Developing and Validating Machine Learning-Driven Risk Indices to Predict Patient Dropout During Referral, Evaluation, and Waitlisting for Kidney Transplant
Solaf Al Awadhi, Enshuo Hsu, Thomas B. H. Potter, Ioannis A. Kakadiaris, David A. Axelrod, Faith Parsons, Andrea M. Meinders, Victoria Cassell, Catherine Pulicken, Zulqarnain Javed, Paula K. Shireman, Stefano Casarin, A. L. Jonathan Gelfond, Amy D. Waterman

TL;DR
This paper develops machine learning models to predict when patients drop out during kidney transplant processes, aiming to reduce disparities in access.
Contribution
The study introduces novel machine learning-driven risk indices for predicting patient dropout at multiple stages of kidney transplant care.
Findings
46% of referred patients did not attend their first transplant evaluation visit.
ML models achieved AUROC scores of 0.79, 0.71, and 0.76 for dropout prediction at referral, evaluation, and waitlisting stages.
Socioeconomic and demographic factors were key predictors of dropout risk at each stage.
Abstract
Transplant is the optimal treatment for kidney failure; however, disparities in access persist. We developed and validated risk indices to predict early dropout at key stages of the transplant-seeking process not captured in national registries. We included patients referred for kidney transplant at Houston Methodist Hospital between June 2016, and November 2023. We collected demographic, clinical, patient- and contextual-level socioeconomic variables from electronic health records and publicly available census data. We used machine learning (ML) models to predict the characteristics of patients at higher risk of dropping out: (1) at referral (before starting evaluation), (2) in the process of evaluation (before waitlisting), and (3) during waitlisting (before receiving a transplant). Model performance was evaluated using AUROC. Of 4133 referred patients, 46% did not attend their…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
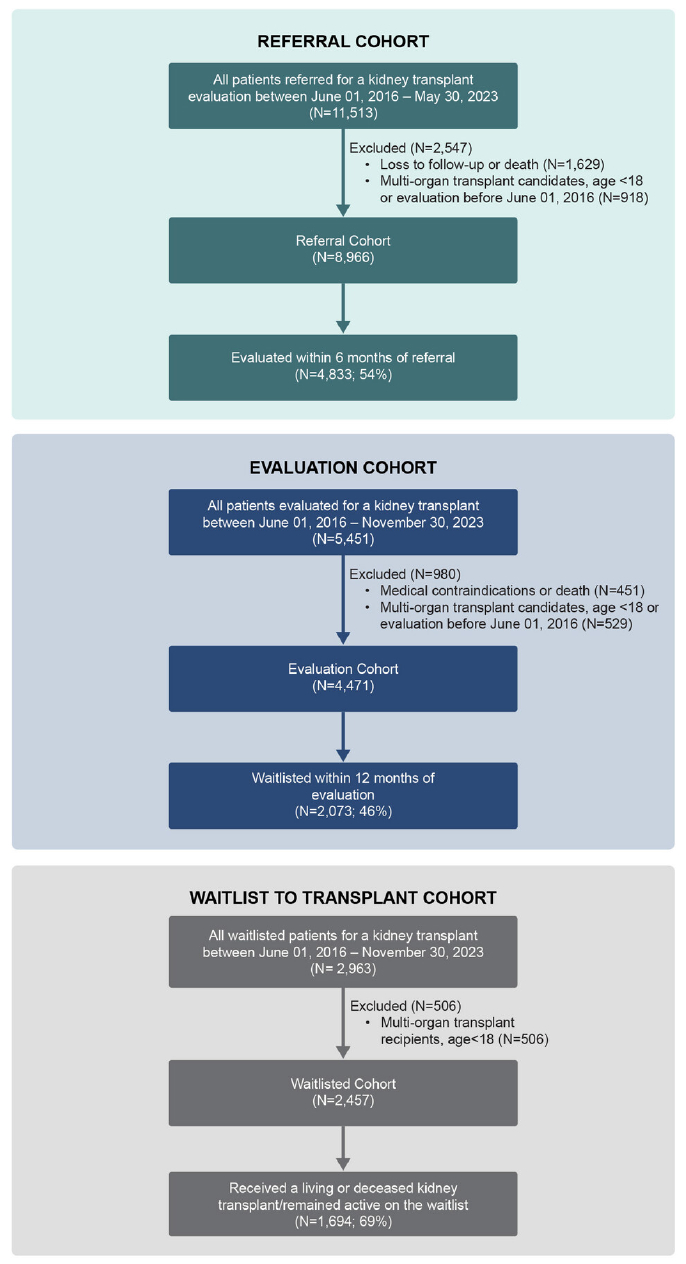 Figure 1
Figure 1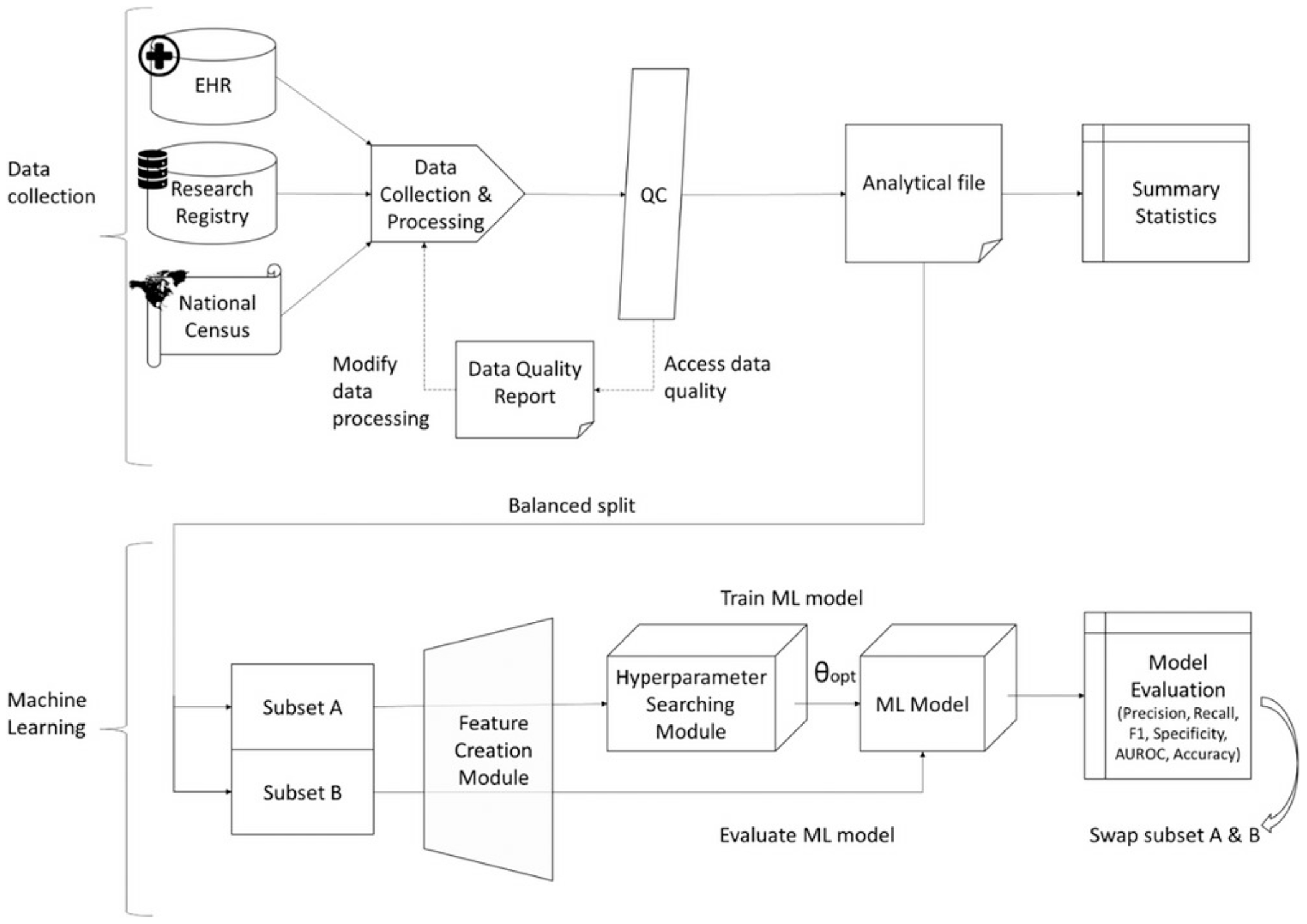 Figure 2
Figure 2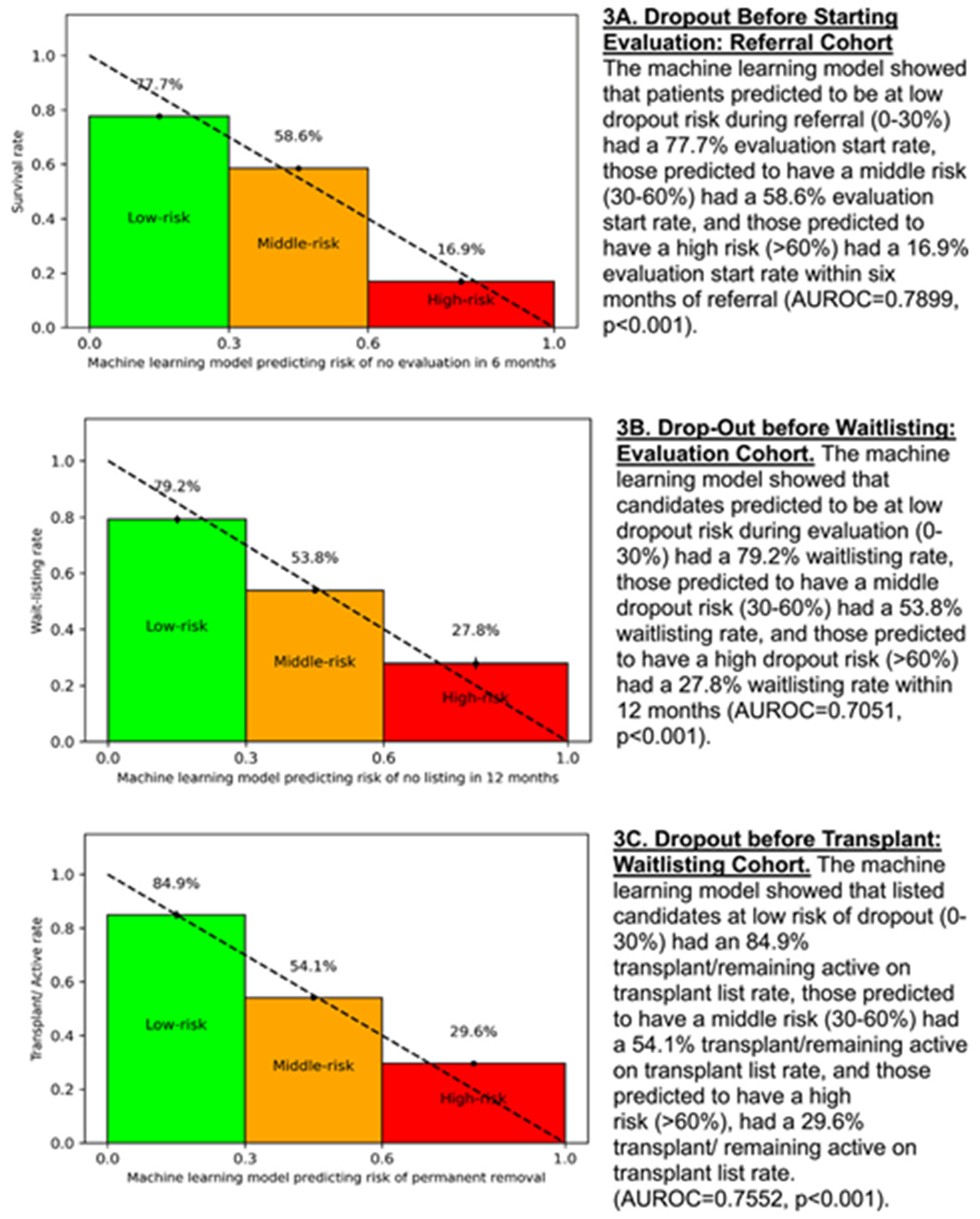 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRenal Transplantation Outcomes and Treatments · Organ Donation and Transplantation · Healthcare Policy and Management
Introduction
1 |
Kidney transplant (KT) is the treatment of choice for patients with chronic kidney disease (CKD) [1]. However, over 800,000 disproportionately minoritized patients with CKD in the US remain on chronic dialysis [2], despite evidence that KT extends survival, improves quality of life, and reduces long-term costs [3–6]. Pursuing KT requires patients to travel to transplant centers and complete a series of rigorous medical and psychosocial assessments before waitlisting [7]. Once waitlisted, patients must complete annual evaluations to maintain their candidacy, with wait times often ranging from 5 to 10 years [8]. Due to the national kidney shortage, transplant candidates without a willing living donor are currently more likely to die than to successfully receive a transplant, especially patients in larger urban centers with prolonged waiting periods and those from underserved communities that experience greater levels of social disadvantage [8]. The complexity and uncertainty of this process is daunting and some potential candidates quit before their evaluation is even completed.
Despite efforts to eliminate disparities in access to KT, African American (AA), Hispanic, and other historically underserved and socioeconomically disadvantaged subgroups are more likely than White patients to drop out or “derail” during the evaluation and waitlisting processes [9–11]. We previously developed an individual-level, single-score Kidney Transplant Derailers Index (KTDI) predicting the risk of transplant dropout, which highlighted demographic and racial disparities in access to KT [12]. However, similar to other studies assessing the risk of dropout [13–18], the KTDI was developed using data from a smaller population (733 adults), focusing on a limited set of socioeconomic status (SES) variables, and used traditional regression modeling to evaluate the impact of social determinants of health (SDOH) on waitlisting and living donor transplantation rate. Machine learning (ML) is an impactful emerging tool in medicine with the advantage of modeling nonlinear relations and accounting for all possible interactions and effect corrections between variables. ML models have provided accurate, comprehensive, and personalized risk indices in breast cancer and acute kidney injury [19–21]. However, ML has not previously been used to predict risk of dropout prior to transplantation due to the lack of sufficiently robust training data as patient information at these early stages is not captured in national transplant registries. In order to target resource interventions to reduce early drop out, we need to effectively identify higher risk candidates based on characteristics identifiable at the time of referral and initial in person evaluation.
Using a novel large data set from an urban transplant program serving a large multiethnic population, we developed three robust ML models which incorporated an expanded list of patient-and contextual-level SES variables to predict the risk of patient dropout at early stages of the KT-seeking process. We developed personalized risk indices identifying key patient characteristics associated with dropout at three key time points: (1) at referral before starting evaluation, (2) before completing evaluation, and (3) after becoming waitlisted.
Materials and Methods
2 |
Study Design and Participants
2.1 |
In this retrospective observational study, we obtained our participants’ sample by querying electronic health records (EHR) from the Houston Methodist Hospital’s (HM) KT population. Patients were divided into three cohorts for analysis: referral, evaluation, and waitlist (Figure 1). For all cohorts, we included patients ≥18 years old presenting for a KT at the HM J.C. Walter Jr. Transplant Center, and excluded patients referred for a multi-organ transplant.
For the referral cohort, we included CKD patients referred by a nephrologist or primary care physician to HM for KT evaluation between June 1, 2016 and May 30, 2023 (N = 8966). Referral was defined as a provider-submitted request that generated a transplant episode in the EHR. Dropout was defined as not presenting to a first evaluation visit at our center within 6 months of referral. Patients who were ineligible due to insurance (not covered under institutional contracts), could not be contacted, or died before evaluation were excluded. At referral, only limited data were available, as complete histories are obtained once evaluation begins; thus, exclusion for absolute contraindications could not be determined at this stage. To assess the impact of exclusions, we conducted a sensitivity analysis comparing patients who were included in the referral cohort with those who were excluded.
For the evaluation cohort, we included CKD patients who began KT evaluation between June 01, 2016 and November 30, 2022 (N = 4471). Patients who died or had absolute medical contraindications per Kidney Disease Improving Global Outcomes (KDIGO) guidelines [7] were excluded, as the study focuses on identifying potentially modifiable reasons for dropout. Dropout was defined as starting but not completing evaluation, excluding those denied for non-modifiable medical contraindications as recorded in the EHR.
For the waitlisted cohort, we included CKD patients waitlisted for KT between June 1, 2016 and November 30, 2022 (N = 2457). Dropout was defined as becoming inactive on the waitlist or not receiving a KT during this period, despite being medically and insurance eligible. The study was approved by the HM Institutional Review Board (IRB ID# MOD00005656) with a waiver of informed consent.
Data Collection and Covariates
2.2 |
We created a transplant registry by integrating patient-level data from Houston Methodist EHRs and the Organ Procurement and Transplantation Network (OPTN). Using ArcGIS [22], we geocoded patient addresses and linked them to publicly available contextual data sources, including the CDC Social Vulnerability Index (SVI), the US Census Bureau’s American Community Survey, and the Neighborhood Atlas for the Area Deprivation Index (ADI). Demographic, clinical, and socioeconomic variables were extracted from the EHR, while contextual SES variables were derived from census-linked data using patient zip codes. Covariates were selected prior to analysis based on relevant literature and expert input from clinicians and researchers [17, 23–25]. A complete list of variables and sources is provided in Table S1.
Outcomes
2.3 |
Primary outcomes were assessed by cohort:
Initiation of transplant evaluation:
defined as the proportion of referred patients who completed at least one initial evaluation visit at the transplant center (attendance at a transplant education class and being seen by at least one provider) within 6 months of referral, a timeframe selected based on research team consensus that patients who do not initiate evaluation within this period are unlikely to do so afterward.
Completion of transplant evaluation (waitlisting):
proportion of patients in the evaluation cohort who were activated on the deceased donor KT waiting list within 12 months of starting the evaluation process, a timeframe aligned with national guidelines that require evaluation to be up to date yearly.
Transplantation:
Proportion of patients in the waitlist cohort who received a living or deceased KT or remained active on the waitlist at the end of data collection.
Statistical Analysis
2.4 |
We summarized continuous variables with means, standard deviations, medians, interquartile ranges, and categorical variables with frequencies and proportions. We compared means and proportions between groups with the Kruskal–Wallis test, one-way ANOVA, Chi-squared tests, or Fisher’s exact tests as appropriate. We used three classic ML algorithms to assess the associations between covariates and the outcomes studied. We followed the Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) guidelines for reporting the development and validation of models [26] (Table S2).
Model Development
2.5 |
Model training and validation:
We followed a nested 2-fold cross-validation method by first splitting the dataset in half into equally-sized training and test subsets, balanced according to patient outcome, race/ethnicity, age, education, preferred language, diabetes and hypertension status, insurance status, distance from the hospital, and poverty as defined by the SVI. After initial model training and testing, data subsets were switched and the overall performance was determined as the average of the two separate runs [27]. To enhance robustness and reduce variability, model hyperparameters within each training set were optimized using nested 5-fold cross-validation grid search [27, 28]. Multiple feature engineering strategies, hyperparameter sets, and ML algorithms were explored for each cohort before training the final ML models (Figure 2). Data quality assessment methods are provided in the Supporting Information.
Feature engineering:
The collected data were pre-processed by categorizing and normalizing variables and treating missing values. We developed two feature engineering modules; in the first, denoted as “feature processor 0”, categorical variables were dummy coded (“one-hot encoding”), and continuous variables were categorized into predetermined buckets and dummy coded. Missing values were handled as a separate category (“missing”). In the second module, denoted as “feature processor 1”, categorical variables were dummy coded into nominal categories, which also allowed handling of missing values by turning them into zero-value vectors. Continuous variables were normalized by removing the mean and scaling to unit variance and missing values were imputed with the median value which was calculated using the training set.
Hyperparametric searching:
The hyperparameter searching was performed solely on the training sets. We performed a grid search with five-fold cross-validation. The ML model training used the hyperparameter set that yields the best area under the receiver operating characteristic curve (AUROC).
ML algorithms:
We tested the following classic ML models that are commonly used in clinical risk evaluation: [29] Support Vector Machines models (SVM), eXtreme Gradient Boosting (XGBoost), and Random Forest (RF). Using cross-validation within the training set, we performed a grid search to find the optional hyperparameters. The final model used was XGBoost for referral, and RF for evaluation and waitlisting (Table S3). We classified patients into low (0%–30%), middle (31%–60%), and high (61%–100%) dropout risk groups for interpretability. Cutoffs were based on the skewed probability distribution (skewness = 0.63; median = 30.3%; top quartile = 57.8%) and rounded to 30% and 60% as intuitive thresholds. These groups reflect the natural risk distribution in our cohort and were selected for descriptive comparison. The model itself remains valid across the full continuous range and the thresholds are intended only as adaptable descriptive strata, not fixed clinical cutoffs.
As a supplementary analysis to account for variable follow-up duration in the waitlist cohort, we performed a Cox proportional hazards analysis to assess baseline factors associated with dropout risk.
Performance assessment:
Performance for each ML algorithm and feature processor combination was assessed using AUROC as the primary metric for model selection, along with precision, recall, F1, specificity, and accuracy (Table S3).
Data were collected and processed using Microsoft SQL server and Python 3.9.7. Statistical analysis and ML were performed with Python scikit-learn 1.3.2 and xgboost 2.0.2.
Results
3 |
Dropout at Referral Before Starting Evaluation: Referral Cohort
3.1 |
Among the 8966 patients who were referred for KT, of whom 36%, 28%, and 26% identified as AA, Hispanic, and White, respectively, 4133 (46.1%) dropped out within 6 months of referral to KT before ever starting evaluation (Table 1). Demographic characteristics differed by race/ethnicity for this cohort: there were fewer married AA patients compared to White and Hispanic patients (43% vs. 64% and 61%, p < 0.001, Table S4). More White patients reported being active or former smokers than AA and Hispanic patients (46% vs. 37% and 35%, p < 0.001). AA and Hispanic patients also had lower rates of private insurance compared to White patients (29% and 35% vs. 39%, p < 0.001).
Clinically, compared to White patients, AA and Hispanics had greater prevalence of hypertension (40% and 31% vs. 30%, p < 0.001) and diabetes (36% and 34% vs. 29%, p < 0.001), and spent a longer time on dialysis (564 and 423 vs. 297 days, p < 0.001). Fewer AA and Hispanic patients presented with possible living donors than White patients (8.5% and 13% vs. 19%, p < 0.001). Contextually, AA and Hispanic patients more frequently lived in geographical areas with a lower median annual household income than White patients (55K vs. $78K, p < 0.001).
A sensitivity analysis comparing patients included in the referral cohort with those who were excluded showed no statistically significant differences in age (p = 0.1044) or sex (p = 0.253). This analysis was limited by the lack of additional variables available at the time of referral for excluded patients.
ML Performance and Predictors of Dropout Before Starting Evaluation
3.2 |
The ML model effectively predicted evaluation initiation within 6 months of referral, with rates of 77.7%, 58.6%, and 16.9% among low-, middle-, and high-risk groups, respectively (AUROC = 0.79, p < 0.001; Figure 3A, Table S3).
Several demographics, clinical, and contextual characteristics differed significantly across risk groups at referral (p values < 0.05). Median age increased with risk (54.7, 57.5, 58.3 years), and African American patients were more prevalent in the middle-and high-risk groups (42.4%, 41.9%) than in the low-risk group (26.3%), while the proportion of White patients declined by risk level (32.7%, 22.1%, 19.8%). Hispanic representation peaked in the middle-risk group (31.1%). Socioeconomic disadvantages generally rose with risk, including higher rates of single status, unemployment, lower education, and Medicare coverage. Obesity increased across risk groups (34.5%, 42.2%, 53.3%), while diabetes was most common in the middle-risk group (36.0%). Contextual disadvantage also followed this pattern, with higher ADI and SVI scores and reduced internet access observed among higher-risk patients (Table S5).
Dropout Before Waitlisting: Evaluation Cohort
3.3 |
Among the 4471 candidates who were evaluated for KT, of whom 33%, 30%, and 28% identified as AA, Hispanic and White, respectively, 2398 (53.6%) dropped out during evaluation before becoming waitlisted (Table 1). Similarly to the referral cohort, fewer AA candidates were married than White and Hispanic patients (49% vs. 67% and 62%, p < 0.001), and more AA and Hispanic candidates were unemployed than White candidates (48%, 55% vs. 32%, p < 0.01; Table S6). Fewer AA and Hispanic candidates had private insurance than White patients (32% and 36% vs. 44%, p < 0.001).
Clinically, compared to White candidates, more AA and Hispanic candidates had comorbidities, including hypertension (54%, 43% vs. 39%, p < 0.01) and diabetes (53%, 62% vs. 46%, p < 0.01), and were on dialysis longer (446 days and 365 vs. 298 days, p < 0.001) and fewer had intended donors (17%, 22%, and 32%, p < 0.001). More AA candidates were obese (51% vs. 42% and 41%, p < 0.01) and compared to Hispanic and White candidates.
Contextually, more AA and Hispanic individuals lived within geographical areas with lower yearly household median incomes than Whites (55K vs. $81K, p < 0.01).
ML Performance and Predictors of Dropout Before Waitlisting
3.4 |
The ML model effectively predicted waitlisting within 12 months of evaluation start, with rates of 79.2%, 53.8%, and 27.8% among low-, middle-, and high-risk groups, respectively (AUROC = 0.71, p <0.001; Figure 3B, Table S3).
Several demographics, clinical, and contextual characteristics differed significantly across risk groups during evaluation (p values < 0.05). Median age increased with risk (46.9, 54.3, 60.0 years), and African American patients were more represented in higher-risk groups (16.7%, 27.2%, 44.9%), while White patient representation declined (48.8%, 31.0%, 18.4%). Hispanic patients were more common in the middle-and high-risk groups (30.9%, 31.6%) than in the low-risk group (16.3%). Socioeconomic disadvantages intensified across risk levels, including higher rates of single status, unemployment, lower education, and Medicare coverage, alongside a decline in private insurance. Clinical burden followed a similar trend, with increased rates of obesity (35.6%, 39.5%, 49.1%), diabetes (21.2%, 48.1%, 69.5%), and coronary artery disease (3.0%, 17.9%, 36.4%) in higher-risk groups. Contextual disadvantage also rose; lower median household costs, increased poverty (SVI), higher ADI, and reduced internet and computer access were observed (Table S7).
Dropout Before Transplant: Waitlisted Cohort
3.5 |
Among the 2457 listed candidates, of whom 31%, 29%, and 33% identified as AA, Hispanic, and White, respectively, 763 (31.1%) did not receive a transplant over 7 years of follow-up or became inactive on the waitlist (Table 1). Similarly to the previous two cohorts, fewer AA listed candidates were married than White and Hispanic (54% vs. 71% and 66%, p < 0.001; Table S8). More AA and Hispanic listed candidates were unemployed compared to White (45%, 49% vs. 33%, p < 0.01).
Clinically, more AA and Hispanic listed candidates had comorbid conditions compared to White candidates, including hypertension (68% and 63% vs. 61%, p < 0.001), and diabetes (50% and 55% vs. 45%, p < 0.001) and fewer had intended donors (29% vs. 34% and 42%, p < 0.001). AA listed candidates were also more likely to be obese (49% vs. 39% and 39%, p < 0.001) than White and Hispanic.
Contextually, more AA and Hispanic candidates lived in areas where individuals had lower median annual household incomes compared to listed White patients (56K vs. $83K, p < 0.001).
ML Performance and Predictors of Dropout Before Receiving a KT
3.6 |
The ML model effectively predicted dropout after waitlisting, with 84.9%, 52.9%, and 32.1% of low-, middle-, and high-risk patients, respectively, remaining active on the waitlist or receiving a transplant by the end of data collection (AUROC = 0.76, p < 0.001; Figure 3C, Table S3).
Several demographics, clinical, and contextual characteristics differed significantly across risk groups during waitlisting (p values < 0.05). Median age rose with risk (49.0, 59.0, 65.3 years), and Hispanic patients were more prevalent in the middle-and high-risk groups (33.1%, 32.6%) than in the low-risk group (25.2%). Socioeconomic disadvantage increased with risk, including higher rates of retirement, lower education, and Medicare coverage, and lower employment rates. Clinical burden also intensified, with higher prevalence of obesity (33.3%, 42.8%, 54.1%), diabetes (27.7%, 67.1%, 95.3%), and coronary artery disease (13.0%, 39.4%, 62.8%). Contextual disadvantage worsened across groups, with increasing ADI scores and decreasing internet access and computer ownership (Table S9).
In the supplementary survival analysis (Table S10 and Figure S1), pulmonary hypertension was the only variable significantly associated with dropout risk (adjusted HR = 3.38, 95% CI 1.34–8.54).
Discussion
4 |
To reduce disparities in access, transplant centers must identify patients likely to face greater challenges in progressing successfully and intervene early to assist them. Although enhanced support can benefit all patients, targeting resources to those most in need is vital in a resource-constrained environment. In this study, we developed and validated three ML-driven risk indices incorporating demographic, clinical, and patient and contextual level SES variables to identify patients at risk of early dropout during the transplant-seeking process at referral, evaluation and waitlisting—stages not captured in national transplant databases.
We found that between 31% and 54% of patients dropped out during referral, evaluation, and waitlisting. Across all three transplant stages, patients at higher risk of dropout consistently exhibited greater sociodemographic and clinical vulnerability. However, the degree and pattern of risk factors varied slightly by stage. At referral, social determinants such as race (higher proportions of African American patients), being single, unemployed, and having lower education were strongly associated with higher dropout risk. During evaluation, these disparities deepened, with older age, lower income, and comorbidities like diabetes and vascular disease becoming more prominent. By waitlisting, clinical burden, particularly diabetes (up to 95%) and cardiovascular disease, as well as structural disadvantage (e.g., highest ADI, lowest digital access) became dominant differentiators. Overall, while sociodemographic disparities were evident early, clinical and neighborhood-level barriers intensified in later stages of the transplant process.
Interventions that have shown promise in the broader transplant literature for supporting patients pursuing transplantation include frequent discussions with social workers, especially for patients who lack family support [30, 31], and peer mentoring, where previous kidney recipients share experiences to help overcome social and psychological barriers [32–35]. Tailored transplant education, culturally and linguistically adapted mobile health resources [36–40], direct home delivery of transplant education [10, 41], and involving patient’s social network in the learning process [32, 42] have improved knowledge, willingness, and pursuit of transplant [36–38, 43, 44]. Early discussions about insurance and financial aid can also reduce dropouts due to cost concerns [45] Targeted strategies—such as insurance navigation at referral, financial support during evaluation, and coverage advocacy at waitlisting—may reduce insurance-related disparities [46]. Although KDIGO guidelines recommend smoking cessation rather than exclusion [47], a US survey found 38% of centers consider active smoking a contraindication [48]. Access to smoking cessation programs helps more patients quit and progress to transplant [49]. However, these interventions have been tested as single-arm or qualitative studies, isolated components, or focused on different outcomes, highlighting the need for rigorous, stage-specific testing. Our study addresses this gap by introducing a systematic, data-driven method to identify high-risk patients across stages to enable targeted intervention development and evaluation.
At the health systems level, our findings align with the Increasing Organ Transplant Access (IOTA) Model mandated by the Centers for Medicare and Medicaid Services (CMS) which seeks to improve patient-centeredness and equity in KT access [50]. The CMS has also proposed “proportion of prevalent patients waitlisted” as a new quality metric to incentivize dialysis centers to increase referrals for KT evaluation [51, 52]. However, a lack of time, training, and resources among transplant educators in dialysis centers has limited their ability to fulfil this mandate [53, 54]. By targeting supplemental education and follow-up to high-risk patients earlier, barriers to waitlisting could be mitigated.
This study builds on previous work [12] by expanding the scope of variables analyzed, increasing the diversity and size of the study population, and applying more advanced methodology. Although both studies identify socioeconomic and demographic contributors to disparities in transplant access, this analysis is more comprehensive, using EHR-extracted clinical and social variables and contextual zip code–linked data instead of patient interviews. It also captures patients across multiple transplant stages—referral, evaluation, and waitlisting—including those who never attended an evaluation, offering a fuller picture of the transplant journey. In contrast to traditional logistic regression models, our use of ML accounts for complex, nonlinear interactions without prespecified assumptions and generates a single, intuitive risk index. This index integrates multiple factors into a unified, data-driven measure, improving usability in clinical settings. Although descriptive summaries of patient characteristics across risk groups provide useful contextual insights, they are observational and not intended for manual risk classification. Instead, the ML-derived risk index should be used for identifying risk. Importantly, because the model relies on structured EHR and publicly available contextual data, this approach improves scalability and generalizability across institutions, supporting broader implementation through strategies such as federated learning [55, 56].
Next steps include externally validating our models via federated learning across multiple transplant centers and convening a patient advisory board—comprised of higher risk patients identified by the risk models—to conduct meetings aimed at identifying potential modifiable barriers and facilitators. Building on these patient-informed insights, we will develop and rigorously evaluate targeted interventions to assess their impact on improving outcomes among higher risk populations across the different transplant stages. Ultimately, we aim to deliver a validated, clinically integrated risk algorithm that enables early identification of high-risk patients and guides the implementation of tailored, evidence-based interventions at each stage of the transplant process. It is essential to be aware of the potential risk of exacerbating inequities by intentionally or unintentionally focusing interventions on the patients deemed most likely to succeed rather than those most at risk necessitating careful ethical consideration when applying these risk indices to clinical decision-making [57, 58]. A set of recommendations outlining individual and system-level responsibilities, along with guidance on effective communication with vulnerable patients, will be needed [59].
The main limitations of the study include, first, its observational design, which prevents causal inferences, and the lack of external validation. Second, the accuracy of the exclusion criteria for medical and surgical contraindications, which rely on EHR reporting, should be further investigated to assess potential misclassification risks. Third, some variables (e.g., smoking history) had substantial missing data, reflecting common challenges in retrospective EHR data analyses, which we addressed by encoding missing categorical variables as a distinct category and imputing missing continuous variables with the median. Although this approach allowed retention of all individuals, median imputation reduces variability and may bias estimates; future studies could explore more robust approaches such as multiple imputation. Fourth, ~14% of referred patients were excluded due to loss to follow-up or death, introducing potential selection bias. Although our sensitivity analysis showed no age or sex differences, referrallevel data are inherently limited; complementary strategies such as prospective follow-up or linkage with referral sources could better characterize this group. Fifth, patients ineligible due to insurance type were also excluded, reflecting institutional policy; future work should examine this group and test interventions to reduce insurance-related barriers to transplant access. Finally, because our ML models do not account for varying times on the waitlist, we added a supplementary survival analysis to address time-to-event outcomes. This analysis identified few predictors, likely due to correlated covariates and non-linear relationships. As our primary goal was risk prediction rather than estimation of hazard over time, we used ML as the main analytic approach, which better handles high-dimensional data [19, 60, 61].
In conclusion, our models effectively identify patients at risk of dropout earlier in the transplant process by leveraging demographic, clinical, and socioeconomic data available in EHR to target interventions to reduce barriers and improve transplant access before dropout occurs. These risk indices can be integrated into clinical workflows to guide tailored solutions—such as education, peer support, and smoking cessation programs—developed in collaboration with clinicians, social workers, community partners, and informed by input from high-risk patients, ultimately enhancing equity and completion of transplant evaluation.
Supplementary Material
Supplemental MaterialSupporting Table 1: Data Collection Covariates. Supporting Table 2: Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. Supplementary Methods: Data Quality Assessment. Supporting Table 3: Machine Learning Configuration and Performance Metrics. Supporting Table 4: Differences in Patient Characteristics by Race at Referral. Supporting Table 5: Patient Characteristics Predicting Risk of Dropping Out at Referral. Supporting Table 6: Differences in Patient Characteristics by Race at Evaluation. Supporting Table 7: Patient Characteristics Predicting Risk of Dropping Out during Evaluation. Supporting Table 8: Differences in Patient Characteristics by Race at Waitlisting. Supporting Table 9: Patient Characteristics Predicting Waitlisting Outcomes.
Additional supporting information can be found online in the Supporting Information section.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Suthanthiran M and Strom TB, “Renal Transplantation,” New England Journal of Medicine 331, no. 6 (1994): 365–376, 10.1056/NEJM 199408113310606.7832839 · doi ↗ · pubmed ↗
- 2Lentine KL, Smith JM, Hart A, , “OPTN/SRTR 2020 Annual Data Report: Kidney,” American Journal of Transplantation 22, no. 2 (2022): 21–136, 10.1111/ajt.16982. Suppl.35266618 · doi ↗ · pubmed ↗
- 3Port FK, Wolfe RA, Mauger EA, Berling DP, and Jiang K, “Comparison of Survival Probabilities for Dialysis Patients vs Cadaveric Renal Transplant Recipients,” Jama 270, no. 11 (1993): 1339–1343.8360969 · pubmed ↗
- 4Schnuelle P, Lorenz D, Trede M, and Van Der Woude FJ, “Impact of Renal Cadaveric Transplantation on Survival in End-Stage Renal Failure: Evidence for Reduced Mortality Risk Compared With Hemodialysis During Long-Term Follow-Up,” Journal of the American Society of Nephrology JASN 9, no. 11 (1998): 2135–2141, 10.1681/ASN.V 9112135.9808102 · doi ↗ · pubmed ↗
- 5Iqbal MM, Rahman N, Alam M, , “Quality of Life Is Improved in Renal Transplant Recipients Versus That Shown in Patients With Chronic Kidney Disease With or Without Dialysis,” Experimental and Clinical Transplantation 18, no. Suppl 1 (2020): 64–67, 10.6002/ect.TOND-TDTD 2019.P 11.32008498 · doi ↗ · pubmed ↗
- 6Wang JH and Hart A, “Global Perspective on Kidney Transplantation: United States,” Kidney 360 2, no. 11 (2021): 1836–1839, doi:10.34067/KID.0002472021.35373000 PMC 8785833 · doi ↗ · pubmed ↗
- 7Transplant Candidate – KDIGO. Accessed October 18, 2023, https://kdigo.org/guidelines/transplant-candidate/.
- 8The Kidney Transplant Waitlist. Transplant Living. Accessed October 18, 2023, https://transplantliving.org/kidney/the-kidney-transplant-waitlist/.