ChatGPT Versus DeepSeek for Breast Cancer Information Retrieval: Quantitative Comparative Study
Rima Hajjo, Dima A Sabbah, Sanaa K Bardaweel

TL;DR
This study compares ChatGPT and DeepSeek in generating breast cancer information, finding both models produce readable content but with different strengths in consistency and accuracy.
Contribution
The study quantitatively evaluates two AI models for breast cancer information generation, focusing on readability, quality, and citation reliability.
Findings
ChatGPT-4.0 provided more consistently readable content with a median Flesch-Kincaid Grade Level score of 10.66.
DeepSeek-V3 showed higher content quality scores (6.22) and stronger alignment with expert ratings compared to ChatGPT-4.0 (6.01).
Abstract
Artificial intelligence (AI) is increasingly used to generate medical content, yet its performance in delivering clinically relevant and reliable information remains underexplored, especially in complex areas such as breast cancer. This study aimed to compare ChatGPT-4.0 and DeepSeek-V3 in generating breast cancer information, focusing on readability, content quality, and citation reliability. On the basis of publicly available patient education materials, 10 frequently asked questions were selected. Each model generated 60 responses. Three expert reviewers rated each response using a 7-point Likert scale across 5 dimensions (ie, accuracy, completeness, clarity, depth and insight, and alignment with expert answers). Readability was assessed using Flesch-Kincaid Grade Level scores. Information reliability was evaluated through interrater agreement metrics, including Cohen κ and Fleiss…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
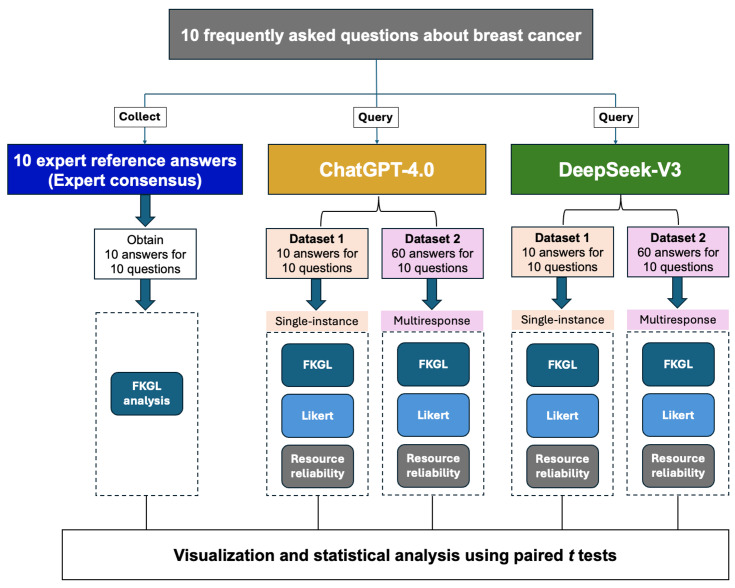 Figure 1
Figure 1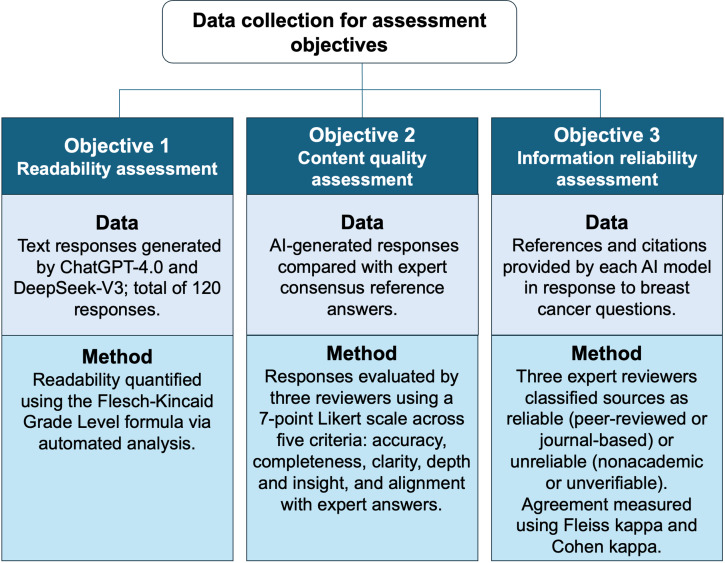 Figure 2
Figure 2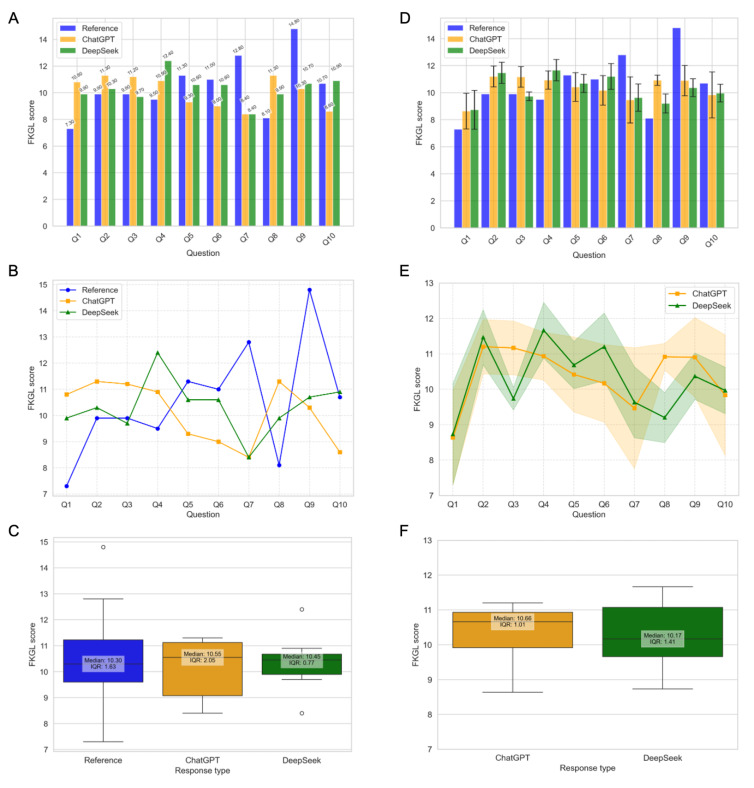 Figure 3
Figure 3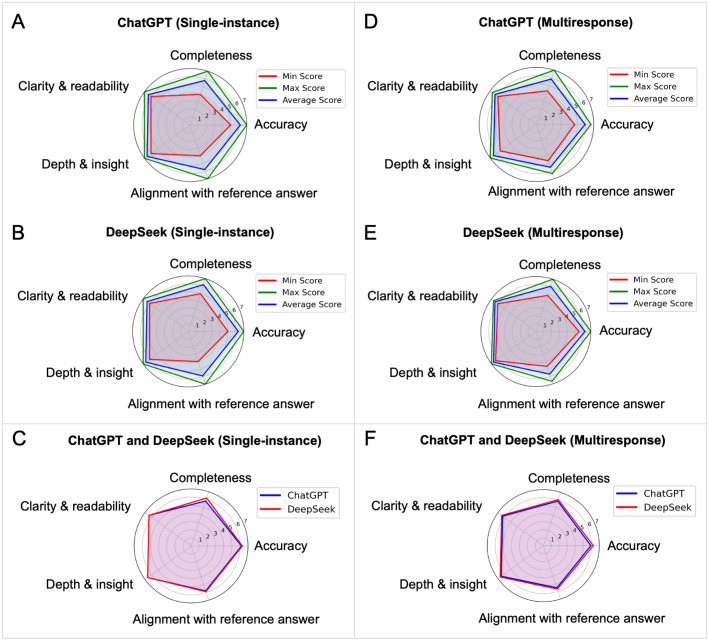 Figure 4
Figure 4| Question | Expert reference answer | ChatGPT-4.0 | DeepSeek-V3 | ||
|---|---|---|---|---|---|
| FKGL score | FKGL score | Difference | FKGL score | Difference | |
| Q1 | 7.30 | 10.80 | 3.50 | 9.90 | 2.60 |
| Q2 | 9.90 | 11.30 | 1.40 | 10.30 | 0.40 |
| Q3 | 9.90 | 11.20 | 1.30 | 9.70 | −0.20 |
| Q4 | 9.50 | 10.90 | 1.40 | 12.40 | 2.90 |
| Q5 | 11.30 | 9.30 | −2.00 | 10.60 | −0.70 |
| Q6 | 11.00 | 9.00 | −2.00 | 10.60 | −0.40 |
| Q7 | 12.80 | 8.40 | −4.40 | 8.40 | −4.40 |
| Q8 | 8.10 | 11.30 | 3.20 | 9.90 | 1.80 |
| Q9 | 14.80 | 10.30 | −4.50 | 10.70 | −4.10 |
| Q10 | 10.70 | 8.60 | −2.10 | 10.90 | 0.20 |
| Question | Expert reference answer | ChatGPT-4.0 | DeepSeek-V3 | ||||
|---|---|---|---|---|---|---|---|
| FKGL score | FKGL score | Difference | SD | FKGL score | Difference | SD | |
| Q1 | 7.30 | 8.63 | 1.33 | 1.32 | 8.73 | 1.43 | 1.43 |
| Q2 | 9.90 | 11.20 | 1.30 | 0.77 | 11.47 | 1.57 | 0.78 |
| Q3 | 9.90 | 11.17 | 1.27 | 0.76 | 9.73 | −0.17 | 0.32 |
| Q4 | 9.50 | 10.93 | 1.43 | 0.67 | 11.67 | 2.17 | 0.79 |
| Q5 | 11.30 | 10.42 | −0.88 | 1.06 | 10.68 | −0.62 | 0.67 |
| Q6 | 11.00 | 10.17 | −0.83 | 1.09 | 11.2 | 0.20 | 0.96 |
| Q7 | 12.80 | 9.47 | −3.33 | 1.71 | 9.63 | −3.17 | 1.00 |
| Q8 | 8.10 | 10.92 | 2.82 | 0.38 | 9.20 | 1.10 | 0.71 |
| Q9 | 14.80 | 10.90 | −3.90 | 1.12 | 10.37 | −4.43 | 0.66 |
| Q10 | 10.70 | 9.83 | −0.87 | 1.70 | 9.97 | −0.73 | 0.66 |
| Comparison | Single-instance | Multiresponse | ||||||
|---|---|---|---|---|---|---|---|---|
| 95% CI | 95% CI | |||||||
| ChatGPT-4.0 versus reference | −0.45 (9) | .66 | −1.69 to 2.53 | −0.24 (9) | .82 | −1.40 to 1.74 | ||
| DeepSeek-V3 versus reference | −0.24 (9) | .81 | −1.58 to 1.96 | −0.40 (9) | .70 | −1.25 to 1.78 | ||
| ChatGPT-4.0 versus DeepSeek-V3 | 0.52 (9) | .61 | −1.23 to 0.77 | 0.35 (9) | .73 | −0.53 to 0.72 | ||
| Evaluation criterion | ChatGPT-4.0 | DeepSeek-V3 | 95% CI | |||
|---|---|---|---|---|---|---|
| Single-instance results | ||||||
| Accuracy | 6.20 | 6.30 | −0.43 (9) | .68 | −0.63 to 0.43 | |
| Completeness | 5.80 | 6.20 | −1.50 (9) | .17 | −1.00 to 0.20 | |
| Clarity and readability | 6.40 | 6.40 | 0.00 (9) | 1.00 | −0.34 to 0.34 | |
| Depth and insight | 6.60 | 6.60 | 0.00 (9) | 1.00 | −0.34 to 0.34 | |
| Alignment with reference answer | 5.80 | 5.90 | −0.43 (9) | .68 | −0.63 to 0.43 | |
| Multiresponse results | ||||||
| Accuracy | 5.95 | 6.25 | −2.38 (9) | .04 | −0.59 to −0.01 | |
| Completeness | 5.85 | 6.05 | −1.91 (9) | .09 | −0.44 to 0.04 | |
| Clarity and readability | 6.27 | 6.43 | −1.73 (9) | .12 | −0.38 to 0.05 | |
| Depth and insight | 6.48 | 6.65 | −1.79 (9) | .11 | −0.38 to 0.04 | |
| Alignment with reference answer | 5.52 | 5.70 | −1.49 (9) | .17 | −0.46 to 0.09 | |
| Metric | ChatGPT-4.0 | DeepSeek-V3 |
|---|---|---|
| References evaluated, N | 45 | 268 |
| Reliability score (majority human; mean) | 0.64 | 0.82 |
| Fleiss κ (inter-rater agreement) | 0.842 | 0.935 |
| Perfect agreement (all 3 raters assigned the same label), n/N (%) | 40/45 (88.9) | 260/268 (97.0) |
| Majority agreement (≥2 of 3 raters assigned the same label), n/N (%) | 44/45 (97.8) | 267/268 (99.6) |
| Complete disagreement (all 3 raters assigned different labels), n/N (%) | 1/45 (2.2) | 1/268 (0.4) |
| Cohen κ (AI vs human majority) | 0.665 | 0.782 |
| Cross-evaluation κ (AI scoring the other model’s references) | ChatGPT on DeepSeek=0.600 | DeepSeek on ChatGPT=0.800 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · AI in cancer detection
Introduction
Breast cancer is the most commonly diagnosed cancer among women and remains a major global health burden. Despite advancements in detection and treatment, late-stage presentation continues to hinder outcomes [1-4]. The World Health Organization highlights the need for improved screening and care access [5], while socioeconomic factors such as education and income shape care-seeking behavior. Many women turn to the internet for information on early signs and symptoms [67], although online health content is often inaccurate or misleading [89].
In response, large language models (LLMs), such as ChatGPT and DeepSeek, have emerged as potential tools for generating medical information and answering patient queries [10-17]. Trained on extensive biomedical literature and general data sources, these generative artificial intelligence (AI) models can produce natural language responses to diverse health-related questions [1819], potentially supporting patient education and access to general medical knowledge [20]. Promising results have been demonstrated across multiple areas, including medical imaging, disease detection, drug discovery, and personalized oncology, with some AI models surpassing traditional diagnostic accuracy [21-24]. In oncology, AI aids in drug delivery, genomics integration, and real-time monitoring to improve outcomes [25-82526undefinedundefinedundefined]. Nonetheless, concerns persist regarding the accuracy, readability, and reliability of AI-generated content, especially in complex domains such as breast cancer, necessitating further validation studies [27-30].
A recent work by Ye et al [31] systematically evaluated ChatGPT-3.5’s performance in responding to frequently asked questions (FAQs) on cervical and breast cancer. Their study used 10 validated FAQs developed through expert consensus and compared ChatGPT’s responses to those of experienced gynecologists and mammography specialists. Using a 7-point Likert scale, they assessed multiple dimensions of response quality, including accuracy, readability, consistency, reliability, efficiency, and relevance. While ChatGPT 3.5 demonstrated high accuracy, often comparable to or exceeding physician responses, it also exhibited limitations in readability, consistency, and the reliability of cited sources. Although foundational, this study did not evaluate more advanced generative AI models, such as ChatGPT-4.0 or DeepSeek-V3, whose capabilities remain largely unexplored [31-33]. Thus, further research is needed to assess how newer models compare in generating high-quality, clinically relevant patient education content.
Therefore, the aim of this study was to systematically evaluate and compare ChatGPT-4.0 and DeepSeek-V3 in their ability to generate high-quality, patient-facing breast cancer information. Using an established, expert-validated set of breast cancer FAQs, we assessed each model across multiple dimensions of response quality, including readability, accuracy, completeness, clarity, depth, insight, alignment with expert reference answers, and citation reliability, with the goal of determining whether these systems can provide trustworthy, clinically relevant educational content for patients.
Methods
Study Design and Workflow
This study evaluated the performance of generative AI models in answering 10 FAQs related to breast cancer as described in the workflow shown in Figure 1. The 10 validated questions and their corresponding expert reference answers were adopted from the study by Ye et al [31], which served as the benchmark dataset for this evaluation. In their foundational study, Ye et al [31] developed a list of FAQs regarding breast cancer and cervical cancer based on popular science materials and current hot topics related to tertiary prevention. A set of 10 questions was designed for each cancer type. Subsequently, experts were invited to review the proposed questions and to formulate expert consensus answers. The final set of questions and expert consensus answers were determined through several rounds of consultation and assessment.
Workflow for evaluating the performance of ChatGPT and DeepSeek in retrieving and presenting medical information. FKGL: Flesch-Kincaid Grade Level.
Data Collection and Processing
Figure 2 summarizes the data collection and assessment procedures used to evaluate the performance of ChatGPT-4.0 and DeepSeek-V3 across three core dimensions: readability, content quality, and information reliability. Each objective shown in Figure 2 was addressed using a tailored methodology aligned with specific types of data and evaluation criteria.
Workflow of data collection for assessment objectives. AI: artificial intelligence.
AI Response Generation
To evaluate AI-generated content, we submitted 10 breast cancer FAQs to two generative AI models: ChatGPT-4.0 (OpenAI) and DeepSeek-V3 (DeepSeek). To ensure reproducibility and minimize bias, 3 independent researchers queried each model twice per question at different times, locations, and internet connections, yielding 6 responses per question per model (total: 60 responses per model and 120 responses overall).
Expert Reference Answers
Expert reference answers for each FAQ were obtained from the consensus of 5 board-certified physicians specializing in mammography, as reported by Ye et al [31]. These physicians independently reviewed each FAQ and provided responses, which were then harmonized into a single consensus answer per question. This consensus served as the gold standard for evaluating AI performance.
The 10 breast cancer FAQs and the corresponding AI-generated answers from each independent researcher are provided in Tables S1-S3 in Multimedia Appendices 1-3, and the expert consensus reference answers are provided in Table S4 in Multimedia Appendix 4.
Data Analysis
Readability Assessment
The readability evaluation was performed using the Flesch-Kincaid Grade Level (FKGL) analysis [3435]. The textstat library (version 0.7.7; developed by Shivam Bansal, open-source project) [36] in Python was used to compute the FKGL scores for expert reference answers and responses generated by ChatGPT-4.0 and DeepSeek-V3. FKGL estimates the US school grade level required to understand a text, with higher scores indicating greater complexity. The FKGL score was calculated using the following formula:
This analysis used two datasets: dataset 1, where expert reference answers were compared to the initial responses from ChatGPT-4.0 or DeepSeek-V3 for all questions (Q1-Q10); and dataset 2, where 3 researchers generated 2 responses each from ChatGPT-4.0 and DeepSeek-V3 for Q1-Q10, resulting in 60 responses per model. To evaluate statistical significance, paired t tests were conducted using the SciPy library (scipy.stats library; SciPy Developers, open-source project) within Python [37], as FKGL scores were normally distributed. These tests assessed mean differences between ChatGPT-4.0 and DeepSeek-V3 while ensuring paired comparisons across identical question sets.
Content Quality Assessment
Content quality was evaluated across five predefined dimensions: accuracy, completeness, clarity, depth and insight, and alignment with expert reference answers. These dimensions were adapted from established guidelines for assessing the quality of health information and AI-generated content [3839]. Each AI-generated answer was independently scored by 3 expert reviewers using a 7-point Likert-type scale, where 1 represented poor performance and 7 represented excellent performance.
To compare the performance of ChatGPT-4.0 and DeepSeek-V3 across these dimensions, statistical analysis was performed using Python’s SciPy library (scipy.stats module, version 1.15.1; SciPy Developers, open-source project) [37]. The Shapiro-Wilk test was first applied to assess the normality of score distributions [4041]. As the data met the normality assumptions, paired t tests [42] were conducted to compare mean scores across the 5 evaluation criteria. This approach enabled a robust and consistent comparison of content quality between the 2 models using identical question sets and standardized scoring methods.
Information Reliability Assessment
The information sources cited by ChatGPT-4.0 and DeepSeek-V3 were independently evaluated by 3 domain experts (RH, DAS, and SKB) with expertise in medicinal chemistry (all), molecular oncology (SKB), and computational drug discovery (RH and DAS). Each unique cited reference was assigned a binary reliability score: 1 for reliable sources (peer-reviewed journal articles, clinical guidelines, or official or authoritative bodies, such as national health agencies or major academic medical centers) and 0 for unreliable sources (commercial health media, foundation blogs, unsourced claims, or otherwise nonverifiable material). Complete source lists and scores are provided in Table S5 in Multimedia Appendix 5 (ChatGPT-4.0) and Table S6 in Multimedia Appendix 6 (DeepSeek-V3), and the full question-level reference data for both ChatGPT-4.0 and DeepSeek-V3 are provided in Table S7 in Multimedia Appendix 7.
For each AI model, we then performed 2 levels of agreement analysis. First, we assessed interrater reliability among the three human experts using Fleiss κ [43], and we also quantified the proportion of references with perfect agreement (all 3 raters assigned the same score), majority agreement (at least two raters agreed on the same score), and complete disagreement. Second, we evaluated how well each model aligned with human judgment by comparing the model’s score for each reference to the majority human score (the score agreed upon by ≥2 raters). Agreement between each AI model and this consensus was quantified using Cohen κ [44].
To further characterize disagreement, we identified references where ChatGPT or DeepSeek diverged from the expert majority score and summarized the frequency and nature of those disagreements. All scoring data (individual rater scores, AI-assigned scores, and majority scores) and all agreement calculations (Fleiss κ and Cohen κ) were generated in Python (pandas, NumPy, and scikit-learn) [45-47] and compiled into Microsoft Excel for audit trails, including disagreement tables and summary statistics for each model.
This evaluation framework allowed us to simultaneously measure (1) consistency among human raters when judging citation reliability and (2) how closely each AI system’s choices agreed with what experts considered acceptable evidence.
Ethical Considerations
This study did not involve human participants, patient data, or intervention and therefore did not require review or approval by an institutional review board or research ethics committee. The analyses were based exclusively on AI-generated text responses and publicly available information sources, without collection of any personal, identifiable, or sensitive data. As no human subjects were recruited or interacted with, informed consent was not required, and no consent waiver was necessary. No compensation was provided. All data were handled in accordance with principles of data minimization and confidentiality, and no private or proprietary information was accessed or stored during the study.
Results
Study Design and Analytical Framework
To evaluate the performance of ChatGPT and DeepSeek, a structured analytical framework was implemented, as illustrated in Figure 1. A comparison of ChatGPT and DeepSeek was conducted using 10 FAQs about breast cancer, with responses evaluated against consensus expert reference answers as outlined in the Methods section. The workflow, illustrated in Figure 1, consisted of three key steps: data collection, model querying, and visual and statistical analysis. In the data collection phase, 10 common breast cancer questions were identified, and expert consensus answers were established. Three independent researchers then queried ChatGPT and DeepSeek, generating responses. Two datasets were created for each model: dataset 1, consisting of single-instance responses (1 response per question); and dataset 2, containing multiresponse outputs (multiple responses per question), resulting in 10 responses from each model for dataset 1 and 60 responses from each model for dataset 2Figure 1.
Readability Assessment
The FKGL readability scores for responses generated by ChatGPT and DeepSeek, compared against expert reference answers, are presented in Tables12 and Figure 3. Two types of analyses were performed: single-instance analysis, where each AI model provided a single response per question; and multiresponse analysis, where multiple responses per question were collected by 3 researchers independently from both models.
Readability assessment using Flesch-Kincaid Grade Level (FKGL) scores for expert reference answers, ChatGPT, and DeepSeek responses. (A) Bar plot comparing FKGL scores for 10 questions using 1 response per question from each platform. The bars represent the FKGL scores for reference, ChatGPT, and DeepSeek. (B) Line plot showing the overall trends of FKGL scores across all questions using 1 response per question from each platform. The lines represent the FKGL scores for reference, ChatGPT, and DeepSeek. (C) Box plot showing the distribution of FKGL scores using 1 response per question from each platform. The boxes represent the IQR, with the median annotated inside each box. Reference, ChatGPT, and DeepSeek are represented in blue, orange, and green, respectively. (D) Bar plot comparing FKGL scores for 10 questions using 6 responses per question per platform. The bars represent the average FKGL scores, with error bars indicating the SD. ChatGPT responses are shown in orange, and DeepSeek responses are shown in green. (E) Line plot showing the overall trends of FKGL scores for ChatGPT and DeepSeek responses across 10 questions using 6 responses per question per platform. The solid lines represent the mean FKGL scores, and the shaded regions indicate the SDs. (F) Box plot showing the distribution of FKGL scores for ChatGPT and DeepSeek responses across 10 questions using 6 responses per question per platform. The boxes represent the IQR, with the median annotated inside each box. The y-axis for all line and box plots ranges from 7 to 15 to ensure a clear comparison of FKGL variations.
In the single-instance analysis, ChatGPT’s mean FKGL score (10.11, SD 1.17) was slightly lower than the expert reference (10.53, SD 2.17), whereas DeepSeek’s mean score (10.53, SD 1.02) matched the expert reference answer exactly. In the multiresponse analysis, ChatGPT’s mean FKGL increased to 10.36 (SD 0.84), whereas DeepSeek’s mean FKGL slightly decreased to 10.27 (SD 0.98). ChatGPT demonstrated reduced variability in the multiresponse case (SD 0.84) compared to the single-instance case (SD 1.17), indicating greater consistency when averaging multiple responses. In contrast, DeepSeek’s variability remained relatively stable across both analyses (SD 1.02 in single instance and 0.98 in multiresponse).
In both analyses, DeepSeek’s median FKGL scores were slightly lower than ChatGPT’s, suggesting that DeepSeek’s responses may be more concise or readable. DeepSeek also exhibited less fluctuation in readability scores, as indicated by its smaller IQR 0.77 (median 10.45) in single instance and 1.41 (median 10.17) in multiresponse. In contrast, ChatGPT’s variability decreased in the multiresponse case, with its IQR narrowing from 2.05 (median 10.55) to 1.01 (median 10.66).
A detailed evaluation of FKGL readability scores reveals variations in how ChatGPT and DeepSeek generate responses compared to expert references. For some questions (eg, Q1, Q2, Q3, and Q4), both models produced more complex responses (higher FKGL scores), potentially reducing accessibility for general readers but could be more suitable for professionals and specialists seeking in-depth information.
In contrast, for other questions (eg, Q5, Q6, Q7, and Q9), DeepSeek generally remained closer to the reference readability (reference) but showed greater variability, whereas ChatGPT exhibited larger deviations, sometimes producing more complex or simpler responses (Figure 3A, B, D and E). The multiresponse analysis improved consistency (Figure 3F), smoothing out extreme deviations (eg, outliers evident in Figure 3C) and leading to more balanced readability. Full per-question FKGL values and paired comparisons for single-instance and multiresponse data are provided in Tables S8-S11 in MultimediaAppendices 811.
A paired t test was conducted to assess the statistical significance of mean differences in FKGL scores among the expert reference answer, ChatGPT-4.0, and DeepSeek-V3 groups (Table 3). The Shapiro-Wilk test confirmed normality (P>.05 for all groups), validating the use of the t test. Results indicated no significant differences in readability scores between the expert reference answers and those generated by ChatGPT-4.0 or DeepSeek-V3, nor between ChatGPT-4.0 and DeepSeek-V3 (P=.61 for single instance and P=.73 for multiresponse). However, high variability in scores across questions was observed. Multiresponse analyses showed smaller differences between AI models and the reference, suggesting that averaging multiple responses yields more balanced readability. Normality was further confirmed by Shapiro-Wilk P values of .16 (ChatGPT-4.0) and .82 (DeepSeek-V3). The corresponding statistical summaries are provided in Tables S8 and S10 in MultimediaAppendices 810.
Content Quality Assessment
Response quality was evaluated using a 7-point Likert scale across five criteria: accuracy, clarity and readability, completeness, depth and insight, and alignment with reference answers. In the single-response analysis, ChatGPT achieved an overall mean Likert score of 5.36 (SD 0.53), whereas DeepSeek had a slightly higher mean score of 5.60 (SD 0.45) across all criteria and questions. At the criterion level, ChatGPT scored higher in alignment and accuracy, whereas DeepSeek performed slightly better in the remaining criteria (Figure 4A–C).
Content quality ratings for ChatGPT-4.0 and DeepSeek-V3 across 5 criteria. (A) ChatGPT response evaluation based on the average scores of 10 answers. (B) DeepSeek response evaluation based on average score of 10 answers. (C) ChatGPT versus DeepSeek comparison based on average scores of 10 answers. (D) ChatGPT response evaluation based on 60 answers. (E) DeepSeek response evaluation based on 60 answers. (F) ChatGPT versus DeepSeek comparison based on average scores of 10 answers.
In the multiresponse analysis (dataset 2), ChatGPT achieved a mean Likert score of 6.01 (SD 0.49), while DeepSeek achieved a comparable mean score of 6.22 (SD 0.43) across all criteria and responses (Figure 4D–F). Differences between the two models were minimal and not statistically significant (P>.05), with overlapping 95% CIs for completeness, clarity & readability, depth & insight, and alignment with the reference answer. However, DeepSeek outperformed ChatGPT based on accuracy (ChatGPT: 5.95 vs DeepSeek: 6.25). This difference was statistically significant (t₉ = −2.377, P = .041; 95% CI −0.585 to −0.015), indicating consistently higher accuracy scores for DeepSeek across the 10 questions.Overall, these findings indicate that both models provide comparably high-quality responses across the assessed dimensions. Detailed summary statistics are provided in Table 4, and full per-question and per-criterion Likert ratings for both the single-instance and multiresponse datasets are provided in Table S12 in Multimedia Appendix 12 and Table S13 in Multimedia Appendix 13.
Information Reliability Assessment
We analyzed the reliability of citations provided by ChatGPT-4.0 and DeepSeek-V3 in response to 10 clinically oriented breast cancer questions. For ChatGPT, 45 distinct references were extracted and scored by all 3 experts. Human raters showed very high internal consistency: Fleiss κ was 0.842, indicating almost perfect agreement. Of these 45 references, 40 (88.9%) received perfect agreement from all 3 raters, and 44 (97.8%) reached majority agreement (ie, at least two raters agreed on the same label). Only 1/45 (2.2%) reference showed complete disagreement among the raters. Detailed results are provided in Table S14 in Multimedia Appendix 14.
For DeepSeek, we evaluated 268 unique references. Interrater reliability among the three experts was even higher: Fleiss κ was 0.935, again in the almost perfect range. Across these 268 references, 260 (97.0%) had perfect agreement, and 267 (99.6%) had majority agreement. Only 1/268 references (0.4%) showed complete disagreement. These results confirm that, despite differences in style and depth of citation between the models, human experts were able to judge source reliability in a highly consistent way across both datasets. All details are provided in Table S15 in Multimedia Appendix 15.
We then assessed how well each AI model’s citation-level reliability scores aligned with human judgment (ie, each reference set was evaluated by both ChatGPT and DeepSeek as reported in Table S11 and Table S12 in MultimediaAppendices 1112, respectively). For the ChatGPT reference set, agreement between ChatGPT’s scores and the human majority score was substantial (Cohen κ=0.665). For the DeepSeek reference set, agreement between DeepSeek’s scores and the human majority score was higher (κ=0.782). When disagreement occurred, ChatGPT differed from the human majority on 7 of its 45 references, whereas DeepSeek differed on 32 of its 268 references. These agreement metrics and disagreement profiles are summarized in Table S14 and Table 15 in MultimediaAppendices 714, respectively.
To enable direct comparison, we also evaluated each model on the other model’s reference set. In the ChatGPT set, DeepSeek’s scoring of those same sources achieved κ=0.800, which exceeded ChatGPT’s own κ=0.665*.* In the DeepSeek set, ChatGPT’s scoring of DeepSeek’s citations achieved κ=0.600, which was lower than DeepSeek’s κ=0.782. In other words, when both models were evaluated against the same expert consensus, DeepSeek was consistently closer to the human majority than ChatGPT.
Qualitatively, ChatGPT tended to cite large US medical organizations and public-facing health information portals (eg, national cancer societies, specialty associations, and patient education sites). These sources were commonly accepted as reliable when they represented established clinical authorities, but they occasionally triggered disagreement when they originated from advocacy foundations or commercial health media. DeepSeek more often cited recent peer-reviewed literature, systematic reviews, and oncology-specific clinical studies, which generally scored as reliable, although some entries contained incomplete metadata (eg, partial author or year strings or nonresolving links) that required manual adjudication.
Taken together, these results show 3 things. First, human expert scoring of reference quality was internally very stable for both models (Fleiss κ=0.842 for ChatGPT’s reference set and 0.935 for DeepSeek’s reference set) with majority agreement observed for 44/45 (97.8%) and 267/268 (99.6%) references, respectively, indicating that reliable versus unreliable source is a reproducible judgment in this context. Second, both AI systems demonstrated substantial alignment with expert consensus, but DeepSeek exhibited stronger agreement with the human majority than ChatGPT (κ up to 0.800 on the ChatGPT set and 0.782 on its own set, versus ChatGPT’s κ of 0.665 and 0.600*,* respectively). Third, the main source of residual disagreement was concentrated in borderline cases, such as advocacy organization content, institutional news posts, and partially specified citations, rather than in conventional peer-reviewed oncology literature (Table 5).
The mean reliability score (majority human) is the mean binary reliability score (1=reliable and 0=unreliable) assigned by the human majority (≥2 of 3 expert raters) across all unique references cited by each model. “Fleiss κ” quantifies agreement among the 3 human experts for each model’s reference set. “Perfect agreement” is the proportion of references where all 3 experts independently gave the same reliability score. “Majority agreement” is the proportion of references where at least two of the 3 experts agreed. “Complete disagreement” refers to cases in which all 3 experts gave different scores. “Cohen κ (AI vs human majority score)” measures agreement between each model’s own reliability classification of its citations and the human majority classification for the same reference set. “Cross-evaluation κ” measures how well each model’s scoring of the other model’s references agreed with the human majority for that reference set (eg, “DeepSeek on ChatGPT”=DeepSeek’s κ when scoring the ChatGPT reference set). All underlying data are provided in Table S14 in Multimedia Appendix 7 (ChatGPT-4.0) and Table S15 in MultimediaAppendices 1415 (DeepSeek-V3).
Discussion
Principal Findings
This study systematically evaluated the performance of ChatGPT-4.0 and DeepSeek-V3 in generating breast cancer information, focusing on readability, content quality, and reference quality. This multidimensional assessment approach (Figure 1), which is rarely addressed collectively in existing literature, offers valuable insights into the capabilities and limitations of generative AI models in health care. Both models generated clinically relevant and readable responses, with ChatGPT-4.0 showing greater consistency and overall readability, whereas DeepSeek-V3 offered more diverse citations but with greater variability and occasional technical issues.
Readability Analysis
The FKGL readability scores revealed that AI-generated responses generally used simpler language structures than expert reference answers, which may enhance accessibility for general audiences. Expert responses had the highest FKGL scores (mean 10.53, SD 2.17), reflecting more complex vocabulary and sentence construction. In contrast, both ChatGPT and DeepSeek produced responses with lower FKGL scores, indicating simpler, more readable content.
This trend aligns with prior studies showing that LLMs often generate linguistically simplified outputs, which may benefit general users [3839]. Notably, ChatGPT-4.0 exhibited more consistent readability across multiple outputs, with a median FKGL of 10.66 (IQR 0.98), compared to DeepSeek-V3, which showed greater variability with a median FKGL of 10.17 (IQR 1.41), suggesting greater stability with repeated querying.
For instance, ChatGPT-4.0 demonstrated improved readability consistency when averaging multiple responses, suggesting stability with repeated querying. In contrast, DeepSeek-V3’s responses were closer to expert reference readability levels in single-instance analysis but displayed greater variability in multiresponse cases (IQR 1.41).
However, statistical comparisons did not reveal significant differences in readability between models or relative to expert references. For instance, in the multiresponse setting, the paired t test for ChatGPT-4.0 versus reference yielded t_9_=−0.24; P=.82 (95% CI −1.40 to 1.74), and for DeepSeek-V3 versus reference, t_9_=−0.40; P=.70 (95% CI −1.25 to 1.78). The difference between ChatGPT and DeepSeek was also nonsignificant (t9=0.35; P=.73). Similar nonsignificant findings were observed in the single-instance analysis.
It is essential to emphasize that FKGL measures linguistic complexity, not clinical accuracy or information richness [35]. Lower FKGL scores do not necessarily indicate that critical medical details were omitted. Therefore, while improved readability may facilitate comprehension, further analysis is necessary to confirm that the content remains accurate, complete, and clinically appropriate.
Content Quality Analysis
Beyond readability, content quality was assessed across 5 predefined evaluation criteria, including accuracy, completeness, clarity, depth and insight, and alignment with expert reference answers. This structured evaluation, based on established frameworks [3839], allowed a more nuanced assessment of response quality. Across analyses, both models achieved high scores across all criteria. In the multiresponse dataset, DeepSeek achieved a higher overall mean score (6.22, SD 0.43) than ChatGPT (6.01, SD 0.49), with DeepSeek scoring numerically higher across all five criteria. Notably, DeepSeek demonstrated a statistically significant advantage in accuracy in the multiresponse analysis (t₉ = −2.377, P = .041; 95% CI −0.585 to −0.015), while differences for completeness, clarity and readability, depth and insight, and alignment with the reference answer did not reach statistical significance (P > .05). Interestingly, averaging multiple responses per question reduced response-level variability and revealed a more consistent performance advantage for DeepSeek, particularly for accuracy.
These findings expand on earlier studies that primarily focused on ChatGPT-3.5 [33] by demonstrating the evolving strengths and remaining limitations of newer generative AI models when applied to clinically relevant educational content. Unlike prior studies limited to single-response analysis, our multiresponse approach highlights how response variability remains an important factor when evaluating AI for health care education.
Information Reliability Assessment
The reference reliability analysis revealed clear differences in both reference selection patterns and interrater scoring agreement for ChatGPT-4.0 and DeepSeek-V3 citations. ChatGPT tended to cite US-based medical institutions, national health organizations, and patient-facing educational resources, whereas DeepSeek more often cited recent peer-reviewed oncology studies and systematic reviews, although some DeepSeek citations were partially specified or contained inaccessible links. Human experts showed very consistent judgments of citation reliability for both models’ outputs: interrater reliability was almost perfect for both sets (Fleiss κ=0.842 for ChatGPT’s 45 references and 0.935 for DeepSeek’s 268 references), with ≥97% majority agreement and only one fully disputed reference in each set. When we compared each model’s scoring of source reliability to the majority expert score, agreement was substantial for ChatGPT and higher for DeepSeek. DeepSeek reached Cohen κ values up to 0.800 (for ChatGPT reference set) and 0.782 (for DeepSeek reference set), indicating strong alignment with expert consensus, whereas ChatGPT’s ability to assess references reached 0.665 for its own reference set and 0.600 when evaluated DeepSeek’s set.
Collectively, these results demonstrate that both models operate within the bounds of medically acceptable sourcing but use distinct strategies. DeepSeek’s output, favoring primary literature, more accurately reflects the evidence-based curation of oncology experts. Conversely, ChatGPT’s propensity for synthesized institutional guidance results in a higher frequency of citations to borderline sources that require expert judgment.
Implications for Practice and Future Research
Collectively, these findings suggest that while generative AI models offer promising capabilities for generating patient education materials, important limitations remain. Oversimplification of complex medical information, variability in response consistency, and the reliability of cited sources remain persistent concerns. Given the growing interest in deploying AI tools for patient counseling, clinical decision support, and health care communication, these results underscore the need for careful validation of AI-generated content before clinical use [48]. Furthermore, while models such as DeepSeek demonstrate the potential for integrating primary literature more effectively, consistent quality control of both content and source reliability will be essential for safe application in clinical settings.
Finally, the structured multidimensional evaluation framework used in this study provides a replicable approach for future evaluations of AI models in health care. Future studies should continue to assess performance across broader clinical domains, expand evaluation across different languages and health literacy levels, and integrate clinical expert validation to further ensure the safety, accuracy, and equity of AI-generated medical information.
Limitations and Future Directions
This study has several limitations. The FKGL test assessed structural readability but not contextual or clinical accuracy, and it is validated only for English, limiting generalizability across languages and literacy levels [2034]. Additionally, the study was conducted in a controlled setting without patient or provider involvement, so real-world usability, comprehension, and clinical outcomes remain unexplored. Future work should include usability testing and assess impacts on decision-making and adherence [49]. Moreover, AI responses were not compared directly to clinical guidelines, and future studies should include validation against established standards before clinical integration. Reference accuracy remains a concern, as AI models may generate outdated or fabricated citations, requiring expert oversight [50].
Furthermore, the risk of bias in training data may lead to inaccuracies for underrepresented populations, highlighting the importance of ongoing monitoring and alignment with validated medical sources [384849]. Evidence from clinical research, including variability in therapeutic outcomes across patient subgroups and molecular subtypes, further emphasizes the necessity for such validation [5152]. Finally, ethical and regulatory considerations are essential for safe deployment of AI in health care; compliance with frameworks from regulatory bodies such as the Food and Drug Administration and the European Medicines Agency will be critical to ensure safety, transparency, and public trust [53]. As these technologies continue to evolve, continuous evaluation, comparative benchmarking, and expert oversight will be necessary to guide their responsible implementation.
Conclusions
This comparative analysis of ChatGPT-4.0 and DeepSeek-V3 demonstrated that both AI platforms effectively retrieve and present medical information on breast cancer, each excelling in different areas. ChatGPT produced more polished, detailed, and readable responses, with strong performance in clarity and completeness, whereas DeepSeek outperformed ChatGPT on accuracy, and provided more comprehensive, globally diverse references with in-text citations resembling academic articles. However, DeepSeek faced challenges such as untagged links, occasional downtime, and corrupted references, which impacted the user experience. Despite these limitations, DeepSeek demonstrated superior citation efficiency and closely aligned with expert consensus answers. Moreover, interrater reliability analyses confirmed high levels of agreement among human evaluators across both models, with Fleiss κ scores exceeding 0.84 and Cohen κ values indicating substantial to almost perfect agreement. These findings support the overall quality of reference sources provided by the models and lend credibility to the evaluation framework used in this study. Furthermore, statistical analysis revealed no significant differences between the models across most evaluation criteria; however, in the multiresponse dataset (i.e., larger datasets), DeepSeek demonstrated a statistically significant advantage in accuracy, underscoring the importance of rigorous evaluation of AI-generated medical information to ensure accuracy, accessibility, and reliability. To optimize their effectiveness in health care applications, future improvements should focus on enhancing platform stability, response consistency, and overall user accessibility.
Supplementary material
10.2196/72839Multimedia Appendix 1Frequently asked questions about breast cancer and answers generated by artificial intelligence models (ChatGPT and DeepSeek) by Researcher 1.
10.2196/72839Multimedia Appendix 2Frequently asked questions about breast cancer and answers generated by artificial intelligence models (ChatGPT and DeepSeek) by Researcher 2.
10.2196/72839Multimedia Appendix 3Frequently asked questions about breast cancer and answers generated by artificial intelligence models (ChatGPT and DeepSeek) by Researcher 3.
10.2196/72839Multimedia Appendix 4Frequently asked questions about breast cancer and expert consensus answers obtained from Ye et al.
10.2196/72839Multimedia Appendix 5Human experts and artificial intelligence reliability scores for references cited by ChatGPT-4.0.
10.2196/72839Multimedia Appendix 6Human experts and artificial intelligence reliability scores for references cited by DeepSeek-V3.
10.2196/72839Multimedia Appendix 7Information sources for ChatGPT-4.0 and DeepSeek-V3.
10.2196/72839Multimedia Appendix 8Average Flesch-Kincaid Grade Level scores for the single-response analysis and results of the paired t test.
10.2196/72839Multimedia Appendix 9Detailed Flesch-Kincaid Grade Level scores for the single-response analysis.
10.2196/72839Multimedia Appendix 10Average Flesch-Kincaid Grade Level scores for the multiresponse analysis and results of the paired t test.
10.2196/72839Multimedia Appendix 11Detailed Flesch-Kincaid Grade Level scores for the multiresponse analysis.
10.2196/72839Multimedia Appendix 12Likert scores for the single-instance analysis.
10.2196/72839Multimedia Appendix 13Likert scores for the multiresponse analysis.
10.2196/72839Multimedia Appendix 14Interrater evaluation of ChatGPT-4.0 references for breast cancer information based on ratings by 3 human experts and alignment with artificial intelligence models.
10.2196/72839Multimedia Appendix 15Interrater evaluation of DeepSeek-V3 references for breast cancer information based on ratings by three human experts and alignment with artificial intelligence models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sung H Ferlay J Siegel RL et al Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries CA Cancer J Clin 052021713209249 doi 10.3322/caac.21660 Medline 33538338 · doi ↗ · pubmed ↗
- 2Sinha A Naskar M Pandey M Rautaray SS Challenges to the early diagnosis of breast cancer: current scenario and the challenges ahead SN COMPUT SCI 202451170 doi 10.1007/s 42979-023-02534-1 · doi ↗
- 3Sunoqrot S Abusulieh S Abusara OH Identifying synergistic combinations of doxorubicin-loaded polyquercetin nanoparticles and natural products: implications for breast cancer therapy Int J Pharm Oct 152023645123392 doi 10.1016/j.ijpharm.2023.123392 Medline 37683979 · doi ↗ · pubmed ↗
- 4Sweidan K Elfadel H Sabbah DA et al Novel derivatives of 4,6‐dihydroxy‐2‐quinolone‐3‐carboxamides as potential PI 3Kα inhibitors Chemistry Select Aug 262022732 UR Lhttps://chemistry-europe.onlinelibrary.wiley.com/toc/23656549/7/32doi 10.1002/slct.202202263 · doi ↗
- 5Global Breast Cancer Initiative Implementation Framework: Assessing, Strengthening and Scaling-up of Services for the Early Detection and Management of Breast Cancer World Health Organization 2023 UR Lhttps://www.who.int/publications/i/item/9789240067134 Accessed 14-01-2026 ISBN 978-92-4-006713-4
- 6Kasper G Momen M Sorice KA et al Effect of neighborhood and individual-level socioeconomic factors on breast cancer screening adherence in a multiethnic study BMC Public Health 012202424163 doi 10.1186/s 12889-023-17252-9Medline 38166942 PMC 10763410 · doi ↗ · pubmed ↗
- 7Chen J Duan Y Xia H Xiao R Cai T Yuan C Online health information seeking behavior among breast cancer patients and survivors: a scoping review BMC Womens Health 01320252511 doi 10.1186/s 12905-024-03509-x Medline 39754199 PMC 11697865 · doi ↗ · pubmed ↗
- 8Loeb S Langford AT Bragg MA Sherman R Chan JM Cancer misinformation on social media CA Cancer J Clin 2024745453464 doi 10.3322/caac.21857 Medline 38896503 PMC 11648589 · doi ↗ · pubmed ↗