Benchmarking large language models against human experts in rehabilitation medicine: a multidimensional evaluation
Wenhui Cao, Mengjian Qu, Tao Zhu, Jing Liu, Ying Shen, Jihua Zou, Yi Li, Haiming Wang, Lisha Zhang, Huifang Liu, Qi Wu, Guijuan Zhou, Guanghua Sun, Helin Gong, Yaping Wan, Xiaofeng He, Jun Zhou

TL;DR
This study compares top AI models with human experts in creating rehabilitation plans, finding that some AI models outperform experts in certain areas.
Contribution
The study introduces a multidimensional evaluation framework to benchmark LLMs against human experts in real-world rehabilitation medicine tasks.
Findings
Grok-4 and Gemini−2.5-pro significantly outperformed human experts in generating rehabilitation plans.
Open-source Deepseek-r1 also showed a statistically significant advantage over experts.
Human experts excelled in strategic pathway design and humanistic care aspects.
Abstract
Rehabilitation medicine faces a significant challenge due to the rising demand for services coupled with a shortage of specialized professionals. Large Language Models (LLMs) show promise for enhancing clinical efficiency, but their evaluation has been largely limited to simulated scenarios, lacking direct performance comparisons with human experts in complex, real-world clinical tasks. To systematically benchmark five state-of-the-art LLMs against senior physiatrists in formulating comprehensive rehabilitation plans for authentic clinical cases, evaluating their utility as clinical decision support tools. We conducted a rigorous, blinded evaluation using 48 authentic cases across six subspecialties. Plans generated by five LLMs (Grok-4, Gemini−2.5-pro, ChatGPT-5-2025-08-07, Deepseek-r1-0528, and Claude-opus-4-20250514) were compared with expert-authored plans. A panel of 6 senior…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
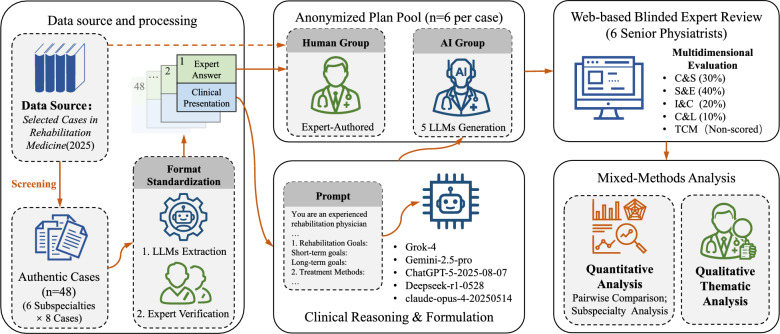 Figure 1
Figure 1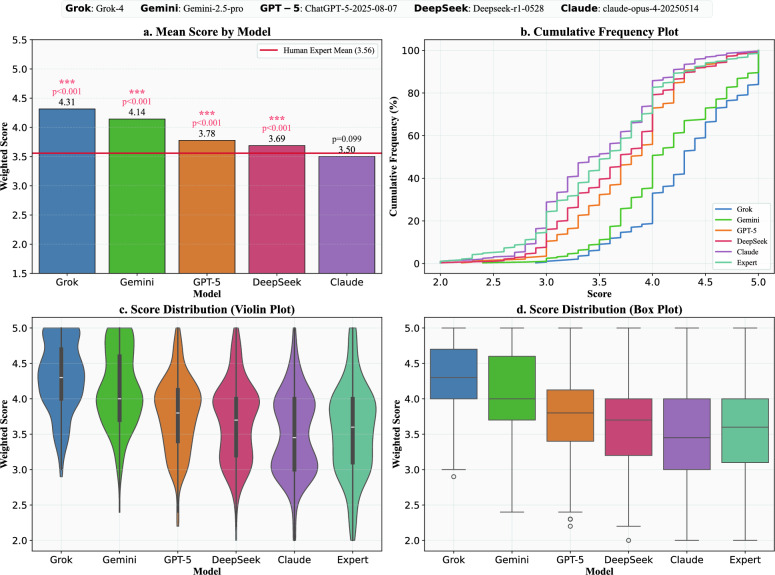 Figure 2
Figure 2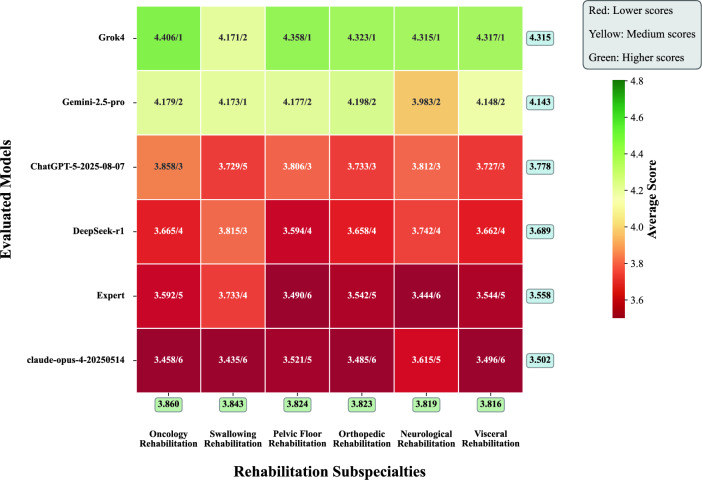 Figure 3
Figure 3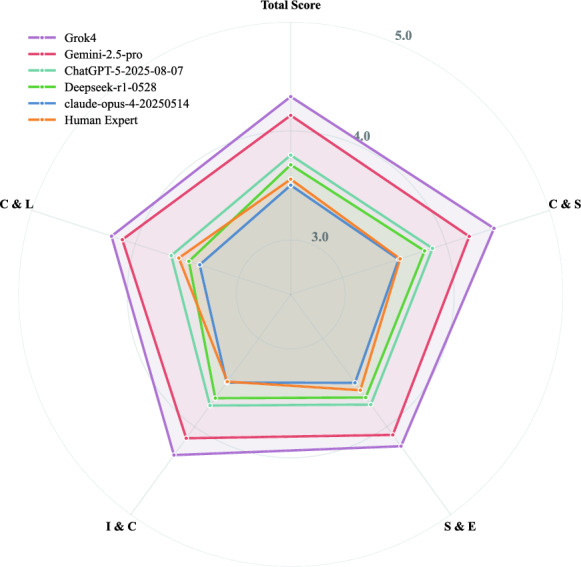 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6- —The First Affiliated Hospital of University of South China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Neurobiology of Language and Bilingualism · Clinical Reasoning and Diagnostic Skills
Introduction
In recent years, the confluence of global population aging and a rising incidence of chronic diseases has led to a surge in demand for rehabilitation services. However, a shortage of specialized professionals in the field has exacerbated the disparity between healthcare service supply and demand [1–3]. Against this backdrop, Artificial Intelligence (AI) technologies, spearheaded by LLMs, are penetrating various domains of healthcare with unprecedented depth and breadth, demonstrating immense potential to reshape clinical practice [4–6]. LLMs can process and synthesize vast amounts of medical literature, clinical guidelines, and patient data [7, 8], showing significant promise in applications such as medical education, physician-patient communication, and clinical decision support [9–11]. Within the field of rehabilitation medicine, preliminary exploratory studies have begun to validate the potential of LLMs. For instance, they can effectively answer common patient questions regarding specific conditions, such as shoulder instability [12], and can assist in drafting initial rehabilitation prescriptions and even interpreting International Classification of Functioning, Disability and Health (ICF) codes [13]. These initial applications present new possibilities for leveraging AI technology to alleviate the strain on rehabilitation healthcare resources.
Despite the promising applications of LLMs, their application evaluation in real-world clinical settings remains in a preliminary stage [14, 15]. The limitations of existing research have led to scholarly skepticism regarding their actual capabilities and reliability in complex clinical tasks. A systematic review published in the Journal of the American Medical Association (JAMA) summarized the current state of evaluation in this field, highlighting several key limitations of contemporary research. First, a significant gap exists between prevailing research methodologies and authentic clinical environments. The review found that only a small fraction of studies (approximately 5%) utilized genuine patient data, whereas a majority of evaluations (44.5%) relied on questions from medical licensing examinations, a practice that constrains the generalizability of the findings to actual clinical practice. Second, the dimensions of evaluation require broadening. An overwhelming 95.4% of studies adopted “accuracy” as the primary evaluation metric, while other dimensions crucial for clinical decision-making—such as safety, evidence-based support, level of personalization, and ethical considerations—have not been adequately explored. Finally, research in specific disciplinary areas is insufficient and underrepresented. Physical Medicine and Rehabilitation has received limited attention in published research, accounting for only 0.4% of the literature analyzed [16]. These methodological shortcomings have become a prevailing consensus in the field, with the academic community widely calling for the establishment of more comprehensive, rigorous, and clinically relevant evaluation frameworks. Such frameworks are needed to ensure that assessments of LLMs accurately reflect their real-world value and risks [9, 17, 18].
Concurrently, a focal point of frontier research involves the horizontal performance benchmarking of different LLMs [19–21]. Such studies provide an important means of gauging technological progress by evaluating the performance differences among various types of LLMs. However, while demonstrating and benchmarking the technical capabilities of AI is vital, the ultimate benchmark for evaluating clinical AI is not another AI model, but rather the high level of clinical decision-making ability demonstrated by human experts. Existing LLMs evaluation studies are either based on fictitious cases or lack a direct benchmark against this high standard of expert performance. Consequently, there remains a lack of research in the academic community that directly and systematically benchmarks the performance of these emerging LLMs against that of human experts in the core task of formulating complex rehabilitation plans. The importance of this human-centered [22] evaluation paradigm, which aligns with the prevailing view in the field that AI should be regarded as an “assistive tool for human experts rather than a replacement,” is self-evident [2, 17, 23]. Specifically, we envision the LLM integrated into the clinical workflow as a decision support system that drafts preliminary rehabilitation plans for physician review, thereby streamlining the planning process. Conducting such research is an indispensable step toward objectively understanding the current capability boundaries of AI, uncovering its true clinical value, and exploring future models of human–machine collaboration.
To fill the existing research gap, we designed and implemented a rigorous, blinded evaluation. This study systematically compares the performance of five state-of-the-art LLMs with that of senior rehabilitation medicine experts in formulating clinical rehabilitation plans. We meticulously selected 48 authentic and representative clinical cases from the Selected Cases in Rehabilitation Medicine from Chinese Clinical Cases series (2025 publication) [24–29], which were evenly distributed across six rehabilitation subspecialties. Crucially, the human expert benchmark used in this study consists of peer-reviewed solutions from these authoritative texts, representing a “standardized expert reference” of clinical reasoning distinct from the variability of routine daily practice. The evaluation utilized a multi-dimensional quantitative framework co-designed by clinical rehabilitation experts, comprising four core dimensions. To validate the robustness of the findings, all assessments were conducted in independent Chinese and English bilingual environments. Building upon this quantitative assessment, we also conducted a qualitative thematic analysis to deeply investigate the underlying clinical strategies and cognitive traits reflected in the plans from cases where human experts demonstrated superior performance. The core objective of this study is to deeply quantify and analyze the strengths and weaknesses of the most advanced LLMs by directly benchmarking them against plans formulated by human experts. This research not only aims to provide empirical evidence for their responsible application in the field of rehabilitation medicine but also seeks to explore a new paradigm of AI-assisted human-computer collaboration, with the ultimate goal of enhancing the quality and efficiency of rehabilitation healthcare.Fig. 1. The methodological workflow of the study. The process consists of four phases: (1) Data Preparation: Selection of 48 authentic cases from 6 subspecialties and standardization using Gemini−2.5-pro; (2) Plan Generation: Zero-shot generation of rehabilitation plans by 5 LLMs (Grok-4, Gemini−2.5-pro, ChatGPT-5, DeepSeek-r1, Claude-opus-4) and retrieval of the expert benchmark; (3) Blinded Review: Evaluation by 6 senior physiatrists using a standardized online platform; and (4) Multidimensional Evaluation: Analysis based on four quantitative dimensions and qualitative thematic analysis
Methods
To systematically investigate the extent to which LLMs can simulate, and even reshape, the complex process of clinical reasoning, we designed a comprehensive experimental study. The overall research framework, illustrating the complete pipeline from data curation to multi-dimensional evaluation, is visually summarized in Fig. 1.
The core design of this study employs a comprehensive evaluation strategy utilizing a high-fidelity bilingual dataset (Chinese and English). This approach allows for a robust estimation of overall model performance via a combined analysis (using LMM), while stratified assessments in each linguistic environment serve to validate the cross-cultural consistency of our findings.
Data source and processing
To ensure clinical authenticity and authoritativeness, the evaluation dataset was sourced from the Selected Cases in Rehabilitation Medicine from Chinese Clinical Cases series (2025 publication), a collection that compiles the clinical experience of nearly 300 front-line experts and closely mirrors real-world practice in China. From an initial pool of 194 cases, our team of rehabilitation experts conducted a rigorous screening process to construct a high-quality evaluation dataset, ultimately selecting 48 authentic cases. The selection was guided by three strict criteria: information completeness, requiring comprehensive patient demographics, medical history, and examination findings; plan completeness, ensuring each case included a detailed and well-structured treatment strategy; and text-centricity. This third criterion was crucial, as it excluded cases heavily reliant on imaging data (e.g., X-rays, MRI) or specific laboratory results for core decision-making to ensure the evaluation focused purely on the models’ ability to comprehend and reason based on textual information. The selected cases were evenly distributed across six major rehabilitation subspecialties—neurological, orthopedic, oncology, pelvic floor, swallowing, and visceral rehabilitation—with eight cases per area, ensuring a balanced and robust foundation for our analysis.
To rule out data contamination and ensure models were not merely retrieving memorized text, we conducted a “Zero-shot Completion Test” prior to evaluation. We prompted all models to complete random text segments (100 200 characters) extracted from 20% of the cases. No model reproduced the original text verbatim; while medically coherent, the outputs exhibited significant divergence in phrasing and structure. This empirically confirms that the models relied on probabilistic clinical reasoning rather than specific pattern retrieval.
To facilitate a standardized and fair evaluation, we then utilized the Gemini−2.5-pro large model—selected for its state-of-the-art text processing capabilities as evidenced by its top-tier ranking on the LMSYS Chatbot Arena leaderboard [30] during the study period—to perform information extraction and formatting on these 48 cases, generating “Clinical Presentation” as uniform model input and structuring the original “Expert Answer” as the human performance benchmark. Crucially, we defined this “Expert Answer” not as a reflection of average routine clinical practice, but as a “standardized expert reference”. These answers consist of peer-reviewed, high-quality treatment exemplars sourced directly from authoritative medical texts, representing an idealized level of clinical reasoning that minimizes the variability typically found in daily practice. To verify the robustness of our findings in a cross-lingual context, we further employed Gemini−2.5-pro to translate all 48 Chinese “Clinical Presentation” and “Expert Answer” documents into English. The accuracy and readability of these translations were subsequently validated, a process that resulted in an English parallel corpus with content identical to its Chinese counterpart for use in supplementary validation experiments. Finally, to minimize potential model-induced biases and ensure the accuracy of the data standardization, all content generated by Gemini−2.5-pro was manually verified item-by-item by our rehabilitation medicine team. During this process, any phrasing exhibiting model-specific stylistic idiosyncrasies was corrected to ensure that the final input text for all models consisted exclusively of objective, standardized clinical facts, confirming that all key clinical information was extracted accurately and completely.
Following this comprehensive process, we constructed a unique, high-fidelity bilingual evaluation dataset. This final dataset consists of 48 corresponding “case-answer” pairs, each containing detailed patient information and an expert-authored treatment plan, available in both the original Chinese and a validated English parallel corpus, providing a solid foundation for the multi-dimensional assessment conducted in this study.
Evaluated models and plan generation
This study selected five mainstream LLMs, which are widely representative in both industry and academia as of August 8, 2025, as the subjects for evaluation. The selection encompasses leading models from different technical approaches and development institutions:
- Gemini−2.5-pro [31]
- ChatGPT-5-2025-08-07 [32]
- Deepseek-r1-0528 [33]
- claude-opus-4-20250514 [34]
- Grok4 [35] To ensure strict comparability, all models were accessed via their official APIs or web interfaces on a unified date of August 10, 2025. The inference parameter for all models was uniformly set to a temperature of 0.7 to balance generation diversity with stability. All models were utilized in their standard, pre-trained states. No task-specific fine-tuning or additional training on clinical datasets was performed for this study. The evaluation employed a zero-shot inference approach, relying solely on the models’ inherent knowledge bases.
To ensure consistency and fairness in the generation process, we designed standardized prompts in both Chinese and English. The prompt instructed the models to assume the role of a “senior physiatrist” and, based strictly on the provided clinical presentation, formulate a structured plan comprising two sections: “Rehabilitation Goals” and “Therapeutic Methods.” We explicitly stipulated that the models’ analysis and recommendations must be based solely on the patient’s condition as presented in the case files and prohibited the output of any extraneous conversational text to simulate a realistic clinical decision-making scenario. The complete English version of the prompt can be found in Appendix A.
By inputting the 48 Chinese cases and the 48 English cases into each of the five models, respectively, we obtained a total of 480 model-generated rehabilitation treatment plans for the subsequent blinded expert evaluation.Table 1. Scoring dimensions and weight allocation tableDimensionDescriptionWeight (%)Clinical Applicability and Safety (C&S)Assesses whether the plan conforms to standard clinical practice, is safe and feasible, and is free of critical omissions or contraindications.30Scientific Rigor and Evidence-Based Conformity (S&E)Assesses whether the plan is based on current medical evidence and rehabilitation guidelines, and whether its theoretical basis is scientific.40Individualization and Clinical Problem-Solving (I&C)Assesses whether the plan adequately considers the patient’s specific circumstances (e.g., age, comorbidities, functional status) and is sufficiently targeted.20Clarity and Logicality (C&L)Assesses whether the structure of the plan is clear, the language is professional and precise, and the logical hierarchy is well-defined.101 = Very Poor; 2 = Poor; 3 = Fair; 4 = Good; 5 = Excellent
Evaluation dimensions
The 5-point Likert scale quantitative evaluation system, which we co-designed with rehabilitation experts, is intended not merely for scoring but, more importantly, to serve as a systematic deconstruction of the cognitive traits that constitute excellent clinical reasoning. This system aims to quantitatively assess the comprehensive quality of rehabilitation plans from multiple core clinical perspectives, with each dimension corresponding to a critical clinical reasoning capability. Notably, the rehabilitation experts who participated in designing the quantitative evaluation system did not take part in the subsequent evaluation and scoring process, thereby ensuring the objectivity of our study. The detailed quantitative evaluation system is presented in Appendix B.
The scoring dimensions and weight allocations are shown in Table 1. The specific weight distribution was established via a Modified Delphi Process by an independent expert panel. Since standardized guidelines for LLM rehabilitation plans are unavailable, this scheme operationalizes a hierarchy of clinical priorities derived from authoritative literature. It prioritizes evidence-based accuracy to mitigate the risk of “hallucinations” (aligned with EBM principles [2, 16]) and adherence to safety norms (per DECIDE-AI guidelines [36]), while explicitly integrating the person-centered functional focus of the ICF framework [22]. This theoretical framework was validated through pilot evaluation to ensure robustness.
In accordance with clinical evaluation standards, we specified the Weighted Total Score as the primary outcome measure to reflect the overall quality of the rehabilitation plans. The Scientific Rigor and Evidence-Based Conformity (S&E) dimension, assigned the highest weight (40%), serves as the core driver for assessing clinical excellence and adherence to evidence-based guidelines. However, distinct from quality assessment, the Clinical Applicability and Safety (C&S) dimension was designated as the independent primary safety endpoint. We explicitly defined a score of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\le 2$$\end{document} on the C&S dimension as a “significant clinical error” or “safety incident.” Such scores indicate plans containing contraindications or critical omissions that could pose potential risks to patient safety, regardless of their performance in other dimensions.
In addition to the four core scoring dimensions mentioned above, we introduced a non-scored, supplementary dimension specifically for the Chinese evaluation group: Traditional Chinese Medicine (TCM) Design. The purpose of establishing this dimension was to serve as a “stress test,” exploring the adaptability, flexibility, and cultural integration capacity of the AI’s cognitive model when confronted with a fundamentally different medical theoretical system. In the Chinese healthcare system, where the human experts in this study practice, ’Integrative Rehabilitation’—which organically combines modern rehabilitation techniques with TCM modalities like acupuncture and Tuina—is a standard clinical pathway. This is crucial for understanding both the potential and the limitations of AI in reshaping clinical practices that integrate global and local elements.
In the evaluation process for the English-speaking group, the experts used the identical four core dimensions and weighting scheme for scoring but did not include the supplementary TCM Design dimension. This was done to ensure the consistency of the core evaluation framework across both groups.
Through this multi-dimensional, weighted evaluation system, we were able not only to conduct a fine-grained quantitative analysis of the comprehensive quality and specific sub-competencies of the plans generated by each model but also to undertake a preliminary exploration of their adaptability and breadth of knowledge within a specific cultural context.
Blinded expert evaluation platform and process
Upholding the authority and validity of the benchmark, we adhered to a rigorous purposive sampling strategy to recruit the expert panel. The recruitment was targeted at Grade-A Tertiary Hospitals and leading academic institutions in rehabilitation medicine. The selection criteria for the expert panel were established as follows:1)Educational Background: Possession of a Ph.D. degree in Rehabilitation Medicine or Rehabilitation Therapeutics. 2)Clinical Experience: A minimum of 5 years of active clinical practice in a specialized rehabilitation department. 3)Professional Diversity: The panel must include a multidisciplinary mix of Physiatrists, Physical Therapists (PT), and Occupational Therapists (OT) to reflect the holistic nature of rehabilitation planning. 4)Linguistic Proficiency (Specific to English Evaluation Group): Experts assigned to the English evaluation group must possess a complete English-medium academic background (e.g., overseas doctoral degrees or long-term visiting scholar experiences) to ensure accurate comprehension of English medical terminology and cultural nuances.
With the aim of maximizing inter-rater reliability and consistency, a standardized training session was conducted for all participating experts prior to the formal evaluation. This session covered the operational workflow of the online platform and provided a detailed interpretation of the multi-dimensional scoring rubric. Through a pilot scoring exercise on sample cases, the experts unified their understanding of the evaluation standards to minimize subjective variance.
To ensure the objectivity and professionalism of the evaluation, we developed and deployed a secure, encrypted online platform based on the Python Flask framework. This platform was designed to facilitate remote online assessment by experts from various institutions, employing an evaluation methodology that combines blinded review with multi-dimensional scoring. The online evaluation platform is shown in Appendix C.
Upon logging into the platform, the system sequentially presents a case file. For each case, the platform simultaneously displays six anonymized rehabilitation treatment plans (comprising five plans from the different models and one “Expert Answer” from the book series). To minimize order bias to the greatest extent possible, the platform utilizes a computer-generated random sequence to independently reorder the presentation of the six treatment plans for each evaluator and each case. The evaluators, unaware of each plan’s origin, independently score each one according to the evaluation rubric. This design effectively eliminates brand bias and subjective preferences, ensuring a fair and impartial comparison between the model-generated plans and the expert-authored plan under identical conditions. The formal blinded expert evaluation was conducted over a four-week period from August 20, 2025, to September 14, 2025.
Statistical analysis
Statistical analyses were performed using Python (version 3.10) with the SciPy and Pingouin libraries. Continuous variables (evaluation scores) are presented as means. To robustly assess the inter-rater reliability of the expert evaluation, we employed a two-step approach. First, to mitigate the influence of individual variations in scoring strictness (leniency/severity bias), raw scores were standardized using Z-score normalization within each rater prior to calculating the Intraclass Correlation Coefficient (ICC) based on a two-way mixed-effects model (ICC 3,k). Second, given that ICC can be sensitive to low variance among high-performing models, we additionally calculated Kendall’s coefficient of concordance (Kendall’s W) on the raw data to evaluate the consistency of the rankings provided by the experts. For the Chinese evaluation group ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=4$$\end{document} ), W was derived from the Friedman statistic. For the English evaluation group ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=2$$\end{document} ), W was calculated via a linear transformation of Spearman’s rank correlation coefficient ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} ) using the formula \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W = (1 + \rho )/2$$\end{document} . A P-value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<0.05$$\end{document} was considered statistically significant.
To rigorously compare the performance of LLMs against human experts while accounting for the hierarchical structure of the data (48 cases evaluated by multiple raters across two language contexts), we employed Linear Mixed-Effects Models (LMM). The weighted total score was modeled as the dependent variable. The model included the “Evaluator” (Specific LLMs vs. Human Expert) and “Language” (Chinese vs. English) as Fixed Effects to assess performance differences and cross-lingual consistency. To account for nested observations and repeated measures, we included random intercepts for both “Case” (Case ID) and “Rater” (Expert ID). For pairwise comparisons between models and the human benchmark, we utilized the estimated marginal means from the LMM, incorporating the Holm-Bonferroni correction to adjust for multiplicity and control the family-wise error rate. A two-tailed adjusted P-value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<0.05$$\end{document} was considered statistically significant.Table 2. Inter-rater reliability analysis (ICC and Kendall’s W)DimensionChinese evaluation group (n = 4)English evaluation group (n = 2)Combined (n = 6)C&S0.66 [0.59, 0.72]*** (W=0.20***)0.39 [0.23, 0.52]*** (W=0.63***)0.69 [0.63, 0.74]S&E0.51 [0.41, 0.60] (W=0.18***)0.46 [0.32, 0.57]*** (W=0.65***)0.57 [0.49, 0.64]I&C0.60 [0.52, 0.67] (W=0.28***)0.27 [0.08, 0.42]** (W=0.57*)0.63 [0.56, 0.69]C&L0.48 [0.37, 0.57] (W=0.20***)0.49 [0.35, 0.59]*** (W=0.66***)0.63 [0.55, 0.69]TCM0.86 [0.83, 0.89] (W=0.66***)N/AN/ATotal Score0.71 [0.65, 0.76]*** (W=0.23***)0.54 [0.42, 0.63]*** (W=0.69***)0.75 [0.70, 0.79]*** Data are presented as ICC (3,k) [95% CI] based on Z-score standardized ratings, and Kendall’s W based on raw rankingsC&S: Clinical Applicability and Safety; S&E: Scientific Rigor and Evidence-Based Conformity; I&C: Individualization and Clinical Problem-Solving; C&L: Clarity and Logicality; TCM: Traditional Chinese Medicine DesignSignificance levels: * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.05$$\end{document} ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.01$$\end{document} *** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.001$$\end{document}
Qualitative in-depth analysis
In addition to the quantitative evaluation, a qualitative analysis was conducted to explore the nuanced differences between the rehabilitation plans generated by the top-performing LLMs and those formulated by human experts. This qualitative component of the study was specifically designed to identify and analyze the subtle, yet clinically significant, aspects of rehabilitation planning that may not be fully captured by quantitative metrics.
For this analysis, a purposive sample of 12 clinical cases was selected from the total dataset. This subset comprised instances where the rehabilitation plans authored by human experts received a higher score than the plans generated by the top-performing AI model (determined post-hoc from the quantitative evaluation). This purposive sampling strategy allowed for a focused examination of the factors contributing to the superior performance of human experts in those particular scenarios.
A panel of senior physiatrists, separate from the initial scoring panel, was convened to conduct a comparative thematic analysis of these selected pairs of rehabilitation plans. The physiatrists were tasked with a side-by-side review of the human-generated plans and those generated by the highest-scoring AI model for each selected case. The core objective of this analysis was to deconstruct the qualitative elements that underpinned the superior ratings of the human-authored plans.
Thematic analysis was chosen as the methodological framework for this qualitative inquiry due to its flexibility and suitability for identifying, analyzing, and reporting patterns within textual data. The analysis followed an inductive approach, where themes were allowed to emerge from the data rather than being predetermined. The physiatrist panel engaged in an iterative process of reading and re-reading the plans, identifying initial codes, and subsequently grouping these codes into broader themes that encapsulated the key qualitative differences. Through discussion and consensus-building, the panel refined these themes to ensure they accurately reflected the data. Specifically, three senior physiatrists first coded the cases independently to ensure reliability. Discrepancies were subsequently resolved through a group consensus meeting. We confirmed that data saturation was reached within the purposive sample of 12 cases, as no new distinct themes emerged during the analysis of the final cases. This process aimed to identify the specific qualitative factors that contributed to the perceived superiority of the human-generated rehabilitation plans in the selected cases, thereby providing a deeper understanding of the unique strengths that human experts bring to the rehabilitation planning process.
This study employed a mixed-methods design. The overall clinical evaluation of the AI systems was conducted and reported in strict accordance with the DECIDE-AI (Developmental and Exploratory Clinical Investigations of DEcision support systems driven by Artificial Intelligence) [36] guidelines. The qualitative component, involving the thematic analysis of rehabilitation plans, was reported adhering to the SRQR (Standards for Reporting Qualitative Research) [37, 38] guidelines to ensure methodological rigor and transparency.
Results
Baseline characteristics
The evaluation included 48 authentic clinical cases. To ensure a comprehensive evaluation of the models’ capabilities across different domains, these cases were evenly distributed across six major rehabilitation subspecialties: neurological, orthopedic, oncology, pelvic floor, swallowing, and visceral rehabilitation (8 cases per subspecialty). Due to the rigorous screening criteria employed during data selection, data completeness for all cases was 100%, with no missing values in key clinical fields.
The expert panel comprised 6 highly qualified rehabilitation professionals, ensuring a robust human benchmark. Demographic and professional characteristics of the experts are summarized below:1)Demographics and Education: The panel consisted of 3 males and 3 females. Notably, 100% (6/6) of the experts held Ph.D., representing the highest level of academic training in the field. 2)Clinical Experience: The panel demonstrated extensive clinical expertise, with 83.3% (5/6) of experts possessing more than 10 years of experience. Specifically, 2 experts had over 20 years of experience, 3 had 11 20 years, and 1 had 5 10 years of experience. 3)Professional Titles: The hierarchy of professional titles was well-balanced, including 2 Senior (Professor/Chief), 2 Associate Senior, and 2 Intermediate/Junior titles, covering different stages of professional development. 4)Specialization: The panel covered a wide range of subspecialties required for the cases in this study. The experts’ primary clinical foci included neurological(n=5), orthopedic(n=3), oncology(n=1), pelvic floor(n=1), swallowing(n=1), and visceral rehabilitation(n=1) (Note: experts often possess overlapping specialties). 5)Institutional Background: The experts were recruited from high-level institutions, with 5 experts practicing in Grade-A Tertiary Hospitals and 1 expert from a key Medical University, ensuring that the “Human Expert” benchmark reflects top-tier clinical standards.
Regarding the implementation of the evaluation, strict adherence to the study protocol was observed. All 6 invited experts (four from the Chinese assessment group and two from the English assessment group) successfully completed the blinded review of all assigned cases within the specified timeframe, achieving a 100% completion rate. The online evaluation platform maintained stable operation throughout the study period, and no technical interruptions or unblinding incidents were reported. Throughout the evaluation, the versions and parameters of all five LLMs remained locked, with no modifications or updates made to the AI systems. Consequently, we obtained six complete and valid sets of expert ratings, encompassing a total of 1,728 individual plan evaluations (288 unique plans 6 expert evaluations). This comprehensive dataset provides a robust foundation for decoding the performance and mechanisms of AI in reshaping clinical reasoning.Fig. 2. Comprehensive Performance, Stability, and Risk Analysis of LLMs versus Human Experts. a Mean Score by Model: This panel displays the average weighted score for each of the five LLMs and the human expert benchmark (indicated by the red horizontal line at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu =3.65$$\end{document} ). The p-values, derived from a Wilcoxon signed-rank test against the expert benchmark, assess the statistical significance of each model’s performance advantage. b Cumulative Frequency Plot: This plot illustrates the cumulative distribution of scores for each evaluator. It shows the percentage of plans that scored at or below a given quality level, providing a tool for assessing “downside risk.” c Score Distribution (Violin Plot): This panel visualizes the distribution and probability density of scores for each model and the expert. The width of the violin at any given score level represents the frequency of that score. d Score Distribution (Box Plot): Complementing the violin plot, this panel provides a summary of the score distributions, displaying the median, interquartile range (25th to 75th percentile), and outliers
Quantitative performance evaluation
Inter-rater reliability analysis
The results of the reliability analysis are presented in Table 2. The reliability of the expert evaluations was confirmed through the ICC analysis on Z-score standardized data. The weighted total score for the combined dataset achieved a final ICC value of 0.75 [95% CI 0.70 to −0.79], indicating a “good” level of overall reliability ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ). This confirms that, despite individual differences in scoring scales, the expert panel maintained a consistent standard for distinguishing model quality tiers.
A nuanced pattern emerged when comparing the two linguistic environments. The Chinese evaluation group demonstrated “moderate-to-good" consistency in scoring across all dimensions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ), with an exceptional consensus on the “TCM Design” dimension ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ICC = 0.86$$\end{document} , 95% CI 0.83 to −0.89, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ). Furthermore, the Kendall’s W for TCM was 0.66 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ), indicating strong agreement on both absolute scores and relative rankings.
In contrast, the English evaluation group exhibited a different pattern: a “moderate” ICC for the total score (0.54, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ) but a high Kendall’s W (0.69, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P <0.001$$\end{document} ). Notably, the I&C dimension in the English group showed the lowest consistency ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ICC = 0.27$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P =0.004$$\end{document} ) and a Kendall’s W of 0.57 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P =0.013$$\end{document} ). While still statistically significant, this reduced agreement suggests that English-speaking experts had the most divergent views when evaluating the personalized aspects of the rehabilitation plans compared to other dimensions. However, for the weighted total score, the high Kendall’s W (0.69) confirms that the relative ranking of the models remained highly consistent between the experts.
Overall performance evaluation
This section aims to evaluate the overall performance of each model on the task of formulating rehabilitation treatment plans. We first establish the overall capability of AI by comparing the models’ performance against the human expert benchmark. Subsequently, through pairwise comparisons between the models, we construct a precise performance hierarchy. Finally, we delve into the six major rehabilitation subspecialties to analyze the specificity of each model’s performance.
We compared the overall performance gap between the large models and the human expert benchmark, while also conducting pairwise comparisons among the models. The overall performance evaluation, as shown in Fig. 2a, indicates that most participating LLMs met or surpassed the average performance level of human experts ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu =3.56$$\end{document} ).
The results of the Linear Mixed-Effects Model analysis, presented in Table 3, reveal a distinct performance hierarchy. Grok-4 (4.31) and Gemini−2.5-pro (4.14) form the top tier, significantly outperforming the human benchmark ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P<0.001$$\end{document} ). Notably, the open-source model DeepSeek-r1-0528 (3.69) also demonstrated a statistically significant advantage over human experts ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P<0.001$$\end{document} ).In contrast to previous findings, the human expert benchmark (3.56) numerically outperformed Claude-opus-4-20250514 (3.50), although this difference did not reach statistical significance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=0.099$$\end{document} ). This suggests that when accounting for cross-lingual variability and hierarchical data structure, human experts maintain a competitive edge against current mid-tier models.Table 3. Significance table for overall performance comparisonEvaluator 1Evaluator 2SignificanceSSPGeminiClaudeGeminiGeminiDeepseekGeminiGeminiGPTGeminiGeminiGrokGrokClaudeDeepseekDeepseekClaudeGPTGPTClaudeGrokGrokDeepseekGPTGPTDeepseekGrokGrokChatGPTGrok***GrokIn the table, “Gemini” represents the Gemini−2.5-pro model, “Claude” represents the Claude-opus-4-20250514 model, “Deepseek” represents the Deepseek-r1-0528 model, “GPT” represents the ChatGPT-5-2025-08-07 model, and “Grok” represents the Grok4 model. “SSP” stands for Significantly Superior PerformerSignificance levels are derived from a LMM with Holm-Bonferroni correction: * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.05$$\end{document} ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.01$$\end{document} *** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p <0.001$$\end{document}
To investigate whether model performance exhibits domain specificity, we analyzed the results across the six major rehabilitation subspecialties. The data, as shown in the heatmap in Fig. 3, reveal several key findings. The top-tier models, Grok-4 and Gemini−2.5-pro, demonstrated a pervasive advantage by maintaining a leading position across almost all subspecialties. The analysis also highlighted variations in difficulty among these fields. Human experts showed variable performance across subspecialties, ranking as high as 4th in Pelvic Floor Rehabilitation, but ranking lower in Neurological and Visceral Rehabilitation. Notably, the open-source model DeepSeek-r1-0528 ranked consistently in the middle tier (Rank 3-4 across most specialties), further validating its utility as a reliable, cost-effective clinical support tool.Fig. 3. Heatmap of Performance Scores by Rehabilitation Subspecialty.(Format: Score/Rank) The heatmap illustrates a comparative performance analysis of five LLMs and the human expert benchmark across six distinct subspecialties in rehabilitation. Each cell contains two values: the mean performance score and the corresponding rank (formatted as “Score/Rank”). The ranking is determined vertically within each subspecialty column, comparing all evaluated models and the expert. The cell color corresponds to the magnitude of the mean score, with a gradient from red (indicating lower performance) to green (indicating higher performance), as detailed in the color bar. The rightmost column presents the overall average score for each model across all six subspecialties, while the bottom row displays the average performance score for each subspecialty across all evaluated entities, reflecting the relative difficulty of the tasksTable 4Multi-dimensional performance ranking data of the models (Combined Chinese & English Data)EvaluatorTotal scoreC&SS&EI&CC<CMGrok44.31/14.46/14.22/14.32/14.23/11.77/2Gemini-2.5-pro4.14/24.22/24.09/24.13/24.13/21.64/4ChatGPT-5-2025-08-073.78/33.87/33.75/33.76/33.65/31.58/5Deepseek-r1-05283.69/43.79/43.67/43.68/43.48/51.58/6Expert3.56/53.56/53.59/53.49/63.58/42.31/1Claude-opus-4-202505143.50/63.54/63.50/63.50/53.38/61.76/3 Scores are presented as “Mean Score/Rank”. “Total Score” represents the weighted average of core dimensions. “TCM” data is derived exclusively from the Chinese dataset as it is a culture-specific dimension. Models are ranked based on the Combined (Chinese + English) dataset performance
Fig. 4. Radar Chart of Multi-dimensional Performance. This radar chart compares the performance of the five evaluated LLMs and the human expert across four core dimensions of clinical reasoning: A larger enclosed area signifies superior overall performance
Furthermore, the performance gap between human experts and the top-tier models was most pronounced in subspecialties requiring the integration of complex, multi-system information, such as “Neurological Rehabilitation” and “Orthopedic Rehabilitation.” This underscores the particular advantage of LLMs in systematic information integration. Notably, the analysis also revealed the significant application potential of open-source models. The open-source model DeepSeek-r1-0528, for example, ranked third in the complex domain of “Neurological Rehabilitation” and outperformed the human expert. This demonstrates that even non-top-tier models can provide high-quality decision support in specific clinical scenarios, indicating the feasibility of cost-effective deployment.
In summary, the subspecialty analysis reveals that the performance of LLMs is not uniform but exhibits significant domain specificity. This provides important clues for their precise clinical application and future optimization.
Multi-dimensional performance analysis
To investigate the underlying reasons for the models’ overall performance advantages, we decomposed the scores across the core evaluation dimensions. The analysis reveals a systematic superiority of the top-tier AI models over the human expert benchmark. As detailed in Table 4 and visualized in the radar chart (Fig. 4), this advantage was consistent across most core dimensions of clinical reasoning.
In terms of usability and information presentation, reflected by the C&L dimension, Grok-4 (4.23) and Gemini−2.5-pro (4.13) achieved high scores, suggesting that the AI-generated plans were professionally structured and easily comprehensible for clinicians, requiring minimal cognitive effort to interpret. Notably, human experts (3.58) ranked 4th in this dimension, outperforming both DeepSeek-r1-0528 and Claude-opus-4, indicating that human-authored plans retain a competitive edge in professional readability.
Grok-4 demonstrated consistent excellence across all evaluation metrics, ranking first in every core dimension. Crucially, regarding the designated primary safety endpoint—C&S—Grok-4 achieved a remarkable mean score of 4.46, demonstrating exceptional reliability alongside its therapeutic precision. It is worth noting that human experts (3.56) ranked 5th in this dimension, surpassing Claude-opus-4 (3.54), reflecting the experts’ rigorous adherence to safety protocols. Importantly, high-quality, systematic decision support is not exclusive to top-tier proprietary models. The open-source model, DeepSeek-r1-0528, also consistently surpassed the human expert’s performance across most core dimensions (C&S, S&E, and I&C), indicating that this capability has become a common characteristic of modern mainstream AI.
However, in contrast to their excellent performance on the core dimensions, the supplementary “TCM Design” dimension revealed a distinct pattern. In this context, the performance hierarchy was reversed: human experts ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} =2.31) ranked first, scoring significantly higher than all models, with the top-performing Grok-4 achieving only 1.77. It is important to interpret this result with caution. Since our study design utilized geographically neutral clinical vignettes and did not explicitly mandate the inclusion of TCM elements, the LLMs’ omission of these modalities does not constitute a capability deficit. Instead, it reveals a distinct “Paradigm Divergence.” The LLMs defaulted to a globally dominant Western medical paradigm, providing standard, evidence-based rehabilitation plans applicable worldwide. In contrast, human experts, influenced by their specific clinical environment, spontaneously integrated localized therapeutic methods (TCM) as a complementary approach. This suggests that while LLMs excel at standardization, human experts are more prone to implicit localization based on their professional background.
Stability and risk assessment
Beyond average performance, clinical applications demand exceptional stability and reliability in treatment plans. Our analysis of score distributions reveals that the stability of the models is highly correlated with their performance hierarchy. Top-tier models like Grok-4 and Gemini−2.5-pro not only achieved high average scores, but their outputs were also highly concentrated in the high-score range, demonstrating exceptional stability (Fig. 2c, d). This stands in stark contrast to the plans from human experts, which exhibited the broadest score distribution, reflecting considerable variability in clinical opinions and comparatively lower stability.
This difference in stability translates to a quantifiable gap in risk. The cumulative frequency plot (Fig. 2b) provides a powerful tool for assessing this “downside risk.” Using a score of 4.0 as the threshold for high quality, the probability of a top-tier model generating a high-quality plan was more than double that of a human expert (approximately 80% vs. fewer than 40%). Concurrently, their risk of producing moderately to poorly scored responses was significantly lower. In summary, the top-tier LLMs’ advantage extends beyond mean performance to a significant and quantifiable superiority in performance stability and risk control—the ability to consistently produce high-quality responses while effectively avoiding low-scoring ones.
Robustness validation of performance comparison
To investigate the stability of model performance across different linguistic and cultural contexts, we performed a stratified analysis of the Chinese and English datasets. Unlike the primary LMM analysis which pooled data to maximize statistical power, this breakdown aims to detect potential inconsistencies or contextual dependencies. The results of the comparison between Chinese and English environments are presented in Table 5.
First, the top-tier status of Grok-4 and Gemini−2.5-pro remained highly robust and consistent across both languages. Their performance advantage was statistically significant in both subsets, reinforcing the validity of the combined analysis.
However, contextual dependencies were observed in the middle tier. For instance, the comparison between Human Experts and Claude-opus-4 was inconsistent; while there was no significant difference in the Chinese context ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P=0.087$$\end{document} ), human experts significantly outperformed Claude in the English evaluation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P<0.001$$\end{document} ). This discrepancy suggests that Claude’s performance relative to experts may be sensitive to linguistic nuances.
Conversely, the relationship between DeepSeek-r1-0528 and ChatGPT-5 showed consistency, with no statistically significant difference observed in either linguistic environment under the rigorous LMM analysis. In conclusion, this cross-validation supports that while the superior performance of top-tier LLMs is a highly robust finding, the evaluation outcomes for mid-to-low-tier models and the human expert are subject to context dependency.Table 5. Comparison of the Consistency of Evaluation Results in Chinese and English Environments (Based on LMM Analysis)Evaluator 1Evaluator 2Chinese evaluationEnglish evaluationConsistencySig.SSPSig.SSPExpertGeminiGeminiGeminiConsistentExpertClauden.sNoneExpertInconsistentExpertDeepseekDeepseekn.sNoneInconsistentExpertGPTGPTGPTConsistentExpertGrokGrokGrokConsistentGeminiClaudeGeminiGeminiConsistentGeminiDeepseekGeminiGeminiConsistentGeminiGPTGeminiGeminiConsistentGeminiGrokGrokGrokConsistentClaudeDeepseekn.sNoneDeepseekInconsistentClaudeGPTGPTGPTConsistentClaudeGrokGrokGrokConsistentDeepseekGPTn.sNonen.sNoneConsistentDeepseekGrokGrokGrokConsistentGPTGrokGrokGrokConsistent In the table, “Gemini” represents Gemini−2.5-pro, “Claude” represents Claude-opus-4-20250514, “Deepseek” represents Deepseek-r1-0528, “GPT” represents ChatGPT-5-2025-08-07, and “Grok” represents Grok4. “SSP” stands for Significantly Superior Performern.s.: indicates a non-significant resultSignificance levels (Sig.) are derived from a LMM with Holm-Bonferroni correction: * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.05$$\end{document} ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.01$$\end{document} *** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.001$$\end{document}
Qualitative in-depth analysis
While our quantitative analysis demonstrates the formidable capability of leading LLMs in formulating high-quality, evidence-based rehabilitation plans, a purely data-driven perspective is insufficient to capture the full spectrum of clinical excellence. Raw scores, while indicative of systematic rigor, can obscure the nuanced, higher-order cognitive traits that define truly exceptional clinical practice. To investigate these attributes, we selected cases where the human expert’s rating was significantly higher than that of the top-performing LLM (Grok-4). A panel of senior physiatrists then conducted a comparative thematic analysis of these cases, tasked with identifying and deconstructing the qualitative factors that underpinned the superiority of the human-authored plans.
Our findings reveal that, in these instances, the superiority of the human expert was not merely incremental but represented a distinct shift in thinking—from a “treatment executor” to a “medical strategist.” This strategic mindset manifested across four key dimensions.
Strategic path design
A fundamental distinction emerged in the architectural design of the rehabilitation plans. The plans generated by the LLMs, while comprehensive, often presented as a static, modular “checklist of therapies.” In contrast, the human expert demonstrated a superior ability to design a dynamic, multi-stage, and interdisciplinary Clinical Pathway that evolves with the patient’s journey.
For instance, in a complex case of dysphagia and aphonia, the human expert structured the intervention into three distinct, theme-based phases (e.g., Phase 1: “Reconstructing the Swallowing Reflex”). All therapeutic modalities—swallowing, physical, vocal, and nursing—were strategically integrated to serve the central goal of each phase, showcasing a clear, time-based progression. Grok-4, conversely, organized its plan by functional domains ("Swallowing Function,” “Motor Function”), which, while logical, lacked this overarching temporal and strategic cohesion.
This strategic foresight was even more pronounced in a cardiac transplant case. The expert’s plan encompassed the entire patient continuum, beginning with pre-weaning interventions in the ICU (e.g., specific exercises on a SIMV ventilator setting) and extending to a detailed follow-up schedule at 3 and 6 months post-discharge. The LLM’s plan focused competently on the inpatient phase but lacked this “whole-lifecycle” management perspective. The human expert, therefore, operated not just as a therapist but as a project manager for the patient’s entire recovery arc.
Clinical insights
The human expert consistently demonstrated an exceptional ability to penetrate the complex layers of a clinical presentation to identify and prioritize the “core problem”—the primary limiting factor hindering the patient’s overall progress. This allowed for a highly effective and efficient allocation of therapeutic efforts.
A compelling illustration was a case involving a patient with cancer and hemiplegia who was experiencing severe emotional distress. The human expert made a crucial strategic decision to place the “Psychiatric Intervention” section before the “Rehabilitation Therapy” section, with “Emotional and Sleep Regulation” listed as the primary short-term goal. This strategy reflects a profound clinical judgment that psychological stability was an absolute prerequisite for any physical rehabilitation to be effective. While Grok-4 also provided a detailed psychological plan, it was listed in parallel with other therapies, missing this critical hierarchical insight.
Furthermore, in a pelvic floor dysfunction case, the expert’s diagnostic thinking transcended the musculoskeletal system. By incorporating “visceral manipulation” and techniques for uterine conditioning, the expert addressed the possibility that the dysfunction originated from deeper visceral or fascial restrictions. Grok-4’s plan, though technically proficient in musculoskeletal interventions, did not exhibit this “inside-out” etiological perspective, showcasing the expert’s deeper, more holistic diagnostic acuity.
Technical specificity and paradigm synthesis
The human expert’s therapeutic toolkit was not only broader but also demonstrated deeper technical specificity and the ability to seamlessly synthesize different medical paradigms. This was particularly evident in the application of advanced technologies and culturally-specific modalities like TCM design.
The expert’s plans often included high-precision, cutting-edge interventions. For instance, when recommending repetitive transcranial magnetic stimulation (rTMS), the expert specified precise parameters (e.g., 90% intensity, 50Hz frequency), elevating the recommendation from a general suggestion to an executable clinical prescription. In the cardiac transplant case, the expert explicitly detailed the “Sternal Precautions” (the “barrel principle”), a cornerstone of safety in this context that was absent in the LLM’s otherwise thorough plan.
Most notably, this analysis highlights a divergence in paradigm integration between LLMs and human experts. As our study used clinical cases from China, the human experts naturally and proactively integrated TCM based on deep theoretical foundations. In one oncology case, the expert provided a precise TCM syndrome differentiation and prescribed a specific herbal formula and detailed acupuncture techniques. This represents a true “chemical fusion” of two medical systems. This qualitative finding strongly corroborates our quantitative results from the supplementary “TCM Design" dimension, where human experts ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu $$\end{document} =2.31) significantly outperformed all LLMs. Given that the prompt did not request TCM, the LLMs’ adherence to a globally dominant Western medical paradigm reflects a tendency towards “Global Standardization.” In contrast, the human expert fluidly navigates and synergizes multiple frameworks to optimize patient care, demonstrating a unique capacity for “Local Contextualization” and implicit cultural adaptation.
Humanistic care
Finally, the essence of the human expert’s plans lay in their profound patient-centeredness. The goal was consistently framed not just as restoring function but as empowering the individual to reclaim their life, social roles, and sense of self.
This was achieved through the “contextualization” and “meaning-making” of therapeutic goals. For a stroke patient who was a “fruit shop owner,” the expert designed cognitive training that simulated the real-world tasks of “stocking, arranging, and selling fruit.” This is profoundly more engaging and transferable than the LLM’s standard, decontextualized exercises like “picture recall” or “number sequencing.” Similarly, a functional goal like “independently don and doff a cardigan” is more tangible and motivating for a patient than an abstract metric like “achieve an MBI score of 80.”
Moreover, the expert’s approach was fundamentally empowering. When addressing a patient’s anxiety, the expert went beyond providing counsel and actively taught the patient a lifelong self-management tool: the “Three-Column Record” technique. This philosophy of equipping patients with the skills to manage their own condition stands in contrast to the LLM’s approach, which positions the therapist as the primary agent of change. It is this focus on restoring the patient’s agency and dignity that represents the highest level of humanistic care.
These qualitative findings, juxtaposed with the quantitative results, paint a comprehensive picture of the complementary strengths of AI and human experts, paving the way for a new collaborative paradigm, as we will discuss in the following section.
Discussion
The core finding of this study is twofold. On one hand, LLMs demonstrate powerful capabilities in the systematic and evidence-based aspects of rehabilitation plan formulation. On the other hand, human rehabilitation specialists possess an indispensable value in higher-order strategic planning and the nuanced dimensions of patient-centered care. This finding directly addresses our primary research objective—to explore the differences between AI and rehabilitation physicians—and offers a clear direction for the future of rehabilitation medicine. Collectively, these findings provide robust empirical evidence supporting the intended use of LLMs as clinical decision support systems. They demonstrate the capability to function as reliable ’drafting assistants’ for preliminary rehabilitation plans, provided they are deployed within a workflow that includes expert human oversight.
Given the multidimensional nature of this evaluation—spanning quantitative metrics, qualitative themes, and cross-cultural comparisons—we adopted a hybrid reporting structure that integrates brief interpretive commentary within the Results section. This approach was chosen to facilitate the immediate contextualization of complex findings and enhance clinical readability.
Our quantitative results, reinforced by the Linear Mixed-Effects Model analysis, provide robust evidence of the potential for LLMs to serve as support tools within rehabilitation medicine. The leading models (specifically Grok-4 and Gemini−2.5-pro) consistently generated systematic, evidence-based treatment plans with a level of consistency, comprehensiveness, and risk mitigation that met or exceeded the benchmark set by human rehabilitation specialists(representing an idealized, standardized level of expertise). A significant finding from the updated analysis is the performance of the open-source model DeepSeek-r1-0528. By statistically outperforming the human benchmark ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P<0.001$$\end{document} ) in the combined analysis, it indicates that LLMs can reliably undertake knowledge-intensive foundational tasks, providing a high-quality and efficient starting point for decision-making in rehabilitation.
However, the analysis also revealed that human experts maintained a higher degree of robustness compared to mid-tier models like Claude-opus-4, particularly when data from diverse linguistic contexts were aggregated. This robust performance, alongside the qualitative findings, sharply accentuates the unique value of the rehabilitation specialist’s expertise. Our qualitative analysis demonstrates that high-quality practice in rehabilitation medicine is a higher-order cognitive activity that transcends information processing. These specialists excel at designing dynamic rehabilitation pathways, applying deep insight to prioritize the core problems that determine recovery outcomes, and delivering empowerment-focused, humanistic care. These capabilities—particularly the wisdom to proactively integrate localized medical paradigms to provide context-aware care—constitute the sophisticated dimensions of expertise in rehabilitation that are not readily codifiable and remain challenging for current AI architectures.
Consequently, our research does not lead to a conclusion of AI replacing rehabilitation specialists, but instead clearly defines a new paradigm of Human-AI Collaboration in Rehabilitation. Within this framework, the role of an LLM is not that of a competitor, but as an essential and highly efficient assistant for the human rehabilitation specialist. Our objective is to merge the systematic strengths of AI with the strategic and holistic wisdom of the human specialist to achieve enhanced rehabilitation outcomes.
In this collaborative paradigm, the division of labor becomes clear and complementary. The LLMs assumes the role of a systematic “executor” and “knowledge base,” tasked with knowledge-intensive but procedural work: rapidly retrieving high-volume evidence from clinical guidelines, integrating fragmented quantitative assessment data (e.g., muscle strength grades, range of motion), and synthesizing this information into a comprehensive, standardized draft of the rehabilitation plan. The rehabilitation specialist, liberated from these laborious tasks, can then focus on higher-value work as the ultimate “strategist” and provider of patient-centered care. Their responsibilities are elevated to addressing the nuanced dimensions of clinical reasoning: designing dynamic clinical pathways that evolve with the patient’s condition, prioritizing core limiting factors in complex comorbidities, and managing the crucial human interactions required to build a therapeutic alliance and align treatment goals with the patient’s personal life and dignity. Crucially, this human-in-the-loop oversight serves as a vital safety gate to mitigate the risks of misaligned or incomplete model recommendations, which, if left unverified, could lead to adverse clinical consequences such as inappropriate therapeutic intensity or overlooked contraindications.
It is critical to emphasize that the effectiveness of this collaboration is predicated on the specialist’s robust clinical knowledge base. Rather than diminishing the importance of expertise, the role of a “Strategist” elevates the cognitive threshold for clinicians, who must possess sufficient mastery of rehabilitation principles to critically audit AI-generated drafts, identify nuanced clinical omissions, and challenge recommendations that may not align with complex, real-world patient needs. Without this foundational knowledge, the therapist risks becoming a passive recipient of AI outputs rather than an informed decision-maker.
Notably, our findings regarding high-performance open-source models provide a critical catalyst for the widespread adoption and future development of this collaborative paradigm. The fact that DeepSeek-r1-0528 achieved a statistically significant advantage over human experts in the LMM analysis demonstrates that building effective and accessible AI assistants for rehabilitation is both technically and economically feasible. This lays the groundwork for developing localized models tailored to specific cultures (such as integrating Traditional Chinese Medicine knowledge), thereby allowing this advanced collaborative model to benefit a broader range of regions and populations.
While this study offers significant conclusions, its findings must be interpreted in the context of several inherent limitations:
- Text-Centricity of the Evaluation: Our assessment was based exclusively on textual case summaries and did not incorporate the multimodal information critical to real-world clinical scenarios, such as medical imaging or video gait analysis. This limits the scope of the evaluation, as the ability to process purely textual information is not entirely equivalent to the comprehensive decision-making capabilities required in a multimodal environment.
- Potential Bias in Data Standardization: This study utilized Gemini−2.5-pro to extract and format information from the original cases to ensure a uniform input structure for all models. While this standardization was a critical methodological step to facilitate a rigorous, blinded evaluation and prevent order or brand bias, a theoretical possibility exists that the text structure generated by a specific model might be more aligned with its own comprehension paradigm. However, we posit this effect is minimal and manageable, as the task primarily involved highly structured information extraction—a capability where current mainstream LLMs demonstrate high accuracy [39]. Furthermore, all extracted “Expert Answers” underwent item-by-item manual verification by our rehabilitation team to ensure that the core therapeutic measures remained consistent with the original clinical expertise in the source text.
- Nature of the “Expert Answer” Benchmark: The “Expert Answer” used as the evaluation benchmark was sourced from authoritative textbooks, representing a refined and standardized ideal case. While this provided a high-quality and stable benchmark, such an ideal exemplar may differ from decision-making processes in routine clinical practice, which are often characterized by uncertainty and significant patient variability [40]. Therefore, our findings are more accurately interpreted as top-tier LLMs surpassing an “idealized expert level” rather than being directly equivalent to outperforming the “average expert in routine practice.” Furthermore, while LLMs showed high alignment with these standardized answers, there is a risk of overestimating their performance in complex, non-textbook scenarios where patient symptoms are often ambiguous and data may be missing—conditions where human clinical expertise remains indispensable for navigating uncertainty. Additionally, real-world clinical data often involves heterogeneous formats (e.g., handwritten notes) and potential human errors in documentation, which present both a challenge for LLM integration and an opportunity for future systems to assist in error detection and data standardization.
- Simulation-Based Study Design: While this study employed authentic cases, it remains a retrospective simulation benchmarking study. The AI systems were evaluated in a controlled, in silico environment rather than in a prospective clinical workflow involving direct patient interaction. Consequently, the study focuses on the theoretical quality of the plans and does not measure actual patient health outcomes or the real-world impact on physician efficiency (e.g., time-saving metrics). Future research should transition to prospective clinical trials to validate these findings in live healthcare settings.
- Representativeness of the Expert Panel: Although the evaluation panel was composed of senior experts, the sample size was relatively limited. Their scoring criteria may have been influenced by regional factors, schools of thought, or personal clinical experience, and thus may not fully represent the entire spectrum of viewpoints within rehabilitation medicine [41].
- Rapid Technological Iteration: LLMs technology is evolving at an unprecedented pace. The conclusions of this study are limited to the specific model versions tested at the time of the evaluation. Future models or updated versions may exhibit different performance characteristics.
- Neutrality of Prompts and TCM Assessment: The lower scores of LLMs in the TCM dimension should be viewed as a reflection of their default behavior under neutral instructions, rather than a lack of knowledge. Our prompts were intentionally designed to be geographically and culturally neutral to simulate a generalized query. Consequently, models provided standard international care regimens. The “TCM Design” dimension therefore serves as an exploratory analysis highlighting the difference between the AI’s “universal” approach and the human expert’s “situated” practice, rather than a metric of core clinical competence.
Conclusions
In summary, this study provides a clear delineation of the core differences in reasoning for rehabilitation planning between LLMs and human rehabilitation specialists through a comprehensive quantitative and qualitative comparison. We have confirmed that LLMs possess the robust capability for systematic, evidence-based plan formulation required to serve as effective assistants in rehabilitation practice. Simultaneously, we have highlighted the distinct value of rehabilitation physicians in strategic planning, practical insight, and humanistic care. The central conclusion of our research is therefore not about AI replacing human rehabilitation clinicians, but the proposal of a more constructive paradigm of human-AI collaboration. In this model, AI serves as a powerful tool to free rehabilitation specialists from burdensome knowledge-based work, allowing them to concentrate on the more nuanced, strategic, and humanistic dimensions of their practice. We believe that this collaborative approach, which merges the systematic strengths of AI with the depth of the human specialist’s wisdom, is the key path toward a future of higher-quality, more efficient, and more humane rehabilitation care.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Google Cloud. Gemini 2.5 pro. https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-pro. 2025. Accessed 8 Oct 2025.
- 2Open AI. Introducing gpt-5. https://openai.com/index/introducing-gpt-5/. 2025. Accessed 8 Oct 2025.
- 3Deep Seek. Deepseek-r 1-0528. https://api-docs.deepseek.com/news/news 250528. 2025. Accessed 8 Oct 2025.
- 4Anthropic. Claude opus 4. https://www.anthropic.com/news/claude-4. 2025. Accessed 8 Oct 2025.
- 5x AI. Grok 4. https://x.ai/news/grok-4. 2025. Accessed 8 Oct 2025.
- 6O’Brien BC, Harris IB, Beckman TJ, Reed DA, Cook DA. The SRQR reporting checklist. In: Harwood J, Albury C, Beyer J de, Schlüssel M, Collins G, editors. The EQUATOR network reporting guideline platform. The UK EQUATOR Centre. 2025. https://resources.equator-network.org/reporting-guidelines/srqr/srqr-checklist.docx.