A Vision-Based Deep Learning Framework for Monitoring and Recognition of Chemical Laboratory Operations
Chuntao Guo, Jing Lin, Shunxing Bao, Xin Liu, Yaru Wang, Yunlin Chen

TL;DR
This paper introduces a deep learning system that uses video to monitor and recognize pipetting actions in chemistry labs, improving safety and consistency.
Contribution
The novel framework uses spatiotemporal features and bidirectional LSTM networks for real-time monitoring of pipetting operations.
Findings
The framework reliably distinguishes standard from non-standard pipetting behaviors across multiple error categories.
It shows improved robustness compared to static or frame-level analysis methods.
The system is feasible for scalable and objective monitoring of laboratory procedures.
Abstract
Standardized operating procedures are essential for ensuring safety and reproducibility in chemical laboratory experiments. However, real-time monitoring of manual laboratory operations, such as pipetting, remains challenging due to complex human–tool interactions, temporal dependencies between procedural steps, and operator variability. In this study, we propose a vision-based deep learning framework that leverages spatiotemporal features for automated monitoring of pipetting operations using non-contact visual sensing. Briefly, human poses and pipette interactions are extracted from video recordings using a YOLO-based perception model, while temporal execution patterns are captured through bidirectional long short-term memory networks. Experimental results demonstrate that the proposed approach can reliably distinguish between standard and non-standard pipetting behaviors across…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
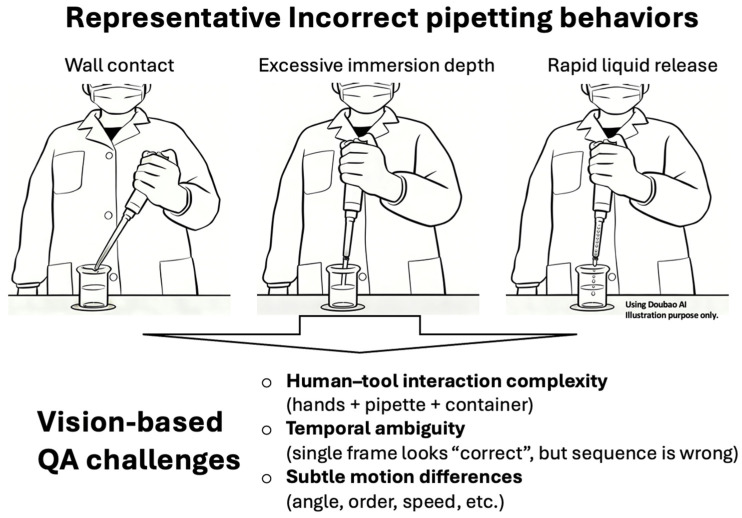 Figure 1
Figure 1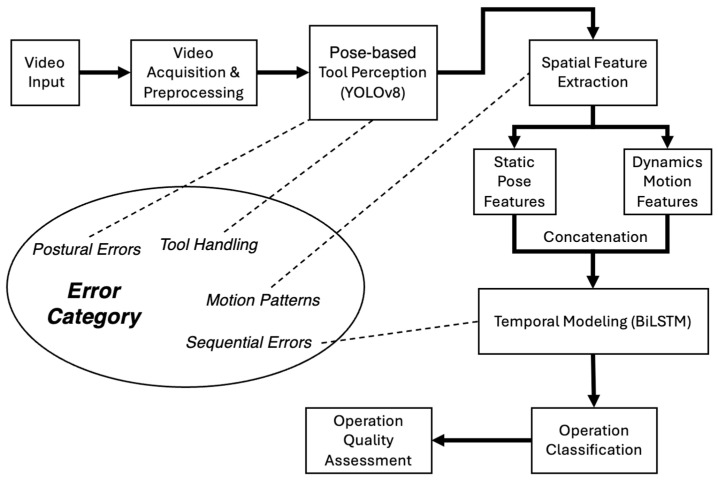 Figure 2
Figure 2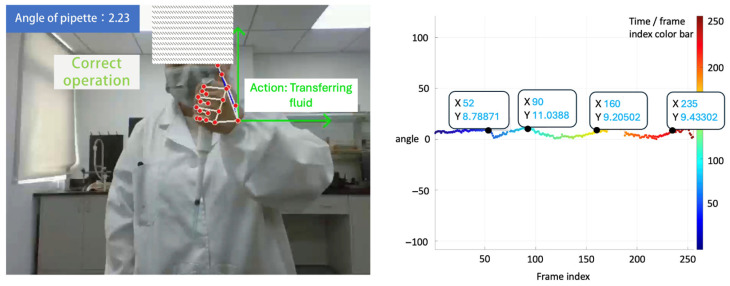 Figure 3
Figure 3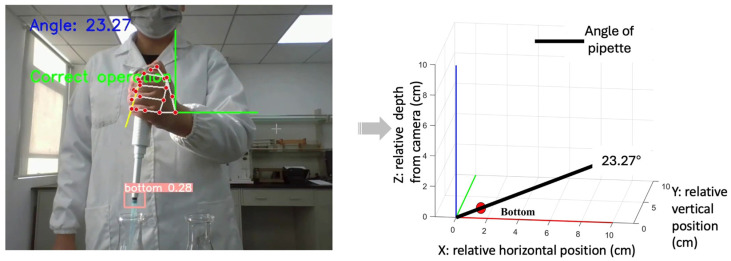 Figure 4
Figure 4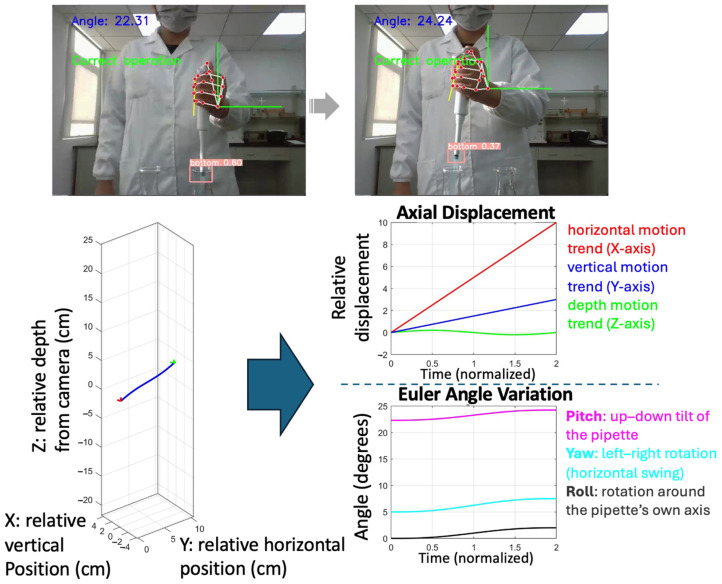 Figure 5
Figure 5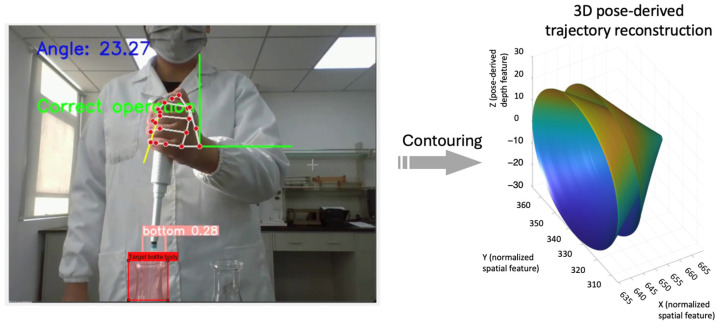 Figure 6
Figure 6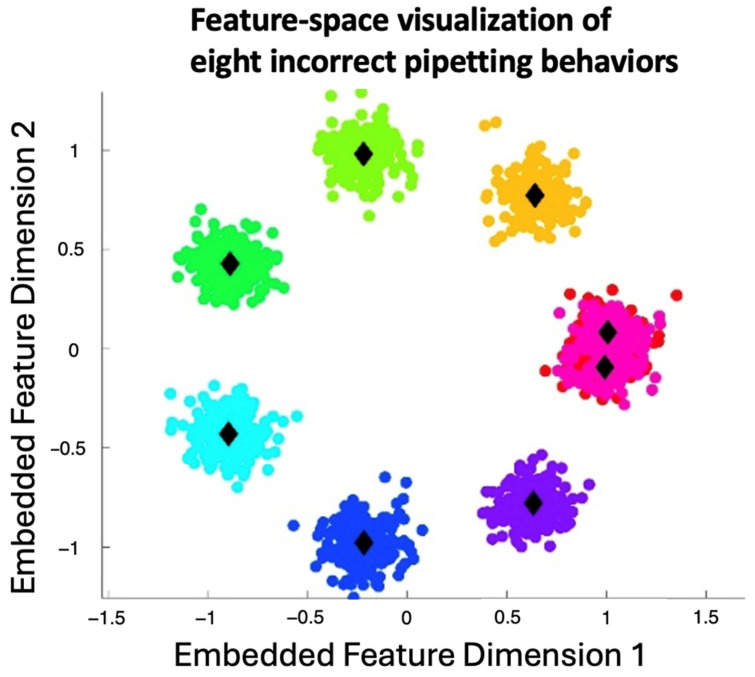 Figure 7
Figure 7- —Jiangsu Provincial Administration for Market Regulation Science and Technology Plan Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Materials Science · Chemical Safety and Risk Management · Advanced Neural Network Applications
1. Introduction
Chemical laboratory experiments rely on standardized operating procedures to ensure experimental safety, result reliability, and procedural reproducibility [1,2]. Deviations from prescribed operation steps—such as improper tool handling or incorrect execution order—can lead to measurement errors, safety risks, and inefficient use of laboratory resources [3,4]. In practice, supervision of laboratory operations is still largely dependent on manual observation and post hoc evaluation by supervisors [5]. Such approaches are labor-intensive and difficult to scale, particularly in training environments or laboratories with high experimental throughput [5]. Consequently, there is a pressing need for objective and automated methods capable of monitoring human operational activities in laboratory settings [6,7].
Recent advances in vision-based sensing and artificial intelligence have enabled non-contact monitoring of human actions through camera systems, offering a promising alternative to traditional supervision methods [8,9]. Compared with wearable or instrumented sensors, vision-based approaches can capture rich spatial information without interfering with experimental procedures [9]. However, accurately recognizing laboratory operations remains challenging due to complex human–tool interactions and strong temporal dependencies between procedural steps [10,11]. Many existing approaches rely on frame-level detection or static posture analysis, which limits their ability to capture sequential dependencies and subtle operational errors [12]. These challenges motivate the development of integrated vision-based sensing frameworks that jointly model spatial and temporal information for reliable operation monitoring [13,14]. Related spatiotemporal and context-aware modeling approaches have been explored in other safety-critical domains, such as flight arrival time prediction and air traffic control communication analysis [15,16]. Although these studies address different applications, they demonstrate the broader value of integrating temporal modeling with domain-specific constraints for standardized operation monitoring. In chemical laboratory environments, similar challenges arise due to complex human–tool interactions and strict procedural requirements. Figure 1 illustrates common incorrect pipetting behaviors and the associated quality assurance (QA) challenges for vision-based monitoring, including complex human–tool interactions, temporal ambiguities and subtle motion difference.
To address these challenges, this study develops an integrated vision-based sensing framework that combines spatial perception of human actions with temporal modeling of operation sequences. Human pose information and tool interactions are extracted from video streams using a YOLO-based pose estimation model, enabling robust detection of key body joints and relevant objects under varying experimental conditions [17,18]. Temporal dependencies between consecutive procedural steps are modeled using a bidirectional long short-term memory (BiLSTM) network, which captures the evolution of pose and motion features over time [19,20]. This spatiotemporal representation allows the system to distinguish subtle differences between correct and incorrect operations that may not be identifiable from static frames alone [21].
Based on the extracted spatiotemporal features, multiple classification models are evaluated to assess operational correctness across predefined laboratory error categories [22]. Rather than introducing new learning architectures, this work focuses on system integration and makes novel contributions by formulating laboratory pipetting quality assessment as a sequence-level vision problem with explicit, standard-driven error definitions, and by integrating pose-based human–tool perception with temporal execution modeling to capture subtle procedural deviations beyond frame-level analysis. The proposed framework operates as a non-contact, camera-based sensing system that can be deployed without modifying existing laboratory instruments or experimental workflows, making it suitable for routine laboratory training settings [23]. The main contributions of this study are threefold:
- Development of a vision-based sensing framework for automated monitoring of laboratory operations.
- Integration of spatial pose perception with temporal sequence modeling to enhance recognition robustness.
- Experimental validation across multiple operational error categories, demonstrating feasibility for objective laboratory monitoring.
2. Materials and Methods
2.1. Problem Definition and System Overview
In this study, improper pipetting behaviors are defined as observable deviations from predefined procedural criteria in chemical laboratory workflows. The problem is formulated as automated monitoring of pipetting operations using non-contact vision-based sensing. Given a video sequence capturing a complete pipetting process, the objective is to determine whether the operation conforms to procedural criteria and, when applicable, to identify specific categories of incorrect behaviors.
To address this task, an integrated vision-based sensing framework is proposed that combines spatial perception of human pose and tool interactions with temporal modeling of operation sequences. Video streams captured by a fixed camera are processed to extract pose- and motion-related features, which are modeled over time to enable classification of correct and incorrect operations. The incorrect pipetting behavior categories considered in this study are defined using objective operational criteria, as summarized in Table 1. The operational definitions are based on established laboratory operating standards and good laboratory practice guidelines, including relevant Chinese national standards (e.g., GB/T 27407-2010 [24] and GB/T 27476.5-2014 [25]) and internationally adopted GLP/GMP regulations. Detailed threshold definitions and numerical values for each error category are provided in the Appendix A (Table A1). These thresholds are derived from standard laboratory operating procedures and expert practice to ensure interpretability and procedural relevance. Each video sequence corresponds to a complete pipetting operation and is treated as one analysis sample.
2.2. Overall Framework Workflow
Figure 2 illustrates the overall workflow of the proposed vision-based sensing framework for automated monitoring of pipetting operations. The framework follows a modular design consisting of spatial perception, feature representation, temporal modeling, and classification.
Video sequences capturing laboratory operations are first processed to extract spatial information related to human pose and tool configuration using a YOLOv8-based pose estimation module. From these spatial observations, two complementary feature representations are constructed: a static stream that captures pose configurations at individual time points, and a motion stream that captures temporal changes in pose and tool movement across consecutive frames based on inter-frame feature differences. These two streams encode complementary spatial and dynamic characteristics of pipetting behaviors.
The static and motion features are concatenated to form a unified spatiotemporal representation, which is subsequently modeled using a recurrent temporal network to capture execution order and temporal dependencies across the operation sequence. Finally, the learned sequence-level features are passed to a classification stage to determine operational correctness and identify predefined categories of incorrect pipetting behaviors.
2.3. Vision-Based Pose and Tool Perception
Vision-based pose and tool perception is employed to extract spatial observations relevant to pipetting operations from monocular video streams. Human body keypoints and pipette-related geometric features are detected using a YOLOv8-based pose estimation model [26], which provides efficient and accurate localization of skeletal joints and tool landmarks in real time. YOLOv8 is adopted due to its favorable trade-off between detection accuracy and computational efficiency, making it suitable for laboratory monitoring scenarios. From each video frame, the model outputs 2D keypoint coordinates of the upper body and hands, along with bounding boxes and orientation cues associated with the pipette. These spatial observations are organized as time-ordered pose vectors and serve as the input to subsequent feature extraction and temporal modeling stages.
2.4. Multimodal Feature Extraction
To characterize both instantaneous posture and temporal motion patterns during pipetting, a dual-stream feature extraction strategy is adopted, consisting of a static pose stream and a motion stream. Both features are concatenated to form a unified spatiotemporal representation that is further passed to the temporal modeling module for sequence-level analysis (Section 2.5).
2.4.1. Static Pose Stream
The static pose stream encodes skeletal joint positions at each time step [27]. Let
denote the 2D coordinates of detected joints at time . To capture local kinematic information, first- and second-order temporal derivatives are computed:
where these features encode joint displacement (Equation (2)), velocity (Equation (3)), and acceleration (Equation (4)), capturing posture stability and fine-grained motion cues relevant to operational correctness.
2.4.2. Dynamics Motion Stream
The dynamic motion stream captures local appearance changes associated with hand and tool movements during pipetting. Motion features are extracted from pose-guided regions of interest to emphasize relevant hand–pipette interactions while reducing background interference. A motion-enhanced Weber Local Descriptor (WLD) is employed to encode relative intensity variations and directional changes, providing a compact representation of motion dynamics that is robust to illumination variation [28]. The resulting motion features reflect execution characteristics such as smoothness and abrupt movement changes. The extracted motion features encode execution characteristics, including movement continuity and abrupt transitions.
2.5. Temporal Modeling of Operation Sequences
Pipetting operations consist of temporally ordered actions that cannot be reliably interpreted from individual frames. To capture sequential dependencies and execution order, the extracted spatial and motion features are modeled over time using a bidirectional long short-term memory (BiLSTM) network. By processing feature sequences in both forward and backward directions, the BiLSTM captures contextual information from the entire operation, enabling discrimination between correct and incorrect execution patterns. The resulting sequence-level representations are subsequently used for operation-level classification.
2.6. Classification Models
Following spatiotemporal feature extraction, a classification stage is employed to assign each operation sequence to a predefined operational category. While temporal modeling captures motion dynamics and execution order, explicit classification is required to enable objective decision making and quantitative evaluation of operational correctness. To ensure that system performance is not dependent on a specific classifier and to support objective evaluation of the extracted spatiotemporal representations, seven representative classifiers are evaluated given the limited sample size. These include ID3, C4.5, AdaBoost, Naive Bayes, Bayesian Network, Random Forest, and Support Vector Machine (SVM). The selected classifiers cover diverse learning paradigms, allowing systematic assessment of classification performance across different decision mechanisms [29].
2.7. Use of Generative AI
Generative AI (ChatGPT 5.2) was used to assist with manuscript writing, including grammar correction and figure generation (Doubao-Seed-1.8, Schematic 1 only, for conceptual illustrations). All scientific analysis and conclusions were based on original research and expert judgment.
3. Experimental Setup
3.1. Dataset Collection and Annotation
Twelve participants were recruited for this study (Table 2), including six novice operators and six experienced operators. Each trial corresponds to one complete pipetting operation sequence and is treated as an independent sample for analysis. In total, the dataset consists of 48 operation sequences, including 24 erroneous (non-standard) sequences and 24 standard sequences. Each participant performed multiple pipetting trials following standardized laboratory protocols. Each trial corresponds to a complete pipetting operation and is treated as a single sequence-level sample for subsequent analysis. Operational correctness was manually assessed by a senior laboratory expert, with erroneous behaviors categorized according to the definitions summarized in Table 1. These sequence-level annotations serve as ground truth labels for error classification and evaluation.
In addition to sequence-level labels, frame-level annotations were generated to support visual modeling of procedural behavior. From the recorded laboratory videos, 15,000 frames were sampled across both correct and erroneous operations. Each frame was annotated with bounding boxes for two categories:
- anatomical joints used to characterize operator posture, and
- key laboratory apparatus, including pipettes, beakers, and test tubes.
This process produced approximately 5000 object-level annotations, which were used to train a YOLOv8-based object detector. Furthermore, 2500 frame sequences corresponding to predefined error types were separately identified and labeled to train and benchmark the error classification module.
3.2. Video Acquisition and Preprocessing
Visual data acquisition was performed using an Intel RealSense D455 stereo depth camera (Intel Corporation, Santa Clara, CA, USA), capturing synchronized RGB and depth streams at 30 Hz with a resolution of 1280 × 720. All pipetting operations were recorded using a fixed monocular camera positioned to capture the experimental workspace and operator hand movements. Video sequences were segmented into individual pipetting actions to ensure that each sample corresponded to a complete operation. Basic preprocessing steps, including frame resizing and temporal alignment, were applied to reduce variability across recordings and ensure consistent input for subsequent feature extraction and temporal modeling.
3.3. Training and Testing Protocol
Due to the limited sample size and to prevent data leakage, a participant-grouped cross-validation protocol was adopted. All sequences from the same participant were assigned to the same fold, ensuring that no participant appeared in both training and test sets. The 12 participants were randomly grouped into five folds (with 2–3 participants per fold), resulting in test set sizes of 8–12 sequences per fold (each participant contributing four sequences). Performance was reported as the average across the five folds.
3.4. Ablation Study Design
To assess the contribution of different feature components, a quantitative ablation study was conducted by selectively removing static pose features or motion features from the proposed framework. Three configurations were evaluated: static-only, motion-only, and combined static–motion features.
When both static and motion features were retained, temporal execution patterns were preserved and modeled using an LSTM-based temporal encoder followed by a fully connected classification layer. When either feature stream was removed, temporal structure was no longer fully available; therefore, non-temporal classifiers (SVM or Random Forest) were used, with the best-performing classifier reported for each reduced-feature configuration.
3.5. Evaluation Metrics
System performance was evaluated using standard classification metrics, including accuracy, precision, recall, and F1-score. Accuracy measures the proportion of correctly classified operation sequences across all categories. Precision and recall quantify the reliability of predicted incorrect behaviors and the system’s ability to detect true operational errors, respectively. The F1-score provides a balanced metric that integrates both precision and recall, particularly under limited or potentially imbalanced data conditions [30].
3.6. Computation Hardware Configuration and Software Implementation
All experiments and analyses were performed on a workstation equipped with an Intel Core i7-13700K CPU, 32 GB of DDR5 RAM, and an NVIDIA GeForce RTX 4090D GPU with 24 GB of GDDR6X memory. The software pipeline was implemented in Python 3.9, using PyTorch 2.0.1 for deep learning model development, TensorFlow 2.12 for auxiliary network training, and OpenCV 4.8.0 for real-time image processing and system integration.
4. Results
4.1. Action Reconstruction and Feature Analysis
Figure 3, Figure 4, Figure 5 and Figure 6 present pose- and motion-based visualizations of a representative pipetting operation, showing changes in position and orientation over time with a consistent temporal ordering across the sequence.
Figure 3 shows pose-based feature extraction from video data. Hand and arm keypoints are used to estimate the orientation of the pipette, and the inclination angle relative to the vertical direction in the camera coordinate system is plotted along the motion trajectory. The angle values vary over time, reflecting changes in pipette orientation during the operation. Hand keypoints are used to support pipette localization and orientation estimation, while the reported angle corresponds to the pipette axis. Temporal progression is indicated using color coding.
Figure 4 presents the geometric reconstruction of pipette orientation in a camera-centered coordinate system. Using pose-derived keypoints, the pipette axis is reconstructed in three dimensions, and the inclination angle relative to the vertical direction is computed for a representative operation.
Figure 5 shows the temporal evolution of pipette motion and orientation. The axial displacement plot illustrates changes in relative position along the horizontal, vertical, and depth directions over time, while the Euler angle curves depict corresponding variations in pipette orientation throughout the operation.
Figure 6 provides a three-dimensional visualization of pose-derived spatiotemporal features for a single pipetting sequence. The trajectory represents coordinated motion of the pipette and hand, with color indicating temporal progression. Variations in spatial position and orientation are observed across the duration of the operation.
4.2. Classification Performance
The classification performance results shown in Table 3, were evaluated using seven different classifiers: ID3, AdaBoost, C4.5, Naive Bayes, Bayesian Network, Random Forest, and Support Vector Machine (SVM). Among these classifiers, ID3 achieved the highest performance, with an impressive accuracy rate of 100% in both the control and experimental groups. Naive Bayes followed closely with 93.3% accuracy across both groups. In contrast, Bayesian Network and SVM classifiers showed weaker performance, particularly in recognizing the subtle distinctions between positive and negative operational categories.
The significant variance in classifier performance can be attributed to the nature of the dataset and the task’s characteristics. The input features in this study were discontinuous, presenting a challenge for certain algorithms, which typically excel with continuous data. As such, decision tree-based methods like ID3, which are designed to handle discrete values efficiently, performed the best. This aligns with previous studies in disease classification where ID3 has shown high reliability for tasks involving categorical outcomes. On the other hand, Naive Bayes performed reasonably well due to its probabilistic nature, but its ability to handle such dynamic sequences with temporal dependencies was less robust compared to ID3. Qualitatively, Figure 7 presents a two-dimensional embedding of sequence-level spatiotemporal features for eight incorrect pipetting behavior categories, with cluster centroids in black markers.
4.3. Ablation Study Results
Table 4 summarizes the quantitative ablation results under different feature configurations. The static-only and motion-only variants yield lower accuracy and F1-score compared with the full model. The configuration that combines static pose and motion features achieves the highest overall performance across all evaluated metrics.
5. Discussions
The results indicate that vision-based sensing combined with deep learning provides a viable approach for monitoring pipetting behaviors in laboratory settings. By integrating pose-based spatial features with motion information and modeling their temporal evolution using a BiLSTM network, the proposed framework captures both postural configuration and execution dynamics associated with pipetting operations. Due to the limited sample size, a formal quantitative ablation study was not conducted; instead, qualitative visual analyses were used to examine the contributions of static pose and motion features.
The visualizations in Figure 5 and Figure 6 illustrate the coordinated movement of the hand and pipette during operation, highlighting consistent positional and orientational changes over time. Figure 7 provides a qualitative view of the distribution of sequence-level spatiotemporal features across eight incorrect pipetting behavior categories. While several categories form relatively compact clusters in the embedded feature space, partial overlap is observed, reflecting similarities in motion patterns and execution order among certain error types. This observation underscores the inherent difficulty of distinguishing closely related operational errors based solely on visual cues and emphasizes the importance of temporal modeling and supervised classification.
The comparatively weaker performance of the Bayesian Network and SVM classifiers may be related to the characteristics of the extracted features, which exhibit discontinuous and time-varying behavior. In contrast, decision tree–based methods such as ID3 appear better suited to handling these feature properties. This finding is consistent with prior observations in application domains involving structured but non-continuous feature representations and suggests that classifier selection plays an important role in laboratory operation analysis tasks. The comparatively strong performance of ID3 in this study may be related to the characteristics of the extracted features, which include discrete thresholds (e.g., angle ranges, depth limits) derived from laboratory operating criteria. Tree-based models are well suited to handling such structured and non-continuous feature representations without requiring assumptions of feature linearity. However, given the limited sample size, this observation should be interpreted with caution, as decision trees are known to be susceptible to overfitting in small datasets. The classifier comparison in this study is intended to provide an empirical reference rather than to claim the general superiority of any specific model. Given the participant-grouped cross-validation setting and the small number of sequences per test fold, perfect fold-level performance may occur and should not be interpreted as evidence of robust generalization.
The ablation results suggest that static pose features and motion features capture complementary aspects of pipetting behavior. While static features encode instantaneous posture and tool configuration, motion features reflect execution dynamics over time. Their combination enables more robust modeling of procedural correctness, particularly for subtle operational errors that cannot be reliably identified using a single feature stream.
While the system performed well with the current dataset, the relatively small sample size and variability in operator behavior may limit the generalization capability of the model. Furthermore, the use of pose-based perception and recurrent temporal modeling has been explored in other application domains [31,32,33], this work focuses on adapting and validating such techniques for fine-grained monitoring of laboratory pipetting operations, where procedural correctness and temporal execution are critical. Future studies will focus on expanding the dataset to include more diverse operational conditions and laboratory environments to improve generalizability, and assessing the system’s generalizability across different experimental environments. Additionally, optimizing classifiers such as Random Forest and SVM with feature engineering could improve the system’s performance for more complex datasets.
Although the proposed framework is designed to operate as a non-contact system without modifying existing laboratory equipment, several practical deployment challenges remain. Variations in lighting conditions, partial occlusions of the hand or pipette, and the presence of multiple operators within the camera field of view may affect perception accuracy in real-world laboratory environments. While the current experiments were conducted under controlled conditions, future work will focus on improving robustness through data augmentation strategies, illumination-invariant feature learning, and multi-view or multi-camera sensing. In addition, extending the framework to handle multi-operator scenarios using multi-person pose tracking and identity association represents an important direction for deployment in shared or high-throughput laboratory spaces.
Extending the framework to multi-site or cross-institutional settings would further improve generalizability but also raises privacy and data governance concerns for video-based behavioral data. Privacy-preserving collaborative learning approaches, such as federated learning combined with differential privacy, offer a promising direction for enabling distributed model training without centralized sharing of raw video data [34]. In addition, secure data governance mechanisms, including blockchain-based access control and auditability frameworks, may support controlled access and traceability when operational videos and derived logs are shared across laboratories or users [35].
In addition to human operation monitoring, the proposed framework may also support future laboratory automation systems. By characterizing fine-grained motion patterns and operational constraints from real human operators, the extracted spatiotemporal features and error definitions could inform quality assessment of robotic pipetting systems and provide guidance for the design and evaluation of automated laboratory instruments.
6. Conclusions
This study demonstrates the effectiveness of integrating vision-based sensing and deep learning techniques for automated monitoring of pipetting behaviors in chemical laboratory settings. By combining YOLOv8 for pose estimation with BiLSTM for temporal modeling, the framework accurately classifies correct and incorrect pipetting operations. The results show that both motion and static features are crucial for optimal performance, and the ID3 classifier provided the best results. Despite the promising outcomes, future work should focus on expanding the dataset, optimizing classifiers, and enhancing system generalizability across diverse experimental conditions. This work provides a foundation for improving laboratory safety, training, and procedural adherence through AI-enabled monitoring systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1National Academies of Sciences, Engineering, and Medicine; Division on Earth and Life Studies; Board on Chemical Sciences and Technology; Committee on Chemical Management Toolkit Expansion: Standard Operating Procedures Chemical Laboratory Safety and Security: A Guide to Developing Standard Operating Procedures National Academies Press Washington, DC, USA 201627512747 · pubmed ↗
- 2Chandra T. Zebrowski J.P. Mc Clain R. Lenertz L.Y. Generating standard operating procedures for the manipulation of hazardous chemicals in academic laboratories ACS Chem. Health Saf.202028192410.1021/acs.chas.0c 00092 · doi ↗
- 3Paredes W.M. Laboratory Lapses: Investigating Common Issues and Violations in Chemistry Laboratory Courses Among Future Science Educators Int. J. Arts Sci. Educ.2025617519310.64358/ijase.v 6i 2.524 · doi ↗
- 4Abbas M. Zakaria A. Balkhyour M.M. Kashif M. Chemical safety in academic laboratories: An exploratory factor analysis of safe work practices & facilities in a university J. Saf. Stud.2016211410.5296/jss.v 2i 1.8962 · doi ↗
- 5National Research Council; Board on Chemical Sciences; Committee on Prudent Practices in the Laboratory and An Update Prudent Practices in the Laboratory: Handling and Management of Chemical Hazards, Updated Version National Academies Press Washington, DC, USA 201121796825 · pubmed ↗
- 6Armbruster D.A. Overcash D.R. Reyes J. Clinical chemistry laboratory automation in the 21st century-Amat Victoria curam (Victory loves careful preparation)Clin Biochem. Rev.20143514325336760 PMC 4204236 · pubmed ↗
- 7Sangoremi A.A. Harnessing Artificial Intelligence for Enhanced Safety in Chemistry Laboratories: A Critical Review World Sci. News 20252073649
- 8Jeon Y. Kulinan A.S. Kim T. Park M. Park S. Vision-based motion prediction for construction workers safety in real-time multi-camera system Adv. Eng. Inform.20246210289810.1016/j.aei.2024.102898 · doi ↗