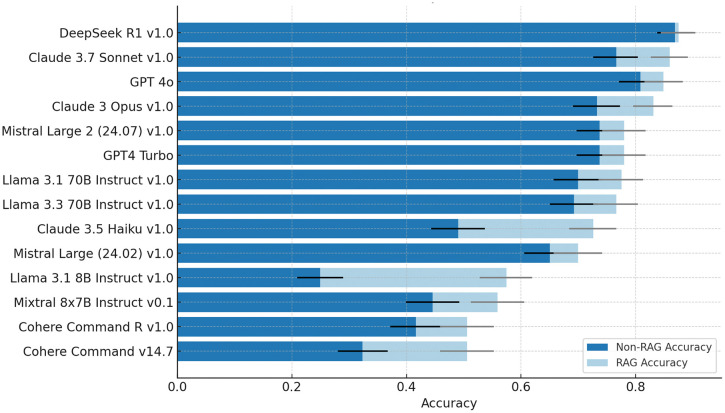 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Topic Modeling · Machine Learning in Healthcare