Adaptive querying for reward learning from human feedback
Yashwanthi Anand, Nnamdi Nwagwu, Kevin Sabbe, Naomi T. Fitter, Sandhya Saisubramanian

TL;DR
This paper introduces a method for robots to learn from human feedback by adaptively choosing when and how to ask for input, improving learning efficiency and safety.
Contribution
The novelty is an adaptive feedback selection method that optimizes both query states and feedback formats to accelerate learning.
Findings
The approach improves sample efficiency in learning to avoid unsafe behaviors in simulations.
User studies with a physical robot show the method effectively gathers informative feedback aligned with user preferences.
Adaptive feedback selection accounts for feedback cost and probability, enhancing practical usability.
Abstract
Learning from human feedback is a popular approach to train robots to adapt to user preferences and improve safety. Existing approaches typically consider a single querying (interaction) format when seeking human feedback and do not leverage multiple modes of user interaction with a robot. We examine how to learn a penalty function associated with unsafe behaviors using multiple forms of human feedback, by optimizing both the query state and feedback format. Our proposed adaptive feedback selection is an iterative, two-phase approach which first selects critical states for querying, and then uses information gain to select a feedback format for querying across the sampled critical states. The feedback format selection also accounts for the cost and probability of receiving feedback in a certain format. Our experiments in simulation demonstrate the sample efficiency of our approach in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
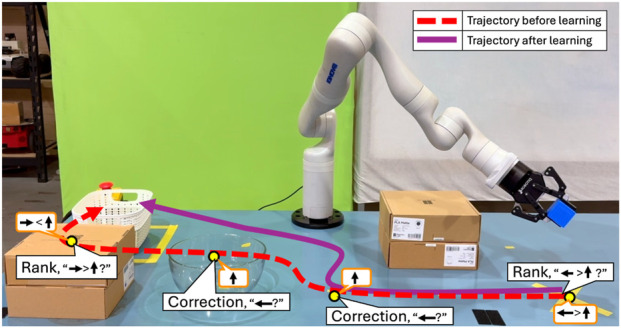 FIGURE 1
FIGURE 1 FIGURE 2
FIGURE 2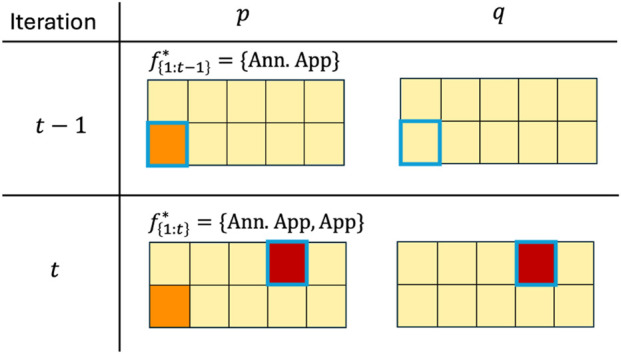 FIGURE 3
FIGURE 3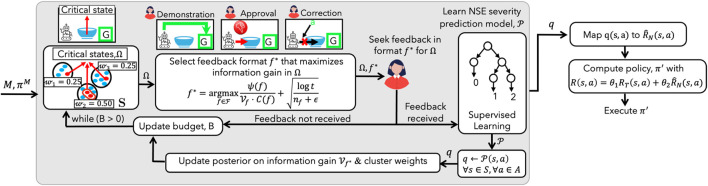 FIGURE 4
FIGURE 4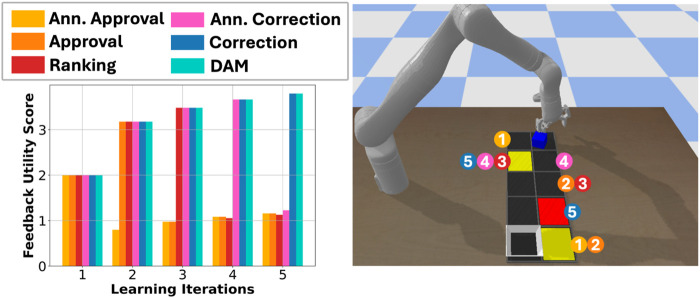 FIGURE 5
FIGURE 5 FIGURE 6
FIGURE 6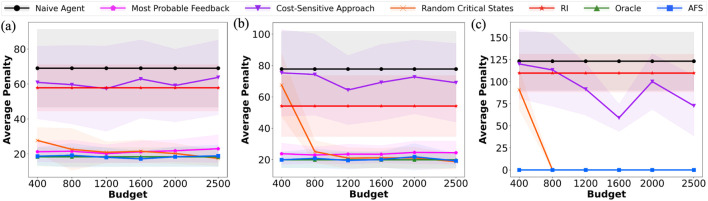 FIGURE 7
FIGURE 7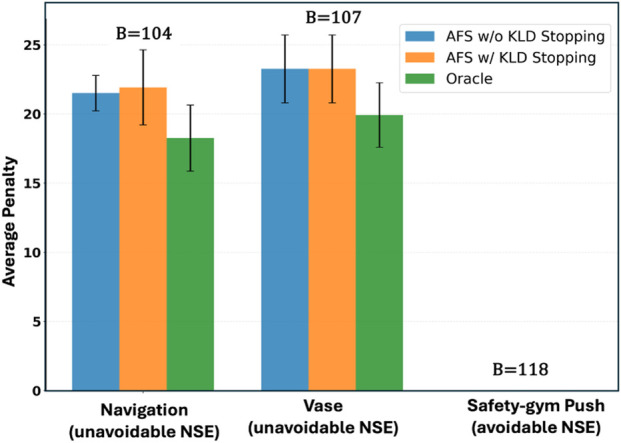 FIGURE 8
FIGURE 8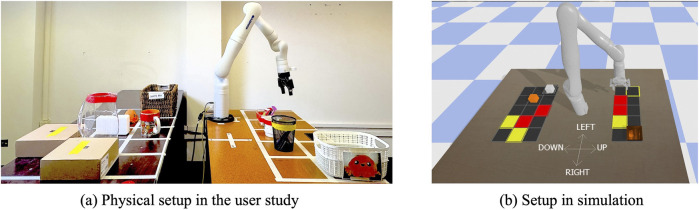 FIGURE 9
FIGURE 9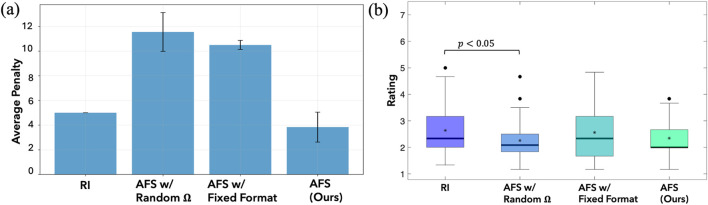 FIGURE 10
FIGURE 10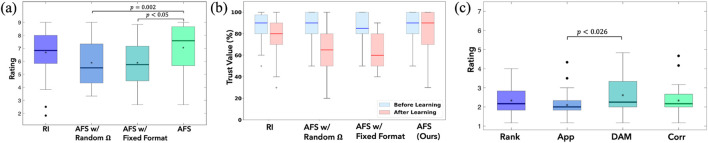 FIGURE 11
FIGURE 11| Method | Navigation: Unavoidable NSE | Vase: Unavoidable NSE | Safety-gym push: Avoidable NSE |
|---|---|---|---|
| Oracle |
|
|
|
| Naive |
|
|
|
| RI |
|
|
|
| AFS |
|
|
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobot Manipulation and Learning · Social Robot Interaction and HRI · Reinforcement Learning in Robotics
Introduction
1
A key factor affecting an autonomous agent’s behavior is its reward function. Due to the complexity of real-world environments and the practical challenges in reward design, agents often operate with incomplete reward functions corresponding to underspecified objectives, which can lead to unintended and undesirable behaviors such as negative side effects (NSEs) (Amodei et al., 2016; Saisubramanian et al., 2021a; Srivastava et al., 2023). For example, a robot optimizing the distance to transport an object to the goal, may damage items along the way if its reward function does not model the undesirability of colliding into other objects in the way (Figure 1).
An illustration of adaptive feedback selection. The robot arm learns to move the blue object to the white bin, without colliding with other objects in the way, by querying the human in different format across the state space.
Human feedback offers a natural way to provide the missing knowledge, and several prior works have examined learning from various forms of human feedback to improve robot performance, including avoiding side effects (Cui and Niekum, 2018; Cui et al., 2021b; Lakkaraju et al., 2017; Ng and Russell, 2000; Saran et al., 2021; Zhang et al., 2020). In many real-world settings, the human can provide feedback in many forms, ranging from binary signals indicating action approval to correcting robot actions, each varying in the granularity of information revealed to the robot and the human effort required to provide it. For instance, a person supervising a household robot may occasionally be willing to provide detailed corrections when the robot encounters a fragile vase but may only want to give quick binary approvals during a routine motion. Ignoring this variability either limits what the robot can learn or burdens the user. To efficiently balance the trade-off between seeking feedback in a format that accelerates robot learning and reducing human effort involved, it is beneficial to seek detailed feedback sparingly in certain states and complement it with feedback types that require less human effort in other states. Such an approach could also reduce the sampling biases associated with learning from any one format, thereby improving learning performance (Saisubramanian et al., 2022). In fact, a recent study indicates that users are generally willing to engage with the robot in more than one feedback format (Saisubramanian et al., 2021b). However, existing approaches rarely exploit this flexibility, and do not support gathering feedback in different formats in different regions of the state space (Cui et al., 2021a; Settles, 1995).
These practical considerations motivate the core question of this paper: “How can a robot identify when to query and in what format, while accounting for the cost and availability of different forms of feedback?” We present a framework for adaptive feedback selection (AFS) that enables a robot to seek feedback in multiple formats in its learning phase, such that its information gain is maximized. Rather than treating all states and feedback formats uniformly, AFS prioritizes human feedback in states where feedback is most valuable and chooses feedback types based on their expected cost and information gain. This design reduces user effort, accommodates different levels of feedback granularity, and focuses on state where learning improves safety. In the interest of clarity, the rest of this paper grounds the discussion of AFS as an approach for robots to learn to avoid negative side effects (NSEs) of their actions. The NSEs refer to unintended and undesirable outcomes that arise as the agent performs its assigned task. In object delivery example in Figure 1, the robot may inadvertently collide with other objects on the table, producing NSEs. Focusing on NSEs provides a well-defined and measurable setting–quantified by the number of NSE occurrences–to evaluate how AFS improves an agent’s learning efficiency and safety. However, note that AFS is a general technique that can be applied broadly to learn about various forms of undesirable behavior.
Minimizing NSEs using AFS involves four iterative steps (Figure 4): (1) states are partitioned into clusters, with a cluster weight proportional to the number of NSEs discovered in it; (2) a set of critical states—states where human feedback is crucial for learning an association of state features and NSEs, i.e., a predictive model of NSE severity, is formed by sampling from each cluster based on its weight; (3) a feedback format that maximizes the information gain in critical states is identified, while accounting for the cost and uncertainty in receiving a feedback, using the human feedback preference model; and (4) cluster weights and information gain are updated, and a new set of critical states are sampled to learn about NSEs, until the querying budget expires. The learned NSE information is mapped to a penalty function and augmented to the robot’s model to compute an NSE-minimizing policy to complete its task.
We evaluate AFS in both simulation and using a user study where participants interact with a robot arm. First, we evaluate the approach in three simulated proof-of-concept settings with simulated human feedback. Second, we conduct a pilot study where 12 human participants interact with and provide feedback to the agent in a simulated gridworld domain. Finally, we evaluate using a Kinova Gen3 7DoF arm and 30 human participants. Besides the performance and sample efficiency, our experiments also provide insights into how the querying process can influence user trust. Together, these complementary studies demonstrate both the practicality and effectiveness of AFS.
Background and related work
2
Markov Decision Processes (MDPs)
2.1
The MDPs are a popular framework to model sequential decision making problems. An MDP is defined by the tuple , where is the set of states, is the set of actions, is the probability of reaching state after taking an action from a state and is the reward for taking action in state . An optimal deterministic policy is one that maximizes the expected reward. When the objective or reward function is incomplete, even an optimal policy can produce unsafe behaviors such as side effects. Negative Side Effects (NSEs) are immediate, undesired, unmodeled effects of an agent’s actions on the environment (Krakovna et al., 2018; Saisubramanian and Zilberstein, 2021; Srivastava et al., 2023). We focus on NSEs arising due to incomplete reward function (Saisubramanian et al., 2021a), which we mitigate by learning a penalty function using human feedback.
Learning from human feedback
2.2
Learning from human feedback is a popular approach to train agents when reward functions are unavailable or incomplete (Abbeel and Ng, 2004; Ng and Russell, 2000; Ross et al., 2011; Najar and Chetouani, 2021), including to improve safety (Brown et al., 2020b; 2018; Hadfield Menell et al., 2017; Ramakrishnan et al., 2020; Zhang et al., 2020; Saisubramanian et al., 2021a; Hassan et al., 2025). Feedback can take various forms such as demonstrations (Ramachandran and Amir, 2007; Saisubramanian et al., 2021a; Seo and Unhelkar, 2024; Zha et al., 2024), corrections (Cui et al., 2023; Bärmann et al., 2024), critiques (Cui and Niekum, 2018; Tarakli et al., 2024), ranking trajectories (Brown et al., 2020a; Xue et al., 2024; Feng et al., 2025), natural language instructions (Lou et al., 2024; Yang Y. et al., 2024; Hassan et al., 2025) or may be implicit in the form of facial expressions and gestures (Cui et al., 2021b; Strokina et al., 2022; Candon et al., 2023).
While the existing approaches for learning from feedback have shown success, they typically assume that a single feedback type is used to teach the agent. This assumption limits learning efficiency and adaptability. Some efforts combine demonstrations with preferences (Bıyık et al., 2022; Ibarz et al., 2018), showing that utilizing more than one format accelerates learning. Extending this idea, recent works integrate richer modalities such as language and vision with demonstrations. Yang Z. et al. (2024) learn reward function from comparative language feedback, while Sontakke et al. (2023) show that a single demonstration or natural language description can help define a proxy reward when used along with a vision-language models (VLM) that is pretrained on a large amount of out-of-domain video demonstrations and language pairs. Kim et al. (2023) use multimodal embeddings of visual observations and natural language descriptions to compute alignment-based rewards. A recent study even emphasizes that combining multiple feedback modalities can further enhance learning outcomes (Beierling et al., 2025). Together, these works highlight that combining complementary feedback formats help advance reward learning beyond using a fixed feedback format. Building on this insight, our approach uses multiple forms of human feedback for learning.
Learning from human feedback has also been used for modeling variations in human behavior. Huang et al. (2024) model the heterogeneous behaviors of human, capturing differences in feedback frequency, delay, strictness, and bias to improve the robustness during the learning process, as optimal behaviors vary across users. Along the same line, the reward learning approach proposed by Ghosal et al. (2023), selects a single feedback format based on the user ability to provide feedback in that format, resulting in an interaction that is tailored to a user’s skill level. Collectively, these works reveal a shift towards adaptive and user-aware querying mechanisms that improves reward inference and learning efficiency, motivating our approach to dynamically select both when to query and in what feedback format.
Problem formulation
3
Setting: Consider a robot operating in a discrete environment modeled as a Markov Decision Process (MDP), using its acquired model . The robot optimizes the completion of its assigned task, which is its primary objective described by reward . A primary policy, , is an optimal policy for the robot’s primary objective.
Assumption 1. Similar to (Saisubramanian et al., 2021a), we assume that the agent’s model has all the necessary information for the robot to successfully complete its assigned task but lacks other superfluous details that are unrelated to the task.
Since the model is incomplete in ways unrelated to the primary objective, executing the primary policy produces negative side effects (NSEs) that are difficult to identify at design time. Following (Saisubramanian et al., 2021a), we define NSEs as immediate, undesired, unmodeled effects of a robot’s actions on the environment. We focus on settings where the robot has no prior knowledge about the NSEs of its actions or the underlying true NSE penalty function . It learns to avoid NSEs by learning a penalty function from human feedback that is consistent with .
We target settings where the human can provide feedback in multiple ways and the robot can seek feedback in a specific format such as approval or corrections. This represents a significant shift from traditional active learning methods, which typically gather feedback only in a single format (Ramakrishnan et al., 2020; Saisubramanian et al., 2021a; Saran et al., 2021). Using the learned , the robot computes an NSE-minimizing policy to complete its task by optimizing: , where and are fixed, tunable weights denoting priority over objectives.
Running Example: We illustrate the problem using a simple object delivery task using a Kinova Gen3 7DoF arm shown in Figure 1. The robot optimizes delivering the blue block to the white bin, by taking the shortest path. However, passing through states with a cardboard box or a glass bowl constitutes an NSE. Since the robot has no prior knowledge about NSEs of its actions, it may inadvertently navigate through these states causing NSEs.
Human’s Feedback Preference Model: The feedback format selection must account for the cost and human preferences in providing feedback in a certain format. The user’s feedback preference model is denoted by where,
- is a predefined set of feedback formats the human can provide, such as demonstrations and corrections;
- is the probability of receiving feedback in a format , denoted as ; and
- is a cost function that assigns a cost to each feedback format , representing the human’s time or cognitive effort required to provide that feedback.
This work assumes the robot has access to the user’s feedback preference model —either handcrafted by an expert or learned from user interactions prior to robot querying, as in our user study experiments. Abstracting user feedback preferences into probabilities and costs enables generalizing the preferences across similar tasks. We take the pragmatic stance that is independent of time and state, denoting the user’s preference about a format, such as not preferring formats that require constant supervision of robot performance. While this can be relaxed and the approach can be extended to account for state-dependent preferences, obtaining an accurate state-dependent could be challenging in practice.
Assumption 2. Human feedback is immediate and accurate, when available.
Below, we describe the various feedback formats considered in this paper, and how the data from these formats are mapped to NSE severity labels.
Feedback formats studied
3.1
The agent learns an association between state-action pairs and NSE severity, based on the human feedback provided in response to agent queries. The NSE categories we consider in this work are . We focus on the following commonly used feedback types, each differing in the level of information conveyed to the agent and the human effort required to provide them.
Approval (App): The robot randomly selects state-action pairs from all possible actions in critical states and queries the human for approval or disapproval. Approved actions are labeled as acceptable, while disapproved actions are labeled as unacceptable.
Annotated Approval (Ann. App): An extension of Approval, where the human specifies the NSE severity (or category) for each disapproved action in the critical states.
Corrections (Corr): The robot performs a trajectory of its primary policy in the critical states, under human supervision. If the robot’s action is unacceptable, then the human intervenes with an acceptable action in these states. If all actions in a state lead to NSE, the human specifies an action with the least NSE. When interrupted, the robot assumes all actions except the correction are unacceptable in that state.
Annotated Corrections (Ann. Corr): An extension of Corrections, where the human specifies the severity of NSEs caused by the robot’s unacceptable action in critical states.
Rank: The robot randomly selects ranking queries of the form , by sampling two actions for each critical state. The human selects the safer action among the two options. If both are safe or unsafe, one of them is selected at random. The selected action is marked as acceptable and the other is treated as unacceptable.
Demo-Action Mismatch (DAM): The human demonstrates a safe action in each critical state, which the robot compares with its policy. All mismatched robot’s actions are labeled as unacceptable. Matched actions are labeled as acceptable.
Mapping feedback data to NSE severity labels: We use , , and to denote labels corresponding to no, mild and severe NSEs, respectively. An acceptable action in a state is mapped to , i.e., , while an unacceptable action is mapped to . When the severity of NSEs for unacceptable actions is known, actions producing mild NSEs are mapped to and those producing severe NSEs to . Mapping feedback to this common label set provides a consistent representation of NSE severity across diverse feedback types. The granularity of information and the sampling biases of the different feedback types affect the learned reward. Figure 2 illustrates this with the learned NSE penalty for the running example of moving an object to the bin (Figure 1), motivating the need for an adaptive approach that can learn from more than one feedback format. In the running example, the robot arm colliding with cardboard boxes is a mild NSE, and colliding with a glass bowl is a severe NSE.
Visualization of reward learned using different feedback types. (Row 1) Black arrows indicate queries, and feedback is in speech bubbles. A small red square on a black background., Red square in a small image format., Solid yellow square with a thin black border. indicates high, mild, and zero penalty. Outer box is the true reward, and inner box shows the learned reward. Mismatches between the outer and inner box colors indicate incorrect learned model.
Adaptive feedback selection
4
Given an agent’s decision making model and the human’s feedback preference model , AFS enables the agent to query for feedback in critical states in a format that maximizes its information gain. We first formalize the NSE model learning process and then describe in detail how AFS selects critical states and the query format.
Formalizing NSE Model Learning: Let denote the true NSE severity label for each state-action pair, which is unknown to the agent but known to the human. The label corresponds to no NSE, denotes mild NSE, denote the label for severe NSE. Let be a sampled approximation of , denoting the dataset of NSE labels collected via human feedback in response to the pairs queried. That is, denotes the data collected from human feedback until iteration , where represents the categorical NSE severity label assigned to the state-action pair . Let denote the labels predicted by the learned NSE model—learned using a supervised classifier with as the training data. In this paper, we use a Random Forest (RF) classifier, though any classifier can be used in practice. Hyperparameters are optimized through randomized search with three-fold cross validation, and the configuration yielding the lowest mean-squared error is selected for training.
Figure 3 shows an example of and for the object delivery task. We encode NSE categories as corresponding to respectively. Each state has four possible actions , and the vector (and similarly ) encodes the categorical NSE labels for in that order. Since the human’s categorization of NSE is initially unknown, is sampled from a uniform prior over the labels, and is initialized to [0,0,0,0] (all actions are assumed to be safe) across all states.
Illustration of p (accumulated feedback) and q (generalized NSE labels) for the object delivery task. f1:t−1 indicates the feedback formats selected until iteration t−1 . Solid yellow square with a thin black border. indicates no NSE; Red square in a small image format. indicates mild NSE; A small red square on a black background. indicates severe NSE. Queried states in each iteration is highlighted in blue.*
At , reflects a single labeled state from the feedback received, while reflects NSE label for the state after learning from . For example, in iteration , an action in state is randomly selected for querying using the Annotated Approval feedback format. The human labels it as mild NSE, so , and consequently . After training on , the classifier may sometimes incorrectly predict , especially in early iterations when there is less data. At the next iteration , the agent queries in a similar state using the Approval format, where the action is randomly selected. Because the NSE severity level (i.e., mild/severe) cannot be indicated through the Approval format, is updated as , and training now yields a prediction (i.e., the NSE model predicts severe NSE outcome on and a mild NSE outcome on ). This illustrates that may initially disagree with , but as feedback accumulates on related states, the generalization of across actions begins to align with .
Each predicted label is then mapped to a penalty value to form the learned penalty function, , with penalties for and set to and respectively, in our experiments. This penalty function is integrated into the agent’s reward model to compute an updated policy that minimizes NSEs while completing the primary task.
In this learning setup, minimizing NSEs using AFS involves four iterative steps (Figure 4). In each learning iteration, AFS identifies (1) which states are most critical for querying (Section 4.1), and (2) which feedback format maximizes the expected information gain at the critical states, while accounting for user feedback preferences and effort involved (Section 4.2). The information gain associated with a feedback quantifies the effect of a feedback in improving the agent’s understanding of the underlying reward function, and is measured using Kullback-Leibler (KL) Divergence (Ghosal et al., 2023; Tien et al., 2023). At the end of each iteration, the cluster weights and information gain are updated, and a new set of critical states are sampled to learn about NSEs, until the querying budget expires or the KL-divergence is below a problem-specific, pre-defined threshold.
Solution approach overview. The critical states Ω for querying are selected by clustering the states. A feedback format f that maximizes information gain is selected for querying the user across Ω . The NSE model is iteratively refined based on feedback. An updated policy is calculated using a penalty function R^N , derived from the learned NSE model.*
Critical states selection
4.1
When the budget for querying a human is limited, it is useful to query in states with a high learning gap measured as the KL-divergence between the agent’s knowledge of NSE severity and the true NSE severity given the feedback data collected so far. States with a high learning gap are called critical states and querying in these states can reduce the learning gap.
Since and contain categorical values rather than probabilities, their corresponding empirical probability mass functions (PMFs) are computed over the three NSE categories (no NSE, mild NSE, and severe NSE), yielding and , respectively. In this case, and will be vectors of length three, since we consider three NSE categories.
In order to select critical states for querying, we compute the KL divergence between and , . Although may appear as a reasonable criterion to guide critical states selection, it only measures how well the agent learns from the feedback at . It does not reveal states where the agent’s predictions were incorrect. For the example shown in Figure 3 with and , and are calculated as the average occurrence of each NSE category (no NSE, mild NSE, severe NSE) across the four actions. That is, for , the frequency is , resulting in . For , the frequency is , yielding . Calculating the divergence between and reveals that the prediction was incorrect at and therefore more data is required to align the learned model, and hence or similar states should be selected for querying. Therefore, the sampling weight of the cluster containing is increased (the region where the NSE model is still uncertain). In the following iteration, critical states are drawn from the reweighted clusters. Algorithm 1 outlines our approach for selecting critical states at each learning iteration, with the following three key steps.
*1. Clustering states *: Since NSEs are typically correlated with specific state features and do not occur at random, we cluster the states into number of clusters so as to group states with similar NSE severity (Lakkaraju et al., 2017). In our experiments, we use KMeans clustering algorithm with Jaccard distance to measure the distance between states based on their features. In practice, any clustering algorithm can be used, including manual clustering. The goal is to create meaningful partitions of the state space to guide critical states selection for querying the user.
*2. Estimating information gain *: We define the information gain of sampling from a cluster , based on the learning gap, as follows:
where denotes the set of states sampled for querying from cluster at iteration . and denote the probability of observing NSE category in state , derived from and , respectively. This formulation quantifies how much the predicted NSE distribution diverges from the feedback received for each state, providing a principled measure of the expected information gain from querying in a cluster, , as defined in Equation 1.
*3. Sampling critical states:
- At each learning iteration , the agent assigns a weight to each cluster , proportional to the new information on NSEs revealed by the most informative feedback format identified at , using Equation 2. Clusters are given equal weights when there is no prior feedback (Line 4). Let denote the number of critical states to be sampled in every iteration. We sample critical states in batches but they can also be sampled sequentially. When sampling in batches of states, the number of states to be sampled from each cluster is determined by its assigned weight. At least one state is sampled from each cluster to ensure sufficient information for calculating the information gain for every cluster (Line 5). The agent randomly samples states from corresponding cluster and adds them to a set of critical states (Lines 6, 7). If the total number of critical states sampled is less than due to rounding, then the remaining states are sampled from the cluster with the highest weight and added to (Lines 9–12).
Algorithm 1Critical States Selection.
- Require: : #critical states; :#clusters;
- 1:
- 2: Cluster states into clusters,
- 3: for each cluster do
- 4:
- 5:
- 6: Sample states at random,
- 7:
- 8: end for
- 9:
- 10: if then
- 11:
- 12:
- 13: end if
- 14: return Set of selected critical states
Feedback format selection
4.2
To query in the critical states, , it is important to select a feedback format that not only maximizes the expected information gain about NSEs but also accounts for likelihood and cost of the feedback. The information gain of a feedback format at iteration , for critical states, is computed as the KL divergence between the observed and predicted NSE severity distributions, and :
where, is an indicator function that checks whether the format provided by the human, , matches the requested format . If no feedback is received, the information gain for that format remains unchanged. The following equation is used to select the feedback format , accounting for feedback cost and user preferences:
where is the probability of receiving a feedback in format and is the feedback cost, determined using the human preference model . is the current learning iteration, is the number of times feedback in format was received, and is a small constant for numeric stability. The selected format represents the most informative feedback format given the agent’s current knowledge, balancing exploration (less frequently used formats) and exploitation (formats known to provide high information gain).
Algorithm 2Feedback Selection for NSE Learning.
- Require: B, Querying budget; , Human preference model; : KL divergence threshold
- 1: ; and
- 2:Initialize actions in to random l ∈ and in to acceptable, l_a_ , RandomNSELabel ;
- 3:while or do
- 4: Sample critical states using Algorithm 1
- 5: Query user with feedback format , selected using Equation 4, across sampled
- 6: if feedback received in format then
- 7: Update distribution based on the feedback received in format
- 8: TrainClassifier
- 9:
- 10: Update , using Equation 3
- 11:
- 12: end if
- 13: ;
- 14:end while
- 15:return NSE classifier model,
Algorithm 2 outlines our feedback format selection approach. Since the agent has no prior knowledge of how the human categorizes NSE for each state-action pairs, the labeling function is instantiated by sampling from a uniform prior over the three NSE labels for every , while q is initialized assuming all actions are safe (Line 2). These initial labels are progressively refined as human feedback is received. At each iteration, the agent samples critical states using Algorithm 1 (Line 4), and selects a feedback format is selected using Equation 4. The agent queries the human for feedback in (Line 5). If the feedback is received (with probability ), the observed NSE labels are updated and an NSE prediction model is trained (Lines 6–8). The classifier predicts the labels for the sampled critical states , yielding . We restrict the prediction to since these states indicate regions of high uncertainty and contribute to reducing the divergence between the true and learned NSE distributions. Further, restricting predictions to also reduces computational overhead during iterative querying. is recomputed using Equation 3, and is incremented (Lines 9–11). This repeats until either the querying budget is exhausted or the KL divergence between and over all states is within a problem-specific threshold .
Figure 5 illustrates the critical states and the most informative feedback formats selected at each iteration in the object delivery task using AFS, demonstrating that feedback utility changes over time, based on the robot’s current knowledge.
Feedback utility of each format across iterations. Numbers mark when a state was identified as critical, and circle colors denote the chosen feedback format.
Stopping criteria
4.3
Besides guiding the selection of critical states and feedback format, the KL-divergence also serves as an indicator of when to stop querying. The querying phase can be terminated when , where is a problem-specific threshold. When , it indicates that the learned model is a reasonable approximation of the underlying NSE distribution, and therefore the querying can be terminated even if the allotted budget has not been exhausted. The choice of provides a trade-off between thorough learning and human effort, and can be tuned based on domain-specific safety requirements.
Experiments in simulation
5
We first evaluate AFS on three simulated domains (Figure 6). Human feedback is simulated by modeling an oracle that selects safer actions with higher probability using a softmax action selection (Ghosal et al., 2023; Jeon et al., 2020): the probability of choosing an action from a set of all safe actions in state is, .
Illustrations of evaluation domains. Red box denotes the agent and the goal location is in green. (a) Navigation: Unavoidable NSE. (b) Vase: Unavoidable NSE. (c) Safety-gym Push.
Baselines (i) Naive Agent: The agent naively executes its primary policy without learning about NSEs, providing an upper bound on the NSE penalty incurred. (ii) Oracle: The agent has complete knowledge about and , providing a lower bound on the NSE penalty incurred. (iii) Reward Inference with Modeling (RI) (Ghosal et al., 2023): The agent selects a feedback format that maximizes information gain according to the human’s inferred rationality, . (iv) Cost-Sensitive Approach: The agent selects a feedback method with the least cost, according to the preference model . (v) Most-Probable Feedback: The agent selects a feedback format that the human is most likely to provide, based on . (vi) Random Critical States: The agent uses our AFS framework to learn about NSEs, except the critical states are sampled randomly from the entire state space. We use and for all our experiments. AFS uses learned .
Domains, Metrics and Feedback Formats: We evaluate the performance of various techniques on three domains in simulation (Figure 6): outdoor navigation, vase and safety-gym’s push. We optimize costs (negations of rewards) and compare techniques using average NSE penalty and average cost to goal, averaged over 100 trials. For navigation, vase and push, we simulate human feedback. The cost for , , and are 0, , and respectively.
Navigation: In this ROS-based city environment, the robot optimizes the shortest path to the goal location. A state is represented as , where, and are robot coordinates, is the surface type (concrete or grass), and indicates the presence of a puddle. The robot can move in all four directions and each costs . Actions succeed with probability 0.8. Navigating over grass damages the grass and is a mild NSE. Navigating over grass with puddles is a severe NSE. Features used for training are . Here, NSEs are unavoidable.
Vase: In this domain, the robot must quickly reach the goal, while minimizing breaking a vase as a side effect (Krakovna et al., 2020). A state is represented as where, and are robot’s coordinates. indicates the presence of a vase and indicates if the floor is carpeted. The robot moves in all four directions and each costs . Actions succeed with probability 0.8. Breaking a vase placed on a carpet is a mild NSE and breaking a vase on the hard surface is a severe NSE. are used for training. All instances have unavoidable NSEs.
Push: In this safety-gymnasium domain, the robot aims to push a box quickly to a goal state (Ji et al., 2023). Pushing a box on a hazard zone (blue circles) produces NSEs. We modify the domain such that in addition to the existing actions, the agent can also wrap the box that costs . Every move action succeeds with probability 0.8, and the wrap action succeeds with probability 1.0. The NSEs can be avoided by pushing a wrapped box. A state is represented as where, are the robot’s coordinates, indicates carrying a box, indicates if box is wrapped and denotes if it is a hazard area. are used for training.
Results and discussion
5.1
Effect of learning using AFS: We first examine the benefit of querying using AFS, by comparing the resulting average NSE penalties and the cost for task completion, across domains and query budget. Figure 7 shows the average NSE penalties when operating based on an NSE model learned using different querying approaches. Clusters for critical state selection were generated using KMeans clustering algorithm with for navigation, vase and safety-gym’s push domains (Figures 7a–c). The results show that our approach consistently performs similar to or better than the baselines.
Average penalty incurred when querying with different feedback selection techniques. (a) Navigation: Unavoidable NSE. (b) Vase: Unavoidable NSE. (c) Safety-gym Push.
There is a trade-off between optimizing task completion and mitigating NSEs, especially when NSEs are unavoidable. While some techniques are better at mitigating NSEs, they significantly impact task performance. Table 1 shows the average cost for task completion at . Lower values are better for both NSEs and task completion cost. While the Naive Agent has a lower cost for task completion, it incurs the highest NSE penalty as it has no knowledge of . RI causes more NSEs, especially when they are unavoidable, as its reward function does not fully model the penalties for mild and severe NSEs. Overall, the results show that our approach consistently mitigates avoidable and unavoidable NSEs, without affecting the task performance substantially.
Figure 8 shows the average penalty when AFS uses KL-divergence (KLD) as the stopping criteria, compared to querying with budget . For comparison, we also annotate in the plot the querying budget used by AFS with KLD stopping at the time of termination. The results show that despite terminating earlier and using few queries, AFS with the KLD stopping achieves comparable performance to that of AFS with query budget , demonstrating the usefulness of KLD as a stopping criterion.
Average penalty incurred when learning with AFS using querying budget B=400 , and KL divergence (KLD) as the stopping criterion. The budget utilized by AFS with KLD stopping is annotated in the plot.
In-person user study with a physical robot arm
6
We conducted an in-person study with a Kinova Gen3 7DoF arm (Kinova, 2025) tasked with delivering two objects—an orange toy and a white box—across a workspace containing items of varying fragility (Figure 9). This setup involves users providing both interface-based and kinesthestic feedback to the robot. The study was approved by Oregon State University IRB. Participants were compensated with a Amazon gift card for their participation in the study.
Task setup for the human subject study. (a) Physical setup of the task for human subjects study; (b) Replication of the physical setup using PyBullet. A dialog box corresponding to the current feedback format is shown for every query.
This user study had three goals: (1) to measure our approach’s effectiveness in reducing NSEs for a real-world task, (2) to understand how users perceive the adaptivity, workload and competence of the robot operating in the AFS framework, and (3) to evaluate the extent to which AFS captures user preferences in practice, while ensuring maximum information gain during the learning process.
Methods
6.1
Participants
6.1.1
We conducted a pilot study in simulation to inform our overall design, the details of which are discussed under Section 2 in the Supplementary Material. We conducted another pilot study with participants to evaluate the study setup with the Kinova arm. In particular, this pilot study assessed the clarity of instructions, survey wording, and feasibility of the task design in the object delivery task of the Kinova arm. Based on the participant feedback, we simplified the survey questions and included example trajectories that demonstrated safe and NSE-causing behaviors. For the main study, we recruited participants with basic computer literacy from the general population through university mailing lists and public forums. Participants were aged 18–72 years , with men and women. Participants reported varied prior experience with robots: had general awareness of similar robot products, had researched or investigated robots, had interacted through product demos, and had no prior awareness of similar products.
Robotic system setup
6.1.2
The Kinova Gen3 arm was equipped with a joint space compliant controller which allowed participants to physically move the joints of the arm through space with gravity compensation when needed. Additionally, a task-space planner allowed for navigation to discrete grid positions for both feedback queries and policy execution (Kinova, 2025). Figure 9a shows the physical workspace and the two delivery objects, while Figure 9b shows the corresponding PyBullet simulation used for visualization during GUI-based feedback. A dialog box was displayed to prompt the participant whenever feedback was queried1.
Interaction premise
6.1.3
The interaction simulated an assistive robot delivering objects to their designated bins. Specifically, the task required the Kinova arm to deliver an orange plush toy and a rigid white box to their respective bins while avoiding collision with surrounding obstacles of different fragility. Collisions with fragile obstacles (e.g., a glass vase) during delivery of the plush toy were considered a mild NSE. Collisions involving the white rigid box were severe NSEs if with a fragile object and were mild NSEs if with a non-fragile object. All other scenarios were considered safe. The workspace was discretized into a grid of cells marked with tape on the tabletop and mirrored in the GUI. Each cell represented a state corresponding to possible end-effector position.
Study design
6.1.4
The robot’s state space was discretized and represented as , where denote the end-effector position, and indicate the presence of either orange plush toy or white rigid box in the end effector, indicates the presence of an obstacle, and indicates obstacle fragility, and and indicate whether either of the objects were delivered in their corresponding goal locations (i.e., orange plush toy in white bin and the white box in the wicker bin).
Participants interacted with the robot through four feedback formats, , during both the training and main experience phases. Depending on the feedback format, the Kinova arm executed the queried action in the physical workspace or displayed a simulation of the action in the graphical user interface (GUI). Interaction across the four feedback formats are described below.
- Approval: The robot executed a single action in simulation, and participants indicated whether it was safe by selecting “yes” or “no” in the GUI.
- Correction: The robot first executes action prescribed by its policy in simulation. If the action in simulation is deemed unsafe by the participant, the robot in the physical setup moves to the queried location. Participants then correct the robot by physically moving the robot arm to demonstrate a safe alternative action.
- Demo-Action Mismatch: The robot first physically moved its arm to a specific end-effector position in the workspace. Participants then provided feedback by guiding the arm to a safe position, thereby demonstrating the safe action. The robot compares the action given by its policy to the demonstrated action. If the robot’s action and the demonstrated actions do not match, then the robot’s action is considered unsafe.
- Ranking: Simulation clips of two actions selected at random in a given state were presented in GUI. Participants compared the two candidate actions and selected which was safer. If both actions were judged equally safe or unsafe, either option could be chosen.
Each participant experienced four learning conditions in a within-subjects, counterbalanced design:
- The baseline RI approach proposed in Ghosal et al. (2023),
- AFS with random , where critical states are randomly selected,
- AFS with a fixed feedback format (DAM) for querying, consistent with prior works that rely primarily on demonstrations, and
- The proposed AFS approach, where both the feedback format and the critical states are selected to maximize information gain.
Each condition is a distinct feedback query selection strategy controlling how the robot queried participants during learning. These conditions are the independent variables. The dependent measures include NSE occurrences, their severity, perceived workload, trust, competence and user alignment.
Hypotheses
6.1.5
We test the following hypotheses in the in-person study. These hypotheses were derived from trends observed in the experiments and human subjects study in simulation (Section 5 and Section 2 in the Supplementary Materials).
H1: Robots learning using AFS will have fewer NSEs in comparison to the baselines.
This hypothesis is derived from the results of our experiments on simulated domains (Figure 7) where AFS consistently reduced NSEs while completing the assigned task. We hypothesize that this trend extends to physical human-robot interactions.
H2: AFS will achieve comparable or better performance compared to the baselines, with a lower perceived workload for the users.
The results on simulated domains (Figure 8) show that AFS achieved better or comparable performance to the baselines, using fewer feedback queries. While the in-person user study requires relatively greater physical and cognitive effort, we expect the advantage of the sample efficiency to persist and investigate whether it translates to reduced perceived workload.
H3: Participants will report AFS as more trustworthy, competent, and aligned with user expectations, in comparison to the baselines.
In the human subjects simulation study (Supplementary Table S2), participants reported that AFS selected intelligent queries, targeted critical states, and improved the agent’s performance, reflecting indicators of trust, competence and user alignment. We hypothesize that this trend extends to physical settings as well.
Hypotheses H1 and H2 explore trends identified in simulation and are therefore confirmatory. Hypothesis H3 builds on the perception measures used in the human subjects study in simulation, and is hence treated as an extended confirmatory hypothesis.
Procedure
6.1.6
Each study session lasted approximately 1 hour and followed three phases.
Training
6.1.6.1
Participants were first introduced to the task objective, workspace, and the four feedback formats. For each format, they provided feedback on four sample queries to practice both GUI-based and kinesthetic interactions. After the completing each format, the participants rated the following: (i) probability of responding to a query in that format, , (ii) perceived cost or effort required to provide feedback, , and (iii) the overall task workload. This phase helped establish measures like feedback likelihood, perceived effort, and workload.
Main experience
6.1.6.2
Following training, participants completed the four learning conditions corresponding to different approaches under evaluation. In each condition, the participants provided feedback to train the robot to avoid collision while performing the object-delivery task. Depending on the feedback format selected by the querying strategy, participants either evaluated short simulation clips on the GUI or physically guided the robotic arm. At the end of each condition, the robot executed its learned policy based on its learning under that condition. The participants then observed its performance and completed a brief post-condition questionnaire assessing workload, trust, perceived competence, and user-alignment.
Closing
6.1.6.3
At the end of the study, participants compared the four learning approaches in terms of trade-offs between learning speed and safety. Participants reported their preferences on providing feedback through multiple formats versus relying on a single feedback format. These responses offered qualitative insight into AFS’s practicality and user acceptance.
Measures
6.1.7
We collected both quantitative and qualitative measures. The quantitative measure captured task-level performance through the frequency and the severity of NSEs (mild and severe). Qualitative measures captured participants’ perceptions of the following.
- Workload: Participants’ perceived workload across the feedback formats and learning conditions were measured using the NASA Task Load Index (NASA TLX) (Hart and Staveland, 1988). The questionnaire scales were transformed to seven-point subscales ranging from “Very Low” (1) to “Very High” (7). Responses were collected during the training phase and after each condition in the main experience phase.
- Robot Attributes: Perceived robot attributes, like competence, warmth and discomfort, were measured using the nine-point Robotic Social Attributes Scale (RoSAS) (Carpinella et al., 2017), ranging from “Strongly Disagree” (1) to “Strongly Agree” (9). Participants completed this questionnaire after each learning condition.
- Trust: A custom 10-point trust scale was used to measure participants’ confidence in the robot’s ability to act safely under each learning condition. Participants rated their trust both before and after the robot’s training phase to capture changes in its learning performance.
- User Alignment: Participants’ perception of user alignment was assessed using a custom seven-point Likert scale ranging from “Strongly Disagree” (1) to “Strong Agree” (7). Participants rated (i) how well the critical states queried by the robot aligned with their own assessment of which states were important for learning, and (ii) how well the feedback formats chosen across conditions matched their personal feedback preferences. Higher rating indicated stronger perceived alignment between the robot’s querying strategy and the participants’ expectations.
Analysis
6.1.8
Survey responses were compiled into cumulative RoSAS (competence, warmth, discomfort) and NASA-TLX workload scores. A repeated-measures ANOVA (rANOVA) tested for significant differences across learning conditions; we report the -statistic, -value and effect size as generalized eta-squared . When effects were significant, Tukey’s post-hoc tests identified pairwise differences. All results are reported with means (M), standard errors (SE), and -values.
Results
6.2
We evaluate hypotheses H1-H3 using both objective and subjective measures. Data from all 30 participants were included in the analysis, as all sessions were completed successfully.
Effectiveness of AFS in mitigating NSEs (H1)
6.2.1
Figure 10a shows the average penalty incurred under each condition. AFS approach incurred the least NSE penalty , substantially lower than AFS with random and AFS with a fixed feedback format . The RI baseline incurred higher penalties compared to AFS. These results confirm hypothesis H1 and demonstrate that adaptively selecting both critical states and feedback formats reduced unsafe behaviors more effectively than random or fixed querying strategies.
Results from the user study on the Kinova 7DoF arm. (a) Average penalty incurred across methods in the human subjects study. (b) NASA-TLX workload across the four conditions.
Learning efficiency and workload (H2)
6.2.2
We first compare the perceived workload across different feedback formats, followed by the results across learning conditions. Demonstration is the most widely used feedback format in existing works but was perceived as the most demanding (Figure 11c). While corrections offer corrective action in addition to disapproving agent’s action, it also imposed substantial effort on the users. Approval required the least workload but conveyed limited information. A repeated-measures ANOVA revealed a significant effect of feedback format on perceived workload, . Post hoc comparisons indicated that Approval imposed significantly lower workload than Demo-Action Mismatch , while no other pairwise differences reached significance. This trade-off underscores the need for an adaptive selection strategy to balance informativeness with user effort.
User study results. (a,b) RoSAS competence and NASA Task-Load across the four conditions in the main study; (c) NASA Task-Load across feedback formats.
The rANOVA analysis across the four learning conditions further revealed a significant effect in the NASA-TLX workload ratings . Among the four conditions, AFS achieved one of the lowest perceived workload ratings , comparable to AFS with random and lower than both AFS with fixed format and RI . Tukey post-hoc tests showed that workload in AFS with random imposed a significantly lower workload than RI . Overall, these results support H2, indicating that adaptively selecting queries helps reduce perceived workload relative to the baselines (Figure 10b).
Trust, competence, and preference alignment (H3)
6.2.3
Participants’ rating on the robot’s ability to act safely increased after learning with AFS, as shown in Figure 11b. A significant effect was also found for perceived robot competence (Figure 11a). AFS was rated highest , significantly greater than AFS with random and AFS with fixed format , while comparable to RI . These results support H3—AFS was perceived as more competent and trustworthy compared to the baselines.
Descriptive analyses of user alignment on state criticality and feedback alignment ratings, indicated consistent trends across participants. While differences between conditions were not statistically significant , AFS consistently received higher ratings for feedback alignment relative to state criticality , suggesting that participants found AFS’s query selections relevant and aligned with their preferences. Participants (both those aware and unaware of similar robotic systems) perceived AFS’s queries as critical for learning and well-aligned with their feedback preferences. Participants with prior research experience rated state criticality and format alignment comparable, indicating confidence in adaptivity of AFS’s querying process.
Discussion
7
Our experiments followed an increasingly realistic progression in design. In the experiments in simulation with both avoidable and unavoidable NSEs, AFS incurred lower penalties and overall costs compared to the baselines, demonstrating its ability to balance task performance with safety. The results of our pilot study, where users interacted with a simulated agent, showed that AFS effectively learns the participant’s feedback preference model and uses them to select formats aligned with user expectations. Finally, the in-person user study with the Kinova arm, showed the practicality of using AFS in real-world settings, achieving favorable ratings on trust, workload, and user-preference alignment. These findings support our three hypotheses regarding the performance of AFS: (H1) it reduces unsafe behaviors more effectively than the baselines, (H2) it improves learning efficiency while reducing user workload, and (H3) it is perceived as more trustworthy and competent. The results collectively highlight that adaptively selecting both the query format and the states to pose the queries to the user enhances learning efficiency and reduces user effort.
Beyond confirming these hypotheses, the findings provide important design implications for human-in-the-loop learning systems. By modeling the trade-off between informativeness and effort, AFS offers a framework to balance user workload with the need for high-quality feedback. The learned feedback preference model allows the agent to adaptively select querying formats while minimizing human effort. Using KL-divergence as stopping criterion further enables adaptive termination of the querying process. This overcomes the problem of determining the “right” querying budget for a problem, and shows that AFS enables efficient learning while minimizing redundant human feedback. These design principles can inform the development of interactive systems that adapt query format and frequency based on agent’s current knowledge and user feedback preferences. Overall the results show that AFS (1) consistently outperforms the baselines across different evaluation settings, and (2) can be effectively deployed in real-world human-robot interaction scenarios.
A key strength of this work lies in its extensive evaluation, from simulation to real robot studies, supporting AFS’s robustness and practicality. One limitation, however, is that the current evaluation focuses on discrete environments. Extending AFS to continuous domains introduces challenges such as identifying critical states and estimating divergence-based information gain in high-dimensional spaces. While gathering feedback at the trajectory-level is relatively easier in continuous settings, gathering state-level feedback, which is the focus of this work, is challenging. These challenges stem from the need for scalable state representations and efficient sampling strategies, which will be a focus for future work.
Conclusion and future work
8
The proposed Adaptive Feedback Selection (AFS) facilitates querying a human in different formats in different regions of the state space, to effectively learn a reward function. Our approach uses information gain to identify critical states for querying, and the most informative feedback format to query in these states, while accounting for the cost and uncertainty of receiving feedback in each format. Our empirical evaluations using four domains in simulation and a human subjects study in simulation demonstrate the effectiveness and sample efficiency of our approach in mitigating avoidable and unavoidable negative side effects (NSEs). The subsequent in-person user study with a Kinova Gen3 7DoF arm further validates these finding, showing that AFS not only improves NSE avoidance but also enhances user trust, competence perception, and user-alignment. While AFS assumes that human feedback reflects a true underlying notion of safety, biased feedback can misguide the robot and lead to unintended NSEs. Understanding when such biases arise and how to correct for them remains an open challenge. Extending AFS with bias-aware inference mechanisms is a promising future direction. Future work will also focus on extending AFS to continuous state and action spaces, strengthening AFS’s applicability to complex, safety-critical domains where user-aware interaction is essential.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abbeel P. Ng A. Y. (2004). “Apprenticeship learning via inverse reinforcement learning,” in Proceedings of the twenty-first international conference on machin learning, (ICML).
- 2Amodei D. Olah C. Steinhardt J. Christiano P. Schulman J. ManéD. (2016). Concrete problems in AI safety. ar Xiv Preprint ar Xiv:1606.06565. 10.48550/ar Xiv.1606.06565 · doi ↗
- 3Bärmann L. Kartmann R. Peller-Konrad F. Niehues J. Waibel A. Asfour T. (2024). Incremental learning of humanoid robot behavior from natural interaction and large language models. Front. Robotics AI 11, 1455375. 10.3389/frobt.2024.1455375 39449715 PMC 11499633 · doi ↗ · pubmed ↗
- 4Beierling H. Beierling R. Vollmer A. (2025). The power of combined modalities in interactive robot learning. Front. Robotics AI 12, 1598968. 10.3389/frobt.2025.1598968 40747445 PMC 12312635 · doi ↗ · pubmed ↗
- 5Bıyık E. Losey D. P. Palan M. Landolfi N. C. Shevchuk G. Sadigh D. (2022). Learning reward functions from diverse sources of human feedback: optimally integrating demonstrations and preferences. Int. J. Robotics Res. (IJRR) 41, 45–67. 10.1177/02783649211041652 · doi ↗
- 6Brown D. S. Cui Y. Niekum S. (2018). “Riskaware active inverse reinforcement learning,” 87. Conference on Robot Learning.
- 7Brown D. Coleman R. Srinivasan R. Niekum S. (2020 a). “Safe imitation learning via fast Bayesian reward inference from preferences,” in International conference on machine learning (ICML) (PMLR).
- 8Brown D. Niekum S. Petrik M. (2020 b). Bayesian robust optimization for imitation learning. Adv. Neural Inf. Process. Syst. (Neur IPS). 10.5555/3495724.3495933 · doi ↗