Textbook-level medical knowledge in large language models: comparative evaluation using Japanese National Medical Examination
Mingxin Liu, Tsuyoshi Okuhara, Zhehao Dai, Minghong Zhao, Wenqiang Yin, Hiroko Okada, Emi Furukawa, Takahiro Kiuchi

TL;DR
This study evaluates the performance of four advanced AI models on a Japanese medical exam, finding they perform well but struggle with clinical reasoning.
Contribution
The study provides the first comparative evaluation of the latest large language models on the Japanese National Medical Examination.
Findings
Gemini 2.5 Pro achieved the highest overall accuracy at 97.2% on the Japanese National Medical Examination.
LLMs performed significantly worse on clinical questions involving complex contexts and diagnostic imaging.
All four models exceeded a 95% accuracy benchmark, suggesting potential for use in medical education.
Abstract
The accuracy of the latest reasoning-enhanced large language models on national medical licensing examinations remains unknown, which is crucial for determining how close they are to serving as effective knowledge sources for medical education. This study aimed to evaluate the performance of four reasoning-enhanced large language models (LLMs)—GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro—on the Japanese National Medical Examination (JNME), providing insights into their potential as educational resources and their future applicability in medical practice. We evaluated LLM performance using the 2019 and 2025 JNME (n = 793). Questions were entered into each model with chain-of-thought prompting enabled. Accuracy was assessed overall and by question type. Incorrect responses were qualitatively reviewed by a licensed physician and a medical student. From highest to lowest, the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
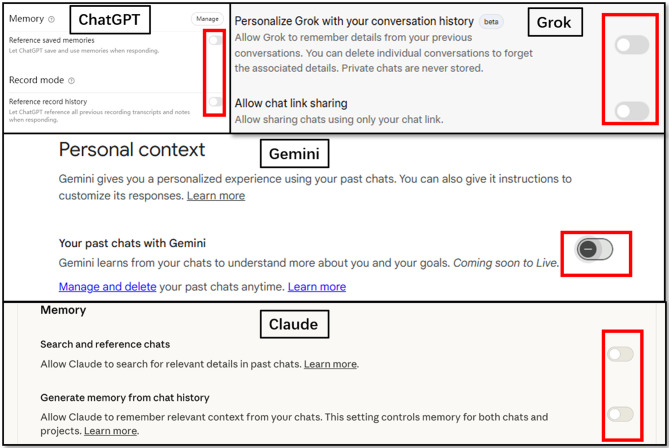 Figure 1
Figure 1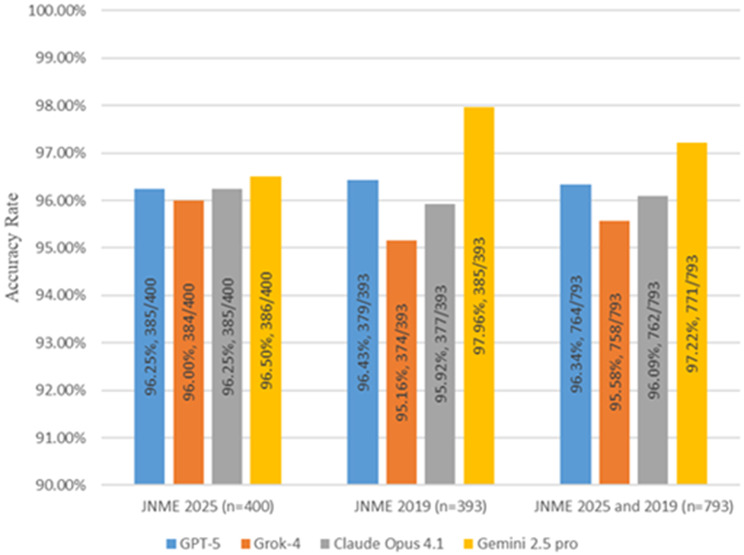 Figure 2
Figure 2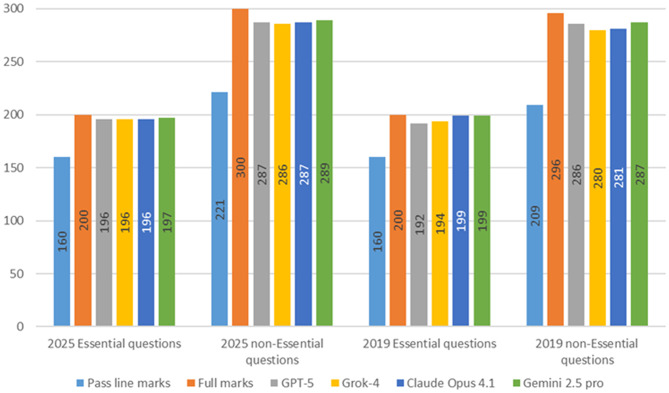 Figure 3
Figure 3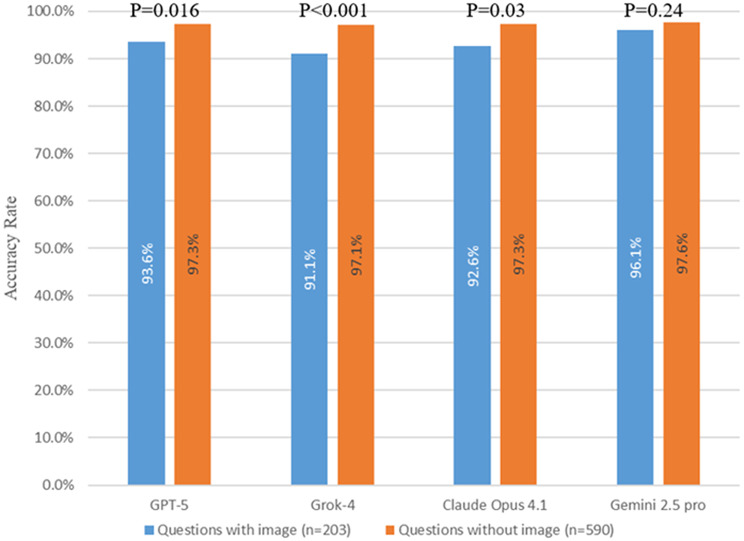 Figure 4
Figure 4- —https://doi.org/10.13039/501100001691Japan Society for the Promotion of Science
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Innovations in Medical Education · Clinical Reasoning and Diagnostic Skills
Introduction
Background
Since OpenAI introduced ChatGPT in November 2022, the first widely adopted artificial intelligence (AI) chatbot powered by a large language model (LLM), these systems have rapidly attracted worldwide interest because of their ability to generate elaborate responses to sophisticated questions [1]. Within the medical domain, LLMs are increasingly recognized for their potential contributions to both clinical decision-making and medical education [2–7]. Many LLMs incorporate image interpretation capabilities, enabling applications in areas such as dermatology and radiology, where they can assist in analyzing skin lesions or X-ray images [2, 3]. Moreover, unlike conventional search engines, which return a list of hyperlinks, LLM-based chatbots are designed to deliver direct and practical answers, thereby functioning as accessible knowledge resources [2].
Despite these advances, the reliability of medical knowledge embedded in LLMs remains a critical hurdle for their integration into education and clinical workflows. Previous research has emphasized that, to serve as dependable medical-education tools, their response accuracy should consistently surpass 95% [8]. Several studies from different countries have used national medical licensing examinations to benchmark LLM performance [9–19]. A systematic review reported that GPT-4 achieved an average accuracy of approximately 81% across multiple national licensing exams, sufficient to pass many of them but remained insufficient to be considered a reliable knowledge source [4].
Building on this body of work, our 2024 study demonstrated that GPT-4o reached an accuracy of 89.2% on the Japanese National Medical Licensing Examination (JNME) [19]. A study evaluating LLM performance on histological questions from the United States Medical Licensing Examination (USMLE) similarly reported that all five tested models—GPT-4.1, Claude 3.7 Sonnet, Gemini 2.0 Flash, Copilot, and DeepSeek R1—achieved accuracies exceeding 90%, with Gemini 2.0 Flash reaching the highest accuracy of 92% [20]. Moreover, in discipline-specific USMLE assessments, such as embryology, GPT-4o achieved an accuracy as high as 89.7% [21]. Similarly, a recent Chinese investigation revealed that DeepSeek-R1 achieved 92% accuracy on the China National Medical Licensing Examination [22]. Notably, the study also highlighted the effectiveness of chain-of-thought (CoT) prompting, in which the model was instructed to articulate intermediate reasoning steps before providing a final answer, leading to significant performance improvements [22]. Collectively, these findings suggest that the most advanced LLMs are approaching, although not yet achieving, the critical 95% accuracy threshold required for reliable educational and clinical applications.
In 2025, a new wave of LLMs equipped with reasoning-enhancement features was introduced. In July 2025, Google and xAI released Gemini 2.5 Pro and Grok-4, respectively, and in August, Anthropic and OpenAI released Claude Opus 4.1 and GPT-5, respectively [23–26]. These models, which incorporate CoT techniques, have drawn considerable attention regarding whether they can achieve sufficiently high accuracy to be regarded as reliable knowledge sources. Thus, this study aimed to evaluate the performance of GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro on the JNME to further examine both their overall applicability to medical education in Japan and the differences among the latest LLMs.
Study aims and objectives
In this study, we employed the JNME to assess the capabilities of the four latest LLMs: GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro. Our evaluation was designed to address the following key questions.
- What levels of accuracy can these LLMs achieve on the JNME, and can any of them pass the exam or meet the 95% threshold?
- How does performance differ between image-based and text-only questions?
- Do the LLMs show varying accuracy on general versus clinical questions?
- Is their performance influenced by the publication year of the exam questions?
- To what extent does question difficulty affect accuracy?
- What characteristics are present in the questions that the LLMs answer incorrectly?
By systematically investigating these aspects, we aim to clarify the strengths and limitations of the latest LLMs in solving medical examination problems. Furthermore, we highlight persistent challenges and propose directions for future model refinement, thereby contributing to the integration of LLMs into medical education and clinical practice.
Methods
Tested LLMs
As of August 2025, four LLMs represent the most advanced publicly available systems: GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro. These models were selected for evaluation in this study [23–26].
Japanese National medical licensing examination (JNME)
The JNME was first introduced in 1946 as a national licensing test for medical school graduates who completed six years of advanced training. Over time, the exam has undergone several revisions, and its current structure has remained unchanged since 2018. The JNME consists of 400 questions divided into six sections (A–F). Sections A, C, D, and F are designated as non-essential, each containing 75 questions, whereas sections B and E are considered essential, each including 50 questions. The scoring systems differ by section. In the essential sections (B and E), general knowledge questions are worth one point each, and clinical questions carry three points, with a minimum of 160 points required to pass. In the non-essential sections (A, C, D, and F), all questions are assigned one point, and the cutoff score is not predetermined but generally falls around 220 points. Additionally, the exam includes approximately 10 multiple-choice questions (MCQs) with “taboo” choices, where selecting more than three of these prohibited options automatically results in failure.
The average annual pass rate for Japanese medical students is approximately 90%. The question formats includes both MCQs and calculation-based items. MCQs appear in several formats: five-option single-answer, five-option multiple-answer (requiring two or three selections), and extended-option types with more than six options. For multiple-answer items, the number of correct responses is explicitly stated. The exam also integrates image-based questions to assess visual diagnostic skills [27].
Questions utilized in this study
As our previous studies had already employed the 2018 and 2024 versions of the JNME, we avoided reusing them to minimize potential data contamination. For this analysis, we utilized the entire set of questions from the 2019 and 2025 JNME. This choice served two purposes: first, to ensure independence from previous work, and second, to allow a clear comparison of LLM performance on exam items created before and after the models’ training cutoff dates. Specifically, the Ministry of Health, Labour, and Welfare of Japan released the official questions and answers to the 2025 JNME on April 28, 2025 [28]. The knowledge cutoff dates for the four evaluated models were September 2024 for GPT-5 [29], November 2024 for Grok-4 [30], January 2025 for Gemini 2.5 Pro [31], and March 2025 for Claude Opus 4.1 [32]. Consequently, none of the LLMs had prior access to the content of the 2025 JNME.
To facilitate a more detailed evaluation, we classified the exam questions based on the following criteria:
- Question type: image-based versus non-image-based.
- Content domain: general versus clinical questions.
- Difficulty level: based on the answer statistics published by Medu4, a preparatory school for the JNME, items were categorized into three groups—easy (≥ 90% of medical students answered correctly), moderate (70–89%), and difficult (< 70%).
Representative examples of each category are provided in Supplementary materials 1.
Inputting questions to LLMs
We input these questions into the LLMs between August 8 and August 20, 2025. Both the textual content and images from the exam were entered directly into each LLM’s chat interface. The text and images input to the four LLMs were identical, with each image having a resolution of 800 × 600 or higher. To ensure that each model operated under its best reasoning settings, we activated reasoning enhancement where available: GPT-5 was tested using its “thinking mode” and Claude Opus 4.1 using the “extended thinking” option. Grok-4 and Gemini 2.5 Pro were evaluated in their default configurations, which incorporated internal reasoning enhancements. Internet search functions were disabled to minimize the risk of data contamination. For Grok-4, which does not provide a direct option to disable web search, we applied the following explicit instruction: “Disable Grok from performing any network searches when generating responses.”
Moreover, to avoid contextual interference from previous interactions, each examination question was presented in a new, independent chat. Additionally, we disabled the memory function through user-accessible settings of all four LLMs to prevent any potential cross-contamination between separate chats (Fig. 1). Exceptions were made only for 40 sets of sequential questions (including 100 individual sub-questions) that required contextual continuity, which were entered within the same chat session.
The order of the questions followed that of the original examination, and each question was presented once. If an LLM failed to generate a response owing to system issues, the item was resubmitted until a valid answer was produced.
Fig. 1. Memory settings disabled for all evaluated LLMs
No additional prompts were provided for answering these questions. However, in rare cases where a model declined to respond, we employed a clarification prompt—“This is a question from the medical licensing examination”—to elicit an answer. All responses were recorded in an Excel spreadsheet and two independent authors (MX Liu and MH Zhao) assessed each output as correct or incorrect.
Statistical analysis
Descriptive statistics were calculated to summarize model performance, including the total number of questions, number of correct responses, accuracy proportions, and mean values. The accuracy rates across different LLMs and question categories were compared using Fisher’s exact test. For multiple comparisons, p-values were reported, with statistical significance set at p ≤ 0.05 (two-tailed). All analyses were performed using R software (version 4.4.0).
In addition to the quantitative analyses, all incorrect responses were reviewed by two co-authors: ZH Dai, a licensed physician in Japan, and WQ Yin, a medical student preparing for the JNME. The review examined both the explanations and reasoning traces provided by the LLMs, in order to identify common patterns of the incorrection.
Ethical considerations
The JNME questions and LLMs used in this study were publicly accessible. Ethics approval was not required for this study.
Results
Characteristics of the JNME questions
For the 2019 JNME dataset, four invalid questions and three questions containing non-public images were excluded, resulting in 393 questions available for analysis. All 400 questions from the 2025 JNME were retained. The combined dataset comprised 793 questions, of which 300 were classified as general and 493 as clinical. A total of 203 questions were image-based, and 590 were text-only. Based on difficulty levels, 437 questions were categorized as easy, 223 as moderate, and 133 as difficult.
Accuracy rates of LLM responses
All four LLMs successfully generated responses for the entire set of 793 questions. Model refusal occurred only with Grok-4 and was limited to six image-based questions in which the images contained identifiable body parts (e.g., facial features or genital regions), triggering content safety restrictions. In these six cases, we re-submitted the question with a clarification prompt - “This is a question from the medical licensing examination”. MX Liu and MH Zhao independently marked each multiple-choice question according to the official answer, which consisted solely of the designated correct option(s). As a result, their evaluations showed complete agreement with no discrepancies. Of the 793 questions, GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro correctly answered 764, 758, 762, and 771 questions, respectively. The corresponding overall accuracy rates, ranked from highest to lowest, were 97.2% for Gemini 2.5 Pro, 96.3% for GPT-5, 96.1% for Claude Opus 4.1, and 95.6% for Grok-4. The complete outputs, along with their correctness annotations, are provided in Supplementary materials 2.
Pairwise comparisons revealed no statistically significant differences in accuracy among the four models (all p-values > 0.05). Similarly, for each LLM, the performance did not differ significantly between the 2025 and 2019 JNME (all p > 0.05) (Fig. 2).
Fig. 2. Overall correct number and accuracy of the four LLMs
The examination scores of the four LLMs were calculated according to the official scoring rules of the JNME to determine whether they would pass the test. All four LLMs exceeded the passing line in both the 2019 and 2025 JNME, as well as in both essential and non-essential sections. Notably, for the essential sections, all four LLMs lost fewer than 10 points, achieving nearly perfect scores (Fig. 3).
Fig. 3. Score of each LLM calculated by the JNME scoring rules
For non-image-based questions, GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro achieved accuracies of 97.3%, 97.1%, 97.3%, and 97.6%, respectively, with no significant differences among the four LLMs (all p-values > 0.05). For image-based questions, the accuracies were 93.6%, 91.1%, 92.6%, and 96.1% for GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro, respectively. A significant difference was observed only between Gemini 2.5 Pro and Grok-4 (p = 0.04) (Table 1). Across both the 2019 and 2025 JNME, the accuracies of all four LLMs were consistently higher for non-image-based questions than for image-based questions. The differences in accuracy rates between the two question types were 3.7%, 6.0%, 4.7%, and 1.5% for GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro, respectively. Three of the LLMs showed significant differences (GPT-5, p = 0.016; Grok-4, p < 0.001; Claude Opus 4.1, p = 0.03) (Fig. 4).
Table 1. Accuracy of image-based and Non image-based questionsGPT-5Grok-4Claude Opus 4.1Gemini 2.5 proCorrect numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Questions with imageJNME 2025 (n = 102)9694.1%, [89.6–98.7%]9391.2%, [85.7–96.7%]9694.1%, [89.6–98.7%]9896.1%, [92.3–99.8%]JNME 2019 (n = 101)9493.1%, [88.1–98.0%]9291.1%, [85.5–96.6%]9291.1%, [85.5–96.6%]9796.0%, [92.2–99.8%]JNME 2025 and 2019 (n = 203)19093.6%, [90.2–97.0%]18591.1%, [87.2–95.0%]18892.6%, [89.0–96.2%]19596.1%, [93.4–98.7%]Questions without imageJNME 2025 (n = 298)28997%, [95.0–98.9%]29197.7%, [95.9–99.4%]28997.0%, [95.0–98.9%]28896.6%, [94.6–98.7%]JNME 2019 (n = 292)28597.6%, [95.8–99.4%]28296.6%, [94.5–98.7%]28597.6%, [95.8–99.4%]28898.6%, [97.3–100.0%]JNME 2025 and 2019 (n = 590)57497.3%, [96.0–98.6%]57397.1%, [95.8–98.5%]57497.3%, [96.0–98.6%]57697.6%, [96.4–98.9%]
For performance across different difficulty levels, the accuracy rates of GPT-5 were 97.5%, 96.4%, and 92.5% for easy, moderate, and difficult questions, respectively. Grok-4 achieved 98.2%, 93.7%, and 90.2% accuracy for easy, moderate, and difficult questions, respectively. Claude Opus 4.1 demonstrated accuracies of 98.2%, 97.3%, and 87.2%, whereas Gemini 2.5 Pro reached 98.4%, 97.3%, and 93.2% across the three difficulty levels (Table 2). When comparing easy versus difficult questions, all four LLMs showed significant differences (all p-values < 0.05) (Table 3). In comparisons between the easy and moderate questions, only Grok-4 showed a significant difference (p < 0.01) (Table 3). In comparisons between moderate and difficult questions, only Claude Opus 4.1 showed a significant difference (p < 0.001) (Table 3).
Fig. 4. Accuracy of image-based and non-image-based questions
Table 2. Accuracy rate of each LLM on different difficulty level questionsGPT-5Grok-4Claude Opus 4.1Gemini 2.5 proCorrect numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]JNME 2025 (n = 400)easy (n = 238, 59.5%)23197.1%, [94.9–99.2%]23498.3%, [96.7–100.0%]23397.9%, [96.1–99.7%]23297.5%, [95.5–99.5%]moderate (n = 100, 25%)9595.0%, [90.7–99.3%]9292.0%, [86.7–97.3%]9696.0%, [92.2–99.8%]9696.0%, [92.2–99.8%]difficult (n = 62, 15.5%)5995.2%, [89.8–100.0%]5893.5%, [87.4–99.7%]5690.3%, [83.0–97.7%]5893.5%, [87.4–99.7%]JNME 2019 (n = 393)easy (n = 199, 50.6%)19598.0%, [96.0–99.9%]19598.0%, [96.0–99.9%]19698.5%, [96.8–100.0%]19899.5%, [98.5–100.0%]moderate (n = 123, 31.3%)12097.6%, [94.8–100.0%]11795.1%, [91.3–98.9%]12198.4%, [96.1–100.0%]12198.4%, [96.1–100.0%]difficult (n = 71, 18.1%)6490.1%, [83.2–97.1%]6287.3%, [79.6–95.1%]6084.5%, [76.1–92.9%]6693.0%, [87.0–98.9%]JNME 2025 and 2019 (n = 793)easy (n = 437, 55.1%)42697.5%, [96.0–99.0%]42998.2%, [96.9–99.4%]42998.2%, [96.9–99.4%]43098.4%, [97.2–99.6%]moderate (n = 223, 28.1%)21596.4%, [94.0–98.9%]20993.7%, [90.5–96.9%]21797.3%, [95.2–99.4%]21797.3%, [95.2–99.4%]difficult (n = 133, 16.8%)12392.5%, [88.0–97.0%]12090.2%, [85.2–95.3%]11687.2%, [81.5–92.9%]12493.2%, [89.0–97.5%]
Table 3P-values for comparisons across difficulty levels of four LLMsGPT-5Grok-4Claude Opus 4.1Gemini 2.5 proEasy vs. difficultp < 0.01p < 0.001p < 0.001p < 0.01Easy vs. moderatep = 0.437p < 0.01p = 0.468p = 0.341Difficult vs. moderatep = 0.101p = 0.228p < 0.001p = 0.064
For general questions, the accuracy rates of GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro were 99.0%, 99.0%, 97.6%, and 98.6%, respectively. The corresponding accuracy rates for the clinical questions were 95.4%, 94.2%, 95.8%, and 97.0%, respectively (Table 4). All four LLMs demonstrated higher accuracy for general questions than for clinical questions; however, a statistically significant difference was observed only for Grok-4 (p < 0.001).
Table 4. Accuracy rate of each LLM on general and clinical questionsGPT-5Grok-4Claude Opus 4.1Gemini 2.5 proCorrect numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]Correct numberCorrect rate, [95%CI]JNME 2025 (n = 400)General questions (n = 149)14698.0%, [95.7–100.0%]14698.0%, [95.7–100.0%]14597.3%, [94.7–99.9%]14396.0%, [92.8–99.1%]Clinical questions (n = 251)23995.2%, [92.6–97.9%]23894.8%, [92.1–97.6%]24095.6%, [93.1–98.2%]24396.8%, [94.6–99.0%]JNME 2019 (n = 393)General questions (n = 151)14495.4%, [92.0–98.7%]14495.4%, [92.0–98.7%]14193.4%, [89.4–97.3%]14696.7%, [93.8–99.5%]Clinical questions (n = 242)23597.1%, [95.0–99.2%]23095.0%, [92.3–97.8%]23697.5%, [95.6–99.5%]23998.8%, [97.4–100.0%]JNME 2025 and 2019 (n = 793)General questions (n = 293)29099.0%, [97.8–100.0%]29099.0%, [97.8–100.0%]28697.6%, [95.9–99.4%]28998.6%, [97.3–100.0%]Clinical questions (n = 497)47495.4%, [93.5–97.2%]46894.2%, [92.1–96.2%]47695.8%, [94.0–97.5%]48297.0%, [95.5–98.5%]
Common error patterns observed in LLM responses
All incorrect responses were reviewed by a licensed physician in Japan and a medical student. Questions for which the LLMs did not provide any explanation were excluded from this analysis. The remaining errors were categorized into three major patterns: (1) selection of multiple options when only a single option was correct, (2) misinterpretation or misdiagnosis of image-based questions, and (3) difficulties in prioritizing appropriate actions in clinical questions with complex contextual information. The frequency of errors across these three patterns for each LLM is summarized as follows (Table 5).
Table 5. Distribution of error patterns across LLMsError patternGPT-5Grok-4Claude Opus 4.1Gemini 2.5 ProTotalMultiple-option selection1219931Image misdiagnosis1097632Action prioritization errors345315
In the error pattern of selecting multiple options, GPT-5 exhibited 12 such errors, while Claude Opus 4.1 and Gemini 2.5 Pro each showed 9, and Grok-4 showed only 1. Notably, in all cases where multiple options were selected, the correct option was always included in the model’s response. For the error pattern of image misinterpretation, GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro showed 10, 9, 7, and 6 errors, respectively. For errors related to difficulties in prioritizing appropriate actions in clinical questions with complex contextual information, GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro showed 3, 4, 5, and 3 errors, respectively. Representative examples for each error pattern are provided in Supplementary Material 3.
It should be noted that, compared with the other three LLMs, Grok-4 frequently produced responses consisting only of selected options without any accompanying explanation. As a result, a substantial proportion of Grok-4’s incorrect responses could not be classified into the three error patterns described above.
Discussion
Principal findings
To the best of our knowledge, this is the first study to evaluate the performance of the most advanced reasoning-enhanced LLMs—GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro—in medical licensing examinations.
According to the official JNME scoring rules, all four models passed both the 2019 and 2025 examinations, achieving near-perfect scores in the essential sections. None of the LLMs selected any taboo choices. In terms of overall accuracy (correct question numbers/total question numbers), the LLMs ranked as follows: Gemini 2.5 Pro (97.2%), GPT-5 (96.3%), Claude Opus 4.1 (96.1%), and Grok-4 (95.6%). All exceeded the 95% threshold, which has been proposed as a benchmark for considering LLMs as reliable sources of medical knowledge. Additionally, although the Japanese government does not publicly release the average scores of medical students on the National Medical Licensing Examination, we identified reports from a Japanese exam-preparation institution (Ishinkai) indicating that students’ average scores tend to be close to the passing threshold [33]. For example, in 2025, the passing cutoff for the non-essential section was 221 out of 300, whereas the reported average student score was approximately 230 [33]. In contrast, the four LLMs evaluated in this study achieved scores of around 290, suggesting substantially higher performance relative to the reported student average. This suggests that the medical knowledge encoded in these LLMs approaches textbook level, representing a milestone in their practical application as educational tools in medicine.
Notably, the accuracies achieved in this study are the highest reported to date among all evaluations of LLMs for medical licensing examinations worldwide, significantly surpassing the performance of GPT-4o (89.2% accuracy) in previous studies [19]. Furthermore, unlike earlier findings in which GPT-4o significantly outperformed Gemini 1.5 Pro and Claude 3 Opus [19], the present evaluation revealed no significant differences in accuracy among the four cutting-edge LLMs. We believe that these four pragmatic advances best explain this improvement over prior models. Firstly, reasoning enhancements that make models “think before answering”—including CoT, Self-Consistency, and search-style Tree-of-Thoughts—are known to improve performance on multistep problems typical of clinical reasoning and computation. Moreover, “process supervision” trains models to produce correct intermediate steps, not just correct final answers, which aligns well with medical exam questions requiring stepwise justification [20, 34, 35]. Second, the latest models plausibly benefit from broader and more recent corpora with improved coverage of medical content (e.g., guideline-like text and exam-style phrasing) and better Japanese biomedical material, narrowing the historical gap seen in earlier English-skewed systems [36]. Third, no instances of AI hallucinations were observed in any of the LLMs examined. Compared with earlier LLMs (e.g., GPT-4o and Gemini 1.5 pro), current LLMs more often ground their answers and self-check their drafts. Techniques like retrieval-augmented generation supply external evidence, while “chain-of-verification” style decoding has been shown to lower hallucinations by planning and answering verification questions before finalizing a response—both of which are valuable for factual, guideline-consistent medical Q&A [37].
All four LLMs achieved accuracies exceeding 97% for non-image-based questions, with Gemini 2.5 Pro demonstrating near-perfect performance by attaining the highest accuracy of 98.6%. Consistent with previous studies [19, 20, 38, 39], their accuracies on image-based questions were lower than on non-image-based questions. GPT-5, Claude 4.1 Opus, and Grok 4 showed a statistically significant difference between image and non-image bases questions, whereas the Gemini 2.5 Pro did not. However, unlike previous studies, in which LLMs typically achieved less than 80% accuracy on image-based questions [4], the present study found that all four models exceeded 90% accuracy even on image-based questions, with Gemini 2.5 Pro reaching the highest accuracy of 96.1%. These findings suggest that the image interpretation capabilities of the latest generation of LLMs have substantially improved compared with earlier models. Notably, Gemini 2.5 Pro performed exceptionally well, achieving an accuracy above the 95% benchmark even for image-based questions, which supports its potential applicability as a medical imaging diagnostic tool. In contrast, the other three LLMs may pose risks if applied prematurely in medical imaging analyses or clinical diagnostic support.
We categorized all questions into three levels of difficulty (easy, moderate, and difficult) based on human medical students’ accuracy and evaluated the LLMs accordingly. All four models demonstrated significantly higher accuracy for easy questions than for difficult questions. However, no significant differences were observed between easy and moderate questions or between moderate and difficult questions. In the easy, moderate, and difficult categories, Gemini 2.5 Pro achieved the highest accuracy across the board. Importantly, except for Grok-4, the remaining three LLMs maintained accuracies above 90% even for difficult questions. These findings suggest that although previous studies have consistently reported that LLMs perform better on easier items [38, 40–44], the performance gap attributable to difficulty narrows as LLM capabilities advance. Collectively, these patterns indicate enhanced stability across difficulty strata, stronger internal consistency in reasoning processes, and greater robustness to item complexity and distributional shifts. Consequently, the classical “difficulty effect” is attenuated, with model accuracies approaching a ceiling and variance across categories being substantially reduced. This enhanced uniformity across difficulty levels suggests that advanced LLMs may serve as more consistent and equitable tools for medical education and assessment, thereby reducing biases introduced by item complexity.
Typically, the performance of LLMs on general questions reflects their accuracy as knowledge sources in medical education, whereas their performance on clinical questions reflects their capabilities in clinical reasoning and diagnostic decision-making. In this study, we found that all four LLMs achieved higher accuracy on general questions than on clinical questions, with the difference reaching statistical significance only for Grok-4. Notably, GPT-5, Grok-4, and Gemini 2.5 Pro achieved 99% accuracy on general questions. Because they generally require factual recall rather than complex reasoning, this near-perfect accuracy further demonstrates that, with training on increasingly large-scale datasets, the latest LLMs have achieved almost textbook-level mastery of fundamental medical knowledge, the latest LLMs have achieved almost textbook-level mastery of fundamental medical knowledge, consistent with findings from prior studies [20]. With appropriate ethical oversight and regulatory safeguards, these models may hold considerable promise as educational tools to support basic medical training. In clinical questions, Gemini 2.5 Pro still achieved the highest accuracy rate of 97.0%, with GPT-5 and Claude 4.1 Opus also exceeding 95%. However, unlike performance on general knowledge items, the Japanese National Medical Examination (JNME), while standardized and transparent, remains an artificial testing environment. The dataset consists of exam-style questions with predefined correct answers and minimal ambiguity, whereas real-world clinical practice rarely offers such clarity. Patients frequently present with multiple comorbidities, incomplete histories, and overlapping imaging findings that require nuanced interpretation. At the same time, LLM capabilities for contextual reasoning, uncertainty management, and longitudinal decision-making required for clinical practice or electronic health record workflows remain insufficient [45, 46]. Therefore, higher accuracy thresholds and greater safety margins are required when evaluating LLM performance on clinical questions, as even small errors in medical education could propagate into clinical practice [21]. By relying solely on licensing exam questions, our study likely overestimates model performance, as these items emphasize factual recall and pattern recognition rather than situational awareness and clinical judgment. More realistic evaluations—such as handling equivocal imaging findings, prioritizing between competing diagnoses, or managing incidental findings—will be necessary to uncover clinically relevant weaknesses that licensing-style assessments cannot capture.
After reviewing the explanation of incorrect questions. We found the most common cause for incorrect answers was misunderstanding of the number of selected options. As instructed in the beginning of each section, the default number of correct choices was one. However, LLMs chose more than one in some questions, leading to incorrect results. It is critical to retain the instruction contents while analyzing the questions until the end of each session. The second most common cause for incorrect answers was misdiagnosis from clinical images such as CT or misunderstanding of illustrations. Gemini 2.5 pro performed better in answering questions with images. Nevertheless, improvement in comprehending images, especially those images that directly contributes to a final diagnosis, remains a common challenged shared by LLMs. In addition, LLMs lack the common knowledge in perceiving the directions of clinical images: they always got the left and right directions wrong on X-ray images or CT. Third, although LLMs presented with high performance in collecting evidence from publicly available information such as clinical guidelines and textbooks, they seem to have a long way to go when it comes to prioritizing clinical actions. They tend to choose incorrect options or falsely choose multiple options in questions asking “the most appropriate action as the immediate next step”.
Finally, we believe that the present findings highlight both the immediate promise and the remaining challenges of applying LLMs in medicine. While the results demonstrate that advanced LLMs have achieved near–textbook-level mastery of medical knowledge, their particularly strong performance in basic medical knowledge highlights substantial potential for use as learning resources in foundational medical education. However, the transition from knowledge recall to real-world clinical reasoning remains a substantial challenge. Clinical decision-making requires not only factual accuracy but also contextual interpretation, prioritization among competing diagnoses, sensitivity to uncertainty, and accountability for patient outcomes. Current LLMs lack these dimensions of professional judgment. Thus, whereas their role in foundational medical training appears increasingly feasible, their translation into frontline diagnostic tools will require further advances in reasoning, reliability, and regulatory oversight.
Limitation
Firstly, although we disabled all internet-search functionalities of the LLMs to prevent reliance on external information, we did not incorporate memorization diagnostics. Therefore, the possibility that some 2019 examination questions were encountered during model pretraining cannot be fully excluded. Importantly, one of the aims of this study was to examine whether publication year of the questions before versus after the cutoff dates would affect LLMs’ performance. In this regard, we observed that Grok-4 and Claude Opus 4.1 performed even worse on the 2019 examination than on the 2025 examination. For these reasons, we clarify that the 2025 examination results should be interpreted as the primary findings of this study, whereas the 2019 results are intended as a supplementary comparison to contextualize performance across examination years.
Secondly, regarding statistical methodology, multiple pairwise comparisons were conducted across models, question types, difficulty levels, and examination years. Although p-values were reported using a conventional threshold (p ≤ 0.05), the risk of Type I error may be inflated. Therefore, some statistically significant findings should be interpreted with caution. Additionally, to ensure reliability, this study evaluated a large sample of 793 questions, which increases statistical power such that very small absolute differences may reach statistical significance. However, such differences may not necessarily reflect meaningful educational or clinical relevance. Future studies should incorporate multiple-testing corrections and effect size measures to provide a more comprehensive interpretation.
Finally, this study exclusively evaluated the performance of LLMs on the JNME, which is written in Japanese. Therefore, these findings may not be generalizable to medical licensing examinations in other countries or languages. However, previous studies indicated that LLMs tend to perform better on examinations written in English than those presented in other languages [4]. Based on this evidence, it is reasonable to hypothesize that the four LLMs tested in the present study might achieve even higher and potentially near-perfect scores on medical examinations delivered in English. In contrast, their performance may be lower in examinations that incorporate traditional medicine domains (e.g., Traditional Chinese Medicine or Korean Traditional Medicine), where relevant training data are likely limited [47]. Therefore, future studies should examine the performance of LLMs across diverse linguistic and cultural contexts to better assess their global applicability in medical education and licensing.
Conclusion
This study evaluated the performance of GPT-5, Grok-4, Claude Opus 4.1, and Gemini 2.5 Pro on the JNME. All four LLMs achieved accuracies exceeding 95%, markedly higher than those reported in previous studies. To the best of our knowledge, this is the first study to demonstrate that LLMs can surpass the accuracy threshold across an entire set of medical licensing examination questions, representing a milestone in their potential application in medical education.
Although image-based questions, clinical questions, and higher-difficulty questions negatively affected the performance of these models, the magnitude of these effects was substantially smaller than that observed in earlier-generation LLMs. This reflects the enhanced stability, internal consistency, and robustness of the latest models in handling complex question formats and reasoning challenges. In this study, the main patterns of errors in LLMs were selecting extra options and failing to correctly identify left and right during X-ray and CT image recognition.
In particular, Gemini 2.5 Pro achieved the highest overall accuracy (97.2%) and consistently maintained a performance above 95%, even in subgroups traditionally disadvantageous for LLMs (e.g., image-based and clinical questions), demonstrating exceptional robustness and reliability. In contrast, Grok-4 showed more pronounced performance gaps between image-based and non-image-based questions and between general and clinical questions.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
Supplementary Material 3
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Open AI. Chat GPT. https://chat.openai.com/chat. Accessed 8 Aug 2025.
- 2Tsang R. Practical Applications of Chat GPT in undergraduate medical education. J Med Educ Curric Dev. 2023;10:23821205231178449. Published 24 May 2023. 10.1177/23821205231178449. PMID: 37255525.10.1177/23821205231178449 PMC 1022629937255525 · doi ↗ · pubmed ↗
- 3Hristidis V, Ruggiano N, Brown EL, Ganta SRR, Stewart S. Chat GPT vs Google for queries related to dementia and other cognitive decline: comparison of results. J Med Internet Res. 2023;25:e 48966. Published 25 Jul 2023. 10.2196/48966. PMID: 37490317.10.2196/48966 PMC 1041038337490317 · doi ↗ · pubmed ↗
- 4Aljindan FK, Al Qurashi AA, Albalawi IAS et al. Chat GPT Conquers the saudi medical licensing exam: exploring the accuracy of artificial intelligence in medical knowledge assessment and implications for modern medical education. Cureus. 2023;15(9):e 45043. Published 11 Sep 2023. 10.7759/cureus.45043. PMID: 37829968.10.7759/cureus.45043 PMC 1056653537829968 · doi ↗ · pubmed ↗
- 5Armitage RC. Performance of generative pre-trained transformer-4 (GPT-4) in membership of the royal college of general practitioners (MRCGP)-style examination questions. Postgrad Med J., 2024;100(1182): 274–275. 10.1093/postmj/qgad 128. PMID: 38142282.10.1093/postmj/qgad 12838142282 · doi ↗ · pubmed ↗
- 6Ebrahimian M, Behnam B, Ghayebi N, Sobhrakhshankhah E. Chat GPT in Iranian medical licensing examination: evaluating the diagnostic accuracy and decision-making capabilities of an AI-based model. BMJ Health Care Inform. 2023;30(1):e 100815. Published 11 Dec 2023. 10.1136/bmjhci-2023-100815. PMID: 38081765.10.1136/bmjhci-2023-100815 PMC 1072914538081765 · doi ↗ · pubmed ↗
- 7Fang C, Wu Y, Fu W et al. How does GPT-4 preform on non-English national medical licensing examination? an evaluation in Chinese language. PLOS Digit Health. 2023;2(12):e 0000397. Published 1 Dec 2023. 10.1371/journal.pdig.0000397. PMID: 38039286.10.1371/journal.pdig.0000397 PMC 1069169138039286 · doi ↗ · pubmed ↗
- 8Flores-Cohaila JA, García-Vicente A, Vizcarra-Jiménez SF, et al. Performance of Chat GPT on the peruvian national licensing medical examination: cross-sectional study. JMIR Med Educ. 2023;9:e 48039. Published 28 Sep 2023. 10.2196/48039. PMID: 37768724.10.2196/48039 PMC 1057089637768724 · doi ↗ · pubmed ↗