In Search of the Most Significant Potential G-Quadruplexes in SARS-CoV-2 RNA: Genomic Analysis
Margarita Zarudnaya, Ivan Voiteshenko, Vasyl Hurmah, Tetiana Shyryna, Alex Nyporko, Maksym Platonov, Szczepan Roszak, Bakhtiyor Rasulev, Karina Kapusta, Leonid Gorb

TL;DR
This paper identifies potential G-quadruplex structures in SARS-CoV-2 RNA and explores their roles in viral replication and possible antiviral drug targets.
Contribution
The study systematically analyzes and identifies the most significant potential G-quadruplexes in SARS-CoV-2 RNA and evaluates their structural and functional roles.
Findings
SARS-CoV-2 RNA contains 42 putative G-quadruplex-forming sequences, many stabilized by U·A-U triads or 3′ U-tetrads.
Most G-quadruplex-forming sequences are highly conserved, with only a few showing transient destabilizing mutations.
Compound EKM showed specific binding to G4 3467 and emerged as a promising antiviral candidate.
Abstract
G-quadruplexes (G4s) are emerging as potential antiviral targets. SARS-CoV-2 genomic RNA contains 42 G-rich regions harboring putative G-quadruplex-forming sequences (PQSs). Here, we performed a systematic genomic and structural analysis of SARS-CoV-2 PQSs. It was proposed that non-G-tetrads or different triads may stabilize most G4s in this RNA. Many G4s may include the most stable U·A-U triad. Several G-quadruplexes may be significantly stabilized by 3′ U-tetrad. Large-scale mutational analysis of RNA structural elements containing PQSs showed that most PQSs are highly conserved, while persistent G4-destroying mutations were observed only for one PQS and were transient for two others. Based on G4 position and structural context, we propose that: (i) G4 370 in nsp1 may contribute to cap-independent translation initiation; (ii) certain putative G4s in different genes may assist in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
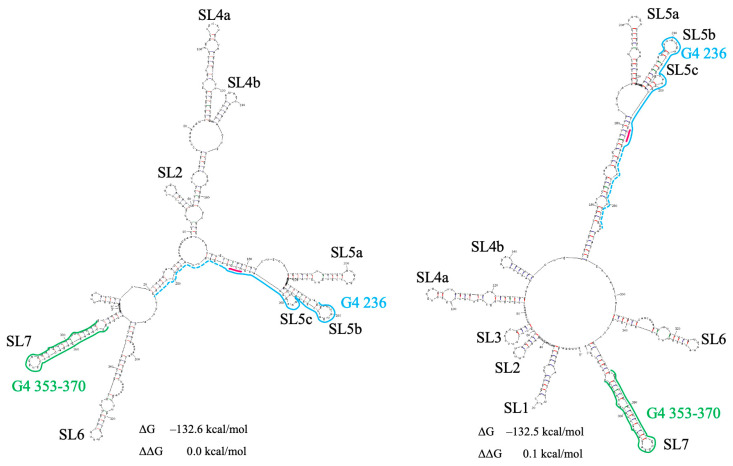 Figure 1
Figure 1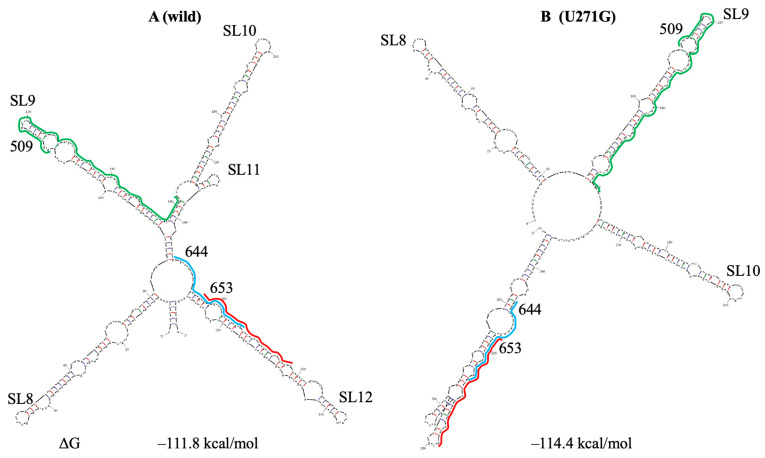 Figure 2
Figure 2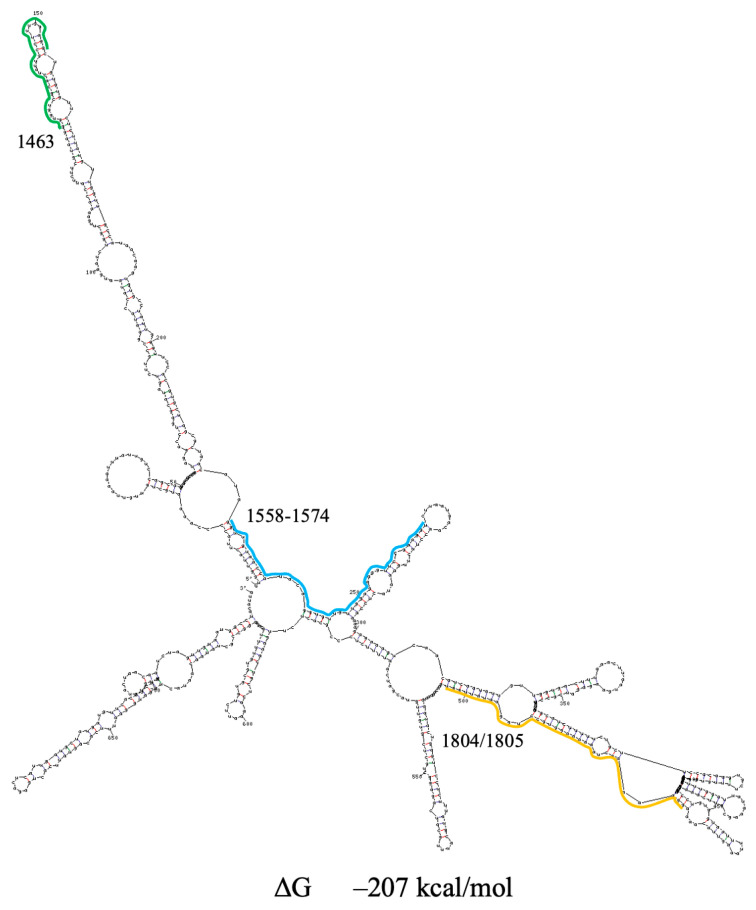 Figure 3
Figure 3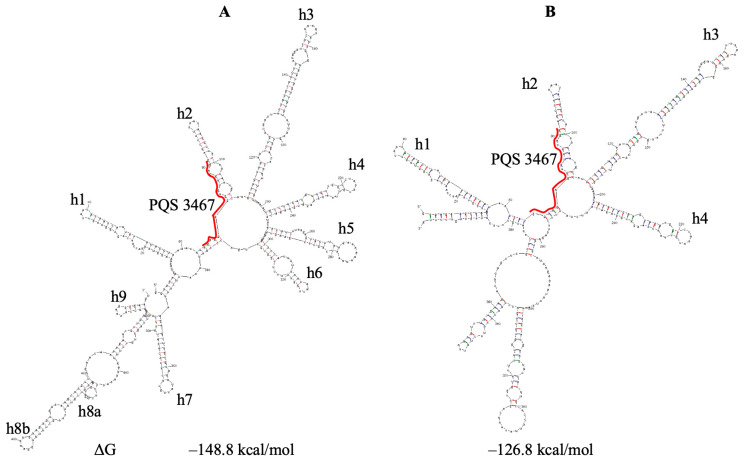 Figure 4
Figure 4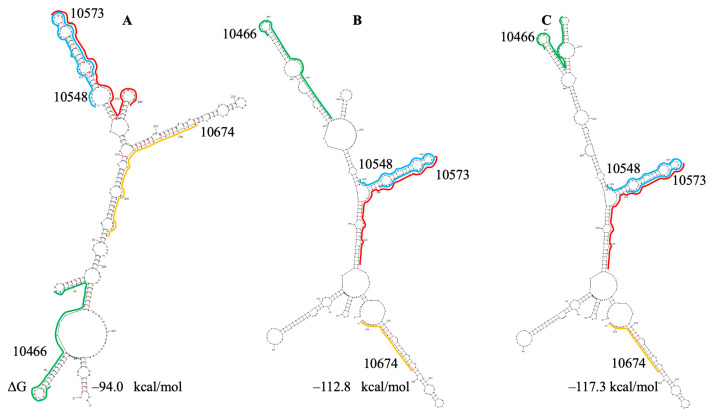 Figure 5
Figure 5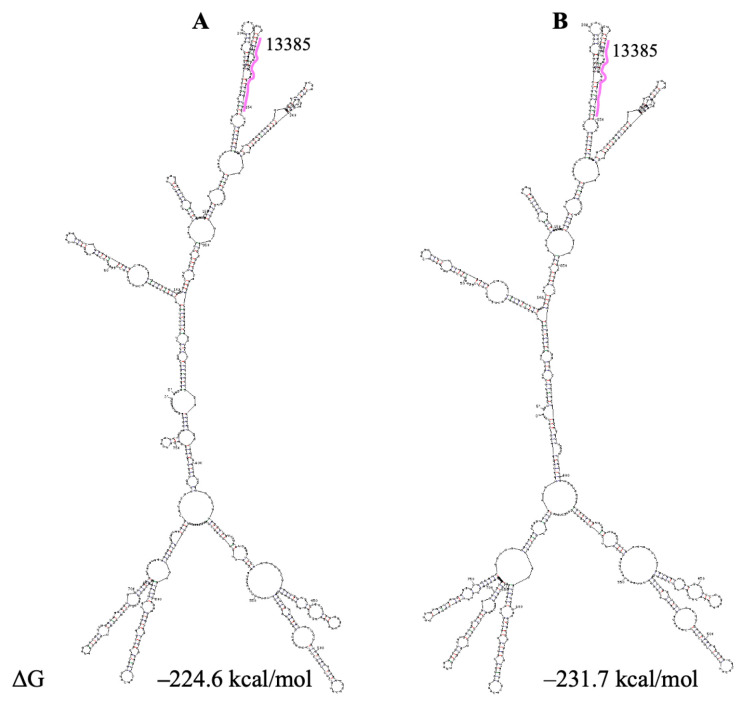 Figure 6
Figure 6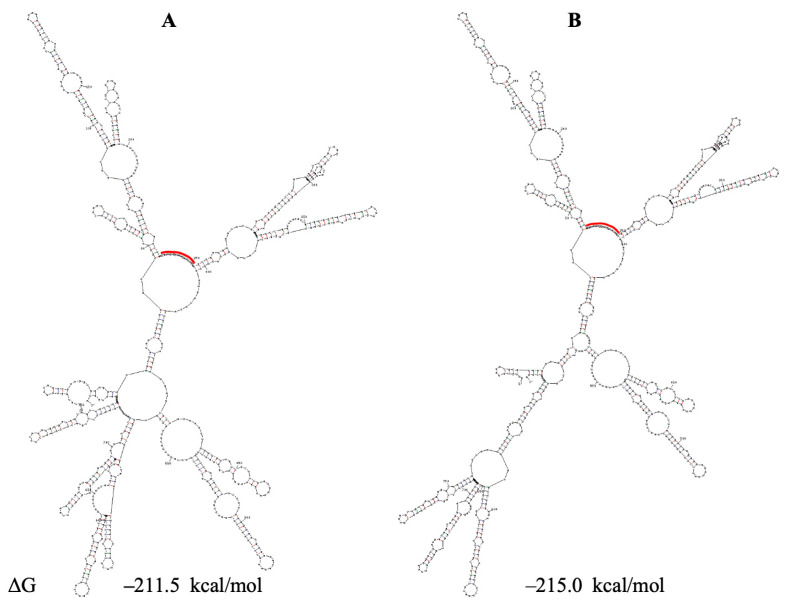 Figure 7
Figure 7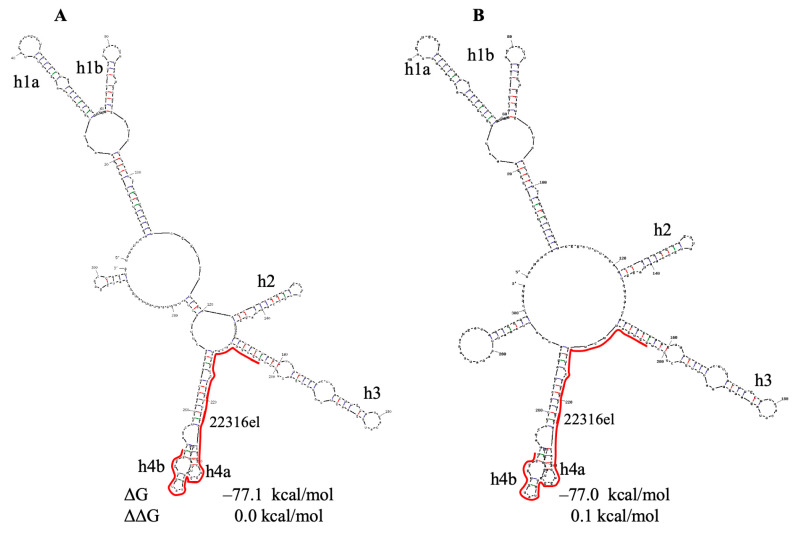 Figure 8
Figure 8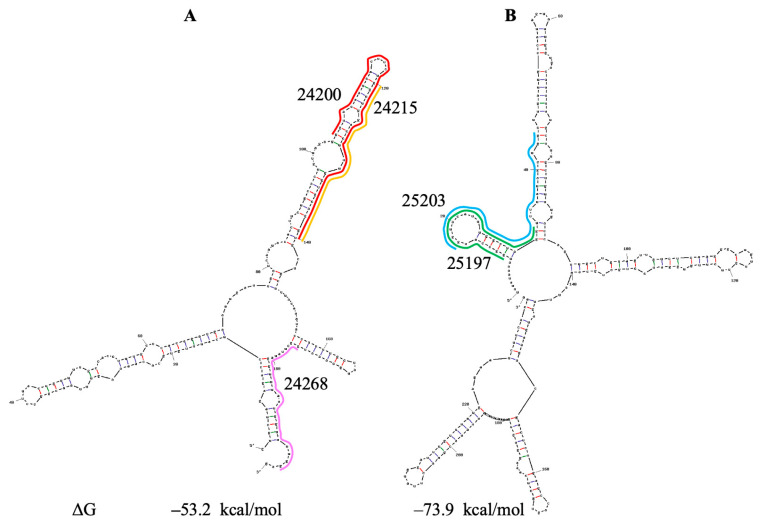 Figure 9
Figure 9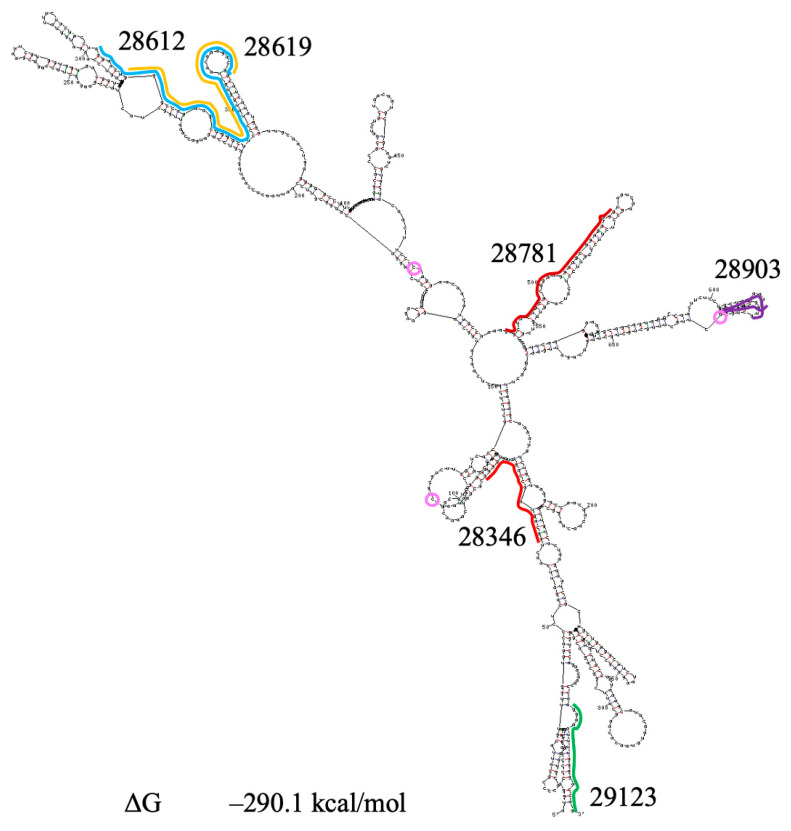 Figure 10
Figure 10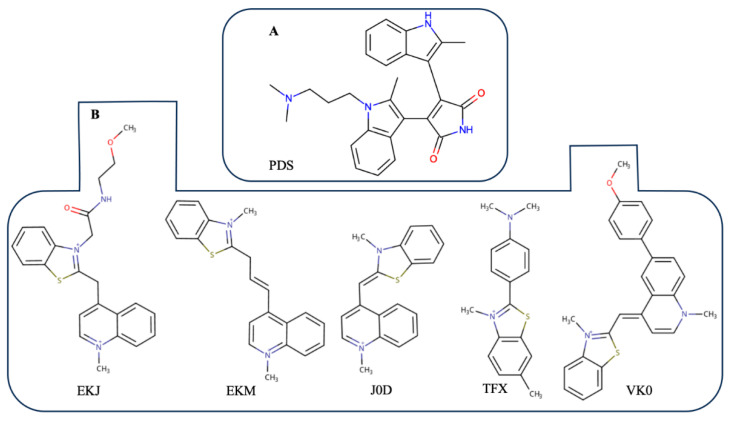 Figure 11
Figure 11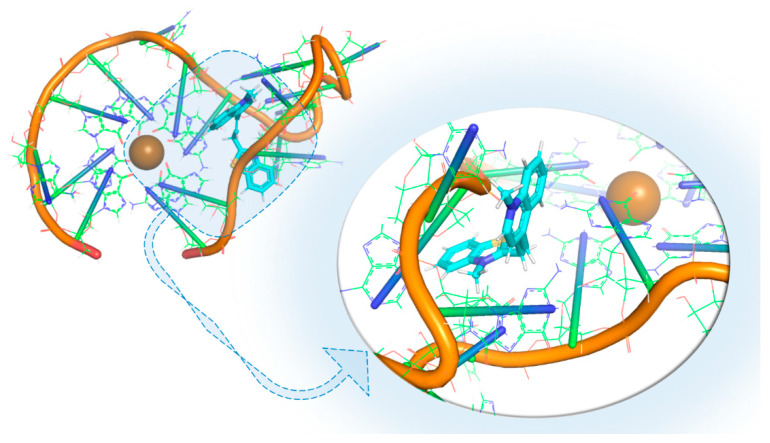 Figure 12
Figure 12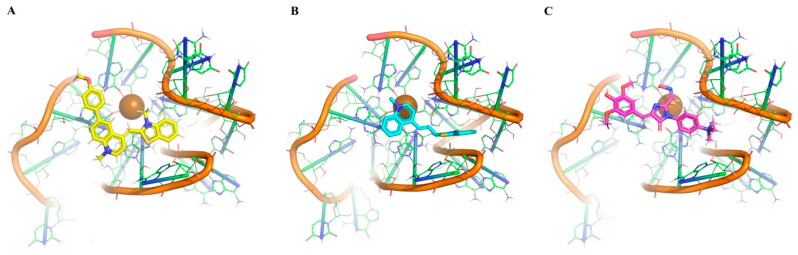 Figure 13
Figure 13- —the National Research Foundation of Ukraine
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDNA and Nucleic Acid Chemistry · RNA and protein synthesis mechanisms · RNA Interference and Gene Delivery
1. Introduction
RNA and DNA G-quadruplexes (G4s) are four-stranded structures built from stacks of at least two G-tetrads stabilized by Hoogsteen hydrogen bonds and monovalent cations. These non-canonical structures, which regulate diverse cellular and viral processes (for review, see [1,2,3,4,5,6,7,8]), are increasingly viewed as attractive therapeutic targets or agents [9,10,11], particularly in the case of COVID-19 caused by the SARS-CoV-2 virus. This virus has the ~30 kb positive-sense RNA genome which contains 47 putative G-quadruplex-forming sequences (PQSs) [12,13]. All these PQSs can form G4s with only two G-tetrads, implying relatively low stability. It was suggested that highly stable G-quadruplexes can be necessary for the inhibition of specific cellular processes, while low-stability G4s can serve as switchable and tunable motifs [14].
To date, the precise functions of individual RNA G4s in the SARS-CoV-2 genomic RNA (gRNA) remain unresolved. In principle, rG4s may up- or downregulate gene expression via at least three non-exclusive mechanisms: (i) acting as kinetic barriers to translocating proteins or protein machines (in particular, ribosomes); (ii) remodeling local secondary structure and thereby masking or exposing regulatory elements; and (iii) recruiting rG4-binding proteins that further modulate RNA fate [15]. At least, G4s in SARS-CoV-2 may slow translation of large proteins to provide additional time for their proper folding (such a function for RNA G-quadruplexes was proposed in [16]) or can attenuate replication to escape cell immune response [17,18].
The 47 PQSs in SARS-CoV-2 gRNA are located in 39 G-rich sequence (GRS) regions, since some of them overlap. The formation of G-quadruplexes by nine PQSs has been investigated in several works [13,17,18,19,20,21,22,23,24,25,26,27,28] using different biophysical assays, mainly CD (circular dichroism) spectroscopy and fluorescence (Table S1). By these main assays, Razzak et al. [27] investigated 16 more PQSs. Detailed atomistic structures have been obtained for only three PQSs through molecular dynamics and quantum chemical calculations [27,29,30,31,32].
For four PQSs, experimental studies have reported conflicting results regarding G4 formation (Table S1). These are PQSs located at positions 8687, 24268, 25197 and 28903 (further, for brevity, PQS or G4 at position N will be referred to as PQS N or G4 N). The discrepancy between the results can be due to different experimental conditions, the peculiarities of the methods used, and possible formation of different structures by PQSs. For example, ThT (Thioflavin T) fluorescence intensities were found to be similar for PQSs 644, 24215 and 24268 in Cui et al. [22], while they were significantly lower for PQSs 24215 and 24268 than for 644 in Razzak et al. [27]. However, in both works, the highest intensity was observed for PQS 13385 (significantly higher than for PQS 644) and the lowest for 25197. In these studies, both the assay conditions and the PQSs differed. In [22], PQSs contained flanking nucleotides that could have influenced the assay results. Moreover, the results of the fluorescence assay depend on fluorescent G4-specific targeting compounds. Contrary to ThT, NMM (N-methyl mesophorphyrin) fluorescence intensities for PQS 644 were higher than for 13385 [18]. CD assays do not clearly confirm the formation of G-quadruplexes but provide information on PQS folding state [24]
Conflicting results in the case of PQS 28903 may be due to its capability to form different structures. Firstly, it was suggested that it forms a hairpin rather than a G-quadruplex [13,19,24]. Qin et al. [18] reported ΔG values for PQSs 644, 1574, 3467, 13385 and 28903 at 25 °C. These values are in the range of −1.8 kcal/mol −3.1 kcal/mol (−2.6 kcal/mol for PQS 28903), and they will be higher at physiological temperature. According to our prediction of the secondary structure of PQS 28903 with flanking nucleotides (see Section 3.1), ΔG of the hairpin formed by it is −2.5 kcal/mol at 37 °C (Table S2); i.e., formation of the hairpin by PQS 28903 will be more preferable than the formation of G-quadruplex or will compete with its formation. Likewise, the hairpin formed by PQS 25197 with ΔG = −5.8 kcal/mol (Table S2) will be the dominant structure, which is in accordance with the experimental results described above.
Secondly, PQS 28903 can form dimeric quadruplex [33] and G-triplex [34]. In addition, multimeric rather than monomolecular G4s may form at high PQS concentrations. Formation of exactly monomolecular G4s was confirmed only for single PQSs. Thus, several different methods are needed to test whether the PQS forms G-quadruplex. In this regard, the formation of G4s by PQSs 644, 1574, 3467 and 13385 is most reliable (Table S1). Moreover, involvement of these G4s in regulating SARS-CoV-2 life cycle was confirmed by Qin et al. [18]. All these PQSs are highly conserved (for example, Ref. [27]) despite the high mutability of the SARS-CoV-2 genome
According to results of mutational analysis conducted in [27] for 25 potential G4 sequences, most PQSs are also highly conserved (mutation rate < 1%), but three PQSs, including 28903, showed very high mutation rates (90–100%). Recently, we separately searched for mutations in this PQS and in the domain containing it across different countries and years [32]. Frequent mutations within GG repeats in PQS 28903 were detected only in 2021–2022 but disappeared in 2023–2024, suggesting that G4-destroying mutations in it were not tolerated in the long term. Instead, a stable triple mutation shifted PQS location from the 5′ arm of a long hairpin to two shorter hairpins at the top of the domain containing it, potentially facilitating its interaction with cellular factors and proteins.
It should be noted that in the literature, the search for PQSs in SARS-CoV-2 was usually first performed using Quadruplex Forming G-Rich Sequences (QGRS) Mapper software (Mapper web server, version 2006, Ramapo College, USA) [35] with different parameters: in particular, with maximal PQS length of 30 nucleotides (nts) or 45 nts and loop size range of 0–12, 1–15 or 0–36 [13,18,22,23,25,27]. The PQSs found were then analyzed by additional algorithms (in particular, G4Hunter [36]) to evaluate the G4 folding capability considering the consecutive G over consecutive C ratio. However, the QGRS algorithm is not rigorous [37], not only because it does not take into account the G and C content but also because it does not take into consideration the structural features of G-quadruplexes. This may be the reason why certain PQSs do not agree with this algorithm and indeed form G-quadruplexes [37]. Neighboring (or/and internal) non-G residues in PQSs can form tetrads or triads stabilizing G-quadruplexes [38,39,40,41,42,43] that are not taken into account in the algorithms used. Furthermore, internal loops in G4s can form hairpins stabilizing them [44].
Therefore, in this work, we searched for PQSs via in-house analysis. We first identified the GG tracts using a simple computer search function and then manually inspected all GG-rich regions, assessing the possibility of G4 stabilization by non-G-tetrads, triads and base pairs. The clustering of GG tracts is clearly visible in RNA sequences. As a result, we identified all PQSs reported in the literature, as well as additional ones. We assessed the influence of GC content on the formation of G-quadruplexes by directly determining the change in free energy (ΔG) of the hairpin formed by PQSs. We included the flanking nucleotides, since they may additionally stabilize the hairpin. The influence of longer tracts encompassing the PQSs will depend not only on their sequence and length but also on their secondary structure, which algorithms do not account for. To set the PQS location, we predicted the secondary structure of the SARS-CoV-2 genomic RNA region containing it.
Thus, to better understand which SARS-CoV-2 G4s are most likely to be biologically relevant and to serve as antiviral targets, here we undertook a comprehensive analysis that integrates: (i) G4 stabilization by non-G-tetrads, triads and base-pairs; (ii) explicit competition between rG4 and minimum-free-energy hairpins; (iii) the impact of frequent mutations on the sequence and location of PQSs; and (iv) assumptions about the functions of some quadruplexes in the cell. For three PQSs, we studied their interactions with several stabilizing ligands using molecular dynamics simulations.
2. Materials and Methods
Sequences of the regions encompassing PQSs in SARS-CoV-2 genomes were extracted from the GISAID database gisaid.org (accessed on 09 10 2025). Mutational analysis was performed using the author’s software algorithm implemented in Python version 3.9.21. The maximum number of genomes from one country in one year was limited to the 10,000 most complete genomes as defined by GISAID: genomes >29,000 bp are considered complete and assigned a high-coverage label of <1% Ns (undetermined bases).
The secondary structure of SARS-CoV-2 regions containing PQSs has been predicted by the UNAFold program (Unified Nucleic Acid Folding, The RNA Institute, University at Albany, New York, USA) [45] for genome Wuhan-Hu-1 (accession number NC_045512, reference sequence). We used 15% suboptimality and window 0 for the automatic folding of RNA fragments. Additionally, we included the flanking nucleotides in all RNA fragments studied and applied folding constraints that prevented these nucleotides from participating in base pairing. In cases of separated hairpins, we included more than one nucleotide upstream and downstream of the hairpin if the single flanking nucleotides could form a base pair.
2.1. Molecular Docking Simulation
The Glide (grid-based ligand docking with energetics) tool, part of Maestro interface of Schrödinger suite of programs [46], was used. During the simulation, the receptor remains rigid, and the binding compounds are flexible. For molecular screening, 13 compounds (PDB Ids: A1AEC, A1AED, A1AEE, A1AEF, A1BC9, EKJ, EKM, J0D, POH, R14, TFX, V5Z and VK0) with known activity were selected. All the compounds were selected based on analysis of the PDB [47] and ChEMBL [https://www.ebi.ac.uk/chembl/ (accessed on 13 06 2025)] databases. All the simulations were done using the SP (standard precision) docking method. In each case, the best five conformations of each investigated compound were selected for visual inspection.
2.2. MD Simulation
The MD simulation was performed to estimate the time stability of the obtained RNA structures. The calculations were done with Gromacs 2021 software [48] using force field Charmm36 [49]. In the case of the RNA G-quadruplex, K^+^ was inserted within the quadruplex structure. Each system was placed into the center of a periodic triclinic box with the next filling by SPC/E water molecules. A minimum 1.5 nm distance was maintained between the nearest atom of the RNA and the edge of the simulation box so that the RNA could fully immerse in water and rotate freely. Before conducting any evaluations, each MD trajectory was subjected to a rotation and translation fit to a reference RNA structure. This step was carried out to eliminate translational and rotational motions of the RNA molecules, allowing subsequent analyses to concentrate on internal molecular motions and interaction. To neutralize the system and mimic the cellular environment (pH 7), K^+^ and Cl^−^ ions were added to bring the ionic concentration to 150 mM. In this process, the solvent molecules are randomly replaced by monoatomic ions. The systems obtained were energy-minimized via the steepest descent algorithm (the maximum number of steps was 50,000) and equilibrated in two stages. The stage of NVT equilibration was performed at 1 ns using a V-rescale thermostat, and the second NPT equilibration of 1 ns was performed appropriately with the same thermostat and a Berendsen barostat. After that, the MD simulations were launched within 100 ns to all the complexes, and then for some that were selected, the MD simulation was extended to 500 ns. All calculations were done at a temperature of 35 °C and constant atmospheric pressure.
2.3. gmx_MMPBSA Calculation
The MM/PBSA (molecular mechanics/Poisson–Boltzmann surface area) [50,51,52] and complex binding energy (Equation (1)) were determined using gmx_MMPBSA (version 1.4.1, University of Medellín, University of Calgary, University of Toronto, Colombia/Canada) [52] software tool.
Here, ∆E_MM_ is the molecular mechanics contribution in a vacuum and is the sum of ΔE_vdW_ (van der Waals’ interaction energy) and ΔE_EE_ (electrostatic interaction). ∆G_ps_ is the polar solvation free energy, ∆G_nps_ is the non-polar solvation free energy, and –TΔS is the entropic contribution.
3. Results and Discussion
3.1. Genome-Wide Search for SARS-CoV-2 PQSs
Results of our search for PQSs are presented in Table S2A,B for G4s in SARS-CoV-2 positive-sense and negative-sense gRNAs, respectively. We presented all PQSs with potential tetrads consisting of A and U bases, while out of the PQSs with triads, we selected only those with a canonical U·A-U triad, which is, along with triad C^+^·G-C, the most stable [53]. Since triplexes can exist as independent structures (for example, in [34]), they can be formed by RNA regions containing only three GG repeats. Therefore, we also presented the sequences of the shortest putative G-triplexes in Table S2C.
We paid special attention to putative 3′ U·U·U·U tetrad in G-quadruplexes. This tetrad significantly stabilizes G4s consisting of four chains [54,55,56,57]; in particular, it increases the melting temperature (T_m_) of G4 formed by the human telomere RNA sequence r(UAGGGU) by 29 °C [55]. Possibly, this tetrad may stabilize monomolecular G-quadruplexes as well.
In the positive-sense strand, we identified 133 PQSs (Table S2A) in 42 G-rich sequences (GRSs)—almost three times more PQSs than published in the literature. From these, we have selected 23 the most significant PQSs based on their length and potential stabilization by non-G-tetrads or triads (Table 1). The first group of PQSs in this Table includes the shortest sequences (≤25 nts), which form only unstable hairpins and have an ΔG greater than −1.0 kcal/mol. PQSs including in other groups of Table 1 are the shortest among those stabilized by non-G-tetrads, triads or base pairs (some of them are also included in the first group).
All PQSs presented in Table 1 were analyzed in detail (in the order of their location in the genome) with respect to their structural context, conservation and possible functional roles.
3.2. Potential G-Quadruplexes in Gene nsp1 of SARS-CoV-2 gRNA
3.2.1. PQSs 353, 359 and 370
In vivo structural model of the whole SARS-CoV-2 gRNA is presented in the work of Sun et al. [58], and a model of most of the gRNA is presented in the work of Huston et al. [59]. We predicted the secondary structure of SARS-CoV-2 RNA fragments by the UNAFold program based on these two models. The structure of the region encompassing the first 294 nts of the genome is similar in both models and in models reported in other works (for example, Refs. [60,61,62]). The secondary structure of the 5′ terminus of SARS-CoV-2 gRNA, predicted by the UNAFold program for the reference genome Wuhan-Hu-1, is presented in Figure S1. Contrary to models in the literature, it exists in two variants with practically identical ΔG values. The optimal structure contains a large domain with two subdomains, whereas the suboptimal structure is similar to the models in the literature with a single domain. Notably, the reactivity data for the linker nucleotides in the models in the literature do not align well with these models. This may be explained by the coexistence of two nearly equally stable structures, but the models present only one of them.
Our large-scale mutational analysis of the SARS-CoV-2 5′ terminal region revealed that three mutations were frequently observed in this region during 2022 to 2024 (Table S3). During this period, the base change C241U was dominant in all five countries, whereas the frequency of base change C21U increased from 0% to 20% in some countries. The double mutation C44A+C241U practically did not alter the structure of the region under study (Figure 1 and Figure S1).
Overlapping PQSs 353, 359 and 370 (Figure S2) are located within stem-loop SL7 of the 5′ leader. These PQSs correspond to the beginning of the first domain of nsp1 protein (Ref. [63] and Figure S3A), implying that their potential roles are unlikely to be co-translational folding of this domain; instead, they may perform other functions. Nsp1 supresses host gene expression through distinct mechanisms [64]; in particular, it disrupts cap-dependent translation by association with the 40S ribosomal subunit, raising the question of how viral mRNAs escape nsp1-mediated repression. Perhaps, G-quadruplexes 353, 359 and 370 play some role in supporting viral transcripts’ translation.
G-quadruplexes located in IRESs (internal ribosomal entry sites) may directly recruit the 40S ribosomal subunit in the vicinity of the AUG start codon ensuring cap-independent translation initiation [65]. IRES can be located both upstream and downstream of AUG. For example, in HIV-1 genomic RNA, one of the IRESs is located within the HIV1 Gag open reading frame and contains G-quadruplex [66]. We suppose that it may participate in translation initiation [67]. By analogy, G4s 353, 359 and 370 may contribute to cap-independent initiation of SARS-CoV-2 translation.
Biophysical assays were conducted only for PQS 353 [27]; they confirmed the formation of G4 by this sequence. At 37 °C, PQSs 353, 353el, 359 and 370 form hairpins with ΔGs of −3.4 kcal/mol, −6.0 kcal/mol, −6.0 kcal/mol and +0.1 kcal/mol, respectively (Table S2). Therefore, G4 formation by PQS 353 and especially by 353el and 359 can compete with a hairpin formation, contrary to PQS 370. Since Razzak et al. [27] used high PQS concentrations in their assays (15 μM), it is possible that multimeric G-quadruplexes could form together with (or instead of) monomolecular G4s in their assays. In addition, hairpins formed by PQSs 353, 353el, 359 and 370 have regions with unpaired GG repeats (Figure S4), which could promote the formation of multimeric structures.
The importance of certain G4s for the SARS-CoV-2 virus may be supported by their strong conservation in other coronaviruses, in particular, in SARS-CoV [22,23]. In SARS-CoV, the hairpin similar to SL7 is also formed (Table S4). It also includes several GG repeats, but only five of them match those in SARS-CoV-2. Thus, there are no direct analogs for PQSs 353, 359 and 370, but there is a similar hairpin encompassing seven redundant GG repeats, which can form different G4s. There are six redundant GG repeats in SARS-CoV-2.
Note that there is one more PQS in the RNA region under study—PQS 236 (Table S2). This sequence has a complete analog in SARS-CoV (Table S4) which may be stabilized by the canonical U·A-U triad. PQSs 236 and 236a form relatively stable hairpins (−8.2 kcal/mol and −9.8 kcal/mol, respectively (Table S2)), and the formation of G4 by PQS 236 without the triad is unlikely. The elongated variant (Table S2) forms a more stable hairpin (−15.5 kcal/mol), but this G4 may be significantly stabilzed by the 3′ U-tetrad. In addition, an internal hairpin (Table S2) can form in its third loop and stabilize it. Stabilization by the 3′ U-tetrad is also possible in the case of SARS-CoV.
PQSs 236, 236a and 236el start at the upper part of SL5b. Whether G-quadruplex stabilized by the 3′ U-tetrad is formed in the domain with SL5a-SL5c and whether it is functionally important is unknown. The repeat UUYYGU hexaloop motif in SL5a and SL5b was proposed to be important for packaging, but its full role in packaging and in other viral functions remains unclear [68]. The dominant mutation C241U did not destroy this motif.
Thus, overlapping G4s 353, 359 and 370 in the SARS-CoV-2 gRNA 5′ terminal region may support cap-independent translation initiation. PQS 370 stands out as a promising drug target: it is short, forms an unstable hairpin and is not affected by dominant 5′ UTR mutations.
3.2.2. PQSs 509, 644 and 653
Further, for brevity, we will refer to the models of SARS-CoV-2 genomic RNA presented in works of Sun et al. [58] and Huston et al. [59] as Sun and Huston models, respectively. In the Sun model, PQSs 509, 644 and 653 are in a large domain with five hairpins, which is located immediately downstream of SL7. Manfredonia et al. [60] designated the hairpin located immediately downstream of SL7 as SL8. We continued numbering the hairpins further. In the Huston model, hairpins similar to those in the Sun model are separate structural elements. UNAFold program predicts the structure of the region with PQSs 509, 644 and 653 as in the Sun model, only in the suboptimal folding with ΔΔG = 0.5 kcal/mol, while in the optimal folding, three out of five hairpins are localized in a subdomain (Figure 2A).
The dominant mutation U271G in the domain containing PQSs 509, 644 and 653 (Table S5) altered its structure (Figure 2B) and introduced a new GG repeat in PQS 653, generating a shortened PQS 653m (Table S2). PQSs 644, 653, and new PQSs 653m and 659m (Table S2) are short and form unstable hairpins; two of them (PQSs 644 and 653m) we included in Table 1 with the most significant PQSs. PQSs 644 and 653 have analogs in SARS-CoV (Table S4).
In the context of the nsp1 protein, PQS 644 lies at the beginning of the linker between the N- and C-terminal domains and might contribute to correct folding of the large N-terminal domain (Figure S3A). PQS 509, not reported in the literature, may form G4 with a 3′ U-tetrad and forms a moderately stable hairpin (ΔΔG = −6.2 kcal/mol). The potential formation of an internal hairpin in its third loop (Table S2) may further stabilize the G4. PQS 509 does not have a direct analog in SARS-CoV, but a putative G4 with 3′ U-tetrad is in the same region (Table S4); however, it forms the stable hairpin with ΔΔG = −13.1 kcal/mol. Although the direct function of G4 509 remains unclear, highly stable local structures such as 3′ U-tetrad-capped G4s may help maintain the overall architecture of very long RNAs without substantially increasing GC content.
3.3. PQSs in Gene nsp2 (1463, 1558, 1574, and 1805)
PQSs 1463, 1558, 1574 and 1805 are located in gene nsp2. PQS 1804/1805a is included in Table 1 as stabilized by a tetrad and base pairs at both sides. PQS 1558/1559 may also be simultaneously capped at both sides of G4 by non-G-tetrads (Table S2). All G4s correspond to the central part of nsp2 (Figure S3B). They may ensure proper protein folding, and their redundancy in this area may be necessary to delay ribosome movement during the synthesis of a rather large protein.
PQSs 1463, 1784 and 1805 have SARS-CoV analogs, whereas PQSs 1559 and 1574 do not (Table S4), although the same genomic region is enriched in PQSs in both viruses.
The secondary structures of the region encompassing PQSs under study are different in the Sun and Huston models; however, PQSs 1559, 1574 and 1805 are located in similar hairpins. We predicted the secondary structure of the region under study based on both models in the literature but additionally included several separated hairpins downstream of the region in the Sun model and upstream of that in the Huston model. UNAFold predicts alternative folds for this region based on the Sun and Huston models, but in all cases, PQS 1805 resides in a conserved subdomain with three hairpins (Figure 3 and Figure S5).
PQS 1463 is among five PQSs which were reported to be the most prone to mutations [27]. It showed a relatively small mutation rate (4%). We did not find mutations with the frequency ≥2% in 2022/2023 directly in this PQS (Table S6). Rare mutation C18A (≤4%) only altered the structure of the middle hairpin in the upper part of the subdomain containing PQS 1805.
At the C-terminus of nsp2, PQSs 2714/2717 lie at the boundary to nsp3 protein (Figure S3B) and may assist in final nsp2 chain folding. PQS 2717 may be stabilized by a 3′ U-tetrad and an internal hairpin (Table S2). PQS 2714 has an analog in the SARS-CoV genome (Table S4), while PQS 2717 has a similar sequence but without all four U bases, which are necessary for the formation of a U-tetrad. UNAFold program predicts structures for the region containing these PQSs, similar to the models in the literature (Figure S6).
Thus, PQSs in gene nsp2 are conserved, and four of them have analogs in the SARS-CoV genome. The probability of forming G4s quadruplexes by some of them is relatively high due to their stabilization by triads or tetrads. They may be necessary for proper nsp2 folding.
3.4. PQSs in Gene nsp3
3.4.1. PQS 3467
PQS 3467 forms the most stable G-quadruplex among SARS-CoV-2 G4s (T_m_ = 63.2 °C [18]). It is located in gene nsp3. We predicted the secondary structure of the region under study directly from the Huston model (Figure 4), whereas, upon folding this region according to the Sun model, we added three small separate structural elements immediately downstream. In both cases, PQS 3467 initiates in short duplexes that close large domains. The formation of G4 by this PQS requires the destruction of not only the second hairpin but also the whole domain, suggesting that this G4 may form only transiently or under specific conditions.
The mutation search (Table S7) showed that unlike many other PQSs, even in 2023, most genomes had practically no mutations in the region under study; they were detected with a relatively high frequency (26%) only in UK (double mutation G62U+U196C). This mutation became dominant (68–82%) in 2024 in all countries for which the mutation search was conducted. All detected mutations, both dominant and rare, did not affect either the PQS 3467 sequence or its location. Since PQS 3467 is located in the gene nsp3 region corresponding to the beginning of Mac1 domain (Figure S3C), presumably, it will not be used for proper folding of the nascent polypeptide chain. In addition, it has no analog in the SARS-CoV genome. However, its high stability and strong conservation suggest an important but as yet unclear function. This PQS is included in Table 1.
3.4.2. PQSs in SARS-CoV-2 gRNA Region Corresponding to SUD Domain (4256/4262,4485/4487 and 4616)
Subdomain SUD (SARS unique domain) of the nsp3 protein attracts special attention because it may be responsible for increased pathogenicity of SARS-type coronaviruses, in particular, SARS-CoV-2 [69]. SUD consists of three subunits: SUD-N, SUD-M and SUD-C. Four GRSs correspond to SUD-N and SUD-M (SUD-core) (Figure S3C). The secondary structure of SARS-CoV-2 gRNA containing PQSs 4256/4262 and 4485/4487 (predicted by the UNAFold program based on the models in the literature) is shown in Figure S7.
A dominant mutation (G380A, later designated G106A in extended searches) emerged in 2022 and rapidly reached frequencies >90%, abolishing G4s 4127/4143/4161 (Table S8). This base change and other most frequent base changes only altered the location of PQSs 4256/4262. Overlapping PQSs 4127, 4143 and 4161 have no analogs in SARS-CoV gRNA, while PQS 4256 has (Table S4). There are sequences similar to PQSs 4487 and 4616 in SARS-CoV gRNA; however, one of four GG repeats is absent in each of these sequences.
SUD-core domains in the nsp3 proteins of SARS-CoV and SARS-CoV-2 can bind DNA and RNA G-quadruplexes [70,71,72,73]. Lavigne et al. [71] showed by HTRF assay (homogenous time-resolved fluorescence) that contrary to cellular G4 TRF2 with three G-tetrads, the most stable viral G4s (13385, 24268 and 28903) do not interact with SUD-NM of SARS-CoV-2. In fact, the affinity of SUD-NM for G4 13385 was approximately five times less than for G4 TRF2, and even less for G4s 24268 and 28903 (Figure 5 in [71]). The absence of SUD-core binding to PQS 28903 was also confirmed by fluorescence assay in the work of Zhang et al. [73]. However, Qin B. et al. [72] showed by EMSA (electrophoretic mobility shift assay) that both G4 TRF2 and G4 24268 bind to SARS-CoV-2 SUD-core.
The formation of G-quadruplex by PQS 24268 has been confirmed in some studies but not in others (Table S1). The absence of G4 was primarily based on the results of the fluorescence assay. However, the low fluorescence intensity could be due to the structural features of this G4 and may not indicate its absence. The HTRF assay in [71] is also based on fluorescence data, and the authors’ results for PQS 24268 may also be due to its specific structure. Thus, viral G4s with two G-tetrads can interact with SUD-core but with significantly less efficiency than those with three tetrads, which are absent in SARS-CoV-2 gRNA but are present in cellular RNAs.
Kusov et al. [74] demonstrated that the SUD-M subunit is indispensable for SARS-CoV replication and suggested that it might be connected with the SUD’s ability to bind G-quadruplexes or oligo(G) tracts. If this is true, then which specific G4s in SARS-CoV-2 might be bound to SUD during replication/transcription? These processes are carried out inside of double-membrane vesicles (DMVs) (for example, Refs. [75,76]). Nsp3, along with other proteins, forms the DMV pore complex. According to Chen et al. [77], nsp3 in the pore complex does not come into contact with the gRNA on which minus-strand synthesis occurs; i.e., there is no interaction between SUD in nsp3 and G4 in gRNA during replication.
However, other nsp3 molecules could be involved in this interaction. Chen et al. [77] do not exclude the possibility that all macromolecules necessary for replication could have been enclosed in DMV at the time of its formation. Nsp3 molecules could have been enclosed in the same way. Weak (transient) SUD binding to RNA G4s and weak nsp3 interaction with most of the other proteins of the replication and transcription complex (RTC) may facilitate reorganization of RTC for participating in different steps of the replication-transcription process, such as minus/plus gRNA and sgRNA synthesis, proof-reading, capping and polyadenylation. Furthermore, SUD may stabilize G-quadruplexes [73]. RTC stalling before stabilized G4s may also facilitate RTC reorganization. Quite recently, Yang et al. [78] showed that RTC localizes in the exterior of DMVs, and nsp12 and other RTC components could be recruited to DMV through direct interaction of nsp12 with nsp3. In this model, gRNA in complex with RTC must enter DMV through the pore complex. In this case, an additional nsp3 protein(s) may also enter DMV either during its formation as free molecules or in complex with gRNA G4s.
The main role in facilitating the RTC reorganization may belong to G4s located at the ends of plus and minus gRNAs where they could regulate initiation or termination events. The first G4 in nascent minus gRNA is located at position 165 of minus gRNA with a potential U-A-U triad in the second loop (Table S2B). A putative G4 that may form when RTC reaches the beginning of plus gRNA is PQS 29867 also stabilized by a U·A-U triad. This G4 may be necessary for initiating the synthesis of the plus-strand RNA and its processing.
In addition to participating in replication (at least in the formation of pore complexes), SUD protein in nsp3 may stimulate translation by binding to 40S/80S ribosome and increasing the interaction between PABP (poly(A)-binding protein) and Paip1 (PABP)-interacting protein 1) [79]. It is unknown whether SUD interacts with G4 during translation initiation, particularly during cap-independent processes. According to Lemak et al. [80], SUD binds to the region 301–545 base including PQSs 353, 359 and 370.
3.5. PQSs in nsp4 and nsp5 (8687, 10058/10085, 10254/10260, 10466, 10548/10573 and 10674)
Nsp4, together with nsp3, shapes DMVs (Section 3.4.2). The single PQS (PQS 8687) in gene nsp4 corresponds to the Ecto domain in this protein (Figure S3D), which is located between transmembrane domains 1 and 2. PQS 8687 has an analogous sequence in the SARS-CoV genome, but this sequence does not contain one of the GG repeats to form G4 (Table S4). SARS-CoV gRNA contains other PQSs, corresponding to the Ecto domain. We included PQS 8687 in Table 1, since it is short (23 nts) and forms an unstable hairpin (with ΔG = −0.6 kcal/mol). However, it is unclear in which structural element of gRNA this PQS is located, since the models in the literature for it are too different. The structure based on the Huston model is presented in Figure S8. PQS 8687 is located in it in a small hairpin.
PQS 8687 is located within a very conserved RNA region (Table S9). In 2024, more than 90% of SARS-CoV-2 genomes studied had no base changes in this region. A frequent base change, C169U, occurred in China in 2022 and 2023 but was not found in 2024.
Four GRSs are located in the SARS-CoV-2 gRNA region corresponding to the nsp5 protein; three of them contain overlapping PQSs (Figure S3E, Table S2). Nsp5 is the main protease for processing of the replicase polyprotein [81]. It consists of three domains. PQSs 10058 and 10085, which correspond to the very beginning of domain 1, and PQS 10674, corresponding to the beginning of domain 3, may serve for proper folding of nsp4 and nsp5, respectively.
PQSs 10058, 10085, 10254 and 10260 (like many other PQSs in SARS-CoV-2 gRNA) are located in similar minimal structural elements in the models in the literature, but the structures of gRNA regions containing these elements are different. The secondary structures of the region containing these PQSs based on the Sun and Huston models are shown in Figure S9. PQSs 10254/10260 are either mostly located in similar hairpins, or they are located in duplexes and linkers. A stable dominant double mutation, C19U+C188U (with the frequency of 88–97% in 2024), was found in the studied region (Table S10). It did not affect the structure and location of PQSs in the foldings based on both the models in the literature.
The secondary structures of the region containing PQSs 10466 and 10674 based on the Sun and Huston models are shown in Figure 5. PQSs 10466 and 10674 start at the same hairpins in both of the models in the literature and in UNAFold predictions, while the localization of PQS 10573 is different in the models and predictions.
The stable double mutation G102A+G104A with a frequency of 89–96% was found in the region of the RNA genome containing PQSs 10466–10674 (Table S11). It did not impact the structure of the domain based on the Sun model but altered the structure of the hairpin containing PQS 10466 in folding based on the Huston model (Figure 5C). Similar to PQS 28903, it is now located in two hairpins instead of a single one. Several PQSs (10085, 10466, 10548, 10562, 10674) have SARS-CoV analogs, while others lack a complete set of GG repeats (Table S4). Although an analog of PQS 10466 is not stabilized by the potential 3′ U-tetrad, it may also be significantly stabilized (by U·A-U triads at both sides of G4).
Triads or tetrads may stabilize the most putative G4s in gene nsp5. In addition, in some long PQSs, triplexes may be formed if any three GG repeats are located close to each other, for example, in PQS 10674. Three PQSs in gene nsp5 may be significantly stabilized by the 3′ U-tetrad. Two of them (10085 and 10466) we included in Table 1. Gene nsp5, along with gene N, harbous the highest number of PQS variants and the highest density of GRSs containing PQSs (Table S12), suggesting that G4-mediated control may be particularly important for the expression of these genes.
3.6. PQS in Gene nsp10 (13385)
PQS 13385 is located in SARS-CoV-2 gene nsp10. This gene contains an important regulatory element, FSE (frameshift stimulation element), which controls the programmed ribosomal frameshifting (Ref. [82] and refs therein). Since PQS 13385 is located 77 nts upstream of the FSE “slippery” sequence, it can impact the structure of the RNA region encompassing FSE. The secondary structures of this region differ across the models in the literature. The Sun model contains a small subdomain and a hairpin within a large domain, which are competent for forming the canonical pseudoknot. In contrast, the Huston model presents two small, separate hairpins, which are competent for forming an alternative pseudoknot. UNAFold program predicts a structure similar to the Sun model (Figure S10) only in the suboptimal folding with a very high value of ΔΔG (7.3 kcal/mol).
In the Huston model, the presence of a large linker region between two small hairpins forming the alternative pseudoknot does not coincide with the authors’ experimental data. Therefore, we predicted, by the UNAFold program, the secondary structure of the regions encompassing two large domains in each model in the literature containing PQS 13385 and putative pseudoknots (Figure 6). The upper parts of the structures presented in this figure are identical and do not contain the hairpin involved in the formation of the classic pseudoknot. However, this hairpin is presented in the optimal foldings with the imitation of G4 13385 formation (Figure 7).
Maybe, the identical upper parts in the folding shown in Figure 6 and Figure 7 present the structures of the domain competent for the formation of the classical pseudoknot. This domain is not presented in the models in the literature.
The structure of a minimal RNA fragment involved in the formation of a classical pseudoknot in the SARS-CoV-2 genome is shown in Figure S11A. It consists of a small domain and a hairpin. In Figure S11B,C, the structures of the corresponding fragment in SARS-CoV are also shown. These structures in the genomes of two coronaviruses are similar; in SARS-CoV, the slippery sequence and the 3′ arm of the stem 1 are more exposed.
PQS 13385 has an almost identical analog in the SARS-CoV genome (Table S4). In 2022 and 2023, mutations in the SARS-CoV-2 gRNA region containing PQS 13385 were absent in most genomes (in 80–90%, Table S13), except base change U188C, which occurred with a frequency 46% in the UK in 2023. In 2024 and 2025, this mutation became dominant (70–90%). It practically does not alter the structure of the subdomain participating in the formation of the pseudoknot.
Thus, PQS 13385 is conserved and has an analog in SARS-CoV. SARS-CoV-2 and SARS-CoV gRNAs both contain regions that form the classical pseudoknot. PQS 13385 is short, does not compete with the hairpin formation and may be additionally stabilized by the classical U·A-U triad at each side. We therefore classify it as one of the most functionally significant PQSs in the genome.
3.7. PQSs in Gene S
3.7.1. PQS 22316
PQS 22316 is located in gene S. In spike protein structure [83], it corresponds to the end of the largest domain of this protein (N-terminal domain, NTD, Figure S3F). Therefore, G4 22316 formation may serve for the proper folding of a nascent polypeptide chain. PQS 22316 has no analog in the SARS-CoV genome. In the Sun model, it is located in a hairpin and a small domain. The structure of the SARS-CoV-2 gRNA region containing this PQS (based on the Sun model) is shown in Figure 8.
According to Razzak et al. [27], base changes in the G4 22316 sequence occur rarely (mutation rate < 2%). Our mutation search (Table S14A) shows that early in the pandemic, PQS 22316 was mainly conserved, but in 2022–2023, two G-to-non-G mutations (G68A and G54U) temporarily reached high frequency and disrupted G4s 22316/22316el. On the other hand, a new base change, A57G, appeared in 2022 (Table S14A), and its frequency increased up to 19% in 2023. This mutation results in the formation of a new GG repeat in PQS 22316 and the formation of shorter G4 (21 nts), which does not form a hairpin (ΔG = +0.4 kcal/mol). Additional analysis of 2024–2025 genomes (Table S14B) showed a disappearance of G4-destroying or G4-stabilizing mutations in this region, indicating adverse selection against long-term disruption of G4 22316. Gene S is highly mutable. In 2025, five to seven frequent mutations (with the frequency of 16–46%) were found in the gRNA region shown in Figure 8. Even seven mutations did not affect the structure of the region encompassing hairpins 2, 3 and the subdomain with hairpins 4a/4b, except of small alterations in the upper part of this subdomain (Figure S12).
PQS 22316 contains one of eight pseudouridines (Ψs), found in the SARS-CoV-2 genome [84]. Frequent mutations did not affect its location. Other Ψs in this genome are not located in PQSs, but some of them are present nearby. Pseudouridylation is an abundant RNA modification which can affect its structure and function, in particular, translation (for example, Ref. [85]).
PQS 22316 has been added to Table 1, since it forms a low-stability hairpin, and G4 formed by this sequence may be stabilized by U·A-U triads at each side. In addition, it is a single PQS which is co-located with Ψ in the SARS-CoV-2 genome.
3.7.2. PQSs 24200/24215, 24267/24268 and 25197
PQS 24267/24268 is included in Table 1, since it is short, forms an unstable hairpin and may be stabilized by a U·A-U triad. The UNAFold program predicts a structure of the region containing PQSs 24267/24268 (and also PQSs 24200/24215) that is similar to the Sun model (Figure 9A). These PQSs correspond (Figure S3F) to the linker between S protein domains FP (fusion peptide) and HR1 (heptapeptide repeat sequence 1) and may serve to fold the preceding domains properly. Frequent base changes occurred in the domain containing PQSs under study in 2021 and 2022 (Table S15). However, in 2023, there were no mutations. There are analogs for all PQSs in the SARS-CoV genome (Table S4); however, the analog of PQS 24200 is unable to form a G-quadruplex stabilized by a 3′ U-tetrad. Conservation of the PQSs 24200, 24215, and 24268, and the availability of analogs, support our proposal regarding their role in the translation process.
At the end of the gene S, there are overlapping PQSs 25197 and 25203. The UNAFold program predicts a structure for the region containing these PQSs that is similar to the Sun model (Figure 9B). Both PQSs are located in two hairpins. A single dominant base change (C21U, about 90%, Table S16) is located in the apical loop of the first hairpin. It does not affect either the region structure or the stability of the hairpins formed by PQSs 25197 and 25203. PQS 25197 corresponds to the boundary between domains HR2 and TM (transmembrane) in S protein (Figure S3F). These PQSs have analogs in SARS-CoV (Table S4); however, they cannot form quadruplexes with a U·A-U triad. So, all PQSs in gene S discussed here may serve to fold S protein domains properly.
Spike protein, along with seven other structural and accessory proteins, is expressed from subgenomic RNAs (sgRNAs) [76]. The sgRNA S is the largest one; it contains the sequence of all SARS-CoV-2 genomes except the ORF1A/ORF1B region. To our knowledge, a structural model of whole sgRNA S is not presented in the literature, although the model of gene S is [86]. The structures of the regions containing different PQSs in gRNA, sgRNA S and gene S will differ (except for the possible presence of identical separated hairpins or small domains).
3.8. PQSs in Gene N
Contrary to spike sgRNA, nucleocapsid sgRNA is the smallest one and the most abundant [76]. The gene N model is reported by Zhao et al. [28]. The UNAFold program predicts a similar structure for this region, as shown in Figures S13 and S14. The gene N sequence is shown in Figure S15. The UNAFold program predicts two distinct optimal structures for the second domain; folding in Figure S14A is similar to that in the Zhao et al. model. In addition to the translation region, sgRNA also includes the leader region and the 3′ untranslated region. We conducted a search for mutations practically in the whole gene N (Tables S17–S20) and found two conserved dominant mutations (mainly ˃90%): a 9-nt deletion in PQS 28346 and a triple mutation in PQS 28903 [32].
The whole sgRNA N has different secondary structures in folding states with close changes in free energy, but all of them contain a large, identical domain containing PQSs 28346, 28613/28619, 28781, and 28903 and partially 29123. The structure of this domain is presented in Figure 10. Two conserved mutations and two frequent mutations identified in 2025 are present in the domain sequence. The domain structure is similar to that of the first domain in gene N. Conserved and frequent mutations affected only the subdomains containing PQS 28903 and PQS 28346.
Gene N includes six GG-rich regions containing overlapping PQSs (Table S2, Figure S2) and four pseudouridine sites (28417, 28759, 28927 and 29418 [84]). Three of them are located in the first domain of gene N, not far from G4s. Contrary to U28759, the locations of U28417 and U28927 are altered in the sgRNA N structure by mutations, which may affect the modification of these uridines. Location of U29418 in a new structure of N gene terminal region was not altered.
The 9-nucleotide deletion in PQS 28346 significantly reduced the length of this PQS and probably increased the stability of G4, which it forms. We only included PQS 29123 in Table 1 as one of the shortest G4 sequences. Furthermore, this PQS can be elongated and stabilized by an A-A-A-A tetrad (Table S2). However, other PQSs in this gene also may form G-quadruplexes, in particular, the shortened PQS 28346 and PQSs with stabilizing triads at both ends of G4 (PQSs 28642 and 29255).
It is unclear which structures a short PQS 28903 forms in the cell—unimolecular G4 (with the help of cellular factors), triplexes [34], dimers [33] or all of them—and what role these structures play in the life cycle of the virus. Considering the great concentration of sgRNA N in a cell, PQSs 28903 can also form tetrameric G-quadruplexes. Moreover, these tetramers may be significantly stabilized by a 3′ U-tetrad, since their bottom part is almost identical to tetramers for which the formation of a highly stabilized structure was reported [56]. One chain of tetramer in PQS 28903 is UGGCUGGCAAUGGCGGU, while that in the work of Andrałojć et al. [56] is UGGUGGU.
All PQSs in gene N have analogous sequences in SARS-CoV; some of them have different GG repeats or have none of the four GG repeats and are not capable of forming a quadruplex (Table S4). Although the structures of nucleocapsid protein are slightly different in different works (for example, Refs. [87,88]), in all of them, PQS 28903 and partially PQS 28781 correspond to the linker region (Figure S3G) and may participate in proper protein N folding.
3.9. Study on the Interaction of G4s in SARS-CoV-2 with Ligands
3.9.1. Factors Influencing the Interaction of Quadruplexes with Ligands
Multiple studies have shown that small compounds targeting G-quadruplexes in SARS-CoV-2 gRNA stabilize certain G4s [18,21,27,28,29,30], which results in inhibition of the viral translation and replication processes [18,27]. In particular, Razzak et al. [27] conducted an extensive study of pyridostatin (PDS, Figure 11A) interaction with G4s in the SARS-CoV-2 genome. They showed that PDS stabilized many out of 25 G4s studied, increasing the melting temperature from 2 °C to 21 °C (in particular, by 14–21 °C for PQSs 644, 3467, 13385 and 29123).
Interestingly, six out of nine G4s which were most significantly stabilized (ΔTm ˃ 8 °C) were unable to form a hairpin (hairpins ΔG were ranged from +1.9 kcal/mol to −0.6 kcal/mol). However, three of these G4s (and each one from the 25 G4s) could be stabilized not intramolecularly but intermolecularly. In addition, all hairpins formed by the studied PQSs have regions with unpaired GG repeats (for example, Figure S4), which could promote the formation of multimeric structures. On the other hand, all nine PQSs forming low-stability hairpins (ΔG ranging from +1.9 kcal/mol to −1.8 kcal/mol) were stabilized by PDS by 4–21 °C, except one with ΔΔ = 0.0 kcal/mol. So, stabilization of G4s by PDSs could depend not only on G4’s structure and the number of chains in it (one, two or four) but also on competence between G4 and a hairpin. Also, flanking nucleotides, which could stabilize G4, were not considered in this work as in most works studying G4 in the SARS-CoV-2 genome. The existence of non-G-tetrads and triads in G4s also could impact the PDS-G4 interaction.
Three G4s in Razzak et al. [27] were destabilized by PDS. These are G4s 1463, 2714 and 25197 destabilized by 1 °C, 7 °C and 3 °C, respectively. PQSs 1463 and 2714 with long loops could not form multimeric G4s, while the formation of a U·A-U triad in G4 25197 might prevent PDS binding. In principle, compounds destabilizing G4 also may serve as therapeutic ligands. Ligands which stabilize G4s, hinder the movement of protein complexes along RNA and impact translation and replication, while destabilizing ligands, could interfere with the performance of important functions of G4s in the viral life cycle. For example, G4 can promote proper folding of nascent polypeptide chain, participate in initiation of translation by binding to 40S ribosome or maintain a certain structure of gRNA and mRNA, in particular, maintain the competent structure in gene nsp 10 for the frameshifting process. In such cases, G4 destabilization can be critical for the survival of the virus.
As a first step, we selected stabilizing ligands for G4s 3467, 13385 and 28903 in this work. For PQSs 3467 and 28903, we previously analyzed structural behavior using molecular dynamics and quantum chemical approaches [31,32]. PQS 3467, as Razzak et al. [27] noted, is located at the 5′ end of ORF1ab, and its stabilization is expected to influence the expression of a number of nonstructural proteins regulating critical processes of the viral life cycle. According to our proposal, G4 13385 may support a competent structure of SARS-CoV-2 gRNA for frameshifting, and destabilizing it could be critical. However, the choice of ligands in this case requires taking into account that U·A-U triads may cap G4 at each side, and this assumption needs to be tested first.
PQS 28903 could serve as an attractive target, as it is located in the gene N region corresponding to a single linker in the protein and may be essential for proper protein folding. However, as mentioned above, it is unclear which structures it forms in the cell. So, as a first step, we searched for stabilizing ligands and only for the monomolecular form of G4.
3.9.2. Ligands Binding to PQS 3467, 13385 and 28903
Taking into account what is written above, molecular docking of 13 compounds into G4s 3467, 13385 and 28903 was performed.
The compounds are presented in Figure 11B and S16. They have the following PDB IDs: A1AEC, A1AED, A1AEE, A1AEF, A1BC9, EKJ, EKM, J0D, POH, R14, TFX, V5Z and VK0. All the compounds were retrieved from the PDB [47]. Four of them (EKM, POH, R14, TFX) are presented in PDB as RNA/DNA G4 binders (predominantly as RNA G4 binders).
In our opinion, there are a few comments about the most common features of docking conformations that are interesting (Figure 13). In the case of interaction with VK0 (Figure 13A), all the aromatic rings are positioned parallel to the plane of the upper guanine tetrad, creating strong π–π stacking interactions with one. As a result, the G-quadruplex is stable. In this binding configuration, the K^+^ ion does not interact with the ligand compound and stays in the central part of the G-quadruplex. The unique feature is that the 3-methyl-1,3-benzothiazol-3-ium fragment partially inserts into the G4 loop. Overall, this binding mode represents a configuration in which the ligand almost completely overlays the planar surface of the G-quadruplex, stabilizing the system predominantly through π–π stacking interactions. Regarding the second binding model shown in Figure 13B, the investigated ligand (EKM) occupies a central position above the tetrad and interacts minimally with it. The 1-methylquinolin-1-ium ligand part is located directly above the K^+^ ion, whereas 3-methyl-1,3-benzothiazol-3-ium (as in the case of VK0) occupies the loop of the G-quadruplex. And at last, for the binding model shown in Figure 13C, the ligand covers the central part of the G-quadruplex above the K^+^ ion. In addition, it forms stacking contacts with one side of the tetrad and partially fills the loop with a charged nitrogen atom. Under these conditions, cation–π interactions are likely to occur, which may further contribute to structural stabilization. Note that this binding mode combines the two previous configurations shown in Figure 13A,B.
The top-ranked molecular docking results (Figure 11B) were selected for a two-stage MD simulation: an initial 100 ns simulation, followed by an extended 500 ns simulation for the most promising complexes (see Materials and Methods for details). Subsequent complexes were investigated: the complex between G4 3467 and EKJ; complexes between G4 13385 and EKJ, VK0, and EKM; and complexes between the gRNA fragment containing G4 28903 and EKM and POH.
MD analysis has shown that the G4 3467-EKM complex remained stable throughout all of the simulation (100, 500 ns). It was found that EKM stabilized in an unusual binding pocket that is located among the G4 3467 loops (Figure 12). We believe that this configuration is a potentially new model target for expanding the search for or creating similar ligands in the future.
In the case of 13385, its interaction with VK0 and EKM results in a stable complex (Figure 13). Furthermore, the interaction mode with those two compounds (creating strong interaction) suggests them as very promising candidates for further investigation and optimization.
Table 2 summarizes the binding free energy (ΔG, kcal/mol) calculated for the investigated ligand–G4 complexes over 100 ns MD simulations. EKM most strongly binds to G4 3467, while EKJ binds to G4 13385 [27] according to MD simulation conducted for the complex of G4 3467 with PDS. This complex is stabilized via π-stacking along with electrostatic interactions between the RNA phosphate backbone and PDS amines. Contrary to EKM, PDS did not interact with G4 3467 loops and, therefore, may be a less selective ligand.
The stabilization of a G4–ligand complex can be realized by contacts with adjacent RNA regions [89]. Indeed, we observed this behavior for the 36-nt gRNA fragment containing G4 28903 in complex with POH. This fragment is the hairpin in the SARS-CoV-2 reference genome (without the triple mutation) containing PQS 28903.
In the pre-MD binding mode, POH is positioned largely parallel to the terminal G-tetrad plane and, in addition to contacts with the G4 core, forms extensive van der Waals interactions with the terminal nucleotides C35 and U36 (Figure S17A, B). Notably, this initial arrangement is dominated by shape/packing complementarity: only one favorable π–π stacking interaction is detected, while strong directional interactions (conventional hydrogen bonds or salt bridges) are absent. During molecular dynamics simulation, the ligand undergoes a pronounced change in its local environment relative to the initial docking pose. The nucleic acid architecture rearranges, and the ligand shifts into a new binding mode that is optimized for the post-MD conformation rather than for the starting structure. In this final state, contacts with the adjacent unpaired segment become a major stabilizing factor and help maintain the ligand–nucleic acid complex over time. Concomitantly, the G4-containing fragment undergoes a major structural transition, with the quadruplex core converting into a G-triplex (Figure S17C,D). Thus, a practical outcome of such remodeling can be the emergence of selective ligand recognition of an RNA region adjacent to a G4. This is precisely the type of specificity that appears to occur in our system.
Finally, we would like to mention the following. The compounds used in this work might bind to both cellular and SARS-CoV-2 viral G-quadruplexes. However, during viral infection, the amount of viral G4s considerably exceeds that of cellular G4s (Ref. [18] and refs therein, Refs. [88,90]). Therefore, we expect that EKM will bind preferentially to viral RNA G4 rather than cellular RNA/DNA G4s.
The SARS-CoV-2 genome contains at least 42 G-rich regions with PQSs, including 28 regions that harbor overlapping PQSs (Table S2). Possibly, the occurrence of redundant GG repeats in the regions with the overlapping G4s ensures the performance of an important function by G4 in these locations. GRSs with PQSs are distributed unevenly in the genome (Table S12), with the largest number of them in genes nsp3 (7 PQSs), N (6 PQSs), S (5 PQSs), nsp2 and nsp5 (4 PQSs each), nsp1 and nsp12 (3 PQSs each).
About 60% PQSs in the SARS-CoV-2 genome may be stabilized by non-G-tetrads, triads or base pairs. Among triads, we considered only the most stable U·A-U triad; however, in some putative G4s, including unstabilized ones, we found an A·A-U triad which also occurs rather frequently in RNAs [53]. Overlapping PQSs and stabilizing elements are not only features of G-quadruplexes in the SARS-CoV-2 genome, but they are also characteristic of G4s in genomes of other viruses, and in each virus, G4s have their own distinctive features. In particular, we did not find putative G4s stabilized by the 3′ U-tetrad in HIV-1 genome, but it contains three regions with 3 tetrad-G4, which are absent in the SARS-CoV-2 genome. Such very stable G4s may serve to maintain a certain structure of RNA. Many putative G4s in the SARS-CoV-2 genome contain U·A-U triads, while those in HIV-1 contain more A·A-U triads than U·A-U ones.
Phylogenetic analysis performed in this work and reported in the literature [27] showed that despite the high mutational rate of the SARS-CoV-2 genome, mutations directly in PQSs (in GG repeats or in loops) occurred rarely (Table S21). Moreover, base changes destroying some G4s (in particular, 22316 and 28903) turned out to be temporary. Contrary to this, in some PQSs (644, 22316, 28346), base changes led to stabilization of G4s. In particular, mutation in the loop of PQS 22316 decreases the stability of the hairpin formed by this PQS by 2.3 kcal/mol, correspondingly increasing the probability of G4 formation. Conservation of G4s in SARS-CoV-2 gRNA and the existence of analogs for many PQSs in the SARS-CoV genome indicates their functional importance.
To our knowledge, the functions of G4s in the SARS-CoV-2 life cycle are not known. Eight Ψ-sites were found in the SARS-CoV-2 genome (in the second half of it); only one of them was co-located with G4, and three Ψ-sites were located near G4s. Their functions are also unknown. Moreover, it is unclear how SARS-CoV-2 G-quadruplexes form in gRNA or sgRNA in the cell. Usually, PQSs are located in hairpins or in several structural elements (hairpins, internal duplexes and linkers) within large RNA domains or subdomains. Due to G4s’ low stability, their formation in RNA domains is disadvantageous, even if there is no competition with hairpin formation.
However, in cells, factors such as crowding agents, peptides, and proteins can promote G4 formation (Mukherjee et al. [17] and refs. therein). In addition, PQSs are mostly partially exposed in the hairpin apical loops, and the hairpins, including them, have internal loops (Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 8, Figure 9 and Figure 10) that may promote PQS interaction with different cellular factors and proteins.
In this work, we also studied the interactions of G4s 3467, 13385 and 28903 with 13 compounds by molecular docking. For further molecular dynamics simulations, we selected EKM (for G4 3467) and EKJ, EKM, and VK0 (for G4 13385). EKM was found as a promising antiviral agent for the interaction with G4 at position 3467, as it has binding sites both to the quadruplex and to the G4 loop, which contributes to its selectivity. The compounds used in this work might preferentially bind to cellular DNA/RNA rather than to viral RNAs. However, it was proposed that during viral infection, the amount of viral G4s considerably exceed that of cellular G4s (Ref. [18] and refs therein, Refs. [88,90]), and ligands will primarily bind to viral G-quadruplexes.
The main stages of our workflow are summarized in Table 3. This scheme can also be applied to search for significant G-quadruplexes in genomes of other viruses. While quantum chemical calculations were not performed within the present study, we previously applied them to G4s 3467 and 28903 [31,32]. Investigation of G4 structures stabilized by tetrads and triads, docking of ligands on G4s as parts of a minimal gRNA structural elements, and other studies are planned to be carried out in the future.
Experimental studies are now required to elucidate the biological functions of the prioritized G4S and to select the most effective ligands for developing antiviral drugs. Since most PQSs are located in large RNA domains, G-quadruplexes’ formation may be a regulated process. It is important to understand these regulatory mechanisms.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fay M.M. Lyons S.M. Ivanov P. RNA G-Quadruplexes in Biology: Principles and Molecular Mechanisms J. Mol. Biol.20174292127214710.1016/j.jmb.2017.05.01728554731 PMC 5603239 · doi ↗ · pubmed ↗
- 2Lavezzo E. Berselli M. Frasson I. Perrone R. PalùG. Brazzale A.R. Richter S.N. Toppo S. G-quadruplex forming sequences in the genome of all known human viruses: A comprehensive guide P Lo S Comput. Biol.201814 e 100667510.1371/journal.pcbi.100667530543627 PMC 6307822 · doi ↗ · pubmed ↗
- 3Kharel P. Becker G. Tsvetkov V. Ivanov P. Properties and biological impact of RNA G-quadruplexes: From order to turmoil and back Nucleic Acids Res.202048125341255510.1093/nar/gkaa 112633264409 PMC 7736831 · doi ↗ · pubmed ↗
- 4BohálováN. Cantara A. Bartas M. Kaura P. ŠťastnýJ. Pečinka P. Fojta M. Mergny J.-L. Brázda V. Analyses of viral genomes for G-quadruplex forming sequences reveal their correlation with the type of infection Biochimie 2021186132710.1016/j.biochi.2021.03.01733839192 · doi ↗ · pubmed ↗
- 5Dumas L. Herviou P. Dassi E. Cammas A. Millevoi S. G-Quadruplexes in RNA Biology: Recent Advances and Future Directions Trends Biochem. Sci.20214627028310.1016/j.tibs.2020.11.00133303320 · doi ↗ · pubmed ↗
- 6Lyu K. Chow E.Y.-C. Mou X. Chan T.-F. Kwok C.K. RNA G-quadruplexes (r G 4s): Genomics and biological functions Nucleic Acids Res.2021495426545010.1093/nar/gkab 18733772593 PMC 8191793 · doi ↗ · pubmed ↗
- 7Qi T. Xu Y. Zhou T. Gu W. The Evolution of G-quadruplex Structure in m RNA Untranslated Region Evol. Bioinform.2021171176934321103514010.1177/11769343211035140 PMC 829988434366661 · doi ↗ · pubmed ↗
- 8Zareie A.R. Dabral P. Verma S.C. G-Quadruplexes in the Regulation of Viral Gene Expressions and Their Impacts on Controlling Infection Pathogens 2024136010.3390/pathogens 1301006038251367 PMC 10819198 · doi ↗ · pubmed ↗