Automatic Bone Removal in CBCT Scans of the Body Trunk: Thorax, Abdomen, and Pelvis
Hinrich Winther, Sabine Maschke, Lena Becker, Cornelia Dewald, Marcel Eicke, Tobias Jakobs, Roman Kloeckner, Axel Schmid, Frank Wacker, Bernhard Meyer

TL;DR
This study evaluates a fully automated software for removing bones from CBCT scans of the thorax, abdomen, and pelvis to improve vascular visibility and diagnostic quality.
Contribution
A modified 3D U-Net enables fully automated bone removal in CBCT scans, validated across multiple body regions with high accuracy.
Findings
The software achieved high accuracy with minimal erosion of non-target structures (B-rating 1.01 ± 0.07, V-rating 1.02 ± 0.13).
Vessel assessment improved significantly, with VA-rating of 1.0 ± 0 indicating better visualization of contrast material.
Quantitative metrics showed strong agreement with manual expert delineation (Dice coefficient 0.95 ± 0.02, IoU 0.9 ± 0.03).
Abstract
To evaluate a fully automated bone removal software for cone beam computed tomography (CBCT) of the thorax, abdomen, and pelvis, enhancing vascular visualization by eliminating bone interference and improving diagnostic quality. 1035 CBCT scans from adults age 66.5 ± 11.9 18–87 years (mean ± std min–max) across nine centers were retrospectively analyzed, divided into training (n = 855, 515 abdomen, 229 pelvis, 111 thorax) and testing (n = 180, 60 for each region, 114 male, 53 female, 13 unknown). Manual bone segmentation was performed using ITK-SNAP. A modified 3D U-Net was trained and clinically evaluated through multireader analysis using ordinal scales from 1 (perfect) to 4 (not usable) bone subtraction (B-rating) and erosion of non-target structures (V-rating) in addition to a vessel assessment (VA-rating), categorizing the subtracted image as “better” (1), “same” (2), or “worse”…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
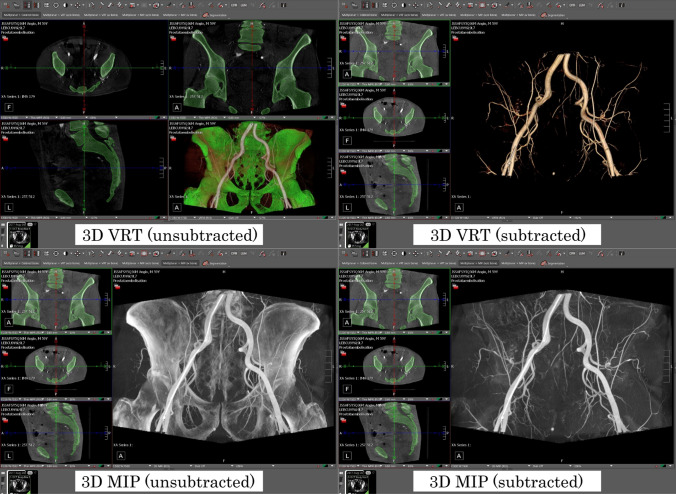 Figure 1
Figure 1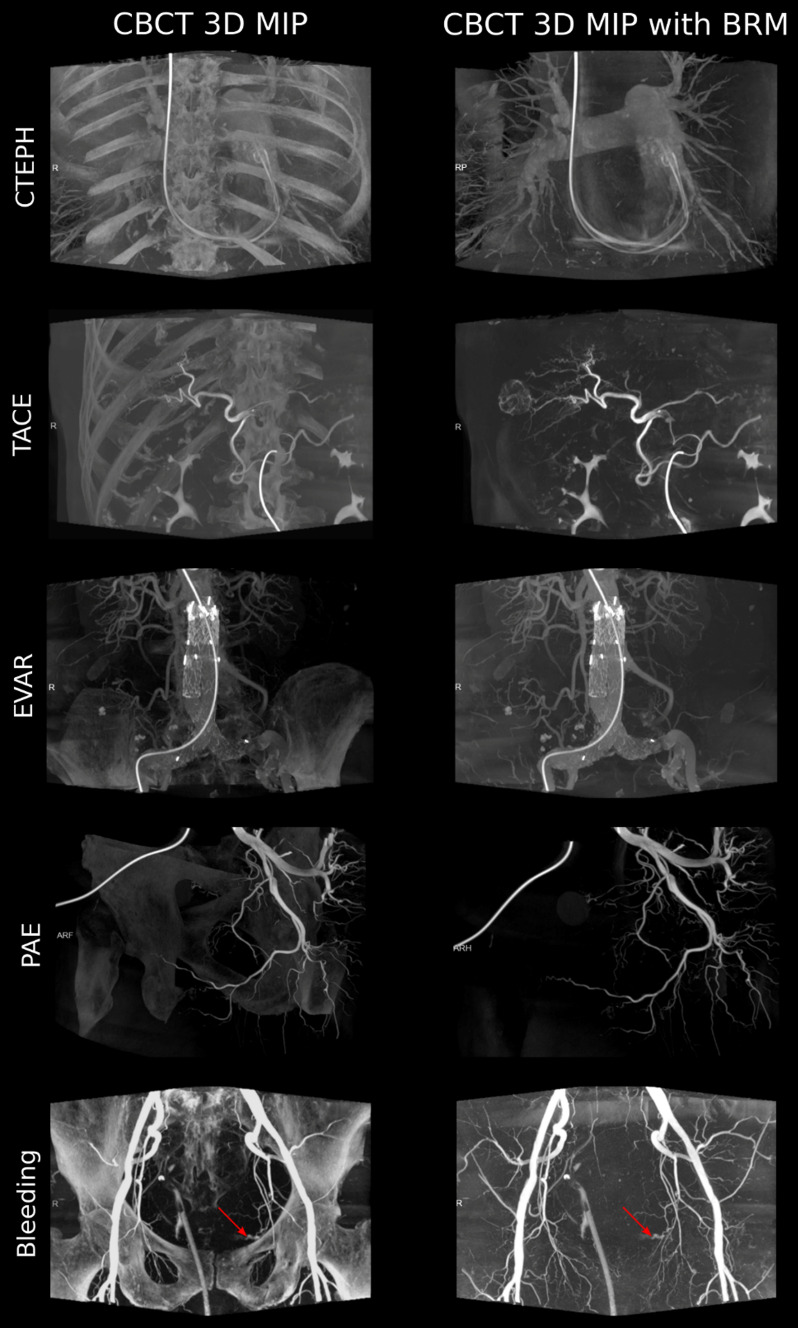 Figure 2
Figure 2 Figure 3
Figure 3- —Medizinische Hochschule Hannover (MHH) (3118)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDental Radiography and Imaging · Anatomy and Medical Technology · Digital Radiography and Breast Imaging
Introduction
Bone removal (BRM) techniques play an important role in CT angiography (CTA) of the head [1], body trunk [2], and the lower extremities [3], as well as in cone beam computer tomographies (CBCT) of the head and trunk. BRM enables the rapid evaluation of the vascular system and is often used to produce overview reconstructions of the scan, utilizing maximum intensity projections (MIP) or volume rendering techniques (VRT). Without BRM, the resulting visualization of the vasculature is often obscured by overlapping bone structures, resulting in severely impaired and therefore inadequate images, impacting both the diagnostic work-up and the peri-procedural guidance [4].
The possible uses for BRM in CBCT scans of the body trunk are manifold and include both diagnostic and therapeutic interventions, e.g., bleeding control, prostate embolization (PAE), pulmonary balloon angioplasty (BPA), and different liver interventions [5–7]. Additionally, it has been suggested that, for transarterial chemoembolization (TACE), the interventional radiologist may catheterize tumor-feeding arteries with CBCT guiding technology more readily than without [8–10]. In the case of BPA, CBCT guidance, using VRT-based road maps, enables a safe procedure with a low risk of severe complications [11].
Different approaches exist to create a bone-free 3D-rendered image: Using thresholding, software-based methods can be employed on post-processing datasets to automatically separate bones concealing relevant information in the field of view (FOV). However, as these technologies rely on specific attenuation values to distinguish between bone and soft tissue, inaccuracies can lead to inadequate removal of bone or incorrect removal of artery segments [12].
CBCT combines DSA and CTA imaging features, but with a higher spatial resolution at the cost of a higher image noise [13]. BRM is particularly important and challenging because it allows arbitrary rotation of the 3D CBCT dataset, offering a luminal view of the vessel. It also displays information about the perivascular soft tissue, helping realize this imaging modality’s potential. Especially in complex procedures, imaging the target structure in as much detail as possible is crucial. However, manual segmentation is usually necessary to achieve BRM in CBCT images of the body trunk, rendering time-consuming post-processing mandatory, requiring two to five minutes [11, 14]. Few prior efforts have been published to achieve automated BRM without relying on the differentiation of attenuation values, e.g., by Wang et al., who have demonstrated the applicability of a deformable model to identify the body cavity on dual-phase CBCT to subtract the rib cage and spine for transarterial chemoembolization (TACE) of the liver [15]. However, to our knowledge, a widely applicable solution for BRM for CBCT of the body trunk is not available.
This study aims to evaluate the performance of a newly developed bone removal software for CBCT imaging, focusing on the thorax, abdomen, and pelvis to enhance vascular system visualization by eliminating bone structure interference, thereby improving diagnostic quality.
Material and Methods
Study Cohort
1035 CBCT scans, each from an individual subject, from the thorax, abdomen, and pelvis of adults (age > 18 years), were retrospectively included in the study cohort from 9 different centers. Each center has been asked to provide chronologically consecutive exams to get a representative real-world sample. The angiography system used in all centers in this study was the Axiom Artis (Siemens Healthcare) with the HU normal reconstruction kernel, except for two exams where the HU sharp reconstruction kernel was used. Non-diagnostic scans due to heavy motion artifacts were excluded. The data have been split into a test and a training set chronologically on a per-center basis, with the oldest data (from 05/2013) being used for training and the newest for testing (until 03/21). Four centers ISI1-4 (In Sample Institution, the center’s data are included in both training and testing) contributed training (n = 855) and testing (n = 60); five centers OSI1-5 (Out of Sample Institution, the center provides testing data only) contributed only testing data (n = 120). The five OSI centers were deliberately not included in the training to estimate any present overfitting of the model, which center was included in the training and testing, as well as in testing only, was decided based on the availability of scans regarding the body region, as many centers strongly focus on specific exam types and the resulting body region. All test cases except three exams of ISI1 have been performed with a contrast agent; however, 21 additional cases show a parenchymal contrast. A detailed breakdown of the study cohort is provided in Table 1.Table 1. Patient cohort characteristicsSplitInstitutionAge (mean ± std min–max)Sex (m/f/o)#Samples#ABD#PEL#THOkVp (mean ± std min–max)FOV mm^2^ (mean ± std min–max)TrainISI162.6 ± 14.7 (18–93)414/226/064044886106ISI270.1 ± 10.0 (47–93)144/1/014521412ISI368.8 ± 9.5 (51–84)54/9/0636210ISI4nan0/0/77313Overall64.4 ± 14.0 (18–93)612/236/7855515229111TestISI165.1 ± 14.0 (29–84)27/23/05020102094.3 ± 5.4 (90–108)249.2 ± 2.3 (240–252)ISI271.6 ± 8.1 (54–80)10/0/0100100106.5 ± 3.2 (101–111)203.8 ± 17.0 (198–252)OSI165.0 ± 11.1 (33–84)21/9/03015150106.6 ± 8.1 (90–124)251.2 ± 0.2 (250–251)OSI269.5 ± 11.8 (51–87)8/4/13252500104.1 ± 8.2 (90–119)251.1 ± 0.0 (251–251)OSI368.0 ± 13.1 (18–87)25/0/0250250105.6 ± 6.4 (95–114)246.5 ± 19.5 (198–271)OSI468.5 ± 5.3 (62–77)10/0/010001090.0 ± 0.0 (90–90)240.3 ± 0.6 (240–241)OSI565.2 ± 10.7 (42–81)13/17/0300030108.4 ± 3.5 (90–109)251.4 ± 2.8 (236–252)Overall66.5 ± 11.9 (18–87)114/53/13180606060102.1 ± 8.6 (90–124)246.8 ± 13.5 (198–271)The institution prefix denotes if the center contributed to the training and test set (ISI) or to the test set only (OSI). Sex is given in male (m), female (f), and anonymized (o). The main body region is given in thorax (THO), abdomen (ABD), and pelvis (PEL). Not a number (nan) is given when the anonymization process discarded the relevant information
Each center anonymized the image studies during the export before inclusion in the dataset. Finally, the data were split into 855 training and 180 test cases.
Data Annotation
We used ITK-Snap [16] version 3.8 to manually segment the bony structures of all 1035 CBCT scans. In ITK-SNAP, this was done using tools such as the “Paintbrush” tool, which allowed us to manually delineate the boundaries of the bone structure on each slice. This process is meticulous and time-consuming, requiring precision to accurately delineate the bones’ anatomical structure. The size of the paintbrush can be adjusted for finer control over the segmentation, especially in areas where bone structures are in proximity or intersect with other anatomical structures, such as vessels. Throughout this process, it was crucial to maintain consistency in segmenting the bone structures across all slices to create a cohesive and accurate 3D representation of the structure. We tried to control this process as closely as possible by employing technical solutions, performing structural component analysis, and including guidelines to review the segmentation in a multiplanar reconstruction and 3D VRT.
Machine Learning
The architecture implemented in PyTorch version 1.8.1 is based on the 3D U-Net model as proposed by Çiçek et al. [17, 18], with an input layer dimensionality increased to 256 × 256 × 256 neurons. The architecture utilizes a symmetrical design that comprises both downsample and upsample blocks. Each downsample block features a batch normalization process followed by two sets of 3 × 3 × 3 convolutions, employing a stride of 3 with zero padding. Upsample blocks incorporate a resampling layer that utilizes linear interpolation to match the resolution of corresponding downsample blocks, succeeded by two 3 × 3 × 3 convolutions with zero padding. Following the recommendations of He et al. [19], traditional ReLU activation functions were replaced with PReLU across the network to enhance model learning dynamics.
The model was trained using weak binary cross-entropy as the objective function. Training commenced with a learning rate of 1e^−3^, which was gradually decreased to 1e^−6^. Each training epoch comprised 200 virtual samples, generated dynamically through image augmentation techniques, including linear (rotation, shearing, resizing) and nonlinear transformations (local displacement), with a batch size of eight. Optimization was facilitated through the adaptive moment estimation (Adam) method [20].
The training infrastructure consisted of a DGX1 system equipped with eight NVIDIA V100 GPUs, each boasting 32 GB of video memory. The training duration extended over a period of seven days.
Upon completion of the training phase, the modified 3D U-Net model was applied to a set of 180 test cases for image segmentation. Notably, the process omitted conventional pre-processing steps such as denoising or anatomical extraction to assess the raw segmentation capability of the model directly.
Qualitative Evaluation
We performed a qualitative multireader analysis, in which three radiological experts (board-certified radiologists with 15, 10, and 8 years of experience in IR) visually evaluated the clinical applicability of the fully automated bone segmentation for bone subtraction. The 180 test cases (see Table 1), 60 each for thorax, abdomen, and pelvis, were pre-loaded into a DICOM viewer (Visage Imaging Inc., Visage 7, Build 3416). A standardized hanging protocol was developed, allowing the reader to quickly switch between the subtracted and the unsubtracted view, featuring multiplane reconstruction (MPR), maximum intensity projection (MIP), and volume rendering technique (VRT) visualization, as depicted in Fig. 1. The quality of the bone subtraction was evaluated using an ordinal scale in two dimensions: completeness of the bone subtraction (B-rating) and erosion of non-target structures, such as soft tissue (V-rating). The criteria for the B- and V-ratings are depicted in Table 2.Fig. 1. Example test case, depicting the different views for the reader: 3D maximum intensity projection (MIP) and volume rendering technique (VRT) unsubtracted and subtractedTable 2Definition of the evaluation criteria for the manual reading of the test casesB-RatingDefinitionB1Complete bone maskIn MIP and VRT, no residuals of the bone are seenIn MPR, at most, small subtraction residues close to the bone can be detected—without a significant correlation in MIP or VRTSoft tissue visualization using VRT and/or MIP is possible without obscuring bony structuresB2Irrelevant residual bone, no need for manual post-processingIn MIP and VRT, only irrelevant residuals (due to location or size) of the bone are seenSoft tissue visualization using VRT and/or MIP is possible without relevant obscuring bony structuresB3Relevant residual bone, manual post-processing necessaryIn MIP and VRT, relevant residuals of the bone are seen obscuring major, but not all soft tissue informationSoft tissue visualization using VRT and MIP is obscured in major parts by bony structures so that manual cropping at the workstation would be (deemed) necessaryThe user would have to apply corrective actions:Manual cropping of residual boneB4No (useful) bone mask was calculatedNo bone mask was calculated or an unusable bone mask even with manual correction was calculatedSoft tissue visualization using VRT and/or MIP is massively obscured by bony structuresThe user would have to apply corrective actions:The bone mask cannot be used and has to be resetV-RatingDefinitionV1No overreaching of the bone maskIn MPR, MIP, and VRT, there is no relevant truncation of soft tissue informationAt most, negligible truncation of soft tissue close to the bone can be detected; e. small arteries running next to or into the bone are affectedSoft tissue visualization using VRT and MIP is possible without restrictionsV2Mild overreaching, Minor truncation of soft tissue information:In MPR, MIP, and VRT, there is negligible truncation of the soft tissue:There are only clinically irrelevant truncations or only marginal truncations of relevant vesselsSoft tissue visualization using VRT and MIP is provided without relevant restrictionsV3Relevant overreaching of the bone maskIn MPR, MIP, and VRT, there is local truncation of clinically relevant information of the soft tissueIn case of truncation of clinically relevant vessels, the vessel’s central continuity is affectedSoft tissue visualization using VRT and MIP is limited due to truncation of clinically relevant structuresThe user would have to apply at least one of the following corrective actions:Manual cropping of the bone mask at the workstation would deem necessaryIn areas of relevant truncation, the original data would have to be used to assess relevant informationIn areas of relevant truncation, navigation would have to be supplemented (e. g. by graphic representations of the course of the vessels) to perform the clinical procedureV4Massive overreaching of the bone maskIn MIP and VRT, relevant truncation of clinically relevant information makes 3D visualization impossible. The bone mask is insufficient and cannot be usedSoft tissue visualization using VRT and MIP is not possibleThe user would have to apply corrective actions:The bone mask cannot be used and has to be resetMIP, Maximum intensity projection; VRT, volume rendering technique; MPR, multiplanar reconstruction
Additionally, we asked for a clinical appraisal of whether bone subtraction improves vessel assessment (VA-rating), classifying the result as “better,” “same,” or “worse.” 24 of the test cases were excluded from the VA-rating due to native (n = 3) or parenchymal contrast (n = 21).
The final score for each case across the three readers was determined by majority voting, yielding a single consensus B-, V-, and VA-rating per case.
Inter-Rater Agreement
In our dataset, almost all ratings fall in a single category (score = 1) with only a handful of discordant observations (score = 2). Under such extreme class imbalance, Krippendorff’s α, which corrects observed disagreement by the disagreement expected from the marginal distributions, suffers from the well-known prevalence/bias paradox. The expected-by-chance disagreement becomes vanishingly small, so even a few mismatches can yield α ≈ 0 or slightly negative despite high raw agreement.
Intraclass correlation coefficients (ICC) are likewise ill-suited here. ICC assumes at least interval-level, approximately normal, and homoscedastic measurement. It quantifies consistency in a linear model and is highly sensitive to restricted range (low between-item variance) and scale skew, both present with a bounded 1–4 ordinal scale dominated by a single category. In this setting, ICCs can be unstable and misleading, conflating lack of variability and reliability.
We report percent agreement as a primary descriptive metric to provide an interpretable summary that directly reflects how often readers make the same judgment. Percent agreement (PA) is unaffected by prevalence/bias corrections.
Quantitative Evaluation
Additionally, we present a quantitative analysis with overlap evaluation metrics, including the Dice coefficient, also referred to as the Sørensen–Dice coefficient, and the intersection over union (IoU), commonly known as the Jaccard index. For these metrics, 0 means no match and 1 means a perfect match.
Results
Qualitative Analysis
The qualitative results depicted in Table 3 demonstrate that the model is able to accurately delineate the bone structure with an overall B-rating of 1.01 ± 0.07 (mean ± std) while not eroding relevant non-target structures in a major way with an overall V-rating of 1.02 ± 0.13.Table 3. Summary statistics of the visual multireader analysisOverallReader 1Reader 2Reader 3B-ratingMean ± std1.01 ± 0.071.02 ± 0.131.04 ± 0.191.01 ± 0.07Median1111Min/max1/21/21/21/2#Test cases180180180180#Rating 1179177173179#Rating 21371V-ratingMean ± std1.02 ± 0.141.02 ± 0.181.09 ± 0.281.02 ± 0.15Median1111Min/max1/21/31/21/2#Test cases156156156156#Rating 1177177164176#Rating 232164#Rating 30100VA-ratingMean ± std1.00 ± 0.001.00 ± 0.001.00 ± 0.001.00 ± 0.00Median1111Min/max1/11/11/11/1#Test cases156156156156The B-rating evaluates the completeness of the bone mask, the V-rating evaluates if there is an overreaching of the bone mask, eroding relevant structures, such as vessels. The vessel assessment (VA) rating is a clinical appraisal of whether bone subtraction using BRM improves vessel assessment. The overall scores have been calculated by performing a majority voting of reader 1, 2, and 3. The number of test cases for the B-rating (# 180) differs from the V- and VA-rating (156) because no or no arterial contrast agent was applied in 24 cases
A selection of examples from the test set for the bone removal software for the thorax, abdomen, and pelvis is depicted in Fig. 2.Fig. 2. The study compares 3D maximum intensity projections (MIP) of cone beam CT (CBCT) scans, both with and without bone removal (BRM). These scans were performed for various medical procedures. One scan of the thorax was conducted to treat chronic thromboembolic pulmonary hypertension (CTEPH). Another scan of the upper abdomen was used for transarterial chemoembolization (TACE). A scan of the lower abdomen was carried out for endovascular aneurysm repair (EVAR). Additionally, scans of the pelvis were performed for prostate artery embolization (PAE) and for the detection of bleeding. The red arrows point to the bleeding
Inter-Rater Agreement
The PA for all three readers, where all the readers agree on the score per observation, is ≈ 94.4% for the B-rating, ≈ 89.1% for the V-rating, and 100% for the VA-rating. A detailed per-reader pair analysis is provided in Table 4.Table 4. Detailed inter-rater analysis with the percent agreement (PA) given for each rater combination for the B-rating, V-rating, and VA-ratingReader AReader BReader CPA (B-rating) [%]PA (V-rating) [%]PA (VA-rating) [%]Reader 1Reader 294.4489.10100Reader 1Reader 397.7897.44100Reader 2Reader 396.6791.03100Reader 1Reader 2Reader 394.4489.10100
Quantitative Analysis
We used the manual segmentation of the 180 CBCT test cases for quantitative analysis. The results depicted in the electronic supplementary material (ESM). Table 1 demonstrates a good alignment of the fully automated bone segmentation using the trained model, with the manual delineation of the bone structure, with a Sørensen–Dice coefficient of 0.95 ± 0.02 (mean ± std) and an IoU of 0.9 ± 0.03 overall. The ESM Table 1 lists a detailed subgroup analysis based on body region, institution, and sex.
Discussion
This study presents a promising advancement in applying fully automated bone removal software for CBCT angiography imaging. The development and deployment of this software offer a potential solution to the longstanding challenge of bony interference in imaging, which has traditionally compromised the clarity and diagnostic utility of such acquisitions, especially in areas densely populated by bone structures like the thorax, abdomen, and pelvis.
The qualitative and quantitative results obtained from the evaluation of 180 test cases indicate that the software achieves high accuracy in bone subtraction and maintains the integrity of non-target structures, such as soft tissues. The three readers concluded that all test cases benefited from applying the bone removal with a VA-rating of 1.0 ± 0.0 (mean ± std). This is also reflected in a high Sørensen–Dice coefficient of 0.95 ± 0.02. Additionally, bone subtraction improved vessel assessment and depiction of contrast material deposition in CBCT.
CBCT guidance has been shown to be beneficial in a wide range of angiographic interventions: Based on CBCT images, the contrasted vessels, e.g., pulmonary arteries in BPA, pelvic arteries in prostatic artery embolization, or hepatic arteries in TACE, can be visualized as a three-dimensional vascular tree by a VRT [5, 11, 21, 22]. This can be used as a graphic overlay with semitranslucent opacity and blended with live fluoroscopic images, allowing the use of CBCT vessel information for a real-time peri-interventional roadmap [5]. The value of CBCT for the pre- and peri-procedural management of super-selective conventional TACE has been highlighted recently in a recommendation from a panel of international expert physicians [21]. Furthermore, CBCT can also play a crucial role in pre-procedural planning and peri-procedural guidance during BPA, providing high-resolution imaging of the entire pulmonary vasculature [23]. Regarding PAE, pre-interventional CBCT can help identify the prostatic arteries, which, due to adjacent arterial branches arising from the internal iliac artery and variable origin of the prostatic artery, can be challenging [22].
However, as bones may obstruct the visualization of the vasculature and, thus, limit the expressiveness of the examination, BRM is usually mandatory. Currently, BRM requires manual interaction, potentially causing an inefficient workflow and delaying the procedure.
Several approaches have been made to automate bone segmentation. The vast majority used gray-value-based thresholding [24, 25], which regularly removes contrast-enhanced vessels, especially in proximity to bone structures. This effect is more pronounced with CBCT, which has higher image noise than CTA. This reduces the general usability of automated BRM for CBCT based on threshold values.
Our fully automated bone removal software, based on semantic segmentation, can facilitate BRM for the whole body trunk, thus offering improvements for manifold interventions. This allows a precise differentiation between vessel and bone, even in the peripheral sections of the vascular tree, regardless of the higher image noise compared to CTA. Additionally, the software may be integrated into existing image processing systems and provides real-time results.
There are study limitations inherent in the field of automated image segmentation. The reliance on specific attenuation values to distinguish between bone and soft tissue can introduce inaccuracies, highlighting the need to refine algorithms and segmentation techniques continuously. Furthermore, the study’s focus on a diverse study cohort from multiple centers adds to the robustness of the findings. However, it also suggests potential variability in scan quality and segmentation challenges across different settings.
Future research should address these limitations by exploring more sophisticated algorithms that can adapt to the variability in imaging data and further reduce the potential for incorrect removal of critical structures. Additionally, expanding the application of this technology to other imaging modalities and anatomical regions could broaden its utility in medical imaging. Integrating such automated BRM software into clinical practice could significantly enhance the efficiency and accuracy of diagnostic processes, particularly in the rapid evaluation of emergency conditions where time is of the essence.
Conclusion
This study demonstrates the feasibility and effectiveness of fully automated bone removal software in improving the clarity and diagnostic utility of CBCT images. By reducing the interference of bone structures without compromising the visibility of essential soft tissues and vascular systems, this technology represents a valuable tool in the interventional and diagnostic imaging arsenal.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 124 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Çiçek Ö, Abdulkadir A, Lienkamp SS, Brox T, Ronneberger O. 3D U-Net: learning dense volumetric segmentation from sparse annotation. Ar Xiv 160606650 Cs [Internet]. 2016 [cited 2017 May 27]; http://arxiv.org/abs/1606.06650. Accessed 27 May 2017.
- 2He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: surpassing human-level performance on Image Net classification. Ar Xiv 150201852 Cs [Internet]. 2015 [cited 2017 March 10]; http://arxiv.org/abs/1502.01852. Accessed 10 March 2017.
- 3Kingma DP, Ba J. Adam: a method for stochastic optimization. Ar Xiv 14126980 Cs [Internet]. 2014 [cited 2017 Mar 21]; http://arxiv.org/abs/1412.6980. Accessed 21 March 2017