Comprehensive Learning-Enhanced Educational Competition Optimizer for Numerical Optimization and Reservoir Production Optimization
Shuaizhen Li, Jinxiong Luo

TL;DR
This paper introduces a new optimization algorithm inspired by human learning and swarm intelligence, which performs better than existing methods in solving complex optimization problems.
Contribution
The novel CL-ECO algorithm introduces a dimension-wise multi-exemplar social learning mechanism to enhance population diversity and convergence.
Findings
CL-ECO outperforms seven state-of-the-art algorithms on the CEC 2017 benchmark suite.
CL-ECO achieves top Friedman rank (1.5862) in convergence accuracy and robustness.
The algorithm successfully maximizes NPV in a reservoir production optimization case study.
Abstract
The performance of metaheuristic algorithms in solving high-dimensional, non-convex optimization problems is intricately linked to the balance between global exploration and local exploitation. Inspired by biomimetic principles of swarm intelligence, this study evaluates the Educational Competition Optimizer (ECO), a human learning-inspired metaheuristic, and addresses its vulnerability to rapid population homogenization and premature convergence in complex landscapes. To bridge the gap between rigid hierarchical competition and flexible biological cooperation, we propose the Comprehensive Learning-Enhanced Educational Competition Optimizer (CL-ECO), which introduces a dimension-wise multi-exemplar social learning mechanism to the ECO framework. Analogous to cooperative information sharing in animal swarms, CL-ECO reconstructs search trajectories by learning from different peers across…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
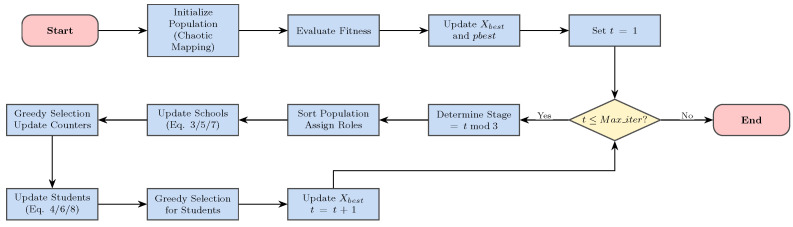 Figure 1
Figure 1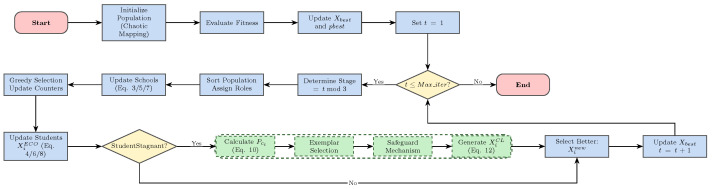 Figure 2
Figure 2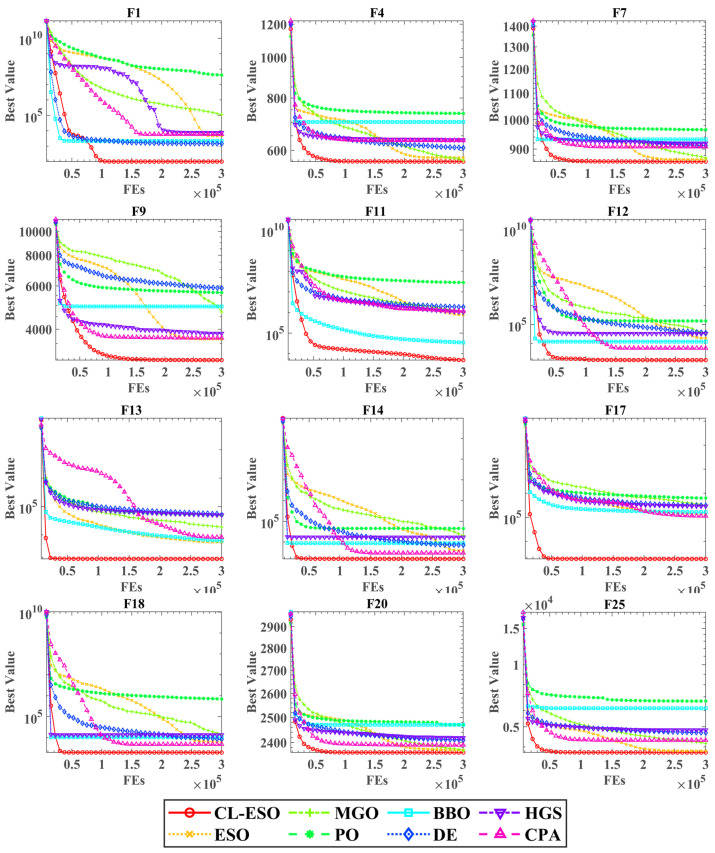 Figure 3
Figure 3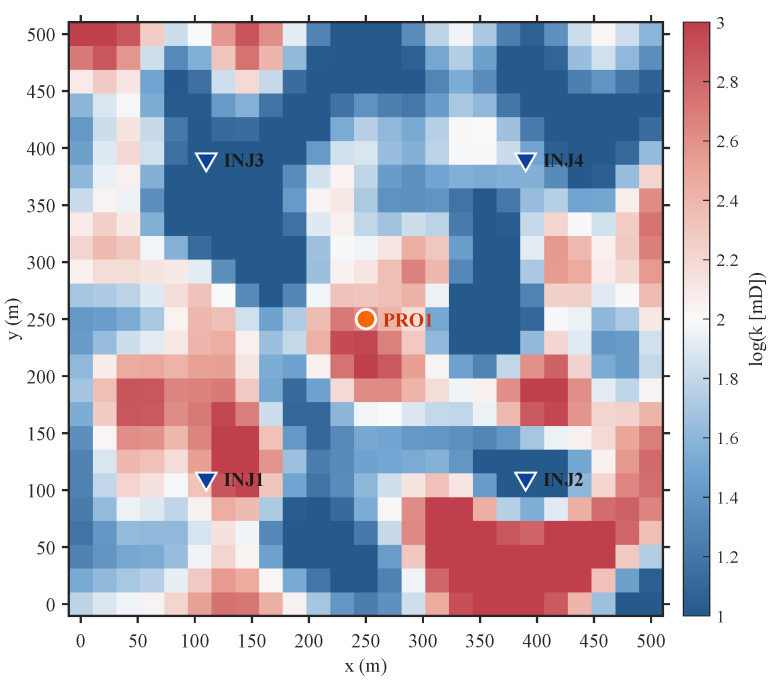 Figure 4
Figure 4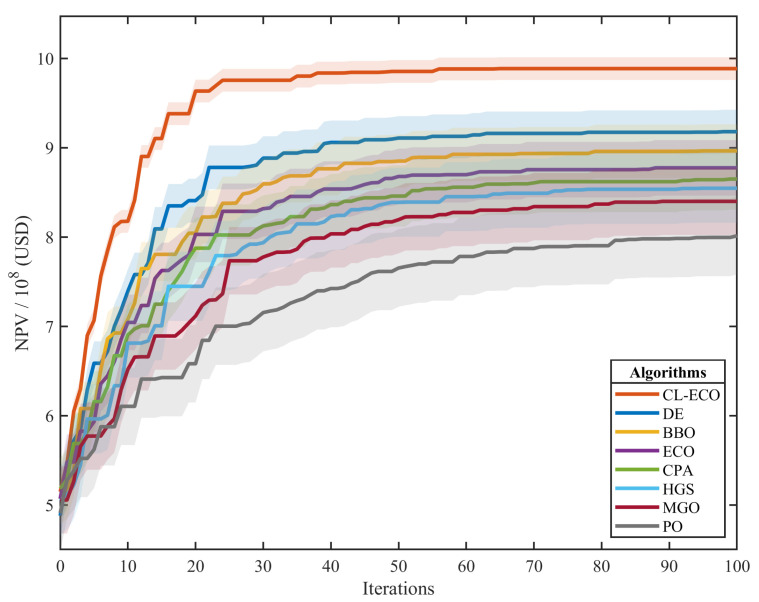 Figure 5
Figure 5- —Comprehensive Study on the Mesozoic Sedimentary System and Reservoirs in the Dagang Exploration Area
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Reservoir Engineering and Simulation Methods · Neural Networks and Reservoir Computing
1. Introduction
Optimization is fundamental to scientific inquiry and engineering design, serving as the cornerstone for maximizing efficiency and utility [1,2]. From calibrating high-fidelity computational models to orchestrating complex logistical networks [3,4], the objective remains constant: identifying the optimal configuration within a massive decision space. However, real-world problems often manifest as high-dimensional, non-convex landscapes riddled with local optima and non-linear interactions, rendering the global optimum elusive [5].
To address such complexity, a suite of traditional optimization methodologies has been historically developed [6]. Classical approaches, including gradient-based methods (e.g., steepest descent [7], Newton–Raphson [8]) and direct search algorithms, provide rigorous mathematical frameworks for seeking optimal solutions. These methods excel within well-defined, convex, and smooth problem domains where objective functions are continuous and differentiable, often guaranteeing convergence to a local optimum [9]. Their efficacy diminishes sharply, however, when confronted with the intricate realities of many contemporary problems. Pronounced limitations include a susceptibility to entrapment in local optima within non-convex landscapes, a reliance on gradient information that may be unavailable or computationally prohibitive, and an exponential escalation in computational cost with increasing dimensionality—a phenomenon known as the “curse of dimensionality” [10].
In response to these constraints, metaheuristic algorithms have emerged as a versatile and powerful class of optimization strategies [11,12,13]. Unlike traditional methods, metaheuristics operate according to higher-level guiding principles, enabling them to explore complex, non-convex, and high-dimensional search spaces without requiring gradient information. These strategies are commonly categorized into two principal lineages: evolutionary algorithms (EAs) and swarm intelligence (SI) algorithms. Evolutionary algorithms emulate processes of biological evolution; representative variants include the Genetic Algorithm (GA) [14] and Differential Evolution (DE) [15]. Conversely, swarm intelligence algorithms derive inspiration from collective intelligence in nature, with exemplary techniques such as Particle Swarm Optimization (PSO) [16,17] and Ant Colony Optimization (ACO) [18] mimicking social foraging behaviors. This inherent flexibility positions metaheuristics as a pivotal advancement, bridging the gap left by conventional approaches.
Among the real-world engineering challenges that demand such robust optimization capabilities, reservoir production optimization (RPO) stands out as a particularly critical high-dimensional problem. RPO aims to maximize the Net Present Value (NPV) of hydrocarbon assets by calibrating dynamic control settings. However, the underlying reservoir models are characterized by highly non-linear fluid dynamics, geological heterogeneity, and computationally expensive black-box simulations. These factors create a rugged, non-convex search landscape where traditional gradient-based methods struggle, making RPO an ideal testbed for advanced metaheuristic algorithms [19,20,21].
The proliferation of diverse metaheuristic paradigms raises a fundamental question: is there a single superior strategy? The No Free Lunch (NFL) theorem [22] provides a definitive answer, establishing that all optimization algorithms perform equally when averaged over all possible problems. This theoretical cornerstone suggests that any algorithmic gain in one domain is inevitably compensated by a performance deficit in another, thereby shifting the research focus from seeking a universal solver to the principled development of algorithms tailored for specific problem topologies. Driven by this imperative, the field has witnessed an explosion of innovative metaheuristics and hybridization strategies. Recent advancements include nature-inspired optimizers such as the Status-based Optimization (SBO) [23,24], Beaver Behavior Optimizer (BBO) [25], and the Comprehensive Learning Moss Growth Optimizer (CLMGO) [26], which demonstrate the efficacy of strategy integration in diverse domains. Other notable developments include the Parrot Optimizer (PO) [27], Escape behavior-based optimization [28], Moss Growth Optimization (MGO) [29], Slime Mould Algorithm (SMA) [30], and Colony Predation Algorithm (CPA) [31]. Furthermore, extensive research has focused on enhancing existing frameworks through multi-strategy integration, such as mutative crow search [32], forensic-based investigation enhancements [33], and horizontal–vertical crossover mechanisms [34]. These developments underscore a collective effort to balance exploration and exploitation more effectively within high-dimensional and non-convex landscapes.
Guided by this insight, this study focuses on the Educational Competition Optimizer (ECO) [35]. Recently proposed, ECO simulates optimization through a hierarchical progression mimicking primary, middle, and high school stages. Structurally, this simulates the natural evolution of foraging behaviors, transitioning from broad, dispersible exploration (primary stage) to focused, intensive resource exploitation (high school stage). Despite its innovative structure, ECO exhibits a notable structural vulnerability in information flow: typically, particles (students) learn predominantly from a single nearest leader or the global best. This centralized attraction mechanism, while efficient for simple unimodal landscapes, often precipitates a rapid decay in population diversity. Consequently, the algorithm becomes highly susceptible to premature convergence and stagnation in sub-optimal basins—a significant liability when navigating the rugged, high-dimensional landscapes of complex scenarios like Reservoir Production Optimization.
To address these limitations, this paper introduces the Comprehensive Learning-Enhanced Educational Competition Optimizer (CL-ECO). Drawing inspiration from biological mechanisms of social facilitation and cooperative foraging, the central innovation is the integration of an adaptive comprehensive learning (CL) strategy. This strategy functions as a “cooperative information sharing” module, akin to how animals in a swarm exchange information to locate food sources when individual searching fails. Whenever an individual is identified as stagnant, CL enables it to rebuild its search trajectory dimension-by-dimension, sampling information from the historical best positions of diverse exemplary peers rather than relying on a single guide. This multi-exemplar approach constructs a hybrid candidate solution that injects vital diversity into the population and provides a robust mathematical escape route from local optima. The principal contributions of this work are threefold:
- Algorithmic Innovation: We introduce an algorithmically tailored enhancement designed to mitigate the premature convergence and diversity loss of the canonical ECO. This mechanism facilitates multi-source information exchange, fundamentally enhancing global exploration capability.
- Benchmark Validation: We formulate the CL-ECO algorithm and conduct a rigorous evaluation against state-of-the-art metaheuristics on the CEC 2017 benchmark suite. Statistical tests, including Friedman and Wilcoxon signed-rank tests, confirm its significant competitive performance.
- Engineering Application: We validate the practical utility of CL-ECO by applying it to the challenging real-world problem of specialized reservoir production optimization. The results show that CL-ECO maximizes the Net Present Value (NPV) more effectively than competing algorithms, confirming its robustness in handling complex engineering constraints.
The remainder of this paper is organized as follows: Section 2 outlines the canonical ECO. Section 3 details the proposed CL-ECO and the comprehensive learning mechanism. Section 4 presents the experimental analysis on benchmark functions. Section 5 discusses the application to reservoir engineering. Finally, Section 6 concludes the study.
2. Original Educational Competition Optimizer
The Educational Competition Optimizer (ECO) [35] is a nature-inspired metaheuristic that abstracts the dynamics of an educational system to drive optimization. The algorithm enables a structured transition from exploration to exploitation by simulating the educational progression of students through primary, middle, and high school stages. The population is dynamically partitioned into “schools” (leaders) and “students” (followers) based on fitness rankings, with the intensity of competition increasing as the iterations proceed. The mathematical formulation of these stages is detailed below.
2.1. Mechanisms
Initialization via Chaotic Mapping:
ECO employs a logistic chaotic map to distribute the initial population. This technique promotes initial diversity by ensuring more uniform coverage of the search space:
where represents the initial position of the i-th individual, while and denote the lower and upper bounds of the decision variables, respectively.
2.Primary School Stage (Exploration):
In the early phase, the algorithm prioritizes global exploration. The top 20% of the population are designated as schools. Schools update their positions by drifting towards the population mean to consolidate the search, while students perform a Levy flight-based random walk towards their nearest school:
Equation (3) utilizes the population mean to promote group cohesion during exploration, while the Levy flight component in Equation (4) introduces high-variance random perturbations, allowing the schools to “jump” across local optima. The use of Gaussian random walks in Equation (5) enables students to fine-tune their search around the vicinity of their assigned leaders. Here, is a time-varying weight, is the mean position, and is the nearest school. This stage fosters wide-ranging exploration of the optimization landscape.
3.Middle School Stage (Transition):
As the search progresses, the focus shifts towards a balance of exploration and exploitation. The school ratio tightens to 10%. Schools begin to incorporate information from the global best solution ( ), while students are segregated based on a “talent” mechanism that probabilistically adjusts their learning strategy:
In this transitional phase, Equation (6) draws schools towards the global best to increase selection pressure. Equation (7) introduces “patience” (P) and “motivation” (E) factors to simulate stochastic student behavior, balancing the focus between global attraction and individual experience. where E and P are motivation and patience factors, respectively, introducing stochastic perturbations to prevent stagnation.
4.High School Stage (Exploitation):
In the final phase, the algorithm focuses on fine-tuning the best solutions. Schools interact with both the best and worst individuals to refine their positions, while all students converge directly towards the global best, maximizing selection pressure:
Finally, Equation (8) enables schools to refine their positions by interacting with the population extremes, while Equation (9) forces rapid convergence of all students toward the global best for precise local refinement. This stage ensures efficient convergence toward the global optimum.
5.Greedy Selection:
Following each update operation, a greedy selection mechanism is applied. The new position replaces if and only if it yields a superior fitness value, ensuring monotonic improvement of the objective function.
2.2. Integrated Iteration
The original ECO algorithm integrates these stages into a cyclic process. The population status is updated iteratively, with the stage determined by the modulus of the iteration count. This structure provides a rudimentary balance between search phases but remains vulnerable to diversity collapse in high-dimensional spaces. The complete workflow is depicted in Figure 1.
3. Proposed CL-ECO Algorithm
3.1. Comprehensive Learning Strategy
The primary limitation of the original ECO is its reliance on a strict hierarchy where students learn predominantly from the nearest leader or the global best. While efficient for unimodal problems, this tight coupling often leads to rapid diversity loss in multimodal landscapes. To mitigate this, we introduce a comprehensive learning (CL) strategy. Inspired by the CL-PSO paradigm, this mechanism effectively decouples the search dimensions, allowing an individual to construct a “hybrid candidate” by learning variable-by-variable from different peers.
The CL strategy operates through four integrated components:
- Stagnation Monitor: A stagnation counter is maintained for each individual. If the personal best ( ) fails to update for a specified number of consecutive generations ( ), the CL strategy is triggered. This conditional activation ensures computational resources are allocated only to stagnant individuals.
- Rank-Based Learning Probability: A learning probability is assigned to each individual i based on its fitness rank. Lower-ranked individuals are assigned higher learning probabilities to facilitate larger perturbations, while higher-ranked individuals retain more personal information:
Equation (10) ensures that individuals with low fitness ranks (higher indices) are assigned higher values, encouraging them to learn more from varied exemplary peers rather than their own histories to facilitate escape from local optima. where i is the rank index (1 being the best), and are empirical constants.
- Dimension-Wise Exemplar Sampling: For each dimension j of a stagnant individual i, the algorithm determines its learning source based on the probability . If a randomly generated number surpasses , the dimension j learns from its own experience ( ). Otherwise, a tournament selection process is invoked: two random peers are selected from the population, and the one with the superior fitness value is chosen as the exemplar for that specific dimension. This mechanism constructs a composite guide vector that aggregates diverse information from across the population:
This dimension-wise sampling allows the algorithm to decompose a high-dimensional problem into multiple independent variable searches, aggregation of which yields a “hybrid” guide vector that represents an unconventional search direction.
- Constructive Position Update: The new candidate position is generated by learning from the composite exemplar:
To prevent the degenerate case where an individual learns entirely from itself, a safeguard ensures that at least one dimension is forced to learn from another particle if for all j.
It is important to distinguish the proposed CL strategy from the standard Comprehensive Learning Particle Swarm Optimization (CL-PSO). While we adopt the dimension-wise multi-exemplar concept, our mechanism is integrated into the hierarchical ECO framework as a conditional “remedial” operator. Unlike CL-PSO, which utilizes comprehensive learning as the primary search strategy throughout the run, CL-ECO triggers the CL update only when an individual is identified as stagnant. This selective activation preserves the rapid convergence efficiency of the canonical ECO while providing a robust escape route from local optima only when necessary. Furthermore, the interaction between the comprehensive learning guide vector and the ECO’s stage-specific roles creates a hybrid search dynamics tailored for complex landscapes.
3.2. The CL-ECO Framework
The proposed CL-ECO integrates this strategy as a “remedial” operator. In each iteration, standard ECO dynamics drive the primary search. However, individuals identified as stagnant enter the comprehensive learning phase. Crucially, the algorithm generates a candidate solution via the standard ECO update and the CL update (if triggered), retaining the one that yields the superior fitness improvement.
This dual-track mechanism preserves the fast convergence characteristics of the original ECO while injecting targeted diversity through orthogonal learning when entrapment occurs. The flowchart in Figure 2 illustrates this extensive decision process.
Algorithm 1 outlines the complete pseudocode. Algorithm 1 Pseudocode of CL-ECO.
- 1:Initialize population X, velocities, and parameters.
- 2:Evaluate initial fitness; initialize and .
- 3:while do
- 4: Determine competition stage (Primary/Middle/High).
- 5: Sort population and assign roles (Schools/Students).
- 6: for each individual to N do
- 7: Standard Update: Generate candidate using ECO rules.
- 8: if Student i is stagnant then
- 9: Calculate .
- 10: for to do
- 11: Select exemplar index via tournament logic.
- 12: end for
- 13: Safeguard: Ensure , .
- 14: CL Update: Generate candidate using composite exemplar.
- 15: Select better candidate: .
- 16: else
- 17: .
- 18: end if
- 19: Evaluation: Evaluate .
- 20: Selection: If , update and ; reset stagnation counter. Else, increment counter.
- 21: end for
- 22: Update global best .
- 23: .
- 24:end while
The time complexity of CL-ECO is dictated by the population size N, dimension D, and iterations T. The base ECO operations (sorting, updating) require . The CL strategy adds a conditional overhead of in the worst case (all stagnant). Thus, the total complexity is asymptotically equivalent to that of the canonical ECO, ensuring that the performance gains do NOT come at the cost of prohibitive computational expense.
4. Experimental Results and Discussion
This section presents a rigorous empirical validation of the proposed CL-ECO framework. To ensure reproducibility and statistical validity, all experiments were performed on a standardized computational platform (MATLAB R2024a, Intel Core 13700KF, Intel, Santa Clara, CA, USA, 16 GB RAM) under strict control parameters. The population size was fixed at with a computational budget of = 300,000. Each algorithm was executed for 30 independent runs to mitigate stochastic variance. Performance is quantified using the mean ( ) and standard deviation ( ) of the objective function values.
4.1. Benchmark Test Suite
The evaluation utilizes the CEC 2017 benchmark suite [36,37], a widely recognized collection of 29 scalable optimization problems categorized into three groups: unimodal functions (F1, F3), characterized by a single global optimum to test convergence velocity and exploitation precision; multimodal functions (F4–F10), possessing exponentially many local optima to rigorously challenge global exploration and stagnation avoidance capabilities; and hybrid (F11–F20) as well as composition (F21–F30) functions, which simulate real-world complexity by superimposing diverse sub-landscapes to assess the algorithm’s versatility and robustness. Table 1 details the specific properties of these functions.
4.2. Comparative Performance Analysis
The efficacy of CL-ECO is benchmarked against the original ECO [35] and six leading metaheuristics: Moss Growth Optimization (MGO) [29], Parrot Optimizer (PO) [27], Beaver Behavior Optimizer (BBO) [25], Differential Evolution (DE) [15], Hunger Games Search (HGS) [38], and Colony Predation Algorithm (CPA) [31]. Identical initialization and termination criteria were applied to ensure a fair comparison. The results, summarized in Table 2 and Table 3, elucidate the performance hierarchy. As evidenced by Table 2, CL-ECO demonstrates a commanding performance, securing the top position with a Friedman mean rank of 1.5862. This ranking significantly outstrips the original ECO (3.3103) and the closest competitor, DE (4.0). Regarding the algorithmic configuration, the key hyper-parameters of CL-ECO, including the stagnation limit and the learning probability constants ( ), are adopted from the recently proposed CLMGO framework [26], as these settings have shown robust performance in complex engineering optimization. Utilizing these literature-verified values ensures a stable and reproducible baseline for our comparative analysis.
This consistent performance suggests that the CL strategy does not merely offer sporadic improvements but fundamentally enhances the algorithm’s consistency across diverse problem structures. Complementing this ranking, the Wilcoxon signed-rank test results (Table 3) provide statistical confirmation of this superiority. Against algorithms like MGO and PO, CL-ECO frequently achieves machine-level precision differences ( ), underscoring its robustness.
Regarding landscape adaptability, CL-ECO exhibits versatile performance across different problem classes. On unimodal functions (F1, F3), it matches or exceeds the precision of ECO, validating that the integration of the CL strategy does not compromise local convergence speed. Conversely, on complex multimodal (F6, F9) and hybrid functions (F11–F20), CL-ECO consistently locates superior basins of attraction. For instance, on F6, CL-ECO reduces the mean error by approximately 5% compared to ECO. This confirms that the dimension-wise learning mechanism successfully diversifies the search trajectory, effectively mitigating the prematurity observed in the canonical algorithm.
The convergence profiles in Figure 3 visually reinforce these findings. CL-ECO (red trajectory) exhibits a characteristic “rapid-descent” behavior in the early phases, indicative of efficient exploration, generally followed by a deeper convergence plateau. This validates the hypothesis that the CL strategy acts as an effective “stagnation trigger,” reactivating the search when standard operators falter.
However, it is observable that the performance improvement of CL-ECO over ECO is more significant in complex multimodal and hybrid functions than in simpler unimodal landscapes like F2. In relatively smooth or single-basin domains, the original ECO hierarchy is already highly optimized, and the trigger frequency of the CL strategy remains minimal. This explains the marginal nature of performance gains in such instances, contrasting with the substantial breakthroughs achieved in rugged, high-dimensional search spaces where the canonical algorithm frequently encounters stagnation checkpoints.
5. Application to Production Optimization
Reservoir production optimization (RPO) represents a fundamental high-dimensional engineering challenge, critical for maximizing the economic lifecycle of hydrocarbon assets. The objective is to determine the optimal control trajectory, which encompasses water injection rates and bottom-hole pressures (BHPs) to maximize the Net Present Value (NPV). This problem is mathematically intractable for classical methods due to the highly non-linear fluid dynamics governing subsurface flow (e.g., multiphase Darcy flow) and the non-convex nature of the objective function. Consequently, it serves as an ideal testbed for assessing the practical efficacy of advanced metaheuristics.
To evaluate the efficacy of the proposed algorithm in a practical setting, a simulation-based framework is adopted. The industry-standard Eclipse reservoir simulator acts as the “black-box” forward model to evaluate candidate production schedules, calculating dynamic reservoir responses to the specified controls [39,40,41]. In a representative application, the improved algorithm is tasked with optimizing the injection and production strategies for a multi-well reservoir model over several control steps, with the simulator providing the necessary production data (oil, water, and gas rates) for each proposed schedule.
The performance of each control strategy is evaluated using the Net Present Value (NPV), which aggregates discounted future cash flows. The objective function to be maximized is formally defined as
where denotes the control vector. The specific economic parameters are: oil price ,water handling costs , and discount rate b. Non-linear production constraints, such as minimum bottom-hole pressure (BHP) limits for producers and maximum water-cut thresholds, are omitted in this specific study to isolate and evaluate the core algorithmic search capability. Future higher-fidelity studies will integrate these operational constraints to further assess the algorithm’s industrial applicability.
5.1. Reservoir Model Description
A two-dimensional, heterogeneous synthetic reservoir model is developed to simulate the intricate architecture of a fluvial channel system. It adopts a classical inverted five-spot well arrangement, with one central producer (PRO1) and four injectors (INJ1–INJ4) at the periphery, illustrated in Figure 4. This design facilitates a robust assessment of the optimization methodology under geologically realistic, spatially variable conditions.
The model domain is spatially discretized using a Cartesian grid, resulting in 625 active cells. Each cell possesses a uniform thickness and planar dimensions of . Porosity is held constant at a value of 0.2. In contrast, the permeability field is stochastically generated to embed high-permeability channels amidst low-permeability background regions, creating preferential flow pathways. The resulting log-permeability distribution, ln(K), which dictates fluid flow behavior, is presented in Figure 4.
The optimization framework is configured with flexibility. The total simulation duration is set to 1000 days, partitioned into 12 control steps. Optimization involves five wells, yielding a problem with 60 decision variables. The goal is to maximize the Net Present Value (NPV) by determining optimal well controls. Economic parameters are assigned plausible values: oil price (85 USD/STB), water injection cost (5 USD/STB), water processing cost (3 USD/STB), and an annual discount rate (3%). These settings maintain realism while concentrating the analysis on the core optimization algorithm’s performance.
5.2. Results and Discussion
The performance of CL-ECO is benchmarked against the original ECO and the competitor algorithms under identical conditions (five independent runs). Table 4 summarizes the statistical outcomes. Regarding economic performance, CL-ECO achieves a mean NPV of 9.842 × 10^8^ , surpassing the baseline ECO (8.745 × 10^8^) by a margin of 12.5%. The distinct advantage of CL-ECO in this reservoir model stems from its dimension-wise learning capability. In geologically heterogeneous fields where fluvial channels create preferential but isolated flow paths, standard exploitative algorithms like ECO tend to lock onto a single moderate-performing injection scheme across all wells. By allowing the control steps of different wells to be optimized independently through learning from diverse exemplars, CL-ECO maintains the flexibility required to discover alternative, better sweep patterns across the model. This significant financial advantage stems from the algorithm’s enhanced ability to navigate the complex trade-offs between injection support and production efficiency within the heterogeneous permeability field. By identifying high-transmissibility pathways more effectively, CL-ECO optimizes the sweep efficiency, thereby recovering more oil at lower water-cut levels. In terms of operational stability, the standard deviation of CL-ECO remains the lowest among all evaluated algorithms (1.27 × 10^7^), suggesting that its “CL-driven search reconstruction” mechanism consistently identifies high-quality basins regardless of initial stochastic seeding. In sharp contrast, competitors like Parrot Optimizer (PO) exhibit large variances (4.33 × 10^7^), indicating a high dependency on initial conditions and a tendency for unstable convergence. Furthermore, as illustrated by the convergence trajectories in Figure 5, CL-ECO (red) identifies superior solutions significantly earlier than its counterparts. The rapid early-stage ascent reflects its high exploration efficiency, confirmed by the algorithm’s ability to quickly bypass local optima traps that frequently hinder the canonical ECO and MGO.
In summary, the integration of dimension-wise comprehensive learning grants CL-ECO a dual advantage: it not only maximizes absolute economic returns but also ensures a robust, repeatable decision-making process. These characteristics are critical for field-scale reservoir management, where stable and high-performance well controls are paramount.
6. Conclusions
This study introduced the Comprehensive Learning-Enhanced Educational Competition Optimizer (CL-ECO), a targeted advancement of the canonical ECO framework designed to address critical limitations in population diversity and its susceptibility to local optima in complex optimization tasks. This is realized through the novel integration of a dimension-wise, multi-exemplar comprehensive learning (CL) strategy, which enables stagnant individuals to reconstruct their search trajectories by sampling information from diverse peers. The resulting framework effectively decouples decision variables, fostering a robust balance between global exploration and local exploitation while preventing the premature stagnation inherent in the original hierarchical structure.
The efficacy of the proposed CL-ECO was substantiated through rigorous empirical validation. In comprehensive assessments on the CEC 2017 benchmark suite, CL-ECO demonstrated superior performance, securing the premier rank in Friedman statistical tests with a score of 1.5862 and showing a statistically validated advantage over established metaheuristics across unimodal, multimodal, and hybrid landscapes. Furthermore, its practical utility was confirmed in a high-fidelity reservoir production optimization case study. In this application, CL-ECO delivered a mean Net Present Value (NPV) of 9.842 × 10^8^, representing a 12.5% improvement over the baseline algorithm with exceptional consistency, thereby validating its reliability for handling complex, real-world engineering constraints. Despite these advancements, the effectiveness of the CL-ECO framework remains contingent upon the proper calibration of the [eqn][eqn]$ per stagnant individual), while a delayed response might hinder the timely escape from local optima. Nevertheless, the algorithm’s dimension-wise reconstruction capability effectively decouples decision variables, ensuring robustness in rugged, non-separable landscapes. This characteristic makes CL-ECO highly adaptable to a broad spectrum of engineering applications, including those involving stochastic or fuzzy uncertainties. Building on these promising results, future research will pursue three key trajectories: (1) conducting systematic ablation studies to quantify the contribution of the stagnation trigger; (2) developing adaptive parameter control mechanisms and extensions for high-dimensional and multi-objective domains; and (3) exploring broader industrial challenges, such as multi-well placement and automatic history matching, to further solidify its status as a robust optimization tool.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rao S.S. Engineering Optimization: Theory and Practice John Wiley & Sons Hoboken, NJ, USA 2019
- 2Belegundu A.D. Chandrupatla T.R. Optimization Concepts and Applications in Engineering Cambridge University Press Cambridge, UK 2019
- 3Sabanza-Gil V. Barbano R. Pacheco Gutiérrez D. Luterbacher J.S. Hernández-Lobato J.M. Schwaller P. Roch L. Best practices for multi-fidelity Bayesian optimization in materials and molecular research Nat. Comput. Sci.2025557258110.1038/s 43588-025-00822-940702272 · doi ↗ · pubmed ↗
- 4Amani M.A. Sarkodie S.A. Sheu J.B. Nasiri M.M. Tavakkoli-Moghaddam R. A data-driven hybrid scenario-based robust optimization method for relief logistics network design Transp. Res. Part E Logist. Transp. Rev.202519410393110.1016/j.tre.2024.103931 · doi ↗
- 5Abualigah L. Elaziz M.A. Khasawneh A.M. Alshinwan M. Ibrahim R.A. Al-Qaness M.A. Mirjalili S. Sumari P. Gandomi A.H. Meta-heuristic optimization algorithms for solving real-world mechanical engineering design problems: A comprehensive survey, applications, comparative analysis, and results Neural Comput. Appl.2022344081411010.1007/s 00521-021-06747-4 · doi ↗
- 6Kar B. Yahya W. Lin Y.D. Ali A. Offloading using traditional optimization and machine learning in federated cloud–edge–fog systems: A survey IEEE Commun. Surv. Tutor.2023251199122610.1109/COMST.2023.3239579 · doi ↗
- 7Zeng J. Yin W. On nonconvex decentralized gradient descent IEEE Trans. Signal Process.2018662834284810.1109/TSP.2018.2818081 · doi ↗
- 8Wasley R. Shlash M.A. Newton-Raphson algorithm for 3-phase load flow Proceedings of the Institution of Electrical Engineers IET Stevenage, UK 1974 Volume 12163063810.1049/piee.1974.0145 · doi ↗