Non-local attention enhanced deep learning for robust cyberattack detection in industrial IoT-based SCADA systems
Mustafa Tahsin Yilmaz, Onur Polat, Enes Algul, Ferdi Doğan

TL;DR
This paper introduces a deep learning model for detecting cyberattacks in industrial IoT systems, achieving high accuracy and performance on benchmark datasets.
Contribution
The novel contribution is a deep learning model combining CNNs with non-local attention blocks for improved cyberattack detection in IIoT-based SCADA systems.
Findings
DeepNonLocalNN achieved an accuracy of 0.9999 and ROC-AUC of 1.0000 on the WUSTL-IIoT-2021 dataset.
The model excelled in detecting minority attack classes like Backdoor and Command Injection with F1 scores of 0.73 and 0.92 respectively.
The architecture is scalable and addresses class imbalance in intrusion detection for IIoT environments.
Abstract
Industrial Internet of Things (IIoT)-enabled Supervisory Control and Data Acquisition (SCADA) systems are pivotal for real-time monitoring and control in critical sectors like energy, manufacturing, and water management. However, their connectivity and complexity expose them to cyber threats, including zero-day vulnerabilities and advanced persistent threats (APTs). Traditional security measures, like signature-based intrusion detection systems (IDSs), are inadequate against dynamic attacks. This study introduces DeepNonLocalNN, a deep learning model combining convolutional neural networks (CNNs) with non-local attention blocks to capture local patterns and global dependencies in IIoT network traffic. Evaluated on the WUSTL-IIoT-2021 dataset, DeepNonLocalNN achieved strong performance, with an accuracy of 0.9999, a receiver operating characteristic-area under the curve (ROC-AUC) of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1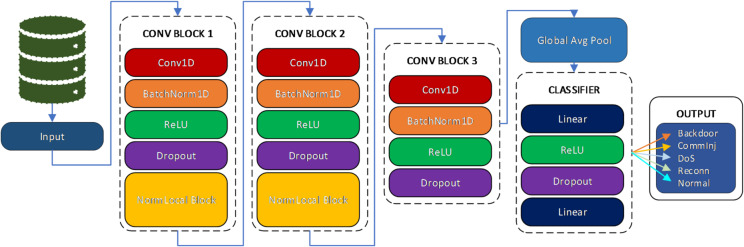 Figure 2
Figure 2 Figure 3
Figure 3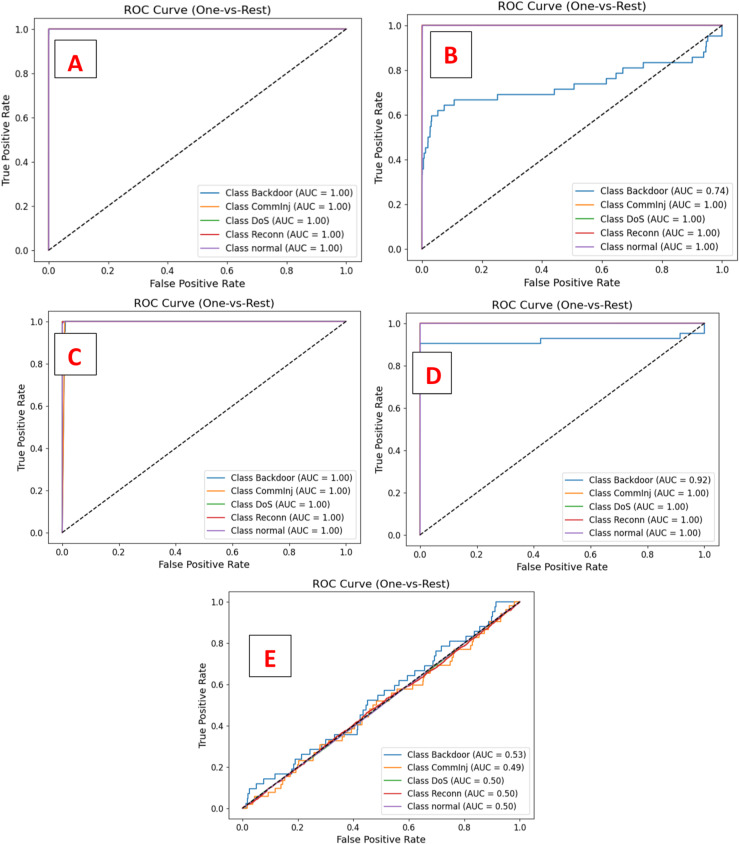 Figure 4
Figure 4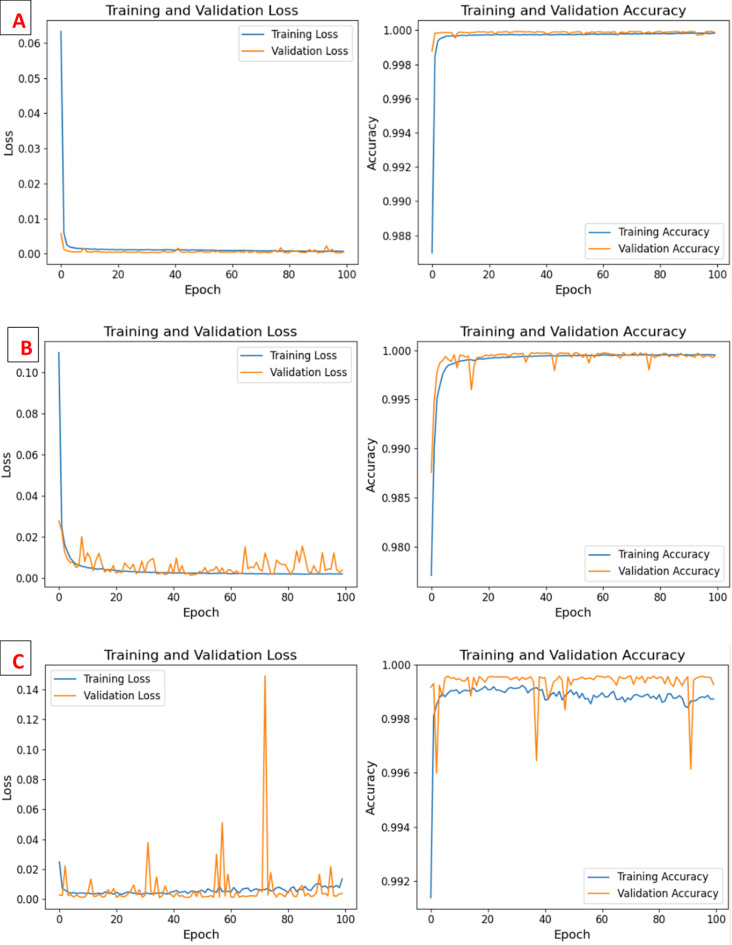 Figure 5
Figure 5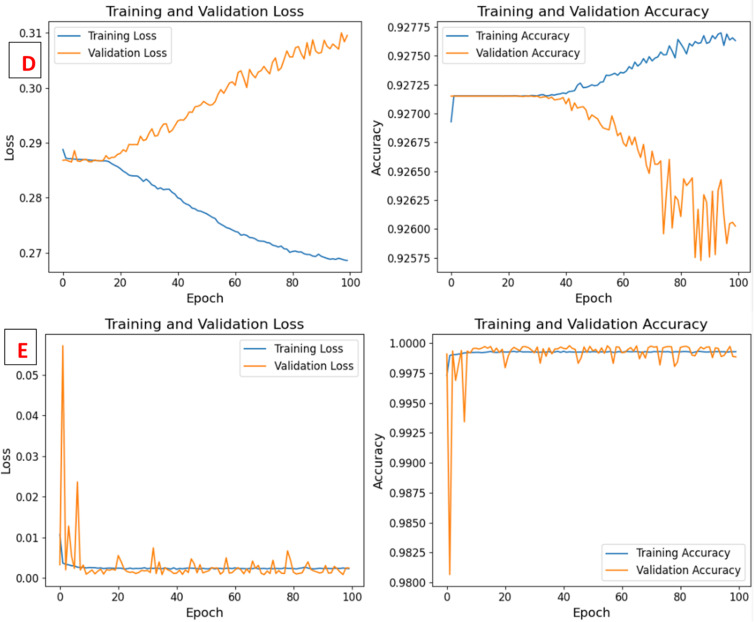 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSmart Grid Security and Resilience · Network Security and Intrusion Detection · Anomaly Detection Techniques and Applications
Introduction
Industrial IoT and SCADA systems
The Internet of Things (IoT) is a virtual environment where devices connected to the internet environment are located that enable devices to communicate with each other. There are many devices within these technologies. These are sensors, smart devices, cameras, and many devices connected to the internet used in homes and workplaces. They are used in many areas such as smart homes, the healthcare sector, systems brought by Industry 4.0, smart cities, and agriculture. IoT devices are part of real-time monitoring and control processes that are based on efficiency and provide cost savings^1^. Figure 1 shows the applications of industrial IoT devices. IoT devices are devices used in daily life. Industrial IoT devices, on the other hand, are devices located in industrial environments that enable data to be sent to a central hub. IIoT devices are used in industrial workspaces such as energy, transportation, shipping, and distribution. The hub where this data is collected and sent is called a SCADA system. It is responsible for processes such as data acquisition, network traffic control, and monitoring of connected devices.
Fig. 1. Industrial IoT devices and their application areas.
Industrial automation has a centralized control structure. These automations are integrated systems created to provide central or remote monitoring and control of large-scale enterprises are called SCADA systems. SCADA systems carry out the monitoring and control processes of devices in the field. Such systems include PLC, sensors, RTU, servers, data storage systems, firewall, HMI (Human Machine Interface)^2^.
SCADA systems contain many devices and management tools. Especially IoT devices are the basic parts of SCADA systems. Data is received or sent from many IoT devices in a SCADA system. Data is analyzed and commands are sent with the central control system. IoT devices operate according to the commands received. The central control system monitors and controls these systems from their internal network or by providing remote connections. The fact that SCADA systems allow remote connections increases the transition of industrial production systems to these systems. It can be used in many areas such as energy transmission and distribution, factories, chemical plants, water treatment and distribution facilities, transportation and control systems, smart building systems, agricultural irrigation and greenhouse management.
Cybersecurity challenges in IoT-Enabled SCADA
Having such a widespread usage network and the possibility of remote access require such systems to be strong in terms of cyber security. An attack on the system will target the central management connected to the system or the IoT devices in the system. The increasing number of cyber attacks worldwide shows that such systems are at risk. SCADA systems where IoT devices are active require both the central management and the connected IoT devices to be strong in terms of security. Especially real-time systems where IoT devices are located are more attractive to attackers. The fact that the hardware software of IoT devices is not up to date, weak authentication processes, and attempts to integrate old-type devices into the new system bring security vulnerabilities. In addition, the low processing power of some IoT devices does not support some security measures. This situation in the network can make the entire system vulnerable. The entire system can be taken over by attackers finding a gap in the system and entering the system. The production line can be stopped, systems can be operated incorrectly, and IoT devices can exhibit approaches that can damage the infrastructure. This increases the importance of security in SCADA systems where IoT devices are located^3^.
Limitations of traditional security mechanisms
Classical security measures are built on signature-based detection systems, firewalls, and static access control systems. These methods are old-style security systems and are effective in classic attack types. However, they are insufficient against dynamic and complex attacks involving industrial IoT devices. Classical security systems operate with a rule-based management. However, today’s cyber attacks, zero-day vulnerabilities, phishing, and advanced persistent threats cannot be detected according to these rules. They need to be analyzed. However, it is not possible to monitor the analyses manually. Such advanced cyber attacks can be detected with machine learning and artificial intelligence systems. Machine learning and artificial intelligence-based systems offer an autonomous security approach. Real-time monitoring of cyber attacks in SCADA systems where IoT devices are located, anomaly detection, zero-day threats, and phishing threats can provide warnings. Artificial intelligence techniques that learn from past data also allow the detection of unknown threats. Thus, it creates a detection and defense system against known and unpredictable attacks^4^.
Role of artificial intelligence in intrusion detection
In IoT-based SCADA systems, artificial intelligence-based detection systems provide an important solution for intrusion detection and attack mitigation strategies. It has advanced detection capabilities. It analyzes network traffic and provides high-precision detection methods against threats. Many artificial intelligence methods such as XGBoost^5^, random forest algorithms^6^, Bi-LSTM^7^, ensemble learning^8^ can be used. It is successful in detecting complex cyber attacks. It can learn new types of attacks. It can also provide a comprehensive security environment against different types of attacks^9^.
The aim and contributions of the study
The main objective of this study is to develop an intrusion detection system for IIoT-based SCADA systems, considering the fundamental problems in network traffic. A model capable of identifying both common and rare attacks, despite the complexity of network traffic, is proposed. The contributions of this study are as follows:
A new hybrid architecture
The DeepNonLocalNN model with non-local attention blocks that can learn local and general features is presented.
Using a realistic dataset
The proposed model has been tested with the WUSTL-IIoT-2021 dataset containing network traffic of SCADA-based IoT devices and has demonstrated its validity by achieving high performance.
Comparative analysis with other models
It has been compared with LSTM, CNNWithAttention, ResidualAttentionNetwork models frequently used in the literature. F1-score, ROC-AUC, accuracy metrics have been measured and the proposed model has shown better performance than other models.
High performance in classes with small sample numbers
High performance was demonstrated in Backdoor and CommInj attack types with small sample numbers, focusing on the class imbalance problem.
A scalable architecture
The design of the model is designed to work with large amounts of data. It is also suitable for heterogeneous IoT data. Thus, it facilitates integration into real industrial applications.
The remaining sections of this paper are organized as follows. Section Related works examines relevant literature studies, attacks on SCADA systems, machine learning and deep learning-based intrusion detection approaches, and the IIoT-SCADA datasets used in such studies. Section Materials and methods provides a detailed description of the WUSTL-IIoT-2021 dataset, preprocessing processes, the underlying models used, the proposed DeepNonLocalNN architecture, and the experimental setup, along with comparative results. Section Results and discussion provides a discussion and comparative analysis of experimental results. Section Conclusion presents the conclusions of the study, and Sect. Limitations and future work discusses limitations and future work.
Related works
There are various attacks against SCADA systems in the literature. Some of these attacks are reconnaissance attacks, response and measurement injection, command injection, denial of service (DoS), man-in-the-middle attacks (MITM), replay and fragmentation attacks, cyber-physical attacks.
Reconnaissance attacks are carried out to collect information to detect vulnerabilities in the network environment. Different network scanning tools are used to obtain information about the system architecture and to find open connections^10^. Input and measurement injection injects data to obtain and manipulate system information. These types of attacks cause the decisions to be taken in the system to be wrong. It can cause physical damage or system outages^11^. In command injection attacks, the aim is to change the processes in the system with unauthorized commands^12^. DoS and DDoS attacks are attacks that occupy network traffic and cause the system to stop^13^. MITM attacks aim to change the data of the components in SCADA systems^14^. Covert attacks such as Hijacking and Blackout change the parameters by taking advantage of network protocol weaknesses and stop the detection of processes^15^. Replay attacks allow data packets on the network to be retransmitted after being captured. Data packets are corrupted, causing a system crash^16^. Cyber-physical attacks target physical components to change the properties of IoT devices to gain unauthorized access^17^.
The healthy operation of IoT-based SCADA systems depends on many factors within the system. Field end devices, communication protocols, servers and control centers, cloud structures and remote access points, and data storage points are targeted. The presence of many connected factors has made SCADA systems a target for attacks^18^.
Attacks on SCADA systems
Many attacks carried out through malware can cause serious damage to such systems^19^. The cyber attack carried out in Ukraine in 2015 was carried out through malware. Biswas, The security vulnerabilities of the technological devices targeted in the attack were revealed in a study^20^. Camargo at all. stated that the malware disrupted the Modbus-TCP communication. This situation can cause delays and interruptions, and the system is affected^21^. Phishing attacks are accessed by taking advantage of human-based vulnerabilities. Ali stated in his study that these attacks are based on deceiving people in various ways. He emphasized that this situation makes phishing detection quite difficult^18^. In order to prevent such attacks, Sen at all. offered solutions such as multi-factor authentication, employee training, and e-mail filtering^22^. Srivastava at all. stated that DDoS attacks cause service interruptions by targeting IoT devices in the network in particular. It can create a bottleneck in the network and try to render the network dysfunctional^23^. Attacks on SCADA systems, targets in the system, methods used and their effects are given in Table 1.
Table 1. Representative cyberattack types targeting SCADA systems and their Impacts.AttacksTarget/MethodImpactBlack Energy Attack^24^Ukraine power grid using malware.Infected over 200,000 people. Caused power outages.Crash Invalidation Attack^25^Ukraine power grid station to cause intermittent power outagesDemonstrated the highly destructive potential of attacks on infrastructure.Modbus TCP Penetration^26^Tested Modbus/TCP protocol vulnerabilities using test tools to penetrate SCADA systems.Compromised system integrity and availability. Identified vulnerabilities.Wastewater Treatment Plant^27^Detected a Denial of Service attack using live memory dump analysis.Water treatment was disrupted. Demonstrated the need for forensic investigation in ICS environments.False Data Injection^28^Injected false data into a photovoltaic (PV) production meter for grid estimation.Settings began to malfunction. Lead to cascading failures and voltage sags.IEC 60870-5-104 Attack^29^Exploited vulnerabilities in IEC 60870-5-104 SCADA protocolDemonstrated the feasibility of attacking smart grid substations using Hardware-in-the-Loop (HIL).Modbus Buffer Overflow^30^Exploited a buffer overflow vulnerability in Modbus protocol communications.Disrupted service and caused potential system crashes.Denial of Service^31^Flood and resource exhaustion attacks on energy meters using Modbus TCPCaused communication disruption and demanded computing resources.Man-on-the-Side^32^Injected fake command responses into an industrial control network.Allowed attackers to manipulate system operations without detection.
Some examples of attacks on SCADA systems are given. There are various attacks in these examples. The attacks and their effects were examined one by one and Table 1 was obtained.
Machine learning and deep learning based detection approaches in IoT-based SCADA systems
The effects of attacks on SCADA systems are increasing. Preventing and detecting these attacks is critical to eliminate possible damage. In recent years, machine learning and artificial intelligence techniques have been particularly successful in detecting attacks. Artificial intelligence techniques provide better results than machine learning techniques. For this reason, the measures taken are often prevented by the success of artificial intelligence models. Artificial intelligence approaches that will be integrated into the system prevent such attacks. Examples of studies conducted with machine learning and artificial intelligence methods have been compiled and turned into a table. These examples are detailed in Table 2.
The table, which includes traditional machine learning methods, deep learning methods, ensemble learning methods and hybrid methods, provides important information. The effectiveness and performance information of each machine learning method in SCADA systems is given. Which methods should be used according to the type of problem is clearly given in this table.
Table 2. Comparative table of the use of machine learning and artificial intelligence methods in IoT-based SCADA systems.Machine Learning MethodDescriptionPerformanceSupport Vector Machine^33^A traditional ML algorithm for nonlinear classification tasks.High accuracy with feature selection techniquesRandom Forest^34^An ensemble method for processing imbalanced datasets.High detection accuracy and robustnessDecision Trees^35^A simple and interpretable classifier for real-time applications.Improved performance with feature selectionK-Nearest Neighbors^36^A simple classifier for anomaly detection.Less effective for low precision attacksNaïve Bayes^37^A probabilistic classifier for anomaly detection.Poor performance in complex environmentsConvolutional Neural Networks^38,39^A deep learning model for feature extraction.Superior performance with XGBoostLong Short-Term Memory^40^Effective for detecting correlated attacks.High detection rates for real-time applicationsRecurrent Neural Networks^41^Suitable for sequential data analysis.Effective with ensemble learning methodsStacked Autoencoders^39^A deep learning model for unsupervised anomaly detection.Effective for high-dimensional datasetsDeep Belief Networks^39^Models complex patterns in network traffic.Effective with ensemble learning methodsEnsemble Learning^42^Combines predictions from multiple models for improved accuracy.High detection accuracy and robustnessHybrid Models^43^Combines deep learning and traditional ML techniques.Improved detection performance for correlated and uncorrelated attacksPyramidal Recurrent Units^8^A deep learning approach for processing irrelevant features.High detection rates in SCADA systems
Innovative studies in recent years have presented various deep learning-based approaches for security in IoT/SCADA systems. One study indicates that leveraging advanced attention-based mechanisms in industrial systems improves the detection of complex cyberattacks^44^. Another study proposes a hybrid neural network architecture to provide a more robust system in unbalanced attack scenarios. These studies reveal trends toward architectures that reveal features representing local and global contextual relationships^45^. This study appears to align with recent studies.
Datasets used to detect attacks on IoT-Based SCADA systems
Along with the methods used, the datasets used in these studies are also of great importance. The data to be trained on these methods must be robust and real-world data. The datasets are expected to be correctly classified datasets representing attacks that will occur on the network. The datasets and their features used in the literature to detect attacks on IoT-based SCADA systems are given in Table 3.
Table 3. Overview of public datasets used for intrusion detection in IoT-based SCADA systems.DatasetsKey FeaturesEvaluation ResultsTon-IoT^45^Heterogeneous IoT data, DDoS, botnet attacks99.9% accuracy with DenseNetUNSW-NB15^46^Network traffic logs, DDoS, R2L, U2R attacks98.4% accuracy with Start TimeBOT-IoT^47^IoT network traffic, botnet attacksValidated for network forensicsWUSTL-IIoT-2018^5,48^ICS-specific attacks, SCADA security99.99% accuracy with Random ForestCICIDS2017^49^DDoS, brute force, ransomware attacksHigh accuracy with Decision TreesX-IIoTID^50^Industrial IoT, multi-stage attacksComprehensive for OT-IDS investigationICS-SCADA^48^ICS-specific traffic, vulnerability detectionHigh accuracy for vulnerability detectionCicDDoS2019^8^Modern DDoS attacksHigh accuracy with deep learningGas Pipeline Dataset^51^SCADA-specific traffic, energy sector attacksHigh accuracy with Bi-LSTM and Bi-GRU
Dataset selection is important for evaluating attack detections. Determining the type of attack depends on the characteristics of the research, such as protocols and system architecture. Datasets such as Ton-IoT and UNSW-NB15 are suitable for general IoT-based research. WUSTL-IIoT-2018 and ICS-SCADA are datasets adapted for industrial SCADA systems. BOT-IoT and Gas Pipline datasets are datasets that can be used for attacks specific to botnets and SCADA systems. In the literature studies, it is stated that appropriate datasets should be preferred for attack detection in IoT-based SCADA systems.
Research gaps
A review of the literature revealed several gaps. The main research gaps in the field of AI-assisted intrusion detection for IIoT-SCADA systems are as follows:
- In literature studies, synthetic data has mostly been studied instead of real world data. Using data from real industrial environments is very important in terms of attack detection.
- Attacks are dynamic with developing technological approaches. Therefore, in many studies, the ability to adapt to dynamic attacks is weak. The dynamic artificial intelligence models to be developed will ensure that the system is kept up to date. The system will be more secure against new attacks.
- Zero-day attacks are weak against existing systems. Studies on detecting abnormalities with artificial intelligence-based approaches should be investigated further.
- Artificial intelligence-based attack detection systems require more resources. Systems expected to be better in terms of hardware may require additional costs to integrate into existing systems. For this reason, new artificial intelligence methods to be developed should focus on models that require less resources.
- There are many different types of attacks on such systems. Combined hybrid approaches should be investigated further for the detection of these attacks. Thus, security can be increased against different types of attacks.
Materials and methods
Dataset description
The main reason for selecting the WUSTL-IIoT-2021 dataset used in the experimental study is that it was created in a testbed environment that accurately replicates real industrial systems. Another reason for choosing this dataset is that it was collected under approximately 53 h of operational traffic and real attack scenarios. The dataset underwent pre-processing to remove outliers and corrupted records. This ensured a high-quality and reliable experimental environment. Furthermore, this dataset includes behaviour-based attack categories that remain relevant in IIoT networks today, such as denial of service, scanning, malicious control, and operational manipulation. It therefore reflects the fundamental attack dynamics representing contemporary threats. A review of recent literature indicates that the WUSTL-IIoT-2021 dataset is still widely used as a benchmark dataset due to its realistic industrial network characteristics and reproducibility advantage. In line with the stated reasons, the technical content and data structure of the data set used in the study are summarised below.
The WUSTL-IIoT-2021 dataset^48^, a comprehensive collection of network traffic data from heterogeneous IoT devices specifically designed for IoT security research. This dataset, stored in a single CSV file, contains features such as source and destination IP addresses, timestamps ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{StartTime}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{LastTime}$$\end{document} ), and traffic categories labeled under the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{Traffic}$$\end{document} column. The target variable, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{Traffic}$$\end{document} , represents categorical labels (‘Backdoor’ ‘CommInj’ ‘DoS’ ‘Reconn’ ‘normal’), with the number of unique categories determined dynamically during preprocessing. The dataset’s severe class imbalance and high dimensionality necessitate robust preprocessing and modeling techniques to achieve effective intrusion detection^52^ .
Basic statistic of the dataset
The WUSTL-IIoT-2021 dataset, utilized in this study, comprises \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{1,194,464}$$\end{document} network traffic samples from heterogeneous IoT devices, designed specifically for evaluating intrusion detection systems in industrial IoT environments. The dataset includes 44 features, capturing attributes such as source and destination ports (Sport, Dport), packet counts (SrcPkts, DstPkts, TotPkts), byte counts (SrcBytes, DstBytes, TotBytes), network load (SrcLoad, DstLoad, Load), and jitter (SrcJitter, DstJitter), among others. The target variable, Traffic, categorizes network flows into five classes: Backdoor, CommInj, DoS, Reconn, and normal, with a highly imbalanced distribution dominated by normal traffic ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{221,490}$$\end{document} samples) compared to attack classes (e.g., Backdoor: 42 samples, CommInj: 52 samples).
Table 4. Descriptive statistics of key numerical features in the WUSTL-IIoT-2021 dataset.FeatureCountMeanStd DevMinSkewnessKurtosisMean1,194,4641.29E-016.86E-010.000005.4327412.85E + 01Sport1,194,4645.45E + 041.20E + 040.000006.8424482.18E + 03Dport1,194,4647.91E + 023.30E + 030.0000013.6431042.06E + 02SrcPkts1,194,4641.67E + 025.27E + 040.00000480.8129922.41E + 05DstPkts1,194,4641.69E + 011.14E + 030.00000179.019873.49E + 04TotPkts1,194,4641.76E + 025.27E + 040.00000480.8044082.41E + 05DstBytes1,194,4647.60E + 037.51E + 050.00000108.2983071.17E + 04SrcBytes1,194,4641.94E + 044.73E + 060.00000347.4436681.35E + 05TotBytes1,194,4642.78E + 051.92E + 070.0000081.0390537.12E + 03SrcLoad1,194,4641.57E + 078.34E + 070.000005.4621762.85E + 01DstLoad1,194,4642.22E + 057.92E + 060.0000059.6694043.76E + 03Load1,194,4641.59E + 078.37E + 070.000005.435632.82E + 01SrcRate1,194,4643.11E + 041.66E + 050.000005.4773972.86E + 01DstRate1,194,4644.14E + 021.53E + 040.0000061.1187323.89E + 03Rate1,194,4643.15E + 041.67E + 050.000005.4529612.84E + 01SrcLoss1,194,4642.29E + 002.64E + 010.0000078.3720616.16E + 03DstLoss1,194,4642.57E + 005.26E + 010.0000080.0638256.97E + 03Loss1,194,4647.17E + 002.53E + 030.000001091.6753661.19E + 06pLoss1,194,4642.01E + 018.08E + 000.000001.9530537.40E + 00SrcJitter1,194,4644.70E + 024.69E + 020.0000011.9357044.91E + 02DstJitter1,194,4641.39E + 011.49E + 020.00000124.1570193.23E + 04SIntPkt1,194,4648.25E + 015.59E + 020.000009.7986891.14E + 02DIntPkt1,194,4648.30E + 007.08E + 010.0000061.2828524.46E + 03Proto1,194,4649.48E + 011.62E + 030.0000021.312914.57E + 02Dur1,194,4648.56E-014.95E + 020.00000792.1594656.37E + 05TcpRtt1,194,4641.83E-035.49E-020.0000052.3614142.74E + 03IdleTime1,194,4641.55E + 092.91E + 070.00000-53.1109662.82E + 03Sum1,194,4641.99E-017.97E-010.000005.3348222.73E + 01Min1,194,4641.99E-017.97E-010.000005.3348222.73E + 01Max1,194,4641.99E-017.97E-010.000005.3348222.73E + 01sDSb1,194,4641.88E-031.85E-010.00000220.3461375.61E + 04sTtl1,194,4641.29E + 022.46E + 010.00000-0.3642361.62E + 01dTtl1,194,4645.83E + 011.86E + 010.00000-2.6664846.06E + 00sIpId1,194,4643.17E + 041.88E + 040.000000.082482-1.16E + 00dIpId1,194,4642.96E + 042.03E + 040.000000.07806-1.24E + 00SAppBytes1,194,4642.19E + 022.85E + 030.0000020.1962824.28E + 02DAppBytes1,194,4647.05E + 037.45E + 050.00000108.3042871.17E + 04TotAppByte1,194,4646.58E + 054.17E + 070.0000077.2052566.53E + 03SynAck1,194,4641.80E-035.49E-020.0000052.3630862.74E + 03RunTime1,194,4641.99E-017.97E-010.000005.3348222.73E + 01sTos1,194,4647.53E-037.44E-010.00000220.7412475.62E + 04SrcJitAct1,194,4646.19E + 014.14E + 020.000008.1481497.11E + 01DstJitAct1,194,4642.65E-015.00E + 000.0000034.9930762.65E + 03Target1,194,4647.28E-022.60E-010.000003.2871798.81E + 00
Table 4 summarizes key statistical properties of selected numerical features, including count, mean, standard deviation, minimum, skewness, and kurtosis. The dataset exhibits significant variability, with features like TotBytes (mean: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:2.78\times\:{10}^{5}$$\end{document} , std: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1.92\times\:{10}^{7}$$\end{document} ) and Load (mean: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1.59\times\:{10}^{7}$$\end{document} , std: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:8.37\times\:{10}^{7}$$\end{document} ) showing high standard deviations, indicative of diverse traffic patterns. Skewness values, such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:480.81$$\end{document} for TotPkts and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:347.44$$\end{document} for SrcBytes, highlight right-skewed distributions, reflecting the presence of extreme values in attack scenarios. High kurtosis, notably \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1.19\times\:{10}^{6}$$\end{document} for Loss and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:6.37\times\:{10}^{5}$$\end{document} for Dur, suggests heavy-tailed distributions, emphasizing the dataset’s complexity and the need for robust preprocessing to handle outliers and class imbalance.
Data preprocessing
Data preprocessing was performed to ensure the dataset was suitable for training a deep learning model. The preprocessing pipeline included the following steps:
- Missing Value Imputation: Missing values, which were sparse (< 1% of entries after initial cleaning) and primarily occurred in numerical traffic metrics (e.g., packet/byte counts, jitter), were imputed with zeros. This choice is semantically appropriate because a zero naturally represents the absence of activity in network flows. Alternative approaches such as mean/median imputation were considered but avoided as they could distort the heavily skewed distributions of several features (e.g., TotBytes, SrcBytes). Zero-imputation preserves the original traffic pattern interpretability, which is critical for intrusion detection tasks^53^.
- Target Label Encoding: The categorical target variable ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{Traffic}$$\end{document} ) was encoded into numerical labels using a LabelEncoder, transforming each class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left({c}_{k}\right)$$\end{document} into a unique integer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:({y}_{i}\in\:\{\mathrm{0,1},\dots\:,K-1\left\}\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} is the number of unique classes^54^.
- Feature Encoding: Non-numeric features were processed as follows: Timestamp columns ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{StartTime}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{LastTime}$$\end{document} ) were converted to Unix timestamps (seconds since epoch) to obtain numerical representations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{t}_{\mathrm{Unix}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:=\:\lfloor\:(t-{T}_{epoch}$$\end{document} ) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:/{10}^{9}\rfloor\:$$\end{document} ). The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{Traffic}$$\end{document} column, if containing a small number of categories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left((\le\:10)\right)$$\end{document} , was one-hot encoded, resulting in binary feature vectors for each category. Other categorical columns (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{SrcAddr}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:DstAddr$$\end{document} ) were label-encoded to map categorical values to integers^55^.
- Feature Normalization: All numerical features were standardized using the StandardScaler to achieve zero mean and unit variance^53^. The preprocessed dataset was split into training, testing, and validation sets using a 60:20:20 ratio, with stratification to preserve the class distribution.
- Data Integrity Verification:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:\left({x}_{i}\right)$$\end{document} validates data type consistency, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\eta\:\left({x}_{i}\right)$$\end{document} checks for null values, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:\left({x}_{i}\right)$$\end{document} verifies structural integrity for each data point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}$$\end{document} .
Deep learning model architectures for tabular data classification
The WUSTL-IIoT-2021 dataset was specifically chosen for this study because it provides a comprehensive and realistic testbed for industrial network security. It features heterogeneous IoT devices and real-world network traffic from a SCADA environment, including challenging conditions such as high data dimensionality and a severe class imbalance. This makes it a robust proxy for evaluating models designed for industrial IoT-SCADA systems, enabling the validation of our model’s ability to handle complex, subtle, and imbalanced attack scenarios.
Baseline models
The classification of IoT network traffic, as exemplified by the WUSTL-IIoT-2021 dataset, requires models capable of capturing both temporal dependencies and complex patterns in tabular network flow data. To evaluate the effectiveness of our proposed DeepNonLocalNN model, we selected four baseline models including LSTM, NonLocalNN, CNNWithAttention, and ResidualAttentionNetwork. Each chosen for their distinct architectural strengths in addressing key aspects of IoT traffic classification, such as sequential modeling, global context, local feature extraction, and deep hierarchical processing. These models provide a comprehensive comparison to assess the contribution of non-local attention mechanisms in our proposed approach.
LSTM: The Long Short-Term Memory model addresses the temporal nature of network traffic by modeling sequential dependencies across time-ordered observations. This approach is particularly relevant for IoT environments where attack patterns may evolve over time. The model employs a 3-layer LSTM architecture with hidden_dim = 128 units per layer. Each LSTM layer includes forget gates, input gates, and output gates that regulate information flow: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{t}=\sigma\:\left({W}_{f}*\left[{h}_{t-1},{x}_{t}\right]+{b}_{f}\right),{i}_{t}=\sigma\:\left({W}_{i}*\left[{h}_{t-1},{x}_{t}\right]+{b}_{i}\right),{o}_{t}=\sigma\:\left({W}_{o}*\left[{h}_{t-1},{x}_{t}\right]+{b}_{o}\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} represents the sigmoid activation. Input sequences of length 10 are generated using sliding window preprocessing, where each sequence represents consecutive network flow observations. The model processes these sequences to predict traffic classification for the subsequent observation, enabling proactive threat detection^55^. The LSTM’s cell state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{t}={f}_{t}*{C}_{t-1}+{i}_{t}*tanh\left({W}_{C}*\left[{h}_{t-1},{x}_{t}\right]+{b}_{C}\right)$$\end{document} provides long-term memory capabilities, crucial for detecting attack patterns that span multiple time steps. The final hidden state from the last LSTM layer feeds into a fully connected classification layer.
NonLocalNN
NonLocalNN serves as a simplified baseline to evaluate the contribution of non-local attention mechanisms without the complexity of deep hierarchical processing^56^. This model isolates the effect of global attention mechanisms in network traffic classification. The model contains a single 1D convolutional layer (1 → 64 channels, kernel_size = 3) followed by batch normalization and one non-local attention block. This minimalist design allows for direct assessment of non-local attention benefits without confounding effects from deep architectures. The single non-local block operates identically to those in DeepNonLocalNN but processes less abstract features. The attention mechanism computes relationships across the 64-dimensional feature space, providing global context for classification decisions.
CNNWithAttention: This hybrid architecture combines the local feature extraction capabilities of convolutional neural networks with the global modeling power of multi-head attention mechanisms, representing a popular approach in modern deep learning. A single 1D convolutional layer (1 → 64 channels, kernel_size = 3) with batch normalization extracts local traffic patterns. The moderate channel depth balances representational capacity with computational efficiency. The 8-head attention mechanism (embed_dim = 64, num_heads = 8) enables the model to attend to different representation subspaces simultaneously^57^. Each attention head computes: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{Attention}}_{i}=softmax\left({Q}_{i}{K}_{i}^{T}/\sqrt{{d}_{k}}\right){V}_{i},$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{k}$$\end{document} = 64/8 = 8 is the key dimension per head. The multi-head attention processes the permuted convolutional features (sequence_length, batch_size, channels) and returns attention-weighted representations. Global mean pooling aggregates these representations for final classification through a two-layer head (64 → 32 → num_classes).
ResidualAttentionNetwork: The most sophisticated baseline model, ResidualAttentionNetwork combines residual connections with attention mechanisms to provide a robust architecture capable of learning complex traffic patterns while maintaining gradient flow through deep networks. The model employs residual connections around the attention mechanism: output = input + attention(layer_norm(input)). This design enables stable training of deeper networks and prevents gradient vanishing problems common in attention-based architectures. The 8-head multi-head attention operates on layer-normalized inputs with embed_dim = 128^58^, providing substantial representational capacity. The attention mechanism includes learnable position encodings and supports both self-attention and cross-attention patterns. The model employs a sophisticated regularization scheme with multiple dropout layers (rates: 0.3 for convolutional layers, 0.2 for attention layers) and batch normalization at multiple stages. This comprehensive regularization prevents overfitting while maintaining model expressiveness. Additional convolutional layers (128 → 128 channels) with residual connections provide deeper feature representations. The combination of convolutional processing, attention mechanisms, and residual connections provides the highest modeling capacity among all baseline methods.
Deep Non-Local neural network (DeepNonLocalNN) (Proposed Model)
The classification of IoT network traffic presents unique challenges due to the complex, dynamic, and often non-stationary nature of the data. Traditional convolutional neural networks (CNNs), while effective at capturing local spatial patterns, suffer from limited receptive fields and struggle to model long-range dependencies and contextual relationships. To address this limitation, we design Deep Non-Local Neural Network (DeepNonLocalNN) architecture that leverages non-local attention mechanisms to capture global dependencies within IoT traffic sequences (Fig. 2).
Fig. 2. Implementation process of the proposed DeepNonLocalNN model for intrusion detection in IoT-based SCADA systems.
The DeepNonLocalNN architecture is designed to process IoT packet flows as spatiotemporal feature maps, where each feature corresponds to an attribute of the packet or traffic behavior (e.g., packet size, inter-arrival time, protocol type). The model combines convolutional layers, which are adept at extracting local patterns, with non-local attention blocks that compute interactions between all pairs of positions in the input feature space. This hybrid architecture allows the model to encode both fine-grained and holistic patterns in the data, making it highly effective for capturing anomalous behavior or subtle protocol variations typical in IoT environments.
The architecture includes the following components:
- Initial Convolutional Feature Extractor: A series of 1D convolutional layers to extract hierarchical features from input traffic representations.
- Non-Local Blocks: Inserted after key convolutional layers to globally refine feature representations by considering distant dependencies^56^.
- Normalization and Pooling: Batch normalization and pooling layers are used to regularize the model and reduce spatial resolution.
- Fully Connected Layers: Final layers for high-level reasoning and classification into traffic categories (e.g., benign, malware, DDoS).
This architecture is particularly suited for IoT applications because it accommodates the non-Euclidean, irregular, and bursty nature of traffic flows, which cannot be effectively captured by purely local operations.
Mathematical foundation of Non-Local attention
The core innovation of DeepNonLocalNN lies in its use of Non-Local Block. Unlike traditional convolutional or recurrent operations that rely on fixed local neighborhoods or sequential processing, non-local attention models all pairwise interactions between elements in the feature space, enabling the learning of long-range and high-order dependencies.
General Non-Local operation
The generic non-local operation computes a response at a position \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} as a weighted sum of the features at all positions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} in the input.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{i}=\frac{1}{C\left(x\right)}{\sum\:}_{\forall\:j}f\left({x}_{i},{x}_{j}\right)\cdot\:g\left({x}_{j}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{j}\:$$\end{document} are input features at positions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} , respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({x}_{i},{x}_{j}\right)$$\end{document} is a pairwise similarity function between positions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g\left({x}_{j}\right)\:$$\end{document} is a representation function applied to the input at position \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:C\left(x\right)$$\end{document} is a normalization factor ensuring that the weights sum to one. This formulation is agnostic to position and scale, making it inherently suitable for irregularly sampled or heterogeneous IoT data.
Pairwise affinity function
The function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({x}_{i},{x}_{j}\right)$$\end{document} measures the affinity or similarity between the feature representations at locations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} . We use a dot-product-based attention with embedded transformations.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f\left({x}_{i},{x}_{j}\right)=\mathrm{exp}\left(\theta\:{\left({x}_{i}\right)}^{T}\varphi\:\left({x}_{j}\right)\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\theta\:\left({x}_{i}\right)={W}_{\theta\:}{x}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\:\left({x}_{j}\right)={W}_{\varphi\:}{x}_{j}$$\end{document} are learned linear projections that map inputs to an embedded feature space. The exponential function enforces positivity and promotes sharper attention over relevant positions. The normalization factor is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:C\left(x\right)={\sum\:}_{\forall\:k}\mathrm{exp}\left(\theta\:{\left({x}_{i}\right)}^{T}\varphi\:\left({x}_{k}\right)\right)$$\end{document}ensuring the resulting attention weights form a valid probability distribution.
Feature transformation function
The function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g\left({x}_{j}\right)$$\end{document} transforms the input features before aggregation.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g\left({x}_{j}\right)={W}_{g}{x}_{j}+{b}_{g}$$\end{document}This enables the model to learn how much influence each position \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} should have on the output at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} , beyond mere similarity.
Query-Key-Value attention mechanism
The non-local mechanism can be reformulated as a query-key-value (QKV) attention mechanism, as popularized by transformer architectures. In this context, each position in the input feature map generates Query matrix( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Q=X{W}_{q}+{b}_{q}$$\end{document} ), Key matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K=X{W}_{k}+{b}_{k}$$\end{document} ), and Value matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:V=X{W}_{v}+{b}_{v}$$\end{document} ). Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\in\:{R}^{N\times\:d}$$\end{document} represents the input sequence or feature map with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} positions and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} dimensions. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}_{q},{W}_{k},{W}_{v}\in\:{R}^{d\times\:{d}_{k}}$$\end{document} are learnable weight matrices projecting input features to a latent space of dimensionality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{k}$$\end{document} . The attention output is computed via scaled dot-product attention.
Multi-Head attention extension
To further enhance the representational power, we implement multi-head attention, which allows the model to jointly attend to information from different representation subspaces. This is particularly important in IoT traffic classification, where different attack types may manifest along different feature dimensions. This mechanism enables the network to capture multiple types of interactions and disentangle complex traffic patterns, improving robustness across diverse IoT scenarios.
Detailed network architecture
Convolutional Feature Extraction: The proposed network initiates feature learning using a stack of three 1D convolutional layers with progressively increasing channel depths:
Convolutional operation
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{i}=\sigma\:\left({\sum\:}_{k=1}^{K}{W}_{k}*{x}_{i+k-1}+{b}_{i}\right)$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:*$$\end{document} denotes the convolution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} is the kernel size, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} is the non-linear activation function.
Output Feature Map Dimensions: Layer 1: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{X}^{\left(1\right)}\in\:{R}^{N\times\:32\times\:L}$$\end{document} , Layer 2: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{X}^{\left(2\right)}\in\:{R}^{N\times\:64\times\:L}$$\end{document} , Layer 3: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{X}^{\left(3\right)}\in\:{R}^{N\times\:128\times\:L}$$\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} denotes the batch size and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L$$\end{document} the sequence length.
Batch normalization
Batch normalization is applied after each convolution to accelerate convergence and stabilize training.
Non-Local block integration
Two non-local blocks are embedded into the network to capture long-range temporal dependencies.
Non-Local Block Output: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{z}_{i}={x}_{i}+\gamma\:\cdot\:\mathrm{NonLocal}\left({x}_{i}\right)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:$$\end{document} is a learnable scaling parameter, initialized as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:\left(0\right)=0$$\end{document} , and updated via: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\gamma\:\left(t+1\right)=\gamma\:\left(t\right)+\alpha\:{\nabla\:}_{\gamma\:}L$$\end{document}
Residual learning
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F\left(x\right)=H\left(x\right)-{x}^{{\prime\:}}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:H\left(x\right)$$\end{document} is the target mapping and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F\left(x\right)$$\end{document} the residual.
Global Feature Aggregation Adaptive Average Pooling: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{GAP}\left(X\right)=\frac{1}{L}{\sum\:}_{i=1}^{L}{X}_{i}$$\end{document} , Fully Connected Layers: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{1}=\sigma\:\left({W}_{1}\cdot\:\mathrm{GAP}\left(X\right)+{b}_{1}\right),\hspace{1em}y={W}_{2}\cdot\:{h}_{1}+{b}_{2},\:$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:\left(x\right)=\mathrm{ReLU}\left(x\right)=\mathrm{max}\left(0,x\right)$$\end{document} .
Regularization techniques
Dropout
Dropout is used during training to prevent co-adaptation, with a dropout rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\:=\:0.5$$\end{document} .
L2 regularization
L2 weight decay is applied to the loss function.
Training Strategy:
Optimizer: We use the Adam optimizer, which is currently one of the most popular and effective choices for training deep neural networks. It adapts the learning rate for each parameter separately based on past gradients, making training more stable and faster than traditional SGD with momentum. Key settings: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:={10}^{-4}$$\end{document} is learning rate, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{1}=0.9$$\end{document} is first moment decay, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{2}=0.999$$\end{document} is second moment decay, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:ϵ=1e-8$$\end{document} is numerical stability.
Loss functions
We primarily train using Cross-Entropy Loss, the standard choice for classification tasks. It measures how well the predicted probability distribution matches the true label. When the dataset has significant class imbalance (some classes appear much more often than others), we switch to or combine with Focal Loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:({L}_{\mathrm{FL}}=-{\alpha\:}_{t}{\left(1-{p}_{t}\right)}^{\gamma\:}\mathrm{log}\left({p}_{t}\right),\hspace{1em}\gamma\:=2$$\end{document} ). This loss automatically down-weights easy, well-classified examples and focuses training on hard, often misclassified samples — especially helpful for rare classes.
Concurrent learning rate scheduling
We apply Cosine Annealing to gradually decrease the learning rate during training. The learning rate starts at its initial value, smoothly decreases following a cosine curve, and reaches a very small minimum value by the end of training. This schedule often leads to better final performance than step decay or constant learning rates.
Model Validation and Selection: To fairly evaluate performance across all classes (especially important with imbalanced data), we use stratified splitting: each fold in cross-validation or the validation set contains roughly the same proportion of samples from every class as the full dataset.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Stratified\:Sampling:\:P\left({y}_{i}=c|{X}_{\mathrm{train}}\right)=P\left({y}_{i}=c|{X}_{\mathrm{val}}\right)=\frac{{n}_{c}}{N}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{n}_{c}$$\end{document} is the number of classes in class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} .
Early stopping
we monitor validation performance on a held-out set. If the chosen metric (usually validation loss or macro F1) does not improve for a certain number of epochs, we stop training to prevent overfitting. Stop training when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{val}\mathrm{\_}\mathrm{loss}\left(t\right)>\mathrm{val}\mathrm{\_}\mathrm{loss}\left(t-\mathrm{patience}\right)+$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{patience}=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\delta\:={10}^{-4}$$\end{document} .
Finally, we save and select the model checkpoint that achieved the best score on the validation set according to the main evaluation metric.
Evaluation metrics
Classification metrics
Accuracy:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{Accuracy}=\frac{TP+TN}{TP+TN+FP+FN}$$\end{document}Precision:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{Precision}}_{c}=\frac{T{P}_{c}}{T{P}_{c}+F{P}_{c}}$$\end{document}Recall:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{Recall}}_{c}=\frac{T{P}_{c}}{T{P}_{c}+F{N}_{c}}$$\end{document}F1**-**Score:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F{1}_{c}=\frac{2\cdot\:{\mathrm{Precision}}_{c}\cdot\:{\mathrm{Recall}}_{c}}{{\mathrm{Precision}}_{c}+{\mathrm{Recall}}_{c}}$$\end{document}Macro F1:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F{1}_{\mathrm{macro}}=\frac{1}{C}{\sum\:}_{c=1}^{C}F{1}_{c}$$\end{document}Weighted F1:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F{1}_{\mathrm{weighted}}={\sum\:}_{c=1}^{C}\left(\frac{{n}_{c}}{N}\right)\cdot\:F{1}_{c}$$\end{document}It is critical to distinguish between the Macro F1-score and the Weighted F1-score in the context of this highly imbalanced dataset. The Macro F1-score is calculated as the unweighted average of the F1-score for each class. It treats all classes, including the small minority attack classes, as equally important, making it the most reliable indicator of a model’s balanced performance. The Weighted F1-score, conversely, is weighted by the number of instances for each class. As the ‘normal’ class heavily dominates, the Weighted F1-score is often artificially inflated, reflecting high performance on benign traffic but masking poor performance on critical minority attacks.
ROC-AUC
ROC Curve:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{TPR}\left(\tau\:\right)=\frac{TP\left(\tau\:\right)}{TP\left(\tau\:\right)+FN\left(\tau\:\right)},\hspace{1em}\mathrm{FPR}\left(\tau\:\right)=\frac{FP\left(\tau\:\right)}{FP\left(\tau\:\right)+TN\left(\tau\:\right)}$$\end{document}AUC:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{AUC}={\int\:}_{0}^{1}TPR\left(FP{R}^{-1}\left(x\right)\right)dx\:$$\end{document}Multi-class AUC (OvR):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{AUC}}_{\mathrm{OvR}}=\frac{1}{C}{\sum\:}_{c=1}^{C}{\mathrm{AUC}}_{c}$$\end{document}Statistical tests
McNemar’s test
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\chi\:}^{2}=\frac{{\left(\left|b-c\right|-1\right)}^{2}}{b+c}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} are the number of samples misclassified by only one of two models.
Confidence interval
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:CI=\widehat{p}\pm\:{z}_{\alpha\:/2}\cdot\:\sqrt{\frac{\widehat{p}\left(1-\widehat{p}\right)}{n}}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{p}$$\end{document} is the sample proportion and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{z}_{\alpha\:/2}$$\end{document} is the critical value.
Implementation and complexity
Computational complexity
Non-Local block
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left({N}^{2}\cdot\:d+N\cdot\:{d}^{2}\right)$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} is the sequence length and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} is the feature dimension.
Overall model
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:O\left(L\cdot\:K\cdot\:{C}_{in}\cdot\:{C}_{out}+{N}^{2}\cdot\:d\right)$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L$$\end{document} is the input length, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} is the kernel size, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{in}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{out}$$\end{document} are input/output channels.
Theoretical insights
Non-Local attention for sequential IoT data
Theoretical Justification: The non-local operation captures long-range dependencies through the following approximation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{i}\approx\:{\sum\:}_{j\in\:\mathcal{N}\left(i,r\right)}{w}_{ij}{x}_{j}+{\sum\:}_{j\notin\:\mathcal{N}\left(i,r\right)}{\alpha\:}_{ij}{x}_{j}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathcal{N}\left(i,r\right)\:$$\end{document} represents the local neighborhood and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{ij}\:$$\end{document} represents learned long-range weights.
Information-Theoretic analysis
Mutual Information:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:I\left(X;Y\right)={\sum\:}_{x,y}p\left(x,y\right)\mathrm{log}\left(\frac{p\left(x,y\right)}{p\left(x\right)p\left(y\right)}\right)$$\end{document}Information gain
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:IG=H\left(Y\right)-H\left(Y|X\right)$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:H\left(Y\right)$$\end{document} is the entropy of the target variable.
Convergence analysis
Convergence theorem
Under Lipschitz continuity conditions, the proposed DNLNN converges with probability 1, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\underset{t\to\:{\infty\:}}{\mathrm{lim}}P\left(|\nabla\:L\left({\theta\:}_{t}\right)|\le\:ϵ\right)=1$$\end{document}
Learning rate bound
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{t}\le\:\frac{2}{\mu\:+L}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mu\:$$\end{document} is the strong convexity parameter and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L$$\end{document} is the Lipschitz constant.
Clarification and novelties of deepnonlocalnn vs. NonLocalNN
The DeepNonLocalNN model introduces significant advancements over the NonLocalNN by incorporating a deeper architecture with multiple convolutional layers and non-local blocks to enhance feature extraction and global dependency modeling for tabular IoT data. While NonLocalNN employs a single 1D convolutional layer (64 filters) followed by one non-local block, DeepNonLocalNN stacks three convolutional layers (32, 64, and 128 filters) with batch normalization, ReLU activation, and dropout (rate 0.3) after each, interspersed with two non-local blocks to capture long-range dependencies at multiple scales. This multi-layer design allows DeepNonLocalNN to learn hierarchical feature representations, improving its ability to model complex patterns compared to the simpler NonLocalNN, which is lightweight but less expressive due to its single-layer structure. Additionally, DeepNonLocalNN uses global average pooling to aggregate features, reducing dimensionality while preserving critical information, whereas NonLocalNN relies on mean pooling after a single non-local block. The increased depth, multiple non-local interactions, and robust regularization make DeepNonLocalNN more effective for high-dimensional, noisy IoT datasets, albeit at the cost of higher computational complexity.
Comparison of deepnonlocalnn with baseline models
Estimated based on layer sizes and complexity; DeepNonLocalNN and ResidualAttentionNetwork have higher parameter counts due to deeper architectures. DeepNonLocalNN and ResidualAttentionNetwork are computationally intensive due to multiple layers and attention mechanisms. Attention-based models (CNNWithAttention, ResidualAttentionNetwork) offer higher interpretability via feature importance or attention weights, while DeepNonLocalNN and NonLocalNN provide moderate interpretability through non-local attention. A comparative analysis of DeepNonLocalNN with other basic models is presented in Table 5.
Table 5. Comparison of deepnonlocalnn with baseline models.ModelArchitecture DescriptionKey FeaturesParametersComputational ComplexityInterpretabilityDeep NonLocalNNThree Conv1D layers (32, 64, 128 filters), two non-local blocks, global avg pooling, FC layersHierarchical feature extraction, multiple non-local blocks, robust regularizationHighHigh (multiple layers and non-local blocks)Moderate (non-local attention)LSTMThree LSTM layers (128 hidden units), FC layerCaptures temporal dependencies, sequence-sensitiveModerateHigh (recurrent computations)Low (recurrent architecture)NonLocalNNSingle Conv1D layer (64 filters), one non-local block, FC layersLightweight, single non-local block for global dependenciesLowLow (single layer and block)Moderate (non-local attention)CNN WithAttentionSingle Conv1D layer (64 filters), multi-head attention, FC layersCombines local convolution with global attention, balanced expressivenessModerateModerate (attention mechanism)High (attention weights)Residual AttentionNetworkConv1D (128 filters), multi-head attention, residual connections, FC layersResidual connections for gradient flow, attention for global dependenciesHighHigh (residual and attention)High (attention and residuals)
Results and discussion
This study evaluated the introduced DeepNonLocalNN model alongside four baseline models NonLocalNN, CNNWithAttention, ResidualAttentionNetwork, and LSTM, on the WUSTL-IIoT-2021 dataset for intrusion detection in IoT-based SCADA systems. The dataset, characterized by its high-dimensionality and severe class imbalance (e.g., 221,490 normal samples vs. 42 Backdoor test samples), posed significant challenges for accurate classification, particularly for minority attack classes. Performance was assessed using accuracy, ROC-AUC, precision, recall, and F1-score metrics, with results summarized in Tables 6 and 7. Training and validation loss/accuracy curves, ROC curves, and confusion matrices (Figs. 3 and 4) provide further insights into model convergence, discriminative ability, and classification performance. The DeepNonLocalNN model consistently outperformed all baselines, demonstrating its robustness and effectiveness in addressing complex cyber threats in industrial IoT environments.
Hyperparameter tuning and Documentation
To ensure robust and reproducible model performance, we implemented a systematic hyperparameter tuning process for the models on the WUSTL-IIoT-2021 dataset. Key hyperparameters, including learning rate (0.001, 0.0001, 0.00001), batch size (64, 128, 256), and dropout probability (0.3, 0.5, 0.7), were optimized using a grid search to maximize validation accuracy. The model was trained for up to 100 epochs with early stopping (patience of 10 epochs) to prevent overfitting, selecting the best model based on the lowest validation loss. All hyperparameters were documented with their rationale, ensuring transparency and facilitating reproducibility, while the tuning process enhanced the model’s performance.
Hardware details and training environment
Our framework is fully implemented in PyTorch and executed end-to-end on a single NVIDIA GeForce RTX 4090 GPU with 24GB of GDDR6X memory, leveraging its 16,384 CUDA cores and 512 fourth-generation Tensor Cores to accelerate the training and evaluation of the learning models on the WUSTL-IIoT-2021 dataset. The GPU’s high memory and bandwidth capacity efficiently handle the dataset’s tabular features, including network traffic attributes such as source/destination addresses and packet counts, enabling rapid processing of large batches (e.g., batch size of 128) during training. This comprehensive pipeline processes tabular data through preprocessing, model training, and evaluation, utilizing the RTX 4090’s computational power to ensure robust and efficient classification of network traffic patterns.
Table 6. Comparative performance of deep learning models on the WUSTL-IIoT-2021 dataset (Accuracy, ROC-AUC, Macro/Weighted F1).ModelAccuracyROC-AUCMacro F1Weighted F1ParametersTraining Time (s)DeepNonLocalNN 0.9999
1.0000
0.93
1.00 ~ 1.2 M1,234.56NonLocalNN0.99960.94760.69 1.00 ~ 0.3 M412.78ResidualAttentionNetwork0.99970.99820.60 1.00 ~ 0.6 M678.92CNNWithAttention0.99980.98400.63 1.00 ~ 1.5 M1,456.21LSTM0.92720.50220.190.89~ 0.8 M892.34
The confusion matrix analysis (Fig. 3) provides a detailed view of classification performance across classes. A confusion matrix is a square matrix where rows represent true labels and columns represent predicted labels, with each cell ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{ij}$$\end{document} ) indicating the number of samples with true class ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} ) predicted as class ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} ). Diagonal elements ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{ii}$$\end{document} ) represent correct classifications, while off-diagonal elements indicate misclassifications. For DeepNonLocalNN, the confusion matrix exhibits near-perfect diagonal dominance, with minimal off-diagonal entries, particularly for normal (221,490 samples), DoS (15,661 samples), and Reconn (1,648 samples), reflecting high precision and recall (1.00). For minority classes (Backdoor and CommInj), DeepNonLocalNN exhibits fewer misclassifications compared to baselines, which often misclassify these classes as normal or other attack types due to their low support. For example, NonLocalNN and CNNWithAttention misclassify all Backdoor samples, while ResidualAttentionNetwork misclassifies most CommInj samples. The robustness of DeepNonLocalNN is attributed to its non-local attention mechanism, which captures global contextual relationships, and focal loss, which prioritizes minority classes, mitigating the bias towards the majority class.
Fig. 3. Confusion Matrix obtained using DeepNonLocalNN (A), NonLocalNN (B), CNNWithAttention (C), D: ResidualAttentionNetwork (D), LSTM (E).
Table 7. Class-wise precision, recall, and F1-Scores for the WUSTL-IIoT-2021 dataset.BackdoorCommInjDoSReconnNormalAccuracyMacro avgWeighted avgSupport425215,6611648221,490238,893238,893238,893 Deep NonLocalNN precision0.901.001.001.001.000.981.00recall0.620.851.001.001.000.891.00f1-score0.730.921.001.001.001.000.931.00 NonLocalNN precision0.001.001.000.981.000.801.00recall0.000.311.001.001.000.661.00f1-score0.000.471.000.991.001.000.691.00 CNN With Attention precision0.000.001.001.001.000.601.00recall0.000.000.991.001.000.601.00f1-score0.000.001.001.001.001.000.601.00 Residual Attention Network precision0.081.000.990.991.000.811.00recall0.100.041.001.001.000.631.00f1-score0.090.070.990.991.001.000.631.00 LSTM precision0.000.000.080.000.930.200.86recall0.000.000.000.001.000.200.93f1-score0.000.000.000.000.960.930.190.89
The DeepNonLocalNN significantly outperformed other models in the precision, recall, and F1-score metrics, as shown in Table 7. Specifically, it achieved a macro average F1-score of 0.93, substantially higher than NonLocalNN (0.69), CNNWithAttention (0.60), ResidualAttentionNetwork (0.63), and LSTM (0.19). For minority classes, DeepNonLocalNN recorded F1-scores of 0.73 (Backdoor) and 0.92 (CommInj), far surpassing NonLocalNN (0.00 and 0.47), CNNWithAttention (0.00 and 0.00), ResidualAttentionNetwork (0.09 and 0.07), and LSTM (0.00 and 0.00). This superior performance is due to its deep architecture with three 1D convolutional layers (32, 64, 128 filters) and two non-local blocks, enabling hierarchical feature extraction and robust modeling of long-range dependencies. The macro average, which treats all classes equally, highlights DeepNonLocalNN’s effectiveness in handling imbalanced classes, while the weighted average, which accounts for class support, reaches 1.00 across all models except LSTM (0.89), reflecting the dataset’s dominance by the normal class.
The DeepNonLocalNN achieved an accuracy of 0.9999 and a ROC-AUC of 1.0000, indicating near-perfect classification across all classes, as evidenced by the ROC curves (Fig. 4). Its macro F1-score of 0.93 reflects strong performance on minority classes, addressing the challenge of class imbalance noted in Sect. Limitations and future works. In contrast, NonLocalNN, with a single convolutional layer and non-local block, achieved a high accuracy (0.9996) but struggled with minority classes, failing to detect Backdoor (F1: 0.00) and exhibiting low recall for CommInj (0.31), resulting in a macro F1-score of 0.69 and ROC-AUC of 0.9476. Its lightweight design limits its ability to model hierarchical features, making it less effective for complex patterns. CNNWithAttention (accuracy: 0.9998, ROC-AUC: 0.9982) and ResidualAttentionNetwork (accuracy: 0.9997, ROC-AUC: 0.9840) performed well on majority classes (DoS, Reconn, Normal) but failed to detect Backdoor and CommInj effectively, with macro F1-scores of 0.60 and 0.63, respectively. These models, while incorporating attention mechanisms, lack the depth and multiple non-local interactions of DeepNonLocalNN. The LSTM model, designed for sequential data, was the least effective (accuracy: 0.9272, ROC-AUC: 0.5022, macro F1: 0.19), failing to detect most attack classes due to its sensitivity to sequence length and the dataset’s imbalanced nature.
The macro average F1-score, which computes the unweighted mean of per-class F1-scores, underscores DeepNonLocalNN’s ability to balance performance across all classes, particularly excelling in detecting rare attacks. The weighted average F1-score, which weights each class by its support, is near 1.00 for all models except LSTM (0.89), reflecting the dataset’s skew towards the normal class. However, the macro average is more informative for evaluating performance on imbalanced datasets, as it does not favor the majority class. DeepNonLocalNN’s macro F1-score of 0.93 significantly outperforms baselines, with statistical significance confirmed by McNemar’s test (p < 0.01) when comparing against NonLocalNN and other models, particularly for minority classes.
Fig. 4. One-vs-Rest ROC Curve Analysis (A: DeepNonLocalNN(ROC-AUC Score: 1.0000), B: NonLocalNN (ROC-AUC Score: 0.9476), C: CNNWithAttention (ROC-AUC Score: 0.9982), D: ResidualAttentionNetwork (ROC-AUC Score: 0.9840), LSTM (ROC-AUC Score: 0.5022)).
Training and validation curves (Fig. 4) demonstrate DeepNonLocalNN’s stable convergence, with training and validation losses converging after approximately 50 epochs, indicating minimal overfitting. This stability is due to robust regularization, including dropout (rate: 0.3), L2 weight decay (0.0001), and batch normalization. In contrast, LSTM exhibits erratic validation loss, reflecting its struggle with class imbalance. ROC curves (Fig. 4) confirm DeepNonLocalNN’s perfect discriminative ability (AUC: 1.0000), with no false positives across classes, unlike LSTM (AUC: 0.5022), which shows near-random performance. The confusion matrices (Fig. 5) further highlight DeepNonLocalNN’s minimal errors, with misclassifications confined to low-support classes, compared to baselines with widespread errors in minority classes.
Fig. 5. Training and Validation Loss and Accuracy Curves of the DeepNonLocalNN (A), NonLocalNN (B), CNNWithAttention (C), ResidualAttentionNetwork (D), and LSTM (E) Models on WUSTL-IIoT-2021 Dataset.
The superior performance of DeepNonLocalNN, including adaptability to dynamic attacks and robustness against imbalanced datasets. Its deep architecture and non-local attention mechanisms enable it to capture both local patterns and global dependencies, making it highly effective for detecting complex attacks like Backdoor and CommInj. However, its high computational complexity necessitates substantial hardware resources, aligning with the noted challenge of high hardware costs. Future work could focus on optimizing its computational efficiency through techniques like sparse attention or model pruning and validating its performance on real-world industrial datasets. These results position DeepNonLocalNN as a state-of-the-art solution for intrusion detection in IoT-based SCADA systems, offering a robust defense against sophisticated cyber threats.
We acknowledge that the near-perfect metrics (e.g., 0.9999 Accuracy, 1.0000 ROC-AUC) may raise scrutiny. This performance is a testament to the proposed DeepNonLocalNN architecture’s efficacy in modeling long-range dependencies and the explicit use of Focal Loss to handle the severe class imbalance of the WUSTL-IIoT-2021 dataset. The high Macro F1-score (0.93) is the critical indicator, showing robust and balanced detection across all classes, including minority attacks (Backdoor F1: 0.73, CommInj F1: 0.92). The combination of deep hierarchical feature extraction and global non-local context modeling allows the model to capture the subtle, high-dimensional patterns that characterize these attacks, which is an intentional outcome of our design choice. Training and validation curves (Fig. 5) demonstrate stable convergence with no significant gap between training and validation performance, supported by comprehensive regularization (dropout rate 0.3, L2 weight decay 0.0001, batch normalization, and early stopping with patience of 10 epochs). These measures effectively prevent overfitting despite the high overall accuracy and perfect ROC-AUC.
The poor performance of baseline models on minority attack classes, such as Backdoor and CommInj, can be attributed to two main factors. First, traditional models (LSTM and standard CNNs) lack a mechanism to capture the subtle, long-range dependencies that characterize low-volume, sophisticated attack traffic, which is a strength of the non-local attention blocks. Second, without a dedicated loss function like Focal Loss, these models are heavily biased by the majority ‘normal’ class due to the extreme class imbalance, leading to a tendency to misclassify minority attack samples as benign traffic.
To validate the superiority of DeepNonLocalNN, statistical tests were conducted. McNemar’s test compared paired predictions between DeepNonLocalNN and each baseline, focusing on minority classes. The test statistic is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{{\upchi\:}}^{2}=\frac{{\left(\left|b-c\right|-1\right)}^{2}}{b+c},$$\end{document}where ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:b$$\end{document} ) and ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:c$$\end{document} ) are the number of samples misclassified by only one of the two models. Results showed significant differences ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\:<\:0.01$$\end{document} ) between DeepNonLocalNN and all baselines for Backdoor and CommInj, confirming its superior performance. Additionally, a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:95\%$$\end{document} confidence interval for the macro F1-score of DeepNonLocalNN ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.93\:\pm\:\:0.02$$\end{document} ) was computed using:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{CI}=\widehat{p}\pm\:z\sqrt{\frac{\widehat{p}\left(1-\widehat{p}\right)}{n}}$$\end{document},
where ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\widehat{p}$$\end{document} ) is the sample proportion, ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:z\:=\:1.96$$\end{document} ), and ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} ) is the sample size. The non-overlapping confidence intervals with baselines (e.g., NonLocalNN: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.69\:\pm\:\:0.03$$\end{document} ) further validate its statistical significance.
Conclusion
This study presents the DeepNonLocalNN model developed to improve the security of industrial IoT-based SCADA systems in critical infrastructures. This deep learning architecture, which combines multilayer convolutional structures and non-local attention mechanisms, can successfully learn both local patterns and global relationships and provides high detection success, especially in minority attack classes.
Experiments on the WUSTL-IIoT-2021 dataset showed that the model achieved impressive performance values such as 99.99% accuracy, 1.0000 ROC-AUC and 0.93 macro F1-score. The model outperformed other methods, especially in low-sample-count attack types such as Backdoor and Command Injection.
Industrial SCADA systems are used in critical sectors such as energy, water and manufacturing, so security is of vital importance in these systems. DeepNonLocalNN has the potential to be integrated into these systems with its flexible architecture and high performance.
The non-local attention mechanism increases both the number of model parameters and the training time, as detailed in Table 6. While the current focus is on maximizing detection accuracy and feature expressiveness, we recognize that deployment on resource-constrained devices, such as PLCs and RTUs in SCADA systems, requires optimization. Therefore, a critical component of our future work is to specifically focus on optimizing the computational efficiency and reducing the model’s footprint for true real-time, low-latency intrusion detection in resource-limited industrial environments.
While DeepNonLocalNN is more robust than traditional signature-based systems in detecting dynamic and zero-day attacks due to its ability to learn complex patterns, its performance will inevitably degrade under severe concept drift (i.e., when new, unknown attack vectors emerge). To maintain high operational performance, the model must be periodically retrained with new, labeled data that captures the latest threat landscape. Our architecture is designed to facilitate this continuous integration and learning process, which is a necessary operational step for any advanced AI-driven Intrusion Detection System.
Limitations and future work
The proposed DeepNonLocalNN model is designed for IIoT-based SCADA systems. It has demonstrated high performance, outperforming most methods in the existing literature, particularly in attacks involving minority classes. The study contributes to developing AI-powered solutions against dynamic and complex threats. Cross-dataset validation on additional industrial SCADA/ICS datasets (e.g., TON_IoT, Edge-IIoT, or newer real-world captures) to confirm generalizability and rule out dataset-specific overfitting.
The proposed model’s multi-layered convolutional structure and non-local attention blocks are key factors that ensure high accuracy. However, this structure also introduces a computational burden. This burden must be properly evaluated for real-time processes in resource-limited embedded systems such as PLCs and RTUs. The model’s 1.2 million parameters can lead to the complexity of non-local attention operations, inference delays, and energy consumption. The time sensitivity of SCADA systems can limit the potential for real-time responses.
The model was validated on WUSTL-IIoT-2021, a simulation-based dataset that is close to reality. A more comprehensive performance evaluation should be conducted against systems with diverse protocols and advanced attack techniques (such as zero-day attacks, BlackEnergy, or CrashOverride) that encompass diverse conditions. The WUSTL-IIoT-2021 dataset’s dependence on specific network protocols and topologies may limit the model’s generalizability.
Given these limitations and constraints, future work is exploring solutions.
- The goal is to reduce computational requirements while maintaining accuracy for resource-constrained hardware. This can be achieved by optimizing the model using techniques such as pruning, quantization, and information distillation.
- An edge-to-cloud collaboration framework is being considered, where lightweight feature extraction is performed for PLCs and RTUs, while complex inferences are performed via edge servers or the cloud.
- The model will utilize online learning capabilities to adapt to new threat types without the need for retraining.
- Validation will be conducted on testbeds with various real-world datasets to increase generalizability.
- Using explainable AI techniques to increase transparency and confidence in attack detection.
The study demonstrates the significant potential of AI technologies for real-time threat detection. It offers an innovative, high-performance solution that can be implemented in critical IIoT-based SCADA systems. Further improving computational efficiency and real-world validation could transform the solution into a scalable, practical, and essential security tool for IIoT-SCADA environments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bayrakcı, H. C. & Büyükpatpat, H. PLC ve SCADA kontrol yöntemleri Ile sıvı dolum Otomasyonu. Avrupa Bilim Ve Teknoloji Dergisi. (27):283–291 (2021).
- 2Yalçın, N., Çakır, S. & Ünaldı, S. Attack detection using artificial intelligence methods for SCADA security. IEEE Internet Things J.. 11:39550–39559 (2024).
- 3Kleinmann, A. et al. Stealthy deception attacks against SCADA systems. in Computer Security: ESORICS 2017 International Workshops, Cyber ICPS 2017 and SECPRE 2017, Oslo, Norway, September 14–15, Revised Selected Papers 3. 2018. (Springer, 2017).
- 4Qassim, Q. S. et al. Compromising the data integrity of an electrical power grid SCADA system. in International Conference on Advances in Cyber Security. (Springer, 2020).
- 5Wali, S. et al. Covert Penetrations: Analyzing and Defending SCADA Systems from Stealth and Hijacking Attacks p. 104449 (Computers & Security, 2025).
- 6Ali, S. Security in SCADA System: A Technical Report on Cyber Attacks and Risk Assessment Methodologies. in: Proceedings of the Computational Methods in Systems and Software. Springer. pp. 420–446. (2023).
- 7Kumar, A. & Sharma, I. Secu SCADA: Building secure SCADA network with obfuscated malware detection technique. In: 11th International Conference on Emerging Trends in Engineering & Technology-Signal and Information Processing (ICETET-SIP). (IEEE, 2023).
- 8Biswas, H. Malware Trend in Smart Grid Cyber Security. In: 2024 IEEE Region 10 Symposium (TENSYMP). (IEEE, 2024).