From gaze to proficiency: deep learning-driven prediction of novice performance in laparoscopic training using AOI-dependent metrics
Aseel F. Khanfar, Sanaz Motamedi, Shawn D. Safford, Jason Moore, Jessica Menold, Scarlett Miller

TL;DR
This study uses deep learning and eye-tracking to predict the skill levels of surgical trainees during laparoscopic training, showing that visual behavior can be classified and adapted for different anatomies.
Contribution
The study introduces AOI-dependent metrics and integrates CV-DL with eye-tracking for real-time skill prediction in laparoscopic training.
Findings
AOI-dependent and motion metrics successfully classified novices into high and mid-low skill levels.
Random Forest achieved the highest accuracy in predicting visual behavior using fixation rates and tool speed.
Visual attention patterns were consistent between pediatric and adult box trainers among novices.
Abstract
The fundamentals of laparoscopic surgery (FLS) program uses box trainers to develop laparoscopic skills. However, these simulators lack personalized training, real-time objective assessment, and primarily represent adult anatomies, neglecting pediatric cases. To address these limitations, advanced objective evaluations like motion analysis and eye-tracking are needed to track trainees’ progress and provide real-time formative feedback. However, dynamic training environments challenge eye-tracking data extraction due to shifting areas of interest (AOI). This study aimed to extract AOI-dependent and motion metrics for differentiating and predicting trainees’ skill levels across different box trainer anatomies. Medical students and residents performed the peg transfer task on adult and pediatric box trainers. Computer Vision-Deep Learning (CV-DL) algorithms were integrated with…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
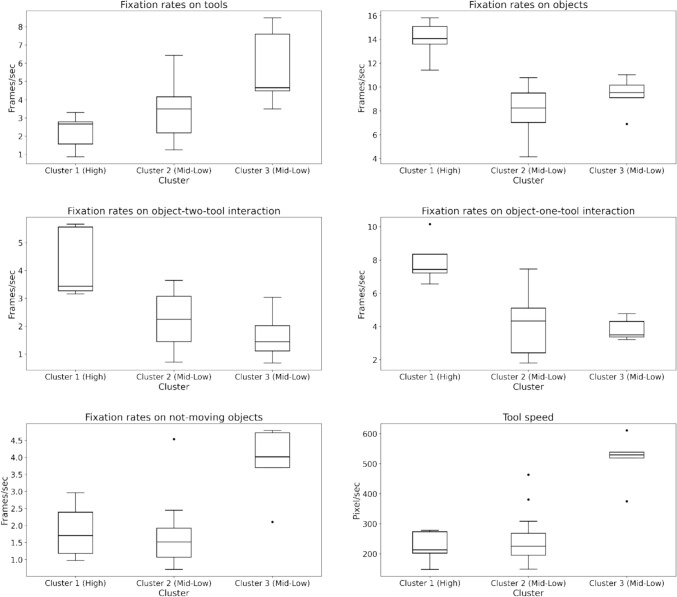 Figure 10
Figure 10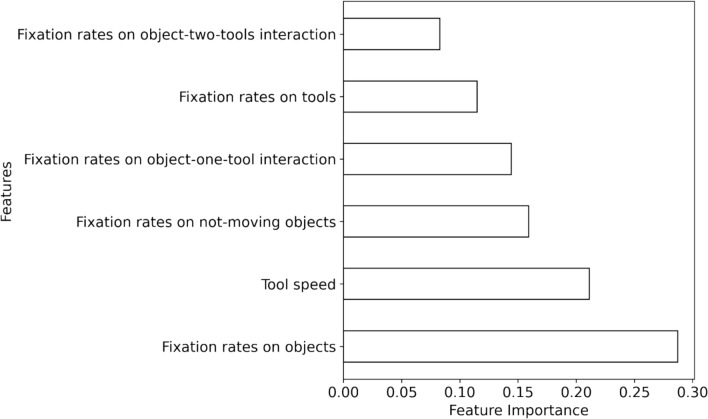 Figure 11
Figure 11 Figure 1
Figure 1 Figure 2
Figure 2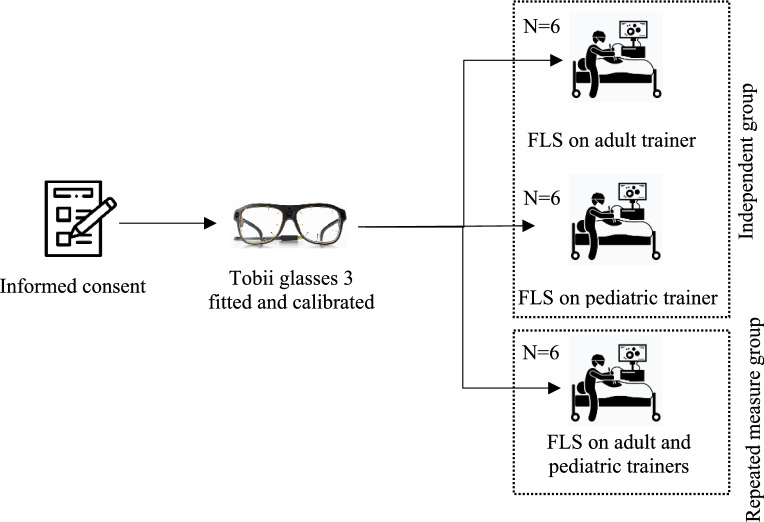 Figure 3
Figure 3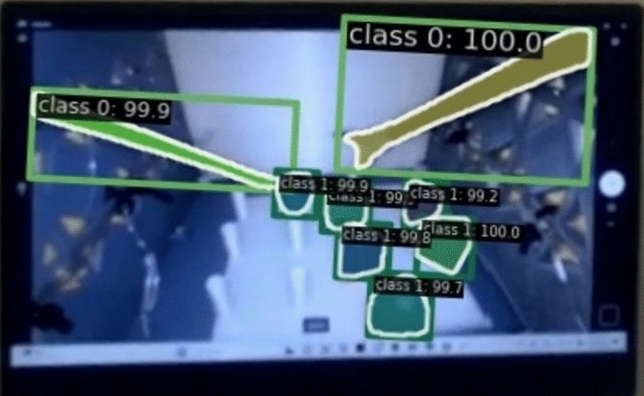 Figure 4
Figure 4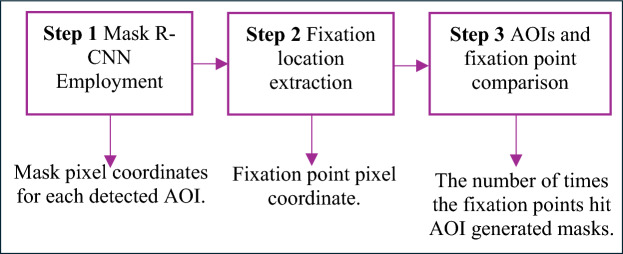 Figure 5
Figure 5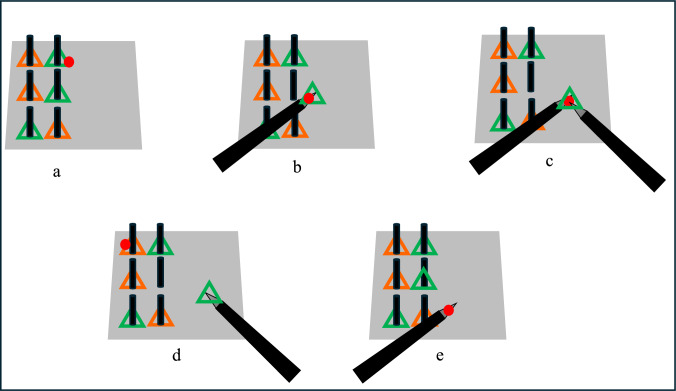 Figure 6
Figure 6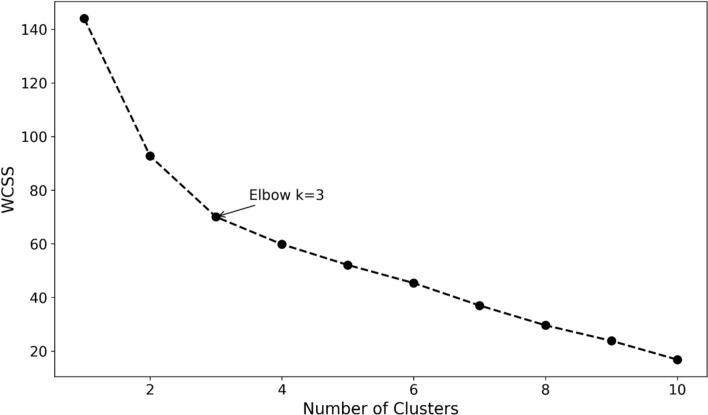 Figure 7
Figure 7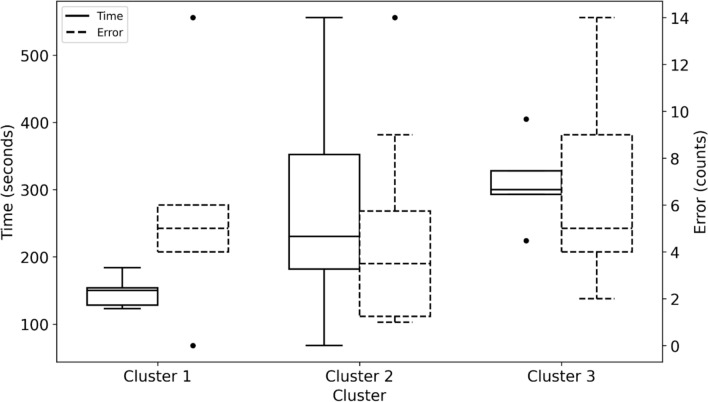 Figure 8
Figure 8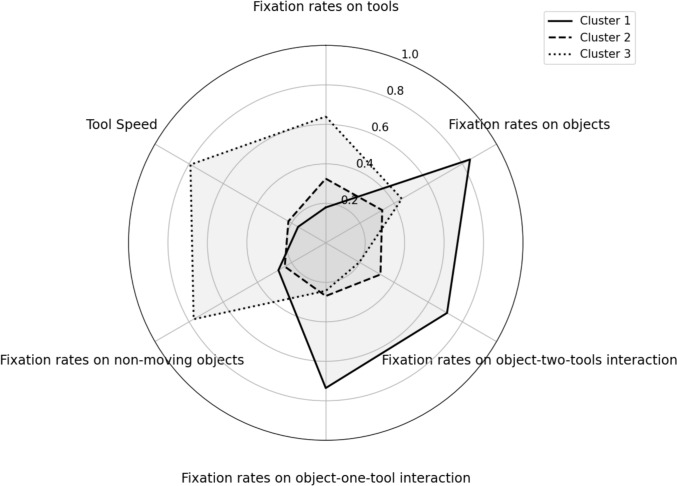 Figure 9
Figure 9 Figure 12
Figure 12- —Chester Ray Trout Chair in Pediatric Surgery at Penn State’s Hershey Medical Center
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSurgical Simulation and Training · Augmented Reality Applications · Minimally Invasive Surgical Techniques
Laparoscopy, a Minimally Invasive Surgery (MIS), is widely used for complex operations, from appendectomies to pancreas resections to adrenalectomies, due to its benefits, including reduced postoperative pain, shorter hospitalization periods, quicker recoveries, and minimal scarring [1–3]. Consequently, laparoscopic cases have increased by 462% from 2000 to 2018, with over 15 million procedures performed annually worldwide [4, 5]. However, the complexity of laparoscopic procedures poses significant challenges for surgeons, such as limited depth perception from two-dimensional monitors and reduced tactile feedback compared to open surgery [6, 7]. Performing the procedure on pediatric patients presents additional challenges due to the small operative space and the increased fragility of the tissue [8]. As such, this procedure requires surgeons to develop advanced skills in perceiving and interpreting visual cues and coordinating their movements to operate effectively [9]. As a result, the traditional “see one, do one, teach one” model is no longer sufficient and has been replaced by Simulation-Based Training (SBT), following the principle of “see one, simulate many, do one completely, and teach everyone.” [10].
SBT has been adopted by laparoscopic surgeons through the Fundamentals of Laparoscopic Surgery (FLS) program to train and evaluate fundamental laparoscopic skills using a series of five tasks on a laparoscopic box trainer (FLS simulator) [11–13]. The peg transfer task, one of the five validated tasks for basic laparoscopic skills [14] is widely used as it is designed to enhance ambidexterity, depth perception, and coordination between both hands, all of which are critical skills in laparoscopic surgery [15, 16]. While the laparoscopic box trainer has demonstrated its effectiveness for training purposes, it has some limitations. One limitation is the lack of a real-time objective assessment [17]. Currently, FLS tasks rely on trained proctors who evaluate performance on-site based on predetermined standards, using speed (time to complete the task) and accuracy (number of errors committed) [11]. Another limitation is that the simulator’s assessment system does not adapt to individual performance, which limits its ability to provide personalized training or feedback [18]. Specifically, variations across novices’ performance in the early stages of training necessitate personalized training programs that more efficiently and effectively contribute to novices’ competency [19, 20]. The third limitation is the scarcity of simulators specifically designed for pediatric patients [21]. The availability of such simulators is important due to the anatomical differences between adult and pediatric patients [8]. Given these limitations, more advanced objective assessment tools should be used to track trainees’ progress and provide constructive feedback to enhance their competency [22–24]. These tools should also be used to predict trainees’ skill levels, enabling personalized training [25, 26]. Furthermore, there is a need for validated pediatric simulators that incorporate such tools for effective training in this specialized field [21]. Among these tools, motion analysis and eye-tracking provide valuable insights into proficiency and visual behaviors to objectively assess trainees’ technical skills [27, 28].
One advanced objective assessment method used in laparoscopic training is motion analysis. This method objectively evaluates trainees' proficiency levels (e.g., novices and experts) by analyzing motion-based metrics of laparoscopic instruments, such as tool speed, path length, and acceleration [29, 30]. These metrics are essential for informing trainees about areas for improvement, allowing them to practice effectively and master the control of laparoscopic instruments [20]. However, motion analysis alone does not capture the cognitive processes involved in surgical training. It lacks the ability to assess how trainees navigate relevant and irrelevant visual information while performing tasks [31]. To address this, eye-tracking technology provides insights into visual attention during surgical procedures [32].
Another tool for advanced objective assessment is eye-tracking, which provides insights into trainees’ visual behavior and cognitive processes, necessary for evaluating their visual attention to relevant targets during training [33]. Eye-tracking is increasingly being applied in medical education as a training tool [34], proficiency assessment [35], and feedback [36]. To derive valuable data from eye-tracking studies, researchers segment the visual field into areas of interest (AOIs) to analyze gaze patterns and make informed decisions [37]. Eye-tracking metrics can be classified into AOI-independent and AOI-dependent eye-tracking metrics [38]. While AOI-independent metrics, such as fixations, saccades, blink rate, and pupil diameter, have been effective in differentiating expertise levels and evaluating mental workload [28, 39], they do not provide direct guidance on how trainees should focus their attention during training [40, 41]. For this reason, in the current work AOI-dependent metrics are used.
AOI-dependent metrics, such as fixation rates and fixation durations within specific AOIs, provide real-time feedback by guiding trainees’ on where to allocate their attention for improving their performance [42]. These metrics reflect both feedback and feedforward gaze behaviors for skill evaluation [43]. Feedback gaze behavior involves tracking relevant targets and tools, with studies showing that experts spent more time gazing at targets, whereas novices allocated more time following the tools [44, 45]. Feedforward gaze behavior is assessed by analyzing eye-tracking metrics from objects or locations where an action is intended before execution. Studies on peg transfer task training found that skilled trainees focus more on future objects than current holding objects, demonstrating greater anticipatory visual control [43, 46]. Despite the effectiveness of these metrics, their application in research remains limited.
Although AOI-dependent metrics could provide formative feedback for trainees, they are rarely used in laparoscopic training [20, 46]. This is mainly due to the challenge of extracting eye-tracking metrics from specific AOIs, as their positions continuously shift based on the gaze data coordination system [47]. Recently, computer vision (CV) algorithms have been explored to automatically extract eye-tracking metrics from dynamic AOIs [20, 38, 48, 49]. For example, a study on peg transfer task training developed a computer vision model to differentiate trainees' skill levels by extracting fixation rates on objects and object-tool combinations [38]. Once extracted, these AOI-dependent metrics, along with motion metrics, can be used in predictive models to classify trainees’ skill levels.
After extracting AOI-dependent and motion metrics and classifying the expertise level of trainees, it is important to predict proficiency based on visual and motion behavior [50]. One approach is the use of machine learning (ML) techniques, which can classify and predict trainees’ proficiency levels (e.g., expert, intermediate, and novice) based on eye-tracking and motion metrics [51]. Previous research applied classifiers such as Support Vector Machine (SVM), Linear Discriminate Analysis (LDA), Artificial Neural Networks (ANNs), Decision Trees (DTs), and Random Forest (RF) to predict expertise levels in laparoscopic training [28, 51]. By determining trainees’ skill levels, these methods can not only monitor their progress but also personalize their training programs to better match their abilities, thus improving their training performance [28, 52].
To sum up, AOI-dependent eye-tracking metrics are effective in differentiating trainees’ skill levels. However, there are significant gaps in the literature including: 1) extracting AOI-dependent eye-tracking metrics in a dynamic environment presents challenges, 2) assessing novices’ proficiency levels during early-stage training using eye-tracking metrics, rather than focusing only on differentiating between experts and novices, and 3) evaluating trainees’ visual attention across different box trainer anatomies (e.g., pediatric and adult box trainers). To address these gaps, a validated computer vision-deep learning (CV-DL) model was employed to extract AOI-dependent eye-tracking, which reflects both feedback and feedforward metrics, along with motion metrics. This study aimed to differentiate skill levels of new trainees, predict their visual behavior during early-stage FLS peg transfer task training, and explore how visual attention may change across different box trainer anatomies. Specifically, the study was designed to answer the following research questions:
RQ1:** Can AOI-dependent and motion metrics extracted from the CV-DL model classify novice skill proficiency levels?** It was hypothesized that a clustering algorithm would identify different skill levels. It was also hypothesized that fixation rates would be higher on objects for participants at higher proficiency levels and higher on tools for participants at lower proficiency levels. Finally, it was hypothesized that the tool speed would be faster at lower proficiency levels than at higher proficiency levels.
RQ2:** Can novices’ visual behavior levels be successfully predicted using metrics extracted from the CV-DL model?** It was hypothesized that using machine learning techniques, the visual behavior levels of trainees can be predicted successfully from the extracted metrics.
RQ3:** Does the type of trainer (pediatric or adult) influence novices’ visual attention across different AOIs during training sessions?** It was hypothesized that the extracted metrics would be higher in the pediatric box trainer than in the adult box trainer, as eye-tracking metrics such as fixations and fixation durations increase with task difficulty [39].
Materials and methods
Participants
Nine medical students and nine residents (10 males and 8 females) were recruited for the IRB-approved study (STUDY0023069) at Hershey Medical Center (HMC). The study included residents from general surgery and anesthesiology programs: seven participants were in Postgraduate Year (PGY) 1, and two participants were in PGY3. The PGY3 residents were enrolled in anesthesiology. Two of the participants were left-handed. All participants had completed fewer than two laparoscopic surgeries in their careers and had less than three years of experience. All participants had normal or corrected-to-normal vision.
Procedure
At the beginning of the study, randomly selected participants received an explanation of the study objectives and procedures, and informed consent was obtained according to IRB protocol. Afterward, Tobii glasses 3, with a 50Hz sampling rate, were fitted and calibrated for each participant. Participants were then instructed to perform the FLS peg transfer task following FLS standards on two box trainers: one representing adult anatomy with internal dimensions 455 × 395x220 mm, which is a commercially available simulator from Medicinology and Co (see Fig. 1) and another low-fidelity custom-built trainer to simulate pediatric patient anatomy with internal dimensions of 140 × 230 × 126 mm. The custom-built pediatric trainer (see Fig. 1) is a 3D-printable design, following a baseball diamond concept [53] to strategically place ports for optimal triangulation. Maintenance is made easy with the replaceable Brrnoo training suture pad. A camera with a high resolution of 1920 × 1080 was used to ensure visual clarity. To represent the surgical instruments for laparoscopic surgery, 3mm “Laparo Scopy Boxx” pediatric laparoscopic needle holders were used.Fig. 1. Experimental setup using an adult (left) and pediatric (right) box trainers
Six novices performed the FLS peg transfer task on the adult box trainer, while another six executed the task on the pediatric box trainer. The remaining participants (six novices) completed the task on pediatric and adult box trainers. The order in which participants used the simulators was randomized to avoid order effects. However, statistical analysis confirmed that task order had no significant effect on performance outcomes. Both box trainers were connected to an optical camera that streamed the internal scenes onto a 15-inch monitor. See Fig. 1 for the experimental setup of the pediatric box trainer.
Before participants started their task, all six rubber objects should be placed on the same side as the participant’s non-dominant hand. They were then asked to lift each of the six rubber triangles using graspers held by their non-dominant hand and transfer it midair to their dominant hand before placing them on the opposite side of the pegboard (see Fig. 2). Due to time constraints and that participants took an average of 30 min to complete the experiment, participants completed only the first half of the task without reversing, as initially stated by the FLS manual [14]. Upon completing the task on one box trainer, the same procedure was replicated on the other box trainer for the six participants assigned to perform the task on both box trainers. Figure 3 shows the experimental procedure for this work.Fig. 2. The peg transfer taskFig. 3Experimental procedure across pediatric and adult box trainers
Computer vision- deep learning (CV-DL) model
Mask R-CNN, a CV-DL model, was developed in our previous research [54] to automatically detect AOIs, such as triangles/objects and tools/graspers, during the peg transfer task training, see Fig. 4. It achieved 98.5% precision in classifying AOIs and 74.8% precision in generating masks around the predicted object. To handle potential noise in frame-level object detection, a confidence threshold was applied such that object detections with a probability greater than 0.5 were considered valid. Two test videos (one from an adult simulator and one from a pediatric simulator), including 3889 frames of the peg transfer task training, were used to validate the model [55, 56]. The AOI annotations (e.g., objects and tools) in both videos were generated using the Mask R-CNN model and annotated manually frame-by-frame to serve as ground truth. These annotated frames from each method were then integrated with the eye-tracking data to (1) count the number of times the fixation point fell on the AOIs and (2) assess the level of agreement, frame-by-frame, using Cohen’s kappa (κ) [57] between the model and the Mask R-CNN annotations. The AOI hits were relatively close, and a high level of agreement between the manual annotations and the Mask R-CNN model was achieved, with Cohen’s kappa (κ) exceeding 0.8 for both objects and tools across the pediatric and adult box trainers.Fig. 4. An example of the mask generated using the Mask R-CNN model, extracted from the eye-tracker recording
Three steps were then applied in this work to extract fixation rates on different areas of interest during the peg transfer task training. Figure 5 shows a summary of the three steps and their outcomes.Fig. 5. Summary of mask R-CNN employment to extract eye-tracking metrics in this work
In Step 1, Tobii glasses recordings were split into individual frames and then used through a developed Mask R-CNN model to automatically identify and label objects and tools. Generated mask pixel coordinates were extracted for all detected objects in each frame.
In Step 2, fixation point pixel coordinates (x, y) were obtained from each participant’s video using Tobii Pro Software. To extract fixation points, the Tobii Velocity-Threshold Identification (I-VT) fixation filter [58] was applied at a 70-degree/sec velocity threshold [59, 60], which considers eye-movement below a velocity of 70 degrees/sec as fixation.
Finally, in Step 3, fixation point coordinates were compared to the generated mask coordinates in each frame. If the fixation point fell within five pixels around the contours of triangle objects or tools, the participant was considered to be fixating on the detected AOI. This approach followed Specian Junior, Litchfield [61] recommendation that chosen AOI boundaries can be extended slightly beyond the actual AOI. This extension helps ensure that any fixations near the edges of the AOI are still captured accurately. The number of frames containing fixation points that hit an AOI was divided by the participant’s task completion time to compute fixation rates (measured in frames/second) [38]. Five AOI-dependent eye-tracking metrics, including one representing feedforward behavior, were extracted in addition to one motion metric.
Metrics
AOI-dependent eye-tracking metrics were extracted based on detected tools and target objects to evaluate novices' visual attention and skill levels during training, e.g., fixation rates on objects and tools, and tool speed. Fixation on objects was further classified into three categories: (1) moving objects manipulated by one tool, (2) moving objects manipulated by two tools, and (3) not moving objects (potentially representing next targets). Hence, in addition to overall fixation rates on objects, fixation rates in these three categories were also computed to provide a more detailed evaluation of novices’ visual behavior. These metrics were derived from previous work [20]. More details about the metrics used in this work are shown below (see Fig. 6):Fig. 6. Examples of fixations on different AOIs used in this study where the red circle represents a fixation point: a fixation on object, b fixation on object being held by one tool, c fixation on object being held by two tools, d fixation on the next object, e fixation on tools
Fixation rates on objects (frames/second)
This feedback metric measures how frequently participants fixate on objects during the task by dividing the number of frames containing fixation points that hit object masks by task completion time.
Fixation rates on object-one-tool interaction (frames/second)
This feedback metric measures how frequently participants fixate on moving objects held by one grasper by dividing the number of frames containing fixation points that hit the intersection area between one object and one grasper by task completion time.
Fixation rates on object-two-tools interaction (frames/second)
This feedback metric measures how frequently participants fixate on moving objects held by two graspers and may provide insights into the object's transitioning behavior from one tool to another. It is computed by dividing the number of frames containing fixation points that hit the intersection area between one object and two graspers by task completion time.
Fixation rates on non-moving objects (frames/second)
This feedforward metric potentially measures participants’ looking-ahead behavior by dividing the number of frames containing fixation points that hit objects outside the intersection area between moving objects and graspers by task completion time.
Fixation rates on tools (frames/second)
This feedback metric measures how frequently participants follow the grasper while performing the task by dividing the number of frames containing fixation points that hit graspers in any area outside the intersection area with any objects.
Tool speed (pixel/second)
This motion metric measures how quickly the tools are being moved during the task. It is computed by measuring the distance between the tool centroids of two consecutive frames divided by their timestamp difference; this process is repeated for each pair of consecutive frames and then averaged to obtain a single average speed. The final tool speed was obtained by summing the average speed of the left and right graspers.
Statistical classifier
To predict trainees’ expertise levels from extracted AOI-dependent and motion metrics, four machine learning algorithms were used: (1) Random Forest (RF), an ensemble technique creating multiple decision trees trained on random features and combining these decision trees to predict the class label [62], (2) Support Vector Machine (SVM), which separates different classes of data by finding an optimal hyperplane in the feature space [63], (3) Classification and Regression Trees (CART), recursively dividing features into smaller, non-overlapping regions, with each region associated with a decision tree for classification [64], and (4) Artificial Neural Networks (ANNs), consisting of interconnected nodes arranged in layers, help in understanding the relationships and patterns within the data for prediction purposes [65]. These classifiers were selected due to their wide use on small datasets and their ability to handle nonlinear feature relationships [66, 67]. Multiple classifiers were used to ensure that the best algorithm was identified to predict the expertise levels of trainees from the extracted metrics, as each classifier employs a different approach (e.g., ensemble, margin-based, tree-based, and neural network-based) [68]. Leave-one-out cross-validation (LOOCV) was used to evaluate the performance of machine learning models. LOOCV trains a model on all samples in the dataset, leaving only one sample for testing, and repeats this process where each sample serves as both training and testing points [69]. LOOCV is applied to small datasets to obtain reliable accuracy for prediction models [70].
Results
This research aims to classify novices’ skill levels and predict their visual behavior using AOI-dependent eye-tracking metrics extracted from the mask R-CNN model and investigate the variations in novices’ visual attention across different box trainer anatomies. The gaze sample percentages for all recordings were at least 87%. Hence, all recordings were included in the analysis. All statistical analysis was conducted using IBM SPSS (V. 29.0) at a significant level of 0.05. A one-way Welch ANOVA was run instead of a one-way ANOVA if the homogeneity of variances was violated. For all analyses in this study, outliers were examined, and analyses were conducted both with and without them. If the results were consistent, the outliers were retained; otherwise, they were excluded. The remainder of this section represents our findings for each of our research questions:
RQ1: Can AOI-dependent and motion metrics extracted from the CV-DL model classify novice skill proficiency levels?
To evaluate and differentiate novices’ skill proficiency levels, three steps were employed: clustering participants based on their proficiency levels, interpreting the resulting clusters using task performance, and analyzing differences in visual and motion patterns. These steps are detailed below:
- Clustering Participants by Proficiency Levels: To classify novices based on their skill levels, we applied an unsupervised ML algorithm, k-means + + , to behavioral metrics extracted by the CV-DL (Mask R-CNN) model (see Metrics Section). [71]. Based on the elbow method [72] three clusters were determined by plotting the within-cluster sum of squares (WCSS) against the number of clusters, see Fig. 7. Participants were classified as follows: Cluster 1 (N = 5), Cluster 2 (N = 14), and Cluster 3 (N = 5).Fig. 7. The elbow method of k-means + + to identify the number of clusters
- Interpreting Clusters with Task Performance: To interpret skill levels associated with each cluster, we compared task completion times and errors committed across groups. Figure 8 shows the number of errors committed and completion times based on the three defined clusters. A one-way ANOVA was conducted to determine if the errors committed between the three groups were different. The number of errors committed was not statistically significant between the three groups F (2, 21) = 2.893, p = 0.563.Fig. 8. Errors committed and completion times of novices in each identified clusterA one-way Welch ANOVA was conducted to determine whether the three clusters' completion times differed. Completion times significantly differed between the three clusters, Welch’s F (2, 9.815) = 14.497, p < 0.001. Hames-Howell post-hoc analysis revealed that the mean increase from Cluster 1 to Cluster 2 (− 112.98, 95%CI [− 211.54, -14.42]) was statistically significant, as well as the increase from Cluster 1 to Cluster 3 (− 162.2, 95%CI [− 263.20, − 61.19]). The completion times mean increase from Cluster 2 to Cluster 3 (− 49.21, 95%CI [− 170.52, 72.1]) was not statistically significant, see Table 1. Since there was no statistically significant difference in completion times between Clusters 2 and 3, we expected their proficiency levels to be the same. These results indicate that based on clustering analysis, novices’ visual behavior was classified into three clusters (e.g., Clusters 1, 2, and 3), and these clusters were identified into two skill levels based on the differences in completion times: High (Cluster 1) and Mid-Low (Clusters 2 and 3). Figure 9 shows the radar chart of the AOI-dependent and motion metrics by clusters, visually comparing clusters’ performance across all extracted metrics.Table 1. Pairwise comparisons between the three clusters using the Hames-Howell post-hoc analysis for errors committed and task completion timesClustersCluster 1, Cluster 2Cluster 1, Cluster 3Cluster 2, Cluster 3MetricsDifferencep-valueDifferencep-valueDifferencep-valueNumber of errors committed1.3000.865− 1.000.946− 2.300.618Completion times− 112.9800.024− 162.2000.008− 49.2140.556Significant p-values are highlighted in boldFig. 9Radar chart of AOI-dependent and motion metrics by clusters
- Differences in Visual and Movement Metrics: To determine whether the clusters reflected different visual behavior patterns, we conducted six one-way ANOVAs and Tukey Post Hoc Comparisons. There was a statistically significant difference between different visual behavior levels across all extracted metrics (p < 0.05), see Fig. 10.Fig. 10. Box plots comparing AOI-dependent metrics and tool speed across the three identified clusters
While one-way ANOVA determined differences between visual behavior levels across all metrics, pairwise comparisons were performed using the Tukey post-hoc test to evaluate the specific differences between each level, as shown in Table 2. Fixation rates on objects, object-one-tool interaction, and object-two-tools interaction significantly differed between Cluster 1 (High)- Cluster 2 (Mid-Low) and Cluster 1 (High)- Cluster 3 (Mid-Low). These metrics significantly increased from Cluster 3 to Cluster 1 and from Cluster 2 to Cluster 1. However, no statistical differences were found between Cluster 2 and Cluster 3. On the other hand, fixation rates on tools, not-moving objects, and tool speed were significantly different between Cluster 1 (High)-Cluster 3 (Mid-Low) and Cluster 2 (Mid-Low)-Cluster 3 (Mid-Low). These metrics significantly increased from Cluster 2 to Cluster 3 and from Cluster 1 to Cluster 3. There was no statistical significance between Cluster 1 and Cluster 2 on tools, not-moving objects, and tool speed metrics.Table 2. Pairwise comparisons between the three skill levels using the Tukey post-hoc testClustersCluster 1, Cluster 2Cluster 1, Cluster 3Cluster 2, Cluster 3MetricsDifferencep-valueDifferencep-valueDifferencep-valueFixation rate on tools− 1.100.372− 3.50****0.005− 2.39****0.019Fixation rate on objects5.98****< 0.0014.640.001− 1.330.34Fixation rate on object-one tool interaction3.89****< 0.0014.11< 0.0010.210.957Fixation rate on object-two tools interaction1.940.0042.56****0.0020.610.485Fixation rate on not moving objects0.150.951**-2.02****0.009**− 2.17**< 0.001Tool speed− 26.180.812− 291.55< 0.001**− 265.37**< 0.001**Significant p-values are highlighted in bold
While these results support our hypothesis that fixation rates on objects would be higher for more-skilled novices and fixation rates on tools and tool speed would be higher for less-skilled ones, the results for the fixation rates on not-moving objects refute our hypothesis. Also, the results show that even clusters with the same skill levels may show different visual behavior and movement skill levels.
RQ2: Can novices’ visual behavior levels be successfully predicted using metrics extracted from the CV-DL model?
Four ML algorithms were used to predict novices’ visual behavior levels from extracted metrics: (1) Random Forest (RF), (2) Support Vector Machine (SVM), (3) Classification and Regression Trees (CART), and (4) Artificial Neural Networks (ANNs). LOOCV was employed, where each sample in the dataset was used once as a test set while the remaining samples were used for training. This process was repeated until all samples had served as training and testing points. Accuracy and F1-score were used to evaluate the algorithm's performance. Accuracy presents the proportion of correctly classified predictions out of the total data, while the F1-score is the harmonic mean of precision and recall [73]. The results showed that RF achieved the highest accuracy and F1-score (83.33%, 0.8333, respectively) in predicting novices’ visual behavior levels, followed by ANNs (79.16%, 0.7647), SVM (75%, 0.6554), and CART (70.83%, 0.5132), with the least accuracy and F1-score.
For evaluating the significance of each predictor (AOI-dependent metrics and tool speed) in the RF model, Gini (impurity) importance was used as a feature selection method [74]. Gini importance measures how much a specific metric contributes to decreasing impurity/ uncertainty when used for splits in RF decision trees [74]. As shown in Fig. 11, fixation rates on objects and tool speed were the most influential features for predicting visual behavior levels, followed by fixation rates on not-moving objects and fixation rates on object-one-tool interaction. Fixation rates on tools and object-two-tools interaction were the least important features. These results support our hypothesis that extracted metrics that reflected feedback and motion metrics would successfully predict novices’ visual behavior levels.Fig. 11. The importance of metrics in predicting visual behavior levels in the RF model based on Gini importance
RQ3: Does the type of trainer (pediatric or adult) influence novices’ visual attention across different AOIs during training sessions?
Using a paired-sample t-test for the repeated measures group, all metrics showed no statistically significant difference between pediatric and adult box trainers (p > 0.05). For the independent measures group, an independent sample t-test was run. The independent group found the same results, with no statistical difference between pediatric and adult box trainers across all metrics (p > 0.05). These results refute our hypothesis that eye-tracking and motion metrics would be higher in pediatric trainer than in adult trainer.
Discussion
The goal of this research was to classify novices’ skill levels, predict their visual behavior, and explore variations in novices’ visual attention across different types of box trainers using AOI-dependent and motion metrics from the Mask R-CNN model. The findings from the first research question support our hypothesis that AOI-dependent and motion metrics would successfully classify novices’ skills into multiple levels. Three clusters were identified through clustering analysis, representing different visual behavior levels. Similar results were found in [20], where three clusters were also identified, corresponding to three skill levels. Differences in completion times among these clusters indicated two distinct skill levels: High (Cluster 1) and Mid-Low (Clusters 2 and 3). ANOVAs revealed significant differences in visual behavior between the three clusters across all AOI-dependent and motion metrics. For Cluster 1 (High), fixation rates on objects, fixation rates on object-one-tool interaction, and fixation rates on object-two-tools interaction showed a consistent pattern, where participants at Cluster 1 (High) had significantly higher values than Levels 2 and 3 (Mid-Low). In addition, fixation rates on tools and tool speed showed the opposite pattern, Cluster 1 (High) had significantly lower values than Cluster 3 (Mid-Low) across these metrics. These results indicate that skilled novices can exhibit similar visual behavior to experts, as previous research indicated that experts allocated their attention more to relevant objects during laparoscopic training [44, 45], and novices tend to fixate more on tracking tools, showing “tool-following behavior” and faster tool speed [30]. In general, fixation rates on object-one-tool interaction were higher than fixation rates on object-two-tools interaction, indicating that fixating on the object while two tools hold it occurs less frequently, such as transitioning the object from one tool to another, with participants concentrating more during initial grasping and manipulation.
On the other hand, fixation rates on not-moving objects were also significantly lower for participants at Cluster 1 (High) compared to those at Cluster 3 (Mid-Low). This result contradicts previous research indicating that more-skilled participants tend to look ahead more frequently than less-skilled ones [20, 43]. It’s worth noting that error incidents were included in this research, and participants at Cluster 3 (Mid-Low) committed more errors on average than those at Cluster 1 (High), although this difference was not statistically significant. This might lead participants to look more at the objects that have been dropped and are not being held by any tools. Results showed that fixation rates on not-moving objects for all skill levels are approximately low. This is reasonable due to their initial trials on the peg transfer task, and perhaps more practice is needed to develop the ability to anticipate future actions as experts.
Interestingly, while Clusters 2 and 3 showed the same skill level based on performance measures, they demonstrated significant differences in their visual behavior and movement skills in terms of fixation rates on tools and tool speed. The results showed that Cluster 2 had significantly lower values across these metrics than Cluster 3. This suggests that participants in Cluster 2 may fall somewhere between low and high skill levels. More studies are necessary to investigate the performance of participants at intermediate skill levels [38].
Results from the second research question are consistent with our hypothesis that visual behavior can be successfully predicted using metrics derived from the Mask R-CNN model. Our findings demonstrated that among the four ML models executed, Random Forest was the one that predicted visual behavior with approximately a good accuracy and an F1-score of 83.33%. Random Forest is considered one of the top classifiers and has been shown to perform well compared to other models, such as Support Vector Machines and Neural Networks, to name a few [75]. This may be attributed to the fact that RF builds multiple decision trees and combines their outputs to improve prediction performance [76].
Besides tool speed, results also showed that fixation rates on objects, fixation rates on non-moving objects, and fixation rates on object-one-tool interaction were the most significant predictors of visual behavior. These results provide evidence that these metrics can be used in early-stage training to predict visual behavior, and feedforward, feedback, and motion metrics are all important for this prediction. Our results slightly differed from those of Kulkarni, Deng [20] who found feedforward metrics to be the most important features for predicting skill levels. However, they predicted skill levels that reflect skill acquisition progression, while our work predicted the differences in novices' visual behavior in their first trial training. Identifying the most important features for predicting novices’ visual behavior is important to enhance skill assessment in medical training, potentially provide real-time formative assessment, and support the development of personalized training to improve competency. Integrating AOI-dependent and motion metrics can support formative assessment by tracking where trainees focus their attention during training and how they perform tasks during training, rather than evaluating them only after the session. This enables identifying areas where trainees struggle and provides real-time guidance to support skill development.
The results of the final research question showed no differences between pediatric and adult box trainers. This result does not align with our hypothesis that metrics would be higher in a pediatric box trainer than in an adult box trainer, as previous research indicates that a pediatric box trainer was more challenging than an adult trainer [50]. Consequently, eye-tracking metrics were expected to increase with more complex tasks [39]. Our study suggests that the task demands between both trainers are the same for novices. One potential explanation could be that the custom-built pediatric trainer might not accurately simulate pediatric anatomy and the associated task difficulty. Additionally, the small sample size may limit the ability to detect statistically significant differences between the two box trainers.
Limitations and future work
While this study shows promising results in classifying and predicting novices’ skill levels, this work has several limitations. While the Mask R-CNN model showed a very good agreement with manual frame-by-frame annotation, it generates mask contours around the detected objects with 74.8% precision. This indicates the existence of potential failure in detecting objects. However, this precision may remain adequate for training feedback. Since eye-tracking captures at high frame rates (e.g., 25 frames/second), AOI predictions are continuously updated, and a large number of correctly detected AOIs accumulate over time. This helps ensure that the feedback remains meaningful for trainees. Additionally, the model’s development was specific to the peg transfer task, and the findings cannot be generalized to other FLS tasks. Another limitation is that data collection was conducted at one large academic institution, which limited the sample size for recruitment. This study did not include expert participants, such as FLS-certified residents, to allow for direct comparison with novices. Furthermore, participants only completed the first half of the peg transfer task due to time constraints, with one trial only on each simulator. To address these limitations, future work may consider further developing the CV-DL model to achieve higher precision, potentially providing a more precise metric estimation. Further studies should focus on developing models and exploring relevant metrics for other FLS tasks, such as suturing. Moreover, large-scale studies involving experts and novices from multiple institutions are necessary to validate the study findings. While this work focused on investigating the differences in novices’ skill levels during early-stage training, further research may use eye-tracking metrics extracted by CV-DL models to evaluate how these metrics change as trainees progress in skill acquisition. Finally, fixation rates on not-moving objects were intended to assess novices’ looking-ahead behavior. Given that the number of errors committed by all skill levels was approximately the same, this facilitated the interpretation of this metric because dropping objects during training shifted trainees’ visual behavior to that object, potentially leading to an inaccurate metric estimation. Further research is important to find a way to extract fixation rates on dropping objects to enhance the skill evaluation.
Conclusions
This research aimed to categorize novices’ skill levels, predict their visual behavior, and evaluate the variations in visual attention across pediatric and box trainers during peg transfer task training using AOI-dependent and motion metrics. The first main finding was that eye-tracking and motion metrics were successfully used to classify novices’ skills into two levels using the clustering algorithm, and there were significant differences in visual behavior levels across all metrics. Second, Random Forest accurately predicted visual behavior levels, highlighting the importance of fixation rates on objects and tool speed as key predictors. Finally, visual attention for novices remained the same across pediatric and adult box trainers. We can conclude that novices present different skill levels and visual behavior even in the early training stages. Metrics extracted from the Mask R-CNN model have great potential to be integrated into training sessions to provide novices with real-time feedback on where to look (e.g., looking to relevant objects during training) and how to allocate their visual attention (e.g., fixating more on objects than tools). ML models can be further employed to predict novices' skill levels and visual behavior with appropriate features, which help customize and adapt their training program. Further studies should validate the effectiveness of custom-built pediatric box trainers in simulating pediatric patient anatomies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Patil Jr M, Gharde P, Reddy K, Nayak K, Patil M (2024) Comparative analysis of laparoscopic versus open procedures in specific general surgical interventions. Cureus 1610.7759/cureus.54433 PMC 1095180338510915 · doi ↗ · pubmed ↗
- 2Blencowe NS, Waldon R, Vipond MN (2018) Management of patients after laparoscopic procedures. BMJ 36010.1136/bmj.k 12029437677 · doi ↗ · pubmed ↗
- 3Sim JH (2017) Focusing on formative assessments: a step in the right direction. Acad Med 92(3):27510.1097/ACM.000000000000154728221225 · doi ↗ · pubmed ↗
- 4Ng IK, Mok SF, Teo D (2024) Competency in medical training: current concepts, assessment modalities, and practical challenges. Postgraduate Med J qgae 02310.1093/postmj/qgae 02338376156 · doi ↗ · pubmed ↗
- 5Ahmidi N, Hager GD, Ishii L, Fichtinger G, Gallia GL, Ishii M (2010) Surgical task and skill classification from eye tracking and tool motion in minimally invasive surgery. medical image computing and computer-assisted intervention–MICCAI 2010: 13th International conference, Beijing, China, September 20–24, 2010, Proceedings, Part III 13, Springer, pp 295–30210.1007/978-3-642-15711-0_3720879412 · doi ↗ · pubmed ↗
- 6Dalveren GGM, Cagiltay NE (2018) Using eye-movement events to determine the mental workload of surgical residents. J Eye Movement Res 1110.16910/jemr.11.4.3PMC 790320333828705 · doi ↗ · pubmed ↗
- 7Liu S, Donaldson R, Subramaniam A, Palmer H, Champion CD, Cox ML, Appelbaum LG (2021) Developing expert gaze pattern in laparoscopic surgery requires more than behavioral training. J Eye Movement Res 1410.16910/jemr.14.2.2PMC 801914333828818 · doi ↗ · pubmed ↗
- 8Olsen A (2012) The Tobii I-VT fixation filter. Tobii Technology 21;4–19. https://www.tobiipro.com/learn-and-support/learn/steps-in-an-eye-tracking-study/data/how-are-fixations-defined-whenanalyzing-eye-tracking-data/