Uncovering miRNA–Disease Associations Through Graph Based Neural Network Representations
Alessandro Orro

TL;DR
This paper introduces a graph-based neural network to predict miRNA-disease associations, improving biomarker discovery and disease understanding.
Contribution
A novel graph-based learning framework that integrates heterogeneous biological data to predict miRNA-disease associations with high accuracy.
Findings
The method achieved an average AUC–ROC of ~98%, outperforming existing computational approaches.
Predictions were consistent across validation folds and robustness analyses confirmed stability.
Abstract
Background: MicroRNAs (miRNAs) are an important class of non-coding RNAs that regulate gene expression by binding to target mRNAs and influencing cellular processes such as differentiation, proliferation, and apoptosis. Dysregulation in miRNA expression has been reported to be implicated in many human diseases, including cancer, cardiovascular, and neurodegenerative disorders. Identifying disease-related miRNAs is therefore essential for understanding disease mechanisms and supporting biomarker discovery, but time and cost of experimental validation are the main limitations. Methods: We present a graph-based learning framework that models the complex relationships between miRNAs, diseases, and related biological entities within a heterogeneous network. The model employs a message-passing neural architecture to learn structured embeddings from multiple node and edge types, integrating…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
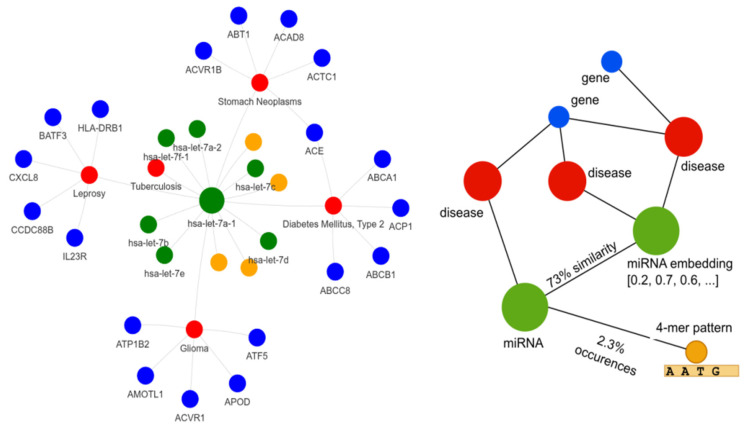 Figure 1
Figure 1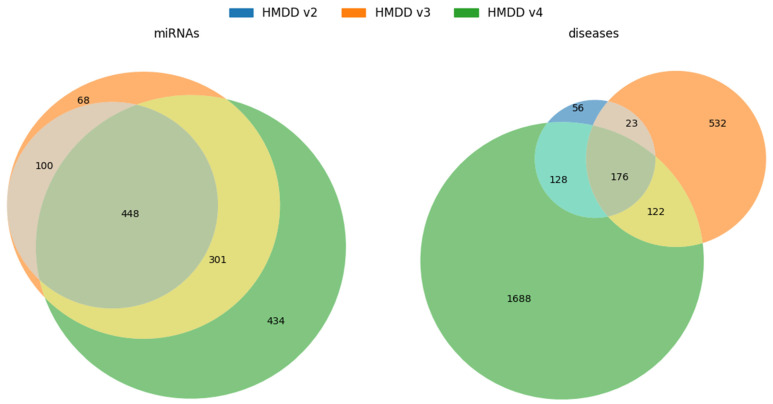 Figure 2
Figure 2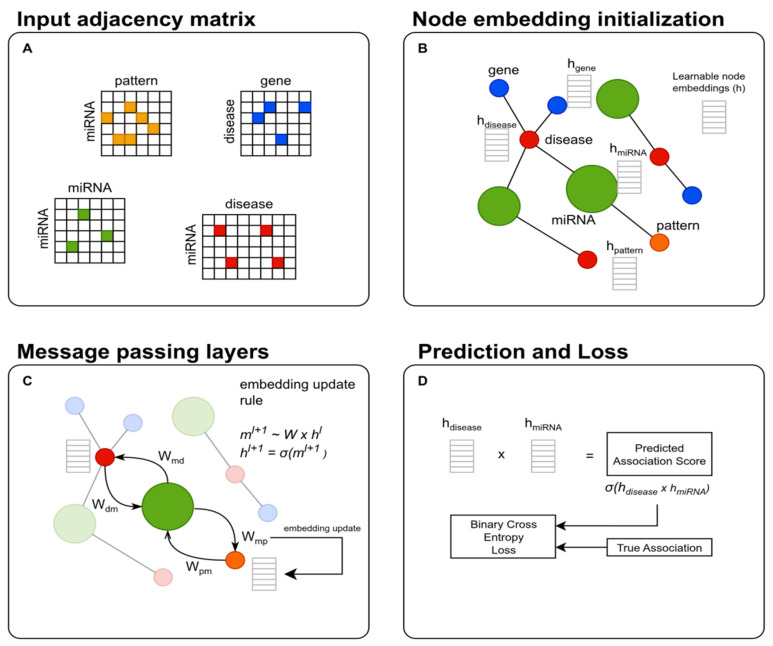 Figure 3
Figure 3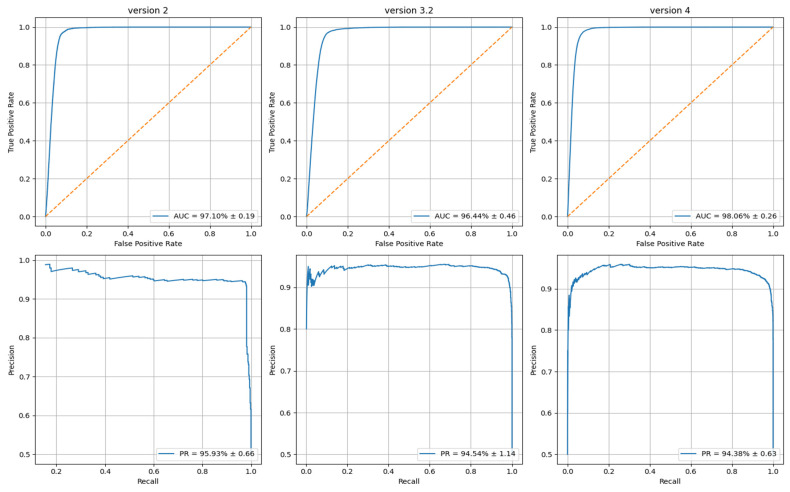 Figure 4
Figure 4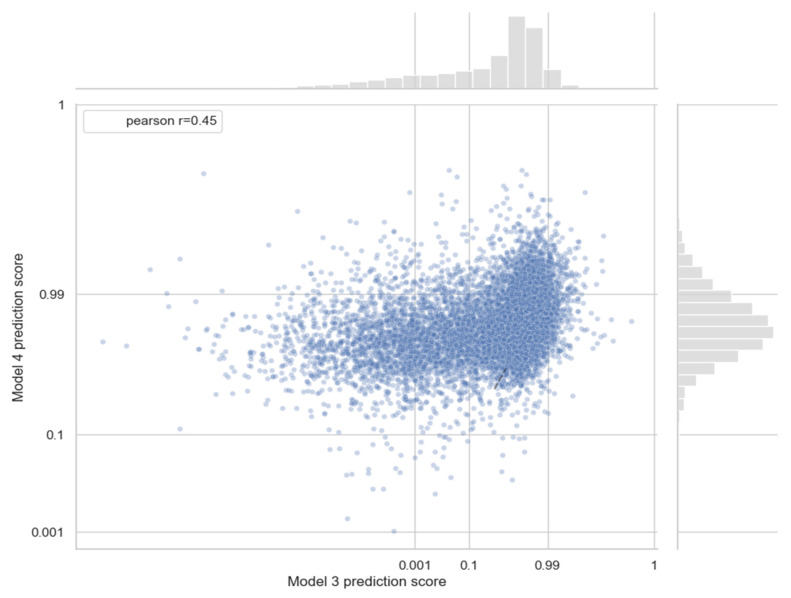 Figure 5
Figure 5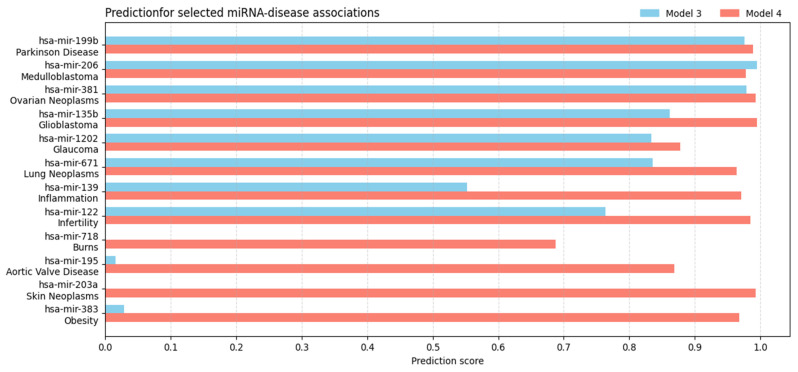 Figure 6
Figure 6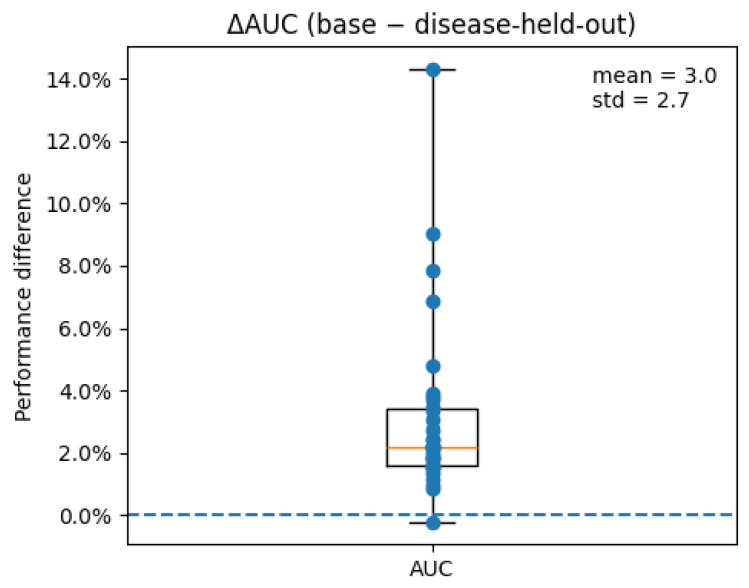 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMicroRNA in disease regulation · Bioinformatics and Genomic Networks · Cancer-related molecular mechanisms research
1. Introduction
MicroRNAs (miRNAs) are short, endogenous RNA molecules, usually 19–25 nucleotides long, that play a key role in regulating gene expression [1,2,3]. They act by incorporating into the RISC complex, which then binds to target messenger RNAs (mRNAs) at the 3′ untranslated regions (UTRs) through sequence complementarity, leading to gene silencing [4]. The resulting interaction normally leads to the inhibition of the target mRNA [5], although cases of translational activation have also been found in the literature [6]. In this way a single miRNA is able to regulate hundreds of gene transcripts, and, on a genome-wide scale, it is estimated that miRNAs are able to control expression of up to 60% of genes in the human genome [7], affecting virtually every physiological process. Starting from the initial discoveries of lin-4 and let-7 [8], the number of known miRNAs has increased rapidly in recent years, with the latest miRbase (Release 22.1) counting about 38,000 entries [9], underlining the evolutionary conservation and functional significance of these regulators. Dysregulation of miRNAs is associated with the pathogenesis of numerous complex human diseases [10], in particular in cancer [11], cardiovascular [12], neurodegenerative [13], and metabolic diseases [14]. For these reasons, identifying specific miRNA–disease associations (MDAs) is a useful step for understanding disease mechanisms and for developing novel therapeutic strategies [15]. Limitations of experimental approaches (PCR and high-throughput sequencing), which are typically resource-intensive, expensive, and time-consuming on a large scale [16], have motivated the development of computational methods to predict potential miRNA–disease associations (MDAs) [17,18].
Many approaches exploit the large amount of public data available today (like HMDD V2.0/V3.0 [19,20], dbDEMC [21], and miR2Disease [22]), relying on the widely accepted principle that functionally similar miRNAs are likely to be associated with diseases exhibiting similar phenotypes [23,24]. Early computational methods to predict MDAs can be broadly categorized into similarity-based approaches and modern machine learning/deep learning approaches. Early similarity-based approaches inferred MDAs by leveraging known interactions between miRNAs and their target genes, or between target genes and diseases. These methods often suffered from incomplete and noisy miRNA–target interaction datasets. This category includes models based on Random Walk over protein–protein interaction (PPI) networks [25] and methods like miRPD [26], which use intermediate networks to identify functional links between miRNAs and diseases.
To overcome these limitations, more sophisticated similarity-based network models were developed [27,28,29,30,31,32,33], integrating miRNA functional and disease semantic or phenotypic similarities with known MDAs. Approaches such as HDMP [34] relied on local similarity metrics, which proved ineffective for diseases without any known associated miRNAs (“new diseases”). This motivated the development of global network methods, for example, those employing the Random Walk with Restart (RWR) algorithm (RWRMDA [35], MIDP/MIDPE [36]). By traversing the entire network, RWR provides a global view of connectivity, significantly improving performance.
Further improvements integrated Gaussian Interaction Profile (GIP) Kernel similarity with functional and semantic similarity. Methods in this category, including WBSMDA [37] and HGIMDA [38], enabled the calculation of similarity for new entities (miRNAs or diseases) without prior associations, representing a significant advance toward predicting associations for both novel miRNAs and novel diseases.
Modern machine learning (ML) techniques provided more powerful tools to approach MDA prediction [39,40,41]. They range from supervised classifiers like Support Vector Machines (SVMs) [42] and Restricted Boltzmann Machines (RBMs) [43] to semi-supervised methods. A critical challenge for supervised learning is the difficulty in accurately obtaining reliable negative MDA samples. Addressing this, semi-supervised models like RLSMDA (Regularized Least Squares [44]) and Matrix Completion (MC) methods, such as MCMDA [45] were proposed. MCMDA, for instance, is highly efficient, operating only on the known positive MDA matrix by leveraging the assumption that the underlying adjacency matrix is low-rank, thereby inherently avoiding the need for negative samples. The high predictive power of MC methods was demonstrated by MCMDA, which achieved high AUC (87.49%) and a strong confirmation rate (up to 90% of top 50 predictions for diseases like prostate neoplasms). More recently, ensemble learning approaches such as ELMDA [46] have been proposed, which do not rely on known associations to calculate miRNA and disease similarities and use multi-classifier voting for prediction, achieving an average AUC of 92.29% on HMDD v2.0, confirming the potential of ensemble strategies in accurately predicting disease-associated miRNAs.
The continuous development of these models now involves various forms of Deep Learning and Network Embedding and Graph Attention Networks (GAT) [47,48,49] to capture complex, non-linear relationships within the integrated biological data.
Despite advances in computational prediction of miRNA–disease associations, key challenges remain. In particular, integrating heterogeneous biological data and capturing complex, non-linear relationships across miRNAs, diseases, and associated patterns is still difficult. Furthermore, limitations in data completeness and the dynamic nature of biological networks constrain model generalizability. Graph-based approaches, especially those leveraging message passing on heterogeneous networks, offer a natural framework to address these issues by propagating information across nodes and edges of multiple types, effectively learning embeddings that encode functional and phenotypic similarities.
In this work, we propose a Heterogeneous Graph Neural Network (GNN) that models miRNA–disease associations by leveraging a multi-node, multi-edge approach to integrate diverse sources of biological information. Similar to state-of-the-art GNN approaches for miRNA–disease prediction, including hypergraph convolution and attention-aware architectures, our model learns structured embeddings directly from the heterogeneous network, preserving relational information that is often lost in vectorized or engineered feature representations. Our framework differs from prior methods in its use of edge-type-specific message-passing layers and node-specific transformations, which enable effective propagation of functional signals across complex biological entities such as miRNAs, diseases, genes, and expression patterns. These mechanisms allow the network to capture non-linear dependencies, leading to robust prediction of miRNA–disease associations. Comparison with existing methods demonstrates improved predictive performance in terms of AUC-ROC.
2. Materials and Methods
2.1. Dataset
The dataset used in this study integrates multiple layers of biological information derived from curated repositories, ontology mapping, and sequence-level analyses. Experimentally validated miRNA–disease associations were obtained from the HMDD database [19,20] (version 2, 3.2, and 4). All miRNA identifiers were manually curated to ensure consistency across resources, including resolving deprecated or ambiguous names, normalizing letter case, and harmonizing naming conventions. The nucleotide sequences of all miRNAs were retrieved from miRBase [9].
Disease names reported in HMDD were manually normalized to match DisGeNET [50] terminology. This included removing formatting inconsistencies, resolving synonyms, and applying uniform rules before mapping each disease to its corresponding UMLS Concept Unique Identifier (CUI) [51]. Based on these CUIs, disease–gene associations were obtained from DisGeNET and represented as binary vectors indicating the presence or absence of gene relationships for each disease.
Similarity graph between miRNAs were computed using pairwise sequence alignments obtained with the well-known Needleman–Wunsch method [52]. Two miRNAs were considered similar if their alignment identity score was greater than 60%, generating a binary miRNA–miRNA adjacency matrix. Furthermore, k-mer frequency vectors (k = 2 and 3) were extracted to obtain sequence-based embeddings. Finally, short sequence motifs of length 4 were computed to derive the miRNA–pattern matrix, providing an additional sequence-derived relational layer.
For HMDD version 4, the final dataset consists of 1183 miRNAs and 2114 distinct diseases, collectively forming 24074 miRNA–disease positive associations (0.96% matrix density). After harmonizing disease names with DisGeNET, we obtained a set of 6356 genes, which resulted in 18653 disease–gene associations mapped through UMLS CUIs. Sequence alignment produced miRNA–miRNA adjacency with 209186 entries, while the k-mer analysis yielded a structured representation of each miRNA through 80 embedding features. The extraction of motifs of length 4 generated 256 distinct patterns, leading to moderately dense adjacency matrices: 73,515 miRNA–pattern associations (~24%). Table 1 describes the details of graph size for the three versions of HMDD datasets. Figure 1 provides a graphical representation of a selected portion of the data graph for illustrative purposes, highlighting the structure and relationships among miRNAs, diseases, genes, and sequence-derived patterns.
Analysis of the Venn diagrams (Figure 2) reveals that successive HMDD versions contain an increasing number of miRNAs and diseases. Notably, a substantial portion of the entries in earlier versions is retained in later releases, reflecting continuity and expansion of the curated data.
2.2. Graph Neural Network Architecture
We model the prediction of miRNA–disease associations using a heterogeneous graph neural network based on message passing [53]. The heterogeneous graph includes multiple node types, each associated with its own feature space, and multiple edge types capturing the biological relations among them (Figure 3). For each edge type , the network learns a distinct linear transformation , that governs how messages are propagated across that relation. Let denote the resulting heterogeneous graph, where the each node has its own type (miRNA, disease, gene, and sequence pattern) and each edge has a type representing the nodes it connects (see Figure 3).
For a node its embedding at layer is computed using a message-passing rule:
where is the set of neighbors of under relation e, and is a non-linear activation function, usually the ReLU function.
This mechanism allows the model to integrate heterogeneous biological signals-sequence-derived miRNA features, similarity relations, and gene-level mechanistic information—into a unified latent representation. This architecture enables end-to-end learning of latent biological relationships across the heterogeneous network.
After the message-passing layer , the model computes node embeddings for miRNAs and diseases, and the association score for each miRNA–disease pair is then predicted by computing the dot product of the corresponding embeddings.
During training, only edges of the miRNA–disease type contribute to the supervised loss defined by the binary cross-entropy calculated for the true ( ) and predicted ( ) associations (edge) of a given batch :
Nonetheless, all other edge types influence the node embeddings through relation-specific message passing, enabling the model to combine sequence-derived miRNA features, similarity networks, and gene-level signals into a unified latent representation.
Each node type in the heterogeneous graph is represented by a learnable embedding, which was initialized as a one-hot identity vector. These embeddings are updated during training through node-specific linear layers and multi-relational message passing, allowing the model to capture complex dependencies between miRNAs, diseases, and genes. No edge features are used; the relational structure is conveyed solely through the graph topology.
2.3. Training and Validation
The prediction of miRNA–disease associations is formulated as a binary link prediction problem on a heterogeneous graph. Known experimentally validated miRNA–disease associations are treated as positive labels, while negative examples are sampled from unannotated miRNA–disease pairs, as detailed below.
The evaluation follows a 10-fold cross-validation scheme, repeated 10 times with different random partitions to ensure robustness. In each fold, the set of miRNAs is randomly divided into a training and a validation subset. All nodes and all edges not involving miRNA–disease associations remain visible in both splits in order to preserve the global structure of the heterogeneous graph.
For the separation of miRNA–disease edges, all associations involving validation miRNAs are removed from the training graph, and symmetrically, all associations involving training miRNAs are removed from the validation graph. As a consequence, during validation the model is required to predict disease associations for miRNAs that were completely unseen during training, relying solely on message passing over the remaining graph structure and heterogeneous biological relations.
Positive samples correspond to all known miRNA–disease associations present in HMDD within the corresponding split. Negative samples are not defined as all unknown associations, but are instead randomly sampled from miRNA–disease pairs not reported in HMDD, following a standard negative sampling strategy for association prediction tasks. This avoids the unrealistic assumption that all unannotated pairs are true negatives and mitigates the strong class imbalance characteristic of miRNA–disease datasets. During training, negative samples involve only training miRNAs and exclude all known positive associations. During validation, negative samples involve only validation miRNAs and are explicitly constructed to exclude any miRNA–disease pair that is annotated as positive in HMDD. This ensures that no true positive associations are incorrectly treated as negatives and prevents label leakage between training and validation.
A similar masking strategy is applied to pattern–disease associations to avoid indirect information leakage through sequence-derived features. Specifically, pattern–disease edges are included in the training graph only if the pattern is connected to the disease through at least one miRNA–disease association belonging to the training set. If a pattern is linked to a disease exclusively through a validation miRNA–disease association, the corresponding edge is removed from the training graph (and symmetrically for the validation graph).
Each fold is trained independently using the Adam optimizer, with early stopping based on the validation loss. The training loss is computed only for miRNA–disease edges, while all other edge types contribute to learning through relation-specific message passing, enabling the model to integrate heterogeneous biological information while being evaluated under a strict and leakage-free generalization setting.
All diseases considered during validation have been previously observed in the training set; the model is thus evaluated on predicting novel miRNA–disease associations rather than on disease cold-start scenarios.
2.4. Evaluation Metrics
Performance was primarily assessed using AUC-ROC, which is the standard evaluation metric in MDA prediction due to the highly imbalanced nature of MDA datasets (<3% of positive samples). For comparison with other approaches, we additionally computed the area under the precision–recall curve (AUPR), Precision, Recall, and F1-score, defined as follows:
3. Results
We first evaluated the proposed heterogeneous graph neural network on two benchmark datasets, namely HMDD v4.0, the most recent release, and HMDD v3.2 and v.2, widely used in prior computational studies, to facilitate direct comparison with the state of the art. All experiments were performed using the 10-fold cross-validation strategy described in Section 2.3, with the entire evaluation repeated 10 times using different random partitions.
Across all repetitions on HMDD v4.0, the presented model achieved an average AUC-ROC of ~98% and an AUPR of ~95%, demonstrating strong discriminative capability also in the presence of class imbalance. Similar results were obtained on HMDD v3.2, where the AUC-ROC reached ~97–98% and the AUPR remained consistently above 94%.
Figure 4 reports the mean ROC and PR curves aggregated over all replications. The narrow confidence bands observed in both curves indicate high stability across validation folds and independent experiments.
3.1. Comparison with Existing Methods
To position the presented approach to current computational models, we compared it against several representative methods evaluated on HMDD v2. We first considered four widely used and powerful machine learning methods that are known to be able to handle complex features, but still constrained to vectorized feature representations: Support Vector Machine (SVM), a margin-based classifier effective in high-dimensional settings; Gradient Boosting Decision Trees (GBDT), a sequential ensemble of decision trees using boosting to reduce errors; Random Forest (RF), an ensemble of decision trees; and eXtreme Gradient Boosting (XGBoost), a regularized boosting method offering strong predictive performance.
Traditional machine learning methods remain highly effective for structured biological prediction tasks, especially when relying on engineered similarity features or association profiles. Nevertheless, their inherent tabular representation of features hinders their ability to capture heterogeneous, multi-relational graph structures. This limits their capacity to exploit the full topology of miRNA–disease–gene–pattern networks—an aspect naturally handled by graph neural architectures.
Next, we included in the comparison six more specialized tools: MDA-CF [54], which leverages weighted hypergraph-based generalized matrix factorization to integrate multi-omics features of microbes and drugs, effectively predicting novel microbe-drug associations; TCRWMDA [55], employing hypergraph-based logistic matrix factorization to capture higher-order relationships between metabolites and diseases, enabling accurate identification of disease-related metabolites; WBSMDA [47], an attention-aware multi-view graph convolutional network combined with hypergraph learning to model miRNA–disease associations by integrating multiple similarity networks and fusing node information from diverse perspectives; ABMDA [56], which explores miRNA-mediated mechanisms underlying disease progression and drug resistance, providing experimentally informed predictions of functional miRNA–disease links; ICFMDA [57], a computational framework exploiting functional similarity and network inference to uncover potential miRNA–disease interactions; and ELMDA [46], an ensemble learning approach that does not rely on known associations to calculate miRNA and disease similarities, combining multiple classifiers via voting to robustly predict disease-related miRNAs across diverse validation settings.
Compared to the most competitive methods—MDA-CF (AUC 92.58%) and ELMDA (AUC 92.29)—our heterogeneous graph-based approach improves performance by a substantial margin, highlighting the benefits of: integrating heterogeneous biological relationships (miRNA–miRNA, disease–gene, miRNA–pattern, pattern–disease), Using message-passing to propagate functional signals across the network, and learning embedding representations directly from multiple node and edge types, rather than depending on pre-defined similarity kernels. These results indicate that the proposed model captures non-linear relationships more effectively than similarity-based or feature-engineering-based models.
Table 2 reports the performance metrics of the methods compared in this study, including AUC and AUPR and, when available, Precision, Recall, and F1-score.
3.2. Analysis of Newly Predicted Associations
In order to evaluate the ability of our models to predict novel miRNA–disease associations, we performed a comparative analysis using two graph neural models trained on two different versions of the HMDD dataset: Model 3 was trained on HMDD v3.2, containing only the associations known at that time, whereas Model 4 was trained on the more comprehensive HMDD v4.0, which includes additional associations reported after v3.2. Both models were then applied to predict association scores for all new miRNA–disease pairs, those not previously observed by Model 3. Since Model 3 is built on a smaller knowledge base, we expect it to perform less accurately. The Pearson correlation between the prediction scores of the two models shows a moderate correlation across all pairs (r ≈ 0.45), indicating that Model 3 is partially able to anticipate novel associations present in version 4 (Figure 5). Moreover, the AUCROC for Model 3 considering only the previously unseen positive associations was 89%, indicating that the model successfully discriminates against the majority of novel miRNA–disease links, further supporting its ability to anticipate associations absent from the training dataset.
To further analyze these differences, we examined a subset of representative positive associations and visualized the corresponding prediction scores from both models (Figure 6). Beyond simply contrasting the two score distributions, several patterns emerge: in many cases Model 4 assigns consistently higher confidence, reflecting the additional knowledge introduced in HMDD v4.0, while a number of pairs show near-identical scores, indicating that Model 3 successfully anticipates future annotations. Conversely, a few outliers (~15%) exhibit substantial divergence (absolute score difference greater than 0.5) between the two models, suggesting either overgeneralization by Model 3 or revised evidence incorporated in the updated dataset.
3.3. Ablation Analysis
Our heterogeneous graph neural network integrates multiple node types and relation-specific message passing to learn latent embeddings for miRNAs, diseases, genes, and sequence patterns. While the network is trained using the full set of edges, we observed that the model’s performance remains largely stable even when certain edge types are removed or perturbed. This indicates that the learned node embeddings capture significant information from node features themselves, and that the graph structure primarily provides additional contextual information rather than being strictly necessary for high predictive performance. Consequently, the predictive accuracy of miRNA–disease associations is robust with respect to partial or noisy graph information.
On the other hand we observe a different picture when the graph is perturbed before training. Specifically, ablating certain edge types prior to model training leads to significant drops in predictive performance, highlighting the importance of relational information during embedding learning. The quantitative effects of these pre-training ablations are reported in Table 3, showing that edge information is crucial for guiding the model to capture biologically meaningful associations.
In addition to edge-level ablations, we performed a disease-level holdout analysis to assess the model’s ability to generalize to unseen diseases. For each target disease, all miRNA–disease associations involving that disease were removed from the training set, while no negative samples were generated for the held-out disease, thereby preventing any form of data leakage. The model was then retrained on the reduced dataset and evaluated exclusively on the associations of the held-out disease.
This analysis was conducted on a representative subset of 35 diseases. Model performance was quantified using the area under the ROC curve (AUC), and the impact of disease removal was assessed by analyzing the difference between baseline and held-out performance ( ).
As shown in Figure 7, holding out an entire disease leads to a consistent but moderate reduction in predictive performance. On average, the AUC decreases from 0.97 to 0.94 across the evaluated diseases, corresponding to a mean ΔAUC of approximately 0.03 (standard deviation ≈ 0.027). Despite this drop, performance remains well above random expectation, indicating that the learned embeddings retain substantial predictive power even when a disease is completely excluded from training. These results demonstrate that the proposed model is able to generalize to new disease contexts and that its predictions are not driven by data leakage from disease-specific associations.
3.4. Biological Interpretation of Selected miRNA–Disease Predictions
In order to provide an external and biologically meaningful assessment of the model predictions, we focused on a representative subset of high-confidence miRNA–disease associations among the top-ranked results. The selected examples (see Table 4) were prioritized based on the presence of independent evidence from published studies, which we verified to be absent from any other HMDD reference for the same miRNA–disease pair, allowing us to qualitatively evaluate the biological relevance of the predicted associations in terms of known pathways, target genes, and disease mechanisms.
For example, hsa-miR-99b was predicted to be associated with Wilms Tumor in our dataset. Independent evidence from a recent study showed that hsa-miR-99b-5p expression is significantly down-regulated in renal cancer tissues compared to adjacent normal kidney, and in silico analysis of its targets suggests involvement in angiogenesis-related pathways such as VEGF signaling. Although this study focused on renal carcinoma, the documented role of miR-99b-5p in tumor-related pathways supports the biological plausibility of the predicted association with Wilms Tumor. Moreover, in our predictions, hsa-let-7e was correctly associated with knee osteoarthritis. Beyond its established down-regulation in KOA patients [60], further independent evidence shows that hsa-let-7e-5p is part of a circulating miRNA signature linked to osteoarthritis phenotypes in a cohort of facet osteoarthritis patients, and that its predicted gene targets are enriched in a broad range of signaling pathways implicated in joint tissue pathology, based on interactome analysis [61]. Together, these findings support the biological plausibility of the predicted association between let-7e and knee osteoarthritis.
The miRNA hsa-miR-152-3p was predicted to be associated with spinal cord injuries in our dataset. Beyond its established association in HMDD [62], independent evidence indicates that hsa-miR-152-3p is upregulated in postmenopausal women with osteoporotic vertebral fractures [63]. Bioinformatic analysis suggests that hsa-miR-152-3p regulates key genes involved in bone matrix production and osteogenic differentiation, including WNT10B, ITGA5, ITGA9, COL2A1, and COL4A1, and modulates signaling pathways such as ECM-receptor interaction and stem cell pluripotency, highlighting a potential role in spinal tissue homeostasis and repair mechanisms.
The miRNA hsa-miR-208a was predicted to be associated with osteosarcoma in our dataset. Beyond its established association in HMDD [64], independent evidence demonstrates that hsa-miR-208a-3p is up-regulated in osteosarcoma tissues and promotes proliferation, migration, and invasion of osteosarcoma cells through targeting of PTEN, thereby implicating the PI3K/AKT signaling pathway in tumor progression [65]. These findings provide additional biological support for the plausibility of the predicted association, linking miR-208a to key pathways in osteosarcoma pathogenesis.
Finally, the extracellular vesicle-associated miRNA hsa-miR-210 was predicted to be associated with Parkinson Disease in our dataset. Independent evidence from studies of exosomal miRNAs in PD patients supports the involvement of EV-contained miRNAs in disease processes, including mechanisms related to intercellular transport of genetic material and modulation of neurodegenerative pathology such as α-synuclein aggregation, neuroinflammation, and neuronal stress responses, although specific targets for miR-210 in PD have not been comprehensively validated to date.
Analysis of a strong newly predicted association (false positive with respect to HMDD) shows that our model predicts a strong link between some miRNA that has been reported in the independent literature. For brevity we report only two cases. Independent experimental evidence supports association between hsa-miR-125b-1 and “Brain Ischemia”: hsa-miR-125b-5p has been shown [68] to protect neurons from ischemia–reperfusion injury by targeting ASIC1, a protein implicated in acidosis-induced neuronal death, thereby reducing neuronal damage in brain ischemia models. Moreover, pathway analysis of predicted gene targets suggests involvement in apoptosis regulation, inflammatory response, and neuroprotective signaling pathways, further supporting the biological plausibility of the predicted miRNA–disease association. This example illustrates the potential of the model to uncover biologically meaningful associations beyond existing database annotations. Finally, the association between hsa-mir-1193 and obesity has been reported in a study of bovine intramuscular fat deposition that shows that miR-1193 is upregulated in tissues with higher fat content and is part of a set of miRNAs identified as novel regulators of adipogenesis and lipid metabolism. In that study, differentially expressed miRNAs and their predicted target genes were associated with pathways involved in adipocyte differentiation and lipid homeostasis, as revealed by Gene Ontology and KEGG enrichment analyses, supporting the potential involvement of miR-1193 in obesity-related fat accumulation processes (e.g., adipocytokine and lipid metabolic pathways) [69].
For the analysis in this session, to support the biological interpretation of selected miRNA–disease predictions, relevant publications were retrieved using the PubMed API and processed using an AI-assisted text mining approach (Python library ScispaCy version 0.5 [70]) to extract information on miRNA target genes and associated pathways, followed by manual curation to ensure accurate interpretation.
4. Discussion and Conclusions
In this study, we presented a heterogeneous graph neural network framework for predicting miRNA–disease associations, leveraging the rich relational structure inherent in biological networks. Biological entities such as miRNAs, genes, diseases, and sequence motifs are naturally represented as nodes in a graph, with interactions forming edges of multiple types. Traditional machine learning approaches, which rely on tabular representations of features, often struggle to fully capture these complex, high-order relationships. In contrast, graph-based models excel at encoding both local and global structural patterns, allowing the integration of multiple types of biological information—ranging from sequence-derived features to gene–disease associations—within a unified latent space. This capability enables the model to infer indirect associations, identify hidden patterns, and generalize to previously unseen nodes with high accuracy.
Message-passing mechanisms within the network allow for effective propagation and aggregation of information, ensuring that the contribution of neighboring nodes is weighted according to their relevance, while attention-based layers enhance interpretability and robustness. Our experiments demonstrated that the model consistently achieves high predictive performance across multiple HMDD datasets, with narrow confidence intervals, confirming stability and reproducibility. Ablation and perturbation studies further highlighted the model’s sensitivity to network structure and its robustness to small levels of noise, underscoring the importance of accurately modeling heterogeneous interactions.
Despite these promising results, several limitations remain. While the model integrates diverse sources of biological information, the construction of the graph relies on pre-defined similarity measures and curated associations, which may overlook emerging or context-specific relationships. Future work could explore alternative strategies for graph construction, incorporating additional biological knowledge such as miRNA–target gene interactions, expression profiles across tissues or conditions, and temporal dynamics of disease progression. Moreover, integrating multi-omics data or environmental factors could enrich node features and edge relationships, improving prediction accuracy and providing deeper mechanistic insights. Advances in graph neural network architectures, including more sophisticated message-passing schemes or hierarchical graph representations, also offer avenues for performance enhancement and better interpretability.
Overall, this study confirms the strength of graph-based learning for miRNA–disease association prediction, demonstrating that modeling biological entities and their relationships as a heterogeneous network allows for accurate, robust, and generalizable inference. The proposed framework not only achieves state-of-the-art performance compared with existing methods, but also provides a flexible and extensible approach for future investigations, supporting the discovery of novel associations and facilitating hypothesis generation in translational research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ambros V. The functions of animal micro RN As Nature 200443135035510.1038/nature 0287115372042 · doi ↗ · pubmed ↗
- 2Bartel D.P. Micro RN As: Genomics, biogenesis, mechanism, and function Cell 200411628129710.1016/S 0092-8674(04)00045-514744438 · doi ↗ · pubmed ↗
- 3Bartel D.P. Metazoan Micro RN As Cell 2018173205110.1016/j.cell.2018.03.00629570994 PMC 6091663 · doi ↗ · pubmed ↗
- 4Eulalio A. Huntzinger E. Izaurralde E. Getting to the Root of mi RNA-Mediated Gene Silencing Cell 200813291410.1016/j.cell.2007.12.02418191211 · doi ↗ · pubmed ↗
- 5Meister G. Tuschl T. Mechanisms of gene silencing by double-stranded RNA Nature 200443134334910.1038/nature 0287315372041 · doi ↗ · pubmed ↗
- 6Vasudevan S. Tong Y. Steitz J.A. Switching from repression to activation: micro RN As can up-regulate translation Science 20073181931193410.1126/science.114946018048652 · doi ↗ · pubmed ↗
- 7De Rooij L.A. Mastebroek D.J. Ten Voorde N. van der Wall E. van Diest P.J. Moelans C.B. The micro RNA lifecycle in health and cancer Cancers 202214574810.3390/cancers 1423574836497229 PMC 9736740 · doi ↗ · pubmed ↗
- 8Wightman B. Ha I. Ruvkun G. Posttranscriptional regulation of the heterochronic gene lin-14 by lin-4 mediates temporal pattern formation in C. elegans Cell 19937585586210.1016/0092-8674(93)90530-48252622 · doi ↗ · pubmed ↗