A Multi-Scale Object Detection Network with Integrated Spatial-Channel Collaborative Attention for Remote Sensing Images
Lijun Ma, Chengjun Xu, Kun Jiao, Wenming Pei, Hongfei Zhang, Lanfeng Liu, Bin Deng, Juan Wu

TL;DR
This paper introduces a new network for detecting objects in remote sensing images that improves accuracy and efficiency using a novel attention mechanism.
Contribution
The novel integration of a cross-channel multi-scale feature extraction module and a channel-spatial cross-attention mechanism for efficient and accurate multi-scale object detection.
Findings
The model achieves 78.1% mAP on DIOR, 90.6% on HRRSD, and 96.5% on RSOD datasets.
It outperforms YOLOv11 and YOLOv8 in accuracy while maintaining lower computational complexity.
The proposed method balances detection accuracy and efficiency with 19.5 M parameters and 75.2 G FLOPs.
Abstract
What are the main findings? The proposed model, which integrates a novel cross-channel multi-scale feature extraction (CC-MSFE) module and a channel-spatial cross-attention (CSCA) mechanism, achieves good performance on three public remote sensing datasets (DIOR: 78.1% mAP, HRRSD: 90.6% mAP, and RSOD: 96.5% mAP). The framework effectively performs multi-scale object detection within complex environments, achieving enhanced accuracy while reducing computational complexity (Parameters: 19.5 M, FLOPs: 75.2 G). What are the implications of the main findings? It provides a practical and efficient solution for multi-scale object detection in complex remote sensing scenarios. This innovative cross-attention structure design provides practical guidance for other feature extraction scenarios in remote sensing applications. In remote sensing object detection, current models typically employ…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1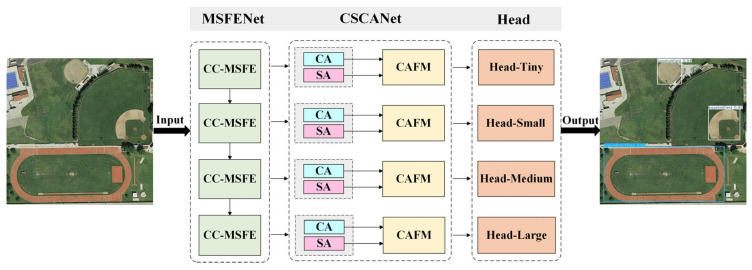 Figure 2
Figure 2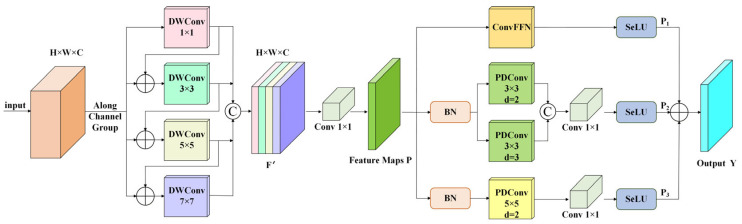 Figure 3
Figure 3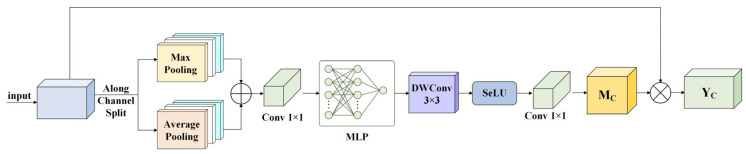 Figure 4
Figure 4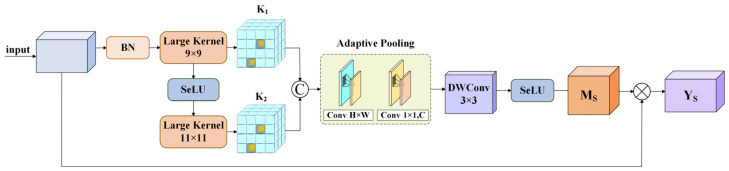 Figure 5
Figure 5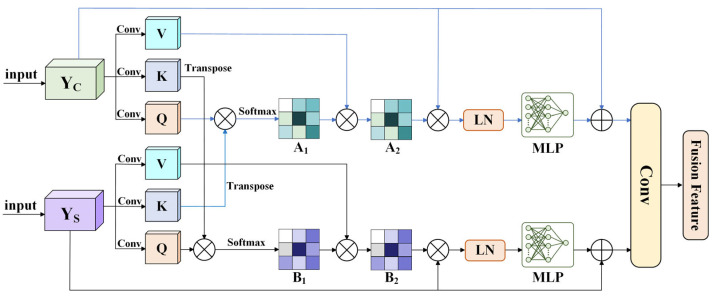 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9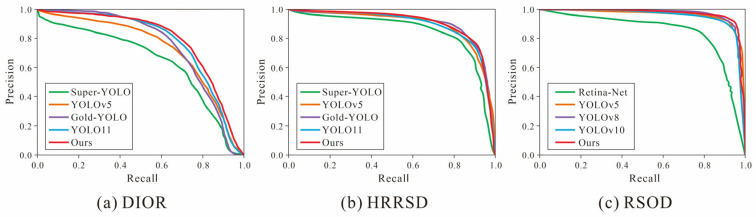 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13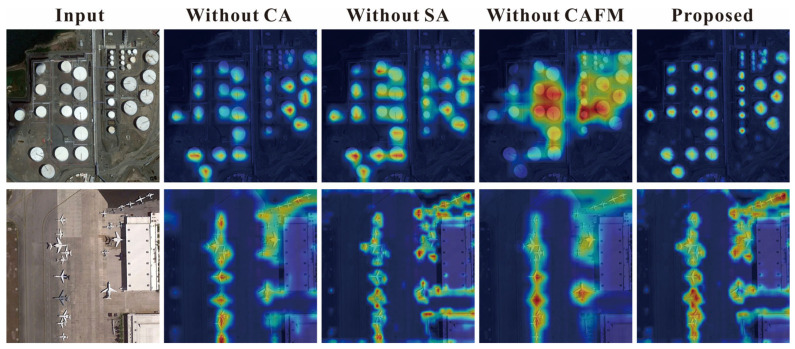 Figure 14
Figure 14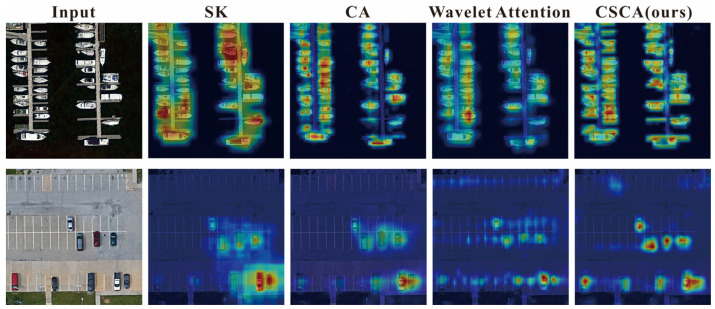 Figure 15
Figure 15- —the National Natural Science Foundation of China
- —Natural Science Foundation of Jiangxi Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Remote-Sensing Image Classification · Advanced Image Fusion Techniques
1. Introduction
Remote Sensing Object Detection (RSOD) aims to automatically identify and locate target objects (such as vehicles, ships, aircraft, etc.) from remote sensing images captured by aviation or satellites [1,2]. It is extensively utilized in various sectors, including resource monitoring [3,4], urban development [5,6] and military reconnaissance [7]. With the rapid advancement of sensor technologies, modern remote sensing images are characterized by ultra-high spatial resolution and extensive coverage, providing abundant visual details [8,9,10]. However, this progress also introduces substantial challenges for object detection, especially for small and densely distributed targets. In addition, remote sensing imagery typically exhibits extreme scale variation, complex and cluttered backgrounds, arbitrary object orientations, and high inter-class similarity, as shown in Figure 1. Small objects often occupy only a few pixels and present weak visual cues, making them easily confused with background textures or suppressed by noise and shadow effects. These characteristics severely limit detection accuracy and robustness, and have become a major bottleneck in fully exploiting the value of large-scale remote sensing data [11].
Initially, object detection based on traditional methods depended on hand-crafted features [12,13], such as Histogram of Oriented Gradients (HOG) [14] and Bag-of-Words (BoW) [15], combined with traditional machine learning classifiers. Although such approaches laid important foundations, their limited representation capacity and dependence on expert-designed features make them difficult to generalize to complex real-world remote sensing scenes. With the emergence of deep learning [16], convolutional neural networks (CNNs) have significantly improved detection performance by learning hierarchical features in an end-to-end manner. For example, two-stage detectors such as Faster R-CNN [17] and one-stage detectors such as SSD [18] and YOLO [19] have become representative object detection frameworks, and have also been widely adopted and extended in remote sensing scenarios. Nevertheless, existing deep learning–based detectors still face notable limitations when applied to remote sensing imagery. In particular, CNNs are relatively limited in explicitly modeling long-range dependencies, and their feature representations are often insufficient for accurately capturing small objects embedded in complex backgrounds.
To address extreme scale variation and improve small-object representation, multi-scale feature extraction and fusion have become central components in modern RSOD frameworks. By aggregating information from different receptive fields and feature levels, multi-scale representations can enhance robustness to object size changes and enrich contextual cues. However, existing multi-scale feature extraction methods, such as Feature Pyramid Network (FPN) [20] and its variants like Dense Feature Pyramid Network (BDFPN) [21], primarily emphasize spatial-scale fusion across pyramid levels, while the interaction among feature channels is largely overlooked. Treating channels independently limits the network’s ability to capture cross-channel semantic correlations and to exchange complementary information across scales, which is crucial for small and densely distributed objects with weak and ambiguous visual patterns.
In recent years, attention mechanisms have been introduced into remote sensing object detection to enhance feature discrimination and improve long-range dependency modeling. Representative RSOD methods, such as SCRDet [22] and RT-DETR [23], incorporate attention mechanisms to suppress background interference and highlight target regions. Despite their effectiveness, most existing attention-based approaches treat channel attention and spatial attention independently or simply combine them in a sequential manner. Such designs fail to fully exploit the intrinsic correlation between channels and space, often leading to redundant features, increased computational cost, and suboptimal performance for small or multi-scale objects.
Moreover, many state-of-the-art RSOD models adopt complex network architectures with a large number of parameters, which hampers their deployment in practical scenarios where computational resources are limited. Therefore, achieving a favorable balance between detection accuracy and computational efficiency remains a critical challenge in RSOD.
Based on the above analysis, we propose a lightweight multi-scale object detection network with integrated spatial–channel collaborative attention. By performing cross-channel feature extraction and deeply coupling channel attention with spatial attention, the proposed method aims to strengthen feature discrimination for multi-scale object detection, especially for small objects in complex and cluttered backgrounds, while maintaining high computational efficiency.
The main contributions are summarized as follows:
- (1)We propose a new cross-channel multi-scale feature extraction module (CC-MSFE), which facilitates the interaction of features across channels through the cross-fusion of various convolutional channels. This approach enhances the holistic perception of multi-scale target feature information and effectively extracts local detail information.
- (2)We propose a new channel-spatial cross-attention mechanism (CSCA). This mechanism first innovatively designs channel attention and spatial attention, which effectively retain key channel and spatial information while improving the context awareness ability. Furthermore, the cross-attention fusion module (CAFM) is utilized to deeply integrate the two attention mechanisms, achieving complementary features between channels and spaces, effectively reducing redundant features, and thereby reducing the computational burden of the model.
- (3)Experimental results on the DIOR, HRRSD and RSOD datasets show that the model significantly enhances detection precision for multi-scale objects in complex backgrounds, while reducing the number of parameters and computational complexity, achieving an efficient lightweight design.
2. Related Work
2.1. Remote Sensing Object Detection Based on CNN
In 2014, Girshick et al. [24] proposed R-CNN, which was the first to apply convolutional neural networks to the detection task and achieved nearly a 30% improvement in detection accuracy. This technique depends on the neural network for the automatic and efficient extraction of target feature information from images, enabling the rapid development of deep learning-based target detection technology. It avoids the errors caused by manually designed features, achieves higher accuracy and shorter detection time than traditional methods, and promotes the transformation of target detection tasks from traditional methods to intelligent, end-to-end learning methods.
RSOD based on deep learning can be divided into two categories: two-stage detectors and single-stage detectors [13]. The two-stage detectors divide the detection process into two steps. The first step is to generate candidate regions that may contain the target, and the second step is to classify each candidate region and perform precise bounding box regression. The R-CNN series of models enhances the efficiency and functionality of target detection through key innovations: R-CNN first applied CNN to detection, but with low efficiency. Fast R-CNN [17] significantly improved the training and detection speed on the basis of R-CNN through RoI Pooling and end-to-end training. The Faster R-CNN [25] algorithm introduced the region proposal network (RPN), which greatly improved the generation speed of candidate boxes and the overall detection efficiency. Mask R-CNN [26] first combined object detection with semantic segmentation, leading to a certain improvement in detection accuracy. While the R-CNN series of algorithms has enhanced the accuracy and reliability of object detection, these methods frequently suffer from high computational demands and reduced efficacy in detecting small objects and complex environments. These limitations have promoted the development of subsequent one-stage detectors.
Compared with two-stage detectors, single-stage detectors treat detection as a regression problem without the need for additional candidate region extraction. The detection system predicts object categories and locations directly from features extracted by a convolutional neural network and outputs detection results, thereby meeting real-time processing requirements. Redmon et al. [19] proposed the single-stage detection framework YOLO, which employs a single convolutional neural network and uses the whole image as the training input, producing bounding box and class probability predictions in a single pass. Since then, the YOLO series of object detection algorithms has experienced numerous iterations and enhancements, including the adoption of various backbone networks, the implementation of anchor mechanisms, multi-scale training strategies, Batch Normalization (BN) [27], FPN [28], Spatial Pyramid Pooling (SPP), Pyramid Attention Networks (PAN), the GIOU loss [29], focal mechanisms, and anchor-free detection [30], among other techniques. These advances have substantially improved both detection speed and accuracy and have driven the trend toward lightweight and efficient models. Meanwhile, Liu et al. [18] proposed the SSD algorithm to address shortcomings in object localization within the YOLO framework.
Although deep learning methods utilize convolutional neural networks to automatically learn multi-level features and thus overcome the limitations of traditional approaches that rely on hand-crafted features, they still face challenges when applied to large-scale, complex, and variable remote sensing imagery, such as small-scale target detection, target blur, and background interference.
2.2. Multiscale Feature Fusion
The drastic scale divergence in remote sensing imagery demands detectors with superior multi-scale representation capabilities. FPN [20] established a baseline by constructing a top-down pathway to propagate semantic information. To further enhance localization, Path Aggregation Network (PANet) [31] introduced an additional bottom-up path, while the Bidirectional Feature Pyramid Network (BiFPN) [32] implemented weighted bi-directional fusion to balance feature importance.
Recent years have witnessed the emergence of numerous advanced feature fusion architectures in diverse domains. YOLOv7 [33] proposed the E-ELAN architecture to optimize gradient path length, enabling deeper networks to learn effectively. Gold-YOLO [34] introduced a Gather-and-Distribute (GD) mechanism, replacing conventional FPNs with a global information fusion module to capture long-range dependencies. Jiang et al. [21] proposed the BDFPN architecture, which broadens the scope of the feature pyramid and leverages skip connections to effectively aggregate features across different scales. In this study, we propose a novel Cross-Channel Feature Fusion Network (MSFENet). By fully exploiting feature interactions across different channels, MSFENet addresses the limitations of previous methods regarding inter-channel dependency. Consequently, it promotes efficient multi-scale feature fusion and significantly enhances the capability to capture local detailed features.
2.3. Attention Mechanisms
Over recent years, scholars have applied the attention mechanism to remote sensing image target detection. The aim is to enhance the model’s ability to capture global context information through dynamic weight allocation, thereby optimizing the accuracy of feature representation for multi-scale targets in complex scenes. This mechanism adaptively focuses on key regions by calculating the correlations between elements in the feature map, effectively suppressing background interference and improving the efficiency of extracting discriminative features in remote sensing images with dense targets, variable scales, and complex backgrounds. For example, Woo et al. [35] proposed the convolutional block attention module (CBAM), which achieves feature refinement in the convolutional block through dual attention mechanisms of channel and space. In addition, the end-to-end target detection framework based on the Transformer network [36] employs a Transformer encoder and self-attention mechanisms to extract global contextual information for object detection and object relationship modeling. For instance, Carion et al. [37] proposed the DETR target detection framework based on the Transformer. This method abandons the redundant operations in the CNN target detection framework, treats target detection as a set prediction problem, and realizes end-to-end detection through the Transformer encoder–decoder structure, effectively improving the detection efficiency and reducing the complexity and computational burden of the model.
Currently, an increasing number of researchers have begun to widely employ the cross-attention mechanism. Its powerful feature interaction and screening capabilities can offer effective solutions to numerous challenges in remote sensing target detection. For example, Wang et al. [38] proposed a long-distance cross-attention module (LDCAM) to capture the dependencies between remote elements across queries and support each feature extraction layer. This module facilitates the exchange of contextual information between images, thereby achieving a more comprehensive feature representation. Lu et al. [39] proposed a semantic-guided cross-attention network (SCANet), which utilizes high-level semantic information to guide low-level spatial details through the attention mechanism. Nevertheless, these methods still treat channel and spatial features largely in a decoupled manner. In contrast, our channel-spatial cross-attention (CSCA) mechanism explicitly models bidirectional interactions between the two dimensions through a dedicated cross-attention fusion module (CAFM). Integrated within a lightweight multi-scale feature network, CSCA enhances the discriminative representation of small and multi-scale objects more efficiently, maintaining lower computational overhead than existing cross-attention designs.
3. Method
As shown in Figure 2, we designed an object detection method based on multi-scale feature fusion and cross-attention feature enhancement for remote sensing images. This method consists of three parts: Multi-Scale Feature Extraction Network (MSFENet), Channel-Spatial Cross-Attention Mechanism Network (CSCANet), and Target Detectors. First, MSFENet is mainly composed of four cross-channel multi-scale feature extraction (CC-MSFE) modules, which process the input original image sequentially. The CC-MSFE module achieves complementary advantages among the features of different channels by cross-fusing multiple convolutional channels. It boosts the global perceptual capability of multi-scale target feature information and can efficiently capture local detailed features. Second, the four different feature maps generated by MSFENet are fed into the corresponding four branches in CSCANet, respectively. CSCANet introduces novel channel attention (CA) and spatial attention (SA), and the two attention mechanisms are deeply cross-fused by constructing the cross-attention fusion module (CAFM) to achieve dynamic interaction and joint optimization in the channel and spatial dimensions. Finally, four scale detection heads are used to locate and detect the targets at varying scales.
3.1. Cross-Channel Multi-Scale Feature Extraction
The CC-MSFE module is a feature extraction unit designed for multi-scale target detection tasks. Its primary role is to extract and integrate cross-channel features across varying scales, facilitating efficient feature representation of targets of various sizes (especially small targets) in complex scenarios, while balancing the accuracy of feature extraction and computational efficiency. The framework structure is shown in Figure 3.
First, the CC-MSFE module divides the input feature map into four groups along the channel dimension, as follows:
where H represents the height of the feature map, W represents the width of the feature map, and represents the number of channels. When the channel number is not divisible by 4, padding is applied by adding zero-valued channels so that the total number of channels becomes divisible by 4. , [·] represents the rounding operation.
Then, each group performs parallel depthwise separable convolutions ( ). Subsequently, the obtained feature maps are concatenated with the other group of feature maps to enhance the interaction of feature information among different channels, thereby achieving multi-scale feature extraction.
In the first group , we employed a 1 × 1 depthwise separable convolution, and the formula is as follows:
Then, the feature map is concatenated with the second group , and the concatenated features are processed using a 3 × 3 depthwise separable convolution to obtain a new feature map . By repeating the above operations, four groups of different feature maps can be obtained. These feature maps are concatenated, the channel dimension is compressed and information is fused through a 1 × 1 convolution to generate Feature Maps . The formula is as follows:
Feature Maps are processed through three parallel branches. In the first branch, the Convolutional Feed-Forward Network ( ) is utilized for information interaction and nonlinear transformation among channels, followed by the use of the activation function. The formula is as follows:
In the second branch, batch normalization ( ) is first applied. Preliminary experiments have shown that performing before convolution operations can accelerate the convergence speed of the model. Next, parallel dilated convolution ( ) using 3 × 3 kernels with dilation rates = 2 and = 3 captures spatial features at different receptive fields concurrently. The two convolution outputs are concatenated, fused and reduced in dimension by a 1 × 1 convolution, and the result is passed through the activation. The formulation is as follows:
The third branch is similar to the second one. The convolution operation is changed to parallel dilated convolution ( ) with a convolution kernel of 5 × 5 (dilation rate = 2), and the formula is as follows:
Finally, the output feature maps of the three branches are concatenated to obtain the output feature map .
3.2. Channel-Spatial Cross-Attention Mechanism
We designed a novel channel-spatial cross-attention mechanism, which aims to further expand the receptive field of the model, enhance the representational ability of target features, and improve the adaptability to targets of different scales. This mechanism mainly consists of three major components: channel attention, spatial attention, and a cross-attention fusion module. We optimized channel and spatial attention and devised the CAFM to cross-integrate them, thereby precisely focusing on key features and improving the model’s robustness and discriminative power.
3.2.1. Channel Attention
The CA module is an efficient enhancement of the classic channel attention mechanism. By introducing multi-branch pooling, non-linear transformation, and depthwise convolution, it dynamically generates channel weights to achieve more precise calibration of key features, as shown in Figure 4.
First, the feature map is split along the channel dimension into and . The two branches perform Max Pooling and Average Pooling, respectively, and then the results of the branches are added together. The added feature vectors first pass through a 1 × 1 convolution that performs a linear transformation and reduces dimensionality, lowering the complexity of subsequent computations. Next, a multilayer perceptron ( ) module and a 3 × 3 depthwise separable convolution ( ) are used to further enhance local context awareness and the ability to capture key information. After that, the Scaled Exponential Linear Unit ( ) activation function is adopted to ensure the non-linear fitting ability of attention weights, followed by a 1 × 1 convolution to produce the channel attention weights . Finally, the channel attention weights are multiplied by the original input feature map to amplify the contributions of critical channels and suppress the responses of unimportant or noisy channels. The calibrated output feature map is finally obtained.
3.2.2. Spatial Attention
The SA module utilizes large-kernel convolution and adaptive pooling strategies to capture wide-range spatial context, enabling dynamic focusing on the key spatial regions of the input feature map. This strengthens the model’s capability to understand spatial relationships and recognize important spatial positions, as shown in Figure 5.
First, the input feature map undergoes batch normalization ( ), followed by a large-kernel convolution with a 9 × 9 kernel. One branch yields , while the other branch applies the activation function first and then a second large-kernel convolution with an 11 × 11 kernel to produce . Next, the feature map obtained by concatenating and passes through an adaptive pooling module, which captures feature information at different scales by dynamically adjusting the window size. In addition, a 3 × 3 depthwise separable convolution further supplements fine-detail information and employs the activation. Finally, the resulting spatial attention weight is multiplied with the original input feature map via matrix multiplication to obtain the output feature map .
3.2.3. Cross-Attention Fusion Module
CAFM achieves deep interaction and integration between channel-attention and spatial-attention features. The two are regulated bidirectionally, which effectively fuses channel and spatial information and substantially enhances the model’s capacity to identify targets in complicated backgrounds, as shown in Figure 6.
The module first receives the output feature from the CA module and the output feature from the SA module. It then performs collaborative computation via two parallel cross-attention branches. Each input feature is projected by an independent Conv-layer to produce three vectors: Query ( ), Key ( ) and Value ( ).
Branch 1 is spatial feature-guided channel enhancement, which enables the key position information in the space to filter and enhance the channel features most relevant to it. The computation is given by the following formula:
where denotes the dimensionality of the key vector , and the term serves as a scaling factor to ensure that the input to the softmax function remains within an appropriate numerical range.
Branch 2 is channel feature-guided spatial enhancement, enabling important channel information to guide the focus on key spatial regions. The corresponding formula is expressed as follows:
where denotes the dimensionality of the key vector .
The weight matrices output by the two pathways are each multiplied by the original features, undergo feature transformation via layer normalization ( ) and a multi-layer perceptron ( ), and are finally residual-connected to the original input features and fused through a convolutional layer to produce the final feature representation.
4. Experiments
4.1. Datasets
We selected three publicly available and challenging datasets: detection in optical remote sensing images (DIOR), high-resolution remote sensing detection (HRRSD) and remote sensing object detection (RSOD). Since the number of images contained in different categories varies among the three datasets, there is a class imbalance phenomenon in all of them. The specific introduction is as follows:
(1) The detection in optical remote sensing images (DIOR) dataset is a large-scale public benchmark dataset for remote sensing image object detection [11]. This dataset contains 23,463 images and 192,472 instances, covering 20 common ground object categories, such as airplanes, airports, ships, vehicles, bridges, etc., as shown in Figure 7. The image size is uniformly 800 × 800 pixels, with a spatial resolution ranging from 0.5 m to 30 m. The images are collected from more than 80 countries and regions around the world, including different seasons, lighting conditions, and angles. In the DIOR dataset, we randomly selected 8207 images as the training set and 3518 images as the validation set from 11,725 images in a 7:3 ratio, with the remaining 11,738 images used as the test set.
(2) The high-resolution remote sensing detection (HRRSD) dataset is a large-scale remote sensing image dataset for multi-class object detection tasks [40]. This dataset includes 13 common categories, such as airplanes, baseball fields, bridges, and ships, with a total of over 20,000 color images, as shown in Figure 8. The images are mainly sourced from Google Earth, with a spatial resolution ranging from 0.15 m to 1.2 m. The large data scale and diverse covered scenarios help improve the generalization ability of the model. The dataset is partitioned into a training set, a validation set, and a test set through algorithm optimization. It has large intra-class differences and high inter-class similarities, posing certain challenges.
(3) The remote sensing object detection (RSOD) dataset is an open remote sensing image object detection dataset [41]. This dataset includes a total of 976 remote sensing images, containing 6950 high-quality annotated instances, covering four typical target categories: aircraft, oil tanks, overpasses, and playgrounds. The spatial resolution ranges from 0.3 m to 3 m, as shown in Figure 9. This dataset covers a variety of scenes and angles, which helps algorithms adapt to object detection in different environments and can effectively verify the model’s detection performance for small-scale targets in complex scenes. We randomly divided the images in each category into a training set and a validation set at a ratio of 7:3, with 651 images in the training set and 285 images in the validation set.
4.2. Experimental Setup and Evaluation Metrics
4.2.1. Experimental Setup
The experimental environment and training parameters are summarized in Table 1. All experiments were conducted on a high-performance computing platform equipped with a Xeon^®^ Platinum 8470Q CPU and an NVIDIA RTX 5090 GPU with 32 GB memory, running Ubuntu 22.04. The model was implemented using PyTorch 2.1.2 with CUDA 12.1. All input images were uniformly resized to 800 × 800 pixels.
Given the complexity and domain specificity of remote sensing datasets, no pre-trained weights were employed; instead, the network was trained, validated, and tested entirely from scratch on the target datasets. The training process adopted a cross-validation strategy to ensure robustness. An initial learning rate of 0.0001 was used with a momentum coefficient of 0.937. To stabilize optimization, a linear warm-up strategy was applied at the early training stage, followed by a cosine annealing schedule to gradually decrease the learning rate and facilitate better convergence. Mosaic data augmentation was introduced during training to enhance data diversity and improve the model’s generalization ability under complex and cluttered backgrounds. Additionally, a weight decay of 0.0005 was applied as a regularization term to mitigate overfitting. The batch size was set to 16, and the model was trained for a total of 300 epochs.
It should be noted that for some compared methods, the official implementations are not publicly available. Consequently, their model parameters and FLOPs cannot be re-evaluated under the exact same hardware environment and are therefore directly taken from the original papers. Except for hardware-related differences, the software configuration, experimental settings, and evaluation pipeline are kept consistent with those described in the corresponding literature. Under this condition, the reported results still provide a reliable reference for comparing detection performance across different methods.
4.2.2. Evaluation Metrics
In this study, we principally employ Average Precision (AP) and mean Average Precision (mAP) as the core metrics to quantify and evaluate the model. AP is the area under the precision-recall (P-R) curve, which comprehensively reflects the model’s performance across different recall levels. mAP is the arithmetic mean of the AP values across all classes and is used to mitigate evaluation bias arising from class imbalance. The computation is given by the following formulas:
where P represents the proportion of the number of correctly detected results to the total number of all detection results, R represents the proportion of the number of correctly detected targets to the total number of actual targets, and N represents the total number of target categories in the dataset.
mAP50 is the average AP of all categories under the condition of IoU = 0.5. It is a key indicator that balances practicality and efficiency in target detection, and it balances the positioning accuracy and the model’s fault tolerance ability through a moderate IoU threshold. mAP50:95 is a comprehensive indicator (with the IoU ranging from 0.5 to 0.95), which comprehensively measures the model’s classification and positioning abilities under different positioning accuracy requirements.
In addition, to account for the large-scale variation of objects in remote-sensing images, this study adopts the COCO grading evaluation system: APs (Average Precision of Small) for areas less than 32^2^ pixels, APm (Average Precision of Medium) for areas between 32^2^ and 96^2^ pixels, and APl (Average Precision of Large) for areas greater than 96^2^ pixels.
Finally, to evaluate the model’s computational efficiency, we computed model parameters to quantify storage requirements and calculated FLOPs to infer the model’s running speed. To reduce experimental randomness, we repeated each experiment ten times and report the mean of the ten results.
4.3. Experimental Results
4.3.1. Results in the DIOR Dataset
We selected 13 mainstream object detection models for comprehensive comparative analysis on the DIOR dataset, as shown in Table 2. The comparison models mainly include single-stage detector models (RetinaNet [42]), two-stage detector models (Faster R-CNN [43] and Cascade R-CNN [44]), transformer-based models (RT-DETR [23] and ViTDet [45]), classic YOLO series models (YOLOv5 [46], YOLOv7 [33], YOLOv8 [47], YOLOX [48], YOLOv11 [49], Super-YOLO [50], and Gold-YOLO [34]), and the latest model MCFM [51].
The experimental results are shown in Table 2. In terms of overall performance, our model achieves the best results. The mAP value of our model reaches 78.1%, representing improvements of 26% and 8.2% compared to the classic two-stage detectors, Faster R-CNN and Cascade R-CNN, respectively. Compared with the single-stage detector RetinaNet, the mAP increases by 10.3%. In comparison with the transformer-based RT-DETR, the mAP increases by 4.9%. When compared with YOLOv5 and YOLOv11 in the YOLO series, the improvements are 4.3% and 0.7%, respectively. Moreover, our model surpasses the recently proposed advanced model MCFM (77.6%) by 0.5%, which demonstrates the advancement and effectiveness of our model in remote sensing object detection tasks. Furthermore, with respect to detection performance on individual categories, our model maintains advantages over competing methods. For example, it achieves the best performance in ship (S, 92.1%), tennis court (TC, 65.3%), and overpass (O, 65.3%) categories, while also ranking among the top performers in airplane (AL, 83.2%), chimney (C, 77.5%), dam (D, 66.8%), and storage tank (ST, 86.2%).
The experimental results presented above demonstrate that the advanced architecture model we designed, which combines multi-scale perception and channel cross, has strong generalization ability and can stably handle diverse ground object targets in remote sensing scenarios. By cross-fusing channel attention and spatial attention, the model’s adaptability to complex scenes is further strengthened. In terms of computational efficiency, compared with other models, the number of parameters and computational complexity of our model are at a relatively low level, achieving model lightweight while improving computational efficiency.
4.3.2. Results in the HRRSD Dataset
The experimental results are shown in Table 3. Compared with the other 11 object detection models, the mAP of our model on the HRRSD dataset reaches 90.6%, which is 5.8% higher than that of the single-stage detector CornerNet [52], 11.1% higher than that of the two-stage detector Faster R-CNN, 16.4% higher than that of the vision transformer-based ViTDet, and 0.6% and 1.4% higher than those of the classic Gold-YOLO and YOLOv11 algorithms, respectively. In addition, the proposed algorithm performs excellently in most specific detection categories of the HRRSD dataset. The model ranks first in terms of accuracy in a total of 7 categories, including airplanes (AL, 99.1%), baseball fields (BC, 77.1%), bridges (BD, 87.7%), crossroads (CR, 95.1%), harbors (HB, 95.9%), parking lots (PL, 67.7%), and storage tanks (ST, 97.2%). The model leads performance in challenging categories such as parking lots and bridges, demonstrating the strong capability of its cross-attention mechanism to detect complex small targets.
Compared with Super-YOLO and YOLOv11, which have similar computational costs, our model not only shows certain advantages in mAP but also significantly improves the detection performance for specific categories. This further demonstrates that the model has good stability and robustness, achieving a balance between efficiency and performance. It also confirms the enhancing effect of the multi-scale cross-channel fusion mechanism and the attention cross mechanism on the detection performance.
4.3.3. Results in the RSOD Dataset
As shown in Table 4, this table presents the comparison results of our model with 8 other remote sensing object detection models on the RSOD dataset. Our model achieved 96.5% mAP. It substantially surpasses two-stage detectors such as Faster R-CNN (69.6%) and single-stage detectors such as RetinaNet (80.4%), and it also outperforms members of the YOLO series, including YOLOv7 (92.8%), YOLOv8 (94.4%), and YOLOv10 (89.7%) [54]. In particular, our model outperforms the latest GAM (95.9%) [55] based on the global attention mechanism by 0.6%, indicating that our model has high accuracy in detecting objects. In the aircraft and oiltank categories, our model achieves detection accuracies of 98.1% and 97.5%, respectively, ranking first in both. In the Overpass category, which features complex structures and substantial background interference, our model achieved 93.3% accuracy, 2.5% higher than the second-ranked GAM (90.8%). This result demonstrates the model’s precise recognition of targets with complex structures.
Further analysis indicates that, compared with the DIOR and HRRSD datasets, the RSOD dataset exhibits pronounced class imbalance. For example, there are 446 images of aircraft but only 165 images of oiltank, which may lead to insufficient feature learning for minority classes. To address such issues, the YOLO series models mainly adopt loss function design, model structure optimization, and advanced training strategies. However, these approaches have not fully resolved the problem of inadequate feature extraction and can sometimes do so at the expense of overall computational efficiency. In contrast, the model we proposed mainly concentrates on critical information within the image through the CSCA mechanism, enhancing its feature learning and discrimination ability. This helps to compensate for the weak feature representation ability caused by the small amount of data and achieves good results in the evaluation metric mAP.
Compared with YOLOv10, although the computational parameters and complexity of our model slightly increase, the detection accuracy is significantly improved. Compared with YOLOv5 with similar computational cost, our model shows obvious improvements in detection performance both overall and for specific categories. The results confirm the superior ability of the proposed algorithm for the detection accuracy of multi-scale objects and computational cost.
Finally, on the three remote sensing datasets of DIOR, HRRSD, and RSOD, the P-R curves of our model are compared with those of multiple current mainstream object detection methods, as shown in Figure 10. The P-R curve reflects the relationship between the precision and recall of the model under different confidence thresholds. The area under the curve corresponds to the mean average precision (mAP). A larger area and a curve nearer the upper right indicate better overall detection performance of the model.
On the DIOR dataset, the P-R curve of our algorithm significantly approaches the upper-right corner, and the area enclosed by the curve is larger than that of other comparison methods, indicating that our model has higher detection accuracy and stronger comprehensive detection ability. On the HRRSD and RSOD datasets, the P-R curve of our model also shows a stable and leading curve shape, suggesting that our model has good adaptability and generalization ability on datasets of different scales.
4.4. Ablation Experiment and Analysis
To verify the effectiveness and role of each module in the overall detection performance, we designed systematic ablation experiments on the DIOR, HRRSD, and RSOD datasets. The experimental details are presented below.
(1) Effects of CC-MSFE: The proposed CC-MSFE module utilizes cross-channel fusion and depthwise separable convolutions to extract multi-scale features, improving target perception across sizes while retaining a lightweight architecture. As shown in Table 5, ablation results confirm the necessity of both components across all three datasets. On the DIOR dataset, replacing the depthwise separable convolution with ordinary convolution and canceling the cross-channel fusion mechanism leads to a 6% decrease in mAP50 and a 3.6% decrease in mAP50:95, where the cross-channel design plays a major role. In addition, APs decreases by 10.9%, APm decreases by 10%, and APl decreases by 0.4%, indicating that the design of depthwise separability and cross-channel mainly enhances the detection precision for small and medium targets. This trend is consistent on the HRRSD and RSOD datasets. Notably, in the enhanced model, the parameter count (Para) only increases from 19.0 M to 19.5 M, and FLOPs rise from 74.5 G to 75.2 G, demonstrating a significant performance improvement with almost no additional computational cost.
(2) Effects of CA and SA: The main functions of the CA and SA modules we designed are to enhance the model’s ability to capture important information. The experimental results demonstrate that introducing either CA or SA individually leads to consistent performance improvements. Specifically, CA mainly enhances the semantic discriminability along the channel dimension, whereas SA significantly strengthens the model’s capability to capture spatial location information of targets, exhibiting particularly notable gains in small-object detection tasks. Under the combined enhancement from the two modules, the model achieved significant improvements in mAP50 and mAP50:95 across all three datasets. Notably, the CA module contributed to APs increases of 2.9%, 2.0%, and 1.4% on the DIOR, HRRSD, and RSOD datasets, respectively, while the SA module improved APs by 4.0%, 1.8%, and 1.6% on the same datasets. These findings indicate that CA and SA play complementary roles in optical remote sensing object detection.
(3) Effects of CAFM: We designed the CAFM to better cross-fuse channel attention and spatial attention, enhancing the model’s comprehensive understanding of multi-source information in complex backgrounds. As shown in Table 6, the integration of the CAFM significantly improved model performance, increasing mAP50 by 3.8%, 5.1%, and 4.9% on the DIOR, HRRSD, and RSOD datasets, respectively. The most pronounced gains were observed on DIOR, with APs, APm, and APL increasing by 5.6%, 9%, and 1.9%, which clearly validates the role of CAFM in optimizing object detection performance. While reducing the computational complexity, it achieved a significant improvement in detection accuracy and robustness.
To further verify the effectiveness and practical value of the proposed CSCA attention mechanism, we conducted additional comparative experiments. As shown in Table 7, on the DIOR dataset, CSCA achieves an mAP50:95 of 67.0%, which is noticeably higher than that of SK [57] (65.3%) and CA [58] (65.9%). Compared with Wavelet Attention [59], CSCA improves the small-object detection accuracy by 5.1%, indicating a stronger capability to recognize small targets under complex backgrounds. On the HRRSD dataset, the superiority of CSCA is further validated, where it attains an mAP50 of 92.2%, outperforming SK, CA, and Wavelet Attention by 1.0%, 0.4%, and 0.2%, respectively. On the RSOD dataset, CSCA likewise delivers the best overall performance. Notably, CSCA incurs a lower parameter efficiency (19.5 M Params, 75.2 G FLOPs) than SK (28.2 M Params, 85.3 G FLOPs) and Wavelet Attention (20.3 M Params, 76.1 G FLOPs), demonstrating a favorable trade-off between detection accuracy and computational complexity.
4.5. Visualization Results
In addition to quantitative comparisons, we also visualize detection results and the feature maps in Figure 11, Figure 12, Figure 13 and Figure 14 to provide an intuitive understanding of our proposed methods.
4.5.1. Visualization of Detection Results
On the three datasets of DIOR, HRRSD, and RSOD, we visually present the detection results of our model and other models, as shown in Figure 11, Figure 12 and Figure 13.
In the DIOR dataset, we selected three types of remote sensing images with different detection categories for comparison with other models. As shown in Figure 11, our model achieves the best detection results and exhibits good robustness. For instance, the first row of images shows the detection results of train stations in a complex urban background. Our model can effectively overcome background interference, accurately identify and locate targets, and achieve the highest detection accuracy. The second row of images presents the detection results of large-scale targets (harbors) and small-scale targets (ships). The proposed model demonstrates robust multi-scale adaptability, delivering balanced accuracy in localizing and classifying targets of varying sizes. The third row of images displays detection results for storage tanks with high inter-class similarity. Through the synergistic optimization of the multi-scale feature extraction module and attention mechanism module, the model can precisely identify subtle feature differences.
In the HRRSD dataset, we also selected remote sensing images from three different scenarios for verification, as shown in Figure 12. The first scenario involves small-target detection in complex backgrounds. For example, the images in the first row illustrate the detection of small vehicles in street scenes. The second scenario focuses on target detection under occlusion. Specifically, the images in the second row show the detection of basketball courts and tennis courts partially occluded by vegetation. The third scenario addresses the detection of objects with similar features. As illustrated in the third row, the model can accurately detect crossroads and T-junctions in similar traffic road scenes. The results indicate that our model exhibits good robustness and generalization ability in the above scenarios.
In the RSOD dataset, we visually compare the remote sensing images of four typical targets with other detection models, as shown in Figure 13. The detection results show that our model exhibits stable and excellent detection performance in different scenarios. Specifically, for densely parked airplanes (first row) and densely arranged oil tank groups (second row), our model maintains high positioning accuracy and recall rate under complex spatial distributions, effectively verifying its excellent feature recognition and anti-occlusion capabilities in high-density small target detection. For large-scale targets such as overpasses with complex structures (third row) and sports fields (fourth row), our model can still accurately capture the overall contours of the targets, demonstrating its strong perception and discrimination abilities for multi-scale targets.
4.5.2. Visualization of Feature Maps
As shown in Figure 14, the feature maps from the ablation study on CSCANet visually demonstrate the functions and synergistic effects of its constituent modules. Removing either the channel attention (CA) or spatial attention (SA) module noticeably weakens the representation of small-object features and leads to missed detections. The degradation becomes more pronounced when the cross-attention fusion module (CAFM) is removed, where boundary cues are blurred and missed detections are more frequent in densely populated small-object scenes. In contrast, the complete model exhibits stronger discriminative capability for target features and delineates object locations and boundaries more accurately, highlighting the complementary and synergistic roles of CA, SA, and CAFM in improving feature representation and localization precision.
Figure 15 shows the effectiveness of the proposed CSCA attention mechanism in comparison with other attention mechanisms, including SK, CA, and Wavelet Attention. SK and CA fail to clearly distinguish targets from surrounding background structures, resulting in diffuse and incomplete responses. Compared with other attention mechanisms, CSCA can better highlight crucial regions and preserve finer-grained features, particularly demonstrating superior performance in dense small-object detection tasks (e.g., ships and vehicles), which indicates that CSCA has a stronger capability in representing and discriminating small targets under complex backgrounds.
5. Conclusions
This study proposes a multi-scale object detection network with integrated spatial-channel collaborative attention, comprising four key modules: cross-channel multi-scale feature extraction (CC-MSFE), channel attention (CA), spatial attention (SA), and channel-spatial cross-attention fusion mechanism (CAFM). To address the issue of insufficient extraction of multi-scale target features, we mainly enhance the feature perception ability of multi-scale targets (especially small targets) through the cross-channel multi-scale feature extraction module, achieving complementarity among features of different channels. Regarding the problem of insufficient feature fusion between space and channels, we innovatively design the channel-spatial cross-attention mechanism. By deeply fusing spatial and channel attention, the context perception ability is significantly improved, and precise focusing on key information is achieved. Finally, we experimentally validated the method on three challenging public remote-sensing datasets: DIOR, HRRSD, and RSOD. The results show that the mAP values of our model on the three datasets reach 78.1%, 90.6%, and 96.5%, respectively, significantly outperforming comparative models such as Faster R-CNN, RetinaNet, and YOLOv11. Notably, the model maintains a low level in terms of the number of parameters (19.5 M) and computational complexity (75.2 G FLOPs), achieving a favorable trade-off between detection accuracy and operational efficiency.
Although the model proposed in this study has achieved good performance in multiple aspects, there are still some limitations. For instance, our model has not been tested on real-scene images. As real scenes usually contain more noise, complex backgrounds, and are affected by cloud and fog interference, the generalization ability of the model needs further verification, and the inference speed will also be affected to some extent. In the future, we will further optimize the model and validate it in real scenes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zaidi S.S.A. Ansari M.S. Aslam A. Kanwal N. Asghar M. Lee B. A Survey of Modern Deep Learning Based Object Detection Models Digit. Signal Process.202212610351410.1016/j.dsp.2022.103514 · doi ↗
- 2Xu C. Shu J. Wang Z. Wang J. Dynamic Convolutional Model Based on Distribution-Collaboration Strategy for Remote Sensing Scene Classification Int. J. Digit. Earth 202518251782410.1080/17538947.2025.2517824 · doi ↗
- 3Liu Z. Xu J. Liu M. Yin Z. Liu X. Yin L. Zheng W. Remote Sensing and Geostatistics in Urban Water-Resource Monitoring: A Review Mar. Freshw. Res.20237474776510.1071/MF 22167 · doi ↗
- 4Xu C. Zhu G. Shu J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification IEEE Trans. Geosci. Remote Sens.20226011510.1109/TGRS.2020.3048024 · doi ↗
- 5Wellmann T. Lausch A. Andersson E. Knapp S. Cortinovis C. Jache J. Scheuer S. Kremer P. Mascarenhas A. Kraemer R. Remote Sensing in Urban Planning: Contributions towards Ecologically Sound Policies?Landsc. Urban Plann.202020410392110.1016/j.landurbplan.2020.103921 · doi ↗
- 6Zhang Z. Xu C. A Lie Group-Based Model for Remote Scene Classification with Multi-Scale Feature Fusion and Mixed Attention Mechanisms Int. J. Remote Sens.2025463800383010.1080/01431161.2025.2491818 · doi ↗
- 7Hudson R.D. Hudson J.W. The Military Applications of Remote Sensing by Infrared Proc. IEEE 19756310412810.1109/PROC.1975.9711 · doi ↗
- 8Xu C. Shu J. Zhu G. Adversarial Remote Sensing Scene Classification Based on Lie Group Feature Learning Remote Sens.20231591410.3390/rs 15040914 · doi ↗