The application of pre-trained large visual-language models for preliminary diagnosis of esophageal whitish plaques in large-scale esophageal cancer screening
Yilin Li, Xin Li, Di Zhang, Wenwen Zhu, Yuan Hu, Zijian Zhao, Qi Zhao

TL;DR
This paper introduces a computer-aided diagnosis system using a pre-trained visual-language model to improve the accuracy of diagnosing esophageal whitish plaques during cancer screenings.
Contribution
The novel contribution is applying the BLIP visual-language model to esophageal whitish plaque diagnosis, outperforming existing methods and endoscopists.
Findings
The proposed model outperforms benchmark models in precision, recall, F1 score, and accuracy.
The model significantly improves keyword accuracy in medical text descriptions compared to LLaVA-Med.
The system excels in early esophageal cancer case recall, surpassing both senior and junior endoscopists.
Abstract
Esophageal whitish plaques are common findings in large-scale esophageal cancer screenings, requiring accurate preliminary differentiation to guide appropriate clinical management. This study presents a computer-aided diagnosis (CAD) system based on the pre-trained large-scale visual-language (VL) model BLIP for automated diagnosis and description of esophageal whitish plaques. A dataset of 13,922 endoscopic images was used for model training, and comparative experiments were conducted with multiple benchmark models, including Poolformer, Swin-Transformer, TransMSF, and ViT. The results demonstrate that our approach outperforms existing methods in terms of precision, recall, F1 score, and accuracy. Compared with LLaVA-Med, our model significantly improves keyword accuracy (K-ACC) in medical text descriptions. A human-machine competition further demonstrated that our model outperforms…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
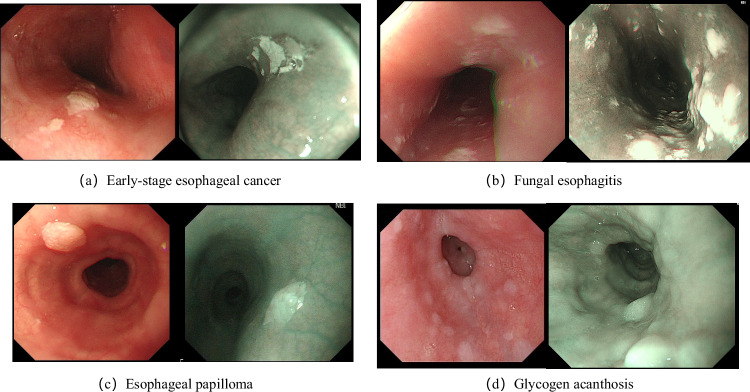 Figure 1
Figure 1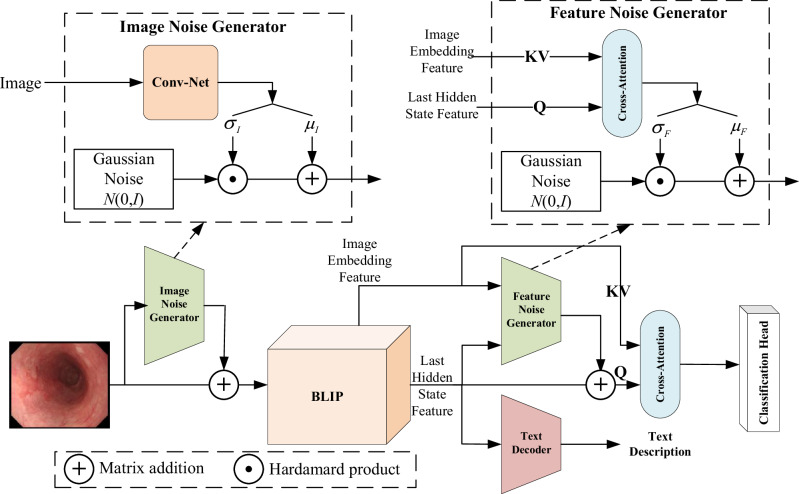 Figure 2
Figure 2- —the Natural Science Foundation of Shandong Province
- —the National Key Research and Development Program of China
- —the Medical Science and Technology Development Plan of Shandong Province
- —Taishan Scholars Project Special funding
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEsophageal Cancer Research and Treatment · AI in cancer detection · Colorectal Cancer Screening and Detection
Introduction
The incidence of digestive diseases remains alarmingly high worldwide, posing a significant threat to human health, particularly in the form of digestive tract cancers, especially esophageal cancer, which claims the lives of 1.8 million people annually^1^. Digestive endoscopy plays a pivotal role in the early detection of gastrointestinal diseases, particularly in identifying early-stage gastrointestinal malignancies, enabling timely intervention and achieving nearly 100% survival rates^2^. In recent years, China has been actively promoting the adoption of these examinations in primary healthcare facilities and conducting large-scale screening campaigns annually to enhance early diagnosis and treatment outcomes.
In large-scale esophageal cancer screening, esophageal whitish plaques are very common^3,4^. In clinical practice, endoscopic whitish plaques in the esophagus do not represent a single disease diagnosis. Instead, they refer to whitish visual changes on the surface of the esophageal mucosa that have a clear boundary with the surrounding normal pink mucosa. The causes of esophageal whitish plaques are numerous. According to our clinical screening statistics, over 20% of patients undergoing gastroscopy will exhibit esophageal whitish plaques that are difficult to erase. Among these cases, a significant portion of the whitish plaques is caused by tightly adherent inflammatory materials, which could be inflammatory exudates on the surface of early esophageal cancer^5^, or plaques and inflammatory deposits in fungal esophagitis^6,7^. The remaining cases may be due to excessive or uneven keratinization of the squamous epithelium, manifesting as glycogenic acanthosis^8,9^ or esophageal papilloma^10^. Specifically, the representative endoscopic appearances of the four diseases included in Fig. 1 are as follows:Fig. 1. Representative endoscopic images of four esophageal diseases.White-light endoscopy (WLE) images are presented on the left and narrow-band imaging (NBI) images are presented on the right. All images illustrate characteristic whitish plaques. Panels are arranged as follows: (a) Early-stage esophageal cancer (upper left); (b) Fungal esophagitis (upper right); (c) Esophageal papilloma (lower left); (d) Glycogen acanthosis (lower right).
- Early-stage esophageal cancer: Presents as plaque-like whitish mucosal areas with slightly elevated and rough surfaces. These white regions result from reduced blood supply or surface exudation and cannot be removed by wiping.
- Fungal esophagitis: Shows punctate, patchy, or geographic white pseudomembranes with a soft ”tofu-dreg-like” texture. These pseudomembranes may detach when flushed or gently scraped, revealing hyperemic or eroded mucosa underneath.
- Esophageal papilloma: Appears as small, white, papillary or granular protrusions. These lesions are usually lobulated and sessile or sub-pedunculated. Under magnified narrow-band imaging, vascular changes can be observed, but without atypical features.
- Glycogen acanthosis: Characterized by multiple small, flat white elevations with sharp boundaries and a slightly granular appearance. Under magnification, the vascular texture disappears. This benign lesion can be distinguished from early cancer using iodine staining.
For these four scenarios, endoscopists need to perform critical preliminary differential diagnoses based on endoscopic images and take different actions accordingly. If a preliminary diagnosis suspects early esophageal cancer, a key biopsy should be promptly conducted. For cases preliminarily diagnosed as fungal esophagitis, a smear biopsy or direct recommendation for antimicrobial therapy is required. Patients preliminarily diagnosed with glycogenic acanthosis or esophageal papilloma may not need an immediate biopsy but can be managed through follow-up observation. Diagnosis relies heavily on the physician’s experience and skill in interpreting subtle differences in endoscopic images. This leads to significant inter-physician variability and a higher risk of misdiagnosis.
Given the over-reliance on doctors’ capabilities and experience for the clinical preliminary diagnosis of esophageal whitish plaques, diagnostic accuracy varies, with more experienced senior diagnostic physicians performing better, followed by those with average years of experience, and the worst being newly graduated medical students. Considering the widespread application of artificial intelligence (AI)^11–14^, especially convolutional neural network (CNN) and large Visual-Language (VL) models, in the medical field, proposing an AI system to assist doctors in completing the preliminary diagnostic tasks for esophageal whitish plaques could significantly improve efficiency and accuracy. Therefore, this paper presents a computer-aided diagnostic (CAD) system based on the pre-trained large VL model—BLIP^15^ for the preliminary differential diagnosis of esophageal whitish plaque images. Compared with traditional CAD methods for endoscopic images^13,14^, the proposed approach based on the VL model not only provides diagnostic outcomes but also generates textual descriptions of endoscopic images, which represents a significant advantage unmatched by conventional techniques.
Results
Experiment Settings
The proposed model is implemented on the Ubuntu 22.04 LTS operating system using the PyTorch 2.0 framework based on Python 3.10, CUDA 11.8, and CUDNN 7.4. The Tesla V100 32G GPU is used as an accelerator for training. The training model initializes the learning rate to 5 × 10^−5^ and uses the momentum method to train. The momentum parameter is set to 0.9, the weight decay is set to 0.0005, the learning rate decay step is 5, the batch size is set to 16, and the training epoch is set to 100.
Comparison with other CNN models
To evaluate the diagnostic performance of the proposed model, we compared it with 4 state-of-the-art (SOTA) CNN models, namely, Poolformer^16^, Swin-transformer^17^, TransMSF^18^, ViT^19^. We trained these 4 CNN models using the data from the Training Set. Subsequently, we tested each model using the Validation Set and calculated four metrics for each model: Precision (PREC), Recall (REC), F1 score, and Accuracy (ACC), as shown in Table 1 (PREC, REC, and F1 score are the average values of the four classes). The experimental results in Table 1 show that, under both white-light endoscopy (WLE) and narrow-band imaging (NBI) modalities, the proposed model has the highest performance indicators in classifying the four digestive tract diseases compared with the four state-of-the-art CNN models.Table 1. Comparison of all models’ performance indicators: Precision (PREC), Recall (REC), F1 score, and Accuracy (ACC)ModelWLENBIPRECRECF1ACCPRECRECF1ACCPoolformer0.81710.79440.80270.81530.74220.72720.73440.7468Swin-transformer0.84050.82370.83040.83820.79020.77420.77990.7945TransMSF0.86870.84340.84060.86520.84420.81580.82660.8408ViT0.82710.80740.81510.82660.73090.70230.71170.735Ours0.87390.88080.87660.89050.86300.86730.86440.8711PREC, REC and F1 score are the average values of the four classes.Bold values denote the highest performance achieved among the compared methods.
Comparison with other VL models
To evaluate the performance of the proposed model in image-text description tasks, we compared it with LLaVA-Med^20–22^, a dedicated VL model pre-trained on a biomedical dataset. Specifically, LLaVA-Med was trained using the publicly available PMC-5M dataset^22^, which comprises 15 million biomedical image-text pairs across diverse categories, including medical images and corresponding textual annotations such as captions or diagnostic reports. We also conducted instruction fine-tuning training on the LLaVA-Med model by using the Training Set.
The performance of both models was assessed using the Keyword Accuracy (K-ACC) metric. We defined four medical keywords: ”fungal esophagitis”, ”esophageal cancer”, ”esophageal papilloma”, and ”glycogenic acanthosis”. A prediction was marked correct if the VL model’s generated description of an image contained at least one keyword that matched the ground-truth annotation for that image (Images with mismatched classification and keywords were excluded from K-ACC calculation). The final K-ACC score was calculated as the ratio of correct predictions to the total number of test images. As shown in Table 2, the proposed model outperformed LLaVA-Med (original and fine-tuned) in overall K-ACC (the performance of the fine-tuned LLaVA-Med model is much better than the original LLaVA-Med model’s, the overall K-ACC has increased by 30% compared to that before fine-tuning). For disease-specific K-ACC, the fine-tuned LLaVA-Med model outperformed the proposed model only in Glycogenic Acanthosis. For the LLaVA-Med model in the diagnosis of WLE and NBI endoscopic images, especially in the diagnosis of WLE-type endoscopic images, the K-ACC is relatively low. In contrast, the K-ACC of the model proposed in this paper is relatively high (more than 37% at least). This demonstrates its superiority in accurately identifying and describing key pathological features in biomedical images. The evaluation methodology ensured a rigorous comparison by focusing on clinically relevant keywords, aligning with the diagnostic requirements of medical practitioners.Table 2. Experiment results in the keyword accuracy (K-ACC) for LLaVA-Med and our modelCategoryLLaVA-MedOursOriginalFine-tunedOverall0.34620.64600.8480Fungal Esophagitis0.23550.60000.9026Esophageal Cancer0.48310.75360.8966Esophageal Papilloma0.40010.64800.8129Glycogenic Acanthosis0.15790.82890.7645WLE0.25830.47680.8534NBI0.50910.66670.8425
Human-machine reading competition
To compare the diagnostic performance between the model proposed in this paper and endoscopists, we organized a human-machine reading competition. Four endoscopists participated in the competition, including two senior ones with 10–20 years of experience and two junior ones with 5–10 years of experience. A total of 596 images used in the competition (298 images each for WLE and NBI) were randomly selected from the test set. During the competition, each endoscopist only needed to determine the disease type of the images. By comparing their judgments with the annotated diagnostic results of the images, a confusion matrix could be obtained for each endoscopist. By aggregating all the confusion matrices, the experimental results for the metrics of PREC, REC, F1 score, and ACC could be obtained, as shown in Table 3.Table 3. Results of the human-machine reading competitionWLENBIPRECRECF1ACCPRECRECF1ACCSenior1EC0.87340.92000.89610.86910.85510.78670.81940.8121FE0.98750.94050.96340.86840.81480.8408GA0.72450.94670.82080.65690.89330.7571EP0.97560.62500.76190.98040.74630.8475Senior2EC0.96080.65330.77780.86240.94740.72000.81820.8557FE0.87370.98810.92740.90360.92590.9146GA0.73470.96000.83240.70870.97330.8202EP0.98150.82810.89830.96360.79100.8689Junior1EC0.93020.53330.67800.76510.97500.52000.67830.7987FE0.77880.96430.86170.68700.97530.8064GA0.62070.96000.75390.75560.90670.8242EP0.98000.54690.70710.98110.77610.8667Junior2EC0.85190.61330.71320.77520.77420.64000.70070.7685FE0.78220.94050.85410.78950.92590.8523GA0.65350.88000.75000.67860.76000.7170EP0.95240.62500.75470.85960.73130.7903OursEC0.83330.92440.87650.89050.94340.92590.93460.8696FE0.95540.94140.94830.90060.92610.9132GA0.81290.76350.78750.82990.76730.7974EP0.89410.89410.89410.77310.84400.8070EC esophageal cancer, FE fungal esophagitis, GA glycogenic acanthosis, EP esophageal papilloma.
As shown in Table 3, regarding the WLE images, the senior endoscopists achieved ACC values of 86.91% and 86.24%, while the junior endoscopists achieved values of 76.51% and 77.52%. In contrast, the model achieved a high ACC of 89.05%. For NBI images, the ACC values were 81.21% and 85.57% for seniors, 79.87% and 76.85% for juniors. The model outperformed them, achieving an ACC of 86.96%. Endoscopists generally showed low recall in detecting early esophageal cancer. In WLE, the endoscopists achieved REC rates of 92.00%, 65.33%, 53.33%, and 61.33%, while in NBI, the rates were 78.67%, 72.00%, 52.00%, and 64.00%. However, the model exhibited significantly higher REC rates for diagnosing esophageal cancer, reaching 92.44% in WLE and 92.59% in NBI. These results revealed the superior performance of the model compared to the endoscopists.
Discussion
In this study, we utilized the pre-trained VL model-BLIP to develop a novel model for the differential diagnosis of esophageal whitish plaques using two different imaging modalities, WLE and NBI. Compared with other SOTA CNN models (see Table 1), the model described in this paper exhibits the best performance in four metrics: PREC, REC, F1 score, and ACC. For WLE, it outperforms by at least 0.52%, 3.74%, 3.6%, and 2.53%, respectively; for NBI, it outperforms by at least 1.88%, 5.15%, 3.78%, and 3.03,% respectively. When compared with the LLaVA-Med (original and fine-tuned) in terms of the performance of text description output for endoscopic image (see Table 2), the model in this paper also shows good performance. By calculating the K-ACC metric, it can be found that the model in this paper has the best performance in text output description, except for one disease type, Glycogenic Acanthosis, outperforming by 20.2% for Overall. In summary, compared with other SOTA AI models, the model described in this paper has significant advantages in both diagnostic performance and text output performance for description. Notably, during inference on the test set, the model relies solely on endoscopic images as input, without any accompanying textual information.
To better demonstrate the diagnostic efficacy of our model, a human-computer comparison was performed. As shown in Table 3, the ACC metric of the model proposed in this paper is the highest, whether for WLE or NBI. For WLE, it is at least 2.14% higher; for NBI, it is at least 1.39% higher. This indicates that the overall diagnostic performance of the proposed model for the four diseases is the best. When it comes to the diagnosis of esophageal cancer, a key disease, we can observe that under WLE, although the PREC metric of the proposed model is the lowest, the REC metric is the highest. This implies that the diagnostic strategy of the proposed model under WLE is not conservative, resulting in a lower rate of missed diagnoses than that of doctors. Under NBI, both the PREC and REC metrics of the proposed model are the highest, which means that the proposed model can achieve both accurate prediction and comprehensive coverage under NBI, leading to low rates of both missed and mistaken diagnoses. On the contrary, looking at the diagnostic result metrics of endoscopists in the competition under WLE and NBI, except for Senior1, the other three endoscopists have the same phenomenon: a relatively high PREC metric and a relatively low REC metric (the maximum difference between the two metrics is over 40%). This shows that endoscopists’ diagnostic strategies tend to be conservative. Although the misdiagnosis rate is reduced, the missed-diagnosis rate is increased. This phenomenon poses a significant risk to patients during the screening process.
Our study was designed to explore the potential of pre-trained VL models in accurately diagnosing esophageal whitish plaques. The results of our research suggest that the proposed model demonstrates high diagnostic performance, which can effectively reduce the diagnostic errors made by endoscopists. It is anticipated that this model will offer real-time guidance for medical decision - making, minimize the necessity for excessive biopsies, and ultimately curtail medical resource expenditures. Nonetheless, our study was not without limitations. First, the classification of esophageal whitish plaques was only applicable to WLE and NBI images, excluding endoscopic videos. Second, due to the limited availability of data, this study only concentrated on four common diseases, overlooking other conditions presenting with esophageal whitish plaques, such as esophageal ectopic sebaceous glands, esophageal xanthomas, and esophageal granular cell tumors. Third, as this was a single-center retrospective study, the performance of the model requires further validation through multi-center studies. Finally, except for early esophageal cancer, which was confirmed by histopathology, the ground-truth labels for fungal esophagitis, esophageal papilloma, and glycogenic acanthosis were based solely on endoscopic diagnosis by experienced clinicians, without histopathological confirmation.
Future work should prioritize three key directions to build upon this research. First, there is a critical need to develop and validate real-time video diagnostic models to transition this technology from static image analysis to dynamic clinical use during live endoscopy. Second, the AI system’s classification capabilities must be expanded to include a broader differential diagnosis of esophageal whitish plaques, such as ectopic sebaceous glands, xanthomas, and granular cell tumors, to improve its clinical utility and reduce misdiagnosis. Finally, the model’s generalizability and robustness must be rigorously evaluated through large-scale, multi-center prospective studies to ensure its efficacy across diverse patient populations and clinical settings. The collection of a large amount of multi-center data is very necessary, and the annotation of the data not only includes class information but also text description information.
Methods
This study was conducted in accordance with the Declaration of Helsinki and was approved by the Ethics Committee of Shandong Provincial Hospital (SWYX: NO.2023-427). The study was retrospective and received approval from the Ethics Committee to waive patients’ informed consent.
Datasets
In this study, we retrospectively collected 13,922 endoscopic images from 2048 patients from January 2009 to July 2023 at Shandong Provincial Hospital. Esophageal cancer was diagnosed based on pathology, while esophageal papilloma, fungal esophagitis, and glycogenic acanthosis were diagnosed by experienced endoscopists. Poor-quality images, such as those that were blurry, with excessive mucus or food debris, or lacking appropriate inflation, were excluded from the study.
In our retrospective study, all selected endoscopic images include 4433 images from 504 patients with fungal esophagitis, 2963 images from 358 patients with early esophageal cancer, 3383 images from 663 patients with esophageal papillomas, and 3143 images from 523 patients with glycogenic acanthosis. Each disease contained both WLE and NBI imaging modalities. The images of fungal esophagitis, early esophageal cancer, esophageal papilloma, and glycogenic acanthosis were randomly selected and divided into a training set and a test set, with 70% of the images in the training set and 30% in the test set In the experiments, random selection is conducted three times, and the experimental results are averaged based on these three selections. The annotations for all images in both the training set and the test set comprise not only category labels but also descriptive textual descriptions of the corresponding images. The textual description for each endoscopic image mainly consists of three parts: location, appearance description, and disease name. For example, ”This image shows the esophagus. There are whitish plaques on the inner wall, and it is most likely Esophageal Cancer.”
Disease Diagnostics and Description on BLIP
Traditional CAD systems for digestive endoscopy images based on deep learning typically reduce the diagnostic process into an image classification task, which only outputs categorical labels (disease types) without supplementary descriptive information such as imaging modality, anatomical location, symptoms, or disease progression. Descriptive information, inherently in natural language form, exhibits a significant modality discrepancy with the input endoscopic images. Cross-modal information output has long been a challenging direction in deep learning; however, recent advancements in large VL model research have enabled notable breakthroughs. Leveraging the cross-modal output capability of large VL models, this study proposes a novel digestive endoscopy CAD system that simultaneously generates diagnostic predictions and descriptive annotations (as shown in Fig. 2). The proposed system is based on the BLIP network architecture, incorporating an input-stage forward noise generator designed to enhance the endoscopic image data through positive-incentive noise injection. At the output-stage, alongside standard text generation capabilities, a positive-incentive noise generator is also applied to the last hidden state features of the BLIP network. These enhanced features are then fused with the original image embeddings of BLIP via a cross-attention module before being fed into a dedicated classification head for diagnostic outputs. The following sections will provide a detailed introduction to this framework.Fig. 2. The framework of our proposed system, which includes two important modules for adding positive-incentive noise.Image Noise Generator, and Feature Noise Generator.
Image Noise Generator
As described in Section 4.1, the collected image dataset in this study comprises fewer than 15,000 samples, which is insufficient for training large VL models. Even when employing the fine-tuning, such limited data volume struggles to guarantee satisfactory training outcomes. Inspired by positive-incentive noise techniques,we added positive incentive noise to both the input (or output) end of the BLIP model. This noise is generated driven by the image input (or image embedding features). According to the theory of^23^, this positive incentive noise is of the same origin as the image signal, and there is mutual information between them. It can effectively reduce the entropy of the classification task, thereby improving the performance of the classification system. This work introduces an image noise generator module at the input stage of the BLIP backbone network (Fig. 2 left). The architecture of this generator is straightforward: it takes an image tensor as input and processes it through a convolutional neural network (Conv-Net) to output two scalar values, σI and μI. If the input image is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I\in {{\mathbb{R}}}^{m\times n}$$\end{document} , we have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left({\mu }_{I},{\sigma }_{I}\right)={f}_{\alpha }\left(Conv-Net\left(I\right)\right)$$\end{document} , where the function fα can be implemented by using various neural network architectures.
Here, σI serves as the variance parameter and μI as the mean parameter for the generated noise. These scalars are combined with a Gaussian noise distribution N(0, 1) via Hadamard product and matrix multiplication operations, producing a noise image matching the original input dimensions. This additive noise image is then superimposed onto the original image before feeding into the BLIP backbone. The Conv-Net architecture can be dimensionally adapted depending on hardware/software constraints to achieve optimal computational efficiency.
Feature noise generator
The noisy image tensor is fed into the BLIP backbone network, where the Image Encoder module generates the Image Embedding Feature, while the final hidden layer of the BLIP model yields the Last Hidden State Feature. These two feature maps incorporate information from both visual and textual modalities, remaining mutually correlated despite their distinct modalities. They serve as inputs to drive the classifier’s diagnostic output. To enhance classification performance, we introduce the positive-incentive noise to the Last Hidden State Feature, generated by the Feature Noise Generator module (as shown in the right part of Fig. 2). This module takes the Image Embedding Feature and Last Hidden State Feature as inputs, which are processed through a cross-attention mechanism to compute the mean μF and variance σF. They are then fused with a Gaussian distribution N(0, 1) to produce the desired positive-incentive noise. If the Image Embedding Feature is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${I}_{e}\in {{\mathbb{R}}}^{d}$$\end{document} ,the Last Hidden State Feature is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L\in {{\mathbb{R}}}^{d}$$\end{document} , the cross-attention module is denoted as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$CrosAtten\left(Q,K,V\right)=Sof{t}_{MAX}\left(\frac{Q{K}^{T}}{\sqrt{d}}\right)V$$\end{document}then we have \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left({\mu }_{F},{\sigma }_{F}\right)={f}_{\theta }\left(CrosAtten\left(Q=L,K={I}_{e},V={I}_{e}\right)\right)$$\end{document} ,where the function fθ can be implemented by using various neural network architectures.
Loss function of training
The proposed system comprises two output modules: the classification head module and the text decoder module. The text decoder module, inherited from the original BLIP architecture, generates image descriptions and outputs the built-in text loss function of the BLIP model, denoted as. The classification head module is configured as a stacked structure (CHNet) consisting of convolutional layers, ReLU layers, pooling layers, and fully connected layers. Its output passes through a Sigmoid function to produce the predicted diagnostic logits
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${P}_{l}=Sigmoid\left(CHNet\left(CrosAtten\left(Q={L}_{N},K={I}_{e},V={I}_{e}\right)\right)\right)$$\end{document}where LN represents the noise-injected Last Hidden State Feature. During training, the classification head’s loss function is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\ell }_{c}=CrossEntropy\left({P}_{l},{Y}_{l}\right)$$\end{document}where Yl denotes the ground truth of classification outcomes. Consequently, the overall loss function of the entire system is formulated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell ={\lambda }_{1}{\ell }_{t}+{\lambda }_{2}{\ell }_{c}$$\end{document}where λ1 and λ2 are the weights of text loss and classification loss, and λ1 + λ2 = 1. The text loss ℓt corresponds to the original BLIP model’s built-in text loss, which is directly used in this study without modification.
Fine-tuning of pre-trained BLIP
The BLIP model used in this paper is a pre-trained model. To enable the pre-trained BLIP model to have a good performance on our task, we employ the LoRA (Low-Rank Adaptation)^24^ method to fine-tune large-scale pre-trained models, aiming to enhance their performance on the diagnosis and description of digestive endoscopy images, while reducing the number of parameters and training overhead. We apply LoRA to the ”query” and ”value” modules of the pre-trained BLIP model. These modules play a crucial role in the self-attention mechanism. By introducing low-rank matrices into these modules, we effectively enhance the model’s performance on specific tasks. Fine-tuning these target modules allows the model to retain pre-trained knowledge while quickly adapting to new tasks of diagnosis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Global, B. et al. Global, regional, and national cancer incidence, mortality, years of life lost, years lived with disability, and disability-adjusted life-years for 32 cancer groups, 1990 to 2015: a systematic analysis for the global burden of disease study. JAMA Oncol. (2017).10.1001/jamaoncol.2016.5688 PMC 610352727918777 · doi ↗ · pubmed ↗
- 2Li, J., Li, D., Xiong, C. & Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, 12888–12900 (PMLR, 2022).
- 3Yu, W. et al. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10819–10829 (2022).
- 4Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021).
- 5Dosovitskiy, A. et al. An image is worth 16x 16 words: Transformers for image recognition at scale. ar Xiv preprint ar Xiv:2010.11929 (2020).
- 6Zhang, S. et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. ar Xiv preprint ar Xiv:2303.00915 (2023).
- 7Li, X. Positive-incentive noise. IEEE Transactions on Neural Networks and Learning Systems (2022).10.1109/TNNLS.2022.322457737015646 · doi ↗ · pubmed ↗