FreqPose: Frequency-Aware Diffusion with Fractional Gabor Filters and Global Pose–Semantic Alignment
Meng Wang, Bing Wang, Huiling Chen, Jing Ren, Xueping Tang

TL;DR
This paper introduces FreqPose, a new method for generating realistic person images from poses by preserving texture details and maintaining identity consistency.
Contribution
The novel framework combines frequency-aware diffusion with global semantic-pose alignment for improved image generation.
Findings
FreqPose outperforms existing methods in SSIM and FID metrics on DeepFashion and Market1501 datasets.
The method preserves high-frequency textures like hair and fabric under complex pose changes.
Global semantic alignment ensures consistent appearance and identity during pose variations.
Abstract
The task of pose-guided person image generation has long been confronted with two major challenges: high-frequency texture details tend to blur and be lost during appearance transfer, while the semantic identity of the person is difficult to maintain consistently during pose changes. To address these issues, this paper proposes a diffusion-based generative framework that integrates frequency awareness and global semantic alignment. The framework consists of two core modules: a multi-level fractional-order Gabor frequency-aware network, which accurately extracts and reconstructs high-frequency texture features such as hair strands and fabric wrinkles, enhances image detail fidelity through fractional-order filtering and complex domain modeling; and a global semantic-pose alignment module that utilizes a cross-modal attention mechanism to establish a global mapping between pose features…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
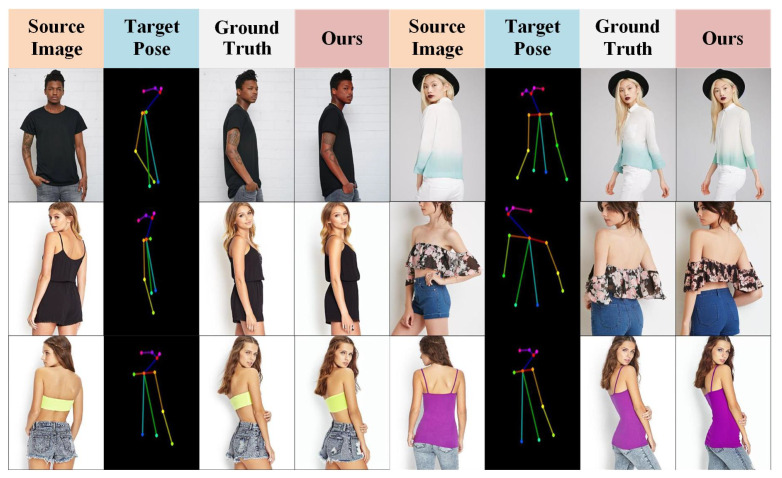 Figure 1
Figure 1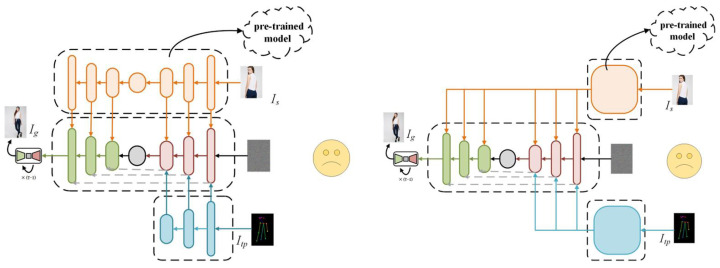 Figure 2
Figure 2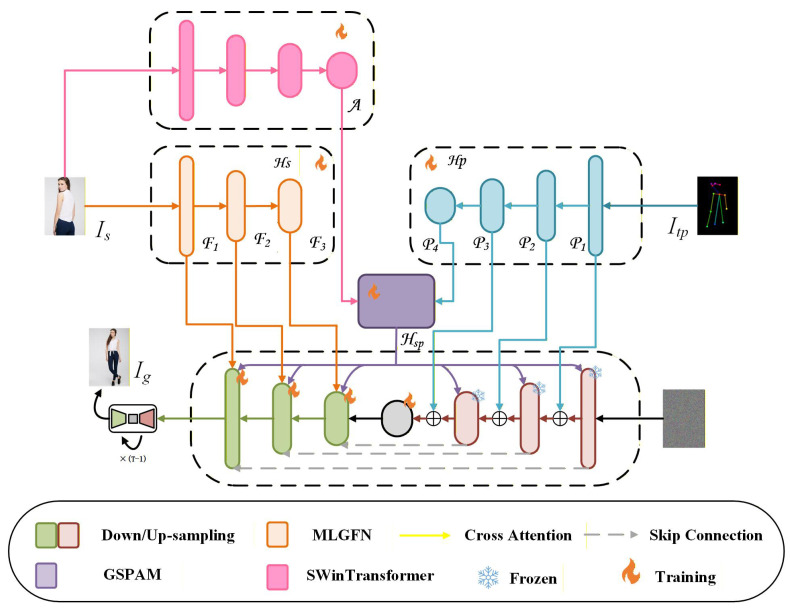 Figure 3
Figure 3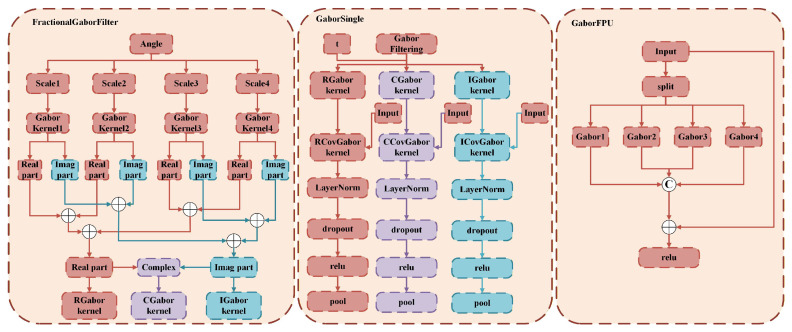 Figure 4
Figure 4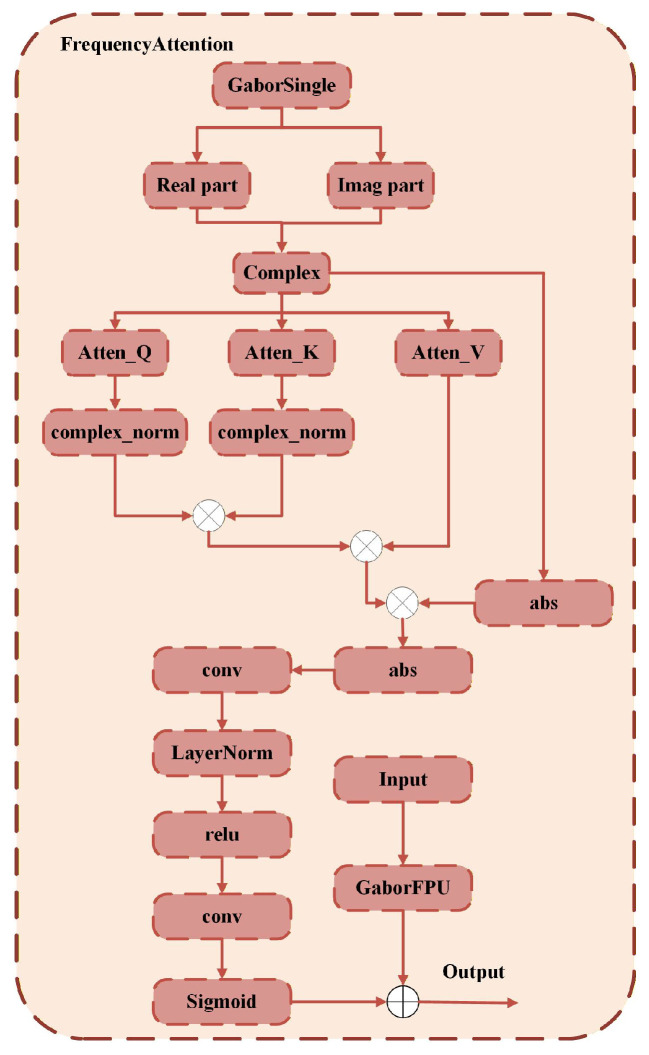 Figure 5
Figure 5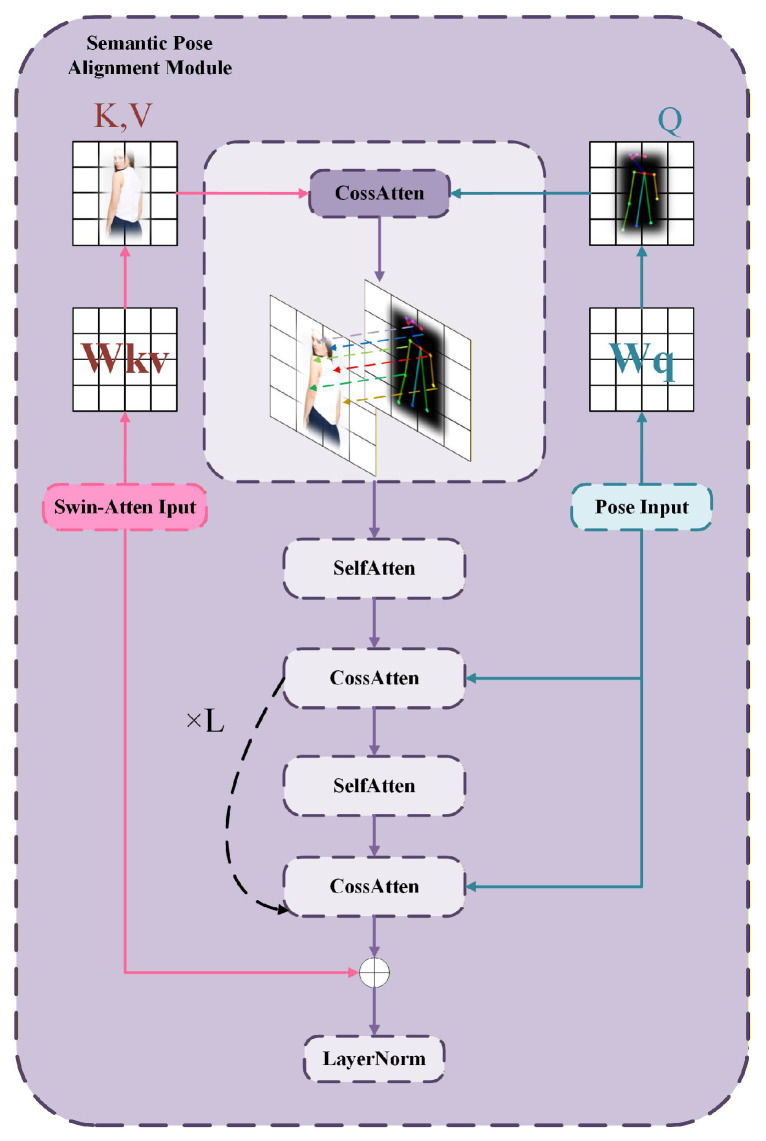 Figure 6
Figure 6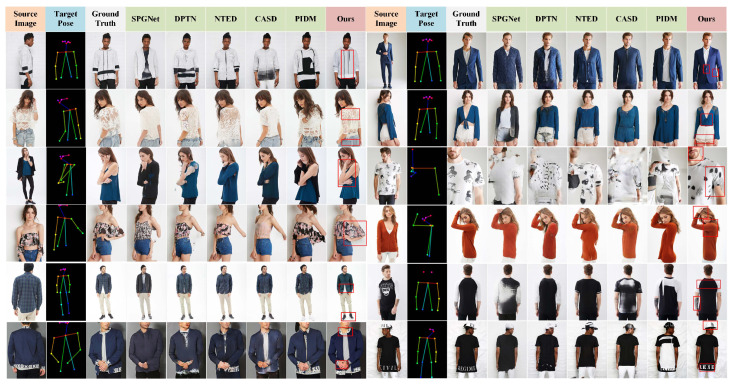 Figure 7
Figure 7 Figure 8
Figure 8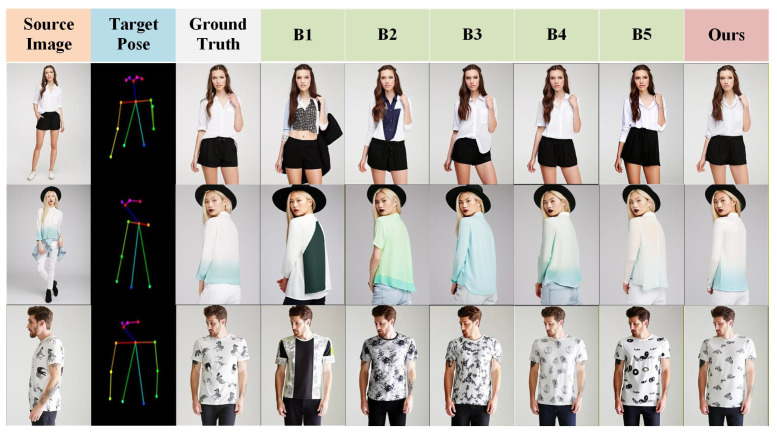 Figure 9
Figure 9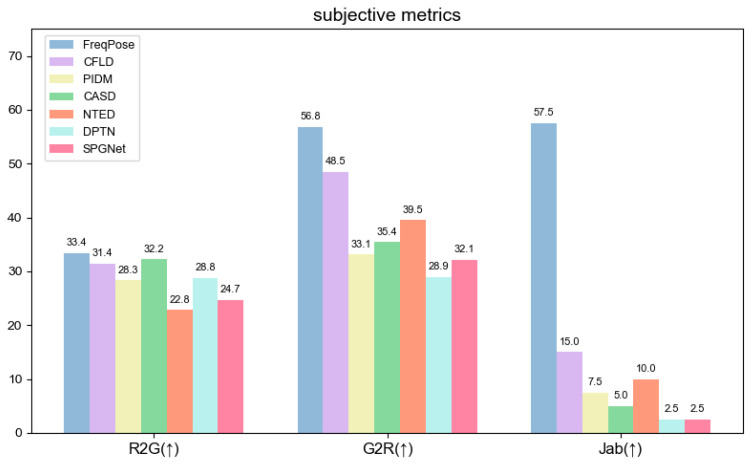 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenerative Adversarial Networks and Image Synthesis · Face recognition and analysis · 3D Shape Modeling and Analysis