Identifying data anomalies in milk component measurements from partial-day milking records
Xiao-Lin Wu, Malia J. Caputo, Chip Donatone, Asha M. Miles, Ransom L. Baldwin, Steven Sievert, Jay Mattison, John B. Cole, Javier Burchard, João Dürr

TL;DR
This paper introduces a new method to detect errors in milk component data at the individual cow-day level, improving data quality for herd management.
Contribution
A novel individual-level intraclass correlation metric is introduced for detecting anomalies in cow-day milk component records.
Findings
The new metric outperforms conventional univariate and multivariate methods in identifying anomalies.
A two-step approach for estimating percentile thresholds effectively flags outliers in milk data.
Data shuffling negatively impacts the accuracy of daily milking records.
Abstract
Summary: High-quality milk and milk component data are essential for accurate genetic evaluations and effective daily herd management. In a recent study, we demonstrated the usefulness of intraclass correlation coefficients as a herd-level metric for assessing the consistency of fat and protein percentages from single milkings. However, a key challenge remains: How can we detect potentially erroneous records at the individual cow-day level? In this study, we introduced a new metric—individual-level intraclass correlations—to assess data quality at the cow-day level. We evaluated its performance in comparison to 3 commonly used methods. Summary: High-quality milk and milk component data are essential for accurate genetic evaluations and effective daily herd management. In a recent study, we demonstrated the usefulness of intraclass correlation coefficients as a herd-level metric for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
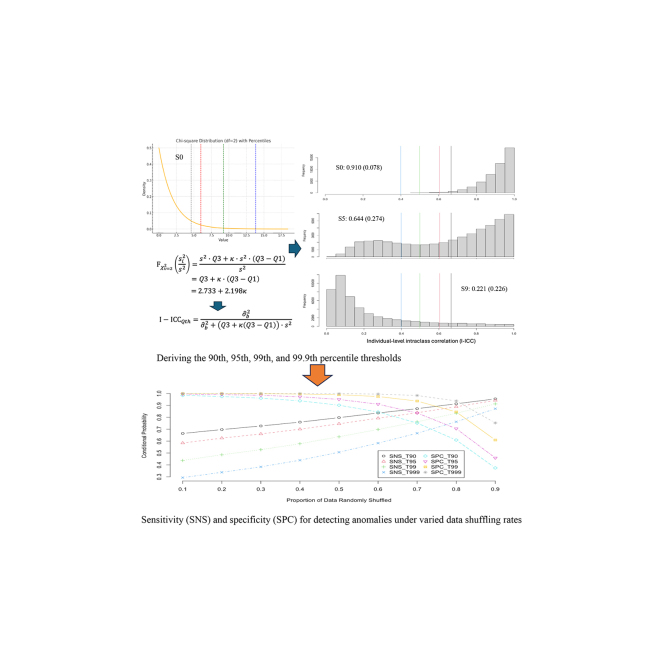 Figure 1
Figure 1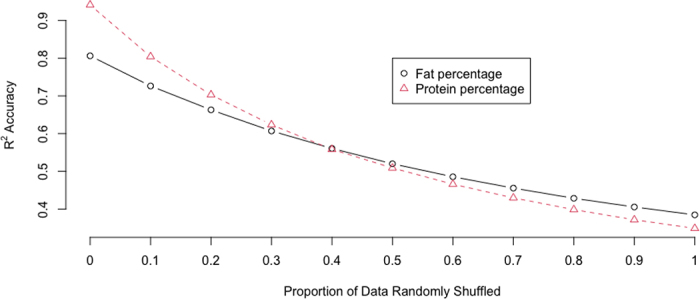 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMilk Quality and Mastitis in Dairy Cows · Genetic and phenotypic traits in livestock · Statistical Methods and Inference
High-quality milk and milk component data are crucial for accurate genetic evaluations and effective routine herd management. However, potential errors can compromise the reliability of these data, leading to inconsistent conclusions and even incorrect decisions. In a recent study, we demonstrated the use of intraclass correlation coefficients (ICC) as a herd-level metric to assess the consistency of milk component data quality (Wu et al., 2025a). Statistically, ICC extends the concept of pairwise correlation to situations involving more than 2 observations per group and quantifies the degree of similarity among them (Harris, 1913; Fisher, 1954). It has been widely used to evaluate measurement reliability and inter-rater consistency across grouped data (Bartko, 1966). In human and animal genetics, ICC can serve as a metric for assessing repeatability (Kumro et al., 2021) and heritability (Visscher, 1992). In the latter applications, for example, the intraclass correlation approximately equals 1/2 heritability under balanced nested full-sib designs, or 1/4 heritability under balanced nested designs (Falconer and Mackay, 1996).
Outlier detection is a common technique in statistical analysis that aims to identify data anomalies. An outlier refers to a data point that deviates markedly from other observations and may result from natural data variability, novel or unexpected events, or measurement errors (Grubbs, 1969). The process of detecting outliers depends on the nature and distribution of the data, as well as the specific context in which the data are generated (Barnett and Lewis, 1994). A univariate outlier is an extreme value in the context of a single variable. For example, a cow produces an extraordinarily high milk yield compared with the population average. In contrast, multivariate outliers are observations that appear unusual only when considering multiple variables simultaneously. For example, a cow may produce a normal fat percentage (FP) in one milking but an abnormally low or high FP in another on the same test day, although both numbers may fall within the ranges of their respective milkings.
In this paper, we introduce a novel metric for identifying data anomalies at the cow-day level and evaluate its performance against 3 commonly used methods (Grubbs, 1969).
Let x_ij_ be an observed value for individual i (where i = 1, . . ., n) in milking j (where j = 1, . . ., m). The z-score approach (Grubbs, 1969) computes the standardized deviation for each observed value as follows:
The estimated within-group variance is calculated as follows:
where
Statistically, the z-score approach assumes a standard normal distribution. Thus, using corresponds to the 99.73rd percentile, meaning that ∼0.27% of the observations may fall outside this threshold. Alternatively, using (or corresponds to the 95.45th (or 99.99th) percentile, flagging ∼4.55% (or 0.0063%) as outliers.
The interquartile range (IQR) approach (Tukey, 1977) is a nonparametric method that works even when the data do not follow a normal distribution. The IQR is calculated as
where Q1 is the 25th percentile and Q3 is the 75th percentile of x_ij_.
Outlier thresholds are often defined using a multiplier of κ = 1.5. That is,
For a standard normal distribution, applying an IQR multiplier of 1.5 corresponds to the 99.65th percentile, implying that about 0.35% of values in the upper tail may fall beyond this threshold. Alternative multipliers, such as κ = 1.0, 2.0, or 3.0, can be used depending on whether more conservative or aggressive detection is desired.
The Mahalanobis distance (MD) is a multivariate measure of the distance from a point to the multivariate mean, taking into account correlations among variables. Unlike Euclidean distance, which treats each dimension independently, the MD accounts for the covariance structure of the data, making it more suitable for detecting multivariate outliers. Let x be a k-dimensional observation vector (e.g., corresponding to k milkings), μ be the corresponding mean vector, and S be the sample covariance matrix across the k milkings. The squared MD is given by
Under a multivariate normal distribution assumption for the data, the squared Mahalanobis distances follow a chi-squared distribution with k degrees of freedom:
Hence, outliers can be identified by comparing them to a chi-squared distribution: where, for example, α = 0.05 or 0.01.
In this study, we introduce a new metric, namely the individual-level intraclass correlation coefficient (I-ICC), for identifying potential data anomalies in daily milk component measurements at the cow-day level. Consider the following one-way random effects model:
where μ is the overall mean, is the random effect of group i with mean zero and variance and denotes the within-group residual deviation from the group mean. Here, a group refers to a unique combination of a cow and a specific DIM.
The variance of an individual measurement x_ij_ is given by
where the within- and between-group variances are estimated as follows:
where and stand for the mean of group i and the population mean, respectively.
The herd-level ICC is then computed as follows (Wu et al., 2025a):
which quantifies the consistency of repeated measurements of cows in a herd. A low ICC value reflects high within-group variability and inconsistency, thereby warranting further examination of the data.
Following similar logic, the I-ICC is defined by replacing the global estimate of within-group variance in Equation 11 with its component corresponding to each cow-day group That is,
where is the observed within-group sample variance across m milkings for a specific cow-day.
Directly defining the threshold for flagging I-ICC outliers using Equation 12 is statistically challenging because it does not follow a standard distribution. Here, we propose a 2-step approach. The first step uses the theoretical chi-squared distribution to analytically derive the upper-boundary threshold (i.e., the 99.9th percentile) for individual within-group variance under the null hypothesis. Next, this variance threshold is then used to compute the corresponding percentile of the I-ICC distribution using Equation 12.
Let the within-group residuals follow a normal distribution and be independent across milkings: Denote the standardized residuals as Then, follows a chi-squared distribution with m − 1 degrees of freedom:
The within-group sample variance for group i, is then a scaled chi-squared distribution:
where the scale parameter is s^2^ = and m − 1 denotes the degrees of freedom.
To develop an outlier flagging criterion in the second step, we use an IQR-based approach. Specifically, we let denote the 99.9th percentile of and express this percentile as a linear function of the interquartile range,
where κ is the IQR multiplier to be determined.
Substituting in terms of chi-squared quantiles gives
For example, with m = 3 (i.e., 3 milkings daily per cow), we have and Thus,
To determine κ, we solve for the value that ensures the upper cutoff corresponds to the 99.9th percentile, which is defined by the following probability (Pr):
Rearranging the left-hand side of the above inequality and noting that we have
Here, represent the cumulative distribution function (CDF) of the chi-squared distribution with m −1 degrees of freedom, evaluated at x.
Reverting the CDF gives 2.773 + 2.198κ = ≈ 13.82, and the 99.9th percentile threshold is obtained as κ = ≈ 5.023. Similarly, the one-sided 90th, 95th, and 99th percentile thresholds for detecting outliers in are 0.834, 1.464, and 2.93, respectively (see the Graphical Abstract for illustration). Importantly, these IQR multipliers are independent of the scaling parameter because it cancels out in Equation 18, thus providing convenience to practical implementation.
Computing the κ multiplier value is easy, as illustrated by the following R function:
In the second step, the corresponding I-ICC threshold is computed as follows:
Any I-ICC value smaller than the threshold is considered an outlier.
We evaluated the performance of this new metric, along with the 3 commonly used methods. The milk component data were collected from 4 Holstein dairy farms (A, B, C, and D) practicing 3 times daily (3×) milking in 3 US states. In this study, milk yields and components from 3× milkings were measured weekly for each cow up to 120 d, followed by monthly tests until 305 d or the end of lactation. After cleaning the data to remove duplicates and missing or incomplete data, we retained 15,995 × 3 (A), 13,336 × 3 (B), 8,363 × 3 (C), and 11,182 × 3 (D) milking records for subsequent analyses.
To investigate the effects of data shuffling, we also simulated a pooled dataset (S0) containing 48,876 × 3 milking records without errors for each trait using multivariate normal distributions. The means and the variance-covariance matrices for the 3 milkings were set to be weighted averages across the 4 Holstein dairy farms. We also generated 9 pooled datasets (designated S1 to S9) for each trait by randomly shuffling between 10% (S1) and 90% (S9) of the records among cows per farm on each milking section.
In practice, record shuffling may occur due to improper labeling of the milk sample vial, misplacement of the milk sample vial in the sample rack, or collecting extra or missing milk samples after the cow ID has already been recorded at farms. Once samples arrive at the laboratory, additional errors may be introduced by adding samples out of order or misaligning the sample rack when moving milk samples from the sample rack to the instrument. Errors in merging the cow ID with the corresponding sample ID can further contribute to record shuffling. All methods showed low outlier rates in the 4 farms, ranging from 0.33% to 6.55% for FP (Table 1) and 0.44% to 5.02% for protein percentage (PP; Table 2). Based on the weighted variance components across the 4 herds, the percentile thresholds for I-ICC were computed as: 0.087 (99.9th), 0.125 (99th), 0.180 (95th), and 0.223 (90th) for FP; and 0.387 (99.9th), 0.486 (99th), 0.593 (95th), and 0.654 (90th) for PP. All 4 Holstein herds had high I-ICC values on average. In these 4 farms, the ICC ranged from 0.508 to 0.666 for FP and 0.875 to 0.927 for PP, whereas the I-ICC ranged from 0.681 to 0.801 for FP and 0.926 to 0.943 for PP (Table 1, Table 2). The higher ICC and I-ICC values for PP suggest that protein percentage records are inherently more consistent among cows than FP records.Table 1. Summary statistics and outlier rates (%) of milk fat percentage using 4 methods in 4 Holstein herds (A, B, C, and D) and 10 simulated datasets (S0-S9)1DatasetnMean (%) ICCI-ICCOutliers2 (%)z-scoreIQRMDI-ICC90I-ICC95I-ICC99I-ICC999A15,9954.040.2740.2440.5290.681 (0.233)0.751.144.554.552.961.370.54B13,3364.050.3080.1540.6660.801 (0.208)0.480.732.812.411.490.730.29C8,3634.510.2560.2480.5080.699 (0.239)0.971.404.635.033.501.941.05D11,1824.150.3680.2830.5650.717 (0.236)1.091.696.554.242.551.030.33S048,8764.150.3080.2110.5930.667 (0.200)0.010.061.120.600.13<0.01<0.01S148,8764.150.2780.2420.5340.630 (0.215)0.160.332.602.451.100.240.04S248,8764.150.2460.2740.4730.590 (0.228)0.320.634.155.232.770.780.15S348,8764.150.2150.3050.4130.546 (0.238)0.470.925.709.195.361.780.41S448,8764.150.1840.3360.3540.500 (0.245)0.611.197.1714.59.163.530.98S548,8764.150.1530.3670.2940.448 (0.248)0.761.478.7122.015.16.772.35S648,8764.150.1210.3990.2330.389 (0.246)0.921.7610.232.023.912.65.39S748,8764.150.0910.4290.1740.323 (0.237)1.052.0411.744.936.122.311.7S848,8764.150.0590.4610.1130.243 (0.217)1.212.3413.361.653.639.225.6S948,8764.150.0290.4910.0550.148 (0.175)1.372.6214.880.675.665.453.31n = number of observation trios; = estimated within-group variance; = estimated between-group variance; ICC = herd-level intraclass correlation coefficients; I-ICC (SD) = mean (SD) of individual-level ICC. S0 = simulated dataset without data shuffling; S1–S9 = simulated datasets with data shuffling from 10% to 90%. Results for S0–S9 are presented as averages across 10 replicates.2z-score, IQR, MD, and I-ICCx = outlier rates detected using the z-score, interquartile range (IQR), Mahalanobis distance (MD), and the I-ICCx approach, where the threshold (x) is set to be the 90th, 95th, 99th, and 99.9th percentile, respectively.Table 2. Summary statistics and outlier rates (%) of milk protein percentage using 4 methods in 4 real dairy farms (A, B, C, and D) and 10 simulated datasets (S0-S9)1DatasetnMean (%) ICCI-ICCOutliers2 (%)z-scoreIQRMDI-ICC90I-ICC95I-ICC99I-ICC999A15,9953.090.0870.0070.9270.943 (0.085)0.440.601.691.831.330.790.50B13,3363.190.0880.0100.8970.929 (0.110)1.031.323.273.652.881.801.14C8,3633.250.1140.0120.9030.940 (0.118)1.732.115.024.273.422.331.34D11,1823.180.1030.0150.8750.926 (0.118)1.391.784.534.253.131.911.14C048,8763.170.0950.0100.9020.910 (0.077)0.030.100.971.010.280.01<0.01C148,8763.170.0860.0200.8130.867 (0.149)2.493.067.268.056.274.402.93C248,8763.170.0760.0290.7210.820 (0.195)5.006.0813.615.913.29.766.76C348,8763.170.0670.0390.6330.768 (0.229)7.449.0319.924.620.916.011.5C448,8763.170.0570.0480.5430.710 (0.255)9.9312.026.234.129.623.417.6C548,8763.170.0480.0580.4510.642 (0.276)12.415.032.544.839.732.325.4C648,8763.170.0380.0670.3590.565 (0.288)15.018.138.856.451.242.935.2C748,8763.170.0280.0770.2700.476 (0.290)17.421.045.168.563.655.347.1C848,8763.170.0190.0860.1800.368 (0.275)19.924.051.480.977.069.962.2C948,8763.170.0100.0960.0900.229 (0.229)22.327.057.792.290.286.081.01n = number of observation trios; = estimated within-group variance; = estimated between-group variance; ICC = herd-level intraclass correlation coefficients; I-ICC (SD) = mean (SD) of individual-level ICC. S0 = simulated dataset without data shuffling; S1–S9 = simulated datasets with data shuffling from 10% to 90%. Results for S0–S9 are presented as averages across 10 replicates.2z-score, IQR, MD, and I-ICCx = outlier rates detected using the z-score, interquartile range (IQR), Mahalanobis distance (MD), and the I-ICCx approach, where the threshold (x) is set to be the 90th, 95th, 99th, and 99.9th percentile, respectively.
For the synthetic dataset without recording errors (S0), the outlier rates were low (∼0%–1.12% for FP and 0%–1.01% for PP). The distribution of I-ICC showed a peak on the high-value end of the distribution (see S0 in the upper panel of the Graphical Abstract). Introducing mismatched data errors by shuffling records among cows progressively distorted the data structure, shifting the peak of I-ICC toward the low-value end of the distribution (see S5 and S9 in the upper panel of the Graphical Abstract). As the proportion of shuffled records increased from 10% to 90%, between-cow variance decreased and within-cow variance increased. As a result, the ICC dropped from 0.593 to 0.055 for FP and from 0.902 to 0.090 for PP. Similarly, the I-ICC declined from 0.667 to 0.148 for FP and from 0.910 to 0.229 for PP.
In the presence of data shuffling, the 2 univariate approaches tended to underestimate the outlier rates: 0.01% to 1.37% (FP) and 0.03% to 22.3% (PP) using the z-score method, and 0.06% to 2.62% (FP) and 0.10% to 27.0% (PP) using the IQR method. Univariate outlier detection methods are fundamentally limited to identifying extreme data values based solely on the variation of a single variable in isolation. However, milk component data are moderately to highly correlated across multiple milkings daily within cows. As a result, measurement errors or data mishandling may not appear abnormal when each milking is evaluated independently.
The MD test identified higher outlier rates: 1.12% to 14.79% for FP and 0.97% to 57.7% for PP, compared with the 2 univariate methods. The MD method leverages information from the variance-covariance matrix, capturing the relationships across the 3 milkings. Nevertheless, it still underestimated the true outlier proportions, given the magnitude of up to 90% of actual data shuffling in the synthetic datasets.
The estimated outlier rates obtained using the I-ICC approach most closely align with the simulated values among all methods (Table 1, Table 2). The percentile thresholds of I-ICC were computed based on the variance components from the simulated data without data shuffling: 0.096 (99.9th), 0.137 (99th), 0.196 (95th), and 0.241 (90th) for FP and 0.407 (99.9th), 0.508 (99th), 0.613 (95th), and 0.673 (90th) for PP. The identified outlier rate increased with the data shuffling rate, ranging from 0.04% to 2.45% under 10% data shuffling to 53.3% to 80.6% under 90% data shuffling for FP and from 2.93% to 8.05% with 10% data shuffling to 81.0% to 92.2% with 90% data shuffling for FP.
It is important to note that the identified outliers may not all be true outliers, and those not identified as outliers may not actually be non-outliers. By the nature of record shuffling, a small portion of them could retain accidental within-cow-day consistency. On the other hand, randomly shuffling records leads to decreased between-cow variance and underestimated I-ICC estimates. Hence, a portion of records with true I-ICC above the cutoff threshold can fall below the cutoff and, therefore, be falsely identified as anomalies.
We showed the estimated sensitivity and specificity rates for PP in the lower panel of the Graphical Abstract. Statistically, sensitivity is the conditional probability of observing a positive case when the actual status is positive (i.e., a true outlier), and specificity is the conditional probability of observing a negative case when the actual status is negative (Wu et al., 2025b). The probability of a false negative equals one minus the sensitivity, and the probability of a false positive equals one minus the specificity.
As the rate of record shuffling increased from 0.1 to 0.9, sensitivity increased from lower values (0.293–0.664) to 0.955 (90th percentile cutoff) and 0.872 (99.9th percentile cutoff), indicating a false negative rate between 0.045 and 0.128. Hence, the method became increasingly effective at detecting true anomalies as more records were mismatched, although a small fraction still went undetected. Meanwhile, specificity decreased from around 1.00 to 0.375 (90th percentile cutoff) and 0.753 (99.9th percentile cutoff), resulting in a false positive rate ranging from 0.625 to 0.247. This indicates that, with more extensive record shuffling, the method became more prone to incorrectly flagging normal records as outliers, possibly due to drastically reduced between-group variance. The changes in sensitivity and specificity for FP showed similar patterns; however, the false positive and false negative rates tend to be higher in general.
Using a lower percentile cutoff makes the method more aggressive, improving its ability to capture true outliers (higher sensitivity) but at the cost of elevated false positives or lower specificity. Conversely, a higher cutoff makes the method more conservative, ensuring that very few false positives occur, but at the risk of missing true outliers when the data are more severely corrupted. Therefore, selecting an appropriate percentile threshold should strike a balance between the tolerance for false alarms and the risk of overlooking actual data errors, taking into account the specific quality control goals.
Record shuffling, like many other milking record errors, compromised the accuracy of estimated daily FP and PP when estimated from partial daily records (Figure 1). We estimated daily fat (protein) percentage from each of the 3 milkings using a linear regression approach, which also included partial daily yield, partial daily fat (protein) percentage, milking interval time, DIM, and a categorical lactation effect as predictors. The R^2^ accuracy was computed as the true phenotypic variance over the sum of the true phenotypic variance and mean squared errors (MSE) evaluated by 3-fold cross-validation, and averaged across 3 milkings and 30 replicates. The R^2^ accuracy decreased from 0.806 to 0.385 for FP and from 0.941 to 0.349 as the record shuffling rate increased from 0% to 100% (Figure 1); the decrease rate was more drastic for PP than for FP. The MSE exceeded the true phenotypic variance, with a record shuffling rate larger than 60%.Figure 1R^2^ accuracy of estimated daily fat and protein percentages using linear regression under varying record shuffling rates. where Var(y) = true phenotypic variance without measurement errors. MSE = mean squared error.
Finally, 2 issues are worth mentioning. First, because each cow-day group contains only 3 milkings (m = 3), the observed within-group variance is estimated from only 2 degrees of freedom and is subject to considerable sampling error. Alternatively, a simple empirical Bayes method can be used, which weighs and the global within-day variance component
where τ is a tuning constant chosen to balance individual and pooled information (typically τ ≈ 5 works well for m = 3). The resulting stabilized estimate of individual repeatability takes the same form as Equation 12, with replaced by
This empirical Bayes method provided more stable estimates of individual within-group variance, thereby yielding slightly smaller I-ICC but substantially decreased standard deviations, depending on the assumed global variance and the degrees of freedom. With τ = 5 assumed for the 4 Holstein farms, the I-ICC estimates dropped by ∼14.4% to 23.7% for FP and 1.45% to 4.51% for PP, yet their standard deviations dropped very drastically by 80.0% to 91.7% for FP and 67.7% to 73.9%. The estimated outlier rates also dropped, yet remained in comparable ranges, when the data error rate was low (∼0.54%–0.04% for FP and 1.04%–0.14% for PP based on the 90th and 99.9th percentiles for the 4 Holstein farms). In general, using stable individual within-group variance allowed more conservative flagging of outliers with small to moderate error rates. Meanwhile, it can lead to a higher false negative rate, failing to detect true data anomalies, when using a substantially larger prior individual within-group variance than the global estimate and a large prior value of the degrees of freedom (e.g., τ > 10). With properly assumed prior values, the conclusions tend to be consistent using either method.
Second, a low I-ICC value does not always imply measurement or recording errors. Because captures all within-day variation, it can also increase under legitimate biological or management-related fluctuations, such as irregular milking intervals, incomplete milk let-down, or transient physiological changes. Consequently, the I-ICC should be interpreted as a consistency measure rather than a strict binary false versus positive test. Empirical threshold calibration, which helps distinguish true anomalies from expected variability, warrants further exploration.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Barnett V.Lewis T.Outliers in Statistical Data 3rd ed.1994 Wiley
- 2Bartko J.J.The intraclass correlation coefficient as a measure of reliability Psychol. Rep.19196631110.2466/pr 0.1966.19.1.359421095942109 · doi ↗ · pubmed ↗
- 3Falconer D.S.Mackay T.F.C.Introduction to Quantitative Genetics 4th Edition 1996 Addison Wesley Longman Harlow
- 4Fisher R.A.Statistical Methods for Research Workers 12th ed.1954 Oliver and Boyd Edinburgh, UK
- 5Grubbs F.E.Procedures for detecting outlying observations in samples Technometrics 11196912110.1080/00401706.1969.10490657 · doi ↗
- 6Harris J.A.On the calculation of intra-class and inter-class coefficients of correlation from class moments when the number of possible combinations is large Biometrika 9191344647210.1093/biomet/9.3-4.446 · doi ↗
- 7Kumro F.G.Smith F.M.Yallop M.J.Ciernia L.A.Mayo L.M.Poock S.E.Lamberson W.R.Lucy M.C.Estimates of intra- and interclass correlation coefficients for rump touches and the number of steps during estrus in postpartum cows J. Dairy Sci.10420212318233310.3168/jds.2020-189223324661033246610 · doi ↗ · pubmed ↗
- 8Tukey J.W.Exploratory Data Analysis 1977 Addison-Wesley Reading, MA