An Improved Mantis Search Algorithm for Solving Optimization Problems
Yanjiao Wang, Tongchao Dou

TL;DR
This paper introduces an improved mantis search algorithm that enhances optimization performance by adapting search strategies and maintaining population diversity.
Contribution
The novel algorithm introduces adaptive probability conversion, dynamic search range adjustment, and mechanisms to preserve diversity and improve convergence.
Findings
The improved algorithm outperforms the original MSA and five other meta-heuristic algorithms on the CEC2017 test set.
The algorithm shows faster convergence and higher accuracy in complex optimization scenarios.
Mechanisms like elite screening and non-greedy replacement effectively maintain population diversity.
Abstract
The traditional mantis search algorithm (MSA) suffers from limitations such as slow convergence and a high likelihood of converging to local optima in complex optimization scenarios. This paper proposes an improved mantis search algorithm (IMSA) to overcome these issues. An adaptive probability conversion factor is designed, which adaptively controls the proportion of individuals entering the search phase and the attack phase so that the algorithm can smoothly transition from large-scale global exploration to local fine search. In the search phase, a probability update strategy based on both subspace and full space is designed, significantly improving the adaptability of the algorithm to complex problems by dynamically adjusting the search range. The elite population screening mechanism, based on Euclidean distance and fitness double criteria, is introduced to provide dual guidance for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
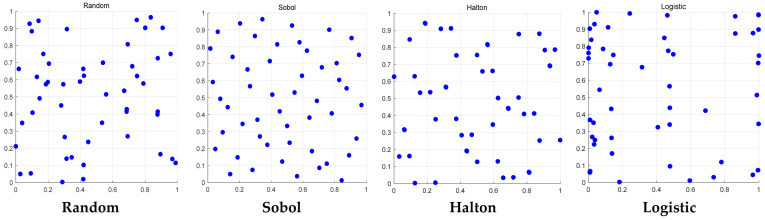 Figure 1
Figure 1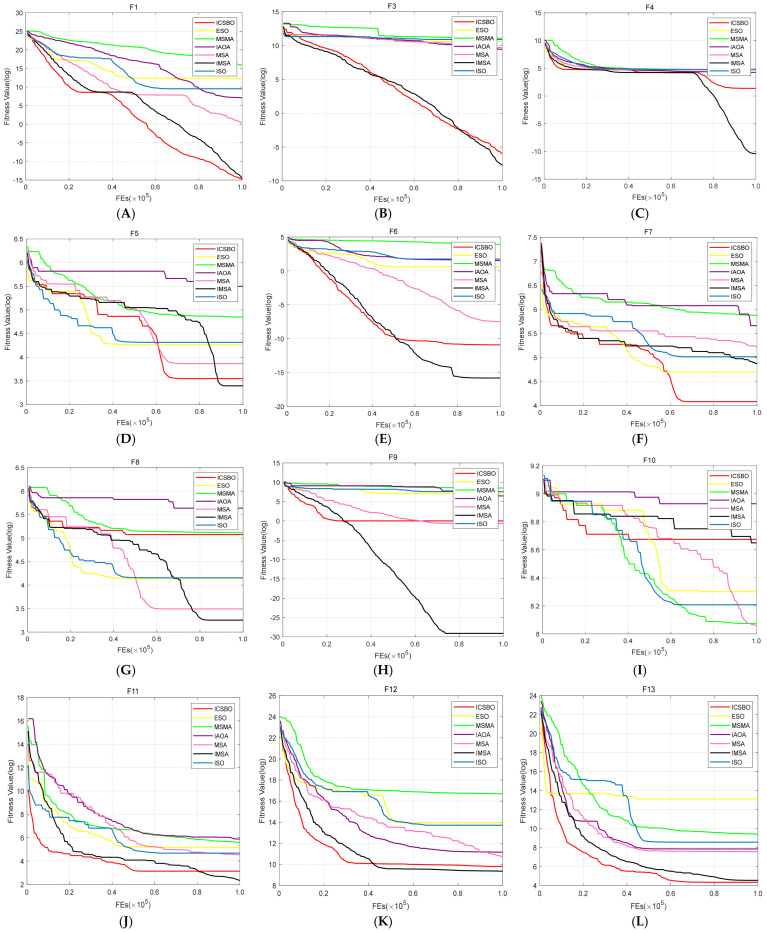 Figure 2
Figure 2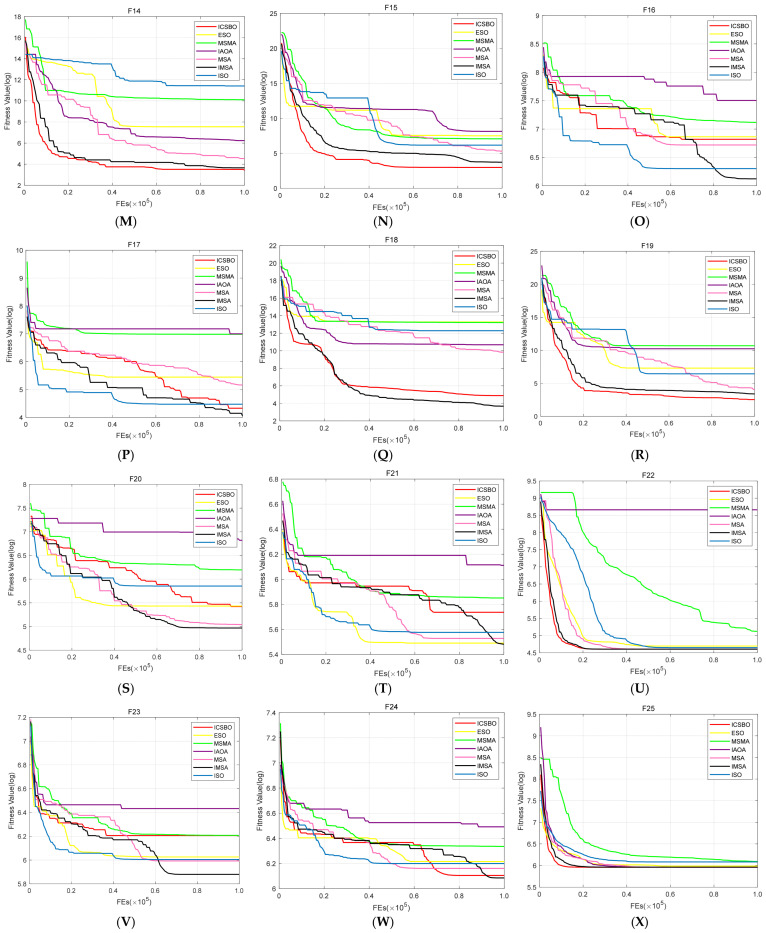 Figure 3
Figure 3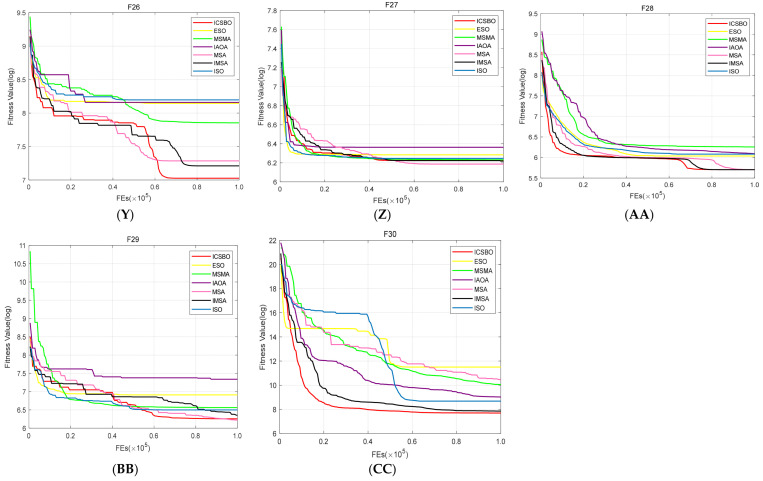 Figure 4
Figure 4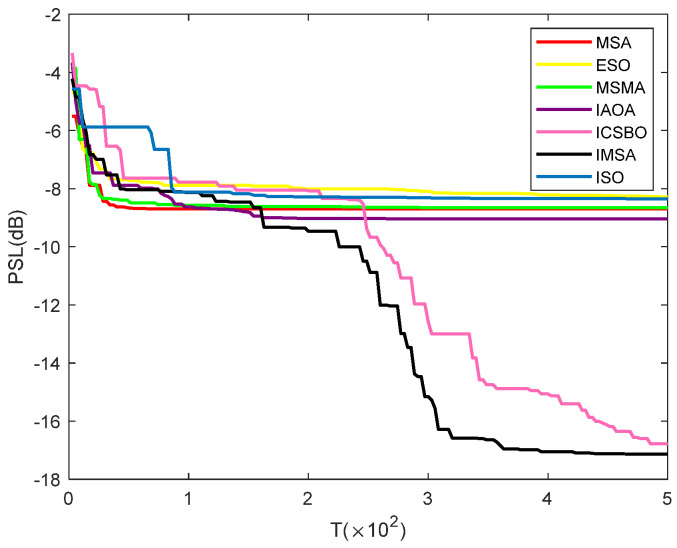 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Advanced Multi-Objective Optimization Algorithms · Vehicle Routing Optimization Methods
1. Introduction
1.1. Related Work
The optimization problem is a core challenge in the fields of natural science and engineering. It is widely used in resource scheduling in industrial production, hyperparameter tuning in machine learning, and energy management in wireless sensor networks [1,2]. The gradient-directed optimization technique is a classical method to deal with optimization problems [3,4,5]. However, this method has extremely high requirements for the objective function. It is difficult to deal with non-convex or non-differentiable function forms, and the amount of calculation will increase sharply with the increase in the dimension of the problem. In contrast, meta-heuristic algorithms such as particle swarm optimization (PSO) [6], artificial bee colony algorithm (ABC) [7], gray wolf optimization (GWO) [8], and differential evolution (DE) [9] use the characteristics of biological systems or physical laws to guide the optimization search process. They have significant adaptability and can efficiently solve complex optimization problems. At present, the research of meta-heuristic algorithms is mainly divided into two categories: (1) an improved meta-heuristic method for enhancement strategy, and (2) a new meta-heuristic method.
On the one hand, the enhanced traditional meta-heuristic algorithm has always been the focus of research. In 2021, Desuky et al. proposed an enhanced Archimedes algorithm (EAOA), which improves the performance of the algorithm by introducing new parameters of a single step in the unit update process [10]. Wang et al. proposed an improved Archimedean algorithm (IAOA) in 2023. The algorithm improves the learning factor of individual attributes and the mechanism of the probability updating individual position, and it adopts the simplex method correction strategy to adjust the position of individuals, which improves the convergence speed and significantly improves the convergence accuracy [11]. In 2023, Yao et al. proposed an enhanced snake optimizer (ESO), which improves the algorithm’s performance by introducing opposition-based learning and adaptive update strategies [12]. Zhu et al. proposed an improved snake optimizer (ISO) in 2025, introducing three strategies: chaotic systems, anti-predator dynamics, and a population two-way co-evolution mechanism. This accelerates the convergence speed and stability of the SO algorithm, and it also greatly improves the accuracy of data classification [13]. In 2022, Deng et al. proposed a multi-strategy improved slime mold algorithm (MSMA), designed adaptive mutation probability, introduced new search equations and dynamic local search techniques, and achieved a good balance between the various stages, thereby improving the performance of the algorithm [14]. In 2024, Wang et al. proposed an improved honeypot optimization algorithm (α4CycρHBA), which combines the distribution coefficient and geometric spiral characteristics of the basic function and also replaces the mining mode of the honeypot picking strategy in the HBA algorithm, thereby improving the accuracy of the algorithm optimization function and the balance of exploration and development capabilities [15]. In 2025, Nan et al. proposed an improved circulatory system-based optimization algorithm (ICSBO) featuring a new venous blood flow pattern, which adopts an adjustable interference learning strategy, combines the simplex search method with the pulmonary circulation mechanism, and establishes an external archive system to maintain the diversity of the population, ultimately improving the efficiency of the algorithm [16].
On the other hand, a new meta-heuristic algorithm has been proposed with good performance. In 2021, I. Naruei et al. proposed a COOT algorithm (COOT), which simulates the random movement of the white-bone top chicken and the behavior of following the leader to find food [17]. In 2022, inspired by the foraging and random hiding behavior of rabbits around the island, Wang et al. developed a new artificial rabbit swarm optimization algorithm (ARO) [18]. In the same year, Zhong et al. studied the behavior of whales swimming in pairs, preying, and whale sinking, and proposed a beluga whale optimization algorithm (BWO) [19]. In 2023, Abdel-Bass et al. proposed the spider bee optimization algorithm (SWO) based on the biological characteristics of female spider bees, such as predation, nesting, and mating [20]. In the same year, Abdel-Basse et al. proposed a mantis optimization algorithm (MSA) based on the predation behavior of mantis in nature, which simulated the behavior of mantis searching for prey, ambushing prey, and female mantises eating male mantises during mating [21]. In 2024, Wang et al. proposed the Black Kite Algorithm (BKA), which is a meta-heuristic optimization algorithm inspired by the migration of the Black Kite to observe the behavior of prey and predation [22]. In 2025, Wang et al. proposed an animated oat optimization algorithm (AOO), which simulates the behavior of animated oats to spread and diffuse seeds through natural elements [23].
1.2. Motivation and Contribution
In recent years, improving the optimization performance of evolutionary algorithms has been a frontier topic in this field. Compared with WOA [24], DE, ABC, GA, CS [25] and other algorithms, the MSA shows significantly better convergence performance, and its performance optimization research continues to attract academic attention. At present, the MSA has shown good application potential in many practical engineering fields, such as economic dispatch [26], parameter optimization [27], multi-objective optimization, and so on [28,29,30]. However, there are limitations in convergence accuracy and speed. In this context, to improve the convergence accuracy and operation speed of the MSA in solving complex optimization problems, this paper proposes an improved mantis search algorithm (IMSA). The innovation and research motivation of this paper are mainly reflected in the following aspects:
(1) An adaptive probability conversion factor is designed, which can dynamically adjust the proportion of individuals entering the global search and local optimization stage, aiming to realize the spontaneous transition from large-scale exploration to fine mining to improve the overall efficiency of the algorithm in the face of complex optimization problems.
(2) Improve the search phase: An adaptive dynamic weight factor is introduced to dynamically adjust the ratio between the pursuit behavior and the ambush behavior in order to strengthen the exploration and development ability of the algorithm in different optimization stages. In the pursuer behavior, a probability update strategy based on the subspace whole space is proposed, and the multi-scale regulation of exploration ability is realized by dynamically adjusting the search radius. In the ambush behavior, a dual-standard elite-oriented mechanism based on Euclidean distance and fitness is designed, which uses the spatial distribution and quality information of elite individuals to accelerate group convergence. At the same time, the simulated binary crossover (SBX) strategy is used to promote information transmission between external archives and the current population, which significantly enhances the algorithm’s global exploration efficiency.
(3) Improve the attack phase: In search method 1, the elite individual guidance strategy is introduced, and the influence weight of the elite individual is dynamically adjusted by the adaptive weight factor to realize the adaptability of the attack phase behavior in different algorithm periods. In search method 2, the adaptive probability selection mechanism of the basis vector is designed, and its weight ratio is adjusted adaptively to effectively prevent the optimization process from falling into the local optimal problem caused by over-reliance on the optimal individual.
(4) Improved sexual cannibalism stage: A non-greedy replacement strategy based on dynamic crossover probability is proposed, which allows inferior individuals to be replaced directly by new individuals with a certain probability rather than deciding whether to retain them only after comparing them with the original individuals. This mechanism significantly enhances the diversity recovery ability of the population in the later stage of iteration, and it is a key innovation to prevent the algorithm from premature convergence and jumping out of the local optimum.
Experimental results on the CEC2017 test set demonstrate that the proposed IMSA outperforms five state-of-the-art algorithms in terms of both convergence accuracy and speed.
The following chapters are arranged as follows: Section 2 systematically discusses the core mechanism and execution flow of the MSA. Section 3 analyzes the limitations of the basic MSA and then proposes an improved IMSA. In Section 4, based on the CEC2017 standard test [31] function set, the simulation comparison experiment is carried out to comprehensively evaluate the optimization performance of the IMSA, the original MSA and the mainstream improved algorithm. Section 5 proves the effectiveness of the IMSA in the beamforming optimization problem. Section 6 summarizes the IMSAs proposed in this paper.
2. Mantis Search Algorithm
In the insect world, the mantis is a typical ambush predator, using camouflage to wait for prey to approach. When the predator enters its attack range, it uses highly developed spined forelegs to attack the prey and complete the capture quickly. An abnormal behavior characteristic was found in the mantis family: that is, females may eat males during mating. Inspired by the above behavior, Abdel-Basset et al [21]. proposed the mantis search algorithm (MSA) in 2023 to solve the function optimization problem. In the MSA, the individual represents the position information of the mantis, and the fitness value represents the positional quality of each mantis individual. Like other swarm intelligence optimization algorithms, the MSA first randomly generates an initial population in the D-dimensional search space and then performs evolutionary iterations. The main evolutionary operations include the search phase, the attack phase, and the sexual cannibalism phase. The pseudo-code of the MSA is shown in Algorithm 1. Algorithm 1 MSAInput: Output: the best mantis and its fitness value
- 1. Initialize N mantises,
- 2. Evaluate each and find the best fitness individual
- 3. t = 1
- 4. While t < T do
- 5. r: a number created randomly between 0 and 1
- 6. If r < p then
- 7. r1: a number created randomly between 0 and 1
- 8. Update exploring factor F using Equation (1)
- 9. For i = 1: N do
- 10. If r1 < F then
- 11. Update using Equation (2)
- 12. Else
- 13. Update using Equation (4)
- 14. End if
- 15. Evaluate the mantis, , replace with, if it is better
- 16. End for
- 17. Else
- 18. For i = 1: N do
- 19. For j = 1: D do
- 20. Update using Equation (7)
- 21. End for
- 22. Evaluate the mantis, , replace with, if it is better
- 23. End for
- 24. End if
- 25. If r < P_c_ then
- 26. For i = 1: N do
- 27. Update using Equation (11)
- 28. Evaluate the mantis, , replace with, if it is better
- 29. End for
- 30. End if
- 31. t = t + 1
- 32.End while
2.1. Search Stage
In the MSA, two kinds of prey capture behaviors are designed, including pursuer behavior and ambush behavior. Each mantis chooses one of the prey capture behaviors to generate a new position as follows. According to Equation (1), the cycle factor is calculated, and then a random number in [0, 1] is generated. When , the mantis individual uses the pursuer behavior to search for prey by a large jump and random walk. On the contrary, after choosing the ambush behavior, the mantis is disguised in the tree or grass, waiting for the prey to enter the attack range. The behavior of pursuers and ambushers is as follows.
where represents the current number of iterations; T is the maximum number of iterations; P is set to a fixed value of 2 in the original MSA; and % represents the remainder operator.
(1)Pursuer behavior
To explore the search space as widely as possible, the mantis uses a combination of Levy flight and normal distribution. By simulating this behavior, the MSA proposes pursuer behavior as shown in Equation (2), that is, randomly selecting three locations to create a sudden direction change to find the most promising region that may contain an approximate optimal solution.
where represents the position of the i-th mantis after chasing prey; represents the current position of the i-th mantis; is the numerical vector generated by the flight strategy; is a random number generated based on the standard normal distribution; , are numbers generated by uniform distribution in [0, 1]; is a D-dimensional vector, and each dimension is a random number uniformly distributed in [0, 1]; , and are randomly selected individuals from the current population, which satisfy ; and is the binary vector that controls each dimension, as shown in Equation (3):
where and are D-dimensional vectors randomly generated in [0, 1] according to a uniform distribution.
(2)Ambush behavior
Biologically, the mantis lurks in the grass, using rotatable triangular eyes to see where their prey is and waiting for it to move closer to the ambush site. Simulating this behavior, the ambush behavior shown in Equation (4) is proposed.
Among them, is a random number in [0, 1]; is a vector composed of the number of randomly generated D in [0, 1]; both and are random numbers in [0, 1], which are used to balance the two behaviors of mantis ambush to observe prey and wait for prey to enter the attack range; is the coefficient to control the head position of the mantis to achieve the ambush distance coverage, as shown in Equation (5); is an individual randomly selected from the current population; and are the upper and lower bounds of the search space, respectively; is an individual randomly selected from the external archive, and the length A of the external archive is set to 1 in the MSA. The creation of an external archive is as follows: if , is directly stored in the archive.
where is a random number in [0, 1]; is a distance factor, and the specific calculation method is shown in Equation (6).
2.2. Attack Stages
In nature, the mantis will evaluate the spatial distance between itself and its prey before attacking, adjusting its angle when the time is right, and using its high-speed forelegs to capture the prey. However, the mantis has a certain proportion of hunting failures during the predation process, and the target needs to be repositioned through posture adjustment. Motivated by this behavior, the MSA designs the attack phase, as shown in Equation (7).
where represents the new position of dimension j of the i-th mantis in generation t + 1; represents the position of prey or the j-th dimension of the best solution so far; and are two mantises randomly selected from the current population; is an individual randomly selected from the external archive; , , and are all random numbers between [0, 1]; is the probability, as shown in Equation (8); represents the speed at which the mantis attacks its prey, as shown in Equation (9); and represents the attack distance of the mantis, as shown in Equation (10).
where is a preset value, which is recommended to be set to 0.5.
Among them, l is a random number within the range of [−2, 1]. When is close to −2 and −1, the attack speed is close to 1 and 0, respectively, reaching the maximum and minimum values. When is close to 0, the mantis believes that now is not the best time to attack prey. Conversely, when is close to 1, the mantis will act quickly to attack and capture the prey, ensuring that it is eaten before the prey escapes. represents the acceleration rate of gravity during mantis attack, which is recommended to be set to 6 in the MSA.
2.3. Sexual Cannibalism Stage
In nature, female mantises attract males to their positions to complete mating. In this process, female mantises may eat male mantises and call this behavior sexual cannibalism. By simulating the above process, the MSA proposed the following stages of sexual cannibalism: for each mantis individual, if the random number between [0, 1] is less than P_c_ (P_c_ is generally set to 0.2), the position is updated as shown in Equation (11); otherwise, maintain the original position.
where represents the female individual of the mantis; is an individual randomly selected from the population; , are vectors composed of the number of randomly generated D in [0, 1]; , are random numbers in the range of [0, 1]; represents the first dimension of the t generation mantis; is the binary vector that controls each dimension, as shown in Equation (3); represents the portion of the male that is eaten by the female, as shown in Equation (6); represents the ability of female individuals to perform position reversal on males in feeding behavior; and the probability P_t_ that the female attracts the male is shown in Equation (12).
where is a random number in the range of [0, 1]. is the attenuation factor, and the specific calculation method is shown in Equation (6).
3. Improved Mantis Search Algorithm
Like other swarm intelligence optimization algorithms, the MSA also uses a random way to generate the initial population, which may lead to an uneven distribution of individuals in the search space or excessive concentration in a certain area, which affects the accuracy of the algorithm to some degree. The Sobol sequence can maintain a good uniform distribution in high-dimensional space, and its difference degree dimension increases slowly, which is more suitable for high-dimensional optimization problems. Given this, the Sobol sequence is used instead of the random method to generate the initial population. To further improve the convergence ability of the MSA, this section comprehensively improves the conversion factor determination method, search stage, attack stage, and sexual cannibalism method in the MSA, and it proposes an enhanced mantis search algorithm. The pseudo-code is shown in Algorithm 2. Algorithm 2 IMSAInput: Output: the best mantis and its fitness value
- 1. Using Sobol sequence Initialize N mantises, using Section 3
- 2. Evaluate each and find the best fitness individual
- 3. t = 1
- 4. While t < T do
- 5. r: a number created randomly between 0 and 1
- 6. Update factor p Using Equation (13)
- 7. If r < p then
- 8. r1: a number created randomly between 0 and 1
- 9. Update exploring factor F using Equation (24)
- 10. For i = 1: N do
- 11. If r1 < F then
- 12. Update using Equation (14)
- 13. Else
- 14. Update using Equation (21)
- 15. End if
- 16. Evaluate the mantis, , replace with, if it is better
- 17. End for
- 18. Else
- 19. For i = 1: N do
- 20. Update using Equation (25)
- 21. Evaluate the mantis, , replace with, if it is better
- 22. End for
- 23. End if
- 24. Update P_c_ using Equation (29)
- 25. If P_c_ < r then
- 26. For i = 1: N do
- 27. Update using Equation (20)
- 28. If P_c_ < CR_i_ then
- 29. Updating using Equation (30)
- 30. End if
- 31. Evaluate the mantis, , replace
- 32. End for
- 33. End if
- 34. t = t + 1
- 35.End while
3.1. Adaptive Probability Conversion Factor
Like most other swarm intelligence evolutionary algorithms, for complex optimization problems, the MSA will feature the following phenomena in the iterative process: in the initial stage of evolution, the exploration is insufficient, and the diversity decreases too fast; in the later stage, the local search is not fine enough, and the population convergence is too slow. In the early stage of evolution, it is necessary to strengthen the exploration mechanism to enhance the global optimization performance. In the later stage of evolution, attention should be paid to fine development.
In-depth analysis reveals that the search phase of the MSA mainly explores new locations and provides population diversity; the attack phase is primarily focused on development. However, the probability conversion factor p in the MSA is 0.5, so relying on the probability conversion factor p, each individual will equally select the search phase or the attack phase for location update at each evolutionary stage. The probability conversion factor of fixed settings makes the algorithm unable to meet the needs of exploration and development at different evolutionary stages. Because of this, this section proposes a method of adaptive probability conversion factor p according to the iterative process, as shown in Equation (13).
where t represents the current number of iterations; T is the maximum number of iterations. It can be seen from Equation (13) that as evolution proceeds, the value of the adaptive probability conversion factor p proposed in this section gradually decreases, and the algorithm gradually shifts from focusing on large-scale global exploration to local fine search. While improving the convergence speed, it can also explore higher-quality solutions. In addition, compared with the p set to 0.5 in the basic MSA, the initial value of p in Equation (13) is 0.8, which further increases the exploration ability during initial evolutionary phases. It can dig out more promising solution regions, improve the global exploration ability of early iterations, and further enhance its demand for population diversity when solving complex function problems.
3.2. Improved Search Stage
It can be seen from Section 2.1 that in the search phase of the MSA, each mantis relies on the weight factor shown in Equation (1) to select the pursuer behavior or ambush behavior for the location update. To obtain better convergence characteristics, this section improves the pursuer behavior, ambush behavior and weight factor, respectively.
(1)Improved pursuer behavior
It can be seen from Equation (2) that the pursuer behavior in the MSA provides the following two types of location update methods: in search method 1, the individual interacts with two other individuals randomly selected, which changes all the genes of the individual and belongs to the full space search; in search method 2, three random individuals in the population interact to form a new individual, which is cross-combined with the current mantis individual in each dimension, retaining the genes in some dimensions of the mantis individual and only changing some genes in other dimensions. It belongs to the subspace search. A full space search has stronger exploration ability, and subspace search can better maintain the diversity of the current population. In-depth analysis of the MSA shows that the attack phase focuses on development, and the search phase focuses more on exploration. However, the above-mentioned pursuer behavior, with equal probability to choose the full space or subspace search, makes the MSA’s overall exploration ability insufficient. In addition, the above-mentioned pursuer behavior does not consider the individual’s characteristics nor does it consider the different needs of exploration ability and diversity in the evolutionary stage, which also affects the search ability of the pursuer behavior to a certain extent.
To further enhance the pursuer behavior’s exploration ability while taking into account the characteristics of population distribution, inspired by the subspace full space design method in the literature [32], this section proposes an improved pursuer behavior, as shown in Equation (14).
where is a D-dimensional vector in [0, 1]; and each dimension of the newly generated individual is selected in the individual and according to the probability . The generation of individual and is shown in Equations (15) and (16), and the probability is shown in Equation (18).
where is the random vector generated by Levy flight; and , are random numbers between [0, 1].
where is a random variable subject to the standard normal distribution; and are random numbers in the range of [0, 1]; , and are randomly selected individuals from the current population, which satisfy ; and is a dynamic weighting factor, as shown in Equation (17):
where t denotes the current iteration count while T corresponds to the maximum iteration.
Among them, the calculation methods of and are shown in Equations (19) and (20).
where is a very small constant, which is generally set to ; represents the fitness value of the i-th mantis; and represent the maximum and minimum fitness values in the population, respectively.
In summary, compared with the pursuer behavior in the MSA, the improved pursuer behavior proposed in this section shows the following advantages. First, the improved pursuer behavior uses an adaptive parameter to dynamically control the proportion and focus the direction of small-scale exploration as shown in Equation (15) and large-scale exploration as shown in Equation (16) in different stages of new individuals in order to better achieve the balance of full space and subspace search in different evolutionary stages and better adapt to the solution of complex optimization problems. Secondly, the set crossover probability CR can sufficiently measure the characteristics of the individual itself according to the fitness value. Individuals with relatively good fitness values have a greater probability of exploring based on their own information without losing their excellent information. Individuals with poor fitness have a greater probability to select the random position in the group as the base vector for random exploration. In summary, CR allocates different individuals to complete the update method that is more suitable for the individual so that it can better complete the evolution in each period of the algorithm.
(2)Improved ambush behavior
In-depth analysis of the ambush behavior in Section 2.1 (2) shows that it has the following defects. First, the external archive length A is set to a fixed value of 1; that is, only one individual can be stored, and individuals participating in the ambush behavior need to learn from it, which reduces the diversity of the population to some degree. In addition, the external archive stores only the last updated individual, which may not be a relatively excellent individual in the population. Learning from leads to a great probability of obtaining failure information. Second, as shown in Equation (4), the ambush behavior provides two types of location update methods. Among them, the first search method involves the individual interacting with the individuals in the archive and the randomly selected individuals. Although the population diversity is maintained to some degree, the population convergence is too slow due to the lack of an excellent ambush position to guide the evolution direction. The essence of the second search method is that the individuals in the archive perform a free search offset in the search space. This method can provide more population diversity on the surface. Still, because this method is too random, the newly generated individuals cannot be superior to the original individuals, so the new individuals cannot be retained to participate in the subsequent evolution, resulting in an invalid search. In short, these two types of search methods cannot effectively provide population diversity, and the convergence speed is too slow.
In summary, while ensuring the diverse characteristics of the population, to further provide high-quality guidance information to the population, this section proposes an improved ambush behavior, as shown in Equation (21).
where and are random numbers in the range of [0, 1]; is the crossover probability, as shown in Equation (19); is an adaptive weight factor, which controls the size of the step forward to the elite individual, as shown in Equation (22); SBX is a cross-operation, as shown in [33]; and is a randomly selected individual in the elite population. The elite population is composed as follows: the elite population count is N/5, and N is the population count. Firstly, the population individuals are sorted according to their fitness value, and the top (N/5 + 5) quasi-elite individuals are selected. The quasi-elite individuals in the top 30% of the fitness value rank directly enter the elite population. The remaining quasi-elite individuals are calculated for their Euclidean distance to the current optimal individual, which is sorted in descending order based on this distance. From the sorted remaining quasi-elite individuals, the top 70% are selected to join the elite population; is the individual selected from the external archive according to the probability P_i_,arc shown in Equation (23). That is, when the selection probability of the i-th individual P_i_,arc > rand, the archive individual is selected as . On the contrary, another individual in the archive is randomly selected as . Different from the composition of external archives in the MSA, where the archive length A = N, when , if |A| < N, is directly stored in the archive; Otherwise, the archive individuals with the largest number of evolutions are selected for replacement.
The calculation method of is shown in Equation (19); is a very small constant, which is generally set as ; where t represents the current number of iterations; and T is the maximum number of iterations
where represents the number of times that the i-th individual in the external archive is selected; and represent the maximum and minimum number of times an individual is selected in the archive, respectively.
In summary, compared with Section 2.1 (2), the new ambush behavior proposed in this section has the following advantages. Firstly, the individual in the elite population is the part with better fitness value and far away from the optimal individual, which represents the excellent evolutionary information in the current population. In search method 1, the elite individual is added to guide the exploration direction, which further improves the convergence speed of the algorithm, and the population diversity is effectively maintained through the selection mechanism of non-single elite individuals. In addition, it can be seen from Equation (22) that the weight factor adaptively determines the degree of individual learning from elite individuals according to the different periods of population evolution. In the early stage, is small, which avoids the problem of local rapid convergence caused by the rapid approach of the population to elite individuals. In the middle stage, increases, which increase the degree of learning from elite individuals and further improve the convergence speed of the algorithm. In the later stage, decreases, which ensures that the population can perform a fine local search and enhance the convergence accuracy of the population. Secondly, search method 2 proposed in this section performs SBX crossover between the current individual and the archive individual, and it interacts with the same generation or the previous generation of individuals. Compared with the original search method 2 in Equation (4), which uses a random walk in the exploration area, it also maintains population diversity and greatly enhances the effectiveness of the new position. Thirdly, in the original ambush behavior, individuals choose search methods 1 and 2 according to the same probability, but this section proposes to choose search methods 1 or 2 according to the cross factor CR. That is, the better individual is more likely to select search method 1 while being guided by the elite individual to generate a new position. Poor individuals are more likely to interact with individuals in the archive according to search method 2 to maintain population diversity. The crossover factor CR plays a prominent role in individuals with different characteristics, maintains diversity and guides the evolutionary direction of the population. Fourth, the external archive stores N better individuals, provides more potential excellent areas for the current population, and can retain the solutions of different iteration cycles, interact with the current population individuals, and maintain better population diversity to some degree. In addition, the selection probability P_i_,arc prevents the repeated selection of an individual in the archive, so that the information of each archive solution is effectively utilized, and the information interaction between individuals in the population is strengthened.
(3)Dynamic weight factor
In summary, it can be seen that the new pursuer behavior proposed in Section 3.2 (1) contains two search modes, which dynamically control their proportion and update their directions at different stages of the algorithm, and they are more biased toward large hybridization steps and random directions for global exploration. The new ambush behavior proposed in Section 3.2 (2) is biased toward information interaction with external archive individuals and learning from elite individuals to ensure the direction of the search. As described in the MSA, the individual selects the pursuer behavior or the ambush behavior for the location update according to the weight factor F shown in Equation (1). An in-depth analysis of Equation (1) shows that F changes cyclically according to the parameter P, and P is set to 2 in the original text, so that F decreases from 1 to 0 in the early stage and from 1 to 0 again in the middle stage. It may lead to an insufficient exploration of the solution space in the early stage of the algorithm. This prevents the exploration of more promising areas, and the convergence rate in the middle and late stages is greatly slowed down. To meet the needs of the population diversity and convergence rate at different stages, this section designs a dynamic weighting factor, as shown in Equation (24):
It can be seen from Equation (24) that in the early stage of the algorithm, the probability of executing the pursuer behavior is high, which greatly improves the exploration ability of the algorithm, finds some promising solution regions, and maintains the diversity of the population. In the middle and late stages, the role of the pursuer behavior is reduced, and the ambush behavior begins to strengthen the ability of local search, which improves the convergence speed of the algorithm.
3.3. Improved Attack Phase
Unlike the search phase, which focuses on exploration, the attack phase focuses more on development. To further significantly strengthen the local development performance of the algorithm, this section improves the attack phase and proposes an enhanced attack phase as shown in Equation (25).
where , , and are random numbers in the range of [0, 1]; and are randomly selected individuals from the current population, which satisfy ; is the individual with the best fitness value in the t generation population; is the elite individual of the t generation; is an adaptive weight factor, as shown in Equation (26); is the parameter of the selection probability of the control equation, as shown in Equation (27). ; Z is the proportion of subspace occupied, as shown in Equation (28).
Compared with the original attack phase, the improved attack phase proposed in this section offers the following advantages. Firstly, three types of individual update methods are proposed in the original attack phase. Among them, search method 3 adds disturbance to the entire search space. Although it is possible to add new evolutionary information different from the current population, it is very likely to exceed the search boundary due to excessive disturbance, resulting in an invalid search. In the improved attack stage, the search method is completely cancelled, effectively avoiding invalid search. Secondly, based on the original search method 1, search method 1 in the improved attack stage increases the learning from the individuals in the elite population, and the introduction of excellent evolution information further strengthens the local development of the better region, thereby significantly enhancing the algorithm’s convergence speed. It can be seen from Equation (26) that as the iteration progresses, the weight factor gradually increases, increasing the role of the elite individual part, further completing the transition from exploration to development, and meeting the needs of different evolutionary stages for development. Third, search method 2 in the original attack phase takes the middle position between itself and the optimal individual as the base vector and develops near it. However, the position of the base vector is relatively simple, which reduces the diversity of the population to some degree. Search method 2 for improving the attack phase, such as Equation (28), shows that as the iteration progresses, the proportion of the current individual in the base vector gradually decreases, and the proportion of the optimal individual gradually increases. While ensuring the diversity of the early stage, the local exploration around the optimal individual in the later stage is strengthened, and the local development efficiency and convergence accuracy of the algorithm are improved. In addition, the introduction of mutual learning with other individuals has further improved the diversity of the population. Compared with search method 1, the convergence speed of search method 2 is faster because the optimal individual exists directly in the base vector. Fourthly, it can be seen from Equation (27) that the algorithm presents an adaptive search behavior change in the evolution process. At the beginning of the iteration, the individuals tend to adopt method 1 to update the population and realize the information interaction with the elite individuals while maintaining the diversity of the population; As the iteration progresses, the algorithm gradually transitions to method 2, and in the later stage of evolution, it mainly relies on method 2 for individual updating, thereby strengthening the fine search ability of the neighborhood of the optimal solution. This dynamic transformation mechanism effectively balances the collaborative optimization of global exploration and local development.
3.4. Improved Sexual Cannibalism Stage
Through an in-depth analysis of Section 2.3, it can be found that each individual enters the stage of sexual cannibalism with the possibility of P_c_ = 0.2. For example, the sexual cannibalism method shown in Equation (11) is very similar to the search stage in Section 2.1, which further increases the exploration of the solution space to some degree. However, in the solution of complex problems, the population diversity of the MSA is slightly insufficient, which makes the algorithm stagnate and unable to further converge.
Given this, this section improves the sexual cannibalism phase as follows: the new adaptive parameter P_c_ is calculated according to Equation (29). It is assumed that the probability of the i-th individual calculated according to Equation (20) is CR. If P_c_ < rand and P_c_ < CR_i_, the new individual is generated according to Equation (30), and it is not necessary to compare the fitness value with the original individual; instead, it can be directly replaced.
where l is a random number from −2 to 1; is a random number in the range of [0, 1]. is an individual selected from the external archive; and and are the upper and lower bounds of the search space, respectively.
In summary, the improved stage of sexual cannibalism proposed in this section offers the following benefits. On the one hand, Equation (30) generates a new solution through a large-scale random disturbance and introduces the population directly by using a non-greedy replacement strategy. This mechanism can significantly expand the search direction and enhance the population diversity in the early stage of the algorithm. In the later stage, local optimal stagnation is effectively avoided. On the other hand, it can be seen from Equations (20) and (29) that whether an individual enters the sexual cannibalism stage is no longer controlled by a fixed parameter P_c_ but rather is determined by the current number of iterations and the individual’s advantages and disadvantages. In the early stage of evolution, due to the population not yet having begun to converge, the frequency of sexual cannibalism is relatively low. As the iteration progresses, when the population diversity gradually decreases and the convergence trend is obvious, the individuals with poor fitness will enter the sexual cannibalism stage with an increasing probability. The poor individuals inject new evolutionary information into the population through directed random disturbance mutation, effectively breaking the local optimal stagnation while ensuring that different evolutionary stages can maintain an appropriate level of diversity.
In summary, at the beginning of the iteration, the adaptive transfer factor has a large value, which guides most individuals to enter the exploration stage to extensively search for high-quality solution regions. In this stage, the dynamic factor F also promotes the individual to tend to perform the pursuer behavior, achieve long-step and large-scale global exploration while still retaining a certain probability to enter the ambush behavior, and provide the key search direction for the population with the help of the elite individual guidance mechanism. As the iteration progresses, the adaptive transfer factor gradually decreases, and the proportion of participation in the attack stage increases accordingly. The algorithm gradually increases the weight of learning from the current optimal individual, and it guides the population to carry out refined development in the potential high-quality areas that have been found, thereby improving the convergence accuracy and speed. At the same time, as the population diversity decreases due to the convergence process, the probability of triggering sex-eating behavior increases accordingly. The mechanism introduces new individuals generated by disturbance through a non-greedy replacement strategy, effectively breaks the stagnation state of the population, injects new diversity into the search process, and then enhances the ability of the algorithm to jump out of the local optimum and explore the better solution area.
4. Experimental Results and Analysis
4.1. Comparative Study on the Performance of Different Initialization Strategies
In this section, we choose the following four representative initialization methods for comparison: random initialization, Sobol sequence initialization, Halton sequence initialization, and logistic initialization. To ensure the fairness of the experiment, all parameters of the algorithm are consistent except for the initialization method. The maximum number of evaluations MaxFEs = 100,000, the maximum number of iterations T = 2000, the population size N = 50, and the dimension D = 30.
From the experimental data in Table 1 and Table 2, although only the population initialization strategy is changed, the numerical differences between the methods are not significant, but the Sobol sequence still shows a clear advantage overall: in all 29 test functions, it achieved the best results on 21 functions. Moreover, the Friedman non-parametric statistical test results also show that the Sobol sequence ranks first in the comprehensive ranking. It can be clearly seen from Figure 1 that the initial population generated by the Sobol sequence is most evenly distributed in the two-dimensional solution space and can cover the entire search area more effectively.
In summary, the initialization method based on the Sobol sequence can generate an initial population with a more uniform distribution and better spatial coverage, thereby providing a more diverse and promising starting point for the subsequent iterative evolution process and ultimately yielding more competitive performance in the overall algorithm’s performance.
4.2. Experiments on the Influence of the Maximum Number of Iterations and Population Size on Algorithm Performance
To analyze the sensitivity of the algorithm to key parameters and determine the optimal parameter configuration, this section studies the influence of population size N and maximum number of iterations T on the IMSA. To ensure fairness, all experiments in this section are completed on the CEC2017 test set. In the population size experiment, the maximum number of iterations T = 2000, the dimension D = 30, and population sizes N = 30, 50, and 100 were tested, respectively, which were recorded as IMSA1, IMSA2, and IMSA3. In the maximum number of iterations experiments, with a fixed population size N = 50 and dimension D = 30, we tested the maximum number of iterations T = 1000, 1500, and 2000 three cases, which were recorded as IMSA4, IMSA5, and IMSA6.
According to the comparative experimental results of different population sizes (IMSA1: N = 30, IMSA2: N = 50, IMSA3: N = 100) in Table 3, under the condition that the maximum number of iterations T remains the same, the following conclusions can be drawn: the population size N = 50 (IMSA2) performs best on most test functions, and its comprehensive performance is better than the settings of N = 30 and N = 100, indicating that the scale has achieved a good balance between exploration and development. On functions F9, F12, F18 and F30, the performance of N = 50 is slightly inferior to other population sizes. On function F7, the performance of N = 50 and N = 30 is basically the same. On the function F22, the performance of the three population sizes is consistent, and there is no significant difference. Although there are a few exceptions, the comprehensive analysis shows that N = 50 is the optimal population size configuration of the algorithm under a given number of iterations.
Based on the comparative experimental results of different maximum iterations in Table 3 (IMSA4: T = 1000, IMSA5: T = 1500, IMSA6: T = 2000), the following analysis can be obtained under the condition of fixed population size N = 50: the experimental data show that when the maximum number of iterations is T = 2000 (IMSA6), the algorithm achieves the best performance on most test functions. This confirms that sufficient iterations are crucial for the algorithm to converge sufficiently under a given population size. When T = 2000, the results are better on all test functions except F9, F20 and F28. On the three functions F9, F20 and F28, their performance is slightly lower than other iteration settings. On the F27 function, the performance of T = 2000 and T = 1500 is basically the same; on the F22 and F25 functions, the results of the three iterations are completely consistent, indicating that the algorithm may have fast convergence or reach the platform period for solving these functions.
The comprehensive evaluation shows that when the population size N = 50, setting the maximum number of iterations T = 2000 as the optimal parameter configuration of the IMSA can achieve stable and excellent performance on a wide range of problem types.
According to the statistical results of the Friedman test shown in Table 4, the following conclusions can be drawn about the parameter configuration of the algorithm: in the comparative experiments of different population sizes (N = 30, 50, 100), when N = 50, the IMSA achieved the best overall average ranking, and its Friedman test ranking value was significantly better than the other two scale settings. In the comparative experiments with different maximum numbers of iterations (T = 1000, 1500, 2000), the algorithm achieves the highest comprehensive ranking when T = 2000. Combining the Friedman test results of the two-parameter experiments, the combination of the population size N = 50 and the maximum number of iterations T = 2000 is determined to be the optimal parameter configuration of the IMSA, which shows the best overall performance in the statistical sense.
4.3. The Effectiveness Experiment of Each Improvement Strategy
To verify the actual effect of these strategies, this paper designs four variant algorithms to remove the corresponding single improvement in the IMSA. Specifically, the newly proposed adaptive probability conversion factor is removed in the IMSA, the improved algorithm of the new search phase is removed in the IMSA, the improved algorithm of the new attack phase is removed in the IMSA, and the improved algorithm of the new cannibalism phase is removed. For the sake of simplicity, the above four new improved algorithms are named IMSA7, IMSA8, IMSA9 and IMSA10, respectively, and compared with the IMSA on the CEC2017 test set.
As shown in Table 5, compared with the IMSA, the four improved algorithms that remove the corresponding strategies show performance degradation on most test functions. Specifically, the number of functions through which the performances of IMSA7, IMSA8, IMSA9 and IMSA10 algorithms are worse than that of the IMSA is 24, 28, 26 and 25, respectively. The synergy of the four improvement strategies has an indispensable and significant contribution to improving the overall performance of the IMSA.
4.4. Performance Comparison Between IMSA and Other Algorithms
The optimization problem studied in this paper is an unconstrained optimization problem, which only contains the target term and does not contain the penalty term. To comprehensively evaluate the effectiveness of the IMSA, this study compares it with the original MSA and five evolutionary calculation methods with excellent performance in the CEC2017 test set. These algorithms include the improved snake optimizer (ISO), enhanced snake optimizer (ESO), improved cyclic system-based optimization algorithm (ICSBO), multi-strategy improved slime mold algorithm (MSMA), and enhanced Archimedes optimization algorithm (IAOA). All experiments are equipped with the Windows 11 operating system and an China Hasee DESKTOP-KCOD0V3 i5-9400U CPU and programmed using MATLAB R2021B.
To ensure the fairness of the comparison, when the population number N = 50 of all algorithms, the dimension D of the optimization problem is 30, and the maximum number of evaluations MaxFEs = 100,000. The other initialization parameter settings of each algorithm are shown in Table 6, and the parameter values of each comparison algorithm are set according to the original setting.
Table 7 shows 30 independent experimental data of the algorithm on the 30-dimensional CEC2017 test set, including mean and standard deviation. The algorithm results for the best optimization of the same function are marked in black. Table 8 and Table 9 show the comparison results of the IMSA and other algorithms in the Wilcoxon rank sum test and the Friedman test.
Wilcoxon rank sum test was used to compare the ordinal number of the two samples. If the ordinal number is concentrated in one sample, it shows that the difference between the sample and the other sample is more obvious, that is, p-value is less than 0.05. When p-value is less than 0.05, the comparison algorithm is obviously better than IMSA, which is represented by ‘+’.Otherwise, it is represented by ‘−’.When p-value is greater than 0.05, it indicates that the difference between each improved algorithm and IMSA is insufficient, which is represented by ‘=’.Statistical analysis based on the data in Table 7 shows that in the 30-dimensional optimization problem, the IMSA performs best among the remaining 22 functions except for the seven functions of F10, F13, F14, F15, F19, F25 and F26. The IMSA and MSA achieve global optimization at the same time in F22. The MSA performs better in F10 and F25 functions. ICSBO performs globally optimally when utilizing the F13, F14, F15, F19, and F26 functions. In summary, the research results show that the IMSA outperforms other algorithms. Table 8 shows that the MSA is superior to the IMSA on one function, but it is significantly inferior on 23 functions, and the remaining four functions remain at the same level. SWO is superior to the IMSA in 1 function, equivalent in 2 functions, and obviously lagging behind in 27 functions. ISO only performs as well as the IMSA on two functions, but it is significantly behind on 27 functions. ESO and the MSMA are significantly behind the IMSA in 29 functions. ICSBO is superior to the IMSA in 4 functions, while 10 functions are comparable, and 15 functions are obviously inferior. Only one function of IAOA is better than the IMSA, and the remaining 28 functions are significantly behind. Table 9 data show that the rank average of the IMSA is lower than the other six algorithms, indicating that the IMSA has better performance.
The data show that the IMSA has obvious advantages over other algorithms, especially in terms of convergence accuracy and robustness. However, in-depth analysis shows that it has the limitation of slow convergence speed in the early stage, which is obvious in F13 and F15 functions. This limitation can be explained by the mechanism: in the initial iteration stage, the algorithm relatively weakens the local development intensity to maintain the population diversity and global exploration ability. Although this design ensures the accuracy and stability of the solution, it delays the initial convergence process to a certain extent. Future research will focus on improving the local development ability of the algorithm on the basis of maintaining the strong global search ability of the algorithm in order to achieve a balance between the early convergence speed and the search quality. To intuitively show the convergence speed difference of each algorithm, Figure 2 shows the evolution curve with random operation once in a 30-dimensional space in the test optimization problem. The abscissa represents the number of function evaluations, and the ordinate corresponds to the logarithm of the fitness value of the prior function.
Through Figure 2, it can be seen that in the F1, F13, F14, F22, F25, F28, and F30 Figure 2A,L,M,U,X,AA,CC functions, the IMSA is only inferior to the ICSBO algorithm in the early convergence speed, but it is consistent with the ICSBO algorithm in the later accuracy, while the IMSA shows a faster convergence rate and higher calculation accuracy in Figure 2C,E,H functions. In the F7 Figure 2F function, the IMSA leads in the early convergence speed, but it is inferior to the ICSBO and ESO algorithms in the later convergence speed. In the F3, F5, F8, F11, F12, F16, F17, F18, F20, F21, F23, F24 Figure 2B,D,G,J,K,O–Q,S,T,V,W functions, although the convergence speed of the IMSA in the early and middle stages is slightly inferior to those of some other algorithms, it shows better accuracy performance in the final stage of convergence. In the F15, F19, and F26 Figure 2M,R,Y functions, the ICSBO algorithm performs better in terms of convergence speed and convergence accuracy, while the IMSA ranks second. The MSA performs better in F27 in Figure 2Z function, which is followed by the IMSA in terms of late convergence accuracy. In the F29 Figure 2BB function, the MSA and ICSBO are slightly slower than some of the other algorithms in the early stage, and they achieve higher convergence accuracy than other algorithms in the later stage. In general, compared with the MSA and the other five excellent improved algorithms, the IMSA performs well on most functions especially in terms of convergence accuracy.
5. The Application Verification of the IMSA in the Beamforming Optimization Problem
To verify the ability of the IMSA to solve practical engineering optimization problems, this section applies it to the typical problem of cooperative array beamforming design. Beamforming is a basic and key technology in the fields of multi-antenna wireless communication and radar detection. Whether it is in mobile communication, satellite signal transmission, or in military radar and other systems, optimizing the beam pattern to enhance the target direction signal and suppress the interference direction sidelobe has significant engineering value and wide application requirements. The core of beamforming is to enhance the coherence of electromagnetic wave energy in the target direction and suppress side lobe interference by cooperatively regulating the emission weight of each antenna unit in the array. The optimization objective of this section is to minimize the peak sidelobe level (PSL), as shown in Equation (31).
where is the array factor, as shown in Equation (32); represents the main lobe direction; and represents the entire angular space excluding the main lobe direction , which is mathematically expressed as , .
where K is the total number of cooperative nodes; is the wavelength of the emitted signal; is the complex emission weight of the k-th node, as shown in Equation (1); R_k_ is the radial distance from the k-th node to the cluster head, and ; is the azimuth of the k-th node relative to the reference direction, .
where is the amplitude weighting coefficient of the signal, ; and is the deviation angle of the signal, .
In order to ensure the comparability of the experiment, this experiment uniformly sets the number of nodes K = 4, the grid radius R = 1, the population size N = 20, the dimension D = 2K, the maximum number of iterations T = 500, and other related parameters as shown in Table 6.
According to the results shown in Table 10, in the cooperative beamforming problem, the minimum peak sidelobe levels (PSLs) obtained by the IMSA, MSA, ISO, ESO, ICSBO, MSMA, and IAOA algorithms are −17.17, −8.70, −8.43, −8.31, −16.91, −8.66, and 9.08, respectively. Experimental data show that the PSL value obtained by the IMSA on this problem is significantly lower than those of other comparison algorithms, showing its superior optimization performance. Further combined with the convergence curve shown in Figure 3, the IMSA is superior to other algorithms in terms of convergence accuracy and stability. In summary, the IMSA not only performs well on standard test functions but also shows excellent solving ability and practical value in practical engineering optimization problems such as cooperative beamforming.
6. Conclusions
This study proposes an improved mantis search algorithm (IMSA), which aims to improve convergence performance and solve the problems of insufficient diversity and vulnerability to local optimal solutions. Firstly, an adaptive probability conversion factor is designed, which adaptively controls the proportion of individuals entering the search phase and the attack phase. This parameter promotes the natural transformation of the algorithm from large-scale global detection to small-scale accurate optimization so as to improve the adaptability of the algorithm in complex optimization scenarios. Secondly, in the search stage, the dynamic weight factor is introduced to balance the pursuer behavior and the ambush behavior as well as strengthen the role of each behavior. A probability updating strategy based on subspace and full space is proposed to realize a multi-scale regulation of exploration capacity by dynamically adjusting the search radius. An elite guidance mechanism based on Euclidean distance and fitness is designed. The spatial distribution and quality information of elite individuals are used to accelerate population convergence. At the same time, the simulated binary crossover (SBX) strategy is used to enhance the information exchange between external archives and the current population, which effectively improves the global search efficiency of the algorithm. In addition, the elite individual guidance strategy is introduced in the attack stage, and the adaptive weight factor dynamically adjusts the influence weight of the elite individual to achieve a smooth transition from global exploration to local development. The basis vector adaptive probability selection mechanism is designed to avoid the problem in which the algorithm learns from the optimal individual to fall into a local optimum. Finally, the updated Equation for jumping out of local optima is introduced in the stage of sex cannibalism. The inferior individuals are screened by a dynamic crossover probability factor for updating, and the population is directly introduced by a non-greedy replacement strategy to increase the population dispersion and local optimal avoidance ability. The experimental results show that the IMSA not only performs well in comparison with traditional algorithms but also shows stronger convergence accuracy and stability on most CEC2017 test functions even compared with the latest meta-heuristic algorithms (such as ICSBO, AOO, etc.) released in 2024–2025. This further proves the continuous competitiveness and algorithm robustness of the IMSA in dealing with the current complex optimization challenges. Nevertheless, the algorithm exhibits slow initial convergence. Future studies could focus on accelerating the early-stage convergence of the mantis search algorithm to enhance its applicability in real-world engineering scenarios. We will further promote the integration of the IMSA with more practical engineering applications, especially in areas with significant socio-economic and energy transformation values. Specifically, we will consider extending the following two directions: the first is to apply the IMSA to the spatial layout optimization of hydrogen electrolyzers; the second is to extend the IMSA to electric vehicle charging intelligent scheduling optimization.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yin Y. Ohtsuki T. Gui G. Yuen C. Wu H.-C. Sari H. Joint Optimization of User Pairing, Power Allocation and Content Server Deployment in NOMA-Assisted Wireless Caching Networks IEEE Trans. Veh. Technol.202372168661687010.1109/TVT.2023.3296495 · doi ↗
- 2Yin Y. Gui G. Liu M. Gacanin H. Sari H. Adachi F. Joint User Pairing and Resource Allocation in Air-to-Ground Communication-Caching-Charging Integrated Network Based on NOMAIEEE Trans. Veh. Technol.202372158191582810.1109/TVT.2023.3291174 · doi ↗
- 3Mercier Q. Poirion F. Désidéri J.-A. A stochastic multiple gradient descent algorithm Eur. J. Oper. Res.201827180881710.1016/j.ejor.2018.05.064 · doi ↗
- 4Giannelos S. Konstantelos I. Pudjianto D. Strbac G. The impact of electrolyser allocation on Great Britain’s electricity transmission system in 2050 Int. J. Hydrogen Energy 202620215309710.1016/j.ijhydene.2025.153097 · doi ↗
- 5European Commission E-Mobility Deployment and Impact on Grids: Impact of EV and Charging Infrastructure on European T&D Grids: Innovation Needs Publications Office Luxembourg 2022
- 6Kennedy J. Eberhart R. Particle swarm optimization Proceedings of the ICNN’95—International Conference on Neural Networks Perth, Australia 27 November–1 December 1995 IEEE Perth, Australia 1995 Volume 419421948
- 7Karaboga D. Basturk B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm J. Glob. Optim.20073945947110.1007/s 10898-007-9149-x · doi ↗
- 8Mirjalili S. Lewis A. Grey Wolf Optimizer Adv. Eng. Softw.201469466110.1016/j.advengsoft.2013.12.007 · doi ↗