Bayesian Tensor Decomposition for Clustering Latent Symptom Profiles for Verbal Autopsy Data
Yu Zhu, Zehang Richard Li

TL;DR
This paper introduces a new Bayesian method to better understand and categorize symptom patterns in verbal autopsy data for determining causes of death.
Contribution
A novel Bayesian tensor decomposition framework that improves accuracy and interpretability in clustering symptom profiles for verbal autopsies.
Findings
The proposed method outperforms existing VA methods in predictive accuracy.
It provides a more interpretable and parsimonious representation of symptom distributions.
New insights into symptom and cause clustering patterns are revealed using the PHMRC dataset.
Abstract
Cause‐of‐death data is fundamental for understanding population health trends and inequalities as well as designing and evaluating public health interventions. A significant proportion of global deaths, particularly in low‐ and middle‐income countries (LMICs), do not have medically certified causes assigned. In such settings, verbal autopsy (VA) is a widely adopted approach to estimate disease burdens by interviewing caregivers of the deceased. Recently, latent class models have been developed to model the joint distribution of symptoms and perform probabilistic cause‐of‐death assignment. A large number of latent classes are usually needed in order to characterize the complex dependence among symptoms, making the estimated symptom profiles challenging to summarize and interpret. In this paper, we propose a flexible Bayesian tensor decomposition framework that balances the predictive…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
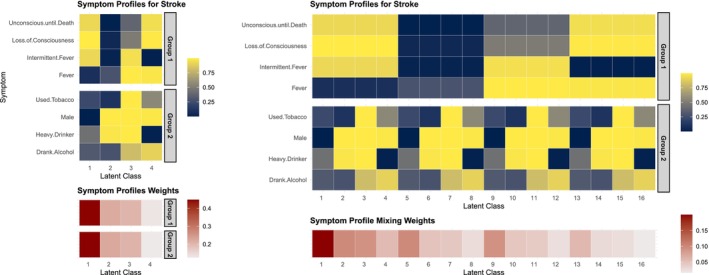 FIGURE 1
FIGURE 1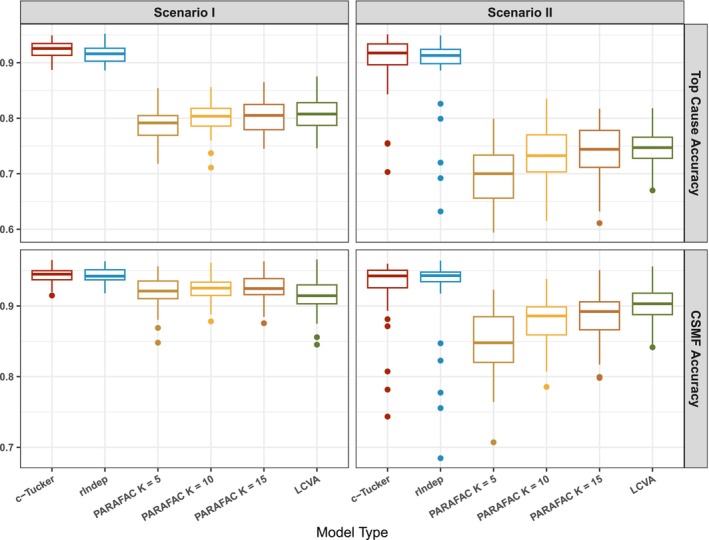 FIGURE 2
FIGURE 2 FIGURE 3
FIGURE 3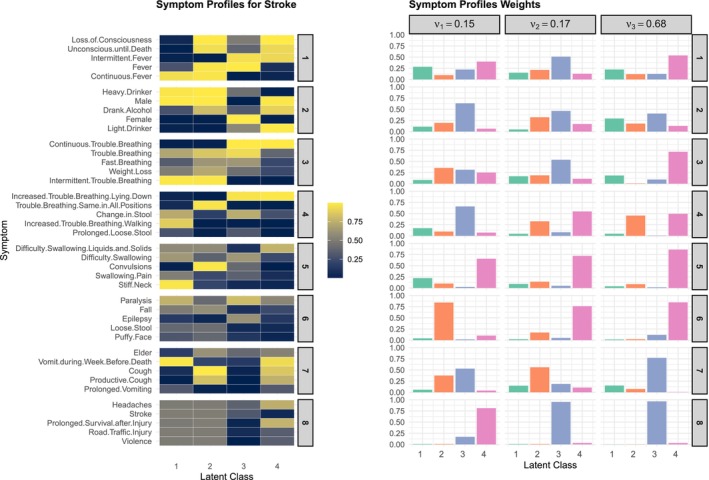 FIGURE 4
FIGURE 4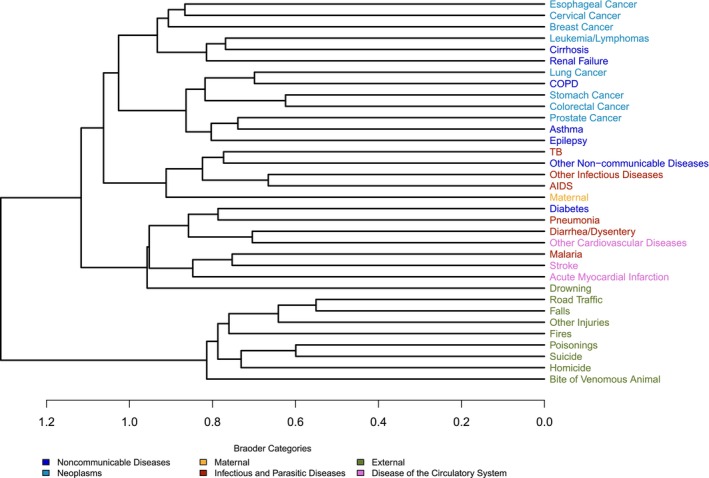 FIGURE 5
FIGURE 5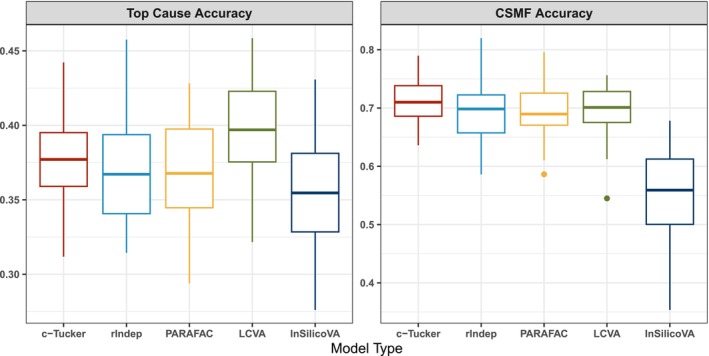 FIGURE 6
FIGURE 6- —Eunice Kennedy Shriver National Institute of Child Health and Human Development10.13039/100009633
- —Bill and Melinda Gates Foundation10.13039/100000865
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Topic Modeling · Data-Driven Disease Surveillance
Introduction
1
Understanding cause‐of‐death distributions is vital for assessing the health status and needs of a population, particularly in low‐resource settings where data scarcity often hampers public health efforts. In many low‐ and middle‐income countries (LMICs), a substantial proportion of deaths occur outside of medical facilities, leaving these deaths unregistered and without medically certified causes of death. To bridge this information gap, verbal autopsy (VA) has emerged as a widely adopted tool, providing an alternative means of cause‐of‐death determination through structured interviews with a deceased individual's family or caregiver. VA helps infer causes of death by collecting data on demographics, symptoms, and circumstances preceding death, especially in settings lacking complete civil registration and vital statistics systems [1, 2, 3].
The process of assigning causes of death using VAs traditionally relies on physicians reviewing the collected data and assigning likely causes of death manually. While effective, physician‐based VA assessment is resource‐intensive, challenging to scale, and often impractical for routine surveillance. As a result, algorithmic and statistical methods have gained traction as cost‐effective, scalable alternatives for automated cause‐of‐death determination. Early VA cause‐of‐death assignment methods usually assume that symptoms are conditionally independent given the underlying cause of death. This simplifying assumption reduces model complexity and computation time, making these algorithms more accessible for large‐scale use in low‐resource settings [4, 5, 6]. However, real‐world symptom patterns usually exhibit complex dependence relationships that are crucial for understanding disease risks and accurate cause‐of‐death assignment. Recent work on VA analysis largely focuses on relaxing this assumption. Kunihama et al. [7] and Moran et al. [8] proposed latent Gaussian factor models to account for symptom dependence and their association with demographic covariates. Li et al. [9] proposed a latent Gaussian graphical model to characterize latent conditional independence relationships across symptoms. One of the main limitations of the latent Gaussian approach to modeling symptom dependence is that the inferred dependence structures cannot be easily interpreted on the scale of the observed discrete response variables. The latent Gaussian models are also computationally more expensive to estimate. Li et al. [10] and Wu et al. [11] addressed these challenges by developing a latent class model framework for VA, where the conditional distribution of binary symptoms given each cause of death is approximated with a finite mixture model. The symptoms are assumed to be conditionally independent given the individual‐level latent class membership. The parameters of the latent representation can then be interpreted as latent symptom profiles given each cause of death, a concept known as the symptom‐cause‐information (SCI) in the VA literature [12].
There are two main challenges with latent class analysis introduced in Li et al. [10] and Wu et al. [11]. First, the classical latent class model framework relies on a single latent variable to cluster observations. Deaths assigned to the same cluster are assumed to have independent and identical symptom distributions. When the assumed number of latent classes is small, the flexibility of the model formulation is limited and the model may not capture nuanced symptom dependence structures for more complex causes of death. On the other hand, models with a large number of latent classes increase the risk of overfitting to the noisy VA data and can degrade the classification performance for the cause‐of‐death assignment. Second, without structural assumptions, standard latent class analysis usually leads to similar latent class profiles on VA data. This phenomenon is known as weak separation [13] and is common in high‐dimensional latent class analysis. The LCVA model proposed in Li et al. [10] mitigates this issue by assuming the latent symptom profiles share similar elements on most dimensions and differ for only a sparse set of symptoms. However, as we illustrate in Section 2, when the similarity across latent profiles are induced because of symptom clustering, the sparsity assumption can be ineffective. The weak separation of latent classes makes the characterization and interpretation of high‐dimensional symptom profiles difficult.
In this paper, we propose a unified framework using hierarchical tensor decomposition that addresses both limitations. In addition to clustering deaths, we also perform simultaneous symptom clustering. Specifically, we propose two new methods for modeling VA data using group‐wise PARAFAC decomposition and collapsed Tucker (c‐Tucker) decomposition [14]. Both models partition the high‐dimensional symptoms into a small number of groups and construct the full symptom profiles by combining group‐specific symptom sub‐profiles. Compared to standard latent class models, our models allow us to capture a wider range of dependence structures among symptoms and causes while using a smaller number of parameters. The symptom groups also provide a more interpretable and parsimonious summary of the symptom‐cause relationship. We develop a scalable estimation strategy using Markov chain Monte Carlo (MCMC). Finally, we demonstrate the effectiveness of our model on VA data, showing that the tensor decomposition approach improves both the accuracy of cause‐of‐death assignments and the interpretability of the latent representations.
The rest of the paper is organized as follows. Section 2 reviews tensor decomposition models in the VA literature. Section 3 proposes two new tensor decomposition approaches to model symptom distribution. Section 4 describes posterior inference using MCMC. Section 5 evaluates the proposed approach with synthetic data and demonstrates the improved performance in cause‐of‐death assignment from the proposed models compared to existing methods. Section 6 describes an in‐depth analysis of a real‐world VA dataset using the proposed models. Section 7 concludes with a discussion and future work.
Tensor Decomposition for VA Data
2
Let Xi∈{0,1}p denote the p‐dimensional vector of binary signs/symptoms collected by VA and Yi∈{1,…,C} denote the reference cause of death for the ith death. In this paper, we consider the scenario where we have access to a training dataset where both X and Y are observed and inference is needed for a target dataset where we only observe X. Let Di=1 indicates the ith death is in the training dataset and Di=0 the target dataset. The goals of cause‐of‐death assignment using VA data usually include two components: Individual cause‐of‐death classification for deaths without a reference cause, that is, predicting p(Y|X), and the estimation of cause‐specific mortality fractions (CSMF), that is, p(Y), in the target dataset. We factorize the joint distribution p(X,Y)=p(Y)p(X|Y) following the convention VA modeling [10, 15]. This factorization corresponds more naturally to the data‐generating process, where the majority of signs and symptoms can be treated as consequences of the underlying disease. It also allows direct estimation of different p(Y) across training and target datasets.
The key to probabilistic VA models is the modeling of the high‐dimensional conditional probability tensor p(X|Y). Most existing VA models can be viewed as model‐based decompositions of these high‐dimensional probability tensors. Tensor decompositions have been successfully applied in various fields, including medical imaging, genomics, social sciences, and recommendation systems. Two most widely used models in the literature are PARAFAC decomposition [16, 17] and the Tucker decomposition [18]. The Tucker decomposition has not been explored in the VA literature due to its computational complexity, thus we leave our review in the Supporting Information. The PARAFAC decomposition, on the other hand, has been commonly used in VA modeling, and is directly relevant to our proposal in this paper. The PARAFAC decomposition decomposes a tensor into a sum of rank‐one tensors, capturing the interactions between multiple modes of the data. The K‐component element‐wise non‐negative PARAFAC decomposition of the probability tensor p(Xi1=x1,…,Xip=xp|Yi=c) assumes
Both λ and ϕ are non‐negative, and ∑k=1Kλck=1 for c=1,…,C. The latent class model in Wu et al. [11] is a hierarchical version of the probabilistic PARAFAC decomposition with multiple training datasets. The model in Li et al. [10] uses a sparse PARAFAC decomposition [19] by introducing spike‐and‐slab priors to ϕ. Furthermore, when K=1, the decomposition reduces to assuming symptoms are conditionally independent given each cause of death, and it results in the widely used InSilicoVA algorithm [5]. As ϕc characterizes K sets of independent Bernoulli distributions from which the symptoms are generated given the cth cause of death, we refer to ϕc as the symptom profiles for the cth cause.
Dimension‐Grouped Tensor Decomposition of VA Symptoms
3
A salient feature of VA data is that many symptoms/signs are naturally organized in groups. For instance, for breathing‐related issues, VA questionnaires typically ask about a series of related questions, such as whether the person had fast breathing, prolonged trouble breathing, intermittent trouble breathing, increased trouble breathing in certain positions, and so forth. VA questionnaires also usually include demographic indicators and indicators associated with risk factors such as drinking and smoking. In order to capture this grouping feature among symptoms, we consider two tensor decomposition models: Grouped independent PARAFACs and c‐Tucker decomposition. Both formulations were studied in Johndrow et al. [14].
Assuming the symptoms can be divided into r groups, where 1<r<p, one straightforward extension to the PARAFAC decomposition is to model each group independently with multiple PARAFAC decompositions. We refer to this model as r‐group independent PARAFACs. Let sj∈{1,…,r} denote the group membership indicator for the jth symptom. The r‐group independent PARAFACs model assumes
where Ks is the number of latent classes in the sth symptom group. In this work, as our main goal is using the decomposition to approximate the joint distribution of symptoms, rather than identifying optimal latent clusters, we treat K1=⋯=Kr and drop the subscript. Similar to the PARAFAC decomposition, the dependence of symptoms within the same group can be arbitrarily flexible with a large enough K. The symptoms from different groups are assumed to be independent a prior.
The between‐group conditional independence assumption is likely too rigid in VA modeling, since groups of symptoms and risk factors are likely dependent given the underlying disease. To further introduce dependence among the groups, we adopt the c‐Tucker formulation in Johndrow et al. [14] and model the mixing weights λ using another non‐negative PARAFAC decomposition. That is,
The c‐Tucker decomposition reduces to the r‐group independent PARAFACs when h=1 and the standard PARAFAC when h=r=1. On the other hand, when r=p, it is equivalent to the standard Tucker decomposition. Therefore, it provides an appealing way to control the complexity of the latent structure. Similar to the r‐group PARAFAC model, we make the simplifying assumption that K1=...=Kr and drop the subscript.
In both dimension‐grouped decompositions, the symptom profile ϕc is still a K by p matrix, but a different latent class is assigned for each symptom group. To illustrate the expressiveness of the symptom profiles estimated by the two dimension‐grouped factorization models, Figure 1 shows an example of a subset of latent symptom profiles ϕ and the corresponding weights λ for deaths due to stroke using the c‐Tucker model and the data described in Section 6. The combinations of these two group‐level sub‐profiles {ϕc,k,j:k∈1,…,K,sj=1} and {ϕc,k,j:k∈1,…,K,sj=2} can be equivalently represented by the standard PARAFAC model with K2 separate latent profiles. The right panel of Figure 1 illustrates this expanded representation. With r symptom groups and K latent classes, the symptom profiles under the dimension‐grouped factorization are parameterized by pK parameters, whereas for the standard PARAFAC, it requires pKr parameters to characterize the same dependence structure, with many repeated elements. In practice, with a finite number of observations, the PARAFAC model will likely not fully utilize Kr latent classes but will approximate it with a smaller rank instead due to prior shrinkage. This leads to a loss of information on the symptom profiles and can make the resulting latent representation more difficult to interpret.
Posterior mean of latent parameters for stroke estimated from the c‐Tucker model in one synthetic dataset. Left two panels are the selected symptoms profile ϕc by latent class from 2 symptom groups (top), ordered by the latent class weights p(Zis=k|Yi=c)=∑l=1hνclψclsk (bottom). Right two panels are the expanded version of selected symptoms profile ϕ (top) if the profiles are parameterized under standard PARAFAC decomposition, and the equivalent mixing weights, that is, p(Zis1=k1,Zis2=k2|Yi=c) for s1,s2∈{1,2} and k1,k2∈{1,…,4}.
Bayesian Hierarchical Representation
3.1
To connect the r‐group independent PARAFACs and c‐Tucker decomposition to the latent class models used for cause‐of‐death assignment, we introduce latent indicators and equivalently represent the conditional probability tensor decomposition using Bayesian hierarchical latent variable models. Under both models, we introduce r latent indicators for each death, where Zis∈{1,…,K} specifies latent class membership in the sth symptom group for the ith death. Let scj∈{1,…,r} denote the group membership for the jth symptom among death due to cth cause. Then the r‐group independent PARAFACs decomposition can be expressed by
For the c‐Tucker model, we introduce another latent categorical variable Hi∈{1,..,h} to facilitate the dependence among the group‐level indicators Zis. That is,
Finally, we complete the model specification with the priors for Y and the latent parameters. We assume the CSMFs in the training and target datasets can differ, but the conditional distribution of symptoms given causes remains the same, that is, there is label shift (also known as prior shift) between the joint distributions p(X,Y) in the two datasets [20]. This is usually a reasonable assumption when both datasets are collected on the same population. Specifically, for g∈{0,1}, we let
Since we are interested in extracting a small number of groups among symptoms, we use a Dirichlet prior λcs∼Dir(as1,…,asK) under the r‐group independent PARAFACs. For the c‐Tucker model, we let ψcls∼Dir(bs1,…,bsK), νc∼Dir(1/h,…,1/h). These Dirichlet priors may be replaced with stick‐breaking priors to further encourage sparsity when the latent dimensions are higher. For the response probabilities, we use non‐informative Beta priors, that is, ϕckj∼Beta(1,1).
As for the symptom groups, they may be predetermined if there exists expert knowledge of symptom grouping. In this paper, we adopt a more general data‐driven approach and estimate the symptom grouping instead. We assume the following priors on the group memberships,
Posterior Computation
4
Posterior distribution of the model parameters can be easily approximated using Gibbs sampling. We describe the MCMC steps for the c‐Tucker model first and then the modifications to the r‐group independent PARAFACs model.
- Sample Yi|Xi,s,π,ϕ,ψ,ν for unknown Yi with
- Sample Zis|Hi=l,Yi=c,Xi,s,ϕ,ψ for i=1,…,n, s=1,…,r with
- Sample Hi|Yi=c,Zis,ψ,ν for l=1,…,h with
- Sample π(g)|Y with
- Sample νc|Y,H with
- Sample ψcls|Y,H,Z with
- Sample ϕckj|Y,X,Z,s, for c=1,…,C, k=1,…,K, j=1,…,p, with
- Sample scj|Y,X,Z,ϕ,ξ for j=1,…,p, s=1,…,r, c=1,…,C with
- Sample ξc|sc for c=1,…,C with
As for the r‐group independent PARAFACs, the sampler proceeds with the following.
- Sample Yi|Xi,s,π,ϕ,ψ,ν for unknown Yi with
- Sample Zis|Yi=c,Xi,s,ϕ,λ for i=1,…,n, s=1,…,r with
- Sample λcs|Y,Z with
- Sample π(g), ϕckj, scj and ξc in the same way as the sampler for the c‐Tucker model.
Simulation Study
5
We start with a simulation study using synthetic data to evaluate the performance of different tensor decomposition models in terms of cause‐of‐death assignment. We consider C=20 causes of death, p=80 symptoms, and a total of 3000 deaths where the training data consist of 2000 labeled VAs and target data consist of 1000 unlabeled VAs. For each training‐target pair, we generate π(g)∼Dir(1,…,1) for g=0 and 1 independently. The symptoms X are generated according to the c‐Tucker model with latent dimensions K=3, r=5 and h=3. For each cause c and latent group l, we set νcl=1/h, ensuring equal contribution across groups. We construct the s matrix where each row consists of r sequential groups arranged in a cyclic pattern:
where g=p/r, 1≤c≤C, and 1≤j≤p. We consider two scenarios of generating the latent class memberships as follows:
- Scenario I: We generate data according to the proposed c‐Tucker model. We consider the more realistic situation where the concentrations of latent classes can vary considerably across causes and symptom groups. We let ψcls∼Dir(βcls1K) for each c∈{1,…,C}, l∈{1,…,h}, and s∈{1,…,r}, where the overall concentration parameters βcls are independently drawn from a discrete uniform distribution on [1,10].
- Scenario II: We generate data according to a misspecified c‐Tucker model where additional distribution shift exists between the training and target dataset in terms of the symptom distribution conditional on causes. In this case, denote p(Zis=k|Hi=l,Yi=c,Di=g)=ψclsk(g). We simulate ψcls(g)∼Dir(βcls(g)1K) and βcls(g) are sampled from independently drawn from a discrete uniform distribution on [1,10]. In this scenario, all models are severely misspecified as p(X|Y) can be different across the training and target data, depending on the sampled mixing weights ψ.
Finally, to mimic the low signal‐to‐noise ratio in real VA datasets, we allow only a small set of the symptoms to be informative to cause‐of‐death classification. More specifically, we let
In both scenarios, we generate 50 synthetic datasets and fit the c‐Tucker and the r‐group independent PARAFACs models. In the simulation study, we fix the latent dimensions to be the same as in the data generating process, that is, K=3,r=5, and h=3. We included additional simulation results with misspecified latent dimensions in the Supporting Information, and discuss practical choices of latent dimensions later in the analysis of real‐world VA data.
We compare the models with the standard PARAFAC with different numbers of latent classes, K=5,10, and 15. As discussed before, the standard PARAFAC corresponds to the c‐Tucker model with h=r=1. We also include comparisons with the LCVA algorithm described in Li et al. [10]. LCVA is based on a version of sparse PARAFAC decomposition of p(X|Y) and has been shown to outperform other existing VA methods. Varying the number of latent classes K in LCVA yields patterns similar to those in the PARAFAC model, with differences being less pronounced because the shrinkage priors in LCVA encourage more latent classes to collapse to similar values. Therefore, we only present a single LCVA specification, using K=10 following the recommendation in Li et al. [10]. Since label shift is assumed for the rest of the models in consideration, we only compare with the single‐domain variation of LCVA, where p(Y) is treated to be different but p(X|Y) is set to be the same across training and target datasets. It should be noted that LCVA implements the cause‐of‐death assignment in two stages, which is slightly different from the rest of the models in terms of the estimation procedure. For each dataset, we fit the proposed model and the PARAFAC model by running MCMC for 3000 iterations, with the first 1000 iterations discarded as burn‐in. For the LCVA, we follow Li et al. [10] and run three parallel chains of MCMC for 4000 iterations with the first 1000 iterations discarded as burn‐in.
The models are compared in terms of two widely used metrics in evaluating cause‐of‐death assignment: The accuracy of the predicted top cause of death and the CSMF accuracy. The CSMF accuracy metric is widely applied to evaluate how closely the estimated population distribution of causes of death matches the true distribution. It is defined as
where πc denotes the true CSMF from the target dataset. This metric measures the discrepancy between the estimated and actual CSMF, and is scaled to be between 0 and 1, where higher values indicate better performance in estimating prevalence. We note that these two metrics do not directly measure the goodness of fit of the tensor decomposition. However, we focus on these two metrics since they are of more direct interest when utilizing different tensor decomposition models to perform cause‐of‐death assignment.
Figure 2 summarizes the accuracy measures for different models. Performance of standard PARAFAC generally improves as K gets larger. Both the c‐Tucker and r‐group independent PARAFACs demonstrate higher accuracy compared to all standard PARAFAC models in both scenarios. Furthermore, the c‐Tucker and r‐group independent PARAFACs are more robust to distribution shift across datasets than the PARAFAC and single‐domain LCVA, with improvements evident in both the mean and variance of accuracy. While distribution shift is not intentionally accounted for in our model, this scenario shows the pitfalls of more rigid models (e.g., PARAFAC) when they fail to approximate the complex data distribution.
Top cause accuracy (top row) and CSMF accuracy (bottom row) for the two simulation scenarios, comparing the c‐Tucker model, the r‐group independent PARAFACs model, the PARAFAC with K=5,10,15 and LCVA with K=10 on the 50 simulated datasets.
Analysis of PHMRC Gold‐Standard Dataset
6
In this section, we comprehensively evaluate our proposed models using the PHMRC gold‐standard VA dataset [21]. The dataset includes 7841 adult deaths across 34 distinct causes. This dataset has been processed into 168 binary symptoms following McCormick et al. [5]. We perform random sampling with replacement from the PHMRC dataset, selecting 80% of the data as training samples. To ensure that this subset is representative of the entire population, we set the prevalence, π(1), to match the true prevalence observed across the full dataset. We then generate target datasets by first sampling the target prevalence π(0) from Dir(1,…,1) and resampling the remaining observations not in the training data with replacement to match the target prevalence. We repeat the process to form 50 target datasets and model fittings are carried out in the same way as described in the previous section.
In the rest of this section, we first describe how we choose the number of latent components for the c‐Tucker and r‐group independent PARAFACs models in Section 6.1. Then we take the c‐Tucker model as a case study and further delve into the estimated latent parameters and the interpretation of model components. We discuss the symptom grouping structure learned from data in Sections 6.2 and 6.3. Finally, we assess the cause‐of‐death assignment accuracies of the proposed model and compare them with existing VA methods in Section 6.4.
Selecting the Number of Latent Components
6.1
In order to select a reasonable K and r, we first fit both models solely on the training data using large values for K and r, setting K=r=10. We select the smallest r that captures at least 95% of the group variation. For the c‐Tucker model, we choose r=8, as the first eight groups were utilized in more than 5% of posterior samples. Similarly, we set r=6 for the r‐group independent PARAFACs model, as the first six groups meet this threshold. The number of latent classes K is selected similarly. A small K is usually preferable in practice to avoid overfitting and reduce computational complexity. We choose K so that the majority of latent classes with a high utilization rate can be captured when fitting the models on labeled data. We let K=4 for the c‐Tucker model and K=5 for the r‐group independent PARAFACs model. This choice is sufficient to capture over 80% of latent classes utilized in at least 5% of posterior samples. More than 99% of such latent classes can be captured by letting K=6 for both models, but in practice, we find larger K usually leads to overfitted models and worse classification performance. As for the c‐Tucker model, we set h=3 for the high‐level decomposition of the mixing weights since we allow only eight symptom groups. Graphical summaries of the latent class utilization are included in the Supporting Information. When fitting the standard PARAFAC model, we select K=10 based on the recommendation of [10] on the same dataset.
We note that selecting the number of components in a mixture model is notoriously difficult [22, 23, 24, 25], and more importantly for our task, the optimal estimation of p(X|Y) does not always translate to the optimal classification performance, as the latter depends more directly on approximating the relative magnitude of p(Y|X) across different causes. Having more latent components can increase the risk of overfitting for some causes and decrease the classification performance. In our experiments, model selection criteria, such as WAIC and leave‐one‐out cross validation, tend to select more components and lead to high computational cost and inferior performance in cause‐of‐death assignment. Cross validation may also be used to find the optimal number of latent classes for a given classification metric, but the computational cost for cross validation on a grid of latent dimension choices is high and impractical for routine use. Thus, while the procedure we take here is ad hoc, we believe it is a practical approach that yields a small number of latent components to use and can be adopted by practitioners.
Grouping of Symptoms
6.2
We now illustrate the estimated symptom structures based on the c‐Tucker model in one resampled dataset based on the PHMRC data. Figure 3 presents a summary of key symptom groups for deaths due to two major causes in the PHMRC dataset: Stroke and AIDS. We determine the symptom group membership based on the posterior mode of the group indicator matrix s. Symptoms within each group are ordered by the posterior probability of each symptom being within that group, that is, p(scj=ŝcj), in decreasing order. We focus on symptoms with high group assignment probabilities because when this probability is close to one, the symptom serves as an anchor to the latent symptom cluster, which has been shown to be key to ensure the identifiability of latent representations [26, 27]. Thus, Figure 3 can be viewed as a representation of key symptom “topics” within each of the eight groups, analogous to the topic modeling literature. In general, our model does not enforce the existence of anchor symptoms for all groups by design, but we have found such anchor symptoms with high group assignment probabilities in our numerical analysis of the PHMRC data consistently. We also note that being in the same group does not determine the sign of pairwise correlations. Rather, symptoms in the same group tend to vary together following the K group‐level sub‐profiles.
The group structure of key symptoms from the c‐Tucker model for two major causes of death: Stroke and AIDS. Within each group, symptoms are ordered by their probability of being in that group, listed from highest to lowest. Due to space, only the first five symptoms are shown. For symptoms with the same probability of being in the group, we sort them based on the empirical probability of observing the symptom given the cause, that is, p(Xij=1|Y=c). The size of the label is also proportional to this empirical conditional probability. The eight groups are re‐ordered to have decreasing average empirical conditional probabilities of individual symptoms.
We now take a closer look at latent symptom profiles and corresponding mixing weights through the posterior distributions of ϕ, μ, and ψ. Figure 4 illustrates these relationships for the cause of death attributed to stroke estimated by the c‐Tucker model. On the left, symptom sub‐profiles ϕc are shown for the eight estimated symptom groups and the first five anchor symptoms within each group, as in Figure 3. The complete set of symptom profiles can be constructed by mixing the group‐level symptom sub‐profiles. In this example, 48=65,536 expanded symptom profiles can be constructed, though many of which have a very low probability of occurrence.
Posterior mean of latent parameters for stroke estimated from the c‐Tucker model in one synthetic dataset. The left heatmap is the selected symptoms profile ϕ by latent class from eight symptom groups, with the group and symptoms matching the same order as Figure 3. The right barplots are the symptoms profile latent weights decomposed with ψ and corresponding ν.
The relative prevalence of the expanded symptom profiles is determined by the estimated weights in the right panel of Figure 3. Let c denote the index for stroke, the weights νc specifies h=3 set of random weights. In this example, νc3=0.68 is the largest latent class on the group weights, indicating that around 68% of deaths due to stroke is expected to follow the third set of group‐level latent weights ψc3s for each group s=1,…,8. While interpreting Figure 4 is selective by nature as only a subset of symptoms is shown due to space limitation, we can still observe interesting patterns that match clinical characterizations of stroke deaths. For this largest cluster, the first symptom group is dominated by latent Class 4, the second symptom group is mostly split between the latent Classes 1 and 3, and so forth. Focusing on the symptom profiles with high conditional probabilities, we can characterize this cluster of stroke deaths as having high probability reporting symptoms including loss of consciousness, unconsciousness until death, continuous trouble breathing, and having difficulty swallowing, which are all common comorbidities of severe stroke. They are also expected to split about evenly between having trouble breathing lying down and in all positions, likely depending on the severity of the stroke. The risk of experiencing paralysis is also elevated slightly based on the sixth group of symptoms and the deaths are slightly more likely to be females than males based on the second group of symptoms. In comparison, for example, in the next largest cluster with νc2=0.17, the deaths are more likely to report symptoms including fever, cough, productive cough, and so forth, which may be related to medical complications such as pneumonia, which are also common among stroke deaths.
Grouping of Causes of Death
6.3
Estimating cause‐specific symptom grouping also allows us to compare causes of death in terms of how symptoms cluster. While we do not assume any information sharing across causes by design, we observe similarities across causes in terms of how symptoms are grouped. For example, comparing stroke and AIDS in Figure 3, some symptom groups are similar, for example, symptom clusters related to breathing problems and loss of consciousness, while some other groups are distinct for each specific cause.
We further explore the similarities of symptom groups across different causes by applying hierarchical clustering to the causes using the estimated s matrix. Figure 5 shows the dendrogram of all causes of death based on the similarity of s. The clustering structure reflects dissimilarity between causes, calculated as 1—adjusted rand index (ARI), where ARI quantifies the similarity in symptom clusters across different causes of death [28]. The clustering corresponds very closely to the medically meaningful broader categories of causes. This suggests that the partitions of symptom groups estimated by the c‐Tucker model are generally similar among related causes.
The cause of death dendrogram from the c‐Tucker model. The x‐axis represents dissimilarity between cause of death labels, calculated as 1—adjusted rand index (ARI), where ARI measures clustering similarity of symptoms across causes based on the posterior mode of group assignments in scj. The cause of death labels are colored by the six broader categories shown in the legend.
Model Performance Comparison
6.4
To assess the model performance, we compare the results with single‐domain LCVA as in the simulation study and InSilicoVA algorithm [5]. InSilicoVA is a widely used VA method by practitioners. While it has been shown in Li et al. [10] that LCVA outperforms InSilicoVA in a variety of contexts, we include InSilicoVA as a practical baseline. Other recent VA algorithms have been shown to perform worse than or comparably to LCVA on the PHMRC dataset and thus we do not include them here for simplicity.
Figure 6 shows the top cause accuracy and CSMF accuracy across different models on 50 resampled target datasets. For both metrics, the simplest model, InSilicoVA, exhibits the lowest overall accuracy and the highest variance. The c‐Tucker model shows slightly lower top cause accuracy than LCVA but outperforms all methods in CSMF accuracy. We caution against overinterpreting the relative performance of methods on the PHMRC dataset, as it is a single dataset with limited sample size and known issues [29]. Nevertheless, the numerical analysis shows that both the c‐Tucker and r‐group independent PARAFACs decomposition achieve comparable performance to existing methods and have the potential to be used as a routine analysis method for VAs. Overall, we prefer c‐Tucker model over the other tensor decomposition approaches since it provides more structured interpretation of the relationship across groups. However, as discussed before, the task of estimating symptom distribution and the task of classification are related but different. The r‐group independent PARAFACs model performs similarly to the c‐Tucker model in the numerical analysis we conducted, indicating that it can provide a reasonable approximation of the joint symptom distribution for the purpose of cause‐of‐death assignment and is also a reasonable approach in practice.
Boxplot of top cause accuracy (left) and CSMF accuracy (right) for different models on the 50 resampled target datasets.
Discussion
7
In this paper, we examined the task of modeling VA data through the lens of conditional tensor decomposition. We proposed two dimension‐grouped tensor decomposition models for VA data, the c‐Tucker decomposition and group independent PARAFACs. Both models can identify multiple latent symptom groups and their corresponding profiles, offering a richer and more robust alternative to models based on standard latent class model formulation. Our approach not only captures complex and meaningful dependence structures among symptoms, but also enhances interpretability of the latent parameters by utilizing a more parsimonious parameterization to represent the symptom distributions. Our models also lead to robust improvements in cause‐of‐death assignment performance at both individual and population levels.
There are several limitations of the proposed model. First of all, while the symptom group structures show strong similarities across related causes of death, we did not explicitly encourage such structures in our model. We do not expect such information sharing to significantly improve predictive performance in the current study when the cause‐specific sample sizes are moderate to large, but we think it is a promising direction for future research and can be very useful to consider with rare diseases and unbalanced datasets. Second, in this paper, we only focus on the case of label shift between training and target datasets. The proposed methods can be naturally extended to deal with distribution shift in p(X|Y) in a multi‐source domain adaptation setting discussed in Li et al. [10]. Third, while our model provides a more flexible characterization of the symptom dependence, it comes at the cost of a heavier computational burden. While computation is feasible on a single laptop for the analysis considered in this paper, it can be challenging when scaling up to large datasets from national mortality surveillance systems, or when cross validation is desired to fine‐tune hyperparameters in the model. More work needs to be done to enable distributed modeling and inference for big data. Fourth, the dimension‐grouped decompositions we consider in this paper can also be extended to incorporate mixed membership models, where each symptom may contribute to multiple groups. Such models have been proposed recently in the literature [30, 31], which is a promising direction of future work. The structures of the latent symptom groups and profiles could also be extended in various ways. For example, when domain knowledge exists about broad symptom grouping, we may restrict the symptom grouping to be within the broad groups only to further simplify the process of choosing the latent dimensions. Lastly, the latent group structures we consider in this paper may be further condensed into lower‐dimensional summaries by adding more model components such as sparsity‐inducing priors. It is an important future direction of research to gain more insight into the interpretability and expandability of VA algorithms, especially as more and more black‐box classification tools are available in the era of artificial intelligence. We leave these challenges to future work.
Funding
YZ and ZRL were supported by Grant R03HD110962 from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD), and in part by the Bill & Melinda Gates Foundation. The findings and conclusions contained within are those of the authors and do not necessarily reflect positions or policies of the Bill & Melinda Gates Foundation.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1. sim70475‐sup‐0001‐Supinfo.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1D. Maher , S. Biraro , V. Hosegood , et al., “Translating Global Health Research Aims Into Action: The Example of the ALPHA Network,” Tropical Medicine & International Health 15, no. 3 (2010): 321–328.20070637 10.1111/j.1365-3156.2009.02456.x · doi ↗ · pubmed ↗
- 2J. Nkengasong , E. Gudo , I. Macicame , et al., “Improving Birth and Death Data for African Decision Making,” Lancet Global Health 8, no. 1 (2020): e 35–e 36.31839138 10.1016/S 2214-109X(19)30397-3 · doi ↗ · pubmed ↗
- 3O. Sankoh and P. Byass , “The INDEPTH Network: Filling Vital Gaps in Global Epidemiology,” International Journal of Epidemiology 41 (2012): 579–588.22798690 10.1093/ije/dys 081PMC 3396316 · doi ↗ · pubmed ↗
- 4P. Byass , L. Hussain‐Alkhateeb , L. D'Ambruoso , et al., “An Integrated Approach to Processing WHO‐2016 Verbal Autopsy Data: The Inter VA‐5 Model,” BMC Medicine 17, no. 1 (2019): 1–12.31146736 10.1186/s 12916-019-1333-6PMC 6543589 · doi ↗ · pubmed ↗
- 5T. H. Mc Cormick , Z. R. Li , C. Calvert , A. C. Crampin , K. Kahn , and S. J. Clark , “Probabilistic Cause‐Of‐Death Assignment Using Verbal Autopsies,” Journal of the American Statistical Association 111, no. 515 (2016): 1036–1049.27990036 10.1080/01621459.2016.1152191 PMC 5154628 · doi ↗ · pubmed ↗
- 6P. Serina , R. Ian , S. Andrea , et al., “Improving Performance of the Tariff Method for Assigning Causes of Death to Verbal Autopsies,” BMC Medicine 13 (2015): 291.26644140 10.1186/s 12916-015-0527-9PMC 4672473 · doi ↗ · pubmed ↗
- 7T. Kunihama , Z. R. Li , S. J. Clark , and T. H. Mc Cormick , “Bayesian Factor Models for Probabilistic Cause of Death Assessment With Verbal Autopsies,” Annals of Applied Statistics 14 (2020): 241–256.33520049 10.1214/19-aoas 1253 PMC 7845920 · doi ↗ · pubmed ↗
- 8K. R. Moran , E. L. Turner , D. Dunson , and A. H. Herring , “Bayesian Hierarchical Factor Regression Models to Infer Cause of Death From Verbal Autopsy Data,” Journal of the Royal Statistical Society: Series C: Applied Statistics 70 (2021): 532–557.34334826 10.1111/rssc.12468 PMC 8320757 · doi ↗ · pubmed ↗