YOLO-Night: Lighting the Path for Autonomous Vehicles with Robust Nighttime Perception
Jinxin Tian, Muhammad Arslan Ghaffar, Zhaokai Li

TL;DR
YOLO-Night is a new object detection framework that improves nighttime perception for autonomous vehicles by adapting the YOLO architecture to low-light conditions.
Contribution
YOLO-Night introduces architectural adaptations like feature conditioning and multi-scale fusion for robust nighttime object detection.
Findings
YOLO-Night outperformed lightweight YOLO baselines in precision and mAP on the NightCity dataset.
YOLO-Night achieved +14.3% precision, +12.4% recall, and +10.4% mAP@50 improvements over YOLO11n under nighttime conditions.
YOLO-Night maintains real-time inference with moderate computational overhead, making it suitable for real-world deployment.
Abstract
What are the main findings? A nighttime-oriented YOLO framework (YOLO-Night) is proposed, integrating feature conditioning, adaptive receptive fields, and staged multi-scale fusion to improve detection robustness under low-illumination conditions.YOLO-Night achieved substantially higher precision and mAP on the NightCity dataset than lightweight YOLO baselines and nighttime-oriented detectors while maintaining real-time inference with moderate computational overhead. A nighttime-oriented YOLO framework (YOLO-Night) is proposed, integrating feature conditioning, adaptive receptive fields, and staged multi-scale fusion to improve detection robustness under low-illumination conditions. YOLO-Night achieved substantially higher precision and mAP on the NightCity dataset than lightweight YOLO baselines and nighttime-oriented detectors while maintaining real-time inference with moderate…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
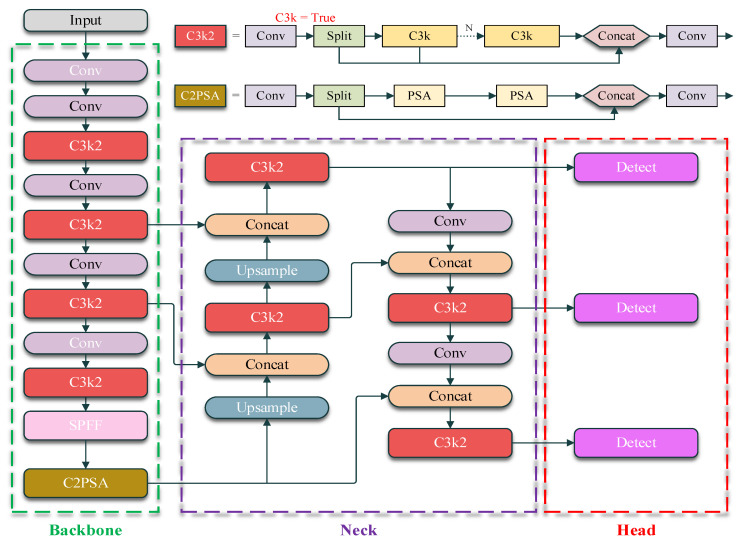 Figure 1
Figure 1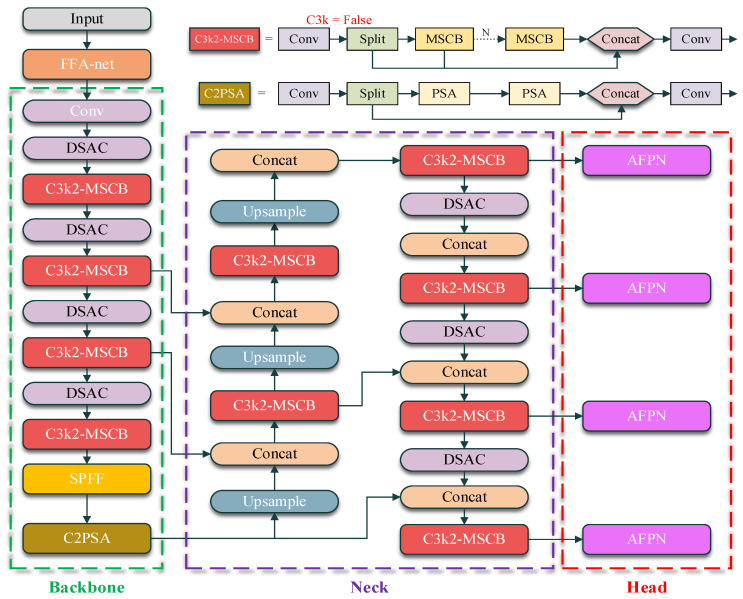 Figure 2
Figure 2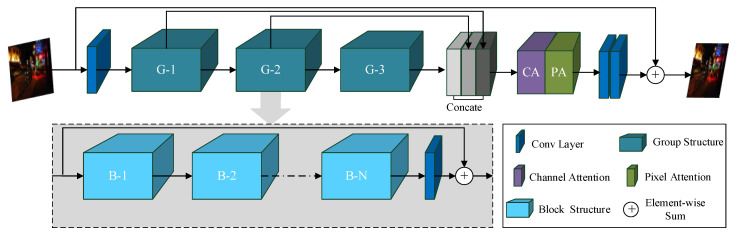 Figure 3
Figure 3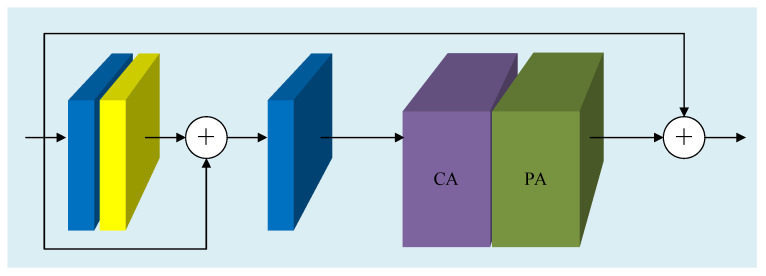 Figure 4
Figure 4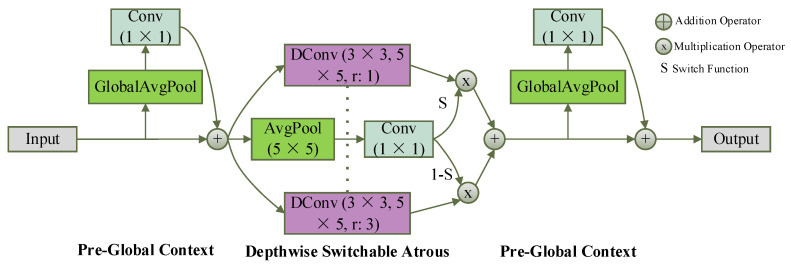 Figure 5
Figure 5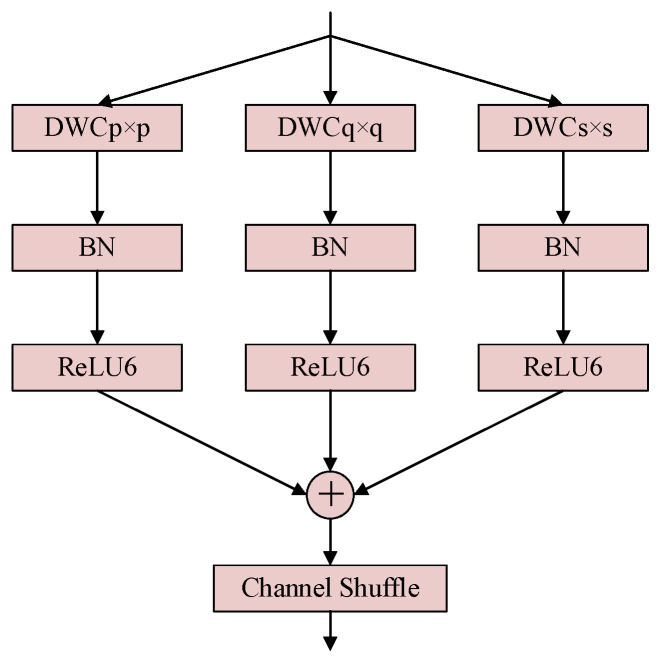 Figure 6
Figure 6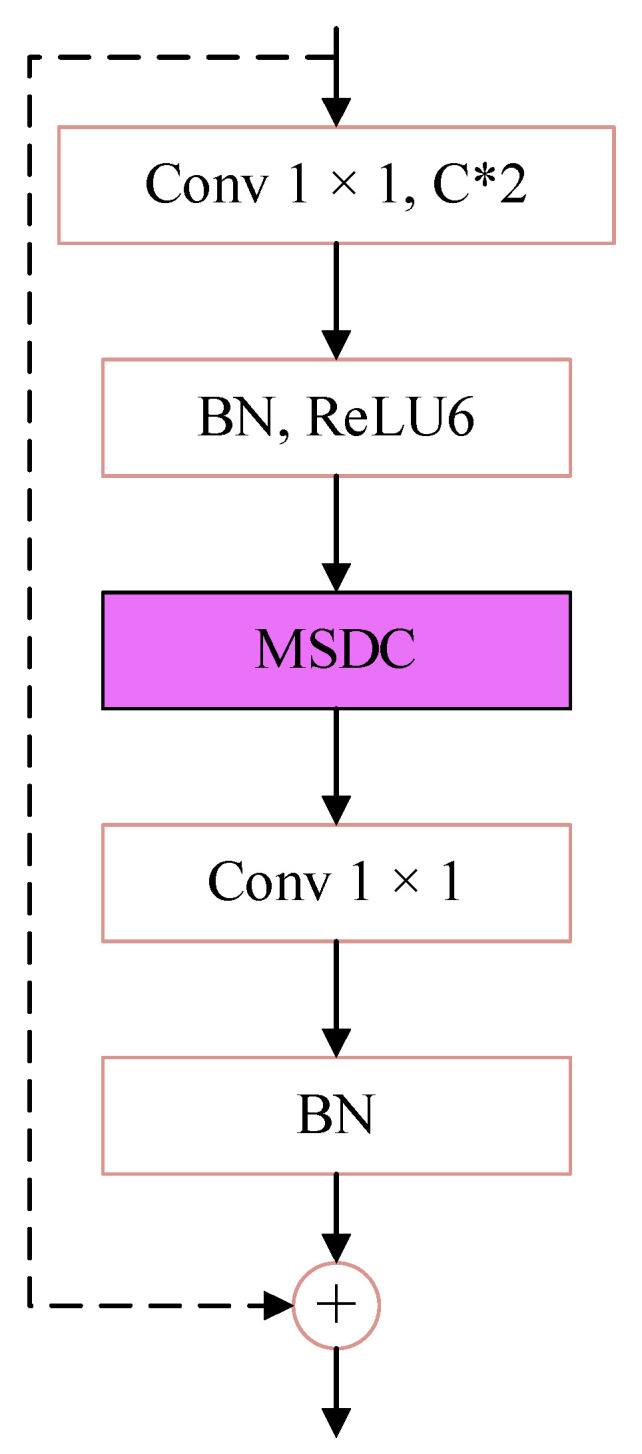 Figure 7
Figure 7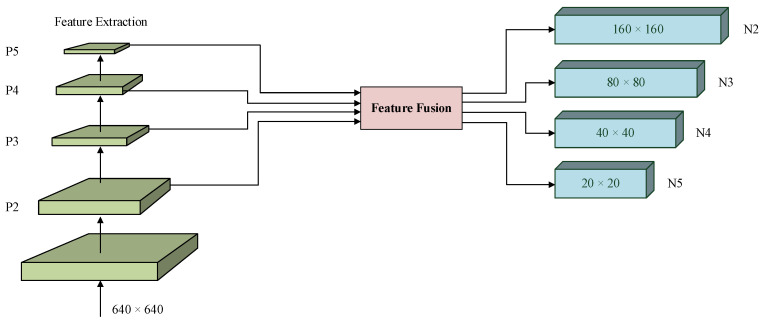 Figure 8
Figure 8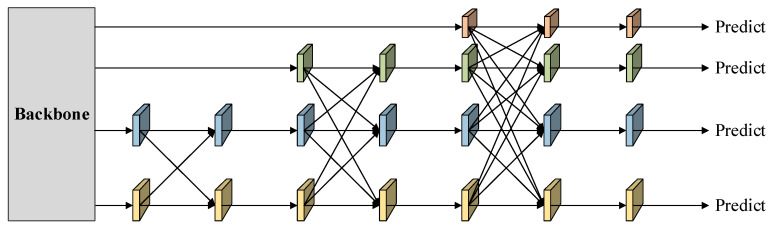 Figure 9
Figure 9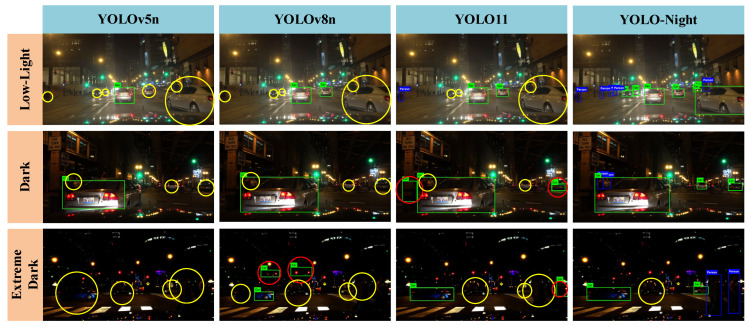 Figure 10
Figure 10- —Natural Science Foundation of Shaanxi Province of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Visual Attention and Saliency Detection · Image Enhancement Techniques
1. Introduction
Object detection is a core component of autonomous driving perception systems [1], enabling reliable scene understanding for tasks such as obstacle avoidance [2,3], trajectory planning [4], and decision-making [5]. While modern deep learning-based detectors have achieved remarkable performance under favorable illumination, their reliability degrades substantially in nighttime and low-light driving scenarios. In such conditions, reduced signal-to-noise ratios, blurred object boundaries, and diminished inter-class contrast fundamentally compromise visual feature representations, leading to missed detections and unstable predictions [6]. Nighttime perception presents challenges that differ qualitatively from those encountered in daytime environments [7]. First, extremely low illumination causes a collapse of discriminative visual cues, where conventional convolutional features fail to preserve object structure under severe noise and contrast degradation [8]. Second, dense nighttime traffic scenes exacerbate scale ambiguity and partial occlusion, particularly for small or distant objects whose features are easily suppressed during multi-scale aggregation. Third, autonomous driving systems impose strict real-time constraints, requiring detectors to maintain high inference speed while preserving robustness under adverse illumination—a balance that remains difficult for existing architectures optimized primarily for daytime imagery [9].
Recent YOLO-based detectors emphasize lightweight design and efficient feature pyramids; however, they typically rely on fixed receptive fields and generic feature fusion strategies that are insufficiently adaptive to nighttime-specific degradation. Image enhancement methods and multi-scale detection strategies have been explored independently, yet their integration into a unified real-time detection framework for nighttime driving remains underexplored. In particular, the interaction between contrast enhancement, receptive field adaptation, and cross-scale feature alignment has not been systematically addressed in existing YOLO-style pipelines.
To address these limitations, we propose YOLO-Night, a nighttime-oriented object detection framework built upon the YOLO11 architecture. The framework introduces a structured combination of feature enhancement [10], adaptive receptive field modeling [11], and staged multi-scale feature fusion [12] to improve robustness under low-light conditions. Specifically, feature-level contrast enhancement is employed to mitigate representation degradation in extremely dark scenes, adaptive atrous convolution is used to accommodate scale variation and blur, and an enhanced multi-scale fusion strategy with a low-level detection head is adopted to reduce semantic misalignment across feature hierarchies [13]. Extensive experiments on the NightCity dataset demonstrate that the proposed framework consistently outperforms the YOLO11n baseline in nighttime detection accuracy while preserving real-time inference capability.
2. Preliminary
2.1. Related Work
Early object detection methods relied on handcrafted features such as Histogram of Oriented Gradients (HOG) [14] and Scale-Invariant Feature Transform (SIFT) [15], which demonstrated reasonable performance under well-illuminated and high-quality imaging conditions. However, these methods are highly sensitive to illumination changes, noise, and contrast degradation, making them unsuitable for complex nighttime or low-light environments. With the advancement of deep learning, Convolutional Neural Network (CNN)-based detectors, including Faster R-CNN [16], SSD [17], and the YOLO series [18], have significantly improved detection accuracy and robustness through end-to-end training. Among them, YOLO-based detectors achieve a favorable balance between accuracy and inference speed, making them widely adopted in real-time applications such as autonomous driving.
To address low-light conditions, existing nighttime object detection approaches often integrate image enhancement techniques with detection models. Representative enhancement methods include RetinexNet [19], EnlightenGAN [20], and Zero-DCE [21], which aim to restore visibility and contrast before detection. However, such preprocessing-based pipelines frequently suffer from noise amplification and increased computational overhead, limiting their effectiveness and deployment on resource-constrained platforms.
Several studies have explored nighttime detection without explicit pixel-level enhancement. Han et al. proposed 3L-YOLO [22], which employs multi-scale feature aggregation and dynamic detection heads to improve nighttime detection performance; however, its ability to detect small objects remains limited. Jiang et al. proposed LOL-YOLO by integrating SCINet [23] to balance computational efficiency and detection accuracy under low-light conditions [24]. While this approach reduces model complexity, its reliance on global enhancement limits robustness in extremely dark scenes, where aggressive illumination amplification can distort local textures and lead to unstable feature representations. As a result, the detection performance degrades when object boundaries are severely blurred or contrast is highly uneven. Peng et al. introduced NLE-YOLO [25], which combines low-frequency filtering with feature enhancement modules to improve detection accuracy in nighttime environments. Although effective in enhancing global visibility, the low-frequency emphasis may suppress fine-grained details critical for small or distant object detection. In addition, the introduction of multiple enhancement and filtering modules significantly increases computational complexity, constraining real-time deployment on edge devices commonly used in autonomous driving systems. Overall, despite recent progress, nighttime object detection remains challenging. Existing methods either rely heavily on image enhancement, which can amplify noise and increase inference cost [26], or struggle to maintain stable performance when confronted with extremely low contrast, blurred targets, and small objects. These limitations highlight the need for lightweight detection frameworks that enhance robustness under adverse illumination while preserving real-time performance.
2.2. Baseline Architecture
The YOLO family of detectors has undergone continuous evolution with a primary focus on achieving real-time performance while maintaining competitive detection accuracy. The original YOLO framework [18] reformulated object detection as a single-stage regression problem, significantly improving inference speed. Subsequent versions, including YOLOv2 [27] and YOLOv3 [28], enhanced detection accuracy through the introduction of anchor boxes and multi-scale feature representations. YOLOv4 [29] and YOLOv5 [30] further improved performance by incorporating advanced data augmentation strategies and architectural components such as CSPNet and PANet. Recent versions, from YOLOv6 to YOLOv11, emphasize efficiency, scalability, and adaptability across different computational budgets by leveraging neural architecture search, reparameterizable convolutions, and optimized feature extraction blocks. These developments have driven YOLO-based detectors toward higher accuracy, reduced model size, and improved inference efficiency, making them well-suited for real-time perception tasks.
YOLO11 [31], released in October 2024, serves as the baseline architecture in this study, and its overall network structure is illustrated in Figure 1. Compared with YOLOv8, YOLO11 replaces the C2f module with C3k2 and introduces a Cross Stage Partial with Parallel Spatial Attention (C2PSA) module after the Spatial Pyramid Pooling Fast (SPPF) layer. The C2PSA module processes features through parallel partial spatial attention branches before fusion, enabling enhanced spatial feature representation. These architectural improvements allow YOLO11 to better preserve fine-grained information and enhance sensitivity to small or partially occluded objects, making it a suitable baseline for further adaptation to nighttime and low-light object detection tasks.
2.3. Key Limitations
Despite achieving competitive performance under normal illumination, YOLOv11n exhibits several critical limitations when deployed in low-light and nighttime environments, which hinder reliable perception in real-world scenarios. First, under extremely low illumination, the visual signal captured by RGB sensors suffers from severe noise contamination and contrast degradation, resulting in a substantial loss of discriminative information. When processed by convolutional backbones optimized for well-lit images, such degradation leads to unstable feature representations in deeper layers. In particular, noise patterns are often propagated through multi-scale feature fusion pathways, causing false activations that resemble object textures, confusion between dark object regions and background areas, and weakened edge cues that are essential for small-object detection, such as pedestrians and animals. Second, YOLOv11n treats RGB channels uniformly during feature extraction, despite the fact that different channels respond differently under low-light conditions. In nighttime imagery, useful structural information becomes unevenly distributed across channels, while noise components may dominate specific spectral responses. As a result, conventional convolutional operations amplify channel-wise noise indiscriminately, leading to degraded feature quality and reduced robustness in subsequent detection stages. Third, although YOLOv11n incorporates attention-based mechanisms to enhance spatial feature representation, these modules are primarily optimized for well-illuminated scenes. Under low-light conditions, attention responses tend to be influenced by high-frequency noise and illumination artifacts, particularly for distant or low-contrast objects and specular reflections, which can be mistakenly interpreted as distinct targets. This limits the effectiveness of attention in distinguishing semantically meaningful regions from background clutter at night. Finally, YOLOv11n performs frame-wise inference without exploiting temporal correlations inherent in video-based autonomous driving scenarios. In nighttime environments, sensor noise varies randomly across frames, whereas true objects exhibit temporal consistency. The absence of temporal modeling prevents the detector from leveraging motion coherence to suppress noise-induced false detections and stabilize predictions across consecutive frames.
These limitations collectively result in a substantial degradation of detection performance when YOLOv11n is evaluated on nighttime benchmarks such as NightCity and ExDark, underscoring the need for illumination-robust architectural adaptations rather than relying solely on data augmentation or daytime-oriented model designs.
3. YOLO-Night Algorithm
3.1. YOLO-Night Architecture
The proposed YOLO-Night architecture is designed as a unified detection framework that explicitly addresses feature degradation caused by low illumination, noise, and scale ambiguity in nighttime environments. The overall network structure is illustrated in Figure 2. Rather than treating nighttime challenges independently, YOLO-Night adopts a staged design that enhances feature robustness, adapts receptive fields, and improves cross-scale feature alignment within a single real-time detection pipeline. At the input stage, a feature enhancement module is integrated to alleviate severe contrast degradation and stabilize feature representations extracted from low-light inputs. This enhancement is embedded directly into the detection pipeline to suppress illumination-induced noise before deep feature extraction. To improve robustness against blur and scale variation commonly observed in nighttime driving scenarios, adaptive receptive field modeling is incorporated within the backbone and neck. In parallel, multi-scale feature extraction is strengthened to preserve fine-grained details and mitigate feature suppression caused by partial occlusion and background interference. Finally, a staged feature fusion strategy with an additional low-level detection branch is employed in the detection head to reduce semantic misalignment across feature scales. This design enhances the detection of small and low-contrast objects in complex nighttime scenes.
Through the coordinated integration of feature enhancement, adaptive receptive field modeling, multi-scale feature extraction, and staged feature fusion, YOLO-Night forms a coherent architecture tailored for robust object detection in dark and low-light environments while maintaining real-time inference capability.
3.2. FFA-Net
The Feature Fusion Attention Network (FFA-Net) was originally designed for image dehazing [10], but its core strengths, channel attention (CA) and pixel attention (PA), are uniquely suited to address nighttime-specific contrast collapse and noise contamination. Unlike daytime scenes, low-light environments suffer from unevenly distributed structural information across RGB channels (e.g., noise dominates blue channels, while red/green channels retain faint object edges) and suppressed local textures (e.g., pedestrian clothing or vehicle contours blending into dark backgrounds).
FFA-Net’s CA mechanism targets channel-wise imbalance by adaptively reweighting feature responses (Equations (4) and (5)), amplifying channels carrying residual structural cues (edge information in low-noise channels) while suppressing noise-dominated channels. This is critical for nighttime scenes, where generic channel-agnostic convolutions indiscriminately propagate noise. The PA module further refines spatial features (Equations (6) and (7)) by focusing on locally informative regions (dimly lit vehicle taillights or pedestrian silhouettes) that are easily lost in low-contrast nighttime imagery. Unlike dehazing, where FFA-Net restores global visibility, its application here is tailored to preserve discriminative object features amid illumination-induced noise, a challenge distinct from haze (which uniformly scatters light).
By embedding FFA-Net at the early stage of the detection pipeline, we stabilize low-level feature representations before deep extraction, directly mitigating the “discriminative cue collapse” that plagues nighttime detection. The network structure of FFA-Net is shown in Figure 3.
As illustrated in Figure 3, CA captures global channel-wise statistics via global average pooling, generating channel descriptors:
where represents the position of the c-th channel at , and represents the global pooling function.
The mathematical expression for generating channel attention weights is:
where represents the Sigmoid function and represents the ReLU function. By multiplying the input feature ( ) with the channel attention weights ( ), the channel-refined feature map ( ) is obtained:
here, represents the intermediate feature map after channel attention refinement, which serves as the input to the pixel attention (PA) module.
PA further refines spatial feature responses by focusing on locally informative regions through pixel-wise attention:
multiply by element by element:
The basic building block of FFA-Net, shown in Figure 4, integrates residual learning with feature attention, enabling stable feature refinement through stacked modules. In the proposed YOLO-Night framework, FFA-Net is applied at the early stage to enhance low-level feature representations before deep feature extraction, providing more reliable inputs for subsequent detection under low-light conditions. FFA-Net uses a simple L1 loss as the default loss function, and its formula is as follows:
In the formula, represents the parameters of FFA-Net, represents real images, and represents the input image.
FFA-Net, through its introduction of channel attention and pixel attention mechanisms, effectively enhances the expression ability of key regions and detail features in images, and improves the perceptibility of targets in dark and low contrast environments.
3.3. DSAC
Nighttime driving images often suffer from motion-induced blur and severe detail loss caused by long exposure times and low signal-to-noise ratios. These effects make it difficult for fixed receptive field convolutions to simultaneously capture fine-grained details and broader contextual information. To address this issue, YOLO-Night incorporates Depthwise Switchable Atrous Convolution (DSAC) [11] to enable adaptive receptive field adjustment under low-light conditions.
Atrous (dilated) convolution has been widely adopted in detection and segmentation tasks to expand the receptive field without increasing kernel size [32,33,34]. However, using a single dilation rate is insufficient for handling the wide range of object scales and blur levels present in nighttime scenes. As illustrated in Figure 5, DSAC integrates global context modeling with parallel depthwise convolutions using different dilation rates and dynamically fuses their outputs through a switch mechanism. Unlike general convolution, DSAC is trained to prioritize nighttime-specific challenges, it uses standard convolution for small, low-contrast targets (e.g., distant pedestrians) and dilated convolution for blurred objects (e.g., moving vehicles in dim light), outperforming fixed receptive fields that fail to balance these low-light-specific tradeoffs.
The operation of DSAC can be expressed as:
where represents the input feature map, is the pre-trained weight for standard convolution, is a trainable weight offset term, and is the set void ratio.
Here, is a learnable switch function implemented using global average pooling followed by a convolution and a Sigmoid activation, producing continuous gating values in . The parameters of are trained end-to-end together with the network, and are used to dynamically control the fusion ratio of standard convolution and dilated convolution.
By jointly modeling local details and broader contextual cues, DSAC enables the network to adapt its receptive field according to target scale and blur severity. In YOLO-Night, DSAC is embedded within both the backbone and neck to enhance feature robustness for blurred and multi-scale targets while maintaining efficient computation.
3.4. C3k2-MSCB
To improve feature robustness under scale imbalance and partial feature suppression in low-light environments, the C3k2 module in YOLO11 is extended with a Multi-Scale Convolution Block (MSCB) [12], forming the proposed C3k2-MSCB. This design aims to enhance multi-scale feature representation while maintaining lightweight computation.
While MSCB was initially used for medical imaging, its adaptation here targets nighttime-specific feature suppression, as small objects (e.g., bicycles) and low-contrast targets lose fine details in dark scenes, and MSCB’s parallel kernels and residual connections preserve these cues better than generic multi-scale modules optimized for well-lit data. Smaller kernels focus on local structures and fine details, while larger kernels provide broader contextual cues. By aggregating these responses, the network improves its ability to preserve object features that may be weakened by low contrast, blur, or partial occlusion in nighttime scenes. To facilitate effective information fusion across scales, channel shuffle and residual connections are employed, promoting feature diversity and stabilizing gradient propagation. The resulting C3k2-MSCB module enhances semantic consistency across feature maps and mitigates the loss of discriminative information during deep feature extraction.
In YOLO-Night, C3k2-MSCB is integrated into both the backbone and neck to strengthen multi-scale feature extraction under adverse illumination, contributing to improved detection performance for small and partially visible objects in dark environments. The structures of the MSDC and MSCB modules are shown in Figure 6 and Figure 7, respectively.
3.5. Improved Detection Head
Unlike daytime scenes, nighttime and low-light driving scenes are dominated by small, distant, and low-contrast objects whose visual cues are easily suppressed during deep feature extraction. In the original YOLOv11 architecture, object detection is performed on three feature scales (P3–P5), which limits the preservation of fine-grained spatial details necessary for reliable detection under adverse illumination.
To enhance small-object sensitivity, YOLO-Night introduces an additional P2 detection head, as illustrated in Figure 8.
This design enables detection on four feature scales corresponding to downsampling factors of 4×, 8×, 16×, and 32×, allowing the network to better retain spatial information critical for micro and small targets in dark environments. The configuration of the improved detection heads is summarized in Table 1.
To further improve cross-scale feature fusion, the Asymptotic Feature Pyramid Network (AFPN) [13] was employed in the detection head. AFPN performs staged feature fusion to progressively align semantic information across different feature levels, reducing the semantic gap commonly introduced by direct cross-layer fusion. In addition, an adaptive spatial feature fusion (ASFF) mechanism [35] was incorporated to dynamically balance spatial contributions from different scales, enabling the more precise localization of low-contrast targets. The overall AFPN structure is shown in Figure 9.
By combining a low-level detection branch with staged multi-scale feature fusion, the improved detection head enhances robustness to scale variation and contrast degradation in nighttime object detection.
4. Experimental Verification
4.1. Dataset
All experiments in this study were conducted on the NightCity dataset [36], a large-scale nighttime semantic segmentation dataset designed for autonomous driving scenarios. NightCity contains 2998 training images and 1299 validation images, each with a resolution of 1024 × 512, collected across multiple countries and diverse nighttime lighting conditions, including dimly lit urban environments, shaded regions, and low-visibility scenes.
To enable object detection evaluation, the NightCity dataset was converted into a bounding-box-based detection format compatible with the YOLO framework. Specifically, object instances were derived from semantic annotations and transformed into rectangular bounding boxes enclosing each labeled region. Following conversion, the dataset was divided into training, validation, and testing subsets using a 6:2:2 ratio. This split was applied consistently across all evaluated methods to ensure fair comparison.
Although random splitting was adopted in this study, we note that scene-level correlations may exist in nighttime datasets. The impact of dataset partitioning on performance is discussed as a limitation in the future work section.
4.2. Experimental Environment
The experimental setup used in this study used a workstation equipped with an Intel^®^ Core™ i7-12700K CPU (Intel, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3090 GPU (NVIDIA, Santa Clara, CA, USA) with 24 GB of video memory. The system was configured with 32 GB of RAM and operated under Windows 11. The implementation was based on Python 3.10, with CUDA and cuDNN libraries used to accelerate model training and inference. Detailed hardware and software configurations are summarized in Table 2. All comparative experiments were performed under identical settings to ensure reproducibility and fairness.
4.3. Evaluation Metrics
To evaluate detection performance, precision (P), recall (R), and mean average precision (mAP) were employed in this study. Model efficiency was assessed using the number of floating-point operations (FLOPs) and the total parameter count. Precision and recall measure the accuracy of positive predictions and the ability to detect ground-truth objects, respectively, and are defined as:
where (True Positive) represents the number of correctly identified samples, (False Positive) represents the number of incorrectly identified positive classes, and (False Negative) represents the number of samples that the model failed to recognize.
Average precision (AP) is computed for each object category based on the precision–recall curve, and the mean average precision (mAP) is obtained by averaging AP across all categories:
where represents the total number of object categories. mAP is reported at an intersection-over-union (IoU) threshold of 0.5 (mAP@50). FLOPs are computed based on an input resolution of 640 × 640 to reflect inference complexity, while parameter count indicates the model size.
4.4. Ablation Experiment
To evaluate the contribution of individual components in YOLO-Night, ablation experiments were conducted by incrementally introducing each module into the YOLO11n baseline. The results are summarized in Table 3, where P indicates that the corresponding modules in the baseline model have been modified.
Table 3 shows that introducing FFA-Net led to a moderate improvement in recall (+1.9%) and mAP@50 (+0.6%), indicating enhanced sensitivity to low-contrast targets in nighttime scenes. This improvement was accompanied by an increase in computational cost, reflecting the additional feature conditioning overhead introduced at the early stage. The inclusion of DSAC improved precision (+3.1%) and mAP@50 (+1.5%) while maintaining comparable computational complexity. This suggests that adaptive receptive field modeling enhances localization accuracy for blurred and multi-scale targets without incurring significant efficiency penalties.
When the C3k2-MSCB module was enabled, recall increased notably (+3.1%), demonstrating improved multi-scale feature preservation under low-light conditions. Importantly, this gain was achieved with only a marginal increase in FLOPs, indicating a favorable balance between performance and efficiency. The addition of the P2-AFPN detection head further improved the precision and mAP@50 by strengthening small-object detection and cross-scale feature alignment. Although this introduced additional computation, the increase remained moderate relative to the overall performance gain.
Finally, combining all proposed modules yielded the best overall performance, achieving improvements of +14.3% in precision, +7.6% in recall, and +5.7% in mAP@50 compared to the baseline. These results demonstrate that the proposed components are complementary rather than redundant, and their joint integration leads to a balanced improvement in detection accuracy and robustness under nighttime conditions.
4.5. Comparative Experiments
To evaluate the effectiveness of the proposed YOLO-Night framework, comparative experiments were conducted against different real-time object detection models on the NightCity dataset. The comparison focused on detection accuracy, robustness under nighttime conditions, and computational efficiency. All baseline models were initialized using their officially released pretrained weights and subsequently fine-tuned on the NightCity dataset using a unified training protocol. Specifically, all methods were trained with the same optimizer, learning rate schedule, batch size, number of epochs, and data augmentation strategy. This ensures that performance differences among the compared methods arise from architectural design choices rather than differences in training strategies or dataset adaptation. The quantitative results of comparison are summarized in Table 4.
As shown in Table 4, early lightweight YOLO variants such as YOLOv3-tiny, YOLOv5n, YOLOv8n, and YOLOv10n, exhibit limited robustness under nighttime conditions, particularly in recall and mAP, indicating their sensitivity to low-contrast and low-illumination environments. Nighttime-specific methods such as Dark-YOLO, LOL-YOLO, and 3L-YOLO improve detection accuracy by incorporating enhancement or multi-scale strategies; however, these gains are often accompanied by increased computational cost or unstable performance under extreme darkness.
More complex models, including RT-DETR, NLE-YOLO, and DimNet, achieve higher mAP values by leveraging transformer-based architectures and frequency-domain feature enhancement. While these approaches demonstrate strong detection capability, they incur substantial computational overhead, with FLOPs exceeding 100 × 10^9^ in some cases, limiting their suitability for real-time deployment in autonomous driving systems.
In contrast, YOLO-Night achieved the highest precision among all compared methods, reaching 86.6% while maintaining competitive recall and mAP performance with significantly lower computational complexity. Although its mAP@50 was slightly lower than that of the most computationally intensive models, YOLO-Night required only 8.5 × 10^9^ FLOPs and 3.8 M parameters, enabling real-time inference without sacrificing detection reliability. This balance between high precision, robust recall, and moderate computational cost demonstrates that YOLO-Night effectively addresses the trade-off between accuracy and efficiency, making it well-suited for practical nighttime autonomous driving applications.
To further analyze the generalization capability of YOLO-Night across different object categories, we conducted a category-wise performance comparison against representative YOLO models. Detection results for 6 object categories in the NightCity dataset are reported in Table 5 using mAP@50 as the evaluation metric.
As shown in Table 5, YOLO-Night achieved the highest detection accuracy in all 6 categories. Significant improvements were observed for small and low-contrast objects such as car, bicycle, and motorbike, where YOLO-Night outperformed the YOLO11n baseline by 10.3%, 2.4%, and 10.2%, respectively. These results indicate that the proposed framework enhances robustness not only at the aggregate level but also across diverse object categories commonly encountered in nighttime driving scenarios.
4.6. Visual Analysis
To qualitatively evaluate detection performance under nighttime conditions, YOLO-Night was tested on the NightCity test set as well as additional real-world nighttime images. Representative detection results were selected for visualization to provide an intuitive comparison between the baseline YOLO11n and the proposed YOLO-Night framework. Figure 10 presents qualitative comparisons among YOLOv5n, YOLOv8n, YOLO11n, and YOLO-Night, where missed detections are highlighted with yellow circles and false detections are marked with red circles.
As shown in Figure 10, the baseline YOLO11n model was able to detect large and nearby objects under mildly low-light conditions; however, its performance degraded noticeably in darker scenes, particularly in the presence of strong reflections, low contrast, or extremely dark backgrounds.
From the visual comparisons in Figure 10, several observations can be made:
- Low-light scenarios with reduced contrast.
YOLO-Night demonstrated more reliable detection results, with fewer missed and false detections compared to baseline models. In these scenes, YOLO-Night preserved object boundaries more effectively and improved the detection of small-scale targets that are often overlooked by other models.
2.Dark environments with blurred targets.
YOLO-Night showed improved robustness to motion blur and illumination degradation, enabling more accurate detection of both blurred and small objects. In contrast, YOLOv5n, YOLOv8n, and YOLO11n frequently missed small targets or generated spurious detections under similar conditions.
3.Extremely dark scenarios.
In extreme low-illumination environments, baseline YOLO models failed to detect most objects, and YOLOv8n occasionally produced false detections, such as misclassifying light sources as vehicle rear lights. YOLO-Night substantially reduced such errors, with remaining missed detections primarily occurring when object appearance closely blended with the background.
The visual results in Figure 10 corroborate the quantitative findings reported in Section 4.5. YOLO-Night consistently improved detection robustness across low-light, dark, and extremely dark scenarios, particularly for small, blurred, and low-contrast targets. These qualitative results further demonstrate the practicality and generalization capability of the proposed framework for nighttime object detection in autonomous driving applications.
5. Conclusions
This work addresses the challenge of degraded perception performance in autonomous vehicles operating under nighttime and low-illumination conditions. We proposed YOLO-Night, a detection framework that enhances robustness to low contrast, blur, and small objects through integrated architectural adaptations while maintaining real-time efficiency. Experimental results on the NightCity dataset demonstrated that YOLO-Night achieved a 14.3% improvement in precision and a 10.4% increase in mAP@50 over the YOLO11n baseline, reaching 86.6% precision and 72.7% mAP@50. Compared with widely used lightweight detectors such as YOLOv5n, YOLOv8n, and YOLOv10n, YOLO-Night consistently delivered superior detection performance under nighttime conditions with a moderate and controllable increase in computational cost. Qualitative visual analyses further corroborate these findings, showing improved robustness in detecting low-contrast regions, blurred objects, and small targets across diverse nighttime scenarios. Despite these improvements, detection performance remains challenging in extremely dark environments where object appearance closely blends with the background. In such cases, YOLO-Night exhibited a residual miss-detection rate of approximately 2%, indicating that extreme illumination degradation remains an open problem.
Future work will focus on further optimizing network efficiency, enhancing robustness under extreme low-light conditions, and exploring adaptive or multimodal perception strategies to improve reliability without compromising real-time performance. Extending the proposed framework to broader autonomous perception tasks may also contribute to advancing practical applications in Advanced Driver Assistance Systems (ADAS) and other safety-critical domains.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chen Z. Zhang Z. Su Q. Yang K. Wu Y. He L. Tang X. Object detection for autonomous vehicles under adverse weather conditions Expert Syst. Appl.202529612899410.1016/j.eswa.2025.128994 · doi ↗
- 2Li X. Yu S. Obstacle avoidance path planning for AU Vs in a three-dimensional unknown environment based on the C-APF-TD 3 algorithm Ocean. Eng.202531511988610.1016/j.oceaneng.2024.119886 · doi ↗
- 3Hu Y. Zhang Y. Song Y. Deng Y. Yu F. Zhang L. Lin W. Zou D. Yu W. Seeing through pixel motion: Learning obstacle avoidance from optical flow with one camera IEEE Robot. Autom. Lett.2025105871587810.1109/LRA.2025.3560842 · doi ↗
- 4Rahman M.H. Gulzar M.M. Haque T.S. Habib S. Shakoor A. Murtaza A.F. Trajectory planning and tracking control in autonomous driving system: Leveraging machine learning and advanced control algorithms Eng. Sci. Technol. Int. J.20256410195010.1016/j.jestch.2025.101950 · doi ↗
- 5Zhang Z. Li H. Chen T. Sze N.N. Yang W. Zhang Y. Ren G. Decision-making of autonomous vehicles in interactions with jaywalkers: A risk-aware deep reinforcement learning approach Accid. Anal. Prev.202521010784310.1016/j.aap.2024.10784339566327 · doi ↗ · pubmed ↗
- 6Abdulrashid I. Chiang W.C. Sheu J.B. Mammadov S. An interpretable machine learning framework for enhancing road transportation safety Transp. Res. Part E Logist. Transp. Rev.202519510396910.1016/j.tre.2025.103969 · doi ↗
- 7Liu D. Zhao X. Fan W. A small object detection algorithm for mine environment Eng. Appl. Artif. Intell.202515311093610.1016/j.engappai.2025.110936 · doi ↗
- 8Zhao L. Ren X. Fu L. Yun Q. Yang J. UWS-YOLO: Advancing underwater sonar object detection via transfer learning and orthogonal-snake convolution mechanisms J. Mar. Sci. Eng.202513184710.3390/jmse 13101847 · doi ↗