Time-delay reservoir for signal demixing using Kalman weight updates in fixed point and limit cycle regimes
S. Kamyar Tavakoli, Jérémie Lefebvre, André Longtin

TL;DR
This paper shows how time-delay reservoir computers with online training can better separate chaotic signals, even when they are statistically similar.
Contribution
The study introduces online Kalman weight updates to improve signal demixing in time-delay reservoirs, especially in limit cycle regimes.
Findings
Online training with Kalman filtering improves signal separation accuracy compared to offline methods.
The approach works well for separating signals from Lorenz and Mackey–Glass systems with similar statistics.
Higher accuracy is achieved near critical points where system behavior changes.
Abstract
In this paper, we study the problem of separating chaotic signals using time-delay reservoir computers with online training via Kalman filtering. Time delay reservoir computers are hardware-efficient and suitable for experimental, high-speed implementation. We demonstrate that incorporating an online training scheme significantly enhances the performance of time-delay reservoirs in challenging signal demixing tasks. In particular, we apply a sliding-window technique to update the readout weights and show that it can improve accuracy compared to the offline ridge regression readout in various scenarios. Here we mainly focus on the separation of two trajectories generated by the Lorenz system with different initial conditions, which is an especially difficult task since both signals share nearly identical statistical properties. We also study mixtures of signals from two different…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
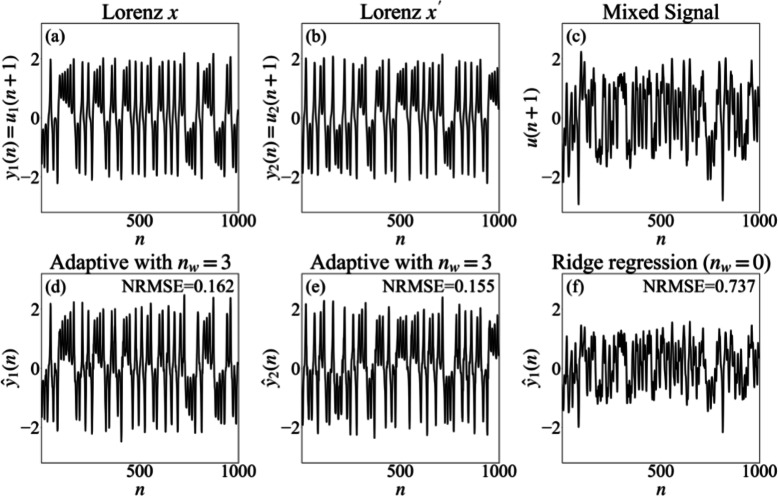 Figure 1
Figure 1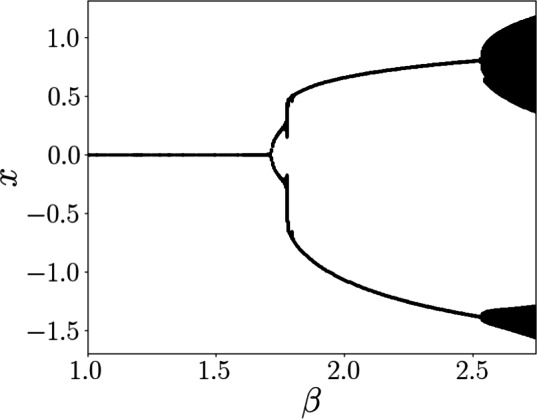 Figure 2
Figure 2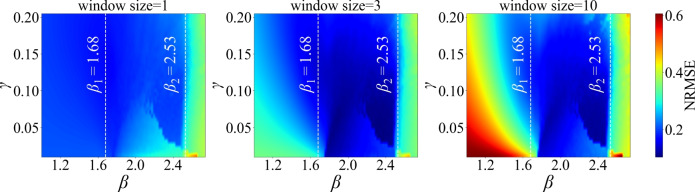 Figure 3
Figure 3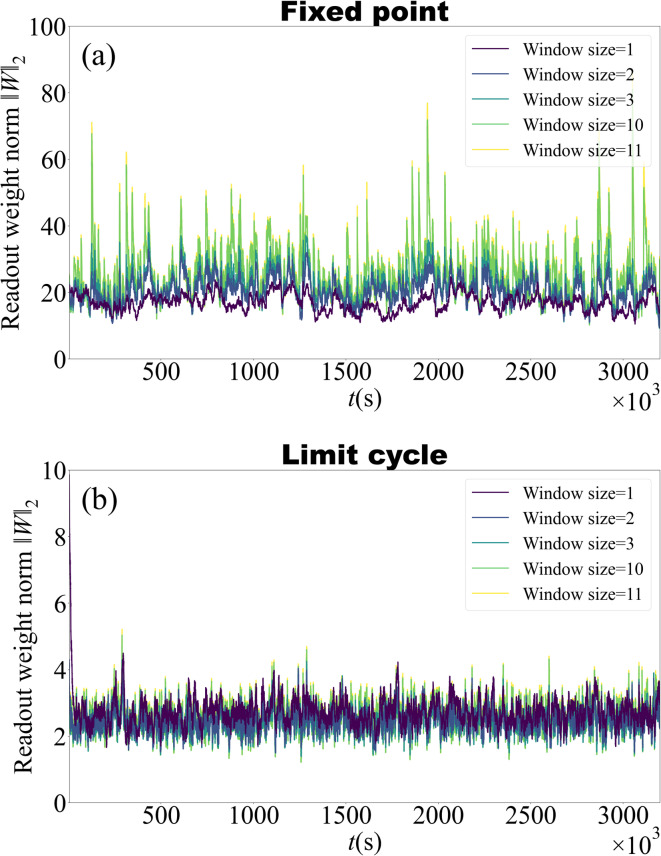 Figure 4
Figure 4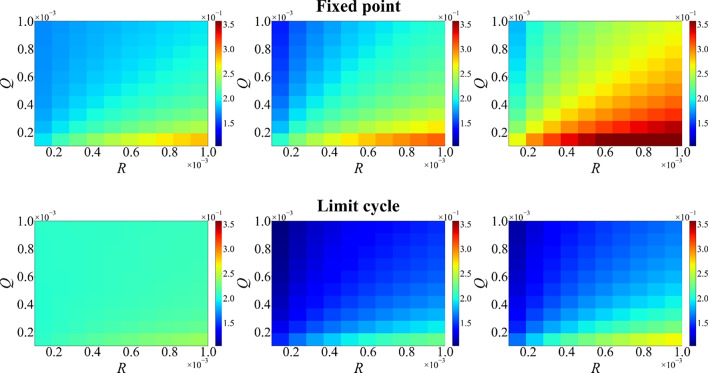 Figure 5
Figure 5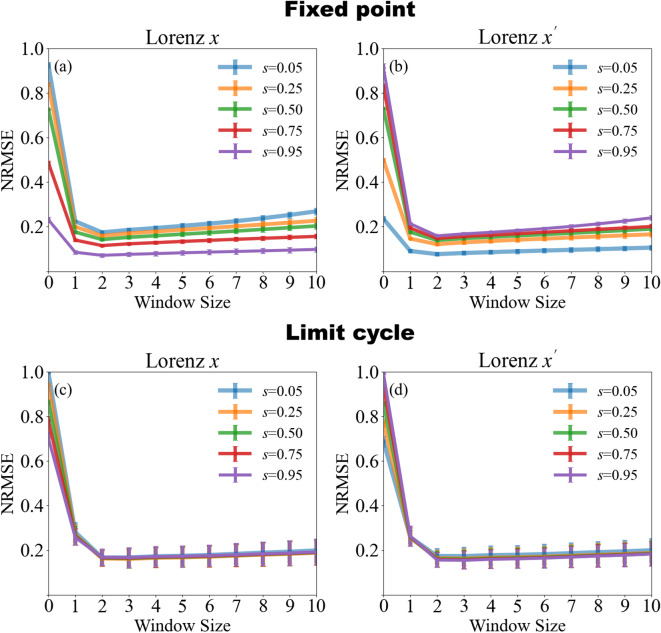 Figure 6
Figure 6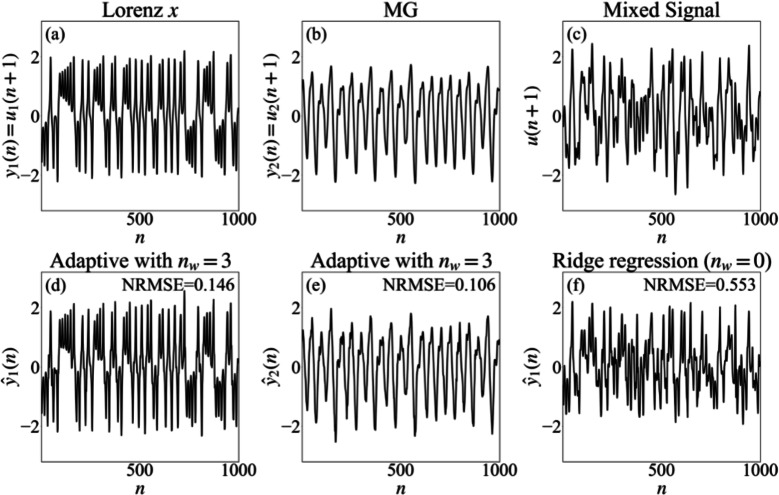 Figure 7
Figure 7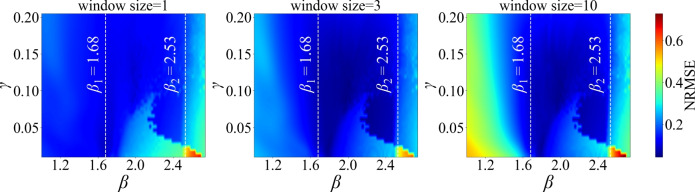 Figure 8
Figure 8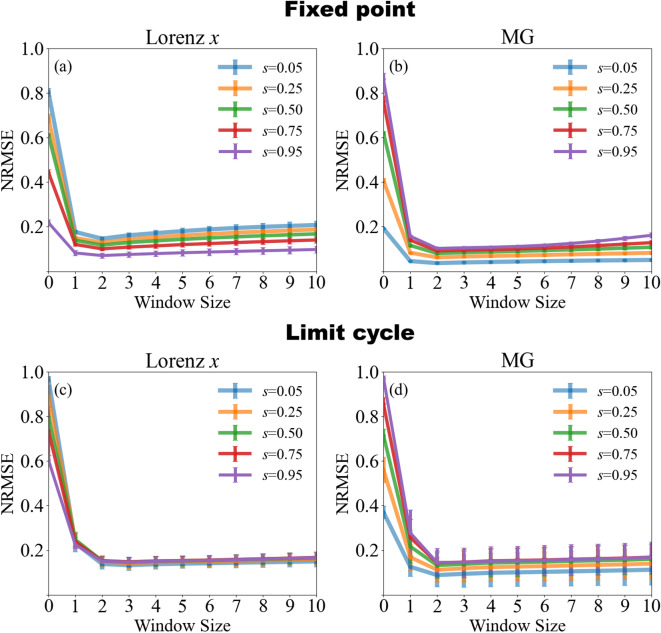 Figure 9
Figure 9- —https://doi.org/10.13039/501100000038Natural Sciences and Engineering Research Council of Canada
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural Networks and Reservoir Computing · Advanced Memory and Neural Computing · Ferroelectric and Negative Capacitance Devices
Introduction
Signal separation, or recovering individual sources from mixed observations, is a fundamental challenge across domains such as neuroscience and communications. In real-world signal processing, observed data typically consist of mixtures of multiple sources rather than isolated components. The brain can selectively attend to one speaker when multiple voices are present, a situation often referred to as the cocktail party problem, in which listeners focus on a specific speaker amidst background speech^1,2^. Although the brain performs this selective processing effectively, its underlying mechanisms remain under investigation. Feedback-based cancellation has also been proposed in studies of weakly electric fish, where a global feedback mechanism enables the cancellation of predictable stimuli and enhances the detection of novel stimuli^3^.
Signal separation is crucial to extracting meaningful information from complex measurements in many scientific and engineering domains. In electroencephalography (EEG), for instance, isolating seizure activity from artifacts and noise is important for accurate seizure detection and monitoring^4^. Computational tools include higher-order statistical methods such as independent component analysis^5^, as well as methods based on time-delayed correlations^6^ and deep learning techniques^7^.
Echo-state networks (ESNs) are reservoir computing models with a fixed high-dimensional recurrent layer (the reservoir) that nonlinearly transforms the input, while only a linear readout is trained. This compact training scheme scales well and has been applied to tasks ranging from speech recognition^8^ to chaotic time-series prediction^9,10^, and robotics tasks^11^. Remarkably, a delayed ESN trained on a single time series at one fixed delay value can predict dynamics for other values of the delay parameter by changing the ESN’s internal delay after training^12^. Reservoir computing models have also been shown to perform source separation. For instance, Krishnagopal et al. demonstrated that an ESN can separate a mixture of two Lorenz trajectories^13^. The reservoir’s large, nonlinear state space can magnify subtle differences between signals, making them more nearly linearly separable by the readout. In contrast, classical ICA is not expected to work reliably here because ICA relies on statistical independence assumptions, whereas signals drawn from the same chaotic system can have similar marginal distributions and exhibit dependencies that can reduce ICA identifiability. By leveraging the ESN’s transient dynamics and memory, however, it can be possible to disentangle even subtly different chaotic trajectories. This challenge has also been addressed using Time-Delay Reservoir Computing(TDRC)^14^, where single-node architectures have successfully separated mixtures of distinct chaotic systems sampled at different rates and disentangled chaotic signals embedded in correlated noise. Beyond signal demixing, TDRC has been applied both computationally and experimentally for signal classification and speech recognition^15–18^.
For single-signal prediction, performance can depend on different dynamical properties; for example, limit cycle operation can enhance computational performance in time-delay reservoir computing^19^. Furthermore, improvements have been achieved through architectural innovations: hierarchical reservoirs and deep multilayer structures reduce prediction error^20,21^, while additional delay lines enhance memory capacity and accuracy^22^. Interestingly, a single nonlinear node with multiple delayed states can realize deep feedforward and recurrent topologies for arbitrary networks via time-unfolding^23^. In multi-delay systems, few delays can increase entropy depending on the system and the spacing between delays, whereas broadly distributed delays may reduce complexity^24,25^.
Nevertheless, a critical limitation persists when conventional TDRC encounters signal mixtures in which a dominant component with strong autocorrelation masks a weaker chaotic source. This occurs, for example, in the mixture of Mackey–Glass (MG) and Lorenz x, where the MG signal can dominate or obscure the less correlated Lorenz x, depending on the mixing ratio. A similar challenge arises in the mixture of two Lorenz x signals with different initial conditions or slightly different parameters. In this case, both components share similar autocorrelation structures, making it difficult to distinguish them based on second-order statistics alone. In both cases, we explore a full range of mixing ratios ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s \in [0,1]$$\end{document} ), for scenarios where one source is dominant, balanced, or weak. The present work addresses this limitation by implementing online training of the readout weights via a Kalman filter ^26^, extended here to incorporate a sliding-window update scheme. This enables reliable recovery of concealed chaotic components while maintaining the efficiency of single-delay reservoir architectures.
Methods
Time–delay reservoir computer
We consider two chaotic signals, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_1(n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_2(n)$$\end{document} , either generated from two Lorenz systems with identical parameters but different initial conditions or from two distinct sources such as the MG and Lorenz systems. These signals are mixed according to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} u(n) = \sqrt{s} \, u_1(n) + \sqrt{1 - s} \, u_2(n), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s \in [0, 1]$$\end{document} controls the relative contribution of each component. Each of the signals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_1 (n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_2 (n)$$\end{document} is normalized to have zero mean and unit variance. The mixed signal u(n) is then used as input to a TDRC, with the goal of recovering one of the source signals. The target output is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_2(n) = u_2(n+1)$$\end{document} when recovering the second source, and analogously \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_1(n) = u_1(n+1)$$\end{document} for the first source. A scalar, pre-processed input sequence u(n) is held constant over each clock cycle of duration T. To create a high-dimensional state space analogous to a reservoir computing’s dynamics, the input is modulated by a binary mask \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m(t) \in \{-1, +1\}$$\end{document} . The mask is piecewise constant over shorter intervals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta$$\end{document} , defined by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} m(t) = m_i \in \{-1, +1\}, \qquad t\in \big [nT+i\theta ,\; nT+(i+1)\theta \big ),\ \ i=0,\dots ,N_v{-}1. \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta = T/N_v$$\end{document} is the spacing between virtual nodes, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_v$$\end{document} is the number of virtual nodes per cycle. The resulting continuous-time driving signal becomes
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} J(t)=u(n)\;m(t)\quad \text {for}\quad t\in \big [nT+i\theta ,\; nT+(i+1)\theta \big ). \end{aligned}$$\end{document}The masked input J(t), defined above, drives the dynamics of the system and causes rich transient responses. The electro-optic oscillator with external input evolves according to:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{x}(t)&= -x(t) + \beta \sin ^2\left( x(t - \tau ) + \phi + \gamma J(t)\right) - y(t), \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{y}(t)&= x(t), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} is the feedback gain, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is the input scaling factor, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi$$\end{document} is a phase offset, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} is the delay time, which governs the dynamics of the system by determining how past states influence the current state. This differs from the clock cycle T, which determines how long each input sample is held constant and defines the sampling steps within that period. Unless otherwise stated, parameter values are listed in Table 1. As established in prior works on TDRCs, absence of input typically leads the dynamics to a stable fixed point. This stable fixed-point regime is typically associated with fading memory and with behaviour analogous to the echo state property in reservoir computing. The node state x(t) is sampled at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_v$$\end{document} equally spaced virtual nodes per cycle, defined at times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{n,i} = nT + i\theta$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i = 0, \dots , N_v{-}1$$\end{document} . The resulting reservoir state vector at step n is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{x}(n) = \bigl [x(t_{n,0}),\, x(t_{n,1}),\, \dots ,\, x(t_{n,N_v{-}1})\bigr ]= \bigl [x(nT),\, x(nT + \theta ),\, \dots ,\, x(nT + (N_v{-}1)\theta )\bigr ]. \end{aligned}$$\end{document}Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_{M \times N_v}$$\end{document} be the matrix formed by stacking reservoir states, with M being the number of datapoints (for example, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M = M_{\text {train}}$$\end{document} during training or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M = M_{\text {test}}$$\end{document} during testing):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X = \begin{bmatrix} \textbf{x}(1) \\ \textbf{x}(2) \\ \vdots \\ \textbf{x}(M) \end{bmatrix},$$\end{document}Following this, a standard ridge regression can be applied to train a linear readout. For signal separation, two independent regression problems are formulated using the target signals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_2$$\end{document} , where each row of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_i$$\end{document} corresponds to the desired output at time step n. The readout weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{1,2}$$\end{document} are obtained by solving:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & W_1 = (X^T X + \lambda \textbf{I})^{-1} X^T O_1, \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & W_2 = (X^T X + \lambda \textbf{I})^{-1} X^T O_2, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} is a regularization parameter and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{I}$$\end{document} is the identity matrix. So this is the process of offline training where two prediction outputs can be obtained:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \hat{O}_1=X W_1 \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \hat{O}_2=X W_2 \end{aligned}$$\end{document}Table 1. Simulation parameters.SymbolDescriptionValue \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\text {train}}$$\end{document} Training size20,000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N_v$$\end{document} Number of virtual nodes50TClock cycle40 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} Time delay40 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi$$\end{document} Phase offset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2\pi /5$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} Regularization parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-6}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} Input scaling (fixed point)0.135 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} Input scaling (limit cycle)0.035 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} Feedback gain (fixed point)1.66 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} Feedback gain (limit cycle)2.38
Kalman read-out adaptation
In this section, we describe the Kalman filtering method for adaptive readout training in time-delay reservoir computing, as introduced in ref.^26^. Kalman filtering has previously been used for blind source separation in state-space models^27^. Once the reservoir state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}(n)$$\end{document} is sampled at each clock cycle, the read-out weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{1,2}$$\end{document} are updated recursively. The recursion is initialized from the offline ridge solution:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} W_{1,2}^0= W_{1,2}^{\text {ridge}} \end{aligned}$$\end{document}This recursive weight update enables online learning by continually adjusting the weights based on the most recent prediction error. At each step, the predicted output is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{y}_{1,2}(n)=\textbf{x}(n)W_{1,2}^{n-1}. \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{1,2}(n)$$\end{document} is the estimate of the target \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1,2}(n)=O_{1,2}(n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{1,2}^{n-1}$$\end{document} is the previous estimate of the weights. In this method, there is uncertainty about the current weight values, which is captured by the covariance matrix P(n) of the weight estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{1,2}^n$$\end{document} . We initialize this covariance as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(0)=I$$\end{document} and the diagonal elements of P(n) represent the variances of individual weights, quantifying the uncertainty associated with each weight estimate. Before incorporating the new observation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{1,2}(n)$$\end{document} , this uncertainty is updated at each step according to:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P_{-}(n) = P(n-1) + Q\,\textbf{I} \end{aligned}$$\end{document}where Q is a non-negative scalar that controls how much we add at each step to model possible weight drift. A larger Q permits the weights to adapt more rapidly, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q \rightarrow 0$$\end{document} recovers the behavior of static regression. The expected variance of the forthcoming prediction error is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} S(n) = R + \textbf{x}(n) P_{-}(n) \textbf{x}^{\!\top }(n), \end{aligned}$$\end{document}By tuning the hyperparameters Q and R, we can control the adaptivity and noise robustness of the system. Balancing these two sources of uncertainty yields the Kalman gain:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} K(n)=P_{-}(n)\textbf{x}^{\!\top }(n)\,S^{-1}(n), \end{aligned}$$\end{document}which shrinks when S(n) is large, and increases when confidence in the prediction is high. Weights and covariance are corrected via
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} W_{1,2}^{\,n}&= W_{1,2}^{\,n-1} + K(n)\bigl [y_{1,2}(n)-\widehat{y}_{1,2}(n)\bigr ],\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(n)&=\bigl [\textbf{I}- K(n)\textbf{x}(n)\bigr ]\,P_{-}(n). \end{aligned}$$\end{document}so the initial prediction matches the one that would be obtained by ridge regression, after which the Kalman updates refine the weights online. Adding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q\textbf{I}$$\end{document} at every step gives the read-out the flexibility to track gradual changes in the signal mixture that an offline training cannot capture. To exploit the correlation between recent samples, which Kalman filtering can enable, we replace the single-sample update with a block update that assimilates the last \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_w$$\end{document} observations at once. This is done by defining stacked matrices that aggregate the past \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_w$$\end{document} samples of the reservoir states and targets:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}^{(n)} = \begin{bmatrix} \textbf{x}(n - n_w + 1) \\ \vdots \\ \textbf{x}(n) \end{bmatrix}\!, \qquad \textbf{y}_{1,2}^{(n)} = \begin{bmatrix} y_{1,2}(n - n_w + 1) \\ \vdots \\ y_{1,2}(n) \end{bmatrix}\!.$$\end{document}Each row of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}^{(n)}$$\end{document} corresponds to a past reservoir state vector, and each entry in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}_{1,2}^{(n)}$$\end{document} is the associated target output value at that time step. In this scheme, although the adaptive training assimilates multiple past steps to update the weights, the prediction task itself remains a one-step ahead prediction.
Inputs
We considered mixtures of chaotic signals in two distinct scenarios. In the first, the signals are generated from two trajectories of the Lorenz system with slightly different initial conditions. The Lorenz system is defined by the following equations:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{x}= & \sigma (y(t)-x(t)), \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{y}= & -x(t)z(t)+\rho x(t)-y(t), \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{z}= & x(t)y(t)-b z(t), \end{aligned}$$\end{document}with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma = 10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho = 28$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = 8/3$$\end{document} . We integrate the system using a time step of 0.002 and downsample the x-component every 0.05 seconds to generate the Lorenz x and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x'$$\end{document} signals used in the experiments.
In the second case, we study a more heterogeneous mixture, combining the Lorenz x signal with a signal generated by the MG delay differential equation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{dx}{dt} = -a x(t) + \frac{b x(t-\tau _{MG})}{1 + x^{10}(t-\tau _{MG})}, \end{aligned}$$\end{document}We use standard parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a = 0.1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b = 0.2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau _{\textrm{MG}} = 17$$\end{document} . The MG signal exhibits strong autocorrelation peaks at specific lags due to its delay-induced structure and has a longer correlation time than the Lorenz x signal. We integrate the system using a time step of 0.1 and sample the output every 1 second. While this mixture may not reflect a realistic mixing scenario, our aim is not to simulate a physical mixture but to evaluate how well a mixture of complex input signals can be separated. Although both signals are generated from continuous-time dynamical systems, they are treated here as discrete input sequences to test demixing performance.
Results
The results for two different scenarios are presented in this section: one involving two Lorenz time series with different initial conditions, and the other involving a mixture of Lorenz and MG signals. These are analyzed across different dynamical regimes. Since the system’s performance strongly depends on the correlation structure and complexity of the input signals, each scenario uses a distinct set of parameters. We first identify optimal parameters for the case of equal contribution from both sources and then examine how varying the mixing ratio affects the system’s dynamics.
Lorenz-Lorenz
We begin by considering two chaotic time series generated by the Lorenz system with slightly different initial conditions. Although chaotic trajectories are highly sensitive to initial conditions, their long-term statistical properties and attractor structure may be nearly indistinguishable. Figure 1 illustrates representative segments of the Lorenz x signal, the Lorenz \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{\prime }$$\end{document} signal generated from the same system but with slightly different initial conditions, and their mixture at a balanced mixing ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 0.5$$\end{document} .Fig. 1. Separation of a mixture of two Lorenz signals using ridge regression and adaptive training. Panel (a) presents the Lorenz x component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_1(n)=u_1(n+1)$$\end{document} , while panel (b) shows a second Lorenz trajectory \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_2(n)=u_2(n+1)$$\end{document} generated from nearby initial conditions. The mixed observation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u(n+1)$$\end{document} for a mixing parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=0.5$$\end{document} is displayed in panel (c). Panels (d) and (e) contain the predictions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_1(n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_2(n)$$\end{document} obtained with an adaptive sliding-window Kalman readout with window size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_w=3$$\end{document} . Panel (f) displays the prediction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_1(n)$$\end{document} of the Lorenz x component obtained with a static linear readout trained by ridge regression \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(n_w=0)$$\end{document} . The NRMSE values computed over the plotted interval are reported inside the corresponding panels.
Figure 2 shows the bifurcation diagram of the electro-optic oscillator model in the absence of input, constructed by plotting the local maxima and minima of the state variable x(t) as a function of the gain parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} . For low values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} , the system converges to a stable fixed point. As \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} increases, a Hopf bifurcation occurs around \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 1.68$$\end{document} , beyond which the system exhibits stable periodic oscillations. The second critical point is close to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =2.53$$\end{document} .Fig. 2. Bifurcation diagram of the electro-optic oscillator model without external input. As \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} increases, the system transitions from a stable fixed point to periodic oscillations near \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 1.68$$\end{document} . At the critical point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 2.53$$\end{document} , the bifurcation diagram exhibits a broadened range of extrema.
Prediction accuracy across dynamical regimes is summarized in Fig. 3 using an adaptive Kalman filter that updates the readout weights based on a fixed number of recent data points. Each panel shows the normalized root mean square error (NRMSE) as a function of the feedback gain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} and the input scaling \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} , with the mixing ratio fixed at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 0.5$$\end{document} for the mixture of two Lorenz x signals with different initial conditions. The parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} modulates the amplitude of the external input J(t). The three panels correspond to window sizes of 1, 3, and 10 steps, respectively. In all cases, the readout is first trained on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\text {train}}= 20000$$\end{document} samples and then evaluated on a separate test sequence of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M_{\textrm{test}} = 5000$$\end{document} points. Lower NRMSE values (darker regions) indicate more accurate prediction. Longer window sizes (multi-step updates) can lead to improved accuracy. However, increasing the window size beyond 3 increases the prediction error in some regions of the parameter space, though accuracy remains higher than with ridge regression or a window size of 1 around the critical points. These improvements are particularly evident near the first and second bifurcation points, corresponding to transitions from a fixed point to a limit cycle and then to a more complex dynamics. This highlights the reservoir’s enhanced computational capacity in regimes of increased complexity. Notably, a window size of 3 yields the broadest region of low error across the parameter space in this example.Fig. 3. Prediction error versus input scaling \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} and feedback gain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} for window sizes of 1, 3, and 10 steps (left to right), using a mixture of two Lorenz x signals generated from identical parameters but different initial conditions. Darker colours denote lower error, i.e., higher prediction accuracy. Bifurcations in the underlying reservoir dynamics occur near \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 1.68$$\end{document} (Hopf bifurcation) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 2.53$$\end{document} (transition to more complex dynamics). Among the three settings, a window size of 3 yields the largest parameter region with consistently low prediction error. In all panels, the Kalman filter hyperparameters are fixed at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = 10^{-3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R = 10^{-4}$$\end{document} .
Figure 4 shows the time evolution of the read-out weight norm \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Vert W_{1}^{n} \Vert _{2}$$\end{document} during online Kalman filter training for window sizes of 1, 2, 3, 10, and 11 samples. The upper panel corresponds to a reservoir operating in a stable fixed-point regime. In this case, the weight norm fluctuates around a baseline, with short-term variability that tends to increase with window size: larger windows are associated with stronger weight fluctuations even in stationary settings. These larger fluctuations may indicate more sensitivity to short-term variations in the prediction error, which may reduce robustness. In contrast, the lower panel shows the system when the parameters correspond to a limit cycle in the absence of input. Here, the weight norm remains roughly one order of magnitude smaller, with fewer and smaller spikes, and exhibits modest, irregular fluctuations of similar variability for all window sizes. This suggests that longer windows can allow adaptation without large increases in variability when the reservoir dynamics are inherently oscillatory.Fig. 4. Temporal evolution of the read-out weight norm \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Vert W_{1}^{n} \Vert _{2}$$\end{document} for different Kalman filter window sizes. (a) Stable fixed-point regime. Longer window sizes increase weight fluctuations but keep them bounded. (b) Limit cycle regime. Weight norms remain low and change only slightly across all window sizes.
The sensitivity of the Kalman filter to its hyper-parameters is mapped in Fig. 5. The prediction errors are plotted as a function of the process-noise level Q, which governs the rate at which uncertainty in the weights is allowed to grow, and the measurement-noise variance R, which expresses the assumed uncertainty in the target value y(n). The lowest prediction error is generally observed when R is roughly one order of magnitude (or more) smaller than Q; if R approaches or exceeds Q, the error increases . In the fixed-point regime the low-error region is narrower and is primarily observed when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R<Q$$\end{document} , whereas in the limit cycle regime it is broader and less sensitive to the exact Q/R ratio as seen from the larger blue region in the (Q, R) parameter space, which represents lower prediction error.Fig. 5. Prediction error as a function of process-noise level Q and measurement-noise variance R for a mixing ratio of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 0.5$$\end{document} . The top row corresponds to the fixed-point regime, and the bottom row to the limit cycle regime. Columns correspond to window sizes of 1 (left), 3 (middle), and 10 (right) samples. The lowest error occurs when R is roughly one order of magnitude smaller than Q.
Dependence on the window size is explored in Fig. 6 which quantifies how the prediction error depends on the number of recent samples used by the Kalman-filter update (window size, horizontal axis) for several values of the mixing ratio s. The upper panels correspond to reservoir parameters that place the system at a stable fixed point, whereas the lower panels show the limit cycle regime. For a window size of 0 (i.e. ordinary ridge regression) the prediction error is low when the target signal is the dominant component of the mixture, but becomes large when the target is weakly represented. In the limit cycle case (lower panels) the NRMSE drops rapidly as soon as one or two additional samples are incorporated and thereafter remains essentially constant, independent of s. In the fixed-point case (upper panels) a small window of one or two samples minimizes the error for mixed signals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s > 0$$\end{document} , but larger windows progressively degrade performance; These results indicate that a short window size is sufficient in the periodic regime, whereas the fixed-point regime exhibits an optimal window that balances adaptation. For this task of separating two Lorenz signals with similar statistics, the fixed-point regime yields lower prediction error with short window sizes, while the limit cycle regime offers more consistent performance across window sizes and mixing ratios.Fig. 6. Prediction error as a function of Kalman-filter window size for different mixing ratios s. The case where the window size is zero corresponds to the standard ridge regression, i.e. the Kalman filtering is not present. When s is large, the Lorenz x signal dominates the mixture; when s is small, the Lorenz \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x'$$\end{document} signal dominates. Panels (a) and (b): reservoir in a stable fixed point. A window of one to three samples minimizes the error for mixed signals, but larger windows increase it. Panels (c) and (d): reservoir in a limit cycle regime. The error decreases sharply once the window size exceeds one sample and then levels off, showing little dependence on either window size or mixing ratio. The hyperparameters were set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = 10^{-3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R = 10^{-4}$$\end{document} , consistent with the setting analyzed in Fig. 5. The limit cycle regime is useful when the target component is weak in the mixture, but outside of those cases, the fixed-point regime generally yields lower prediction error.
Lorenz + MG
We also examine the case where the signals originate from two distinct sources: a MG time series and the x-component of the Lorenz system. The two signals were generated and sampled at different rates, and representative segments are shown in Fig. 7.Fig. 7. Signal separation of a mixture of Lorenz x and MG signals using ridge regression and adaptive readouts. Panels (a)–(c) show, respectively, the Lorenz x component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_1(n)=u_1(n+1)$$\end{document} , the MG signal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_2(n)=u_2(n+1)$$\end{document} , and the observed mixture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u(n+1)$$\end{document} with mixing parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s=0.5$$\end{document} . Panels (d) and (e) display the predictions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_1(n)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_2(n)$$\end{document} produced by a sliding-window Kalman readout with window size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n_w=3$$\end{document} . Panel (f) shows the prediction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_1(n)$$\end{document} of the Lorenz x component obtained from a static linear readout trained using ridge regression \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(n_w=0)$$\end{document} . For each predicted signal, the NRMSE between the prediction and its source over the plotted interval is reported inside the corresponding panel.
The prediction error across different input scalings and feedback gains is shown in Fig. 8 for various window sizes. Compared to the same-system mixture (Lorenz–Lorenz) case in Fig. 3, the optimal parameters yielding the lowest prediction error can occur at different values of the input scaling and feedback gain. In the fixed-point regime, the minimum error occurs near the first bifurcation point, close to the onset of oscillations. In the limit cycle regime, the best performance is achieved farther into the limit cycle region, whereas in Fig. 3, it occurs closer to the second critical point.Fig. 8. Prediction and separation error for window sizes of 1, 3, and 10, shown across varying feedback gains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} and input scalings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} . In the fixed-point regime, the lowest error occurs near \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 1.68$$\end{document} , while in the limit cycle regime it occurs around \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 2.14$$\end{document} . In all cases, the mixing ratio is set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 0.5$$\end{document} , and the Kalman filter hyperparameters are fixed at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Q = 10^{-3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R = 10^{-4}$$\end{document} .
It was shown in a multi-delay multi-layer system that when Lorenz x dominates the mixture, the structure of the MG signal remains somewhat detectable due to its strong temporal correlations, whereas when MG dominates, the less predictable and weakly correlated Lorenz x component becomes much harder to extract ^14^. Introducing online adaptation reduces this imbalance: larger window sizes allow the Kalman filter to track the MG-dominated mixture more effectively, leading to the accuracy gains shown in Fig. 9. Previously, it was shown that demixing accuracy depends on the mixing ratio ^13,14^. In Fig. 9, we see that increasing the window size using the Kalman technique is especially effective in high-error regimes, such as when the target component is weakly represented in the mixture. In all cases, increasing the window size beyond 2 or 3 steps often yields no further improvement, regardless of the signal.Fig. 9. Prediction error as a function of Kalman-filter window size for mixtures of a Lorenz x signal and a MG signal sampled at different rates. The case where the window size is zero corresponds to standard ridge regression, i.e., Kalman filtering is not present. When s is small, the MG signal dominates the mixture, whereas for large s, the Lorenz x signal becomes dominant. (a), (b): reservoir in a stable fixed-point regime. A window of two to three samples minimizes the error for balanced mixtures ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s = 0.5$$\end{document} ), while further increases provide little additional benefit even when one signal dominates. (c), (d): reservoir in a limit cycle regime. Prediction improves with window size up to a point, but performance gains are more modest than in the Lorenz x+Lorenz \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{\prime }$$\end{document} case. These improvements are enabled by the Kalman algorithm, which adapts the readout weights based on recent prediction errors.
Discussion
In this paper, we studied online adaptive training for the separation of complex signal mixtures using time-delay reservoir computing in combination with Kalman filtering with various window sizes. This approach is particularly effective when one aims to extract features that are not easily observable in the raw signal, such as uncovering temporally correlated components that are hidden in the mixture due to the dominance of other signals, or when the two signals in the mixture are from identical chaotic sources sampled from different initial conditions. A representative case is when a Lorenz x signal, which lacks clear autocorrelation structure, is contaminated by an MG signal, which exhibits pronounced autocorrelation peaks at specific lags. Although this synthetic example does not directly correspond to a real-world situation, it highlights a fundamental principle: online training enables the readout to adapt continuously, which can improve separation when the mixture components have different temporal structure and uncover informative structure that static readouts may overlook. These results suggest that, even for mixtures of qualitatively different sources, an online adaptive scheme such as updating the weights using the Kalman formalism based on prediction error can substantially improve signal demixing performance.
This type of online training (finite window size) offers enhanced accuracy relative to static learning (zero window size). The main drawback, however, is the need for continuous weight updates, which may introduce computational complexity. Despite this limitation, continuous updating can potentially be beneficial in settings involving nonstationary time series or signals corrupted by noise whose characteristics change over time. In such cases, the ability to track and respond to ongoing shifts in the signal structure may enhance demixing and signal extraction performance.
Predicting the Lorenz z signal from a mixture is feasible with good accuracy when the Lorenz x component is the dominant contributor, as shown by the fact that Lorenz x can be used as the input to predict Lorenz z and perform cross prediction using a static linear readout trained by ridge regression^22^. In contrast, attempting to recover Lorenz x when Lorenz z dominates yields poor accuracy. This asymmetry is related to the correlation properties of the signals, since the autocorrelation of the Lorenz z component exhibits distinct peaks at non-zero time lags. Similar behaviour has been shown for mixtures of MG and Lorenz x^14^. In this study we considered only scalar inputs taken from time series, but we do not see any conceptual barrier to applying the same approach to scalar observables extracted from more complex spatiotemporal systems such as the Kuramoto–Sivashinsky equation. Separation of mixed Lorenz-96 and KS signals using a simulated water-tank dynamical system has also been demonstrated^28^, which indicates that such mixtures can be separated using dynamical-systems-based methods.
To enhance the performance of the adaptive training, we examined the effect of incorporating multiple past data points in the weight update process. Increasing the window size initially improves prediction accuracy, but beyond a certain point, excessive reliance on past data leads to larger weight fluctuations. These fluctuations can degrade performance by introducing noise into the weight estimates, ultimately harming the separation quality.
An interesting observation was that, with a single-step update, optimal separation often occurred near the stable fixed-point regime (Figs. 6 and 9). As the window expands to include multiple past steps, the limit cycle regime can yield lower error for certain targets and mixing ratios. In the oscillatory regime, the main predictive power arises from the adaptive Kalman weight updates, which continuously retune the readout to compensate for the tendency of the underlying delayed system to relax back to its limit cycle (where a static readout performs poorly at low input scalings). In fact, the lowest prediction errors are often observed when the system parameters lie near critical points, where the qualitative nature of the dynamics changes. This suggests that the system’s computational capacity is enhanced near bifurcation boundaries. While the absolute prediction error in these regimes may not be as low as in the stable fixed point regime, a notable advantage is that moderately low error can be achieved across a wide range of mixture ratios, highlighting the robustness of the system under varying input conditions.
Interestingly, in the limit cycle regime, the magnitude of variability of the learned weights tends to decrease. This may reflect a greater stability in readout weights, which could be particularly beneficial for offline training or hybrid schemes that combine online Kalman filtering with offline refinement. Smaller weights may also contribute to robustness with respect to hyperparameter choices.
In this paper, we focused exclusively on the effectiveness of Kalman filtering for training time-delay reservoir computers, and did not investigate other important factors that may further enhance performance. For example, the role of the delay parameter in the underlying dynamical system has been extensively studied in the literature, particularly in relation to harmful resonance effects. Incorporating multiple delays or extending the system to a multi-layer architecture may offer additional benefits, which we leave for future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Makeig, S., Bell, A., Jung, T.-P. & Sejnowski, T. J. Independent component analysis of electroencephalographic data. In Advances in Neural Information Processing Systems, vol. 8. MIT Press (1995).
- 2Hershey, J. R., Chen, Z., Le Roux, J. & Watanabe, S. Deep clustering: Discriminative embeddings for segmentation and separation. In ICASSP 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, 31–35 (2016).10.1109/ICASSP.2017.7952118 PMC 579153329398973 · doi ↗ · pubmed ↗
- 3Triefenbach, F., Jalalvand, A., Schrauwen, B. & Martens, J.-P. Phoneme recognition with large hierarchical reservoirs. In Adv. Neural Inf. Process. Syst. (Neur IPS), 2307–2315 (2010).
- 4Jaeger, H. & Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science. 304, 78–80 (2004).10.1126/science.109127715064413 · doi ↗ · pubmed ↗
- 5Antonelo, E. A., Schrauwen, B. & Stroobandt, D. Event detection and localization for small mobile robots using reservoir computing. Neural Netw.21, 862–871 (2008).10.1016/j.neunet.2008.06.01018662855 · doi ↗ · pubmed ↗
- 6Cichocki, A. & Amari, S. Linear blind filtering and separation using a state-space approach. In Adaptive Blind Signal and Image Processing: Learning Algorithms and Applications, Ch.11, 423-441 (John Wiley & Sons, 2002).