Use of Small-Molecule Inhibitors of CILK1 and AURKA as Cilia-Promoting Drugs to Decelerate Medulloblastoma Cell Replication
Sean H. Fu, Chelsea Park, Niyathi A. Shah, Ana Limerick, Ethan W. Powers, Cassidy B. Mann, Emily M. Hyun, Ying Zhang, David L. Brautigan, Sijie Hao, Roger Abounader, Zheng Fu

TL;DR
This paper explores drugs that promote cilia formation to slow down the replication of medulloblastoma cancer cells.
Contribution
The study introduces a novel method using AI to identify cilia-promoting drugs and validates their anti-cancer effects.
Findings
Alvocidib and Alisertib increase cilia frequency in cancer cells.
These drugs significantly reduce medulloblastoma cell replication.
Gemini AI outperformed other models in literature search accuracy.
Abstract
Background/Objective: The primary cilium is the sensory organelle of a cell and a dynamic membrane protrusion during the cell cycle. It originates from the centriole at G0/G1 and undergoes disassembly to release centrioles for spindle formation before a cell enters mitosis, thereby serving as a cell cycle checkpoint. Cancer cells that undergo rapid cell cycle and replication have a low ciliation rate. In this study, we aimed to identify cilia-promoting drugs that can accelerate ciliation and decelerate replication of cancer cells. Methods: To perform a comprehensive and efficient literature search on drugs that can promote ciliation, we developed an intelligent process that integrates either the GPT 4 Turbo, Gemini 1.5 Pro, or Claude 3.5 Haiku application programming interfaces (APIs) into a PubMed scraper that we coded, enabling the large language models (LLMs) to directly query…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
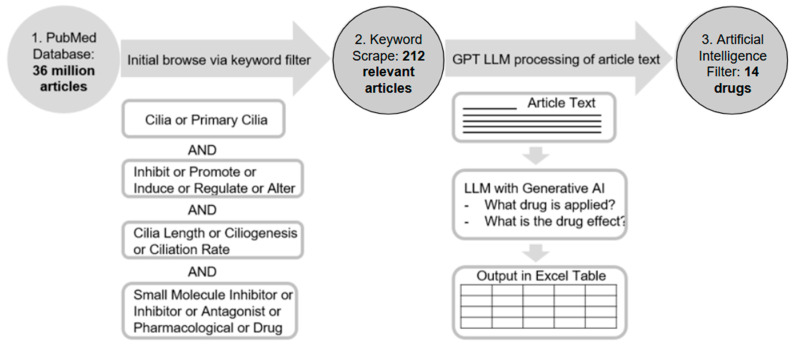 Figure 1
Figure 1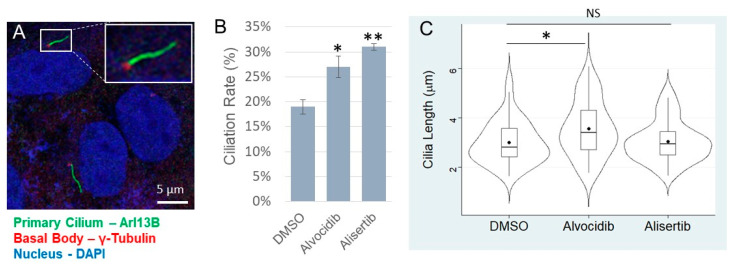 Figure 2
Figure 2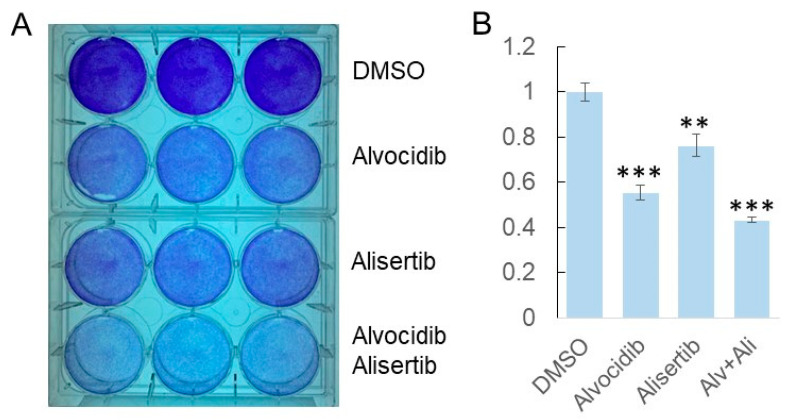 Figure 3
Figure 3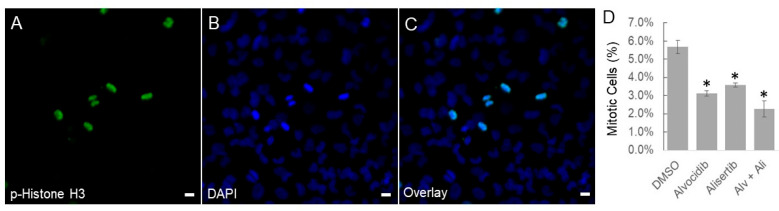 Figure 4
Figure 4- —University of Virginia Cancer Center
- —NIH R01 grants
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic and Kidney Cyst Diseases · Microtubule and mitosis dynamics · Hedgehog Signaling Pathway Studies
1. Introduction
Eukaryotic cells use a tiny cell membrane protrusion called the primary cilium to communicate with the environment [1,2,3]. They play a vital role in cell sensing and signaling, and defects in the structure and function of primary cilia have been associated with various diseases, collectively known as ciliopathies [4,5]. The primary cilium is a dynamic cellular organelle during the cell cycle. It is resorbed before cells enter mitosis, freeing centrioles to serve as spindle poles, and reformed after cells exit mitosis [6]. Thus, primary cilia are viewed as a structural barrier to mitosis [7,8]. Cancer cells have a low ciliation rate, which allows them to undergo rapid cell division and replication. It has been postulated that restoring primary cilia in cancer cells may decelerate cilia retraction and cancer cell replication [9,10,11]. There has been much interest in finding methods, particularly drugs and small-molecule inhibitors (SMIs), to increase the frequency and the length of primary cilia in cancer cells to slow their cell cycle and proliferation. In the field of cilia biology, many signaling molecules and regulatory pathways have been uncovered to control primary cilia formation and elongation [8,9], but their roles in the regulation of primary cilia and cell replication in cancer cells have not been fully elucidated. Therefore, a systematic literature search may reveal candidate cilia-modulating drugs, which we can further test for their impact on cancer cells.
Here, we attempted a comprehensive literature review to identify promising candidate drugs that can be further tested on the wet bench. The traditional literature review process consists of multiple steps, from beginning with searching scientific literature databases, to filtering inclusion criteria, to manual confirmation of results [12]. Manual search is time-consuming and prone to errors, since we would have to filter hundreds of thousands of loosely related articles. As such, many techniques currently exist to mitigate these issues, including Boolean searches, where logic such as “AND” and “OR” allow for more accurate results. For example, requiring “drugs AND cilia” would prevent drugs that impact other cellular organelles. Medical Subject Headings (MeSH) is another way to improve search results, using a hierarchical system of controlled vocabulary terms in PubMed. A popular tool that combines and automates these strategies is web scrapers, in which computer programs “scrape” websites (in this case, scientific literature databases) to perform a comprehensive review [13]. The user will often provide the search parameters for the program to use, including MeSH terms, as well as a certain logical flow of keywords to narrow in on exactly what they want to retrieve. For our scenario, we would want to create a scraper that could parse through PubMed, a vast and reputable database, to retrieve a smaller subgroup of relevant articles. Although this process drastically narrows down gigantic databases to relevant search results, all those articles still must be manually processed for the relevant information, a step that, especially for larger-scale searches, can take several weeks or longer, and that would greatly benefit from an AI approach. Our new method seeks to integrate artificial intelligence into the scraper, applying all the current techniques mentioned previously, while additionally allowing for retrieved articles to be automatically processed for information.
Recently, many of the popular large language models (LLMs) have released their APIs, providing the backbone of their model for integration into other applications for a very reasonable price [14]. As a result, there has been an influx of using those models for tasks far beyond the original purpose of a chatbot, ranging from educational tools [15] to programming assistants [16]. We thus proposed an AI-powered solution whereby scraped articles are automatically run through a large language model to be searched for the answers to user-predefined questions. This would enable a researcher to see exactly what they are searching for, with the relevant information automatically extracted and summarized.
LLM integration into the literature review process has previously been explored, but focuses primarily on the classification of articles based on inclusion criteria rather than the processing of those resulting articles [17,18,19,20]. Some solutions pertaining to the question-answering aspect do exist, but those models are trained to field-specific corpora of data [17]. One such study proposed a hybrid solution of traditional methods plus LLMs to better evaluate literature. They first used the BM25 model [21] to identify articles that align with query terms, and then fine-tuned various LLMs based on field-specific literature, such as COVID-19 data, and evaluated metrics [17]. However, these LLMs often have limitations in their capability and knowledge set, and can also be hard to employ for new users. Our approach instead seeks to identify an easy, accessible, and overarching pipeline that has the potential to automate multiple steps of the literature review process in a variety of areas, expanding upon previous methods and greatly increasing the efficiency of research (Table 1).
Using this LLM-integrated scraper is, in theory, a very attractive solution, but the following question remains: will the quality and accuracy of the automated results show true potential to advance research in biomedical fields? For us specifically, we wanted to test whether the drug(s) parsed via this method would induce a significant increase in ciliation rate to thereby reduce the replication rate of cancer cells.
In summary, promoting cilia growth with drugs or small-molecule inhibitors (SMIs) presents a promising approach to reducing the rate of cancer cell replication [22,23,24,25]. Finding these drugs via a manual search process is time-consuming and inefficient. Here, we attempted a solution of integrating a large language model into a PubMed web scraper, which will filter through the expansive database for relevant articles and then answer predefined user questions about the articles to retrieve important information. Furthermore, we attempted to validate the effects of two representative drugs on cancer cells. Such an intelligent and automated method, if dependably accurate, would significantly shorten the literature search process whilst ensuring high-quality results.
2. Methodology
2.1. LLM-Integrated PubMed Scraper
The primary package that we used to code the scraper was BeautifulSoup, which is very well-known for its ability and flexibility when web scraping. We imported that package into the Visual Studio code editor, where all the programming would be performed. Using a method included in the BeautifulSoup package, we fed the program the URL to PubMed, and within that, we included the specific search parameters for the retrieval of specific articles. The package also includes functions to query defined aspects of each article, such as its DOI link, abstract, title, and authors. These attributes were each saved as variables. For the large language model portion, we chose to use the GPT 4 Turbo, Gemini 1.5 Pro, and Claude 3.5 Haiku APIs, as they are the most widely used and accessible models. After creating an account on each respective website, we acquired an API key, which gave us access to all the methods associated with the large language models. We then fed the API keys into the Visual Studio file. Each time we called the large language model for a response, we invoked a method that takes two parameters: a system message and a human message. The specific wording of these terms varied by model, but the idea was constant across the models. The system message is the question or prompt defined by the user and answered by the API. The human message is the background data that we feed the model; in other words, it is the information provided to the API to allow it to accurately answer the system message. In our case, the human message would be portions of the articles we want information extracted from. Because, eventually, we wanted the answers to each of our questions to be displayed in a separate Excel cell, we created a function for each of the questions. The human message remains the article text, and the system message varies for each function to cover a different question. These answers are then assigned to individual variables. We finally use the xlsx package, a popular package to create and edit Excel files, to transfer the results for each article stored into the variables to an organized Excel file, which is ultimately returned to the user.
2.2. Fluorescence Imaging and Quantification of Primary Cilia and Mitotic Cells
Medulloblastoma cell line DAOY was maintained at 37 °C and 5% CO_2_ in Dulbecco’s modified Eagle’s medium (DMEM), supplemented with 10% fetal bovine serum. To image primary cilia, cells were fixed by 4% formaldehyde, rinsed in PBS, and then permeabilized by 0.2% Triton X-100 in PBS. After one hour in blocking buffer (3% goat serum, 0.2% Triton X-100 in PBS), cells were incubated with primary antibodies at 4 °C overnight, followed by rinses in PBS and one hour incubation with Alexa Fluor-conjugated secondary antibodies from Abcam (Cambridge, MA, USA). After multiple rinses, slides were mounted in antifade reagent containing DAPI (4′,6-diamidino-2-phenylindole) for imaging via a confocal Laser Scanning Microscopy 700 from ZEISS (Chester, VA, USA) at the UVA Advanced Microscopy Facility. Arl13B rabbit polyclonal antibody (17711-1-AP) and γ-tubulin mouse monoclonal antibody (66320-1-Ig) from Proteintech (Rosemont, IL, USA) were used in this study to label primary cilia and basal bodies, respectively.
The Zen 2009 program was used with a confocal Laser Scanning Microscope 700 from ZEISS to collect z-stacks at 0.5 μm intervals to incorporate the full axoneme based on immunostaining of cilia marker Arl13b and basal body marker γ-Tubulin. All cilia were then measured in ImageJ1.54p (http://imagej.org, accessed on 21 January 2026) [26] via a standardized method based on the Pythagorean Theorem, in which cilia length was based on the equation L2 = z2 + c2, in which “c” is the longest flat length measured of the z slices, and “z” is the number of z slices in which the measured cilia were present, multiplied by the z-stack interval (0.5 μm).
Phospho-Histone H3 [pSer10] rabbit polyclonal antibody (H0412) from Sigma (Saint Louis, MI, USA) was used to label mitotic cells. To calculate the mitotic rate, we counted the number of mitotic cells (phospho-H3 positive) and divided it by the total number of cells (DAPI positive). Mitotic rates of medulloblastoma cells treated with small-molecule inhibitors were compared with the DMSO control.
2.3. Drug Treatment and Crystal Violet Assay for Cell Viability
Alvocidib (Cat# S2679) and Alisertib (Cat# S1133) were purchased from Selleckchem (Houston, TX, USA) and dissolved in DMSO at 10 mM. Cancer cells were incubated with medium containing 100 nM Alvocidib and 1 µM Alisertib to ensure full inhibition of CILK1 and AURKA, respectively [27,28]. Three days after drug treatment, floating/dead cells were removed with medium, and adherent/live cells left on the plates were stained with crystal violet dye (Cat# C6158) from Millipore Sigma (Burlington, MA, USA). After extensive rinses, cells were lysed, and dyes in the lysis buffer were quantified by spectrophotometer [29].
2.4. Statistical Analysis
ANOVA tests were used to analyze experimental data between pairs of group means, with a p-value of less than 0.05 considered significant. When ANOVA tests deemed the data to be significant, post hoc Tukey HSD tests were conducted to compare group means and determine the significance of all possible experiment group pairings. This analysis was performed with alpha values of both 0.05 and 0.01. Two-tailed Student’s t tests were used to compare the means of two groups. For the t test, p-values less than 0.05 were considered significant.
3. Results
Our main objectives in this study were two-fold. From this novel LLM-integrated web scraper, we wanted to identify the best popular large language model for conducting efficient and accurate literature reviews and identify drugs that can increase the ciliation rate and decrease the proliferation rate of cancer cells. The study was conducted in a series of steps: 1. We used LLM-integrated literature review tools to perform a comprehensive sweep of existing related publications, running the scraping and processing program once with each of the models being tested; 2. we compared the results of each model to the results produced by experts in the field regarding those same articles to acquire metrics; 3. from model results and expert recommendations, we selected the top drugs that show the most promise in promoting ciliogenesis; 4. we validated the effects of such drugs on cilia length and ciliation rates in cancer cells; and 5. we evaluated the impacts of such drugs, both individually and in combination, on cancer cell replication.
3.1. An Intelligent Literature Search by LLM-Integrated Scraper
Due to the extensive literature on scientific databases, it is challenging to execute a wide search that can encompass all the potential articles related to promoting ciliogenesis manually. Parsing through articles by hand is draining, incomprehensive, and slow, and severely limits the scope of the drugs that can be discovered. To combat such an issue, we developed a PubMed scraper that we built around the Beautiful Soup package in Python 3.14.2 and integrated the GPT 4 Turbo, Gemini 1.5 Pro, or Claude 3.5 Haiku APIs to query specific articles. The scraper operated in two distinct phases: 1. Find all relevant articles on the PubMed database using the user-provided keyword parameters; and 2. answer predefined questions using an integrated large language model (Figure 1).
The first step involved optimizing the keyword search, which was achieved by testing different combinations of related terms such as “ciliogenesis”, “drug”, or “lengthen”. The flexibility of adjusting the keywords, as well as where they show up, such as in the abstract, title, or MeSH terms, gave us multiple combinations to test, after each of which we analyzed the relatedness of the resulting articles to narrow or broaden our search as necessary. For example, if our keyword test run mainly returned articles only loosely tied to the subject (such as drugs for other organelles), we added more parameters to narrow down the results. Conversely, if only a few articles were returned in total, we knew to take away some of the requirements or adjust the logic. Ultimately, we opted for generally broader search terms, as we would much rather have unrelated articles that we can manually process after the scraper runs than have related articles that are never returned due to the specificity of terms (Figure 1). We also ensured that variations in words were considered (i.e., inhibits, inhibited, and inhibiting). For each article the scraper found, all of the basic information, such as the publication date, authors, and abstract, was saved. This initial step of extracting articles via keyword search served as a preliminary filter to create a smaller subgroup of related articles, since running the large language model on the entire PubMed database would be unfeasible and a waste of resources.
The second step was to use the integrated large language models to answer questions about each of the articles chosen by the initial keyword search. The specific questions we asked were, “What is the name of the drug?”, “What is the target of the drug?”, and “What effect(s) does the drug have on the target and primary cilia?”. For each article, the program first uses the headers to identify the abstract and results sections, as these were the only two sections we passed into the models for inquiry. Most of the information we sought was contained in these sections, so querying the entire article would give diminishing returns in terms of benefit to the added runtime ratio. So, the abstract and results sections were fed in as context for the model, as well as the three questions for the model to generate responses on. Through this method, the scraper automatically generated answers for each paper. Each article from the initial keyword-selected group, along with its basic information and answers to the questions provided by the LLM, was automatically converted to an organized Excel table format accessible immediately after the scraper finished running (Figure 1). Every row was a different article, and the columns denoted everything from the basic information about each paper to the LLM-generated answers. After optimizing the search terms, our ultimate scraper runs returned initial groups of 212 articles and took an average of five minutes to process those articles and return the Excel files. While conducting the search, we ensured that all privacy policies were adhered to. Excluded from the search were preprints and retracted articles, leaving only open-access publications accessible on PubMed.
3.2. Gemini 1.5 Pro Achieved the Highest Metrics and Was Identified as the Best-Performing Model
For the purpose of comparing the quality of each of the model responses, we proceeded to perform an expert-conducted manual review of the same set of articles, answering the same questions as the ones provided to the models. This process was performed independently of any model runs, and the experts did not have access to any of the model results. After completing the manual processing, we compared the expert results to each of the model results, recording true positive (TP), true negative (TN), false positive (FP), and false negative (FN) numbers accordingly. In order to be considered a true positive, the model had to have answered each of the questions correctly, including the accurate identification of the drug, the target, and the effect of the drug on cilia. A true negative occurred when both the expert and the model could not find a valid set of drug, target, and effect on cilia. A false positive occurred when the expert did not identify a valid set in the article, but the model did. A false negative occurred when the expert found a valid set in the article, but the model did not. If both the manual review and the model returned a response set, but the response from the model was incorrect, we logged both a false positive and a false negative. Using these data, we calculated accuracy, precision, recall, and F1 scores for each model. In the end, Gemini outperformed the other models in every metric (Table 2). We observed the largest differences in the recall scores, meaning that Gemini did comparatively well when it came to minimizing false negatives. The second-best model was GPT, which had roughly the same precision as Claude but a higher recall.
3.3. Alvocidib and Alisertib Identified as Promising Cilia-Promoting Drugs
The experts browsed through the answers provided by the LLM to the previously listed questions and looked specifically for drugs that targeted different pathways controlling cilia assembly or disassembly. For the drugs that showed the most promise (Table 3), we manually processed the article to ensure that all summarization information was accurate. Due to the limited time and scope for this project, we only selected two representative drugs based on their effects, well-established mechanisms of action, and the FDA-approval status (Figure 2). We chose Alvocidib, a cancer drug known to target cyclin-dependent kinases that regulate the cell cycle at high µM concentrations [30]. Such a high concentration of Alvocidib was toxic and caused strong side effects in clinical trials. However, Alvocidib instead targets a protein kinase called CILK1 (ciliogenesis-associated kinase 1) at lower nM concentrations to elongate primary cilia [27]. Recently, we have shown that the ciliary scaffold protein KATNIP (Katanin-interacting protein) can stabilize and facilitate activation of CILK1 to control ciliogenesis [31]. We propose that KATNIP-CILK1-Katanin is a new signaling axis to promote Katanin-mediated microtubule severing and cilia disassembly [31]. We also picked Alisertib, a cancer drug that targets AURKA (Aurora Kinase A) and has been shown to induce an increase in the ciliation rate [32]. AURKA phosphorylates and activates HDAC6 (histone deacetylase 6) to deacetylate tubulin and increase microtubule instability, leading to cilia disassembly [33]. Thus, inhibition of these two cilia disassembly pathways in cancer cells has the potential to impede cell proliferation by restoring or enhancing the ciliary control of the cell cycle.
3.4. Impact of Alvocidib and Alisertib on Primary Cilia of Medulloblastoma Cells
The papers that were associated with each drug (Alvocidib and Alisertib) showed that they statistically significantly increased ciliogenesis. However, such studies were performed on non-cancerous cells, so we needed to validate those effects on the primary cilia of cancer cells. CILK1 and AURKA are both negative regulators of ciliogenesis and can be fully inhibited by Alvocidib (100 nM) and Alisertib (1 µM), respectively. We treated DAOY medulloblastoma cells with either Alvocidib, Alisertib, or DMSO (solvent control) for 16 h and then fixed, permeabilized, and immunolabelled cells for Arl13b, the primary cilia marker, and ϒ-tubulin, the basal body marker (Figure 2A). We acquired z-stack images using a confocal immunofluorescence microscope and measured ciliation rate (Figure 2B) and cilia length (Figure 2C) using ImageJ. Compared to the DMSO control, Alvocidib induced a statistically significant increase in ciliation rate and cilia length, and Alisertib induced a statistically significant increase in cilia length (Figure 2). We conclude that both Alvocidib and Alisertib can promote the ciliation rate of medulloblastoma cells.
3.5. Alvocidib and Alisertib Significantly Reduce the Replication of Medulloblastoma Cells
To evaluate the effect of Alvocidib and Alisertib on medulloblastoma cells, we treated the medulloblastoma cell line DAOY with DMSO (solvent control), Alvocidib, or Alisertib. Given the possibility that CILK1 and AURKA may drive two parallel cilia disassembly pathways, we also included an additional treatment, the combination of Alvocidib and Alisertib, to test potential additive or synergistic effects of inhibiting both CILK1 and AURKA. We applied the inhibitors to fast-replicating medulloblastoma cells when the cell density reached about 50–60% confluency. After 3 days of treatment, we performed a crystal violet dye-based cell viability assay to determine the drug effects (Figure 3A). Our findings indicate that relative to DMSO control, Alvocidib induced a 40% decrease in the total cell number, Alisertib induced a 20% decrease, and their combination induced a 60% decrease (Figure 3B). These data show that Alvocidib and Alisertib significantly decrease the number of replicating medulloblastoma cells.
To examine if the decrease in viable cell counts is due to changes in cell cycle, we fixed and permeabilized medulloblastoma cells and immuno-stained a reliable mitotic marker, phospho-Histone H3, around 24 h after drug treatment (Figure 4A–C). We observed mitotic cells, such as metaphase and anaphase, shown in Figure 4A. Quantification of the percentages of mitotic cells revealed that Alvocidib and Alisertib, either individually or in combination, caused a statistically significant decrease in mitosis of medulloblastoma cells relative to the DMSO control (Figure 4D). Dual inhibition produced a modest additive effect on the mitotic rate (Figure 4D), similar to their additive effect on the viable cell counts (Figure 3B). These data together support the hypothesis that cilia-promoting drugs decelerate medulloblastoma cell replication.
4. Discussion
Our study results show that the drugs discovered by this method of LLM-integrated web scraping, Alvocidib and Alisertib, can significantly promote ciliogenesis and reduce the replication of medulloblastoma cells. Under a microscope, we observed a very small number of floating dead cells after drug treatment, indicating that these drugs served primarily to hinder the cell cycle and cell replication rather than to cause massive cell death. This corroborates the mechanism of primary cilia described in the introduction as a key structural checkpoint to cell cycle and replication. Given the goal of our wet bench work in this study is to provide proof-of-principle, we focused our tests on Alvocidib and Alisertib in medulloblastoma cells because we were able to determine the effectiveness of these two drugs to promote ciliogenesis of DAOY medulloblastoma cells. Although our data are promising, more research must be carried out to determine the applicability of different cilia drug combinations to many other types of cancers, both in vitro and in vivo. For example, although Alvocidib and Alisertib can reduce replication of MCF-7 and MDA-MB-231 breast cancer cells (Figure S1), the extent of their effects in these two breast cancer cell lines varied greatly. They also failed to produce any additive effect in both breast cancer cell lines, in contrast to DAOY medulloblastoma cells (Figure 3) and A549 lung adenocarcinoma cells (Figure S1). It is worth pointing out that the assembly and disassembly of primary cilia, coupled with cell cycles, are intricate and highly regulated processes [46]. There is a significant gap in our knowledge of the molecular mechanisms by which cancer cells disable the ciliary control of cell cycles. Therefore, it would be imperative to better understand the underlying pathways and mechanisms of action of these cilia-promoting drugs in different cancer cell contexts, providing the molecular basis to expand on their applications.
One possible concern for the application of cilia-promoting drugs is their cytotoxicity on non-cancerous cells. We thus tested the effects of Alvocidib and Alisertib on non-cancerous HEK293 human embryonic kidney cells (Figure S2). The effect of Alvocidib compared with the DMSO control is not statistically significant. Alisertib and the combination of Alisertib and Alvocidib produced only a modest reduction (10–20%) in the total viable cell counts. These preliminary results suggest slight cytotoxicity of these two drugs on normal cells. To minimize the concern for off-target cytotoxic effects on normal cells, we will explore targeted delivery and controlled release of cilia-promoting drugs to cancer cells in our future in vivo studies.
Our findings also underscore the strong potential of integrating artificial intelligence-assisted scrapers into literature review and biomedical research, though further studies must be conducted to support more widespread positive LLM performance. In addition to providing accurate answers to the questions posed by the user that enabled identification of the drugs to promote ciliogenesis, the LLM-backed scraper performed those tasks at rapid speeds. The scraper parsed through the 212 articles it located in just over 5 min, meaning that in less than a second, an article had its basic information extracted, it was parsed thoroughly by the LLM to locate answers to user questions, and then that answer was generated and saved to the Excel sheet. Moreover, due to the nature of those specific answers being pre-generated when we opened the Excel sheet, it only took a couple of hours to identify those top drugs and complete the literature review process. By contrast, a manual review process would require one to click into each individual article and then parse the article for relevant information. Oftentimes, one must go beyond the abstract to find some of the finer details necessary for the search. Compounded with breaks and inconsistencies, this process could easily take days or even weeks. Our proposed method drastically reduces this time with minimal sacrifices to quality.
Additionally, our approach is very versatile in terms of applying to various other areas of study. This is due to our overarching framework’s flexibility of using a keyword search-centered web scraper to select a subset of research and then ask questions to synthesize article information. Within this process, there are two major places where adjustments can be made to alter the content of the literature search. The first is the set of keywords and logic used to conduct the initial filtration of articles, determining which field the literature search is being performed in. Furthermore, there is much flexibility in this step regarding the specificity of the keywords chosen. Fewer keywords and logic will lend themselves to a broader search that encompasses more articles, while more keywords with stricter logic will return fewer and more specific papers. The second place in the process is the selection of questions given to the LLM for the analysis of the keyword-selected articles. Questions can range from summarizing the paper to finding a very specific attribute of the study that the reviewer is looking for.
Despite the significant enhancement in speed, the LLM-integrated literature search aspect of our study also has certain limitations. As stated previously, the manual selection of keywords and questions dictates the results that are returned. In our study, professionals in the field validated the keywords used for the initial search and the questions that were used by the LLM for the detailed processing step. Even then, we had to perform several searches and compare the results to judge the best combination of keywords and questions. This manual trial-and-error process for the literature search means that there is no guarantee that the specific keywords and questions—as well as the number of keywords and questions we used—are optimized. This lack of objectivity and heavy reliance on human input introduces bias into the process, enabling the possible omission of relevant studies. One alternative is to use generative artificial intelligence methods to create optimal Boolean searches, but the current state of those methods is very imperfect. A recent study conducted by Wang et al. [47] prompted ChatGPT to generate Boolean searches based on a field of interest. Though certain results were promising, the team also experienced many instances of nonexistent MeSH terms, as well as inconsistencies between different executions of the same prompt. Adam et al. [48] sought to expand upon these results by training models with large amounts of relevant data, but they concluded that the results were still too inconsistent to implement without manual verification. Conversely, an older but generally more consistent method involves some form of word or phrase tokenization and subsequently training a neural network on that data [49]. Such an example includes a model that takes a word and quantifies whether or not that word would be beneficial to expanding a query. This could be especially helpful for optimizing query length. Thus, in future studies, we hope to automate this segment of the process with the aforementioned artificial intelligence or machine learning-based solutions that operate consistently, giving us the maximum amount of confidence that the results and answers produced are the best suited for that specific literature search scenario. An example of such an implementation could include automatically assigning resulting articles a score based on word and phrase relevancy, and having a model optimize that score by experimenting with various keyword combinations.
Another aspect that shows much room for improvement is the answers generated by LLMs when processing the articles. The overall solid metrics show much potential for these models, and it must be noted that these scores are considerably more difficult to achieve than a simple classification task, because the responses to all three questions must be accurate to count. Many of the false positive cases by the model were due to mislabeling non-drugs as drugs, since, in context, they may have seemed to take on the role of a drug. In other cases, the models falsely identified drug–target combinations that were invalid because the drug did not directly affect the target. Most of the false negative cases were due to the limited scope of the models, and especially due to a decreasing accuracy in the middle of long texts. As such, there is still room for improvement in terms of identifying this information when it is contained deep within a text’s body. Other minor errors included the accidental switching of drug and target when converting to the Excel sheet or failing to directly relate the consequences of the drug–target combination on cilia. Thus, a human professional is still crucial to ensuring the validity of articles and drugs.
5. Conclusions
Our study demonstrated how to use an intelligent language system to conduct a fast and comprehensive literature search for effective cilia-promoting drugs. We validated that two such drugs, small-molecule inhibitors for CILK1 and AURKA, achieved the desired goal of increasing ciliation and reducing replication of medulloblastoma cells. Our findings implicated a strong potential of cilia-promoting drugs in cancer therapy. A major challenge to our future investigations is to determine the optimal drug combinations for restoring or enhancing ciliation in each specific type of cancer and to minimize off-target cytotoxicity on normal cells. Such findings also highlight the incredible potential of these newly emerging and widely accessible large language models to conduct fast and accurate literature searches. However, further research must be conducted to confirm applications in other fields, improve upon the current shortcomings of LLMs, and find objective procedures to automate the optimization of keywords. Despite these areas for further improvement, this method of LLM-integrated literature scrapers presents significant potential for use as an assistive tool for biomedical research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fry A.M. Leaper M.J. Bayliss R. The primary cilium Organogenesis 201410626810.4161/org.2891024743231 PMC 7092719 · doi ↗ · pubmed ↗
- 2Singla V. Reiter J.F. The primary cilium as the cell’s antenna: Signaling at a sensory organelle Science 200631362963310.1126/science.112453416888132 · doi ↗ · pubmed ↗
- 3Malicki J.J. Johnson C.A. The Cilium: Cellular Antenna and Central Processing Unit Trends Cell Biol.20172712614010.1016/j.tcb.2016.08.00227634431 PMC 5278183 · doi ↗ · pubmed ↗
- 4Reiter J.F. Leroux M.R. Genes and molecular pathways underpinning ciliopathies Nat. Rev. Mol. Cell Biol.20171853354710.1038/nrm.2017.6028698599 PMC 5851292 · doi ↗ · pubmed ↗
- 5Badano J.L. Mitsuma N. Beales P.L. Katsanis N. The ciliopathies: An emerging class of human genetic disorders Annu. Rev. Genom. Hum. Genet.2006712514810.1146/annurev.genom.7.080505.11561016722803 · doi ↗ · pubmed ↗
- 6Plotnikova O.V. Pugacheva E.N. Golemis E.A. Primary Cilia and the Cell Cycle Methods Cell Biol.20099413716010.1016/S 0091-679X(08)94007-320362089 PMC 2852269 · doi ↗ · pubmed ↗
- 7Goto H. Inoko A. Inagaki M. Cell cycle progression by the repression of primary cilia formation in proliferating cells Cell. Mol. Life Sci.2013703893390510.1007/s 00018-013-1302-823475109 PMC 3781298 · doi ↗ · pubmed ↗
- 8Izawa I. Goto H. Kasahara K. Inagaki M. Current topics of functional links between primary cilia and cell cycle Cilia 201541210.1186/s 13630-015-0021-126719793 PMC 4696186 · doi ↗ · pubmed ↗