Adaptive graph contrastive learning with hard negative mining for multimodal hyperspectral and LiDAR classification
Linfeng Wu, Huiqing Wang

TL;DR
This paper introduces a self-supervised method for classifying hyperspectral and LiDAR data using adaptive graph learning and contrastive techniques.
Contribution
AGCL introduces adaptive graph construction and hard negative mining for self-supervised multimodal remote sensing classification.
Findings
AGCL improves classification accuracy through adaptive graph refinement and cross-modal alignment.
Hard negative mining enhances contrastive learning by reducing false negatives.
The method outperforms existing approaches on benchmark datasets.
Abstract
Joint classification of hyperspectral imagery (HSI) and light detection and ranging (LiDAR) data has attracted increasing attention in remote sensing. However, effective multimodal fusion and robust feature modeling remain challenging due to data heterogeneity. Graph neural networks (GNNs) are well suited for modeling non-Euclidean structures and cross-modal relations, but most existing GNN-based methods rely on supervised learning, limiting their applicability in label-scarce scenarios. We propose adaptive graph contrastive learning (AGCL), a self-supervised graph framework for HSI and LiDAR classification. AGCL performs adaptive graph construction through input-conditioned neighborhood selection and learns dynamic affinity matrices for flexible message passing. A hard negative mining strategy constructs informative negative samples for contrastive learning. During self-supervised…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
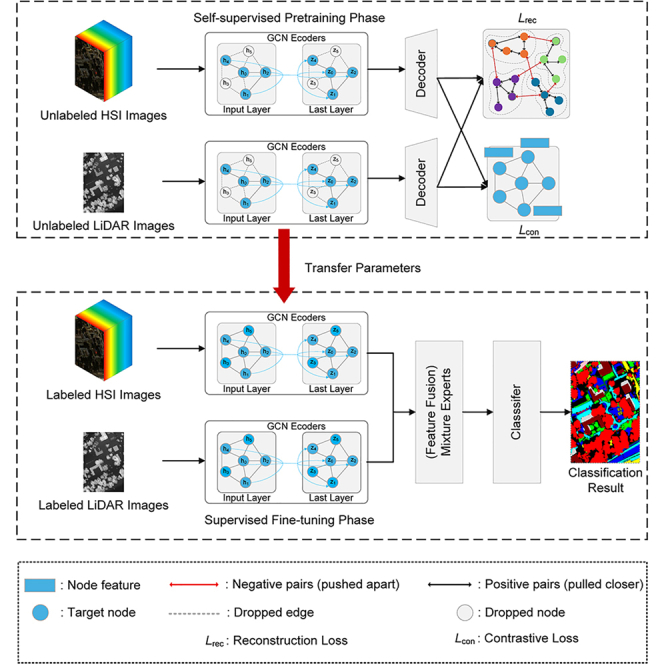 Figure 1
Figure 1 Figure 2
Figure 2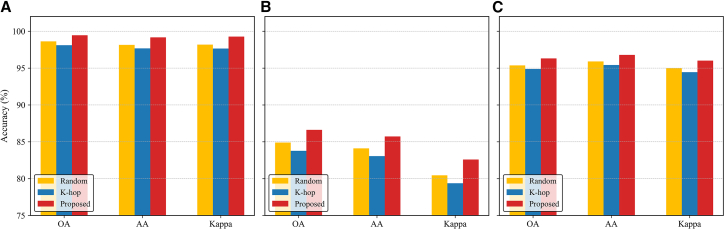 Figure 3
Figure 3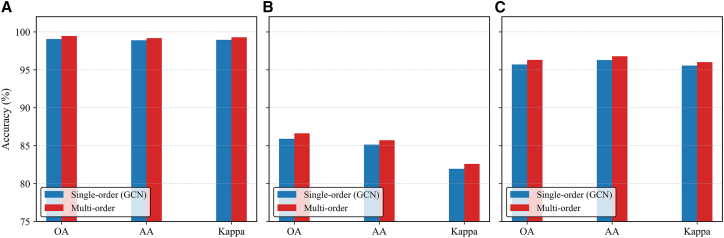 Figure 4
Figure 4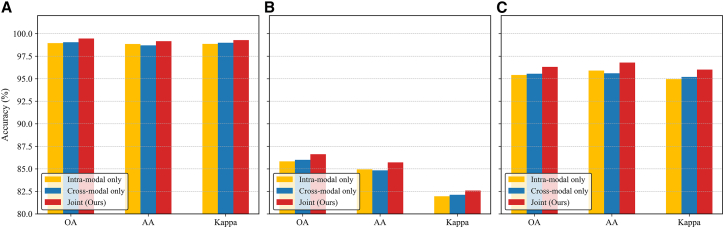 Figure 5
Figure 5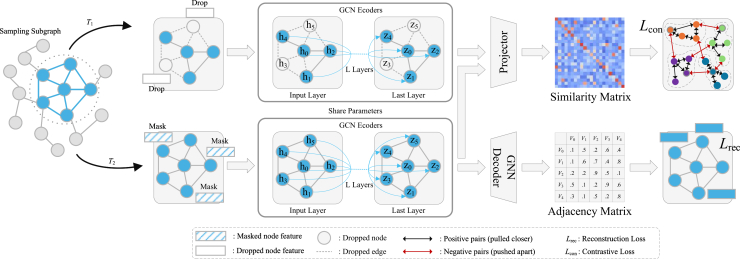 Figure 6
Figure 6 Figure 7
Figure 7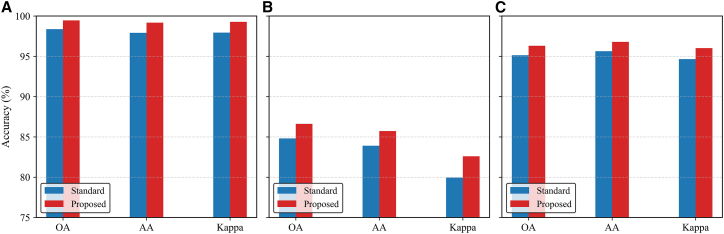 Figure 8
Figure 8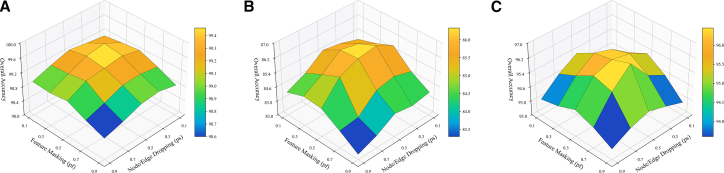 Figure 9
Figure 9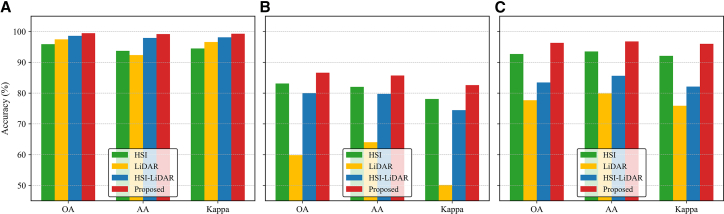 Figure 10
Figure 10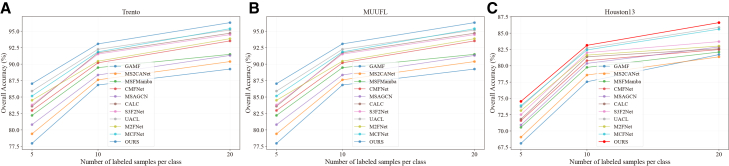 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13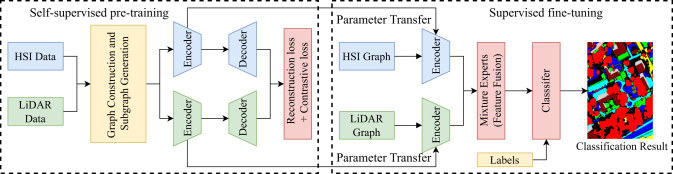 Figure 14
Figure 14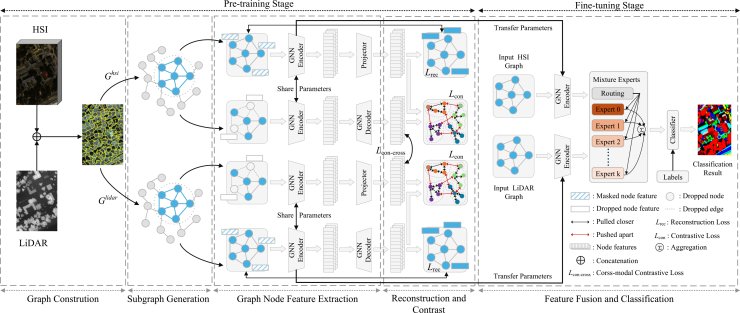 Figure 15
Figure 15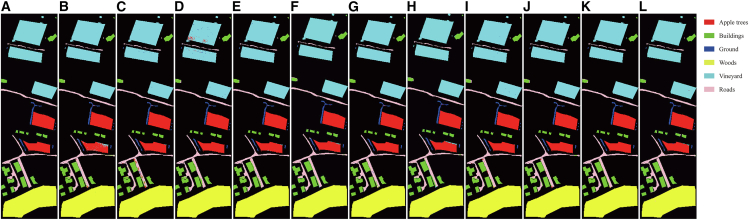 Figure 16
Figure 16 Figure 17
Figure 17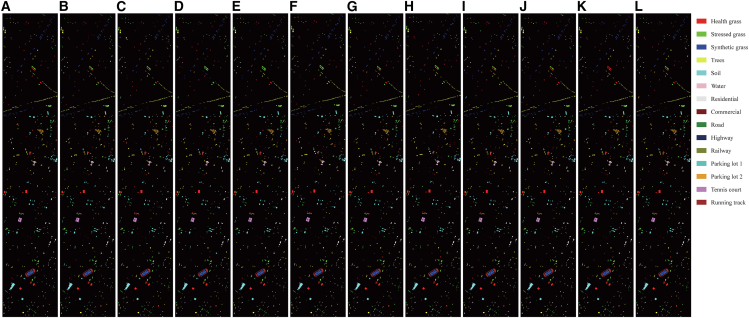 Figure 18
Figure 18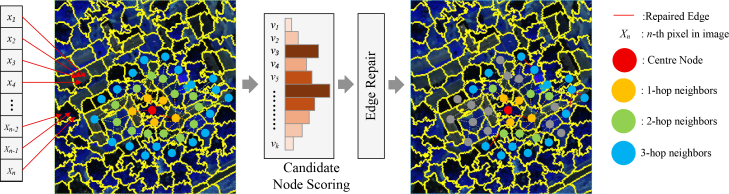 Figure 19
Figure 19Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace and Expression Recognition · Advanced Graph Neural Networks · Domain Adaptation and Few-Shot Learning
Introduction
Remote sensing image classification, a fundamental task in intelligent remote sensing interpretation,1^,^2 plays a crucial role in diverse applications, such as land-use mapping,3^,^4^,^5 environmental monitoring,6^,^7^,^8 precision agriculture,9^,^10 and medical diagnosis.11 As remote sensing technology advances, modern sensors provide abundant multi-source and multimodal data. Among them, hyperspectral imagery (HSI),12 characterized by continuous high-dimensional spectra, enables fine-grained material identification but often suffers from class confusion when different objects exhibit similar spectral signatures,13 highlighting the need for complementary structural information. To compensate for this limitation, light detection and ranging (LiDAR) supplies accurate 3D structural and elevation information, making it an effective complement to HSI.14 Consequently, HSI-LiDAR fusion has become a major research direction,15^,^16 where the key challenge lies in effectively combining complementary information while preserving the inherent heterogeneity of each modality.17^,^18
Early remote sensing classification largely relied on handcrafted features and traditional classifiers like support vector machine (SVM),19 random forests (RFs),20 k-nearest neighbors (KNNs),21 and extreme learning machines (ELMs).22 Although effective to some extent, such handcrafted features and shallow classifiers struggle to model nonlinear spectral-spatial relationships and complex cross-modal interactions. Consequently, deep learning techniques were introduced, with convolutional neural networks (CNNs) being among the first due to their strong local modeling capabilities.23^,^24 With the increasing demand for global context modeling, transformer architectures have been introduced.25^,^26 More recently, state space models (SSMs) have shown strong capabilities in sequence modeling while offering improved computational efficiency.27^,^28 Graph convolutional networks (GCNs) offer a fundamentally different paradigm from patch or token-based deep models by operating directly on graph-structured data and aggregating information from node neighborhoods.
Their ability to model arbitrary non-Euclidean structures has led to growing interest in multimodal remote sensing. For example, Jamali et al. proposed an attention-based GCN that integrates graph attention to overcome CNN limitations in boundary delineation and global context modeling.29 Gao et al. developed an interactive enhanced GCN that constructs fusion features from multimodal inputs for more effective feature integration.30 However, general GCN models are trained in a supervised or semi-supervised fashion, and they typically require large amounts of labeled data for training to avoid overfitting. Recently, self-supervised learning (SSL) methods, especially contrastive learning (CL), have proven effective at learning high-level semantic features from unlabeled samples,31 reducing reliance on manual annotations. Zhang et al. proposed a hybrid CNN-Mamba network, in which a joint multimodality contrastive loss is designed to align the semantics between two cross-fusion sources and to mitigate distribution discrepancies across modalities.32 Li et al. proposed a contrastive multilayer perceptron (MLP)-based network to improve the discriminability of unlabeled target-domain representations in zero-shot HSI transfer.33 The fundamental principle is to cluster similar samples and separate dissimilar ones in the embedding space.34 Recent advanced contrastive-learning methods achieve strong generalization even under small-sample conditions.35
Despite the good performance achieved by the above methods, two problems are still insufficiently addressed. First, many graph-based multimodal methods rely on predefined Gaussian or Euclidean similarity metrics, which are sensitive to noise and may fail to accurately capture local and global structural relationships in complex spatial patterns.36 This issue is further amplified in multimodal remote sensing, where heterogeneous HSI-LiDAR spectral features and spatial sampling densities complicate the construction of a unified graph representation. Second, previous CL methods often overlook spatial and cross-modal context during negative sample selection, increasing the risk of false negatives in which semantically similar samples are incorrectly treated as dissimilar. This issue is especially prominent in pixel-wise remote sensing classification tasks, where sliding-window sampling leads to overlapping patches with high spatial correlation. Such false negatives distort the embedding space and ultimately degrade representation quality.
To this end, we propose a self-supervised contrastive graph learning framework for multimodal HSI and LiDAR classification. Unlike conventional graph construction algorithms that directly operate in the original feature space and generate static adjacency matrices, our method introduces a learnable and adaptive graph refinement process. Specifically, the proposed framework adaptively refines the graph structure in a feature-driven manner, enabling the topology to evolve alongside feature learning. To capture both local and global dependencies, the framework further incorporates a multi-order aggregation strategy and jointly optimizes contrastive and graph reconstruction objectives, guiding the model toward semantically discriminative and structurally consistent representations. Furthermore, to mitigate the impact of false negatives arising from spatially adjacent or cross-modally correlated samples, we incorporate a hard negative mining strategy that selectively filters misleading negatives and improves the reliability of CL. The main contributions are as follows:
- (1)We propose a graph-based self-supervised multimodal framework, named adaptive graph contrastive learning (AGCL), for joint HSI and LiDAR classification. AGCL learns discriminative cross-modal representations from unlabeled data and effectively transfers them to downstream classification using limited labeled samples. Extensive experiments on three benchmark datasets validate its effectiveness, demonstrating competitive performance and strong generalization ability.
- (2)We propose an adaptive graph construction strategy that dynamically builds input-specific subgraphs based on feature similarity and contextual relationships. This strategy adaptively selects the neighboring nodes most relevant to the current task, enabling efficient mini-batch graph learning. To enhance feature learning across different neighborhood scales, we introduce a multi-order aggregation mechanism that propagates information across different ranges, capturing both short and long-range dependencies within subgraphs. These mechanisms enable flexible message passing and improve the discriminative capacity of the representations.
- (3)AGCL integrates contrastive representation learning and the graph reconstruction task to enhance both feature discrimination and structural consistency. The contrastive branch employs intra- and cross-modal objectives to align the representations of HSI and LiDAR while preserving their modality-specific characteristics. The reconstruction branch learns to rebuild the graph connections, helping the model keep the original spatial structure and learn more stable representations. Moreover, a hard negative mining strategy is introduced to select feature-similar but spatially distant or cross-modally mismatched samples, thereby reducing false negatives and improving the robustness of CL.
Results
Related work
Graph-based methods in multimodal remote sensing
In recent years, GCN-based methods have gained increasing attention in multimodal remote sensing applications for their capability to learn from non-Euclidean data. Early multimodal GCN approaches in fully supervised settings adopted various graph construction strategies. Some methods built dense pixel-wise graphs over the entire scene to aggregate information,37 while others employed region-based38 or superpixel-level graphs39 to reduce redundancy. These methods demonstrate effectiveness in capturing complex spectral-spatial context but face challenges under limited annotations.
As the field progressed, label-efficient learning became a focal point due to the scarcity of annotations in multimodal data. Graph neural networks (GNNs) inherently support semi-supervised training, where unlabeled pixels contribute to the graph structure used during training. For example, Xiu et al. introduced a multisource attention network incorporating a transductive graph module to propagate scarce labels across a discriminative multimodal graph.40 Beyond the inherent semi-supervised nature of GNNs, another branch of research has focused on pseudo-labeling strategies to further exploit unlabeled data. The core idea is to assign pseudo-labels to unlabeled samples and use them as additional supervision. Li et al. introduced a semi-supervised triplet network that expands supervision through pseudo-labels generated from multi-view predictions and superpixel consistency.41 However, a key challenge is avoiding confirmation bias. Thus, recent works highlight the importance of reliable pseudo-label selection.42 In addition, unsupervised clustering methods have been investigated,43 but their performance is constrained by the lack of semantic guidance. More recently, self-supervised methods have been explored in HSI,44 offering stronger representation learning by leveraging pretext tasks rather than relying on explicit labels. However, despite these advancements, existing methods still largely rely on static and hand-crafted similarity metrics, which limit their adaptability to varying spatial distributions and semantic dependencies.
Contrastive representation learning for multimodal data
CL is a self-supervised paradigm that learns discriminative and generalizable representations by pulling semantically related samples closer and pushing unrelated samples farther apart in the feature space. Representative CL methods in computer vision, including SimCLR,45 MoCo,46 BYOL,47 SimSiam,48 and CLIP,49 have demonstrated their effectiveness in large-scale visual and cross-modal representation learning.
In multimodal remote sensing classification, CL has been used to improve feature discriminability and transferability under unsupervised or weakly supervised settings. Guan and Lam proposed CMCL,50 performing label-free cross-modal CL between HSI and LiDAR to achieve semantic alignment. Jia et al. introduced CCL,51 which combines unsupervised pretraining and few-shot fine-tuning through a multi-level structural constraint for few-shot multimodal classification. Ding et al. presented UACL, combining semi-supervised CL with uncertainty modeling to enhance robustness under limited labels.52 Zhou et al. proposed MACL,53 which aligns modality-specific samples and incorporates an attention fusion module for multimodal CL. However, these methods mainly align modalities via semantic feature similarity, without explicitly modeling spatial-topological relationships. In remote sensing, heterogeneous modalities, such as HSI and LiDAR, often exhibit geometric misalignment and intrinsic scale differences due to distinct sensor geometries and sensing principles. These disparities persist even after co-registration and resampling, hindering robust semantic alignment.
Dataset description
The Trento dataset was acquired over a rural area in the southern part of Trento, Italy, and contains co-registered HSI- and LiDAR-derived digital surface model (DSM) data. The HSI was captured by the AISA Eagle sensor, covering 63 spectral bands in the 0.42–0.99 μm range, with a spatial resolution of 1 m and an image size of 600 × 166 pixels. The LiDAR data were collected using the Optech ALTM 3100 EA system, providing precise surface elevation information. The dataset includes six land-cover classes, and the sample distribution is summarized in Table 1. Representative false-color HSI and grayscale LiDAR images are shown in Figure 1.Table 1. Training and test sample counts per class across three datasetsDatasetTrentoHouston2013MUUFLNo.Class nameTrainTestClass nameTrainTestClass nameTrainTest1apple trees204,014grass healthy201,231trees2023,2262buildings202,883grass stressed201,234grass pure204,2503ground20459grass synthetic20677grass ground surface206,8624woods209,103tree201,224dirt and sand201,8065vineyard2010,481soil201,222road materials206,6676roads203,154water20305water204467–––residential201,248shadow building202,2138–––commercial201,224buildings206,2209–––road201,232sidewalk201,36510–––highway201,207yellow curb2016311–––railway201,215cloth panels2024912–––parking lot1201,213–––13–––parking lot220449–––14–––tennis court20408–––15–––running track20640–––Total–12030,094–30014,729–22053,467Figure 1Representative false-color HSI and grayscale LiDAR images from the Trento datasetLeft: false-color HSI image; right: grayscale LiDAR image.
The MUUFL Gulfport dataset was acquired over the Gulf Park campus of the University of Southern Mississippi in Gulfport, USA, using airborne hyperspectral and LiDAR sensors in a co-registered manner. The original HSI consists of 72 spectral bands (0.38–1.05 μm); after removing noisy bands at both ends, 64 bands are retained. The spatial resolution is 0.5 m × 0.5 m, and the image size is 325 × 220 pixels. The LiDAR data provide both elevation and intensity information, with a ground sampling distance of approximately 1 m. The dataset contains 11 land-cover classes, with per-class sample counts listed in Table 1. False-color HSI and grayscale LiDAR images are presented in Figure 2.Figure 2. Representative false-color HSI and grayscale LiDAR images from the MUUFL datasetLeft: false-color HSI image; right: grayscale LiDAR image.
The Houston 2013 dataset was collected over the University of Houston campus and surrounding areas in Texas, USA, using airborne hyperspectral and LiDAR sensors. The HSI contains 144 spectral bands covering the 0.38–1.05 μm range, with an image size of 349 × 1,905 pixels and a spatial resolution of 2.5 m. The LiDAR data provide surface elevation information, when co-registered with the HSI. The dataset consists of 15 distinct land-cover classes, and the sample distribution is provided in Table 1. Example false-color HSI and grayscale LiDAR images are shown in Figure 3.Figure 3. Representative false-color HSI and grayscale LiDAR images from the Houston2013 datasetLeft: false-color HSI image; right: grayscale LiDAR image.
Compared methods
To evaluate the effectiveness of the proposed method, we compare it with ten recent mainstream methods for hyperspectral-LiDAR fusion classification, briefly described as follows:
- (1)MS2CANet54: multi-scale convolution with spectral-spatial channel attention for shallow HSI and LiDAR feature fusion.
- (2)GAMF55: graph attention-based token interaction for cross-modal HSI-LiDAR representation and joint classification.
- (3)MSFMamba56: multi-scale spatial mamba and spectral mamba modules for cross-domain representation learning and fusion.
- (4)MW-CMFNet57: mamba-wavelet fusion with graph pooling, integrating spatial, frequency, and structural information.
- (5)CALC15: adversarial learning with shared generator-discriminator and spatial attention for modality alignment.
- (6)UACL52: hybrid CL with multi-level uncertainty estimation for reliable sample adaptation.
- (7)M2FNet58: multi-scale 3D-2D hybrid CNN with morphological enhancement and dilated convolution fusion.
- (8)MCFNet59: spatial frequency fusion via discrete wavelet transform (DWT), with multimodal and cross-domain fusion modules for joint classification.
- (9)MSAGCN30: an interactive enhanced GCN that builds fusion features from the HSI-LiDAR data using multi-head self-attention and graph convolution for efficient multimodal classification.
- (10)S3F2Net36: a CNN-GCN hybrid network that leverages LiDAR-derived graph structures to model spatial topology and capture global structural dependencies for improved HSI-LiDAR fusion classification.
All methods are re-implemented under the same datasets and evaluation metrics, using their official code or publicly released configurations for fair comparison.
Experimental settings
All experiments are implemented in PyTorch 2.7.1 with Python 3.10 and CUDA 12.6, using torch_geometric 2.6.1 for graph processing, and conducted on an NVIDIA RTX 4060Ti 8 GB GPU platform. The training follows a two-stage pipeline consisting of unsupervised contrastive pre-training and supervised fine-tuning, as illustrated in Figure 4. During pre-training, we adopt the Adam optimizer with an initial learning rate of 1e-4, which is gradually decayed to 1e-6 using cosine annealing to ensure stable convergence, with a batch size of 64. The hardness threshold θ is determined via a coarse-to-fine sweep on the validation split, where θ∈[0.3, 0.7] is varied with a step of 0.05, and the value that yields the highest validation overall accuracy (OA) over ten independent runs is selected. The final thresholds are θ = 0.4, 0.5 and 0.55 for the Trento, MUUFL, and Houston2013 datasets, respectively. This range balances easy and hard negatives and adapts to the spectral-spatial complexity of different datasets. The contrastive temperature τ is dynamically scheduled to stabilize training:
where e is the current epoch, E = 400 is the total number of epochs, τmin = 0.1, and τmax = 1.0. A higher temperature in early epochs prevents premature convergence, while a lower one in later stages enhances fine-grained discrimination. In the fine-tuning stage, the pretrained GCN encoders extract HSI and LiDAR features, which are fused via a mixture-of-experts (MoE) module before being fed into a linear classifier for the final prediction. The details of this architecture are shown in Figure 5.Figure 4. Overall training pipeline of the proposed AGCL frameworkFigure 5Overall framework of the proposed multimodal data classification
Classification results
Tables 2, 3, and 4 present the quantitative comparison between the proposed method and state-of-the-art approaches on the Houston, MUUFL, and Trento datasets, respectively. Figures 6, 7, and 8 show the ground-truth maps and the classification maps produced by different methods. The comparison is evaluated using OA, average accuracy (AA), and Kappa coefficient as performance metrics. In each row, the bold font indicates the best result among all methods.Table 2. Classification performance on the Trento dataset obtained by different methodsClassGAMFMS2CANetMSFMambaCMFNetMSAGCNCALCS3F2NetUACLM2FNetMCFNetOursApple trees96.2599.7799.9899.4599.2099.9897.6199.9599.8099.9299.32Buildings98.6099.2398.8199.1397.8199.0998.8697.2798.9598.8898.11Ground95.2597.7099.5497.2496.8897.4796.9596.7798.16100****100Woods99.98100****10099.9710099.9999.9610010010099.96Vineyard10099.839899.9110099.9810099.8599.9810099.95Roads92.3587.389290.8695.0494.6692.4994.9893.5895.0297.70OA98.4998.4898.4198.8199.1299.3198.7299.1199.1799.3699.46AA97.0797.3298.1297.7698.1598.5397.6498.1498.4198.9799.17Kappa97.9897.9797.8898.4198.8299.0798.2998.8198.8999.1599.28Bold values indicate the best performance for each metric.Table 3. Classification performance on the MUUFL dataset obtained by different methodsClassGAMFMS2CANetMSFMambaCMFNetMSAGCNCALCS3F2NetUACLM2FNetMCFNetOursTrees87.3484.1789.1086.9279.9189.1486.3487.5889.0192.6991.30Grass pure71.4283.2666.2668.9186.9379.4887.4680.6474.5477.2879.60Grass ground surface71.3865.5877.9870.1072.9056.7162.7981.9973.5071.1876.15Dirt and sand84.3266.6389.0990.4391.8388.9795.2788.8471.8478.3386.23Road materials80.1079.9080.3786.7676.9884.4485.2288.4385.3284.6182.07Water98.3698.1297.0999.5398.5997.65100****10099.5398.8398.83Buildings shadow85.1385.0489.4777.7587.5179.0792.5390.5873.7370.5081.76Buildings81.5394.7172.0789.1090.8191.7491.1586.4285.6193.4895.90Sidewalk60.2258.2261.2549.2958.5951.5253.0360.5953.6860.8263.12Yellow curb96.5087.4177.3089.5189.5175.5288.7287.3490.2188.8192.31Cloth panels96.0796.0787.1595.6397.3895.2010095.9096.0792.1495.63OA81.7281.3782.1182.4980.8982.6183.7185.9083.0385.6286.62AA82.9481.7480.6582.1784.6380.8685.6886.2181.1982.6185.72Kappa76.4576.1876.8177.4475.8277.5179.0381.8278.0581.2282.59Bold values indicate the best performance for each metric.Table 4. Classification performance on the Houston2013 dataset obtained by different methodsClassGAMFMS2CANetMSFMambaCMFNetMSAGCNCALCS3F2NetUACLM2FNetMCFNetOursGrass healthy93.8990.2687.3798.0285.2099.2690.4295.6499.7598.1099.17Grass stressed88.7178.4299.9287.3196.5596.1399.8396.4796.2387.0798.27Grass synthetic99.70100****10099.7010010010099.25100100100Tree97.9296.6893.1998.6797.5294.0299.0899.4298.6898.9299.92Soil98.5099.1798.6710099.9299.4210099.1799.7599.83100Water10097.8996.84100****10097.8910097.9397.5910096.84Residential80.6297.3983.7993.8184.7594.2295.4093.5992.6297.3996.25Commercial86.6386.0586.3078.2494.7984.8095.0694.2975.3585.4790.78Road67.0881.8584.0888.5370.0984.4181.4588.0978.6490.0284.57Highway92.1799.7593.8597.8993.0496.0494.5699.4196.6499.8397.56Railway94.9096.4085.7799.0891.5899.7592.8393.8395.7596.8298.58Parking lot180.2268.2386.8486.5085.8191.0388.2584.3196.4194.4792.46Parking lot276.9275.9998.3785.0891.4794.4191.8997.4793.3291.6197.44Tennis court99.2310099.48100100100100100100100****100Running track99.1999.6899.8410010010010010099.68100****100OA89.2590.3991.4993.5391.3294.7094.4895.1993.8795.3996.31AA90.3891.1892.9594.1992.7195.4295.2595.9394.6995.9796.79Kappa88.3889.6190.8093.0090.6194.2694.0394.8093.3795.0196.01Bold values indicate the best performance for each metric.Figure 6. Classification maps of the Trento dataset(A) Ground truth.(B–L) Classification results obtained by GAMF, MS2CANet, MSFMamba, CMFNet, MSAGCN, CALC, S3F2Net, UACL, M2FNet, MCFNet, and the proposed method.Figure 7. Classification maps of the MUUFL dataset(A) Ground truth.(B)–(L) Classification results obtained by GAMF, MS2CANet, MSFMamba, CMFNet, MSAGCN, CALC, S3F2Net, UACL, M2FNet, MCFNet, and the proposed method.Figure 8. Classification maps of the Houston2013 dataset(A) Ground truth.(B–L) Classification results obtained by GAMF, MS2CANet, MSFMamba, CMFNet, MSAGCN, CALC, S3F2Net, UACL, M2FNet, MCFNet, and the proposed method.
Trento
The Trento dataset contains fewer land-cover classes and exhibits a relatively regular spatial layout, enabling all methods to achieve strong classification performance. As shown in Table 2, the proposed multimodal CL method outperforms the competing approaches, achieving an OA of 99.46%, an AA of 99.17%, and a Kappa of 99.28%, representing improvements of 0.10%, 0.20%, and 0.13%, respectively, over the second-best method, MCFNet. Notably, our method attains a classification accuracy of 97.70% for the roads class, exceeding CALC, UACL, and MCFNet by 3.04%, 2.72%, and 2.68%, respectively. This class exhibits narrow, winding linear structures interspersed among various land-cover types, with irregular boundaries and spectral signatures highly similar to those of surrounding classes, making it a typical fine-grained linear target. Moreover, parts of the road network are obscured by shadows or vegetation, further aggravating boundary ambiguity and class confusion, thus increasing recognition difficulty.
The proposed method, through the adaptive subgraph sampling mechanism, effectively focuses on the local key neighborhood of the center node and, in conjunction with the graph structure reconstruction task, strengthens topological constraints and semantic consistency in boundary regions. This enhances the model’s discriminative ability for the roads class. Figure 6 shows the classification maps of different methods on the Trento dataset. It can be observed that our method produces clearer boundary delineations and stronger spatial continuity across multiple classes, particularly for roads, where it more faithfully preserves their linear trajectories and spatial distribution patterns. The overall classification results exhibit superior visual quality compared with other methods, which is consistent with the quantitative findings shown in Table 2.
MUUFL
The MUUFL dataset presents pronounced class imbalance, spectral overlap, and variable spatial scales of land-cover structures, making classification challenging. Table 3 summarizes the quantitative results of different methods on the MUUFL dataset. UACL achieves a strong overall performance due to its uncertainty-aware CL that distinguishes reliable and unreliable samples. This hybrid learning strategy effectively alleviates class imbalance by applying confidence-based sample partitioning and adaptive contrastive loss weighting. However, its heavy dependence on pseudo-label quality can introduce noise into training when confidence estimation is inaccurate, leading to unstable decision boundaries. Graph-based models such as MSAGCN and S3F2Net demonstrate strong capabilities in structural representation by explicitly modeling spatial topology. MSAGCN benefits from multi-head self-attention for adaptive feature fusion, whereas S3F2Net integrates CNN and GCN to exploit LiDAR-derived structural priors. However, both rely on static or pre-defined graph structures, which constrain their adaptability and generalization to scenes with diverse or noisy spatial layouts. MCFNet and M2FNet perform competitively in capturing local spatial details through multi-scale convolution, but purely convolutional architectures limit the modeling of global context and long-range dependencies. Our AGCL achieves the highest OA and Kappa and the second-best AA (only 0.49% below UACL). These performance gains mainly come from its ability to build more reliable graph connections and to aggregate neighborhood information at multiple scales, which helps the model capture both local and global HSI and LiDAR features. Moreover, the combination of contrastive and reconstruction learning enhances feature discrimination and consistency across modalities.
As shown in Figure 7, the classification map produced by AGCL exhibits strong spatial coherence and clearly defined object boundaries across the MUUFL scene. Large homogeneous areas, including trees and buildings, appear smooth inside and contain very little salt-and-pepper noise. Narrow linear structures such as roads, sidewalks, and yellow curbs are clearly depicted. Transitions between neighboring classes, for example, between buildings and their shadows, are sharp and consistent with the actual scene layout. Mixed areas of grass and bare soil are also well separated, indicating that the model effectively captures subtle differences in both spectral and spatial information. Overall, the consistency between the visual and quantitative results on the MUUFL dataset demonstrates the robustness and generalization ability of AGCL.
Houston2013
The Houston2013 dataset exhibits a larger image size, highly diverse land-cover types, and partial cloud occlusion, which demands stronger global spatial modeling and multi-scale semantic integration. As presented in Table 4, MCFNet performs well by leveraging DWT-based spatial-frequency fusion and multimodal fusion modules, surpassing UACL by 0.40%, 0.13%, and 0.41% in OA, AA, and Kappa, respectively. Nevertheless, its convolutional backbone restricts the modeling of long-range dependencies, which may limit its ability to capture complex spatial relationships in heterogeneous regions. UACL shows unstable results in this dataset due to unreliable pseudo-label generation in complex areas, while CALC effectively maintains inter-class discrimination but lacks flexibility for adaptive cross-modal dependency modeling. Graph-based methods such as S3F2Net exhibit strong structural representation ability by modeling spatial topology with attention-enhanced GCNs, yet their reliance on fixed LiDAR-derived graphs limits adaptability to varying spatial patterns across heterogeneous scenes.
Our AGCL consistently achieves the best OA, AA, and Kappa, exceeding MCFNet by 0.92%, 0.82%, and 1.00%, respectively. Notably, for spectrally similar classes, such as Grass healthy, Grass stressed, Grass synthetic, and Tree, it attains an AA of 99.34%, about 3.41% higher than other methods, demonstrating its capability to suppress confusion among highly correlated categories. Figure 8 shows the classification maps of different methods on the Houston2013 dataset. As illustrated, our method produces maps that are more consistent with the ground truth, featuring sharper boundaries and fewer noisy predictions.
Ablation and sensitivity analysis
Ablation analysis
To evaluate the contribution of each component, we perform extensive ablation experiments on five key strategies of the proposed AGCL framework: (1) adaptive graph construction, (2) multi-order aggregation, (3) CL, (4) graph reconstruction, and (5) hard negative mining. Unless otherwise specified, all variants are trained under identical settings on Trento, MUUFL, and Houston2013 datasets.
Ablation of adaptive graph construction
To evaluate the effectiveness of the adaptive graph construction strategy, which is designed to adaptively select informative neighbors during subgraph generation, we conduct ablation studies on the Trento, MUUFL, and Houston2013 datasets by comparing three subgraph generation schemes. The first scheme, k-hop sampling, retains all nodes within the k-hop neighborhood of a center node without further filtering, which often introduces redundant or noisy information. The second, random sampling, selects the same number of neighbors as our method but ignores both structural and semantic relevance, resulting in unstable graph representations. Third, our dynamic neighbor selection, as detailed in Figure 9, employs a learnable scoring function to rank neighbors within the k-hop range, followed by randomized perturbation and edge repair. This process adaptively preserves the most informative and structurally consistent nodes for subgraph construction. As shown in Figure 10, the proposed adaptive strategy consistently achieves the best results across all datasets. On Trento, it improves OA by 0.83% and 1.36% compared with k-hop and random sampling, respectively. On MUUFL, the gains reach 1.72% and 2.85%, while on Houston2013, improvements of 1.43% and 0.94% are observed. These results indicate that although k-hop sampling captures basic topology, it suffers from redundancy, and random sampling reduces graph density but lacks guidance. In contrast, our adaptive graph construction effectively balances subgraph compactness and structural relevance, leading to more discriminative and robust representations across diverse remote sensing scenarios.Figure 9. Graph construction and subgraph sampling workflow with dynamic node scoring and selectionFigure 10Comparison of different subgraph generation strategies(A) Trento.(B) MUUFL.(C) Houston2013.
Ablation of multi-order aggregation
To evaluate the effectiveness of the multi-order aggregation mechanism, we compare two configurations. The first is the baseline single-order aggregation, which corresponds to a standard GCN that updates node features using only first-order neighbor information. The second is our proposed multi-order aggregation, which aggregates features from multiple powers of the dynamic adjacency matrix in parallel. Each order employs an independent transformation matrix, and the outputs are concatenated to preserve order-specific structural semantics. As shown in Figure 11, the proposed multi-order aggregation mechanism consistently outperforms the single-order baseline across all datasets, achieving improvements of approximately 0.5%–0.7% in OA on Trento, MUUFL, and Houston2013. Similar performance gains are also observed in AA and Kappa, demonstrating that incorporating multi-scale neighborhood information effectively enhances relational perception and yields more discriminative and robust graph representations.Figure 11. Comparison of different aggregation mechanisms(A) Trento.(B) MUUFL.(C) Houston2013.
Ablation of CL
To evaluate the effect of different contrastive strategies, we compare three variants: intra-modal, cross-modal, and joint CL. As shown in Figure 12, the intra-modal scheme enhances feature compactness within each modality, leading to slightly higher AA but lower OA and Kappa due to the lack of cross-modal alignment. In contrast, the cross-modal strategy improves global consistency and semantic alignment, resulting in higher OA and Kappa but a minor drop in AA. By jointly optimizing both objectives, the proposed framework achieves the best performance on all datasets, outperforming the single-path variants by approximately 0.5%–1.0% in OA, 0.3%–0.7% in Kappa, and 0.2%–0.6% in AA, demonstrating that complementary supervision from intra- and cross-modal contrastive paths produces more unified and discriminative representations. The specific architectural design of these paths is shown in Figure 13.Figure 12. Comparison of different contrastive learning strategies(A) Trento.(B) MUUFL.(C) Houston2013.Figure 13. Illustration of the dual-branch contrastive-reconstruction learning module used in the pre-training stage
Ablation of graph reconstruction
To evaluate the contribution of the graph reconstruction strategy, we compare two configurations: one trained only with contrastive objectives and another incorporating the proposed reconstruction task that enforces structural consistency between the original and reconstructed graphs. As shown in Figure 14, integrating the reconstruction constraint consistently improves performance on all datasets. Specifically, incorporating the reconstruction branch increases OA by about 0.5%–0.9%, AA by 0.4%–0.7%, and Kappa by 0.5%–1.0%, compared with the model trained without it. These results demonstrate that the reconstruction task effectively preserves graph topology and regularizes the learned representations, leading to more stable and structurally discriminative representations.Figure 14. Ablation results of the graph reconstruction strategy(A) Trento.(B) MUUFL.(C) Houston2013.
Ablation of hard negative mining
To evaluate the impact of negative sample construction on multimodal CL, we compare two strategies. The first is standard in-batch sampling, where each anchor pairs with its augmented view as a positive, while all other samples in the batch are treated as negatives. This approach ignores semantic similarity and spatial structure, often introducing false or overly easy negatives. The second is our proposed hard negative mining strategy, which selects negatives based on both feature similarity and spatial distance. A difficulty score prioritizes feature-similar but spatially distant samples, forming a more informative negative set for intra- and cross-modal CL. As shown in Figure 15, the proposed strategy consistently improves performance. On Trento, the proposed method improves OA, AA, and Kappa by 1.09%, 1.25%, and 1.34%, respectively. On MUUFL, it achieves larger gains of 1.81%, 1.82%, and 2.64%, demonstrating effectiveness in complex spatial contexts with ambiguous class boundaries. On Houston2013, the improvements of 1.17%, 1.16%, and 1.36% further confirm its generalization ability across large-scale scenes. These results demonstrate that spatial-semantic hard negative mining enhances discriminability and robustness across diverse remote sensing scenarios.Figure 15. Impact of the hard negative mining strategy on(A) Trento.(B) MUUFL.(C) Houston2013.
Hyperparameter sensitivity
This section analyzes the sensitivity of the proposed AGCL framework to key design factors and hyperparameters, including the k-hop neighborhood radius, downstream classifier architecture, superpixel segmentation scale, sampled neighbor number, and graph augmentation strength. To ensure objective and consistent tuning across datasets, all numerical hyperparameters were optimized via a systematic grid-based search on the validation split. For the downstream classifier comparison, the pretrained feature encoders and all other parameters were kept fixed, and only the classifier architectures were varied. Each model was evaluated on the validation split, and the configuration achieving the highest validation OA was adopted for subsequent experiments.
Influence of the k-hop neighborhood radius
We examined the impact of the neighborhood expansion range by varying K from 1 to 15. This parameter controls the receptive field of each subgraph. Too small a value limits contextual information, while too large a value may introduce redundancy, noise, and additional computation. Table 5 shows that the optimal K differs across datasets. For Trento, OA increases steadily from K = 1 to K = 5 before gradually declining at larger values. For MUUFL, accuracy improves up to K = 7 and then shows a slight downward trend. For Houston2013, performance rises consistently with increasing K and peaks at K = 9, with minimal fluctuation thereafter. These results suggest that a properly chosen K can balance contextual coverage and noise suppression, leading to more stable and accurate classification.Table 5. Impact of k-hop neighborhood radius across three datasetsDatasetNeighborhood radius (k-hop)1235791113Trento98.72%99.12%99.36%**99.46%**99.39%99.22%99.04%98.83%MUUFL83.27%84.89%85.77%86.21%**86.33%**86.18%85.67%85.02%Houston201394.06%95.15%95.76%96.01%96.21%**96.31%**96.28%96.09%Bold values indicate the best performance for each metric.
Impact of the downstream classifier architecture
We assessed the impact of different downstream classifiers on the discriminability and transferability of the learned multimodal structural embeddings. After pretraining, the encoders were frozen, and the embeddings were fed into five representative classifiers: MLP, SVM, RF, KNN, and logistic regression (LR). For the SVM, a radial basis function (RBF) kernel was adopted. The penalty parameter C and kernel coefficient γ were tuned through a two-stage grid search with 3-fold cross-validation. A coarse search over C∈{2^−3^,2^−1^, …,2^7^} and γ∈{2^−7^,2^−5^, …,2^3^} was first performed to identify an initial optimal pair (C0,γ0), followed by a fine search within [C0 × 2^−1.5^,C0 × 2^1.5^] and [γ0 × 2^−1.5^,γ0 × 2^1.5^] with a step size of 0.25 in the exponent for further refinement. The parameter combination achieving the highest validation accuracy was then used for testing. For the KNN classifier, the number of neighbors k was chosen from {3, 5, 7, 9, 11} based on validation accuracy, using the Euclidean distance metric. As shown in Table 6, MLP achieves the highest accuracy on MUUFL and Houston2013, demonstrating its strong nonlinear modeling capability in handling complex feature distributions. On the Trento dataset, SVM slightly surpasses MLP, while RF also shows competitive results. Therefore, the choice of downstream classifier should be adapted to the specific dataset characteristics to achieve optimal performance.Table 6. Impact of downstream classifier choice across three datasetsDatasetDownstream classifierMLPSVMRFKNNLRTrento99.28%**99.46%98.63%96.42%95.56MUUFL86.33%83.51%84.08%80.64%81.17%Houston201396.31%**92.73%94.48%91.22%90.84%Bold values indicate the best performance for each metric.
Impact of superpixel segmentation scale
We investigated the effect of the superpixel segmentation scale by varying it from 10 to 1,000. The number of nodes was determined by the SLIC algorithm as n=(H×W)/scale, where smaller scales produce denser graphs with finer spatial detail, while larger scales yield coarser but more representative structures. As shown in Table 7, performance improves steadily with increasing scale and reaches the highest accuracy at 150, 300, and 400 for the Trento, MUUFL, and Houston2013 datasets, respectively. When the scale exceeds 500, the graphs become overly sparse, weakening neighborhood connectivity and reducing stability. These results indicate that an appropriate segmentation scale balances structural granularity, diversity, and efficiency.Table 7. Impact of superpixel segmentation scale across three datasetsDatasetSuperpixel scale10501001502003004005008001,000Trento96.9398.2198.9299.4699.3399.1198.7498.1297.4695.32MUUFL80.6180.9482.6384.8285.6786.3385.5784.3282.2678.45Houston201391.4291.5693.4894.7195.4495.9396.3195.0693.3790.76Bold values indicate the best performance for each metric.
Impact of the number of sampled neighbors Kn
In the dynamic subgraph sampling strategy, each subgraph is centered on a randomly selected node, and its neighborhood is refined using a Gumbel-TopK mechanism that selects the top-Kn neighbors with the highest importance scores from the k-hop candidates. This parameter controls the structural density and representational richness of each subgraph. We varied Kn from 10 to 250 on the Trento, MUUFL, and Houston2013 datasets. As shown in Table 8, the highest accuracies (99.46%, 86.33%, and 96.31%) were obtained with Kn = 100 for Trento and Kn = 150 for MUUFL and Houston2013. Smaller values lead to insufficient contextual information, while larger ones introduce redundancy and higher computational costs. Hence, a moderate Kn achieves the best trade-off between completeness and efficiency.Table 8. Impact of the sampled neighbor number Kn across three datasetsDatasetSampled neighbors2502001501008060402010Trento98.7298.9499.1299.4698.1996.9095.5994.2692.91MUUFL84.3385.2286.3385.5183.8982.2580.5878.8877.16Houston201395.4795.7396.3195.4294.0892.7291.3689.9788.57Bold values indicate the best performance for each metric.
Impact of graph augmentation strength
To investigate the impact of subgraph augmentation strength on model performance, we perform a grid search over two perturbation dimensions: structural dropout (ps) and feature masking (pf). Specifically, ps determines the ratio of dropped nodes and edges, while pf controls the proportion of masked node features. Low probabilities preserve most of the original graph structure and semantics, whereas high probabilities introduce greater view diversity but risk discarding critical information. Experiments on the Trento, MUUFL, and Houston2013 datasets show that moderate perturbation levels lead to higher classification accuracy, as illustrated in Figure 16. The highest OA is achieved at (ps = 0.3,pf = 0.3) for Trento, (0.3, 0.5) for MUUFL, and (0.5, 0.7) for Houston2013. These results highlight the importance of balanced augmentation across both structural and feature domains, which enables the model to better capture robust and generalizable graph representations.Figure 16. Impact of graph augmentation ratios across the three datasets(A) Trento.(B) MUUFL.(C) Houston2013.
Model complexity analysis
We analyze the computational complexity of the proposed AGCL framework to evaluate its theoretical efficiency. Let N denote the number of nodes, E the number of edges, and d the feature dimension. During adaptive graph construction, computing KNNs and pairwise distances require approximately O(Nk) operations. The graph convolutional operation, which performs both node transformation and multi-order neighborhood aggregation up to the K-th order, has an overall complexity of O(K(Ed+Nd^2^)). The subgraph sampling further introduces a soft ranking process with a theoretical cost of O(NLogN). Combining these terms, the total time complexity of AGCL can be expressed as O(Nk)+O(K(Ed+Nd^2^))+O(NLogN). Since both k and K are small constants, the overall complexity scales almost linearly with the number of nodes.
Table 9 presents the model complexity in terms of parameter count, floating point operations (FLOPs), and training time, evaluated on the Houston2013 dataset. MS2CANet exhibits not only the lowest complexity but also the poorest classification accuracy. UACL achieves a good balance of model size and computational cost, but its contrastive pretraining, pseudo-label generation, and subsequent supervised retraining lead to increased training time. In contrast, MCFNet and M2FNet, despite their decent performance, are large and structurally complex. Our method uses only 210K parameters, lower than most models, while maintaining strong performance. It also achieves 12.58 MFLOPs, significantly more efficient than methods like CALC and M2FNet. In terms of training and testing efficiency, our model completes in 168 s and 1.54 s, respectively, which is faster than most structurally complex methods. Overall, our design offers a good trade-off between accuracy and efficiency, making it well suited for resource-constrained remote sensing tasks.Table 9. Model complexity analysis on Houston2013MethodsMS2CANetGAMFMSFMambaMSAGCNCMFNetCALCS3F2NetUACLM2FNetMCFNetOursParams179K16.6M1,225K462K520K336K275K183K319K549K210KFLOPs (M)2.231,30032.3517.735.6881.2157.515.6390.6339.0212.58Training times (s)98684176126172287447280326183168Testing times (s)1.2315.751.463.882.385.411.881.614.535.121.54
Performance under different modality settings
To examine how different modality configurations affect classification performance, we conduct experiments on the Trento, MUUFL, and Houston2013 datasets using four settings: (1) HSI-only, (2) LiDAR-only, (3) direct concatenation of HSI and LiDAR features, and (4) the proposed method. Figure 17 reports the OA, AA, and the Kappa coefficient for each setting. Results show that the HSI modality performs consistently well across datasets, demonstrating strong discriminative power from rich spectral information. LiDAR performs competitively on Trento but degrades significantly on MUUFL and Houston2013, suggesting its effectiveness is more context-dependent, relying on spatial structure and terrain. Direct feature concatenation yields modest gains on Trento but harms performance on the other two datasets, likely due to ineffective fusion and noise interference. In contrast, the proposed method consistently achieves the highest OA, AA, and Kappa across all datasets. These results highlight the robustness and adaptability of the proposed cross-modal contrastive framework, particularly in complex or imbalanced scenarios.Figure 17. Classification performance under different modality settings(A) Trento.(B) MUUFL.(C) Houston2013.
Performance under different numbers of labeled samples
To further evaluate the robustness and effectiveness of the proposed AGCL framework, we investigated its performance when using 5, 10 and 20 labeled samples per class on the Trento, MUUFL, and Houston2013 datasets, respectively, with the remaining samples used for testing. The detailed experimental findings are illustrated in Figure 18. It is evident that the OA of all compared methods generally increases as the number of labeled samples per class grows, reflecting the typical dependency of deep learning models on the availability of labeled data. Nevertheless, AGCL consistently achieves superior performance across all supervision levels and datasets, demonstrating its strong robustness and generalization ability. In particular, the performance of AGCL remains remarkably stable when the amount of labeled data is reduced, highlighting its resilience to supervision scarcity.Figure 18. Classification performance with different numbers of labeled samples(A) Trento.(B) MUUFL.(C) Houston2013.
Discussion
This paper presents AGCL, a self-supervised graph framework for multimodal HSI-LiDAR classification, which enhances structural modeling and semantic alignment of multimodal features. Experiments on the Trento, MUUFL, and Houston2013 benchmark multimodal remote sensing datasets demonstrate that the proposed method achieves average improvements of 0.56%, 3.35%, and 3.67% in OA over state-of-the-art approaches, with comparable gains in AA and Kappa. Systematic hyperparameter sensitivity analyses and ablation studies verify the independent contributions of each key module in strengthening feature representation. Unlike conventional fixed-graph approaches, our method employs an adaptive strategy that dynamically constructs subgraphs and predicts node connectivity from input features, enabling more precise spatial-semantic modeling. Coupled with graph structure perturbation and feature masking, dual-branch contrastive-reconstruction pretraining, and spatial-semantic hard negative mining, the framework achieves high accuracy, robustness, and generalization in multimodal remote sensing classification, even under low-sample conditions. Future work will focus on incorporating more heterogeneous modalities such as multispectral, synthetic aperture radar, and infrared data to enhance cross-modal fusion, and on extending the framework to multi-task learning for unified classification, change detection, and semantic segmentation. In addition, we will continue to optimize efficient graph construction and training strategies to better meet the computational and storage demands of large-scale remote sensing applications.
Limitations of the study
Despite the promising results, this study has several limitations. The proposed method relies on predefined graph construction parameters and feature-based hard negative selection, which may require careful tuning and can be influenced by representation quality at early training stages. In addition, the experimental validation is conducted on a limited number of benchmark hyperspectral and LiDAR datasets under fully observed multimodal settings. Further evaluation on more diverse scenes and comparative baselines would be beneficial to fully assess the generalization capability of the proposed approach.
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Huiqing Wang ([email protected]).
Materials availability
This study did not generate new unique reagents.
Data and code availability
- •The datasets used in this study are publicly available. The Trento hyperspectral and LiDAR dataset can be accessed at https://github.com/tyust-dayu/Trento. The MUUFL Gulfport hyperspectral and LiDAR dataset is available at https://github.com/GatorSense/MUUFLGulfport. The Houston2013 hyperspectral and LiDAR dataset can be obtained from https://machinelearning.ee.uh.edu. All raw data reported in this manuscript will be available from the lead contact upon request.
- •The source code is publicly available at https://github.com/Zenro2000/AGCL/tree/main.
- •Any additional information required to reanalyze the data reported in this paper can be obtained from the lead contact upon request.
Acknowledgments
This work was supported by the Doctoral Research Initiation Fund of 10.13039/501100014895Southwest Medical University (grant no. 00170092) and the research start-up funds of 10.13039/100010144Chengdu Technological University (grant no. 2025RC105).
Author contributions
Conceptualization, L.W.; methodology, L.W.; validation, L.W.; investigation, L.W.; writing – original draft, L.W.; writing – review and editing, L.W. and H.W.; funding acquisition, L.W. and H.W.; resources, H.W.; supervision, H.W.
Declaration of interests
The authors declare no competing interests.
STAR★Methods
Key resources table
REAGENT or RESOURCESOURCEIDENTIFIERDeposited dataTrentoCai et al.55https://github.com/tyust-dayu/TrentoMUFFLGader et al.60https://github.com/GatorSense/MUUFLGulfportHouston13Debes et al.61https://machinelearning.ee.uh.eduSoftware and algorithmsPythonPython Foundationhttps://www.python.org/PyTorchPyTorch Foundationhttps://pytorch.org/Torch_geometricPyg Teamhttps://pyg.org/AGCL codeThis paperhttps://github.com/Zenro2000/AGCL/tree/main
Method details
The overall architecture of the proposed adaptive graph contrastive learning (AGCL) framework for HSI–LiDAR classification is illustrated in Figure 5. The framework consists of two main stages: (1) a pre-training stage, in which dynamic graph construction and multimodal contrastive learning are jointly optimized; and (2) a fine-tuning stage, in which the pretrained features are fused through a MoE module for pixel-wise classification. The following subsections describe each component of the framework in detail.
Graph construction and subgraph generation
To jointly model spatial structures and semantic correlations in HSI and LiDAR data, we transform the original regular grid representation into a non-Euclidean graph. Let the HSI be and the co-registered LiDAR be . We first construct a joint feature by channel-wise concatenation of the two modalities, . To reduce computational cost and avoid redundant edges in pixel-level graphs, we apply superpixel segmentation to X^joint^, producing M semantically homogeneous and spatially contiguous regions . For each superpixel , the node features for the two modalities are computed as:
Each corresponds to a node vi, forming the node set . Edges are constructed by computing Euclidean distances between spatial centroids and applying a KNN strategy. For node vi, the neighbor set is and the edge set is . To preserve modality-specific characteristics, we construct two separate graphs and , where , .
Although superpixels representation greatly reduce graph size, full-graph processing is still computationally intensive and may dilute the modeling of local semantic structures. To address this, we adopt a subgraph-based learning strategy, where each subgraph is centered on a randomly selected node and constructed from its most informative neighbors, as shown in Figure 9. In each training batch, a set of center nodes is sampled from . For a center node vi, its k-hop neighborhood is first defined as the candidate node set based on the shortest-path distance Distsp(·,·) in the graph:
Since a static k-hop neighborhood often includes irrelevant nodes, we adopt a Gumbel-TopK dynamic sampling mechanism on , adaptively selecting the most valuable neighborhood nodes based on node importance scores. For each , an importance score is computed using a learnable scoring function sj = fθ(hj), where fθ(·) is the scoring network parameterized by θ, and hj is the node feature. Next, we apply the Gumbel reparameterization method to approximate the discrete TopK operation as a differentiable process. Standard Gumbel gj ∼ Gumbel(0,1) is generated as noise gj = -log(-log(uj)),uj ∼ Uniform(0,1). The perturbed scores are then used to compute soft sampling weights:
where τ is the temperature parameter controlling the smoothness of the sampling distribution, initialized to 0.5. We sort nodes by and select the top Kn neighbors to form the final subgraph node set:
To ensure all nodes remain connected to the center component after discrete sampling, we adopt a repair strategy. Let the center node be vi, and define its center component in the sampled subgraph as . For any node vk∉C including degree-zero nodes and nodes in disconnected components, we construct a candidate connection set Ck = C∖{vk} and select:
where Sim(·,·) denotes cosine similarity score. We then add the edge ( ) to , thereby bridging into the center component. If is empty, is directly linked to the center node vi as a fail-safe. Unlike fixed KNN graphs, the neighborhood of each center node is re-estimated at every iteration based on learnable, feature-driven importance scores. Thus, the local adjacency structure evolves dynamically with the feature representations, achieving input-conditioned adaptive graph construction. Moreover, this strategy preserves global structural consistency and mitigates the computational cost of full-graph training, thereby enabling efficient mini-batch GNN modeling.
Dual-branch contrastive-reconstruction learning
Contrastive learning learns representations by pulling positive samples closer and pushing negative samples farther apart, with its effectiveness largely depending on the design of positive-negative sample generation. In multimodal HSI-LiDAR learning, spectral confusion and spatial overlap often cause random negatives to be either too easy or semantically misleading. To mitigate this, AGCL introduces a hard negative mining strategy that selects samples with high spectral or spatial similarity but different semantics. This design forces the network to distinguish between spectrally confusing and spatially adjacent instances, thereby strengthening the decision boundary across modalities. As a result, the learned representations become more discriminative, modality-robust, and resilient to spectral noise or geometric misalignment. Based on this, the proposed framework (Figure 13) integrates a dual-branch contrastive-reconstruction module consisting of five components.
Subgraph Augmentation
In the pre-training stage, we sample aligned subgraphs and from the HSI and LiDAR modalities, respectively. Each subgraph is perturbed using two transformation functions: a structure-perturbation operator , which randomly drops nodes and edges, and a feature-masking operator , which masks node features while preserving the topology. The resulting views are then processed by a shared GCN encoder for subsequent representation learning:
Multi-order GCN encoding
To model the structural and attribute heterogeneity between HSI and LiDAR, we employ separate GCN modules to encode subgraph structures for each modality. Each GCN takes as input the node features of a subgraph X∈R^N×C^ and performs graph convolution over the graph . The relationships between nodes are represented by an adjacency matrix A = [Aij]∈{0,1}^N×N^, where . The standard GCN propagation rule60 is defined as:
is the adjacency matrix with self-loops added, is the degree matrix defined as is the node representation matrix at the l-th layer, W^(l)^ is the learnable weight matrix of the l-th layer, and σ (·) denotes the rectified linear unit (ReLU) activation function. While the subgraph-level sampling adaptively updates local connectivity, the message passing within each subgraph still relies on a static adjacency. To achieve adaptive adjacency refinement during propagation, we further introduce a dynamic GCN layer that adaptively learns connection weights from node features. The adjacency matrix of the l-th layer is defined as:
where denotes batch-normalized node features, and is a learnable projection matrix. In this way, the adjacency matrix is no longer fixed but recalculated at every layer, making the graph structure responsive to evolving semantic relations. Despite this improvement, conventional GCN propagation is still limited to 1-hop feature aggregation. With a small number of layers, it remains difficult to capture long-range dependencies, leading to insufficient high-order neighborhood information.61 To this end, we adopt a multi-order aggregation strategy that computes and aggregates features from multiple powers of the dynamic adjacency matrix in parallel. Each order is equipped with an independent weight matrix W^(l,k)^ to preserve its unique structural semantics, and the results are concatenated along the feature dimension:
where denotes concatenation along the feature dimension, and Kord is the maximum order, set to 3 in this work. This design allows efficient integration of multi-scale neighborhood information with fewer layers. For each modality, the two augmented views and are fed into our dynamic multi-order GCN encoders fhsi(·) and flidar(·), respectively, producing the latent representations:
which are subsequently fed into the decoder for graph reconstruction and the projection head for contrastive learning.
Graph reconstruction
To further enhance structural modeling, we incorporate a graph reconstruction task as an auxiliary objective, which strengthens structural awareness during feature learning and improves the generalization of the resulting representations. Specifically, the feature-masked views are passed through modality-specific decoders ghsi(·) and glidar(·), obtaining the reconstructed node embeddings v^h,2^ = ghsi(z^h,2^) and v^d,2^ = glidar(z^d,2^). For any pair of nodes (i,j), within the same modality, the predicted edge probability is computed as:
To optimize this edge prediction mechanism such that the predicted adjacency closely approximates the original subgraph adjacency A, we adopt a binary cross-entropy loss function:
where, Apq indicates whether an edge exists between nodes (i,j) in the original subgraph. Similarly, the reconstruction loss for the LiDAR modality is and the total reconstruction loss is:
Nonlinear projection
To perform contrastive learning in a unified embedding space, the final node representations H^(L+1)^ of each subgraph are first aggregated through global mean pooling to obtain subgraph-level features h. These are then passed through a multilayer perceptron (MLP) projection head:
where W1 and W2 denote learnable weight matrices and σ(·) is a ReLU activation function. For the four subgraph views from the HSI and LiDAR modalities, the projected embeddings are computed as:
Contrastive learning with hard negative mining
In contrastive learning, given an anchor sample and its positive sample, all other samples in the same batch are typically treated as negative samples to be separated. However, this approach tends to introduce false negatives and easy negatives, thereby weakening optimization effectiveness. To address this issue, we propose a hard negative mining mechanism that combines feature similarity and spatial distance constraints when constructing negative samples. This mechanism prioritizes samples that are semantically similar yet spatially separated, thus reducing false-negative interference and enhancing the discriminative power and challenge of the contrastive constraints. Specifically, for any sample pair (i, j), we first compute their normalized spatial distance and normalized feature similarity , where Dij denotes the Euclidean distance between samples i and j, and Sij denotes their cosine similarity. We then define the hardness score:
Next, the negative sample candidate set is defined as: . In each mini-batch, we sample N pairs of HSI-LiDAR subgraphs and apply two types of augmentations and , resulting in four sets of projected features: . For intra-modal contrastive Loss, we take as the anchor, as the positive, and select negatives from the candidate set: . We adopt the information noise-contrastive estimation (InfoNCE) objective for the intra-modal contrastive loss:
where sim(·) denotes cosine similarity and τ is the temperature parameter. Similarly, for the LiDAR modality, we compute . The total intra-modal contrastive loss is:
For the cross-modal, the anchor is defined as: and the positive as: . Negative samples are first selected from and then generated via modality mismatch: . Where and . The cross-modal loss is defined as:
We jointly optimize the intra-modal contrastive loss, cross-modal contrastive loss, and graph reconstruction loss:
Transfer to downstream classification
After completing unsupervised contrastive learning, we freeze the parameters of the pre-trained encoder and use it as a feature extractor for the downstream pixel-wise supervised classification task. The constructed graphs and are fed into the pretrained GCN encoder to obtain modality-specific features for each pixel node vi: and . These vectors are concatenated to form a joint representation , and all pixel-level joint features compose the fused image feature matrix . For feature fusion, a MoE module is adopted prior to classification. Given the joint feature fi, the gating network computes the expert weights:
where Wϕ and bϕ are learnable parameters, and ϕj(fi) denotes the weight assigned to the j-th expert, and MLP_j(·) denotes the transformation of the j-th expert branch. In this work, the MoE module employs Kexp_ = 4 experts. The fused representation oi is then passed through a linear classifier to produce the class probability distribution for each pixel.
Module configuration
To provide a clearer understanding of the AGCL architecture, we summarize the key parameters of its core components. The GCN encoder for each modality adopts a 4-layer structure with hidden dimensions of [256, 128, 64, 64], incorporating batch normalization and ReLU activation. The contrastive projection head consists of two linear layers with output sizes of 128 and 64, followed by L2 normalization. The multimodal fusion component employs a MoE module with four expert MLPs, each having layer sizes of [128, 64, 32]. The gating network is a two-layer MLP with a hidden size of 64 and a Softmax output over four experts. Key hyperparameters, including the k-hop size, number of sampled neighbors, and augmentation strength, are further analyzed in the hyperparameter sensitivity section to assess the robustness of the proposed configuration.
Quantification and statistical analyses
Evaluation metrics
The classification performance was quantitatively evaluated using OA, AA, and the Kappa coefficient, which are widely adopted metrics in hyperspectral and multimodal remote sensing classification. OA measures the proportion of correctly classified samples over all test samples and is defined as:
where nii denotes the number of samples correctly classified in class i, C is the total number of classes, and N is the total number of test samples.
AA is computed as the means of class-wise accuracies and is given by:
where ni represents the total number of samples belonging to class i.
The Kappa coefficient evaluates the agreement between the predicted labels and the ground truth while accounting for chance agreement, and is defined as:
where po is the observed agreement (equivalent to OA) and pe denotes the expected agreement by chance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhao X.Qi J.Xu H.Yu Z.Yuan L.Chen Y.Huang H.Evaluating the potential of airborne hyperspectral Li DAR for assessing forest insects and diseases with 3D Radiative Transfer Modeling Remote Sensing of Environment 297202311375910.1016/j.rse.2023.113759 · doi ↗
- 2Dou P.Huang C.Han W.Hou J.Zhang Y.Gu J.Remote sensing image classification using an ensemble framework without multiple classifiers ISPRS J. Photogrammetry Remote Sens.208202419020910.1016/j.isprsjprs.2023.12.012 · doi ↗
- 3Rwanga S.S.Ndambuki J.M.Accuracy assessment of land use/land cover classification using remote sensing and GIS Int. J. Geosci.8201761162210.4236/ijg.2017.84033 · doi ↗
- 4Li R.Zheng S.Duan C.Wang L.Zhang C.Land cover classification from remote sensing images based on multi-scale fully convolutional network Geo-Spatial Inf. Sci.25202227829410.1080/10095020.2021.2017237 · doi ↗
- 5Naushad R.Kaur T.Ghaderpour E.Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study Sensors 212021808310.3390/s 2123808334884087 PMC 8662416 · doi ↗ · pubmed ↗
- 6Sankey T.Donager J.Mc Vay J.Sankey J.B.UAV lidar and hyperspectral fusion for forest monitoring in the southwestern USA Remote Sensing of Environment 1952017304310.1016/j.rse.2017.04.007 · doi ↗
- 7Vaglio Laurin G.Zabeo C.Giuliarelli D.Tesfamariam B.G.Cotrina-Sanchez A.Valentini R.Tufail B.Ventura B.Calfapietra C.Barbati A.Monitoring habitat diversity with PRISMA hyperspectral and lidar-derived data in Natura 2000 sites: Case study from a Mediterranean forest Ecol. Indic.172202511325410.1016/j.ecolind.2025.113254 · doi ↗
- 8Michez A.Piégay H.Lisein J.Claessens H.Lejeune P.Classification of riparian forest species and health condition using multi-temporal and hyperspatial imagery from unmanned aerial system Environ. Monit. Assess.188201614610.1007/s 10661-015-4996-226850712 · doi ↗ · pubmed ↗