Using Large Language Models to Predict Advanced Liver Fibrosis in Metabolic Dysfunction-Associated Steatotic Liver Disease (MASLD): A Proof-of-Concept Analysis
Basile Njei, Nelvis Njei, Sarpong Boateng, Omar Al Ta'ani, Yazan Al-Ajlouni

TL;DR
This study shows that large language models like GPT-4 can accurately predict advanced liver fibrosis in patients with MASLD using clinical data, outperforming traditional methods.
Contribution
The novel use of GPT-4 and GPT-3.5 for predicting advanced liver fibrosis in MASLD using structured clinical variables is demonstrated for the first time.
Findings
GPT-4 achieved an AUROC of 0.91 for predicting advanced fibrosis in MASLD patients.
GPT-4 and GPT-3.5 outperformed traditional risk scores like FIB-4 in fibrosis prediction.
Both models showed strong calibration and high specificity for detecting advanced fibrosis.
Abstract
Background: Metabolic dysfunction-associated steatotic liver disease (MASLD) is a prevalent condition linked to type 2 diabetes and other metabolic risk factors. Timely detection of advanced fibrosis (≥F3) in MASLD patients is critical for effective clinical management. Traditional risk scores, such as the Fibrosis-4 Index (FIB-4) and NAFLD Fibrosis Score (NFS), have limitations, prompting the exploration of machine learning models for improved risk prediction. Objectives: This proof-of-concept study evaluates the feasibility of using large language models (LLMs), specifically GPT-4 and GPT-3.5 (OpenAI, Inc., San Francisco, United States), to predict advanced liver fibrosis in individuals with MASLD using only structured clinical variables from the National Health and Nutrition Examination Survey (NHANES). Methods: We used NHANES 2017-2020 data, including 162 participants with MASLD.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2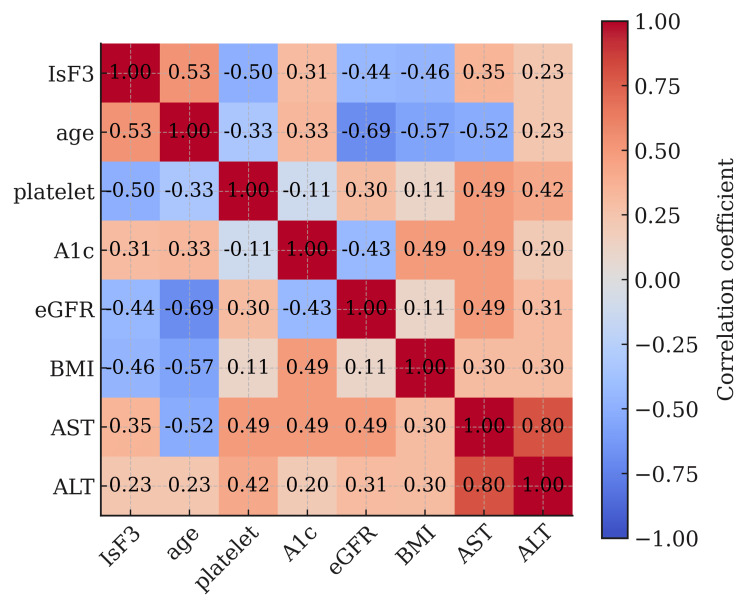 Figure 3
Figure 3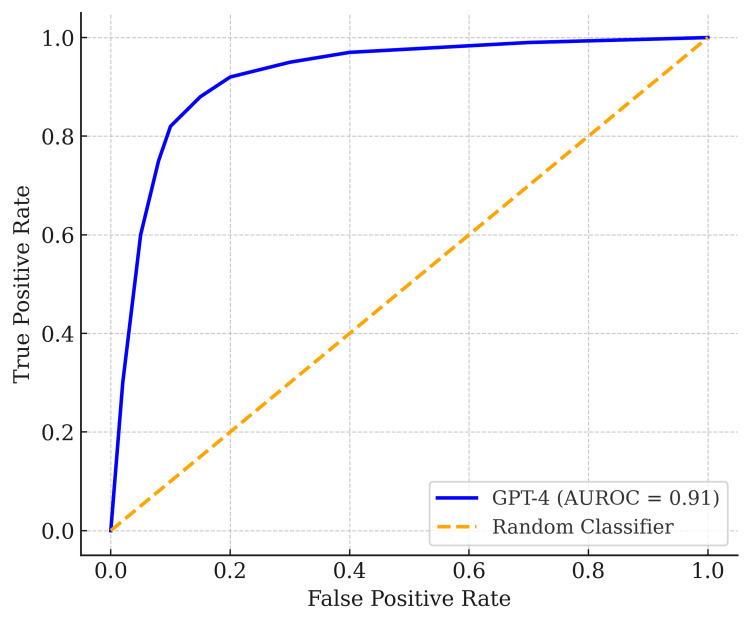 Figure 4
Figure 4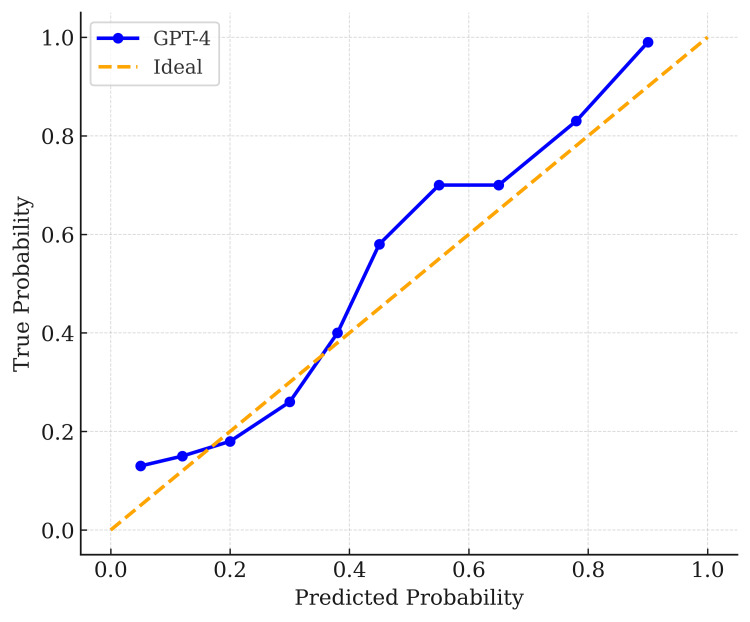 Figure 5
Figure 5| Variables | Training cohort (N=162) |
| Age* | 49.5 (16.3) |
| Female | 78 (48.1) |
| Male | 84 (51.9) |
| Hispanic | 53 (32.7) |
| Non-Hispanic Asian | 18 (11.1) |
| Non-Hispanic Black | 25 (15.4) |
| Non-Hispanic White | 58 (35.8) |
| Other | 8 (4.9) |
| Body-mass index (kg/m²)* | 32.5 (5.8) |
| Alanine aminotransferase (U/L)* | 24.4 (17.2) |
| Aspartate aminotransferase (U/L)* | 21.6 (14.1) |
| Gamma glutamyl transferase (IU/L) | 36.5 (48.6) |
| Platelet count (1000 cells/µL)* | 256.8 (72.8) |
| Hemoglobin A1c (%) | 6.0 (1.1) |
| Direct HDL-cholesterol (mg/dL) | 47.8 (12.8) |
| Triglyceride (mg/dL) | 156.5 (176.9) |
| 2021 CKD-EPI GFR* | 96.2 (20.5) |
| Creatinine (mg/dL) | 0.8 (0.3) |
| Albumin (g/dL) | 4.0 (0.3) |
| Obesity | 157 (96.9) |
| Type 2 diabetes mellitus | 124 (76.5) |
| Hypertension | 105 (64.8) |
| Dyslipidemia | 107 (66.0) |
| Fibrosis-4 | 1.0 (0.8) |
| NAFLD Fibrosis Score | 0.3 (1.4) |
| Model | AUROC (95% CI) | Brier (95% CI) | Sensitivity (95% CI) | Specificity (95% CI) | F1 Score (95% CI) |
| GPT-4 | 0.91 (0.86, 0.96) | 0.12 (0.10, 0.14) | 0.84 (0.71, 0.95) | 0.86 (0.80, 0.92) | 0.70 (0.57, 0.81) |
| GPT-3.5 | 0.90 (0.85, 0.95) | 0.10 (0.08, 0.13) | 0.91 (0.79, 1.00) | 0.82 (0.76, 0.89) | 0.69 (0.58, 0.80) |
| Patient Profile | LLM Risk Prediction | Model Explanation |
| Age: 50 | Platelet: 150 | HbA1c: 6.0 | eGFR: 85 | BMI: 30 | AST: 40 | ALT: 35 | 42.7% | Mildly elevated liver enzymes and borderline platelet count with metabolic risk factors (BMI, HbA1c). |
| Age: 60 | Platelet: 110 | HbA1c: 7.5 | eGFR: 65 | BMI: 33 | AST: 55 | ALT: 60 | 78.3% | Significantly elevated transaminases, thrombocytopenia, and diabetes suggest a high risk of advanced fibrosis. |
| Age: 45 | Platelet: 200 | HbA1c: 5.5 | eGFR: 95 | BMI: 24 | AST: 22 | ALT: 25 | 12.1% | Normal liver enzymes and platelets with a favorable metabolic profile suggest low risk of fibrosis. |
| Age: 72 | Platelet: 135 | HbA1c: 6.8 | eGFR: 58 | BMI: 28 | AST: 35 | ALT: 32 | 55.9% | Advanced age, borderline renal function, and impaired glucose control contribute to moderate fibrosis risk. |
| Age: 63 | Platelet: 175 | HbA1c: 6.3 | eGFR: 70 | BMI: 31 | AST: 38 | ALT: 40 | 47.5% | Mild liver enzyme elevation and insulin resistance indicate intermediate fibrosis risk. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLiver Disease Diagnosis and Treatment · Hepatitis C virus research · Genetic Associations and Epidemiology
Introduction
Metabolic dysfunction-associated steatotic liver disease (MASLD) represents a paradigm shift in the classification of liver disease, emphasizing the role of metabolic dysfunction rather than the exclusion of alcohol-related etiologies. Formerly termed non-alcoholic fatty liver disease (NAFLD), MASLD encompasses a continuum from simple steatosis to steatohepatitis, advanced fibrosis, cirrhosis, and hepatocellular carcinoma [1-3]. The condition is highly prevalent among individuals with type 2 diabetes and other metabolic risk factors, with estimates suggesting MASLD affects up to 67% of those with T2DM [4-6].
Timely identification of patients with advanced fibrosis (≥F3) is essential for guiding clinical management and preventing liver-related morbidity and mortality. Traditional risk scores such as Fibrosis-4 Index (FIB-4) and NAFLD Fibrosis Score (NFS) are limited by modest performance and frequently require follow-up imaging, constraining their use in primary care settings [7,8]. Meanwhile, new machine learning and AI-based approaches have shown promise in enhancing risk prediction and early detection. Interpretable models applied to structured data have demonstrated improved accuracy in identifying MASLD among high-risk populations, including hypertensive individuals and those with metabolic syndrome [9,10].
Large language models (LLMs), such as GPT-4 and GPT-3.5 (OpenAI, Inc., San Francisco, United States), represent a novel application of AI in clinical risk stratification [11]. These transformer-based models, traditionally used in natural language processing, are capable of synthesizing structured inputs into individualized, explainable risk predictions. Unlike traditional models, LLMs can dynamically adapt to new data and provide contextual rationales for predictions, offering a scalable tool for early fibrosis detection in routine care settings [12,13]. In this proof-of-concept study, we evaluate the feasibility of using GPT-based LLMs to predict advanced liver fibrosis in individuals with MASLD using only structured clinical variables. By leveraging publicly available NHANES data, we aim to assess whether transformer models can provide accurate, interpretable risk estimates based on routine laboratory and anthropometric features.
Materials and methods
Study population
This study used publicly available data from the National Health and Nutrition Examination Survey (NHANES) 2017-2020, a program of the National Center for Health Statistics (NCHS), Centers for Disease Control and Prevention (CDC), Hyattsville, Maryland, United States. As this was a secondary data analysis of a national survey, no single hospital or institute was involved in data collection. The data analysis was performed at Yale School of Medicine, New Haven, Connecticut, United States. MASLD was defined in accordance with the 2023 MASLD consensus criteria: presence of hepatic steatosis (controlled attenuation parameter (CAP) ≥274 dB/m) and at least one cardiometabolic risk factor (CMRF), including BMI ≥ 25 kg/m² (23 kg/m² in Asians) or waist circumference (WC) >94 cm (males), 80 cm (females); fasting serum glucose ≥100 mg/dL or HbA1c ≥5.7% or history of type 2 diabetes or treatment for type 2 diabetes; blood pressure ≥130/85 mmHg or antihypertensive drug treatment; plasma triglycerides ≥150 mg/dL or lipid-lowering treatment; plasma high-density lipoprotein (HDL)-cholesterol ≤40 mg/dL (males), ≤50 mg/dL (females) or lipid-lowering treatment.
Exclusion criteria included viral hepatitis (positive hepatitis B core antibody or hepatitis C RNA), significant alcohol consumption (≥1 drink/day for women, ≥2 drinks/day for men), and other known causes of chronic liver disease where data were available, including autoimmune liver disease and congestive hepatopathy. Participants with clinical or laboratory features suggestive of alternative etiologies of cirrhosis were excluded when identifiable within NHANES. The race category "Others" includes Non-Hispanic Asian individuals, Non-Hispanic multiracial individuals, Other Hispanic individuals, and other races not classified in the primary NHANES categories. No protocol was pre-registered for this proof-of-concept study, and the study was not registered in a public registry or conducted with public involvement.
Fibrosis classification
The fibrosis stage was estimated using a modified two-step approach aligned with the 2024 American Association for the Study of Liver Diseases (AASLD) guidance. Initially, participants were stratified using blood-based non-invasive liver disease assessment (NILDA) tools, FIB-4, and NFS into low, indeterminate, or high risk for advanced fibrosis. Subsequently, liver stiffness measurements (LSM) via vibration-controlled transient elastography (VCTE) were used to assign fibrosis stages (e.g., LSM 8-14 kPa for F3, ≥15 kPa for F4). A modified approach was used to assign patients to the higher end of overlapping categories (e.g., F2-F3 classified as F3).
The primary outcome of our study was advanced fibrosis (estimated fibrosis stage ≥3). Predictors included age, BMI, alanine aminotransferase (ALT), aspartate aminotransferase (AST), platelet count, estimated glomerular filtration rate (eGFR) calculated using the 2021 Chronic Kidney Disease Epidemiology Collaboration (GFR-EPI) equation, and hemoglobin A1c. These variables were selected based on prior evidence linking them to advanced liver fibrosis [14,15].
LLM prompt design
Two publicly available transformer-based LLMs developed by OpenAI’s GPT-4 and GPT-3.5 were accessed via application programming interface (API) through a secured Python interface (Python Software Foundation, Wilmington, Delaware, United States). A synthetic validation dataset of structured patient profiles was curated for this analysis, each consisting of the following seven variables: age (years), platelet count (×10³/µL), hemoglobin A1c (%), eGFR (mL/min/1.73 m²), BMI (kg/m²), AST (U/L), and ALT (U/L).
Each patient’s data was converted into a structured, human-readable text prompt to standardize the input format and minimize model variability. For example, a representative synthetic patient profile included the following values: age 63 years, platelet count 135 ×10³/µL, HbA1c 6.8%, eGFR 58 mL/min/1.73 m², BMI 28 kg/m², AST 35 U/L, and ALT 32 U/L. These variables were formatted into a single, human-readable prompt submitted to the model as follows: "You are a clinical decision support tool specializing in hepatology. You will receive structured patient data, including age, platelet count, HbA1c, eGFR, BMI, AST, and ALT. Based on these variables, estimate the probability (as a percentage) that the patient has advanced liver fibrosis (stage F3 or higher) in the context of metabolic dysfunction-associated steatotic liver disease (MASLD). Output your response in the following format:\nRisk percentage = [numerical value]%\nBrief reason: [concise clinical rationale for your prediction]\n\nBe precise, clinically grounded, and provide a percentage between 0 and 100."
The system instruction accompanying each batch of inputs directed the LLM to output both a numerical estimate of advanced fibrosis risk, phrased as "Risk percentage = [value]%", and a concise explanation. For the above example, the model returned: "Risk percentage = 55.9%\nBrief reason: Advanced age, borderline renal function, and impaired glucose control contribute to moderate fibrosis risk" [16].
The numerical probability (0.559) was programmatically extracted using regular expressions and used for AUROC, calibration, and Brier score calculations. To ensure data quality, 100% of outputs were parsed successfully, and 20% of records were manually reviewed to verify correctness. The temperature was set to 0.0 for reproducibility, and identical synthetic validation cases were repeatedly tested across five runs, confirming consistent risk percentages. An overview of the entire process is illustrated in Figure 1.
Workflow for converting structured patient variables into LLM prompts and parsed outputsLLM: large language model; NHANES: National Health and Nutrition Examination Survey; eGFR: estimated glomerular filtration rate; ALT: alanine aminotransferase; AST: aspartate aminotransferase; API: application programming interface
To optimize efficiency and reduce API call overhead, patient prompts were batched into groups of 20. Model responses were programmatically parsed to extract numerical values for predicted risk. If a batch failed to return valid responses due to API errors or timeouts, a retry mechanism was implemented to submit individual records within the batch.
Model performance evaluation
We applied Youden’s Index (J) to determine the optimal binary classification thresholds from the models' continuous risk outputs. This index, defined as J = Sensitivity + Specificity - 1, is a standard criterion for selecting a classification threshold that equally weights false positives and false negatives. As described in the Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy, it provides a general index of test performance at a chosen cutoff, where values close to 1 indicate high accuracy and a value of zero indicates performance equivalent to random guessing. Youden’s Index identifies the point on the ROC curve that maximizes the sum of sensitivity and specificity. In our analysis, these optimal thresholds were 40.5% for GPT‑4 and 45% for GPT‑3.5. We evaluated model discrimination, calibration, and overall performance using the following metrics: sensitivity, specificity, area under the receiver operating characteristic curve (AUROC), F1 score, and the Brier score (a composite measure of calibration and accuracy).
We generated 95% confidence intervals (CIs) for each performance metric using bootstrap resampling with 1,000 iterations. Model calibration was assessed by plotting predicted vs. observed probabilities using calibration plots.
All analyses were conducted in Python (version 3.8) using the scikit-learn package for model evaluation and Seaborn/Matplotlib for visualization and graphical interpretation of results. A TRIPOD+AI statement, i.e., updated guidance for reporting clinical prediction models that use regression or machine learning methods, is provided in Appendix 1.
Results
A total of 15,560 participants from NHANES 2017-2020 were initially screened. Participants younger than 18 years, those without evidence of hepatic steatosis, or those without valid VCTE measurements were excluded, yielding 3,234 adults with steatotic liver disease. Among these, individuals with viral hepatitis, excess alcohol consumption, or without CMRFs were excluded, resulting in 604 participants meeting MASLD criteria. Of these, participants with missing data required for model inputs, fibrosis estimation, or comparator scores (FIB-4 and NFS) were excluded, leaving a final analytic cohort of 162 individuals for model development and evaluation (Figure 2).
Flow chartNHANES: National Health and Nutrition Examination Survey; CMRF: cardiometabolic risk factor; MASLD: metabolic dysfunction-associated steatotic liver disease; NFS: NAFLD fibrosis score; FIB-4: Fibrosis-4 Index
Among the 162 MASLD participants, 84 (51.9%) were male, and the mean age was 49.5 (SD 16.3) years. Full cohort characteristics are shown in Table 1.
Figure 3 presents the correlation matrix. AST and ALT were positively correlated (r = 0.80). Platelet count was inversely associated with fibrosis severity (r = -0.53). BMI showed a modest positive correlation with AST and ALT, suggesting metabolic risk interplay.
Correlation matrixeGFR: estimated glomerular filtration rate; ALT: alanine aminotransferase; AST: aspartate aminotransferase
Table 2 shows the performance metrics for GPT-4 and GPT-3.5, including 95% CIs via bootstrapping. GPT-4 displayed an AUROC of 0.91 (0.86-0.96), indicating excellent discriminative ability (Figure 4). Its Brier score was 0.12, signifying good calibration and overall accuracy. Meanwhile, GPT-3.5 showed comparable performance with an AUROC of 0.90 (0.85-0.95), a slightly lower Brier of 0.10, and higher sensitivity (0.91). GPT-4, however, maintained superior specificity (0.86 vs. 0.82).
Receiver operating characteristic (ROC) curve for GPT-4, with an area under the receiver operating characteristic curve (AUROC) of 0.91The diagonal orange line represents the random classifier reference.
Table 3 illustrates examples of LLM-generated risk predictions with accompanying explanations. For instance, one patient’s prediction of 42.7% risk was accompanied by the explanation, 'Mildly elevated liver enzymes and borderline platelet count with metabolic risk factors (BMI, HbA1c).' These explanations help clinicians understand the rationale behind the model’s predictions, enhancing trust and supporting clinical validation.
Additionally, Figure 5 presents the calibration plot for GPT-4, where the predicted probabilities (x-axis) align closely with the observed outcomes (y-axis), suggesting good calibration. Calibration curves for both models indicated that predicted probabilities aligned well with observed risk. GPT-3.5’s calibration curve also approached the diagonal line, although there was minor underestimation at higher predicted probabilities.
Calibration plot for GPT-4Predicted probabilities (x-axis) align closely with observed frequencies (y-axis), suggesting good calibration. The blue line shows the relationship between predicted probabilities and observed event rates, while the orange dashed line represents perfect calibration (predicted probability = true probability).
Discussion
This study aimed to evaluate the feasibility of using GPT-based LLMs to predict advanced fibrosis (≥F3) in individuals with MASLD using only structured clinical variables. By prompting GPT-4 and GPT-3.5 with basic anthropometric and laboratory data, we explored a novel, minimally invasive approach for fibrosis risk stratification that avoids the need for imaging or proprietary feature engineering [17]. Traditional non-invasive tests such as FIB-4 and NFS use fixed formulas based on a few laboratory parameters. In contrast, LLMs have the ability to recognize complex, non-linear patterns in clinical data that these conventional scores may miss.
This study is, to our knowledge, the first to apply general-purpose transformer-based LLMs for fibrosis prediction in MASLD, offering an interpretable, scalable, and real-time tool for frontline clinical deployment. The novelty of this approach lies in its dual advantages: leveraging off-the-shelf, publicly available LLMs with no task-specific fine-tuning; and enabling both numerical and narrative outputs to support clinician understanding and trust. In an environment where existing tools like FIB-4 and NFS are limited by either accuracy or clinical adoption, our model offers a streamlined alternative that may be easier to integrate into primary care settings [18]. For instance, Franck et al. demonstrated that FIB-4 underperformed in identifying significant fibrosis, with false-positive rates of 43% and false-negative rates of 26%, highlighting the risk of both over- and under-classification in routine practice [18]. The implications for early MASLD detection and triage are significant, especially in resource-limited contexts.
Overall, our findings demonstrated that both GPT-4 and GPT-3.5 performed well, with AUROCs of 0.91 and 0.90, respectively, values that exceed the typical range reported for traditional scores like FIB-4 (0.80-0.86) and NFS (0.73-0.86) in MASLD populations [19-21]. Prior research has highlighted FIB-4’s clinical simplicity and reasonable rule-out performance [22,23], but it still suffers from poor specificity and high indeterminate zones [24,25]. In our study, GPT-4 demonstrated higher specificity than GPT-3.5 (86% vs 82%), while GPT-3.5 yielded higher sensitivity (91% vs 84%), emphasizing the potential for tailored model selection depending on the desired trade-off between over- and under-referral.
These results compare favorably to machine learning models previously applied to MASLD and fibrosis prediction. For instance, Alizargar et al. reported strong performance (AUC 0.951) using XGBoost in gender-stratified NAFLD risk models, while Chang et al. employed deep learning on ultrasound data to achieve an AUC of 0.97 in fibrosis staging [26,27]. However, these models often depend on imaging features or proprietary feature sets, limiting their portability. Our approach required only seven routine variables, all available in standard electronic health record (EHR) systems, enabling frictionless integration into real-world clinical workflows.
While our previous work demonstrated that XGBoost-based models can accurately predict high-risk metabolic dysfunction-associated steatohepatitis (MASH) using routine clinical data, this study evaluates the transition to transformer-based LLMs. Unlike tree-based ensemble models, LLMs can flexibly scale to accommodate both structured and unstructured data, suggesting broader potential for future clinical applications [28].
In addition to the strong predictive performance demonstrated by both GPT-4 and GPT-3.5, an important feature of these models is their ability to provide human-readable rationales for each risk estimate. This transparency allows clinicians to identify the key variables driving a prediction, effectively refining real-time decision-making. This capability for generating rationale allows clinicians to validate the model’s outputs, ensuring that the decisions align with clinical knowledge and patient-specific factors. For instance, if the model indicates a high risk of advanced fibrosis due to elevated AST and ALT levels, specialists can focus on these markers when planning further diagnostic steps or therapeutic interventions. Furthermore, this interpretability fosters trust in AI-assisted decision-making, as healthcare providers are more likely to adopt tools they understand and can validate.
Clinical and public health implications
The application of GPT-based LLMs to fibrosis risk prediction has important implications for both clinical care and population-level screening strategies. Clinically, this low-cost approach enables rapid identification of high-risk individuals while providing interpretable rationales to support clinician decision-making and potentially reduce reliance on more invasive or expensive diagnostics such as liver biopsy or elastography, particularly in settings with limited access to hepatology expertise.
From a public health perspective, scalable tools that facilitate earlier identification of high-risk MASLD individuals could help shift liver disease management upstream, toward prevention and early intervention. This is especially relevant given the high and growing burden of MASLD. The use of LLMs could support opportunistic screening within primary care and community health settings, identifying candidates for lifestyle interventions, pharmacotherapy, or referral to specialty care before irreversible liver damage occurs. Moreover, the adaptability of LLMs enables real-time, scalable screening that aligns with evolving clinical guidelines to address gaps in MASLD detection.
Data privacy and cost-effectiveness considerations
While the clinical potential of GPT-based LLMs is promising, their integration into hepatology practice requires careful consideration of data protection and economic implications. LLMs, particularly when applied to patient-level data, raise concerns regarding the potential leakage of personal health information and the propagation of plausible but incorrect responses (error in interpretation) [29,30]. Future LLM deployment should prioritize privacy and security. In our study, models used only de-identified NHANES data, reducing immediate privacy risks. Real-world use will still require robust safeguards and transparency.
Strengths and limitations
This study has several notable strengths. First, it uses a publicly available, nationally representative data set (NHANES), increasing transparency and reproducibility. Second, it demonstrates that general-purpose LLMs can yield performance comparable to, or better than, specialized models without requiring retraining or proprietary infrastructure. Third, we enforced a standardized, human-readable input format, enabling reproducibility and interpretability at scale.
Limitations should also be considered. Our sample size was relatively small after applying strict inclusion criteria, and fibrosis was classified using a composite surrogate approach rather than histological staging. While practical, this may have introduced misclassification bias. The model’s performance has not yet been validated in external or prospective cohorts, and its generalizability beyond NHANES remains unknown. Additionally, GPT-generated explanations, while often clinically plausible, are not guaranteed to reflect causal relationships or pathophysiologic reasoning and should be used with appropriate caution. Although we excluded alternative etiologies of liver disease when identifiable, residual misclassification is possible given the survey-based nature of NHANES and the absence of histologic confirmation.
Importantly, GPT-4 and GPT-3.5 were used without task-specific fine-tuning, relying on public APIs. Fine-tuning with MASLD and AASLD guidelines could improve clinical precision and alignment with clinical standards, though further work is needed to validate this approach with real-world data and clinical inputs. Although the results are promising, further work is needed to validate this approach with real-world data and clinical inputs.
Conclusions
In this proof-of-concept study, GPT-4 and GPT-3.5 demonstrated excellent performance for advanced fibrosis risk prediction, with robust AUROC, acceptable calibration, and clinically relevant sensitivity and specificity tradeoffs. These findings highlight the potential for LLMs to enhance early detection of advanced fibrosis in patients with MASLD. However, the study is limited by the use of surrogate fibrosis measures, a relatively small sample size, and a lack of external validation. Future research should expand on these preliminary results to optimize and validate LLM-based screening in real-world clinical settings. With further validation, LLMs may complement traditional scoring systems and enable precision screening strategies in clinical hepatology.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mega MASLD: an interactive platform for exploring stratified transcriptomic signatures in MASLD progressionbio Rxiv Cheng HS Chua D Chan ST Yew KC Wong SH Tan NS 2024
- 2MAFLD: How is it different from NAFLD?Clin Mol Hepatol Gofton C Upendran Y Zheng MH George J 03129202310.3350/cmh.2022.0367 PMC 1002994936443926 · doi ↗ · pubmed ↗
- 3Dietary characteristics associated with the risk of non-alcoholic fatty liver disease and metabolic dysfunction-associated steatotic liver disease in non-obese Japanese participants: a cross-sectional study JGH Open Taniguchi H Ueda M Sano F Kobayashi Y Shima T 08202410.1002/jgh 3.13082 PMC 1110999738779132 · doi ↗ · pubmed ↗
- 4Screening for chronic renal insufficiency should focus on people with diabetes, insulin resistance or advanced fibrosis in MASLD [PREPRINT] Yang T Yang B Yin J Hou C Wang Q 2024 https://www.researchgate.net/publication/380415996_Screening_for_Chronic_Renal_Insufficiency_Should_Focus_on_People_with_Diabetes_Insulin_Resistance_or_Advanced_Fibrosis_in_MASLD
- 5A prospective study on the prevalence of MASLD in patients with type 2 diabetes and hyperferritinaemia Aliment Pharmacol Ther Amangurbanova M Huang DQ Noureddin N 4564646120253949916810.1111/apt.18377 · doi ↗ · pubmed ↗
- 6Metabolic dysfunction-associated steatotic liver disease (MASLD) in people with diabetes: the need for screening and early intervention. A consensus report of the American Diabetes Association Diabetes Care Cusi K Abdelmalek MF Apovian CM 105710824820254043410810.2337/dci 24-0094 · doi ↗ · pubmed ↗
- 7Exploring biomarkers in nonalcoholic fatty liver disease among individuals with type 2 diabetes mellitus J Clin Gastroenterol Ahmadizar F Younossi ZM 36465920253935201510.1097/MCG.0000000000002079 PMC 11630663 · doi ↗ · pubmed ↗
- 8Clinical and pathological characteristics of metabolic dysfunction-associated steatotic liver disease and the key role of epigenetic regulation: implications for molecular mechanism and treatment Ther Adv Endocrinol Metab Li Y Li L Zhang Y 204201882513216021620254009872610.1177/20420188251321602 PMC 11912175 · doi ↗ · pubmed ↗