A Cross-Subject Band-Power Complexity Metric for Detecting Mental Fatigue Through EEG
Ang Li, Zhenyu Wang, Tianheng Xu, Ting Zhou, Xi Zhao, Honglin Hu, Marc M. Van Hulle

TL;DR
A new EEG metric called ST-SODE detects mental fatigue without needing subject-specific calibration, making it suitable for real-world applications like driving and healthcare.
Contribution
ST-SODE is a novel EEG-based metric that improves cross-subject and cross-domain fatigue detection by suppressing background brain rhythm interference.
Findings
ST-SODE achieves a correlation coefficient of 0.56 on the SEED-VIG dataset, outperforming differential entropy.
ST-SODE reaches 93.75% binary classification accuracy on a vigilance dataset based on the N-Back task.
ST-SODE reduces the need for calibration and enables lightweight cross-subject deployment for fatigue monitoring.
Abstract
What are the main findings? The proposed Short-Term Second-Order Differential Entropy (ST-SODE) can capture fatigue from short-term band-power dynamics.ST-SODE improves the robustness of cross-domain EEG fatigue detection. The proposed Short-Term Second-Order Differential Entropy (ST-SODE) can capture fatigue from short-term band-power dynamics. ST-SODE improves the robustness of cross-domain EEG fatigue detection. What are the implications of the main findings? ST-SODE reduces calibration burden for real-world fatigue monitoring.ST-SODE enables lightweight cross-subject deployment. ST-SODE reduces calibration burden for real-world fatigue monitoring. ST-SODE enables lightweight cross-subject deployment. Background/Objectives: Electroencephalography (EEG) is a promising modality for fatigue detection because it directly reflects neural states; however, it is hindered by the need…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
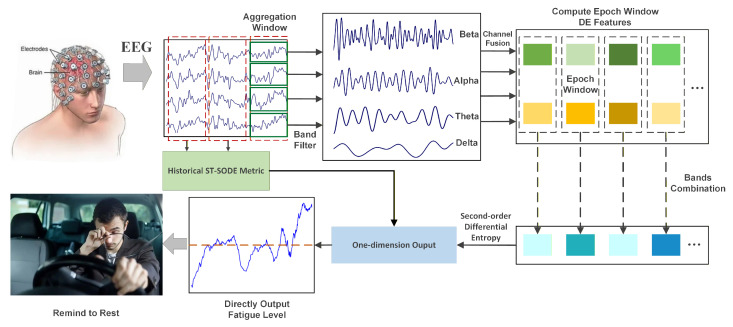 Figure 1
Figure 1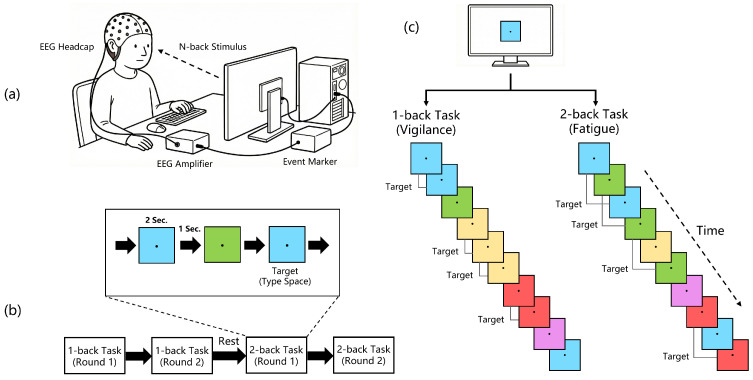 Figure 2
Figure 2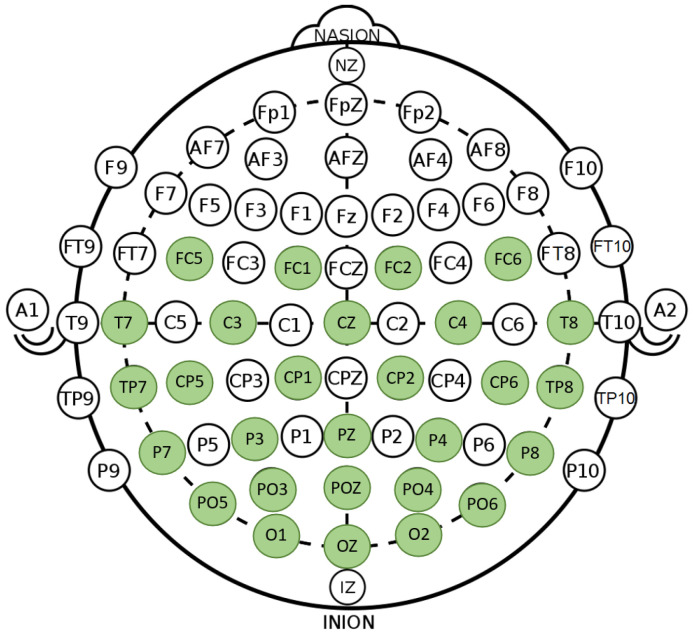 Figure 3
Figure 3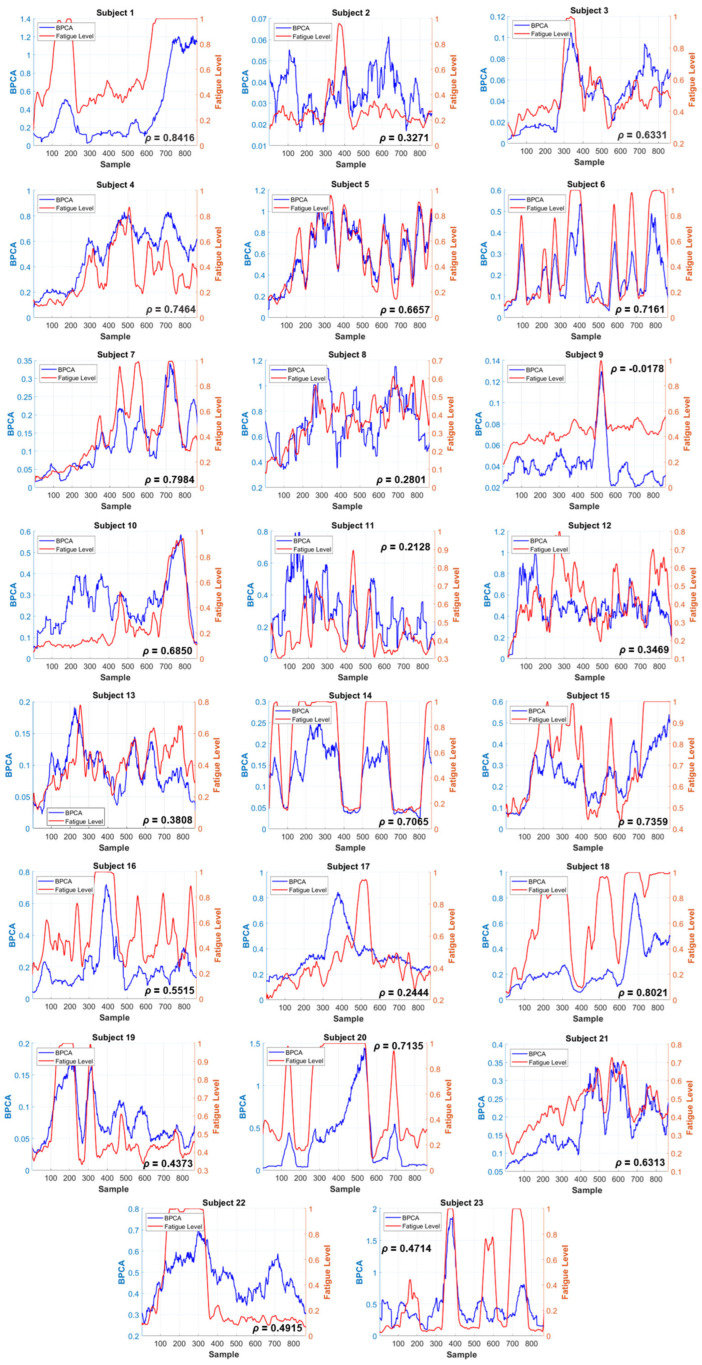 Figure 4
Figure 4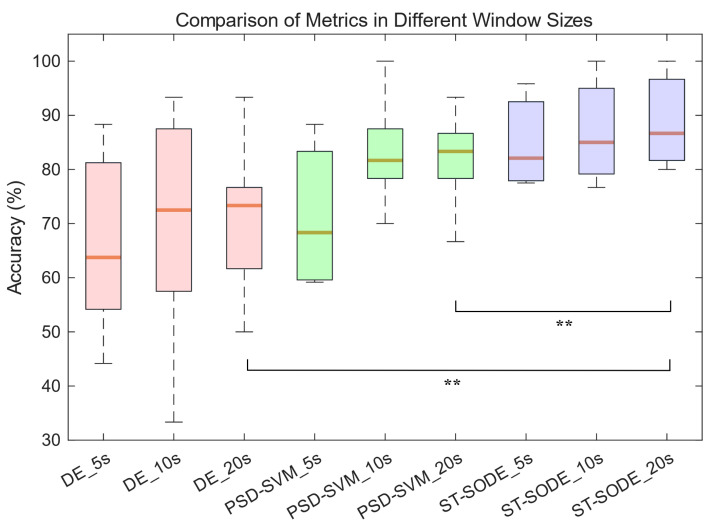 Figure 5
Figure 5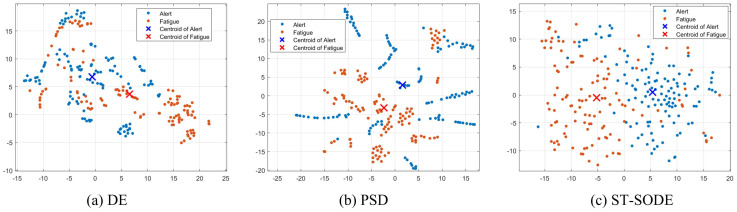 Figure 6
Figure 6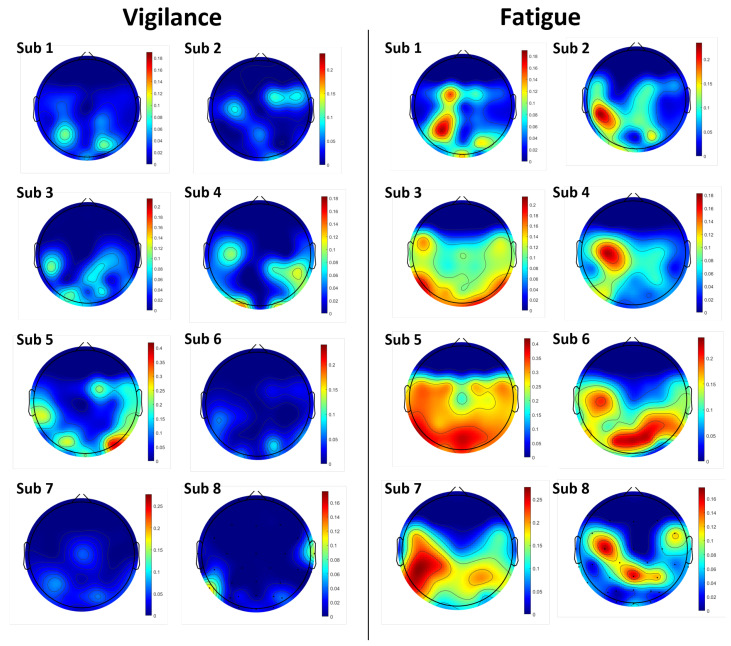 Figure 7
Figure 7- —Horizon Europe’s Marie Sklodowska-Curie Action
- —Horizon 2020 research and innovation programme
- —Special research fund of the KU Leuven
- —Belgian Fund for Scientific Research—Flanders
- —Hercules Foundation
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSleep and Work-Related Fatigue · EEG and Brain-Computer Interfaces · Emotion and Mood Recognition
1. Introduction
Statistics from the World Health Organization (WHO) show that 1.19 million people die from road traffic accidents every year [1]. Fatigue is one of the main culprits among the factors causing traffic accidents, predominantly in terms of rear-end car accidents; as such, fatigue is responsible for both human casualties and economic burden to society [2,3]. Fatigue reduces a driver’s vigilance, affecting the normal execution of driving tasks such as attention level, braking decisions, and reaction times [4,5]. Therefore, how to monitor and reduce driving fatigue has been a focus of research on traffic safety.
From the perspective of fatigue detection, three methodologies are used: physical feature identification [6], vehicle trajectory assessment [7], and biological signal assessment [8,9,10]. Biological signal assessment methods, among which Electroencephalography (EEG) stands out prominently, offer an effective and intuitive means of gauging a driver’s mental state. Consequently, signals such as EEG are frequently used to assess driver fatigue [11,12,13].
However, EEG signals are typically noisy and vary among subjects, leading researchers to develop a number of decoding methods. These methods primarily belong to two categories: the first involves traditional feature construction, in which time and frequency domain features such as Differential Entropy (DE) [14] and Power Spectral Density (PSD) [15,16] are constructed from EEG signals and supplied to machine learning classifiers; the second involves neural networks such as CNNs and RNNs [17,18,19,20], which can directly learn hidden features related to fatigue.
Although researchers have proposed various fatigue detection methods based on machine learning and deep learning, insufficient attention has been paid to the cross-session and cross-subject performance of these methods, which can lead to overfitting in practical applications because of lack of training data.
The brain exhibits rhythmic phenomena in which the power across different frequency bands of the brain varies over time and between subjects [21,22]. Classical fatigue features such as DE features use the magnitude of frequency-band power as an indicator of fatigue intensity; as such, they are susceptible to intrinsic fluctuations in brain rhythms, resulting in feature distribution shifts across subjects and across time periods. Deep learning models impose stricter requirements on feature distribution consistency, but these models typically need data recollection and model retraining for cross-subject and cross-session applications, which is a highly time-consuming process.
Therefore, this work aims to find a more robust metric to quantify mental fatigue. Fatigue is a protective response of the brain to prolonged high workloads. In realistic scenarios, the subject needs to maintain vigilance while driving or working. Through long-term experiments, we found that normally, when subjects feel tired, if they allow fatigue to develop, then they naturally fall into sleep. This is reflected by changes in the magnitude of the band’s power within the DE feature description [14]. When subjects fight against fatigue, such as during driving or working, this is manifested by fluctuation in the EEG frequency band power, known as the fatigue rebound effect [8,23,24]. In other words, as mental fatigue develops, EEG-band power does not exhibit a monotonic drift from vigilance to fatigue; instead, it typically progresses from a relatively stable alert state to a transient oscillatory phase, subsequently settling into a new stable state. Focusing on the fluctuations instead of on changes in the absolute magnitude helps to reduce the confounding effects of baseline cross-subject and cross-session variations.
Here, we use these fluctuations over a certain time window to describe the subject’s fatigue state during that period and propose the Short-Term Second-Order Differential Entropy (ST-SODE) metric to describe human fatigue. Because ST-SODE depends on fluctuation patterns rather than the absolute band-power magnitude, it is less sensitive to baseline shifts and scale differences across subjects and sessions, allowing for improved robustness under cross-subject and cross-session variability. We validated ST-SODE on a public fatigue dataset and a private binary vigilance–fatigue dataset. The results show that ST-SODE consistently outperforms existing metrics on both regression and cross-subject classification tasks. The contributions of this study are as follows:
- This study proposes using the fatigue rebound effect to assess fatigue levels, then introduces ST-SODE to characterize this phenomenon.
- ST-SODE describes the fluctuation of the short-term frequency-band power of the EEG signal without training; the one-dimensional output can directly represent fatigue states with cross-subject and cross-session robustness.
- We provide theoretical evidence that short-time DE features computed from long EEG sequences approximately follow a Gaussian distribution, which supports the statistical modeling assumptions of ST-SODE.
- This study includes a fatigue experiment based on the N-Back task for classification purposes. The proposed method was validated on both the N-Back dataset and the public SEED-VIG dataset. The results show that ST-SODE outperforms DE and PSD features in cross-subject scenarios using the Leave-One-Subject-Out (LOSO) strategy.
The rest of this paper is organized as follows: Section 2 introduces related works; Section 3 describes the proposed method; Section 4 introduces the datasets and experiment; Section 5 and Section 6 respectively present and discuss the results; finally, we conclude the paper in Section 7.
2. Related Works
An EEG-based fatigue detection system typically comprises four main components: signal acquisition, preprocessing, decoding, and postprocessing. Signal acquisition involves using an EEG cap to record the EEG signals associated with fatigue and vigilance states. Signal decoding forms the system’s core and includes two critical stages: feature construction or extraction, and decoding. Feature construction or extraction aims to derive key features that facilitate effective classification, employing methods such as the wavelet transform, Differential Entropy (DE) [25], Power Spectral Density (PSD) [16,26], etc. Extracted features such as entropy and time–frequency domain characteristics are utilized to differentiate between fatigue and vigilance states. Finally, features are decoded by training a classifier or regressor using machine learning methods. The results also require postprocessing (outlier detection, etc.) before application.
2.1. Feature Extraction
Methods for extracting EEG fatigue features primarily include time–frequency domain features and nonlinear features. Cui et al. [27] utilized the Fast Fourier Transform (FFT) to extract frequency-based features, integrating these with the Feature Weighted Episodic Training (FWET) classifier to detect fatigue. Zhang et al. [28] applied the Discrete Wavelet Transform (DWT) to extract entropy-based features, including the Wavelet Entropy (WE), Peak-to-Peak Approximate Entropy (PPApEn), and Peak-to-Peak Sample Entropy (PP-SampEn) to classify four driving fatigue stages. Duan et al. [25] were the first to employ DE features for driving fatigue detection. As a benchmark feature provided by the SEED-VIG dataset, DE has subsequently been widely cited and utilized in numerous studies [29,30]. When combining various features that have been proposed for EEG-based fatigue detection, the resulting high-dimensional feature space calls for dimensionality reduction or a feature selection process prior to or as part of the training process of the classifier or regressor. However, dimensionality reduction requires extensive labeled data, and challenges generalization to new subjects due to the cross-subject and cross-session variability of EEG signals.
2.2. Traditional Machine Learning Algorithms Applied in Classification
The classical machine learning methods of Support Vector Machine (SVM) and Support Vector Regression (SVR) for regression problems are extensively utilized in EEG-based fatigue detection. Shen et al. [31] proposed a probabilistic multiclass SVM detector for automatically classifying mental fatigue levels from EEG data. Li et al. [32] introduced the Auto-Correlation Function-based Sparse Support Matrix Machine (ACF-SSMM) algorithm, which incorporates location information into EEG signals and employs sparsity to reduce redundant features, resulting in enhanced fatigue detection performance. Wang et al. [33] extracted four graph-related features using Partial Directed Coherence (PDC)-based brain functional network construction. They utilized SVM for offline classification, achieving an accuracy of 87.16% for binary classification in a simulated driving experiment. For the SEED-VIG dataset labeled with continuous values, Zheng et al. [34] applied Differential Entropy (DE) features and Support Vector Regression (SVR) for regression-based prediction. In addition to SVM-based methods, other machine learning classifiers have also been applied to EEG-based fatigue detection, such as K-Nearest Neighbor (KNN) [35], Bayesian Neural Network (BNN) [36], and Feature Weighted Episodic Training (FWET) [27].
2.3. Deep Learning Models
Compared to traditional machine learning algorithms, deep learning methods require larger training datasets but offer significantly better prediction performance on test data within the same subject. Convolutional Neural Networks (CNN) are widely employed in image recognition and classification [17,18,37]. They possess the ability to automatically and adaptively learn the hierarchical feature space at each level, which effectively reduces the number of learned parameters [17]. Recent studies have highlighted the strong feature extraction capabilities of CNNs in EEG analysis. For instance, Wu et al. [18] proposed a deep sparse contractive autoencoder network combined with Finite Impulse Response (FIR) filters to extract local features and predict fatigue status, achieving 94.58% classification accuracy on a three-class private flight simulation fatigue dataset. Similarly, Hu et al. [19] introduced the Spatio-Temporal Fusion Network with Brain Region Partitioning Strategy (STFN-BRPS), a multi-branch deep learning network designed to enhance the accuracy and robustness of EEG-based driver fatigue detection. The model incorporates a recurrent multiscale convolution module for temporal features, a dynamic graph convolution module for spatial features, and a channel attention-based feature fusion module. This approach demonstrated superior performance compared to conventional methods on real-world driving tests.
While deep learning enhances feature extraction performance for specific domains, it is susceptible to overfitting [38]. EEG data exhibit significant variability across subjects [39,40], which means that new data must be collected from each subject in order to retrain the model or recalibrate the original model. This requirement poses a major challenge to the practicality of EEG-based fatigue detection methods.
3. Methods
3.1. EEG Frequency Bands
An Electroencephalograph (EEG) is a biosignal representing changes in surface potentials on the scalp, which reflect the electrophysiological activity of neural cells in the brain. EEG features are generally defined by their distinct frequency ranges and spatial patterns. Functionally, EEG frequency domain features are categorized into the five frequency bands shown in Table 1. Notably, the alpha and theta bands are strongly associated with fatigue [41,42,43,44]. Specifically, when subjects are mentally fatigued, their theta-band power will increase significantly. Their alpha-band power also increases; however some studies have observed weakening of the alpha band due to engagement in task-related areas [45]. The beta-band power may also weaken; however, the specific performance varies greatly between subjects.
To provide a more stable representation of fatigue, the frequency-band ratios , , and are commonly used. This approach helps to mitigate baseline shifts that often occur when relying solely on a single frequency band over extended periods. However, the power within EEG frequency bands is sensitive to both long-term shifts and transient fluctuations caused by intrinsic physiological states or external environmental factors. These short-term variations can lead to instability in features from combined frequency bands, posing challenges for accurate fatigue prediction. Therefore, predicting the fatigue state of a subject solely based on the increase or decrease in frequency-band power is unreliable. In practical applications, frequency-band power features are extracted first, then machine learning methods are applied to learn their characteristics.
3.2. Short-Term Second-Order Differential Entropy
The framework of the proposed Short-Term Second-Order Differential Entropy (ST-SODE) method is illustrated in Figure 1. To quantify fatigue levels using EEG signals, we employ a dual-windowing strategy comprising the epoch window ( ) and the aggregation window ( ). The epoch window is a short-time window used to extract the instantaneous spectral features, while the aggregation window is a longer sliding window designed to capture the temporal variability of these features. Let denote the number of epoch windows contained within one aggregation window, the sampling rate, and s the fixed step size between adjacent epoch windows.
For each epoch window , the power spectrum is computed using Welch’s power spectral density estimate [46]:
where is the Hamming window, represented as
Then, the band power is calculated in four frequency bands (delta: 0.5–4 Hz theta: 4–8 Hz, alpha: 8–12 Hz, beta: 13–30 Hz). The Differential Entropy (DE) was initially defined as
with the time series X assumed to follow a Gaussian distribution . It has since been proven that for a fixed-length EEG sequence, the DE is equivalent to the logarithm of the energy spectrum or the signal variance in a certain frequency band [14].
Subsequently, based on Section 3.1, the logarithm of the energy spectrum features is calculated. To capture the global state, the features are pooled by averaging across all channels and combined through frequency band to obtain the final DE feature for each epoch window:
where represents the different band-power combinations discussed in Section 3.1.
Next, we prove that the distribution of DE features of windows from long-length EEG signals approximates a similar Gaussian distribution. Let signal segment X of length N follow a stationary Gaussian distribution, denoted as . The estimator for the Differential Entropy (DE), denoted as , is provided by
where represents the sample variance of the segment. According to the Central Limit Theorem [47], as the sample size , the sample variance exhibits asymptotic normality:
This implies that for large N, is approximately distributed as .
To derive the distribution of , we apply the Delta method [48]. Let , such that . The first-order Taylor expansion of around the true variance is
The derivative of the function is . Evaluated at , we have .
Because a linear transformation of a Gaussian random variable remains Gaussian, follows a normal distribution asymptotically. The variance of is derived as follows:
Consequently, as , the segmented DE values follow a similar Gaussian distribution:
Based on this proof, over the aggregation window containing epoch windows, we calculate the ST-SODE feature as the variance of the sequence . The ST-SODE is given by
where is the mean DE value over the aggregation window and is the number of epoch window in one aggregation window. It has been proven in [14] that the variance estimation of signal sequence is just its average energy; therefore, the above operation can be regarded as a simplified version of the DE computation. We do not further apply a logarithmic operation here, since the potential negative values are undesirable for directly outputting the fatigue index. However, due to the monotonicity of the logarithm, its variation trend remains strictly consistent with that of the standard DE. A larger ST-SODE value indicates greater fluctuation and instability in the relative activity between the two frequency bands.
4. Datasets and Experiment Setup
In this study, we utilized two EEG-based fatigue datasets. The first public dataset, SEED-VIG, was collected by Shanghai Jiao Tong University and contains EEG signals recorded during simulated driving tasks. Eye-tracking devices were employed to monitor blink and closure, which served as the basis for fatigue regression labeling. The second dataset is a private dataset using the N-Back task to induce fatigue in subjects. In a typical N-Back paradigm, subjects continuously respond to a stream of stimuli by indicating whether the current stimulus matches the one presented N steps earlier, thereby demanding working memory and sustained attention. The N-Back task was initially introduced by Kirchner in [49] to impose varying cognitive workloads. Subsequently, Tanaka et al. [50] and Pergher et al. [51] demonstrated that the N-Back task can effectively induce fatigue when its design closely mirrors that of the control 1-Back task. The 1-Back task can induce fatigue, but less than the 2-Back task because of the higher task difficulty. Other fatigue classification studies have also employed N-Back experiments to induce varying degrees of fatigue [52,53]. Detailed descriptions of the experiment setup and data formats for both datasets are provided in the following subsections.
4.1. SEED-VIG
The first dataset was compiled and released by a research team at Shanghai Jiao Tong University [34]. They developed a simulated driving system to collect EEG data. The system was composed of a large LCD screen and a real vehicle without engine and other components. The vehicle was modified so the participants could operate the vehicle through the steering wheel and gas pedal using a screen in front of them. To induce fatigue, the LCD screen displayed a primarily straight and monotonous four-lane highway scene.
A total of 23 volunteers with an average age of 23.3 years participated in the fatigue driving experiments. To facilitate the induction of driving fatigue, subjects were required to participate in the experiment in the afternoon or late at night. The experiment lasted about 2 h, during which data were recorded. Both EEG and forehead EOG signals were recorded during the fatigue driving experiment; however, only EEG data are analyzed in this paper. EEG signals were recorded from eleven channels at the posterior site and six channels at the temporal site, following the international 10–20 electrode system. The sampling rate was 200 Hz. An annotation, called the PERCLOS measure, was adopted to quantify subjects’ fatigue. PERCLOS indicates the percentage of eye blink and closure, with the PERCLOS value between 0 (vigilance) and 1 (fatigue).
4.2. Vigilance Dataset
4.2.1. Experimental Protocol
The second dataset consists of a binary vigilance–fatigue dataset collected from eight subjects. To induce fatigue, we designed an experiment based on cognitive load experiments in psychology. In the N-Back task, participants are presented with a sequence of stimuli, which can be either visual or auditory, and must identify whether the current stimulus matches the one presented “N” steps earlier in the sequence. The value of “N” can be varied to adjust the difficulty of the task, with larger values requiring participants to hold more items in memory and track them over longer intervals.
In this study, we used different colors as stimuli and carried out two tasks for each subject, as illustrated in Figure 2. The 1-Back task was used to represent a relative vigilant working state, while the 2-Back task was used to induce the fatigue working state. To minimize interference between the two tasks, each subject first completed the 1-Back task; after a 10-min rest, the same subject then performed the 2-Back task. For the 1-Back task, the monitor displayed changing color blocks, each lasting 2 s with an interval of 1 s. The subject was instructed to concentrate on the screen and press the space bar when two consecutive colors were the same. For the 2-Back task, the subject was instructed to press the space bar when the current color was the same as two steps prior. Both tasks consisted of two rounds of 5 min each, with no interval between them.
Eight healthy subjects were recruited, seven males and one female (age: 23.75 ± 2.11 years, mean ± standard deviation). All subjects reported normal or corrected-to normal vision, with no history of substance addiction or mental disorders. The subjects were required to obtain a full night (>7 h) sleep before the day of the experiment. On the day of the experiment, they were required to avoid consuming caffeine or alcohol. The experiment was conducted in an electromagnetically shielded room. Before the start of the experiment, the subjects were trained to familiarize themselves with the N-Back task and to understand the necessity of completing the tasks as accurately as possible even when feeling tired. The study complied with the principles of the 2024 Declaration of Helsinki and was approved by the Research Ethics Committee of Shanghai University (no. ECSHU 2024-072). All subjects signed informed consent forms.
4.2.2. EEG Data Acquisition
Brain activity was recorded using EEG recording equipment (Compumedics Neuroscan, Charlotte, NC, USA) with 28 wet electrodes using the 10–20 system (without forehead electrodes, according to SEED-VIG). The selection and position of the channels are shown in Figure 3. The sampling rate was 1000 Hz. The impedances of all EEG channels were kept below 10 k .
4.3. Experiment Setup
4.3.1. Effectiveness Experiment on SEED-VIG
The label of SEED-VIG is a floating value from 0 to 1; thus, we use the prediction curves and correlation analysis to demonstrate the performance of ST-SODE. The SEED-VIG dataset contains three parts: EEG (temporal lobe and posterior lobe), Forehead EEG, and EOG. Only the EEG data were utilized in this experiment, with the Forehead EEG and EOG data left out. Forehead electrodes can cause eye movement artifacts; after these data were removed, the raw EEG data were processed with a fourth-order Butterworth band-pass filter between 0.5 and 45 Hz to reduce artifacts and noise, referencing [34]. The filtering was completed before epoch window segmentation to reduce the edge effect. The epoch window size was set to 0.5 s and the aggregation window size to 8 s. The epoch window strategy was non-overlapping, with the step size the same as the epoch window length. After ST-SODE, the result was min–max normalized, then displayed in the same figure with PERCLOS labels.
4.3.2. Vigilance Dataset
The Vigilance dataset involves two tasks with different levels of workload, namely, the 1-Back task and 2-Back task. Each task consisted of two rounds, each of which began with the cue “Round 1/2 begins”. We selected the first round of the 1-Back task as the vigilant case and the second round of the 2-Back task as the fatigue case. The preprocessing was the same as SEED-VIG. The epoch window size was set at 0.5 s and the aggregation window size at 5, 10, and 20 s to assess the effect on the results. Each subject had 120, 60, and 30 trials for 5 s, 10 s, and 20 s, with fatigue and vigilance being equally divided. To classify fatigue without training on the test subject, we calculated the average value of the obtained segmented ST-SODE features from the other seven subjects, excepting the test subject. The training data length was [840/420/210, 5/10/20 * 1000 (Hz)] (trials, data points). Features from the test subject that were above the average value were predicted as fatigue, and vice versa as vigilance. The Differential Entropy (DE) and Power Spectral Density (PSD) were employed as a comparison. DE features were processed consistently with ST-SODE, and a Support Vector Machine with a Gaussian kernel was used to classify PSD features using the LOSO strategy, with the data of the other seven subjects excepting the test subject used for training. To compare the performance of ST-SODE with supervised subject-specific methods, we also conducted within-subject 5-fold cross-validation experiments using the DE and PSD features with supervised SVM classifiers.
In addition, we calculated the average ST-SODE results of fatigue and vigilance trials for each subject.
5. Results
5.1. Performance on SEED-VIG
A comparison of the PERCLOS labels and ST-SODE results among all subjects is depicted in Figure 4. ST-SODE (blue line) exhibits varying degrees of correlation with PERCLOS (red line), which are collected in Table 2. The performance is divided into three categories, as discussed below:
- Most experiments show significant correlation between ST-SODE and PERCLOS changes: S01, S03, S04, S05, S06, S07, S10, S14, S15, S17, S18, S20, and S21. All their correlation coefficients are above average 0.56. Their peaks and troughs along the rising and falling edges remain largely coincident. Because ST-SODE and PERCLOS are both complete data modalities, the heights of the two curves may differ.
- The second category consists of correlation coefficients between 0.2 to 0.56 but which still exhibit strong correlation in the image. This is specifically manifested as follows: when PERCLOS shows a peak in a short period of time, ST-SODE also demonstrates a similarly temporally coincident fluctuation. This category contains S11, S12, S13, S16, S19, S22, S23.
- The third category comprises subjects with a correlation coefficient below 0.2. This group includes S02, S08, and S09. For S09, it can be observed that the two curves coincide almost exactly when there is a crest.
At the same time, we also calculated the performance of PSD and DE, which are widely used as features in fatigue prediction. In order to show the result without training, the processing method of PSD and DE was kept consistent with ST-SODE. The feature average of all channels was calculated to obtain a one-dimensional time series, then the correlation coefficient was calculated with the label. The results are shown in Table 2.
According to Table 2, when the PSD and DE features are not trained using classifiers with labels, their correlation with the labels is lower than ST-SODE. Among the four different frequency band combinations, the highest PSD is only 0.0325, the DE is 0.4001, and the chance level of the random signal between 0 and 1 is 0.005. The untrained ST-SODE method can achieve an average correlation coefficient of 0.56, significantly higher than DE or PSD (** p < 0.01 and *** p < 0.001, Wilcoxon signed-rank), which proves the effectiveness of ST-SODE in predicting fatigue without training.
5.2. Performance on Vigilance Dataset
The classification results of ST-SODE and the two compared methods (DE and PSD) are shown in Table 3 and Figure 5. Each method employs three different aggregation window lengths (5S, 10S, 20S).
It can be observed that the mean accuracy of ST-SODE across all three window lengths significantly exceeds those of the DE and PSD-SVM methods. ST-SODE achieves the highest average accuracy (93.75%) at a window length of 20 s, which is 6.46% higher than at 5 s and 1.46% higher than at 10 s. However, while increasing the sampling window length improves accuracy, it also leads to a reduction in system response speed. For the DE and PSD methods, accuracy significantly improves as the window length increases from 5 s to 10 s, with gains of 3.86% and 11.88%, respectively; however, when the sampling window length is further extended from 10 seconds to 20 s, DE and PSD show minimal accuracy gains or even slight declines, with changes of 0.62% and −1.05%, respectively. We believe that this is because keeping the total data length fixed while increasing the size of the sampling window results in a reduced number of training samples.
To quantify the magnitude of performance differences beyond statistical significance, we additionally report the rank-biserial correlation r as an effect-size measure for the paired Wilcoxon signed-rank test. The value of r ranges from , with indicating that ST-SODE achieves higher accuracy than the comparator and larger implying a stronger and more consistent advantage across subjects. Based on the subject-wise paired accuracy results in Table 3, ST-SODE exhibits positive effect sizes over DE, with for window lengths of 5 s/10 s/20 s. Compared to PSD-SVM, the effect sizes are for 5 s/10 s/20 s, respectively. Overall, these results suggest that ST-SODE provides a consistent improvement over both DE and PSD-SVM across subjects.
In Table 4, we report the performance comparison between the cross-subject ST-SODE method and DE/PSD features with supervised SVM classifiers. The comparison indicates that the within-subject supervised method DE-SVM achieves the highest accuracy (97.50–98.44%), representing an accuracy improvement of 3.75–11.15% at the 20 s and 5 s window settings compared to the cross-subject ST-SODE. This performance gap reflects the advantage of subject-specific calibration in capturing individual EEG characteristics. Therefore, the choice of whether to sacrifice accuracy in order to avoid subject-specific calibration represents a tradeoff that users must evaluate based on their practical requirements.
In Table 5, it can be observed that the average of ST-SODE on the vigilance task is significantly lower than on the fatigue task (** p < 0.01). For example, when using an aggregation window length of 5 s, the average of ST-SODE on the vigilance task data is 0.000077, while on the fatigue task data it reaches 0.064361. Although ST-SODE scores higher for some subjects on the vigilance task, such as Subject 5 with 0.000257, this is still much lower than the lowest score on the fatigue task (Subject 1 with 0.000893). Meanwhile, the smallest difference between vigilance and fatigue is also from Subject 1, with 0.000079 and 0.000893, respectively, while the largest difference is from Subject 5, with 0.000257 and 0.219803.
5.3. Effectiveness Analysis
5.3.1. Performance When Using Other Band Power Ratios
ST-SODE uses as the band-power combination due to its high performance compared to other combinations. We calculated the Spearman correlation between the predictions and PERCLOS on SEED-VIG using different band power ratios of , and , with the results shown in Table 2. The chance level is calculated using the shuffled label and the results of .
From Table 2, it can be seen that achieves the highest correlation among the four methods. The results obtained from the other three combinations are poorly correlated with the PERCLOS labels.
5.3.2. Feature Visualization
To validate the representation ability of the proposed method, we plot the t-SNE [54] transformed features in Figure 6.
The t-SNE is a nonlinear manifold learning technique that projects high-dimensional feature vectors into a low-dimensional space (typically 2D) for visualization by preserving local neighborhood relationships. Therefore, points that are closer together on the 2D map generally indicate more similar representations.
Specifically, we exhibit the DE, PSD, and ST-SODE features extracted from all subjects’ data in the Vigilance dataset. We used a learning rate of 500 and an iterative display frequency of 20 for the t-SNE calculation.
From the visualized features represented in the figure, it can be observed that the ST-SODE features are more class-discriminative than the other features. Additionally, the DE features are distributed in several regions which contain both vigilance and fatigue features. This issue illustrates why decoding methods are prone to significant deterioration on cross-subject tasks. Meanwhile, it is notable that some points of the PSD features are close to straight lines, which proves that features from the same subject in the same state are very similar compared to ST-SODE and DE while being very different from other subjects. This proves the difficulty of training a classifier that is universal for all subjects, as it is challenging to learn a hyperplane (or neural network) that can effectively distinguish the two types of states based on the confusing features.
6. Discussion
6.1. Topography of Channel-Level ST-SODE
The standard ST-SODE does not focus on the features between channels, but instead averages the values of all channels. To explore the spatial variation of ST-SODE across the scalp, Figure 7 shows the channel-level ST-SODE topography.
Notably, the fatigue condition shows significant increases in ST-SODE values within particular cortical regions for most subjects. Specifically, Subjects 1, 2, 4, 7, and 8 exhibit high ST-SODE activity in the left temporal electrodes and left parietal electrodes, while Subjects 5 and 6 show stronger ST-SODE features in the occipital electrodes.
This suggests that it is difficult to use individual channels for ST-SODE detection. The spatial differences in performance during fatigue and non-fatigue are different across subjects; therefore, attempting to use all of the channels for ST-SODE analysis can enhance generalizability to all subjects. However, when considering realistic application scenarios such as driver fatigue detection, it may not be possible to provide electrode caps that cover the whole brain, as in laboratory scenarios. Consequently, employing localized portable electrode setups centered on the left posterior region would optimize detection efficacy within these practical constraints.
6.2. Importance of Cross-Subject Method
Previous studies have shown that neuronal activities exhibit variability in the frequency and time domains over the states of vigilance and fatigue [11,12]. This variability is mainly exhibited by changes in the frequency domain features. Recent neurophysiological studies have suggested that this phenomenon captured by ST-SODE is likely attributable to Locus Coeruleus (LC) oscillations [55,56]. During fatigue, LC neurons exhibit functional fatigue and infra-oscillations. These fluctuations in noradrenergic gain cause cortical networks to oscillate between low-excitability and high-excitability states, generating the high spectral variance that ST-SODE measures. This mechanism aligns with observations by Doran et al. [57], who noted unstable fluctuations in attentional states during sleep deprivation. Most existing studies focus on utilizing a classifier trained on a single subject. This provides stronger fitting ability, but at the same time constrains realistic applications due to the need for subject-specific training data. In real-world situations, especially driving fatigue detection, there is urgent need for a white-box algorithm with clear internal workings and decision-making logic.
ST-SODE metrics effectively meet this requirement. Our findings reveal significant power fluctuation on EEG bands when subjects are in a fatigued state. The proposed ST-SODE method is designed based on this phenomenon to be white-box and training-free, and as such can be used in realistic fatigue detection scenarios.
Compared to PSD and DE features, ST-SODE features are less susceptible to shifts in frequency-band power across session and subject. Under normal conditions, frequency-band power varies with circadian rhythms [58] and arousal levels [59], making it challenging to evaluate fatigue changes using absolute power values across different periods. In contrast, ST-SODE features are unaffected by absolute value changes, enabling consistent fatigue standards to be applied for monitoring drivers across various sessions.
It is important to clarify the definition of “calibration-free” in this context. Although ST-SODE does not require any subject-specific calibration (where a new subject must provide labels to train a personal model), it still requires preparation for the classification threshold. As demonstrated by the LOSO setting, the threshold is derived from existing subjects. Therefore, the system preparation phase requires a database of labeled subjects in order to establish the threshold before the system can be applied to new subjects.
6.3. Labels of Fatigue Experiment
One of the major challenges in fatigue detection is labeling. The fatigue state of a subject is highly random and unstable, and is also affected by various factors. Sleeping state, circadian rhythms, task difficulty, and physical differences can all affect the fatigue level of the subject [60,61]. Most fatigue monitoring methods use supervised learning methods that require labeled data to fit a classifier [25,27,28,29,62], in which case the accuracy of the labeling affects the performance of the model for fatigue prediction.
Previously, fatigue was usually inferred indirectly by analyzing subject metrics such as eye blinks [63], frequency of yawns [64], and task errors [65]. However, there are many other factors associated with these signs. A classifier obtained by training on indirect labels still predicts indirect labels, leaving the correlation between fatigue level and indirect labels in need of further validation.
Our Vigilance dataset used cognitive load to induce the fatigue state. It was designed to produce a similar state to driving or performing other long-time tasks by means of a high-difficulty repetitive task over a short period of time, while utilizing a low-difficulty task to control for variables. We designed the metrics with reference to the properties of the brain when fatigued in order to avoid introducing other disturbances using supervised learning.
The test results on the Vigilance dataset demonstrate that ST-SODE metrics can effectively distinguish between two different work states. The process is a result-oriented one, and we consider that fatigue can be effectively detected if the two states can be distinguished.
6.4. Limitations
Despite its promising results, this study still has limitations that need to be addressed in future work. First, while ST-SODE achieves promising performance on the SEED-VIG dataset, poor performance on some subjects indicates that this metric alone is currently insufficient for operational deployment in safety critical scenarios, and should ideally be integrated into multimodal and distributed monitoring systems [66] to ensure reliability. Second, the Vigilance dataset employed an N-Back task to induce fatigue through high cognitive load, which differs from the vigilance decline typical of real-world driving; consequently, the generalizability of these findings to real driving conditions requires further validation in future on-road experiments.
Third, the frequency-band ratio ( ) utilized in ST-SODE was selected based on its best performance on the SEED-VIG dataset. While this combination demonstrated effectiveness for the Vigilance dataset, we acknowledge that this selection is empirical. Therefore, when applying ST-SODE to new scenarios, users would need to obtain labeled data from their domain in order to determine the optimal frequency-band combination.
Last, although proportional drift across bands offers a reasonable hypothesis for the effectiveness of ST-SODE in cross-subject scenarios, the mechanistic explanation remains empirically demonstrated but theoretically underspecified in the current study. Conclusive validation of these specific drift patterns requires further targeted research into the neurophysiological mechanisms.
7. Conclusions
This study has proposed a cross-subject EEG-based fatigue metric called ST-SODE which can be applied to scenarios such as driving, manufacturing, and healthcare that require low fatigue levels. ST-SODE utilizes the fatigue rebound effect to represent fatigue levels; this approach reports fatigue levels by calculating the fluctuation of short-window DE features, equivalent to the second-order differential entropy. We validated the effectiveness of ST-SODE on the public SEED-VIG dataset as well as on a private dataset based on the N-Back task. ST-SODE achieved a correlation coefficient of 0.56 on the SEED-VIG regression dataset and 93.75% binary classification accuracy on the Vigilance dataset, outperforming other metrics under the same LOSO settings. ST-SODE can be deployed in existing environments while requiring no subject-specific calibration, thereby addressing the limitations of supervised fatigue detection methods in real-world applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1World Health Organization Global Status Report on Road Safety 2023 World Health Organization Geneva, Switzerland 2024
- 2Zhang H. Wu C. Yan X. Qiu T.Z. The effect of fatigue driving on car following behavior Transp. Res. Part F Traffic Psychol. Behav.201643808910.1016/j.trf.2016.06.017 · doi ↗
- 3Zou S. Qiu T. Huang P. Bai X. Liu C. Constructing multi-scale entropy based on the empirical mode decomposition (EMD) and its application in recognizing driving fatigue J. Neurosci. Methods 202034110869110.1016/j.jneumeth.2020.10869132464125 · doi ↗ · pubmed ↗
- 4Fountas G. Pantangi S.S. Hulme K.F. Anastasopoulos P.C. The effects of driver fatigue, gender, and distracted driving on perceived and observed aggressive driving behavior: A correlated grouped random parameters bivariate probit approach Anal. Methods Accid. Res.20192210009110.1016/j.amar.2019.100091 · doi ↗
- 5Chen J. Wang H. Wang Q. Hua C. Exploring the fatigue affecting electroencephalography based functional brain networks during real driving in young males Neuropsychologia 201912920021110.1016/j.neuropsychologia.2019.04.00430995455 · doi ↗ · pubmed ↗
- 6Gu H. Ji Q. An automated face reader for fatigue detection Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition IEEE New York, NY, USA 2004111116
- 7Rezaei M. Klette R. Look at the driver, look at the road: No distraction! no accident!Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Columbus, OH, USA 23–28 June 2014129136
- 8Lal S.K. Craig A. A critical review of the psychophysiology of driver fatigue Biol. Psychol.20015517319410.1016/S 0301-0511(00)00085-511240213 · doi ↗ · pubmed ↗