Maximizing Single-Feature Separability for Improving Transfer Learning in Motor Imagery EEG Decoding
Zefeng Xu, Zhuliang Yu

TL;DR
This paper introduces a new method called MSFS to improve brain-computer interfaces by enhancing transfer learning in motor imagery EEG decoding.
Contribution
The novel contribution is the MSFS regularization technique that improves subject-specific EEG decoding using within-dataset transfer learning.
Findings
MSFS consistently improves transfer learning performance across multiple datasets and neural network architectures.
MSFS remains effective even when the target subject has limited labeled data.
Ablation studies confirm the effectiveness of MSFS components.
Abstract
Background/Objectives: Motor imagery (MI) EEG-based brain–computer interfaces (BCIs) are promising for neurorehabilitation, but practical use is often hindered by time-consuming per-user calibration and performance instability across sessions/users. Methods: To mitigate this issue, we aim to improve subject-dependent MI classification by leveraging labeled training data from other subjects within the same dataset via transfer learning. We propose Maximizing Single-Feature Separability (MSFS), a lightweight plug-in regularization applied during target–subject fine-tuning. MSFS operates on the network feature layer and constructs batch-wise target positions by maximizing a silhouette-based separability criterion for each feature dimension. The target position computation is implemented in a fully vectorized GPU-friendly manner. Results: We evaluate MSFS on BCI Competition IV-2a and IV-2b…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
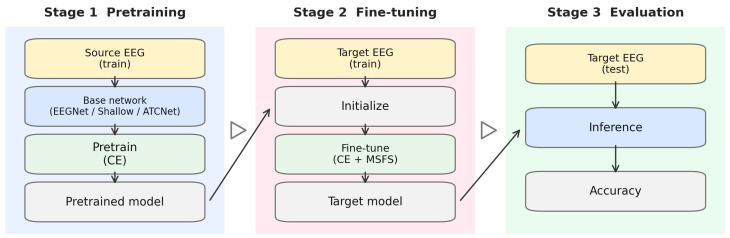 Figure 1
Figure 1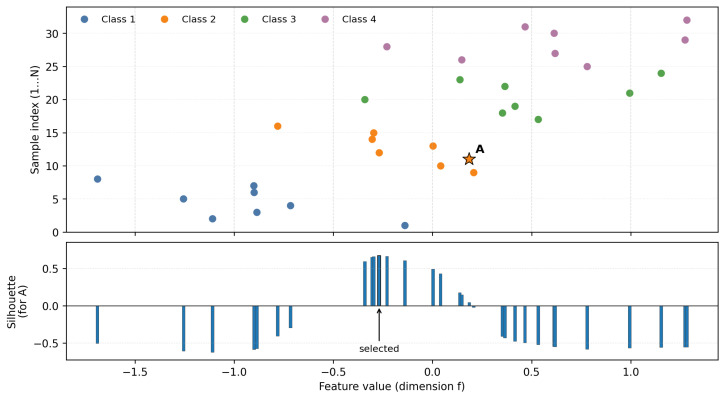 Figure 2
Figure 2- —Technology Innovation 2030
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEEG and Brain-Computer Interfaces · Epilepsy research and treatment · Functional Brain Connectivity Studies
1. Introduction
Brain–computer interfaces (BCIs) provide a direct pathway between neural activity and external devices, enabling communication and control without relying on peripheral nerves or muscles [1]. Among multiple BCI paradigms, electroencephalography (EEG)-based systems remain particularly attractive due to their noninvasiveness, portability, and high temporal resolution [2]. Motor imagery (MI) is one of the most widely studied EEG paradigms, where users voluntarily imagine limb movements (e.g., left/right hand) without actual movement execution. MI induces characteristic modulations of sensorimotor rhythms (SMRs), typically reflected by event-related desynchronization/synchronization (ERD/ERS) in the (8–13 Hz) and (13–30 Hz) bands over sensorimotor cortices [2,3]. From a neurophysiological perspective, MI engages neural substrates partially overlapping with motor preparation and action execution, which helps explain why rhythmic power changes and spatial topographies over the sensorimotor cortex carry discriminative information for decoding [3,4,5].
Traditional MI decoding commonly follows a “feature extraction + feature selection + classifier” pipeline. The Common Spatial Pattern (CSP) algorithm is a representative spatial filtering technique that learns linear projections maximizing the variance ratio between two classes, enhancing discriminative oscillatory components in sensorimotor channels [2,6]. To address the frequency-specific nature of MI and improve robustness, Filter Bank CSP (FBCSP) decomposes EEG into multiple sub-bands and applies CSP per band, followed by feature selection and classification [7]. Further variants such as probabilistic CSP (P-CSP) incorporate uncertainty modeling [8], while discriminative FBCSP attempts to optimize class separability more directly [9]. In practice, these CSP-based approaches often rely on additional steps such as selecting informative components using Fisher-type criteria [10] and applying linear classifiers (e.g., LDA) for final decision-making. Although effective, such pipelines are sensitive to preprocessing choices, stationarity assumptions, and inter-session/inter-subject shifts; moreover, they depend heavily on handcrafted features and may not capture complex spatiotemporal patterns in raw EEG [11,12].
Deep learning has increasingly become a dominant approach in EEG/MI decoding because it can learn hierarchical representations directly from raw or minimally preprocessed signals, reducing reliance on handcrafted features [13,14,15,16,17,18]. EEGNet [13] is a compact convolutional neural network (CNN) designed for EEG decoding that combines 1D convolutions (acting as learnable band-pass filters) with depthwise spatial convolutions (acting as data-driven spatial filters), followed by separable convolutions for efficient feature mixing. ShallowConvNet [14] and subsequent refinements [19] mimic elements of classical band-power pipelines by using temporal filtering and nonlinear transformations (e.g., squaring/log) but remain fully end-to-end trainable, yielding strong performance with modest parameter counts. Ingolfsson et al. [20] introduced the Temporal Convolutional Network (TCNet) by incorporating temporal convolution layers into the EEGNet framework. Musallam et al. [21] further refined TCNet by introducing architectural and optimization improvements, enabling high classification accuracy across subjects using a single set of hyperparameters. Motivated by the success of self-attention in sequence modeling [22], Transformer-style components have also been explored in EEG decoding to capture global dependencies beyond local convolutional receptive fields [23,24]. For example, EEG Conformer combines convolutional front-ends with self-attention modules and reports strong performance with additional interpretability via activation/topography visualization [25]. For MI specifically, CTNet has been proposed to jointly learn local spatiotemporal features and global dependencies, showing competitive results in both subject-specific and cross-subject evaluations [26]. ATCNet incorporates attention mechanisms and a sliding-window strategy into TCNet to strengthen temporal modeling and inter-channel dependency learning, achieving competitive results across MI benchmarks [27].
Despite progress, reliable MI classification remains challenging in realistic settings. A key challenge is limited labeled data: collecting high-quality MI EEG requires time-consuming sessions, and subjects often experience fatigue and reduced attention, leading to small numbers of usable trials per class [2,4]. This small-sample regime is further complicated by pronounced nonstationarity across sessions and substantial inter-subject variability caused by differences in anatomy, cognitive strategies, electrode placement, and signal-to-noise ratios [28,29]. As a result, models trained on one subject/session may generalize poorly to another, and deep networks are particularly prone to overfitting when fine-tuned with few target trials. Reducing the dependence on extensive per-subject calibration while maintaining high accuracy has therefore become an important research direction, motivating transfer learning (TL), domain adaptation (DA), and other cross-subject learning strategies [29,30,31,32,33].
Transfer learning aims to leverage knowledge learned from source subjects/sessions to improve performance on a target subject, especially when target samples are scarce. A common and effective strategy in deep learning is “pretraining + fine-tuning”: the network is first pretrained on pooled data from other datasets to learn generalizable representations, then adapted to the target subject via fine-tuning. However, naïve fine-tuning may still overfit to limited target trials and may amplify subject-specific noise, calling for regularization and alignment mechanisms.
Alignment-based methods attempt to reduce distribution mismatch between subjects. Euclidean-space alignment (EA) estimates an alignment transform using second-order statistics so that EEG trials from different subjects are mapped into a more consistent feature space before classification [30]. More generally, Riemannian geometry-based approaches represent EEG trials as symmetric positive definite (SPD) covariance matrices and perform learning or alignment on the SPD manifold, often exhibiting strong robustness to noise and variability [32,34]. In particular, Riemannian Procrustes Analysis (RPA) aligns covariance distributions across subjects/sessions via geometric transforms, enabling effective transfer with reduced calibration [31]. Recent extensions also align subjects in tangent space or combine alignment with end-to-end deep learning, reflecting a broader trend toward geometry-aware transfer [35,36].
Another line of work draws from general domain adaptation in machine learning, where the goal is to learn representations that are both discriminative for labels and invariant across domains [37]. Adversarial DA methods (e.g., DANN) introduce a domain discriminator and a gradient reversal mechanism to encourage domain-invariant features [38]. Moment-matching approaches reduce distribution discrepancies using statistics such as maximum mean discrepancy (MMD) or deep correlation alignment (Deep CORAL) [35]. These generic DA principles have inspired EEG/MI transfer designs and provide a useful conceptual framework for understanding why cross-subject generalization often fails: the model may learn features that separate classes well in the source subjects but still encode subject identity.
Beyond alignment/DA, several strategies specifically target small-sample overfitting during fine-tuning. These include importance reweighting to correct distributional mismatch [39], stochastic regularization objectives in transfer settings [40], freezing or selectively adapting subsets of parameters/layers for MI-specific transfer [41], meta-learning approaches that learn initialization/updates that adapt quickly with few target trials [42], and augmentation-driven auxiliary objectives to improve robustness [43]. Nevertheless, in practical MI decoding, there remains a need for simple, architecture-agnostic mechanisms that can stabilize fine-tuning and preserve discriminative representations under limited target data.
In rehabilitation-oriented MI-BCI training, models must adapt from brief calibration and remain stable across repeated sessions to support reliable feedback, motivating transfer learning strategies that are robust in the low-calibration regime. In this work, we propose a transfer learning strategy named Maximizing Single-Feature Separability (MSFS) for subject-dependent MI EEG classification. Our hypothesis is that, in a trained network, the feature layer (i.e., the representation immediately before the final classifier) contains a subset of individual feature dimensions that already exhibit meaningful class separability. During fine-tuning with scarce target trials, however, non-discriminative features may spuriously correlate with each other and begin to contribute to the classifier, which might be an indicator of overfitting. To counteract this drift, MSFS introduces an auxiliary objective that explicitly encourages each individual feature dimension to remain discriminative with respect to the classes.
Specifically, we use the silhouette coefficient—a classical cluster separability measure [44]—to quantify how well samples of different classes separate along each feature. During fine-tuning, we compute feature-wise target positions that maximize silhouette separability within each batch and impose a regression-style constraint that pulls features toward these optimal positions. Because the target positions depend on the batch composition, shuffling data each epoch naturally yields a stochastic auxiliary objective, acting as regularization and reducing the risk of memorizing idiosyncratic target–subject noise. Importantly, MSFS is model-agnostic and can be integrated into representative MI networks without modifying their main architectures, which facilitates its use in practical MI-BCI pipelines where calibration time and robustness are key considerations.
The main contributions of this work are summarized as follows:
- 1.Intra-dataset transfer learning for low-calibration MI-BCI: We leverage data from other subjects within the same dataset to improve target–subject classification without introducing external datasets, thereby mitigating the few-sample calibration problem commonly encountered in practical MI-BCI use.
- 2.Feature-level discriminability enhancement: We employ the Silhouette coefficient to quantify class separability of each learned feature dimension and introduce an auxiliary objective that preserves single-feature discriminability during fine-tuning, improving accuracy and robustness under limited target trials.
- 3.Stochastic auxiliary regularization to reduce overfitting: By computing batch-dependent optimal feature targets, random shuffling induces a stochastic auxiliary objective across iterations, regularizing adaptation and reducing sensitivity to idiosyncratic training-set noise, which is important for stable performance across sessions.
The remainder of this paper is organized as follows. Section 2 provides a detailed description of the proposed MSFS architecture. Section 3 presents the experimental results, including performance comparison against models from the literature and an ablation analysis to evaluate the contribution of each proposed enhancement. Section 4 analyzes the experimental results. Finally, Section 5 concludes the paper and discusses potential directions for future work.
2. Methods
2.1. Problem Definition and Notation
We consider an EEG MI classification task with K classes. For each trial, the input EEG segment is denoted as
where C is the number of channels and T is the number of time points. The corresponding label is .
A neural network is decomposed into a feature extractor and a classifier head . For a batch , the feature vector and logits are
and the predicted class probabilities are .
2.2. Datasets and Input Construction
We evaluate MSFS on the BCI Competition IV datasets 2a and 2b [24].
BCI IV-2a contains EEG from 22 channels and nine subjects. Each subject has two sessions (training and testing), each with 288 trials. Signals are sampled at 250 Hz and processed with a 0.5–100 Hz band-pass filter. The MI task includes four classes (left hand, right hand, foot, tongue).BCI IV-2b contains EEG from three channels and nine subjects. Each subject has five sessions. Sessions 1–2 are recorded with feedback, and sessions 3–5 are recorded without feedback. We use sessions 1–3 for training and sessions 4–5 for testing. Signals are sampled at 250 Hz and processed with a 0.5–100 Hz band-pass filter. The task includes two classes (left vs. right hand).
We perform no additional preprocessing and no data augmentation to keep the pipeline end-to-end and consistent with prior deep MI decoding practices (e.g., ATCNet). Each trial is obtained by directly cropping the raw EEG around the cue onset, using a 4.5 s segment including 0.5 s before and 4 s after the cue, resulting in samples per trial at 250 Hz. The cropped trials are fed into networks as input tensors.
2.3. Base Networks
We adopt three representative deep MI classifiers: EEGNet [13], ShallowConvNet [14], and ATCNet [27]. For EEGNet and ShallowConvNet, we follow the original architectures and hyperparameters reported in their respective papers. For ATCNet, we also follow the original design and additionally clarify the decision strategy used in this work: ATCNet has a sliding-window module and multiple parallel branches. Let denote the logit of branch b. The final output logit is computed by averaging branch logits:
In EEGNet and ShallowConvNet, the feature layer refers to the layer immediately preceding the final dense layer that outputs logits (i.e., the input of the final dense layer). In ATCNet, which contains multiple branches, each branch produces a logit; the feature layer refers to the layer immediately preceding the final dense layer within each branch.
2.4. Transfer Learning Protocol and Hyperparameter Selection
We use the following transfer setting: for each target subject, we pretrain the model on all other subjects (source subjects) and then fine-tune on the target subject. The overall pipeline is shown in Figure 1.
Pretraining stage: The model is trained on pooled data from all source subjects to learn a subject-independent initialization. Only cross-entropy (CE) loss is used in this stage.
Fine-tuning stage: The pretrained model is adapted using the target subject’s training data. In fine-tuning, MSFS is activated to regularize feature learning (Section 2.5).
All MSFS-related hyperparameters are selected using a leave-one-subject-out protocol on the training set. For each target subject, we randomly split the target subject’s available training trials within each class into two equal parts: one for fine-tuning training and the other for validation. Hyperparameters are chosen to maximize the mean validation accuracy averaged across all target subjects. The final reported test results are then obtained by training with the selected hyperparameters and evaluating on the predefined test set.
2.5. MSFS: Maximizing Single-Feature Separability During Fine-Tuning
2.5.1. Motivation and Overall Objective
During fine-tuning with limited target data, deep models may over-adapt and begin exploiting non-discriminative features. MSFS introduces a feature-level auxiliary objective that encourages every single feature to maintain class separability. Importantly, we do not apply MSFS from the beginning of fine-tuning because adding stochastic regularization too early can destabilize optimization; instead, MSFS is activated only after the model has reached a sufficiently low classification loss.
2.5.2. Silhouette-Based Target Positions and Feature Regression Loss
The standard cross-entropy loss is
For each batch, MSFS computes a batch-dependent target position matrix for the feature matrix , such that single-feature class separability (measured by the silhouette coefficient) is maximized. We use the absolute distance for one-dimensional feature values:
Following the silhouette definition [44], for each sample i, let be the mean intra-class distance and be the minimum mean inter-class distance, defined respectively as
where is the set of samples in class q, the silhouette score is
MSFS searches, for each , a candidate value among existing batch feature values and selects the candidate that maximizes the silhouette score under the condition that other samples are fixed. The selected candidate value becomes the target for the feature .
Figure 2 shows an example of target position selection in MSFS. The upper and lower panels share the same horizontal axis, which represents the feature value along feature dimension f. The upper panel is a scatter plot showing the feature values of N = 32 samples in a mini-batch, where we assume eight samples per class. The vertical axis indicates the sample indices. We seek a target position for sample A, which belongs to Class 2 and is highlighted by an orange star. Candidate target positions are given by the feature values of all samples in the current mini-batch. The lower panel presents a histogram of the silhouette score obtained when relocating A to each candidate position. As shown, candidates far from the Class 2 cluster yield low silhouette values, sometimes even negative, whereas candidates closer to the cluster center produce higher silhouette values. We select the candidate with the maximum silhouette score as the target position for A. The target positions of the remaining samples in the mini-batch are determined in the same manner.
Given the target matrix t, MSFS defines a mean squared error objective:
MSFS is activated only when the batch cross-entropy loss is below a threshold , yielding a hard-gated objective:
where controls the contribution of the MSFS loss.
When a batch contains any class with ≤1 samples, the silhouette computation for that class becomes ill-defined. In such cases, we skip MSFS for that batch and optimize only . This situation is rare in our experiments and has negligible impact on results.
2.5.3. Vectorized Computation and Complexity
The determination of target position is implemented in a fully vectorized manner across samples and features. In brief, for each feature dimension f, we compute the pairwise distance tensor
then aggregate within-class and between-class mean distances to compute silhouettes for all candidate replacements simultaneously, and finally take an over candidate indices j to obtain . This results in an approximate per-batch time complexity of
which is efficient in practice under GPU vectorization with typical batch sizes.
2.6. Algorithm Summary
Algorithm 1 summarizes the complete training procedure (pretraining + fine-tuning with gated MSFS). For each mini-batch during fine-tuning, a forward pass was performed to obtain both the logit and the intermediate feature representations. The function CE_Loss computes the cross-entropy loss between the predicted logit and the ground-truth label. If the obtained loss value was smaller than a predefined minimum threshold , the optimization process proceeded to the MSFS computation stage. The function Opt_Pos_Sil was employed to determine the optimal target feature positions for all samples within the batch. The mean squared error between the network features and , denoted as , was then calculated by the function MSE_Loss. Finally, model parameters were updated by backpropagation with respect to loss. Algorithm 1 Training with MSFS
-
- Input: number of subjects n, training data of all subjects D[1:n], training label of all subjects L[1:n], number of pre-training epochs , number of fine-tune epochs , batch size b, minimal loss , loss weight w
- Output: trained model of all subjects M
- 1: void list
- 2: for to n do
- 3: initial model
- 4: , ← training data and label of all subjects except from D and L
- 5: Pre-train with and for epochs
- 6: , ← training data and label of subject from D and L
- 7: DataLoader( , , batch_size = b, shuffle = True)
- 8: for to do
- 9: for , in do
- 10: , ← .forward( )
- 11: ← CE_Loss( , )
- 12: if < then
- 13: Opt_Pos_Sil( , )
- 14: MSE_Loss( , )
- 15: + *w
- 16: end if
- 17: Back propagate
- 18: end for
- 19: end for
- 20: Add to M
- 21: end for
- 22: return M
To promote training stability and prevent the network from converging toward a fixed feature configuration, the training data were randomly shuffled at the beginning of each epoch. This randomization ensures that the samples in each batch used by the Opt_Pos_Sil function vary across iterations, introducing stochasticity into the computed optimal positions and enhancing generalization.
Algorithm 2 provides the vectorized computation of the silhouette-based target positions (function Opt_Pos_Sil) used in MSFS. Algorithm 2 Function Opt_Pos_Sil
-
- Input: Feature matrix , label vector
- Output: Optimal position matrix
- 1: Compute pairwise distances
- 2: For each class c, compute mean distances
- 3: For each sample i, derive within-class means
- 4: For each sample i, obtain between-cluster distances
- 5: Compute silhouette values
- 6: For each , find
- 7: Assign optimal positions
- 8: return Opt
3. Experiments
3.1. Experimental Settings
We conduct experiments on the BCI Competition IV datasets 2a and 2b. For BCI IV-2a, we follow the official split by using the training session for model training and the testing session for evaluation. For BCI IV-2b, we adopt a commonly used session split: sessions 1–3 are used for training and sessions 4–5 are used for testing. In the evaluation of transfer learning, each subject is treated as the target subject, while the remaining subjects constitute the source domain. The model is first pretrained on the pooled source-subject data and then fine-tuned on the target subject’s training set. MSFS is applied only during the fine-tuning stage.
All backbones (EEGNet, ShallowConvNet, and ATCNet) are optimized using Adam (PyTorch 2.0, Python 3.9) with a fixed learning rate of 0.001 and weight decay of 0.009. The batch size is set to 64. To account for randomness in optimization, all results are reported as the average of three independent runs.
Hyperparameters are selected using training data only. Specifically, for each target subject, the target training trials are randomly split in a class-balanced manner into two equal parts: one part is used for fine-tuning training and the other for validation. Hyperparameters are determined by maximizing the mean validation accuracy averaged across target subjects. The final evaluation is performed once on the target test set using the selected hyperparameters. Performance is measured using classification accuracy.
Table 1 summarizes the hyperparameters used in the final experiments for each dataset–backbone combination, including the pretraining epochs ( ), fine-tuning epochs ( ), MSFS weight ( ), and the gating threshold ( ).
3.2. MSFS on Two Datasets and Three Backbones
In this section, we evaluate the effectiveness and generality of MSFS under the transfer learning setting on two MI datasets (BCI IV-2a and IV-2b) and three representative deep EEG classifiers (EEGNet, ShallowConvNet, and ATCNet). We compare the following training strategies:
- 1.Original: the model is trained only on the target subject’s training set, without using data from other subjects.
- 2.Standard transfer learning (TL, CE only): the model is pretrained on the pooled source subjects and then fine-tuned on the target subject using cross-entropy loss only.
- 3.TL + MSFS (ours): the same pretraining and fine-tuning procedure is used, while MSFS is additionally applied during fine-tuning.
All results are reported as mean accuracy and subject-level Wilcoxon p-values over three independent runs. Hyperparameters for each dataset–backbone pair are fixed as summarized in Table 1. The main results on BCI IV-2a and BCI IV-2b are presented in Table 2 and Table 3, respectively.
Overall, standard transfer learning consistently outperforms subject-dependent training, indicating the benefit of leveraging source-subject data for initialization. More importantly, TL + MSFS further improves performance over CE-only fine-tuning across different backbones on both datasets, demonstrating that MSFS provides a backbone-agnostic regularization effect that is beneficial for target–subject adaptation.
3.3. Comparison to Literature Models
To further position MSFS against representative transfer-learning and domain-adaptation approaches in the literature, we compare our method with the following baselines: EEGNet (without TL), Transfer Learning (EEGNet with Standard TL), EA (Euclidean Alignment) [30], Adaptive TL [41], MixDual-Tuning [43], Meta-learning [42], and DIW (Dynamic Importance Weighting) [39]. For a fair comparison, all methods use EEGNet as the backbone and are evaluated under the same transfer learning protocol on BCI IV-2a and BCI IV-2b. We select EEGNet for literature baselines because many prior TL or DA methods were originally reported with EEGNet, enabling a faithful reproduction under a unified pipeline.
All results reported in this section are obtained from our own reproductions under a unified training and evaluation pipeline (Section 3.1). For each target subject, the model is pretrained on source subjects and fine-tuned on the target subject. Hyperparameters are selected according to the original paper.
Table 4 and Table 5 report per-subject accuracies on IV-2a and IV-2b, respectively. The experimental results demonstrate that applying transfer learning notably improved classification performance compared to the original EEGNet, indicating that this framework can effectively increase classification accuracy across the dataset without introducing external data. The five methods—EA, DIW, Meta-Learning, Adaptive Transfer Learning, and MixDual-Tuning—when combined with standard transfer learning, did not achieve significant performance gains over standard transfer learning. Among them, only Adaptive Transfer Learning slightly outperformed the standard transfer learning baseline, suggesting limited improvement under the evaluated settings. In contrast, the proposed MSFS method achieved a substantial accuracy increase, raising the average classification accuracy from 0.7616 to 0.8184 for BCI IV-2a and moderate improvement for 2b, validating the effectiveness of the MSFS framework.
3.4. Ablation Studies
To validate the key design choices of MSFS, we conduct two ablation studies targeting (i) the effectiveness of the silhouette-based target position optimization and (ii) the necessity of the gated activation strategy.
3.4.1. Rand_Pos: Effect of Silhouette-Based Target Positions
In MSFS, the target position matrix t is determined by maximizing silhouette scores within each batch. To assess whether the improvement is indeed brought by the silhouette-driven optimization (rather than simply adding an auxiliary regression loss), we replace the optimized target positions with random target positions, referred to as Rand_Pos, which is presented in Algorithm 3. Rand_Pos uses the same loss form as MSFS, but removes the separability criterion. Algorithm 3 Function Rand_Pos
-
- Input: Feature matrix
- Output: Random position matrix
- 1: for each feature to F do
- 2: Compute ▹ Minimum value in feature f
- 3: Compute ▹ Maximum value in feature f
- 4: for each sample to N do
- 5: Draw uniformly from
- 6: end for
- 7:end for
- 8:return Opt
3.4.2. No-Gating: Effect of the Gated Activation
MSFS is designed to be activated only when the batch loss becomes sufficiently small. This gating is introduced to avoid injecting stochastic regularization at the beginning of fine-tuning, which may impair optimization stability. In the No-gating variant, we apply MSFS throughout fine-tuning (i.e., the MSFS term is always active), while keeping all other settings identical.
3.4.3. Results and Analysis
Table 6 summarizes the ablation results on both datasets (BCI IV-2a and IV-2b) and all three backbones. Overall, MSFS achieves the best performance across most dataset–backbone combinations, indicating that both components are important. Rand_Pos consistently underperforms MSFS, suggesting that maximizing silhouette score provides meaningful target positions that better preserve class separability at the feature level. No-gating tends to degrade performance compared with MSFS, supporting the hypothesis that enabling MSFS too early can disturb optimization and that the proposed gating strategy improves stability during fine-tuning.
It is also observed that even with random feature targets, the accuracy remained higher than that of standard transfer learning, suggesting that introducing stochastic guidance at the feature level can itself provide a beneficial regularization effect. This form of randomness is preserved in the proposed MSFS framework through the shuffling of training samples in each epoch of Algorithm 1, ensuring that every batch yields distinct feature–label pairings and thereby generating naturally varying values across iterations.
3.5. Few-Shot Target Data Study
In practical MI-BCI scenarios, only a limited amount of labeled data may be available for a new user. To evaluate the robustness of MSFS under scarce target supervision, we conduct a few-shot target-data study where the fine-tuning set of the target subject is subsampled at different labeled-data budgets.
For each target subject, we perform stratified sampling on the target training set by selecting 10%, 25%, 50%, and 100% of trials from each class, ensuring class balance at every budget level. For each budget, we compare:
- 1.TL (CE only): pretrain on source subjects and fine-tune on the subsampled target data using cross-entropy loss only.
- 2.TL + MSFS (ours): the same procedure, with MSFS additionally applied during fine-tuning.
All other settings follow Section 3.1. Table 7 summarizes the results on BCI IV-2a and IV-2b using the EEGNet backbone. In general, performance improves monotonically with more labeled target data for both methods. MSFS still provides large relative gains in the low-data regime (10% and 25%).
3.6. Efficiency
MSFS introduces an additional per-mini-batch computation to determine silhouette-optimized target positions and compute the auxiliary regression loss. To examine the practical overhead, we report the average training time per epoch for standard transfer learning (TL, CE-only) and TL with MSFS (TL+MSFS) across both datasets and all three backbones.
As summarized in Table 8, TL + MSFS incurs only a modest increase in per-epoch training time compared with TL. This is because the core routine of MSFS is implemented in a fully vectorized manner and is executed efficiently on the GPU. Overall, the results indicate that MSFS improves adaptation performance with moderate additional computational cost, making it easy to incorporate into real training pipelines. Timing was measured on an NVIDIA GeForce RTX 4090 GPU (batch size = 64).
Despite the modest overhead observed in our current setting, the exact MSFS computation scales with the number of feature dimensions and the batch size due to the pairwise distance terms in the 1D silhouette (approximately ). In practice, several approximations can substantially reduce this cost without changing the overall training pipeline. First, the silhouette target position for each feature can be estimated using candidate subsampling, i.e., evaluating the objective on a small set of values per class (randomly sampled from the batch), rather than enumerating all possible targets. Second, MSFS can be applied only to the top-K most informative feature dimensions, identified by separability statistics. These approximations provide a natural path to extend MSFS to larger batches and higher-dimensional representations while retaining its core objective of regularizing fine-tuning.
4. Discussion
This work proposed MSFS, a simple and architecture-agnostic feature-level regularization strategy for transfer learning in MI EEG classification. Across two public benchmarks (BCI IV-2a/2b) and three representative backbones (EEGNet, ShallowConvNet, and ATCNet), MSFS consistently improved the standard “pretrain + fine-tune” baseline, indicating that enforcing single-feature discriminability can stabilize target–subject adaptation under limited labeled data. On BCI IV-2a, the gain is especially pronounced for EEGNet (from 0.7616 to 0.8184 in mean accuracy), while improvements remain positive for ShallowConvNet and ATCNet. On BCI IV-2b, the absolute gains are smaller but still consistent across backbones, suggesting that MSFS remains beneficial even when baseline performance is already high. Such changes can still be meaningful in MI-BCI: small average improvements that are consistent across subjects may translate into noticeably reduced calibration effort and more reliable control for individual users. These observations support the central premise that fine-tuning on scarce target trials may introduce spurious feature co-adaptation, and that preserving per-dimension separability provides an effective regularization.
The ablation studies provide evidence that both components of MSFS contribute to performance. First, replacing silhouette-optimized targets with random targets (Rand_Pos) consistently reduces accuracy compared with MSFS on most dataset–backbone combinations, implying that the silhouette criterion is not merely injecting noise but is producing meaningful target directions that better preserve class structure at the feature level. Second, removing the loss-based activation gate (No-gating) typically degrades performance relative to MSFS, supporting the hypothesis that applying the auxiliary objective too early can interfere with optimization before the classifier becomes sufficiently discriminative. Notably, Rand_Pos can still remain competitive with (and sometimes close to) MSFS, which suggests that even stochastic feature-level guidance may yield a mild regularization benefit; MSFS retains this beneficial stochasticity while further steering it toward increased separability through silhouette maximization.
Although MSFS introduces additional computations for batch-wise target position estimation, the time-per-epoch measurements indicate only a modest overhead across both datasets and all three backbones. This is largely due to the fully vectorized implementation of the silhouette-based target computation, which is amenable to GPU acceleration. Therefore, MSFS offers a favorable trade-off: measurable accuracy improvements with limited additional training time, making it easy to incorporate into existing transfer learning pipelines.
Although the silhouette coefficient is typically used as a global clustering measure in multi-dimensional spaces, we use it as a per-feature (1D) discriminability proxy to regularize target-domain fine-tuning. From a representation learning perspective, this auxiliary objective can be viewed as a lightweight constraint that mitigates representation drift under scarce target supervision by encouraging a favorable trade-off between within-class compactness and between-class separation along individual feature dimensions. MSFS is not intended to replace joint-feature decision making: the standard cross-entropy loss still optimizes the classifier in the full feature space and captures multi-feature interactions, while MSFS provides a complementary regularization that helps preserve informative feature dimensions. MSFS may be less effective when discriminative information of the original model primarily arises from strong feature interactions.
In terms of online or adaptive MI-BCI deployment, MSFS in its current form is a supervised fine-tuning regularizer and thus relies on access to target labels. In practice, labels may be delayed or noisy. A straightforward way to accommodate delayed labels is to apply MSFS in buffered updates, where recent trials are accumulated, and the model is updated intermittently once labels become available. For noisy labels, MSFS could be applied by weighting the auxiliary objective using soft labels or uncertainty estimates (e.g., posterior variance from Bayesian approximations). Exploring these label-efficient and noise-robust extensions constitutes an important direction for future work.
Overall, the results suggest that preserving single-feature discriminability is a simple yet effective principle for stabilizing deep fine-tuning under target data scarcity. MSFS provides a lightweight plug-in regularization that improves transfer learning for MI EEG classification across multiple backbones and datasets.
5. Conclusions
This paper presented MSFS, a lightweight and architecture-agnostic regularization strategy for transfer learning in motor imagery EEG classification. MSFS augments standard TL pipelines by encouraging feature-level class separability during target–subject adaptation through a silhouette-driven target-position mechanism with a loss-based activation gate.
Extensive experiments on BCI Competition IV-2a and IV-2b with three representative backbones (EEGNet, ShallowConvNet, and ATCNet) demonstrate that MSFS consistently improves CE-only fine-tuning. Comparisons with reproduced literature baselines further confirm the competitiveness of MSFS under a unified EEGNet-based evaluation. Ablation studies validate the contributions of the silhouette-based target optimization and the gated activation, while the few-shot study indicates that MSFS is beneficial when only limited labeled target data are available. Finally, efficiency results show that the proposed vectorized implementation introduces only a modest computational overhead.
Overall, MSFS offers a plug-in module that strengthens target–subject adaptation with minimal additional cost, which may support more usable MI-BCI rehabilitation workflows by shortening calibration and improving reliability of feedback-driven training (e.g., cue-based neurofeedback or device-assisted therapy). The present study is scoped to within-dataset transfer, which limits the conclusions we can draw about MSFS under more challenging distribution shifts, such as cross-session variability, cross-hardware shifts, and cross-dataset transfer, where additional non-stationarities may be more pronounced. Future work will explore combining MSFS with alignment or self-supervised pretraining techniques and extending the evaluation to more challenging adaptation scenarios (e.g., cross-session and cross-dataset transfer).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wen D. Fan Y. Hsu S.H. Xu J. Zhou Y. Tao J. Lan X. Li F. Combining Brain–Computer Interface and Virtual Reality for Rehabilitation in Neurological Diseases: A Narrative Review Ann. Phys. Rehabil. Med.20216410140410.1016/j.rehab.2020.03.01532561504 · doi ↗ · pubmed ↗
- 2Pfurtscheller G. Neuper C. Motor Imagery and Direct Brain-Computer Communication Proc. IEEE 2001891123113410.1109/5.939829 · doi ↗
- 3Pfurtscheller G. Lopes Da Silva F. Event-Related EEG/MEG Synchronization and Desynchronization: Basic Principles Clin. Neurophysiol.19991101842185710.1016/S 1388-2457(99)00141-810576479 · doi ↗ · pubmed ↗
- 4Decety J. The Neurophysiological Basis of Motor Imagery Behav. Brain Res.199677455210.1016/0166-4328(95)00225-18762158 · doi ↗ · pubmed ↗
- 5Jeannerod M. The Representing Brain: Neural Correlates of Motor Intention and Imagery Behav. Brain Sci.19941718720210.1017/S 0140525 X 00034026 · doi ↗
- 6Ramoser H. Muller-Gerking J. Pfurtscheller G. Optimal Spatial Filtering of Single Trial EEG during Imagined Hand Movement IEEE Trans. Rehabil. Eng.2000844144610.1109/86.89594611204034 · doi ↗ · pubmed ↗
- 7Ang K.K. Chin Z.Y. Zhang H. Guan C. Filter Bank Common Spatial Pattern (FBCSP) in Brain-Computer Interface Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008 IEEE Piscataway, NJ, USA 20082390239710.1109/IJCNN.2008.4634130 · doi ↗
- 8Wu W. Chen Z. Gao X. Li Y. Brown E.N. Gao S. Probabilistic Common Spatial Patterns for Multichannel EEG Analysis IEEE Trans. Pattern Anal. Mach. Intell.20153763965310.1109/TPAMI.2014.233059826005228 PMC 4441303 · doi ↗ · pubmed ↗