A Bio-Inspired Comprehensive Learning Strategy-Enhanced Parrot Optimizer: Performance Evaluation and Application to Reservoir Production Optimization
Boyang Yu, Yizhong Zhang

TL;DR
A new bio-inspired optimization algorithm, CL-PO, is developed to solve complex engineering problems by improving exploration and avoiding local optima.
Contribution
The novel CL-PO algorithm introduces a multi-exemplar social learning mechanism inspired by parrot behavior to enhance optimization performance.
Findings
CL-PO outperformed nine state-of-the-art algorithms on 29 CEC 2017 test functions with an average Friedman rank of 1.28.
CL-PO achieved a maximum net present value of 9.625×108 USD in a reservoir production optimization task using the Egg benchmark model.
Abstract
The efficacy of swarm intelligence algorithms in navigating high-dimensional, non-convex landscapes depends on the dynamic balance between global exploration and local exploitation. Drawing inspiration from the intricate social dynamics of Pyrrhura molinae, this study proposes a novel bio-inspired metaheuristic, the Comprehensive Learning Parrot Optimizer (CL-PO). While the original Parrot Optimizer (PO) simulates collective foraging and communication, it often suffers from population homogenization and entrapment in local optima due to its reliance on single-source social learning. To address these limitations, CL-PO incorporates a dimension-wise multi-exemplar social learning mechanism analogous to the cross-individual knowledge transfer observed in avian colonies. This strategy enables stagnant individuals to reconstruct their search trajectories by learning from multiple superior…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
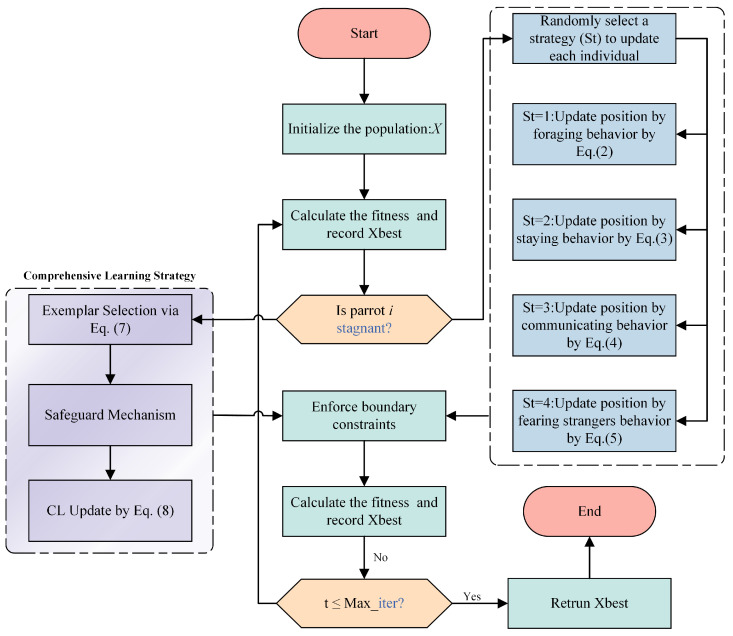 Figure 1
Figure 1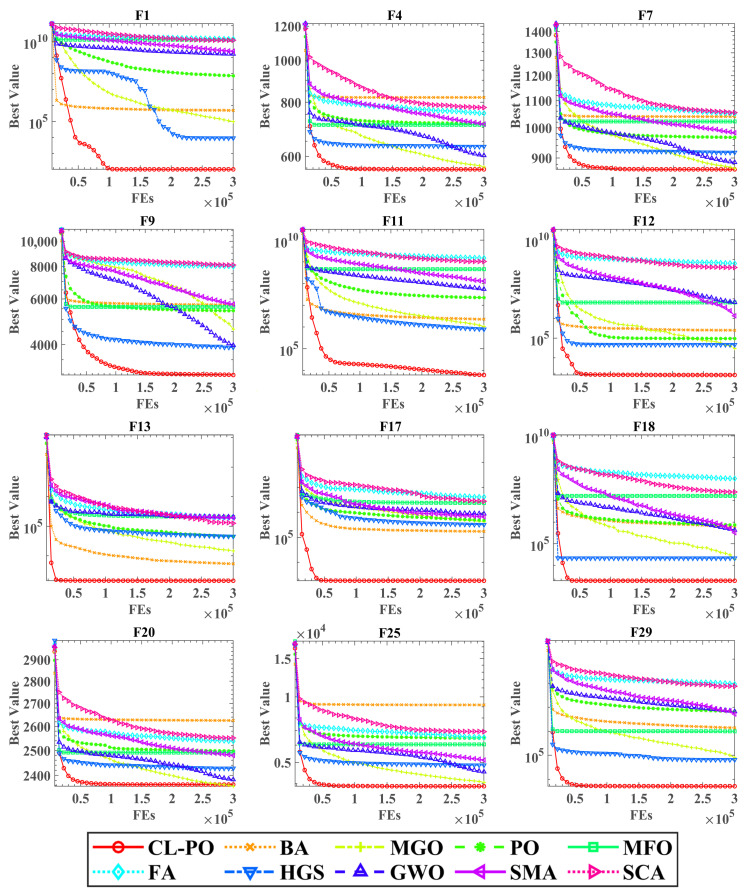 Figure 2
Figure 2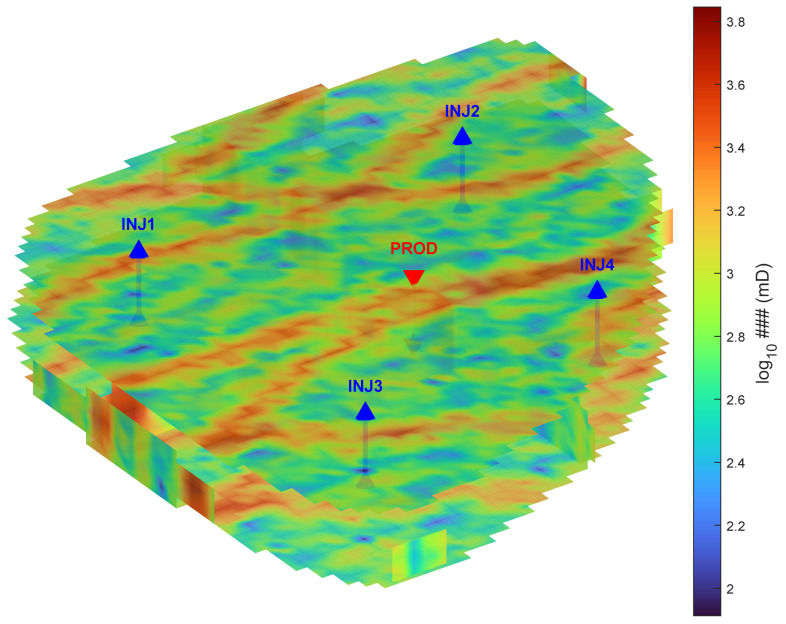 Figure 3
Figure 3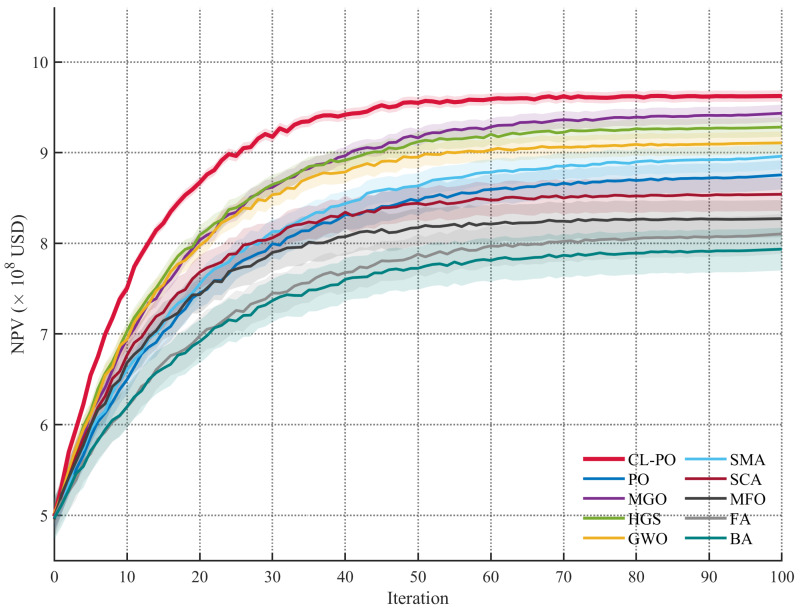 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetaheuristic Optimization Algorithms Research · Neural Networks and Reservoir Computing · Fish Ecology and Management Studies
1. Introduction
Optimization serves as a cornerstone of modern scientific and engineering research, underpinning critical advancements in fields ranging from artificial intelligence and machine learning to logistics and sustainable energy systems [1,2]. Its principal objective—to systematically identify optimal solutions within vast alternatives under defined constraints—makes it indispensable for enhancing efficiency, performance, and economic viability [3,4]. In practice, however, real-world optimization problems often present formidable computational challenges [5]. Many are formulated within high-dimensional, non-convex, and discontinuous search spaces, characterized by numerous local optima and computationally expensive objective evaluations. These intricacies often render conventional analytical or gradient-based approaches inadequate for a broad spectrum of practical applications [6,7].
Classical optimization methodologies, such as gradient-based techniques and linear programming, are theoretically rigorous and computationally efficient within well-defined domains [8]. Gradient descent excels in locating optima within smooth, convex landscapes, while the simplex method remains a robust standard for linear programming [9]. However, these methods encounter fundamental obstacles when confronted with complex real-world landscapes. Their reliance on derivative information or linearity assumptions becomes a critical weakness in non-convex, multimodal, or discontinuous spaces, where they are prone to entrapment in suboptimal local solutions [10]. Furthermore, their efficacy deteriorates sharply with increasing dimensionality—the “curse of dimensionality”—making the exponential expansion of the search space computationally intractable for traditional approaches. This mismatch between methodological assumptions and the complexity of real-world problems necessitates more robust and adaptable solution strategies [11,12].
To address these limitations, metaheuristic algorithms have emerged as a powerful and versatile class of optimization strategies [13]. Unlike classical methods, metaheuristics navigate complex landscapes without relying on restrictive mathematical properties like gradient information or convexity. They operate based on high-level principles, often inspired by natural phenomena, social behaviors, or physical processes [14]. In recent years, a plethora of innovative metaheuristics have been proposed to tackle increasingly intricate optimization tasks, including the Colony Predation Algorithm (CPA) [15], Moss Growth Optimization (MGO) [16], Educational Competition Optimizer (ECO) [17], and the Beaver Behavior Optimizer (BBO) [18]. These algorithms have demonstrated exceptional performance in diverse domains, from medical image processing and PV parameter identification to complex industrial control systems [19,20,21]. Their core strength lies in robust global search capabilities and a flexible framework that balances exploration (diversification) and exploitation (intensification) [22]. This characteristic enables them to effectively escape local optima and identify near-optimal solutions for problems that are otherwise intractable, positioning metaheuristics as essential tools in modern optimization.
Given the considerable diversity within the metaheuristic paradigm, these algorithms are commonly classified into two principal lineages based on their foundational inspirations: evolutionary algorithms (EAs) and swarm intelligence (SI) algorithms. Evolutionary algorithms are grounded in the principles of biological evolution, primarily employing mechanisms such as selection, crossover, and mutation to evolve a population of candidate solutions over successive generations, mimicking natural selection. Prominent representatives include the Genetic Algorithm (GA) [23] and Differential Evolution (DE) [24]. In contrast, swarm intelligence algorithms derive their methodology from the collective, decentralized behaviors observed in social animal colonies, such as flocks or ant colonies. These algorithms guide a population of agents through the search space using simple rules that model cooperation and information sharing. Notable examples are Particle Swarm Optimization (PSO) [25], which simulates the social dynamics of bird flocking, and Ant Colony Optimization (ACO) [26], which abstracts the foraging behavior of ants using pheromone trails. This taxonomic distinction provides a structured framework for understanding the dominant design philosophies in metaheuristic optimization and underscores the breadth of natural and social metaphors harnessed for problem-solving.
The proliferation of metaheuristics is fundamentally supported by the No Free Lunch (NFL) theorem [27], which posits that no single algorithm can outperform all others across all possible optimization problems. This theoretical insight suggests that superior performance in one domain is inevitably compensated for by inferior performance in another, providing a strong impetus for the development of specialized or enhanced methodologies. While metaheuristics offer powerful general-purpose strategies, they often face challenges such as premature convergence, sensitivity to parameters, and the delicate trade-off between exploration and exploitation. Consequently, ongoing research remains essential to refine their convergence properties and extend their applicability to complex, domain-specific tasks.
This work focuses on the recently proposed Parrot Optimizer (PO) [19], a swarm intelligence metaheuristic inspired by the social dynamics of Pyrrhura molinae parrots. The motivation for choosing PO as the baseline for this research is threefold. First, PO’s “four behavioral rules” offer a unique and flexible framework that naturally mimics social dynamics, providing a versatile foundation for optimization. Second, our preliminary analysis revealed a specific “architectural vulnerability”: its reliance on single-source social learning makes it particularly prone to diversity loss in the late stages of search, presenting a clear opportunity for improvement. Third, the stochastic selection of behaviors in PO makes it an ideal candidate for testing the effectiveness of multi-source learning strategies across different update patterns. Since its inception, PO has garnered significant attention and has been successfully applied to various domains, including control engineering, feature selection, and energy system dispatch [19]. Recent variants have also explored hybridizations with other mechanisms to further enhance its search capability suitable for specific landscapes.
However, a critical analysis of the original PO reveals a unified yet restrictive learning paradigm: position updates are predominantly governed by attraction toward either the global best solution or the population mean. This single-source guidance constitutes a significant architectural vulnerability; as iterations progress, the population rapidly loses diversity and converges toward a limited region. This limitation severely hinders the algorithm’s ability to maintain parallel exploration in multimodal landscapes, rendering it susceptible to stagnation in local optima.
To address these shortcomings, this paper introduces the Comprehensive Learning Parrot Optimizer (CL-PO). The central innovation is the conditional integration of a comprehensive learning strategy (CLS) for stagnant individuals. Rather than learning holistically from a single attractor, a stagnant agent constructs a composite guiding vector by learning dimension by dimension from the historical best positions of various superior peers. This multi-source learning mechanism dramatically diversifies search trajectories, effectively breaking the pull of local optima. The contributions of this study are threefold:
- We propose CL-PO, which seamlessly integrates CLS with the original PO behaviors to provide a targeted escape mechanism;
- The performance is rigorously validated against the original PO and state-of-the-art metaheuristics on comprehensive benchmark functions, with statistical tests confirming superior solution accuracy and convergence reliability;
- We demonstrate the practical utility of CL-PO by applying it to the high-stakes reservoir production optimization problem, consistently achieving higher net present value (NPV) and greater reliability than its peers.
The remainder of this paper is organized as follows. Section 2 reviews the original PO and its specific limitations. Section 3 details the proposed CL-PO and its integration mechanics. Section 4 presents the experimental setup and performance analysis on benchmark functions. Section 5 demonstrates the application of CL-PO to reservoir production optimization. Finally, Section 6 summarizes the key findings and suggests future research directions.
2. Original Parrot Optimizer
The Parrot Optimizer (PO), proposed by Lian et al. in 2024 [19], is a population-based metaheuristic algorithm inspired by the social behaviors of domesticated Pyrrhura molinae parrots. Its core optimization principle involves modeling a flock of N parrots, where each individual’s position in a D-dimensional space represents a candidate solution. Unlike algorithms with distinct exploration and exploitation phases, PO employs a stochastic update mechanism where each parrot randomly selects one of four biological behaviors—Foraging, Staying, Communicating, and Fear of Strangers—in each iteration to update its position. This design aims to enhance population diversity and mitigate the risk of premature convergence.
The algorithm translates from its biological inspiration to a formal mathematical model comprising initialization, four behavior-specific update equations, and an iterative optimization loop.
2.1. Mathematical Model of PO
- Population initialization: The algorithm commences by randomly generating the initial position for each parrot (candidate solution) within the predefined search space bounds. This establishes a diverse starting population for the iterative search process, which is calculated as follows:
where is the initial position of the i-th parrot; and are the lower and upper bounds of the search space; and is a uniform random number in .
- Foraging behavior: Inspired by parrots foraging in groups near food sources and their owner, this behavior guides an individual toward promising areas. The update combines a Lévy flight directed by the difference from the global best position ( , representing the owner/food location) and a social component influenced by the flock’s mean position ( ). The positional movement is dictated by
where is the current position; is the best-found position so far; denotes a Lévy flight random step; and is the population’s mean position at iteration t. The Lévy flight, a type of random walk pattern commonly observed in natural foraging behaviors, introduces large-scale exploratory jumps. It is calculated as , where and v are random values drawn from a standard normal distribution, , and is a scaling parameter involving the Gamma function.
- Staying behavior: Modeling a parrot perching randomly on its owner, this behavior adds a random step based on the owner’s position ( ) and a small stochastic vector. It represents localized, random movement around a trusted point, formulated as
where is a D-dimensional vector with all elements equal to 1, introducing uniform random perturbation.
- Communicating behavior: This behavior simulates two equally probable social actions: flying to the flock’s center to communicate or moving randomly while communicating. Both sub-behaviors apply incremental position updates. The process is modeled as
where P is a uniform random number in determining which sub-behavior is executed.
- Fear of strangers’ behavior: Driven by a natural aversion to unfamiliar individuals, this behavior models a parrot fleeing from strangers and seeking safety with its owner ( ). The movement is modulated by cosine functions, creating oscillatory attraction towards the owner and repulsion from perceived threats:
The first cosine term regulates flight toward the owner, while the second term governs movement away from strangers.
2.2. Integrated Iteration
The complete PO workflow operates as follows. First, the population is initialized, and the global best position is identified. The algorithm then enters the main loop for iterations. In each iteration, the mean position of the entire population is computed. Subsequently, for every individual parrot, one of the four behaviors is selected uniformly at random (25% probability each). The parrot’s position is updated according to the corresponding mathematical model. After all individuals are updated, their fitness is evaluated. Each parrot’s personal best and the swarm’s global best ( ) are updated if better solutions are found. This process repeats until the termination criterion (maximum iterations) is met, upon which the final solution is output. The complete optimization procedure is visually summarized in Figure 1.
2.3. Pseudocode of the Original PO
The algorithmic framework of the Parrot Optimizer is formally presented in Algorithm 1. The pseudocode delineates the complete iterative process, from initialization through behavior-based position updates to fitness evaluation and best solution tracking. Algorithm 1 Original Parrot Optimizer (PO)
- 1:Input: Population size N, Maximum iterations , Dimension D, Boundaries .
- 2:Initialize population X randomly within using Equation (1).
- 3:Set Lévy flight parameter .
- 4:Evaluate initial fitness for all individuals.
- 5:Identify global best position .
- 6:for to do
- 7: Calculate population mean position of the flock.
- 8: for to N do
- 9: Randomly select behavior index with equal probability.
- 10: if then
- 11: Update position using Foraging Behavior (Equation (2)).
- 12: else if then
- 13: Update position using Staying Behavior (Equation (5)).
- 14: else if then
- 15: Generate random probability .
- 16: Update position using Communicating Behavior (Equation (6)).
- 17: else if then
- 18: Update position using Fear of Strangers Behavior (Equation (7)).
- 19: end if
- 20: Enforce boundary constraints: clip to .
- 21: end for
- 22: Evaluate fitness for all updated individuals.
- 23: Update global best if a better solution is found.
- 24:end for
- 25:Output: Global best solution and its fitness value.
3. The Proposed CL-PO Algorithm
This section outlines the core components of the Comprehensive Learning Parrot Optimizer (CL-PO), specifically the integration of the comprehensive learning strategy (CLS) and the augmented algorithmic framework.
3.1. Comprehensive Learning Strategy (CLS)
The primary enhancement introduced in this work is the comprehensive learning strategy, which aims to diversify information sources available to individuals during the search process. Instead of relying exclusively on a single global attractor, CLS enables stagnant individuals to selectively inherit information from the dimension-wise best-performing dimensions of multiple peers. This approach synthesizes a composite guiding exemplar that effectively revitalizes localized search trajectories. The strategy comprises three integrated components: adaptive learning probability, dimension-wise exemplar construction, and a safeguard mechanism.
First, an individual-specific learning probability, , is assigned to each parrot to regulate the trade-off between self-guided exploitation and peer-informed exploration. This probability is defined as
where a and b are set to 0 and 0.5, respectively, and i represents the individual’s rank index.
Second, the learning exemplar vector is constructed by determining the target source for each dimension j via tournament selection. For each dimension, the algorithm compares the fitness values of the personal best positions of two distinct, randomly selected peers ( ):
Finally, a safeguard mechanism is implemented to prevent complete self-reliance, ensuring that at least one dimension is learned from a peer: if for all , then a randomly chosen dimension is forced to learn from a superior peer .
It is important to differentiate the proposed CLS from the original Comprehensive Learning Particle Swarm Optimizer (CLPSO) [28]. While both approaches leverage the concept of “comprehensive learning,” CL-PO differs significantly in its implementation and target framework. Unlike CLPSO, which applies CL to all particles in every generation, CL-PO uses a “dual-track” mechanism where CLS is only conditionally triggered for individuals that have exceeded a stagnation threshold . This maintains the unique biological behaviors of PO while using CLS as a surgical intervention for diversity recovery. Furthermore, the learning exemplar construction in CL-PO is adapted to suit the multi-behavioral update rules of the Parrot flock, which is fundamentally different from the velocity-update mechanism in standard PSO.
3.2. Implementation Framework of CL-PO
The proposed CL-PO integrates CLS into the standard PO framework as a conditionally triggered phase based on stagnation detection. A counter, , tracks consecutive iterations without improvement for each individual’s personal best. When exceeds a predefined threshold , the individual enters the CLS phase. This targeted intervention allows the original PO behaviors to drive exploration under normal conditions, while CLS provides a robust mechanism to escape local optima when progress stalls.
The iterative progression of CL-PO follows a dual-track mechanism. Non-stagnant individuals execute the original PO behavioral updates (Section 2.1). Conversely, for stagnant individuals, the CLS path is activated to construct the learning exemplar and perform the position update as
Following this, all new positions undergo evaluation, and fitness records are updated greedily. This dimension-wise, multi-source learning directly counteracts the diversity loss inherent in the original PO, sustaining robust exploration across complex landscapes.
The comprehensive workflow is illustrated in Figure 1, with the formal procedure detailed in Algorithm 2. This dual-track structure preserves the rapid convergence of PO while injecting necessary diversity for multimodal optimization.
3.3. Complexity Analysis
The computational complexity of the original PO is for T iterations. The CLS integration adds a conditional overhead for stagnant individuals: for each such agent, constructing the exemplar vector and updating positions requires . In the worst-case scenario where all individuals are stagnant in every generation, the added complexity is . Consequently, the overall time complexity of CL-PO remains , which is asymptotically equivalent to the original PO. This ensures that the global search enhancements are achieved without elevating the order of computational cost. Algorithm 2 Comprehensive Learning Parrot Optimizer (CL-PO).
- 1:Input: Population size N, Max iterations , Dimension D, Stagnation threshold .
- 2:Initialize population X; Evaluate fitness; Initialize and .
- 3:Initialize stagnation counters for all individuals.
- 4:Pre-calculate learning probabilities via Equation (8).
- 5:for to do
- 6: for to N do
- 7: if then ▹ Stagnation-triggered CLS Phase
- 8: for to D do
- 9: Select exemplar index via tournament selection.
- 10: end for
- 11: Safeguard: Ensure such that .
- 12: Update .
- 13: else ▹ Base Algorithm Phase
- 14: Randomly select behavior index .
- 15: Generate candidate using PO behavioral rules.
- 16: end if
- 17: Enforce boundary constraints.
- 18: Evaluate fitness .
- 19: if then
- 20: ; .
- 21: else
- 22: .
- 23: end if
- 24: end for
- 25: Update global best .
- 26:end for
- 27:Output: Global best solution .
4. Experimental Results and Analysis
This section presents a comprehensive experimental evaluation to assess the performance, robustness, and convergence behavior of the proposed Comprehensive Learning Parrot Optimizer (CL-PO). All experiments were conducted on a consistent computational platform (Intel Core i7-10700K CPU, 16GB RAM, Santa Clara, CA, USA, MATLAB R2021a) to ensure a fair comparison. The algorithm’s performance was rigorously tested on the CEC2017 benchmark suite under standardized conditions: a population size (N) of 30, a maximum of function evaluations ( ), and 30 independent trials for each function to account for stochastic variability. The critical control parameter for CL-PO, the stagnation threshold , was set to 2 to ensure a highly responsive escape mechanism. Performance is primarily quantified using the mean (Mean) and standard deviation (Std) of the best-found fitness values, reflecting solution accuracy and algorithmic stability, respectively.
4.1. Benchmark Functions and Experimental Setup
The CEC2017 suite comprises 29 challenging real-parameter numerical optimization problems (F1–F29, excluding F2). These functions are categorized into four distinct groups: unimodal functions (F1–F3) for assessing exploitation efficiency; simple multimodal functions (F4–F10) for evaluating basic exploration; hybrid functions (F11–F20) for testing combined search capabilities; and complex composition functions (F21–F29) with numerous local optima. This diverse categorization allows for a multi-faceted examination of an optimizer’s ability to balance global diversification and local intensification. The detailed properties of these functions are summarized in Table 1.
4.2. Performance Comparison and Statistical Analysis
To validate the efficacy of the proposed CL-PO, it was compared against its base version, the original Parrot Optimizer (PO) [19], and eight other prominent metaheuristics: Moss Growth Optimization (MGO), Hunger Games Search (HGS) [29], Grey Wolf Optimizer (GWO) [30], Slime Mould Algorithm (SMA) [31], Sine Cosine Algorithm (SCA) [32], Firefly Algorithm (FA) [33], and Bat Algorithm (BA) [34]. This selection encompasses a range of representative algorithms from recent and classical literature. A fair comparison was ensured by employing identical population sizes, maximum iteration limits, and independent run counts for all competitors.
The comprehensive numerical results are summarized in Table 2, which reports the mean and standard deviation of the fitness values for each algorithm across all 29 functions. The table also includes the overall average rank for each algorithm, calculated via the Friedman test, and a pairwise statistical comparison between CL-PO and the original PO. In this comparison, the symbols ‘+’, ‘=’, and ‘−’ denote that CL-PO’s performance is statistically significantly better than, equivalent to, or worse than PO, respectively, based on a non-parametric test at a 5% significance level.
The results from Table 2 reveal that the proposed CL-PO achieves the best overall performance, securing the top rank with an average Friedman rank of 1.28. Among ten competitors, a rank approaching 1.0 demonstrates that the algorithm’s superiority is not limited to a specific type of problem but extends across multimodal, hybrid, and composition functions, proving its robust global search and local exploitation capabilities. It demonstrates statistically significant superiority (‘+’) over the original PO on 27 out of 29 benchmark functions, with equivalent performance (‘=’) on only 2 functions. This decisive outcome highlights the substantial enhancement brought by the integrated strategies. The original PO itself ranks second, followed by HGS and GWO, indicating a strong baseline. Algorithms such as MFO, FA, and SCA exhibit relatively weaker overall rankings on this diverse set. Furthermore, CL-PO frequently attains very low Std values, signifying high solution consistency and robust convergence stability across independent runs.
To rigorously substantiate these findings, the Wilcoxon signed-rank test was performed at a significance level of . The resulting p-values, consolidated in Table 3, confirm a consistent statistical advantage for CL-PO. Against nearly all competitors, CL-PO demonstrates significant improvement ( ) across the majority of cases. These results confirm that the performance gains are statistically robust and not attributable to random chance.
The convergence behavior, illustrated in Figure 2 for twelve representative functions, provides visual insight into the search dynamics. The figure plots the best fitness value against the number of function evaluations (FEs), using a logarithmic scale for high-magnitude functions. CL-PO is distinctively marked by a red line with circular markers. On the majority of functions, CL-PO exhibits a rapid initial descent, indicating efficient early-stage exploration facilitated by the comprehensive learning strategy. More importantly, it consistently maintains the lowest trajectory throughout the search process, ultimately converging to superior solutions compared to all competitors. This demonstrates the algorithm’s effective balance, where the comprehensive learning strategy limits stagnation and enables escape from local optima in later stages.
In summary, the integrated experimental and statistical analysis confirms that the proposed CL-PO, through its comprehensive learning strategy and multi-exemplar update mechanism, achieves statistically significant and robust performance superiority over its predecessor and a range of established metaheuristics across a diverse benchmark suite.
5. Application to Reservoir Production Optimization
Reservoir production optimization represents a formidable engineering challenge, aimed at determining operational strategies that maximize the economic recovery of hydrocarbons, typically quantified by the net present value (NPV) [35]. This problem is inherently high-dimensional and non-deterministic (NP-hard), as the search space is defined by multiple control variables (e.g., well production rates or bottom-hole pressures) across discrete management periods. The resulting complex, non-convex, and computationally intensive objective landscape makes it particularly well-suited for population-based metaheuristics, which navigate such terrains without requiring gradient information.
To evaluate the practical efficacy of CL-PO, we integrated it into a standard reservoir simulation workflow. A high-fidelity synthetic reservoir model was implemented using the Eclipse simulator, serving as the forward model. CL-PO was tasked with optimizing control settings for both production and injection wells, where each candidate solution encoded a complete control schedule for simulation and economic evaluation.
The primary objective is the maximization of NPV, formulated as
where and denote the vectors of control and reservoir state variables, respectively. , , and represent the average oil production, water production, and water injection rates during period t. The coefficients , , and are the unit prices and costs associated with oil and water handling. The parameter b is the annual discount rate, and is the cumulative production time.
Physical constraints and operational limits were incorporated using two methods: (1) Box constraints were enforced directly on the control variables (e.g., BHP limits) during the position update phase. (2) Non-linear physical constraints (e.g., maximum water cut or minimum pressure thresholds) were handled via penalty functions within the objective function calculation. If a strategy violates these operational limits during simulation, the NPV is penalized, guiding the optimizer toward feasible regions.
5.1. Standard Case: The Egg Benchmark Model
The reservoir model utilized in this study is the well-known Egg model [36], a standardized geological ensemble widely used for waterflooding optimization and closed-loop management research. The model represents a channelized fluvial reservoir system characterized by significant spatial heterogeneity.
Our implementation used a single three-dimensional realization of the Egg model to assess the optimization framework. It should be noted that while this single realization provides a robust baseline for algorithmic comparison, comprehensive validation will require multi-realization studies in future to fully account for geological uncertainty. The model consists of a Cartesian grid ( ) with approximately 18,553 active cells, forming an egg-shaped domain. High-permeability meandering channels are embedded within a low-permeability background, creating preferential flow paths. Production is primarily driven by waterflooding, as the model lacks an aquifer or gas cap. Figure 3 illustrates the 3D permeability field and the five-spot well configuration (four injectors and one central producer).
5.2. Experimental Results and Discussion
The proposed CL-PO was benchmarked against the original PO and eight other metaheuristics on the reservoir optimization task. Each algorithm was executed five times to ensure consistency. Performance was evaluated based on the mean NPV, standard deviation (Std), and the best/worst outcomes.
The quantitative results in Table 4 show that CL-PO achieves the highest mean NPV ( USD) and the lowest standard deviation, indicating enhanced optimization capacity and stability. While MGO and HGS provide competitive results, they exhibit higher variability. Slower-converging algorithms like BA and FA suffer from premature stagnation, resulting in significantly lower economic returns.
Convergence trajectories in Figure 4 further confirm CL-PO’s efficiency. Its ascent is more rapid and stable compared to competitors, ultimately reaching a higher plateau. This indicates that the comprehensive learning strategy effectively prevents the algorithm from being trapped in local optima, which is common in high-dimensional reservoir problems. In conclusion, CL-PO demonstrates high reliability and efficacy, making it a promising tool for real-world oilfield development.
6. Conclusions
This study introduces the Comprehensive Learning Parrot Optimizer (CL-PO), a robust enhancement of the original Parrot Optimizer (PO) tailored for complex numerical and engineering optimization tasks. The core advancement is the integration of a comprehensive learning strategy (CLS), which enables stagnant individuals to selectively leverage personal best information from multiple peers on a dimension-by-dimension basis. This mechanism directly addresses the architectural limitations of the original PO, specifically its susceptibility to diversity loss and premature convergence in multimodal landscapes.
Rigorous validation on the CEC2017 benchmark suite demonstrates that CL-PO significantly outperforms the base PO and several state-of-the-art metaheuristics. Statistical analyses, including the Friedman and Wilcoxon signed-rank tests, confirm its superior solution accuracy and convergence reliability. Furthermore, the successful application of CL-PO to the reservoir production optimization problem underscores its practical utility in solving high-stakes, high-dimensional engineering challenges, consistently delivering superior net present value with minimal variability.
Future research will explore the extension of CL-PO to constrained and multi-objective optimization domains. Specifically, we aim to investigate the application of CL-PO to large-scale infrastructure planning, such as the spatial allocation of hydrogen electrolyzers, to address interdependent challenges in renewable resource siting [37]. Additionally, integrating reinforcement learning frameworks to dynamically tune the stagnation threshold or behavioral probabilities represents a promising direction for enhancing algorithmic adaptability [38]. In conclusion, the proposed CL-PO offers a powerful, dependable, and computationally efficient tool for the global optimization community.
Notably, the current version of CL-PO primarily addresses box constraints. While it handles some physical limits via penalty functions, further adaptation is required to effectively manage the complex, non-linear geological and engineering constraints typical of real-world oilfield development.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rao S.S. Engineering Optimization: Theory and Practice John Wiley & Sons Hoboken, NJ, USA 2019
- 2Belegundu A.D. Chandrupatla T.R. Optimization Concepts and Applications in Engineering Cambridge University Press Cambridge, UK 2019
- 3Du J. Hu H. Wang J. A Two-Stage Multi-Evolutionary Sampling Optimization Framework for Expensive Optimization Problems Proceedings of the 2025 International Conference on New Trends in Computational Intelligence (NTCI)Jinan, China 17–19 October 20251710.1109/NTCI 67886.2025.11308646 · doi ↗
- 4Hu H. Shan W. Tang Y. Heidari A.A. Chen H. Liu H. Wang M. Escorcia-Gutierrez J. Mansour R.F. Chen J. Horizontal and vertical crossover of sine cosine algorithm with quick moves for optimization and feature selection J. Comput. Des. Eng.202292524255510.1093/jcde/qwac 119 · doi ↗
- 5Shan W. Hu H. Cai Z. Chen H. Liu H. Wang M. Teng Y. Multi-strategies boosted mutative crow search algorithm for global tasks: Cases of continuous and discrete optimization J. Bionic Eng.2022191830184910.1007/s 42235-022-00228-7 · doi ↗
- 6Abualigah L. Elaziz M.A. Khasawneh A.M. Alshinwan M. Ibrahim R.A. Al-Qaness M.A. Mirjalili S. Sumari P. Gandomi A.H. Meta-heuristic optimization algorithms for solving real-world mechanical engineering design problems: A comprehensive survey, applications, comparative analysis, and results Neural Comput. Appl.2022344081411010.1007/s 00521-021-06747-4 · doi ↗
- 7Hu H. Wang J. Huang X. Ablameyko S.V. An Integrated Online-Offline Hybrid Particle Swarm Optimization Framework for Medium Scale Expensive Problems Proceedings of the 2024 6th International Conference on Data-driven Optimization of Complex Systems (DOCS)Hangzhou, China 16–18 August 20242532
- 8Kar B. Yahya W. Lin Y.D. Ali A. Offloading using traditional optimization and machine learning in federated cloud–edge–fog systems: A survey IEEE Commun. Surv. Tutorials 2023251199122610.1109/COMST.2023.3239579 · doi ↗