Adaptive multi-feature fusion architecture with optimized learning for high-fidelity brain tumor classification in MRI
Mohammed Safy, Mahmoud Khaled Abd-Ellah, Esraa Salah Bayoumi, Gerges M. Salama

TL;DR
This paper introduces a new framework for classifying brain tumors in MRI images with high accuracy using a combination of preprocessing, deep learning, and feature fusion techniques.
Contribution
The novel contribution is a multi-stage framework combining adaptive preprocessing, multi-feature fusion, and optimized learning for high-fidelity brain tumor classification.
Findings
The framework achieved 99.05% accuracy, outperforming state-of-the-art methods.
Hybrid features from CNNs and GLCM texture measures improved classification stability and robustness.
Statistical validation confirmed the framework's significant performance improvements.
Abstract
Brain gliomas represent one of the most aggressive cancers worldwide and remain difficult to diagnose accurately at an early stage. Although computer-aided diagnostic (CAD) approaches have progressed notably in recent years, distinguishing between high-grade glioma (HG-G), low-grade glioma (LG-G), and healthy brain tissue on magnetic resonance images is still a major challenge. To address this issue, we propose a multi-stage framework designed to push the boundaries of current classification methods. The framework begins with a preprocessing phase that integrates Adaptive Gamma Correction (AGC) for improved contrast adjustment with a Denoising Convolutional Neural Network (DnCNN) for noise removal. Feature extraction is then carried out from three representative layers across three fine-tuned transfer learning CNNs (TRCNNs), where each model is optimized by a different algorithm. These…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
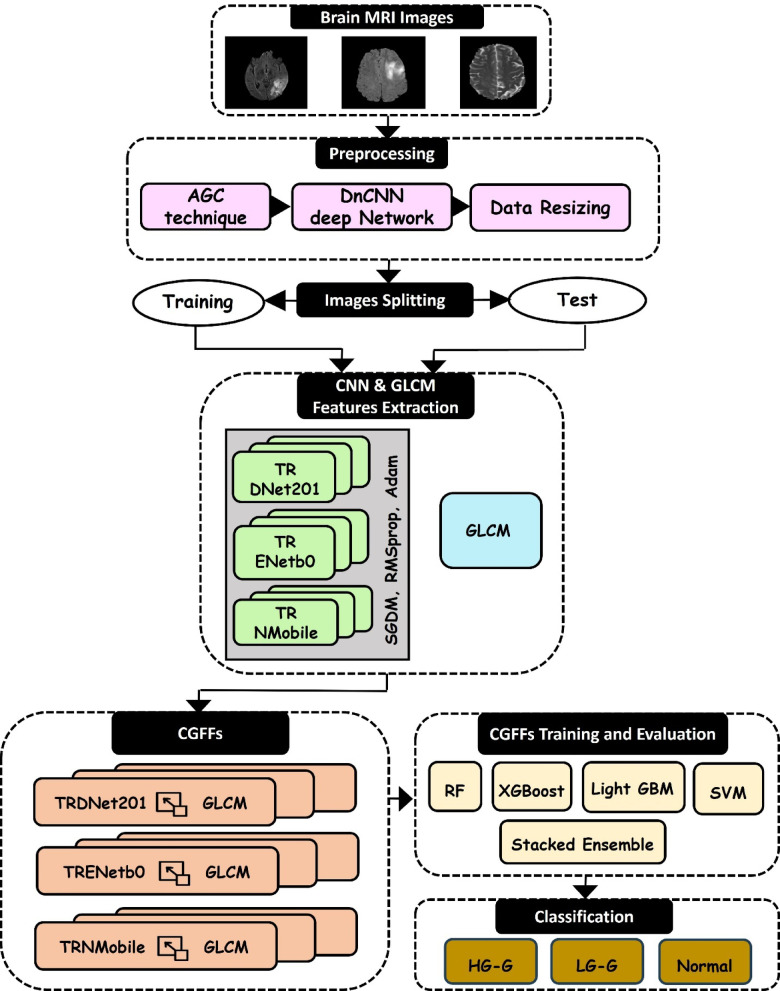 Figure 1
Figure 1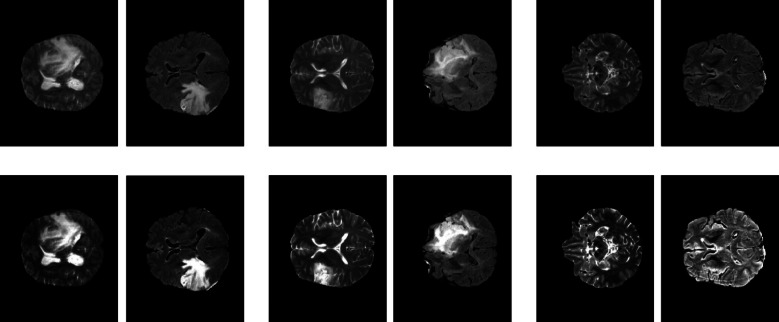 Figure 2
Figure 2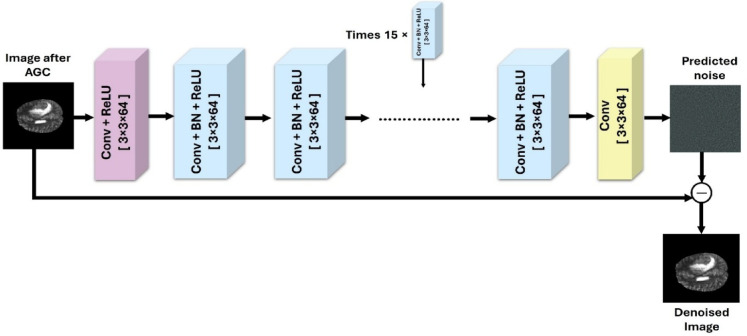 Figure 3
Figure 3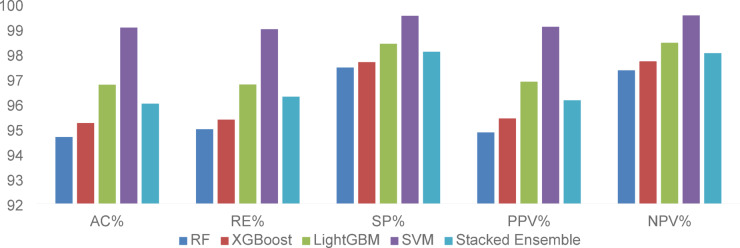 Figure 4
Figure 4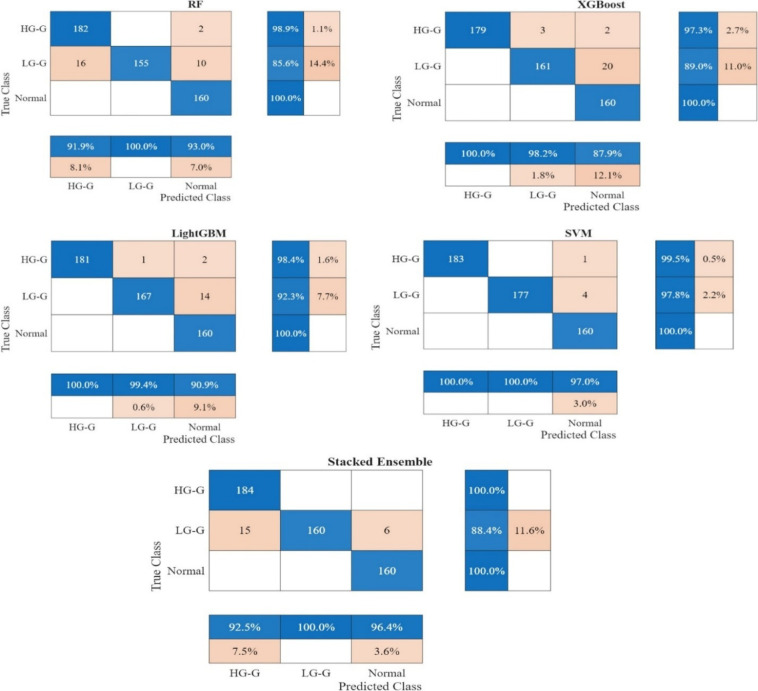 Figure 5
Figure 5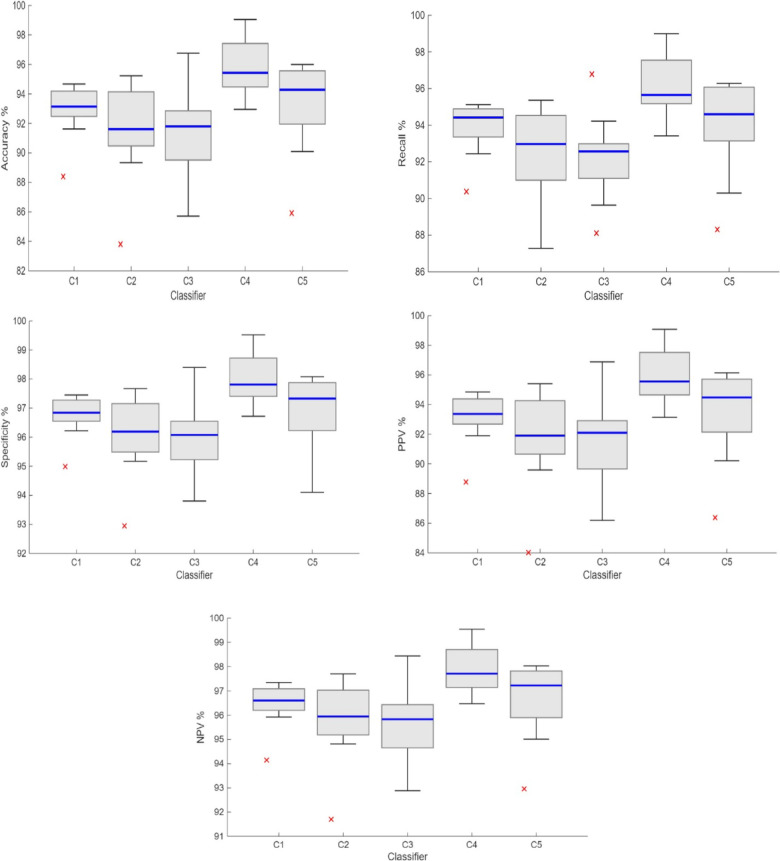 Figure 6
Figure 6- —Egyptian Academy for Engineering & Advanced Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBrain Tumor Detection and Classification · Glioma Diagnosis and Treatment · Advanced Neural Network Applications
Introduction
The prompt and precise detection of the brain tumor grade directly influences the patient’s anticipated survival and plays a crucial role in treatment planning and evaluating tumor growth^1^. Significantly, brain tumors contribute to 85–90% of all central nervous system damage across all medical conditions^2^. Based on recent data provided by the National Brain Tumor Society (NBTS), one million Americans are living with a brain tumor. By the end of 2023, 94,390 cases of primary brain tumors were recorded, and 18,990 individuals died^3^. Gliomas are viewed as the most aggressive primary brain tumors within the central nervous system (CNS)^4^. The World Health Organization (WHO) classifies glioma tumors into two groups: low-grade (LG-G) and high-grade (HG-G)^5^. This classification relies on the microscopic appearance of tumor cells. Examination under the microscope reveals that cells in low-grade gliomas divide slowly. Although non-cancerous, low-grade gliomas can create issues by exerting pressure on normal brain structures. In contrast, high-grade gliomas exhibit more rapid and aggressive growth when compared to low-grade gliomas^6^.
Magnetic resonance imaging (MRI) is an advanced imaging technology known for its ability to offer detailed insights into brain tissue, making it a common choice for automated tumor detection^7^. MRI, which produces highly accurate images of brain tumor features, may provide patients with alternative therapy options. The high prevalence of brain tumors generates massive amounts of brain tumor MRI data, underscoring the urgent need for a reliable automated brain tumor diagnostic system^7,8^. Utilizing a Computer-Aided Diagnosis (CAD) system is crucial for swift and accurate brain tumor identification without human intervention^9^. The treatment approach for a brain tumor will differ based on the specific type of tumor. Automated detection of brain tumors through MRI scans can greatly enhance diagnosis and treatment planning. The process of automatic tumor diagnosis involves two key stages: detection and classification. Detection focuses on distinguishing between MRI images that either show a tumor (abnormal) or are tumor-free (normal). Classification is concerned with sorting glioma MRI images into either high-grade or low-grade gliomas^10^.
In radiology, using artificial intelligence (AI) can reduce error rates beyond what is achievable by human effort alone^11^. Machine learning (ML) and deep learning (DL), both are subsets of AI, assist radiologists in rapidly detecting and classifying tumors without the need for surgical procedures^12^. Deep learning techniques have recently drawn heightened interest in the research community. The Convolutional Neural Network (CNN) is a deep learning technique that has recently seen significant success in addressing medical imaging challenges^13^. CNNs have the capability to automatically extract essential features while reducing dimensionality^14,15^. This eliminates the need for traditional handcrafted features, as CNNs independently learn the critical features necessary for making final predictions^16^. Multiple CNN models have been utilized for brain tumor classification, showing remarkable success in medical classification tasks. These models have also been effective in areas such as skin lesion detection, breast cancer diagnosis, cardiac fibrosis detection, stroke identification, and arrhythmia classification^17–20^.
The high prevalence of brain tumors has led to the accumulation of extensive MRI data. Gliomas are particularly difficult to detect due to their irregular shapes and unclear boundaries. Detecting and classifying brain tumors are crucial processes that rely heavily on the expertise of diagnosing physicians. Despite these advancements, a significant gap remains in classifying low-contrast brain MRI images. This challenge is particularly evident when working with limited datasets^7^. The gap is two-fold. First, the lack of robust, adaptive enhancement for low-contrast MRI limits the performance of subsequent classifiers. Second, CNN-based approaches face inherent architectural limitations. Existing CNNs are optimized to learn global context and high-level shapes. However, their hierarchical pooling layers progressively reduce spatial resolution. Consequently, these networks are often less effective in capturing subtle, fine-grained textural patterns indicative of glioma grades. Furthermore, relying solely on deep features with limited data increases the risk of overfitting. Therefore, fusing deep semantic features from Transfer Learning CNNs (TRCNNs) with handcrafted texture descriptors is essential. This explicit fusion preserves diagnostically critical information and enhances model generalization^21,22^. Developing an intelligent system for contrast enhancement, detection, and classification of brain tumors is vital for assisting physicians. Such a system might serve as a significant resource in hospital emergency departments, enabling quicker diagnoses. For instance, such a technology might assist clinicians by analyzing images from an MRI to determine if they are normal or indicative of HG-G or LG-G. After an image is automatically detected as abnormal, clinicians may simply detect the brain tumor to assess its type during the classification stage. They can then identify the most suitable treatment approach for the severity of the brain tumor and manage it accordingly^23^.
To address these limitations and bridge the gap between deep semantic understanding and fine-grained texture analysis, this study introduces a hybrid framework. It begins with a specialized Adaptive Gamma Correction (AGC) and Denoising Convolutional Neural Network (DnCNN) preprocessing pipeline designed to simultaneously enhance contrast and suppress noise. Unlike standard approaches, our method introduces CNN-GLCM Fused Features (CGFFs), a new feature-level fusion strategy that explicitly combines deep features from three diverse TRCNNs with handcrafted texture descriptors to capture both global abstractions and micro-patterns. These composite feature vectors are subsequently utilized in a robust classification phase involving multiple classifiers: Support Vector Machine (SVM), Random Forest (RF), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LightGBM), and Stacked Ensemble model, which collectively aim to improve diagnostic reliability. The classifiers are trained to effectively discriminate among HG-G, LG-G, and normal brain MRI categories from BraTS 2020 dataset, demonstrating enhanced diagnostic precision. To further validate the reliability of these improvements, the statistical significance of the system’s performance is rigorously verified using the Friedman test. The proposed framework contributes significantly to the field through:
- Development of MRI image enhancement strategy combining AGC and DnCNN techniques applied to the BraTs 2020 dataset, effectively addressing image contrast deficiencies and noise interference.
- Development of a multi-feature fusion approach, integrating deep CNN layer features with GLCM-derived texture descriptors to form the robust CGFFs representation.
- Comprehensive utilization of advanced classifiers as RF, XGBoost, LightGBM, SVM and a Stacked Ensemble, systematically trained and optimized to enhance overall classification robustness.
- Demonstration of high computational efficiency with a total inference time of approximately 0.723s per image, validating the framework’s potential for integration into real-time clinical diagnostic workflows.
- Implementation of Friedman test to statistically evaluate the performance of the five classifiers across the nine CGFFs representations.
- Extensive validation of the proposed methodology against contemporary state-of-the-art techniques, demonstrating superior performance across critical metrics.
The paper is structured as follows: “Related work” section reviews relevant literature on brain tumor diagnosis. “Methodology” section introduces the proposed methodology. “Examination environment” section describes the experimental setup, datasets, and evaluation criteria. “Results and discussion” section presents and discusses the experimental findings comprehensively. Lastly, “Conclusion” section concludes the study.
Related work
In recent years, significant research attention has been focused on detection of tumor presence or not and the classification of brain tumors. The accuracy of tumor diagnosis has been enhanced through the application of various automated detection and classification techniques. Machine learning and deep learning approaches play a vital role in the identification and categorization of brain tumors. For brain tumor detection targeting, Togacar et al.^24^ introduced a CNN model called BrainMRNet to detect normal and tumor MR images. They demonstrated that their model surpassed the performance of pretrained CNN models, achieving an accuracy of 96.05%. In^25^, a combination of five deep learning and five machine learning models were implemented to identify tumors in MRI scans. Each model was applied on 2156 MRI images. An ensemble algorithm, based on majority voting, was used to enhance the diagnostic accuracy of the models. Remarkably, the results achieved an accuracy of 96.51%. Alanazi et al.^26^ constructed a standalone CNN model with 22 layers for detecting the presence or absence of tumors. This model is then fine-tuned to adjust neuron weights for brain tumor detection through transfer learning. Consequently, the transfer-learned model achieves a high accuracy of 95.75%.
In^27^, various CNN architectures were utilized to create feature maps, which were then classified to identify possible tumor samples. The approach was tested on a brain dataset consisting of 253 MRI images, of which 155 contained tumors. The method achieved classification accuracies of 96% with CNN, 98.5% with VGG-16, and 98.14% with an ensemble model. Regarding the work in^28^, ResNet, AlexNet, and VGG were applied into data containing 253 MRI images. Due to the challenges posed by limited data availability in medical imaging, this study expanded the dataset through techniques such as flipping and rotation. Using the VGG-16 model architecture, the approach achieved a detection accuracy of 96%. Salama et al. introduced a system for brain tumor detection by creating more datasets using generative models. The dataset used in the study comprises 253 MRI images, with the generative model expanding it to a more robust size. They applied a classifier for reliable tumor detection in MRI images. The framework achieved a detection accuracy of 96.88%^29^.
In^30^, authors applied CNN-based pretrained models, specifically VGG-16, ResNet-50, and Inception-v3, to detect the presence of tumors. By leveraging transfer learning, they enhanced prediction accuracy while optimizing computational time. The VGG-16 model achieved the highest accuracy of 96%. In another work, six different machine learning algorithms were employed, including random forest, naïve bayes, neural network, CN2 rule induction, support vector machine, and decision tree, to enhance accuracy in addressing this gap. These methods were tested on a Kaggle dataset, where classification accuracy was assessed. A tenfold cross-validation approach was used to reinforce the training and testing processes. The findings reveal that SVM achieved the highest performance among the algorithms, with an accuracy of 95.3%^31^. In 2024, a hybrid detection framework was implemented to identify brain tumors. This system integrated five distinct CNNs for feature extraction, with each network selecting the best five layers for this purpose. These extracted features were then classified using SVM. They had an accuracy of 97.22%^32^.
Recently, a significant amount of research has been directed towards differentiating between HG-G and LG-G using various automated classification methods. Authors in^33^ explored CNN-based transfer learning for preoperative glioma grading on conventional MR images. Two CNN architectures AlexNet and GoogLeNet were evaluated, trained both from scratch and fine-tuned. Using fivefold cross-validation, the best model GoogLeNet with fine-tuning attained around 91% test accuracy. In^34^, the authors introduced a machine learning technique for differentiating LG-G from HG-G by analyzing radiomic features. This research employed MRI images from the MICCAI BRATs 2015 training set. After extracting features, the model classified tumor grades using ML algorithms, achieving an overall accuracy of approximately 91.3%. Mzoughi et al.^35^ proposed a deep multi-scale 3D CNN architecture using the BraTS 2018 dataset. Their model was trained in 284 volumetric MRI cases and validated in 67 cases. The 3D CNN employed small 3D kernels to capture local and global contextual features. This fully automatic method yielded 96.5% accuracy.
Ge et al. developed a semi-supervised learning framework for glioma grading that utilizes both labeled and unlabeled MRI data. They worked with the BraTS 2017 dataset containing 285 subjects across four MRI modalities. The process began by extracting deep CNN features and then utilizing a graph-based technique for label propagation. A constraint ensured consistency between 3 and 2D data to assign pseudo-labels to unlabeled scans. A CNN classifier was subsequently trained on the augmented labeled set, and GAN-generated synthetic MRI slices were added to combat overfitting on the moderate-sized dataset. This strategy achieved 90.7% test accuracy^36^. Özcan et al. introduced a custom CNN and compared it against pre-trained AlexNet, GoogLeNet, and SqueezeNet for classifying gliomas. The models were trained and evaluated on MRI scans from 104 patients. The approach used data augmentation and five-fold cross-validation to improve generalization. The custom CNN achieved the best results with an accuracy of 97%^13^. In^37^, the authors built a high-precision ensemble model using deep transfer learning and stacking. In this approach, seven distinct CNN architectures were fine-tuned using a brain tumor MRI dataset. The ensemble then integrated predictions from these models, selecting the result with the highest confidence as the ultimate decision. A tenfold cross-validation was used to evaluate performance. This model achieved accuracy around 98%.
Gull et al.^38^ proposed a CNN-based pipeline for classification, training on the BraTS 2020 dataset. Their model achieved an accuracy of 98.25%. Farajzadeh et al.^39^ introduced a deep hybrid representation learning approach that combines a CNN with traditional machine learning classifiers and evolutionary optimization. This hybrid model obtained an average classification accuracy of 98%. Ali et al.^40^ introduced a federated deep learning framework based on MRI data. Their method employed a 3D federated learning architecture trained on MRI scans from 142 patients obtained from the MICCAI dataset. The federated model utilized a multi-stream convolutional network combined with focal loss optimization to address class imbalance, achieving an accuracy of 90.72%. Nazir et al.^41^ propose a 3D CNN built on a U-Net with a multi scale feature attention module for glioma grading. Using the shared encoder’s feature vector and three dense layers with SoftMax, their classifier achieves 95.1% accuracy on the test set. Liu et al.^42^ conducted a comparative study evaluating Large Language Models (LLMs) against fine-tuned 3D CNNs for glioma classification on BraTS 2020. Their custom 3D CNN baseline achieved 80.0% accuracy on the binary classification of HGG vs. LGG.
Recent research has focused on automatic classification techniques used to categorize MRI brain images into normal, HG-G and LG-G. An automated framework for glioma classification was developed using a modified CNN architecture based on AlexNet^43^. This study focused on analyzing MRI scans obtained from the Cancer Imaging Archive (TCIA). The proposed model incorporated optimized convolutional and pooling layers to enhance feature extraction from MRI slices. The framework demonstrated a classification accuracy of 91.16% across three categories. An advanced cascaded deep convolutional neural network was designed to detect and classify gliomas^10^. The framework employed dual-path CNN architecture, enhanced with residual connections, to distinguish between normal, LG-G, and HG-G cases in MRI scans. The model was trained and evaluated using 1,800 MRI images from the BraTS 2017 dataset. It achieved an outstanding classification accuracy of 98.88%. Salama et al.^23^ developed the DCBT system, utilizing a transfer-learned EfficientNet-B0 backbone combined with a parallel CNN path for feature extraction. Evaluating their model on the BraTS 2020 dataset for a 3-class task (HG-G, LG-G, Normal), they achieved an accuracy of 98.5%. Topannavar et al.^44^ proposed a framework integrating Spatial Transformer Networks (STN) and Non-local Attention Mechanisms (NAM) into ResNet50 for 3-class classification (HG-G, LG-G, Normal) on BraTS 2020. Their approach achieved 98.66% accuracy. The various approaches presented have been summarized in Table 1, providing a comprehensive comparison of their techniques and performance metrics.Table 1A comparative analysis of various studies on glioma detection and classification.TaskReferencesYearTechniqueDatasetAccuracy (%)LimitationDetection (normal/tumor)^24^2020BrainMRNetKaggle96.05Lacks interpretability, making predictions hard to understand^25^2021Ensemble CNNClinical MRI97.80Combining multiple models increases computational cost^26^2022Custom CNN + Transfer LearningCE-MRI (Figshare)95.75Does not evaluate robustness under different noise conditions^27^2022CNNs + Ensemble253 MRI98.5High accuracy on a small dataset poses a risk of overfitting^28^2022CNNs with Augmentation253 MRI96Relies on basic augmentation techniques^29^2022Generative Model + CNN253 MRI96.88Generative augmentation can add unrealistic patterns absent in real MRI scans^30^2022CNNs–96Relies on standard transfer learning models without architectural changes^31^2023CNN + ML classfiersKaggle MRI95.3Handcrafted features often overlook complex patterns^32^2024CNN + SVM394 MRI120 MRI97.22Small dataset used for training and testingClassification (HG-G/LG-G) (HG-G/LG-G/normal)^33^2024GoogLeNetBrain MRI91The performance is limited by a relatively small training set^34^2025ML on radiomic featuresBraTS 201591.3Handcrafted radiomic features and prior segmentation, limiting full utilization of imaging data^35^2020Deep 3D Multi-scale CNNBraTS 201896.53D CNN models require high computational resources^13^2021Custom CNN, AlexNet, GoogLeNet104 Patients MRI97Lacks comparison with more recent or advanced deep models^37^2021Ensemble of 7 CNNs + StackingBrain MRI98The design is resource-intensive and complex^38^2022CNNBraTS 202098.25Need for large volumes of labeled MRI data for training^39^2023Hybrid deep CNN + MLBraTS 202098High computational cost^40^2023Federated multi-stream 3D CNNBraTS 201790.72The design indicates challenges in maintaining performance consistency across distributed data^41^20243D CNN with U-NetBraTS 202095.1High computational and memory requirements^42^20253D CNN and LLMBraTS 202080Limited classification accuracy^43^2024Modified AlexNetTCIA MRI91.16Small dataset used for training and testing^10^2024Cascaded CNN with Residual PathsBraTS 2017 (1800 MRIs)98.88The design is resource-intensive and complex^23^2025DCBTBraTS 202098.5lacking the feature diversity^44^2025ResNet50 + STN-NAMBraTS 202098.66High computational complexity
In summary, previous studies encountered common challenges (as outlined in Table 1), including limited explanation capability for predictions, susceptibility to image noise, overfitting due to small training datasets, extensive computational demands, dependence on manually designed features, and inadequate representation of image textures. The proposed model in this study introduces an advanced method specifically developed to solve these drawbacks. Initially, the AGC-DnCNN preprocessing approach is applied, significantly enhancing MRI images by improving their contrast and reducing noise, thereby ensuring reliable results across various imaging conditions. Subsequently, the framework introduces CGFFs, effectively merging deep semantic features obtained from CNN models with detailed texture descriptors derived from GLCM, addressing previous shortcomings related to texture representation. Additionally, the utilization of multiple TRCNNs, each optimized independently with different optimization algorithms, diversifies the extracted features, reducing the risk of overfitting, particularly valuable when dealing with small datasets. This comprehensive strategy resolves critical issues highlighted in previous studies and establishes a powerful and precise system for brain tumor classification, demonstrating clear improvements compared to previous approaches.
Methodology
The proposed system shown in Fig. 1 initiates with preprocessing brain MRI images using a hybrid enhancement pipeline that integrates AGC and DnCNN, followed by uniform resizing to standardize input dimensions. The preprocessed dataset is then divided into training and testing subsets to facilitate supervised learning. Feature extraction is performed using three TRCNN models: TRDNet201, TRENetB0, and TRNMobile. For each architecture, transfer learning is applied by replacing the original final classification layer to support the three target classes. Additionally, each model is individually fine-tuned through distinct optimizers: SGDM, RMSprop, and Adam to optimize feature representation. From each TRCNN, the three most informative layers are selected, and their deep features are concatenated with texture features extracted via GLCM, forming a total of nine CGFF representations. This fusion effectively captures semantic and texture-based characteristics within the MRI data. The resulting CGFF vectors are subsequently input to multiple classifiers; RF, XGBoost, LightGBM, SVM and a Stacked Ensemble to enhance classification robustness. The framework is designed to accurately differentiate between HG-G, LG-G, and normal cases.Fig. 1. The overall structure of the proposed model comprises three primary phases: an initial preprocessing phase including AGC and DnCNN models, feature extraction through two pathways leading to the fused layers (CGFFs), and evaluation phase utilizing various classifiers.
Brain images preprocessing
Image enhancement and noise reduction are pivotal techniques in medical image processing, crucial for improving image quality and ensuring accurate diagnosis. The primary goals of these techniques are to enhance contrast, highlight important features, suppress irrelevant details and improve the performance of automated systems for detection and classification. In our study, we utilize MRI brain images obtained from the BRATS 2020 dataset, specifically T2-weighted and FLAIR modalities, which include labeled data for three diagnostic categories HG-G, LG-G and normal. To ensure optimal image clarity, the proposed framework employs a specific sequential pipeline: AGC followed by DnCNN. This sequence is designed to first enhance global contrast and reveal fine structural details, enabling the subsequent DnCNN stage to effectively preserve these features while suppressing noise. Theoretically, applying denoising prior to contrast enhancement risks amplifying residual noise artifacts during the contrast adjustment phase. Fig. 2 illustrates the proposed preprocessing algorithm for all diagnosis classes.Fig. 2. The output of the preprocessed three-class images. The first two columns from the left contain HG-G images, the next two columns contain LG-G images, and the final two columns contain normal images. Original images are displayed in the top row, while preprocessed images are shown in the bottom row.
The AGC
AGC is an image processing technique designed to enhance the visual quality of an image by adjusting its brightness and contrast. Gamma correction involves modifying the luminance of an image through a non-linear transformation controlled by a gamma value (γ). While standard adaptive methods calculate γ locally, such approaches often amplify background noise in low-contrast MRI slices. To address this, this study adopts a dataset-optimized global approach. The γ value was empirically determined through a comprehensive grid search (ranging from 0.5 to 2.5) tailored to the BraTS 2020 dataset characteristics, selecting γ = 1.65 as the optimal parameter that maximizes tumor contrast without noise amplification. The transformation is governed by Eq. (1):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{out} = P_{in}^{\gamma }$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{in}$$\end{document} is the input pixel intensity, γ is the gamma value and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{out}$$\end{document} is the output pixel intensity. This optimized transformation adjusts pixel values to make anatomical details more discernible, providing a stable and noise-resistant enhancement suitable for the subsequent denoising stage.
The DnCNN
DnCNN is a deep convolutional neural network that aims to remove noise from images while preserving important details. The network is trained in a supervised manner on pairs of noisy and clean images to learn the mapping between noisy inputs and clean outputs. DnCNN takes a noisy image as input and processes it through its layers to generate a denoised output. The network leverages its learned filters to suppress noise while preserving essential features and structures in the image. The depth of the network and the size of convolutional (Conv) kernels are typically chosen based on the complexity of the denoising task and the available computational resources. The DnCNN model comprises 59 layers arranged sequentially, including an input layer, one layer block of Conv + Relu, 18-layer blocks of Conv + batch normalization (BN) + ReLU, one layer of Conv and the final layer is a regression layer that outputs the residual noise. The denoised image is obtained by subtracting the network’s output from the noisy input. Formally, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} denote the noisy input image and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R\left( x \right)$$\end{document} represent the predicted residual noise estimated by the DnCNN. Consequently, the final denoised output image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}$$\end{document} is defined in Eq. (2) as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y} = x - R\left( x \right).$$\end{document}The network is trained to minimize the Mean Squared Error (MSE) between the predicted residual noise and the true residual noise. Fig. 3 shows the architecture of DnCNN, where three of the Conv + BN + ReLU blocks are explicitly drawn, while the remaining 15 are denoted using a repetition marker.Fig. 3. The structure of the DnCNN network.
Data resizing for CNNs
Resizing the images is necessary to ensure they are compatible with the employed CNN networks. The first network is DenseNet201; it has 201 deep layers including dense blocks and transition layers, allowing it to learn complex and hierarchical features^45^. As detailed by MathWorks, the complete network includes 708 operational layers from the input to the classification stage, with approximately 20 million learnable parameters^46^. The second Network is EfficientNetB0, according to MathWorks, it has a total of 290 layers with size of 5.3 million. This architecture is part of the EfficientNet family, known for its balanced approach to model scaling that optimizes accuracy and computational efficiency^46^. The last one is NmasNetMobile network which consists of repeated building blocks, enabling a highly efficient and modular structure. Despite being designed for mobile environments, NasNetMobile achieves high accuracy in image classification. NasNetMobile comprises 913 layers with a size of 5.3 million, representing the total learnable parameters. This work employs a dataset comprising 2100 images, each originally sized at 240 × 240 pixels. To align with the input dimension requirements of DenseNet201, EfficientNetB0, and NASNetMobile, all images are uniformly resized to 224 × 224 pixels.
Fusion of multi-level feature extraction (CGFFs)
Feature extraction plays a crucial role in brain tumor classification by leveraging both deep learning and texture-based methods. In this work, two main types of features are extracted: deep features from CNNs and handcrafted texture features using the GLCM. For the deep features, various layers from TRDNet201, TRENetB0, and TRNMobile are employed. To identify the most informative layers, a comprehensive empirical evaluation was conducted. We extracted features from various depths within each CNN architecture and evaluated their individual classification performance. The top three layers were selected because they consistently yielded the highest accuracy and class separability. These layers are strategically located at different stages of the network to capture a rich hierarchy of features, ranging from fine-grained textural details to high-level semantic abstractions. To further optimize feature extraction, SGDM, RMSprop, and ADAM optimizers were employed during the training process. These optimizers adjust the CNN weights based on the gradient of the loss function. A comparative analysis was performed to determine the most suitable optimizer for enhancing deep feature quality. Table 2 outlines the selected layers, their positions within the networks, and the extracted activations.Table 2. The parameters of the optimal three layers from each network.NetworkLayer orderLayer typeActivationsTRDNet201165ReLU[14, 14, 128]493Depth concatenation[7, 7, 960]704Batch normalization[7, 7, 1920]TRENetB01152-D convolution[1, 20]178Batch normalization[14, 14, 672]273Element-wise multiplication[7, 7, 1152]TRNMobile748Batch normalization[7, 7, 176]895Batch normalization[7, 7, 176]905Addition[7, 7, 176]
The second type of feature extraction involves GLCM, which provides valuable texture information by analyzing the spatial relationship between pixel intensities. As a second-order statistical method, GLCM captures structural characteristics such as contrast, correlation, energy, and homogeneity. These features are particularly effective in highlighting subtle textural patterns relevant to glioma classification^47^. In this study, the GLCM calculation was performed using a pixel distance of d = 1 and an angle of θ = 0 degree. Consequently, ten statistical features were computed from the GLCM as defined in Table 3. While deep learning models offer strong capabilities in capturing abstract and high-level semantic features, they often lack sensitivity to fine-grained texture patterns that are essential in distinguishing subtle tumor characteristics. To address this limitation, a feature-level fusion strategy is proposed by integrating CNN-derived deep features with handcrafted texture descriptors obtained via the GLCM.Table 3. Statistical extracted features from GLCM.Feature NoFeature nameEquation1Contrast \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j}^{n - 1} \left| {i - j} \right|^{2} { }f\left( {i,j} \right)$$\end{document} 2Correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j}^{{n - 1{ }}} \frac{{\left( {i - \mu_{x} } \right)\left( {j - \mu_{y} } \right)f\left( {i,j} \right)}}{{\sigma_{i} \sigma_{j} }}$$\end{document} 3Energy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j}^{n - 1} f\left( {i,j} \right)^{2}$$\end{document} 4Homogeneity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j}^{n - 1} \frac{{f\left( {i,j} \right)}}{{1 - \left( {i - j} \right)^{2} }}$$\end{document} 5Dissimilarity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j} \left| {i - j} \right|.f\left( {i,j} \right)$$\end{document} 6Entropy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i,j} f\left( {i,j} \right)\log \left( {f\left( {i,j} \right)} \right)$$\end{document} 7Difference variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$variance{ }of{ }f_{x - y}$$\end{document} 8Maximum probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop {\max }\limits_{i,j} f\left( {i,j} \right)$$\end{document} 9Inverse difference moment \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} \frac{{f\left( {i,j} \right)}}{{1 + \left| {i - j} \right|^{2} }}$$\end{document} 10Inverse difference moment normalized \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} \frac{{f\left( {i,j} \right)}}{{1 + \left( {i - j} \right)^{2} /n^{2} }}$$\end{document}
Regarding the feature fusion process, each selected CNN layer’s deep feature vector is fused explicitly with texture descriptors extracted from GLCM features. This fusion procedure combines the high-level semantic insights provided by CNN features with the fine-grained textural characteristics identified by GLCM, yielding nine enriched, unified feature representation termed CGFFs. Specifically, each of the top three layers selected from TRDNet201, TRENetB0, and TRNMobile provides a 3D feature map. To ensure compatibility with the 1D texture descriptors, these 3D maps are processed using a flattening operation. This converts the 3D tensors into 1D feature vectors, thereby preserving the complete spatial information extracted by the CNNs. These vectors are then individually fused with the corresponding GLCM feature vector. Regarding the feature fusion dimensionality, the final CGFF vector size is the sum of the flattened deep feature dimension and the GLCM feature dimension. This fusion is designed to enrich the descriptive power of the feature space, allowing the model to simultaneously capture both global patterns and micro-structural variations that may be diagnostically relevant in differentiating glioma classes.
Classification techniques
Following the fusion stage, the resulting nine CGFFs features were evaluated using five supervised machine learning classifiers to categorize brain MRI scans into HG-G, LG-G, and normal classes. The selected classifiers include RF, XGBoost, LightGBM, SVM and a Stacked Ensemble model that combines the strengths of individual learners.
Random Forest is an ensemble-based classification algorithm that builds multiple decision trees during training^48^. Each tree is trained on a bootstrapped subset of data, with random feature selection at each split, ensuring model diversity. Final predictions are made through majority voting across all trees^48^. RF is highly effective in handling high-dimensional datasets and is tolerant of missing values. It also provides feature-important metrics, which help identify the most influential variables^49^. Although excessive similarity among trees can reduce classification accuracy, RF remains a strong, interpretable, and efficient model for multi-class medical image classification.
Extreme Gradient Boosting is an efficient gradient boosting algorithm known for its high accuracy and scalability. It builds decision trees sequentially, where each new tree minimizes the residual errors of prior ones using a second order Taylor approximation of the loss function^50^. XGBoost avoids overfitting and performs reliably in complex tasks such as classifying using combined features. Its support for parallel computing, handling missing values, and sparsity aware algorithms enhances its performance in clinical datasets^50^. In the proposed system, XGBoost effectively learned the non-linear relationships embedded in hybrid features, allowing precise differentiation between HG-G, LG-G, and normal brain images.
Light Gradient Boosting Machine is a gradient boosting framework optimized for speed and efficiency on high dimensional data. It employs a leaf-wise tree growth strategy along with histogram-based feature binning, which helps speed up training and allows for deeper trees than traditional methods. LightGBM natively handles categorical features and supports parallel learning, making it ideal for real-time medical applications. In this study, LightGBM efficiently processed concatenated CNN–GLCM features, providing accurate multi-class classification across brain tumor grades. Its capacity to reduce memory consumption and adapt to imbalanced data makes it a valuable component in the classification pipeline of glioma detection using MRI slices.
Support Vector Machine is a widely used supervised learning algorithm for classification tasks. It works by finding the optimal hyperplane that separates data points of different classes with the maximum margin^51^. While SVM is inherently a binary classifier, it can be extended to handle multi-class classification problems, such as distinguishing between three classes. Error-Correcting Output Codes (ECOC) extend the capability of SVM for multi-class classification by encoding each class into a unique binary string, or code. For a three-class problem, ECOC generates binary codes for each class and decomposes the multi-class problem into multiple binary classification tasks^51^. Each binary classifier is trained to distinguish between two subsets of the classes, as defined by the binary codes. For instance, considering three classes designated X, Y, and Z, they can be encoded as follow: 00, 01 and 10.
The Stacked Ensemble model is critical to our framework, designed to synthesize the predictions of the base classifiers (RF, XGBoost, LightGBM, and SVM) by training a meta-classifier on their outputs. In this study, a Logistic Regression model was employed as the meta-classifier due to its interpretability and efficiency in combining probabilistic outputs from heterogeneous base learners. This hierarchical structure aims to reduce prediction variance by exploiting the diverse predictive power of its base learners. Its true advantage in this application lies in integrating fundamentally different classification paradigms. For instance, the SVM is highly adept at finding an optimal separating hyperplane in the high-dimensional CGFF feature space. In contrast, the tree-based models (RF, XGBoost, and LightGBM) excel at capturing complex, non-linear, and hierarchical interactions between features by creating a series of axis-parallel decision boundaries. By synthesizing these complementary strengths, the meta-learner intelligently weights each model’s contribution, improving the detection of subtle differences between tumor types. This mitigates the risk of overfitting to the biases of any single model and achieves a more generalized and robust final classification, ensuring the high reliability and adaptability required for a clinical diagnosis^52,53^.
Examination environment
Machine tool
The work was conducted on a device with the following specifications: an AMD Ryzen 7 5800H processor with Radeon Graphics, CPU running at 3.20 GHz, 16.0 GB of RAM, NVIDIA GeForce RTX 3070 with 8 GB and a 64-bit operating system × 64-based processor. The computations for the proposed system were implemented using MATLAB R2024a.
Dataset overview
The dataset used in this study is derived from the BraTS 2020 collection^54^, which natively consists of 3D multimodal MRI volumes. In this work, we utilized the T2-weighted and Fluid- FLAIR modalities. To ensure compatibility with the proposed 2D CNN architectures, a 3D-to-2D conversion process was applied. Slices containing tumor regions were selected for the HG-G and LG-G classes, while slices from non-tumorous regions were extracted to form the Normal class. The final curated dataset comprises 2,100 2D images, originally sized at 240 × 240 pixels, which were subsequently resized to 224 × 224 pixels during preprocessing (Table 4).Table 4. Training and testing dataset.Training dataTesting dataTotal datasetHG-GLG-GNormalHG-GLG-GNormal2100540537498184181160
Evaluation criteria
The efficacy of the proposed method was assessed through two distinct criteria: the enhancement of the brain image and the classification of brain tumors. The enhancement outcomes were evaluated based on two factors: peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). The classification outcomes were appraised using five metrics: accuracy (AC), recall (RE), specificity (SP), positive predictive value (PPV) and negative predictive value (NPV) measures.
Evaluating parameters for preprocessed brain images
The performance of the enhancement results was evaluated by measuring two key parameters: the peak signal-to-noise ratio and the structural similarity index measure. These parameters have been utilized across other multiple image enhancement techniques, specifically Histogram Equalization (HE), Adaptive Histogram Equalization (AHE), and Contrast Limited Adaptive Histogram Equalization (CLAHE).
The peak signal-to-noise ratio of a brain MRI image is a quality metric that compares the peak signal level to the amount of noise in the image. In the context of MRI imaging, the PSNR is especially helpful for assessing the fidelity of reconstructed or processed images since it quantifies the ratio of the greatest achievable signal power to the power of the image’s corrupting noise^55^. The formula for calculating the PSNR is denoted by Eq. (3):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PSNR = 10log_{10} \left( {\frac{PS}{{MSE}}} \right)$$\end{document}where the Peak Signal (PS) is the highest possible signal value, while the mean squared error (MSE) is a measure of the average squared difference between the original and processed image pixel values. A higher PSNR value implies greater picture quality, indicating that the image has fewer distortions and more original data content. A high PSNR in brain MRI imaging is desired because it indicates a better and more accurate picture of brain structures, allowing healthcare providers and researchers to make precise diagnoses and analyses^56^.
The structural similarity index measure is a statistic that measures the similarity of two images based on more than just their pixel values^55^. In the context of brain MRI imaging, SSIM is critical for assessing image quality and fidelity by quantifying brightness, contrast, and structure. The SSIM measure is useful for comparing the anatomical features contained in various brain scans, which aids in activities such as image registration and quality evaluation^56^. Equation (4) represents the formula used to compute SSIM.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$SSIM\left( {f,g} \right) = \frac{{\left( {2\mu_{f} \mu_{g} + C_{1} } \right)\left( {2\sigma_{fg} + C_{2} } \right)}}{{\left( {\mu_{f}^{2} + \mu_{g}^{2} + C_{1} } \right)\left( {\sigma_{f}^{2} + \sigma_{g}^{2} + C_{2} } \right)}}$$\end{document}In this equation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu_{f} \;and\;\mu_{g}$$\end{document} represent the mean pixel values of the two images, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma_{f}^{2} \;and\;\sigma_{g}^{2}$$\end{document} denote their variances, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma_{fg}$$\end{document} shows the covariance between the images. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_{2}$$\end{document} are constants to prevent division by zero. The SSIM value ranges from − 1 to 1, with values closer to 1 signifying higher structural similarity between the images.
Evaluating parameters for brain tumor classification
We evaluated classification performance using a combination of training and testing datasets. The evaluation of the classification model involved the use of the following parameters: AC (Eq. 5), which is a metric that measures the number of correct predictions based on both true positives and true negatives compared to the total number of predictions; RE (Eq. 6), which measures the number of cases that were positive accurately detected by the model; SP (Eq. 7), which measures the number of cases that were negative accurately detected by the model; PPV (Eq. 8), which is the fraction of true positives among all positive predictions; and NPV (Eq. 9), which is fraction of true negatives among all negative predictions.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AC = \frac{{\checkmark }P + {\checkmark }N}{{ \times P + \times N}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RE = \frac{{\checkmark }P}{{{\checkmark }P + \times N}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$SP = \frac{{\checkmark }N}{{{\checkmark }N + \times P}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PPV = \frac{{\checkmark }P}{{{\checkmark }P + \times N}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$NPV = \frac{{\checkmark }N}{{{\checkmark }N + \times P}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\checkmark }P$$\end{document} is the number of true positives, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\checkmark }N$$\end{document} is the number of true negatives, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times P$$\end{document} is the number of false positives, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times N$$\end{document} is the number of false negatives.
Results and discussion
Analysis of enhancement technique of preprocessed brain images
This section presents a two-stage analysis of the enhancement process applied to the BraTS 2020 dataset using PSNR and SSIM metrics. Initially, the performance of the proposed enhancement system (AGC followed by DnCNN) was compared against conventional enhancement methods, including HE, AHE and CLAHE. As illustrated in Table 5, the proposed method consistently outperformed traditional techniques across all image classes, achieving the highest PSNR and SSIM values. This result emphasized the potential of the proposed system to improve medical image clarity and enhance visibility of anatomical structures, especially in glioma detection.Table 5. The evaluation of the performance of various image enhancement techniques.DatasetHEAHECLAHEProposed methodPSNRSSIMPSNRSSIMPSNRSSIMPSNRSSIMHG-G20.370.0222.510.4423.640.5125.98****0.97LG-G20.250.0224.590.4425.770.5127.98****0.96Normal18.320.0118.820.3920.610.4521.64****0.84Significant values are in [bold].
Subsequently, an ablation study was conducted to assess the impact of the enhancement order. Four combinations were tested: AGC only, DnCNN only, DnCNN followed by AGC (Dn-AGC), and AGC followed by DnCNN (AGC-Dn). As shown in Table 6, the results validated that applying AGC prior to DnCNN yielded the most favorable outcome. The rationale is that AGC enhances image contrast and reveals finer details before denoising is applied, allowing DnCNN to preserve the enhanced features while effectively removing noise. Conversely, applying DnCNN before AGC may lead to residual noise amplification during contrast enhancement. These observations confirmed the strategic importance of the processing order.Table 6. Assessment of enhancement sequences based on PSNR and SSIM.Enhancement techniqueClassPSNRSSIMAGCHG-G24.210.88LG-G25.640.86Normal20.900.80DnCNNHG-G24.870.90LG-G26.450.88Normal21.120.82Dn-AGCHG-G25.560.93LG-G27.320.91Normal21.450.83AGC-Dn (proposed)HG-G25.98****0.97LG-G27.98****0.96Normal21.64****0.84Significant values are in [bold].
Evaluation of classification performance using various classifiers
Table 7 presents a detailed comparative analysis of the five advanced classifiers which were applied to the nine CGFFs sets of the three transferred CNNs. The classification performance was evaluated across five metrics: AC, RE, SP, PPV, NPV. Most of the results were obtained using the ADAM optimizer, as it consistently provided the best performance among the three tested optimizers. However, the values marked with () indicate cases where the RMSprop optimizer achieves superior results for those specific feature sets. A critical observation from the table is the impact of optimizer selection on the classification results. ADAM provided consistent and effective training for extracting deep features. However, in some layers, RMSprop led to better feature learning and improved the overall classification results. This hybrid optimization strategy underlines the importance of tailored model tuning in medical image analysis tasks, where minor improvements can substantially affect clinical utility.Table 7. Comparative classification results for each classifier across the nine CGFFs layers.ClassifierMetrics%CGFFs of TRDNet201CGFFs of TRENetB0CGFFs of TRNMobile165493704115178273748895905RFAC92.9594.1092.7694.6794.4894.1093.1488.3891.62RE94.4295.1294.2994.9894.8294.8693.6690.3792.44SP96.7697.2496.6697.4597.3897.2496.8494.9896.22PPV93.1994.2992.9594.8594.6694.2993.3788.7791.90NPV96.3896.9896.2997.3497.3497.096.6094.1595.92XGBoostAC90.8583.8092.5794.2895.2394.0991.6191.0489.33RE92.9787.2893.5494.5395.3694.5492.4891.2490.28SP95.8092.9496.5797.2397.6797.1396.1995.5995.17PPV91.0284.0392.8294.4495.4194.2091.9091.1589.59NPV95.3191.7196.2397.1597.7096.9995.9495.4994.81LightGBMAC90.4791.8086.6692.3896.7692.3894.2891.4285.71RE92.5492.5889.6492.5796.7792.5794.2291.5988.11SP95.6296.0893.8096.3398.4096.3397.2195.7594.03PPV90.6092.1086.8492.4796.8892.4794.2691.4686.19NPV95.1395.8393.2196.1998.4496.1997.1695.6892.88SVMAC94.6797.7193.9099.0597.3395.6295.4392.9595.05RE95.6097.9694.9798.9997.4195.7995.6593.4295.24SP97.4998.8897.1599.5298.6797.9197.8196.7297.66PPV94.8497.7794.0899.0897.4395.7695.5693.1495.21NPV97.2698.8396.7899.5498.6697.7397.7196.4797.57Stacked ensembleAC95.4295.4292.5793.90969694.2890.0985.90RE95.5796.0994.0994.2496.0796.2894.6090.3088.30SP97.8197.8296.5997.1198.0598.0897.3395.1494.10PPV95.5895.5692.7994.1196.1496.1394.4890.2186.37NPV97.7697.6696.1996.9598.0397.9997.2295.0192.96*Significant values are in [bold].
Among the evaluated classifiers, it can be ranked from strongest to weakest as follows: SVM, LightGBM, Stacked Ensemble, XGBoost, and RF. SVM showed the highest and most consistent performance, particularly when applied to CGFF115 TRENetB0. This configuration recorded a remarkable accuracy of 99.05%, along with outstanding recall of 98.99%, specificity of 99.52%, and predictive values: PPV of 99.08% and NPV of 99.54%. The superior results from this CGFF stem from the architectural efficiency of TRENetB0, which balances network depth, width, and resolution. This structure enables CGFF 115 to extract mid-level semantic features that are both expressive and computationally efficient. When combined with SVM’s capacity to identify optimal decision boundaries in complex feature spaces, this led to highly accurate classification across the three MRI categories.
For LightGBM, its highest performance is attained with CGFFs 178 from TRENetB0, where it records an accuracy of 96.76%, recall of 96.77%, and specificity of 98.40%. The success of this configuration further validated the importance of layer 178 from TRENetB0 in producing highly discriminative features across various classifiers. Regarding Stacked Ensemble, the optimal performance appeared when using CGFFs of layer 178 from TRENetB0, achieving an accuracy of 96%, a recall of 96.07%, and a specificity of 98.05%. This CGFFs layer corresponds to a batch normalization stage that contributes to feature consistency for enhancing ensemble learning stability. The architectural strengths of TRENetB0 thus played a pivotal role in its repeated effectiveness across different classifiers. Notably, the single SVM outperformed the Stacked Ensemble, attributed to its superior capability in finding optimal separating margins within the high-dimensional CGFF feature space.
For XGBoost, the most favorable results emerged from CGFFs 178 from TRENetB0, with accuracy reaching 95.23%, recall at 95.36%, and specificity at 97.67%. RF performs best when utilizing CGFFs 115 from EfficientNetB0, achieving an accuracy of 94.67%, recall of 94.98%, and specificity of 97.45%. These differences are illustrated in Fig. 4 with the bar chart, where SVM’s metrics are highest across all five measures and the other classifiers exhibited progressively lower yet still high-performance levels. Fig. 5 illustrates the confusion matrix heatmap representing the optimal performance for each classifier. It was clearly observed that SVM achieved the best performance, demonstrating significantly fewer misclassifications compared to the other classifiers.Fig. 4. Comparative performance of classifiers based on evaluation metrics.Fig. 5. Heatmap visualization of the confusion matrix for the optimal performance for each classifier.
Statistical analysis based on Friedman test
A Friedman test was applied to compare the performance of the five classifiers across the nine CGFF feature representations. This test is non-parametric, making it particularly suitable for repeated measures designs where the same data is evaluated across the classifiers^57^. The Friedman analysis revealed highly significant differences among the five classifiers for every evaluation metric. As summarized in Table 8, the Friedman test results indicated significant differences in classifier performance for all evaluated metrics. In particular, the null hypothesis of equal performance was rejected for AC, RE, SP, PPV, and NPV, with all p-values ≤ 0.002. All these values were well below the 0.05 significance level, confirming that at least one classifier outperformed the others in each metric. Any metric exceeding this value would indicate no significant statistical differences among classifiers, but this was not observed in the current analysis. Table 8 summarizes the specific Friedman test statistics, including the Chi-square \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( {X^{2} } \right)$$\end{document} values and corresponding p-values, confirming statistically significant performance differences across all evaluation metrics.Table 8. The Friedman test results (Chi-square and p-value) for each evaluation metric, calculated with degrees of freedom \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left( {df} \right) = 4$$\end{document} .ParameterACRESPPPVNPVChi-Square ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X^{2}$$\end{document} )17.6419.3718.417.5117.51p-value0.001 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<$$\end{document} 0.0010.0010.0020.002
For clarity in the discussion, we denote RF as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1}$$\end{document} , XGBoost as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2}$$\end{document} , LightGBM as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3}$$\end{document} , SVM as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{4}$$\end{document} , and the Stacked Ensemble as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{5}$$\end{document} . As shown in the Table 9, the post-hoc pairwise comparisons revealed that the SVM ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{4}$$\end{document} ) exhibited statistically significant differences when compared to all other classifiers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1}$$\end{document} – \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{5}$$\end{document} ) across all evaluation metrics, as indicated by consistently low p-values (p < 0.05). In contrast, many comparisons among the other classifiers did not show statistically significant differences. For instance, the performance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1}$$\end{document} vs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2}$$\end{document} vs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3}$$\end{document} was roughly on par, with p-values well above the 0.05 threshold, indicating no meaningful difference in those cases. Similar non-significant results are observed for other pairings that do not involve SVM, implying that the three tree-based models: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3}$$\end{document} performed comparably on this task. Overall, SVM achieved significantly higher accuracy, recall, specificity, and predictive values than its peers. This confirmed that the superior performance of the SVM was not due to random variation but rather reflects a genuine and substantial advantage over the competing models.Table 9p-values of Friedman post-hoc pairwise comparisons between classifiers across all evaluation metrics. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{{\text{i }}} \;{\mathrm{vs}}\;{\mathrm{C}}_{{\mathrm{j}}}$$\end{document} Friedman p-valueACRESPPPVNPV \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1} \;{\mathrm{vs}}\;{\mathrm{C}}_{2}$$\end{document} 0.4120.2960.3710.4560.456 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1} \;{\mathrm{vs}}\;{\mathrm{C}}_{3}$$\end{document} 0.3320.2330.2960.2960.296 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1} \;{\mathrm{vs}}\;{\mathrm{C}}_{4}$$\end{document} 0.0070.0070.0070.0070.007 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{1} \;{\mathrm{vs}}\;{\mathrm{C}}_{5}$$\end{document} 0.5510.7650.4560.5510.551 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2} \;{\mathrm{vs}}\;{\mathrm{C}}_{3}$$\end{document} 0.8810.8810.8810.7650.765 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2} \;{\mathrm{vs}}\;{\mathrm{C}}_{4}$$\end{document} < 0.001 < 0.001 < 0.001 < 0.001 < 0.001 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{2} \;{\mathrm{vs}}\;{\mathrm{C}}_{5}$$\end{document} 0.1560.1790.1010.1790.179 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3} \;{\mathrm{vs}}\;{\mathrm{C}}_{4}$$\end{document} < 0.001 < 0.001 < 0.001 < 0.001 < 0.001 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{3} \;{\mathrm{vs}}\;{\mathrm{C}}_{5}$$\end{document} 0.1170.1360.0730.1010.101 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{C}}_{4} \;{\mathrm{vs}}\;{\mathrm{C}}_{5}$$\end{document} 0.0360.0170.0520.0360.036Significant values are in [bold].
Figure 6 provides a visual summary of the performance distributions, showing boxplots for each metric across the five classifiers. Each boxplot represents the distribution of classifier performance across the nine CGFF feature layers, highlighting the median (blue central line), interquartile range (box edges), and range excluding outlier. Outliers are marked by red crosses to indicate cases that deviate notably from typical performance. Examining these boxplots across all evaluation metrics, SVM consistently demonstrated superior median performance compared to the other classifiers. This consistently high and stable performance across all metrics confirmed the Friedman test findings to select SVM as the optimal classifier for the brain tumor classification task in our study.Fig. 6. Boxplot comparison of classifiers performance across nine CGFF feature layers.
Comparative analysis with SOTA approaches
Recent progress in brain tumor classification has produced promising results. However, several limitations persisted across existing approaches. Table 10 provides a comparative analysis with existing approaches from recent literature from SOTA models that were evaluated on the same dataset. The study of Gull et al.^38^ was limited by its reliance on traditional preprocessing (Gabor filtering and skull stripping) and generic feature extraction through a pre-trained VGG-19 model. These choices restrict the ability of the model to capture highly discriminative features and reduce generalization, which limited their classification accuracy to 98.25%. The approach of Farajzadeh et al.^39^ suffered from excessive preprocessing steps, dependence on handcrafted statistical features, reliance on synthetic data generation, and a highly resource-demanding architecture. Specifically, their pipeline integrated five consecutive image filtering operations followed by wavelet decomposition and statistical descriptors, which considerably increase computational burden and make the framework less practical for real-time use. Moreover, the dependence on manually engineered features reduced the generalization capacity of the model across heterogeneous datasets.Table 10A comparative analysis between the proposed model and SOTA on the same data source.ReferencesBraTsClassAC (%)RE (%)SP (%)PPV (%)NPV2022^38^2020HGG/LGG98.259898.597.21–2023^39^2020HGG/LGG98.9398.93–98.93–2024^41^2020HGG/LGG95.1––––2025^42^2020HGG/LGG8084.0963.6490.24–2025^23^2020HGG/LGG/Nor98.5––––2025^44^2020HGG/LGG/Nor98.6699.04–99.25–2023^40^2017HGG/LGG/Nor90.7282.8593.33––2024^10^2017HGG/LGG/Nor98.8898.6699.00––Proposed model2020HGG/LGG/Nor99.0598.9999.5299.0899.54
The model of Nazir et al.^41^ was computationally heavy, as it integrated an encoder with additional fully connected layers for multiple tasks. This design substantially increased training overhead, slows inference, and dilutes feature specialization for classification. Their method was restricted to an accuracy of 95.1%. The study by Liu et al.^42^ revealed significant limitations in adapting general-purpose text-based models to pixel-based medical tasks. Specifically, their models struggled with specificity and achieved notably lower accuracy compared to specialized deep learning architectures. The DCBT system introduced by Salama et al.^23^ utilized a transfer-learned EfficientNet-B0 backbone. The system relied on a single backbone architecture which limited the diversity of learned features compared to multi-model ensemble strategies that capture a broader range of semantic patterns. The classification pipeline of Topannavar et al.^44^ was sequentially dependent on a prior segmentation stage to isolate tumor regions. While this multi-stage dependency increased the computational complexity and makes the final classification performance contingent on the segmentation quality.
The framework of Ali et al.^40^ was constrained by its computationally heavy design, which integrated federated learning, CycleGAN-based domain mapping, and multi-stream CNNs. In addition, the reliance on 3D scan-level post-processing further increased training and inference costs, limiting its efficiency and clinical applicability. The reported accuracy of their method did not exceed 90.72%. The cascaded CNN architecture proposed by Abd-Ellah et al.^10^ employed multiple residual blocks, parallel local and global paths, and fully connected layers. This design made the system computationally heavy and less practical for real-time use. Moreover, extracting features across multiple paths might had introduced redundancy instead of improving discriminative ability. They also used fewer data samples compared with our study.
Overall, compared with the existing SOTA approaches, the proposed model demonstrated clear advantages that accounted for its superior performance. Unlike methods that relied on heavy preprocessing pipelines^39^, cascaded residual networks^10^, single-architecture backbones^23^, or federated multi-stream designs^40^, our framework adopted a streamlined yet powerful strategy. By contrast, the proposed framework introduced advanced preprocessing with AGC-DnCNN, which enhanced image quality and reduced noise effectively, and employed multi-CNN deep features fused with GLCM descriptors to capture both semantic and texture information. Furthermore, unlike VGG-based classifiers^38^, our model eliminated unnecessary preprocessing, avoided reliance on handcrafted descriptors or synthetic data generation, and adopted end-to-end deep feature learning with a more computationally efficient design. These methodological choices enabled the proposed system to surpass all compared models, achieving the highest accuracy of 99.05% together with high sensitivity, specificity, PPV, and NPV, thereby confirming its robustness, efficiency, and clinical applicability.
Computational complexity and optimization
To assess the potential for translating the proposed framework into real-time clinical workflows, we evaluated the computational complexity of the best-performing network, TRENetB0 (layer 115). The inference time was calculated as the average processing duration per single MRI image. The processing pipeline entails varying computational demands across its stages. The preprocessing phase, utilizing the 59-layer DnCNN for image denoising and enhancement, represents the primary computational overhead, requiring an average of 0.70 s per image. In contrast, the feature extraction phase demonstrated the remarkable efficiency of the proposed TRENetB0. The forward pass through the TRENetB0 architecture combined with GLCM feature extraction is extremely fast, consuming only 0.022 s per image. This highlighted the lightweight nature of the proposed architecture. Finally, the classification stage via the SVM was computationally negligible, taking less than 0.001 s. Consequently, the total inference time for diagnosing a single MRI image was approximately 0.723 s. This sub-second processing time confirmed that the proposed framework was highly suitable for real-time computer-aided diagnosis without causing workflow delays.
Regarding optimization strategies, the proposed framework incorporated both algorithmic and operational refinements to maximize performance. First, at the training level, we employed adaptive optimization algorithms, specifically Adam, RMSprop, and SGDM to fine-tune the TRCNNs. Our results indicated that Adam generally provided the most stable convergence and superior accuracy for deep feature extraction, while RMSprop showed specific advantages in selected layers, justifying the use of a tailored optimization strategy for each network component. Second, to address the computational overhead in the preprocessing phase, specifically within the DnCNN, several optimization avenues are suggested for future clinical deployment. Since the 59-layer DnCNN consumes most of the inference time, employing model compression techniques is a practical solution. For instance, network pruning and model quantization can be utilized to lower the computational load. Quantization achieves this by reducing precision from 32-bit floating-point to 8-bit integers without compromising image quality. Furthermore, leveraging hardware acceleration would drastically decrease the processing time of the denoising stage. This can be implemented using high-performance GPUs with NVIDIA TensorRT or dedicated neural processing unit chips. These enhancements would ensure the system integrates seamlessly into daily medical workflows without processing delays.
Conclusion
This study introduced a robust and efficient framework for brain tumor classification using MRI images, integrating deep learning and texture-based features to achieve superior diagnostic performance. The proposed algorithm began with an adaptive preprocessing stage utilizing ACG-DnCNN to enhance image clarity and suppress noise. Deep features were extracted from selected layers of three TRCNNs models, each optimized differently to capture diverse semantic representations. These were fused with rich texture descriptors to form nine CGFF sets that reflect both structural and contextual information. A comprehensive evaluation was conducted using five classifiers: RF, XGBoost, LightGBM, SVM, and a stacked ensemble. Among them, the SVM model trained on EfficientNetB0’s CGFF at layer 115 with the ADAM optimizer consistently delivered the best performance. On the BraTS 2020 dataset, it achieved 99.05% accuracy, 98.99% recall, 99.52% specificity, 99.08% PPV, and 99.54% NPV. The statistical significance of these findings was confirmed through Friedman tests and pairwise comparisons with p-values below 0.05. These results highlighted the effectiveness of combining deep semantic features with fine-grained textural details for accurate glioma classification. Future work will explore multi-class tumor subtype classification, domain generalization across institutions, and integration of the proposed model into real-time clinical workflows for enhanced decision support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Shahi, M. & Cooks, R. G. Ambient ionization mass spectrometry in brain cancer diagnosis. J. Mass Spectrom. Adv. Clin. Lab (2025).10.1016/j.jmsacl.2025.10.002PMC 1259044141211508 · doi ↗ · pubmed ↗
- 2van Zandvoort, M. J., Snijders, T. J., Oomens, J. E., van Kessel, E. & Robe, P. A. J. T. Drivers and Consequences of Cognitive Functioning in Glioma, Vol. 203 (2022).
- 3Özcan, H. et al. A comparative study for glioma classification using deep convolutional neural networks. Mol. Biol. Evol. (2021).10.3934/mbe.202108033757198 · doi ↗ · pubmed ↗
- 4Salama, G. M., Ashraf, S., Bayoumi, E. S., Elwan, M. & Abd-Ellah, M. K. in 2024 International Telecommunications Conference (ITC-Egypt). 72–77 (IEEE).
- 5Hemanvitha, K. & Dhiman, V. Leveraging predictive analytics: Enhancing brain tumor classification with xgboost. In The Impact of Algorithmic Technologies on Healthcare, 85–101 (2025).
- 6Gull, S., Akbar, S., Hassan, S. A., Rehman, A. & Sadad, T. in International Conference on Emerging Technology Trends in Internet of Things and Computing. 182–194 (Springer).
- 7Liu, F., Yoo, J. J. & Khalvati, F. A Comparison and evaluation of fine-tuned convolutional neural networks to large language models for image classification and segmentation of brain tumors on MRI. ar Xiv preprint http://arxiv.org/abs/2509.10683 (2025).
- 8Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4700–4708.