EpiSmokEr2: a robust epigenetic classifier for smoking status inference using Illumina EPIC methylation data
Tianyu Zhu, Teodóra Faragó, Sailalitha Bollepalli, Aino Heikkinen, Mikaela Hukkanen, Olli Raitakari, Terho Lehtimäki, Tellervo Korhonen, Jaakko Kaprio, Fang Fang, Kaitlyn G. Lawrence, Dale P. Sandler, Mari Roberts Spildrejorde, Kristina Gervin, Yanyu Pan, Ricardo Costeira

TL;DR
EpiSmokEr2 is a DNA methylation-based tool that accurately identifies smoking status from blood samples, even when data is incomplete.
Contribution
EpiSmokEr2 is a novel, robust DNAm classifier for smoking status inference using 511 CpGs from the EPIC array.
Findings
EpiSmokEr2 achieved 87% sensitivity and 86% specificity in identifying current versus never smokers.
The classifier correlated strongly with established smoking-related DNAm scores and GrimAge.
EpiSmokEr2 remains robust even with up to 10% missing CpG data.
Abstract
Tobacco smoking induces persistent DNA methylation (DNAm) changes in blood that can serve as long-term biomarkers for smoking exposure. We aimed to develop and validate a DNAm classifier of smoking status using Illumina EPIC array data. We built Epigenetic Smoking status Estimator2 (EpiSmokEr2), a Least Absolute Shrinkage and Selection Operator (LASSO) regression-based DNAm classifier using 511 CpGs from Illumina Infinium MethylationEPIC array (EPIC) data. The model was trained on 1343 samples from the Young Finns Study cohort and validated across six independent datasets from four cohorts and two array platforms (EPIC and EPICv2). EpiSmokEr2 achieved an average sensitivity of 0.87 and specificity of 0.86 in distinguishing current from never smokers. Predicted smoking status correlated strongly with established DNAm smoking scores and GrimAge, indicating its ability to capture…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
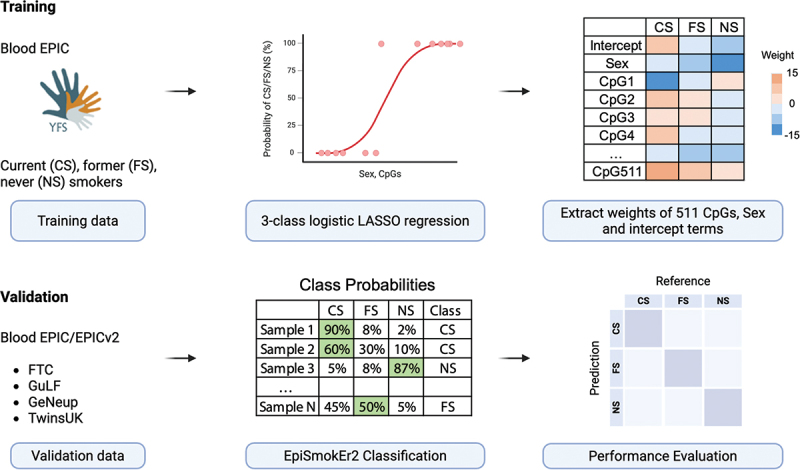 Figure 1
Figure 1 Figure 2
Figure 2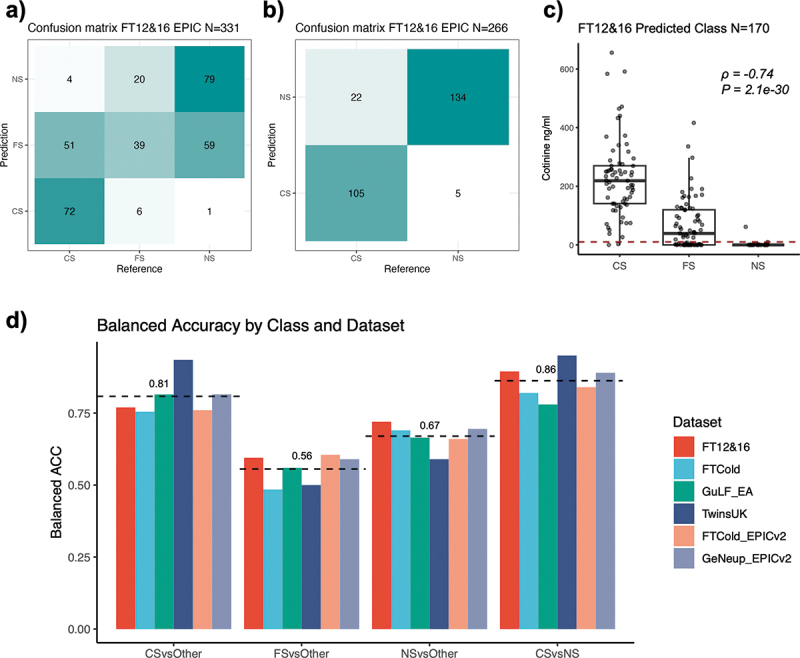 Figure 3
Figure 3 Figure 4
Figure 4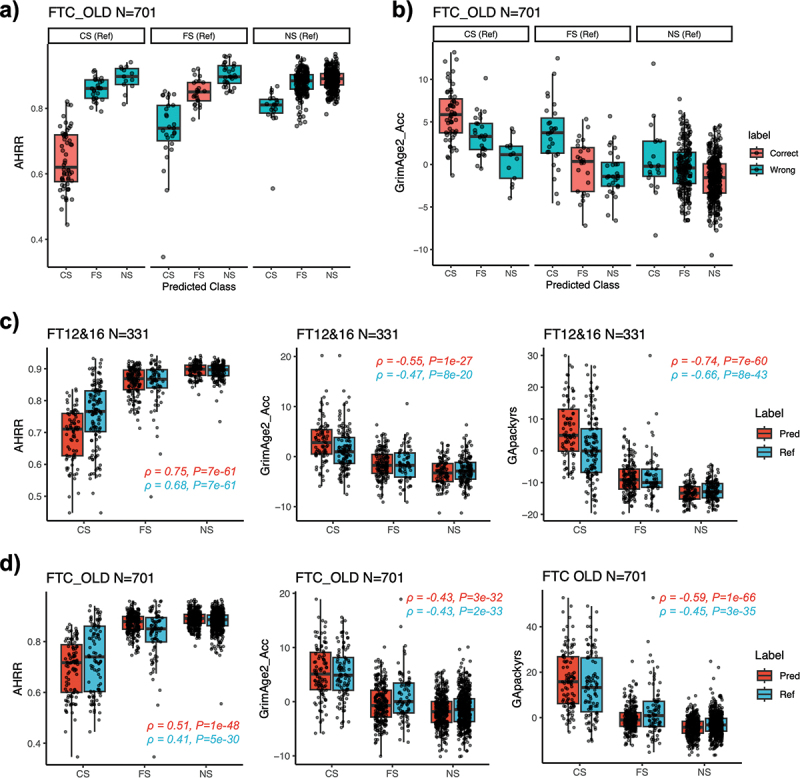 Figure 5
Figure 5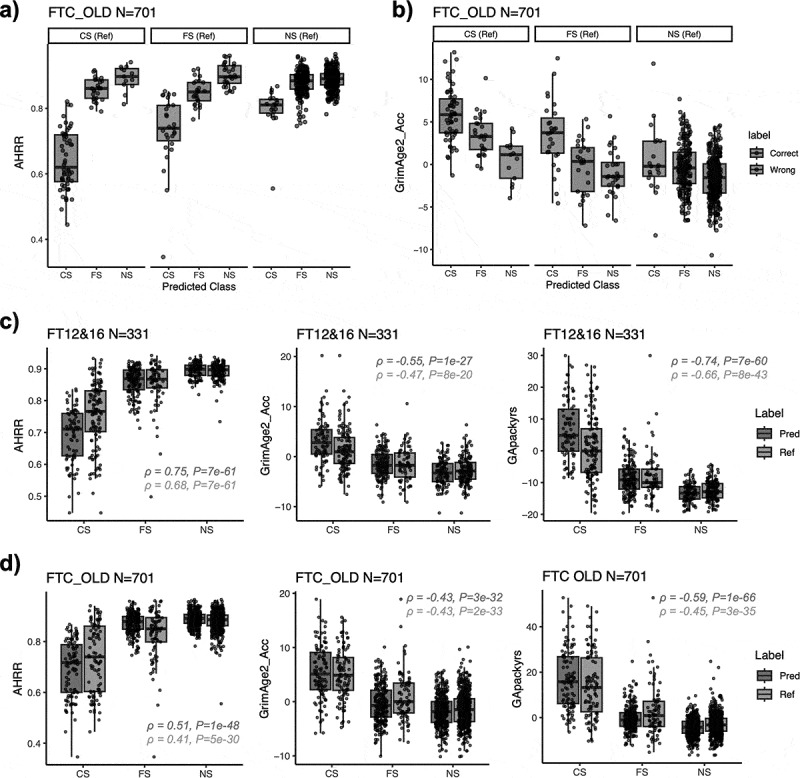 Figure 6
Figure 6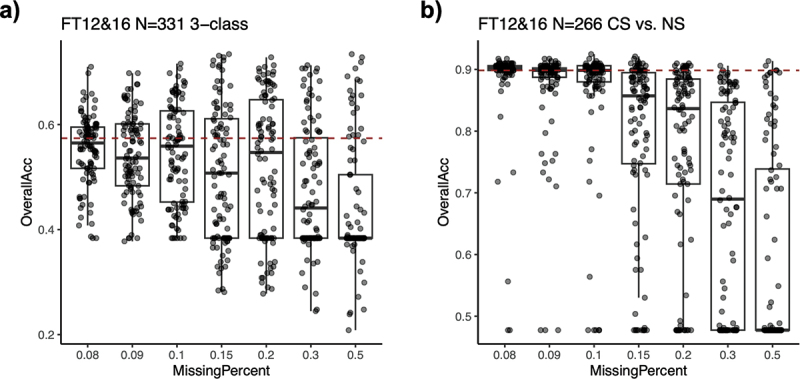 Figure 7
Figure 7 Figure 8
Figure 8- —Academy of Finland10.13039/501100002341
- —Liv o Hälsa rf
- —Finnish Cultural Foundation10.13039/501100003125
- —Sigrid Juselius Foundation
- —Social Insurance Institution of Finland
- —Competitive State Research Financing of the Expert Responsibility area of Kuopio, Tampere and Turku University Hospitals
- —Juho Vainio Foundation10.13039/501100004037
- —Paavo Nurmi Foundation10.13039/501100008484
- —Finnish Foundation for Cardiovascular Research10.13039/501100005633
- —Tampere Tuberculosis Foundation10.13039/501100006706
- —Emil Aaltonen Foundation10.13039/501100004756
- —Yrjö Jahnsson Foundation
- —Signe and Ane Gyllenberg Foundation10.13039/501100004325
- —Diabetes Research Foundation of Finnish Diabetes Association
- —EU Horizon 2020
- —European Research Council10.13039/100010663
- —Tampere University Hospital Supporting Foundation
- —Finnish Society of Clinical Chemistry
- —the Cancer Foundation Finland
- —CVDLink
- —Jane and Aatos Erkko Foundation10.13039/501100004012
- —Wellcome Trust10.13039/100004440
- —Medical Research Council10.13039/501100000265
- —Versus Arthritis
- —European Union Horizon 2020
- —Chronic Disease Research Foundation (CDRF)
- —Zoe Ltd
- —National Institute for Health and Care Research (NIHR) Clinical Research Network (CRN)
- —Biomedical Research Centre based at Guy’s and St Thomas’ NHS Foundation Trust in partnership with King’s College London
- —TwinsUK
- —European HDHL Joint Programming Initiative funding scheme DIMENSION award
- —BACMETH award
- —ERC consolidator award
- —Engineering and Physical Sciences Research Council10.13039/501100000266
- —Economic and Social Research Council10.13039/501100000269
- —GuLF Long-Term Follow-up Study
- —Intramural Research Program of the National Institutes of Health (NIH), National Institute of Environmental Health Sciences
- —U.S. Department of Health and Human Services10.13039/100000016
- —National Institute on Drug Abuse10.13039/100000026
- —GeNeup study
- —Research Council of Norway10.13039/501100005416
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEpigenetics and DNA Methylation · Genetic Associations and Epidemiology · Health, Environment, Cognitive Aging
Introduction
Tobacco smoking is a leading risk factor for cardiovascular disease, respiratory disorders, and multiple cancers [1–3]. While self-reported smoking status is widely used in research and clinical practice, it is susceptible to recall bias (inaccurate memory of smoking history), and social desirability bias (deliberate misreporting of smoking status due to stigma) [4,5]. Although metabolic biomarkers such as blood or urine cotinine provide objective measures of recent tobacco exposure, their utility is limited to short-term detection within 24–72 hours since the last tobacco use due to their short half-life [6].
DNA methylation (DNAm) has emerged as a persistent, long-term biomarker of smoking exposure, capturing both current and past smoking behavior in a dose-dependent manner [7–9]. Notably, hypomethylation at cg05575921 mapped to the gene body of AHRR (Aryl hydrocarbon receptor repressor) and other smoking-associated CpG sites can discriminate smokers from nonsmokers with area under the curves (AUCs) >0.9 and reflect the recency of cessation [8,10,11]. However, these scores are typically continuous measures and translating them into categorical smoking status (current/former/never smokers) requires thresholding. Due to variability in population characteristics, technological platforms and data processing methods, there is no such threshold that is universally applicable across datasets.
To address these challenges, we previously developed Epigenetic Smoking status Estimator (EpiSmokEr), a machine learning classifier designed for Illumina 450K methylation array data [7]. With the transition from 450K arrays to the more advanced EPIC and EPICv2 arrays, which cover ~900,000 and ~930,000 CpG sites, respectively, compared to 450K’s ~ 480,000 CpG sites, there is a growing need for updated classification tools. In this study, we introduce EpiSmokEr2, a new DNAm-based classifier designed for EPIC and EPICv2 data. We rigorously evaluated its performance in seven independent datasets across four cohorts comprising individuals from different ancestries (European and African) and provide it as an open-source R package to facilitate smoking classification in epidemiological and clinical research.
Methods
Selection and categorization of training samples
2.1.
The training set is from the Young Finns Study (YFS) cohort [12,13], which includes EPIC samples from 1445 individuals with available smoking information [14]. A detailed description of the YFS dataset is provided in supplementary material. The smoking status at the time of sampling is obtained from self-reported questionnaires, based on the following question:What is your current smoking status?
1: Smokes once a day or more often
2: Smokes once a week or more often, but not daily
3: Smokes less often than once a week
4: Attempts to quit smoking
5: Has quit smoking
6: Has never smoked
Participants were categorized into 3 groups:
Never smokers (answer 6),
Former smokers (answer 5),
Current smokers (answers 1, 2, and 4).
Individuals who reported smoking less than once a week (answer 3, occasional smokers) were excluded from the training sample to reduce ambiguity in smoking status, as their DNAm profile (proxied by cg05575921 mapped to AHRR gene body [15]) was much closer to those of never smokers than current smokers (Figure S1). Self-reported passive smokers, as well as never smokers who have reported smoking in previous questionnaires were also removed. The final training set consisted of 1343 samples (current-smoker: 274; former-smoker: 337; never-smoker: 732).
Training of EpiSmokEr2
2.2.
To reduce dimensionality and exclude uninformative probes, CpGs were first filtered based on variability, retaining 192,549 probes with variance above the 75th percentile (variance > 0.00153) within the training dataset. A multinomial LASSO regression model was then trained using glmnet R package [16,17], including sex as an unpenalized covariate. The penalization parameter (λ) was determined via cross-validation by minimizing the multinomial deviance, following the same procedure described for EpiSmokEr [7]. The final model selected 511 CpGs in a data-driven manner and estimated the weights based on the optimal λ value.
For classification, the model outputs the log-odds of a sample belonging to each of the 3 smoking statuses. These log-odds were converted to class probabilities using the softmax function, ensuring that the probabilities sum to one across all classes for one individual. The final smoking status classification was assigned to the category with the highest posterior probability.
Validation of EpiSmokEr2
2.3.
We evaluated EpiSmokEr2 in seven independent datasets across four cohorts: The Finnish Twin Cohort (FTC) [18–20], The GuLF Study (GuLF) [21], TwinsUK [22,23], and the GeNeup Study [24]. A detailed description of these datasets is provided in the supplementary material. Using self-reported smoking status as the reference, we evaluated classification performance by calculating sensitivity and specificity for each smoking category, as well as overall accuracy. The balanced accuracy of each smoking category was calculated as the mean of sensitivity and specificity. The metrics were calculated using the confusionMatrix function from caret R package [25]. We assessed performance in both 3-class (current, former, never smokers) and 2-class (current vs. never smokers) frameworks, excluding former smokers in the latter due to their ambiguous classification and potential overlap with other groups.
DNA methylation GrimAge2 and smoking pack-years calculation
2.4.
DNAm GrimAge2 [26] is an epigenetic biomarker of aging based on DNA methylation patterns. It was calculated based on 9 DNAm-based surrogates of plasma proteins, an estimator of smoking pack-years (DNAm PACKYRS) and 2 demographic characteristics: chronological age and sex. Age acceleration (AgeAccelGrim2) was determined as the residuals from regressing DNAm GrimAge2 on chronological age. We correlated the EpismokEr2-predicted smoking status with AgeAccelGrim2 as well as DNAm PACKYRS, following established protocols [26].
Evaluation of EpiSmokEr2 robustness to missing CpGs
2.5.
To assess the robustness of EpiSmokEr2 to missing CpGs in the input data, we systematically introduced missing values by randomly excluding 8% to 50% of CpGs in the FT12&16 dataset, covering a range above the baseline missing rate of 7% observed in the original quality-controlled beta matrix. For each missingness percentage (8%, 9%, 10%, 15%, 20%, 30%, 50%), we performed 50 independent iterations of random CpG exclusion and subsequent classification. Model performance was evaluated by comparing the overall accuracy of both 3-class (current/former/never smoker) and 2-class (current/never smoker) classifications against the baseline performance (7% missing CpGs).
Results
EpiSmokEr2 model
3.1.
An overview of workflow is shown in Figure 1. We trained a 3-class LASSO logistic regression model using blood sample DNAm EPIC data from the YFS, with self-reported smoking status. The final model is based on 511 CpGs, a sex and an intercept term (Figure S2). Top CpGs with the highest coefficients were mapped to AHRR gene body (cg05575921, cg26703534) and an intergenic smoking-related CpG (cg21566642). These CpGs were enriched in unannotated genomic regions and were underrepresented in TSS200 (two-sided Fisher’s exact test, FDR = 4e-6) and first exon regions (two-sided Fisher’s exact test, FDR = 8e-3, Figure S3). Figure 1.EpiSmokEr2 study overflow. EpiSmokEr2 was trained on 1343 EPIC samples from the Young Finns Study (YFS) Cohort, with smoking status (current, former, and never) determined by self-reported questionnaires. A 3-class logistic regression model with LASSO penalty (including sex as a fixed covariate) selected 511 discriminative CpGs. For validation, we applied the model to seven independent EPIC and EPICv2 data from four cohorts, assigning smoking status based on the highest predicted probability. Performance was assessed using sensitivity and specificity for each smoking category, as well as overall accuracy. Partially created in BioRender. Zhu, T. (2026) https://BioRender.com/yku3y2g.
Validation in EPIC datasets
3.2.
We evaluated our model across seven independent EPIC (v1 and v2) datasets from four cohorts: FTC, GuLF, TwinsUK, and GeNeup (Table 1, Methods). The confusion matrices showing the reference (self-reported) and predicted smoking status can be found in Figure 2(a,b), for FT12&16 FTC sub-cohort, and Figures S4-S9, for other cohorts. To assess the performance of our classifier, we calculated the sensitivity and specificity of classifying individuals into each category, as well as overall accuracy (Table 2, Methods). The 3-class classification only achieved average balanced accuracy (defined as average of sensitivity and specificity) of 0.81, 0.56 and 0.67 for current, former and never smokers respectively across all datasets, primarily due to misclassification of former smokers. When excluding the former smokers, the 2-class classification of current versus never smokers attained a higher average balanced accuracy of 0.86 (Figure 2(d)). Performance varied across populations, with one subset of the GuLF cohort (individuals of African ancestry) showed reduced accuracy compared to those of European ancestry (Table 2, Figure S6). Notably, the model performed well on datasets from the latest platform EPICv2 (Figure 2(d), Table 2). Figure 2.Validation of EpiSmokEr2. (a) Confusion matrix for EpiSmokEr2 applied to 331 FT12&16 EPIC samples. Numbers represent sample counts with reference (self-reported) smoking status (x-axis) versus predicted status (y-axis). (b) the same as (a), but excluding self-reported former smokers. Predictions were based on probability comparisons between current and never smokers. (c) Boxplot of cotinine levels in predicted current, former and never smokers. The red dashed line (10 ng/ml) indicates the threshold above which individuals are considered to have smoked within 24 hours before blood draw. Spearman’s rank correlation coefficients (ρ) and p-values were calculated between cotinine levels and the predicted smoking status, with current smokers (CS), former smokers (FS), and never smokers (NS) coded as 1, 2, and 3, respectively. (d) Barplot showing the balanced accuracy (defined as the mean of sensitivity and specificity) for predicting each class across six independent datasets (excluding the GuLF African ancestry dataset), using self-reported status as reference. CSvsOther, FSvsOther, and NSvsOther correspond to one-vs-rest evaluations in the 3-class classification. CSvsNS corresponds to 2-class classification of current versus never smokers. The black dashed line shows the mean balanced accuracy per smoking category. Colors indicate datasets.Abbreviations: CS, current smoker; FS, former smoker; NS, never smoker.Table 1.Statistics of the datasets in this study.DatasetTotalCSFSNSSex (F/M)Age (mean±SD)RacePlatformYFS1343274337732751/59241.8 ± 5.1EuropeanEPICFT12&1633112765139164/16725.3 ± 2.2EuropeanEPICFTCOLDv17019580526641/6065.6 ± 9.4EuropeanEPICGuLF_EA8433021813600/84346.0 ± 11.8EuropeanEPICGuLF_AA632214753430/63241.4 ± 11.0AfricanEPICTwinsUK64129235377632/962.3 ± 9.6EuropeanEPICFTCOLDv22235269102145/7857.5 ± 7.2EuropeanEPICv2GeNeup1054185520349498/55657.5 ± 9.5EuropeanEPICv2Abbreviations: SD = standard deviation; CS = current smoker; FS = former smoker; NS = never smoker.Table 2.Validation Performance Metrics.DatasetSensitivitySpecificityOverall accuracyFT12&16 (N = 331) 0.57CS vs others0.570.97 FS vs others0.600.59 NS vs others0.570.87 CS vs NS0.830.960.90FTC OLD EPIC (N = 701) 0.57CS vs others0.590.92 FS vs others0.310.66 NS vs others0.610.77 CS vs NS0.730.910.88GuLF_EA (N = 843) 0.58CS vs others0.990.64 FS vs others0.330.79 NS vs others0.370.96 CS vs NS0.990.570.76GuLF_AA (N = 632) 0.37CS vs others0.960.44 FS vs others0.200.71 NS vs others0.040.99 CS vs NS1.000.170.49TwinsUK_EPIC (N = 641) 0.63CS vs others0.900.97 FS vs others01 NS vs others10.18 CS vs NS0.9010.99FTC OLD EPICv2 (N = 223) 0.56CS vs others0.650.87 FS vs others0.580.63 NS vs others0.490.83 CS vs NS0.790.890.86GeNeup_EPICv2 (N = 1054) 0.57CS vs others0.860.77 FS vs others0.500.68 NS vs others0.510.88 CS vs NS0.960.820.87Predicted smoking status was compared with self-reported smoking status. For each smoking status category, the sensitivity and specificity values were calculated by comparing that one with the other two categories (3-class classification), and current to never smokers (2-class classification). Overall accuracy is the proportion of all correctly classified samples out of the total number of samples.Abbreviations: CS = current smoker; FS = former smoker; NS = never smoker.
Among samples with blood cotinine measurements in FT12&16 cohort (112 current, 34 former, and 24 never smokers), EpiSmokEr2-predicted smoking statuses were strongly correlated with cotinine levels (Spearman’s correlation coefficient ρ=−0.74, p = 2.1e-30). The predicted current smokers exhibited significantly higher cotinine levels compared to predicted never smokers, while predicted former smokers displayed intermediate levels, reflecting mixed profiles of current and never smokers (Figure 2(c)).
EpiSmokEr2 predicts biological smoking status
3.3.
To further explore the high misclassification rate among self-reported former smokers, we examined time since cessation, smoking duration, and pack-years in 60 samples from FT12&16 cohorts and 32 samples from FTC OLD cohort. Although these data were available only for a limited number of individuals, predicted smoking status showed consistent trends: self-reported former smokers with shorter cessation time (Spearman’s ρ=0.25, p = 0.054), marginally longer smoking duration (Spearman’s ρ=−0.21, p = 0.10), and higher pack-year (Spearman’s ρ=−0.50, p = 3.6e-3) were often classified as current smokers, whereas those with longer cessation time, shorter smoking duration, and lower pack-years were more often classified as never smokers (Figure S10).
We then correlated EpiSmokEr2 classifications with well-established biomarkers of smoking exposure: AHRR methylation [15] (smoking-related hypomethylation on cg05575921) and GrimAge2 [26] (an epigenetic clock related to smoking exposure). In the FTC OLD cohort, EpiSmokEr2-predicted smoking status consistently correlated with AHRR methylation, which was lowest in predicted current smokers, highest in predicted never smokers, and intermediate in former smokers, suggesting that methylation profiles in misclassified cases reflect biological smoking effects (Figure 3(a)). Similar trends were also observed across other independent cohorts (Figures S4-S9). Predicted current smokers also showed accelerated GrimAge2 aging compared to predicted former or never smokers (Figure 3(b)). Moreover, AHRR methylation, GrimAge2 age acceleration, and GrimAge2 pack-years showed stronger correlations with EpiSmokEr2 predictions than with self-reported status (Figure 3(c,d)), supporting its utility in capturing biologically meaningful smoking effects. Figure 3.Correlation between EpiSmokEr2 predictions and DNAm biomarkers. (a) Boxplots showing AHRR (cg05575921) methylation levels in the FTC OLD cohort, stratified by reference (self-reported) smoking status (panels) and predicted smoking status (x-axis). Correctly classified samples are shown in red and misclassified samples in blue. (b) Same as (a), but for GrimAge2 age acceleration. (c) Boxplots showing the AHRR methylation (left), GrimAge2 age acceleration (middle) and GrimAge pack years (right) in the FT12&16 dataset. Predicted smoking status is shown in red and reference (self-reported) smoking status in blue. Spearman’s rank correlation coefficients (ρ) and p-values were calculated between the smoking-related scores and smoking status, with current smokers (CS), former smokers (FS), and never smokers (NS) coded as 1, 2, and 3, respectively. (d) Same as (c), but for FTC old cohort.Abbreviations: GrimAge2_Acc, GrimAge2 age acceleration; GApackyrs, GrimAge pack years; CS, current smoker; FS, former smoker; NS, never smoker.
EpiSmokEr2 is robust for up to 10% of missing CpGs
3.4.
A key advantage of EpiSmokEr2 is its incorporation of 511 CpG sites, which ensures robust performance even with partial missing data. To systematically evaluate this, we conducted simulations by artificially introducing varying proportions of missing CpGs (8%, 9%, 10%, 15%, 20%, 30%, 50%) in the FT12&16 test dataset. When compared to the baseline scenario (which contained ~7% missing CpGs), the model maintained high predictive accuracy with up to 10% missing CpGs, demonstrating its robustness to missing data (Figure 4(a,b)). Figure 4.Robustness of EpiSmokEr2 under missing CpGs. (a) Boxplots showing the overall accuracy (y-axis) under varying percentages of missing CpGs (x-axis). For each percentage, CpGs were randomly masked for 50 times, and overall accuracy was derived from 3-class classification. The red dashed line indicates the baseline performance under 7% of missing CpGs. (b) Same as (a), but for 2-class classification of current and never smokers.Abbreviations: CS, current smoker; FS, former smoker; NS, never smoker.
Comparison to EpiSmokEr
3.5.
The original EpiSmokEr was developed using Illumina 450K data and ultimately selected 121 CpGs through its model-fitting procedure [7]. Among them, only four CpGs were present in EpiSmokEr2 model, including highly weighted cg05575921 (mapped to AHRR) and cg21566642 (an intergenic smoking-related loci). Comparing the model performance of the two models on 450K and EPIC data respectively, we found that EpiSmokEr was better in 450K samples while EpiSmokEr2 remains optimal for EPIC samples (Figure S11). Together, the two tools provide complementary, platform-specific estimators aligned with the ongoing transition from 450K to EPIC in epigenetic epidemiology. The features of EpiSmokEr and EpiSmokEr2 are summarized in Table 3.Table 3.Comparison of EpiSmokEr and EpiSmokEr2.CategoryEpiSmokErEpiSmokEr2Array platform used in model trainingIllumina 450KIllumina EPICTraining method3-class LASSO regression3-class LASSO regressionNumber of CpGs selected121 (94 available on EPIC)511 (230 available on 450K)Intended useOptimal for 450K datasetsOptimal for EPIC/EPICv2 datasetsLimitationsReduced performance on EPIC due to missing probesReduced performance on 450K due to missing probes
Performance comparison between male and female participants
3.6.
To assess potential sex-specific differences in model performance, we applied EpiSmokEr2 separately to male and female participants in three FTC datasets (Table S1). In the FT12&16 datasets, where male and female sample sizes are relatively balanced, classification performance was highly comparable between sexes. In contrast, in the FTC EPICv1 and EPICv2 datasets, where there are more female participants, performance appeared higher in females than in males.
Classification of self-reported never smokers with inconsistent smoking histories
3.7.
We also examined a subset of uncertain self-reported never smokers with inconsistent smoking histories – individuals who had previously reported smoking or who had documented passive exposure and were excluded from the primary analyses. EpiSmokEr2 classified 2 of 17 individuals in YFS and 18 of 32 individuals in FT12&16 as former smokers, and 1 FT12&16 individual as a current smoker (Figure S12).
Discussion
Performance and advantages of EpiSmokEr2
4.1.
We present EpiSmokEr2, an advanced DNAm-based classifier for smoking status that is compatible with EPIC and EPICv2 array data. Our model was rigorously validated in six independent European ancestry datasets across four cohorts, demonstrating robust performance in distinguishing current, former, and never smokers.
Performance in the FTC OLD cohort (EPIC and EPICv2) was slightly reduced compared with FT12&16 cohorts, likely due to differences in smoking status definition. In the FTC OLD cohort, missing smoking-status (N = 240) at the time of blood sampling was inferred from the questionnaire completed closest to the sampling date (within 10 years), introducing potential smoking status errors that may have impacted classification accuracy.
Performance was highly comparable between females and males in the FT12&16 dataset, where sample sizes were balanced. Although higher accuracy was observed in females than in males in the FTC OLD cohort (EPIC and EPICv2), this difference is more likely due to the substantially larger number of female participants and uneven distribution of smoking status across sexes, rather than a true sex-specific effect on model performance. Sex was explicitly included as a covariate to account for known sex-related differences in DNAm. While sex contributes to the model, the effect size is small relative to the major smoking-associated CpGs (Figure S2), indicating that the classification is primarily driven by smoking-related DNAm patterns rather than sex-specific effects.
EpiSmokEr2 offers two key advantages over existing methods. First, unlike conventional approaches that rely on DNAm scores which require arbitrary cutoffs to determine smoking status, EpiSmokEr2 directly outputs smoking status probabilities without the need for post-hoc thresholding. Supplementary analyses indicate broadly comparable performance between score-based classification using optimized thresholds and EpiSmokEr2 (Figure S13; Supplementary Methods). However, these approaches are not directly comparable, as DNAm scores are primarily intended to model smoking exposure as a continuous variable in association analyses, whereas EpiSmokEr2 is designed for robust categorical inference. We further note that although EpiSmokEr2 also outputs smoking probability that is well correlated with cotinine level (Figure S14), these probabilities are best interpreted as complementary measures reflecting classification uncertainty rather than precise estimates of smoking exposure. Second, like the first version, EpiSmokEr2 leverages a machine learning framework incorporating a large number of CpG sites compared to previous score-based methods. This not only enhances predictive power but also ensures robustness in the presence of missing CpGs – a common issue in real-world datasets due to probe filtering or platform differences.
CpG features and biological relevance
4.2.
Among the CpGs selected in EpiSmokEr2, the top-ranked sites overlapped with well-established smoking-associated loci identified in multiple epigenome-wide association studies (EWAS). For instance, cg05575921 and cg26703534 in the AHRR gene body and cg21566642 in an intergenic region have been repeatedly highlighted as robust smoking biomarkers [15,27–29]. While most of the remaining CpGs selected by the model were located in unannotated regions and showed no clear pathway enrichment, their selection suggests that they may capture biologically relevant signals not yet characterized. This highlights a key advantage of machine learning approaches in uncovering predictive features that appear random but may represent novel markers of interest.
Classification challenges in former smokers
4.3.
A limitation of our model is the seemingly reduced accuracy in classifying self-reported former smokers. This limitation is likely due to varying definitions of smoking cessation (e.g., time since quitting, smoking intensity prior to cessation), social desirability to report cessation in a health-related survey despite continuing to smoke, possibility for passive smoking or active nicotine replacement therapy (NRT), and the dynamic nature of post-cessation DNAm changes. Thus, former smokers do not represent a biologically homogeneous group, creating substantial overlap between current and former smokers as well as between former and never smokers. Consistent with this interpretation, classification among former smokers was associated with time since cessation, smoking duration, and pack-years, indicating that discrepancies primarily reflect underlying exposure history rather than random model error. Importantly, the biological signal of smoking captured by EpiSmokEr2 may be more relevant for downstream health-risk assessment than strict agreement with self-reported smoking categories. This was further supported by the result that EpiSmokEr2-predicted smoking status showed stronger correlations with both AHRR methylation levels and accelerated epigenetic aging than self-reported smoking status. Harmonized and detailed smoking-history variables would further improve interpretability and classification of former smokers.
Ancestry considerations
4.4.
While performance was excellent in European ancestry populations, predictive accuracy was reduced in individuals of African ancestry. The discrepancy likely stems from the European ancestry of our training data, as population-specific DNAm patterns have been well-documented for smoking-associated loci [30,31]. Although CpGs with known SNPs were removed from our training set, ancestry-related differences in methylation quantitative trait loci (meQTL) landscapes and baseline DNAm distributions may still influence the magnitude and direction of smoking-associated DNAm changes, thereby affecting model performance. However, many of the CpGs selected by the model map to well-established smoking-associated loci (e.g., AHRR) that have been replicated across diverse ancestries in previous epigenome-wide association studies [15,27–29,32]. This suggests that the core biological smoking signal is broadly conserved and that ancestry-specific DNAm effects are likely to be modest on smoking-related DNAm changes. In addition to ancestry-related biological differences, definitions of “current,” “former,” and “never” smoking status may vary across cultural or study-specific contexts [33]. Such variation can lead to label inconsistency between cohorts and likely contributed to the reduced performance. Achieving optimal cross-population performance may therefore require ancestry-specific calibration or harmonized phenotype definitions. Together, these findings emphasize the importance of incorporating more diverse populations into future training datasets.
Identification of misreporting in questionnaire
4.5.
To further assess the utility of EpiSmokEr2 in situations where self-reported smoking history may be uncertain, we also evaluated a subset of uncertain self-reported never smokers from the YFS and FTC cohorts. EpiSmokEr2 classified a subset of them as former or current smokers, indicating the presence of detectable smoking-related DNAm signatures. While the true smoking status of these individuals cannot be definitively established due to potential inconsistencies in questionnaire data and the possibility of occasional (non-daily) or sporadic smoking, these results highlight that the classifier reflects underlying biological exposure rather than reliance on categorical self-report. This reinforces the value of DNAm-based classification, particularly in contexts where misreporting or recall bias may affect questionnaire-derived smoking status.
Future directions
4.6.
Future predictions could involve further validation in larger, more diverse populations and exploration of longitudinal DNAm changes. Additionally, as single-cell and whole-genome sequencing technologies advance, adapting EpiSmokEr2 to these platforms may further expand its utility in both research and clinical settings.
Conclusion
EpiSmokEr2 provides a reliable DNAm-based approach for classifying smoking status across diverse cohorts and array platforms. It improves on traditional score-based methods by giving smoking status directly, using a wide set of CpG sites, and staying reliable even when some probes are missing. While former smokers remain challenging to classify because of heterogeneous cessation patterns, the tool nevertheless captures biologically meaningful smoking effects, as reflected in its strong association with time since cessation, duration of smoking, smoking pack-years, AHRR methylation and epigenetic aging. As an open-source and practical resource, EpiSmokEr2 offers an effective solution for enhancing smoking exposure assessment in epidemiological and clinical research.
Supplementary Material
Supplementary_Methods_RV2.docx
Supplementary_Figures_RV2.docx
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jha P, Ramasundarahettige C, Landsman V, et al. 21st-Century hazards of smoking and benefits of cessation in the United States. N Engl J Med. 2013;368(4):341–350. doi: 10.1056/NEJ Msa 121112823343063 · doi ↗ · pubmed ↗
- 2Ambrose JA, Barua RS. The pathophysiology of cigarette smoking and cardiovascular disease. J Am Coll Cardiol. 2004;43(10):1731–1737. doi: 10.1016/j.jacc.2003.12.04715145091 · doi ↗ · pubmed ↗
- 3Doll R, Peto R, Boreham J, et al. Mortality in relation to smoking: 50 years’ observations on male British doctors. BMJ. 2004;328(7455):1519. doi: 10.1136/bmj.38142.554479.AE 15213107 PMC 437139 · doi ↗ · pubmed ↗
- 4Gorber SC, Schofield-Hurwitz S, Hardt J, et al. The accuracy of self-reported smoking: a systematic review of the relationship between self-reported and cotinine-assessed smoking status. Nicotine Tob Res. 2009;11(1):12–24. doi: 10.1093/ntr/ntn 01019246437 · doi ↗ · pubmed ↗
- 5Singh PK, Jain P, Singh N, et al. Social desirability and under-reporting of smokeless tobacco use among reproductive age women: evidence from National family Health survey. SSM - Popul Health. 2022;19:101257. doi: 10.1016/j.ssmph.2022.10125736263294 PMC 9573902 · doi ↗ · pubmed ↗
- 6Murphy SE, Wickham KM, Lindgren BR, et al. Cotinine and trans 3′-hydroxycotinine in dried blood spots as biomarkers of tobacco exposure and nicotine metabolism. J Expo Sci Environ Epidemiol. 2013;23(5):513–518. doi: 10.1038/jes.2013.723443235 PMC 4048618 · doi ↗ · pubmed ↗
- 7Bollepalli S, Korhonen T, Kaprio J, et al. Epi Smok Er: a robust classifier to determine smoking status from DNA methylation data. Epigenomics. 2019;11(13):1469–1486. doi: 10.2217/epi-2019-020631466478 · doi ↗ · pubmed ↗
- 8Langdon RJ, Yousefi P, Relton CL, et al. Epigenetic modelling of former, current and never smokers. Clin Epigenet. 2021;13(1):206. doi: 10.1186/s 13148-021-01191-6 · doi ↗