Integrating Dynamic Representation and Multi-Priors for Transnasal Intubation via Visual Foundation Model
Jinyu Liu, Yang Zhou, Ruoyi Hao, Mingying Li, Yang Zhang, Hongliang Ren

TL;DR
This paper introduces Glottis-SAM, a new framework for accurate and efficient glottis localization during transnasal intubation using a visual foundation model.
Contribution
The novel contribution is the integration of dynamic representation learning and multi-prior modeling in a lightweight framework for medical image segmentation.
Findings
Glottis-SAM achieves 72.6% mDice segmentation accuracy on clinical data.
The model has a compact size of 55.2 MB and an inference speed of 44.3 FPS.
It outperforms existing methods in robustness and generalization across diverse anatomical conditions.
Abstract
Accurate and real-time glottis localization is critical for ensuring intraoperative oxygenation and patient safety during nasotracheal intubation. However, representative foundation models exemplified by the Segment Anything Model exhibit notable limitations in medical applications, stemming from their rigid attention mechanisms, feature space misalignment, and insufficient generalization to complex glottal anatomies. To address these challenges, we propose Glottis-SAM, a lightweight and task-adaptive segmentation framework that integrates dynamic representation learning with multi-prior contextual modeling. Specifically, we introduce a hierarchical low-rank adaptation strategy that enables efficient fine-tuning of visual foundation models by preserving geometric priors while significantly reducing computational overhead. To further enhance semantic fusion and generalization, we design…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
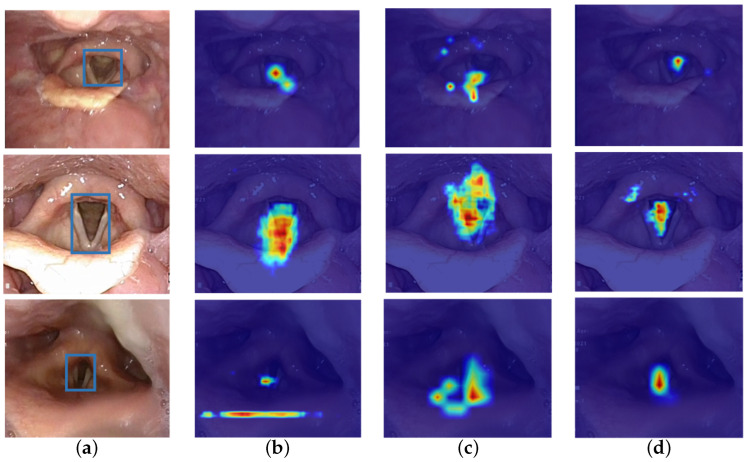 Figure 1
Figure 1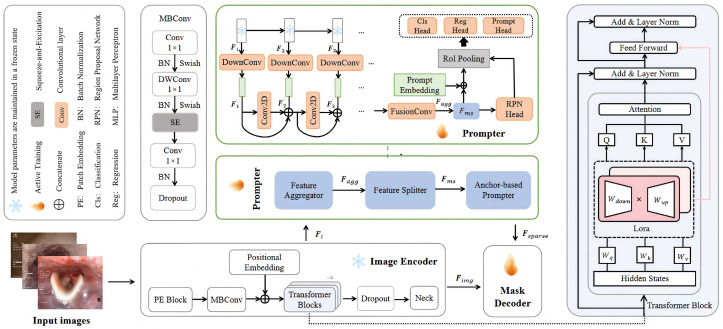 Figure 2
Figure 2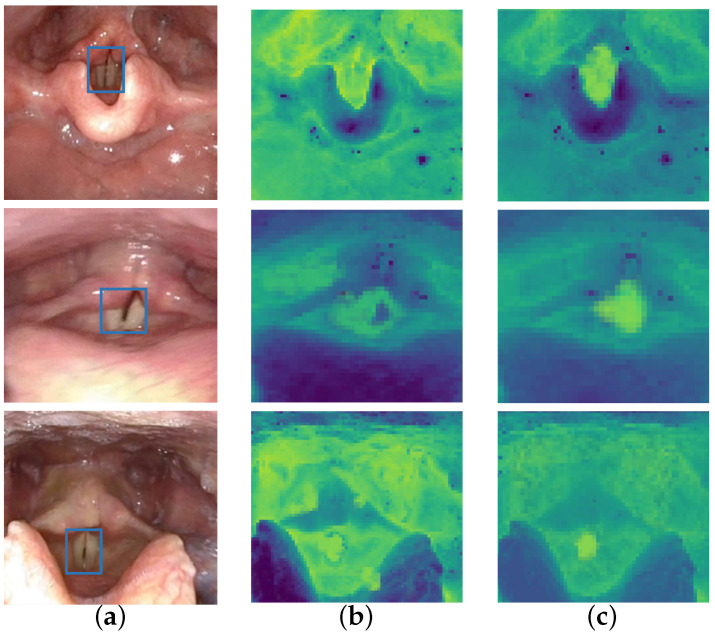 Figure 3
Figure 3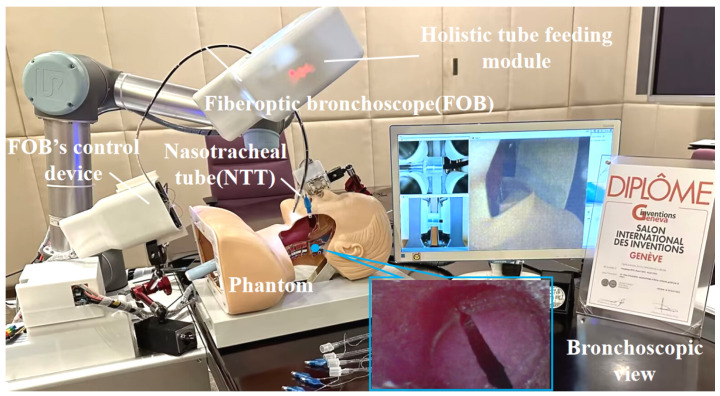 Figure 4
Figure 4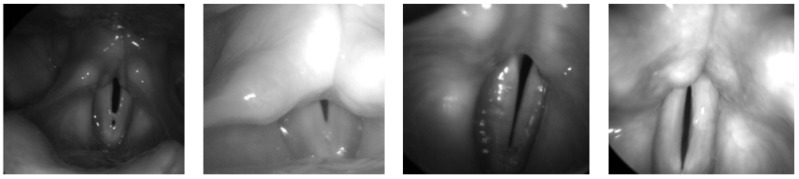 Figure 5
Figure 5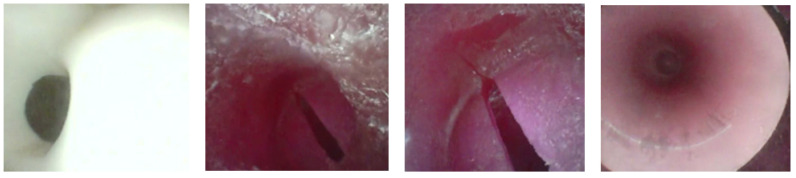 Figure 6
Figure 6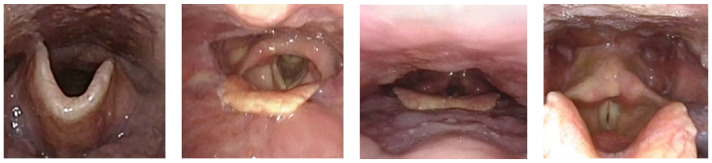 Figure 7
Figure 7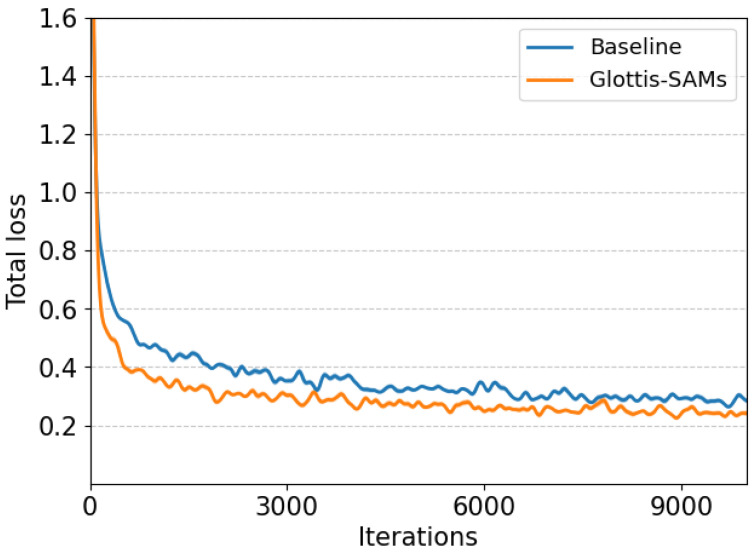 Figure 8
Figure 8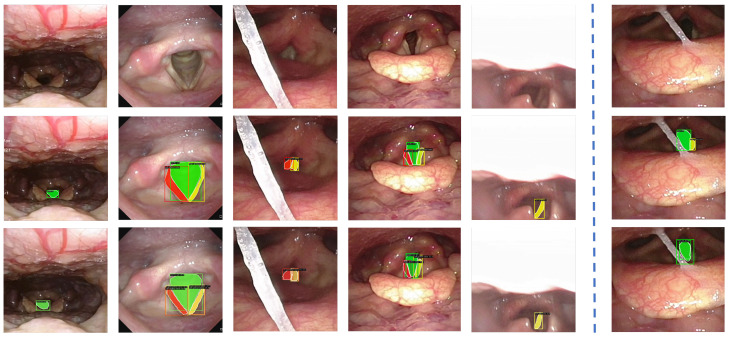 Figure 9
Figure 9- —National Natural Science Foundation of China
- —Natural Science Foundation of Hubei Province
- —Fundamental Research Funds for the Central Universities
- —Hong Kong Research Grants Council (RGC) Collaborative Research Fund
- —General Research Fund
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAirway Management and Intubation Techniques · Anesthesia and Sedative Agents · Multimodal Machine Learning Applications
1. Introduction
Medical image segmentation, as a core component of computer-aided diagnosis systems, plays a pivotal role in precisely characterizing anatomical structures and pathological features from multimodal medical images [1]. Among various clinical procedures, nasotracheal intubation (NTI) presents unique challenges for real-time anatomical localization. Inaccurate or delayed identification of the glottis during NTI can lead to severe complications, including hypoxemia, tracheal injury, and hemodynamic instability, especially in patients with difficult airways or in emergency settings [2]. Currently, clinical tracheal intubation is primarily performed by anesthesiologists, critical care physicians, or emergency clinicians using visual laryngoscopy [3]. The success of the procedure strongly depends on the operator’s experience and technical proficiency. To improve the accuracy, efficiency, and standardization of NTI, the integration of computer-aided diagnosis technologies and intelligent medical systems has emerged as a promising direction in clinical practice. Unlike conventional static segmentation tasks, NTI necessitates real-time localization of highly deformable and dynamic glottal structures under intricate clinical conditions. Key visual perturbations arise from motion-induced blur due to endoscopic movement, inconsistent illumination within confined anatomical cavities, and substantial inter-patient anatomical variability. These factors collectively impose stringent requirements on segmentation models, which must ensure not only high accuracy but also computational efficiency and robustness across diverse patient anatomies.
Traditional glottis segmentation methods [4] fundamentally rely on low-level image statistics. Due to the absence of anatomical semantics, they struggle to differentiate glottal boundaries from spatially adjacent structures, such as deformed vocal folds. CNN-based architectures have improved robustness through hierarchical feature learning; however, single-stage models typically compromise the accuracy of small targets to gain speed, while two-stage instance segmentation networks often lose edge details of large targets and introduce latency spikes, rendering them unsuitable for real-time NTI. Given these limitations, there is an urgent need for more robust and adaptable segmentation approaches that are capable of meeting the complex demands of clinical NTI scenarios. A recently proposed general-purpose vision segmentation foundation model, the Segment Anything Model (SAM) [5], has gained widespread recognition for its strong cross-object segmentation capability and zero-shot generalization performance. It can identify and segment objects based on user prompts, including points, bounding boxes, and coarse masks. Despite its success in natural image domains, SAM exhibits significant limitations in medical applications. The fundamental differences in imaging modalities, contrast distribution, and feature spaces often result in unstable segmentation across medical datasets [6]. Moreover, in vivo environments are characterized by weak boundaries, low contrast, and irregular structural deformations. Specifically, the dynamic opening and closing of the glottis varies dramatically in scale, which conflicts with SAM’s fixed-size window attention mechanism and hinders fine anatomical parsing.
As illustrated in Figure 1, SAM tends to produce spatially diffuse and structurally inconsistent attention maps when applied to glottic regions. In contrast, our proposed Glottis-SAM model produces more compact and precisely localized activation maps that better conform to the glottic region. Additionally, the default input resolution of SAM leads to excessive computational resource consumption, which exceeds the capacity of most endoscopic devices. These technical constraints, coupled with feature space misalignment, significantly hinder SAM’s direct clinical applicability and raise concerns regarding its deployment in real-time surgical scenarios.
In this paper, we present Glottis-SAM to transfer the exceptional segmentation performance and strong generalization ability of SAM to glottis image segmentation while reducing computational complexity. Our encoder effectively captures rich spatial contextual information to enable multi-scale context feature modeling. We propose a low-rank adaptation fine-tuning strategy, where learnable low-rank matrices are introduced to progressively adapt the hierarchical features of SAM while preserving its pretrained geometric priors and significantly reducing the number of trainable parameters compared to full fine-tuning. Furthermore, we design a feature aggregation module that dynamically calibrates feature responses via channel attention, establishes a continuous representation of spatial anatomical transformations, and promotes cross-layer feature complementarity. A dual-path dynamic feature pyramid is constructed to adaptively model multi-scale geometric features, incorporating multi-head collaboration under dynamic spatial constraints to achieve effective feature decoupling. Notably, comprehensive evaluations on the Glottis, Phantom, and Clinical datasets demonstrate that our model outperforms the state-of-the-art methods. The size of our tiny version model is only 55.2 MB. The primary contributions of this work include:
- Dynamic representation and adaptation of multi-scale glottal image features to precisely parse local details and global semantic priors, enhancing robustness to deformation and motion blur.
- A high-efficiency fine-tuning strategy that extends low-rank adaptation for hierarchical feature adaptation, preserving geometric priors while reducing computational overhead.
- A feature aggregator that dynamically calibrates feature responses and constructs a dual-path dynamic feature pyramid by incorporating attention-based adaptive fusion of multi-scale features, which improves generalization under complex internal cavity anatomies.
2. Related Work
2.1. Glottal Detection and Segmentation
Accurate localization of the glottis is essential in robot-assisted NTI as it supports clinicians in precise regional assessment and provides critical guidance for subsequent surgical procedures. The early approaches primarily relied on thresholding and region-growing algorithms. For instance, Cerrolaza et al. [7] proposed an adaptive seeded region-growing method with dynamic edge constraints to detect the glottal gap. Karakozoglou et al. [8] introduced a vibration-mode-coupled active contour model to improve segmentation stability under noisy conditions. However, these traditional techniques are highly sensitive to grayscale distributions and perform poorly in the presence of complex biological contamination.
With the rapid advancement of deep learning, CNN-based segmentation methods have become increasingly prominent in medical image analysis. Fehling et al. [9] introduced a hybrid architecture for dynamic glottis segmentation, incorporating temporal modeling across video sequences to enhance temporal consistency. To address the light scattering artifacts commonly observed in endoscopic imagery, Deng et al. [10] proposed an improved CycleGAN framework with phase consistency constraints, effectively suppressing sputum interference and improving the peak signal-to-noise ratio. Classical two-stage instance segmentation frameworks, such as Mask R-CNN [11], PointRend [12], MS-RCNN [13], and QueryInst [14], have shown promise by leveraging region of interest (RoI) alignment for precise feature refinement. However, these methods often suffer from significant feature degradation near object boundaries, particularly for large anatomical targets, limiting their applicability in dynamic glottis monitoring. In contrast, one-stage methods, including YOLACT [15], BoxInst [16], CondInst [17], SOLOv2 [18], RTMDet [19], and SparseInst [20], offer higher inference speed and real-time capabilities. Yet, their segmentation accuracy on small or occluded structures tends to degrade due to the absence of explicit positional priors and fine-grained boundary supervision. In parallel, the U-Net architecture remains a foundational design in medical image segmentation and has been widely applied to glottal region analysis. Extensions such as U-Net++ [21] and U-Net 3+ [22] have improved multi-scale feature fusion, enhancing sensitivity to fine anatomical details. A subsequent study [23] validated the effectiveness of these models in glottis segmentation. Nonetheless, their limited representational capacity and reduced robustness under noisy or anatomically variable conditions constrain their performance in real-world clinical settings.
Despite recent progress laying the groundwork for robot-assisted glottis localization, several critical challenges remain. These include limited adaptability to glottal shape variations and imaging artifacts, stringent latency constraints, and inconsistent semantic prediction of segmentation masks under clinical conditions.
2.2. Foundation Model Adaptation for Medical Image Segmentation
In recent years, extensive efforts have been devoted to adapting general-purpose vision architectures for medical image segmentation, where challenges such as clinical datasets, anatomical variability, and domain shifts are prevalent. Several studies focus on enhancing architectural efficiency and semantic consistency. Chen et al. [24] proposed contextual and structural similarity losses to enforce semantic coherence across voxels. Huang et al. [25] introduced a hybrid network featuring dynamic positioning attention and bilevel routing attention, which improves both local detail extraction and computational efficiency. Task-specific frameworks such as RASNet [26] leverage multi-scale spatial perception and attention-based decoding for renal image segmentation. Meanwhile, the emergence of foundation models such as SAM sparked a surge of interest in harnessing their zero-shot segmentation capabilities for clinical applications. However, SAM’s performance often degrades significantly in medical imaging tasks due to challenges such as heterogeneous imaging modalities, indistinct tissue boundaries, and complex pathological variations. To address this technical bottleneck, researchers proposed various adaptations of SAM tailored for medical imaging. Regarding model fine-tuning strategies, MedSAM [27] introduced an innovative dual-encoder freezing mechanism, where both the image and prompt encoders were kept fixed and only the segmentation decoder was trained to adapt to medical scenarios. Silva et al. [28] proposed a few-shot efficient fine-tuning strategy, which enabled efficient adaptation of foundation models to few-shot medical image segmentation tasks through parameter-efficient tuning and black-box adapters. Wen et al. [29] employed a dual-branch architecture to extract critical medical semantic information and adopted a hierarchical fusion strategy, demonstrating strong performance across various multimodal medical image fusion tasks.
Moreover, recent studies have increasingly focused on integrating medical prior knowledge into model architecture design. PFEMed [30] introduced a dual-encoder framework combining general visual priors with task-specific representations, further enhancing feature robustness via a prior-guided variational autoencoder. Zhao et al. [31] introduced a novel Prior Attention Network that adopted a coarse-to-fine strategy for multi-lesion segmentation in medical imaging. Shi et al. [32] proposed a mask-enhanced adaptive encoder that incorporated multi-scale feature fusion and a lesion-aware attention module. You et al. [33] developed a novel shape prior module that explicitly integrated both global and local shape priors to enhance the segmentation performance of UNet-based models. Inspired by the versatility of foundation models, we propose Glottis-SAM, which integrates task-critical and dynamic contextual priors to learn image embeddings from glottis images. To enable efficient fine-tuning, we adopt a low-rank adaptation (LoRA) strategy [34]. The model focuses on multi-scale feature learning and reduced computational cost, aiming for practical deployment in clinical NTI applications.
3. Methods
We propose Glottis-SAM, a dynamic segmentation framework that integrates multi-scale features and task-specific priors. As shown in Figure 2, the framework comprises a parameter-efficient fine-tuned encoder for multi-scale feature extraction, a dynamic multi-prior feature aggregation prompter for cross-layer complementary optimization, and a decoder.
3.1. Multi-Scale Contextual Feature Encoding
In medical tasks involving NTI, imaging-guided navigation systems must accurately identify and localize complex anatomical structures, including nasal morphology, pharyngeal curvature, and the precise position of the trachea, while simultaneously meeting the clinical demand for real-time dynamic responsiveness. Significant variability across patients further exacerbates the challenges for achieving high segmentation accuracy and effective multi-scale feature extraction. SAM is built upon a transformer architecture, and its encoder inherits a powerful self-attention mechanism that effectively captures long-range dependencies and rich spatial contextual information. Its efficient feature encoding and boundary modeling capabilities allow for precise delineation of anatomical structures, which is crucial for identifying key landmarks during intubation. However, due to the computational constraints of medical hardware, direct deployment of SAM remains impractical in real-world clinical settings. To address this issue, we adopt a Vision Transformer (ViT) backbone as the encoder, which offers a favorable balance between representation capacity and computational cost under constrained medical hardware. By adjusting the scaling factors that control the embedding dimensions at each stage, we construct encoder variants with different capacities, enabling flexible trade-offs between accuracy and efficiency. The encoder captures both local texture and global structure, thereby enhancing the representation of glottal features. Overall, this design supports robust multi-scale contextual feature modeling in clinical environments with limited computational resources.
Given a glottis image , it is first processed by a patch embedding module composed of two consecutive convolutional layers, each configured with a stride of 2 and padding of 1. This design facilitates hierarchical feature extraction and spatial downsampling, resulting in feature maps of size , which are suitable for efficient representation learning. As shown in Table 1, ViT adopts a hybrid architecture that integrates MBConv and transformer blocks. Adjustable scaling factors control the embedding dimensions at each of the four stages. ViT-B uses , while ViT-T uses , enabling flexible control over the model’s capacity and computational cost.
In the initial stage, MBConv performs downsampling and leverages a bottleneck design to reduce computational complexity while effectively encoding low-level features. In the subsequent three stages, transformers equipped with a window-based self-attention mechanism perform deep feature extraction and multi-scale feature fusion . This localized attention strategy retains the modeling benefits of self-attention while significantly lowering computational overhead. Specifically, denote the multi-scale feature maps extracted from different transformer stages. Each feature map is transformed by a mapping function and weighted by a learnable coefficient to obtain the fused representation . Here, denotes a lightweight alignment operator that projects each to a unified channel dimension and resizes it to a common spatial resolution so that features from different stages can be aggregated by summation.
To further enhance the perception of local structural information, a depthwise-separable convolutional layer is inserted between the self-attention module and the multi-layer perceptron. This hybrid architectural design exploits the advantages of convolutional operations in local feature extraction, thereby improving the model’s representational capacity. By integrating multi-scale feature extraction strategies with a hybrid computational paradigm, the model achieves efficient and robust visual representation learning under constrained computational resources.
3.2. Hierarchical Low-Rank Adaptation for Efficient Fine-Tuning
Achieving task-specific adaptation for glottal features without compromising the global visual representation capabilities of a pretrained model remains a fundamental challenge in glottal image analysis. Although traditional full fine-tuning yields strong performance in downstream tasks, the billion scale parameters of the SAM model impose substantial computational and memory burdens, resulting in superlinear growth in resource consumption and hindering practical deployment where accuracy and efficiency must be balanced. Recent studies have shown that low-rank representation offers a promising solution to balance efficiency and performance. Inspired by LoRA [34], we propose a hierarchical low-rank adaptation mechanism for parameter-efficient fine-tuning. Specifically, we model the weight update in a factorized low-rank form using two trainable matrices, which enables efficient adaptation of high-dimensional weights with a small number of additional parameters. By extending LoRA across layers, the model learns task-specific representations while preserving the strong geometric priors of SAM, thereby improving its modeling capability and adaptability for glottal image analysis. The LoRA rank is selected based on ablation studies and detailed analysis, and the final configuration is provided in Section 4.4.2.
Specifically, we freeze the transformers to maintain fixed parameters . This approach preserves the structural inductive biases learned from large-scale natural image datasets, particularly those that capture geometric priors such as edge continuity, spatial layout, and anatomical symmetry, while improving the model’s ability to adapt to specific glottal features. Simultaneously, we introduce trainable low-rank matrices into the query–key–value ( ) projection matrices of the self-attention mechanism and the two fully connected layers of the feedforward network ( , ). The low-rank update is defined as , while and are learnable matrices. Only these localized parameters are updated, and the changes can be efficiently captured using a small number of principal components. The updated weights are formulated as , where r denotes the rank of the low-rank matrices used for normalization, and is a scaling factor controlling the magnitude of .
By incorporating low-rank updates into the projections, the model is able to learn attention patterns that are more specific to glottal structures. The attention computation is modified as follows:
This modification enhances the sensitivity to task-specific anatomical features while maintaining its general visual understanding capabilities. Additionally, LoRA within the feedforward network reinforces the nonlinear representation of glottal features. By constraining parameter updates to a low-dimensional subspace, the model is encouraged to learn essential and robust representations rather than overfitting to spurious patterns or noise. From a clinical deployment perspective, this lightweight adaptation strategy significantly reduces hardware requirements and improves inference efficiency, making it well suited for real-time applications in resource-constrained medical environments.
3.3. Dynamic Semantic Feature Aggregation
3.3.1. Feature Aggregation
To further construct an efficient multi-scale semantic representation system, we design a feature aggregation module that employs a structured feature interaction mechanism to extract discriminative cross-scale semantic information from the intermediate features generated by the backbone network. For each feature map , the feature aggregate module first applies differential spatial scaling to dynamically align spatial dimensions. A 1 × 1 convolution is used for channel compression, which significantly reduces computational complexity while preserving critical discriminative information. This is followed by a 3 × 3 convolution for local receptive field enhancement, allowing the model to better capture spatial context. To further improve feature extraction efficiency, batch normalization is applied after the convolutional operations.
where denotes a parameterized downsampling operator, represents the convolution kernels with dilation rate d, and represents the dilated convolution operation. Subsequently, residual connections and element-wise addition are applied for adaptive fusion of multi-level features. The resulting temporary feature map is computed as
where ⊕ denotes element-wise addition, represents the residual connection, and are learnable channel attention weights. Finally, are adjusted in the channel dimension to provide a structured and informative feature representation for subsequent tasks.
This aggregation process effectively integrates multi-scale contextual cues, enabling the model to focus on semantically consistent patterns, such as glottal contours and surrounding anatomical regions. By implicitly encoding semantic priors through channel attention and hierarchical fusion, the module enhances the spatial discriminability and robustness of feature representations under clinical variations, including deformation and lighting fluctuations. To qualitatively validate the effectiveness of the feature aggregation module, we visualize the attention feature maps before and after enabling the module, as shown in Figure 3. The results demonstrate that, after aggregation, attention becomes more concentrated around the glottal region, with enhanced activation intensity and spatial coherence. This confirms that the proposed module successfully amplifies task-relevant semantic signals, thereby improving downstream segmentation quality.
3.3.2. Dual-Path Dynamic Feature Pyramid
Building upon the previously aggregated multi-scale features, we introduce a dual-path dynamic feature pyramid to further enhance hierarchical semantic representation and structural awareness. This module leverages two complementary parameter-adaptive pathways to transform features across multiple resolutions while preserving rich contextual priors. Specifically, each hierarchical level is processed through two parallel paths, an upsampling path that employs transposed convolution to perform learnable interpolation and a downsampling path that applies max pooling to retain high-response local features. These pathways jointly enable the model to capture both fine-grained spatial details and high-level semantic abstractions. We construct a five-level feature pyramid. This design is consistent with the encoder’s hierarchical resolutions and provides sufficient scale granularity to capture both fine glottic structures and broader anatomical context without incurring excessive computation. At each level, we generate an upsampled feature and a downsampled feature and obtain the final representation by dynamically weighted fusion of the two paths:
where and represent upsampling via transposed convolution and downsampling via max pooling, respectively. The adaptive weights and are generated by an attention mechanism and satisfy the constraint . This fusion strategy adaptively regulates the influence of each pathway according to local feature variations, thereby enhancing the semantic richness and spatial consistency of the resulting feature representation. The design also facilitates stable gradient flow across scales, contributing to improved generalization under complex internal cavity conditions.
3.3.3. Multi-Head Cooperative Feature Decoupling
We utilize region proposal network (RPN) and multi-head perception mechanism to transform the obtained multi-scale semantic features into prompt embeddings required by the SAM mask decoder. The RPN predicts a set of anchor boxes at each spatial location of the feature map, utilizing a combination of scales and aspect ratios to identify potential targets. These candidates are refined via RoI pooling to standardize features into fixed-size vectors, serving as inputs to the subsequent multi-head decoupling stage. The multi-head module consists of three parallel heads: a classification head, a localization head, and a prompt head. The classification head identifies semantic categories, encoding high-level semantic priors. The localization head predicts bounding-box offsets and aligns the prompt with precise spatial locations, capturing spatial priors. The prompt head generates embedding vectors that integrate both visual content and contextual cues for each candidate region, thereby providing semantic guidance for the SAM decoder. These outputs are fused into a unified sparse prompt representation through parallel processing. To further enhance spatial awareness, explicit position encoding is introduced, assigning unique spatial representations to each region, which facilitates precise structural alignment and improves downstream mask decoding. A total loss function is defined, which includes the region proposal network loss , classification loss , bounding-box regression loss , and mask loss :
where consists of the classification loss and bounding-box regression loss for anchor boxes. The is used to optimize the overlap between the predicted bounding box and the ground-truth bounding box, typically computed using the smooth L1 loss. The weights of these losses are controlled by hyperparameters and , which help to balance the impact of the different losses. Finally, the sparse prompt features that are enriched with positional information are fed into the SAM decoder for bilinear interpolation. This process unifies the feature representation space, enabling progressive refinement of prediction results through iterative decoding.
4. Experiments
4.1. Hardware System
To comprehensively verify the effectiveness and reliability of the proposed algorithm in real medical application scenarios in Figure 4, we design a NTI robotic system to autonomously and accurately insert a nasotracheal tube (NTT) through the nostrils and thus build a stable and efficient connection between the patient’s airway and the oxygen concentrator. During the testing phase, a robotic arm is used to remotely manipulate the distal portion of the fiberoptic bronchoscope (FOB) according to a predefined bending angle, ensuring that the desired position is achieved with each maneuver. The bronchoscope view, an important part of the system, shows the field of view captured by the camera at the distal tip of the FOB in real time, providing clear and intuitive visual feedback to the operator. Meanwhile, the integral feeder module is responsible for collaboratively controlling the movement of the external components of the FOB and NTT to ensure a smooth and accurate insertion process. The FOB tip is guided from the exterior of the body model into the nostril, and then along the nasal cavity, the pharynx, through the glottic opening, and ultimately into the trachea. These images not only contain the details of key areas, such as the nostrils and nasal passages, but also clearly demonstrate key structures, such as the glottic suture and the right and left glottic valves, which provide invaluable data support for subsequent algorithm optimization and performance evaluation.
4.2. Experiments Setup
4.2.1. Dataset
This study uses three datasets to evaluate the effectiveness of our method.
Glottis: The Benchmark for Automatic Glottis Segmentation (BAGLS) [35] dataset comprises high-speed videoendoscopic recordings from 640 subjects, including both healthy individuals and patients with various laryngeal disorders. The data are collected by multiple medical professionals using diverse endoscopic systems, introducing substantial heterogeneity in image resolution, lighting conditions, and anatomical variations, as illustrated in Figure 5. To adapt this dataset for object detection tasks, we derive bounding boxes that tightly enclose the original segmentation masks and convert the annotations into the COCO [36] format. The resulting dataset includes 55,750 images for training and 3500 for testing. This large-scale and diverse dataset serves as a critical benchmark for evaluating the generalization capability and real-world applicability of our model across different patient groups and imaging devices.Phantom 2025: To mitigate ethical constraints during the initial development stage, we construct a synthetic dataset using our robotic NTI system. The Phantom dataset [37] is collected in a controlled laboratory setting using a fiberoptic bronchoscope equipped with real-time navigation and feedback control, with representative samples shown in Figure 6. The dataset includes 2267 training images and 479 test images. Bounding boxes are used to label general structures, such as the nose, channel, glottis, and trachea. Masks are employed to annotate structures with more clearly defined boundaries or specific shapes, including the right nostril, left nostril, glottic slit, right glottal valve, and left glottal valve, providing pixel-level accurate representations of their form and extent. These samples provide diverse anatomical representations that support early-stage model training and validation without involving human subjects.Clinical 2025: The Clinical dataset [37] is obtained from nasopharyngoscopy procedures conducted at the Singapore General Hospital. It comprises 82 high-definition video recordings, each obtained from a unique patient, reflecting a broad spectrum of anatomical diversity and clinically realistic imaging conditions, as exemplified in Figure 7. All procedures are conducted by board-certified otolaryngologists using commercial flexible nasopharyngoscopes to ensure procedural consistency and clinical realism. From these recordings, we extract 2683 training images with 7030 annotated structures and 1131 validation images with 3295 annotations. These images capture key anatomical landmarks, such as the nose, nostrils, epiglottis, glottic valves, and surrounding tissues, as the endoscope passes through the glottis into the trachea.
4.2.2. Implementation Details
We conduct comprehensive ablation and qualitative experiments to evaluate the proposed framework. All experiments were implemented in PyTorch (v1.13.0) with CUDA 11.7 on an NVIDIA GeForce RTX 4090. All models listed in Table 2 are trained for 100 epochs across three datasets. The input images are uniformly resized to a resolution of 256 by 256 pixels. A batch size of 32 is used for the main experiments, while a smaller batch size of 16 is applied during the ablation studies. The training procedure adopts the AdamW optimizer with an initial learning rate of 0.001, a weight decay of 0.05, and a stepwise learning rate scheduling strategy. To ensure a fair comparison, each baseline model is trained using the hyperparameters recommended in its original publication. For reproducibility, all experiments are conducted with fixed random seeds, and model selection is based on the highest validation accuracy achieved during training.
4.2.3. Evaluation Metrics
To comprehensively evaluate the effectiveness of the proposed segmentation method, we adopt a set of evaluation metrics that jointly consider segmentation accuracy and computational efficiency. For segmentation performance evaluation, we adopt the COCO instance segmentation evaluation protocol. The primary metric is mean average precision for masks ( ), which measures the overall segmentation quality across all classes and confidence thresholds. Additionally, we report and , representing average precision at IoU thresholds of 0.5 and 0.75, respectively, where IoU is calculated based on pixel-level mask overlap. These metrics specifically reflect the model’s ability to generate high-quality instance-level masks at low and high matching precision levels. To further evaluate pixel-wise segmentation quality, we incorporate the mean Dice coefficient ( ), which directly quantifies the spatial overlap between predicted and ground-truth masks. The Dice coefficient for multi-class instance segmentation is calculated as
where and represent the predicted and ground-truth binary masks for instance i, respectively, and n denotes the total number of instances across all classes. This metric is particularly sensitive to boundary precision and complements the AP-based metrics by providing direct pixel-level accuracy assessment. In addition to mDice, we report the Jaccard Index in terms of mean intersection over union as a complementary overlap-based metric. measures the overlap between predicted and ground-truth masks via the intersection over union ratio, computed for each instance and then averaged across all instances and classes. Compared with Dice, IoU is typically more sensitive to both over- and under-segmentation, offering an additional view of pixel-level segmentation quality.
For practical deployment considerations, we evaluate computational efficiency through three key metrics. The number of trainable parameters reflects the actual parameters updated during LoRA-based fine-tuning, directly impacting training memory requirements and adaptation efficiency. Inference speed, measured in frames per second (FPS), quantifies real-time processing capability essential for practical applications. Model size in megabytes (MB) reflects the storage requirement and memory usage, which is essential for deployment on devices with limited computational resources. This comprehensive evaluation framework allows for a detailed analysis of the trade-off between accuracy and efficiency in our segmentation method, ensuring both precise mask prediction and practical applicability across various hardware platforms.
4.3. Comparison with State-of-the-Art Methods
To comprehensively assess the performance of the proposed Glottis-SAM, we conduct systematic comparative experiments on three public datasets: Glottis, Phantom, and Clinical. The comparison includes traditional CNN-based segmentation models, transformer-based frameworks, and recent architectures derived from SAM, as presented in Table 2. We observe notable performance variations across different datasets when using various methods. Classical CNN-based models, such as Mask R-CNN [11] and PointRend [12], often struggle with distinguishing anatomically similar and morphologically variable structures like the epiglottis and vocal folds. This is largely due to their limited ability to capture global contextual information, resulting in unstable segmentation accuracy. Although more advanced transformer-based models like Mask2Former [38] with Swin-T backbone are introduced, the actual performance improvement remains modest. This suggests that simply increasing model complexity does not necessarily yield proportional gains in segmentation accuracy, particularly in medical imaging tasks. Moreover, lightweight models such as SOLOv2 [18] offer faster inference speed but experience drops in performance, making them inadequate for clinical scenarios that demand high precision. SAM-based model variants exhibit promising performance, demonstrating the potential of foundation models in medical image segmentation, but their large model sizes pose a major obstacle to practical deployment.
4.3.1. Glottis
The FastSAM series further pushes accuracy boundaries, and FastSAM-X [40] reaches the highest , but at the cost of a model size of 868.0 MB and a drastic drop in inference speed to 7.4 FPS, which is unsuitable for resource-limited environments. In contrast, Glottis-SAM demonstrates a significant advantage, striking an optimal balance between accuracy and computational efficiency through LoRA-based fine-tuning. Leveraging a ViT-T backbone, Glottis-SAM achieves 54.3% mAP with a model size of only 55.2 MB, nearly an order of magnitude smaller than most conventional methods. This efficient design makes it particularly suitable for edge computing scenarios.
4.3.2. Phantom
This dataset presents additional challenges, including imaging artifacts and blurry boundaries, which lead to greater performance degradation. Traditional methods such as SparseInst [20] struggle under these conditions, highlighting their limitations in complex visual environments. Even SAM [5] achieves only 40.7% . In contrast, Glottis-SAM obtains a superior of 43.8% by leveraging hierarchical feature adaptation and geometric perception mechanisms, outperforming all compared methods. It also maintains robust segmentation performance under degraded imaging conditions.
4.3.3. Clinical
The Clinical dataset represents the most challenging scenario, encompassing various real-world clinical interferences, such as occlusion, motion blur, and lighting variations, which increase the difficulty of the segmentation. Even YOLACT [15], which performs well on the other two datasets, can only achieve 24.2% . Large models like FastSAM also struggle to maintain stable performance. Our analysis attributes this to the rigidity of their feature extraction mechanisms, which lack adaptability to real-world environmental variations. Glottis-SAM achieves stable performance under various interference conditions, demonstrating the robustness of our proposed feature aggregation in handling complex medical imaging tasks.
In summary, Glottis-SAM consistently outperforms state-of-the-art methods across all datasets, demonstrates superior accuracy, and shows strong robustness to real-world variability. These advantages highlight its strong potential for deployment in practical medical scenarios, particularly on resource-constrained devices such as portable and embedded systems.
4.4. Ablation Study
4.4.1. Low-Rank Aaptation
A well-chosen scope for LoRA layers can reduce model size while maintaining strong performance. We investigate how different LoRA deployment strategies across network modules affect overall performance. As shown in Table 3, the model achieves of 66.9 without any LoRA layers. When LoRA is applied solely to the attention matrices, increases from the baseline 40.7% to 43.3%, indicating that introducing low-rank structures into attention computation helps to extract effective features. We further expand the application to the feedforward layers of the MLP, integrating LoRA in both and . When , , and adaptations are jointly enabled, the model achieves optimal balance, with improving to 70.5%. This configuration maximizes the feature extraction and representation capability of the model.
4.4.2. Rank and Scaling Factor
The low-rank constraint helps to suppress redundant feature interference, while the scaling factor enhances the representation of glottal microstructures. We investigate the synergistic effects of LoRA on the performance under various rank r and scaling factor configurations. In Table 4, when r increases from 2 to 64, model performance first improves and then declines. Although a higher rank enables the capture of more high-frequency details, it may also introduce noise, thereby impairing segmentation accuracy. With fixed, the configuration with achieves a higher than despite having only 0.15 M trainable parameters. This confirms the beneficial effect of a moderate scaling factor in enhancing model generalization. Specifically, when and , the model achieves well-balanced performance on the Phantom dataset, with an of 42.7% and an of 67.2%, significantly outperforming other configurations. This setting is thus identified as the optimal configuration for glottis segmentation.
4.4.3. Channels in FPN
To investigate the influence of hyperparameter settings on network performance, we conduct an ablation study on the number of channels to evaluate the impact on model performance. In Table 5, reducing the number of channels from 256 to 64 leads to a significant improvement in key performance metrics while maintaining real-time inference speed. When the channel is set to 64, the model achieves its highest accuracy, with an of 67.2%. This improvement can be attributed to the fine-grained anatomical structures of the glottis, where an excessive number of channels may introduce redundant noise, whereas moderate channel compression helps to enhance focus on salient edge features. However, when the number is further reduced to 32, the declines due to the loss of shallow semantic information. An extreme reduction to 8 channels causes a dramatic drop in , leading to feature collapse. These findings suggest that 64 channels represent the optimal configuration for glottis segmentation.
4.4.4. Weight of the Loss Function
We adjust the weight parameters and in the loss function to evaluate the impact of and on model performance. As shown in Table 6, the model achieves the best performance when is 0.5 and is 2, reaching of 44.7%, with and of 71.3% and 51.9%, respectively. Meanwhile, the coefficient for the mask also reaches its highest value of 74.4%. In contrast, increasing or decreasing leads to performance degradation across all metrics to varying degrees. These findings indicate that, in our task, placing relatively more emphasis on the and appropriately reducing the weight of the is beneficial for improving model performance. Although the model size fluctuates slightly between 410 MB and 427 MB under different weight configurations, this variation has minimal impact on performance.
4.4.5. Qualitative Results
Figure 8 presents the training loss curve on the Phantom dataset, where our model exhibits strong convergence stability throughout the optimization process. The integrated channel attention mechanism helps to alleviate gradient interference during hierarchical feature fusion, while the proposed loss weighting scheme ensures a balanced focus between bounding-box regression and mask accuracy.
Figure 9 illustrates segmentation examples under challenging clinical conditions, including lighting variation, anatomical differences, and interference from saliva. Driven by dynamic feature representation and the incorporation of multiple priors, our model consistently achieves precise glottis localization and maintains robust mask quality despite background complexity. Nevertheless, failure cases occasionally occur when the glottal region is severely occluded by anatomical tissue, which limits the effectiveness of current sparse prompt embeddings and leads to incomplete detection or inaccurate segmentation. These observations highlight the need for more robust prompt decoding and feature reasoning under extreme conditions.
5. Discussion
We present Glottis-SAM, a foundation model adaptation framework for glottis segmentation in NTI. The framework combines dynamic multi-scale feature aggregation with multi-prior guidance and uses a rank-constrained parameter adaptation strategy. Together, these designs help the model to focus on the glottal structure under complex anatomy, illumination changes, and motion blur that are common in endoscopic scenes.
From a broader perspective, Glottis-SAM offers a practical path to adapt general foundation models to structure-centric medical segmentation. Rank-constrained adaptation supports efficient transfer with limited training cost, which is valuable when computational resources are constrained or when fast deployment across devices is required. Meanwhile, the joint use of multi-prior guidance and multi-scale aggregation encourages consistent boundary awareness and improves the preservation of fine-grained structural cues, which is critical for small and deformable targets such as the glottis.
There are still challenging cases. Severe occlusions by surrounding tissues or reflective fluids can reduce the reliability of sparse prompts and lead to partial masks. In addition, the current study focuses on static images and does not yet benefit from temporal continuity in endoscopic videos, which could further stabilize predictions and reduce frame-to-frame jitter. These observations motivate future work on occlusion-aware decoding, stronger robustness-oriented data synthesis, and temporally consistent video segmentation, together with broader validation across clinical centers and endoscopic devices.
6. Conclusions
Glottis-SAM provides an effective and deployable solution for glottis segmentation in transnasal intubation. Across three datasets, it delivers strong segmentation accuracy while remaining compact and fast enough for real-time use. With a ViT-T backbone, it reaches an mDice of 94.7 and an mIoU of 89.9 on the Glottis dataset, and an mDice of 72.6 and an mIoU of 57.0 on the Clinical dataset. It also supports compact and fast inference, with a model size of 55.2 MB and an inference speed of 44.3 FPS. These results indicate that Glottis-SAM can serve as a reliable component for real-time endoscopic guidance and provide a solid basis for future extensions toward video-level understanding and more robust performance under extreme visual disturbances. In future work, we will incorporate temporal modeling to leverage frame continuity in endoscopic videos, aiming to improve stability and reduce prediction jitter in challenging scenes. We will also perform broader multi-center validation across diverse endoscopic devices to further assess generalization in real clinical settings.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhu Z. Wang Z. Qi G. Mazur N. Yang P. Liu Y. Brain tumor segmentation in MRI with multi-modality spatial information enhancement and boundary shape correction Pattern Recognit.202415311055310.1016/j.patcog.2024.110553 · doi ↗
- 2Liu H. Liu S.Q. Xie X.L. Li Y. Zhou X.H. Feng Z.Q. Li G.T. Ma X.Y. Hou Z.G. Yuan Y.Y. An Original Design of Robotic-Assisted Flexible Nasotracheal Intubation System 2023 IEEE International Conference on Robotics and Biomimetics (ROBIO)IEEE New York, NY, USA 20231610.1109/ROBIO 58561.2023.10354806 · doi ↗
- 3Zheng L. Wu H. Yang L. Lao Y. Lin Q. Yang R. A Novel Respiratory Follow-up Robotic System for Thoracic-Abdominal Puncture IEEE Trans. Ind. Electron.2020682368237810.1109/TIE.2020.2973893 · doi ↗
- 4Gloger O. Lehnert B. Schrade A. Völzke H. Fully automated glottis segmentation in endoscopic videos using local color and shape features of glottal regions IEEE Trans. Biomed. Eng.20146279580610.1109/TBME.2014.236486225350912 · doi ↗ · pubmed ↗
- 5Kirillov A. Mintun E. Ravi N. Mao H. Rolland C. Gustafson L. Xiao T. Whitehead S. Berg A.C. Lo W.Y. Segment Anything Proceedings of the IEEE/CVF International Conference on Computer Vision Paris, France 2–6 October 20234015402610.48550/ar Xiv.2304.02643 · doi ↗
- 6Huang Y. Yang X. Liu L. Zhou H. Chang A. Zhou X. Chen R. Yu J. Chen J. Chen C. Segment Anything Model for Medical Images Med. Image Anal.20249210306110.1016/j.media.2023.10306138086235 · doi ↗ · pubmed ↗
- 7Cerrolaza J.J. Osma-Ruiz V. Sáenz-Lechón N. Villanueva A. Gutiérrez-Arriola J.M. Godino-Llorente J.I. Cabeza R. Fully-automatic glottis segmentation with active shape models MAVEBA Firenze University Press Firenze, Italy 20113538
- 8Karakozoglou S. Henrich N. d’Alessandro C. Stylianou Y. Automatic Glottal Segmentation Using Local-Based Active Contours and Application to Glottovibrography Speech Commun.20125464165410.1016/j.specom.2011.07.010 · doi ↗