The diffusion model’s drift rate parameter primarily reflects efficiency, rather than speed, of evidence accumulation
Alexander Weigard, M. Fiona Molloy, Chandra Sripada, Andrew Heathcote

TL;DR
The study shows that the drift rate in the diffusion model reflects evidence accumulation efficiency, not speed, and is linked to higher cognitive abilities.
Contribution
The research introduces a distinction between evidence accumulation speed and efficiency using racing accumulator models.
Findings
The drift rate (v) is more strongly related to evidence accumulation efficiency (EEA) than speed (SEA).
EEA correlates with general cognitive ability, working memory, and executive function.
SEA explains less than 1% of variance in cognitive measures.
Abstract
Applications of the diffusion decision model (DDM) to the study of cognitive individual differences consistently find that the model’s drift rate (v) parameter forms a cohesive factor across many tasks and relates to measures of higher-order cognitive functioning, including general cognitive ability and working memory. This parameter is often interpreted as a measure of “processing speed,” a traditional psychometric construct thought to reflect an individual’s basic speed of information processing across tasks. However, conceptual differences between v and traditional notions of processing speed make this mapping far from straightforward. Racing accumulator models, which provide a more flexible and comprehensive account of behavioral data than the DDM, allow for the speed with which individuals accumulate evidence to be dissociated from the efficiency with which they accumulate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
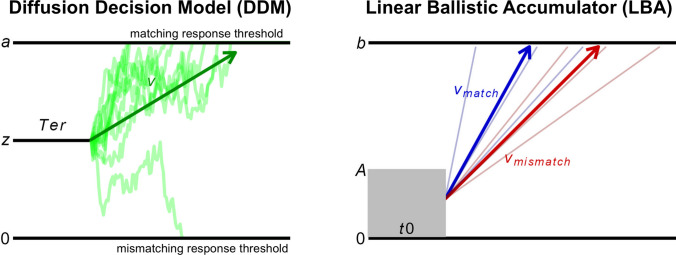 Figure 1
Figure 1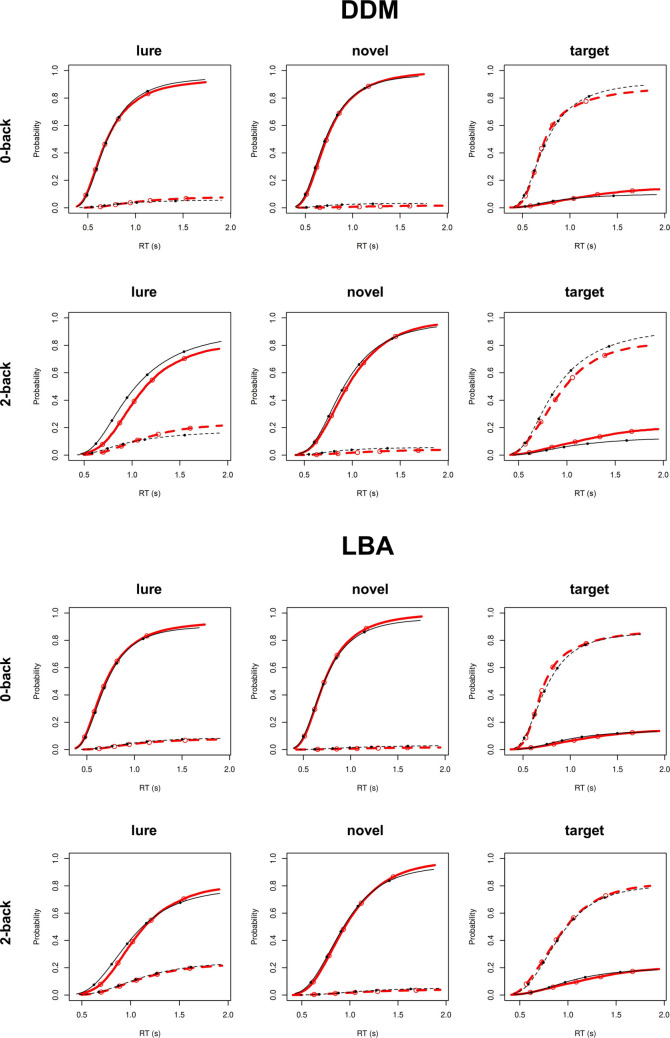 Figure 2
Figure 2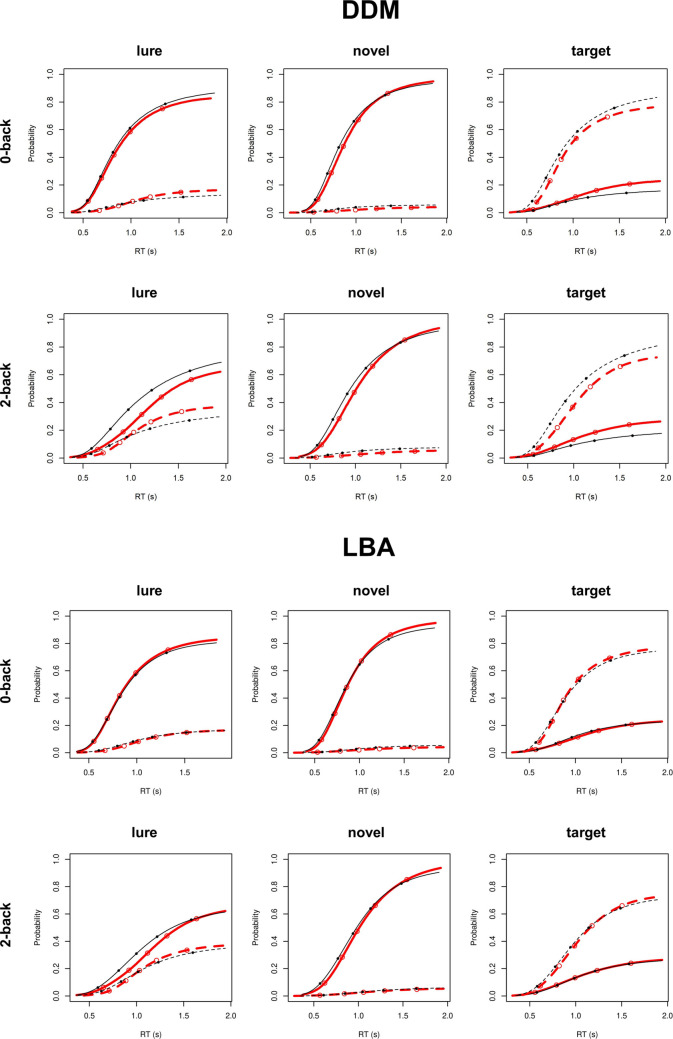 Figure 3
Figure 3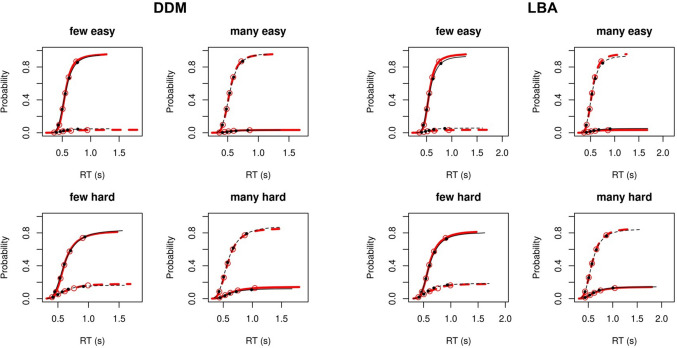 Figure 4
Figure 4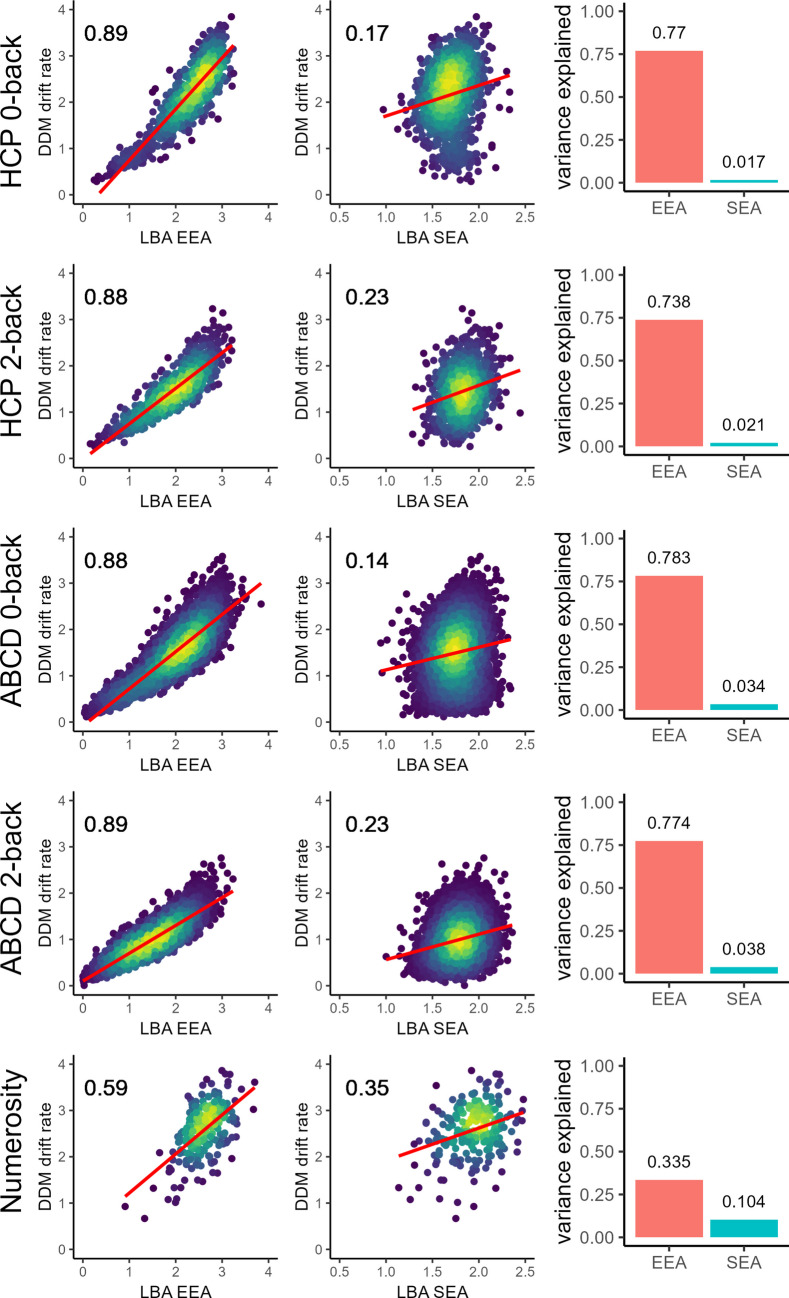 Figure 5
Figure 5- —http://dx.doi.org/10.13039/100000006Office of Naval Research
- —http://dx.doi.org/10.13039/100000025National Institute of Mental Health
- —http://dx.doi.org/10.13039/100000027National Institute on Alcohol Abuse and Alcoholism
- —http://dx.doi.org/10.13039/100000026National Institute on Drug Abuse
- —http://dx.doi.org/10.13039/501100008812Defence Science and Technology Group
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural and Behavioral Psychology Studies · Functional Brain Connectivity Studies · Visual and Cognitive Learning Processes
Introduction
Cognitive models posit formal, mathematically specified explanations for how people complete cognitive tasks. Given the longstanding interest in cognitive science with understanding reasons for individual differences in cognitive performance (Ackerman & Lohman, 2006; Carroll, 2003; Kane & Engle, 2002), fitting these models to individuals’ empirical data provides a unique opportunity to characterize mechanistic processes that drive such differences (Lerche et al., 2020; Ratcliff et al., 2011; Schubert & Frischkorn, 2020). The diffusion decision model [DDM]; Ratcliff, 1978; Ratcliff et al., 2016) posits that individuals generate responses on cognitive tasks requiring binary decisions by accumulating noisy evidence from stimuli until the accumulation process crosses an evidence threshold for one response (Fig. 1). The DDM is highly influential due to its success in providing empirically well-supported, psychologically grounded explanations of a wide variety of behavioral phenomena (Dutilh et al., 2019; Ratcliff et al., 2016; Starns et al., 2019; Voss et al., 2004).Fig. 1. Schematics of the diffusion decision model (DDM) and a commonly used accumulator model, the linear ballistic accumulator (LBA). In the DDM, noisy evidence accumulation causes a single evidence total to drift over time from a start point (z) between two boundaries alternately representing the response that matches the stimulus (set at a) and the response that mismatches the stimulus (set at 0). A single drift rate (v) parameter determines the average rate at which the evidence accumulation process drifts towards the matching response boundary. In the LBA, linear ballistic accumulators for responses matching, versus mismatching, the stimulus start at a point drawn from a uniform distribution (bounded by 0 and A) and race towards a common response threshold (b). The accumulators have rates that vary across trials (as opposed to the within-trial variability assumed by the DDM) and their mean rates are described by vmatch and vmismatch parameters. Both models also account for “nondecision” time spent on peripheral perceptual and motor processes (Ter in the DDM, t0 in the LBA). In the LBA, efficiency of evidence accumulation (EEA) can be measured by subtracting vmismatch from vmatch and speed of evidence accumulation (SEA) can be measured as the mean (or sum) of vmatch and vmismatch. (Color figure online)
One of the most consistent findings from this literature concerns the DDM’s drift rate (v) parameter, which indexes the average rate at which the evidence accumulation process approaches the threshold for the correct response (Fig. 1). Although v was originally characterized as reflecting the quality of stimulus information in the experimental literature from which the DDM emerged (Leite & Ratcliff, 2011), individual differences studies have repeatedly demonstrated that* v* reliably forms a cohesive and trait-like general factor that drives individual differences in performance across many tasks (Eisenberg et al., 2019; Lerche et al., 2020; Löffler et al., 2024; Schmiedek et al., 2007; Schubert et al., 2016; Weigard et al., 2021). Further, individual differences in the v parameter, even measured on relatively simple two-choice perceptual decision-making paradigms, appear to be closely related to measures of individuals’ higher-order cognitive functioning, including general cognitive ability (also called “general intelligence”: Carroll, 2003; McGrew, 2009), working memory, and executive functions (Karalunas & Huang-Pollock, 2013; Lerche et al., 2020; Löffler et al., 2024; Schmiedek et al., 2007; Schmitz & Wilhelm, 2016; Schubert & Frischkorn, 2020; Weigard, Suzuki, et al., 2024b; Weigard & Huang-Pollock, 2017). Hence, v presents as a compelling candidate for a basic cognitive capacity that influences individuals’ ability to accurately complete a wide variety of complex cognitive operations.
It has been commonplace throughout the individual differences literature to refer to the DDM’s* v* parameter as an index of “processing speed” or “speed of information processing” (Hedge et al., 2022; Karalunas & Huang-Pollock, 2013; Lerche et al., 2020; Löffler et al., 2024; Ratcliff et al., 2011, 2012; Reinhartz et al., 2023; Schubert et al., 2015; Schubert & Frischkorn, 2020; van Ravenzwaaij et al., 2011; Vermeent, Young, DeJoseph, et al., 2024a, Vermeent, Young, Van Gelder, et al., 2024b), including in prior work by the first author of this report (Weigard & Huang-Pollock, 2017). According to the traditional conceptualization of “processing speed” from the psychometric literature, this capacity represents the speed with which individuals process information across essentially all cognitive tasks (Fry & Hale, 1996, 2000; Kail & Salthouse, 1994; Salthouse, 1996). As processing speed is thought to be an elemental ability, it is typically measured as the average response time (RT) on relatively simple cognitive tasks that, in theory, have few higher-order demands on information processing (e.g., top-down control demands).1 Because the DDM’s v parameter has some conceptual similarities to this theoretical construct, and because it shows evidence of being a domain-general process that influences performance on even simple tasks, linking the two is understandable.
However, this link is not entirely straightforward. Although the effects of processing speed on performance have been assumed to manifest primarily in the latencies of RTs, the v parameter strongly affects the variability and positive skew of RT distributions as well as their mean latency (Matzke & Wagenmakers, 2009). Further, mean RT latency is also largely explained by alternative DDM parameters for perceptual encoding, motor speed, and response caution (Matzke & Wagenmakers, 2009). Therefore, a positive manifold in mean RTs (Thurstone, 1931) is likely to be explained, in part or in whole, by alternative processes such as an individuals’ overall level of response caution (Hedge et al., 2019; Weigard et al., 2021), rather than exclusively by v. This substantial theoretical and methodological disconnect between the v parameter and the construct of processing speed—as the latter construct has been defined and measured in decades of previous literature—indicates that that equating the two constructs is likely to create confusion.
Perhaps more importantly, the v parameter does not actually measure the overall rate at which a person accumulates information, but rather the rate at which the information they accumulate moves the decision process towards the threshold for the correct response. An individual may be able to quickly accumulate information about a stimulus, but if they are inefficient at parsing information relevant to the task goal from task-irrelevant information, the quality of the accumulated evidence and, therefore, the value of their v parameter will nonetheless be low.
The more flexible class of racing accumulator models, which have a similar track record to the DDM of successfully explaining patterns in behavioral data (Brown & Heathcote, 2008; Heathcote & Matzke, 2022; Usher & McClelland, 2001), provide a way of disentangling the overall speed of evidence accumulation from an individual’s ability to accumulate task-relevant over irrelevant evidence. These models assume that noisy evidence for each response is gathered in separate accumulators that race, with the first to reach its threshold triggering the corresponding response (Fig. 1). In this framework, two separate dynamics govern the evidence accumulation process:
- The overall speed of evidence accumulation (SEA), captured by the average or sum of the accumulation rates, and
- The efficiency of evidence accumulation (EEA), captured by the difference between the rate of the accumulator matching the correct response and the rate(s) of mismatching accumulators.
As with the DDM’s v parameter, neither EEA nor SEA has an exact mapping to the traditional theoretical construct of processing speed. However, SEA is much more closely theoretically aligned with this construct because it reflects individuals’ overall speed of accumulating evidence, regardless of the quality of that evidence. In contrast, EEA represents individuals’ ability to efficiently parse task-relevant information from irrelevant information, which is orthogonal to SEA and has little conceptual overlap with the theoretical processing speed construct. At the level of how the theoretical processing speed construct has been empirically defined—as mean choice RT—SEA almost exclusively affects mean choice RT while EEA primarily affects accuracy, as detailed in simulations outlined in Supplemental Materials.2 Hence, traditional measures of “speed” may be influenced by either EEA or SEA, but SEA has a more selective relationship. One prior study applying accumulator models to a battery of decision-making tasks has identified a positive manifold in EEA that mimics the positive manifold in the DDM’s v parameter (Stevenson et al., 2024). Yet despite the widespread practice of referring to the DDM’s v parameter as “speed,” no prior studies have explicitly used racing accumulator models to compare EEA and SEA’s empirical relations with the DDM’s v parameter. Nor have prior studies clarified whether EEA or SEA plays a similar role to v in supporting higher-order cognitive processes.
The current report sought to fill this gap by simultaneously estimating parameters of the DDM and the linear ballistic accumulator (LBA) model (Brown & Heathcote, 2008) in three independent samples. We evaluated how closely EEA and SEA estimates were related to the DDM’s v parameter and assessed whether EEA, SEA, or both processes played a similar role to v in supporting performance on tasks that involve complex cognitive processing.
Methods
HCP sample and task
The Human Connectome Project (HCP) is consortium study that aimed to use functional neuroimaging to facilitate the mapping of the human connectome by collecting and freely distributing data from 1,200 healthy young adults, aged 22–35 (Van Essen et al., 2013). The HCP consortium recruited a sample of twins and their nontwin siblings from the local communities of consortium sites to facilitate estimation of heritability in connectome features. Participants completed an extensive battery of both task-based and resting state functional neuroimaging measures and behavioral testing. Data for the HCP sample were taken from the HCP-1200 release (Van Essen et al., 2013; WU-Minn, 2017).
We used data from the HCP’s n-back task, which was completed during functional neuroimaging data acquisition. In each of two conditions of this task, participants were presented with a series of images of faces, places, tools and body parts in 10-trial blocks. In the 0-back condition, participants were shown a target image during a 2.5-s cue at the beginning of each block and were asked to respond as to whether each image presented matched the target image. In the 2-back, participants were asked to evaluate whether the presented stimulus was the same as the stimulus presented two trials back. Therefore, the 0-back was essentially a simple recognition memory task while the 2-back required the active maintenance of information in working memory. In addition to “target” trials, both task conditions included “lure” trials, which were stimuli that were presented before in the block but that did not meet target criteria, and “novel” trials that were never presented before.
Of the 1,073 individuals in the HCP-1200 release with complete n-back task data, 0-back data from all 1,073 individuals and 2-back data from 1,065 individuals met data quality inclusion criteria (outlined below). In addition, the LBA model displayed persistent convergence difficulties with one participant’s 0-back data, leaving total samples of 1,072 for the 0-back and 1,065 for the 2-back.
ABCD sample and task
The Adolescent Brain Cognitive Development Study (ABCD)^®^ is a large, multi-site longitudinal study of 11,875 U.S. youth recruited at ages 9–10 at 22 consortium sites (Casey et al., 2018). Youth were recruited using school-based sampling methods designed to allow for a sample that was reflective as possible of the diversity of the U.S. population (Garavan et al., 2018). Twins and nontwin siblings were recruited, similar to HCP, but most participants were from different families. We used data from the ABCD baseline session (ages 9–10) included in ABCD Release 5.0.
ABCD study participants completed an n-back task with 0-back and 2-back blocks during neuroimaging data acquisition that each had an identical design to the corresponding tasks used in HCP, except for the stimuli used. The ABCD 0-back and 2-back included blocks that presented face stimuli with happy, fearful or neutral facial expressions as well as blocks that presented images of places, a design choice intended to elicit activity in “emotion” and “place” processing brain regions.
Of the 10,042 individuals with complete n-back data at the ABCD baseline session, 0-back data from 9,286 individuals and 2-back data from 9,104 individuals met data quality inclusion criteria (outlined below). In addition, the LBA model displayed persistent convergence difficulties with two participants’ 0-back data, leaving total samples of 9,284 for the 0-back and 9,104 for the 2-back.
Prolific numerosity discrimination sample and task
The final dataset was drawn from an online study that included Simon and flanker conflict tasks and a numerosity discrimination task (Molloy et al., in press), the last of which was included in the current report due to it being a basic perceptual discrimination task that is commonly used in the DDM literature (Leite & Ratcliff, 2011; Ratcliff, 2008; Ratcliff et al., 2012; Weigard & Huang-Pollock, 2017). Participants recruited using the Prolific online research platform (n = 234) were presented with arrays of asterisks on a 10 × 10 grid and asked to report if there were “few” (<50) or “many” (>50) stimuli. The task contained both two difficulty conditions, hard (41–45 or 55–59 asterisks) and easy (31–35 or 65–69 asterisks), with 100 trials each (200 total) and trials were randomly interspersed. Of the 234 participants recruited, numerosity discrimination data from 226 individuals (mean age = 27.64 years, age range: 18–35 years, 115 women) met data quality inclusion criteria outlined below.
Criterion measures
Both the ABCD and HCP data sets contained the NIH Toolbox Battery, which was designed to be a comprehensive and efficient battery capable of measuring an array of cognitive domains across youth and adult participants (Akshoomoff et al., 2013; Weintraub et al., 2013). The NIH Toolbox Total Composite Score, which reflects performance across all domains in the NIH Toolbox battery, was used as a measure of general cognitive ability. The List Sorting Working Memory test, which involves the serial presentation of pictures and names of animals or foods of different sizes followed by a request for the participant to repeat back the items presented in the order of smallest to largest size, was used as a measure of working memory. The Dimensional Change Card Sort test, which asks participants to sort objects according to two different dimensional criteria (color and shape) that alternate across blocks and are interleaved pseudorandomly in a third block, was used as a measure of cognitive flexibility. The flanker test, a variant of the traditional arrow flanker, was used as a measure of inhibition. Standardized NIH Toolbox scores, uncorrected for age, were used for each of these measures.
Model estimation and model fit
The DDMs for the 0-back and 2-back tasks allowed drift rate to vary by n-back trial type (vnovel,* v_target, vlure), and also included parameters for boundary separation (a), start point (z), nondecision time and its between-trial variability (t0, st0), as well as a “go failure” (pgf) parameter to account for omissions (Damaso et al., 2021). The LBAs for the 0-back and 2-back tasks allowed accumulator drift rates to vary across both trial-type and whether the accumulator’s response was the correct match for the trial stimulus (vnovel-match,_ v_target-match, vlure-match_, v_novel-mismatch,_ v_target-mismatch, vlure-mismatch), and also included parameters for response threshold (B), start point variability (A), nondecision time (t0), “go failure” (pgf), and between-trial variability in the rate of the accumulator mismatching the correct response (svmismatch). Between-trial variability in the rate of the accumulator matching the correct response (svmatch*_) was fixed to 1 as a scaling parameter (Donkin et al., 2009).
The DDMs for the numerosity discrimination task allowed drift rate to vary by stimulus type and difficulty (vmany-easy,* v_few-easy, vmany-hard, vfew-hard) and contained the other standard DDM parameters also estimated for the n-back tasks (a, z, t0, st0, pgf). The LBAs for the numerosity discrimination task allowed accumulator drift rates to vary across stimulus type, difficulty, and whether the accumulator’s response was the correct match for the trial stimulus (vmany-easy-match,_ v_few-easy-match, vmany-hard-match, vfew-hard-match, vmany-easy-mismatch,_ v_few-easy- mismatch, vmany-hard- mismatch, vfew-hard- mismatch). We also allowed thresholds to vary by response type (Bmany,_ B_few) given prior work demonstrating that doing so improves model fit (Weigard et al., 2018) and otherwise estimated the remaining parameters across all trials (A, t0, pgf*_).
Before estimation of any models, participants were excluded for poor data quality if their accuracy rate was below 55% or if they displayed omissions (non-responses) on more than 25% of trials (proportions excluded are reported above). DDM and LBA parameters were then estimated in the Dynamic Models of Choice (DMC) R suite (Heathcote et al., 2019) using individual Bayesian estimation with the “RUN.dmc()” function. Broad and uninformative priors were used for the estimation of both models (Supplemental Tables 1–2). Following prior work (Damaso et al., 2021), both models accounted for the probability that some responses would be omitted due to falling after the response window (2 s for the ABCD and HCP n-back tasks, 3 s for the numerosity task) and also estimated the probability of additional omitted responses due to inattention to the task (the “go failure” parameter: pgf). Sampling from parameter posteriors was conducted with the differential evolution Markov chain Monte Carlo (DE-MCMC) method (Turner et al., 2013) and convergence was defined as the Gelman-Rubin statistic falling below 1.10 (Gelman & Rubin, 1992).
Model fit was investigated using posterior predictive plots (Gelman et al., 1996) that compare data predicted by the model to the empirical task data. Plots for the HCP, ABCD, and Prolific numerosity discrimination samples are displayed in Figs. 2, 3 and 4, respectively. The LBA displayed very good fit across all tasks and samples as it was generally able to reproduce both choice proportions and RT quantiles across each task condition. The LBA only displayed some minor misfits to error RT quantiles, which tend to be more difficult to estimate due to the lower number of errors than correct trials. The DDM displayed similarly good fit to the 0-back and numerosity discrimination tasks, but displayed greater misfit to the target and lure trial conditions in the 2-back task, overestimating individuals’ accuracy rates in these conditions in both the HCP (Fig. 2) and ABCD (Fig. 3) samples. Notably, previous work using informative priors derived from hierarchical model fits to independent empirical data (Weigard, Angstadt, et al., 2024a; Weigard, Suzuki, et al., 2024b) finds the DDM displays good fit to target and lure trials in these data sets when the model is constrained by the informative priors. Therefore, we attribute these accuracy misfits to our choice to use broad and uninformative priors in this study. Regardless, as the LBA displayed consistently good fit across all tasks, indicating that EEA and SEA estimates are likely to be trustworthy, we investigated whether the DDM’s v parameter was reliably related to EEA or SEA across both tasks to which the DDM displayed good fit (0-back, numerosity) and to which it displayed relatively poorer fit (2-back).Fig. 2. Posterior predictive plots for linear ballistic accumulator (LBA) model and diffusion decision model (DDM) fits to the Human Connectome Project (HCP) n-back task data. Each plot displays the cumulative probability of a “target” response (dotted line) and a “nontarget” response (solid line) for the empirical (red) and model-predicted (black) data. The five points shown in each plot represent response time (RT) quintiles (.1,.3,.5,.7,.9) for the empirical (open point) and model-predicted (solid point) data. (Color figure online)Fig. 3. Posterior predictive plots for linear ballistic accumulator (LBA) model and diffusion decision model (DDM) fits to the Adolescent Brain Cognitive Development Study (ABCD) n-back task data. Each plot displays the cumulative probability of a “target” response (dotted line) and a “nontarget” response (solid line) for the empirical (red) and model-predicted (black) data. The five points shown in each plot represent response time (RT) quintiles (.1,.3,.5,.7,.9) for the empirical (open point) and model-predicted (solid point) data. (Color figure online)Fig. 4. Posterior predictive plots for diffusion decision model (DDM) and linear ballistic accumulator (LBA) fits to numerosity discrimination task data. Each plot displays the cumulative probability of a “many” response (dotted line) and a “few” response (solid line) for the empirical (red) and model-predicted (black) data. The five points shown in each plot represent response time (RT) quintiles (.1,.3,.5,.7,.9) for the empirical (open point) and model-predicted (solid point) data. (Color figure online)
EEA was defined by taking the average, across all task conditions, of the difference between drift rates for accumulators that match, versus those that mismatch, the correct response. SEA was defined by taking the average, across all task conditions, of the mean of drift rates for the matching and mismatching accumulators. The DDM’s v parameter was similarly averaged across all task conditions.
Data visualization and inferential analyses
All data visualization and analysis was conducted within R (R Core Team, 2013) and code is available at OSF (osf.io/9nd4h.). Bivariate relations of EEA and SEA with v were visualized using the “geom_pointdensity()” function from the ggplot2 R package. As the ABCD and HCP samples contain data nested by family and consortium site, linear mixed effects models with random intercepts for levels of nested variables were fit using the “lmer()” function from the lme4 R package to determine the individual contributions of EEA and SEA to explaining variance in DDM* v* and in the cognitive criterion measures. Marginal r-squared and bootstrapped (1000 iterations) confidence intervals (CIs) for r-squared values were computed using the partR2 R package.
Results
The DDM’s v parameter is more closely related to EEA than to SEA
Relations of EEA and SEA with the DDM’s v parameter in all tasks and samples are displayed in Fig. 5. Raw correlations, reported in the scatterplots, indicated that EEA consistently displayed strong relations with v (r =.59–.89). For the ABCD and HCP tasks the correlations were uniformly above 0.80, suggesting that v could be viewed functionally as a proxy measure for EEA in these tasks. In contrast, correlations between SEA and v were substantially lower across all tasks (r =.14–.35). Multivariate linear models that evaluated the unique contributions of EEA and SEA to explaining variance in v indicated that EEA consistently explained a substantially larger proportion of the variance in v than SEA did (bar plots in Fig. 5). The strength and selectivity of EEA’s relation to v was lowest in the numerosity task data set. However, even in this data set, EEA explained over three times more variance in v than SEA did.Fig. 5. Relations of individuals’ speed of evidence accumulation (SEA) and efficiency of evidence accumulation (EEA), estimated from the linear ballistic accumulator model (LBA), with the drift rate parameter of the diffusion decision model (DDM). Rows represent individual cognitive tasks drawn from the Human Connectome Project (HCP), Adolescent Brain Cognitive Development study (ABCD), and a sample of Prolific participants who completed a numerosity discrimination task online. Scatterplots illustrate the raw correlations of EEA and SEA with drift rate. Pearson correlation estimates are reported in the upper left corner. The color scale reflects the density of the points, with blue indicating lower density and yellow indicting greater density, and the red lines indicate the linear relations between the variables. Bar plots in the rightmost column show the proportion of variance explained in drift rate by EEA and SEA when both parameters are included within the same linear mixed model. (Color figure online)
We also investigated relations between other LBA and DDM parameters that have similar mechanistic interpretations across the models. These included relations between the height of LBA response thresholds and the DDM boundary separation parameter, both of which are thought to index an individual’s level of caution in responding, and relations between nondecision time parameters across each model. Consistent with prior work (Donkin et al., 2011), correlations of these parameters across the LBA and DDM models (Supplemental Fig. 2) were uniformly strong and positive (r >.50), suggesting that the models also provide generally similar accounts of other mechanistic processes.
Higher-order cognitive functions previously linked to v are related to EEA but not SEA
Results from multivariate linear models predicting criterion measures of higher-order cognitive functioning collected in the ABCD and HCP samples are displayed in Table 1. Estimates of variance explained and their confidence intervals indicated that, although effect sizes varied, EEA consistently explained a significant portion of the variance in these criterion measures (with the only exception being the relation between 0-back EEA and the flanker task in the HCP sample). In contrast, SEA explained less than 1% of the variance in each of the criterion measures and confidence intervals always contained 0. Therefore, only EEA, and not SEA, shows evidence of relations with measures of higher-order cognitive functions that have well-replicated associations with the DDM’s v parameter. Table 1. Variance explained (r^2^) in NIH Toolbox criterion measures by efficiency of evidence accumulation (EEA) and speed of evidence accumulation (SEA) when both parameters are simultaneously included in linear mixed models and 95% confidence intervals (CIs) for r^2^ estimatesSampleMeasureTaskEEA r^2^EEA 95% CISEA r^2^SEA 95% CIHCPTotal Cognition0-back0.0510.032**0.0790.0000.000**0.0282-back0.2050.164**0.2510.0020.000**0.053List (working memory)0-back0.0300.014**0.0520.0010.000**0.0242-back0.0910.059**0.1280.0030.000**0.043Card Sort (flexibility)0-back0.0350.018**0.0620.0020.000**0.0302-back0.0890.059**0.1270.0000.000**0.039Flanker (inhibition)0-back0.0080.000**0.0250.0030.000**0.0202-back0.0450.025**0.0760.0010.000**0.032ABCDTotal Cognition0-back0.1480.135**0.1610.0030.000**0.0172-back0.2020.188**0.2180.0060.000**0.026List (working memory)0-back0.0790.068**0.0890.0020.000**0.0132-back0.1090.097**0.1200.0020.000**0.014Card Sort (flexibility)0-back0.0570.048**0.0670.0030.000**0.0132-back0.0620.053**0.0730.0040.000**0.015Flanker (inhibition)0-back0.0410.033**0.0490.0000.000**0.0092-back0.0600.051**0.0710.0010.0000.012Note**. ABCD = Adolescent Brain Cognitive Development Study; HCP = Human Connectome Project.Italics indicate the 95% CI values.
Discussion
This report sought to provide greater clarity about whether the drift rate parameter (v) of the DDM (Ratcliff et al., 2016) can be thought of as a measure of “processing speed,” a traditional psychometric construct defined as an individual’s basic speed of information processing across nearly all cognitive tasks (Fry & Hale, 1996, 2000; Kail & Salthouse, 1994; Salthouse, 1996). We fit both the DDM and a racing accumulator model, the LBA, to data from three tasks across a set of three samples that varied substantially by age and by the participant sampling methods used. The LBA allows estimates of two dissociable features of information processing:
- The speed of evidence accumulation (SEA), which reflects the speed with which individuals accumulate evidence, regardless of the quality of that evidence, and is therefore closely aligned with traditional construct of “processing speed”, and
- The efficiency of evidence accumulation (EEA), which reflects individuals’ ability to selectively accumulate evidence relevant to task goals instead of task-irrelevant evidence, which has an ambiguous relationship to the traditional construct of “processing speed.”
We sought to clarify whether SEA or EEA was more strongly related to the DDM’s* v* parameter and to measures of higher-order cognitive abilities with which the v parameter has been previously linked.
Across all tasks and data sets, EEA was consistently strongly related (r >.50) to the DDM’s v parameter, and in nearly all tasks this relationship was strong enough that v could be thought of as a proxy measure for EEA (r >.80). In contrast, SEA displayed far weaker relations with v (r =.14–.35). When both LBA parameters were included in a multivariate regression predicting* v*, EEA consistently explained many times more variance in v than SEA did. Furthermore, when investigating EEA’s and SEA’s relations with measures of higher-order cognitive functions (general cognitive ability, working memory, executive functioning) that have well-replicated links to v, EEA consistently explained meaningful portions of the variance in all measures, whereas SEA did not explain more than 1% of the variance in any of them. Taken together, these results indicate that, from a functional standpoint in cognitive individual differences research, the DDM’s* v* parameter is primarily an index of the efficiency with which individuals selectively process relevant - as opposed to irrelevant - information, rather than an index of the overall speed with which they process information.
We used a racing accumulator modeling framework to pull apart SEA from EEA. The “processing speed” construct, as traditionally defined, would be expected to manifest in SEA, and has at best a weak and ambiguous conceptual link with EEA. In accumulator models, EEA and SEA can vary completely independently of one another and only SEA theoretically represents the overall speed with which information is processed. Although v and EEA can also influence the most common traditional summary measure of processing speed, mean choice RT, these relations are not as strong or selective as the relation of SEA with mean choice RT (Supplemental Materials). Thus, if widely accepted theoretical and empirical definitions of “processing speed” are taken at face value, our results, which show the DDM’s v parameter primarily indexes EEA and not SEA, suggest that v has little to do with processing speed and much more to do with individuals’ efficiency of parsing task-relevant from task-irrelevant information.
Further questions arise as to the mechanistic interpretation of SEA and EEA in terms of more basic cognitive processes. Providing a detailed discussion of these questions is beyond the scope of this report and this topic is an active area of inquiry in the field. SEA has only been explored in a limited number of studies (Hawkins & Heathcote, 2021; Miletić et al., 2021; Stevenson et al., 2022; van Maanen et al., 2016; Weigard et al., 2023), and authors have suggested interpretations of SEA in terms of “urgency” (Hawkins & Heathcote, 2021; Miletić et al., 2021) or “arousal” (van Maanen et al., 2016). EEA, in contrast, has been posited to be more closely related to the efficacy of selective attention or cognitive control processes that allow individuals to parse goal-relevant information from goal-irrelevant information (Weigard et al., 2021; Weigard & Sripada, 2021). Importantly, SEA, and EEA can each also reflect factors that are related to stimulus properties rather than individual differences, such as the intensity and discriminability of choice options (Stafford & Gurney, 2004; van Ravenzwaaij et al., 2020). Additional work is required to disentangle the multiplicity of factors that contribute SEA and EEA and elucidate the mechanistic basis of their inter-individual differences.
Although we found very strong relationships between v and EEA in tasks from two large community-recruited samples (ABCD and HCP), the relation between* v* and EEA was not as strong or selective in the numerosity discrimination task drawn from an online sample of Prolific participants. This finding may be due to differences in the cognitive domain involved in the Prolific study (perceptual discrimination) or due to features of Prolific participants. For example, Prolific participants may be generally higher-functioning (producing range restriction) compared with community-recruited samples in which people with lower cognitive abilities may be better represented. Nonetheless, we note that EEA continues to explain more than three times the amount of variance in v from the numerosity task than SEA does, suggesting that our general pattern of findings holds up well across all samples and all tasks.
Another important caveat is that our inferences are based on the assumption that the LBA and DDM provide appropriate theoretical accounts of the data. If both models fail to reflect the underlying data-generating process, their parameter estimates may nonetheless behave similarly if the models describe the data in similar (but incorrect) ways. The fact that the LBA provided very good fit across all tasks and samples (Figs. 2, 3, and 4) lends confidence to our assumption that the LBA’s EEA and SEA parameters reflect the appropriate data generating processes on these tasks. As the DDM’s v parameter was consistently related to EEA both in tasks in which the DDM also provided very good fit (0-back, numerosity discrimination) and in tasks in which the DDM’s fit was relatively poorer (2-back), we can infer that v is a fairly robust index of the EEA data-generating process across many applications of the DDM. Nonetheless, we cannot completely rule out the possibility that these tasks involve data-generating processes that are very different from those assumed by the LBA and that may be supported by future work. However, this caveat applies across essentially all cognitive model applications.
In summary, our results strongly suggest that the DDM’s v parameter should not be equated with the traditional construct of processing speed. This is supported by our findings that v, and its relations with other cognitive abilities, cannot be explained only by individuals’ speed of evidence accumulation and instead largely reflects individuals’ ability to parse relevant from irrelevant information, a mechanism that can vary independently of speed. At the very least, this pattern of results suggests that v’s determinants are far too complex to attribute solely to “speed of information processing.” As noted in the beginning of this report, the value of cognitive models lies in their precise formal definitions of the mechanisms underlying cognitive performance. Prior work in cognitive science has instead often relied on verbal definitions of cognitive constructs, which are inherently less precise. We acknowledge that, for the sake of communicating to broader audiences and establishing bridges with prior work, it can be tempting to map cognitive model parameters onto these popular verbally defined constructs. However, as even the highly intuitive mapping of v to “processing speed” appears deeply questionable, this approach may add more confusion than clarity to model-based studies. Instead, we believe that cognitive modeling research programs should rely on an ontology of processes that are defined clearly in terms of formal model parameters and their respective functional roles. Moreover, theorists should acknowledge that these formally defined constructs may resist straightforward mapping to more traditional terms and concepts.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 758 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akshoomoff, N., Beaumont, J. L., Bauer, P. J., Dikmen, S. S., Gershon, R. C., Mungas, D., ... Heaton, R. K. (2013). VIII. NIH toolbox cognition battery (CB): Composite scores of crystallized, fluid, and overall cognition. Monographs of the Society for Research in Child Development,78(4), 119–132.
- 2Casey, B. J., Cannonier, T., Conley, M. I., Cohen, A. O., Barch, D. M., Heitzeg, M. M., … ABCD Imaging Acquisition Workgroup. (2018). The adolescent brain cognitive development (ABCD) study: Imaging acquisition across 21 sites. Developmental Cognitive Neuroscience,32, 43–54.
- 3Dutilh, G., Annis, J., Brown, S. D., Cassey, P., Evans, N. J., Grasman, R. P., ..., & Donkin, C. (2019). The quality of response time data inference: A blinded, collaborative assessment of the validity of cognitive models. Psychonomic Bulletin & Review, 26, 1051–1069.
- 4Garavan, H., Bartsch, H., Conway, K., Decastro, A., Goldstein, R., Heeringa, S., ... Zahs, D. (2018). Recruiting the ABCD sample: Design considerations and procedures. Developmental Cognitive Neuroscience,32, 16–22.
- 5Molloy, M., Lee, T., Jonides, J., Zhang, H., Sellers, J., Heathcote, A., ... Weigard, A. (in press). Joint cognitive models reveal sources of robust individual differences in conflict processing. Computational Brain & Behavior.
- 6R Core Team (2013). R: A language and environment for statistical computing. https://cran.r-project.org/
- 7Starns, J. J., Cataldo, A. M., Rotello, C. M., Annis, J., Aschenbrenner, A., Bröder, A., … Wilson, J. (2019). Assessing theoretical conclusions with blinded inference to investigate a potential inference crisis. Advances in Methods and Practices in Psychological Science,2(4), 335–349.
- 8Weigard, A., Suzuki, T., Skalaban, L. J., Conley, M., Cohen, A. O., Garavan, H., ... Heathcote, A. (2024 b). Dissociable contributions of goal-relevant evidence and goal-irrelevant familiarity to individual and developmental differences in conflict recognition. Cognitive Science,48(11), Article e 70019.