Cross-Protocol Domain Gap in Internet of Things Intrusion and Anomaly Detection: An Empirical Internet Protocol-to-Bluetooth Low Energy Study of Domain-Adversarial Training
Hyejin Jin

TL;DR
This study examines how well intrusion detection systems trained on IP traffic work when applied to Bluetooth Low Energy (BLE) devices, finding significant variability and risks in performance.
Contribution
The study introduces R3, a domain-aware checkpointing method that improves target performance in label-free settings for cross-protocol domain adaptation.
Findings
Domain-adversarial training shows transient domain confusion and high seed-to-seed variability in label-free target conditions.
R3 improves target ROC-AUC by ~+0.053 across three seeds using domain-discriminator accuracy as an alignment proxy.
UDA performance collapses under capture-wise LOCO evaluation, highlighting risks of optimistic random splits.
Abstract
What are the main findings? Cross-protocol IP → BLE transfer yields high seed-to-seed variability under label-free target conditions.Domain-adversarial training shows transient domain confusion; R3 (domain-aware checkpointing via domain-discriminator accuracy) improves target ROC-AUC without target labels, while classical ML baselines remain strong in this 14D setting. Cross-protocol IP → BLE transfer yields high seed-to-seed variability under label-free target conditions. Domain-adversarial training shows transient domain confusion; R3 (domain-aware checkpointing via domain-discriminator accuracy) improves target ROC-AUC without target labels, while classical ML baselines remain strong in this 14D setting. What are the implications of the main findings? Random window-level splits can be optimistic; capture-wise/LOCO evaluation and operating-point audits (e.g., micro-FPR) are…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
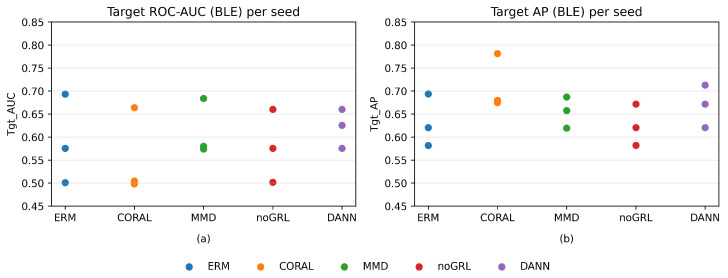 Figure 1
Figure 1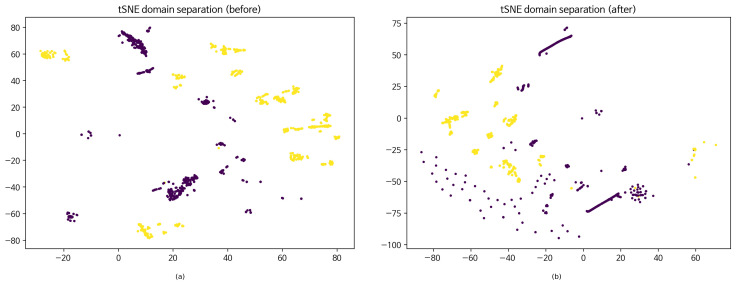 Figure 2
Figure 2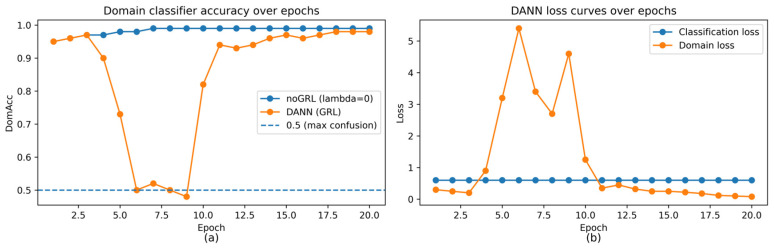 Figure 3
Figure 3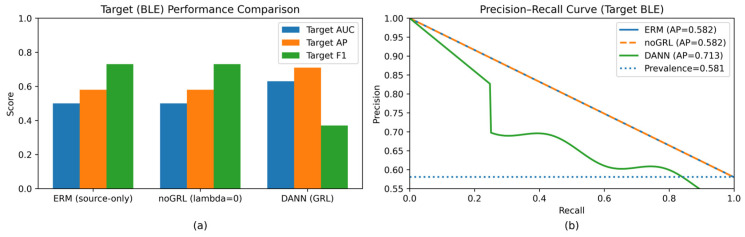 Figure 4
Figure 4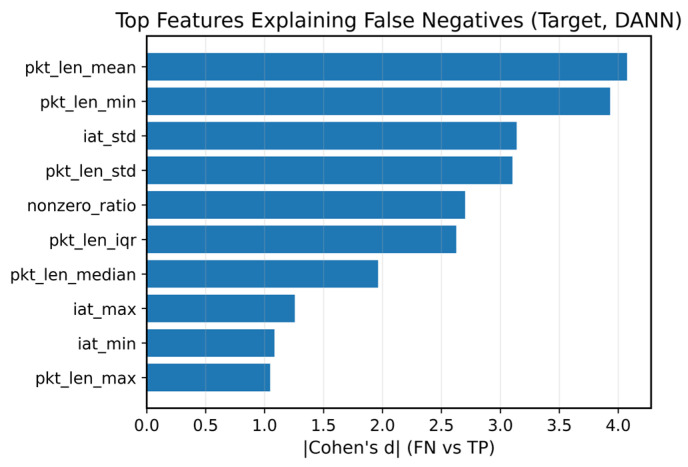 Figure 5
Figure 5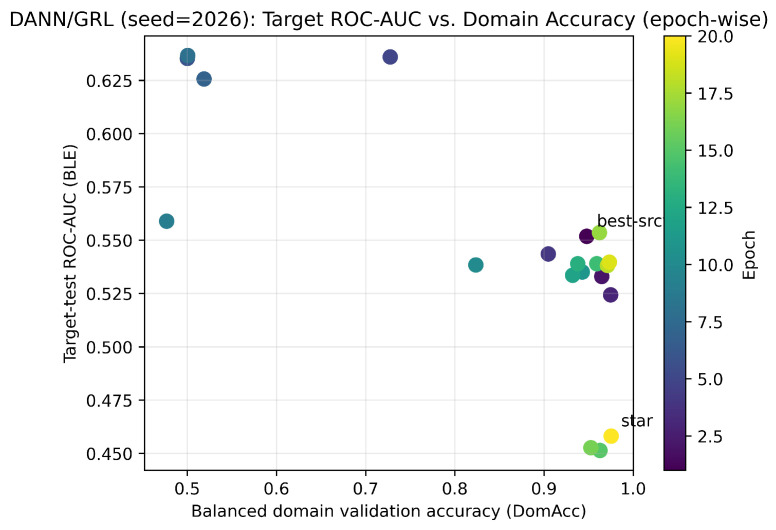 Figure 6
Figure 6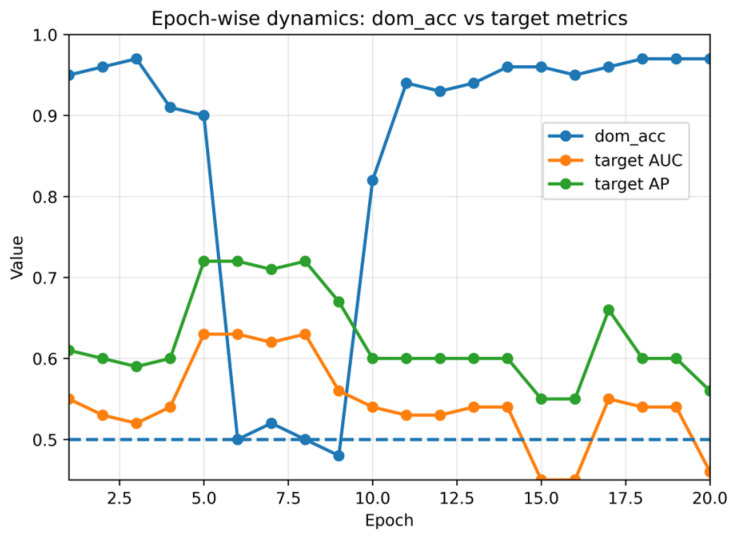 Figure 7
Figure 7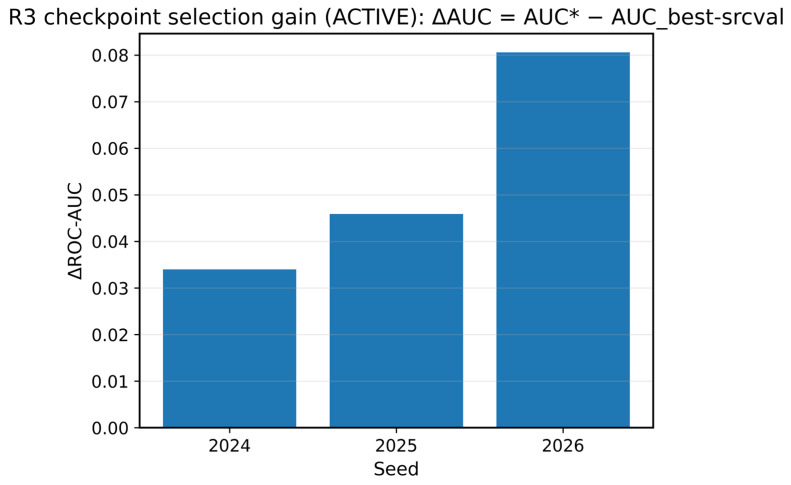 Figure 8
Figure 8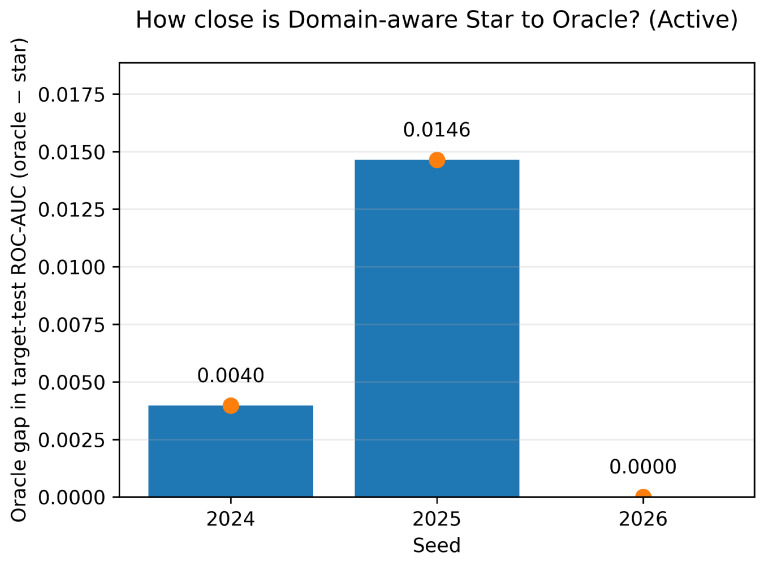 Figure 9
Figure 9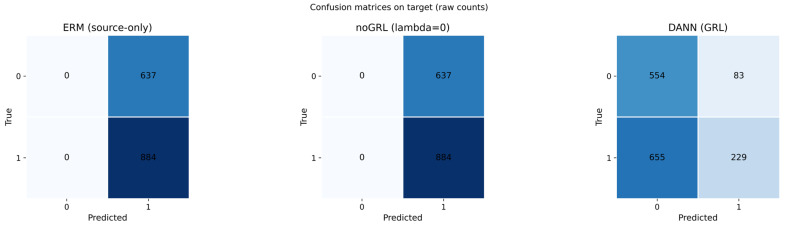 Figure 10
Figure 10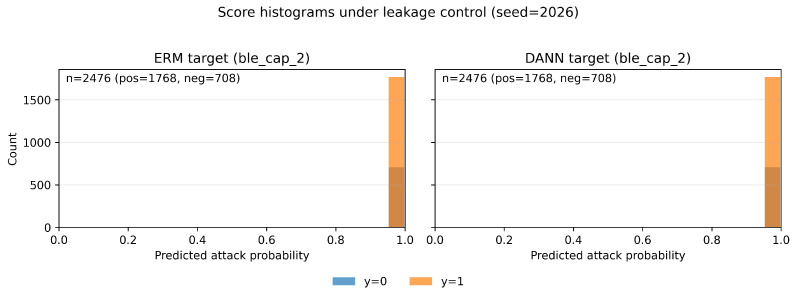 Figure 11
Figure 11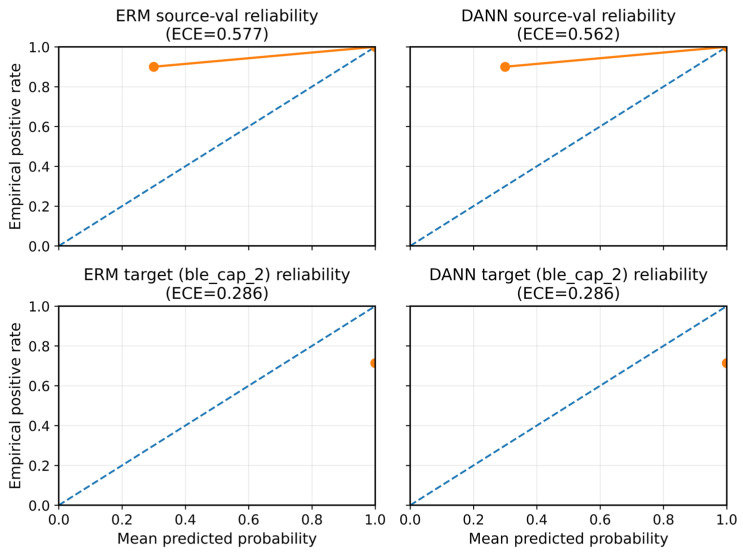 Figure 12
Figure 12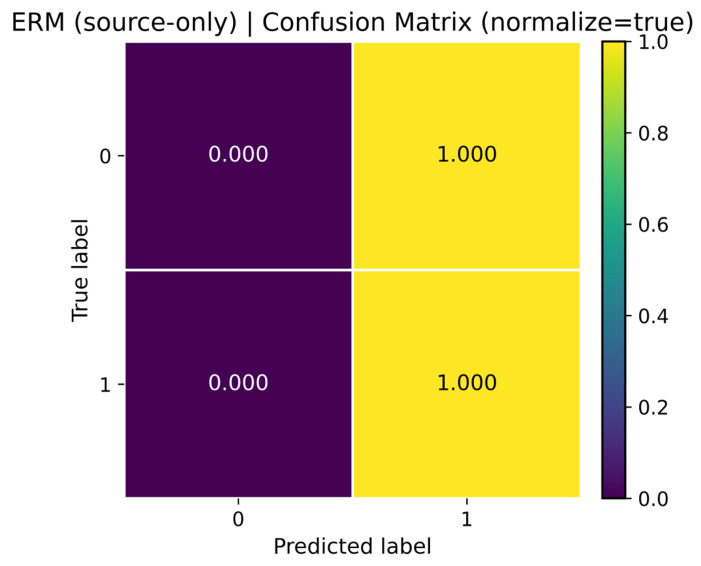 Figure 13
Figure 13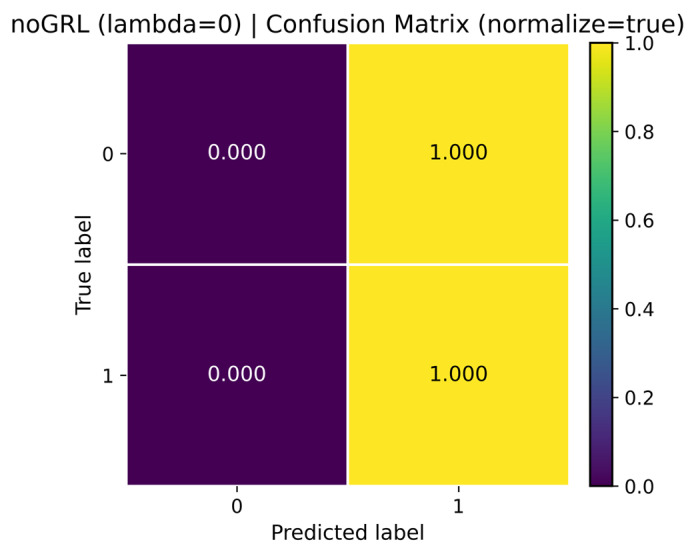 Figure 14
Figure 14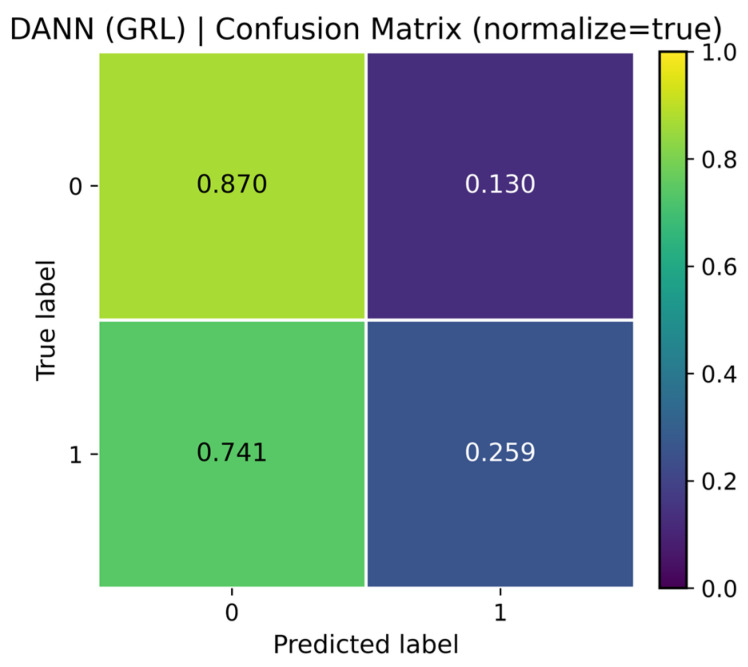 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBluetooth and Wireless Communication Technologies · Opportunistic and Delay-Tolerant Networks · Wireless Body Area Networks
1. Introduction
Internet of Things (IoT) deployments are increasingly heterogeneous: the same security analytics pipeline may be required to operate across multiple communication protocols and sensing stacks. In practice, intrusion and anomaly detectors are often trained on a single source domain and then deployed to a different target domain, where the feature distribution and traffic dynamics differ. This cross-protocol domain shift is a critical yet under-studied failure mode for IoT intrusion/anomaly detection, especially when target-domain labels are limited or unavailable. This perspective aligns with broader AI-IoT security and privacy challenges in advanced IoT services [1].
Motivating scenario: Many sensor-rich IoT systems use Bluetooth Low Energy (BLE) for low-power device-to-gateway communication and IP for backhaul. In practice, security analytics are frequently developed and tuned using IP network telemetry, but deployment at the edge (e.g., BLE gateways or embedded monitors) changes the observable traffic statistics due to protocol- and link-layer dynamics. This cross-protocol mismatch can induce substantial domain shift and degrade intrusion/anomaly detection, motivating principled cross-protocol adaptation.
We study a concrete cross-protocol transfer setting, IP → BLE, where the detector is trained on IP traffic features and evaluated on BLE traffic features. Our focus is on unsupervised domain adaptation (UDA): model selection and hyperparameter tuning are performed without target-domain training labels, and the target labels are used only for final evaluation.
Our contributions are as follows:
- We provide an empirical, reproducible evaluation of cross-protocol transfer (IP → BLE) using three randomized seeds for the main analyses, complemented by additional 20-seed repeats and paired statistical tests reported in the Appendix A and Appendix B/Supplementary Sections to quantify seed-to-seed instability.
- We benchmark classical distribution-alignment baselines (CORAL, correlation alignment; MMD, maximum mean discrepancy) and neural unsupervised domain adaptation (UDA) strategies, including domain-adversarial neural networks (DANNs) with a gradient reversal layer (GRL) and a control variant without the adversarial signal (noGRL).
- We complement performance metrics with domain-gap diagnostics and calibration/operating-point audits, and we propose domain-aware checkpoint selection (R3) without target labels, using the domain discriminator accuracy as a proxy for transient alignment and checkpoint sensitivity. Our contribution is primarily empirical and diagnostic: we do not introduce a new UDA algorithm but instead provide actionable findings for cross-protocol deployment.
The remainder of this study is organized as follows: Section 2 reviews related work; Section 3 describes the datasets, protocols, and methods; Section 4 presents the experimental results; Section 5 discusses practical implications and limitations; and Section 6 concludes the paper.
2. Related Work
2.1. IoT Intrusion and Anomaly Detection Under Distribution Shift
Learning-based IoT intrusion detection systems (IDSs) and anomaly detectors are often developed under a closed-world assumption: deployment traffic is drawn from the same distribution as the training data. In operational IoT, distribution shift is the norm—device firmware and protocol stacks evolve, deployments vary in topology and background services, and feature-extraction pipelines differ across platforms. Therefore, public IDS benchmarks (e.g., UNSW-NB15, CICIDS2017, Bot-IoT, TON_IoT, IoT-23, and Edge-IIoTset) exhibit heterogeneous benign traffic composition and attack implementations, which makes cross-dataset generalization difficult [2,3,4,5,6,7]. Recent work has quantified this effect in domain-specific settings (e.g., IoT vs. Internet of Medical Things (IoMT)), reporting large cross-dataset F1 drops when models trained on one dataset are tested on another [8].
Protocol heterogeneity further amplifies this shift. Moving from IP traffic to BLE changes framing, timing, and link-layer behavior, which can distort common flow features and induce a cross-protocol domain gap, even when the attack semantics are comparable. While BLE security procedures and threat surfaces are increasingly documented [9,10], BLE intrusion/anomaly detection remains relatively less explored and is often constrained by monitoring limitations (e.g., reliance on sniffers) and protocol dynamics such as channel hopping [11,12]. These characteristics motivate empirical cross-protocol studies that explicitly measure the domain gap and evaluate adaptation strategies under realistic constraints.
2.2. Unsupervised Domain Adaptation and Adversarial Alignment
Unsupervised domain adaptation (UDA) leverages labeled source data and unlabeled target data to learn representations that generalize to the target domain. Classical alignment includes moment matching with maximum mean discrepancy (MMD) [13] and covariance alignment (Deep CORAL) [14], while adversarial approaches such as DANNs optimize a feature extractor via gradient reversal to confuse a domain discriminator [15]. More recent UDA strategies include self-training/pseudo-labeling and contrastive representation learning objectives, but these often require additional confidence calibration or augmentation design; we use a DANN as a canonical adversarial baseline because its domain discriminator explicitly exposes domain-separability dynamics that we can audit under the target-unlabeled constraint. In network security, transfer learning has been explored to improve robustness across networks and datasets, including transfer learning-based IDS frameworks in IoT/5G settings [16,17] and domain-confusion architectures designed specifically for intrusion detection [18]. However, adversarial alignment can be unstable and sensitive to optimization and model selection choices, especially when target labels are unavailable for early stopping [15,19,20]. Our study isolates these dynamics in an IP → BLE shift and links them to measurable domain-gap diagnostics and epoch-wise behavior.
2.3. Thresholding, Calibration, and Imbalanced Evaluation in IDS
Intrusion detection commonly operates under class imbalance, which motivates reporting threshold-free metrics such as ROC-AUC, and, especially, average precision (AP, area under the precision–recall curve). Precision–recall curves are often more informative than ROC curves in skewed settings [21,22]. By contrast, F1-score and confusion-matrix-derived rates depend on a chosen decision threshold and can be misleading when posterior scores are poorly calibrated. Modern neural networks can be miscalibrated even in distribution [23], and calibration may further deteriorate under distribution shift, making threshold transfer from source to target brittle. To avoid optimistic bias in UDA, our main protocol selects thresholds only on labeled source validation data, and we complement thresholded metrics with PR curves, confusion matrices, and bootstrap confidence intervals for key results [24].
3. Materials and Methods
3.1. Datasets and Feature Construction
We use two preprocessed packet-table datasets representing distinct protocols: an IP-based dataset (source domain) and a BLE dataset (target domain). Raw packet captures are restricted due to privacy and security considerations; however, we release the derived, anonymized window-level feature tables and all scripts/tables needed to reproduce the reported metrics and figures (Supplementary File S1). For feature construction, we extract packet length and time from the preprocessed packet tables using the columns {IP: length = ‘http.content_length’, time = ‘http.time’, label = ‘is_malicious’; BLE: length = ‘frame.len’, time = ‘nordic_ble.packet_time’, label = ‘is_malicious’}. We segment each trace into non-overlapping windows (window size = 64 packets; stride = 64) and compute 14 lightweight statistical features (packet-length statistics, inter-arrival-time statistics, and ratio features). The binary label y is inherited from the dataset-provided maliciousness indicator and is used only for source-supervised learning and final target evaluation under the UDA protocol.
Sanitized provenance and labeling: The released packet tables originate from curated packet captures collected for IoT intrusion/anomaly detection experiments and are distributed in sanitized CSV form; raw pcap files are not released to prevent leakage of sensitive network identifiers. The packet tables are produced by an upstream preprocessing pipeline that anonymizes the original captures and provides a binary packet-level label (is_malicious) for each record. Although the concrete packet realizations differ across IP and BLE, the label is intended to encode the same high-level semantics (attack vs. benign) across protocols; accordingly, we treat this setting as label-aligned cross-protocol domain adaptation. Residual semantic shift due to protocol-specific packetization and timing cannot be fully ruled out and is treated as part of the cross-protocol domain gap studied here.
A structured provenance summary and a data-usage map are provided in Table A5 and Table A6.
To improve reproducibility under restricted raw data, we provide sanitized provenance metadata (windowing parameters and column mappings) and the full derived feature tables in Supplementary File S1 (‘features/feature_build_meta.json’, ‘features/*_stat_features.csv’).
As shown in Table 1, the target BLE domain has a higher positive-class prevalence (attack ratio 0.581) than the source IP domain (0.500), indicating the class-prior shift in addition to covariate/representation shift across protocols.
3.2. Experimental Protocol and Splits
We evaluate cross-protocol transfer from IP (source) to BLE (target). For each seed, the source domain is split into train/validation/test, while the target domain is split into validation/test. Target labels are not used for training, only for reporting final target-domain metrics. Table 2 summarizes the split sizes for the representative run (seed = 2026).
Active protocol (zero-activity filtering): We exclude zero-activity windows defined by nonzero_ratio = 0; this filter is applied to both domains without labels. Relative to the passive window set (Table 1), active filtering removes 384/15,625 (2.46%) IP windows and 324/3041 (10.65%) BLE windows. Retained window counts per split are reported in Supplementary File S1.
Leakage control: Windowing uses a non-overlapping configuration (stride equals window size), so no packet appears in multiple windows. Splits are performed after windowing; thus, packet-level overlap across train/validation/test is prevented by construction. Nevertheless, windows derived from the same capture/session may remain temporally correlated. Therefore, we interpret the reported results as window-level generalization and recommend group-wise splitting (e.g., by capture file or device/session ID) as a stricter protocol when such identifiers are available; see the Limitations subsection (Section 5, Discussion).
Randomization and seeds: We report mean ± std over three seeds (2024/2025/2026). Each seed initializes all random number generators (Python 3.10.12, NumPy 1.26.4, PyTorch 2.7.1+cu118), affecting the deterministic generation of source/target splits, model initialization, and mini-batch shuffling. Target labels are never used for training or model selection under the UDA protocol. Unless otherwise noted, main tables/figures report three seeds (2024/2025/2026); Appendix A.4 and Supplementary File S2 provide a 20-seed robustness analysis (seeds 2024–2043).
3.3. Compared Methods
We compare five methods implemented with the same backbone and optimization settings. All methods share a feature extractor and a label classifier; adaptation methods add an alignment loss term computed from source and target mini-batches.
Alignment hyperparameters (CORAL/MMD): For CORAL, we use a closed-form covariance alignment (no extra scaling term). For MMD-ERM, we use a scheduled scalar weight β(ep, step) with loss = L_cls + β(ep, step)·L_mmd, where EPOCHS = 20, WARMUP_EPOCHS = 3, β_max = 1.0. We set β(ep, step) = 0 for ep ≤ WARMUP_EPOCHS; otherwise, β(ep, step) = β_max·clip(p, 0, 1), with p = ((ep − WARMUP_EPOCHS − 1)·n_steps + step)/((EPOCHS − WARMUP_EPOCHS)·n_steps) (see Supplementary File S1).
ERM (empirical risk minimization; source only): Trains only on labeled source data.CORAL-ERM (correlation alignment): Adds a covariance alignment loss between source and target feature representations [14].MMD-ERM: Adds a maximum mean discrepancy (MMD) loss to match source and target distributions in feature space [13].noGRL (lambda = 0): Uses the DANN architecture but disables the gradient reversal layer (GRL), serving as a control for the domain-classification head.DANN (domain-adversarial neural network; GRL): Domain-adversarial training with a gradient reversal layer (GRL) encourages domain-invariant features [15].
Objective functions and training procedures are summarized below to fix the optimization targets and improve reproducibility.
Notation: Let Ds be the labeled source (IP) set, and Dt be the unlabeled target (BLE) set. We use a feature extractor G(·), a label classifier C(·) that outputs class logits, and (when applicable) a domain discriminator D(·) that outputs domain logits. The domain label is d ∈ {0, 1} (d = 0 for source/IP, d = 1 for target/BLE).
Objectives: ERM optimizes Equation (1) using labeled source samples only. CORAL-ERM and MMD-ERM add the alignment terms in Equations (2) and (3), respectively, computed from source and target mini-batches. The DANN optimizes the min–max objective in Equation (4) via a gradient reversal layer (GRL). noGRL shares the same architecture as the DANN but disables adversarial gradients to the feature extractor (i.e., GRL is removed). The training loop is summarized in Algorithm 1. Algorithm 1. Unsupervised domain adaptation training for IP → BLE (ERM/CORAL/MMD/DANN/noGRL) Input: Labeled source set Ds = {(xs, ys)}; unlabeled target set Dt = {xt}; feature extractor G; label head C; (optional) domain head D; training epochs E; batch size b; alignment weight β(ep, step) (for CORAL/MMD); adversarial weight λ (for GRL/DANN). Output: selected model checkpoint (G, C) and evaluation logs. 1. Initialize parameters of G and C (and D if applicable). 2. For epoch = 1 to E: 2.1. Sample a labeled mini-batch (Xs, Ys) from Ds (source-train) and an unlabeled mini-batch Xt from Dt (target split). 2.2. Compute features Fs = G(Xs) and Ft = G(Xt). 2.3. Compute classification loss L_cls on (Xs, Ys) using Equation (1). 2.4. If CORAL: Compute alignment loss using Equation (2). If MMD: compute alignment loss using Equation (3). Otherwise, set alignment loss to 0. 2.5. If DANN or noGRL: Compute domain loss L_dom_ on (Xs, Xt) using Equation (4), update D to minimize L_dom_. For DANN, update G via the GRL with weight λ to maximize L_dom_; for noGRL, update G without the GRL signal (λ = 0). 2.6. Update (G, C) using source labels only; do not use any target labels during training or checkpoint selection (UDA protocol). 2.7. Evaluate on the source validation set; save a checkpoint if it improves the selection criterion (source-val ROC-AUC; tie-breaker: source-val AP; then earliest epoch). 3. Return the selected checkpoint. Optional diagnostic: record the epoch where domain accuracy is closest to 0.5 as epoch * for analysis. The asterisk (*) denotes the diagnostic epoch (the epoch where domain accuracy is closest to 0.5).
3.4. Evaluation Metrics and Statistical Validation
We report target-domain receiver operating characteristic area under the curve (ROC-AUC) and average precision (AP); additionally, we provide an F1 score for a fixed decision threshold. To quantify uncertainty on a challenging split, we report bootstrap 95% confidence intervals on seed = 2026 by resampling target test windows with replacement.
In addition to performance metrics, we compute diagnostic measures of distribution shift between source and target representations. Specifically, we report the maximum mean discrepancy (MMD) [13] and sliced Wasserstein distance (SWD) [25] before and after adaptation (seed = 2026).
Decision thresholding: For threshold-dependent metrics (precision/recall/F1 and confusion matrices), we select a decision threshold, , by maximizing the attack-class F1 on the labeled source validation split and then apply the same to BLE target test predictions. This protocol avoids target-label leakage, which is essential in UDA. Because cross-protocol shift can induce score miscalibration, may not transfer optimally; therefore, we treat AP/PR curves as primary indicators of detection quality under imbalance [21,22] and provide thresholded error analysis in Appendix A (Table A1).
Concrete mitigation for threshold transfer: Beyond auditing the source F1 threshold, τ*, we also compute a conservative source-validation threshold, τ (FPR = 1%), that achieves a 1% false-positive rate on source negatives and transfer it unchanged to BLE (see the calibration audit results in Section 4.6). While cross-protocol shift can still distort score calibration (and thus cannot guarantee a fixed target FPR), this provides an explicit risk-limiting knob and turns threshold transfer from a passive observation into a concrete audit + baseline mitigation under the target-unlabeled constraint.
Calibration considerations: Post hoc calibration techniques such as temperature scaling can improve in-distribution probability calibration [23]. However, calibration itself can drift across domains, and thus, source-only calibration does not guarantee well-calibrated target scores. Therefore, we report both threshold-free metrics (ROC-AUC and AP) and thresholded summaries, and we interpret F1 in conjunction with PR curves and confusion matrices rather than as a standalone indicator.
3.5. Implementation Details, Checkpoint Selection, and Reproducibility
Software/hardware: Experiments were run with Python 3.10.12 and PyTorch 2.7.1+cu118 (CUDA 11.8) on a single NVIDIA A100 80 GB GPU; NumPy 1.26.4, pandas 2.3.3, and scikit-learn 1.7.2 were used for preprocessing and evaluation. A complete environment snapshot is provided in Supplementary File S1. Key architecture and training settings are summarized in Table 3.
Model specification: All methods use the same multilayer perceptron (MLP) backbone on 14 statistical features. The feature extractor G is a 2-layer MLP (14 → 128 → 128 with ReLU); the label head C is a linear layer (128 → 2 logits); and for DANN/noGRL, the domain head D is a 2-layer MLP (128 → 64 → 2 logits).
GRL schedule: The DANN uses a 3-epoch warm-up ( = 0 for epochs 1–3), followed by a standard monotone schedule that increases the GRL weight toward 1 by the final epoch. The exact per-epoch values are provided in ‘logs/dann_train_history.csv’ in Supplementary File S1.
Checkpoint selection: To avoid target-label leakage in UDA, the default ‘best checkpoint’ for each method is selected solely using labeled source-validation performance (primary: max source-val ROC-AUC; tie-breakers: source-val AP, and then earliest epoch). For DANN/GRL, we additionally evaluate R3 (Section 3.6), a domain-aware selection rule that uses only domain labels (source vs. target) to prefer checkpoints with maximal domain confusion (DomAcc near 0.5), without using target class labels.
Baseline fairness (classical ML): Classical baselines (LogReg/RF/XGB) are trained and configured without using any target-domain class labels. Any hyperparameter choices are fixed a priori or selected using labeled source-only validation; target samples are not used for tuning or selection. For thresholded audits, the decision threshold τ* is chosen based on source validation and transferred unchanged to the target, consistent with the UDA constraint.
Reproducibility package: Supplementary File S1 includes derived feature tables (IP/BLE), a split summary and seed list, trained checkpoints, training logs, and scripts to regenerate the reported tables and figures. This enables independent verification of the reported metrics without requiring access to restricted raw packet traces.
3.6. Domain-Aware Checkpoint Selection (R3)
Default checkpoint selection in UDA relies on labeled source validation only. For adversarial alignment, we additionally consider a domain-aware rule (R3): among near-best source-validation epochs, we select the checkpoint whose domain discriminator accuracy (DomAcc) is closest to chance (0.5). We define near-best epochs as those whose source-validation ROC-AUC is within δ of the best epoch, i.e., AUC_src_val(e) ≥ max_{e′} AUC_src_val(e′) − δ (δ = 0.001 in our experiments). This tolerance safeguards against selecting clearly undertrained/overfit epochs; when the source-validation ROC-AUC is nearly flat, R3 effectively reduces to selecting the epoch with DomAcc closest to 0.5. DomAcc is computed on a balanced domain-validation set by subsampling equal numbers from the source-validation split and the unlabeled target split (not the target test set) at each epoch; therefore, chance corresponds to 0.5, even when the two splits differ in size. Oracle epochs (maximizing target-test ROC-AUC) are reported only as an analysis upper bound. R3 never uses target class labels; it uses only domain labels (source vs. target). DomAcc is computed on unlabeled target data reserved for checkpointing (not on the target test set). To further reduce selection bias, we describe a stricter target-unlabeled holdout protocol in Supplementary File S1 (split definitions) and discuss its implications in Section 5.
4. Results
4.1. Cross-Protocol Target Performance
As summarized in Table 4 and visualized in Figure 1, DANN (GRL) achieves the best mean target ROC-AUC among the neural UDA strategies, while CORAL-ERM attains the highest mean target AP. For this low-dimensional (14D) feature space, classical baselines are competitive on the random window split: logistic regression (LogReg) achieves target AUC/AP 0.683 ± 0.027/0.756 ± 0.078, random forest (RF) achieves 0.758 ± 0.051/0.770 ± 0.062, and XGBoost (XGB) achieves 0.711 ± 0.013/0.706 ± 0.009. Our aim is not to claim that deep UDA dominates classical ML in this 14D setting but to characterize cross-protocol failure modes and stabilize label-free model selection under UDA constraints. Finally, these random window-split results should be interpreted as optimistic upper bounds for deployment; Section 4.7 reports leakage-controlled leave-one-capture-out evaluation. Notably, an apparently high F1@ for ERM/noGRL can correspond to a degenerate all-positive operating point under threshold transfer, which is operationally unsafe despite benign-looking summary scores (Table A1).
4.2. Bootstrap Confidence Intervals on Seed 2026
To validate the target-domain gains under a challenging split (seed = 2026), Table 5 reports bootstrap 95% confidence intervals. On this split, ERM and noGRL yield near-chance ROC-AUC, whereas DANN (GRL) provides a substantial AUC improvement. The paired bootstrap additionally yields ΔAUC = 0.124 [0.096, 0.153] and ΔAP = 0.131 [0.106, 0.157] (DANN−ERM), confirming a statistically meaningful improvement on seed = 2026.
4.3. Unified Diagnostic Workflow for Cross-Protocol Domain Shift
To make the diagnostics in this section directly actionable under the target-unlabeled UDA constraint, we consolidate them into a deployment-oriented workflow (Table 6) that maps each proxy signal to a concrete modeling or reporting decision. This unified view aligns with broader risk auditing perspectives in safety-critical IoT/cyber-physical systems, where vulnerability assessment and defense should be accompanied by clear operational guidance [26,27]. The workflow is instantiated below with quantitative divergence proxies (Table 7 and Table 8) and a semantic-shift screen (Table 9).
Step 2 of Table 6 reports global representation-gap proxies. In the representative split (seed = 2026), SWD decreases after adaptation, whereas RBF-kernel MMD increases (Table 7), indicating that conclusions about ‘alignment’ can be metric-dependent. Given that kernel MMD is bandwidth-sensitive, Table 8 provides an RBF σ sweep to contextualize the reported value and avoid over-interpreting a single kernel setting.
Step 3 of Table 6 complements global discrepancies with a within-class semantic shift check: class-conditional Kolmogorov–Smirnov (KS) tests compare marginal feature distributions across domains within each label. Table 9 lists the most shifted features, helping explain why improvements in an aggregate discrepancy metric do not necessarily translate into deployment-faithful target performance.
4.4. Representation Alignment and Training Dynamics
Figure 2 visualizes the learned feature space using t-distributed stochastic neighbor embedding (t-SNE) before and after adaptation (panels (a) and (b), respectively). Figure 3 summarizes the key DANN training dynamics used by R3: domain classifier accuracy (DomAcc; panel (a)) and the corresponding loss curves (panel (b)).
To probe target-domain failure modes beyond aggregate scores, we compute a simple feature-level error analysis for the DANN on the BLE target test set. For each standardized feature, we compute the mean value within the four confusion groups (TP/FN/TN/FP) and rank features by | (FN − TP)|, i.e., the magnitude of the separation between missed attacks (FN) and correctly detected attacks (TP). The top contributors (Figure 5) are dominated by packet-length dispersion statistics (e.g., pkt_len_mean, pkt_len_min, pkt_len_std) and timing variability (e.g., iat_std), suggesting that protocol-dependent burstiness and length distributions are key sources of cross-protocol errors.
Figure 3b reports DANN loss curves, complementing the domain accuracy dynamics in Figure 3a. Figure 4 summarizes target BLE performance across methods (seed = 2026), and Figure 4b provides the corresponding precision–recall curve.
Figure 3 summarizes domain-discriminator behavior and DANN training losses (seed = 2026). Figure 4 reports target BLE performance across methods (seed = 2026): Figure 4a shows the metric summary, and Figure 4b shows the precision–recall curve. Figure 5 provides feature-level error contributors for DANN on the target test set, while Figure 6 and Figure 7 relate target ranking performance to transient domain confusion and training dynamics via DomAcc.
4.5. Evaluation of Domain-Aware Checkpoint Selection (R3)
We propose R3 (risk rank by confusion), a label-free checkpoint selection heuristic for UDA that leverages the domain discriminator. Specifically, we first identify a set of near-best epochs whose source-validation ROC-AUC is within δ of the best value (δ = 0.001 unless noted) and then choose the epoch whose balanced domain accuracy (DomAcc; Figure 3a) is closest to 0.5. The intuition is that a fully confused discriminator indicates stronger domain invariance, which can correlate with improved target performance under domain shift. The results are summarized in Table 10 and Table 11 and Figure 8, Figure 9 and Figure 10.
Given that R3 selects checkpoints based on transient domain confusion (DomAcc close to 0.5) rather than directly optimizing precision–recall ranking, modest AP decreases can occur even when ROC-AUC improves. In practice, the preferred checkpoint should reflect the operational objective (ROC-oriented ranking vs. PR-oriented early warning) and the chosen thresholding strategy under the prior shift.
Supplementary analyses further examine (i) the sensitivity of R3 to δ (Table S1). All split definitions and scripts required to reproduce these analyses are included in Supplementary File S1.
We summarize domain-aware checkpoint selection (R3) under the Active protocol and report a per-seed comparison between the default best (selected by source-validation ROC-AUC) and domain-aware star (selected by DomAcc closest to 0.5 among near-best epochs) in Table 10.
We report an oracle upper-bound analysis for checkpoint selection under the active protocol in Table 11, where the oracle epoch is defined post hoc as the checkpoint maximizing the target test ROC-AUC.
As shown in Figure 9, the oracle gap quantifies the remaining headroom of the domain-aware star relative to the oracle (oracle ROC-AUC − star ROC-AUC); the oracle is computed post hoc and used only as an upper bound for analysis.
4.6. Threshold Transfer and Operating-Point Sensitivity
Although AUC and AP are threshold-free, the reviewers requested that we evaluate a direct threshold-transfer scenario. In the active protocol, we compute the optimal decision threshold, τ*, on the source validation split (maximizing F1) and then apply the same τ* without recalibration to the target test split. We audit (i) the F1 drop under τ* transfer (Table 12) and (ii) calibration behavior (reliability diagrams in Figure 12). Figure 10 shows a representative threshold-transfer failure case on the BLE target (seed = 2026).
4.7. Extended Evaluation: Leakage-Controlled Evaluation and Operating-Point Analysis
To approximate deployment-faithful conditions where a detector is evaluated on an entirely unseen BLE capture, we additionally report a leakage-controlled leave-one-capture-out (LOCO) evaluation. Windows are generated with a non-overlapping scheme (window size = 64 packets, stride = 64) from preprocessed packet-level tables. For the source (IP) domain, we construct a mixed time-block group identifier (group_id_mixed) by accumulating consecutive windows in chronological order until both classes appear within each group, yielding 16 mixed groups (one-class group ratio = 0). For the target (BLE) domain, we define capture groups (ble_cap_k) using capture IDs. The LOCO protocol holds out an entire mixed-class BLE capture (ble_cap_2) for testing, while ble_cap_0/1 (benign-only) are used to audit operating-point behavior under purely benign deployments.
Figure 11 shows target score histograms on the mixed-class BLE capture group (ble_cap_2) under leakage control (seed = 2026): ERM (left) vs. DANN (right).
Notably, on the only mixed-class capture (ble_cap_2), deep UDA does not improve ranking over ERM, and both the DANN and noGRL can even underperform a simple logistic regression baseline (Table 13; Figure 11 and Figure 12). For the two benign-only captures (ble_cap_0 and ble_cap_1), ROC-AUC and AP are undefined; therefore, we report micro-FPR at a source-calibrated operating point (FPR = 1% on source) and observe that the false-positive burden can be severe in a multi-capture LOCO analysis (Table 12). Consistent with Table 12, Figure 12 further illustrates that domain-adversarial training can improve calibration on the held-out mixed-class capture, although ranking performance remains near chance.
Given that two BLE capture groups (ble_cap_0 and ble_cap_1) contain only negative samples (pos_ratio = 0), ROC-AUC and average precision are undefined for those groups. Accordingly, we report ROC-AUC/AP only on the mixed-class capture group (ble_cap_2) and complement them with operating-point metrics (false positive rate and specificity) aggregated across all capture groups. Given that the positive prevalence in ble_cap_2 is high (pos_ratio = 0.714), AP should be interpreted relative to this prior; therefore, Table 13 includes AP-lift (AP − pos_ratio) to quantify improvement over a prevalence-only baseline. In the worst case, this corresponds to micro-FPR = 1.0 on benign-only captures (Table 12).
5. Discussion
Our results show that domain-adversarial training can improve cross-protocol target AUC, but the training dynamics are not monotonic. In particular, DomAcc_last remains high for DANN/GRL (0.973 ± 0.002), indicating that domain-discriminative information persists at convergence. The epoch-wise analysis suggests that the period of strongest domain confusion (domain accuracy near 0.5) coincides with peak target AUC/AP and that later epochs may overfit to domain-specific cues. As an exploratory check under the random-window setting (and not a like-for-like comparison with the capture-wise protocol summarized in Table A4), we evaluate self-training with pseudo-labeling over 20 seeds (Supplementary Tables S2–S5; Figures S1–S4). Across 20 seeds, the AUROC change is modest and not statistically significant (Wilcoxon p = 0.231), while AP improves modestly and is statistically significant (Wilcoxon p = 0.024); the paired Wilcoxon test results are provided in Table S3; benign-only micro-FPR remains degenerate under τ_F1 (micro-FPR = 1.0) but is reduced under a source threshold calibrated at FPR = 1% (Table S4). We report these results solely to document consideration of a representative recent UDA strategy; our main conclusions and key comparisons are based on the capture-wise protocol and operating-point audits (Table A4 and Table 12, and Figure 10, Figure 11 and Figure 12).
Why classical ML can outperform neural UDA in a 14D feature space: In our setting, the 14 window-level statistics are already a compact, engineered representation; the remaining learning problem is primarily a low-dimensional decision function rather than representation learning from raw packet sequences. Therefore, tree ensembles (RF/XGB) and regularized linear models can exploit non-linear feature interactions or stable convex optimization with limited risk of overfitting, whereas adversarial objectives in a DANN introduce an additional minimax optimization that is sensitive to learning rates, initialization, and discriminator capacity. Moreover, forcing domain confusion can attenuate class-discriminative cues when the feature space offers limited degrees of freedom, which helps explain why classical models can be competitive—or even superior—on the random window split (Table 4). We include this discussion to avoid over-interpreting the results as evidence against deep learning in general; with richer representations and higher-capacity sequence models, the relative ordering may differ.
Interpreting domain-gap metrics: In the representative split (seed = 2026), SWD decreases after DANN (66.115 → 40.679), whereas MMD increases (0.579 → 0.669). This is not necessarily contradictory, because MMD and SWD capture different facets of distribution mismatch. MMD is kernel-based and can be sensitive to the kernel choice/bandwidth, effectively emphasizing certain moment/higher-order discrepancies in an RKHS [13], while SWD approximates optimal transport by averaging 1D Wasserstein distances over random projections [25]. Adversarial training can reduce discrepancies along many projections (lower SWD) while still increasing kernel-based discrepancy if alignment changes higher-order statistics or creates sharper modes. Accordingly, we avoid treating any single domain-gap metric as a definitive “alignment score” and interpret gap diagnostics jointly with target performance and training dynamics. Practically, this implies that early stopping or checkpoint selection based on a single discrepancy (MMD or SWD alone) can be misleading; combining discrepancy diagnostics with DomAcc curves is safer in unlabeled target settings. Consistent with this sensitivity, our σ sweep (Table 8) shows that the magnitude of MMD^2^ varies substantially across bandwidths, underscoring that conclusions based on a single kernel setting can be unstable.
The LOCO collapse likely reflects a mixture of capture-dependent artifacts and genuine semantic/label shifts across captures. Given that the BLE domain exhibits both class-prior shift (Table 1) and score miscalibration under threshold transfer (Section 4.6), label-shift and calibration effects can amplify even modest representation mismatch. In addition, LOCO removes the within-capture temporal correlation that can make random window splits optimistic, thereby exposing capture-specific characteristics (e.g., device mix, channel conditions, and capture setup) that are not represented in training. While our current 14D statistics cannot fully disentangle these factors, the combined evidence from discrepancy metrics (Table 7), domain-discriminator dynamics (Figure 3), and operating-point failures (Table 12 and Figure 10) supports reporting capture-wise evaluation whenever possible. This interpretation is further supported by the class-conditional KS diagnostic (Table 9), which reveals substantial within-class distribution differences between IP and BLE for multiple packet-length and inter-arrival-time statistics.
These findings motivate two practical recommendations for cross-protocol IoT intrusion/anomaly detection: (i) monitor both unlabeled target split proxies and domain-classifier behavior during training and (ii) consider domain-aware checkpointing strategies, such as selecting checkpoints when the domain classifier is closest to chance or when the correlation between domain accuracy and target metrics becomes unfavorable.
Relation to unsupervised model selection in UDA: Model selection without target class labels is a recognized challenge in UDA, and prior work has proposed proxy criteria such as Deep Embedded Validation (DEV) for deep UDA model selection and Soft Neighborhood Density (SND) for unsupervised validation of domain adaptation; recent benchmarks further highlight that reliable unsupervised selection remains difficult across datasets and methods [28,29,30]. R3 is complementary: it leverages the domain discriminator already present in adversarial UDA and requires only domain labels (source vs. target) and a small tolerance, δ, for near-best source performance. Its main limitation is that it applies only when the domain discriminator is trained and informative (e.g., if DomAcc saturates near 1.0 throughout training, R3 reduces to source-only selection).
Threshold sensitivity and imbalance: Our analysis also highlights an evaluation pitfall that is common in IoT IDS under domain shift. At seed = 2026, ERM and noGRL produce near all-positive predictions at the source-selected threshold , yielding perfect attack recall but zero true negatives on the BLE target (Table A1). This behavior inflates attack-class F1 while failing to discriminate benign traffic, and it is consistent with near-random ROC-AUC. Therefore, we emphasize AP/PR curves as primary in imbalanced regimes [21,22] and recommend explicitly reporting threshold-selection rules and calibration limitations under cross-protocol deployment [23]. Figure 10 (Section 4.6) visualizes this failure mode for seed = 2026, and Table A1 provides split-level operating-point audits.
Limitations: This study focuses on a single cross-protocol pair (IP → BLE) and a compact 14-feature family to isolate the domain-gap mechanism. We chose this lightweight, protocol-agnostic statistical representation because it is compatible with resource-constrained IoT deployments and enables apples-to-apples cross-protocol evaluation without relying on raw packet payloads. Nevertheless, absolute performance levels may differ under richer sequence/flow representations and higher-capacity architectures; our primary claims target diagnostic behaviors (evaluation optimism, checkpoint sensitivity, and threshold-transfer brittleness) rather than state-of-the-art accuracy. Although non-overlapping windowing prevents packet-level overlap across splits, stricter group-wise splits (e.g., by capture file or device/session ID) would further reduce potential temporal correlation; future work will include such protocols when group identifiers can be released. In addition, because the feature space is low-dimensional, classical ML baselines (e.g., logistic regression, SVM, random forests, and gradient boosting) are valuable for establishing whether deep UDA is necessary; we provide scripts and the derived feature tables in Supplementary File S1 to facilitate these comparisons. To partially broaden protocol coverage without changing the main scope, we provide an addendum evaluation on IP → Zigbee in Appendix B and Supplementary File S3; gains are less consistent in this secondary pair, reinforcing the need for broader protocol coverage. Finally, richer feature families and calibrated decision making under prior shift remain important directions for deployment-faithful cross-protocol IDS. Future work should validate these findings on additional protocol pairs and richer representations and explore adaptation objectives or training schedules that maintain domain confusion more stably toward convergence. Future work should also consider additional divergence diagnostics (e.g., proxy A-distance/C-distance or JS-based measures) to better separate semantic shift from capture artifacts. For additional optional diagnostic schematics and exploratory analyses that support reviewer discussion (e.g., PAD/MCD), see Supplementary File S4.
6. Conclusions
In this work, we examined cross-protocol domain shift when transferring an IP-trained IoT intrusion/anomaly detector to BLE traffic under target-unlabeled UDA constraints. Across leakage-aware random-window splits and a stricter capture-wise LOCO protocol, we found that reported UDA gains can be split-dependent: modest improvements under random splits can vanish (or reverse) under LOCO, where target ranking approaches chance, and simple baselines may dominate. Therefore, we treat LOCO evaluation, group-wise splitting, and operating-point audits as first-class requirements for deployment-faithful reporting, rather than optional stress tests.
We also show that domain-adversarial training is highly sensitive to checkpoint selection because domain confusion is transient. Over 20 seeds, DANN (default) does not provide statistically significant gains over ERM, while our domain-aware R3 rule yields more consistent AP improvements without using target labels for selection (Wilcoxon p < 0.05 for AP), although ROC-AUC gains are positive but not statistically significant. Finally, threshold transfer from the source domain can produce unsafe decisions (micro-FPR = 1.0 on benign-only captures), unless calibration and PR-oriented operating points are explicitly audited. Taken together, this study contributes both (i) an empirical account of when lightweight UDA succeeds or fails in cross-protocol IoT settings and (ii) a practical diagnostic workflow (Table 6) and reproducibility package to support robust, risk-aware model deployment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Seranmadevi R. Addula S.R. Kumar D. Tyagi A.K. Security and Privacy in AI: Io T-Enabled Banking and Finance Services Monetary Dynamics and Socio-Economic Development in Emerging Economies IGI Global Hershey, PA, USA 202616319410.4018/979-8-3693-9765-7.ch 006 · doi ↗
- 2Koroniotis N. Moustafa N. Sitnikova E. Turnbull B. Towards the Development of Realistic Botnet Dataset in the Internet of Things for Network Forensic Analytics: Bot-Io T Dataset Future Gener. Comput. Syst.201910077979610.1016/j.future.2019.05.041 · doi ↗
- 3Alsaedi A. Moustafa N. Tari Z. Mahmood A. Anwar A. TON_Io T Telemetry Dataset: A New Generation Dataset of Io T and I Io T for Data-Driven Intrusion Detection Systems IEEE Access 2020816513016515010.1109/ACCESS.2020.3022862 · doi ↗
- 4Ferrag M.A. Friha O. Hamouda D. Maglaras L. Janicke H. Edge-I Io Tset: A New Comprehensive Realistic Cyber Security Dataset of Io T and I Io T Applications for Centralized and Federated Learning IEEE Access 202210402814030610.1109/ACCESS.2022.3165809 · doi ↗
- 5Garcia S. Parmisano A. Erquiaga M.J. Io T-23: A Labeled Dataset with Malicious and Benign Io T Network Traffic (Version 1.0.0) [Dataset]. Zenodo Available online: https://zenodo.org/records/47437462020(accessed on 3 January 2026)10.5281/zenodo.4743746 · doi ↗
- 6Sharafaldin I. Lashkari A.H. Ghorbani A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018)Funchal, Portugal 22–24 January 201810811610.5220/0006639801080116 · doi ↗
- 7Moustafa N. Slay J. UNSW-NB 15: A Comprehensive Data Set for Network Intrusion Detection Systems Proceedings of the 2015 Military Communications and Information Systems Conference (Mil CIS)Canberra, Australia 10–12 November 20151610.1109/Mil CIS.2015.7348942 · doi ↗
- 8Doménech J. León O. Siddiqui M.S. Pegueroles J. Evaluating and Enhancing Intrusion Detection Systems in Io MT: The Importance of Domain-Specific Datasets Internet Things 20253210163110.1016/j.iot.2025.101631 · doi ↗