Real World Human-LLM Interactions – Prospective blinded versus unblinded expert physician assessments of LLM responses to complex medical dilemmas
Itamar Ben Shitrit, Daphna Idan, Mark Volevich, Hadar Sharabi Goldenberg, Dolev Vaknin, Or Degany, Nitzan Abelson, Yair Binyamin, Raouf Nassar, Majd Nassar, Aviya Kedmi, Alexander Zlotnik, Sharon Einav

TL;DR
This study explores how physicians rate responses from large language models (LLMs) in real clinical scenarios, finding that physician satisfaction does not reliably reflect the quality of LLM-generated medical content.
Contribution
The study introduces a novel approach to evaluating LLMs in healthcare by comparing physician ratings of LLM and human-generated responses in a blinded setting.
Findings
Physician satisfaction scores were similar for LLM and human-generated responses in a blinded evaluation.
Satisfaction did not correlate with the accuracy of cited literature in the responses.
Physician resistance to change did not affect their ratings of LLM responses.
Abstract
Current evaluations of large language models (LLMs) in healthcare have largely emphasized theoretical benchmarks and clinician oversight, with limited exploration of real-world physician-AI interaction. In this two-stage prospective study, we assessed physician satisfaction with LLM-generated responses to real clinical queries. This study did not evaluate clinical accuracy, patient outcomes, or patient safety. In the first unblinded stage, physicians used three models - a general-purpose model (GPT-4o), a reasoning-focused model (GPT-o1), and a healthcare-specific model (OpenEvidence) - to address 25 clinical dilemmas - and rated the quality of the responses. In the second blinded stage, the same physicians evaluated responses generated either by an LLM or by a human alone, without knowledge of the source. Across 100 real-world medical responses, median physician scores on a 5-point…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
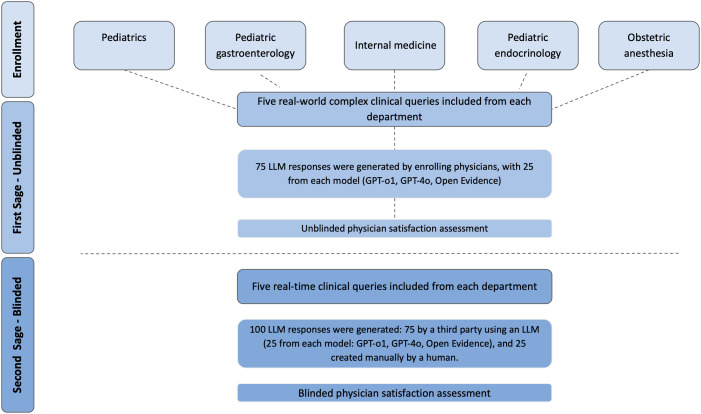 Figure 1
Figure 1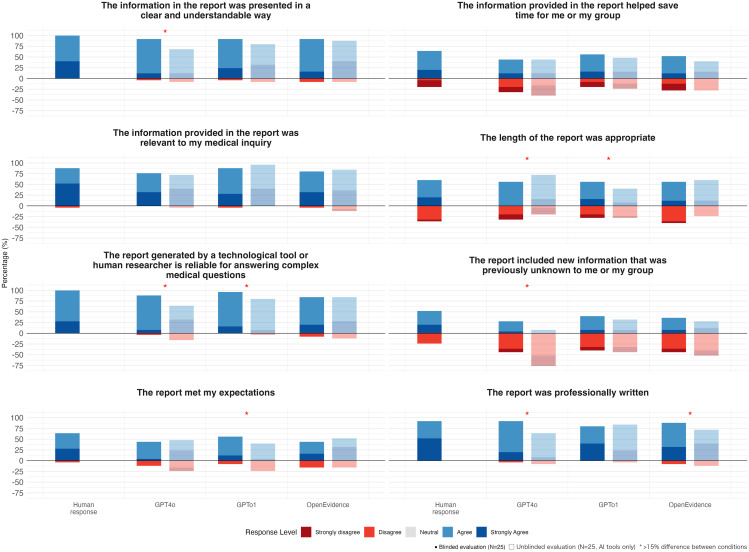 Figure 2
Figure 2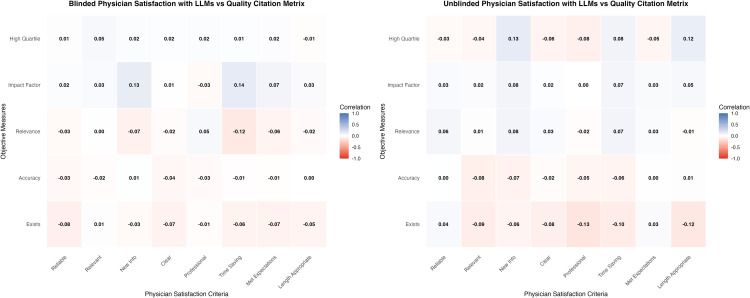 Figure 3
Figure 3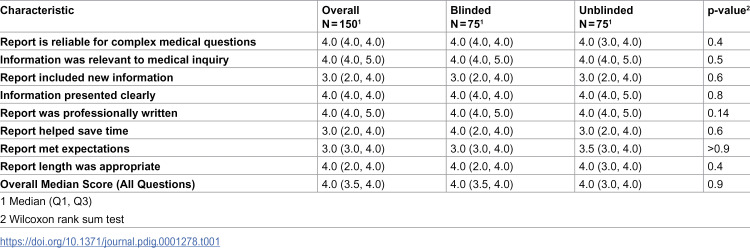 Figure 4
Figure 4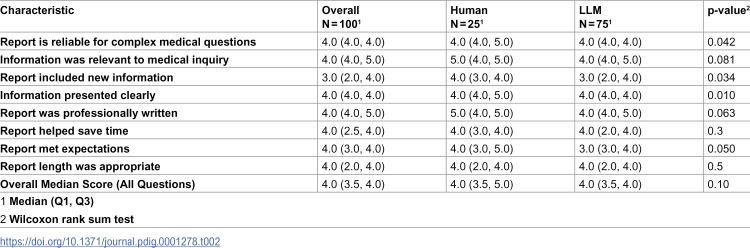 Figure 5
Figure 5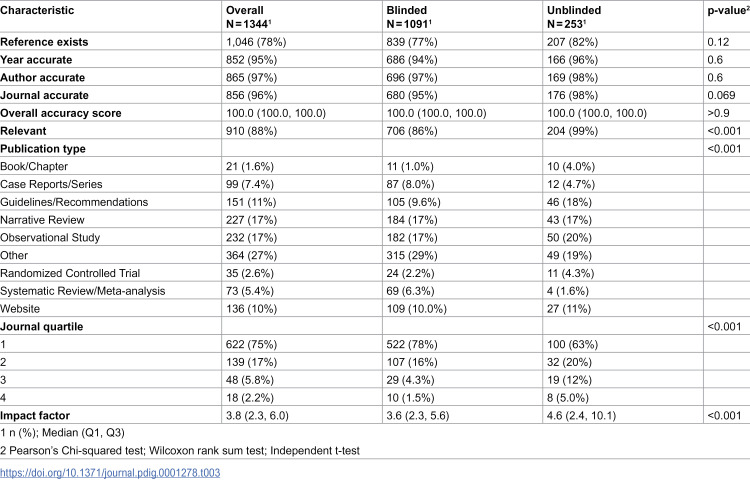 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Electronic Health Records Systems