AI-Assisted Differentiation of Dengue and Chikungunya Using Big, Imbalanced Epidemiological Data
Thanh Huy Nguyen, Nguyen Quoc Khanh Le

TL;DR
This study uses AI to accurately differentiate between dengue and chikungunya using large-scale epidemiological data, aiding diagnosis in resource-limited areas.
Contribution
The novel use of AI models, particularly ANN, to classify dengue, chikungunya, and discarded cases with high accuracy in a real-world, imbalanced dataset.
Findings
Random Forest achieved high multi-class classification performance (Recall: 0.9288, AUC: 0.9865).
ANN excelled in identifying chikungunya cases (Recall: 0.9986, AUC: 0.9283).
Models showed generalizability, especially for distinguishing discarded cases.
Abstract
Dengue and chikungunya are endemic arboviral diseases in many low- and middle-income countries, often co-circulating and presenting with overlapping symptoms that hinder early diagnosis. Timely differentiation is critical, especially in resource-limited settings where laboratory testing is unavailable. We developed and evaluated machine-learning (ML)- and deep-learning (DL) models to classify dengue, chikungunya, and discarded cases using a large-scale, real-world dataset of over 6.7 million entries from Brazil (2013–2020). After applying the Synthetic Minority Oversampling Technique (SMOTE) to address class imbalance, we trained six ML models and one artificial neural network (ANN) using only demographic, clinical, and comorbidity features. The Random Forest model achieved strong multi-class classification performance (Recall: 0.9288, the Area Under the Curve (AUC): 0.9865). The ANN…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
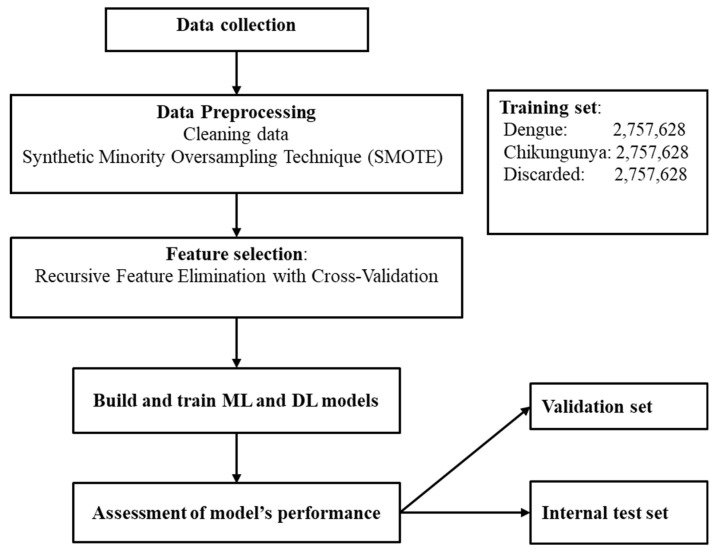 Figure 1
Figure 1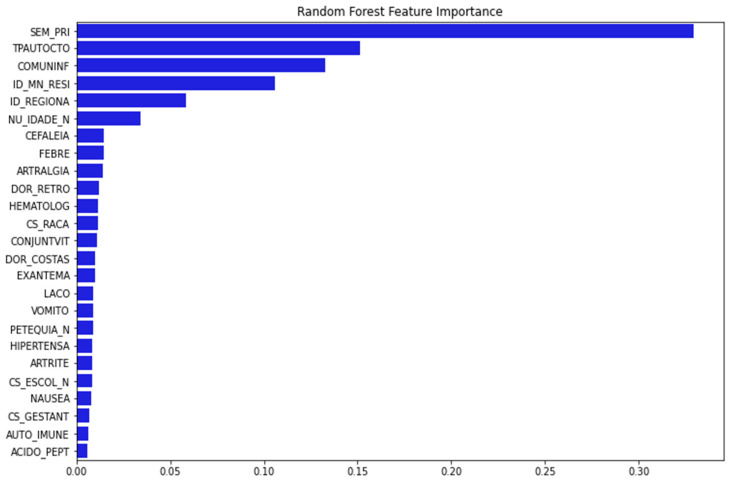 Figure 2
Figure 2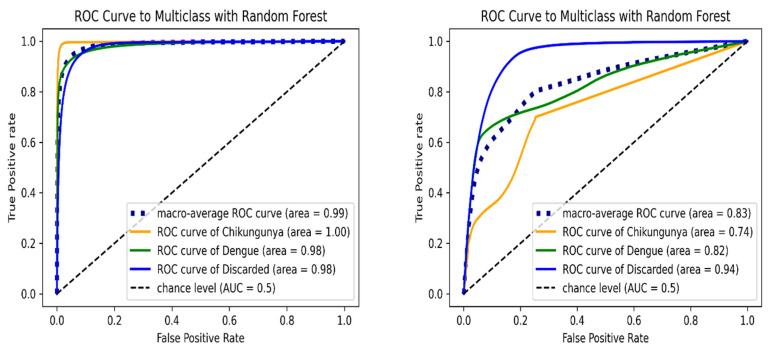 Figure 3
Figure 3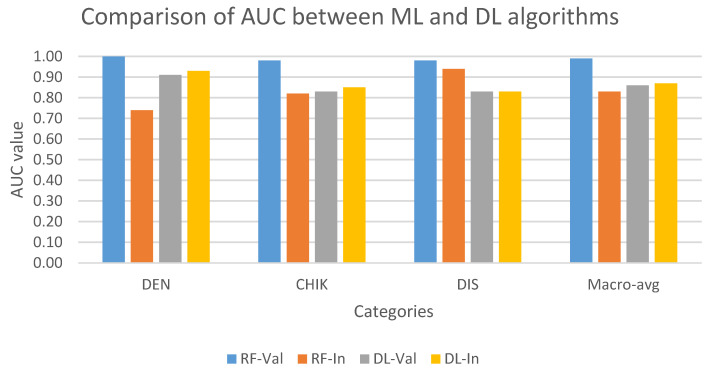 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMosquito-borne diseases and control · Digital Imaging for Blood Diseases · COVID-19 epidemiological studies
1. Introduction
Neglected tropical diseases (NTDs) continue to burden impoverished communities in tropical and subtropical regions, contributing significantly to global health inequities. Among these, arboviral infections such as dengue and chikungunya have re-emerged as major public health concerns [1], particularly in low- and middle-income countries across Latin America, Southeast Asia, and Africa [2,3]. Both diseases are transmitted by the Aedes mosquito and frequently co-circulate, making clinical differentiation challenging due to their overlapping symptomatology [4].
In 2021, the World Health Organization (WHO) declared the roadmap for NTDs in 2021–2030 with the new ambitious target: reducing 75% of deaths from vector-borne NTDs, including dengue and chikungunya [5]. However, the global scenario of dengue is still not optimistic: over 6.5 million cases and more than 7300 dengue-related deaths were reported across all six WHO regions in 2023, with the Americas reporting the highest number of infected individuals with 4.5 million cases and 2300 deaths. The year 2024 surpassed 2023 as the worst year for recorded dengue cases, with over 10 million cases reported, 24,000 severe cases, and 6508 deaths [6]. Dengue cases increased more than 50%, from 26.5 million in 1990 to 59.0 million in 2021 [7], with a higher incidence in children and adolescents [8].
Although dengue usually presents with common flu-like symptoms such as fever, myalgia, and headache, and most cases self-recover, a small number of patients develop severe dengue [9]. Regardless of if a patient has prior exposure to only dengue or combined with another arboviral viruses, such as Zika, they are at an increased risk of developing severe dengue, which could be fatal [10].
Beside dengue, chikungunya is also a public health concern as a re-emerging vector-borne disease [11] with 18.7 million cases in 110 countries between 2011 and 2020, causing 1.95 million disability-adjusted life years, USD 2.8 billion in direct costs, and USD 47.1 billion in indirect costs worldwide; the majority of the disease burden was observed in the Americas [12,13]. An estimated 51% of symptomatic chikungunya patients with laboratory-confirmed tests developed chronic disability after infection [14]. The clinical manifestations of chikungunya at the early stage include fever, arthralgia, myalgia, and joint pain and swelling, which are almost indistinguishable from dengue and other febrile diseases [15].
Many health efforts have been made to differentiate dengue from chikungunya and other febrile diseases. A three-year study in Puerto Rico identified arthritis, joint pain, skin rash, any bleeding, and irritability as clinical predictors that distinguish chikungunya from dengue; while joint pain, muscle, bone, or back pain, skin rash, and red conjunctiva are significant predictors for chikungunya compared with other acute febrile infections [16]. Researchers in Brazil proposed a clinical rule scoring system to diagnose chikungunya infection in a dengue-endemic area, using fever, exanthema, myalgia, arthralgia or arthritis, and joint edema; this system achieved an AUC of 0.695 [17]. However, in remote areas, human- and equipment resources are limited. While dengue and chikungunya share the same vector—known as the Aedes mosquito—similar symptoms with other arboviral pathogens make correctly diagnosing patients more challenging [18,19,20]. Therefore, an alternative approach is needed to assist healthcare workers in the early detection and classification of patients with these diseases without laboratory confirmation.
Machine Learning (ML), a subset of Artificial Intelligence (AI), is algorithms that can learn the patterns inside a dataset and use these experiences to automatically improve the accuracy of their output [21]. In recent years, advances in clinical practice using ML and its subfield—Deep Learning (DL)—have proven to improve diagnostic performance [22,23,24], including arboviral-diseases detection [25,26]. These techniques can assist in classifying, supporting diagnosis and treatment for patients with arboviral diseases in resource-limited settings. Previous studies attempted to develop ML models for a binary classification of dengue fever (DF). These models aimed to predict dengue positivity/negativity or to differentiate between severe dengue (SD) and non-severe dengue, using various types of data, including meteorology, genomic, socio-demographic, clinical, and laboratory data [27]. Recently, a novel approach using micro-spectroscopy techniques combined with machine learning showed a promising application in rapid classification of dengue and chikungunya in remote areas [28].
Due to the aim of predicting clinical dengue cases, we examined the previous literature that applied ML for dengue diagnosis based on demographic, clinical, and laboratory data only, focusing on dataset size, features used, the ML models implemented, and the metrics used to evaluate the models’ performance. For example, Ho et al. applied different ML models to identify 2942 dengue cases from a dataset of 4894 patients with dengue-like illnesses, using only age, body temperature, white blood cell count, and platelet count as input features. Logistic regression (LR), Decision Tree (DT), and Deep Neural Networks (DNN) were used to build predictive models; the proposed DL model achieved the best performance with an AUC of 0.8587 [29]. Abdualgalil et al. analyzed 6694 samples containing one continuous variable (age) and 20 binary categorical features (including sex, fever, headache, arthralgia, myalgia, conjunctivitis, skin rash, generalized weakness, jaundice, decrease in urine or anuria, abdominal pain, vomiting,) with the train/test split ratio of 70/30 to build five ML models: k-Nearest Neighbor (KNN), Gradient Boosting Classifier, eXtreme Gradient Boosting (XG), Extra Tree Classifier (ETC), and Light Gradient Boosting Machine [30]. The target variable was dengue positivity or negativity; the ETC model using the hold-out cross-validation approach achieved the highest accuracy of 0.9912.
In predicting SD cases, Phakhounthong et al. used DT to predict 38 SD cases out of 198 laboratory-confirmed dengue cases in Cambodian children, using five clinical and laboratory attributes (hematocrit, Glasgow Coma Score, urinary protein, creatinine, and platelet count). The DT model achieved 0.605 sensitivity, 0.65 specificity, and 0.641 accuracy [31]. Huang et al. analyzed 798 laboratory-confirmed dengue cases, including 138 SD cases, to develop various ML models for assessing the risk of dengue severity based on six features: age, sex, viral RNA amounts, the positivity of NS1, and IgM and IgG test results. Different ML methods, including LR, Random Forest (RF), Gradient Boosting Machine (GB), Support Vector Classifier (SVC), and Artificial Neural Networks (ANN)—a DL algorithm—were applied for building prognostic models. The ANN model outperformed others with an AUC of 0.8324 and 0.7523 accuracy [32].
Besides binary classification models, the development of multi-class classification algorithms, which can differentiate between dengue and other mosquito-borne diseases, are of great importance to clinicians when more than one arbovirus is present in endemic areas. Lee et al. implemented LR and DT models to differentiate between 862 DF, 55 dengue hemorrhagic fever (DHF), and 117 chikungunya cases in two scenarios: with and without laboratory testing (suitable for well-resourced and resource-limited settings, respectively). Multiple demographic, epidemiological, and clinical features were used for the prediction. Without laboratory results, the DT model achieved an overall AUC of 0.59 in classifying DF and chikungunya cases, while performing better in discriminating DHF versus chikungunya with 0.91 AUC [33].
Tabosa de Oliveira et al. used seven ML models: RF, Adaptative Boosting (AD), GB, XG, KNN, NB, and Multilayer Perceptron, to train a dataset of 17,272 records, with 5724 for each of the three classes: dengue, chikungunya, and others (patients classified as “inconclusive” or “negative” for both dengue and chikungunya). The dataset consists of 26 features: socio-demographic (age, sex, gestational age in case sex is female, race, residence area, days that patient feels the symptoms), clinical (fever, myalgia, headache, rash, vomiting, nausea, back pain, conjunctivitis, arthritis, arthralgia, petechiae, tourniquet test, eye pain), and comorbidities (diabetes, hypertension, and hematological, liver, kidney, peptic acid, and autoimmune disease). The GB model achieved the best performance with 0.6240 accuracy, 0.6257 precision, 0.6205 recall, and 0.6196 F1-score [34].
Previous studies that focused on multi-class classification of dengue and other diseases are still limited compared with binary tasks [35]. Moreover, a previous study aimed to differentiate dengue with malaria, leptospirosis, and scrub typhus, also indicated that ML models (DT, RF, AD) only achieved 55–60% overall predictability on the multi-class classification task, far lower than binary classification using the LR model with an average of 79–84% correct predictions for one versus other diseases [36]. Previous studies have examined the applicability of ML-based models for disease diagnosis; however, there are no studies that have attempted to apply DL algorithms for multiclass classification of multiple arboviral diseases [35]. To the best of our knowledge, there are no studies that have investigated the multi-class task on an imbalanced dataset with more than 100,000 records.
Therefore, in this study, we built different ML and DL models to investigate the ability of differentiating dengue and chikungunya cases with discarded cases (inconclusive cases of the two diseases) using a big, highly imbalanced open-source dataset.
2. Materials and Methods
2.1. Data Collection
We used an open-source dataset from da Silva Neto et al. [37], which consists of 4,307,513 dengue, 325,000 chikungunya, and 2,100,029 discarded cases in Brazil from 2013 to 2020 for classification. There are 55 variables, but 9 from laboratory data were excluded. The remaining features were classified into three groups: demographic, clinical, and comorbidity data. One important characteristic of this dataset is that some important diagnostic features such as days from symptom onset and severity markers were not collected by the researchers. Figure 1 illustrates the workflow of this study.
2.2. Data Preprocessing
First, the data was checked for missing values and typos. Next, the outcome variable was encoded as follows: 0 for discarded cases, 1 for chikungunya, and 2 for dengue. Apart from the age variable, which is numeric, all other categorical variables were converted into numeric format according to the number of classes within each variable. Third, the dataset was split into two parts: training data and testing data, with an 80/20 ratio. The testing data is also called the internal test set, which has similar features to the training set, including years, geographic regions, municipalities, and class distribution. This test set is kept separately during model training. Then, the training data was split further into two parts, with the same ratio for training and validation purposes. For the training dataset, the imbalanced data was handled using various techniques, including random undersampling, random oversampling, and the Synthetic Minority Oversampling Technique (SMOTE) [38], since the dataset used in this study has the minority class of interest (chikungunya cases). The performance of models was compared after applying different approaches to handle the issue of imbalanced data and SMOTE showed the prominent advantage over techniques. Therefore, SMOTE was applied in this study despite its potential concern of overfitting. After applying SMOTE for training data, we had 8,272,884 samples, and the number of instances in each class after using SMOTE was 2,757,628. Important features for predicting dengue and chikungunya were chosen after using the ML algorithm which shows the best performance as baseline. Last, train- and test sets were normalized using z-score scaling technique.
2.3. ML Model Development
We used various ML techniques to develop six models to diagnose different diseases: Random Forest (RF), Decision Tree (DT), Adaptive Boosting (AD), Gradient Boosting Machine (GB), eXtreme Gradient Boosting (XG), and K-nearest Neighbor (KNN). The proposed algorithms were trained with different hyperparameters and random_state = 42, using RandomizedSearchCV package in Scikit-Learn library. Table 1 displays the hyperparameters that presented the best results. The model with the best performance was chosen for feature selection with the Recursive Feature Elimination with Cross-Validation (RFECV) technique, using the following parameters: estimator = the ML classifier with best performance; step = 1; cv = StratifiedKFold (5); scoring = ‘accuracy’.
2.4. Artificial Neural Network (ANN) Model
The main advantage of ANN model is that it does not require human intervention for any of its processes, which allows automatic feature extraction in comparison with ML [39]. Table 2 describes model configuration of ANN model. The hidden layer had two layers with 64 output shapes.
The above model was trained in 30 epochs, 128 batch_size using keras and tensorflow package, and hyperparameter optimization was performed with RandomSearchCV to perform effective differential diagnosis between three classes.
2.5. Model Evaluation
In this research, we have evaluated our multi-class arbovirus diseases classification models by using the accuracy, precision, recall, specificity, balanced accuracy, F1-score, and area under the receiver operating characteristics (ROC) curve (AUC). These evaluation metrics are based on the confusion matrix, which seeks to calculate True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN).
Accuracy measures the model’s performance according to the total samples correctly classified, and is defined as
Precision, also called positive predictive value, is the metric used to represent the proportion of positive classifications that are true positive, calculated as
Recall, also called sensitivity, determines the proportion of real positives that were correctly classified, defined as
Specificity determines the proportion of real negatives that were correctly classified, defined as
Balanced accuracy is the arithmetic mean of sensitivity and specificity, and is defined as
F1-score is a metric that calculates the harmonic mean of precision and recall, and is defined as
The metrics for multi-class classification were obtained by using macro averaging. Initially, precision, recall (sensitivity), specificity, F1-score, accuracy, and balanced accuracy were calculated for each class. The metrics for multi-class classification were obtained using macro averaging, i.e., by taking the average of the values obtained for three classes. Balanced accuracy, along with AUC metric, are identified to be more robust to imbalanced data than traditional accuracy [40]. In multi-class classification task, balanced accuracy is defined as the average of recall, which equals the macro-average recall.
2.6. Software
Tensorflow and Keras frameworks implemented the proposed method. A free cloud service from Google Colab performed the training and testing process. The evaluations metrics were calculated using the Scikit-Learn library version 1.5.0.
3. Results
3.1. Data Characteristics
As depicted in Table 3, 55.8% of cases were women with a mean age of 33 years; most did not have information about race, stage in pregnancy, or education degree. The most common symptoms included fever (37.3%), headache (34.5%), myalgia (34%), retro-orbital pain (14.3%), and nausea (14.2%).
3.2. ML Models’ Performance
Table 4 presents a comparison of the performance of ML models with and without applying the SMOTE technique on training set. Before applying SMOTE, the XG model outperformed others with a recall of 0.9333, precision of 0.8711, F1-score 0.8983, and an AUC of 0.9831. Among the ML models after applying SMOTE, RF algorithm showed the best performance in classifying dengue, chikungunya, and discarded cases with the macro-average values of accuracy (0.9292), recall/balanced accuracy (0.9288), precision (0.9111), F1-score (0.9196), and AUC (0.9853).
Figure 2 depicts 25 important variables chosen for model training after running the feature importance procedure with RF as baseline.
Figure 3 shows the ROC curve of RF algorithm for each class. In the validation test set, the macro-average AUC was 0.9865, and chikungunya class had the maximum AUC value. For the internal test set, the RF model achieved a lower overall AUC of 0.8329; the highest AUC was observed in discarded class. The RF model presented similar AUC values of discarded class in both the validation and external test set, illustrating the high capability of the proposed algorithm in predicting discarded cases.
3.3. The Performance of DL Model
Table 5 illustrates the proposed DL model which achieved 0.8984 macro-average specificity, 0.8401 recall/balanced accuracy, and 0.8693 AUC. The dengue class achieved the best specificity (0.9879), precision (0.9283), and F1-score (0.8297). The chikungunya class achieved the best recall (0.9986), balanced accuracy (0.9283), and AUC (0.9283). These results demonstrated that the ANN model worked best as a screening tool for chikungunya cases.
Figure 4 compares the performance of multi-class models on the validation and internal test set. In validation set, the AUC of ML model (RF) was higher than the DL model (ANN) in all three classes. In contrast, except for the discarded class, the ANN model performed better RF in classifying dengue and chikungunya classes in the internal test set. In addition, RF showed the best result in predicting discarded class with the approximate AUC values in the validation and internal test set, while the ANN model showed a stable performance in both datasets in all three classes.
4. Discussion
In this study, we investigated different ML and ANN models in differentiating dengue and chikungunya with the discarded cases. Our work suggested that the RF model works best in differentiating dengue and chikungunya with a macro-averaged recall of 0.92288, precision of 0.9111, and F1-score of 0.9196 which are higher than the metrics of a previous work using the GB model on the balanced dataset and achieved the recall, precision, and F1-score of 0.6257, 0.6205, and 0.6196, respectively [34]. Previous studies also indicated tree-based ML algorithms, such as DT and RF, achieved better performance in the multi-class classification of target variable [33,34]. A recent study also agreed that a tree-based ML model could be a suitable choice for building a decision-making support application and deploying on portable devices to assist doctors and nurses in diagnosing dengue patients [41].
Some clinical symptoms that are declared as important in dengue diagnosis were absent in the input data used for training the models. For instance, abdominal pain and myalgia were identified as better predictors of dengue infections with logistic regression and decision-tree models [36]. Some comorbidities, like pre-existing renal disease or diabetes, were ignored by the models although these symptoms are important risk factors of SD [42]. Diabetes is also associated with an increased risk for severe outcomes in dengue and West Nile fever [43].
Moreover, our study exclusively used demographic- and clinical data to train the models, which achieved a high performance. From a clinical perspectives, epidemiological and demographic variables are perceived as less influential and are usually ignored when diagnosing patients with dengue or chikungunya. In a previous study, experienced physicians only selected clinical symptoms, two pre-existing diseases (diabetes and hypertension), and days from symptoms onset as input data for training ML models [34]. Prior investigations [34,41], along with our study, indicate that epidemiological and demographic data, such as gender, age, indigenous status, and epidemiological week-of-symptoms onset, are important features for differentiating diagnosis of dengue with other arboviral diseases. For chikungunya, Vidal et al. reported gender differences in virus infection, where chikungunya symptoms are more frequent in women than men [44], these results are similar to our study’s findings. Researchers also observed that male patients confirmed to have dengue required longer recovery time compared to female patients, and patient age has a significant positive correlation with the number of clinical symptoms [45].
Our study has some advantages: First, we utilized a dataset of more than one million records as input, representing the largest dataset to date used for the multi-class classification task of dengue and chikungunya. Dataset size can affect model performance, as a larger input generally enhances the accuracy of both ML and DL algorithms [46]. Second, the input data demonstrated a high imbalance across target categories, similar to the real-world conditions while two previous studies only used the same dataset with the balanced records of each category in the target feature [34,47]. Lastly, the use of internal test sets for evaluating performance of proposed algorithms is a specific approach. To the best of our knowledge, this is the first study to incorporate internal test set to evaluate model performance for arboviral diseases.
The use of an internal test set will enhance the reliability of ML and DL algorithms when predicting data not previously encountered When deployed through computer interfaces or portable devices, these models can assist frontline healthcare workers by providing accurate and timely differentiation of arboviral diseases such as dengue and chikungunya. For instance, a young physician in remote areas of one province can use the model, enter epidemiological and clinical information of a new patient who comes from another province, and achieve a reliable diagnosis of that patient to plan medical assistance for him/her, such as hospitalization. This model could be trained with other arboviral diseases like Zika or yellow fever for active disease-surveillance and case-management in the field.
However, this study has some limitations. First, our data did not have some important features, such as the number of days from the symptom onset, one of critical criteria for deciding which laboratory test will be used. If symptom onset is less than 5 days, the NS1 antigen test kit may be preferred, whereas IgM will be used after day 5 of onset [18]. Another concerns the approach used to address the imbalanced dataset. We only applied the SMOTE technique, which made it difficult to compare the models’ performance with previous studies that either used balanced data or applied other methods like down sampling technique. In addition, the lack of interpretability analysis of top prediction features for clinical adoption is another limitation of this study, and we hope to apply SHAP analysis in future work to understand more which features contribute most to disease prediction.
5. Conclusions
In this study, we developed a multi-class classification method for predicting dengue and chikungunya diseases using ML and DL models. Our proposed models showed promising results as a decision-making support system to assist health physicians in differentiating dengue from chikungunya and inconclusive cases with high sensitivity, particularly in settings where laboratory testing is not readily accessible. By incorporating an internal test set, these models might have a potential application as a supportive tool in screening dengue and chikungunya diseases in Brazilian populations. Future work will continue to enhance the capability of these algorithms to differentiate more arboviral diseases, such as Zika, yellow fever, and West Nile fever diseases.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Soni S. Gill V.J.S. Singh J. Chhabra J. Gill G.J.S. Bakshi R. Dengue, Chikungunya, and Zika: The causes and threats of emerging and re-emerging arboviral diseases Cureus 202315 e 4171710.7759/cureus.4171737575782 PMC 10422058 · doi ↗ · pubmed ↗
- 2Colón-González F.J. Sewe M.O. Tompkins A.M. Sjödin H. Casallas A. Rocklöv J. Caminade C. Lowe R. Projecting the risk of mosquito-borne diseases in a warmer and more populated world: A multi-model, multi-scenario intercomparison modelling study Lancet Planet. Health 20215 e 404e 41410.1016/S 2542-5196(21)00132-734245711 PMC 8280459 · doi ↗ · pubmed ↗
- 3Mohapatra R.K. Bhattacharjee P. Desai D.N. Kandi V. Sarangi A.K. Mishra S. Sah R. Ibrahim A.A.A. Rabaan A.A. Zahan K.E. Global health concern on the rising dengue and chikungunya cases in the American regions: Countermeasures and preparedness Health Sci. Rep.20247 e 183110.1002/hsr 2.183138274135 PMC 10808844 · doi ↗ · pubmed ↗
- 4Hotez P.J. Aksoy S. Brindley P.J. Kamhawi S. World neglected tropical diseases day P Lo S Neglected Trop. Dis.202014 e 000799910.1371/journal.pntd.0007999 PMC 698891231995572 · doi ↗ · pubmed ↗
- 5Casulli A. New global targets for NT Ds in the WHO roadmap 2021–2030 P Lo S Neglected Trop. Dis.202115 e 000937310.1371/journal.pntd.000937333983940 PMC 8118239 · doi ↗ · pubmed ↗
- 6The Lancet Dengue: The threat to health now and in the future Lancet 202440431110.1016/S 0140-6736(24)01542-339067890 · doi ↗ · pubmed ↗
- 7Li X.-C. Zhang Y.-Y. Zhang Q.-Y. Liu J.-S. Ran J.-J. Han L.-F. Zhang X.-X. Global burden of viral infectious diseases of poverty based on Global Burden of Diseases Study 2021 Infect. Dis. Poverty 202413536710.1186/s 40249-024-01234-z 39380070 PMC 11459951 · doi ↗ · pubmed ↗
- 8Deng J. Zhang H. Wang Y. Liu Q. Du M. Yan W. Qin C. Zhang S. Chen W. Zhou L. Global, regional, and national burden of dengue infection in children and adolescents: An analysis of the Global Burden of Disease Study 2021 e Clinical Medicine 20247810294310.1016/j.eclinm.2024.10294339640938 PMC 11617407 · doi ↗ · pubmed ↗