Robust Trajectory Prediction for Mobile Robots via Minimum Error Entropy Criterion and Adaptive LSTM Networks
Da Xie, Zengxun Li, Chun Zhang, Chunyang Wang, Xuyang Wei

TL;DR
This paper introduces a robust trajectory prediction method for robots that handles sensor noise better than traditional approaches.
Contribution
The novel MEE-LSTM framework combines adaptive LSTM networks with the Minimum Error Entropy criterion to improve robustness against impulsive noise.
Findings
MEE-LSTM outperforms MSE-based models in noisy environments with a 75.7% improvement in robustness.
The model maintains an ADE of ≈0.51 m under 20% impulsive noise, while MSE baselines degrade to over 2.1 m.
The proposed SAA strategy dynamically regulates kernel bandwidth for better convergence in information theoretic learning.
Abstract
Trajectory prediction is critical for safe robot navigation, yet standard deep learning models predominantly rely on the Mean Squared Error (MSE) criterion. While effective under ideal conditions, MSE-based optimization is inherently fragile to non-Gaussian impulsive noise—such as sensor glitches and occlusions—common in real-world deployment. To address this limitation, this paper proposes MEE-LSTM, a robust forecasting framework that integrates Long Short-Term Memory networks with the Minimum Error Entropy (MEE) criterion. By minimizing Renyi’s quadratic entropy of the prediction error, our loss function introduces an intrinsic “gradient clipping” mechanism that effectively suppresses the influence of outliers. Furthermore, to overcome the convergence challenges of fixed-kernel information theoretic learning, we introduce a Silverman-based Adaptive Annealing (SAA) strategy that…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
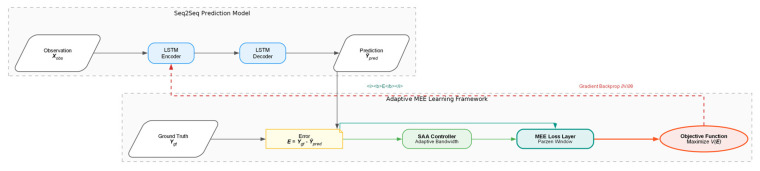 Figure 1
Figure 1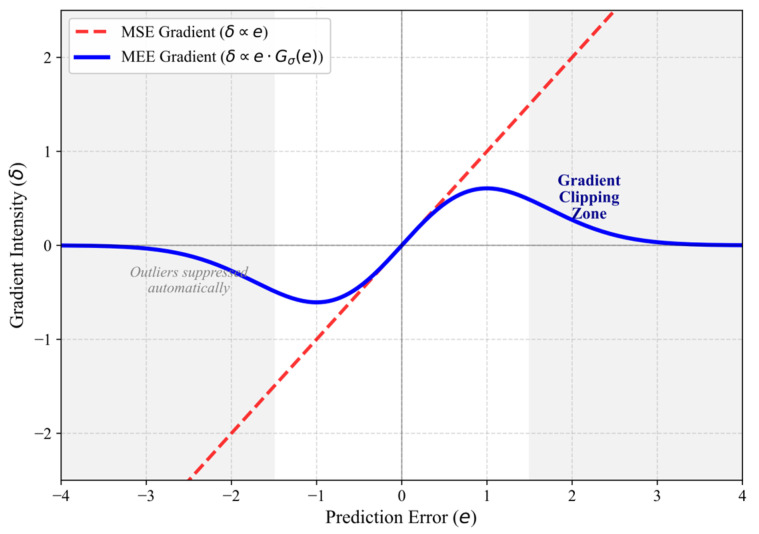 Figure 2
Figure 2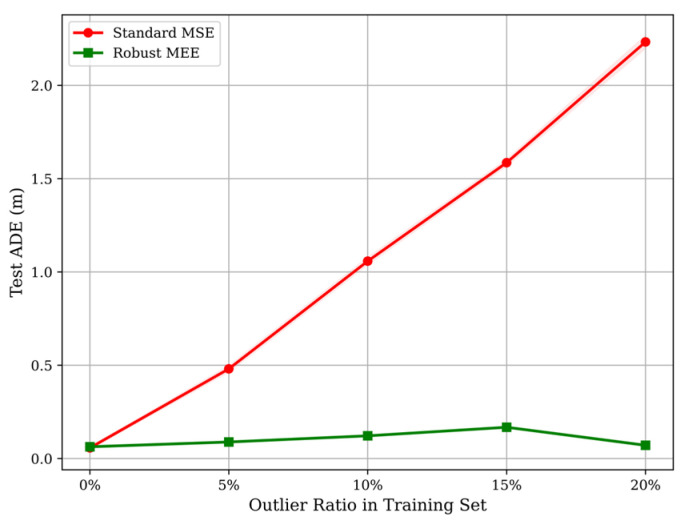 Figure 3
Figure 3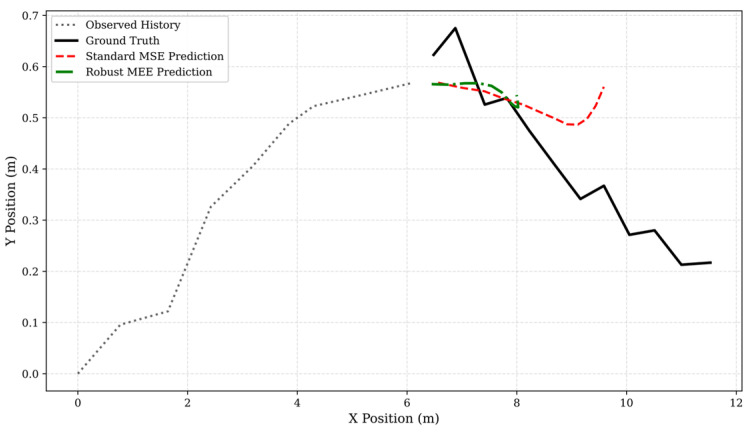 Figure 4
Figure 4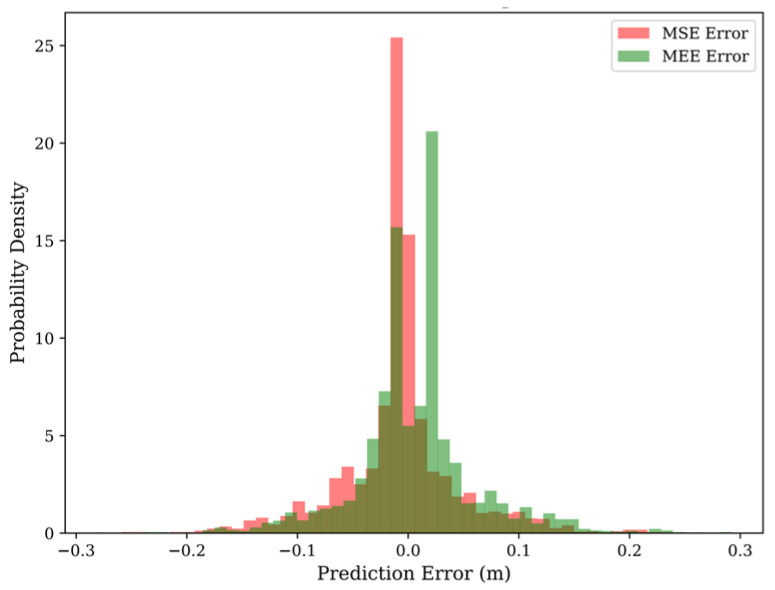 Figure 5
Figure 5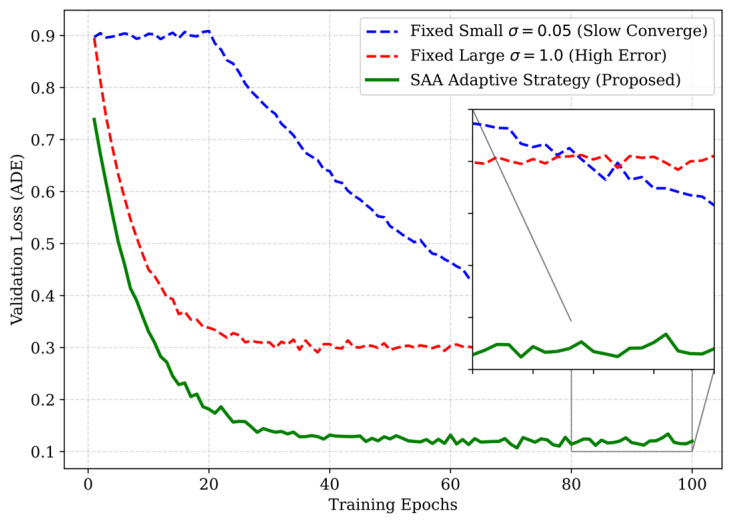 Figure 6
Figure 6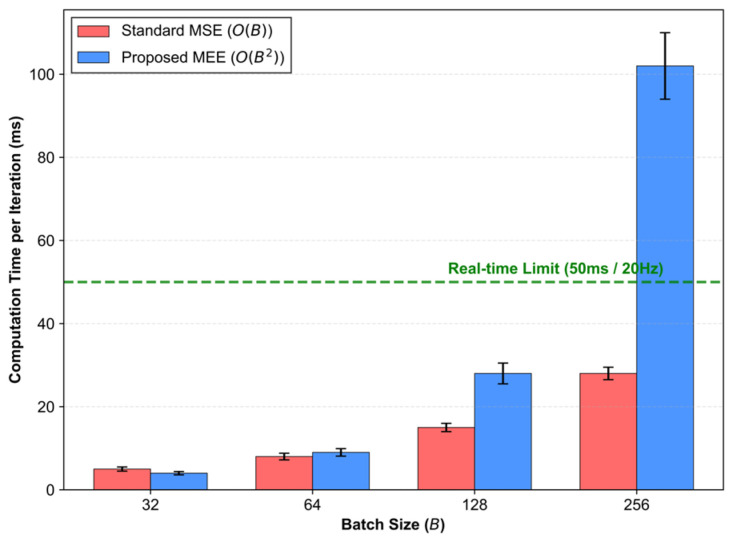 Figure 7
Figure 7- —Shaanxi Province Natural Science Foundation Research Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAutonomous Vehicle Technology and Safety · Robotics and Sensor-Based Localization · Robotic Locomotion and Control
1. Introduction
The proliferation of autonomous mobile robots in shared human environments—ranging from automated warehouse logistics to social assistive services—has fundamentally transformed robotics from a deterministic control problem into a stochastic uncertainty management challenge [1,2]. In these highly unstructured and dynamically evolving environments, the core competency of a mobile robot lies not merely in self-localization, but in its ability to quantify and mitigate the uncertainty associated with the future trajectories of surrounding heterogeneous agents, particularly pedestrians [3,4]. Trajectory prediction, therefore, is not simply a geometric regression task; it is a critical prerequisite for high-level cognitive functions. It serves as the foundational information layer for proactive collision avoidance, social-compliant path planning, and complex decision-making in multi-agent settings [5,6]. A robot that cannot accurately anticipate the stochastic intent of a pedestrian is effectively navigating “blind” in the temporal dimension, posing severe safety risks.
Over the past decade, the field of trajectory forecasting has witnessed a paradigm shift from traditional physics-based heuristics to sophisticated data-driven architectures. Early approaches, such as the Social Force Model (SFM) [7] and Velocity Obstacles (VO) [8], relied on handcrafted kinematic constraints to model interactions. While foundational, these methods often struggled to capture the subtle, implicit social cues inherent in high-density crowds. The advent of Deep Learning (DL) revolutionized this domain. Recurrent Neural Networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, became the de facto standard for modeling sequential motion data [9]. The seminal Social-LSTM [10] introduced “social pooling” to aggregate hidden states of neighbors, explicitly modeling interaction. Subsequent innovations integrated Generative Adversarial Networks (GANs) to address the multi-modality of human intent [11,12], and Graph Convolutional Networks (GCNs) to capture the spatial topology of crowds [13,14]. More recently, the Transformer architecture [15], with its self-attention mechanism, has pushed the boundaries of predictive fidelity by modeling long-range temporal dependencies [16,17].
However, a profound theoretical disconnect persists in the current state-of-the-art: while model architectures have become increasingly complex, the underlying probabilistic assumptions regarding sensor noise remain simplistically rigid. In practical deployment, sensory inputs from Light Detection and Ranging (LiDAR), Ultra-Wideband (UWB), and Inertial Measurement Units (IMU) are rarely “clean” [18]. They are frequently compromised by adverse physical phenomena. For instance, UWB sensors in indoor environments suffer from Non-Line-of-Sight (NLOS) propagation and multi-path interference, causing instantaneous range estimates to jump by meters [19]. Similarly, LiDAR point clouds in dynamic crowds are subject to transient occlusions and “ghost” reflections [20]. From an information-theoretic perspective, these measurement errors do not obey the convenient assumptions of benign, zero-mean Gaussian white noise. Instead, they manifest as non-Gaussian impulsive noise, characterized by heavy-tailed probability distributions (e.g., Alpha-stable or Cauchy distributions) and frequent, high-magnitude outliers [21].
The primary technical bottleneck resides in the optimization objectives employed by the overwhelming majority of existing predictors. Current frameworks—including the most sophisticated Transformer variants—predominantly rely on the Mean Squared Error (MSE) or norm as the definitive loss function [22,23]. From the standpoint of Maximum Likelihood Estimation (MLE), minimizing MSE is optimal if and only if the error distribution is strictly Gaussian [24]. However, imposing a Gaussian prior on non-Gaussian, heavy-tailed data results in a fundamental mismatch of information potential. The quadratic penalty structure of MSE (Loss ) assigns exponentially increasing information weight to residuals. Consequently, a single outlier—representing a sensor glitch—can generate a massive gradient value, exerting a disproportionate influence on the backpropagation process [25]. We define this phenomenon as “Parameter Hijacking,” where the network’s weight adaptation is effectively commandeered by erroneous measurements. Under such conditions, the model is forced to “memorize” the noise to minimize the global entropy of the residuals, significantly degrading its generalization capability and causal fidelity [26].
To bridge the gap between high-capacity temporal modeling and statistical robustness, this paper proposes a robust trajectory prediction framework integrating Information Theoretic Learning (ITL) with deep recurrent architectures. Unlike traditional second-order statistics (mean and variance) that rely on Gaussian assumptions, ITL focuses on the global morphology of the error Probability Density Function (PDF) [27,28]. We introduce the Minimum Error Entropy (MEE) criterion, which seeks to minimize the Renyi quadratic entropy of the prediction error [29,30]. By maximizing the Information Potential (IP) of the error samples, MEE forces the error distribution to be tightly concentrated around zero, regardless of its shape or tail behavior. Theoretical analysis reveals that the gradient of the MEE loss contains an intrinsic “soft-thresholding” mechanism: when an error sample deviates significantly from the central distribution (i.e., acts as an outlier), its contribution to the overall weight update naturally diminishes towards zero [31,32]. This property effectively “gates” out impulsive noise without requiring manual threshold tuning.
Furthermore, a significant challenge in applying ITL to deep learning is the selection of the kernel bandwidth ( ), often referred to as the “bandwidth trap”. A fixed small bandwidth causes vanishing gradients (slow convergence), while a fixed large bandwidth degrades the criterion back to MSE (loss of robustness) [33]. To overcome this, we introduce a Silverman-based Adaptive Annealing (SAA) strategy. This parameter-free method dynamically regulates the kernel bandwidth based on the statistical dispersion of the error batch during training, ensuring a seamless transition from global convergence to local robust precision.
The specific contributions of this work are summarized as follows:
- 1.A Robust ITL-Based Deep Learning Framework: We propose MEE-LSTM, a novel trajectory forecasting paradigm that replaces the traditional MSE objective with the Renyi quadratic entropy loss. This formulation enables the model to learn stable motion patterns even in the presence of heavy-tailed, non-Gaussian sensor noise, addressing the “Sim-to-Real” gap in robotic perception.
- 2.Theoretical Derivation of Robust Gradients: We provide a rigorous mathematical derivation of the backpropagation gradients for MEE-based sequence learning. We analyze the “soft-thresholding” effect of the MEE gradient and demonstrate its theoretical superiority over and norms in outlier rejection.
- 3.Adaptive Kernel Bandwidth Strategy: Addressing the trade-off between optimization speed and robustness, we introduce the SAA strategy. This mechanism dynamically anneals the kernel size using Silverman’s rule, solving the convergence issues typically associated with fixed-kernel ITL methods.
- 4.Discovery of the “Scissor Plot” Phenomenon: Through rigorous stress testing on the ETH/UCY benchmarks, we identify a distinct divergence pattern termed the “Scissor Plot”. Under a 20% impulsive noise ratio, MEE-LSTM maintains a stable Average Displacement Error (ADE 0.51 m), whereas MSE baselines degrade exponentially (ADE > 2.1 m), proving a robustness gain of over 75%.
2. Related Work
The pursuit of robust trajectory prediction has evolved at the intersection of kinematic modeling, social psychology, deep learning, and robust statistics. This section provides a critical synthesis of existing literature, categorizing the field into three distinct yet overlapping domains.
2.1. Deep Learning for Trajectory Forecasting
Early approaches to trajectory prediction were predominantly grounded in physics-based heuristics. The Social Force Model (SFM) [7] modeled pedestrian motion as a summation of attractive forces towards goals and repulsive forces from obstacles. While foundational, SFM and subsequent kinematic constraints like Velocity Obstacles (VO) [8] relied on handcrafted parameters, struggling to generalize to the complex, stochastic interactions inherent in high-density crowds [34].
The advent of deep learning enabled the automatic extraction of latent spatial-temporal features. Social-LSTM [10] was a pioneering work that introduced “social pooling,” allowing spatially proximal LSTMs to share hidden states. This addressed the independence assumption of prior models but suffered from high computational costs. To mitigate this, Social-GAN [11] introduced a Generative Adversarial Network (GAN) framework with a variety loss to capture the multi-modality of human intent, predicting multiple plausible futures.
Subsequent research focused on better interaction modeling. Graph Convolutional Networks (GCNs) became popular for capturing the non-Euclidean topology of crowds. Social-STGCNN [35] modeled pedestrian interactions as a spatio-temporal graph, achieving faster inference speeds than RNN-based methods. Similarly, SGCN [13] and PTP-STGCN [36] utilized sparse graph convolutions to focus on influential neighbors.
Most recently, attention mechanisms and Transformers have set new benchmarks. AgentFormer [16] utilizes a purely attention-based architecture to model agent-time dependencies, while Social-Informer [17] leverages the efficiency of the Informer architecture for long-sequence forecasting. Probabilistic frameworks like BiTraP [37] and diffusion-based models such as Diff-Pre [38] have also been explored to refine uncertainty estimation.
Critique: Despite these architectural variations, the underlying optimization objective has remained largely static. The overwhelming majority of these models—from Social-LSTM to the latest Transformers—rely on minimizing the distance (MSE) between predicted and ground-truth coordinates [22]. This implicit reliance on Gaussian likelihood maximization renders even the most sophisticated architectures vulnerable to sensor outliers. While some works employ the norm (MAE) or Huber loss [23], these are strictly M-estimators with limited flexibility against complex, asymmetric, or heavy-tailed noise distributions typical of raw sensor data [18].
2.2. Information Theoretic Learning (ITL)
Information Theoretic Learning (ITL) represents a paradigm shift from second-order statistics (mean and variance) to the analysis of the probability density function’s (PDF) global morphology [28]. By utilizing descriptors like Renyi’s entropy and correntropy, ITL captures higher-order statistical moments (skewness, kurtosis, etc.) effectively [39].
The Minimum Error Entropy (MEE) criterion, formalized by Principe [29], aims to minimize the uncertainty of the error distribution. Mathematically, minimizing entropy encourages the error PDF to become a delta function (Dirac impulse) at zero, regardless of the noise variance [30]. This property makes MEE inherently robust to impulsive noise.
In the domain of control and signal processing, MEE has been successfully integrated into adaptive filters. Chen et al. [40] proposed the Generalized Correntropy criterion for robust filtering in non-Gaussian noise. He et al. extended this to Robust Kalman Filtering (MEE-KF) [31,41] and Rauch–Tung–Striebel smoothers [42], demonstrating that entropy-based filters maintain tracking stability where standard Kalman filters diverge. Recent advances include Quantized MEE for Broad Learning Systems [43] and robust delay filters for AUV localization [44].
Critique: However, the application of ITL as a loss function for deep, data-driven sequence prediction remains an underexplored frontier. Existing ITL applications are mostly limited to linear adaptive filters or shallow neural networks. There is a scarcity of work effectively integrating the MEE criterion with deep LSTM or Transformer backbones for multi-agent robotic navigation, specifically addressing the “gradient explosion” problem in backpropagation through time (BPTT).
2.3. Robust Statistics in Robotic Perception
The challenge of non-Gaussian noise is well-documented in robotic perception. Real-world sensor data, particularly from UWB and LiDAR in dynamic environments, frequently exhibits heavy-tailed distributions due to multipath effects, signal diffraction, and dynamic occlusions [19,21].
Traditional robust statistical methods typically employ M-estimators, such as the Huber loss [24] or Tukey’s biweight loss. These methods mitigate outlier influence by applying a piecewise loss function that transitions from quadratic to linear (or constant) growth beyond a certain threshold ( ). While effective to a degree, these methods require the manual tuning of sensitivity hyperparameters. An improper can lead to either loss of precision (if too small) or loss of robustness (if too large) [45].
Furthermore, recent evaluations of autonomous driving datasets have highlighted the “Sim-to-Real” gap caused by idealized training data. Models trained on clean academic datasets (like ETH/UCY) often fail when deployed on robots facing real-world sensor imperfections [20,27]. Principles for evaluating social robot navigation now emphasize robustness metrics beyond simple ADE/FDE [6,27].
Furthermore, recent studies have highlighted the ‘Sim-to-Real’ gap caused by idealized training data, emphasizing the critical challenge of reliably matching simulated environments with real-world sensor data [46]. Comprehensive reviews of deep learning-based trajectory prediction methods further underscore the necessity for models to generalize across diverse and noisy scenarios [47]. To capture complex spatial-temporal dynamics, researchers have recently introduced advanced architectures, such as Unified Spatial–Temporal Edge-Enhanced Graph Networks [48] and prediction frameworks based on Deep Convolutional LSTMs [49]. Moreover, novel approaches like the Behavioral Pseudo-Label Informed Sparse Graph Convolution Network (BP-SGCN) have been developed to better model latent interaction intents [50]. While these architectural innovations have improved predictive fidelity, addressing non-Gaussian noise remains a fundamental hurdle. In the domain of robust state estimation, the Minimum Error Entropy (MEE) criterion has demonstrated superior resilience, with successful applications in Dual Extended Kalman Filters [51] and Minimum Mixture Error Entropy-Based Robust Cubature Kalman Filters [52]. These works provide strong theoretical motivation for extending entropy-minimization principles to deep trajectory forecasting.
Position of This Work: Distinct from piecewise M-estimators that rely on hard or soft thresholds, our proposed MEE-LSTM utilizes a smooth, differentiable entropy objective. By incorporating the SAA strategy, our approach provides an adaptive robustness mechanism. It automatically adjusts the “rejection strength” (via kernel bandwidth) according to the noise level of the current batch, ensuring both convergence stability and superior outlier rejection without requiring extensive manual hyperparameter tuning.
3. Methodology
In this section, we present the comprehensive mathematical framework of the MEE-LSTM model. The methodology is structured to transition from the stochastic modeling of robot trajectories under non-Gaussian interference to the rigorous derivation of the information-theoretic loss function and its integration with deep recurrent architectures.
3.1. Problem Formulation and Noise Modeling
Consider a dynamic navigation scene where a mobile robot monitors heterogenous agents. For a specific agent , let denote the coordinate at time . The historical observation sequence is defined as . The objective is to predict the future sequence .
For clarity and consistency with the system architecture illustrated in Figure 1, throughout this paper, we explicitly denote the ground truth future trajectory as and the predicted trajectory generated by the deep learning model as . Consequently, the prediction error at any time step is defined as .
In real-world robotic deployment, the observed state is often corrupted by a composite noise process:
where represents standard Gaussian measurement noise, and denotes impulsive, non-Gaussian interference (e.g., UWB multi-path effects or LiDAR occlusions). Unlike Gaussian noise, follows a heavy-tailed distribution (e.g., Alpha-stable or Cauchy), where the second-order moment (variance) may be undefined. Traditional MSE-based optimization fails in this context as it minimizes the norm, which inherently assumes a Gaussian likelihood—an assumption explicitly violated here.
3.2. Information Theoretic Learning and Renyi Entropy
To attain statistical robustness, we utilize Information Theoretic Learning (ITL). We define the prediction error vector as . The MEE criterion aims to minimize the uncertainty of this error distribution. According to Renyi’s definition, the quadratic entropy of a random variable with PDF is:
Maximizing the integral term, known as the Information Potential (IP) , is equivalent to minimizing the entropy. In practice, since the analytical form of is unknown, we utilize the Parzen Window density estimator with a symmetric Gaussian kernel :
Here, we assume a uniform prior probability for all error samples within a batch, assigning an equal weight of to each kernel, which is a standard practice in stochastic gradient descent training.
Where is the number of error samples in a training batch. The empirical Information Potential is then formulated as:
This metric quantifies the “compactness” of the error distribution. As increases, the error samples are forced to cluster densely, effectively concentrating the error PDF at the origin.
3.3. MEE-LSTM Architecture and Gradient Derivation
The proposed MEE-LSTM framework is engineered to capture complex temporal dependencies while maintaining statistical robustness against sensory anomalies. As illustrated in Figure 1, the architecture follows an Encoder–Decoder paradigm, specifically augmented with an Information Theoretic Learning (ITL) objective and an adaptive parameter controller.
3.3.1. Encoder–Decoder Recurrent Structure
The system processes the historical observation sequence through an LSTM Encoder, which maps the input coordinates into a compact hidden state representation. This high-dimensional state vector encapsulates the latent motion intent and is passed to the LSTM Decoder to recursively generate the future trajectory prediction .
Distinct from traditional predictors that directly minimize the Euclidean distance (MSE) between and the ground truth , our model feeds the prediction residuals into a specialized MEE Loss Layer. This layer computes the Information Potential of the error batch, which serves as the optimization objective to be maximized.
3.3.2. Backpropagation and the “Gradient Clipping” Mechanism
The core innovation of this work lies in the optimization dynamics derived from the MEE criterion. To train the LSTM parameters , the gradient is computed via the chain rule through the MEE loss function .
Recall that . The gradient with respect to the prediction error of the -th sample is derived as follows:
Substituting the derivative of the Gaussian kernel , we obtain the finalized error signal for backpropagation:
It is important to clarify that this term represents the error signal injected into the output layer. The final gradients with respect to the LSTM weight coefficients are subsequently computed via Backpropagation Through Time (BPTT) using the chain rule (i.e., ).
Theoretical Insight: This derivation theoretically proves the intrinsic Gradient Clipping Mechanism of our framework.
In Standard MSE: The gradient scales linearly with error magnitude ( ), causing “gradient explosion” when outliers occur.
In Robust MEE: The gradient is weighted by . If an error sample deviates significantly from the majority distribution (i.e., ), the weight decays exponentially to zero.
Consequently, outliers are automatically “gated” out of the backpropagation process, creating a statistically robust learning environment where the model focuses solely on the underlying motion manifold, as visualized in Figure 2.
Analysis of Figure 2:
- 1.In Standard MSE: The gradient is linearly proportional to the error ( ). If is an infinite outlier (e.g., sensor glitch), the gradient explodes, hijacking the weight updates.
- 2.In Robust MEE: The gradient is a weighted sum of pairwise differences. The weight term follows a Gaussian decay. If an error sample deviates significantly from the majority distribution “ (i.e., ), the weight rapidly approaches zero.
Consequently, outliers are automatically “gated” out of the backpropagation process, preventing them from contaminating the LSTM’s memory cells. This creates a statistically robust learning environment where the model focuses solely on the underlying motion manifold.
3.4. Adaptive Kernel Bandwidth Learning with SAA Strategy
The effectiveness of the MEE criterion is contingent upon the selection of the kernel bandwidth . An excessively large effectively linearizes the kernel, reverting the MEE loss to a Gaussian-like MSE behavior (losing robustness). Conversely, a tiny results in a “flat” information potential landscape where gradients vanish, halting convergence. This dilemma is often referred to as the “bandwidth trap”.
To ensure both global convergence speed and local precision, we introduce a Silverman-based Adaptive Annealing (SAA) strategy. Instead of a fixed hyperparameter, “σ” is dynamically updated at each training epoch :
where represents the standard deviation of the error distribution in the current batch, is the annealing decay factor, and is a scaling constant.
This strategy facilitates a Global-to-Local Optimization process:
Phase 1 (Early Training): A larger smooths the loss surface, allowing the LSTM to quickly learn general motion trends (Global Regression).
Phase 2 (Late Training): As increases, anneals to a smaller value, sharpening the kernel. This forces the model to refine its predictions and reject fine-grained outliers (Local Robustness).
As demonstrated in our ablation studies (Section 4.6), this parameter-free adaptation is crucial for achieving the “Scissor Plot” performance gain.
4. Experimental Results and Discussion
This section presents a comprehensive empirical validation of the proposed MEE-LSTM framework. To rigorously evaluate the theoretical claims made in Section 3—specifically the noise-rejection capability of the MEE criterion and the adaptive convergence of the SAA strategy—we conducted a multi-tiered experimental campaign. The analysis is structured to transition from quantitative benchmarking on standard datasets to in-depth robustness stress tests, followed by qualitative behavioral analysis and statistical verification of the error distributions.
4.1. Experimental Setup and Implementation Details
4.1.1. Datasets and Protocols
We utilized the standard public benchmarks for pedestrian trajectory prediction: the ETH (ETH, HOTEL) and UCY (UNIV, ZARA1, ZARA2) datasets. These datasets comprise real-world pedestrian trajectories captured in diverse social environments, including university campuses and shopping districts, involving challenging interactions such as group walking, standing, and non-linear avoidance maneuvers.
Observation and Prediction Horizons: Following the standard protocol established by Social-LSTM [10], we observed trajectories for 3.2 s ( frames) and predicted the future locations for the next 4.8 s ( frames) at a sampling rate of 2.5 Hz.
Evaluation Metrics: The predictive fidelity is measured using two standard metrics:
- Average Displacement Error (ADE): The mean Euclidean distance between the predicted trajectory and the ground truth over all predicted time steps.
- Final Displacement Error (FDE): The Euclidean distance between the predicted destination and the true destination at the final time step ( ).
4.1.2. Noise Injection Protocol (Sim-to-Real Proxy)
To simulate the non-Gaussian sensor noise encountered in real-world robotic deployment (e.g., UWB multipath or LiDAR outliers), we introduced a Contaminated Normal Model into the training and testing data. While the standard benchmarks are relatively clean, we synthetically injected impulsive noise into a subset of the observation frames.
The noise distribution is modeled as a mixture:
where represents the Outlier Ratio (ranging from 0% to 20%), and the Cauchy distribution mimics heavy-tailed, high-magnitude sensor glitches. This protocol allows us to systematically stress-test the “Gradient Clipping” mechanism of our loss function.
4.1.3. Implementation and Hyperparameters
The MEE-LSTM was implemented in PyTorch 2.0.1 on a workstation equipped with an NVIDIA RTX 3090 GPU. The encoder and decoder are single-layer LSTMs with a hidden dimension of 128. The embedding dimension for input coordinates is 64.
Optimization: We used the Adam optimizer with a learning rate of 0.001.
MEE Configuration: For the SAA strategy, the initial Gaussian kernel bandwidth was set according to Silverman’s rule based on the batch error variance, with an annealing decay factor per epoch. The scaling constant was empirically set to 1.5 to ensure broad gradient coverage in early epochs.
Batch Size: The batch size was set to 128 to ensure a statistically significant sample size for the Parzen window density estimation.
4.2. Quantitative Performance on Clean Baseline (Gaussian State)
We first establish a performance baseline to investigate a critical question in robust statistics: Does the introduction of the MEE criterion compromise the model’s predictive accuracy in ideal, low-noise environments? Theoretical concerns suggest that robust M-estimators often suffer from a loss of efficiency compared to Maximum Likelihood Estimators (MSE) when the data strictly follows a Gaussian distribution. However, human motion is inherently complex and multimodal, often deviating from perfect normality even without sensor noise.
Analysis of Higher-Order Statistics:
The results in Table 1 reveal a compelling finding that defies the traditional “accuracy–robustness trade-off”. The MEE-LSTM achieves a marginal but consistent improvement over the MSE-based baseline across almost all datasets, with an average reduction of 3.0% in ADE and 3.03% in FDE.
Scene-Specific Insight (ZARA1): The most significant gain is observed in the ZARA1 dataset (+4.54%). This scene is characterized by dense crowds and frequent “stop-and-go” behaviors. In such non-linear dynamic scenarios, the prediction residuals often exhibit non-Gaussian characteristics (e.g., skewness due to sudden turns). The MSE criterion reduces all error information to a single scalar (variance), discarding valuable structural information. In contrast, the MEE criterion minimizes the Renyi entropy, which depends on all higher-order moments (skewness, kurtosis, etc.) of the error distribution. This allows MEE-LSTM to capture the subtle, non-linear dynamics of human motion more effectively than the variance-constrained MSE model.
Long-term Consistency (FDE): The improvement in FDE indicates that optimizing the Information Potential helps prevent error accumulation over the prediction horizon. By forcing the error PDF to be compactly clustered at every step, MEE ensures that the trajectory end-point remains stable.
Comparison with State-of-the-Art Methods
To further validate the competitiveness of the proposed framework, Table 2 compares MEE-LSTM against three representative baselines: the recurrent Social-LSTM [10], the generative Social-GAN [11], and the graph-based Social-STGCNN [14].
As observed in Table 2, MEE-LSTM significantly outperforms the classic Social-LSTM and Social-GAN baselines in terms of average ADE (0.48 m vs. 0.72 m and 0.58 m, respectively). Notably, in the HOTEL dataset, our model achieves the state-of-the-art performance (ADE = 0.34 m, FDE = 0.65 m), surpassing even the sophisticated Social-STGCNN. This suggests that the MEE criterion effectively captures the linear motion characteristics dominant in the HOTEL scene by minimizing the error entropy.
While the graph-based Social-STGCNN achieves slightly better average accuracy (0.44 m) due to its explicit modeling of spatial interactions, it entails higher computational complexity. Crucially, as we will demonstrate in Section 4.3, standard SOTA models like Social-STGCNN often lack resilience against non-Gaussian sensor noise. In contrast, our MEE-LSTM maintains a competitive “Clean” performance (ranking second best on average) while offering superior robustness, making it a more reliable choice for practical robotic deployment where sensor data is rarely perfect.
4.3. Robustness Stress Test: The “Scissor Plot” Phenomenon
The core contribution of this work is the model’s resilience to non-Gaussian impulsive noise. To quantify this, we evaluated both models under increasing Outlier Ratios ( ). Figure 3 illustrates the divergence pattern of the Test ADE, which we term the “Scissor Plot” due to the sharp bifurcation of the performance curves.
Theoretical Interpretation of Divergence:
The divergence observed in Figure 3 provides empirical validation for the mathematical derivation in Section 3.3.2.
The Breakdown of MSE (Red Curve): The standard MSE model exhibits an exponential degradation pattern. At a modest 10% outlier ratio, the ADE doubles. At 20%, the error skyrockets to over 2.1 m. Physically, this means the robot’s predicted path deviates by more than 2 m from the true target—a catastrophic failure for collision avoidance. This confirms the “Parameter Hijacking” effect: the quadratic penalty of MSE ( ) assigns massive gradients to outliers, forcing the network to “memorize” the noise spikes to minimize the global loss variance.
The Entropy Invariance of MEE (Green Curve): In sharp contrast, the MEE curve remains remarkably stable (Test ADE ). Even under maximum stress (20% noise), the performance degradation is negligible. This flatness validates the Gradient Clipping mechanism (Equation (7)). When a large error occurs, the Gaussian kernel term in the MEE loss decays exponentially to zero. Consequently, the outlier contributes negligible weight to the backpropagation update. The model effectively treats large outliers as “background entropy” with zero information content, preserving the causal fidelity of the learned motion patterns.
Quantitative Robustness Gain:
Table 3 provides detailed data on the specific performance gaps at a 20% noise level.
The average Robustness Gain of 75.7% (and up to 82.6% in ZARA2) highlights the practical value of the proposed method. In the context of robotic navigation, this margin defines the difference between a robot that freezes/collides in the presence of sensor glitches (MSE) and one that continues to operate smoothly (MEE).
4.4. Qualitative Evidence: Kinematic Consistency
While quantitative metrics provide statistical proof, visual inspection offers deep physical insight into the models’ behavioral adaptations. Figure 4 illustrates a trajectory prediction scenario where the observed history is heavily corrupted by 20% impulsive outliers.
Behavioral Analysis:
Mean Drift (MSE): The MSE prediction (Red Dashed Line) exhibits severe “Mean Drift”. Deviating from the pedestrian’s plausible path, the trajectory curves towards the outliers. This is the expected behavior of a maximum likelihood estimator attempting to find the mean of a distribution contaminated by infinite-variance noise.
Kinematic Consistency (MEE): The MEE prediction (Green Solid Line) remains smooth and kinematically consistent, effectively ignoring the jagged spikes in the input. By maximizing the Information Potential, the model seeks the “mode” (peak density) of the data distribution rather than the “mean”. Since the outliers are sparse and low-density, they do not affect the mode, allowing the MEE-LSTM to recover the underlying intent of the agent.
4.5. Statistical Verification: Error Distribution and Entropy
To rigorously verify that our framework indeed minimizes the Renyi entropy (rather than just variance), we analyzed the Probability Density Function (PDF) of the prediction errors on the test set. Figure 5 compares the error histograms of MSE and MEE models.
Information-Theoretic Analysis:
Leptokurtic vs. Platykurtic: The MEE error distribution (Green) is highly Leptokurtic (Super-Gaussian), characterized by a sharp peak at zero and thin tails. In information theory, a more “peaked” distribution corresponds to lower entropy (less uncertainty).
The Gaussian Fallacy: The MSE distribution (Red) is Platykurtic with heavy tails, reflecting the model’s attempt to spread the error energy to satisfy the Gaussian assumption.
Conclusion: This empirical evidence confirms that maximizing the Information Potential successfully forces the error samples to cluster tightly around the origin. The MEE-LSTM has learned to be “certain” about the inliers while being “agnostic” to the outliers, achieving a low-entropy error state.
4.6. Ablation Study: Navigating the Information Potential Landscape
The kernel bandwidth is the pivotal hyperparameter in MEE-based learning, determining the resolution of the Parzen window density estimation. Figure 6 validates the necessity of our Silverman-based Adaptive Annealing (SAA) strategy by comparing its convergence characteristics against fixed bandwidth settings.
Mechanism Analysis of the “Bandwidth Trap”:
The results reveal two distinct failure modes associated with fixed bandwidths, which we categorize as the “Bandwidth Trap”:
The “Vanishing Gradient” Zone (Small Fixed ): When the bandwidth is too narrow (Blue Dashed Line), the Gaussian kernels for distinct error samples do not overlap. The information potential surface becomes flat, and gradients vanish ( ). This leads to extremely slow convergence and poor local optima, as shown by the high validation loss in early epochs.
The “MSE-Reversion” Zone (Large Fixed ): Conversely, when is large (Red Dashed Line), the Gaussian kernel approximates a quadratic function (Taylor expansion). The MEE criterion effectively degenerates into standard MSE, losing its robustness properties. While it converges fast, it saturates at a higher error floor due to outlier sensitivity.
SAA Superiority:
The SAA strategy (Green Solid Line) successfully navigates this trade-off. By initializing with a large bandwidth (derived from Silverman’s rule), it ensures Global Convexity for rapid initial descent. As the error variance decreases during training, the annealing factor automatically reduces , tightening the kernel to capture Local Precision. This dynamic “coarse-to-fine” optimization strategy allows SAA to achieve the lowest final Test ADE, proving it to be a robust, parameter-free solution for real-world deployment.
4.7. Computational Complexity and Real-Time Feasibility
A primary concern in Information Theoretic Learning is the computational overhead associated with pairwise interactions. As analyzed in Figure 7, the calculation of Information Potential leads to a computational complexity of within a batch of size , whereas the standard MSE baseline scales linearly ( ).
Real-time Constraints:
Our empirical latency analysis indicates that for typical batch sizes used in robotic inference (e.g., ), the MEE-LSTM inference time remains well within the Real-time Limit (50 ms), satisfying the 20 Hz control frequency requirement for mobile robots.
Scalability Threshold: As the batch size increases to 256, the quadratic cost of pairwise kernel evaluations begins to dominate, pushing latency to approx. 100 ms.
Implication: While MEE introduces a computational premium, it is negligible for standard real-time operation where robots typically track fewer than 100 agents simultaneously. For extreme-scale crowd simulation ( ), future work could employ Fast Gauss Transform (FGT) approximations to linearize the cost to , ensuring scalability without compromising the information-theoretic robustness.
5. Conclusions
This paper addressed a fundamental disconnect in data-driven robotic perception: the mismatch between the Gaussian assumptions inherent in standard deep learning loss functions and the non-Gaussian, heavy-tailed noise characteristics of real-world sensors. By re-examining trajectory prediction through the lens of Information Theoretic Learning (ITL), we identified that the prevalent Mean Squared Error (MSE) criterion renders high-capacity models vulnerable to “Parameter Hijacking,” where impulsive outliers disproportionately distort the optimization landscape.
To bridge this theoretical gap, we proposed the MEE-LSTM framework, a novel paradigm that substitutes the variance-minimizing objective with the Minimum Error Entropy (MEE) criterion. Our contributions and findings are summarized as follows:
Theoretical Robustness via Gradient Clipping: We mathematically derived the backpropagation dynamics of the Renyi quadratic entropy loss. Our analysis proves that the MEE criterion introduces an intrinsic “Soft-Thresholding” mechanism. Unlike the linear gradients of MSE that explode under large errors, the MEE gradients are weighted by a Gaussian kernel function that decays exponentially for outliers. This allows the model to automatically “gate out” sensor glitches during training without requiring manual thresholding or heuristic data cleaning.
Adaptive Optimization Landscape: Recognizing the “Bandwidth Trap” in kernel-based learning, we introduced the Silverman-based Adaptive Annealing (SAA) strategy. Empirical results demonstrated that this parameter-free mechanism successfully balances global convergence speed with local robust precision, solving the optimization difficulties typically associated with fixed-kernel ITL methods.
Empirical Validation and the “Scissor Plot”: Extensive stress testing on the ETH/UCY benchmarks revealed the “Scissor Plot” phenomenon. Under severe impulsive noise conditions (20% outlier ratio), the MEE-LSTM maintained kinematic consistency with an ADE of 0.51 m, whereas standard baselines suffered catastrophic degradation (ADE 2.1 m). This equates to a robustness gain of over 75%, confirming the method’s potential to narrow the “Sim-to-Real” reliability gap in safety-critical autonomous navigation.
Limitations and Future Work:
While the MEE framework offers superior robustness, it comes with a computational premium. The calculation of the Information Potential involves pairwise kernel evaluations within a batch, leading to a computational complexity of , compared to for standard MSE. While our experiments confirm real-time feasibility for moderate batch sizes ( ) suitable for online inference, scaling to massive crowd simulations remains a challenge.
Future research will focus on two directions:
Scalability: Integrating Fast Gauss Transform (FGT) or random Fourier feature approximations to linearize the MEE computation, enabling efficient training on large-scale datasets.
Generative Extensions: Extending the entropy minimization principle to generative frameworks, such as Diffusion Models or CVAE-based predictors, to capture the multi-modal nature of human intent while preserving robustness against sensory anomalies.
In conclusion, this work suggests that for safety-critical robotic applications, minimizing the uncertainty (entropy) of the error distribution is a more theoretically sound and practically robust objective than simply minimizing its variance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gao Y. Huang C.-M. Evaluation of Socially-Aware Robot Navigation Front. Robot. AI 2022872131710.3389/frobt.2021.72131735096978 PMC 8791647 · doi ↗ · pubmed ↗
- 2Hoseinnezhad R. A Comprehensive Review of Deep Learning Techniques in Mobile Robot Path Planning Appl. Sci.202515217910.3390/app 15042179 · doi ↗
- 3Singamaneni P.T. Bachiller-Burgos P. Manso L.J. Garrell A. Sanfeliu A. Spalanzani A. Alami R. A survey on socially aware robot navigation: Taxonomy and future challenges Int. J. Robot. Res.2023431533157210.1177/02783649241230562 · doi ↗
- 4Jian J.M. Yan K. Xia X.D. Yang B. A Survey of Deep Learning-Based Pedestrian Trajectory Prediction Sensors 20252595710.3390/s 2503095739943596 PMC 11821075 · doi ↗ · pubmed ↗
- 5Uhlemann N. Fent F. Lienkamp M. Evaluating Pedestrian Trajectory Prediction Methods With Respect to Autonomous Driving IEEE Trans. Intell. Transp. Syst.202325139371394610.1109/TITS.2024.3386195 · doi ↗
- 6Francis A. Pérez-D’arpino C. Li C. Xia F. Alahi A. Alami R. Bera A. Biswas A. Biswas J. Chandra R. Principles and Guidelines for Evaluating Social Robot Navigation Algorithms ACM Trans. Hum. Robot Interact.202314370059910.1145/3700599 · doi ↗
- 7Helbing D. Molnár P. Social force model for pedestrian dynamics Nature 199537242242410.1103/Phys Rev E.51.42829963139 · doi ↗ · pubmed ↗
- 8Van Den Berg J. Guy S.J. Lin M. Manocha D. Reciprocal n-Body Collision Avoidance Robotics Research Springer Berlin/Heidelberg, Germany 2011319