Coarse-to-Fine Contrast Maximization for Energy-Efficient Motion Estimation in Edge-Deployed Event-Based SLAM
Kyeongpil Min, Jongin Choi, Woojoo Lee

TL;DR
This paper introduces a more energy-efficient method for motion estimation in event-based SLAM by progressively refining image resolution and reducing redundant computations.
Contribution
The novel coarse-to-fine contrast maximization (CCMAX) method reduces computational costs while maintaining accuracy in event-based SLAM.
Findings
CCMAX reduces floating-point operations by up to 42% compared to full-resolution baselines.
Energy consumption is lowered by up to 87% on a custom RISC-V–based edge SoC.
Abstract
Event-based vision sensors offer microsecond temporal resolution and low power consumption, making them attractive for edge robotics and simultaneous localization and mapping (SLAM). Contrast maximization (CMAX) is a widely used direct geometric framework for rotational ego-motion estimation that aligns events by warping them and maximizing the spatial contrast of the resulting image of warped events (IWE). However, conventional CMAX is computationally inefficient because it repeatedly processes the full event set and a full-resolution IWE at every optimization iteration, including late-stage refinement, incurring both event-domain and image-domain costs. We propose coarse-to-fine contrast maximization (CCMAX), a computation-aware CMAX variant that aligns computational fidelity with the optimizer’s coarse-to-fine convergence behavior. CCMAX progressively increases IWE resolution across…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2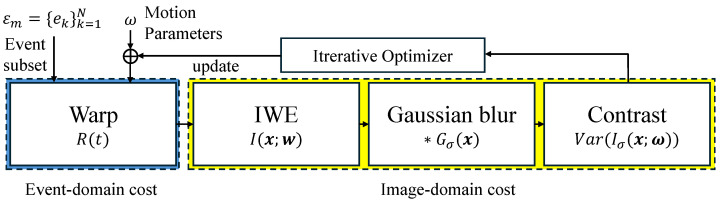 Figure 3
Figure 3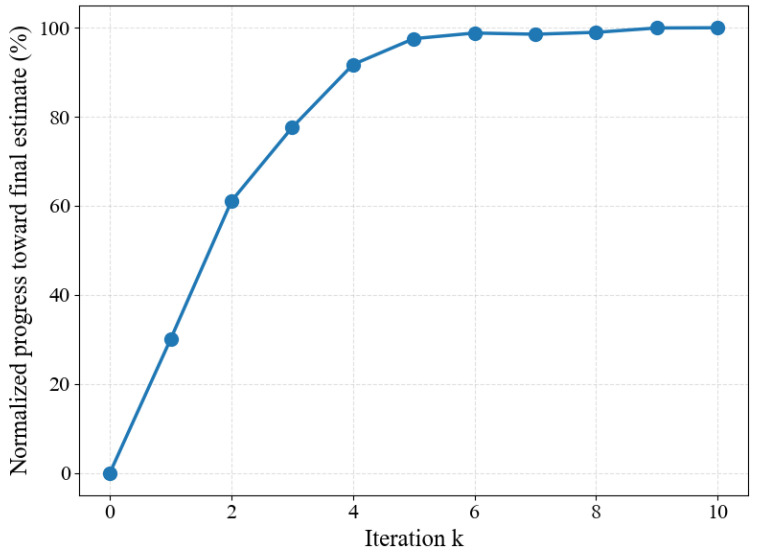 Figure 4
Figure 4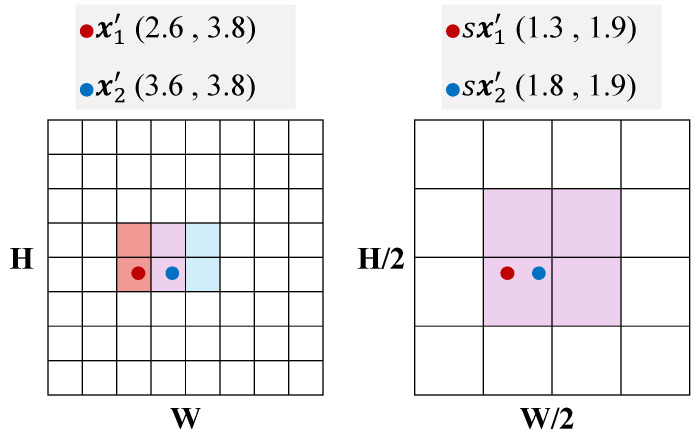 Figure 5
Figure 5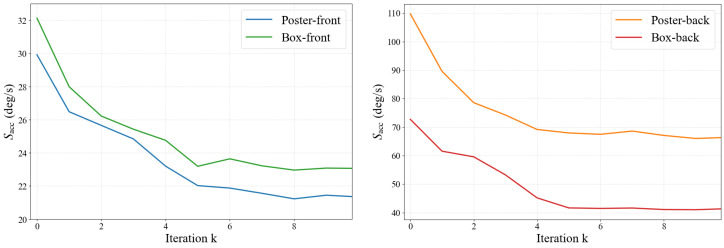 Figure 6
Figure 6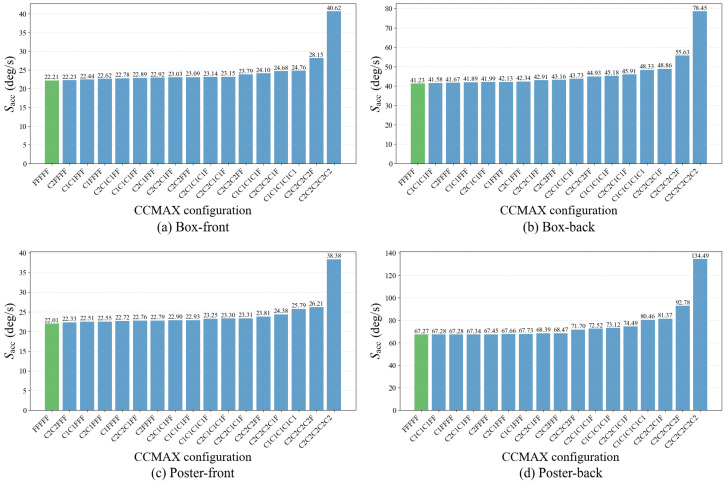 Figure 7
Figure 7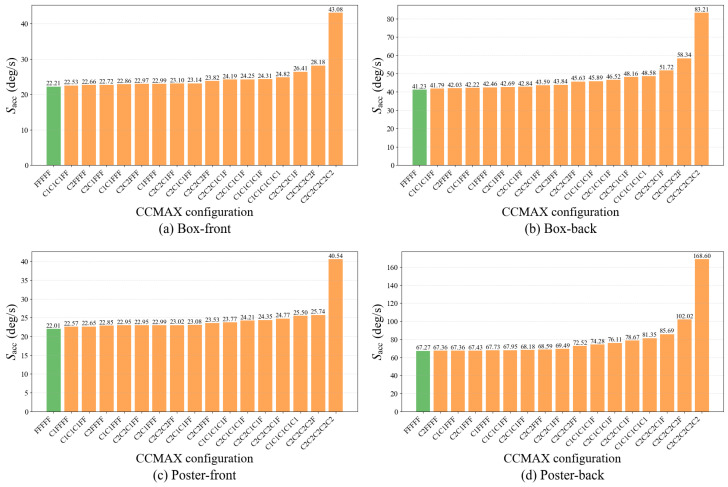 Figure 8
Figure 8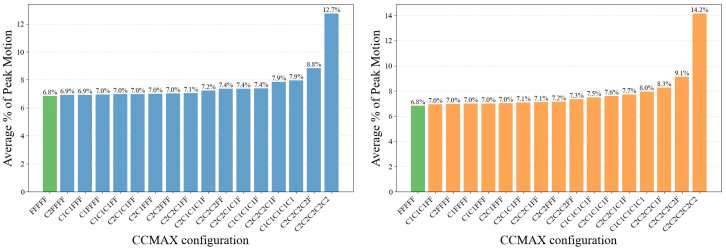 Figure 9
Figure 9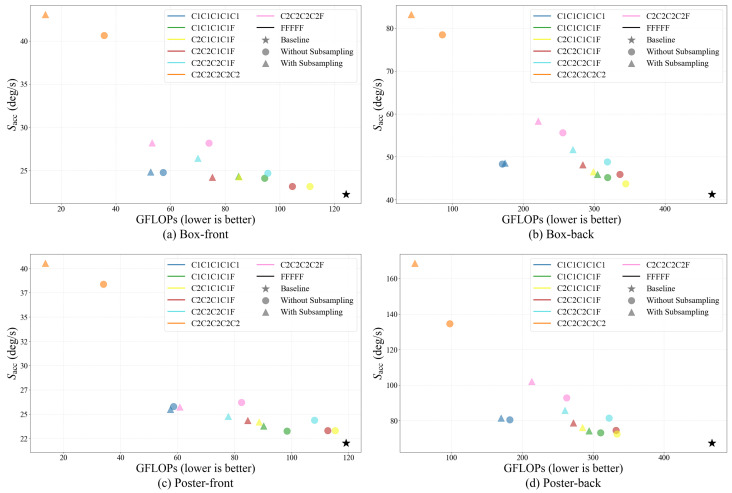 Figure 10
Figure 10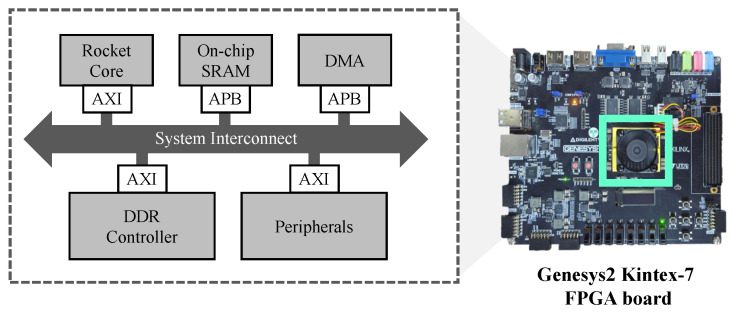 Figure 11
Figure 11 Figure 12
Figure 12- —Korea Institute for Advancement of Technology (KIAT)
- —National Research Foundation of Korea (NRF)
- —Chung-Ang University Graduate Research Scholarship
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Robotics and Sensor-Based Localization · Advanced Optical Sensing Technologies
1. Introduction
Visual simultaneous localization and mapping (visual SLAM) is a core capability for intelligent platforms such as mobile robots, autonomous vehicles, and drones, enabling concurrent ego-localization and environment reconstruction [1,2,3]. Although a SLAM pipeline typically consists of multiple modules (e.g., feature extraction, data association, mapping, and optimization), the motion estimation module in the front-end plays a particularly critical role, as it directly affects tracking robustness, map quality, and the long-term drift behavior of the entire system [1,2,4,5]. Conventional motion estimation has been largely developed around frame-based RGB cameras, which assume periodic sampling and dense image processing. This assumption often leads to high computational load and power consumption, making it increasingly problematic in resource-limited edge settings where real-time operation and energy efficiency must be simultaneously satisfied [6,7]. In addition, frame-based cameras are susceptible to motion blur under fast dynamics and may suffer from degraded performance in low-light environments or under extreme illumination changes due to noise amplification and exposure limitations.
Event-based vision sensors, commonly referred to as Dynamic Vision Sensors (DVSs) [8], have emerged as a compelling alternative sensing modality for motion estimation under such challenging conditions [7,9,10,11,12,13,14]. Instead of transmitting full image frames, a DVS asynchronously outputs events only when per-pixel brightness changes exceed a threshold. This sensing principle provides (i) microsecond-level temporal resolution, (ii) inherent immunity to motion blur, (iii) a wide dynamic range robust to abrupt illumination variations, and (iv) sparse, scene-dependent data generation that naturally suppresses redundant processing [15,16,17]. These characteristics make event cameras well aligned with the requirements of high-speed robotics and energy-constrained edge perception, motivating extensive research on event-based motion estimation.
Existing event-based motion estimation approaches have diverged into multiple directions. On one hand, learning-based methods have been introduced to improve estimation accuracy in complex scenarios [18,19,20,21,22]. On the other hand, sensor fusion strategies combine events with inertial measurements [23,24,25] or with standard intensity images [26,27,28] to enhance robustness and generalization. While effective in many cases, these approaches often introduce practical limitations for edge deployment, including reliance on large-scale training data, synchronization and calibration overhead across sensing modalities, and increased system complexity. As a result, motion estimation methods with predictable computational structure and strong energy efficiency remain highly desirable for edge-centric robotics pipelines [17].
In this context, learning-free and sensor-fusion-free geometric approaches that rely solely on event streams provide an attractive foundation for edge deployment. Among them, contrast maximization (CMAX) has become a widely adopted framework for estimating motion by directly maximizing the spatial contrast of motion-compensated events [10,11]. Given a motion hypothesis, events are temporally warped to a common reference time, accumulated into an image of warped events (IWE), and evaluated using a contrast objective. When the motion hypothesis matches the true ego-motion, events generated by the same physical edges become spatially aligned, resulting in a sharper and higher-contrast IWE; otherwise, the IWE appears blurred due to misalignment, as illustrated in Figure 1. Owing to this direct geometric interpretation, CMAX has served as a key building block across a broad range of event-based vision problems, including rotational motion estimation [10,13,29], feature-flow estimation [23,30], and motion segmentation [14,31,32].
Despite its effectiveness, conventional CMAX is inherently iterative and computationally demanding. Each optimization iteration repeatedly performs (i) per-event warping and accumulation, typically implemented via bilinear voting, and (ii) image-domain operations such as smoothing and contrast or gradient evaluation. Accordingly, the computational burden is dominated by two terms: an event-domain cost that scales with the number of warped events N, and an image-domain cost that scales with the IWE resolution , where H and W denote the height and width of the IWE grid. With warm-start initialization and gradient-based iterative optimization, CMAX typically exhibits a coarse-to-fine convergence behavior: early iterations capture dominant motion components through large parameter updates, whereas later iterations focus on fine refinement with diminishing returns. However, standard implementations apply the same computational granularity across all iterations, incurring nearly identical cost even when the marginal benefit of refinement becomes limited. This mismatch between optimization needs and computational effort is particularly inefficient on edge platforms, where energy budget, memory bandwidth, and execution predictability are tightly constrained.
To address this issue, we propose CCMAX (coarse-to-fine contrast maximization) for rotational ego-motion estimation. This paper focuses on contrast maximization-based rotational angular velocity estimation performed through iterative optimization in the SLAM front-end, rather than addressing the entire event-based SLAM pipeline. CCMAX explicitly aligns computation with the coarse-to-fine nature of contrast maximization by introducing two complementary strategies: (i) coarse-to-fine IWE construction, which progressively increases the IWE resolution across optimization stages to reduce image-domain cost in early iterations; and (ii) coarse-grid event subsampling, which removes redundant event contributions within coarse spatial bins to reduce event-domain cost during coarse stages. By allocating higher computational fidelity only when fine refinement is required, CCMAX systematically reduces the dominant cost of the CMAX pipeline while preserving estimation accuracy. We evaluate CCMAX on standard event-camera benchmarks using IMU-based ground truth and demonstrate that carefully designed coarse-to-fine schedules achieve accuracy comparable to a full-resolution CMAX baseline with substantially reduced computation. Furthermore, our analysis shows that CCMAX reduces floating-point operations (FLOPs) by up to 42%, and energy measurements on an FPGA-based prototype edge SoC report up to 87% energy reduction for the iterative CMAX pipeline under coarse configurations.
The remainder of this paper is organized as follows. Section 2 reviews the principles of contrast maximization and analyzes its computational structure in edge settings. Section 3 introduces CCMAX, detailing coarse-to-fine IWE construction and coarse-grid event subsampling. Section 4 evaluates the proposed approach in terms of accuracy, floating-point operations (FLOPs), and energy efficiency on an edge prototype platform. Section 5 discusses limitations of the proposed approach and outlines directions for future work. Finally, Section 6 concludes the paper.
2. Contrast Maximization: Principles and Edge-Oriented Analysis
Following the motivation in Section 1, we review the CMAX framework for learning-free event-based ego-motion estimation and then analyze its computational structure from an edge-deployment perspective. We focus on rotational ego-motion estimation, which is one of the most widely adopted settings of CMAX and directly matches the target problem addressed in Section 3.
2.1. Rotational Ego-Motion Estimation via Contrast Maximization
Event representation. An event camera outputs asynchronous events when the change in log-intensity at a pixel exceeds a contrast threshold. Each event is represented as
where ∈ denotes the image-plane location, the timestamp, and the polarity (brightness increase or decrease). We consider a short temporal segment and define the associated event window as , where N is the number of events in the window. CMAX estimates ego-motion by finding the motion parameters that best align events in this window.
Geometric interpretation of event warping. Under the pure-rotation assumption, a scene point projects to an image bearing that rotates according to the camera angular velocity . Let denote a homogeneous image coordinate (projective ray) corresponding to an image point . Assuming constant angular velocity within the short window, the bearing evolves as
where maps a vector to a skew-symmetric matrix and ∼ denotes equality up to scale in homogeneous coordinates. This constant angular velocity assumption is standard in window-based contrast maximization frameworks and enables tractable motion compensation over short temporal intervals [10]. Accordingly, an event occurring at time can be warped to the reference time as
so that all events are compared in a common time frame. For short windows and small inter-event rotation, a first-order approximation is commonly used [10]:
which reduces computational overhead and enables efficient gradient computation in practice, making it well-suited for iterative contrast maximization in event-based rotational motion estimation.
Image of Warped Events (IWE). Given a motion hypothesis , warped events are accumulated to form an IWE,
where is the Dirac delta. Directly working with is not practical in discrete implementations and, moreover, optimization requires differentiating the objective with respect to . Therefore, standard CMAX implementations approximate event accumulation on a pixel grid using bilinear voting (i.e., distributing a sub-pixel event contribution to the four neighboring pixels) [10]. This discretization also enables stable numerical gradients by approximating spatial derivatives on the pixel grid via finite differences.
Because the IWE is inherently sparse and can yield a non-smooth objective surface, CMAX typically optimizes a smoothed IWE, obtained by convolving I with a small Gaussian kernel (e.g., pixel) [10]:
This smoothing spreads each event contribution locally, improves the continuity of the contrast functional, and facilitates convergence of gradient-based optimization.
Contrast maximization and intuition. Events are predominantly triggered by moving intensity edges; events originating from the same physical edge form coherent spatiotemporal trajectories. If matches the true motion, warping brings these trajectories into spatial agreement, causing events from the same physical edges to spatially accumulate and reinforce edge structures in , as illustrated in Figure 2. CMAX quantifies this alignment by maximizing the spatial contrast of . In this work, we define contrast as the variance of over the valid image domain :
where is the area (or, in discrete form, the number of pixels) and is the spatial mean. In typical scenes, positive/negative polarities are often roughly balanced and can be close to zero, so maximizing encourages the IWE to become spatially peaky, which corresponds to strong edge alignment.
Gradient of the contrast functional. Efficient numerical optimization requires the gradient of . For the variance-based contrast, the gradient can be expressed as
Since , the derivative commutes with convolution, yielding
In practice, is obtained alongside event warping by differentiating the discretized (bilinear-voted) accumulation with respect to the motion parameters, and spatial derivatives are approximated by finite differences on the pixel grid.
Optimization and warm-up strategy. Rotational ego-motion estimation is formulated as
Because is generally non-convex, CMAX employs iterative gradient-based optimization. Classic choices include conjugate-gradient methods such as Fletcher–Reeves (CG–FR) [35] or Polak–Ribière variants [36], which have been shown to produce comparable solutions in common event-motion settings [10].
For streaming operation, the event stream is partitioned into consecutive event windows . After solving (10) for window , the estimate is used to initialize the next window (warm-start), leveraging the fact that angular velocity varies slowly over short time intervals [10]. This assumption is widely adopted in event-based rotational motion estimation, as short event windows are typically used to ensure that angular velocity can be reasonably approximated as locally constant. This warm-start strategy improves convergence speed but does not change the per-iteration computational structure of the CMAX pipeline, which we analyze next.
2.2. Edge-Oriented Cost Decomposition of CMAX
Figure 3 summarizes the conventional CMAX computation loop. Given a motion hypothesis , each iteration evaluates the same fixed pipeline: (i) warp events to the reference time, (ii) accumulate them into an IWE, and (iii) compute contrast and its gradient to update via an iterative optimizer.
From an edge-deployment perspective, the per-iteration cost is dominated by two terms. First, the event-domain cost scales with the number of processed events N. Event warping, coordinate transforms, and bilinear voting are performed per event; thus both arithmetic operations and memory accesses grow linearly with N. Second, the image-domain cost scales with the IWE resolution . Gaussian smoothing, contrast computation (variance), and gradient-related image operations traverse the full pixel grid, so their cost grows linearly with the number of pixels. As a result, each iteration incurs approximately event-domain work and image-domain work, and the total cost per window scales linearly with the iteration budget.
A key observation is that, in practice, CMAX exhibits a coarse-to-fine convergence trend: early iterations produce large updates that rapidly capture dominant rotational motion, whereas later iterations mainly perform fine refinement with diminishing alignment improvements, as illustrated in Figure 4. However, standard implementations do not adapt computational granularity to this convergence behavior. They keep the same number of events N and the same IWE resolution for every iteration, repeatedly paying almost identical event-domain and image-domain costs even when the expected improvement per iteration becomes small.
This mismatch between diminishing optimization returns and fixed computational cost is particularly inefficient on edge platforms. Therefore, an explicit edge-oriented decomposition into event-domain and image-domain bottlenecks is crucial, and it motivates our coarse-to-fine strategy in Section 3, which allocates cheaper computation to early iterations and progressively increases fidelity only when fine refinement is necessary.
3. Coarse-to-Fine Contrast Maximization (CCMAX)
Although CMAX typically converges in a coarse-to-fine manner, standard implementations apply fixed event and image resolutions across all iterations. This mismatch between diminishing optimization gains and constant per-iteration cost calls for an adaptive, coarse-to-fine optimization strategy. Accordingly, we propose CCMAX for rotational ego-motion estimation. The key idea is to adapt the computational granularity across optimization iterations so that inexpensive, low-fidelity computations are used when coarse alignment is sufficient, and high-fidelity computations are reserved for the final refinement. Concretely, CCMAX combines two complementary mechanisms:
- Coarse-to-Fine IWE Construction progressively increases the IWE grid resolution across optimization stages, directly reducing the image-domain cost in early stages.
- Coarse-Grid Event Subsampling reduces redundant event contributions at coarse resolutions by selecting representative events within coarse spatial bins, reducing the event-domain cost during coarse stages.
For a given event window , CCMAX runs a fixed number of optimization stages . Each stage k uses (i) a resolution scale for IWE construction and (ii) a keep ratio for event subsampling (with meaning no subsampling). Compared to the baseline cost , the stage-wise cost in CCMAX becomes approximately
highlighting how resolution scaling and subsampling jointly reduce the dominant costs identified in Section 2.2.
3.1. Coarse-to-Fine IWE Construction for Reducing Image-Domain Cost
Coarse-to-fine IWE construction reformulates the CMAX optimization on an event window as a sequence of stages with progressively increasing spatial resolution. In this context, a stage corresponds to a single iteration of the CMAX optimization loop: given the current motion estimate , events are warped and accumulated into an IWE, followed by contrast and gradient evaluation to update once. In CCMAX, early stages operate on downscaled IWE grids (e.g., ) to form a coarse alignment at low computational cost, while later stages progressively increase the resolution ( ) to recover fine alignment at the original grid resolution.
Starting from the IWE definition in (5), we define a scaled IWE on a grid with resolution scale as
where denotes coordinates on the scaled grid and is the discrete accumulation kernel (e.g., bilinear voting). The term maps warped event locations into the scaled coordinate system, so that the same event set is accumulated into a smaller grid. If the original IWE resolution is , the scaled grid covers with resolution , where and . This effect is illustrated in Figure 5 for the case , where events that would spread over a neighborhood on the full-resolution grid are merged into a single coarse cell.
From an edge-oriented perspective, this resolution scaling directly reduces the dominant image-domain cost. Image-domain operations in CMAX—including Gaussian smoothing, contrast (variance) computation, and gradient-related image processing—scale linearly with the number of grid cells. Since , reducing the resolution by a factor s lowers the image-domain cost by approximately : for , the cost becomes about one quarter of the full-resolution cost, and for it becomes about one sixteenth. This behavior directly targets the dominant image-domain bottleneck.
Importantly, coarse IWE grids remain effective in early optimization stages. Using a coarse grid implicitly performs spatial pooling, whereby multiple nearby warped events contribute to the same grid cell. This pooling suppresses fine spatial details that are not yet necessary during early optimization, while retaining the dominant alignment structure induced by the primary rotational motion. As a result, coarse stages can provide stable and informative ascent directions at substantially reduced cost, and later stages recover precision by progressively increasing the IWE resolution.
3.2. Coarse-Grid Event Subsampling for Reducing Event-Domain Cost
While coarse-to-fine IWE construction reduces the image-domain cost by shrinking the IWE grid, coarse-grid event subsampling further reduces the event-domain cost by decreasing the number of events processed during coarse optimization stages. The key observation is that, at low IWE resolutions, many events become redundant because they fall into the same coarse grid cell and contribute similarly to the contrast objective. For example, when using in (12), events that would originally spread across a neighborhood on the full-resolution grid are merged into a single coarse cell. As a result, contrast becomes primarily influenced by the aggregated cell-level event mass rather than by fine sub-pixel differences. This redundancy can be exploited by selecting a subset of representative events per coarse cell, preserving coarse alignment capability while reducing event processing cost [37,38].
To control the degree of subsampling, we design the keep ratio as a function of the resolution scale s. At resolution scale s, the number of coarse grid cells scales approximately as relative to the full-resolution grid. A naive choice would maintain the same average number of events per cell. However, event streams are typically highly non-uniform and temporally bursty, and overly aggressive reduction can eliminate informative alignment cues in important regions. We therefore choose
which intentionally increases the per-cell event density by a factor of compared to the full-resolution average. For instance, at , the grid area is reduced to while the number of processed events is reduced to , effectively doubling the average number of events per coarse cell. This design improves the robustness of coarse-stage contrast estimation while still providing substantial event-domain savings.
The subsampling procedure is summarized in Algorithm 1. For each event window, we first apply a reference warp using , which we set to the warm-start estimate (e.g., from the previous window). This reference alignment increases the likelihood that events originating from the same physical edge cluster into the same coarse grid cell, making cell-wise redundancy more explicit. Each warped event is then mapped to the scaled coordinates and assigned to a one-dimensional cell index over the scaled domain . Algorithm 1: Coarse-grid event subsampling
Within each coarse cell, we select events, where is proportional to the number of events in the cell via and is lower-bounded by . Cells containing only a single event ( ) are discarded, as they are more likely to correspond to isolated noise events rather than stable edge structures. Moreover, because event generation can be temporally bursty, selecting events purely at random or only from the beginning of a cell’s event list can bias the temporal distribution and distort the motion cue within the window. To mitigate this effect, we employ time-stratified selection: after sorting events in each cell by timestamp, we sample events approximately uniformly over the cell’s temporal extent (Algorithm 1, Lines 16–17). In CCMAX, event subsampling is applied only during coarse stages ( ), while the final fine stage uses all events ( ) to recover full-resolution accuracy.
Overall, coarse-grid event subsampling complements coarse-to-fine IWE construction. The former reduces the dominant event-domain cost by limiting the number of processed events in coarse stages, while the latter reduces the dominant image-domain cost by shrinking the IWE grid. Together, these two mechanisms form an edge-oriented coarse-to-fine CMAX pipeline whose computational fidelity is aligned with the refinement requirements of each optimization stage.
3.3. Evaluation of CCMAX Configurations
Section 3.1 and Section 3.2 presented two complementary mechanisms for aligning computational fidelity with the coarse-to-fine convergence behavior of contrast maximization: (i) resolution scheduling for IWE construction (image-domain cost control) and (ii) coarse-grid event subsampling (event-domain cost control). In this subsection, we empirically evaluate how different CCMAX configurations affect estimation accuracy. The goal is twofold: first, to validate the design choices in CCMAX from an optimization perspective, and second, to understand which coarse-to-fine schedules preserve baseline-level accuracy while remaining suitable for resource-constrained edge deployment.
Evaluation metric and setup.
We evaluate CCMAX on the Boxes rotation and Poster rotation sequences from the Event Camera Dataset [34], which were recorded using a DAVIS event camera with a spatial resolution of pixels. These sequences predominantly contain rotational motion with increasing angular speed and provide synchronized IMU measurements used as ground-truth angular velocity. To assess performance under different motion regimes, we analyze two disjoint temporal segments per sequence: 0–15 s (Front, slow motion) and 45–60 s (Back, fast motion). These segments are intentionally selected to contrast low- and high-angular-speed regimes, enabling a controlled analysis of the accuracy–efficiency trade-off under edge-oriented computational constraints.
The event stream is processed using overlapping event windows. Each window contains = 40,000 events, and consecutive windows are shifted by = 20,000 events (50% overlap), a common strategy to reduce boundary effects in windowed time-series analysis [39]. This window size provides sufficient event density for a stable IWE-based contrast and gradient estimation, while keeping the locally constant angular-velocity assumption reasonable within a single window. The angular velocity of the first window is initialized to zero and is not obtained from IMU measurements. The same initialization strategy is consistently applied to both the baseline and all proposed configurations. For each window m, the optimizer is warm-started using the previous estimate .
Accuracy is measured using the per-window angular-velocity error with respect to the IMU reference. Let denote the estimated angular velocity and the ground truth. We define the error vector and the corresponding scalar error . Because event streams can be bursty and occasional window-level failures may occur, we summarize the error distribution using robust statistics. Specifically, we define the accuracy score as the sum of the median and the interquartile range (IQR) of the window-level errors , where the IQR is defined as the difference between the 75th and 25th percentiles ( and ):
which captures both the typical error magnitude and its variability across windows. The resulting score has the same physical unit as the angular velocity (i.e., deg/s in our experiments), with lower values indicating better estimation accuracy.
Iteration budget and configuration notation.
Contrast maximization is inherently iterative, and unconstrained iteration counts can lead to unpredictable runtime. Since our target setting is edge deployment, where bounded latency is desirable, we adopt a fixed maximum iteration budget. Figure 6 reports of a full-resolution baseline configuration as a function of the iteration budget k. Across all four scenarios, the accuracy improves rapidly during the first few iterations and exhibits diminishing returns thereafter, with only marginal improvement observed for . Accordingly, we set for all subsequent experiments and treat each iteration as one stage.
A CCMAX configuration is represented by a length- stage string, where each stage specifies the IWE resolution scale s and, when enabled, the event keep ratio . We consider three stage types: F (fine), with full-resolution IWE construction ( ) and no event subsampling ( ); C1 (coarse-1), with half-resolution IWEs ( ); and C2 (coarse-2), with quarter-resolution IWEs ( ). When event subsampling is enabled, coarse stages follow the rule , while fine stages always use all events ( ). For example, the configuration C2C2C1C1F corresponds to a five-stage schedule in which stages 1–2 use and , stages 3–4 use and , and the final stage uses full resolution with and . The full-resolution baseline used for comparison corresponds to FFFFF, where all stages operate at full IWE resolution using all events.
For experiments that isolate the effect of coarse-to-fine IWE construction, event subsampling is disabled and all stages use the full event set (i.e., for all s), so C1 and C2 denote resolution scaling only. For experiments that evaluate coarse-grid event subsampling, subsampling is applied only in coarse stages following the scheme described in Section 3.2.
Effect of coarse-to-fine IWE construction.
Figure 7 compares across different stage-resolution schedules when event subsampling is disabled. As expected, coarse-only schedules, such as C2C2C2C2C2 and C1C1C1C1C1, consistently lead to substantial accuracy degradation across all scenarios. Without any fine stage, the optimization lacks high-resolution spatial cues required for final refinement, and residual misalignment remains. This effect is particularly pronounced in challenging scenarios such as Poster-back, where the baseline score of 67.27 increases to 134.49 under the C2C2C2C2C2 configuration.
In contrast, mixed coarse-to-fine schedules that include one or more fine stages are able to recover most of the baseline accuracy. This behavior reflects the intended role of resolution scheduling. Early coarse stages perform a low-pass aggregation of warped events: nearby events are merged into shared coarse cells, preserving dominant alignment trends while suppressing fine spatial details. As a result, these stages are effective for rapidly capturing the dominant motion components at reduced image-domain cost. Subsequent fine stages reintroduce high-frequency spatial structure in the IWE, enabling precise correction of the residual error left by the coarse alignment.
This effect can be clearly observed when a fine stage is appended to an otherwise coarse-only schedule. For example, switching from C2C2C2C2C2 to C2C2C2C2F reduces the accuracy score from 40.62 to 28.15 in the Box-front scenario, and from 134.49 to 92.78 in the Poster-back scenario, demonstrating the strong corrective effect of even a single fine refinement stage. Configurations that combine intermediate-resolution and fine stages, such as C2C2C1FF and C2C1C1C1F, further stabilize performance, yielding scores of 68.39 and 72.52 in Poster-back, respectively.
From a cost perspective, these results also highlight an important trade-off. Because image-domain cost scales linearly with the IWE resolution, placing too many fine stages significantly increases the cumulative computation over all iterations. Nevertheless, configurations with a single fine stage already achieve a substantial recovery relative to coarse-only schedules, indicating that most of the benefit of high-resolution refinement can be obtained with limited fine-stage usage. Overall, these results justify coarse-to-fine IWE construction as an edge-oriented design: image-domain cost is reduced through low-resolution early stages, while accuracy degradation is effectively mitigated by reserving a small number of fine stages. The stage configuration can be adapted to different accuracy requirements and computational budgets.
Effect of coarse-grid event subsampling.
Figure 8 evaluates the effect of adding coarse-grid event subsampling on top of the same coarse-to-fine resolution schedules. In these experiments, subsampling is applied only in coarse stages, while fine stages always use the full event set. Across mixed coarse-to-fine schedules that include at least one fine stage, introducing event subsampling results in only minor changes in , indicating that a substantial reduction in the number of processed events can be achieved without materially degrading estimation accuracy.
For example, in the C2C2C1C1F configuration, event subsampling reduces the number of events by approximately one quarter in the C2 stages and one half in the C1 stages. Despite this aggressive reduction, the increase in remains limited, ranging from 1.04 to 4.18 across the four scenarios. Similarly, in C1C1C1C1F, the difference introduced by subsampling ranges from 0.21 to 1.71, and becomes even smaller (0.21 to 0.67) when two fine stages are included, as in C1C1C1FF. These results show that coarse-grid event subsampling has a consistently limited impact on accuracy when sufficient fine-stage refinement is preserved.
This robustness can be explained by the redundancy structure exploited by the subsampling scheme. With warm-start initialization, events are already partially aligned under the reference motion, so events generated by the same physical edge tend to cluster into the same coarse grid cell after warping and scaling. At low resolutions, the contrast objective and its gradient are driven primarily by aggregated cell-level contributions rather than by the exact sub-pixel placement of individual events. As a result, many events within the same cell are redundant for coarse-stage optimization. By retaining a fixed fraction of events per active cell and enforcing time-stratified sampling, the proposed subsampling scheme preserves both spatial and temporal coverage of motion cues within each window.
Importantly, when at least one fine stage is included, most configurations maintain consistent accuracy regardless of whether subsampling is applied. In other words, the presence of a fine stage is sufficient to compensate for the information loss introduced by event reduction in coarse stages, allowing subsampling to be used aggressively without degrading final estimation accuracy.
In contrast, the limitations of subsampling become apparent in configurations that lack fine refinement. When all stages operate at the lowest resolution, as in C2C2C2C2C2, adding subsampling further amplifies the accuracy degradation, with the accuracy score increasing by a factor of 1.84–2.51 relative to the baseline across the four scenarios. This behavior reflects the fundamental limitation of coarse-only optimization: without any high-resolution stage, neither resolution scheduling nor subsampling can recover the fine alignment details required for accurate estimation.
The primary contribution of coarse-grid event subsampling lies in reducing the event-domain cost. Because event warping and bilinear voting are performed on a per-event basis, the event-domain cost scales linearly with the number of processed events. For example, in the C2C2C1C1F configuration, reducing the number of events to approximately one quarter in the first two stages results in an event-domain cost reduction of about 75% in those stages, and retaining approximately one-half of the events in the C1 stages yields a corresponding event-domain cost reduction of about 50%. This reduction complements the image-domain cost savings achieved by coarse-to-fine IWE construction.
In summary, the proposed CCMAX framework achieves substantial computational savings in both the image and event domains while maintaining nearly the same estimation accuracy. This balance between robust error performance and computational efficiency justifies CCMAX as an edge-oriented design that explicitly accounts for both accuracy and resource constraints.
4. Experimental Evaluation
In this section, we quantify the efficiency benefits of CCMAX from two complementary perspectives. First, we provide a platform-agnostic compute analysis based on FLOPs and characterize the accuracy–efficiency trade-off across the configuration design space. Second, we verify that these computational savings translate into tangible energy reductions on a prototype edge SoC platform.
4.1. Compute Analysis for Edge Deployment
in (14) provides a robust absolute error measure for each evaluation segment. However, because the four segments considered in Section 3.3 exhibit substantially different motion magnitudes, directly comparing absolute errors across scenarios can be misleading. To enable a compact, motion-scale-agnostic comparison, we additionally introduce a normalized summary metric referred to as Average % of Peak Motion.
Let denote the peak ground-truth angular velocity for scenario j. For the four evaluation segments, these values are 300 deg/s (Boxes-front), 700 deg/s (Boxes-back), 300 deg/s (Poster-front), and 1000 deg/s (Poster-back). We define the scenario-normalized score as
and summarize performance using the average . This metric preserves the robustness of while enabling direct comparison across scenarios with different motion scales.
Figure 9 reports the average normalized error for all configurations. For the full-resolution baseline FFFFF, the average normalized error is across the four scenarios. Because the CMAX optimization process is iterative and not strictly deterministic, we observe small but consistent relative variations in this normalized error even for the same configuration. Based on empirical evaluation of the baseline, this variation remains within approximately 1 percentage point, which we adopt as a conservative tolerance for acceptable accuracy degradation in edge deployment.
Using this tolerance, configurations that include one fine stage are partially edge-feasible, and those with two or more fine stages are consistently within the acceptable accuracy range, whereas coarse-only schedules fall outside the tolerance. Within the tolerance region, increasing the number of fine stages leads to only marginal accuracy improvement, while the computational overhead of the CMAX pipeline grows rapidly due to repeated full-resolution image-domain processing. As a result, configurations with exactly one fine stage form the most compact accuracy–efficiency trade-off near the tolerance boundary, whereas additional fine stages yield diminishing accuracy gains relative to their cost increase. Accordingly, the subsequent analysis focuses on configurations with a single fine stage, which best capture the practical trade-off between estimation accuracy and computational efficiency.
To quantify computational cost in a platform-agnostic manner, we measure FLOPs following common practice in efficiency analysis [40,41]. Additions and multiplications are counted explicitly, and constant divisions are replaced by multiplications using precomputed reciprocals so that all configurations are evaluated under the same counting rules. As discussed in Section 2.2, the dominant cost of contrast maximization arises from repeated execution of the CMAX pipeline. This cost is governed by two factors: the number of processed events, which determines the event-domain cost of warping and bilinear voting, and the spatial resolution of the IWE, which determines the image-domain cost of smoothing and contrast/gradient evaluation. Accordingly, reducing the event count through coarse-grid subsampling and reducing the IWE resolution through coarse-to-fine scheduling directly target the two dominant contributors to the overall FLOPs. Finally, we verified that the arithmetic overhead of the iterative optimizer itself is negligible compared to the pipeline cost; in our measurements, optimizer-related FLOPs account for less than of the total, confirming that the FLOPs reduction is attributable to changes in the CMAX pipeline itself, with optimizer overhead being negligible.
Figure 10 visualizes the design space in terms of total FLOPs and the accuracy score . Two consistent trends emerge across all scenarios. First, enabling coarse-grid event subsampling systematically shifts configurations toward lower FLOPs, confirming that reducing the number of processed events in coarse stages directly lowers the event-domain cost. Second, coarse-only schedules achieve very large FLOPs reductions but incur unacceptable accuracy degradation. For instance, C2C2C2C2C2 achieves approximately 89% and 91% FLOPs reduction on Boxes-front and Boxes-back, respectively, but degrades the accuracy score to roughly – the baseline, indicating limited practical utility. Similarly, C1C1C1C1C1 reduces FLOPs by about 58% (Boxes-front) and 63% (Boxes-back), yet still exhibits clear accuracy loss and is not edge-feasible under the baseline-accuracy criterion.
Among mixed schedules that include a fine stage, the accuracy–efficiency trade-off becomes substantially more favorable, but it remains strongly configuration dependent. In particular, introducing a single fine stage is sufficient to recover most of the baseline accuracy, whereas adding additional fine stages yields diminishing accuracy gains while rapidly increasing FLOPs due to the dominance of full-resolution image-domain computation. Using the motion-normalized tolerance defined in Figure 9, this trend becomes quantitative.
Across the four scenarios, C2C2C2C2F achieves a large FLOPs reduction of 53.4% relative to FFFFF, but exceeds the acceptable accuracy margin by +2.3 p.p., indicating that aggressive early coarsening without sufficient refinement is insufficient. In contrast, C1C1C1C1F remains within the tolerance (+0.7 p.p.) with a moderate FLOPs reduction of 34.3%, while C2C2C1C1F provides a stronger reduction of 39.2% FLOPs while still satisfying the accuracy constraint (+0.9 p.p.). These results highlight that the resolution level and duration of the early coarse stages play a critical role in determining the final accuracy–efficiency balance, even when the number of fine stages is fixed. Notably, C2C2C1C1F exhibits consistent FLOPs reductions across all scenarios (approximately 39% on Boxes-front, 39% on Boxes-back, 29% on Poster-front, and 42% on Poster-back), indicating robust efficiency gains over a wide range of motion regimes.
Overall, the FLOPs analysis supports the design rationale of CCMAX: allocating coarse computation to early iterations and reserving a limited fine refinement stage enables a favorable accuracy–efficiency trade-off under resource-constrained edge settings.
4.2. Energy Validation on a Prototype Edge SoC
To directly validate that the computational savings achieved by CCMAX translate into tangible energy reductions in edge settings, we measure the energy consumption of the proposed method on a prototype edge-class SoC platform. Figure 11 illustrates the overall architecture of the prototype system.
The prototype processor is designed based on RISC-V eXpress (RVX), an EDA tool widely adopted for developing edge processors on the RISC-V platform [8,42,43,44,45], and integrates a low-power Rocket core [46] operating at 50 MHz. As shown in Figure 11, this platform consists of 128 KB of on-chip SRAM, a DDR controller, and a low-power NoC [47] with AXI/APB interconnect. The design is validated on a Genesys2 Kintex-7 FPGA board [48], and power estimation is performed using a 45 nm technology model [49]. FPGA resource utilization and power consumption breakdown are summarized in Table 1. Resource usage is reported based on Xilinx Vivado [50] synthesis results, and power analysis for the same RTL configuration is carried out using Synopsys Design Compiler [51], which reports a total system power of 57.01 mW.
To quantify the energy benefit of CCMAX at the platform level, we focus on the dominant computational bottleneck of the algorithm: the repeated CMAX pipeline shown in Figure 3, which consists of event warping, IWE accumulation, and contrast/gradient evaluation. This pipeline block concentrates both arithmetic operations and memory accesses, and it is executed identically at every optimization stage. As confirmed in the FLOPs analysis, this block dominates the overall computation and energy budget, while the overhead of the iterative optimizer itself is negligible. Accordingly, energy measurements are targeted specifically at this pipeline to directly capture the impact of reduced event-domain and image-domain workloads. This targeted measurement does not aim to capture the end-to-end system energy consumption of a complete SLAM pipeline. Instead, it is intended to evaluate the transferability of algorithmic computational savings—introduced by coarse-to-fine scheduling and event reduction—to hardware-level energy consumption in a controlled and repeatable manner.
Energy measurements are conducted under the same fixed-size event-window processing setup used in Section 3.3. For the Fine baseline configuration, each window processes = 40,000 events and uses the full IWE resolution of . To examine how energy scales with reduced event count and reduced IWE resolution, we measure two representative coarse configurations. Configuration C1 uses a resolution scale of , corresponding to a IWE, and processes an average of approximately 20,800 events per window. Configuration C2 uses , corresponding to a IWE, and processes an average of approximately 10,500 events per window. These two configurations are selected because they isolate the effect of reducing the number of processed events and the IWE resolution on the dominant CMAX pipeline, enabling direct quantification of event-domain and image-domain energy scaling at the platform level.
Table 2 reports the measured energy consumption of the CMAX pipeline normalized to the Fine baseline (Fine = 100%). The measured normalized energies are 35.47% for C1 and 12.97% for C2, which correspond to energy reductions of approximately and , respectively. These results demonstrate that coarse-to-fine configuration alone, without any change to the underlying hardware, can yield substantial energy savings on an edge-class SoC.
If pipeline energy were dominated solely by event-domain processing, reducing the number of events by half would be expected to yield approximately 50% of the baseline energy consumption. However, C1 consumes only 35.47% of the baseline energy, indicating that image-domain savings due to the quadratic reduction in IWE pixel count also play a significant role. To further analyze this behavior, we consider a simple two-term energy model:
where and denote the event-count and pixel-count ratios relative to the Fine baseline. Fitting this model to the C1 measurement yields an estimated image-domain energy contribution of approximately under the baseline setting. Using the same model to predict the energy of C2 gives an expected normalized energy of approximately 14.1%, which closely matches the measured value of 12.97% (within ∼1.1 p.p.).
Overall, these measurements corroborate the edge-oriented cost decomposition discussed earlier. The energy consumption of the CMAX pipeline is jointly governed by event-domain and image-domain costs, and reducing only one of these components is insufficient for maximal efficiency. CCMAX is explicitly designed to reduce both terms: coarse-grid event subsampling directly lowers the event-domain cost by reducing the number of processed events, while coarse-to-fine IWE construction structurally reduces the image-domain cost by shrinking the IWE resolution. The observed energy reductions confirm that the FLOPs savings achieved by CCMAX can be transferred into tangible hardware-level energy benefits on a representative edge SoC platform, supporting CCMAX as a feasible and energy-efficient motion-estimation front-end for resource-constrained edge systems.
5. Discussion
In this work, we focus on rotational ego-motion to enable a controlled analysis of the computational efficiency of contrast maximization (CMAX). Pure rotation admits a depth-independent warping model, which allows us to isolate how the dominant computational components of CMAX—namely, event-domain processing and image-domain IWE construction—scale under different coarse-to-fine configurations, without confounding effects from scene geometry or depth estimation.
Extending the same approach to motion models that include translation introduces additional challenges. With translation, event warping becomes depth-dependent and different scene points experience different apparent motions due to parallax. In practice, this typically requires additional scene representation (e.g., depth/inverse-depth, planar modeling, or a map) or joint optimization over pose and structure, which increases the number of unknowns and the per-iteration complexity of event warping, IWE construction, and contrast/gradient evaluation. These factors can further exacerbate runtime and energy constraints on resource- and power-limited edge platforms. Designing depth-aware coarse-to-fine schedules that retain informative parallax cues while maintaining computational efficiency remains an important direction for future work.
Beyond modeling considerations, event-based motion estimation is influenced by non-ideal real-world conditions. Sensor jitter, high-frequency vibration, mechanical shocks, independently moving objects, and loss of fine visual details can alter the spatiotemporal distribution of events. Such disturbances may reduce IWE contrast, introduce outlier or inconsistent event patterns, and flatten the objective-function landscape, weakening informative gradients and degrading optimization stability [52].
In the present work, we do not explicitly model or compensate for these factors, as our primary goal is to analyze and reduce the computational and energy cost of contrast maximization under the rotational setting. CCMAX should be viewed as a computation-efficient scheduling layer that preserves the original CMAX objective, and thus can be combined with complementary robustness mechanisms such as background-activity filtering, adaptive window sizing, inertial sensing or sensor fusion, and robust/weighted objective formulations. Developing CMAX frameworks that jointly address robustness under real-world disturbances while preserving computational efficiency is essential for reliable deployment and remains an open research challenge.
6. Conclusions
In conclusion, the main contributions, findings, and limitations of this work are summarized as follows:
- 1.We analyzed the computational inefficiency of contrast maximization (CMAX) for iterative rotational ego-motion estimation and identified two dominant cost components: event-domain processing that scales with the number of events, and image-domain IWE processing that scales with IWE resolution.
- 2.We proposed coarse-to-fine contrast maximization (CCMAX), which aligns computational fidelity with the coarse-to-fine convergence behavior of CMAX via (i) coarse-to-fine IWE construction and (ii) coarse-grid event subsampling, while explicitly retaining a final full-resolution refinement stage.
- 3.Experiments on standard event-camera benchmarks with IMU ground truth show that properly designed schedules achieve accuracy comparable to the full-resolution baseline under a fixed iteration budget.
- 4.CCMAX reduces floating-point operations by up to 42% and achieves up to 87% lower energy consumption for the iterative CMAX pipeline on a custom RISC-V–based edge SoC prototype, demonstrating suitability for real-time edge SLAM front-end deployment under tight compute and power constraints.
- 5.Limitations and future work: The proposed approach focuses on rotational ego-motion under a depth-independent warping model. Extensions to translation-including motion, which introduce depth dependence and parallax, as well as improved robustness to non-ideal real-world conditions (e.g., jitter, shocks, and dynamic objects), remain important directions for future research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cadena C. Carlone L. Carrillo H. Latif Y. Scaramuzza D. Neira J. Reid I. Leonard J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age IEEE Trans. Robot.2016321309133210.1109/TRO.2016.2624754 · doi ↗
- 2Macario Barros A. Michel M. Moline Y. Corre G. Carrel F. A Comprehensive Survey of Visual SLAM Algorithms Robotics 2022112410.3390/robotics 11010024 · doi ↗
- 3Chen L. Li G. Xie W. Tan J. Li Y. Pu J. Chen L. Gan D. Shi W. A Survey of Computer Vision Detection, Visual SLAM Algorithms, and Their Applications in Energy-Efficient Autonomous Systems Energies 202417517710.3390/en 17205177 · doi ↗
- 4Jia G. Li X. Zhang D. Xu W. Lv H. Shi Y. Cai M. Visual-SLAM Classical Framework and Key Techniques: A Review Sensors 202222458210.3390/s 2212458235746363 PMC 9227238 · doi ↗ · pubmed ↗
- 5Wang B. Song X. Lu K. Yang L. Research and Application of SLAM Algorithm for Mobile Robots in Indoor Dynamic Scene Proceedings of the International Conference on Control and Intelligent Robotics Tianjin, China 20–22 June 2025 Association for Computing Machinery New York, NY, USA 2025455210.1145/3757940.3757947 · doi ↗
- 6Sahili A.R. Hassan S. Sakhrieh S.M. Mounsef J. Maalouf N. Arain B. Taha T. A Survey of Visual SLAM Methods IEEE Access 20231113964313967710.1109/ACCESS.2023.3341489 · doi ↗
- 7Cimarelli C. Millan-Romera J.A. Voos H. Sanchez-Lopez J.L. Hardware, Algorithms, and Applications of the Neuromorphic Vision Sensor: A Review Sensors 202525620810.3390/s 2519620841095030 PMC 12526923 · doi ↗ · pubmed ↗
- 8Choi J. Choi E. Choi S. Lee W. E-BTS: A low-power Event-driven Blink Tracking System with hardware-software co-optimized design for real-time driver drowsiness detection Alex. Eng. J.202512886787710.1016/j.aej.2025.07.020 · doi ↗