X2P-Net: Context-Aware 2D/3D Vertebra Localization
Rong Tao, Kangqing Ye, Weijun Zhang, Wenyuan Sun, Derong Yu, Donghua Hang, Guoyan Zheng

TL;DR
X2P-Net is a new method for accurately locating vertebrae in 3D from 2D X-rays during spine surgery, improving alignment and accuracy.
Contribution
X2P-Net introduces a novel Transformer architecture, BrickFormer, for efficient and accurate 2D/3D vertebra localization.
Findings
X2P-Net achieves 96.9% and 98.8% accuracy at 10 mm and 20 mm thresholds on the BiSpineX dataset.
The method shows a mean position error of 2.99 mm and an AUC of 0.9923 on BiSpineX.
On SheepSpineX, it achieves 98.4% and 100.0% accuracy with a mean position error of 1.08 mm and an AUC of 0.9972.
Abstract
In the context of minimally invasive spine surgery, accurately estimating the 3D coordinates of the vertebrae from intraoperative 2D X-ray images is crucial for aligning preoperative data with the patient’s real-time posture. However, existing methods are hindered by the ill-posed nature of 2D-to-3D localization and the distinctive anatomical features of the spinal column, leading to ambiguities and reduced accuracy. In this paper, we introduce X2P-net, a novel prompt-guided and semantic context-enhanced 2D/3D vertebra detection framework. To achieve this, we design a novel Transformer architecture, referred to as BrickFormer, which can automatically extract the refined vertebral foreground context at low computational cost using a dual-attention mechanism. Comprehensive experiments were conducted to validate the proposed approach on two datasets: a large-scale synthetic dataset…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
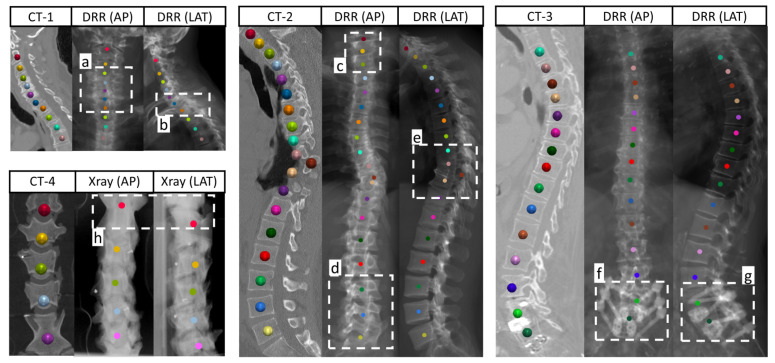 Figure 1
Figure 1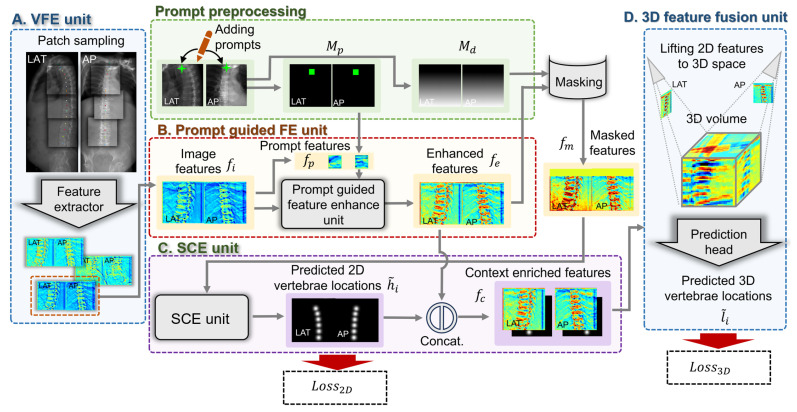 Figure 2
Figure 2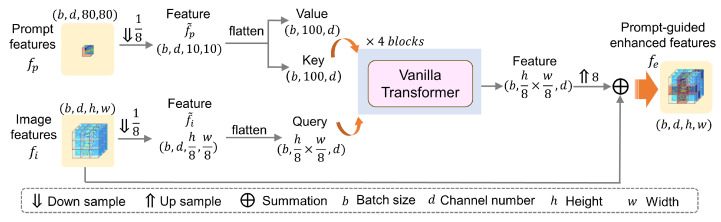 Figure 3
Figure 3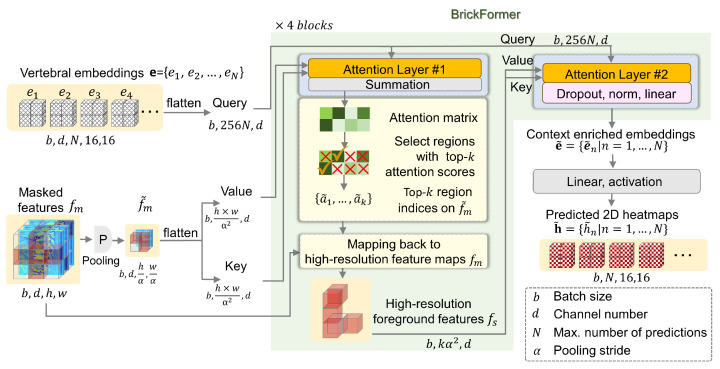 Figure 4
Figure 4 Figure 5
Figure 5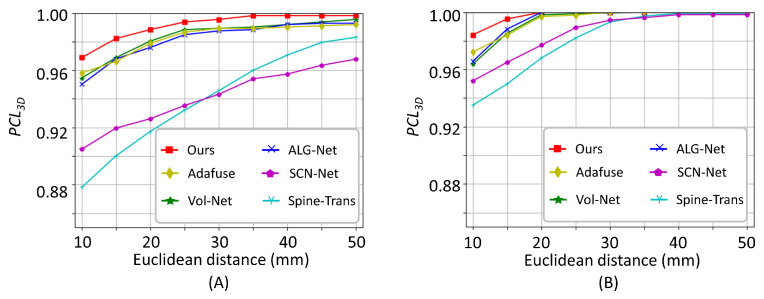 Figure 6
Figure 6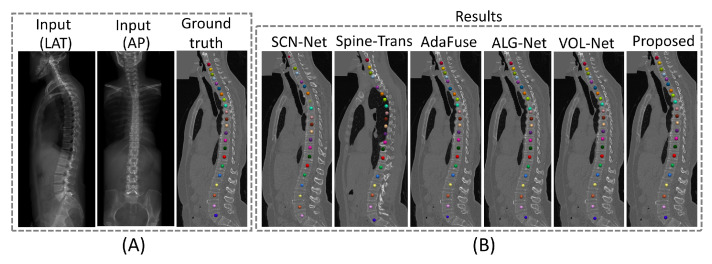 Figure 7
Figure 7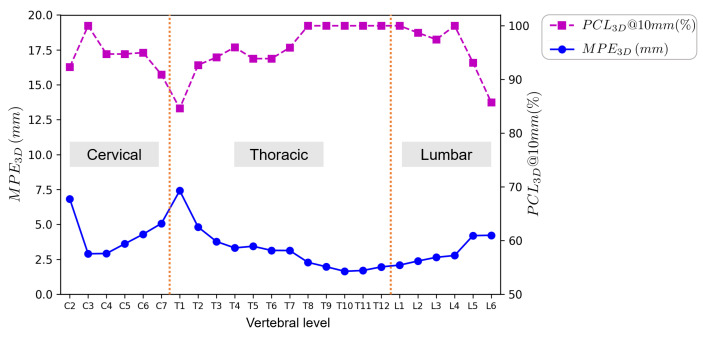 Figure 8
Figure 8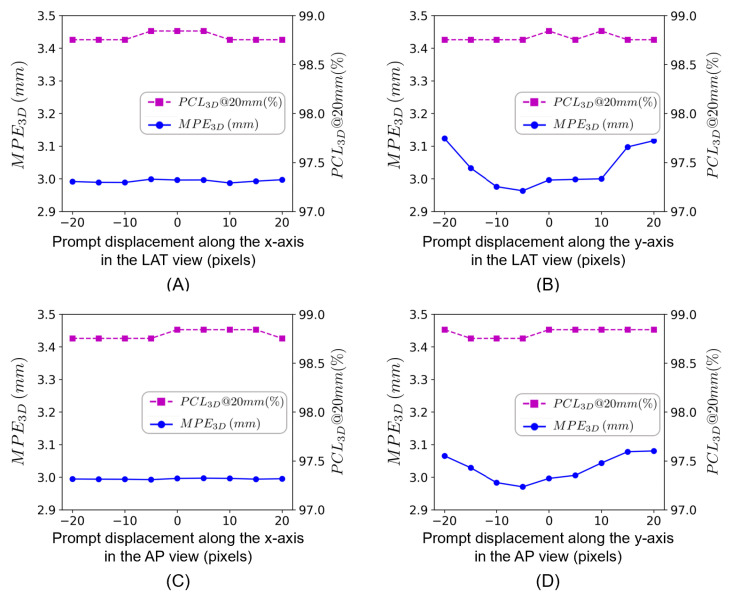 Figure 9
Figure 9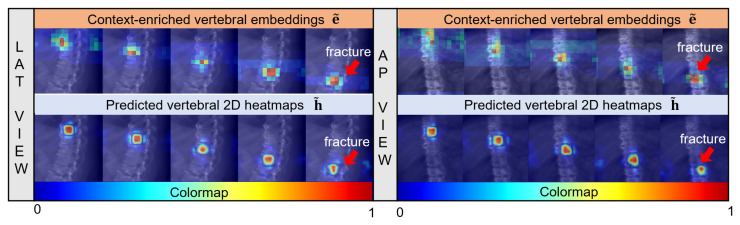 Figure 10
Figure 10- —National Key R&D Program of China
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging and Analysis · Spinal Fractures and Fixation Techniques · Scoliosis diagnosis and treatment
1. Introduction
Recent years have witnessed an increasing demand for minimally invasive spine surgery (MISS) [1,2]. The success of the surgical procedure depends significantly on the precision with which preoperative planning is mapped onto the patient’s intraoperative position [3]. X-ray fluoroscopy is one of the most popular intraoperative imaging modalities because of its high flexibility, low radiation exposure, and cost-effectiveness. Using intraoperative 2D X-ray images to estimate the 3D locations of the vertebrae—also known as 2D/3D vertebra localization—is crucial for aligning preoperative data with the patient’s intraoperative posture. However, because an X-ray image offers a 2D projected view of the 3D anatomical structures, the 2D/3D vertebra localization task is inherently ill-posed, leading to ambiguities and reduced localization precision [4,5].
Many existing studies have utilized biplanar 2D X-ray images to infer 3D morphological characteristics of the spine [2,6,7,8,9,10,11,12], where the spatial information can be supplemented by two calibrated images acquired from two typical views, i.e., the anteroposterior (AP) and lateral (LAT) views. Currently, two main challenges limit the accuracy of 2D/3D vertebra localization. The first challenge is depth ambiguity, which arises from the superimposition of anatomical structures and the low contrast between the vertebrae and the surrounding soft tissues. The second challenge is semantic ambiguity, which stems from the spine’s chain-like structure, characterized by repetitive vertebrae, making it difficult to distinguish between adjacent vertebrae. Furthermore, metal implants, spinal deformities, and variability in the field of view (FOV) increase the complexity of the task.
To address these challenges, recent studies have proposed various methods that can be largely divided into two categories [13]: lifting-based approaches and direct regression-based approaches. Lifting-based approaches [6,14,15,16,17] involve estimating 2D landmark locations from each view before lifting them into 3D space through triangulation and optimization techniques, such as the least-squares method [16] and statistical shape models [14,15]. Despite its utility, these methods have several limitations, as shown in Figure 1. Notably, 2D landmarks may lack essential depth information for accurate 3D prediction. In particular, when the vertebral centroid landmarks are occluded due to superimposition (Figure 1b), spinal deformities (Figure 1e), or metal implants (Figure 1f,g), it is difficult to estimate precise 3D locations using incomplete visual information. Furthermore, the relationship between 2D visual appearance and 3D structures varies across images. For example, the projection of the vertebral centroid from CT volumes to the 2D detector plane is not always positioned at the center of the projected vertebrae, leading to 2D/3D annotation inconsistency, as demonstrated in Figure 1 a,c,d. Lastly, view-angle disparities between multi-view X-ray images make it difficult to establish one-to-one correspondence between landmarks identified independently on each view, as demonstrated in Figure 1h. On the other hand, direct regression-based methods [6,12,18,19] use 2D visual features from multi-view images to construct a pseudo-3D feature volume, which is then processed by 3D convolutions to regress the voxel-wise likelihood of each landmark. However, the accuracy of these methods is constrained by the spatial resolution of the projected volume, since increasing this resolution leads to a quadratic increase in computational cost.
In this study, we tackle the aforementioned challenges by leveraging advanced semantic context integration strategies to reduce ambiguities and to enhance localization accuracy. First, in contrast to previous works [21,22], which depend only on visual context, we introduce an interactive learning scenario where users can place a point-like prompt on each view to target a reference vertebra. The position and visual features of the reference vertebra are then utilized to enhance the semantic context of the remaining vertebrae. Second, we incorporate the anatomical prior information of the spine through a set of learnable vertebral embeddings. These embeddings are employed to delineate each vertebra using the enhanced 2D features. Subsequently, the delineated 2D vertebral location context is fused with high-resolution features, creating a context-enriched pseudo-3D volume for accurate 3D vertebra localization. To demonstrate the effectiveness of our approach, we designed a context-aware 2D/3D vertebra localization framework that uses biplanar X-ray images to estimate vertebral positions in 3D space, hereafter referred to as X2P-Net. The core of X2P-Net is a novel Transformer architecture, referred to as BrickFormer, which facilitates computational efficiency while maintaining performance. Unlike the vanilla Transformer [23], which computes attention weights over all pixels in the feature maps, BrickFormer benefits from a dual-attention mechanism, which automatically discriminates foreground pixels from the background. By removing background pixels, BrickFormer uses sparse foreground pixels as building bricks to support the localization task. Key contributions of this paper are summarized as follows:
- We introduce an end-to-end context-aware 2D/3D vertebra localization framework, referred to as X2P-Net. The framework takes advantage of vertebral context, which is first enhanced by a prompt-guided reference vertebra and then extracted using learnable vertebral embeddings, for high-performing 2D/3D vertebra localization.
- We design a novel BrickFormer architecture, which leverages a dual-attention mechanism. The initial attention layer automatically identifies the foreground region from the background, and the subsequent attention layer then focuses only on the foreground features. This approach achieves high localization accuracy at a low computational cost.
- We conduct comprehensive experiments on two datasets to demonstrate the efficacy of the proposed method: a large-scale synthetic dataset of biplanar digitally reconstructed radiographs (DRRs) and a real biplanar X-ray image dataset of sheep spines, captured by a C-arm imaging system.
2. Related Work
2.1. Leveraging Semantic Context in Vertebra Localization
Automatic localization of vertebrae from spinal images is a challenging task due to the unique morphology of the spinal column [24]. Published vertebra localization methods have leveraged vertebral context to improve localization accuracy. These methods can be broadly categorized into three groups: statistics-based, context-based, and object detection-based.
In statistics-based approaches, traditional methods employed statistical shape models or atlas-based methods to learn the statistical distribution of all vertebrae [25,26]. Subsequent studies combined machine learning [27] or fully convolutional neural networks [28] with a hidden Markov model (HMM) to identify the locations of vertebral bodies. With recent advancements, deep generative models such as generative adversarial networks (GANs) [29] and normalizing flows [30,31] were proposed to learn the prior distribution of vertebral landmarks. These models were able to implicitly capture the prior distribution, at the cost of additional computational complexity.
Conversely, context-based methods often employ sequential and structural modeling techniques to improve the robustness of vertebra localization by integrating global contextual cues or anatomical priors [32]. For instance, Chen et al. [33] proposed a joint learning model that combined the local appearance of one vertebra and the pairwise conditional dependencies of neighboring vertebrae for vertebra localization from CT images. Similarly, Wang et al. [34] designed an anatomically constrained optimization module that employed a soft constraint to regulate the distance between estimated vertebrae and a hard constraint on the consecutive estimated vertebra labels. Payer et al. [21] proposed a spatial configuration network (SCN-Net) to encode the semantic context of the landmarks. Tao et al. [22] proposed Spine-Transformers that formulated vertebra labeling as a one-to-one set mapping problem and introduced a global loss to incorporate the sequential relationships of vertebrae. Acknowledging the constraints of strict sequential assumptions in prior studies [21,22], especially when handling pathological deformations, researchers have also proposed graph neural networks (GNNs) [35] or reinforcement learning [36] to incorporate anatomical prior information. Specifically, Transformers [23] excel at capturing long-range dependencies, while GNNs and reinforcement learning provide greater flexibility in modeling non-linear spatial relationships and anatomical topologies [37]. For example, Bürgin et al. [38] proposed a hybrid network combining convolutional neural networks (CNNs) and GNNs for robust vertebra identification from CT images. Xiang et al. [39] proposed VLD-Net for localizing and detecting the vertebrae from X-ray images using reinforcement learning with an adaptive exploration mechanism and spine anatomy information.
Recently, object detection models like the You Only Look Once (YOLO) series [40,41,42] and Faster R-CNN [43] have gained increasing adoption for vertebra localization tasks owing to their speed and efficiency. For example, Zhang et al. [44] proposed a method that combined 3D Swin Transformers [45] with YOLOX [41] for accurate spine segment detection from 3D CT images. Huang et al. [46] proposed a method that integrated a bidirectional long short-term memory (LSTM) layer into the Faster R-CNN architecture to implicitly ensure sequential consistency. Although object detector-based approaches showed significant potential in accelerating vertebra localization while maintaining acceptable accuracy, they encountered challenges under severe pathological deformations, primarily due to the lack of explicit anatomical modeling.
A common limitation of the above-mentioned studies on vertebra localization was that they mainly focused on single-image (either a 3D volume or a 2D image) scenarios. However, few studies have addressed the more complex problem of multi-view vertebra localization, where the model not only needs to distinguish each vertebra within each image but also needs to establish cross-view semantic correspondence for landmarks detected on each view. Limited attempts have been made to address this task. For example, Wu et al. [16] proposed a multi-view contrastive learning strategy to capture the anatomical structural information from different views. Huang et al. [9] introduced a multi-perspective network for cross-view vertebra localization, where they used a recurrent module to incorporate contextual information and to enforce anatomical order for the detected vertebrae. While achieving promising results, these methods required either extra post-processing steps or repetitive sampling strategies to assemble the landmarks detected on each view.
2.2. Estimating 3D Landmarks from 2D Images
Estimating 3D landmarks from 2D images is inherently an ill-posed problem because multiple 3D predictions may result in the same 2D projection. To alleviate such ambiguities, existing approaches resort to either multi-view visual correspondence [5,47] or long-term temporal clues [48]. As this study focuses on enhancing 3D landmark localization from 2D images for intraoperative applications, we concentrate on studies in the multi-view scenario.
Multi-view images significantly reduce ambiguity in 3D landmark localization, yet effectively aggregating and fusing information from multiple perspectives remains challenging. In the literature, both lifting-based approaches and direct regression-based approaches have been proposed. Lifting-based approaches, such as those by Dong et al. [49] and Bridgeman et al. [50], associate 2D landmark estimations and fuse them into 3D poses. However, establishing cross-view correspondence is still an issue. Existing studies have utilized methods like triangulation [47,51], 4D graph cuts [49], plane sweep stereo [52], cross-view graph matching [53], or statistical shape models [54] to generate 3D poses from 2D landmarks. These methods often adopt a multi-stage framework [55] to refine 3D pose estimation, leading to increased computational cost and accumulated uncertainty. In contrast, direct regression-based approaches [12,47,56,57,58] first build a pseudo-3D feature volume through heatmap estimation and then regress 3D coordinates from the feature volume with 3D CNNs. However, the accuracy of these methods is constrained by the spatial resolution of the projected volume, and increasing this resolution leads to a quadratic increase in computational cost.
3. Methodology
3.1. Overview
Figure 2 illustrates the network architecture of the proposed context-aware X2P-Net, which consists of a 2D visual feature extraction (VFE) unit, a prompt-guided feature enhancement (FE) unit, a semantic context extraction (SCE) unit, and a 3D multi-view feature fusion unit. The network first utilizes positional information and visual features of the reference vertebra, as indicated by prompts, to enhance the features of the remaining vertebrae. Subsequently, the 2D vertebral context is captured through a series of learnable vertebral embeddings, yielding a set of 2D vertebral heatmaps. These 2D heatmaps are then integrated with high-resolution multi-view image features to construct a pseudo-3D volume, which is used to estimate the 3D coordinates of the vertebrae. Unlike previous 2D/3D landmark localization methods that require pretraining a 2D feature extraction backbone, the proposed method leverages the simultaneous learning of 2D vertebral context and 3D vertebral locations, thereby enabling end-to-end training. Details about each unit are presented below.
3.2. The VFE Unit
The VFE unit is shared across both the LAT and the AP views of the spine radiographs. Given a pair of input images, we denote and as the LAT and the AP views, respectively. Each view is represented as , where , and pixels and represent the width and height in pixels, respectively. To capture multi-scale visual cues, we utilize a 2D U-Net-like architecture that comprises four levels and a spatial pyramid pooling (SPP) module [59] for feature integration. Subsequently, the 2D VFE unit generates a pair of feature maps corresponding to the respective LAT and AP views, denoted as , as follows:
where and is the number of feature channels.
In the case where the height of the input images exceeds 512 pixels, we employ a sliding window technique to sample consecutive image patches, as depicted in Figure 2A.
3.3. The Prompt-Guided FE Unit
For a given pair of input images, the prompt-guided FE unit requires users to specify a point-like prompt on each image as the input. It is worth noting that the two prompts in the AP and the LAT images need to be placed around the ground truth centers of the same vertebral body, usually the top-most vertebra in both images. These prompts serve as reference points, guiding the network to predict the locations of the vertebral body center for the remaining levels. Similarly, in the case of long-length images, which are divided into a series of contiguous image patches, the bottom-level vertebra from the preceding patch is utilized as the prompt for the subsequent patch. For simplicity, we introduce the prompt-guided FE unit and the SCE unit for a single image patch.
Let us denote the position of the prompt on an image patch as , where and correspond to the horizontal and vertical coordinates of a point-like prompt, respectively. We first preprocess the input prompt to create two types of masks: a binary prompt mask and a unidirectional distance mask . Specifically, the binary prompt mask is constructed as follows:
where represents pixel coordinates within the image patch, is the set of pixel coordinates covered by the square patch centered at the prompt, and is an empirical value that delineates a region that can cover the area of the reference vertebral body.
Next, using the features from the 2D VFE unit and the prompt mask , we can obtain prompt features :
Meanwhile, the unidirectional distance mask is derived as follows:
is essential to establish cross-view correspondence, which will be explained in detail in the next section.
Following the preprocessing steps, both and are down-sampled by a factor of 8, yielding and , respectively. These down-sampled features are then fed into a 4-layer vanilla Transformer block with 8 heads and a hidden dimension of 64, as depicted in Figure 3. Within the Transformer block, serves as both the key and the value, which enables the enhancement of repetitive vertebral features present in . The output of the Transformer layer can be presented by the following equation:
where , , and represent the learnable weight matrices for the query, key, and value, respectively.
Eventually, the prompt-guided FE unit produces a set of enhanced features, represented as , which are then fed into the SCE unit to extract the important contextual information of the remaining vertebrae.
3.4. The SCE Unit
The SCE unit aggregates spatial contextual information using learnable vertebral embeddings. These embeddings are structured as a sequence of spatial feature maps, denoted as with , where is the spatial dimension, and N is the maximum number of predicted vertebrae. In conventional Transformers, the computational expense of the attention mechanism increases quadratically with the spatial dimensions of the key and the query matrices. To mitigate this issue, we develop a novel Transformer variant, referred to as BrickFormer, as illustrated in Figure 4. Notably, BrickFormer reduces computational cost by incorporating a dual-attention mechanism. Specifically, in the first attention layer, it automatically delineates the foreground regions from the background using low-resolution feature maps, while in the second attention layer, it refines the process by engaging only the selected high-resolution but sparse foreground features for the extraction of 2D vertebral context.
Mathematically, we first combine the enhanced features with the distance mask as follows:
Here, the masked features integrate the vertical distance from each pixel to a reference vertebra indicated by the prompt, thus facilitating spatial alignment of 2D features extracted from different views.
Next, undergoes a max pooling operation with a stride of , obtaining , which is fed into the first attention layer of BrickFormer. Specifically, within the first attention layer, the attention matrix is calculated as follows:
where and represent the learnable weight matrices for the query and the key, respectively.
Following the attention computation, we sort the elements of the matrix by their attention scores in descending order. This sorting operation allows us to identify the indices of the top-k highest-scoring elements, resulting in a set of indices . Then, we map to the corresponding positions on the high-resolution features (one position at the low-resolution features will be mapped to positions at the high-resolution features), obtaining the new set of indices , which will be used to extract the subset of foreground features . Subsequently, these foreground features are input into the second attention layer of BrickFormer for fine-grained attention computation, where the attention matrix is calculated by the following:
Finally, the output of BrickFormer is a set of context-enriched vertebral embeddings with
where , , and are the corresponding weight matrices for the query, key, and value, respectively.
These embeddings are then fed into linear layers to obtain the predicted 2D vertebral heatmaps , with .
To summarize, in a standard stacked Transformer with L attention layers, the complexity of the attention computation is , where denotes the spatial dimension of and represents the product of the spatial dimension and the total number of vertebral embeddings. In contrast, our proposed BrickFormer, utilizing the same number of attention layers, significantly reduces the computational complexity to . Here, the first term corresponds to the attention computation on the low-resolution features, which identifies foreground vertebral regions. The second term represents the fine-grained attention computation on the high-resolution but sparse foreground features, aimed at improving localization accuracy while maintaining low computational cost.
3.5. The 3D Multi-View Feature Fusion Unit
The predicted 2D vertebral heatmaps, denoted as , are rescaled to match the input dimensions. These heatmaps are combined with the respective feature maps to obtain the concatenated features , which are then fed into the 3D multi-view feature fusion unit. Within the unit, we unproject the 2D features into a fixed-size pseudo-3D feature volume based on projective geometry. Specifically, we assume that each calibrated view (LAT and AP) is associated with a projection matrix , which is used to project 3D coordinates to 2D image space. During unprojection, each voxel in the pseudo-3D volume is projected onto the 2D image space using the projection matrix. The voxel feature is assigned by sampling the corresponding 2D feature value at the projected location. Then, the volumes from multiple views are aggregated and processed by 3D convolutions to output heatmaps representing 3D vertebral locations. These 3D vertebral heatmaps are subsequently passed through a soft-argmax function, which transforms the heatmaps into precise vertebral coordinates. Finally, the 3D multi-view feature fusion unit produces a set of predicted 3D vertebral coordinates with .
3.6. Loss Functions
Assuming that the 2D ground truth heatmap for the n-th vertebra in view i is and the predicted heatmap for each vertebra is , we compute the MSE loss and Dice loss as follows:
and
where and indicate, respectively, the ground truth and the predicted probabilities of a pixel at position for the n-th vertebra in view i.
Therefore, we obtain the 2D localization loss as follows:
To predict the 3D coordinates of the vertebrae, we assume that the ground truth vertebral locations are with , where is the number of vertebrae present in the current input. We compute an MSE loss for each vertebra, as follows:
Then, the overall localization loss is defined as follows:
3.7. Implementation Details
The proposed method was developed in Python 3.9 using the PyTorch 2.0 framework and was trained on a workstation equipped with two NVIDIA GeForce RTX 4090 GPUs. The input images had a size of . The network was trained from scratch in an end-to-end fashion for 100 epochs, employing the AdamW optimizer [60] with a weight decay of 0.05 and a batch size of 2. For the synthetic dataset, we set the maximum number of predicted vertebrae to and the hyperparameters of BrickFormer to and . In contrast, for the real sheep spine dataset, we set , , and . These parameter choices were guided by empirical estimates of the foreground-to-background ratio for each dataset.
During the training phase, we incorporate random cropping as a data augmentation technique and take the ground truth centers of the top-most vertebral bodies in both LAT and AP images as prompts. During inference, a point-like prompt is manually placed around the center of the top-most vertebral body in each image. After that, the network simultaneously generates N heatmaps for each view and N sets of 3D vertebral coordinates. For each predicted heatmap, a vertebra was considered present if the maximum probability was higher than . Thus, we used as a criterion to assess the validity of the 3D predictions.
4. Experiments
In this section, we present experimental results on a synthetic dataset consisting of biplanar spine DRR images and a real dataset consisting of biplanar sheep spine X-ray images. Below, we first describe the datasets and the evaluation metrics used in our experiments, and then present the experimental results.
4.1. Datasets
4.1.1. Synthetic Biplanar Spine DRR Dataset (BiSpineX Dataset)
Given the scarcity of biplanar spine X-ray datasets and the difficulty in obtaining accurate 3D annotations, we generated biplanar DRRs from CT images with precise annotations of vertebral body centroids and created a synthetic dataset, referred to as the BiSpineX dataset. To construct the dataset, we utilized CT volumes from the Large Scale Vertebrae Segmentation Challenge (VerSe) held at MICCAI 2019 and MICCAI 2020 [20]. Since the VerSe dataset included images with a variety of FOVs and resolutions, we excluded cases with mismatched CT volumes and annotations, images with fewer than three vertebrae, and those with file reading errors. This resulted in a dataset of 337 spinal CT volumes, including cases with fractures and metal implants, which were reoriented and resampled to a 1 mm isotropic resolution. For each CT volume, we generated LAT and AP DRRs [61] by simulating X-ray projections using a ray-tracing method that accounts for photon attenuation and scattering. A virtual detector plane of size m^2^ with a resolution of was used. To address view-angle disparities, we applied random spatial transformations to the CT volumes, including rotations in a range from −15° to 15° about the vertical axis, and from −5° to 5° about both the coronal and sagittal axes. Consequently, we derived 337 pairs of biplanar spine X-ray images from the corresponding CT volumes. The number of vertebrae present in each radiograph ranged from 3 to 24, covering both traditional C-arm X-ray radiographs that typically contain 3 to 5 vertebrae and emerging long-film X-ray images capable of capturing a larger FOV that spans the entire spinal column. The dataset was partitioned into an 80–20% train-test split, with an additional 5% of the training set reserved for validation purposes.
4.1.2. Sheep Spine X-Ray Dataset (SheepSpineX Dataset)
To demonstrate the performance and efficacy of the proposed method, we further conducted experiments on a real sheep spine biplanar X-ray dataset, referred to as the SheepSpineX dataset. This dataset comprises radiographs of 9 sheep cervical spines, which were obtained from a commercial slaughterhouse. For each sheep cervical spine, the radiographs were captured in both AP and LAT views, utilizing a Siemens Arcadis Varic C-Arm system (see Figure 5 for the experimental setup). For each case, we acquired 30 pairs of X-ray images, each pair consisting of LAT and AP views. The number of vertebrae present in each case ranged from 4 to 7. The ground truth 3D vertebral locations were obtained by annotating the centroids of each vertebral body on the corresponding CT volumes. These 3D coordinates were then projected onto the 2D views, yielding precise 2D ground truth vertebral locations. The dataset was divided into 5 cases for training, 1 case for validation, and 3 cases for testing.
4.2. Evaluation Metrics
We adopt commonly used metrics [13,20,62] for both 2D and 3D vertebra localization, as follows:
Percentage of Correct Landmarks (PCL): The is defined as the ratio of correctly detected landmarks to the total number of landmarks. A landmark is considered correctly detected if the Euclidean distance to the corresponding ground truth location is below a given threshold . is calculated as follows:
where denotes the total number of annotated vertebral locations, denotes the ground truth location of the n-th landmark, and denotes the corresponding predicted location.
Mean Position Error (MPE): It is defined as the average Euclidean distance, expressed in millimeters (mm) for 3D measurements and pixels for 2D measurements. is calculated as follows:
Area Under the Curve (AUC): It is defined as the area under the curve between the upper limit and the lower limit on the x-axis. This metric is used to evaluate the overall performance of a landmark detection method.
For each of the three metrics, we report the corresponding vertebrae localization performance in both 2D and 3D spaces. Specifically, for the measurement of PCL in 2D, we calculate both and by setting to be 10 pixels and 20 pixels, while for the measurement of PCL in 3D, we compute both and by setting to be 10 mm and 20 mm, respectively. Similarly, we estimated in 2D by setting the lower limit to be 10 pixels and the upper limit to be 50 pixels, and in 3D by setting the lower limit to be 10 mm and the upper limit to be 50 mm.
4.3. Results
4.3.1. Results on the BiSpineX Dataset
Due to the limited research on 3D vertebral localization utilizing biplanar radiographs, we evaluated the performance of X2P-Net in comparison with state-of-the-art (SOTA) methods, including benchmark approaches for vertebrae localization, such as SCN-Net [21] and Spine-Transformers (Spine-Trans) [22]. In these methods, 2D vertebral locations are initially identified on the LAT and AP views of radiographs, followed by a triangulation process to derive their 3D coordinates. For the Spine-Transformers, which were initially designed for vertebral localization from CT volumes, we have re-engineered the network and loss functions to adapt them for use with spinal radiographs. Furthermore, we have incorporated classic 2D-3D landmark detection algorithms that have been previously applied to human pose estimation for comparative analysis, including AdaFuse [57], ALG-Net [47], and VOL-Net [47]. All aforementioned methods were trained from the ground up, with methods following the original two-stage training protocol: pretraining the feature extractor, followed by end-to-end fine-tuning of the network.
Results of the comparison study are shown in Table 1. For 3D vertebral landmark localization, X2P-Net achieves the top performance in terms of all evaluation metrics. Specifically, it obtained a of 96.9%, a of 98.8%, an average of 2.99 mm, and an of 0.9923. In contrast, the second-best method (ALG-Net [47]) obtained a of 95.7%, a of 98.3%, an average of 3.25 mm, and an of 0.9846. Our method outperforms ALG-Net [47] with a 1.2% increase in and a 0.5% increase in , a 0.26 mm decrease in , and a 0.0077 increase in .
Furthermore, we report the 2D vertebra localization performance in Table 1. For X2P-Net, the 2D vertebral locations were derived from the auxiliary output of the predicted vertebral locations for the LAT and AP views. Although our method was not designed for 2D landmark localization, its performance closely matched the best-performing 2D vertebra localization network (SCN-Net [21]), indicating that our method effectively captured the semantic context of each vertebra. Specifically, our method achieved a of 96.6% for the LAT view and 96.0% for the AP view, and SCN-Net obtained a of 96.9% for the LAT view and 96.8% for the AP view. Thus, compared to SCN-Net, our method exhibited a higher 2D localization error. In particular, our method achieved an average of 5.84 pixels for the LAT view and 6.14 pixels for the AP view, while SCN-Net obtained an average of 3.78 pixels for the LAT view and 4.96 pixels for the AP view. This higher 2D error is attributed to the lower spatial resolution of our predicted 2D heatmaps. Nonetheless, by integrating the semantic context from 2D landmark predictions with high-resolution 3D features, our method achieved the lowest 3D localization error, demonstrating the efficacy of the proposed method. This efficacy is further illustrated by a visualization of curves in Figure 6A.
Figure 7 illustrates a challenging case for 2D/3D vertebra localization, where the presence of scoliosis complicates accurate localization. Despite this, our method effectively identifies each vertebra’s location, demonstrating the method’s robustness.
We additionally conducted a per-level analysis of the landmark localization results. We evaluated the per-level landmark localization performance in terms of and ; the results are presented in Figure 8. Localization errors exceeding 10 mm were observed for 35 out of 1123 testing vertebrae. Among these 35 vertebrae, 29 were from cases with scoliosis, and 4 were from cases with metal implants.
4.3.2. Results on the SheepSpineX Dataset
Using the sheep spine dataset, we evaluate X2P-Net against the aforementioned SOTA techniques. The comparative analysis is presented in Table 2, where X2P-Net demonstrates superior performance across all metrics. Specifically, it achieved a of 98.4%, a of 100%, an average of 1.08 mm, and an of 0.9972. In contrast, the second best-performing method (ALG-Net [47]) attained a of 96.5%, a of 100%, an average of 1.56 mm, and an of 0.9948. The PCL curves for the various methods are depicted in Figure 6B. Despite influences such as variations in viewing angles, for the sheep spine X-ray images, X2P-Net can still accurately estimate the 3D locations of vertebrae.
4.4. Analytical Ablation Studies
We conducted analytical ablation studies on the BiSpineX dataset to evaluate the performance of the proposed X2P-Net. We designed and conducted the following ablation studies: (1) We first performed major component ablations by systematically removing key components to understand their essential role in the landmark localization pipeline. (2) We then conducted a study to compare the proposed BrickFormer with other attention mechanisms. To achieve this, we replaced the BrickFormer attention layers in the network with either vanilla attention layers [23] or sparse attention layers [63] using the same hyperparameter settings (i.e., 4 layers, 8 heads, and a hidden dimension of 512), while keeping the remaining components of the network unchanged. The inputs to these attention layers were the same as those of the first attention layer in BrickFormer. (3) Subsequently, we investigated the impact of different hyperparameters on the performance of our method by systematically varying key hyperparameters while keeping others fixed, to determine the optimal balance between landmark localization accuracy and computational efficiency. (4) Additionally, we investigated the sensitivity of our method to prompt displacement. Specifically, we shifted the prompt along the x- and y-axes in both the LAT and AP images and evaluated performance under these perturbations. (5) Finally, we performed an in-depth analysis of the dual-attention mechanism of BrickFormer by visualizing features at different stages. For each study, the efficiency of each algorithm was quantified by the number of floating-point operations (FLOPs). The larger the FLOPs, the less efficient the algorithm.
4.4.1. Results on Investigating the Effectiveness of Key Components
The results from ablation experiments evaluating the contribution of each unit are shown in Table 3. We explored three network configurations: (1) In the first experiment, named No Prompt, we removed the prompt-guided FE unit, allowing features from the VFE unit to proceed directly to the SCE unit. As shown in Table 3, incorporating the prompt information led to a 6.7% increase in , a 5.7% increase in , a 3.28 mm decrease in average , and a 0.0270 increase in . (2) In the second experiment, named No SCE, we removed both the SCE unit and the . Consequently, the 3D volumes were solely constructed from the masked features from the previous unit. Compared to the No SCE method, our method improved and by 4.6% and 4.0%, respectively, reduced average by 2.96 mm, and increased by 0.0266. (3) In the last experiment, named No Fusion, we excluded the fusion operation between the predicted 2D vertebral heatmaps and the masked features . As shown in the results, the No Fusion method achieved better performance than the No SCE method because of the learned vertebral context. However, it still fell short of the performance achieved by our proposed context fusion strategy. Specifically, compared to the No Fusion method, our method achieved 4.1% and 2.3% improvements in and , respectively, a 2.91 mm reduction in average , and a 0.0101 increase in .
4.4.2. Results on Examining Different Attention Mechanisms
The results of investigating the influence of different attention mechanisms on the performance of the proposed method are presented in Table 4. From this table, one can see that when compared to the vanilla attention mechanism, the proposed BrickFormer demonstrates improved performance with an increase in by 2.2% and by 1.6%, a decrease in average by 1.14 mm, and an increase in by 0.0129. When compared to the sparse attention mechanism, our method achieved 3.7% and 0.7% improvements in and , respectively, a 1.73 mm reduction in average , and a 0.0053 increase in . These enhancements are attributed to the dual-attention mechanism embedded within BrickFormer, which effectively filters out irrelevant information from high-resolution foreground features, thereby enhancing localization precision.
4.4.3. Results on Investigating the Impact of Different Hyperparameters
We first examined the impact of the spatial dimensions of the vertebral embeddings on the performance of our proposed method, with dimensions set at , , and , corresponding to the resolution of the predicted 2D vertebral heatmaps. The results are shown in Table 5A. It was evident from the results that the accuracy of vertebra localization improved with an increase in the embedding dimension, peaking at a dimension of . This enhancement was likely due to the higher resolution of the predicted 2D vertebral heatmaps, which provided more contextual information for improving the precision of 3D vertebra localization. However, increasing the resolution from to raised the computational cost by approximately 20 million FLOPs, as shown in Table 5A.
Next, we explored the effect of varying the top-k value, which was set to 2, 4, or 8, on the performance of our method. The results of this analysis are reported in Table 5B. Increasing the top-k from 4 to 8 resulted in a 1.2% and 2.1% increase in and , respectively, a reduction in the average by 1.2 mm, and an increase in by 0.0110. The top-k value was directly related to the number of regions selected for fine-grained attention computation during the second stage, with a larger k indicating a greater number of features involved in this computation.
In our final hyperparameter ablation study, we investigated the influence of the pooling stride . As shown in Table 5C, we tested three configurations: , , and . Optimal performance on the BiSpineX dataset was achieved with . Specifically, when was set to 2 (compared to ), increased by 1.8% and 1.5% at the 10 mm and 20 mm thresholds, respectively, decreased by 0.25 mm, and increased by 0.0117. When was increased to 4, the performance improved, with increasing by 2.2% and 1.1% at the respective thresholds, decreasing by 1.08 mm, and increasing by 0.0117. This improvement was attributed to the fact that a larger corresponded to a larger receptive field for the attention computation on the low-resolution features and provided more context for fine-grained attention computation, thereby improving localization accuracy.
4.4.4. Results of Investigating the Sensitivity of Our Method to Prompt Displacement
To assess the sensitivity of our method to prompt displacement, we investigated the effects of shifting the point-like prompt along the x- and the y-axes (ranging from −20 to +20 pixels away from the ground truth center of the top-most vertebral body in each image) in each image. The performance of the proposed method under different point-like prompt inputs was assessed in terms of and . Furthermore, to compare the performance when different point-like prompts were used, we conducted one-sided Wilcoxon signed-rank tests [64] and chose a significance level of 0.05. The results of this ablation study are shown in Figure 9. From this figure, one can see that the performance of our method is not sensitive to displacement along the x-axis in both images. In particular, with displacement along the x-axis in either image, the average was below 3.00 mm, and the remained above 98.7% for both views. When comparing the results using the ground truth centers with those using the displaced prompts, the maximal change in terms of was less than 0.01 mm, and no statistically significant difference was detected (p-value = 0.77 for the LAT view and p-value = 0.42 for the AP view). However, this is not the case for displacement along the y-axis. In particular, when the displacement was constrained to be 10 pixels around the ground truth center in each image, the maximal change in terms of the average increased to 0.06 mm, although no statistically significant difference was detected when comparing the results using the ground truth centers with those using the displaced prompts (p-value = 0.09 for the LAT view, p-value = 0.83 for the AP view). As the displacement along the y-axis increased further to 20 pixels, the maximal change in terms of the average increased to 0.14 mm, and the differences between the results using the ground truth centers and those using the displaced prompts were statistically significant (p-values < 0.001 for both views), though the remained above 98.7%.
4.4.5. Analysis of BrickFormer
To obtain a deeper understanding of the dual-attention mechanism in BrickFormer, we conducted an analysis to determine whether the vertebral embeddings effectively capture vertebral context. To this end, we visualized features at various stages of BrickFormer, as depicted in Figure 10.
Given a pair of input images consisting of LAT and AP views, we visualized the context-enriched vertebral embeddings (the first row) as well as the predicted 2D vertebral heatmaps (the second row) of a thoracic spine with a fractured vertebra, which was taken from the BiSpineX dataset. Note that while BrickFormer can handle up to 10 vertebral embeddings, only the first five, corresponding to valid vertebral predictions, were visualized here. Each column represents a single predicted vertebra, ordered from superior to inferior. As illustrated in Figure 10, the locations of the vertebrae can be readily estimated from these context-enriched embeddings, demonstrating the effectiveness of the proposed context-enriched representations.
5. Discussions
Estimation of the 3D coordinates of the vertebrae from intraoperative 2D X-ray images is challenging, especially for MISS procedures. This study aimed to develop a novel framework, X2P-Net, that integrated vertebral context to overcome this challenge. Considering the complex and dynamic environment in the operating room, we designed a context-aware 2D/3D vertebra localization framework, which incorporated user interaction in the form of prompts to guide vertebra localization in 3D space. Along with the framework, we introduced BrickFormer, which was a Transformer architecture based on a dual-attention mechanism to delineate each vertebra at low computational cost. The estimated 2D vertebral heatmaps from BrickFormer were fused with multi-view image features to regress 3D vertebral coordinates. Both quantitative and qualitative results demonstrated the effectiveness of the proposed method.
The design of X2P-Net offered several advantages: it leveraged rich vertebral semantics to reduce localization ambiguity and supported a flexible, computationally efficient setup that could be trained end-to-end. This setup ensured high-performance localization in both 2D and 2D/3D scenarios, as demonstrated on synthetic and real spine datasets. Specifically, the prompt-guided FE unit generated masks that extracted the reference vertebral features within specified regions and incorporated positional information for detecting the remaining vertebrae, thereby improving localization performance, as shown in Table 5A. The localization accuracy was further improved by incorporating the proposed dual-attention mechanism in BrickFormer, which could automatically distinguish the foreground regions from the background, as shown in Figure 10.
In comparison with the SOTA methods, X2P-Net achieved better results. Specifically, when evaluated on the BiSpineX dataset, X2P-Net attained a of 96.9% and a of 98.8%, an average of 2.99 mm, and an of 0.9923. In contrast, the second-best method in terms of and (ALG-Net [47]) achieved an average of 3.25 mm and an of 0.9846. Qualitative results shown in Figure 6 and Figure 7 also demonstrate the superior performance of the proposed method. On the SheepSpineX dataset, we observe similarly superior performance of X2P-Net over the SOTA methods [21,22,47,57], with a of 98.4% and a of 100.0%, an of 1.08 mm, and an of 0.9972.
Our method was computationally efficient, with 3.24M parameters and 130.8 GMacs. For an input image of size 512 × 512, the average inference time was 0.1 s, with a GPU memory usage of approximately 3 GB. Moreover, in practical clinical workflows, it was typically unnecessary to perform full 3D vertebral localization on every X-ray image [65]; instead, the localization method could be executed on key frames, thereby further reducing computational and memory demands.
It is worth discussing the limitations of the present study. First, although the BiSpineX dataset did involve abnormal cases such as cases with scoliosis or metal implants, and the present method demonstrated superior performance on the BiSpineX dataset, the superiority of the proposed method in more complex clinical scenarios involving more severe abnormal anatomy or more challenging imaging conditions remained to be further validated. Another limitation lies in the requirement of manual placement of a point-like prompt in each view. Results (Figure 9) obtained from the ablation study investigating the sensitivity of the proposed method to the prompt displacement indicated that the proposed method was robust to moderate prompt displacement from the ground truth center (up to 20 pixels along the x-axis and up to 10 pixels along the y-axis) in either view. Thus, in clinical workflows, such prompts are doable with mouse clicks or touchscreen taps [66]. Furthermore, several studies [21,22,37,39,45,46] have shown that one can design an end-to-end network for fully automatic vertebra localization from input X-ray images, which may be used to eliminate the manual placement. Third, potential domain shift arising from differences between synthetic data and real clinical images (e.g., acquisition protocols, anatomy) may affect the generalization of the proposed method to clinical data. Nevertheless, our method was validated on both a synthetic dataset (the BiSpineX dataset) and a real dataset (the SheepSpineX dataset). On both datasets, the proposed method demonstrated better results than the SOTA competing methods, indicating its efficacy in 2D/3D landmark localization.
6. Conclusions
In this paper, we introduced X2P-Net, a prompt-guided and context-aware network that estimated the 3D positions of the vertebrae from biplanar X-ray images using a novel BrickFormer architecture. Our network included a prompt-guided FE unit, an SCE unit, and a 3D multi-view feature fusion unit. In addition to visual features, we leveraged vertebral context and positional information from the reference vertebra as indicated by the prompt. We further introduced a generic and novel way to incorporate the anatomical prior information of the spine using a set of learnable vertebral embeddings, which were trained to delineate each vertebral level using BrickFormer. Comprehensive experiments on two datasets demonstrated the superior performance of the proposed method over other SOTA methods. Future work will focus on prospective clinical trials to validate the method in real-world surgical practice. Upon successful validation, X2P-Net could be integrated into MISS systems to support intraoperative guidance, thereby enhancing the safety and quality of spinal surgery.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Tajsic T. Patel K. Farmer R. Mannion R. Trivedi R. Spinal navigation for minimally invasive thoracic and lumbosacral spine fixation: Implications for radiation exposure, operative time, and accuracy of pedicle screw placement Eur. Spine J.2018271918192410.1007/s 00586-018-5587-z 29667139 · doi ↗ · pubmed ↗
- 2Maken P. Gupta A. 2D-to-3D: A review for computational 3D image reconstruction from X-ray images Arch. Comput. Methods Eng.2023308511410.1007/s 11831-022-09790-z · doi ↗
- 3Unberath M. Gao C. Hu Y. Judish M. Taylor R.H. Armand M. Grupp R. The impact of machine learning on 2d/3d registration for image-guided interventions: A systematic review and perspective Front. Robot. AI 2021871600710.3389/frobt.2021.71600734527706 PMC 8436154 · doi ↗ · pubmed ↗
- 4Drover D. MVR. Chen C.H. Agrawal A. Tyagi A. Huynh C.P. Can 3D Pose Be Learned from 2D Projections Alone?Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018 European Computer Vision Association Milan, Italy 20187894
- 5Zhao Q. Zheng C. Liu M. Chen C. A single 2d pose with context is worth hundreds for 3d human pose estimation Adv. Neural Inf. Process. Syst.2024362739427413
- 6Aubert B. Vazquez C. Cresson T. Parent S. de Guise J.A. Toward automated 3D spine reconstruction from biplanar radiographs using CNN for statistical spine model fitting IEEE Trans. Med. Imaging 2019382796280610.1109/TMI.2019.291440031059431 · doi ↗ · pubmed ↗
- 7Wang L. Xu Q. Leung S. Chung J. Chen B. Li S. Accurate automated Cobb angles estimation using multi-view extrapolation net Med. Image Anal.20195810154210.1016/j.media.2019.10154231473518 · doi ↗ · pubmed ↗
- 8Kasten Y. Doktofsky D. Kovler I. End-to-end convolutional neural network for 3D reconstruction of knee bones from bi-planar X-ray images Proceedings of the Machine Learning for Medical Image Reconstruction: Third International Workshop, MLMIR 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 8 October 2020 Proceedings 3Springer Berlin/Heidelberg, Germany 2020123133