Correction: Discrimination of missing data types in metabolomics data based on particle swarm optimization algorithm and XGBoost model
Yang Yuan, Jianqiang Du, Jigen Luo, Yanchen Zhu, Qiang Huang, Mengting Zhang

Abstract
Click any figure to enlarge with its caption.
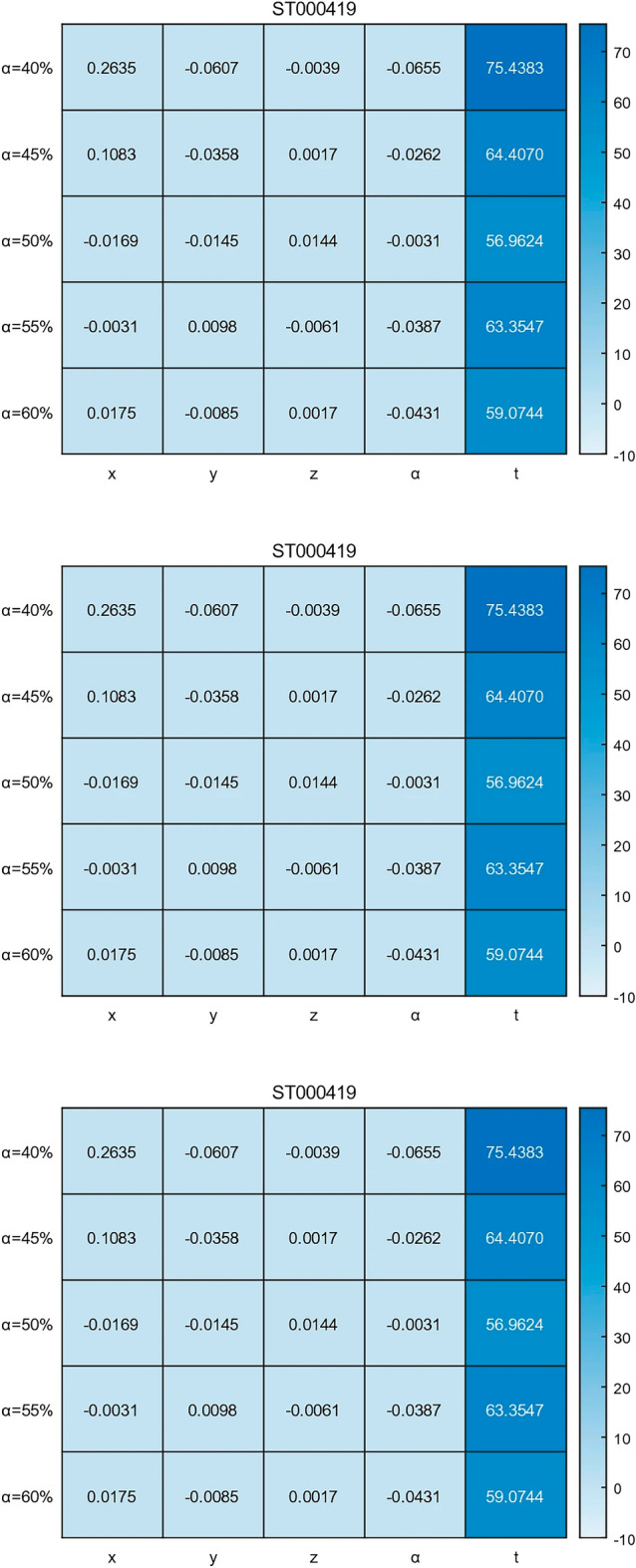 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetabolomics and Mass Spectrometry Studies · Machine Learning in Bioinformatics · Traditional Chinese Medicine Studies
Correction to: Scientific Reports 10.1038/s41598-023-50646-8, publihed online 02 January 2024
The original version of this Article contained errors in Figure 6, where panel ST000419 was duplicated twice and panels ST000118 and ST000385 were omitted. The original Figure 6 appears below.
Fig. 6. The search results of the particle swarm algorithm and the enumeration method were compared. The formula for calculating the percentage difference is the absolute value of the difference between the particle swarm results and the enumeration results divided by the particle swarm results. The heatmap clearly shows that the search time t has a greater impact than the difference.
The original Article has been corrected.