Enhancing Bone Conduction Sensor Signals via Self-Supervised Acoustic Priors and Key-Value Memory
Changyan Zheng, Hao He, Xiaohu Fan, Lin Li, Yang Zhao, Ye Yan, Erwei Yin

TL;DR
This paper introduces a method to enhance bone conduction sensor signals using self-supervised learning and memory modules to recover lost high-frequency speech components.
Contribution
A novel time-domain framework combining SSL priors and a Key-Value Memory module to improve BC signal quality without reference signals.
Findings
The proposed method achieves significant PESQ gains of over 51% and 73% on the ABCS and ESMB datasets.
The Key-Value Memory module effectively bridges the sensor domain gap by retrieving high-fidelity acoustic priors.
The compact architecture is optimized for real-world deployment while maintaining high performance.
Abstract
Bone conduction (BC) sensors naturally resist ambient noise, but the captured speech suffers from severe high-frequency attenuation due to the low-pass filtering characteristics of body tissue. To compensate for this hardware-induced information deficiency, we propose a time-domain framework leveraging highly generalized representations from Self-Supervised Learning (SSL). Specifically, we employ a large-scale pre-trained SSL model to generate embeddings that function as robust acoustic priors. Subsequently, a Key-Value Memory module is integrated to bridge the sensor domain gap, enabling the retrieval of high-fidelity priors from BC queries in the absence of reference air conduction signals. These retrieved cues are then processed by a Gated Attention Projection and dynamically fused into the primary network’s bottleneck, effectively recovering the high-frequency harmonics attenuated…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
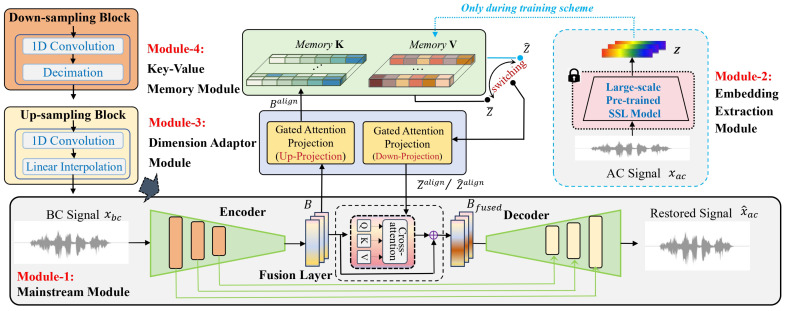 Figure 1
Figure 1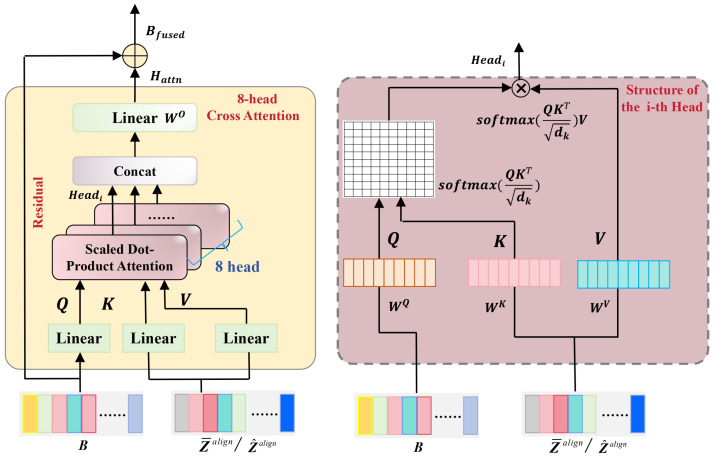 Figure 2
Figure 2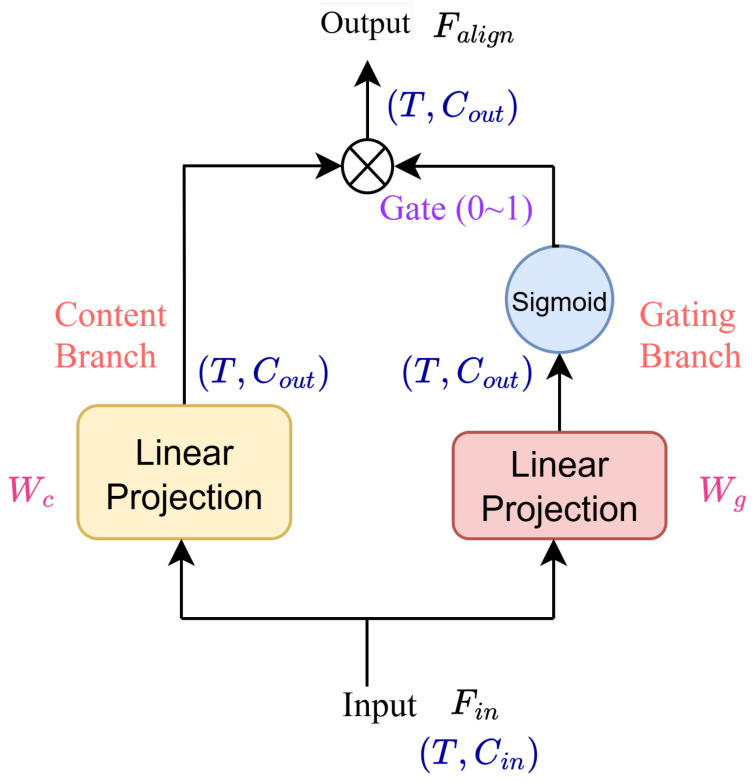 Figure 3
Figure 3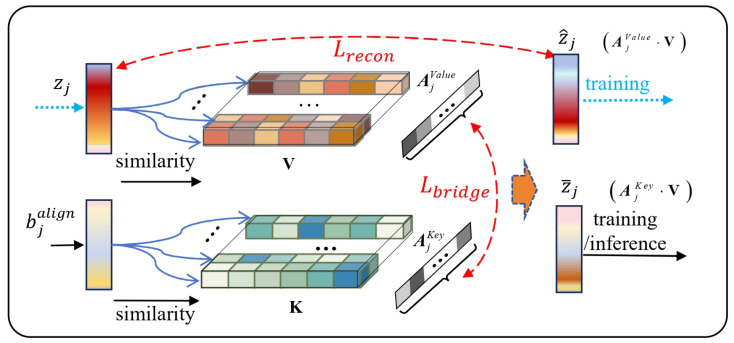 Figure 4
Figure 4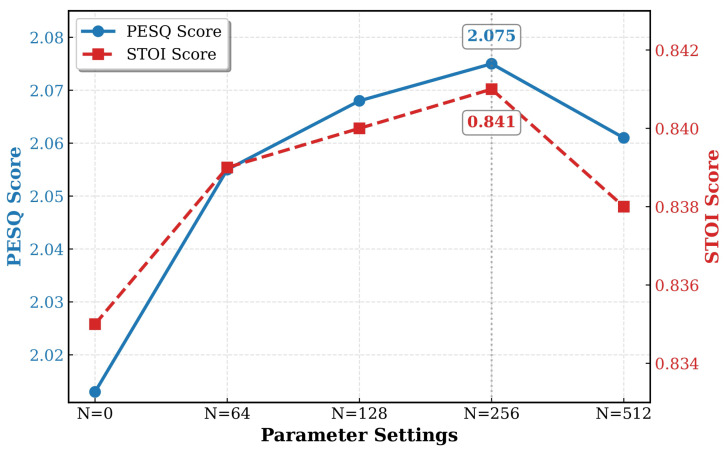 Figure 5
Figure 5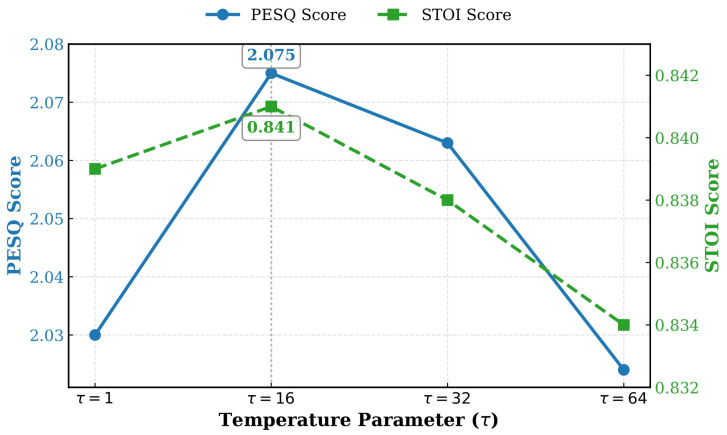 Figure 6
Figure 6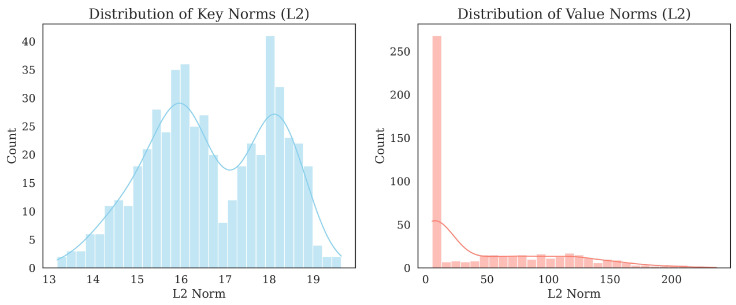 Figure 7
Figure 7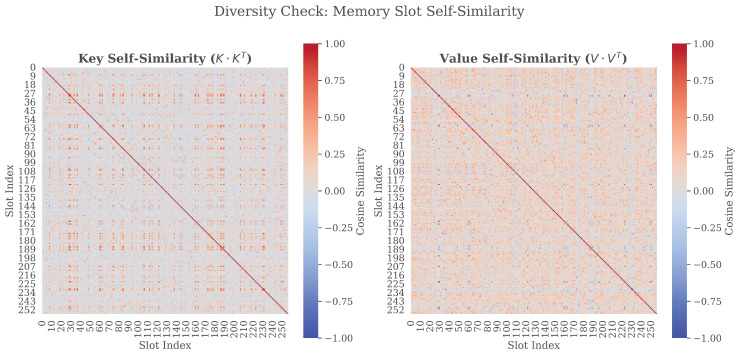 Figure 8
Figure 8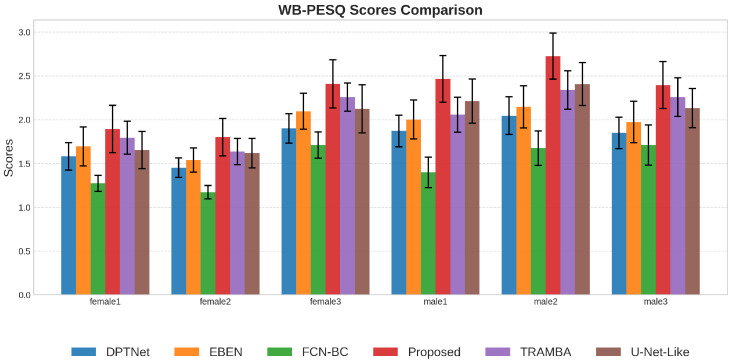 Figure 9
Figure 9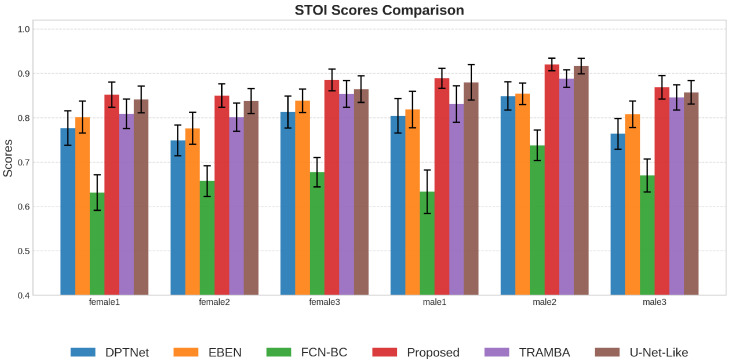 Figure 10
Figure 10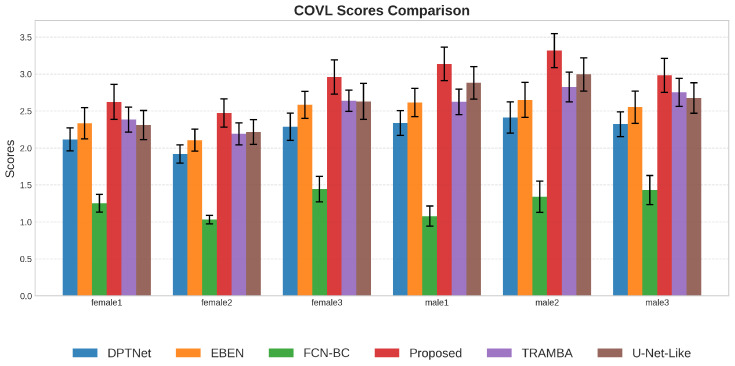 Figure 11
Figure 11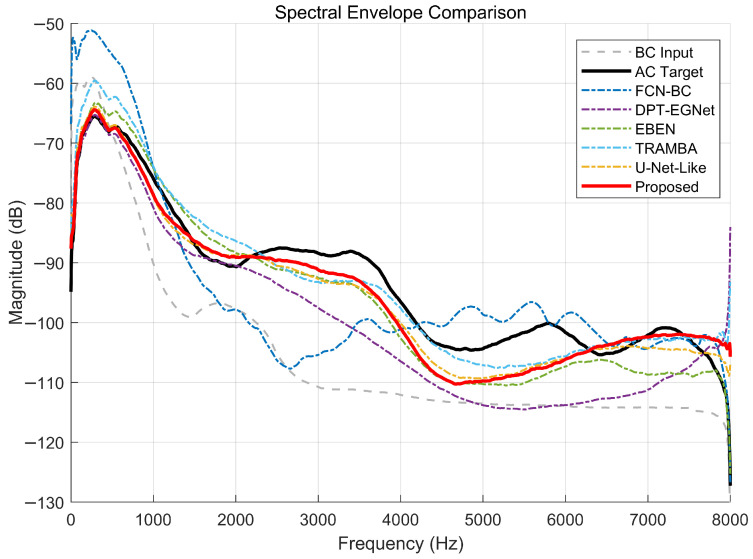 Figure 12
Figure 12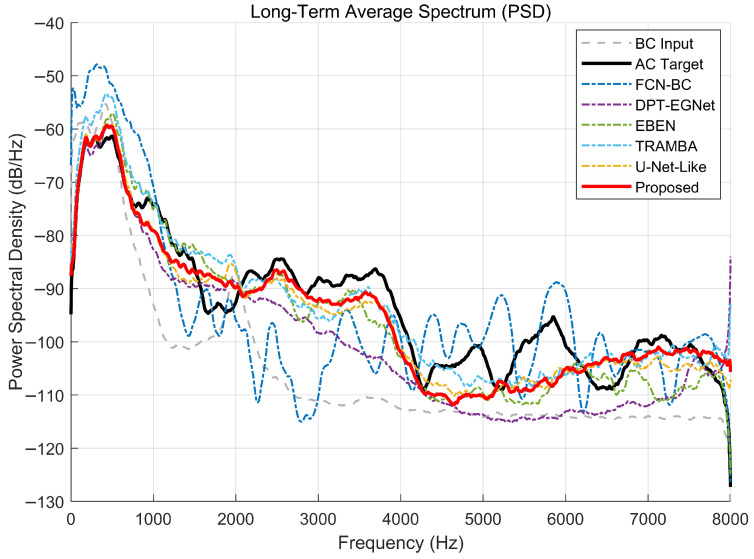 Figure 13
Figure 13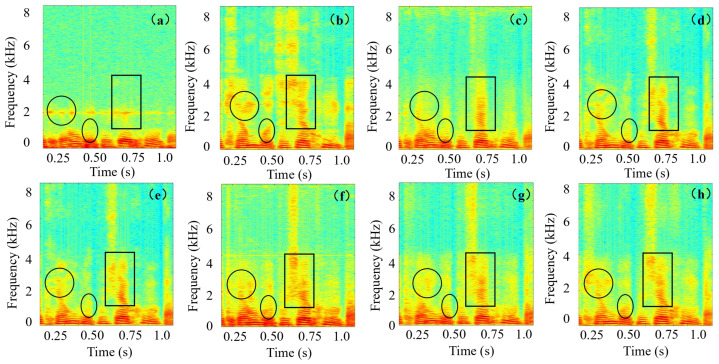 Figure 14
Figure 14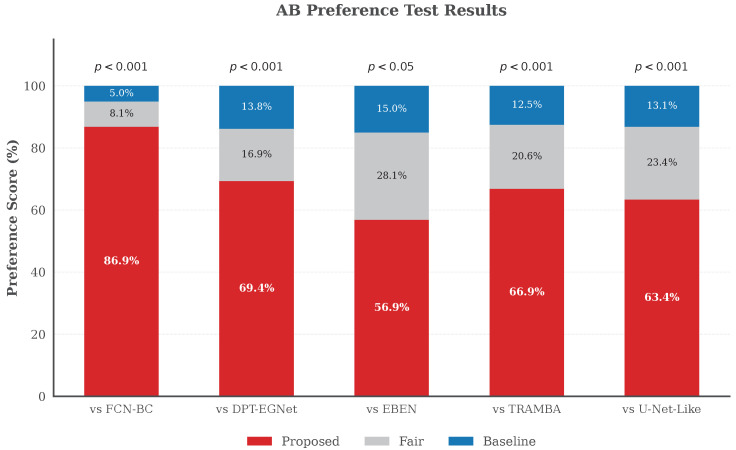 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPhonocardiography and Auscultation Techniques · Speech Recognition and Synthesis · Gait Recognition and Analysis