Community structure unveils the path multiplicity in complex networks
Ye Deng, Jun Wu, Xin Lu, Petter Holme, Daqing Li, Zengru Di, Guanrong Chen, Jürgen Kurths

TL;DR
This paper shows that community structures in networks strongly influence the number of shortest paths between nodes.
Contribution
The study introduces relative path multiplicity and links community structure as a key driver of path multiplicity.
Findings
Community structure is more strongly correlated with path multiplicity than other network metrics.
Targeted edge-rewiring experiments confirm the link between community structure and path multiplicity.
A tribal-structure-based model reproduces real-world network phenomena.
Abstract
Networks with complex topologies describe numerous natural and social systems. Recent studies on path multiplicity have shown strong heterogeneity in shortest paths between node pairs in real-world networks. However, the mechanism underlying this phenomenon remains unexplored. Here, we reveal that community structure is a key factor shaping path multiplicity. To explore the intrinsic factors that influence path multiplicity, we first introduce the concept of relative path multiplicity and find that community structure is more strongly correlated with path multiplicity than other network metrics. Through targeted edge-rewiring experiments, we verify the link between path multiplicity and community structure. The underlying mechanism can be interpreted as an interface-driven effect that sharply increases the number of shortest paths. Inspired by these findings, we propose a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
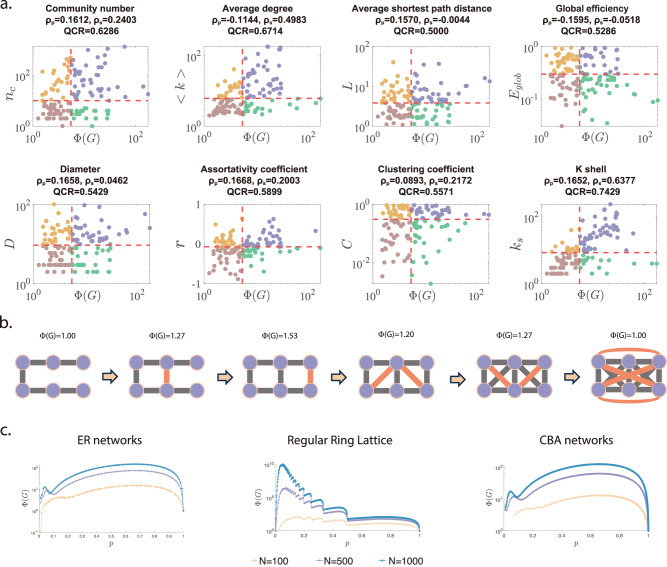 Figure 1
Figure 1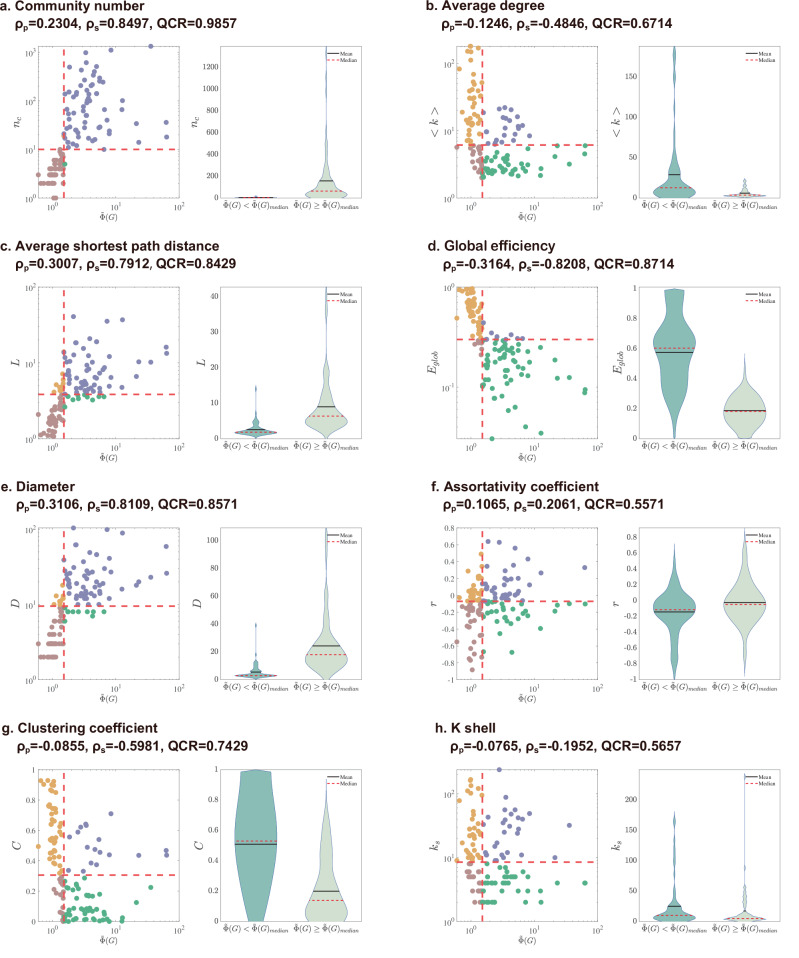 Figure 2
Figure 2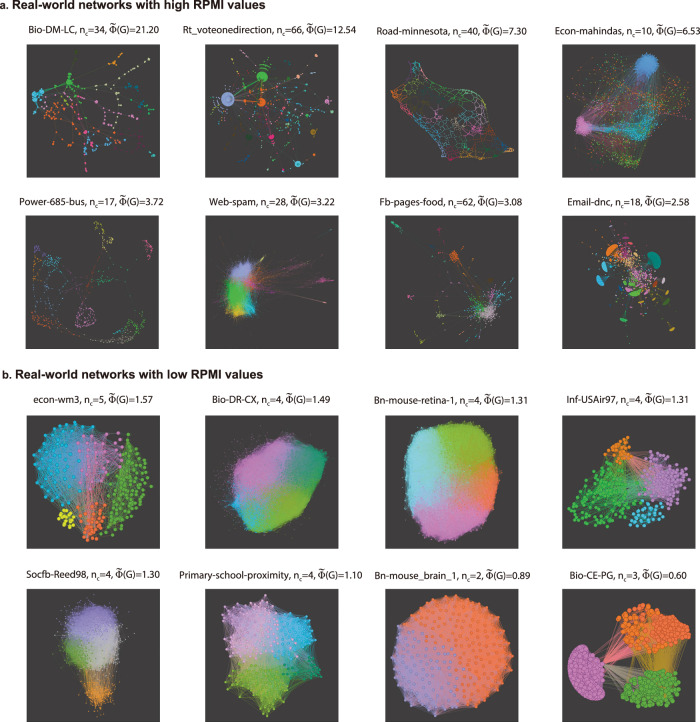 Figure 3
Figure 3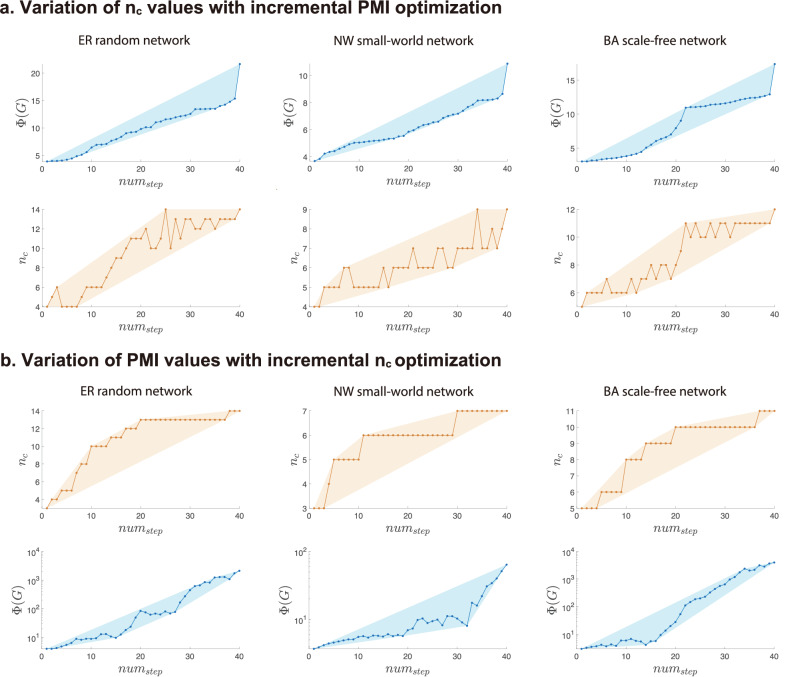 Figure 4
Figure 4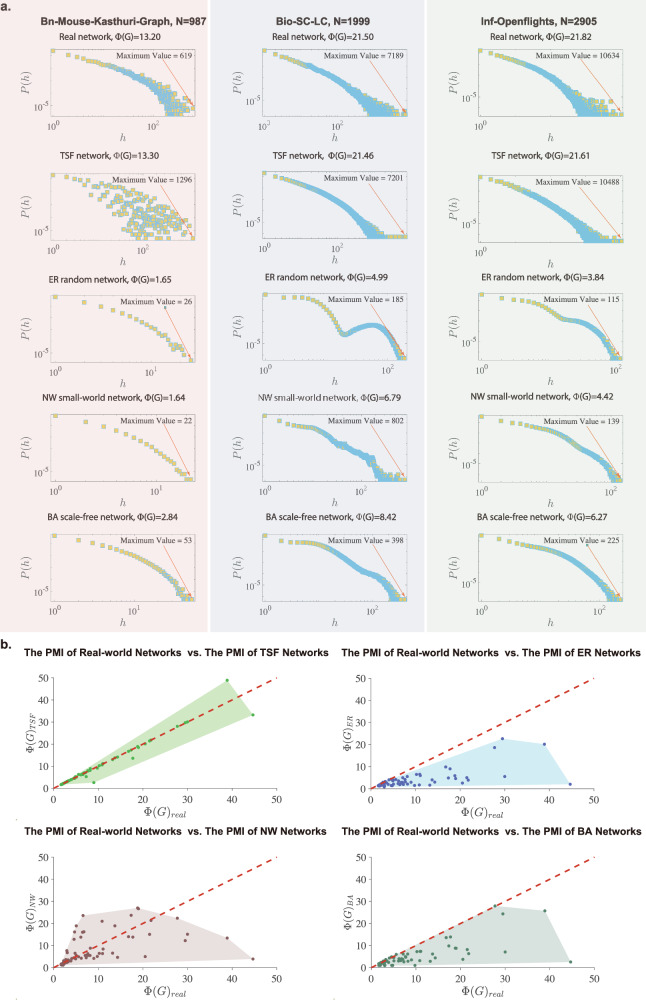 Figure 5
Figure 5- —501100001809National Natural Science Foundation of China (National Science Foundation of China)
- —Innovation Teams Project in Ordinary Universities of Guangdong Province (No. 2024KCXTD050)
- —501100003453Natural Science Foundation of Guangdong Province (Guangdong Natural Science Foundation)
- —the Brain Science and Brain-like Intelligence Technology—National Science and Technology Major Project (No. 2025ZD0215700)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Advanced Graph Neural Networks · Mental Health Research Topics
Introduction
Complex networks form the backbone of many natural and technological systems and are crucial to revealing structural and functional relationships in a wide variety of domains^1,2^. From social interactions and biological processes to technological systems, these networks are characterized by complex connections among their components^3–6^. Despite the diversity of their applications, complex networks often exhibit common topological properties, including small-world effect^7,8^ and scale-free structures^9,10^, which have become central themes in network science^11–25^. In the study of complex networks, paths between node pairs play a critical role in understanding the dynamics and efficiency of the network. Traditional research has largely focused on the shortest routes between nodes, which serve as a fundamental measure of network connectivity and routing efficiency^2^. The small-world phenomenon, in which even large networks often have surprisingly short path lengths, has been extensively investigated^7,26^. Beyond the length of the shortest path, the centrality of the interconnections has been widely studied as a measure of the influence of nodes (edges) on the basis of their frequency of appearance on the shortest paths between other node pairs^27,28^. This metric is thus essential for analyzing network flow and information diffusion and identifying key nodes^29^. Furthermore, research on navigability, namely, how easily nodes can be reached through paths, has been conducted to explore how decentralized routing decisions are made in networks^26^.
Despite the advances in the study of paths, path multiplicity—the number of equidistant shortest paths between node pairs—remains unexplored. Recently, some studies have revealed the existence of a universal power-law scaling of path multiplicity, indicating that a few node pairs have a large number of shortest paths^30^. For example, even in the Bn-Macaque-Rhesus-Brain-1 brain network with only 242 nodes^31^, the largest count of shortest paths between node pairs can reach 649, with an average value of 11.07. This observation reveals that the world we live in is not just a “small-world”, but also a “hesitant-world”. The “small-world” effect means that most nodes are connected through only a few steps, even in a large network; meanwhile, the “hesitant-world” effect implies that one may hesitate among numerous choices, even when the network itself is small.
Although the multiplicity of shortest paths is a structural feature, it actively governs how networks function. First, path multiplicity shapes a network’s robustness and vulnerability. While redundant shortest paths can preserve connectivity when links fail, they may also concentrate traffic on common bridges or hubs, creating bottlenecks that increase susceptibility to congestion or targeted attacks—a dual role noted in studies of network flows^32^. Second, it affects spreading processes and transport. Multiple, equally short routes can accelerate the propagation of information, diseases, or resources by offering parallel transmission channels, while also redistributing loads across the network and influencing diffusion outcomes^20^. Finally, it has consequences for routing and decision-making. For any agent—whether a packet, an individual, or an algorithm—navigating among many “optimal” paths can induce “choice overload,” a psychological effect known to impair decision efficiency^33^, potentially degrading the performance of navigation strategies^26^.
Our recent finding^30^—a strong power-law distribution in path multiplicity across diverse real-world networks—reveals that the path multiplicity is a fundamental and widespread architectural signature. Given the functional relevance outlined above, a central unanswered question emerges: which underlying network structure produces such strong heterogeneity in path multiplicity? Uncovering this structural origin is essential for explaining observed network dynamics and designing networks with desired functional properties. In this study, we introduce the concept of relative path multiplicity to systematically compare real-world networks with equivalent random networks. Using this approach, we identify the structural factors that shape path multiplicity in complex networks. Furthermore, we develop a network model that can reproduce the empirical characteristics, offering mechanistic insights into the observed power-law distribution of path multiplicity.
Results
Concept of relative path multiplicity
Let G(V, E) be a simple undirected graph representing a complex network, where V is the set of nodes and E ⊆ V × V is the set of edges. Let N = ∣V∣ and M = ∣E∣ represent the numbers of nodes and edges, respectively. The adjacency matrix of the network is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A(G)={({a}_{ij})}_{N\times N}$$\end{document} , where ai**j = aj**i = 1 if nodes vi and vj are connected and ai**j = aj**i = 0 otherwise. The edge density of the network is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=\langle k\rangle /(N-1),$$\end{document}where 〈k〉 denotes the average node degree.
For any pair of nodes (vi, vj), the shortest path length between nodes vi and vj is denoted by li**j. Then we define the path multiplicity amount (PMA) between two nodes as the number of shortest paths hi**j connecting them, and the matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H(G)={({h}_{ij})}_{N\times N}$$\end{document} is called the path multiplicity matrix (PMM). To quantify the overall multiplicity of the path of a network, we define the path multiplicity index (PMI) as the average value of the PMA in all pairs of nodes. Mathematically, this relationship is expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi (G)=\frac{{\sum }_{i=1}^{N}{\sum }_{j\ne i}{h}_{ij}}{N(N-1)}\,.$$\end{document}The PMI reflects the complexity of path selection within the network: a large PMI suggests that the network has a hesitant-world property, with many shortest paths between node pairs, potentially leading to a more complex decision-making process. To reveal the relationships between the PMI and classical network metrics, we present corresponding scatter plots along with the Pearson’s correlation coefficient ρp^34^, Spearman’s correlation coefficient ρs^35^, and the quadrant count ratio (QCR)^36,37^ in 140 real-world networks in Fig. 1a. Pearson’s correlation coefficient quantifies the strength of a linear relationship between two variables, whereas Spearman’s correlation coefficient is a nonparametric rank-based measure of monotonic association and is often preferred when nonlinearity or outliers make Pearson’s coefficient undesirable. The QCR provides a coarse-grained measure of association by dichotomizing each variable at a central location (typically the median) and quantifying how often paired observations fall in the same corresponding half (see the “Methods” section for details). Together, Pearson’s correlation, Spearman’s correlation, and QCR offer complementary perspectives on association by targeting linear association, monotonic rank-based association, and median-split concordance, respectively. Consistent results across these measures provide a robustness check for the reported association. Overall, the scatter plots exhibit a disordered distribution, with points broadly dispersed, showing no clear trend. Moreover, it can be observed that all three correlation metrics are relatively low, indicating that there is no significant correlation between PMI and classical network metrics.Fig. 1. Potential factors influencing path multiplicity.a The scatter plots show the correlation between path multiplicity and classical network metrics in 140 real-world networks. As a reference, the median values of the PMI Φ(G) and classical network metrics are shown as dashed lines. These scatter plots reveal that the points are widely distributed throughout the plane in all four quadrants, suggesting that there are no significant correlations between path multiplicity and classical network metrics. The metadata and results for all 140 networks are provided in the Supplementary Information. The community detection algorithm used in this study is Newman’s deterministic leading eigenvector modularity algorithm^43^; the specific algorithmic steps and parameter settings are detailed in the “Methods” section. b The example simple network is initially a chain network with an initial PMI value of 1. As the edge density increases to a fully connected network, the corresponding PMI value eventually returns to 1. c The PMI is plotted as a function of the edge density p for three classical network models, ER random networks, regular ring lattices, and CBA scale-free networks, with different network sizes N = 100, 500, 1000. For all of the model networks, the PMI changes with the edge density p in some kind of complex non-linear relationship forms.
Intuitively, according to the definition of PMI, edge density may affect path multiplicity. The simple example network shown in Fig. 1b is initially a chain network with an initial PMI value of 1. As the edge density increases, and thus the network becomes fully connected, the corresponding PMI value returns to 1. Furthermore, the changing trend of PMI as the edge density p increases is shown in Fig. 1c for three typical model networks: Erdős-Rényi random networks (ER)^38^, regular ring lattices (RRL)^39^, and cluster Barabási-Albert scale-free networks (CBA)^40^. Unsurprisingly, one can see that the PMI values are strongly related to edge density p with some form of complex nonlinear relationship. To analyze the intrinsic factors influencing the PMI, it is necessary to exclude the effects of network size and edge density on path multiplicity. Thus, it inspires us to introduce the concept of the relative path multiplicity index (RPMI), denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{\Phi }(G)$$\end{document} , which is calculated by normalizing the PMI of the network G with the PMI of an equivalent ER random network GER with the same size and edge density as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{\Phi }(G)=\frac{\Phi (G)}{\Phi ({G}_{{{\rm{ER}}}})}.$$\end{document}The RPMI allows us to assess how the intrinsic structural properties influence path multiplicity relative to a randomized baseline.
Intrinsic factors of path multiplicity
To investigate the intrinsic factors influencing path multiplicity in real-world networks, we present scatter plots for the RPMI and classical network metrics along with Pearson’s correlation coefficient, Spearman’s correlation coefficient, and the QCR for 140 real-world networks in Fig. 2 (see the Supplementary Information for the metadata). Given that real-world networks can be disconnected, we focus only on the giant connected component of each network to ensure consistent comparisons. First, it is easy to see that these network metrics are not significantly linearly correlated with path multiplicity, where the highest Pearson’s correlation coefficient is ρp = 0.3164. By inspecting Spearman’s correlation coefficients, we find that the community number, global efficiency, average shortest path length, and network diameter are correlated with path multiplicity with ρs > 0.6. Furthermore, using QCR, we observe that the association between the number of communities and path multiplicity reaches a remarkably high value of 0.9857, where the data points are mostly located in the first and third quadrants in the scatter plot shown in Fig. 2a. However, the majority of the QCR values for the other metrics are below 0.9, suggesting that the number of communities is more significantly correlated with the RPMI. In addition to the scatter plots, we display the violin plots of each network metric, which are divided into two parts on the basis of the median values of the RPMI. If a stronger correlation exists between a network metric and the RPMI, the overlap between two violin subplots should be small. As shown in Fig. 2, compared with other network metrics, the narrow overlap corresponding to the number of communities further demonstrates that the community structure^41,42^ plays a key role in determining path multiplicity.Fig. 2. Correlations between the relative path multiplicity and classical network metrics in 140 real-world networks.The metadata and results for all 140 networks are provided in the Supplementary Information. The metrics include: a the community number nc, b the average degree 〈k〉, c the average shortest path length L, d the global efficiency Eglob, e the diameter D, f the assortativity coefficient r, g the clustering coefficient C, and h the k-shell index ks. Each a–h presents a scatter plot on the left, illustrating the correlation between the relative path multiplicity and the classical network metrics based on the given metric and their RPMI values. The networks are categorized into four quadrants, divided by the median values of the given metric and the RPMI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{\Phi }(G)$$\end{document} . The right-hand violin plots show the distribution, mean and median values of the corresponding network metric, which are divided into two parts based on the median value of the RPMI. If there are more overlap between two violin subplots, it suggests a weaker correlation between a network metric and the RPMI.
Moreover, we visualize 16 networks out of the total of 140 in Fig. 3, where the upper row presents 8 networks with high RPMI values, and the lower row shows 8 networks with lower RPMI values. In this way, we observe that networks with higher RPMI values tend to have a larger number of communities. For example, the Bio-DM-LC network with n = 483 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{\Phi }(G)=21.20$$\end{document} ) displays highly modular structures with many well-defined communities (nc = 34). In contrast, networks with lower RPMI values, such as Bio-DR-CX with n = 3287 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{\Phi }(G)=1.49$$\end{document} ), exhibit fewer distinct communities (nc = 4). This comparison clearly demonstrates that networks with higher RPMI values tend to have a greater number of communities, whereas networks with lower RPMI values are generally characterized by less modular topologies.Fig. 3. Visualization of empirical networks based on RPMI values.a Eight real-world networks with higher RPMI values. b Eight real-world networks with lower RPMI values. Each network visualization is colored based on its community structure, where each color represents a distinct community.
Considering that a specific community detection algorithm may influence the causal attribution of RPMI to community structure, we have tested classical community detection algorithms, including the Leading Eigenvector method^43^, Walktrap method^44^, Leiden method^45^, Label Propagation method^46^, Infomap method^41^, and Louvain method^47^. Our experimental results are reported in the Supplementary Information section. Although these algorithms yield somewhat different community counts, the Spearman correlation between RPMI and the number of communities remains consistently high (all ρs > 0.8), and all the corresponding QCR values are above 0.9. These results indicate that our findings do not depend on any particular community detection algorithm; accordingly, we emphasize that our main conclusions are robust to the choice of a community detection algorithm.
Impact of community structure on path multiplicity
To verify the relationship between path multiplicity and community structure, we implement a target-oriented edge rewiring procedure on paradigmatic model networks with 1000 nodes, namely ER random networks, Newman-Watts small-world networks (NW)^48,49^, and Barabási-Albert scale-free networks (BA)^9^. As shown in Fig. 4a, we utilize the greedy principle to increase the PMI values while maintaining the same network size and edge density to observe the changes in community number during the optimization process. We find that as the PMI value increases, the community number tends to rapidly increase. For example, in the ER random network shown in the first subplot of Fig. 4a, the value of Φ(G) monotonically increases from 3.90 to 21.65, whereas the community number nc exhibits a fluctuating upward trend, increasing from 4 to 14. We also implement a target-oriented edge rewiring procedure to increase the community number and observe the changes in the PMI, as shown in Fig. 4b. Similar to the findings above, we observe that the PMI value also tends to strongly increase as the community number is optimized. These two experimental results confirm that there is a notable causal relationship between community structure and path multiplicity. As a point of comparison, we perform the above target-oriented edge rewiring experiments based on the clustering coefficient, network diameter, and assortativity. The results are provided in the Supplementary Information and show that there is no significant causal relationship between these topological properties and path multiplicity.Fig. 4. Target-oriented edge rewiring in three types of model networks.a The panels depict the variation in the nc values with incremental optimization of the PMI through target-oriented edge rewiring. As the PMI increases, the number of detected communities nc tends to increase overall. b The panels show the variation in the PMI values with incremental optimization of the community number nc through target-oriented edge rewiring. In this scenario, edge rewiring is directed toward increasing nc, resulting in a trend exhibiting rising PMI values. Shaded regions indicate simple envelopes for visual guidance, not uncertainty or confidence intervals.
Community-based network model
Inspired by the above results, we next develop a Tribal Scale-Free (TSF) model that can reproduce the hesitant-world features of real-world networks. The TSF model generates networks with hierarchical and modular structures by creating scale-free subnetworks and interlinking them through a controlled number of intercommunity edges. The specific generation rules are described in the “Methods” section. To verify the effectiveness of the proposed TSF model, we compare the real PMA distributions P(h), the maximum PMA values and the PMI values Φ(G) with the synthetic results based on four typical model networks, i.e., the TSF network, the ER random network, the NW small-world network, and the BA scale-free network. As shown in Fig. 5a, we find that the TSF model reproduces the hesitant-world features observed from real-world networks much better than the other model networks. For example, in the Bio-SC-LC network with Φ(G) = 21.50, where the maximum PMA value is 7189, the corresponding TSF network has a PMI value of 21.46, with a maximum PMA value of 7201. However, the PMI values are 4.99, 6.79 and 8.42 in the ER random network, the NW small-world network and the BA scale-free network, respectively, and the maximum values of the PMA are 185, 802 and 398, respectively. In addition, in Fig. 5b, we present the PMI values of representative real-world networks along with the PMI values of the reference model networks with the same network size and similar edge density. We find that the TSF model can better reproduce the PMI values observed from real-world networks and thus can capture the hesitant-world feature, whereas the other three classical network models significantly deviate from the empirical PMI values.Fig. 5. Verification of the effectiveness of the proposed TSF model.a Comparisons of real PMA distributions, maximum PMA values and PMI values with the synthetic results are conducted with four typical model networks, i.e., the TSF network, ER random network, NW small-world network, and BA scale-free network. Compared with real-world networks, classical model networks have the same number of nodes and similar edge densities. b Scatter plots for the Φ(G) of representative real-world networks and the corresponding model networks GTSF, GE**R, GN**W, and GB**A with the same network size and similar edge densities. The dashed line, with the darker shaded area, denotes a reference line with a slope of 1.
Discussion
Following the introduction of the concept of path multiplicity, recent studies have revealed that empirical networks display not only the well-known “small-world” effect, but also an intriguing “hesitant-world” feature, accompanied by a universal power-law governing path multiplicity. In this study, we investigated the mechanisms underlying path multiplicity. We introduced the concept of the relative path multiplicity index (RPMI) to explore the intrinsic factors that influence path multiplicity by excluding the effects of network size and edge density. We uncovered a robust positive correlation between the number of communities and the RPMI by employing comprehensive correlation analysis methods: Pearson correlation, Spearman correlation, and QCR. This reveals that networks with more communities exhibit significantly greater path multiplicity. Then, we verified this observation by using the target-oriented edge rewiring procedure, where a higher path multiplicity was associated with a greater number of communities, and vice versa. The underlying mechanism can be interpreted as an interface-driven effect: intercommunity edges constitute an effective cut set, and therefore, path multiplicity between modules necessarily passes through boundary nodes and bridges; when multiple boundary-equivalent intramodular segments and cross-community links are length-equivalent, their combinations multiply, leading to a sharp increase in the shortest path counts. Finally, inspired by the above results, we designed the TSF model to replicate the hesitant-world feature observed from empirical networks. By comparing the TSF model with typical model networks such as the ER random network, the NW small-world network and the BA scale-free network, we demonstrated that the TSF model can much better reveal the power-law distribution of the PMA, the maximum values of the PMA, and the PMI values observed from real-world networks. The hesitant-world feature, characterized by an abundance of shortest paths, presents challenges and opportunities in the study of network science. It could facilitate valuable applications in diverse fields—including urban infrastructures, communication networks, neuroscience, and artificial intelligence—thereby driving innovation. Our work represents a foundational step that will enable deeper exploration of path multiplicity in the future.
This study identifies community structure as the key driver of path multiplicity in unweighted networks. A crucial next step is to extend this analysis to weighted networks—the structure of most real-world systems, from transportation to social interactions. Edge weights fundamentally alter the shortest path landscape: the condition for multiplicity (multiple paths with an identical total weight) becomes mathematically strict, often reducing many shortest paths to a single optimal route. This shift reveals an important gap and opportunity, as practical applications often concern near-optimal alternatives rather than perfectly equivalent paths. To bridge this gap, future work could generalize the concept by introducing such a tolerance parameter ϵ ≥ 0, defining the paths within (1 + ϵ) of the minimum weight as “tolerant shortest paths.” Analyzing the multiplicity of such paths would clarify how network architecture—particularly the community structure—supplies robust routing options under realistic conditions, directly linking our topological findings to challenges in resilient infrastructure, adaptive traffic routing, and the analysis of neural or social networks with continuous link strengths.
Moreover, this paper only draws evidence from empirical networks and simulations; a fuller theoretical account remains to be developed. Promising high-impact research directions could include an analytical relationship between path multiplicity and structural parameters, spectral approaches to bound the path multiplicity, and cut/flow arguments via Menger’s theorem that link cross-community cut size and boundary redundancy.
Methods
Fast algorithm for counting shortest paths
The shortest path lengths between node pairs can be calculated by using the classical Floyd algorithm^50^, which has a time complexity of O(N^3^). However, this algorithm does not provide the count of shortest paths between node pairs. Although Breadth-First Search or Depth-First Search can identify all paths between a pair of nodes in O(N^2^) time, calculating the number of shortest paths for all pairs of nodes with these methods increases the complexity to O(N^4^).
Path multiplicity focuses on the number of shortest paths between node pairs rather than on the nodes traversed. In this study, we implement a fast algorithm to calculate both the number and length of shortest paths between all node pairs simultaneously. The procedure is described as follows.
Step 0. Initialize the Path Multiplicity Matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H={\{{h}_{ij}\}}_{N\times N}$$\end{document} and the Path Length Matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L={\{{l}_{ij}\}}_{N\times N}$$\end{document} , setting hi**j = hj**i = 0 and li**j = lj**i = 0. Define k = 1.
Step 1. If hi**j = hj**i ≠ 0 for all i ≠ j, terminate the algorithm. Otherwise: (a) Compute the transition matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T={\{{t}_{ij}\}}_{N\times N}$$\end{document} , where ti**j = 0 if hi**j ≠ 0, and ti**j = 1 if hi**j = 0. (b) Update H to H = H + T ⊙ A^k^, where ⊙ denotes the Hadamard product. (c) Update L to L = L + k ⋅ (T ⊙ J), where J is an N × N all-ones matrix.
Step 2. Increment k by 1 and return to Step 1.
Quadrant count ratio
To quantify the monotonic relationship between relative path multiplicity and a given network metric, we employ the improved QCR, a non-parametric measure of association derived from quadrant analysis. The QCR provides a coarse-grained measure of association by dichotomizing each variable at a central location (typically the median) and quantifying how often paired observations fall in the same corresponding half. Specifically, QCR is computed by splitting each variable into “low” and “high” groups using its median (or another robust central threshold) and then calculates the proportion of paired samples that are concordant—i.e., simultaneously high-high or low-low—among all pairs.
Given paired observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\{({x}_{i},{y}_{i})\}}_{i=1}^{N}$$\end{document} for two variables X and Y, define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{x}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widetilde{y}$$\end{document} as the sample medians of {xi} and {yi}, respectively. The plane is divided by the vertical line \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x=\widetilde{x}$$\end{document} and the horizontal line \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y=\widetilde{y}$$\end{document} into four quadrants:
- Quadrant I ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x\ge \widetilde{x},\,y\ge \widetilde{y}$$\end{document} );
- Quadrant II ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x < \widetilde{x},\,y > \widetilde{y}$$\end{document} );
- Quadrant III ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x\le \widetilde{x},\,y\le \widetilde{y}$$\end{document} );
- Quadrant IV ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x > \widetilde{x},\,y < \widetilde{y}$$\end{document} ).
We count the number of points nI, nII, nIII, nIV that fall in each quadrant. If a positive monotonic relationship is hypothesized, points in Quadrant I and Quadrant III share the same sign of deviation from the medians and are deemed consistent, whereas points in Quadrants II and Quadrant IV are inconsistent. Thus, the QCR is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{QCR}}}}_{+}\,=\,\frac{{n}_{{{\rm{I}}}}+{n}_{{{\rm{III}}}}}{N},$$\end{document}which takes values in [0, 1]. A value close to 1 indicates that most observations lie in the first or third quadrant, implying a strong positive association, while a value near 0.5 suggests no directional preference. When a negative monotonic association is hypothesized, we instead treat Quadrants II and IV as consistent and define
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{QCR}}}}_{-}\,=\,\frac{{n}_{{{\rm{II}}}}+{n}_{{{\rm{IV}}}}}{N}.$$\end{document}Consequently, a higher QCR indicates stronger association, because a larger fraction of observations exhibit consistent co-movement in the same direction relative to the central location (whereas QCR near 0.5 suggests weak or no systematic alignment, and values below 0.5 indicate predominantly discordant pairing).
Community detection via leading eigenvector modularity
Non-overlapping communities are detected by maximizing the modularity of the undirected graph G(V, E) in a deterministic spectral framework. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A(G)={({a}_{ij})}_{N\times N}$$\end{document} denote the adjacency matrix defined above, ki = ∑j ai**j the degree of node vi, and M = ∣E∣ the number of edges, so that 2M = ∑i, jai**j. Define the modularity matrix
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B\,=\,A(G)\,-\,\frac{{{\bf{k}}}\,{{{\bf{k}}}}^{\top }}{2M},$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{k}}}={({k}_{1},\ldots,{k}_{N})}^{\top }$$\end{document} .
For a bipartition encoded by s ∈ {±1}^N^, the modularity can be written as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q\,=\,\frac{1}{4M}\,{{{\bf{s}}}}^{\top }B\,{{\bf{s}}}.$$\end{document}Let u1 be the leading eigenvector of B. An initial split is obtained by the sign rule \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${s}_{i}={{\rm{sign}}}\,\left({u}_{1i}\right)$$\end{document} . A single-vertex refinement is then applied: iteratively move the node that yields the largest positive modularity gain Δ**Q, and repeat until no further improvement is possible (Δ**Q≤0).
To obtain more than two groups, recursion is applied to any accepted vertex subset U ⊆ V (a current community). The net modularity change from subdividing U is evaluated with the generalized modularity matrix
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${B}_{ij}^{(U)}\,=\,{B}_{ij}\,-\,{\delta }_{ij}\,{\sum }_{\ell \in U}{B}_{i\ell },\,\,i,j\in U,$$\end{document}where δi**j is the Kronecker delta, and the same spectral-plus-refinement steps are applied within U. A subdivision is accepted only if it increases Q (Δ**Q > 0); recursion stops when all current groups are indivisible under this criterion.
Matrix-vector products with B are evaluated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B\,{{\bf{x}}}\,=\,A(G)\,{{\bf{x}}}\,-\,\frac{{{{\bf{k}}}}^{\top }{{\bf{x}}}}{2M}\,{{\bf{k}}},$$\end{document}so each multiply costs O(M + N). Using the power or Lanczos method for u1, the overall cost is typically O(N^2^) on sparse graphs. The procedure is deterministic given A(G) (up to a global sign flip of u1, which does not affect the partition). The algorithm returns the final community labels \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\{{c}_{i}\}}_{i=1}^{N}$$\end{document} and the achieved modularity Q. In practice, we used the Brain Connectivity Toolbox function modularity_und^51^ with the resolution parameter fixed at its default value γ = 1 for all community detection analyses.
Target-oriented edge rewiring procedure
A greedy algorithm for target-oriented edge rewiring is designed to iteratively optimize a specific network metric while preserving structural properties such as the network size and edge density. The algorithm is operated by modifying the edge structure of a network to enhance a target metric and simultaneously observe its impact on the associated metric, providing insight into the integration of these properties. The procedure involves the following steps:
Step 1: Initialize the network metrics
Begin with a given connected network G^0^ of size N and edge density p, which serves purely as a rewiring seed for subsequent optimization. Some initial networks may already have high baseline metric values (e.g., community number or clustering coefficient), potentially biasing the early search toward local optima; accordingly, the first recorded iteration reflects the best outcome of the initial rewiring trials rather than the original network, and its metric value can be higher or lower than the initial one without affecting subsequent optimization.
Step 2: Identify potential edge rewiring
At iteration t, starting from the current network G^(t)^ with ∣E∣ = m edges, generate a set of candidate rewiring trials \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{R}}}}^{(t)}=\{{r}_{1}^{(t)},\ldots,{r}_{Q}^{(t)}\}$$\end{document} . Each trial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{q}^{(t)}$$\end{document} consists of a sequence of admissible edge rewirings applied to G^(t)^, with a random rewiring budget b per trial, where 1 ≤ b ≤ m. Each trial can modify multiple edges while strictly preserving N, m, and network connectivity; any tentative swap that would violate these structural constraints is rejected and reverted.
Step 3: Select the optimal edge rewiring with tie handling
For each trial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{q}^{(t)}\in {{{\mathcal{R}}}}^{(t)}$$\end{document} , compute the target metric on the resulting network and identify the trial(s) that achieve the maximum target metric value, i.e.,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal{Q}}}}_{\max }^{(t)}=\arg {\max }_{1\le q\le Q}f\,\left({G}^{(t)}\circ {r}_{q}^{(t)}\right),$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${G}^{(t)}\circ {r}_{q}^{(t)}$$\end{document} denotes applying trial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{q}^{(t)}$$\end{document} to G^(t)^. If multiple trials attain the same maximum value (including the case where the maximum equals the target value of the previous accepted network), randomly select one trial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${q}^{\star }\in {{{\mathcal{Q}}}}_{\max }^{(t)}$$\end{document} and use the corresponding rewired network as the next state.
Step 4: Update the network and metrics
Apply the selected trial to obtain the updated network G^(t+1)^. Recalculate both the target and associated metrics on G^(t+1)^. Record these values to track the optimization progress, noting that the first recorded iteration reflects the best candidate network from the initial trials rather than the original network.
Step 5: Termination check
Repeat Steps 2-4 until a predefined number of valid rewired networks has been recorded, where “valid” means the rewired network satisfies the structural constraints (e.g., fixed N and m, and any additional constraints such as connectivity).
Step 6: Analyze the results
Once the optimization is complete, examine the relationship between the optimized target metric and the associated metric. For example, after maximizing Φ(G), observe how the community number nc changes across iterations.
This algorithm enables a systematic exploration of how network metrics influence each other through structural modifications. By maintaining the network size and edge density, the approach ensures that the observed trends are solely attributable to the optimization process, rather than external structural changes. The experimental results, such as those shown in Fig. 4, demonstrate the effectiveness of this method in terms of revealing the causal relationship between community structure and path multiplicity.
Tribal Scale-Free (TSF) network model
The TSF model is a generative model designed to capture the hierarchical and modular features typical of real-world networks, adding the separation of distinct communities (cf. the “connected caveman model”^7^). The TSF model builds a network by integrating intracommunity scale-free subnetworks with controlled intercommunity connections, allowing for an examination of the relationship between modularity and path multiplicity. The detailed mathematical formulation of the TSF model is presented below, with a step-by-step description of its generation process.
Step 1: Initialization
Start with a total network size N and a specified number of communities nc. The N nodes are randomly assigned to nc distinct communities, representing different “tribes”. Let Ci denote the i-th community, where i ∈ 1, 2, …, nc. The size of each community ∣Ci∣ is determined such that
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sum }_{i=1}^{{n}_{c}}| {C}_{i}|=N\,.$$\end{document}Step 2: Generation of scale-free subnets
Within each community Ci, a scale-free network is generated by using the the Goh-Kahng-Kim (GKK) static scale-free network model^52^. The GKK model constructs a random graph by assigning each vertex v ∈ Ci a weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${p}_{v}\propto {v}^{-{\alpha }_{i}}$$\end{document} with αi ∈ [0, 1), then repeatedly selecting two different vertices according to the normalized weights and adding an edge between them unless one exists already. By tuning αi, the degree distribution follows a power-law characterized by an exponent λi via λi = (1 + αi)/αi. The resulting degree distribution adheres to the following form:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(k) \sim {k}^{-{\lambda }_{i}},\,\,{{\rm{for}}}\,k\ge {k}_{\min }\,.$$\end{document}Other approaches for generating scale-free networks can also be adopted, such as the BA scale-free model and configuration model (CM)^53^.
Step 3: Intercommunity edge allocation
Once scale-free intracommunity subnets are generated, proceed with intercommunity edge allocation. Given a predefined number of intercommunity edges ne, two distinct communities, Ci and Cj, are selected, and then ne edges are created between them. For subsequent connections, an unconnected community Cm is chosen uniformly at random, and this community is linked with ne edges to any of the already connected communities. This process is repeated iteratively until all of the communities are connected, ensuring the formation of a single connected component throughout the network.
Step 4: Construction and finalization of the network
The TSF network G = (V, E) consists of ∣V∣ = N nodes and a set of edges E, combining the intracommunity edges Eintra and the intercommunity edges Einter such that E = Eintra ∪ Einter. The total number of edges in the network is expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$| E|={\sum }_{i=1}^{{n}_{c}}| {E}_{\,\!\!{{\rm{intra}}}}^{i}|+{n}_{e}\cdot ({n}_{c}-1)\,.$$\end{document}Notably, to keep the model simple, the proposed TSF model assumes a common scaling exponent across communities. In practice, scaling exponents can differ between communities in real-world networks^54–57^, and future extensions of the TSF model can therefore allow heterogeneous, community-specific scaling exponents rather than enforcing a single global value.
Furthermore, the TSF model can effectively capture the modular and hierarchical nature of complex networks by combining scale-free substructures within communities and interconnecting them through a controlled number of intercommunity edges. By adjusting the parameters nc (number of communities) and ne (number of intercommunity edges), the model facilitates a systematic exploration of the impact of community structure on network properties such as the path multiplicity and overall network efficiency.
Supplementary information
Supplementary Information LaTeX Supplementary File Transparent Peer Review file
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pósfai, M. & Barabási, A. L. Network Science (Cambridge University Press, 2016).
- 2Newman, M. E. Networks (Oxford University Press, 2018).
- 3Estrada, E. The Structure of Complex Networks: Theory and Applications (Oxford University Press, 2012).
- 4Deng, Y. & Wu, J. Power-law of path multiplicity in complex networks. PNAS Nexus, 3, pgae 228 (2024).10.1093/pnasnexus/pgae 228PMC 1118497838894880 · doi ↗ · pubmed ↗
- 5Rossi, R. & Ahmed, N. The network data repository with interactive graph analytics and visualization. Proc. Conf. AAAI Artif. Intell. 29, 4292–4293 (2015).
- 6Choudhary, P.K. & Nagaraja, H.N. Measuring Agreement: Models, Methods, and Applications (Wiley Online Library, 2017).
- 7Van Der Hofstad, R. Random Graphs and Complex Networks (Cambridge University Press, 2024).