JMSC: Joint Spatial–Temporal Modeling with Semantic Completion for Audio–Visual Learning
Xinfu Xu, Fan Yang, Zhibin Yu

TL;DR
This paper introduces JMSC, a new framework for audio-visual learning that improves understanding of dynamic scenes by combining spatial and temporal information with semantic completion.
Contribution
The novel JMSC framework uses cross-modal latent reconstruction and joint modeling of spatial and temporal features under audio guidance.
Findings
JMSC achieves state-of-the-art performance on multiple audio-visual tasks.
The method maintains high computational efficiency while improving semantic understanding.
Cross-modal reconstruction enhances the model's ability to capture complementary audio-visual semantics.
Abstract
Audio–visual learning seeks to achieve holistic scene understanding by integrating auditory and visual cues. Early research focused on fully fine-tuning pre-trained models, incurring high computational costs. Consequently, recent studies have adopted parameter-efficient tuning methods to adapt large-scale vision models to the audio–visual domain. Despite the competitive performance of existing methods, several challenges persist. Firstly, effectively leveraging the complementary semantics between the audio and visual modalities remains difficult, as these two modalities capture fundamentally different aspects of a video. Secondly, comprehending dynamic video context is challenging because both spatial attributes (such as scale) and temporal characteristics (such as motion) of objects co-evolve over time, making semantic comprehension more complex. To address these challenges, we propose…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
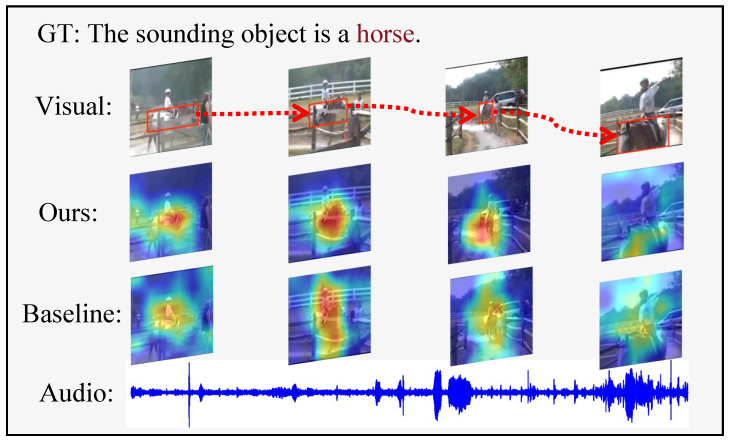 Figure 1
Figure 1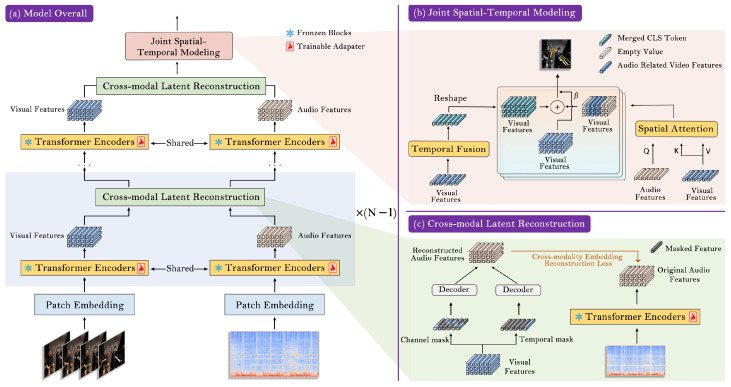 Figure 2
Figure 2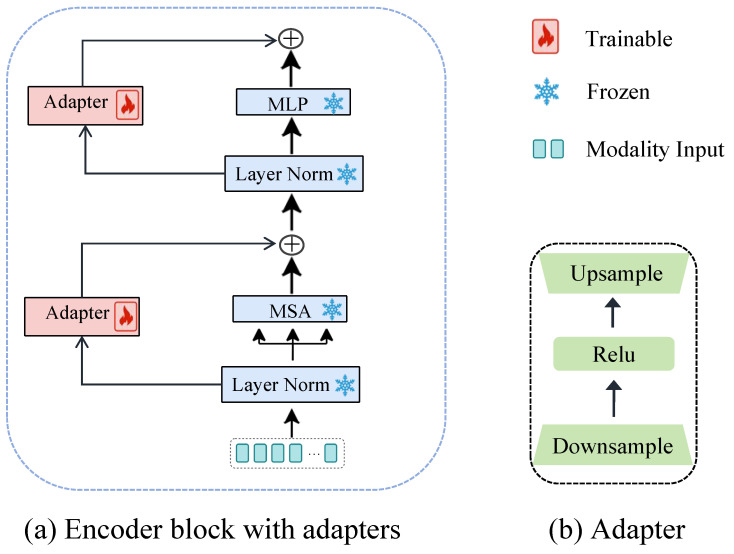 Figure 3
Figure 3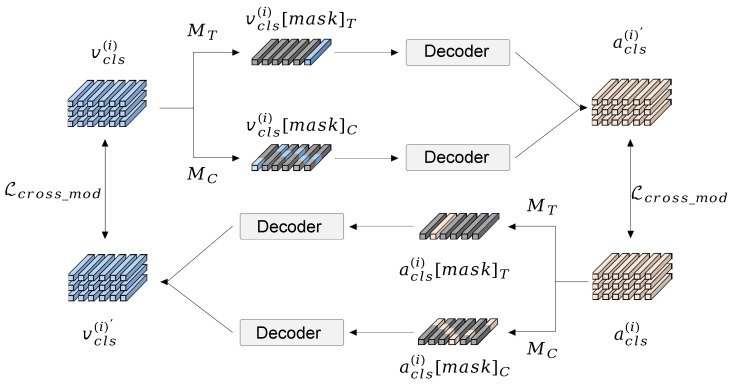 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Music and Audio Processing · Multimodal Machine Learning Applications