PreprintToPaper dataset: connecting bioRxiv preprints with journal publications
Fidan Badalova, Julian Sienkiewicz, Philipp Mayr

TL;DR
The PreprintToPaper dataset links bioRxiv preprints to their journal publications, helping researchers study how scientific papers evolve from preprint to final publication.
Contribution
The dataset introduces a large-scale, time-separated analysis of preprint-to-journal publication dynamics, including pandemic-era changes and a human-annotated subset for reliability.
Findings
The dataset includes metadata for 145,517 preprints from 2016–2018 and 2020–2022.
A version-history subset allows analysis of preprint evolution over time.
A human-annotated subset of 299 records improves reliability for Gray Zone cases.
Abstract
The PreprintToPaper dataset connects bioRxiv preprints with their corresponding journal publications, enabling large-scale analysis of the preprint-to-publication process. It comprises metadata for 145,517 preprints from two periods, 2016–2018 (pre-pandemic) and 2020–2022 (pandemic), retrieved via the bioRxiv and Crossref APIs. We selected the two periods to capture preprint-publication dynamics before and during the COVID-19 pandemic while avoiding transitional years. Each record includes bibliographic information such as titles, abstracts, authors, institutions, submission dates, licenses, and subject categories, alongside enriched publication metadata including journal names, publication dates, author lists, and further information. In addition to the main dataset, a version-history subset provides all available versions of preprints within the two selected periods, enabling analysis…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
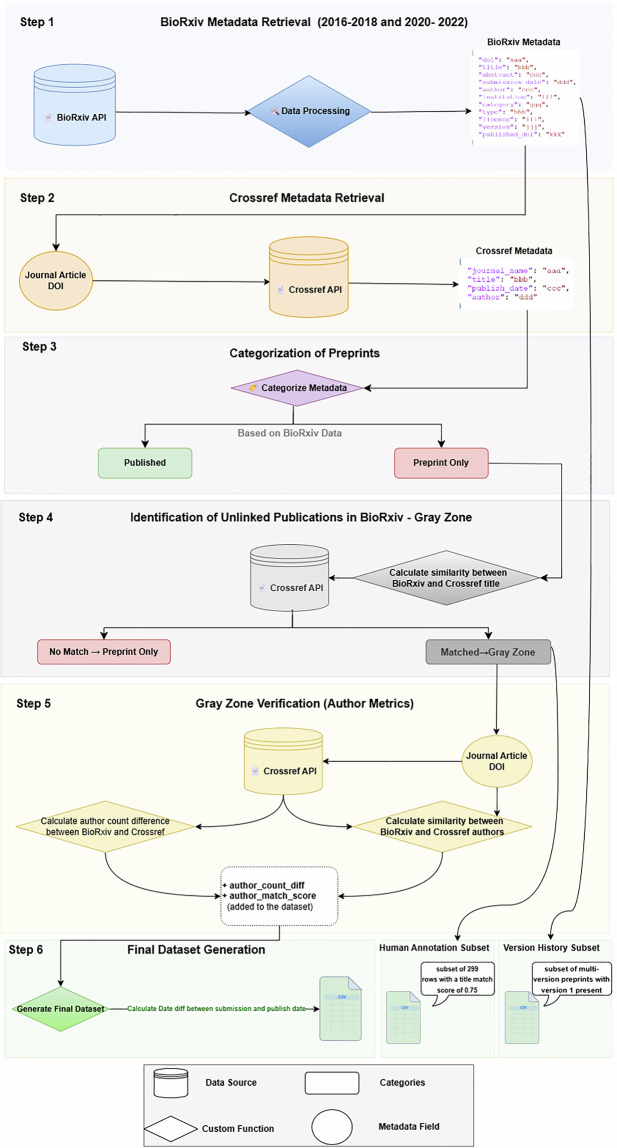 Figure 1
Figure 1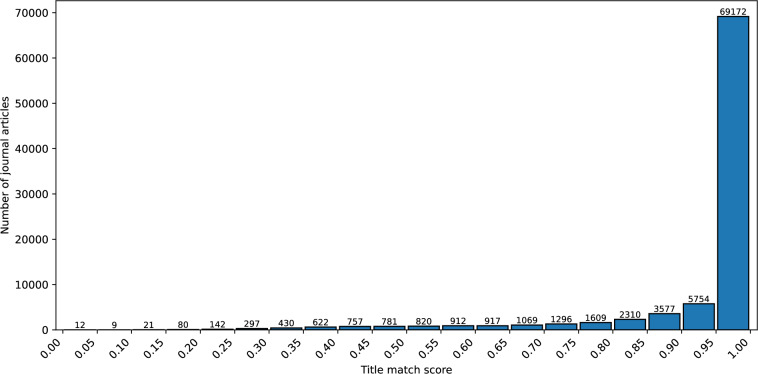 Figure 2
Figure 2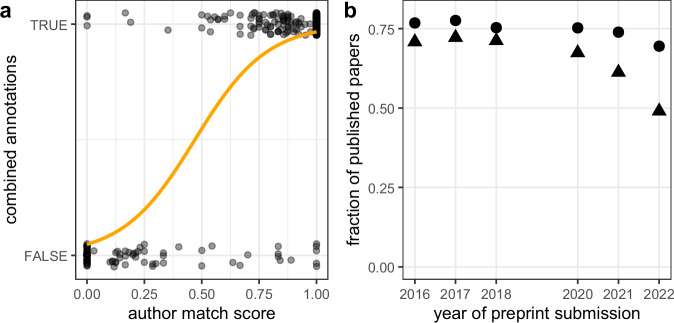 Figure 3
Figure 3- —OMINO – Overcoming Multilevel INformation Overload. Grant Reference Number: 101086321
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAcademic Publishing and Open Access
Background & Summary
Preprints have become an essential channel for the rapid dissemination of scientific findings, particularly in the life sciences, where timely access to results can accelerate discovery and collaboration. Their importance was intensified during the COVID-19 pandemic, when preprints served as a primary means of sharing the newest research across domains before formal peer review^1,2^.
The PreprintToPaper dataset^3^, which we describe in this paper, links bioRxiv preprints with their subsequent journal publications, allowing for large-scale analysis of the preprint-to-publication process. It includes metadata on more than 145,000 preprints from two distinct periods (2016–2018, the pre-pandemic period, and 2020–2022, the COVID-19 pandemic period), with information on titles, authors, abstracts, institutions, licenses, submission and publication dates, and subject categories. Preprints are categorized into “Published”, “Preprint Only”, and “Gray Zone” cases, based on automated linking procedures combining Digital Object Identifier (DOI) information, title similarity, and author similarity. In addition to the main dataset, two subset files are provided: (i) a human-annotated subset of Gray Zone cases is provided to support evaluation of the automated matching approach (this subset includes records with title similarity (title_match_score = 0.75) and was independently checked by two annotators; further details on the annotation procedure are provided in the Methods section - Step 5: Gray Zone Verification) and (ii) a version-history subset that lists all available versions for preprints that have version one and at least one additional version. This subset is intended for detailed, version-level analyses of preprint evolution.
The motivation for creating the PreprintToPaper dataset is to provide a comprehensive resource for studying how preprints evolve into published journal articles or remain as preprints posted only on a preprint server^4,5^. While some preprints are eventually linked to formal publications, many others stay as preprints without ever appearing in journals. This dataset is the systematic effort to automatically collect and link metadata from bioRxiv^6^ with publication records, making it possible to analyze patterns in the preprint-to-publication process at scale^7^. We selected the 2016–2018 (pre-pandemic) and 2020–2022 (pandemic) periods to capture preprint-publication dynamics before and during the COVID-19 pandemic while avoiding transitional years.
We identify the following potential reuse cases for the PreprintToPaper dataset.
- Policy and evaluation studies: Provides evidence for assessing the role of preprints in accelerating scientific dissemination, informing open science policies, and tracking uptake during events such as the COVID-19 pandemic^2,8,9^. To enable comparison, we included preprints from 2016–2018, which we designate as the pre-pandemic period.
- Scholarly communication research: Enables analysis of publication delays, changes in titles, abstracts, and authorship between preprints and journal articles, and differences across research fields or time periods^10,11^.
- Tool and method development: Serves as a reference dataset for testing algorithms in informetrics, metadata linking, and similarity matching (e.g., title and author disambiguation).
- Natural language processing and text analysis: Supports research on linguistic and structural changes between preprints and their corresponding journal articles, such as title reformulations, abstract rewriting, and shifts in author order or contribution statements.
In the following, we summarize related work that has used preprint data from bioRxiv.
Research on bioRxiv has shown that articles posted as preprints tend to receive more citations and online attention than comparable articles not deposited, although the causal mechanisms behind this effect remain uncertain^12^. Surveys of authors indicate that the main motivations for posting preprints are to increase visibility and accelerate dissemination, while concerns about peer review and lack of awareness are the main barriers^2^. Large-scale bibliometric analyses further confirm a citation and altmetric advantage for bioRxiv-linked publications, with preprints themselves increasingly cited and shared on social media^12^. During the COVID-19 pandemic, preprints on bioRxiv and medRxiv played an unprecedented role, being accessed, cited, and shared at higher rates, and influencing both journalistic reporting and policy discussions^1^. An analysis of biomedical publishing during the first months of the COVID-19 pandemic reveals a sharp rise in publication volume, faster acceptance times for COVID-19 papers, and reduced international collaboration, with these shifts occurring largely at the expense of non-COVID-19 research^8^. Other studies of bioRxiv preprints have found that approximately 30% remain as preprints posted only on a preprint server, that many are posted too late to enable substantive feedback, and that nearly half of preprints published in a journal are concentrated among four major publishers, suggesting that the platform is used more for priority setting and visibility than for pre-publication peer review^4,13^.
Below, we provide an overview of related datasets based on bioRxiv preprints and collections of COVID-19-related preprints.
The Rxivist database provides a snapshot of preprints from bioRxiv and medRxiv collected via a custom web crawler, enabling readers to sort, filter, and analyze tens of thousands of preprints based on a PostgreSQL-importable database^7,14^.
The covid19_preprints dataset compiled weekly updated metadata on COVID-19-related preprints from multiple sources (Crossref, DataCite, arXiv, and RePEc), using keyword-based matching and deduplication procedures to track their distribution over time^1,15^.
Europe PMC^16^ maintains a large corpus of preprints and journal articles, including bioRxiv preprints, and links them to their corresponding publications.
Compared with the three related preprint resources discussed above, the PreprintToPaper dataset offers two main advantages:
- It stores both the initial and final versions of bioRxiv preprints, along with detailed metadata (e.g., title, authors, journal, and publication date) for their corresponding journal articles. In addition, a separate version-history file contains all available preprint versions for cases with more than one version within our study periods.
- It identifies articles that are not formally linked but may have been published in a journal (Gray Zone cases) by using title and author similarity, which tolerate minor title changes and variations in author order, thereby going beyond exact-match linking.
Find a detailed comparison of the four datasets in Table 1.Table 1. Comparison of the covid19_preprints, Rxivist, Europe PMC, and PreprintToPaper datasets.Aspectcovid19_preprintsRxivistEurope PMC corpusPreprintToPaper (Ours)Time span2017–2021Nov 2013 - Feb 20232013–20232016–2018 (pre-pandemic) and 2020–2022 (pandemic)CoverageMultiple preprint servers (bioRxiv, arXiv, OSF, ESSOAR, Figshare, Zenodo, etc.)bioRxiv and medRxivMultiple 32 life-science preprint serversbioRxivScopeCOVID-19 related preprints onlyAll subjects (bioRxiv + medRxiv)All subjects (32 servers)All subjects (bioRxiv)Size66,130 records223,541 records761,123 records145,517 recordsPreprint informationSource, identifier (DOI), posted date, title, abstractTitle, abstract, DOI, category, submission date, authors, institutionsTitle, abstract, DOI, submission date, authors, full text of COVID-19 and Europe PMC funder preprints in JATS XML, author affiliations, license, funding, versions, status (Withdrawal/removal)Title, abstract (initial + last), DOI, category, submission date (initial + last), authors (initial + last), corresponding authors, institutions, license, version number, category, fulltext JATS XMLPublication informationNonePublished journal article DOI, journal namePublished journal article DOI, journal name, publication date, citations, referencesPublished journal article DOI, title, authors, journal name, publication date (from Crossref)VersioningOnly one version per preprintOnly one version per preprintAll versions (except from bioRxiv, medRxiv, SSRN)All versions at the relevant period (bioRxiv)Publication linkingNonePublished journal article DOIs partially incomplete (crawling stopped early)Official bioRxiv links enriched with journal metadata + an investigation of unlinked preprints where an exact match of title and first author is required. Even minor changes in title or author names are ignored; as a result, many preprints with slightly different titles are not linked to their journal papersOfficial bioRxiv links enriched with Crossref + additional Gray Zone investigation where both titles and full author lists are compared using similarity scores. Preprint-paper pairs with title similarity between 75% and 100% are identified and added as potential links (≈19,000)
Two further resources provide data related to preprint-publication links: PreprintMatch^17^ and the Crossref relationships dataset^18^. In contrast to PreprintToPaper, they focus on DOI-to-DOI linkage and matching infrastructure, rather than delivering a bioRxiv-specific dataset with enriched metadata.
Methods
Dataset generation workflow
Figure 1 illustrates the data generation workflow for the PreprintToPaper dataset. The process consists of six main steps: (1) collecting metadata from the bioRxiv preprint platform; (2) retrieving additional metadata from Crossref based on the published journal article DOIs listed in the bioRxiv records; (3) categorizing preprints into published and preprint-only; (4) identifying unlinked publications in bioRxiv (Gray Zone); (5) verifying Gray Zone preprints using author-based metrics (author match score and author count difference); and (6) generating the final dataset.Fig. 1. PreprintToPaper dataset creation workflow. Final enriched dataset and two derived subsets are generated: (i) a human-annotated Gray Zone subset of 299 title-matched cases (title match score = 0.75) and (ii) a version history subset, in which multi-version preprints that retain version 1 and at least one later version within the study periods are included.
Step 1: bioRxiv Metadata Retrieval
The first step in this study was to obtain metadata from the bioRxiv preprint platform using the official bioRxiv API (https://api.biorxiv.org/details/server/interval/cursor/format. The API has the following structure: server indicates the source of the data (e.g., bioRxiv or MedRxiv), interval indicates the desired date range, cursor indicates the pagination of the results, and format indicates the output format (e.g., JSON). The following data fields were collected through the API, and the retrieved metadata fields were mapped to the following structure in the dataset (see Table 2).Table 2. Mapping of bioRxiv API fields to the dataset columns.bioRxiv API fieldDataset columnDescriptionDOIbiorxiv_doiUnique digital identifier of the preprintTitlebiorxiv_titleTitle of the preprintAuthorsbiorxiv_authorsList of all authorsCorresponding authorbiorxiv_author_correspondingName of the corresponding authorCorresponding author institutionbiorxiv_author_corresponding_institutionInstitution of the corresponding authorDatebiorxiv_submission_dateSubmission date of the preprintVersionbiorxiv_versionVersion number of the preprintTypebiorxiv_typeDocument type of the preprintLicensebiorxiv_licenseLicenseCategorybiorxiv_categorySubject categoryJATS XML pathbiorxiv_jatsxmlLink to the XML fileAbstractbiorxiv_abstractAbstract textPublishedbiorxiv_published_doiPublication DOI in a journal
Data were collected for two periods: 2016–2018 (pre-pandemic period) and 2020–2022 (COVID-19 pandemic period). The collected metadata was then processed. Because most preprints have multiple versions, only records that met the following criteria were retained during the processing stage:
- If the preprint is in the relevant period and both the first and last versions of the preprint are available, then both versions were kept.
- If the preprint has only one version and this version is the first, then this version was also retained.
If only non-initial versions were available during the relevant period, the corresponding records were deleted. Additionally, a pivoting step was applied to the entire dataset to prevent DOI duplication. To avoid this, each preprint was stored only once, but non-repeating fields were stored in separate columns. For example, the title, authors, corresponding author, submission dates, and abstract of both the first and last versions were stored in new columns. For this purpose, the _1st and _last suffixes were systematically added to the column names (e.g., biorxiv_title_1st and biorxiv_title_last).
In addition to the main table, a separate version-history subset was created that contains all available versions for preprints with a first version and at least one subsequent version within our study periods. The filtering applied to the main dataset is designed to track changes between the first and last preprint versions, as well as changes that occur upon journal publication, whereas the version-history subset supports more detailed, version-level analyses. However, because the bioRxiv API was observed to return identical abstract text across different versions of the same preprint, abstracts were not included in the version-history subset.
Step 2: Crossref Metadata Retrieval
For preprints that were later published as journal articles, the corresponding journal DOI is stored in the bioRxiv dataset. About two weeks after journal publication, bioRxiv automatically adds a link to the corresponding journal article (https://www.biorxiv.org/about/FAQ). Detailed metadata for these articles was retrieved via the official Crossref API (https://api.crossref.org/works/doi), by replacing the doi field with the DOI of the corresponding article. This query returns an extensive metadata package for the corresponding journal article. The following fields were retrieved from the Crossref database (see Table 3).Table 3. Mapping of Crossref API fields to the dataset columns.Crossref API fieldDataset columnDescriptionContainer-titlecrossref_journal_nameName of the journal in which the article was publishedTitlecrossref_titleOfficial title of the corresponding journal articleAuthorcrossref_authorsList of authorsPublished-onlinecrossref_online_publication_dateDate the journal article was first made available onlinePublished-printcrossref_issue_online_dateDate associated with the volume or issue of the journal in which the article appeared
The official publication dates of 500 journal articles were manually compared with the online_publication_date and issue_online_date obtained from Crossref. In most cases, the online_publication_date matched with the actual publication date of the article.
Based on the results of manual checks, we retained the online_publication_date when available and used the issue_online_date otherwise. Both values were then merged into a single column, crossref_publication_date. Additionally, a new column, crossref_publication_type, was created to indicate whether the date refers to the online or issue version.
Step 3: Categorization of Preprints
In the third step, the dataset was categorized based on whether the preprints had DOIs linked to journal articles on the bioRxiv preprint server.
- If a journal article DOI was available for the preprint, the preprint was included in the published group.
- If a DOI was not available, the preprint was categorized as preprint only.
The categorization result was stored in the column custom_status.
Step 4: Identification of unlinked publications in bioRxiv - Gray Zone
Although bioRxiv metadata is expected to include DOIs for all preprints that have been published as journal articles, verification revealed that in some cases the DOI of the corresponding journal article is missing, even when the preprint has been published in a journal. For example, the fourth version of a preprint with 10.1101/170381was submitted to bioRxiv on August 6, 2020, but the same article was later published in Brain Structure and Function with 10.1007/s00429-020-02136-0 on September 18, 2020. Nevertheless, the preprint still appears as preprint only in the bioRxiv record.
Previous studies have also documented this issue^1,5,7^. For example, Abdill and Blekhman (2019) found that 37.5% of 120 bioRxiv preprints were missing publication links. Fraser et al. (2021) reported that 7.6% of 12,788 preprints had missing publication links. Cabanac et al. (2021) reported that 60.3% of preprints marked as journal-published on medRxiv and three other servers lacked corresponding publication links.
To identify such cases, we compared the titles of works marked as preprint only with the titles of the corresponding journal articles in the Crossref database. First, a separate request was sent to the Crossref database for each DOI, and matching titles were identified. Python’s SequenceMatcher library was then used to assess title similarity. The algorithm determines the longest common subsequence between two texts, accounts for the total length of matching parts, and calculates a similarity coefficient ranging from 0 to 1. A coefficient close to 1 indicates a complete match, whereas a value near 0 indicates substantial differences.
To assess our choice of similarity measure, we compared Python’s SequenceMatcher with two FuzzyWuzzy metrics on a random sample of 100 preprint and publication title pairs from our dataset, all of which were confirmed as published in a journal. In 58% of the cases, all three measures produced identical scores, and in the remaining cases the differences were small and did not change the classification of any pair with respect to our 0.75 threshold. We therefore retained SequenceMatcher as our main measure, as it is part of the Python standard library.
Matches with a similarity index of 0.75 or higher were classified into the Gray Zone category. This threshold was chosen because, in tests comparing preprints already marked as journal-published in bioRxiv with their corresponding journal versions, results in this range proved most reliable in Fig. 2.Fig. 2. Distribution of journal papers by title match score.
The calculated title similarity values were stored in the title_match_score column of the dataset. Additionally, for the preprints classified as Gray Zone, the corresponding metadata retrieved from the Crossref API including journal name, title, published date, author list, and publication date was stored in these fields crossref_journal_name, crossref_title, crossref_authors, crossref_publication_date, crossref_publication_type.
Step 5: Gray Zone Verification (Author Metrics)
To further improve the accuracy of preprints in the Gray Zone category, additional author-based metrics were applied. At this stage, the author names from the bioRxiv and Crossref metadata were compared. Two main metrics were calculated:
- Author Count Difference – the difference between author counts in the bioRxiv and Crossref records.
- Author Match Score – the similarity score between the author lists.
For the second metric, Unicode normalization was first performed to minimize differences in name format, diacritical marks were separated and removed, and all letters were reduced to lowercase. Then, for each record, the author list was first divided into individual authors by the “;” separator, and each author line was tokenized by splitting it into words using the space character. As a result, a nested (i.e., list-within-a-list) structure consisting of authors was constructed for each line. Based on this structure, the SequenceMatcher library was applied, and the author’s match score was calculated. This approach allowed for more accurate results in cases such as variations in the order of first and last names or when only initials were recorded.
Additionally, to validate these metrics, a human-annotated subset with a title match score of 0.75 was created, representing the lower bound of our title similarity threshold. Two annotators manually checked the corresponding bioRxiv and Crossref abstracts, and inter-annotator agreement was high.
Thus, the publication status of preprints in the Gray Zone category was determined more accurately using the author match score and author count difference metrics.
Step 6: Final Dataset Generation
In the final stage, several additional calculations were performed to enrich the dataset with further features. For example, the difference between the submission dates of the first and last versions of each preprint was calculated, as well as the difference between the official journal publication date and the last submission date on bioRxiv for the preprints published in journal. These values were stored in the custom_biorxivVersion_dateDifference and custom_submission&publication_dateDiff columns.
These operations made it possible to track the time dynamics between preprint versions and their subsequent journal publication. The finalized dataset was then saved in CSV format.
Data Record
The dataset is based on data collected from the bioRxiv and Crossref databases. It is stored in CSV format and is publicly available via Zenodo^3^ (10.5281/zenodo.17992421). The dataset consists of three main files:
- The Main dataset includes metadata of preprints collected in 2016–2018 and 2020–2022. This file contains primary fields obtained from the bioRxiv API (DOI, title, authors, corresponding institutions, abstract, version, category, license, etc.) and additional fields obtained from the Crossref API (e.g., journal name, title in the journal, publication date, author list). In addition, there are custom fields calculated by us: title match score, author match score, author count difference, the difference between the first and last version submission dates, and the difference between the last preprint submission date and the publication date. Only fields that are not self-explanatory are described in detail below:
• custom_status: Classification indicating the publication status of preprints: Published (officially published in a journal and confirmed with a DOI in bioRxiv), Preprint Only (posted on a preprint server), or Gray Zone (no official link in bioRxiv, but a possible publication identified based on title and author match).
• biorxiv_published_doi: DOI of the corresponding journal articles. This information is collected from two sources: (1) official publication DOIs provided by bioRxiv; (2) DOIs additionally identified in Gray Zone cases.
• custom_submission&publication_dateDiff: The difference in days between the last preprint submission date and the publication date of the corresponding journal article.
• custom_biorxivVersion_dateDifference: The difference in days between the submission dates of the first and last bioRxiv versions.
• biorxiv_version_last: The serial number of the last version of the preprint available on bioRxiv (e.g., a value of “5” indicates that five versions have been published).
• biorxiv_jatsxml: A URL that references a JATS XML file containing the full text and metadata of the preprint, if available.
• crossref_publication_date: The publication date retrieved from Crossref. This date can refer either to the online publication or the issue publication.
• crossref_publication_date_type: Indicates the type of date given in the crossref_publication_date column: online publication or issue publication. If the online publication date is available, it is preferred; otherwise, the issue publication date is used.
• author_count_diff: The difference between the number of authors in the preprint and the number of authors in the corresponding journal article. Positive values indicate that the preprint published in journal has more authors, while negative values indicate fewer.
• title_match_score: The similarity score between the preprint and the journal article titles. Values range from 0 to 1 and are calculated with the SequenceMatcher algorithm. Only matches within the 0.75–1.0 range were considered potential publication candidates.
• author_match_score: Similarity score between the preprint and corresponding journal article author lists. Ranges from 0 to 1 and is primarily used to verify Gray Zone cases, with higher values indicating stronger similarity.
Table 4 presents the distribution of preprints in the dataset by period and category (Gray Zone, Preprint Only, Published) along with the total numbers.Table 4. Distribution of preprints in the PreprintToPaper dataset.PeriodGray ZonePreprint OnlyPublishedTotal Preprints** 20163591 0193 3434 721 20178412 3148 19111 346 20181 1214 11512 94318 179 20203 7468 88426 08138 711 20215 2928 98722 53936 818 20227 73110 49417 51735 742 Total**** 19 090**** 35 813**** 90 614**** 145 517**
-
2.The Version History Subset is a separate, version-level file that contains all available versions for preprints that have version one and at least one additional version within our study periods (2016–2018 and 2020–2022). Preprints with only a single version or without the first version present are not included in this file. Each row corresponds to a bioRxiv version and includes the DOI, version number, submission date, title, authors, category, license, and other core bioRxiv metadata. This subset allows detailed analyses of how preprints evolve across multiple versions.
-
3.The Human-Annotated Subset, containing 299 records, includes only cases with a title match score of 0.75. Preprints from both periods (2016–2018 and 2020–2022) were selected, and two annotators verified potential matches by manually checking the corresponding abstracts from bioRxiv and Crossref. To support evaluation of the Gray Zone category, this file is provided as an additional resource. The dataset includes the following variables: year, biorxiv_doi, suspected_published_doi, author_match_score, annotator1, and annotator2.
-
suspected_published_doi: Suspected DOI of the journal-published article. Includes DOIs identified for Gray Zone preprints where a potential corresponding journal article was found but could not be fully confirmed.
-
annotator.1/annotator2: Labels provided independently by two annotators to validate Gray Zone matches. Values: True (confirmed as correct match), False (not a valid match), or NA (uncertain).
Technical Validation
To assess the validity of the proposed approach, all the records characterized by the title_match_score = 0.75 (in total 299 records) have been selected and annotated by two referees; each of them had an option to mark a record as TRUE (the identified journal publication was based on the preprint), FALSE (there was no connection between the preprint and the publication) or NA (the annotator was unable to make a call). The Cohen’s kappa coefficient^19^ for non-NA data among annotators is equal to κ = 0.86, indicating strong agreement among the annotators^20^.
The annotations have been then merged by taking the conjunction of two annotations, i.e., only if both annotators deemed the identified publication to be true, it was considered as such; if either of the annotators regarded the publication as NA, it was assigned NA. The resulting distribution gives 69% of positive recognition and 28% of falsely assigned publications, with the remaining 3% that cannot be resolved. These outcomes suggest that the title matching score alone might be an insufficient indicator. Figure 3a presents the combined annotation versus author match score, presenting evidence that preprint – publication pairs with a low level of author match score are more likely to be among false positives than ones characterized by an author match score close to 1. To provide a more qualitative description of this fact and motivated by the observed relation between the combined annotation and author match score seen in Figure 3a, we used the logistic regression model^21^ given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log \left(\frac{\pi }{1-\pi }\right)={\beta }_{0}+{\beta }_{1}x$$\end{document}where π is interpreted as the probability of the dependent variable (annotation) equaling a success, x reflects author match score and β0, β1 are regression coefficients. The model was fitted on the set of non-NA data, resulting in β0 = − 2.99 ± 0.46 and β1 = 6.36 ± 0.67 (see the curve in Figure 3a). The location parameter μ = − β0/β1 – the midpoint of the curve, where π crosses 1/2 is μ = 0.47 ± 0.12 where the standard deviation of μ has been calculated using propagation of uncertainty^22^, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\sigma }_{\mu }^{2}=| {\beta }_{0}/{\beta }_{1}| \sqrt{{\sigma }_{{\beta }_{0}}^{2}/{\beta }_{0}^{2}+{\sigma }_{{\beta }_{1}}^{2}/{\beta }_{1}^{2}}$$\end{document} . To assess the validity of the logistic regression approach, we performed 10-fold cross-validation^21^, obtaining the accuracy = 0.92 and Cohen’s κ = 0.81.Fig. 3(a) Combined annotations versus author match score for records characterized by the title match score equal to 0.75 (see text for rationale). Symbols are data points, and the curve comes from the fit to the logistic regression model (1). Data points are artificially jittered around TRUE and FALSE values to avoid overlap. (b) The fraction of preprints that were eventually published as journal articles versus the year of preprint submission. Triangles represent data without the gray zone records, circles take into account gray zone records, with the author match score larger than 0.47 (suggested by logistic regression analysis, see text in Technical Validation) used to distinguish between preprints and eventually published journal papers.
Let us now see the ramifications of the author match score threshold μ on the possible use of the dataset. Figure 3b presents the fraction of preprints that were eventually published as journal articles f versus the year of preprint submission. The first series, marked by triangles, disregards the gray zone papers, taking into account only records marked as “published”, which leads to a spectacular decrease in f by over 30% between years 2016 and 2022. However, if we take into account that all gray zone records with author match score exceeding μ = 0.47 (obtained as threshold from the logistic regression analysis) can be regarded as journal-published ones, the decrease does not exceed 11%.
Usage Notes
PreprintToPaper dataset can be used in a variety of studies: one of the principal ideas is connected to the issue of information overload^23^ in academia – a notion that is widely understood^24^ (e.g., paper tsunami^25^) but for which no measures have been defined yet. The very construction of our dataset (i.e., a set of preprints submitted before / during the outbreak of the COVID-19 pandemic), along with the information about the period between the preprint submission, can help find the patterns of preprint-to-paper transformations under the stress exerted by the pandemic^25^. Similarly, the characteristics of “preprints posted on preprint server” – treated in a manner analogous to uncited papers^26,27^ – can be examined using the provided dataset. These include stylometric factors: title and abstract length, text complexity (e.g., Herdan’s measure^28^), readability scores (e.g., Gunning FOG index^29^) as well as text sentiment, number of authors, and other that have been shown to play role in the previous studies linking textual factors and paper popularity^30–32^.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fraser, N., Mayr, P. & Peters, I. Motivations, concerns and selection biases when posting preprints: a survey of bio Rxiv authors. P Lo S ONE 17, 10.1371/journal.pone.0274441 (2022).10.1371/journal.pone.0274441 PMC 963278036327267 · doi ↗ · pubmed ↗
- 2Badalova, F., Mayr, P. & Sienkiewicz, J. Preprint To Paper dataset: Connecting bio Rxiv preprints with journal publications, 10.5281/zenodo.17992421 (2025).10.1038/s 41597-026-06867-3PMC 1293620841735295 · doi ↗ · pubmed ↗
- 3Sever, R. et al. bio Rxiv: the preprint server for biology, 10.1101/833400 (2019).
- 4Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning. Springer Series in Statistics (Springer New York Inc., New York, NY, USA, 2001).
- 5Herdan, G. Language as choice and chance (Springer Berlin Heidelberg, Berlin, Germany, 1960).
- 6Gunning, R. The technique of clear writing (Mc Graw-Hill, New York, NY, 1952).
- 7R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2025).
- 8Wilke, C. O. cowplot: Streamlined Plot Theme and Plot Annotations for ’ggplot 2’ R package version 1.2.0., 10.32614/CRAN.package.cowplot (2025).