Development and Temporal Validation of Explainable Machine Learning Models for Predicting Vitamin B12 Deficiency Using Routine Laboratory Analytes
Ferhat Demirci, Oktay Yıldırım, Aylin Demirci, Pınar Akan

TL;DR
This study developed and validated machine learning models to predict vitamin B12 deficiency using routine lab tests, offering a cost-effective way to detect the condition early.
Contribution
A novel, explainable machine learning framework for predicting vitamin B12 deficiency using only routine laboratory data, validated over time.
Findings
CatBoost model achieved high sensitivity (0.92) and AUC-ROC (0.88) in predicting vitamin B12 deficiency.
Temporal validation showed improved discrimination (AUC-ROC 0.90) and stable model performance.
Hematologic indices and age were key predictors, aligning with known B12 deficiency pathophysiology.
Abstract
Background/Objectives: Vitamin B12 deficiency is a prevalent yet frequently underdiagnosed condition, largely due to the limited diagnostic accuracy of serum total B12 and the restricted availability of confirmatory biomarkers such as holotranscobalamin and methylmalonic acid. This study aimed to develop and validate explainable machine learning (ML) models capable of predicting vitamin B12 deficiency using only routinely available laboratory examinations, thereby supporting early detection within standard diagnostic workflows. Methods: This retrospective study included 51,630 adult patients who underwent concurrent vitamin B12 testing and routine laboratory evaluation between 2015 and 2025. An independent temporal validation cohort of 34,744 patients was used to assess generalizability. Eight supervised ML algorithms were developed within a four-stage experimental framework…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
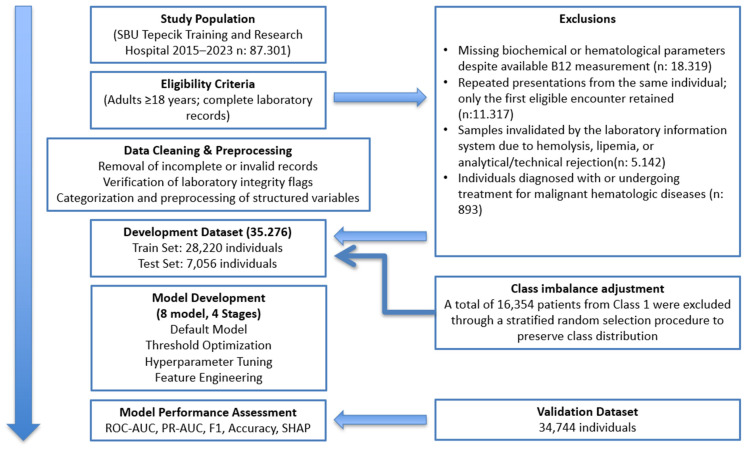 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFolate and B Vitamins Research · Explainable Artificial Intelligence (XAI) · Artificial Intelligence in Healthcare and Education
1. Introduction
Vitamin B12 (cobalamin) is an essential micronutrient required for DNA synthesis, myelin maintenance, and one-carbon metabolism. Deficiency can result in macrocytic anemia, neurocognitive impairment, and increased cardiovascular risk mediated through hyperhomocysteinemia [1]. Although serum total B12 concentration is the most frequently used diagnostic test, it often fails to reflect intracellular cobalamin status, leading to “functional B12 deficiency” even when serum levels fall within the low-normal range [1,2]. More specific biomarkers—such as holotranscobalamin (holo-TC), methylmalonic acid (MMA), and homocysteine (Hcy)—provide improved diagnostic accuracy, yet their higher cost, limited availability, and lack of integration into routine laboratory workflows restrict widespread use [3,4]. Consequently, clinically significant deficiency may remain undetected until hematological or neurological manifestations become evident [2].
In recent years, the growing availability of large-scale laboratory datasets and advances in machine learning (ML) have opened new possibilities for leveraging routinely collected biochemical and hematological measurands to predict micronutrient deficiencies. Tamune et al. demonstrated that ML models using standard blood tests can efficiently predict vitamin B group deficiencies, including B12, in patients with acute psychiatric episodes [5]. Beyond B12, several studies have applied ML to other micronutrients and lipid biomarkers: Sharifmousavi and Borhani developed an SVM-based model that incorporated selenium, vitamin B12, and vitamin D3 levels for the diagnosis of multiple sclerosis [6], while Sancar and Tabrizi showed that ML approaches can accurately classify vitamin D status using routine laboratory variables [7]. Similarly, ML-based models have been proposed for predicting low-density lipoprotein cholesterol (LDL-C) from standard biochemical profiles, achieving good agreement with directly measured and calculated LDL-C values [8]. Collectively, these findings highlight the feasibility of using routinely available laboratory data to build predictive models for diverse biochemical targets.
Another important development has been the increasing emphasis on explainable artificial intelligence (XAI) in clinical prediction models. Hu et al. reported an explainable ML model for predicting spontaneous bacterial peritonitis in cirrhotic patients with ascites, using SHAP-based explanations to identify the most influential laboratory and clinical variables. In a broader perspective, a recent systematic review by Alkhanbouli et al. underscored the role of explainable AI techniques in disease prediction and clinical decision support, emphasizing transparency, trust, and model interpretability as essential requirements for implementation in healthcare settings [9]. For high-stakes decisions such as the detection of vitamin B12 deficiency—where underdiagnosis may lead to irreversible neurological damage—models that are both accurate and interpretable are particularly valuable.
Given the high prevalence of vitamin B12 deficiency, its often subtle or delayed clinical presentation, and the limited accessibility of confirmatory biomarkers, there is a clear need for robust, low-cost, and scalable predictive models based entirely on routine laboratory measurands. Such models could be integrated into hospital information systems as automated decision-support tools, providing real-time alerts for individuals at high risk and reducing unnecessary second-line testing.
The present study aims to address these gaps by developing and validating several machine learning algorithms—including artificial neural networks, boosting-based ensemble models, support vector machines, and logistic regression—to predict laboratory-defined low vitamin B12 status using a large, multiyear dataset of routinely collected biochemical and hematological measurands. Model performance was evaluated using ROC-AUC, PR-AUC, F1-score, accuracy, and the Matthews correlation coefficient. To ensure clinical interpretability, SHAP and LIME techniques were employed to identify the variables contributing most substantially to model predictions. Furthermore, an independent temporal validation cohort was used to assess the generalizability and robustness of the final model under real-world conditions. Overall, this study aims to establish a reliable, scalable, and explainable machine learning framework capable of supporting early identification of individuals at risk for vitamin B12 deficiency within routine clinical practice.
2. Materials and Methods
2.1. Study Population/Subjects
This retrospective study included adult patients who underwent serum vitamin B12 testing together with routine hematological and biochemical examinations at Health Sciences University İzmir Tepecik Training and Research Hospital between 1 January 2015 and 1 October 2025. Prior to study initiation, approval was obtained from the hospital’s Non-Interventional Research Ethics Committee (initial ethics approval: 13 July 2023—2023/06-38; additional approval: 30 October 2025—293077648). Laboratory data were extracted from the hospital information system (HIS) and were based on instrument outputs verified and authorized by a board-certified medical biochemistry specialist. Only the first eligible laboratory encounter for each patient was included in the study, and all records were anonymized during data extraction. Only outpatient laboratory encounters were included in this study. Inpatient laboratory data were intentionally excluded in order to minimize potential confounding effects related to acute illness severity, ongoing medical treatments, intravenous fluid administration, and rapid physiological fluctuations, which may substantially influence hematological and biochemical parameters independent of vitamin B12 status. By restricting the analysis to the first eligible outpatient laboratory encounter for each patient, we aimed to ensure greater biological stability of the measured variables and to improve the clinical interpretability and real-world applicability of the developed machine-learning models.
2.2. Inclusion Criteria
Age ≥ 18 yearsAvailability of serum vitamin B12 measurement performed concurrently with all predefined hematological and biochemical testsFirst eligible outpatient laboratory encounter within the study periodComplete numerical laboratory results available for all required parametersSpecimen processed within the institution’s standardized pre-examination workflow and quality limits
2.3. Exclusion Criteria
Age < 18 yearsMissing, corrupted, or non-numerical laboratory resultsMultiple encounters for the same patient, in which case only the first eligible record was retainedSpecimens exhibiting pre-examination delays exceeding institutional workflow limitsPregnancyActive oncologic disease or hematologic malignancyForensic/medico-legal casesEmergent conditions associated with spontaneous acute bleeding or requiring immediate emergency evaluation, including but not limited to:
- -Acute coronary syndrome
- -Pulmonary embolism
- -Aortic dissection/rupture
- -Subacute arachnoid hemorrhage
- -Transient ischemic attack
- -Massive gastrointestinal hemorrhage
Pregnancy, active oncologic disease, hematologic malignancy, and acute emergent conditions were excluded because these states are known to induce substantial physiological and treatment-related alterations in hematological indices and biochemical parameters, independent of vitamin B12 status. Such alterations may introduce confounding variability and obscure the underlying relationship between routine laboratory measurands and vitamin B12 deficiency. Excluding these conditions was therefore intended to improve the biological validity and interpretability of the machine-learning models.
This cohort represents a clinically enriched population in which serum vitamin B12 testing was performed based on clinical suspicion rather than population-wide screening. Accordingly, the model is intended for risk stratification and decision support within routine diagnostic workflows, and not for indiscriminate population screening. Accordingly, the observed prevalence of vitamin B12 deficiency in this cohort should not be interpreted as population prevalence but rather as reflecting a clinically selected diagnostic setting.
Venous whole-blood samples were collected into K_2_-EDTA tubes, and serum samples were obtained in additive-free plain tube, in accordance with routine clinical protocols. In line with the National Health Quality Standards (Version 5.1), all specimens were delivered to the laboratory within 30 min, and biochemical measurements were completed within two hours of sample collection.
Hematological measurands, including hemoglobin (HGB), red blood cell count (RBC), hematocrit (HCT), mean corpuscular volume (MCV), red cell distribution width (RDW), mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), white blood cell count (WBC), neutrophil count (NEU), lymphocyte count (LYM), monocyte count (MONO), basophil count (BASO), platelet count (PLT), mean platelet volume (MPV), and platelet distribution width (PDW), were measured using LH-780 (Beckman Coulter Inc., Mannheim, Germany) and XN-1000 (Sysmex Corporation, Kobe, Japan) hematology analyzers. Biochemical assays, including glucose, creatinine, alanine aminotransferase (ALT), aspartate aminotransferase (AST), alkaline phosphatase (ALP), gamma-glutamyl transferase (GGT), lactate dehydrogenase (LDH), serum iron, C-reactive protein (CRP), albumin, total protein, and total bilirubin, were performed on an AU5800 analyzer (Beckman Coulter Inc., Mannheim, Germany). Chemiluminescence-based immunoassays, including vitamin B12, folate, ferritin, free thyroxine (fT4), and thyroid-stimulating hormone (TSH), were conducted on the DxI800 analyzer (Beckman Coulter Inc., Mannheim, Germany).
All reagents, calibrators, and internal quality-control materials were certified and approved by the manufacturer. Standard institutional internal and external quality-control procedures were maintained throughout the examination process. All laboratory results were reviewed and analytically validated by a medical biochemistry specialist before being transferred to the hospital information system.
2.4. Study Design
To ensure data confidentiality, all patient identifiers were irreversibly removed prior to analysis. A comprehensive dataset containing age, gender, and all hematological and biochemical measurands was generated through the hospital information system (HIS). A total of 87,301 laboratory records from the study period were reviewed and exported to Microsoft Excel 2021 (USA). After applying the predefined exclusion criteria, 51,630 patients were deemed eligible and included in the study, while all other records were excluded.
To address class imbalance in the machine-learning analyses and enable the model to effectively learn the minority class, a random undersampling strategy was applied to construct the development dataset. This procedure was performed in Python, whereby all observations belonging to the minority class were retained, and an equal number of records were randomly selected from the majority class. As a result of this class-balancing step, 16,354 records from the majority class were randomly discarded, yielding a final development cohort of 35,276 patients. Class balancing was applied exclusively during model development to improve learning of the minority class. All reported performance metrics were interpreted with careful consideration of the underlying class distribution, and final model evaluation was performed on an independent temporal validation cohort without any modification of the trained model. This intentional 1:1 class ratio was implemented solely to facilitate algorithmic learning and to reduce the risk of overfitting and majority-class dominance; it does not represent the underlying clinical prevalence of vitamin B12 deficiency in the source population.
The development dataset (1 January 2015–30 May 2023) was subsequently split into 80% training and 20% test sets using stratified random partitioning, in order to preserve class distribution and reduce the risk of overfitting. Using identical preprocessing steps and the same random under sampling strategy, an independent temporal validation set consisting of 34,744 patient records (collected between 1 June 2023 and 1 October 2025) was used for external validation. This approach enabled evaluation of the model’s temporal generalizability on data derived from a later clinical period. The temporal validation cohort was evaluated without any additional class balancing or recalibration, allowing assessment of model performance under a naturally evolving clinical data distribution.
All data preprocessing, model development, class balancing, training–test partitioning, and reporting procedures were conducted in accordance with the TRIPOD guidelines. A flow diagram summarizing patient selection, exclusion criteria, and the final analytic cohorts is presented in Figure 1.
2.5. Data Preprocessing and Training of Machine-Learning Algorithms
All preprocessing steps—including removal of duplicate records, unit standardization, exclusion of entries with missing values, categorical encoding based on reference intervals, and feature engineering—were predefined and applied to the dataset prior to splitting into training, test, and temporal validation sets. This ensured a consistent and reproducible preprocessing pipeline across all data subsets and prevented discrepancies arising from heterogeneous data preparation.
Raw laboratory data extracted from the HIS were preprocessed through removal of duplicate patient records, standardization of unit inconsistencies for selected biochemical measurands (e.g., albumin, total protein), and exclusion of entries containing missing parameters. Given that extreme values may represent true biological measurements within clinical practice and can directly influence model performance, outliers were not removed. This approach was adopted to preserve real-world clinical variability and avoid discarding clinically meaningful extremes. To mitigate potential sensitivity of certain algorithms to extreme values, the only continuous variable (age) was standardized prior to model training. This strategy is consistent with prior clinical machine-learning studies emphasizing the importance of retaining biologically plausible extreme values to enhance generalizability [10].
Study Flow Diagram for Cohort Selection and Data Processing.
Age was retained as a continuous variable, whereas all biochemical and hematological analytes were transformed into categorical variables based on clinically defined threshold values. Evidence-based clinical decision limits were used when available; otherwise, manufacturer-provided reference intervals were applied. Each analyte was encoded as 0 (below reference interval), 1 (within reference interval), or 2 (above reference intyerval). For parameters without a biologically meaningful lower bound, a binary scheme was adopted. Gender was coded as 1 for males and 2 for females.
Serum vitamin B12 concentrations were initially classified into three categories according to established clinical guidelines: deficiency (<180 pg/mL), possible vitamin B12 deficiency (180–350 pg/mL), and normal status (>350 pg/mL). These thresholds reflect clinically meaningful decision limits and are consistent with international recommendations (e.g., NICE guidelines [11]).
For the primary machine-learning analyses, the initial three-category structure of vitamin B12 was subsequently converted into >350 a binary variable (0 = deficient/insufficient (<350 pg/mL); 1 = within reference interval (>350 pg/mL). This transformation was performed to reduce class imbalance and to reflect real-world clinical practice, in which patients with borderline vitamin B12 levels are often managed similarly to those with overt deficiency. Classification thresholds for all measurands are provided in Supplementary Material S1, Table S1.
Eight supervised machine-learning algorithms—logistic regression, random forest, decision tree, support vector machines, k-nearest neighbors, XGBoost, CatBoost, and artificial neural networks—were developed within a four-stage experimental framework. These algorithms were selected to represent a diverse set of supervised learning paradigms commonly used in clinical prediction modeling. Logistic regression was included as a transparent linear baseline model, whereas decision tree and random forest algorithms were used to capture non-linear relationships and feature interactions. Support vector machines and k-nearest neighbors represent kernel-based and distance-based learning strategies, respectively, but may be sensitive to feature scaling and data dimensionality. Gradient boosting methods (XGBoost and CatBoost) were selected due to their strong performance on structured tabular data, with CatBoost offering additional robustness through built-in regularization. Artificial neural networks were included to model complex non-linear patterns despite their lower interpretability. Other model families were not considered to avoid unnecessary methodological complexity and to maintain a focused, interpretable comparison aligned with current best practices in clinical machine-learning research [12]. In experiment 1, all algorithms were trained using default hyperparameters. In experiment 2, probability-threshold optimization was performed using the Youden J index and F1-maximization criterion. The Youden J index was used to identify the optimal classification threshold by maximizing the sum of sensitivity and specificity, which is a widely accepted approach in diagnostic accuracy studies. In parallel, F1-score maximization was applied to balance precision and recall, particularly in the presence of class imbalance. These complementary strategies ensure robust threshold selection from both diagnostic and machine-learning perspectives [13,14]. Experiment 3 involved extensive hyperparameter tuning conducted exclusively within the training set after the initial train–test split to prevent information leakage. Cross-validation was applied only to internal folds of the training data, while the test set and the independent temporal validation cohort were reserved solely for performance evaluation. Hyperparameter optimization was performed sequentially: GridSearchCV was used for exhaustive tuning of a limited set of key hyperparameters, followed by RandomizedSearchCV for stochastic exploration of broader parameter spaces. Subsequently, Optuna-based Bayesian optimization was employed to efficiently refine hyperparameters in high-dimensional search spaces by iteratively updating probabilistic performance estimates. These complementary approaches are widely used in machine-learning research to improve model generalization and reduce overfitting [15]. All cross-validation procedures were conducted exclusively on the training set to prevent information leakage. In experiment 4, a large-scale feature-engineering pipeline generated more than 250 derived variables, including variance-based metrics, ratio-based biomarkers, composite indices, and biologically meaningful interaction terms (Supplementary Material S2). No explicit feature selection or dimensionality reduction techniques (such as principal component analysis) were applied after feature generation. This decision was motivated by the use of algorithms with built-in regularization and feature selection properties, particularly tree-based ensemble and gradient boosting methods. Potential overfitting was further controlled through strict separation of training, test, and independent temporal validation datasets, as well as through cross-validation and hyperparameter optimization performed exclusively on the training set. The generalizability of the expanded feature space was ultimately assessed using an external temporal validation cohort.
All preprocessing and model-building steps were implemented in Python 3.11 (The Netherlands) using Kaggle Notebook and Google Colab environments. Age was the only variable retained in continuous form and was therefore the only feature subjected to standardization using the StandardScaler. Continuous variables were standardized using the StandardScaler function, and the final dataset was randomly split into training (80%) and test (20%) subsets using a stratified approach to preserve the distribution of vitamin B12 classes.
After completion of all stages of the experimental framework, the methodological strategy yielding the highest overall performance was selected and applied—without modification—to an independent temporal validation cohort of 34,744 patients from a later time period, in order to assess real-world, time-dependent generalizability. Model interpretability and clinical utility were comprehensively evaluated using SHAP (feature contributions), LIME (local explainability), and Decision Curve Analysis (net clinical benefit).
2.6. Performance Evaluation
Descriptive analyses were performed for both the development and validation cohorts. Continuous variables were summarized as mean ± standard deviation, and between-group differences were assessed using p-values and Cohen’s d. Additional stratified analyses by age and sex were conducted separately for the development and validation datasets. Subsequently, the performance of the eight algorithms included in the four-stage experimental framework was evaluated using sensitivity, specificity, positive and negative predictive values, accuracy, F1 score, Matthews correlation coefficient, area under the ROC curve (AUC-ROC), and area under the precision–recall curve (AUC-PR), the latter being particularly informative for imbalanced outcomes. For each model, confusion-matrix components (TP, FP, TN, FN) were computed, and ROC/PR curves were generated across a range of probability thresholds. Because positive and negative predictive values, likelihood ratios, and decision curve analyses are sensitive to outcome prevalence, these metrics were interpreted in the context of the study’s clinically enriched cohort and the applied class-balancing strategy during model development.
After completion of all experimental stages, the methodological strategy demonstrating the highest overall performance on the test set was selected and applied unchanged to the validation cohort. Clinical interpretability was assessed using SHAP beeswarm plots, LIME-based local explanations, and Decision Curve Analysis, providing complementary insights into feature contributions and net clinical utility.
Throughout the analyses, the categorical vitamin B12 variable was used exclusively as the ground-truth outcome label (0 = deficient/insufficient, 1 = within reference interval). Serum vitamin B12 was not included among the model input features at any stage of model development, training, or evaluation. These two representations were explicitly distinguished across all analytical steps to avoid interpretive ambiguity.
2.7. Statistical Comparison of Experimental Models
Since all machine-learning algorithms were evaluated on the same test set, statistical comparisons accounted for the dependence arising from correlated prediction structures. DeLong’s test was used to compare AUC-ROC values derived from correlated ROC curves. Differences in continuous performance metrics such as F1 score and accuracy were assessed using paired t-tests.
To examine false-positive/false-negative imbalance and asymmetry in misclassification patterns across models, the McNemar test was applied. In addition, Net Reclassification Improvement (NRI) and Integrated Discrimination Improvement (IDI) were calculated to quantify the relative gains in reclassification performance between models. These metrics enabled a more comprehensive evaluation of the methodological advantages achieved through model optimization, particularly regarding improvements in accuracy and discrimination.
Together, these complementary procedures allowed for a rigorous, multidimensional, and model-agnostic comparison of all experimental configurations.
2.8. Statistical Analysis
Continuous variables were summarized as mean ± standard deviation, whereas categorical variables were presented as counts and percentages. Given the large sample size, parametric methods were preferred. Group comparisons for continuous variables were performed using one-way ANOVA, and Welch’s ANOVA was applied when the assumption of homogeneity of variances was violated. When appropriate, Tukey’s HSD or Games–Howell tests were used for post hoc multiple comparisons. Categorical variables were compared using the Pearson chi-square test.
The diagnostic performance of the machine-learning models was assessed using sensitivity, specificity, positive and negative predictive values, accuracy, F1 score, AUC-ROC, AUC-PR, positive and negative likelihood ratios (LR^+^/LR^−^), and the Matthews correlation coefficient. All statistical analyses were conducted in Python 3.11 using the pandas, scipy, scikit-learn, and statsmodels libraries. A two-sided p-value < 0.05 was considered statistically significant.
3. Results
Statistically significant differences were observed across numerous hematological and biochemical measurands between the development (n = 35,256) and independent validation (n = 34,744) cohorts (with p < 0.05 for most comparisons). However, Cohen’s d analyses indicated that the magnitude of these differences was predominantly very small from a biological perspective. Age, hemoglobin, hematocrit, erythrocyte count, and MCV values were lower in the validation cohort, demonstrating small to moderate effect sizes (d = 0.18–0.33). In contrast, parameters reflecting inflammatory or hematologic variability—such as RDW, CRP, LDH, and PLT—were higher, corresponding to small effect sizes (d ≈ −0.16 to −0.20). Among liver enzymes, only ALP exhibited a moderate effect size at the cohort level (d = −0.546). Although serum vitamin B12 concentrations were higher in the validation period, the biological magnitude of this difference remained very small (d = −0.143). Means, standard deviations, p-values, and Cohen’s d effect sizes for all variables are presented in Table 1. Additionally, age- and sex-stratified distributions and comparative statistics for both cohorts are provided in Supplementary Material S1, Tables S2 and S3.
Following binary transformation of the original three-category vitamin B12 classification, the development dataset was balanced using random undersampling, resulting in an equal distribution of vitamin B12–deficient/insufficient and reference-interval groups (50% each). All machine-learning models were trained and evaluated using this balanced binary outcome.
Across the eight machine-learning algorithms evaluated within the four-stage experimental framework, CatBoost demonstrated the most balanced sensitivity–specificity profile and the highest overall classification performance in all experiments. Notably, the threshold-optimized configuration (Experiment 2), despite yielding performance metrics numerically similar to the other strategies, provided a clinically decisive advantage. This approach improved model accuracy not only from a statistical perspective but also in terms of clinical safety, achieving the lowest number of false negatives and thereby minimizing the risk of missing true vitamin B12 deficiency cases. Given the association of vitamin B12 deficiency with neurological sequelae and irreversible damage, this marked reduction in false negatives represents the key outcome defining the model’s clinical applicability rather than merely its methodological strength.
For this reason, the primary findings highlighted in the manuscript are derived from the F1-maximization–based threshold-optimized configuration, which is summarized in Table 2. Performance distributions for all experimental strategies are provided in Supplementary Material S1, Tables S4–S6.
In the test set, the threshold-optimized CatBoost model achieved sensitivity 0.92, specificity 0.67, F1 score 0.82, PPV 0.73, and NPV 0.88, yielding the most balanced performance among all models; AUC-ROC was 0.88 and AUC-PR was 0.86. XGBoost and the neural network produced comparable AUC values but demonstrated lower accuracy, specificity, MCC, and PPV. Logistic regression and random forest failed to maintain overall classification balance, whereas SVM, KNN, and decision tree models showed markedly reduced specificity and MCC.
Performance metrics for the four CatBoost configurations are summarized in Table 3. Statistical comparisons revealed no significant differences across configurations for AUC-ROC (DeLong test) or for F1 and accuracy (paired t-tests) (all p > 0.05). In contrast, the McNemar test demonstrated a clear advantage for the threshold-optimized model, particularly through its favorable asymmetry in the distribution of false negatives versus false positives. This model substantially reduced false-negative decisions—the clinically most critical error type—supporting its selection as the final model.
For the threshold-optimized CatBoost model, the calculated NRI = 0.359 and IDI = 0.147 further confirmed that the approach produced meaningful improvements in both correct reclassification and discrimination capacity. These findings align with the McNemar test results demonstrating improved false-negative/false-positive asymmetry, collectively indicating that the optimized model provides a substantially enhanced risk-classification framework. Accordingly, the model exhibits strong potential as a reliable and effective clinical decision-support tool for the early identification of vitamin B12 deficiency.
The performance of the selected CatBoost model remained robust in the independent temporal validation cohort, with sensitivity 0.85, specificity 0.77, accuracy 0.81, F1 score 0.82, and MCC 0.63. Discrimination improved compared with the internal test set, with AUC-ROC 0.90 and AUC-PR 0.91. The likelihood-ratio profile (PLR = 3.74; NLR = 0.19) also indicated strong clinical utility under real-world conditions. These results are presented in Table 4 and Figure 2.
SHAP analyses demonstrated that hematologic and inflammatory measurands—such as MCV, HGB, HCT, RBC, RDW, age, iron and ferritin—were the strongest contributors to model predictions. The SHAP beeswarm plot (Figure 3) showed that physiologically abnormal measurements consistently shifted predictions toward deficiency. From a clinical perspective, commonly used rule-based indicators such as macrocytosis or anemia reflect late or incomplete manifestations of vitamin B12 deficiency and may fail to identify early or subclinical cases. By integrating multidimensional routine laboratory information, the proposed model provides incremental decision support beyond single-parameter heuristics and complements conventional clinical assessment.
LIME analyses confirmed the internal consistency of feature contributions for individual-level predictions and reinforced the clinical interpretability of the model (Supplementary Material S1, Figure S1). Decision Curve Analysis (DCA) demonstrated that the model provided a consistently higher net benefit across a wide threshold range compared with “treat-all” or “treat-none” strategies (Figure 4), supporting its potential integration into clinical decision-support systems. In clinical practice, the proposed model is intended to function as a screening and risk-stratification tool within routine laboratory workflows. A positive model prediction is designed to prompt targeted clinical actions, such as prioritization of confirmatory assessment or repeat serum vitamin B12 testing when clinically indicated, rather than immediate therapeutic intervention.
4. Discussion
This study represents the first comprehensive machine-learning investigation designed to predict serum vitamin B12 levels directly from routinely collected laboratory measurands. Current literature contains predictive models for vitamin D, folate, lipid metabolism, and other biochemical markers, yet no prior study has focused specifically on estimating B12 status using hematologic and biochemical indices at scale [7,16,17]. By integrating routine laboratory features with explainable artificial intelligence (XAI) techniques, the present work offers a novel and clinically actionable framework that bridges biomedical informatics, laboratory medicine, and nutritional neuroscience.
Across eight machine-learning algorithms evaluated in four sequential experimental settings, gradient-boosting models consistently demonstrated superior ability to capture the nonlinear and population-level variability inherent in biochemical data. Linear models such as logistic regression and support vector machines showed limited generalizability with AUC values around 0.86, consistent with prior work by Sharifmousavi et al. using SVM-based micronutrient prediction in neurological populations [6]. Artificial neural networks yielded lower accuracy (0.78) than the 85% reported by Tamune et al. in B6 deficiency [5], while also suffering from well-recognized limitations in interpretability—an important consideration for clinical deployment. Tree-based ensembles such as random forest similarly demonstrated moderate discrimination but experienced performance instability under external validation, a finding aligned with previously reported limitations of over-partitioning in high-dimensional biomedical data [18].
XGBoost outperformed these baseline models, reflecting its strong capacity to capture interactions between biochemical variables, consistent with prior lipid profiling work (r = 0.98) by Anudeep et al. [8]. However, CatBoost provided the most robust and generalizable performance across all experimental conditions—an observation supported by previous reports emphasizing its unbiased handling of categorical variables and resilience in clinical datasets [19,20]. In our study, CatBoost achieved an AUC-ROC of 0.88, AUC-PR of 0.86, F1 of 0.82, and the most balanced sensitivity–specificity profile across both test and validation cohorts.
Interpretability analyses further strengthened the biological plausibility of the model. SHAP and LIME consistently highlighted MCV, RDW, HGB, HCT, ferritin, CRP, folate, and age as principal contributors to classification. These findings reinforce well-established hematological consequences of B12 deficiency, including macrocytosis, anisocytosis, and impaired erythropoiesis. Elevated contributions of ferritin and CRP mirror the known inhibitory effects of systemic inflammation on circulating B12 bioavailability via haptocorrin-mediated sequestration, as reported by Jensen et al. [21,22]. The observed interplay between folate and B12 also aligns with their shared role in one-carbon metabolism and DNA synthesis [2,17,23]. Age contributed positively, consistent with declining intrinsic factor secretion and reduced gastrointestinal absorption in older adults [24]. Together, these patterns demonstrate that the model not only predicts deficiency but also captures meaningful pathophysiological signatures associated with B12 metabolism.
The sequential experimental framework provided additional insight into how model performance evolved under different analytical strategies. Experiment 1 established baseline performance; Experiment 2 applied F1-maximizing threshold optimization and yielded the most clinically balanced results, increasing sensitivity to 0.92 and reducing false negatives by nearly 45%. Experiment 3 evaluated hyperparameter tuning, which improved discrimination modestly but introduced mild overfitting in the validation cohort—consistent with prior findings on the trade-off between complexity and generalizability in clinical ML models [25]. Experiment 4 introduced feature engineering; however, CatBoost’s intrinsic ability to manage correlated and categorical variables meant that manual engineering added minimal incremental benefit. Collectively, these findings validated Experiment 2 as the optimal configuration for clinical decision support.
When compared with the only available machine-learning study on B12 deficiency, conducted by Tamune et al. in psychiatric patients using a sample of 497 individuals (AUC-ROC 0.62), our model showed substantially higher discrimination (AUC-ROC 0.88) using a dataset nearly 150 times larger, highlighting its superior generalizability and methodological rigor [5]. In contrast to genetic Mendelian randomization studies such as Lu et al. [26], which explore upstream determinants of B12 metabolism, our work emphasizes biochemical phenotypes and their downstream hematologic expression—providing complementary but clinically more immediate insights. Similarly, while Duman et al. demonstrated hematologic alterations in pediatric B12 deficiency [27], their narrower variable set lacked inflammatory and metabolic markers that contributed substantially to our model’s predictive signal.
The proposed AI framework is designed to complement, rather than replace, advanced biomarkers such as holotranscobalamin and methylmalonic acid. By leveraging routinely available hematological and biochemical parameters, the model provides an initial risk stratification layer that may help identify patients who are most likely to benefit from further confirmatory testing. In this respect, the approach supports a stepwise diagnostic strategy, particularly in settings where advanced biomarkers are costly, not routinely available, or reserved for selected cases.
From an implementation perspective, the model has strong potential for integration into laboratory information systems (LIS) or hospital information systems (HIS). Because it relies entirely on existing routine tests (e.g., hemogram, ferritin, CRP, albumin), it imposes no additional cost and can be deployed passively in background systems. LIME-based patient-specific explanations could be displayed to clinicians, allowing early recognition of biochemical patterns suggestive of deficiency before irreversible neurological or hematological complications arise. Early identification of vitamin B12 deficiency may facilitate timely clinical management and help prevent downstream clinical complications. Such a model could therefore contribute to both clinical and economic decision-making. From a patient-centered perspective, the proposed model has the potential to improve diagnostic efficiency by leveraging routinely available laboratory measurands without requiring additional or specialized testing. By supporting earlier and more accurate identification of individuals at risk for vitamin B12 deficiency, the model may help reduce unnecessary repeat measurements or downstream confirmatory tests, thereby lowering laboratory examination expenditure. Earlier diagnosis may also facilitate timely therapeutic intervention, with potential benefits for clinical outcomes and overall healthcare resource utilization.
Limitations
This study has several limitations. Its retrospective nature prevented inclusion of symptoms, dietary intake, medication history, gastrointestinal disorders, and genetic factors—variables known to influence B12 metabolism. Only adult patients were included, limiting generalizability to pediatric populations. Although data were obtained from the laboratory information system, all results had undergone biochemical specialist approval, ensuring that pre-examination artifacts such as hemolysis or improper storage were already filtered out. Missing values were removed rather than imputed, eliminating imputation bias but introducing a theoretical selection bias. Classification thresholds were based on the NICE 2024 guideline, ensuring standardization across laboratories [11]. Nevertheless, total serum B12 is an imperfect marker of functional deficiency; lack of holo-transcobalamin or methylmalonic acid data may lead to misclassification in certain subgroups [28]. Finally, micronutrient patterns may vary across regions and populations, suggesting that model recalibration may be necessary before widespread deployment [29]. As with all clinical ML models, temporal performance drift remains a potential risk and requires periodic re-evaluation [30]. Although the present model was developed using data from a single tertiary-care center, it relies exclusively on routinely available laboratory analytes and reference-based encoding schemes that are widely standardized across clinical laboratories. This design enhances its potential transferability to institutions using comparable analytical platforms and quality-control procedures. The use of a fully independent temporal validation cohort further supports real-world generalizability across time. Nevertheless, external multicenter validation and site-specific recalibration will be required before widespread clinical deployment. Serum total vitamin B12 levels were not measured using the gold-standard isotope-dilution liquid chromatography–tandem mass spectrometry (ID-LC–MS/MS) method. Instead, a chemiluminescence immunoassay was used, which is subject to method-dependent analytical bias, including variability in antibody specificity and differential detection of protein-bound B12. Therefore, assay-related misclassification cannot be fully excluded. Accordingly, the model should be interpreted as a screening and risk-stratification tool for laboratory-defined vitamin B12 deficiency rather than a definitive diagnostic instrument for functional cobalamin deficiency. Therefore, predictive values and net clinical benefit estimates may differ if the model is applied in population-level screening settings with lower prevalence of vitamin B12 deficiency.
5. Conclusions
Despite these limitations, this study introduces the first large-scale, explainable, and clinically validated machine-learning model for predicting vitamin B12 deficiency using routine laboratory measurands. The model demonstrates high discrimination, strong biological interpretability, and stable performance across internal and temporal validation cohorts. When integrated into clinical workflows, it has the potential to support early diagnosis, reduce unnecessary testing, and enhance decision-making in nutritional and hematologic assessments. Future work should focus on multi-center prospective validation, continuous monitoring for model drift, and extension of the framework to other micronutrient deficiencies such as folate, vitamin D, and ferritin. In parallel, evaluating how this explainable AI model behaves when quietly embedded into routine laboratory workflows—augmenting clinical decisions without disrupting established pathways—will be essential for realizing its full translational impact.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1O’Leary F. Samman S. Vitamin B 12 in Health and Disease Nutrients 2010229931610.3390/nu 203029922254022 PMC 3257642 · doi ↗ · pubmed ↗
- 2Stabler S.P. Vitamin B 12 Deficiency N. Engl. J. Med.201336814916010.1056/NEJ Mcp 111399623301732 · doi ↗ · pubmed ↗
- 3Hannibal L. Lysne V. Bjørke-Monsen A.-L. Behringer S. Grünert S.C. Spiekerkoetter U. Jacobsen D.W. Blom H.J. Biomarkers and Algorithms for the Diagnosis of Vitamin B 12 Deficiency Front. Mol. Biosci.201632710.3389/fmolb.2016.0002727446930 PMC 4921487 · doi ↗ · pubmed ↗
- 4Stover P. Discussion: Folate and Vitamin B 12 Metabolism: Overview and Interaction with Riboflavin, Vitamin B 6, and Polymorphisms Food Nutr. Bull.200829 S 17S 1910.1177/15648265080292 S 10418709878 · doi ↗ · pubmed ↗
- 5Tamune H. Ukita J. Hamamoto Y. Tanaka H. Narushima K. Yamamoto N. Efficient Prediction of Vitamin B Deficiencies via Machine-Learning Using Routine Blood Test Results in Patients With Intense Psychiatric Episode Front. Psychiatry 201910102910.3389/fpsyt.2019.0102932153432 PMC 7044238 · doi ↗ · pubmed ↗
- 6Sharifmousavi S.S. Borhani M.S. Support vectors machine-based model for diagnosis of multiple sclerosis using the plasma levels of selenium, vitamin B 12, and vitamin D 3Inform. Med. Unlocked 20202010038210.1016/j.imu.2020.100382 · doi ↗
- 7Sancar N. Tabrizi S.S. Machine learning approach for the detection of vitamin D level: A comparative study BMC Med. Inform. Decis. Mak.20232321910.1186/s 12911-023-02323-z 37845674 PMC 10580577 · doi ↗ · pubmed ↗
- 8Anudeep P.P. Kumari S. Rajasimman A.S. Nayak S. Priyadarsini P. Machine learning predictive models of LDL-C in the population of eastern India and its comparison with directly measured and calculated LDL-C Ann. Clin. Biochem. Int. J. Lab. Med.202259768610.1177/0004563221104680534612076 · doi ↗ · pubmed ↗