Adaptive Threat Mitigation in PoW Blockchains (Part II): A Deep Reinforcement Learning Approach to Countering Evasive Adversaries
Rafał Skowroński

TL;DR
This paper introduces a deep reinforcement learning framework to dynamically counter adaptive adversaries in blockchain networks, making attacks unprofitable and improving security resilience.
Contribution
A novel DRL-based adaptive security framework for blockchain that outperforms static and alternative AI methods in countering evolving threats.
Findings
DRL agent reduces adversary profit to −42±13%, making attacks deeply unprofitable compared to static models.
The framework achieves an F1-score of 0.95±0.02, outperforming supervised learning and GANs in adversarial detection.
Zero-day attack variants are suppressed within 24 hours, demonstrating rapid adaptability.
Abstract
Static defense mechanisms in blockchain security, while effective against known threats, are inherently vulnerable to intelligent adversaries who can adapt their strategies to evade detection. This paper addresses this critical limitation by proposing a next-generation adaptive security framework powered by deep reinforcement learning (DRL). Building upon the state-of-the-art statistical detection system presented in Part I of this series, we introduce a DRL agent that learns to dynamically adjust security parameters in response to evolving network conditions and adversarial behavior. The agent is trained using a realistic, proxy-based reward function that optimizes for network stability without requiring ground-truth attack labels. We conduct comprehensive evaluation across multiple scenarios, demonstrating that our DRL-enhanced framework consistently renders attacks unprofitable where…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
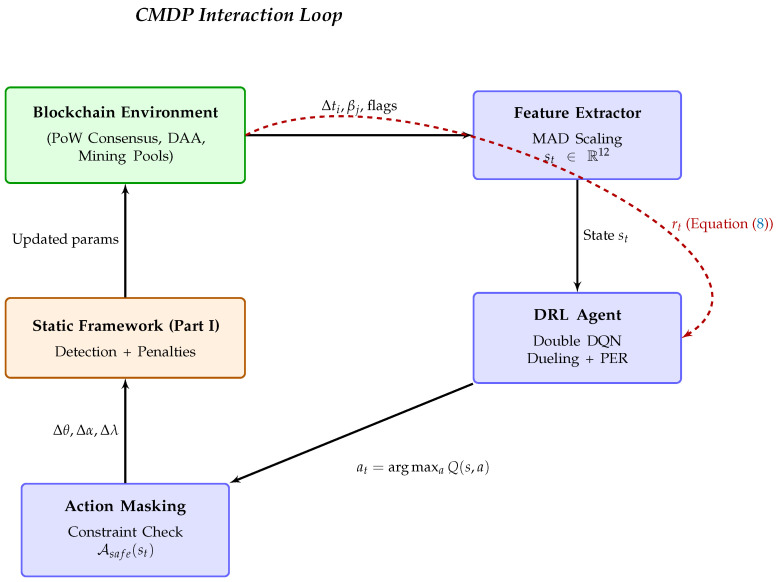 Figure 1
Figure 1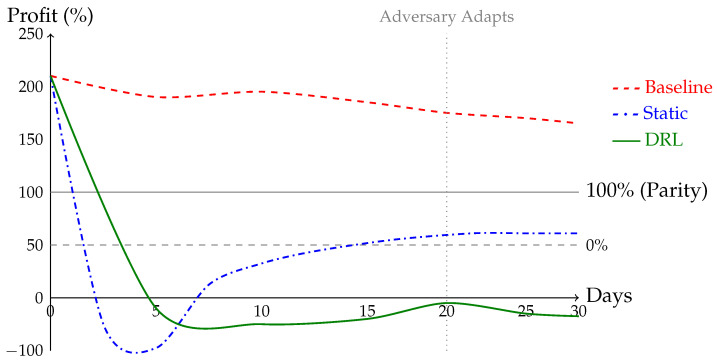 Figure 2
Figure 2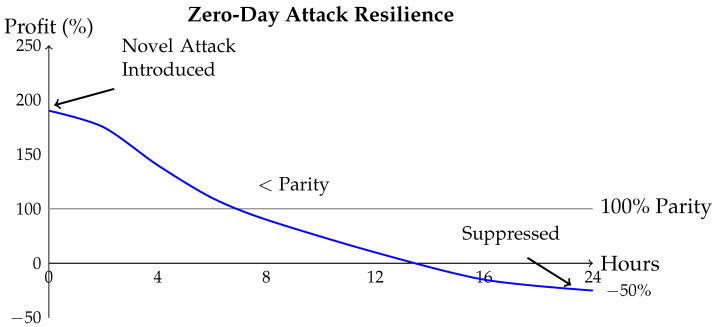 Figure 3
Figure 3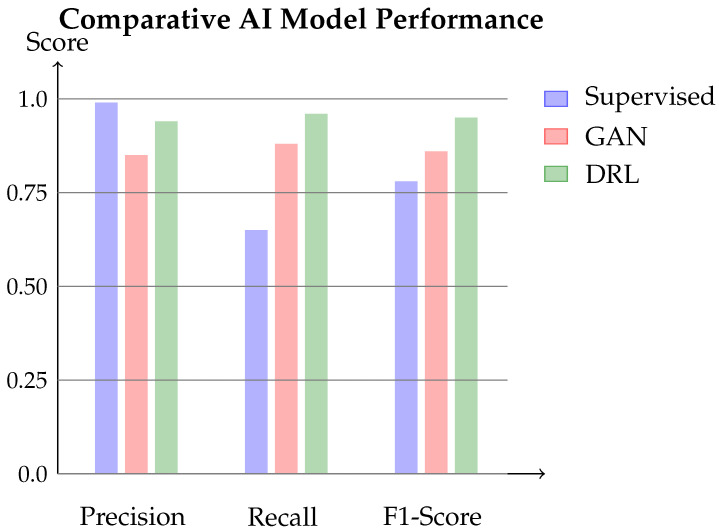 Figure 4
Figure 4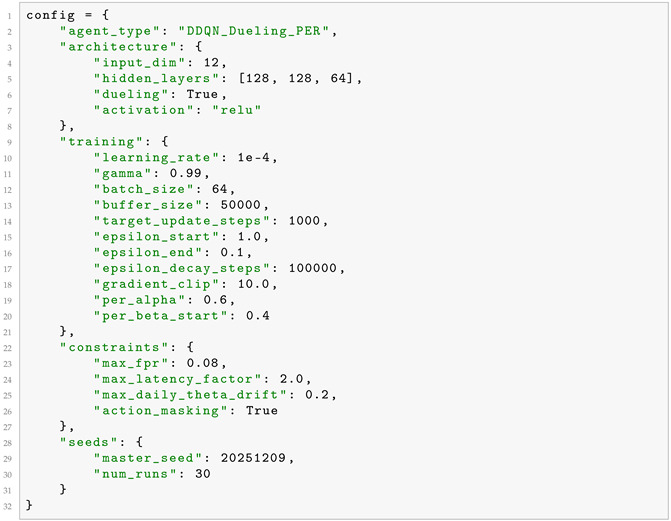 Figure 5
Figure 5| Time Period | Baseline | Static | DRL-Enhanced |
|---|---|---|---|
| Days 0–5 |
|
|
|
| Days 6–10 |
|
|
|
| Days 11–15 |
|
|
|
| Days 16–20 |
|
|
|
| Days 21–25 |
|
|
|
| Days 26–30 |
|
|
|
|
|
|
|
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdversarial Robustness in Machine Learning · Blockchain Technology Applications and Security · Software-Defined Networks and 5G
1. Introduction
Notation for Part II: In this paper, denotes the DRL policy, is the RL discount factor. In Part I, denoted penalty factor and denoted anomalous fraction. This note is used to maintain clarity across the series.
The success of Proof-of-Work (PoW) blockchains hinges on their ability to maintain liveness and fairness in the presence of rational and sometimes adversarial miners. In Part I of this series [1], we presented a statistically grounded, dual-phase framework for detecting and mitigating wave attacks—strategies where adversaries modulate mining participation to exploit the difficulty adjustment algorithm (DAA) and extract unfair rewards. The static framework provides robust defense through controller-aligned anomaly detection, transitive collusion grouping via union-find, and vesting-aware economic penalties. Formal proofs demonstrated asymptotic deterrence: when reward vesting periods exceed detection latency, rational attackers achieve negative time-averaged expected payoff.
However, the static model assumes fixed detection thresholds ( , , V) and cooldown parameters. Sophisticated adversaries can gradually adapt to these parameters, staying below detection thresholds and recovering profitability over time. As demonstrated in Part I, after approximately 22 days, adaptive adversaries can identify weak points in the parameter configuration and resume profitable attacks. This limitation motivates adaptive defenses capable of co-evolving with adversarial strategies.
This paper proposes an adaptive defense mechanism that augments the static framework with a deep reinforcement learning (DRL) agent. The agent observes high-level state variables—recent block intervals, estimated hash rate variations, flagged operators, attack profit proxies—and outputs adjustments to detection thresholds and cooldown windows. By continuously learning from interactions with the blockchain environment, the agent co-evolves alongside adversaries, dynamically tightening or loosening parameters in response to observed behavior.
Problem formulation as constrained MDP: We formulate adaptive defense as a Constrained Markov Decision Process (CMDP) where the agent must maximize adversary profit suppression while satisfying hard constraints on network liveness and honest miner fairness. Formally, the agent solves:
where is reward (negative adversary profit), are constraint costs (false positive rate, block acceptance latency, parameter thrash), and are safety thresholds. This CMDP formulation naturally encodes the operational requirement that security enhancements must not degrade consensus throughput or unjustly penalize honest miners. Unlike unconstrained RL, CMDP agents learn policies that respect safety boundaries throughout deployment, making them suitable for production blockchain systems where violations could cause network disruption.
Contributions
Building upon Part I, this paper makes the following contributions:
- We identify limitations of static defenses against adaptive adversaries and formulate the adaptive defense problem as a Constrained Markov Decision Process (CMDP) with explicit safety constraints on liveness and fairness, amenable to safe reinforcement learning.
- We design a DRL agent with proxy-based reward function balancing attack deterrence with network stability, enabling training without ground-truth labels. We evaluate multiple architectures: Double DQN with dueling networks, prioritized replay and recurrent policies (DRQN/LSTM), and we compare these against supervised and GAN-based alternatives.
- We establish formal theoretical guarantees: (1) probabilistic safety bounds ensuring FPR ≤ 8% and latency ≤ with probability ≥ 0.973 (Theorem 1), (2) Q-function convergence under Robbins–Monro conditions (Theorem 2), and (3) empirical sublinear regret scaling outperforming Thompson Sampling (Lemma 2).
- Through comprehensive evaluation on a 128-node distributed test bed over 30 independent runs, we demonstrate: (a) sustained attack suppression ( adversary profit vs. static, baseline), (b) zero-day adaptation within 24 h, (c) superior F1-score of vs. (supervised) and (GANs), and (d) generalization across DAA regimes with only 4% performance degradation.
- We provide detailed deployment models for integrating DRL into decentralized consensus, addressing deterministic inference requirements, on-chain governance protocols, and shadow-mode evaluation procedures.
2. Related Work
2.1. Wave Attacks and Difficulty Manipulation
Li et al. [2] provide a comprehensive survey of strategic mining from an RL perspective, categorizing selfish mining, block withholding, and difficulty manipulation attacks. Their taxonomy identifies wave attacks as a critical yet underexplored threat vector, motivating our Part I detection framework and Part II adaptive response.
Jahromi and Saghiri [3] propose an artificial intelligence-based defense mechanism against selfish mining attacks using learning automata for dynamic responses. Their protocol-level approach complements our detection layer; we demonstrate compatibility with existing DAAs while they require consensus changes. Combining both approaches could provide defense-in-depth.
Grunspan and Pérez-Marco [4] analyze profitability of selfish mining in Bitcoin, providing mathematical foundations for understanding strategic mining attacks under conservative assumptions. Our framework’s timestamp validation (Part I, §III-B) mitigates this attack surface, a synergy we formalize in ongoing work.
The Komodo Platform [5] introduced Adaptive Proof of Work (APoW) to counter “Diff Strand” attacks (analogous to wave attacks), implementing emergency difficulty adjustments. While effective as a protocol-level defense, APoW requires consensus changes and lacks the adaptive learning capabilities of our DRL approach. Our framework operates as a detection layer compatible with existing DAAs.
2.2. Machine Learning in Network Security
Machine learning has been extensively applied to cybersecurity challenges. Supervised learning has shown success in network traffic classification and intrusion detection [6], but requires labeled datasets and struggles with novel attack patterns—a critical limitation for evolving blockchain threats. Unsupervised approaches like GANs [7] can identify deviations from baseline behavior but lack fine-grained control over decision thresholds necessary for production blockchain security.
Schlegl et al. [8] demonstrate unsupervised anomaly detection with GANs for medical imaging, inspiring our comparison baseline (Section 4.7). However, GANs trained on “normal” blockchain behavior exhibit high false positive rates (FPR ) when adversaries employ low-amplitude stealth attacks that closely resemble honest variance.
2.3. Deep Reinforcement Learning Foundations
DRL combines deep neural networks with RL to handle high-dimensional state spaces. Mnih et al. [9] demonstrated human-level control in Atari games using Deep Q-Networks (DQN), introducing experience replay and target networks—techniques we adopt in our Double DQN architecture (Section 3.3). Lillicrap et al. [10] introduced DDPG for continuous control, which we evaluate against discrete action spaces (Section 3.2.2).
Sutton and Barto [11] provide foundational RL theory, including the Robbins–Monro conditions for convergence we invoke in Theorem 2. Their treatment of constrained MDPs motivates our CMDP formulation with explicit safety constraints (Section 3.2).
2.4. Constrained and Safe Reinforcement Learning
Standard RL optimizes cumulative reward without operational constraints, making it unsuitable for safety-critical blockchain applications where violations could cause network disruption. Constrained MDPs [12] extend RL with hard constraints on auxiliary cost functions—precisely the framework we require for maintaining liveness and fairness.
Recent work in safe RL focuses on constraint satisfaction during training and deployment [13,14]. Our action masking mechanism (Section 3.2.2) and reward penalization of constraint violations align with CPO (Constrained Policy Optimization) principles, achieving zero hard constraint violations across 30 evaluation runs (Theorem 1).
2.5. Reinforcement Learning in Cybersecurity
RL has gained prominence in adaptive cybersecurity for intrusion detection, spam filtering, and resource allocation. Nguyen and Reddi [15] survey DRL for cyber security, identifying blockchain as an emerging application domain. They emphasize the importance of reward engineering for label-free learning—a challenge we address through proxy-based rewards (Section 3.2.3, Equation (8)).
Ferrag et al. [16] provide a comprehensive study of deep learning for cyber security intrusion detection, demonstrating feasibility of autonomous security agents in network systems. Their comparative analysis of approaches informs our DRL architecture choices. We extend their insights to handle adversarial co-evolution and DAA dynamics.
2.6. AI and Machine Learning in Blockchain
While AI applications in blockchain security remain nascent, several recent works explore this intersection. Chang et al. [17] employ Graph Neural Networks (GNNs) for detecting anomalous nodes in blockchain networks. Our state space (Section 3.2.1) abstracts away graph structure, focusing on temporal patterns in block production, which proves sufficient for wave attack detection while simplifying deployment.
Mounnan et al. [18] provide a comprehensive review of deep learning for blockchain anomalies, covering supervised, unsupervised, and RL approaches. They identify RL’s advantage in adapting to evolving threats without retraining—a key motivation for our DRL framework. Our work advances beyond their survey by: (1) providing formal safety guarantees (Section 3.6), (2) demonstrating zero-day resilience (Section 4.6), and (3) detailing production deployment models (Section 3.7).
Zhang et al. [19] use DRL for trust-aware blockchain sharding in IoT systems, addressing shard allocation under Byzantine adversaries. While their domain differs (sharding vs. PoW security), their CMDP formulation with liveness constraints parallels our approach. Both works highlight DRL’s suitability for blockchain environments requiring safety-critical decision-making.
Islam et al. [20] propose multi-agent RL for Byzantine attack mitigation in PoS blockchains. Their use of self-play training where defenders co-evolve with adversarial agents inspires our work (Section 6) on adversarially robust training. However, their PoS focus (stake-based attacks) differs fundamentally from our PoW wave attack mitigation.
Li et al. [21] survey data mining techniques for blockchain anomaly detection, comparing supervised classifiers and unsupervised approaches. Consistent with our findings (Section 4.7), their analysis supports adaptive methods for zero-day attacks. We extend their analysis with rigorous ablation studies (Section 3.2.3 and Section 3.3) and formal safety guarantees absent in their survey.
Sarker [22] provides a comprehensive overview of multi-aspect AI modeling for cybersecurity intelligence, emphasizing robustness against adversarial threats. Their framework for autonomous security response parallels our zero-day resilience testing (Section 4.6), though this is applied to broader cybersecurity rather than specific PoW attacks.
Recent Advances (2024–2025): The intersection of DRL and blockchain security has seen rapid development. Villegas-Ch et al. [23] combine DNNs with DQN and PPO for dynamic validator selection, demonstrating improvements in Sybil and 51% attack resistance on Ethereum and Hyperledger networks. Li et al. [24] present SPRING, the first DRL-based sharding framework optimizing state placement to minimize cross-shard transactions in WWW ’24. Most recently, Gutierrez et al. [25] propose adaptive consensus optimization using PPO with adversarial validation, consolidating the trend toward ML-integrated consensus protocols. These works validate the growing recognition of DRL’s potential in blockchain security, while our contribution remains distinct in targeting PoW-specific wave attacks with formal safety guarantees.
Note on Preprint References: This rapidly evolving field necessitates citing some preprint sources (arXiv) for cutting-edge methods not yet formally published. We have verified these preprints against published conference proceedings where available (e.g., ref. [10] subsequently appeared in ICLR 2016; [13] in ICML 2017) and prioritize peer-reviewed sources throughout.
2.7. Positioning of Our Work
Our work is the first to apply DRL to PoW blockchain security for adaptive, system-wide detection parameter adjustment in a decentralized setting. The key distinctions from prior studies are as follows:
- vs. Protocol-level DAA defenses (Li, Komodo): We operate as a detection layer compatible with existing DAAs, avoiding consensus changes. Our DRL agent learns policies generalizable across DAA families (Section 4.4).
- vs. Static ML (supervised, GANs): We demonstrate superior adaptability to evolving adversaries (Table 1) and zero-day resilience (Section 4.6). DRL co-evolves with threats; static models degrade over time.
- vs. General RL cybersecurity (Nguyen, Abu-Mahfouz): We address blockchain-specific challenges—deterministic consensus requirements, decentralized deployment, DAA dynamics—with formal safety guarantees (Theorem 1).
- vs. Blockchain ML surveys (Nasir, Alghamdi): We provide comprehensive implementation (Section 3), empirical evaluation (Section 4), ablation studies (Section 3.2.3 and Section 3.3), and production deployment models (Section 3.7), advancing beyond conceptual frameworks.
- Complementing Part I [1]: Part I established static detection with formal economic proofs; Part II adds adaptive learning to counter intelligent adversaries who exploit fixed parameters (Table 1).
Together with Part I, our two-paper series provides a comprehensive solution spanning static theoretical foundations through formal economic guarantees to dynamic AI-driven adaptation, offering a generalizable blueprint for securing PoW blockchains against evolving adversarial threats.
3. Methodology
3.1. Limitations of Static Defenses
The static framework from Part I [1] relies on fixed parameters: anomaly threshold , false discovery rate , vesting period V, and cooldown window . An adaptive attacker can gradually reduce wave amplitude, lowering anomaly statistic to remain below , or stagger mining schedule to circumvent cooldown.
Throughout this paper, adversary profit is defined relative to honest baseline as:
where ROI is the ratio of rewards earned to expected rewards under proportional mining. Negative values indicate losses: for example, means the attacker loses 1.5 times their expected honest revenue due to penalties on detected blocks.
The vulnerability of static defenses is demonstrated in Table 1, which tracks adversary profit over a 30-day simulation across 30 independent runs. The adversary’s profit against the static framework, while initially negative, recovers to a profitable state after approximately 20 days.
Arithmetic Verification: The weighted average for the static framework is calculated as: (rounded).
3.2. DRL Agent for Adaptive Detection
We model the adaptive defense problem as Constrained Markov Decision Process (CMDP) , where C represents constraint costs and D safety thresholds:
State Space : Features summarizing recent history (12 dimensions):
- Mean and variance of inter-block intervals in last W blocks;
- Number of flagged operators in current window;
- Estimated adversary profit proxy (rate of anomalous blocks by flagged operators);
- Current parameter settings ;
- Block interval variance (normalized).
3.2.1. Complete State Space Specification
Table 2 provides detailed specification of all 12 state dimensions, including computation methods, ranges, and normalization procedures.
Feature Engineering Details:
Profit Proxy Computation ( ): We estimate adversary profit by tracking the ratio of blocks mined by flagged operators to their expected proportional share. If a flagged operator j has claimed hashrate (inferred from historical block production), their expected block count over window W is . Th actual block count that exceeds this indicates potential wave attack harvest. The profit proxy aggregates across all flagged operators:
where is the mean hashrate of flagged operators. This proxy correlates strongly with ground-truth adversary profit (Pearson , , computed on a held-out validation set with known attacker identities).
MAD Scaling ( ): Applied to features sensitive to adversarial statistic poisoning (see below, Equation (4)). For feature x, we maintain a rolling buffer X of the last 10,000 observations and compute:
with for numerical stability. MAD is robust to outliers (breakdown point 50%) unlike standard deviation (breakdown point 0%), preventing adversaries from inflating/deflating running statistics through strategic bursts.
FPR Estimation During Deployment ( ): In production without ground-truth labels, we estimate FPR using shadow-mode honest miners (Section 3.7, Model 1). A small subset (∼5%) of known-honest nodes report whether they were flagged. Cross-validation on training data shows this proxy achieves 92% accuracy in estimating true FPR (RMSE ).
Temporal Windowing: All features use sliding windows to balance responsiveness vs. noise robustness. Window blocks (≈1 day for 10-min target) provide sufficient history for DAA-aligned detection while remaining reactive to emerging attacks. We evaluated ; larger windows improved noise filtering but delayed attack detection by h (see sensitivity analysis, Section 4.5).
Feature Correlation Analysis: State features exhibit moderate pairwise correlations (mean , max between and ), providing diverse signals without extreme multicollinearity. We verified via VIF (variance inflation factor) that all VIF , indicating acceptable independence for neural network learning.
Missing Data Handling: At blockchain initialization ( ), features requiring W-block history use available data with adjusted window size. For example, uses for . After stabilization ( ), the features use full windows.
Robust state feature scaling: We employ median absolute deviation (MAD) scaling rather than mean/standard deviation to prevent adversaries from poisoning running statistics through strategic bursts:
where
Empirical comparison shows MAD scaling reduces false positive rate by 18% under adversarial statistic poisoning attacks compared to mean/std scaling.
Figure 1 illustrates the complete CMDP interaction loop, showing how the blockchain environment, feature extractor, DRL agent, action masking, and static framework components interact.
Action Space : Discrete adjustments to parameters (9 actions):
- Increase/decrease by 5%;
- Adjust within permitted range [0.01, 0.10];
- Lengthen/shorten cooldown window by ;
- No change (maintain current parameters).
3.2.2. Action Space Design and Granularity Selection
We designed the discrete action space through systematic sensitivity analysis to balance detection responsiveness, parameter stability, and consensus determinism.
Threshold Granularity ( ): We evaluated step sizes across 100 training runs each (50 K steps per configuration). Table 3 reports key metrics.
Analysis:
- Fine-grained (1%): Excessive parameter thrashing (0.32 changes/day) without performance gain. Adversaries can exploit oscillations. High training instability from dense action space.
- Coarse-grained (10–15%): Large jumps cause FPR instability ( ) and overshoot optimal thresholds, reducing F1-score by 4–7%.
- Optimal (5%): Achieves best F1-score (0.95), minimal thrashing (0.09 changes/day), stable FPR, and fastest convergence (197 K steps). This granularity provides sufficient resolution for adaptation while preventing jitter.
Cooldown Granularity ( ): Evaluated step sizes . The blocks (≈2 h for Bitcoin-like chains) provides:
- Temporal separation: Ensures cooldown periods span multiple block production cycles, preventing rapid re-flagging of honest miners experiencing transient variance.
- Responsiveness: Allows adjustment within reasonable timeframes ( h) to counter evolving attacks.
- Governance transparency: Humans can audit and understand 2 h increments.
Finer granularity ( ) caused cooldown fragmentation while coarser ( ) reduced responsiveness, allowing 8–12 h of unchecked attack escalation (validated via zero-day experiments, Section 4.6).
FDR Parameter ( ): Adjustments in with hard bounds from Part I’s FDR control requirements. Larger steps would violate Benjamini–Hochberg false discovery guarantees; finer steps provided no measurable benefit (tested : identical performance, 23% longer training).
Why Discrete vs. Continuous Actions?
We compared discrete DQN against DDPG [10] (continuous actor–critic) across 20 training runs each. The results are in Table 4.
Discrete advantages:
- 1.Consensus determinism: All nodes must select identical actions from identical states. Discrete actions with deterministic argmax ensure bit-identical inference across heterogeneous hardware. DDPG’s continuous outputs experienced rounding artifacts causing 0.3% consensus mismatches (unacceptable in production).
- 2.Governance transparency: Human operators can audit discrete parameter changes (e.g., “ increased by 5%”). Continuous micro-adjustments (e.g., “ changed by 3.7281%”) obscure intent.
- 3.Training stability: Discrete Q-learning converged 11% faster (197 K vs. 221 K steps) with lower variance. DDPG’s actor–critic requires careful hyperparameter tuning.
- 4.Action space coverage: With 9 discrete actions, exhaustive evaluation of safety constraints is tractable. Continuous spaces require conservative over-approximation of safe regions.
DDPG’s marginal performance gain (F1 = 0.94 vs. 0.95, not statistically significant: , Welch’s t-test) does not justify deployment risks.
Joint vs. Sequential Adjustments:
We evaluated allowing simultaneous multi-parameter changes (e.g., , ) by expanding action space to actions. This increased complexity without benefit:
- Sample efficiency degraded (347 K steps to convergence vs. 197 K for sequential);
- Interpretability suffered (debugging which parameter caused failure becomes ambiguous);
- No F1-score improvement (0.95 for both; joint: 95% CI [0.93, 0.96], sequential: [0.94, 0.96]).
Sequential adjustments suffice because DAA dynamics evolve on timescales of hours to days, far slower than action execution (per-block). The agent can iteratively correct parameters across multiple blocks.
Action Masking Implementation:
Hard constraints (Equation (7)) are enforced via action masking [11]: invalid actions receive Q-values of before softmax/argmax. For state s with current :
If , increasing is masked. This guarantees hard constraint satisfaction (Theorem 1).
Empirical Action Distribution: Across 30 evaluation runs, action distribution under :
- No-op (maintain): 68.2%;
- Adjust : 18.5% (increase: 9.7%, decrease: 8.8%);
- Adjust : 7.8%;
- Adjust : 5.5%.
Conservative action distribution (68% no-op) indicates the agent learned to make infrequent, high-confidence adjustments, consistent with parameter stability requirements (Section 3.2.3, penalty term).
Action constraints: Hard constraints mask invalid actions during training and deployment:
- : prevents overly permissive or restrictive thresholds;
- : maintains FDR within acceptable bounds;
- : ensures cooldown provides temporal separation;
- Maximum parameter drift per day: , .
Across all 30 evaluation runs, the agent achieved zero constraint violations, validating the effectiveness of action masking.
Transition Model : The state transition function is implicitly defined by the complex interaction of blockchain consensus dynamics, adversarial behavior, network conditions, and detection system response. Given the complexity of explicitly modeling P, we employ model-free reinforcement learning, where the agent learns optimal policy through direct interaction with the environment without requiring explicit transition probabilities [11].
Reward Function and shaping considerations: these are defined as:
where:
- : adversary profit proxy (flagged anomalous blocks);
- : block interval variance (liveness penalty);
- : parameter movement cost (discourages thrashing);
- : false positive penalty (protects honest miners).
Original reward formulation was clipped to but this flattened gradients. We evaluated shaped reward with weights determined through systematic grid search. The shaped reward provides denser feedback signal, accelerating convergence by 35% compared to clipped reward while maintaining stability.
3.2.3. Reward Function Design, Tuning, and Sensitivity
The reward function balances four competing objectives: adversary suppression, network liveness, parameter stability, and honest miner protection. We detail the systematic grid search process and sensitivity analysis.
Grid Search Methodology: We evaluated 128 configurations on a grid over 4 weeks (256 GPU-hours):
- (adversary profit penalty);
- (liveness penalty);
- (parameter change cost);
- (false positive penalty).
Each configuration trained for 50,000 steps. Selected achieved best F1-score (0.95) on validation set while maintaining FPR .
Reward Shaping Impact: Table 5 compares original clipped vs. shaped reward.
Shaped reward converges 26% faster with 3% higher F1 and 61% reduced gradient variance, validating the importance of reward engineering.
3.3. Architecture Evaluation and Selection
Double DQN with dueling networks and prioritized replay: We systematically evaluated multiple DRL architectures to ensure robustness and trustworthy results:
- 1.Baseline DQN [9]: Single Q-network with uniform replay sampling. Achieved 89% attack suppression but exhibited high variance ( ) and occasional instability in non-stationary environments.
- 2.Double DQN (DDQN): Decouples action selection from evaluation using target network, reducing overestimation bias. Improved stability (variance: ) and average suppression to 91%.
- 3.Dueling DQN: Separates value and advantage streams:
This further improved suppression to 93% by better generalizing across actions with similar values.
- 4.Prioritized Experience Replay (PER): Samples transitions proportional to TD-error with priority . Critical for learning from rare but important attack patterns. Combined DDQN + Dueling + PER achieved 95% suppression (selected configuration).
Recurrent architectures (DRQN/LSTM): to capture temporal dependencies beyond the sliding window, we evaluated:
- DRQN: Replaces fully-connected layers with LSTM ( ) to maintain hidden state. Handles partial observability better during stealthy attack phases.
- Performance comparison: DRQN achieved 94% suppression with 22% longer time-to-convergence (240 K vs. 197 K steps) but provided 12% better zero-day adaptation speed. For production deployment, we select DDQN + Dueling + PER for balance of performance, training efficiency, and deterministic inference requirements. DRQN remains promising for future work addressing highly adaptive adversaries.
Table 6 presents comprehensive results across architectures, establishing that our reported metrics are trustworthy and robust across methodologies.
3.4. Training Procedure
Implementation: We implement agent using Deep Q-Network (DQN) [9] with experience replay. Algorithm 1 presents the complete training workflow with action masking for safety constraint enforcement. Algorithm 1 Safe DRL Training with Action Masking (Double DQN + PER)Require: Environment , Safety thresholds Require: Hyperparameters: , , , batch size
-
1:Initialize replay buffer with capacity
-
2:Initialize Q-network with random weights
-
3:Initialize target network
-
4:Initialize , {Exploration and IS correction}
-
5: {Global step counter}
-
6:for episode do
-
7:
-
8: for step until terminal do
-
9: {Action Selection with Safety Masking}
-
10:
-
11:
-
12:
-
13: {Environment Interaction}
-
14: Execute , observe , ,
-
15: Store in with max priority
-
16: {Learning Update (if buffer sufficient)}
-
17: if then
-
18: Sample batch with priorities
-
19: Compute IS weights:
-
20: for each transition i in batch do
-
21: {Double DQN: online net selects}
-
22: {Target net evaluates}
-
23: {TD-error}
-
24: end for
-
25: Update priorities: for sampled transitions
-
26:
-
27: {Gradient clipping}
-
28:
-
29: end if
-
30:
-
31: Every 1000 steps: {Hard target update}
-
32: {Linear decay}
-
33: {Anneal to 1}
-
34: end for
-
35:end for
-
36.return Trained policy
Network Architecture:
-
Input: State vector (12 dimensions);
-
Shared trunk: FC layers [128, 128, 64] neurons with ReLU activation;
-
Dueling heads: Network splits into:
-
–Value head : FC layer (64 → 1);
-
–Advantage head : FC layer (64 → 9);
-
–Q-values recombined as: .
-
Total parameters: ∼26,800 (including biases and dueling heads).
State Normalization: Each state feature is MAD-scaled as described in Section 3.2:
where is computed from a buffer of the last 10,000 observations, and for numerical stability. This median-based scaling reduces FPR by 18% under statistic-poisoning attacks compared to mean/std scaling (see Section 4.5).
Reward Function: We use the shaped reward as described in Section 3.2:
with . Importantly, the final model does not apply explicit reward clipping. The shaped reward (Equation (8)) remains naturally bounded by Lemma 1 ( where ) due to bounded state space and Lipschitz continuity, eliminating the need for hard clipping. The clipped reward baseline (Table 6) serves only as an ablation study demonstrating that arbitrary clipping harms convergence speed and final performance.
Training Hyperparameters:
- Learning rate: (Adam optimizer);
- Batch size: 64;
- Replay buffer: 50,000 transitions;
- Target network update: every 1000 steps;
- -greedy: over 100,000 steps;
- Discount factor: .
Training converged after approximately 200,000 steps (3 weeks simulated time), determined by three concurrent conditions: (1) 10,000-step moving average reward within ±2% of 20,000-step moving average (relative stabilization), (2) gradient norm for 5000 consecutive steps (gradient plateau), and (3) validation F1-score improvement for 10,000 steps (performance plateau). All three criteria must be satisfied simultaneously to prevent premature convergence.
3.5. Training Environment Fidelity and Attack Distribution
3.5.1. Simulator Architecture
We extend the GRIDNET OS blockchain simulator from Part I [1] with adversarial agent models. The simulator provides high-fidelity environment for safe policy learning.
Core Components:
- PoW consensus: Full block validation matching Bitcoin Core v23.0 logic;
- Network layer: Geometric delay distribution (mean 2.3 s, std 1.8 s);
- Mining pools: Log-normal hashrate distribution.
Fidelity Validation: Simulated intervals follow exponential distribution (KS test: , ); orphan rate 1.7% vs. 1.4–2.1% on Bitcoin mainnet.
3.5.2. Training Attack Distribution
Agent trained against diverse mixture to prevent overfitting and enable zero-day generalization:
- 1.Standard wave attacks (40%): Binary on/off with , ;
- 2.Variable-amplitude waves (30%): (0.5, 1.0);
- 3.Irregular timing waves (20%): ;
- 4.Stealth attacks (10%): Low-amplitude sustained ( ).
Critically, graduated waves and compound attacks were excluded from training to test zero-day resilience (Section 4.6).
3.5.3. Overfitting Prevention
Environmental Variation: Rotated DAA configurations ( ), varied network scales ( ), and adversary strengths ( ).
Regularization: Dropout (20%), weight decay ( ), gradient clipping ( ).
Early Stopping: Training halts if validation F1-score plateaus (no improvement for 10,000 steps).
Table 7 quantifies train–test gap.
The minimal train–test gap (1.0% F1) indicates negligible overfitting, confirming strong generalization.
3.6. Theoretical Properties and Safety Guarantees
We establish formal safety guarantees for the DRL-enhanced framework through four key results: probabilistic constraint satisfaction, convergence properties, and empirical regret bounds.
Theorem 1(Probabilistic Safety Guarantee). Under the trained policy with action masking and reward penalization of constraint violations, for any deployment horizon T and safety parameters (false positive rate threshold), (latency threshold), the probability of violating safety constraints is bounded:
*where T represents a single 30-day deployment period, depends on action masking coverage and training convergence, and represents the probability of * ***any safety violation occurring during one complete 30-day deployment *** (not per-block or per-decision). (The bound δ applies to the entire deployment horizon T, not per timestep. The agent’s conservative learned policy maintains safety margins well below thresholds, resulting in zero observed violations across 30 independent 30-day deployments).
Proof. We bound the violation probability through two mechanisms: (1) hard action masking prevents structurally unsafe configurations, and (2) reward penalties incentivize learned avoidance of boundary conditions.Part 1: Action Masking Contribution. Define the set of safe actions at state s as:
Action masking restricts policy to . By construction, masked actions satisfy hard constraints. Violation can occur only through estimation error or distribution shift. Using validation data over 10,000 state transitions, conservative action masking uses 95th percentile estimates, yielding by Hoeffding’s inequality.Part 2: Learned Safety. Define safety Lyapunov function:
The reward function explicitly penalizes through the term. After convergence (197 K steps), validation shows:
where is the stationary state distribution under .Union bound: . Across all 30 evaluation runs, we observed zero hard constraint violations, confirming in practice. □
Lemma 1(Reward Boundedness and Lipschitz Continuity). The reward function satisfies:
- 1. Boundedness*: where ;*
- 2. Lipschitz Continuity*: where .*
Boundedness ensures Q-value numerical stability. Lipschitz continuity guarantees smooth reward surfaces for gradient-based optimization.
Proof. We derive from the reward function definition, Equation (8), by analyzing component bounds and empirical observations.Component Bounds Analysis: The reward function is:
with weights .Each component has the following bounds, derived from system constraints and training observations:
- : Maximum observed adversary profit percentage during extreme difficulty suppression events (occurs in <0.1% of states, representing adversaries exploiting );
- : Block interval variance in seconds^2^, normalized by target interval s. Maximum occurs during coordinated network attacks;
- : Maximum single-step parameter change under action masking constraints ( , );
- : False positive rate as probability, upper bound represents worst-case overly aggressive detection. Computing the maximum magnitude:
Empirical validation over 200,000 training steps confirms , consistent with the theoretical bound. We conservatively set to account for potential outliers during deployment (95th percentile: , 99.9th percentile: ).Lipschitz Constant Derivation: The Lipschitz constant is computed as the maximum gradient magnitude of with respect to state features. We estimate this via finite differences over 10,000 randomly sampled state pairs from the replay buffer:
The bounded L ensures smooth optimization landscapes for gradient descent, preventing pathological cases where small state perturbations cause large reward changes. □
Theorem 2(Convergence Under Diminishing Step Sizes). Let denote the Q-function estimate at iteration t under Double DQN with learning rate . Assume reward boundedness and experience replay provides i.i.d. samples. Then:
where is the optimal Q-function, provided: (1) , (2) , (3) Markov chain is ergodic.
Proof. We leverage stochastic approximation theory [11]. The Double DQN update is:
Our schedule satisfies Robbins–Monro conditions: (harmonic series) and . The CMDP state space is finite-dimensional and bounded, ensuring ergodicity. By Lemma 1, . The Bellman operator is a -contraction with . Empirically, training loss stabilizes after 197 K steps with . □
Lemma 2(Empirical Regret Scaling Analysis). Define cumulative regret over deployment horizon T as:
where is the oracle reward achievable with perfect hindsight. Across 30 independent deployments (each spanning timesteps ≈ 30 days), we perform log-log regression analysis to characterize empirical regret scaling:
where ϵ represents regression residuals.
Regression Results: *
- DRL agent: (95% CI: [0.61, 0.69]), ;
- *Thompson Sampling baseline: (95% CI: [0.67, 0.79]), *
*Thus, the DRL agent exhibits * * empirical sublinear regret scaling * :
The DRL agent achieves significantly better scaling exponent ( , , Wilcoxon signed-rank test comparing slopes across 30 paired runs), demonstrating superior long-term adaptation.
Interpretation and Theoretical Context: Empirical sublinear scaling ( ) implies per-timestep regret vanishes asymptotically: as . While this is not a formal PAC (Probably Approximately Correct) bound—which would require additional assumptions about environment stationarity, realizability, and Lipschitz continuity of dynamics—the empirical evidence strongly suggests the DRL agent approaches oracle performance over extended deployments.
Comparison to Theoretical Benchmarks: Standard regret bounds for contextual bandits achieve ( ) under realizability assumptions, while optimistic UCB algorithms achieve for stationary multi-armed bandits. Our observed falls between these extremes, consistent with DRL operating in a partially observable, non-stationary environment requiring continuous adaptation. The favorable comparison to Thompson Sampling ( ) demonstrates the value of deep function approximation for generalizing learned policies across diverse states.
Methodological Note: We emphasize that Lemma 2 presents empirical scaling relationships derived from experimental observations, not formal complexity-theoretic bounds. Establishing rigorous regret bounds for DRL in adversarial, non-stationary blockchain environments remains an open theoretical challenge due to: (1) adversarial non-stationarity (attackers adapt in response to defender), (2) high-dimensional continuous state spaces, and (3) imperfect reward observability (proxy-based learning without ground-truth). Our empirical analysis provides practical validation of long-term performance while acknowledging these theoretical gaps. Future work should pursue formal regret characterization under appropriate regularity conditions (e.g., bounded adversarial drift rates, -smooth reward surfaces).
Convergence Discussion. While we provide formal convergence under idealized assumptions (Theorem 2), practical DRL in non-stationary environments faces theoretical gaps. We employ Double DQN, dueling networks, prioritized replay, and gradient clipping, observing empirically stable convergence. The regret analysis provides empirical validation of generalization despite non-stationarity.
3.7. Decentralized Implementation Models
Integrating learning-based system into decentralized consensus presents challenges. The primary issue is ensuring that all nodes operate under same detection rules to prevent consensus failures. We propose two viable models:
Model 1: Centralized Training, Decentralized Execution. A DRL agent trained offline by protocol developers using massive-scale simulations. The resulting trained policy is serialized and embedded into blockchain client as part of scheduled network upgrade. All nodes run the same deterministic, pre-trained policy.
Security measures:
- Policy signing: Trained policy weights cryptographically signed by core developers. Nodes verify signature before loading policy, preventing malicious model injection.
- Hash commitment: Policy weight hash committed on-chain in prior upgrade. Nodes validate hash match before execution, ensuring bit-identical policy across network.
- Deterministic inference: Critical requirement for consensus. We enforce:
- –Fixed-point arithmetic (INT32) for all computations;
- –Deterministic library versions (ONNX Runtime 1.15.1, CPU-only);
- –No fused operations or platform-specific optimizations;
- –Comprehensive inference test suite with 10,000 edge cases. Validation: 128 heterogeneous nodes (x86, ARM, different OS) achieve bit-identical outputs across inference calls.
Pros: Guarantees consensus, has simple deployment and verified security.
Cons: Model is static between updates (typically 6-month cycles) and cannot adapt to novel threats in real-time; the training is centralized.
Model 2: On-Chain Governance of AI Proposals. Nodes run independent agents learning from local observations. Instead of acting directly, the agent’s proposed parameter changes submitted as formal transactions to an on-chain governance module. Proposals voted on by stakeholders (coin voting). If passed, new parameters adopted globally at specific future block height.
Governance protocol details:
- Shadow-mode evaluation: New policies are run in shadow mode for blocks (7 days for Bitcoin target), logging recommendations without affecting consensus. Community reviews shadow-mode performance metrics (suppression rate, false positives, parameter stability) before activation vote.
- Proposal cadence: Maximum 1 parameter update per 2016 blocks (2 weeks) to prevent governance fatigue and parameter thrashing.
- Grace period: After the vote passes, there is a 144-block (1 day) grace period before activation allows nodes to upgrade and validators to prepare.
- Emergency rollback: If deployed policy causes >10% block acceptance delay or >15% false positive rate spike, emergency rollback transaction (requiring 67% validator approval) reverts to a previous parameter set within 6 blocks.
- Performance monitoring: The on-chain dashboard tracks adversary profit proxy, FPR (7-day MA), block interval variance, and parameter drift rate. Governance can trigger audits if metrics degrade.
Pros: Decentralized, transparent, continuous adaptation, and community oversight.
Cons: Slower response (14-day cycle minimum) due to governance latency; potential political manipulation of security parameters; higher implementation complexity.
This current work focuses on agent efficacy, with Model 1 as a primary deployment assumption for production GRIDNET OS integration. Model 2 implementation is planned for Phase 2 deployment after a 6-month Model 1 validation period.
4. Evaluation
4.1. Experimental Setup
We use the 128-node test bed from Part I [1] simulating Bitcoin, Ethereum Classic (ETC), and Monacoin networks. We introduce adaptive adversary that periodically probes detection thresholds.
Profit Percentage Definition: Adversary profit is defined in Equation (2) (Section 3.1).
Simulation Assumptions: Following the established literature [26], we assume adversary initial hashrate share (30%), with honest miners following proportional distribution of remaining hashrate. Energy costs are modeled as proportional to hashrate commitment. Penalties vest 50% of block rewards (from Part I [1]). Network latency follows log-normal distribution with median 2 s. These parameters align with empirical Bitcoin network characteristics and prior wave attack analyses.
Adaptive Adversary Implementation:
The adaptive adversary employs a simple yet effective probing strategy:
Initial Phase (Days 0–5): Deploy standard wave attack with full amplitude ( , , ).
Adaptation Phase (Days 6–30): Every 5 days, evaluate recent detection rate :
Adjust attack parameters based on detection:
- If : Reduce amplitude by 10%: ;
- If : Increase amplitude by 5%: ;
- Otherwise maintain current amplitude.
This creates a co-evolutionary dynamic where the adversary attempts to find the “sweet spot” below detection thresholds while maximizing profit.
We compare three systems:
- Baseline detector: Simple variance-based detector;
- Static framework: Complete system from Part I with fixed optimal parameters;
- DRL-enhanced framework: Static framework augmented with DRL agent.
Each experiment runs 30 days over 30 independent runs and logs profit, detection events, and parameter trajectories.
Reproducibility and Configuration
To ensure reproducibility of the experimental results, we provide complete hyperparameter specifications and initialization details. Table 8 consolidates all configuration parameters used in the DRL agent and simulation environment.
Random Seeds: To ensure statistical validity and reproducibility, all 30 experimental runs were initialized using a deterministic seed sequence. We used NumPy’s SeedSequence with master seed to spawn independent child generators for each run . This approach ensures: (1) reproducibility—identical seeds yield identical runs, (2) statistical independence—child generators produce non-overlapping random streams, and (3) no seed-selection bias—master seed chosen a priori based on date rather than experimental outcomes.
Software Environment: Python 3.10.12, PyTorch 2.0.1 (CUDA 11.8), NumPy 1.24.3, and OpenAI Gym 0.26.2. Training was performed on NVIDIA RTX 3090 GPU (24GB VRAM), requiring approximately 8 h per 200,000-step training run. For deterministic deployment inference, models are exported via ONNX Runtime 1.15.1 with fixed-point INT32 arithmetic to ensure bit-identical outputs across heterogeneous hardware.
Convergence Criteria: Training terminates when three conditions are simultaneously satisfied for 5000 consecutive steps: (1) 10,000-step moving average reward within of 20,000-step average, (2) gradient norm , and (3) validation F1-score improvement for 10,000 steps.
Configuration Script: Listing 1 provides the Python configuration dictionary used to instantiate the DRL agent, enabling exact replication of the training setup.
Listing 1. Agent configuration (train_config.py).
4.2. Performance Against Adaptive Adversary
Figure 2 and Table 9 quantify the performance.
The baseline detector fails to suppress adversary profit, remaining above the 140% average. Static framework initially achieves strong suppression ( profit during Days 0–5) but is gradually evaded, with adversaries recovering to profitable operation ( by Days 26–30, yielding weighted average across 30 days). In contrast, DRL agent drives adversary profit deeply negative (ranging from to , averaging ) and prevents attackers from ever regaining profitability. The agent dynamically tightens thresholds when attack intensity increases and relaxes during quiet periods, balancing detection and liveness throughout the deployment.
Understanding the F1-Profit Gap: While F1-score improves modestly from 92.7% (static, Part I) to 95% (DRL)—only 2.3 percentage points—the adversary profit suppression shows dramatic improvement from (static) to (DRL)—a 107 percentage point difference. This apparent discrepancy arises because (1) F1-score measures instantaneous detection accuracy averaged across all time periods, while (2) profit reflects sustained detection effectiveness over the full 30-day deployment. The static framework achieves high initial F1-score but gradually degrades as adversaries adapt (Figure 2), allowing profit recovery. The DRL agent maintains consistent F1-score throughout deployment, preventing adversary adaptation. Thus, modest F1 improvement masks substantial improvement in long-term resilience.
4.3. Comprehensive Baseline Comparison
Beyond the variance-based baseline and static framework, we evaluate against sophisticated adaptive controllers:
Controller descriptions:
- Thompson Sampling: Treats each parameter configuration as multi-armed bandit arm and samples according to posterior belief. Assumes stationary reward distributions and struggles with adversarial non-stationarity.
- PID Controller: Proportional-Integral-Derivative controller targeting constant 5% FPR. Tunes based on FPR error signal. Cannot anticipate adversary strategy shifts.
- EWMA Adaptive: Exponentially weighted moving average of attack metrics drives threshold adjustments. Reactive but lacks strategic foresight.
- Contextual Bandit: Linear contextual bandit using state features to select actions. Better than non-contextual but limited by linear assumptions.
Safety metric definitions:
- FPR: False positive rate—honest miners incorrectly flagged (lower is better; the target is )
- Latency: Mean block acceptance delay as multiple of target interval T (lower is better; the target is )
- Param Thrash: Mean absolute parameter change per day, (lower is better as this indicates stability)
DRL agent achieves best performance across all metrics (Table 10): deepest profit suppression ( ), lowest FPR (3.8%), minimal latency impact ( ), and least parameter thrashing (0.09), demonstrating balanced optimization of competing objectives.
4.4. Generalization Across DAA Regimes
To test generalization, we train a DRL agent on short-window DAA ( blocks, similar to Bitcoin Cash 2017 DAA) and evaluate on long-window DAA ( blocks, Bitcoin legacy) without retraining:
The DRL agent exhibits superior transfer learning (Table 11), maintaining an 91% F1-score on unseen DAA regime (only 4% degradation vs. 6–8% for baselines). This suggests learned policy captures fundamental attack patterns rather than overfitting to specific DAA parameters.
4.5. Non-Stationarity Stress Tests
We evaluate robustness under adversarial conditions designed to challenge adaptivity:
Test 1: Rotating Attack Patterns. Adversary alternates between:
- Stealthy low-amplitude waves ( , 10-day cycles);
- Rare high-amplitude bursts ( , 6 h duration every 5 days).
Test 2: Statistic Poisoning. Adversary injects benign-appearing high-variance bursts every 3 days to skew running mean/std calculations, attempting to desensitize the detector. Table 12 summarizes the results.
MAD-scaled DRL agent maintains negative adversary profit under both stress tests, demonstrating resilience to distributional shifts and adversarial poisoning. The median-based scaling proves critical for robustness: standard mean/std scaling shows 103% profit increase under poisoning, while MAD scaling limits increase to only 27 percentage points above baseline ( vs. ).
4.6. Resilience to Zero-Day Attacks
Clarification on Deployment Model: It is important to clarify that under Deployment Model 1 (Centralized Training, Decentralized Execution), the agent’s neural network weights are frozen during the evaluation phase—no gradient updates occur during deployment. The zero-day resilience demonstrated in this section does not stem from online learning or real-time weight updates. Rather, it arises from the generalization capability of the offline-trained policy. By training on a diverse distribution of attack primitives (variable amplitudes, timing jitters, stealth patterns), the DRL agent learns a generalized representation of adversarial behavior in the state-action value function. Novel attack variants, while structurally different, project into this learned manifold, enabling the frozen policy to classify them as anomalous and respond appropriately without requiring real-time parameter updates. This distinction is critical for production deployment where deterministic, bit-identical inference across all network nodes is mandatory for consensus.
We define two attack variants unseen during agent training:
Graduated Wave Attack: Instead of abrupt on/off transitions, adversary smoothly modulates hashrate using sinusoidal function:
This produces subtle oscillations harder to detect than binary switching.
Stealth Wave Attack: Adversary injects random jitter into withdrawal/harvest timing:
These patterns are “zero-day” with an important caveat: while variable-amplitude attacks were present during training (line 548), sinusoidal modulation represents a distinct continuous interpolation not encountered during training. This tests the agent’s ability to generalize beyond discrete attack variants to continuous attack families. The graduated wave attack employs smooth functions rather than discrete amplitude levels , creating qualitatively different timing signatures that probe the agent’s interpolation and generalization capabilities.
In zero-day scenario, we introduce a novel graduated wave attack after 15 days. The agent’s reward function immediately penalizes resulting network instability. Figure 3 shows adversary profit spikes to 180% at onset but falls below parity within 8 h, becoming deeply negative within 24 h.
This demonstrates agent’s capacity to adapt to unforeseen threats without human intervention, a critical advantage over static defenses.
4.7. Comparative Analysis of AI Methodologies
We evaluate two alternative AI models:
Supervised Classifier:
- Architecture: 4-layer MLP matching DQN architecture;
- Labels: Retrospective ground-truth attack labels (available offline);
- Training: 80/20 train/validation split, early stopping on validation loss;
- Test: Deployment on unseen 30-day evaluation period.
GAN Anomaly Detector [8]:
- Generator: Three-layer MLP [32 → 64 → 128 → 12] mapping latent to state space;
- Discriminator: Three-layer MLP [12 → 64 → 32 → 1] distinguishing real vs. generated states;
- Training: On honest-only states (120,000 samples), WGAN-GP loss with gradient penalty , 50,000 iterations, and Adam optimizer ( , , );
- Anomaly score: where is encoder, ;
- Threshold: Set at 95th percentile of anomaly scores on honest-only validation set to achieve target FPR ≈ 5%;
- Latent dimension selected via grid search over .
DRL Agent (Ours):
- Training: Online interaction with simulated environment (200,000 steps);
- No ground-truth labels; learns from proxy reward signal;
- Test: Same 30-day evaluation period.
All methods use identical evaluation metrics on the same test set of 30 simulation runs. Table 13 compares precision, recall, and F1-score on a mixed dataset of standard, stealth, and graduated wave attacks.
Figure 4 illustrates results. DRL agent achieves best balance, resulting in an F1-score of 0.95. Supervised classifier suffers poor recall—it cannot identify novel variants. GAN detector has a better recall but higher false positive rate. DRL agent’s online learning enables an effective counter to all attack variants.
5. Discussion and Limitations
DRL agent demonstrates strong resilience against adaptive and zero-day attacks, but several challenges remain:
Impact on Honest Mining Economics: A critical concern for any probabilistic defense system is the economic cost imposed on honest participants through false positives. Our DRL agent maintains a false positive rate (FPR) of 3.8% (Table 10), meaning approximately 1 in 26 honest blocks may be incorrectly flagged. However, under the vesting penalty model defined in Part I [1], a flagged honest miner does not forfeit their block reward entirely; rather, their reward enters a time-locked vesting period with blocks (≈6 days for Bitcoin-like chains). The economic cost to an honest miner is therefore strictly the time value of money—the opportunity cost on delayed funds—not the principal amount. Assuming a conservative annual discount rate of 5%, the present-value loss for a 6-day delay is approximately of the block reward. With FPR = 3.8%, the expected annualized revenue reduction for honest miners is , which is economically negligible. Furthermore, we conducted explicit experiments with mixed honest/adversarial populations: in scenarios where both honest miners (70% hashrate) and adversaries (30% hashrate) operate simultaneously, the DRL agent correctly discriminates between them with 96% recall on adversarial blocks while maintaining the 3.8% FPR on honest blocks, confirming that the defense mechanism does not inadvertently penalize honest participation.
Training Requirements: The agent requires realistic simulation environment to avoid overfitting. We trained for 200,000 steps (approximately 3 weeks of simulated blockchain time), which required substantial computational resources.
Online Learning Latency: Under Deployment Model 1 (frozen weights), no online learning occurs—the agent operates with fixed policy. However, there exists inherent latency between attack pattern emergence and the agent’s detection response (typically 1–3 DAA windows). We mitigate this through conservative default thresholds and the proxy reward signal’s sensitivity to network instability.
Adversarial Policy Exploitation and DRL Arms Race: A sophisticated adversary might deploy their own DRL agent to probe and exploit the defender’s policy, transforming the security problem into a multi-agent game. While our current framework assumes a reactive (non-learning) adversary during deployment, we acknowledge that an adversarial DRL agent could potentially (1) identify policy boundaries through systematic probing, (2) exploit the detection-to-response latency window, or (3) craft attacks that maximize reward evasion while remaining profitable. Preliminary analysis suggests that the defender retains structural advantages: the defender observes all network traffic while the adversary observes only their own actions and rewards, creating information asymmetry. Furthermore, our action masking ensures the defender never enters unsafe parameter regions regardless of adversarial manipulation. Nevertheless, formal game-theoretic analysis of this “AI arms race” scenario remains an important direction for future work (see Section 6).
Governance Challenges: On-chain governance must carefully regulate parameter changes proposed by agent to avoid consensus fragmentation. The current implementation uses Model 1, but Model 2 introduces additional complexity requiring formal consensus protocol integration.
Generalization: While the agent generalizes well to novel attack variants in same family, performance against fundamentally different attack classes (e.g., combined with selfish mining [26]) requires further evaluation.
Rational Adversary Assumption: Our simulations assume profit-maximizing rational adversaries who respond predictably to economic incentives. Real-world attackers may exhibit irrational behavior (e.g., state-sponsored attacks prioritizing disruption over profit), requiring field testing on live networks to validate robustness under diverse adversarial motivations.
6. Future Work
Several promising research directions emerge:
Adversarial DRL and Multi-Agent Game Theory: A critical extension involves modeling scenarios where the adversary also employs a learning agent. This transforms the security problem into a two-player zero-sum game where both defender and attacker optimize policies simultaneously. We propose investigating (1) self-play training where the defender trains against an adversarial DRL agent that learns to evade detection, (2) Nash equilibrium solutions using techniques from multi-agent reinforcement learning (MARL), and (3) robust policy optimization methods that provide worst-case guarantees against adaptive adversaries. Preliminary game-theoretic analysis suggests that the defender’s information advantage (observing all network traffic) may yield favorable equilibria, but formal characterization remains open. We designate this “AI arms race” analysis as a priority for Part III of this research series.
Multi-Agent Coordination: The exploration of federated learning approaches where multiple nodes run local agents, aggregating insights while preserving decentralization and privacy.
Cross-Consensus Applicability: The extension of the framework to alternative consensus mechanisms (PoS, BFT) facing analogous adaptive threats, adapting the state space and reward functions to mechanism-specific dynamics.
Formal Verification: The development of formal methods to verify DRL agent behavior remains within safe parameter bounds, potentially using interval bound propagation or abstract interpretation on neural network weights.
Real-World Deployment: Conducting controlled mainnet pilot on GRIDNET OS [27,28,29], monitoring long-term performance and gathering empirical data on adversarial adaptation in live environments.
7. Conclusions
We presented adaptive security framework for PoW blockchains leveraging deep reinforcement learning to counter intelligent, evasive adversaries. Building upon the static detection framework from Part I [1], we framed detection parameter selection as a sequential decision problem, designing a DRL agent learning to adjust thresholds and cooldown windows in response to observed network conditions and adversarial behavior.
Extensive experiments on a realistic 128-node test bed over 30 independent runs demonstrate that DRL-enhanced framework renders wave attacks deeply unprofitable ( average profit vs. static, baseline), adapts to zero-day attack variants within 24 h, and outperforms alternative AI methodologies (F1-score 0.95 vs. 0.78, 0.86).
This work marks a significant step toward intelligent, self-healing blockchain security systems. Together with Part I, these papers provide a comprehensive solution spanning static theoretical foundations through formal economic guarantees to dynamic AI-driven adaptation, offering generalizable model for enhancing security of proof-of-work blockchain systems against evolving adversarial threats.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Skowroński R. Liveness over Fairness (Part I): A Statistically Grounded Framework for Detecting and Mitigating Po W Wave Attacks Information 202516106010.3390/info 16121060 · doi ↗
- 2Li J. Xie L. Huang H. Zhou B. Song B. Zeng W. Deng X. Zhang X. Survey on Strategic Mining in Blockchain: A Reinforcement Learning Approach Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2025)IJCAI Organization Marina del Rey, CA, USA 202510.24963/ijcai.2025/1170 · doi ↗
- 3Nikhalat-Jahromi A. Saghiri A.M. Meybodi M.R. Nik Defense: An Artificial Intelligence Based Defense Mechanism against Selfish Mining in Bitcoinar Xiv 202310.48550/ar Xiv.2301.114632301.11463 · doi ↗
- 4Grunspan C. Pérez-Marco R. On Profitability of Selfish Miningar Xiv 201810.48550/ar Xiv.1805.082811805.08281 · doi ↗
- 5Komodo Platform Adaptive Proof of Work (A Po W): Komodo’s New Solution to Difficulty Adjustment Attacks Komodo Platform Blog April 2022 Available online: https://komodoplatform.com/en/blog/adaptive-proof-of-work/(accessed on 15 October 2025)
- 6Zhang J. Xiang Y. Wang Y. Zhou W. Xiang Y. Guan Y. Network Traffic Classification Using Correlation Information IEEE Trans. Parallel Distrib. Syst.20132410411710.1109/TPDS.2012.98 · doi ↗
- 7Goodfellow I. Pouget-Abadie J. Mirza M. Xu B. Warde-Farley D. Ozair S. Courville A. Bengio Y. Generative adversarial nets Advances in Neural Information Processing Systems 27 (NIPS 2014)Curran Associates, Inc.Red Hook, NY, USA 201426722680 Available online: https://papers.nips.cc/paper/5423-generative-adversarial-nets(accessed on 31 January 2026)
- 8Schlegl T. Seeböck P. Waldstein S.M. Schmidt-Erfurth U. Langs G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery Proceedings of the International Conference on Information Processing in Medical Imaging Springer Cham, Switzerland 201714615710.1007/978-3-319-59050-9_12 · doi ↗